
1. Przegląd
Pamiętasz, jak tworzyliśmy dynamiczne hybrydowe rozwiązanie dla handlu detalicznego z użyciem AlloyDB, łącząc filtrowanie fasetowe i wyszukiwanie wektorowe? Ta aplikacja była doskonałym przykładem nowoczesnych potrzeb handlu detalicznego, ale jej stworzenie i ulepszanie wymagało znacznego nakładu pracy. W przypadku deweloperów full-stack ciągłe przełączanie się między edytorami kodu a narzędziami do obsługi baz danych może być wąskim gardłem, które spowalnia innowacje i kluczowy proces zrozumienia danych.
Rozwiązanie
Właśnie w tym miejscu widać prawdziwą moc przyspieszonego tworzenia aplikacji. Dlatego z przyjemnością dzielę się informacjami o tym, jak zestaw narzędzi MCP (Modern Cloud Platform), dostępny za pomocą intuicyjnego interfejsu wiersza poleceń Gemini, stał się nieodzowną częścią mojego zestawu narzędzi. Wyobraź sobie, że możesz bezproblemowo korzystać z instancji AlloyDB, pisać zapytania i analizować zbiór danych – wszystko to bezpośrednio w zintegrowanym środowisku programistycznym (IDE). Nie chodzi tu tylko o wygodę, ale przede wszystkim o zmniejszenie tarć w cyklu życia rozwoju, dzięki czemu możesz skupić się na tworzeniu innowacyjnych funkcji, a nie na zmaganiach z narzędziami zewnętrznymi.
W przypadku naszej aplikacji do handlu elektronicznego, w której musieliśmy wydajnie wysyłać zapytania o dane produktów, obsługiwać złożone filtrowanie i wykorzystywać niuanse wyszukiwania wektorowego, możliwość szybkiego iterowania interakcji z bazą danych miała kluczowe znaczenie. Zestaw narzędzi MCP oparty na interfejsie wiersza poleceń Gemini nie tylko upraszcza ten proces, ale też go przyspiesza, zmieniając sposób, w jaki możemy eksplorować, testować i dopracowywać logikę bazy danych, która jest podstawą naszych aplikacji. Przyjrzyjmy się, jak ta przełomowa kombinacja sprawia, że tworzenie pełnej wersji aplikacji jest szybsze, inteligentniejsze i przyjemniejsze.
Czego się nauczysz i co utworzysz
Aplikacja Retail Search korzystająca z zestawu narzędzi MCP w IDE, obsługiwana przez interfejs wiersza poleceń Gemini. Te aspekty to:
- Jak zintegrować zestaw narzędzi MCP bezpośrednio ze środowiskiem IDE, aby zapewnić bezproblemową interakcję z AlloyDB.
- Praktyczne przykłady używania interfejsu wiersza poleceń Gemini do pisania i wykonywania zapytań SQL dotyczących danych o sprzedaży detalicznej.
- Korzystaj z interfejsu wiersza poleceń Gemini, aby wchodzić w interakcje z naszym zbiorem danych e-commerce, pisać zapytania, które zwykle wymagają oddzielnych narzędzi, i natychmiast wyświetlać wyniki.
- Odkrywaj nowe sposoby analizowania i interpretowania danych – od sprawdzania struktur tabel po szybkie weryfikowanie poprawności danych – wszystko to za pomocą znanych interfejsów wiersza poleceń w naszym środowisku IDE.
- Jak ten przyspieszony przepływ pracy w bazie danych bezpośrednio przyczynia się do szybszych cykli programowania pełnego stosu, umożliwiając szybkie tworzenie prototypów i iteracji.
Techstack
Używamy:
- AlloyDB dla bazy danych
- Zestaw narzędzi MCP do wyodrębniania zaawansowanych funkcji generatywnych i opartych na AI z baz danych do aplikacji
- Cloud Run do wdrożenia bezserwerowego.
- Interfejs wiersza poleceń Gemini do analizowania zbioru danych i tworzenia części bazy danych aplikacji e-commerce dla handlu detalicznego.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: kliknij link i włącz interfejsy API.
Możesz też użyć polecenia gcloud. Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Konfiguracja bazy danych
W tym module użyjemy AlloyDB jako bazy danych dla danych e-commerce. Używa klastrów do przechowywania wszystkich zasobów, takich jak bazy danych i logi. Każdy klaster ma instancję główną, która zapewnia punkt dostępu do danych. Tabele będą zawierać rzeczywiste dane.
Utwórzmy klaster, instancję i tabelę AlloyDB, do których zostanie wczytany zbiór danych e-commerce.
Tworzenie klastra i instancji
- Otwórz stronę AlloyDB w konsoli Cloud. Najprostszym sposobem na znalezienie większości stron w Cloud Console jest wyszukanie ich za pomocą paska wyszukiwania w konsoli.
