
1. Visão geral
Lembra da nossa jornada para criar uma experiência híbrida dinâmica de varejo com o AlloyDB, combinando filtragem facetada e pesquisa vetorial? Esse aplicativo foi uma demonstração poderosa das necessidades do varejo moderno, mas chegar lá e fazer iterações exigiu um esforço de desenvolvimento significativo. Para desenvolvedores full-stack, a constante troca entre editores de código e ferramentas de banco de dados pode ser um gargalo, atrasando a inovação e o processo crucial de compreensão dos dados.
Solução
É exatamente aqui que o poder do desenvolvimento acelerado de aplicativos realmente se destaca. Por isso, estou muito feliz em compartilhar como a caixa de ferramentas do MCP (Modern Cloud Platform), acessível pela CLI do Gemini intuitiva, se tornou uma parte indispensável do meu kit de ferramentas. Imagine interagir perfeitamente com sua instância do AlloyDB, escrever consultas e entender seu conjunto de dados, tudo diretamente no seu ambiente de desenvolvimento integrado (IDE). Não se trata apenas de conveniência, mas de reduzir fundamentalmente o atrito no ciclo de vida de desenvolvimento, permitindo que você se concentre na criação de recursos inovadores em vez de lidar com ferramentas externas.
No contexto do nosso app de e-commerce de varejo, em que precisávamos consultar dados de produtos com eficiência, processar filtragens complexas e aproveitar as nuances da pesquisa vetorial, a capacidade de iterar rapidamente nas interações com o banco de dados foi fundamental. A MCP Toolbox, com tecnologia da CLI do Gemini, não apenas simplifica, mas também acelera e transforma a maneira como podemos explorar, testar e refinar a lógica de banco de dados que sustenta nossos aplicativos. Vamos saber como essa combinação inovadora está tornando o desenvolvimento full-stack mais rápido, inteligente e agradável.
O que você vai aprender e criar
Um aplicativo de pesquisa no varejo que usa a MCP Toolbox no ambiente de desenvolvimento integrado, com tecnologia da CLI do Gemini. Abordaremos:
- Como integrar a MCP Toolbox diretamente ao seu ambiente de desenvolvimento integrado para uma interação perfeita com o AlloyDB.
- Exemplos práticos de como usar a CLI do Gemini para escrever e executar consultas SQL nos seus dados de varejo.
- Use a CLI do Gemini para interagir com nosso conjunto de dados de e-commerce de varejo, escrevendo consultas que normalmente exigem ferramentas separadas e vendo os resultados instantaneamente.
- Descubra novas maneiras de analisar e entender os dados, desde a verificação das estruturas de tabelas até a realização de verificações rápidas de integridade dos dados, tudo isso usando interfaces de linha de comando conhecidas no nosso ambiente de desenvolvimento integrado.
- Como esse fluxo de trabalho acelerado de banco de dados contribui diretamente para ciclos de desenvolvimento full-stack mais rápidos, permitindo prototipagem e iteração rápidas.
Techstack
Estamos usando:
- AlloyDB para banco de dados
- MCP Toolbox para abstrair recursos avançados de IA e generativos de bancos de dados do aplicativo
- Cloud Run para implantação sem servidor.
- CLI do Gemini para entender e analisar o conjunto de dados e criar a parte do banco de dados do aplicativo de e-commerce de varejo.
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando executado no Google Cloud. Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: siga o link e ative as APIs.
Como alternativa, use o comando gcloud. Consulte a documentação para ver o uso e os comandos gcloud.
3. Configuração do banco de dados
Neste laboratório, vamos usar o AlloyDB como banco de dados para os dados de e-commerce. Ele usa clusters para armazenar todos os recursos, como bancos de dados e registros. Cada cluster tem uma instância principal que fornece um ponto de acesso aos dados. As tabelas vão conter os dados reais.
Vamos criar um cluster, uma instância e uma tabela do AlloyDB em que o conjunto de dados de e-commerce será carregado.
criar um cluster e uma instância
- Navegue até a página do AlloyDB no console do Cloud. Uma maneira fácil de encontrar a maioria das páginas no console do Cloud é pesquisar usando a barra de pesquisa do console.
- Selecione CRIAR CLUSTER nessa página:

- Você vai ver uma tela como esta. Crie um cluster e uma instância com os seguintes valores. Verifique se os valores correspondem caso você esteja clonando o código do aplicativo do repositório:
- ID do cluster: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mais recente recomendado
- Região: "
us-central1" - Rede: "
default"
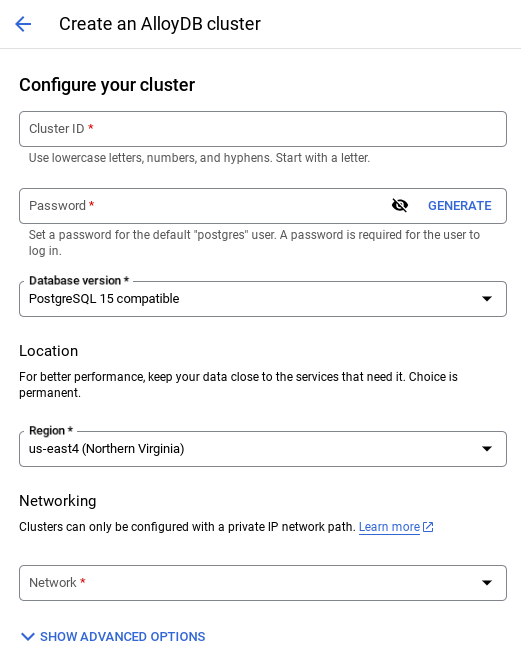
- Ao selecionar a rede padrão, você vai ver uma tela como a abaixo.
