
1. Обзор
Помните наш опыт создания динамичного гибридного решения для розничной торговли с использованием AlloyDB, сочетающего фасетную фильтрацию и векторный поиск ? Это приложение стало убедительной демонстрацией современных потребностей розничной торговли, но для его создания и дальнейшего совершенствования потребовались значительные усилия. Для full-stack разработчиков постоянное переключение между редакторами кода и инструментами баз данных часто становится узким местом, замедляя инновации и важнейший процесс понимания данных.
Решение
Именно здесь по-настоящему проявляется мощь ускоренной разработки приложений, и именно поэтому я с таким энтузиазмом делюсь тем, как набор инструментов MCP (Modern Cloud Platform), доступный через интуитивно понятный интерфейс командной строки Gemini, стал незаменимой частью моего инструментария. Представьте себе беспрепятственное взаимодействие с вашим экземпляром AlloyDB, написание запросов и анализ вашего набора данных — всё это непосредственно в вашей интегрированной среде разработки (IDE). Речь идёт не просто об удобстве; речь идёт о фундаментальном снижении трения в жизненном цикле разработки, позволяя вам сосредоточиться на создании инновационных функций, а не на борьбе с внешними инструментами.
В контексте нашего приложения для электронной коммерции, где нам необходимо было эффективно запрашивать данные о товарах, обрабатывать сложные фильтры и использовать нюансы векторного поиска, возможность быстро вносить изменения во взаимодействие с базой данных имела первостепенное значение. Инструментарий MCP Toolbox, работающий на базе Gemini CLI, не только упрощает этот процесс, но и ускоряет его, преобразуя способы исследования, тестирования и совершенствования логики базы данных, лежащей в основе наших приложений. Давайте разберемся, как это революционное сочетание делает разработку полного стека быстрее, умнее и приятнее.
Чему вы научитесь и что создадите
Приложение для поиска в розничной торговле, использующее MCP Toolbox в составе IDE и работающее на базе Gemini CLI. Мы рассмотрим:
- Как интегрировать MCP Toolbox непосредственно в вашу IDE для бесперебойного взаимодействия с AlloyDB.
- Практические примеры использования Gemini CLI для написания и выполнения SQL-запросов к вашим данным о розничной торговле.
- Используйте интерфейс командной строки Gemini для взаимодействия с нашим набором данных по розничной электронной коммерции, составляйте запросы, для которых обычно требуются отдельные инструменты, и мгновенно получайте результаты.
- Откройте для себя новые способы анализа и понимания данных — от проверки структуры таблиц до быстрой проверки корректности данных — и все это с помощью привычных интерфейсов командной строки в нашей IDE.
- Как этот ускоренный рабочий процесс с базами данных напрямую способствует ускорению циклов разработки полного стека, позволяя быстро создавать прототипы и проводить итерации.
Технологический стек
Мы используем:
- AlloyDB для баз данных
- MCP Toolbox — это инструмент для абстрагирования расширенных генеративных и ИИ-функций баз данных от приложения.
- Cloud Run для бессерверного развертывания.
- Gemini CLI используется для понимания и анализа набора данных, а также для построения базы данных в рамках приложения для розничной электронной коммерции.
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: перейдите по ссылке и включите API.
В качестве альтернативы можно использовать команду gcloud. Для получения информации о командах gcloud и их использовании обратитесь к документации .
3. Настройка базы данных
В этой лабораторной работе мы будем использовать AlloyDB в качестве базы данных для данных электронной коммерции. Она использует кластеры для хранения всех ресурсов, таких как базы данных и журналы. Каждый кластер имеет основной экземпляр , который обеспечивает точку доступа к данным. Таблицы будут хранить сами данные.
Давайте создадим кластер AlloyDB, экземпляр и таблицу, куда будут загружены данные об электронной коммерции.
Создайте кластер и экземпляр.
- Перейдите на страницу AlloyDB в Cloud Console. Большинство страниц в Cloud Console легко найти, используя строку поиска консоли.
- На этой странице выберите пункт «СОЗДАТЬ КЛАСТЕР» :

- Вы увидите экран, похожий на тот, что показан ниже. Создайте кластер и экземпляр со следующими значениями (убедитесь, что значения совпадают, если вы клонируете код приложения из репозитория):
- идентификатор кластера : "
vector-cluster" - пароль : "
alloydb" - Рекомендуемая последняя версия PostgreSQL: 15.