- Na tej stronie kliknij UTWÓRZ KLASTER:

- Wyświetli się ekran podobny do tego poniżej. Utwórz klaster i instancję z tymi wartościami (upewnij się, że wartości są zgodne, jeśli klonujesz kod aplikacji z repozytorium):
- id klastra: „
vector-cluster” - password: "
alloydb" - PostgreSQL 15 / najnowsza zalecana
- Region: "
us-central1" - Sieć: „
default”
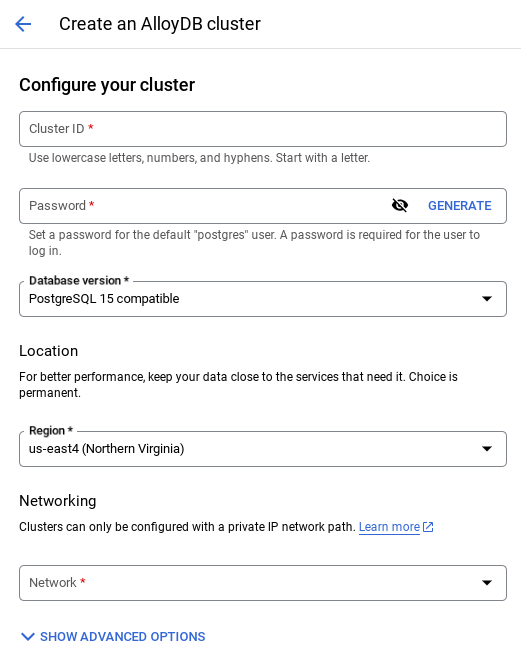
- Po wybraniu sieci domyślnej zobaczysz ekran podobny do tego poniżej.
Kliknij SKONFIGURUJ POŁĄCZENIE.
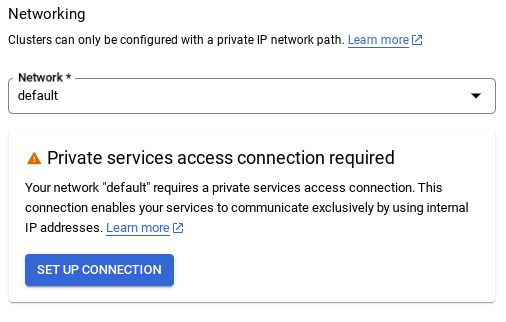
- Następnie wybierz „Użyj automatycznie przydzielonego zakresu adresów IP” i kliknij Dalej. Po sprawdzeniu informacji kliknij UTWÓRZ POŁĄCZENIE.
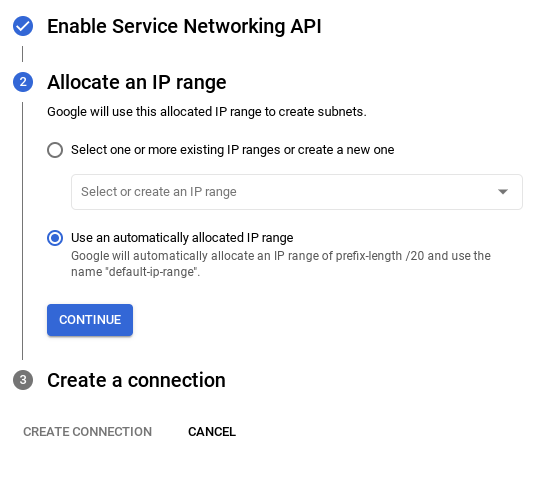
- Po skonfigurowaniu sieci możesz kontynuować tworzenie klastra. Kliknij UTWÓRZ KLASTER, aby dokończyć konfigurowanie klastra, jak pokazano poniżej:
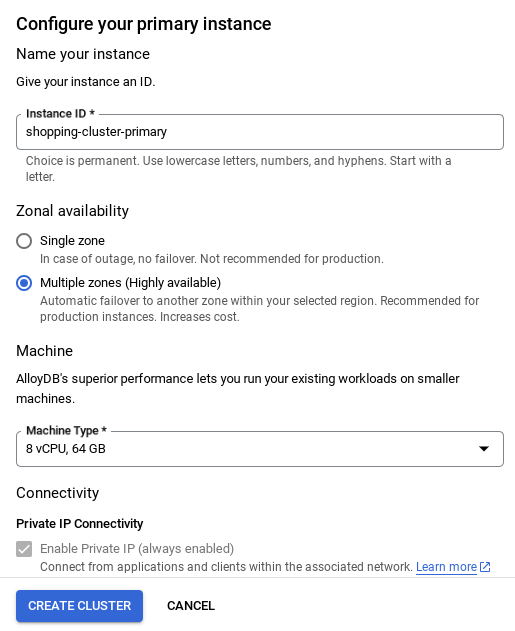
WAŻNA UWAGA:
- Pamiętaj, aby zmienić identyfikator instancji (który możesz znaleźć podczas konfigurowania klastra lub instancji) na**
vector-instance**. Jeśli nie możesz go zmienić, pamiętaj, aby **używać identyfikatora instancji** we wszystkich kolejnych odwołaniach. - Pamiętaj, że utworzenie klastra zajmie około 10 minut. Po zakończeniu procesu powinien wyświetlić się ekran z omówieniem utworzonego klastra.
4. Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz AlloyDB, wybierz klaster główny, a następnie AlloyDB Studio:
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb”
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wprowadzane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, używając w razie potrzeby opcji Uruchom, Formatuj i Wyczyść.
Włącz rozszerzenia
Do utworzenia tej aplikacji użyjemy rozszerzeń pgvector i google_ml_integration. Rozszerzenie pgvector umożliwia przechowywanie wektorów dystrybucyjnych i wyszukiwanie ich. Rozszerzenie google_ml_integration udostępnia funkcje, których możesz używać do uzyskiwania dostępu do punktów końcowych prognozowania Vertex AI w celu uzyskiwania prognoz w SQL. Włącz te rozszerzenia, uruchamiając te DDL:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Jeśli chcesz sprawdzić, które rozszerzenia są włączone w bazie danych, uruchom to polecenie SQL:
select extname, extversion from pg_extension;
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Kolumna wektorów dystrybucyjnych będzie umożliwiać przechowywanie wartości wektorowych tekstu.