Selecione CONFIGURAR CONEXÃO.
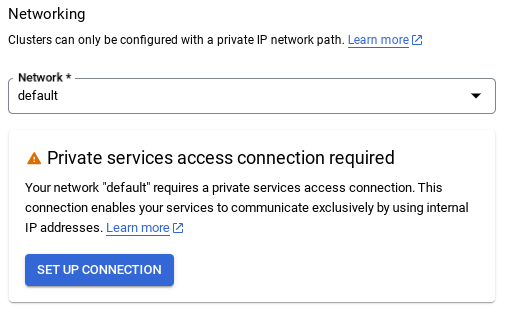
- Em seguida, selecione Usar um intervalo de IP alocado automaticamente e clique em "Continuar". Depois de revisar as informações, selecione CRIAR CONEXÃO.
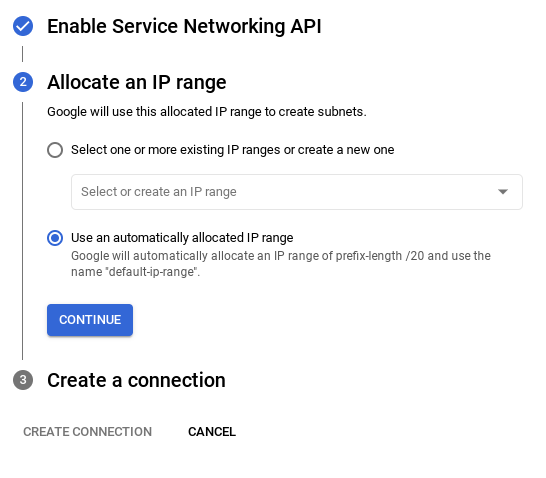
- Depois que a rede for configurada, você poderá continuar criando o cluster. Clique em CRIAR CLUSTER para concluir a configuração do cluster, conforme mostrado abaixo:
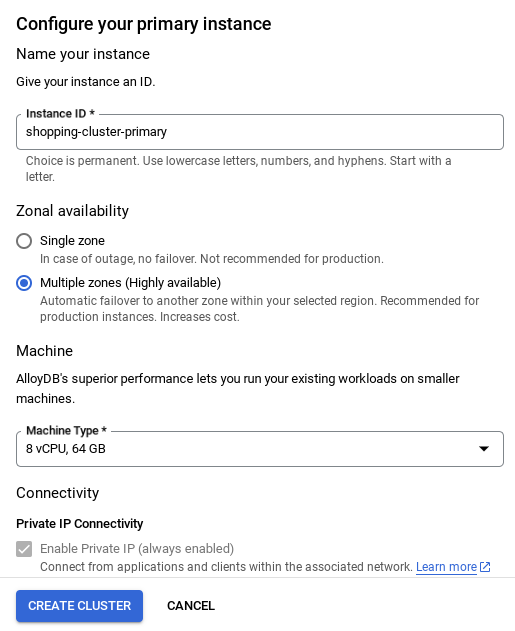
OBSERVAÇÃO IMPORTANTE:
- Mude o ID da instância (que pode ser encontrado no momento da configuração do cluster / instância) para **
vector-instance**. Se não for possível mudar, lembre-se de **usar o ID da instância** em todas as referências futuras. - A criação do cluster leva cerca de 10 minutos. Quando a operação for concluída, uma tela vai mostrar a visão geral do cluster que você acabou de criar.
4. Ingestão de dados
Agora é hora de adicionar uma tabela com os dados da loja. Acesse o AlloyDB, selecione o cluster principal e o AlloyDB Studio:
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb"
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Ativar extensões
Para criar esse app, vamos usar as extensões pgvector e google_ml_integration. A extensão pgvector permite armazenar e pesquisar embeddings de vetores. A extensão google_ml_integration oferece funções que você usa para acessar endpoints de previsão da Vertex AI e receber previsões em SQL. Ative essas extensões executando os seguintes DDLs:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Para verificar as extensões ativadas no seu banco de dados, execute este comando SQL:
select extname, extversion from pg_extension;
Criar uma tabela
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
A coluna de embedding permite o armazenamento dos valores de vetor do texto.
Conceder permissão
Execute a instrução abaixo para conceder a execução da função "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Conceder o papel de usuário da Vertex AI à conta de serviço do AlloyDB
No console do Google Cloud IAM, conceda à conta de serviço do AlloyDB (que tem esta aparência: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) acesso à função "Usuário da Vertex AI". PROJECT_NUMBER vai ter o número do seu projeto.