- Регион : "
us-central1" - Сетевые настройки : "
default"
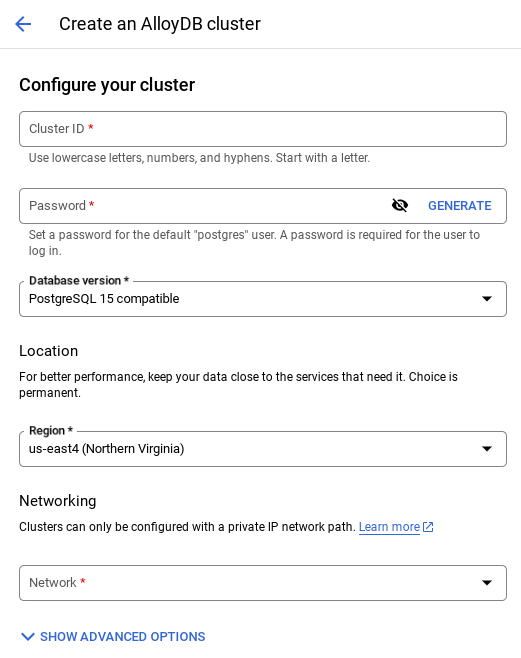
- При выборе сети по умолчанию вы увидите экран, похожий на тот, что показан ниже.
Выберите «НАСТРОЙКА СОЕДИНЕНИЯ» .
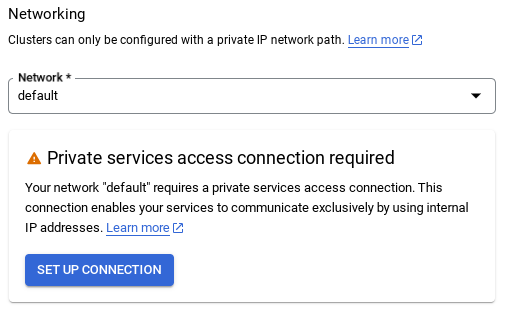
- Затем выберите « Использовать автоматически выделенный диапазон IP-адресов » и продолжите. После проверки информации выберите «СОЗДАТЬ СОЕДИНЕНИЕ».
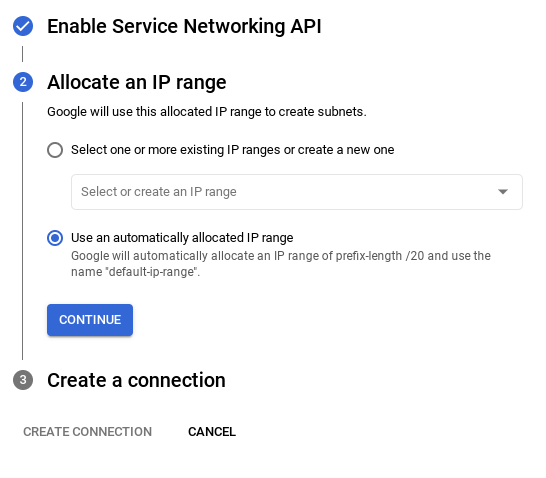
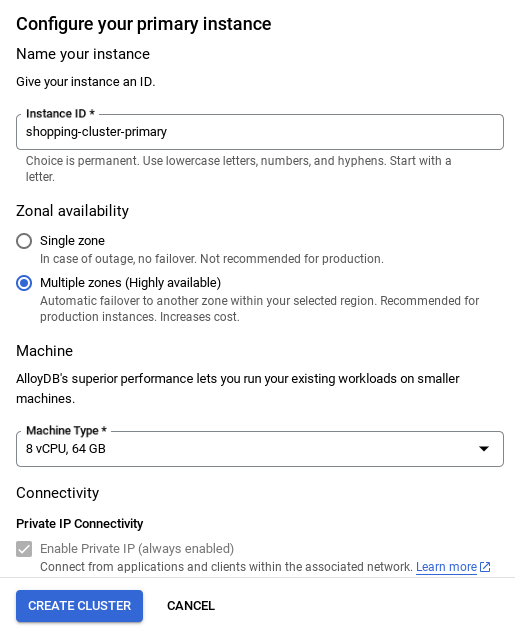
- После настройки сети вы можете продолжить создание кластера. Нажмите кнопку «СОЗДАТЬ КЛАСТЕР» , чтобы завершить настройку кластера, как показано ниже:
ВАЖНОЕ ЗАМЕЧАНИЕ:
- Обязательно измените идентификатор экземпляра (который можно найти во время настройки кластера/экземпляра) на **
vector-instance**. Если вы не можете его изменить, помните, что во всех последующих ссылках следует **использовать свой идентификатор экземпляра**. - Обратите внимание, что создание кластера займет около 10 минут. После успешного завершения процесса вы увидите экран с обзором только что созданного кластера.