Przyznaj uprawnienia
Aby przyznać uprawnienia do wykonywania funkcji „embedding”, uruchom to polecenie:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Przyznawanie roli Użytkownik Vertex AI kontu usługi AlloyDB
W konsoli IAM Google Cloud przyznaj kontu usługi AlloyDB (które wygląda tak: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) dostęp do roli „Użytkownik Vertex AI”. Zmienna PROJECT_NUMBER będzie zawierać numer Twojego projektu.
Możesz też uruchomić to polecenie w terminalu Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Wczytywanie danych do bazy danych
- Skopiuj
insertinstrukcje zapytania zinsert scripts sqlw arkuszu do edytora. Możesz skopiować 10–50 instrukcji wstawiania, aby szybko zaprezentować ten przypadek użycia. Wybrana lista wstawek znajduje się na tej karcie „Wybrane wstawki 25–30 wierszy”. - Kliknij Wykonaj. Wyniki zapytania pojawią się w tabeli Wyniki.
WAŻNA UWAGA:
Skopiuj tylko 25–50 rekordów do wstawienia i upewnij się, że pochodzą one z zakresu kategorii, podkategorii, kolorów i typów płci.
5. Tworzenie wektorów dystrybucyjnych dla danych
Prawdziwa innowacja w nowoczesnym wyszukiwaniu polega na rozumieniu znaczenia, a nie tylko słów kluczowych. W takich sytuacjach przydają się wektory dystrybucyjne i wyszukiwanie wektorowe.
Opisy produktów i zapytania użytkowników przekształciliśmy w wielowymiarowe reprezentacje numeryczne zwane „osadzaniem” za pomocą wstępnie wytrenowanych modeli językowych. Te wektory dystrybucyjne odzwierciedlają znaczenie semantyczne, dzięki czemu możemy znajdować produkty, które są „podobne pod względem znaczenia”, a nie tylko zawierają pasujące słowa. Początkowo przeprowadziliśmy eksperymenty z bezpośrednim wyszukiwaniem podobieństwa wektorowego w przypadku tych osadzeń, aby ustalić wartość bazową. Pokazało to, jak ważne jest zrozumienie semantyczne jeszcze przed optymalizacją skuteczności.
Kolumna wektorów dystrybucyjnych będzie umożliwiać przechowywanie wartości wektorowych tekstu opisu produktu. Kolumna img_embeddings umożliwi przechowywanie wektorów dystrybucyjnych obrazów (multimodalnych). W ten sposób możesz też używać wyszukiwania na podstawie odległości tekstu od obrazu. W tym module użyjemy jednak tylko osadzania tekstu.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Powinien on zwrócić wektor dystrybucyjny, który wygląda jak tablica liczb zmiennoprzecinkowych, dla przykładowego tekstu w zapytaniu. Wygląda to tak:
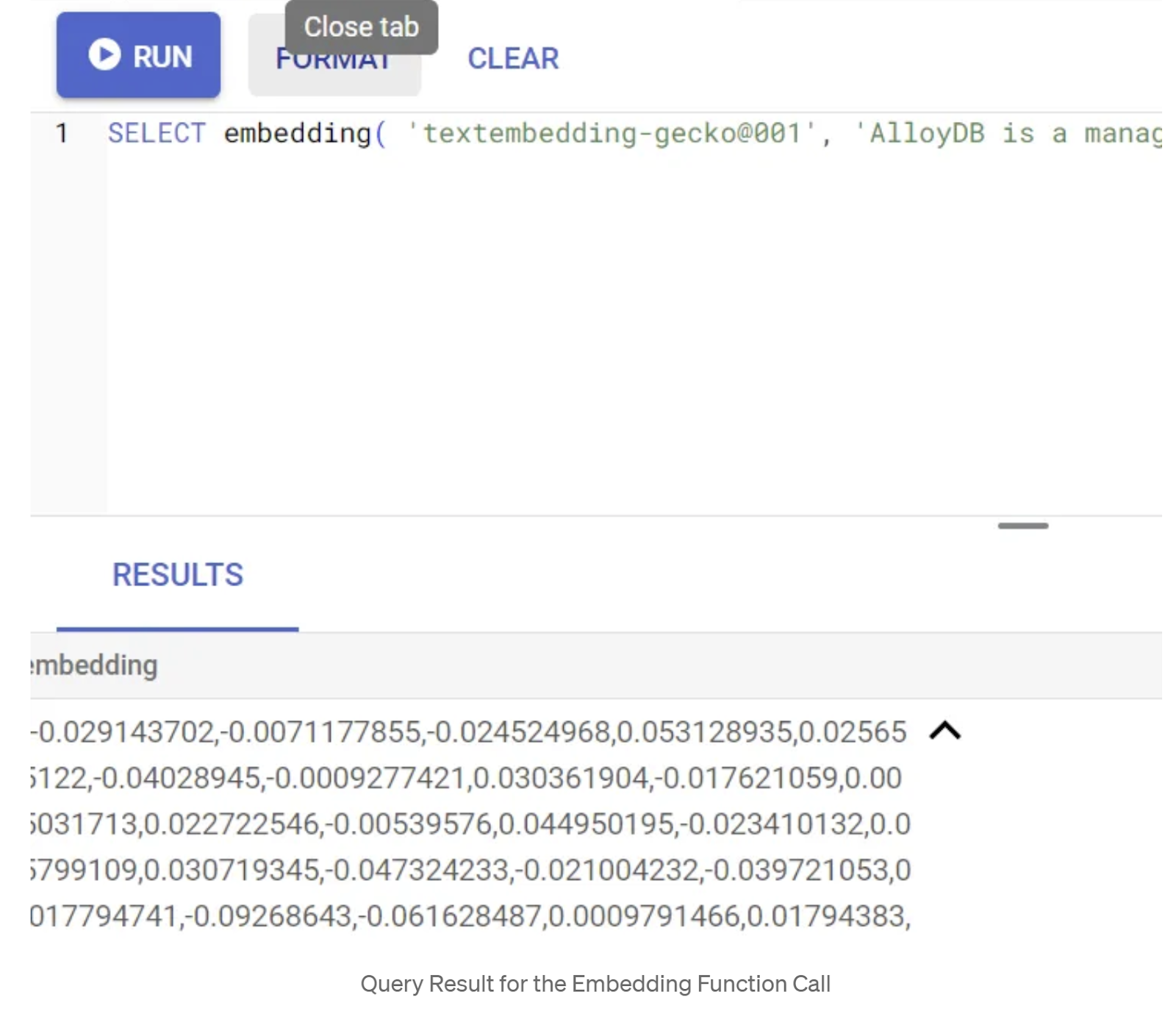
Zaktualizuj pole wektora abstract_embeddings.