Como alternativa, execute o comando abaixo no terminal do Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Carregar dados no banco de dados
- Copie as instruções de consulta
insertdainsert scripts sqlna planilha para o editor, conforme mencionado acima. Você pode copiar de 10 a 50 instruções de inserção para uma demonstração rápida desse caso de uso. Há uma lista selecionada de inserções na guia "Inserções selecionadas: 25 a 30 linhas". - Clique em Executar. Os resultados da consulta aparecem na tabela Resultados.
OBSERVAÇÃO IMPORTANTE:
Copie apenas 25 a 50 registros para inserir e verifique se eles são de um intervalo de categoria, subcategoria, cor e tipos de gênero.
5. Criar embeddings para os dados
A verdadeira inovação na pesquisa moderna está em entender o significado, não apenas as palavras-chave. É aqui que entram em jogo os embeddings e a pesquisa vetorial.
Transformamos descrições de produtos e consultas de usuários em representações numéricas de alta dimensão chamadas "embeddings" usando modelos de linguagem pré-treinados. Esses embeddings capturam o significado semântico, permitindo encontrar produtos que são "semelhantes em significado", em vez de apenas conter palavras correspondentes. Inicialmente, testamos a pesquisa direta por similaridade vetorial nesses embeddings para estabelecer um valor de referência, demonstrando o poder da compreensão semântica mesmo antes das otimizações de performance.
A coluna de embedding permite o armazenamento dos valores de vetor do texto de descrição do produto. A coluna "img_embeddings" permite o armazenamento de embeddings de imagens (multimodais). Assim, você também pode usar a pesquisa baseada na distância entre texto e imagem. Mas, neste laboratório, vamos usar apenas embeddings de texto.
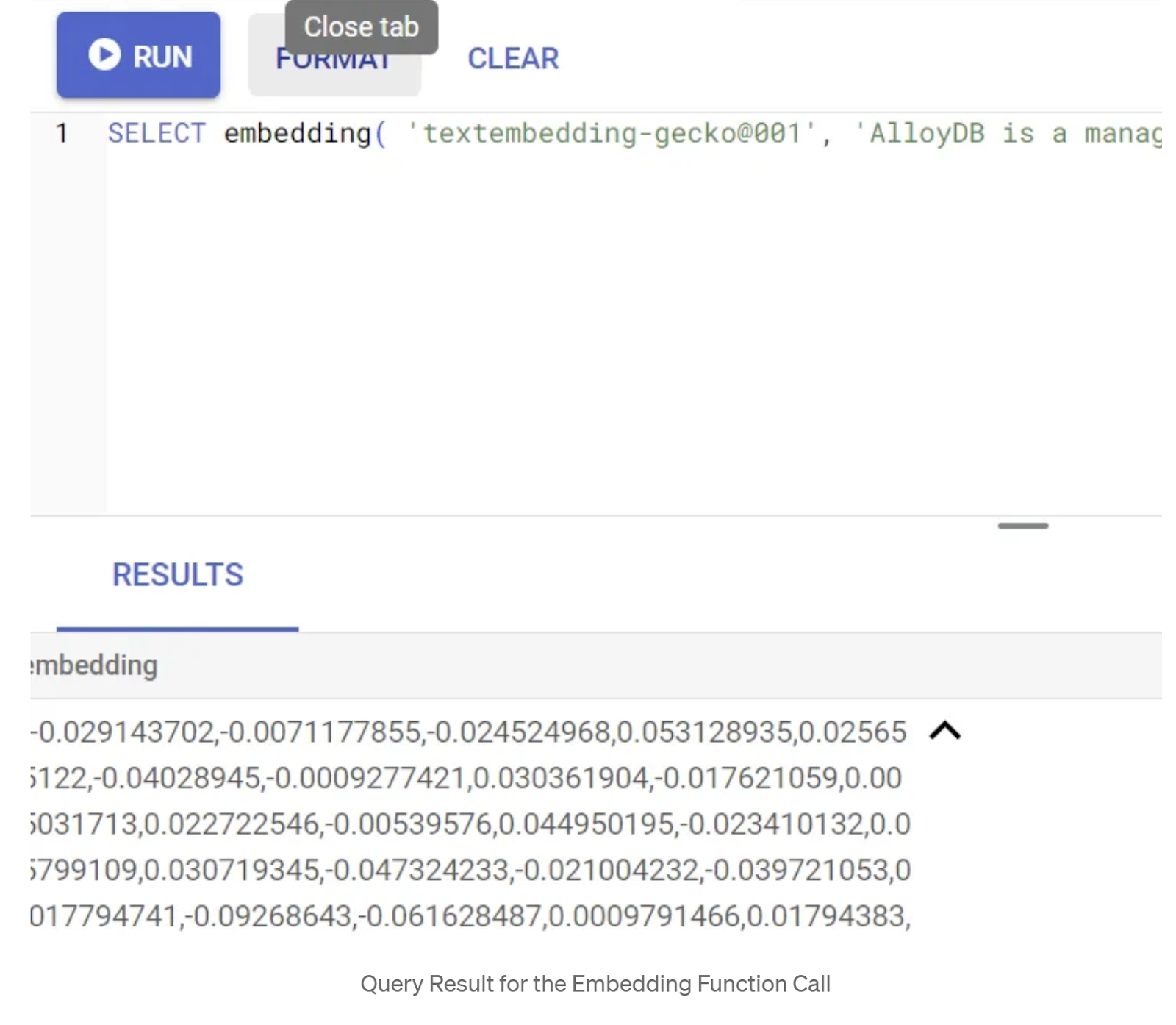
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Isso vai retornar o vetor de embeddings, que parece uma matriz de números de ponto flutuante, para o texto de exemplo na consulta. Ela tem esta aparência:
Atualizar o campo de vetor abstract_embeddings
Execute a DML abaixo para atualizar a descrição do conteúdo na tabela com os embeddings correspondentes:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Talvez você tenha problemas para gerar mais do que alguns embeddings (digamos, no máximo 20 a 25) se estiver usando uma conta de faturamento de crédito de teste do Google Cloud. Portanto, limite o número de linhas no script de inserção.