Uruchom poniższy język DML, aby zaktualizować opis treści w tabeli za pomocą odpowiednich wektorów dystrybucyjnych:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Jeśli korzystasz z konta rozliczeniowego z kredytem próbnym w Google Cloud, możesz mieć problem z wygenerowaniem więcej niż kilku osadzeń (maksymalnie 20–25). Dlatego ogranicz liczbę wierszy w skrypcie wstawiania.
Jeśli chcesz wygenerować osadzanie obrazów (do przeprowadzania multimodalnego wyszukiwania kontekstowego), uruchom też poniższą aktualizację:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Zestaw narzędzi MCP dla baz danych (AlloyDB)
Za kulisami działają zaawansowane narzędzia i dobrze skonstruowana aplikacja, które zapewniają płynne działanie.
Zestaw narzędzi MCP (Model Context Protocol) dla baz danych upraszcza integrację generatywnej AI i narzędzi opartych na agentach z AlloyDB. Jest to serwer open source, który usprawnia pulę połączeń, uwierzytelnianie i bezpieczne udostępnianie funkcji bazy danych agentom AI lub innym aplikacjom.
W naszej aplikacji użyliśmy zestawu narzędzi MCP dla baz danych jako warstwy abstrakcji dla wszystkich naszych inteligentnych zapytań dotyczących wyszukiwania hybrydowego.
Aby skonfigurować i wdrożyć Toolbox w naszym przypadku użycia, wykonaj te czynności:
Jak widać, jedną z baz danych obsługiwanych przez MCP Toolbox for Databases jest AlloyDB. Skonfigurowaliśmy ją już w poprzedniej sekcji, więc teraz skonfigurujmy zestaw narzędzi.
- Otwórz terminal Cloud Shell i sprawdź, czy projekt jest wybrany i wyświetlany w prompcie terminala. Aby przejść do katalogu projektu, uruchom w terminalu Cloud Shell to polecenie:
mkdir gemini-cli-project
cd gemini-cli-project
- Aby pobrać i zainstalować pakiet narzędzi w nowym folderze, uruchom to polecenie:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
W bieżącym katalogu powinien zostać utworzony zestaw narzędzi. Skopiuj ścieżkę do przybornika.
- Otwórz edytor Cloud Shell (w trybie edycji kodu) i w folderze głównym projektu „gemini-cli-project” dodaj plik o nazwie „tools.yaml”.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Omówmy plik tools.yaml:
Źródła to różne źródła danych, z którymi narzędzie może wchodzić w interakcje. Źródło to źródło danych, z którym narzędzie może wchodzić w interakcje. Źródła możesz zdefiniować jako mapę w sekcji źródeł w pliku tools.yaml. Zwykle konfiguracja źródła zawiera wszystkie informacje potrzebne do połączenia z bazą danych i korzystania z niej.
Narzędzia określają działania, które może wykonywać agent, np. odczytywanie i zapisywanie danych w źródle. Narzędzie reprezentuje działanie, które może wykonać agent, np. uruchomienie instrukcji SQL. Narzędzia możesz zdefiniować jako mapę w sekcji narzędzi w pliku tools.yaml. Zwykle narzędzie wymaga źródła, na którym ma działać.
Więcej informacji o konfigurowaniu pliku tools.yaml znajdziesz w tej dokumentacji.
Jak widać w pliku Tools.yaml powyżej, narzędzie „get-apparels” zawiera wszystkie szczegóły odzieży z bazy danych.
7. Konfigurowanie interfejsu wiersza poleceń Gemini
W edytorze Cloud Shell utwórz nowy folder o nazwie .gemini w folderze gemini-cli-project i utwórz w nim nowy plik o nazwie settings.json.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
W sekcji poleceń w powyższym fragmencie kodu zastąp ciąg „/home/user/gemini-cli-project/toolbox” ścieżką do narzędzi.
Instalowanie interfejsu wiersza poleceń Gemini
Na koniec zainstaluj interfejs wiersza poleceń Gemini w tym samym katalogu gemini-cli-project, wykonując to polecenie w terminalu Cloud Shell:
sudo npm install -g @google/gemini-cli
Ustawianie identyfikatora projektu
Sprawdź, czy w środowisku jest ustawiony aktywny identyfikator projektu:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Pierwsze kroki z interfejsem wiersza poleceń Gemini
W wierszu poleceń wpisz to polecenie:
gemini
Powinna pojawić się odpowiedź podobna do tej poniżej:
Uwierzytelnij się i przejdź do następnego kroku.