Se você quiser gerar embeddings de imagem (para realizar uma pesquisa contextual multimodal), execute a atualização abaixo também:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
Nos bastidores, ferramentas robustas e um aplicativo bem estruturado garantem uma operação tranquila.
A caixa de ferramentas MCP (Protocolo de Contexto de Modelo) para bancos de dados simplifica a integração da IA generativa e das ferramentas agênticas com o AlloyDB. Ele funciona como um servidor de código aberto que simplifica o pool de conexões, a autenticação e a exposição segura de funcionalidades de banco de dados para agentes de IA ou outros aplicativos.
No nosso aplicativo, usamos a MCP Toolbox for Databases como uma camada de abstração para todas as nossas consultas de pesquisa híbrida inteligente.
Siga as etapas abaixo para configurar e implantar a caixa de ferramentas no nosso caso de uso:
Um dos bancos de dados compatíveis com a MCP Toolbox for Databases é o AlloyDB. Como já provisionamos isso na seção anterior, vamos configurar a caixa de ferramentas.
- Acesse o terminal do Cloud Shell e verifique se o projeto está selecionado e aparece no prompt do terminal. Execute o comando abaixo no terminal do Cloud Shell para acessar o diretório do projeto:
mkdir gemini-cli-project
cd gemini-cli-project
- Execute o comando abaixo para fazer o download e instalar a caixa de ferramentas na nova pasta:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Isso vai criar a caixa de ferramentas no diretório atual. Copie o caminho para a caixa de ferramentas.
- Acesse o editor do Cloud Shell (para o modo de edição de código) e, na pasta raiz do projeto "gemini-cli-project", adicione um arquivo chamado "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Vamos entender o arquivo tools.yaml:
As origens representam as diferentes fontes de dados com que uma ferramenta pode interagir. Uma origem representa uma fonte de dados com que uma ferramenta pode interagir. É possível definir origens como um mapa na seção "sources" do arquivo tools.yaml. Normalmente, uma configuração de origem contém todas as informações necessárias para se conectar e interagir com o banco de dados.
As ferramentas definem as ações que um agente pode realizar, como ler e gravar em uma fonte. Uma ferramenta representa uma ação que o agente pode realizar, como executar uma instrução SQL. É possível definir ferramentas como um mapa na seção "tools" do arquivo tools.yaml. Normalmente, uma ferramenta precisa de uma fonte para agir.
Para mais detalhes sobre como configurar o arquivo tools.yaml, consulte esta documentação.
Como você pode ver no arquivo Tools.yaml acima, a ferramenta "get-apparels" lista todos os detalhes das roupas do banco de dados.
7. Configurar a CLI do Gemini
No editor do Cloud Shell, crie uma pasta chamada .gemini dentro da pasta gemini-cli-project e crie um arquivo chamado settings.json nela.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Na seção de comandos do snippet acima, substitua "/home/user/gemini-cli-project/toolbox" pelo caminho para a caixa de ferramentas.
Instalar a CLI do Gemini
Por fim, no terminal do Cloud Shell, instale a CLI do Gemini no mesmo diretório gemini-cli-project executando o comando:
sudo npm install -g @google/gemini-cli
Definir o ID do projeto
Verifique se o ID do projeto ativo está definido no ambiente:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Começar a usar a CLI do Gemini
Na linha de comando, insira o comando:
gemini
Você vai receber uma resposta semelhante a esta:
Autentique e continue para a próxima etapa.
8. Começar a interagir com a CLI do Gemini
Use o comando /mcp para listar os servidores MCP configurados.