8. Rozpoczęcie interakcji z interfejsem wiersza poleceń Gemini
Aby wyświetlić listę skonfigurowanych serwerów MCP, użyj polecenia /mcp.
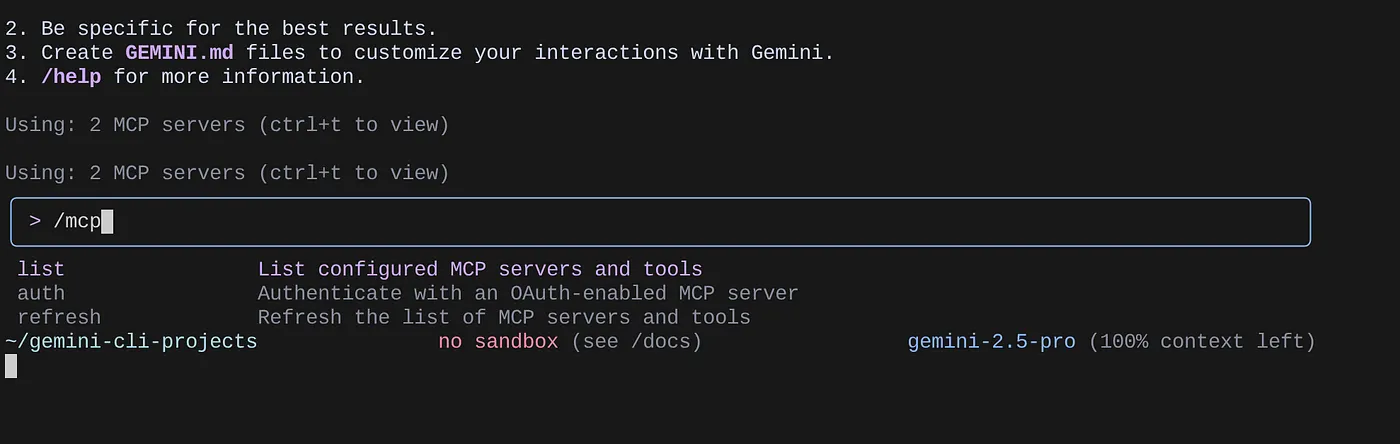
Powinny być widoczne 2 skonfigurowane przez nas serwery MCP: GitHub i MCP Toolbox for Databases wraz z narzędziami.
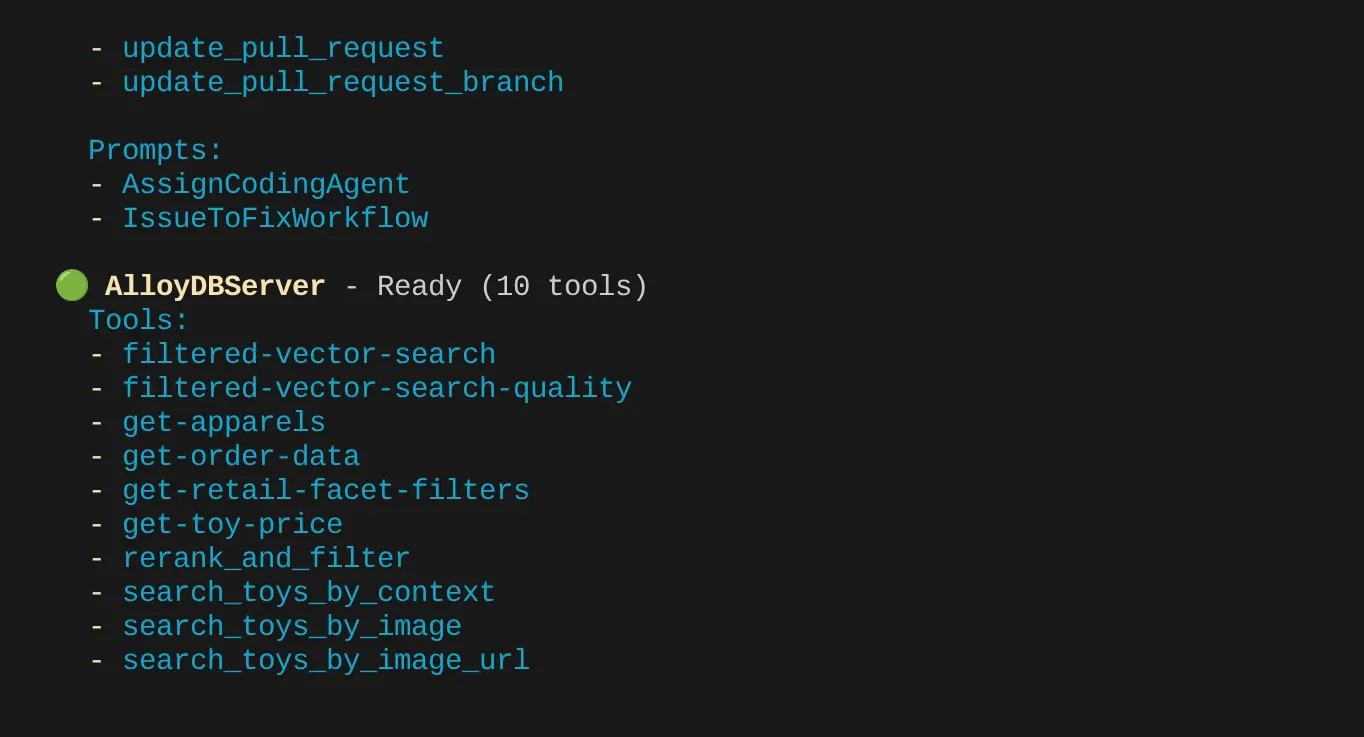
W moim przypadku mam więcej narzędzi. Na razie zignoruj ten komunikat. Na serwerze MCP AlloyDB powinno być widoczne narzędzie get-apparels.
Rozpoczynanie wysyłania zapytań do bazy danych za pomocą narzędzi MCP
Teraz spróbuj zadawać pytania w języku naturalnym, aby pobierać odpowiedzi i zapytania dotyczące zbioru danych, z którym pracujemy:
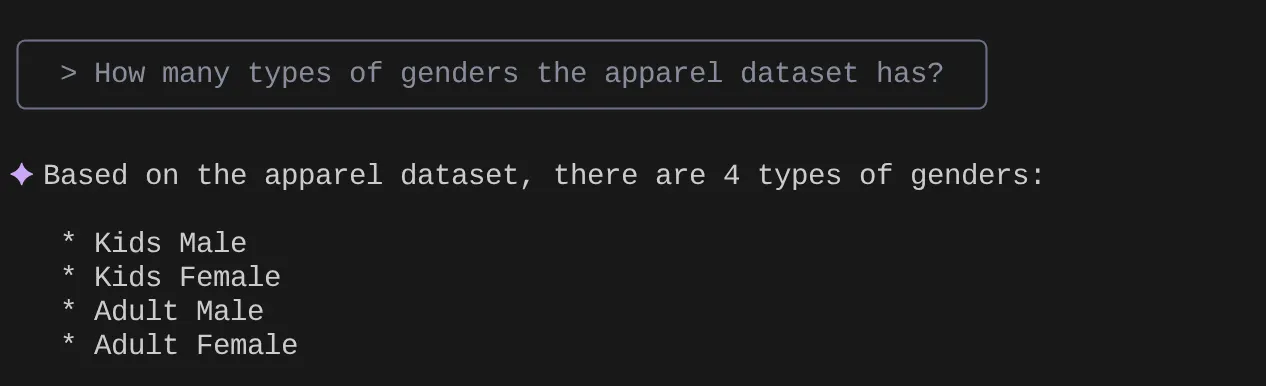
> How many types of genders the apparel dataset has?
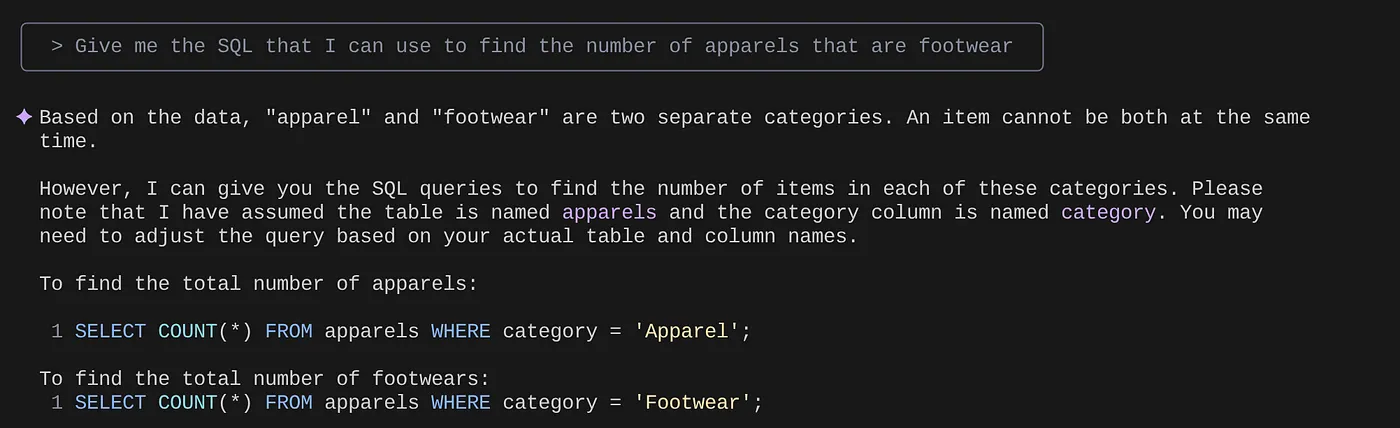
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
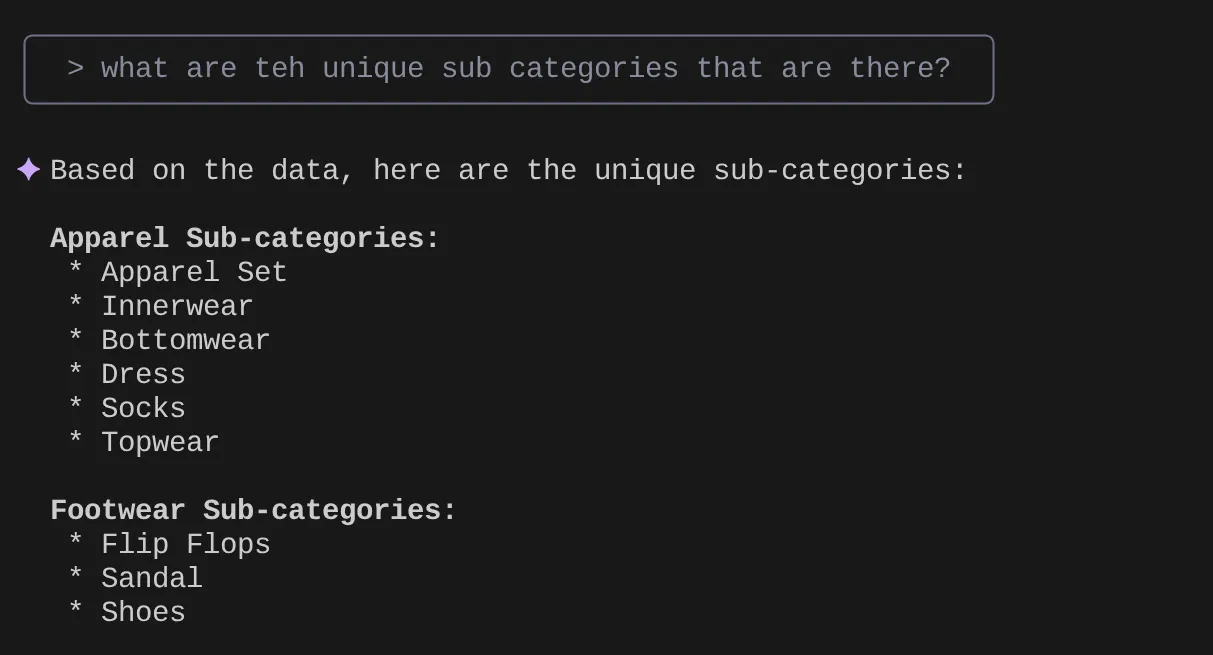
Załóżmy, że na podstawie statystyk i wielu podobnych zapytań udało mi się opracować szczegółowe zapytanie i chcę je przetestować. Załóżmy, że inżynierowie baz danych utworzyli już plik Tools.yaml w sposób pokazany poniżej:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Teraz spróbujmy wyszukiwania w języku naturalnym:
> How many yellow shirts are there for boys?