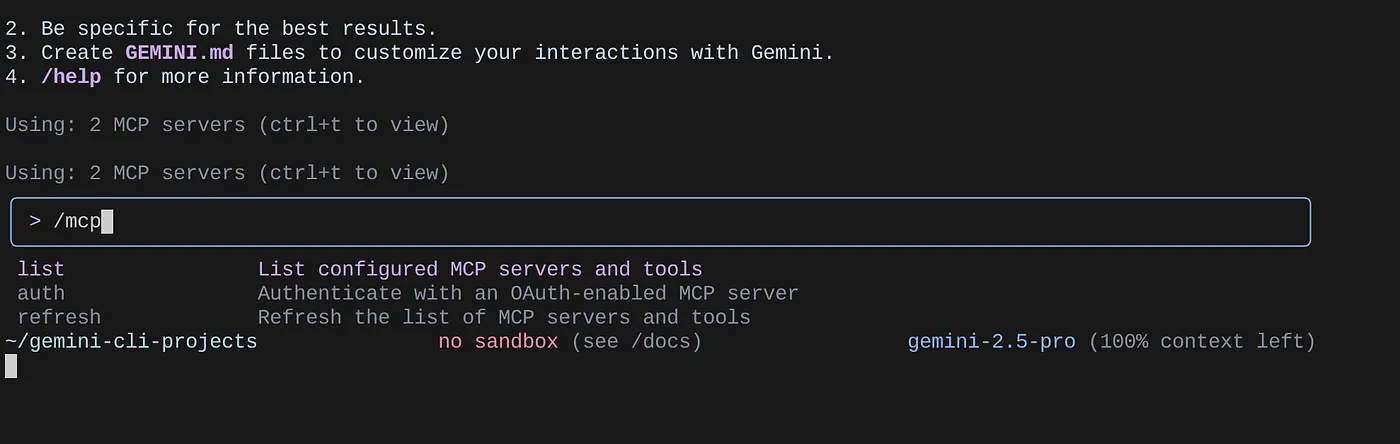
Você vai encontrar os dois servidores MCP que configuramos: GitHub e MCP Toolbox for Databases, listados com as ferramentas deles.
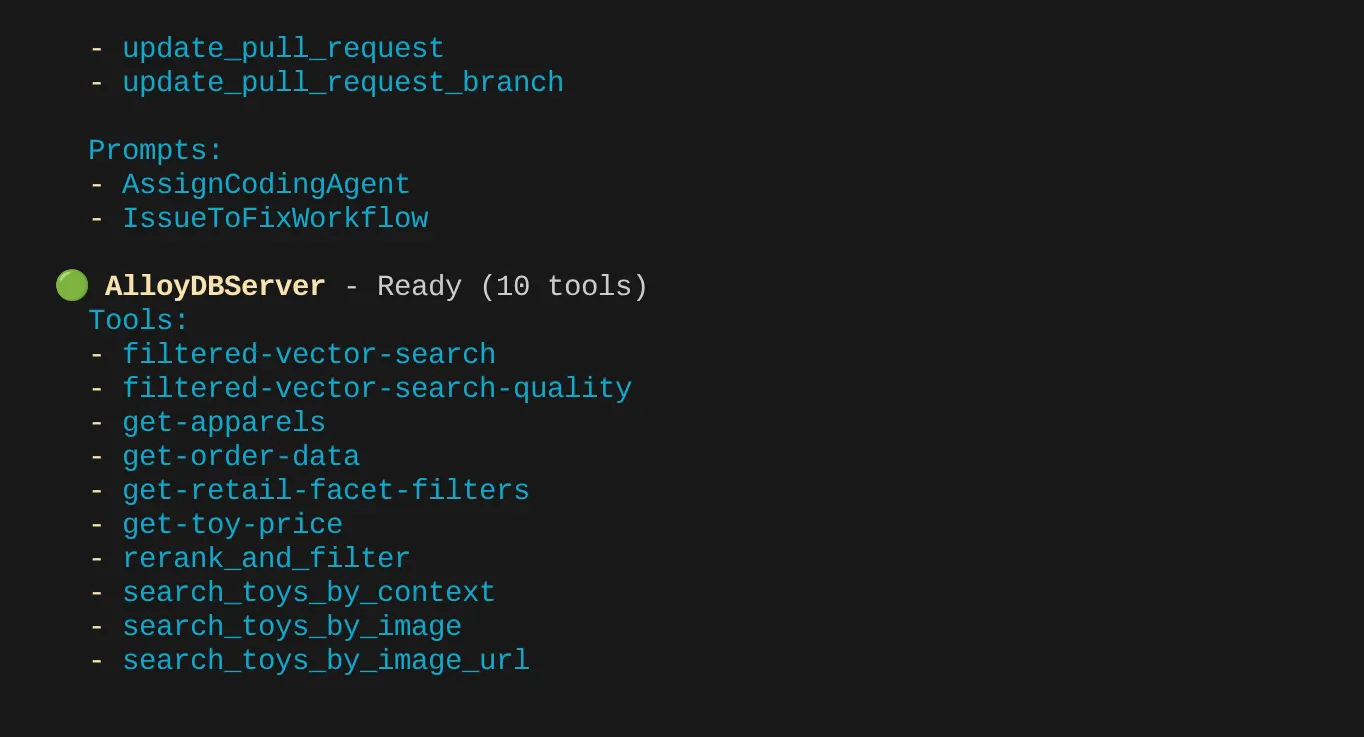
No meu caso, tenho mais ferramentas. Por isso, ignore por enquanto. A ferramenta get-apparels vai aparecer no servidor MCP do AlloyDB.