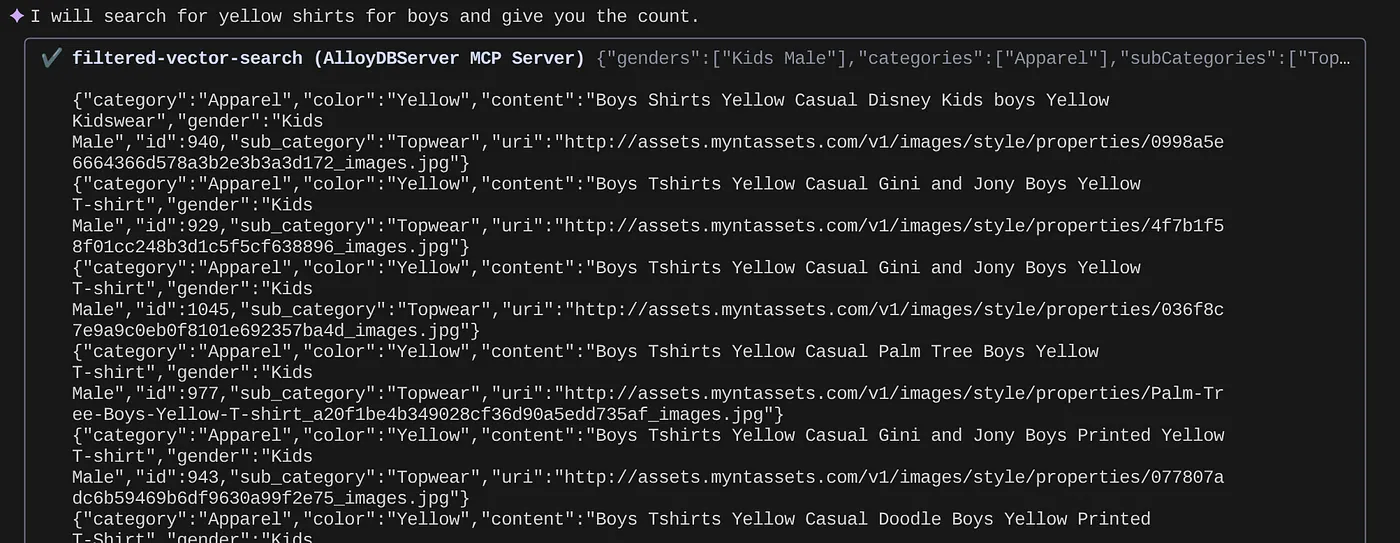

Całkiem nieźle, prawda? Teraz mogę poprawić plik YAML, aby uzyskać lepsze wyniki zapytań, a jednocześnie szybciej wdrażać nowe funkcje w aplikacji.
9. Szybsze tworzenie aplikacji
Zalety wprowadzenia funkcji bazy danych bezpośrednio do środowiska IDE za pomocą interfejsu wiersza poleceń Gemini i MCP Toolbox nie są tylko teoretyczne. Przekłada się to na konkretne, przyspieszające pracę przepływy pracy, zwłaszcza w przypadku złożonej aplikacji, takiej jak nasze hybrydowe rozwiązanie dla handlu detalicznego. Przyjrzyjmy się kilku scenariuszom:
1. Szybkie iterowanie logiki filtrowania produktów
Wyobraź sobie, że właśnie rozpoczęliśmy nową promocję „letniej odzieży sportowej”. Chcemy sprawdzić, jak nasze filtry fasetowe (np. według marki, rozmiaru, koloru czy przedziału cenowego) działają w przypadku tej nowej kategorii.
Bez integracji z IDE:
Prawdopodobnie przełączę się na oddzielnego klienta SQL, napiszę zapytanie, wykonam je, przeanalizuję wyniki, wrócę do IDE, aby dostosować kod aplikacji, ponownie przełączę się na klienta i powtórzę te czynności. Przełączanie się między kontekstami jest bardzo uciążliwe.