Comece a consultar o banco de dados pela MCP Toolbox
Agora, faça perguntas em linguagem natural para buscar respostas e consultas sobre o conjunto de dados com que estamos trabalhando:
> How many types of genders the apparel dataset has?
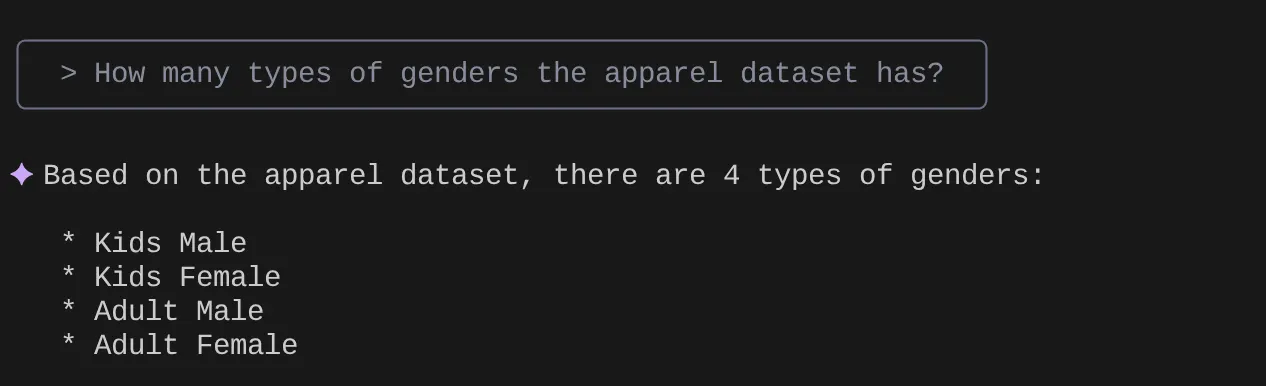
> Give me the SQL that I can use to find the number of apparels that are footwear
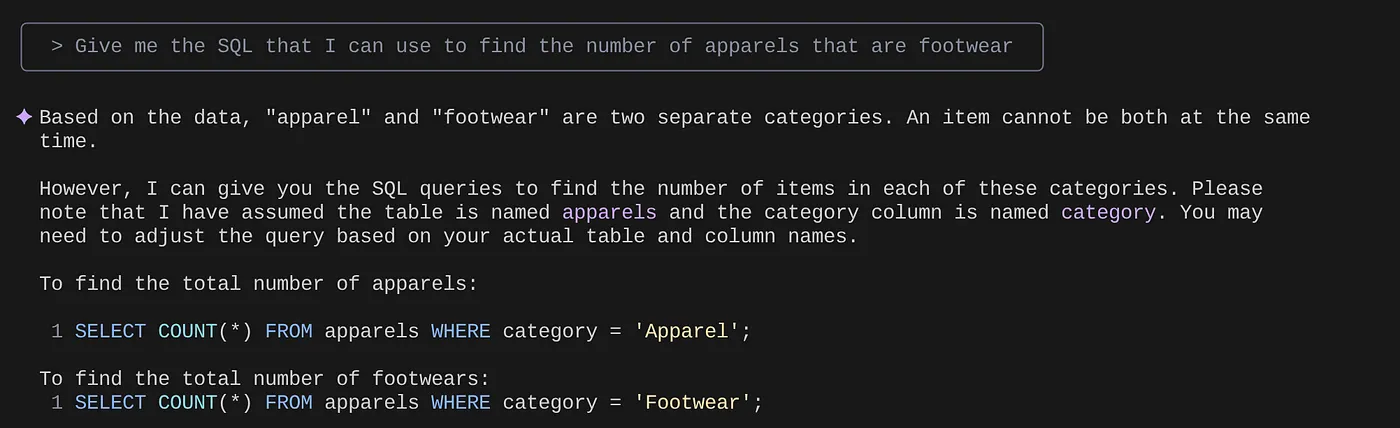
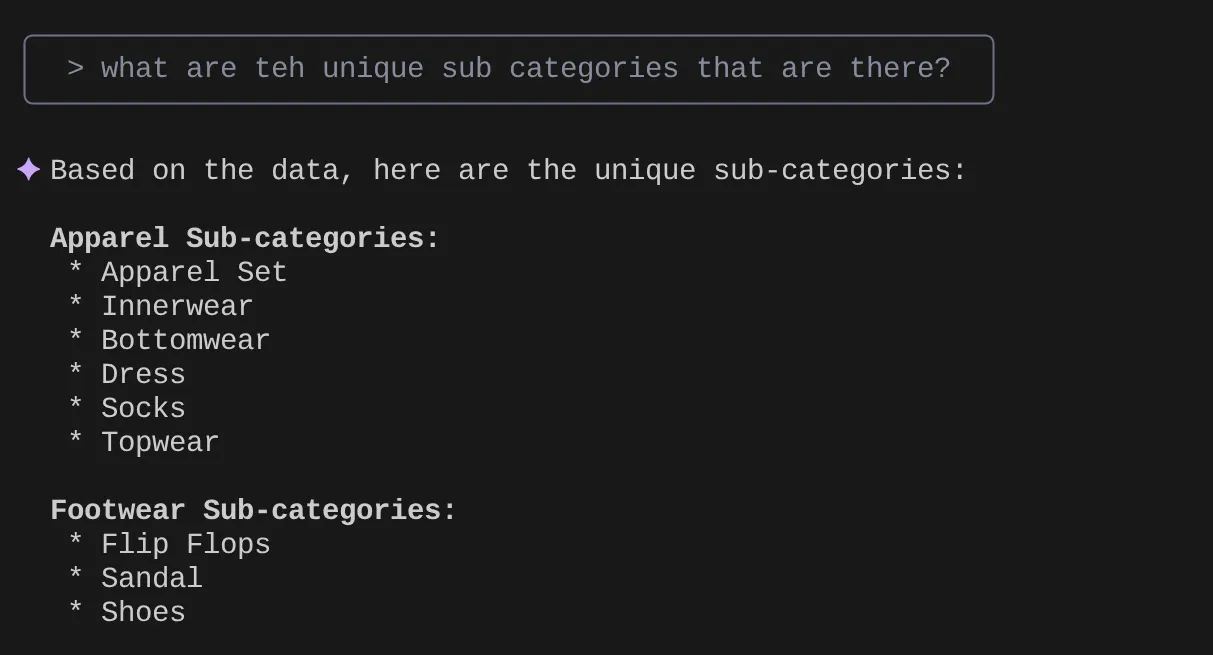
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
Agora, digamos que, com base nos meus insights e em muitas consultas desse tipo, eu criei uma consulta detalhada e quero testá-la. Ou digamos que os engenheiros de banco de dados já tenham criado o arquivo Tools.yaml para você, como abaixo:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Agora vamos tentar uma pesquisa com linguagem natural:
> How many yellow shirts are there for boys?
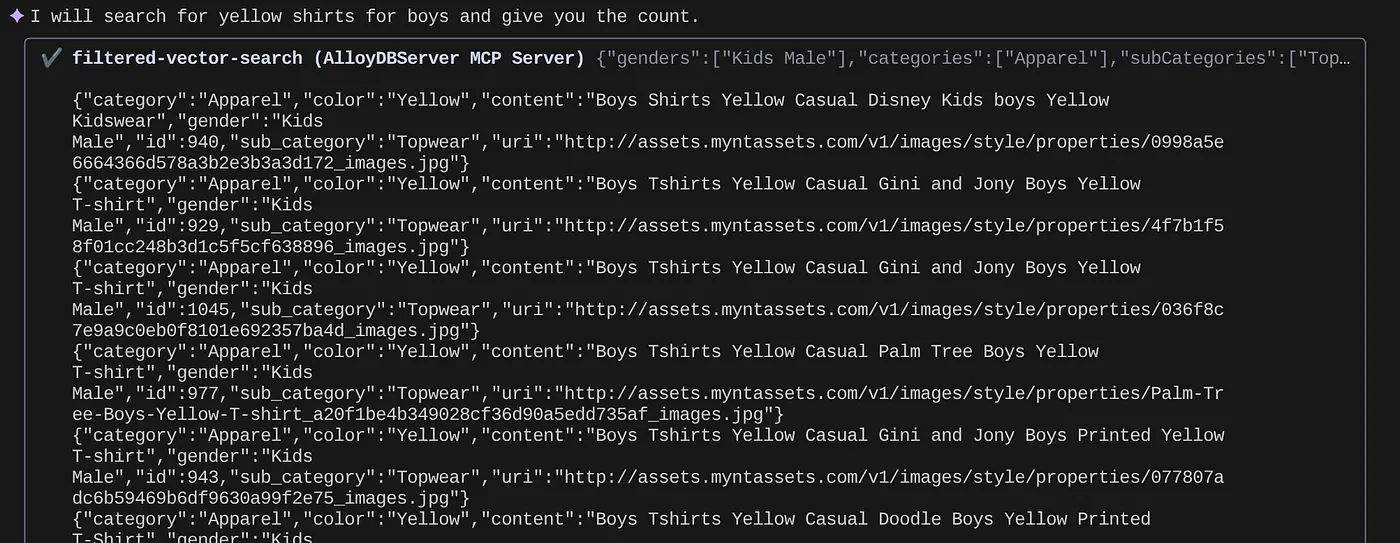

Legal, não é? Agora posso corrigir o arquivo YAML para mais avanços nas consultas enquanto continuo oferecendo novas funcionalidades no meu aplicativo em um cronograma acelerado.
9. Desenvolvimento acelerado de apps
A beleza de trazer recursos de banco de dados diretamente para seu ambiente de desenvolvimento integrado via CLI do Gemini e MCP Toolbox não é apenas teórica. Isso se traduz em fluxos de trabalho tangíveis que aumentam a velocidade, especialmente para um aplicativo complexo como nossa experiência de varejo híbrida. Vamos analisar alguns cenários:
1. Iteração rápida na lógica de filtragem de produtos
Imagine que acabamos de lançar uma nova promoção de "roupas esportivas de verão". Queremos testar como nossos filtros facetados (por exemplo, por marca, tamanho, cor, faixa de preço) interagem com essa nova categoria.