Za pomocą interfejsu wiersza poleceń Gemini i MCP:
Mogę pozostać w IDE i wykonywać inne czynności:
- Tworzenie zapytań: mogę szybko zaktualizować zapytanie w pliku YAML, używając (hipotetycznego zbioru danych) „SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'” i wypróbować je bezpośrednio w terminalu.
- Eksploracja danych: natychmiastowe wyświetlanie zwróconych marek. Jeśli chcę sprawdzić dostępność produktu określonej marki i w określonym rozmiarze, mogę użyć innego szybkiego zapytania: „SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'”.
- Integracja kodu: na podstawie tych szybkich informacji o danych w IDE mogę od razu dostosować logikę filtrowania frontendu lub wywołania interfejsu API backendu, co znacznie skraca pętlę informacji zwrotnych.
2. Dostrajanie wyszukiwania wektorowego pod kątem rekomendacji produktów
Nasze wyszukiwanie hybrydowe opiera się na wektorach osadzonych, które służą do generowania trafnych rekomendacji produktów. Załóżmy, że obserwujemy spadek współczynnika klikalności rekomendacji „męskie buty do biegania”.
Bez integracji z IDE:
Uruchamiałbym niestandardowe skrypty lub zapytania w narzędziu do obsługi baz danych, aby analizować wyniki podobieństwa rekomendowanych butów, porównywać je z danymi o interakcjach użytkowników i próbować znaleźć korelacje między nimi.
Za pomocą interfejsu wiersza poleceń Gemini i MCP:
- Analizowanie wektorów: mogę bezpośrednio wysyłać zapytania o wektory produktów i powiązane z nimi metadane: „SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10” (WYBIERZ product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10).
- Sprawdzanie krzyżowe: mogę też szybko sprawdzić rzeczywiste podobieństwo wektorowe między wybranym produktem a jego rekomendacjami. Jeśli na przykład produkt A jest rekomendowany użytkownikom, którzy oglądali produkt B, mogę uruchomić zapytanie, aby pobrać i porównać ich osadzenia wektorowe.
- Debugowanie: umożliwia szybsze debugowanie i testowanie hipotez. Czy model wektora dystrybucyjnego działa zgodnie z oczekiwaniami? Czy w danych występują anomalie, które wpływają na jakość rekomendacji? Mogę uzyskać wstępne odpowiedzi bez opuszczania środowiska kodowania.
3. Informacje o schemacie i dystrybucji danych w przypadku nowych funkcji
Załóżmy, że planujemy dodać funkcję „opinie klientów”. Zanim napiszemy interfejs API backendu, musimy zrozumieć istniejące dane klientów i sposób, w jaki mogą być ustrukturyzowane opinie.
Bez integracji z IDE:
Muszę połączyć się z klientem bazy danych, uruchomić polecenia DESCRIBE w tabelach takich jak klienci i zamówienia, a następnie wysłać zapytanie o przykładowe dane, aby poznać relacje i typy danych.
Za pomocą interfejsu wiersza poleceń Gemini i MCP:
- Eksploracja schematu: mogę po prostu wysłać zapytanie do tabeli w pliku YAML i wykonać je bezpośrednio w terminalu.
- Próbkowanie danych: mogę pobrać dane próbne, aby poznać dane demograficzne klientów i historię zakupów: „SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5”.
- Planowanie: szybki dostęp do schematu i dystrybucji danych pomaga nam podejmować świadome decyzje dotyczące sposobu projektowania nowej tabeli opinii, kluczy obcych, które należy utworzyć, oraz skutecznego łączenia opinii z klientami i produktami – wszystko to jeszcze przed napisaniem choćby jednej linii kodu aplikacji dla nowej funkcji.
To tylko kilka przykładów, ale podkreślają one główną korzyść: zmniejszenie tarć i zwiększenie szybkości pracy deweloperów. Dzięki możliwości interakcji z AlloyDB bezpośrednio w IDE interfejs wiersza poleceń Gemini i zestaw narzędzi MCP umożliwiają nam szybsze tworzenie lepszych i bardziej responsywnych aplikacji.
10. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Menedżer zasobów.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
- Możesz też usunąć klaster AlloyDB (jeśli podczas konfiguracji nie wybrano lokalizacji us-central1, zmień ją w tym hiperlinku), który został utworzony w tym projekcie, klikając przycisk USUN KLASER.
11. Gratulacje
Gratulacje! Udało Ci się zintegrować MCP Toolbox bezpośrednio ze środowiskiem IDE, aby bezproblemowo korzystać z AlloyDB, oraz użyć interfejsu wiersza poleceń Gemini do interakcji z naszym zbiorem danych e-commerce, aby pisać zapytania, które zwykle wymagają oddzielnych narzędzi. Poznaliśmy nowe sposoby sprawdzania i analizowania danych – od sprawdzania struktur tabel po szybkie weryfikowanie poprawności danych – wszystko to za pomocą znanych interfejsów wiersza poleceń w naszym IDE.
Sklonuj repozytorium, przeanalizuj je i daj mi znać, czy udało Ci się ulepszyć aplikację za pomocą interfejsu wiersza poleceń Gemini i MCP Toolbox for Databases.
Aby dowiedzieć się więcej o takich aplikacjach opartych na danych, które zostały utworzone za pomocą interfejsu wiersza poleceń Gemini i MCP oraz wdrożone w środowiskach wykonawczych bezserwerowych, zarejestruj się na nasz nadchodzący sezon Code Vipassana, w ramach którego będziesz mieć możliwość uczestniczenia w praktycznych sesjach prowadzonych przez instruktorów i wykonywania podobnych ćwiczeń.