Sem a integração do IDE:
Provavelmente, eu mudaria para um cliente SQL separado, escreveria a consulta, executaria, analisaria os resultados, voltaria ao IDE para ajustar o código do aplicativo, mudaria de volta para o cliente e repetiria. Essa troca de contexto é um grande problema.
Com a CLI do Gemini e o MCP:
Posso ficar no meu ambiente de desenvolvimento integrado e muito mais:
- Consulta: posso atualizar rapidamente a consulta no yaml com (conjunto de dados hipotético) "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'" e testar direto no meu terminal.
- Análise de dados: veja as marcas retornadas instantaneamente. Se eu precisar verificar a disponibilidade do produto de uma marca e tamanho específicos, basta fazer outra consulta rápida:"SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'"
- Integração de código: posso ajustar imediatamente a lógica de filtragem de front-end ou as chamadas de API de back-end com base nesses insights rápidos de dados no ambiente de desenvolvimento integrado, reduzindo significativamente o ciclo de feedback.
2. Ajuste da Pesquisa Vetorial para recomendações de produtos
Nossa pesquisa híbrida usa embeddings de vetor para recomendações de produtos relevantes. Digamos que as taxas de cliques das recomendações de "tênis de corrida masculinos" estejam caindo.
Sem a integração do IDE:
Eu executaria scripts ou consultas personalizadas em uma ferramenta de banco de dados para analisar as pontuações de similaridade dos tênis recomendados, compará-las aos dados de interação do usuário e tentar correlacionar padrões.
Com a CLI do Gemini e o MCP:
- Analisar incorporações:posso consultar diretamente as incorporações de produtos e os metadados associados: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- Referência cruzada:também posso fazer uma verificação rápida da similaridade real do vetor entre um produto escolhido e as recomendações dele. Por exemplo, se o produto A for recomendado para usuários que olharam o produto B, posso executar uma consulta para recuperar e comparar as embeddings de vetor deles.
- Depuração:permite uma depuração e um teste de hipóteses mais rápidos. O modelo de embedding está se comportando como esperado? Há anomalias nos dados que afetam a qualidade da recomendação? Posso receber respostas iniciais sem sair do meu ambiente de programação.
3. Entender o esquema e a distribuição de dados para novos recursos
Digamos que você esteja planejando adicionar um recurso de "avaliações dos clientes". Antes de escrever a API de back-end, precisamos entender os dados do cliente existentes e como as avaliações podem ser estruturadas.
Sem a integração do IDE:
Preciso me conectar a um cliente de banco de dados, executar comandos DESCRIBE em tabelas como "customers" e "orders" e consultar dados de amostra para entender relacionamentos e tipos de dados.
Com a CLI do Gemini e o MCP:
- Análise do esquema:posso consultar a tabela no arquivo YAML e executar diretamente no terminal.
- Amostragem de dados:posso extrair dados de amostra para entender a demografia dos clientes e o histórico de compras: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Planejamento:esse acesso rápido ao esquema e à distribuição de dados ajuda a tomar decisões informadas sobre como projetar a nova tabela de avaliações, quais chaves externas estabelecer e como vincular avaliações a clientes e produtos de maneira eficiente, tudo isso antes de escrever uma única linha de código do aplicativo para o novo recurso.
Esses são apenas alguns exemplos, mas destacam o principal benefício: reduzir o atrito e aumentar a velocidade do desenvolvedor. Ao trazer a interação do AlloyDB diretamente para o ambiente de desenvolvimento integrado, a CLI do Gemini e o MCP Toolbox nos permitem criar aplicativos melhores e mais responsivos com mais rapidez.
10. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página do Gerenciador de recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
- Como alternativa, você pode excluir o cluster do AlloyDB (mude o local neste hiperlink se não tiver escolhido us-central1 para o cluster no momento da configuração) que acabamos de criar para este projeto clicando no botão EXCLUIR CLUSTER.
11. Parabéns
Parabéns! Você integrou a MCP Toolbox diretamente ao seu ambiente de desenvolvimento integrado para uma interação perfeita com o AlloyDB e usou a CLI do Gemini para interagir com nosso conjunto de dados de e-commerce de varejo e escrever consultas que normalmente exigem ferramentas separadas. Você aprendeu novas maneiras de analisar e entender os dados, desde a verificação das estruturas de tabelas até a realização de verificações rápidas de integridade dos dados, tudo isso usando interfaces de linha de comando conhecidas no nosso ambiente de desenvolvimento integrado.
Clone o repositório, analise e me diga se você melhorou o aplicativo usando a CLI do Gemini e a MCP Toolbox para bancos de dados.
Para mais aplicativos orientados a dados com a tecnologia do Gemini CLI, MCP e implantados em ambientes de execução sem servidor, inscreva-se na próxima temporada do Code Vipassana, em que você participa de sessões práticas guiadas por instrutores e mais Codelabs como este.