4. Ввод данных
Теперь пришло время добавить таблицу с данными о магазине. Перейдите в AlloyDB, выберите основной кластер, а затем AlloyDB Studio:
Возможно, вам потребуется дождаться завершения создания экземпляра. После этого войдите в AlloyDB, используя учетные данные, которые вы создали при создании кластера. Для аутентификации в PostgreSQL используйте следующие данные:
- Имя пользователя: "
postgres" - База данных: "
postgres" - Пароль: "
alloydb"
После успешной аутентификации в AlloyDB Studio команды SQL вводятся в редакторе. Вы можете добавить несколько окон редактора, используя значок плюса справа от последнего окна.
Команды для AlloyDB будут вводиться в окнах редактора, используя при необходимости параметры «Выполнить», «Форматировать» и «Очистить».
Включить расширения
Для создания этого приложения мы будем использовать расширения pgvector и google_ml_integration . Расширение pgvector позволяет хранить и искать векторные представления. Расширение google_ml_integration предоставляет функции, которые вы используете для доступа к конечным точкам прогнозирования Vertex AI и получения прогнозов в формате SQL. Включите эти расширения, выполнив следующие DDL-скрипты:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Чтобы проверить, какие расширения включены в вашей базе данных, выполните следующую SQL-команду:
select extname, extversion from pg_extension;
Создайте таблицу
В AlloyDB Studio можно создать таблицу, используя приведенный ниже оператор DDL:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Столбец "Встраивание" позволит хранить векторные значения текста.
Предоставить разрешение
Выполните указанное ниже выражение, чтобы предоставить права на выполнение функции "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Предоставьте учетной записи службы AlloyDB роль пользователя Vertex AI.
В консоли Google Cloud IAM предоставьте учетной записи службы AlloyDB (которая выглядит следующим образом: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) доступ к роли "Пользователь Vertex AI". В поле PROJECT_NUMBER будет указан номер вашего проекта.
В качестве альтернативы вы можете выполнить следующую команду в терминале Cloud Shell:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Загрузите данные в базу данных.
- Скопируйте операторы запроса
insertизinsert scripts sqlв указанной выше таблице в редактор. Для быстрой демонстрации этого варианта использования можно скопировать от 10 до 50 операторов INSERT. На вкладке «Выбранные вставки (25-30 строк)» представлен список выбранных вставок . - Нажмите кнопку «Выполнить» . Результаты вашего запроса отобразятся в таблице «Результаты» .
ВАЖНОЕ ЗАМЕЧАНИЕ:
Убедитесь, что для вставки копируется только 25-50 записей, и что они относятся к диапазону категорий, подкатегорий, цветов и типов пола.
5. Создайте векторные представления данных.
Истинное новшество в современном поиске заключается в понимании смысла, а не только ключевых слов. Именно здесь вступают в игру векторные представления и векторный поиск.
Мы преобразовали описания товаров и пользовательские запросы в многомерные числовые представления, называемые «эмбеддингами», используя предварительно обученные языковые модели. Эти эмбеддинги отражают семантическое значение, позволяя нам находить товары, «похожие по смыслу», а не просто содержащие совпадающие слова. Первоначально мы экспериментировали с прямым векторным поиском сходства на этих эмбеддингах, чтобы установить базовый уровень, продемонстрировав возможности семантического понимания даже до оптимизации производительности.
Столбец embedding позволит хранить векторные значения текста описания товара. Столбец img_embeddings позволит хранить векторные представления изображений (мультимодальные). Таким образом, вы также сможете использовать поиск по расстоянию между текстом и изображением. Но в этой лабораторной работе мы будем использовать только векторные представления текста.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Эта функция должна вернуть вектор эмбеддингов, который выглядит как массив чисел с плавающей запятой, для примера текста в запросе. Выглядит это так:
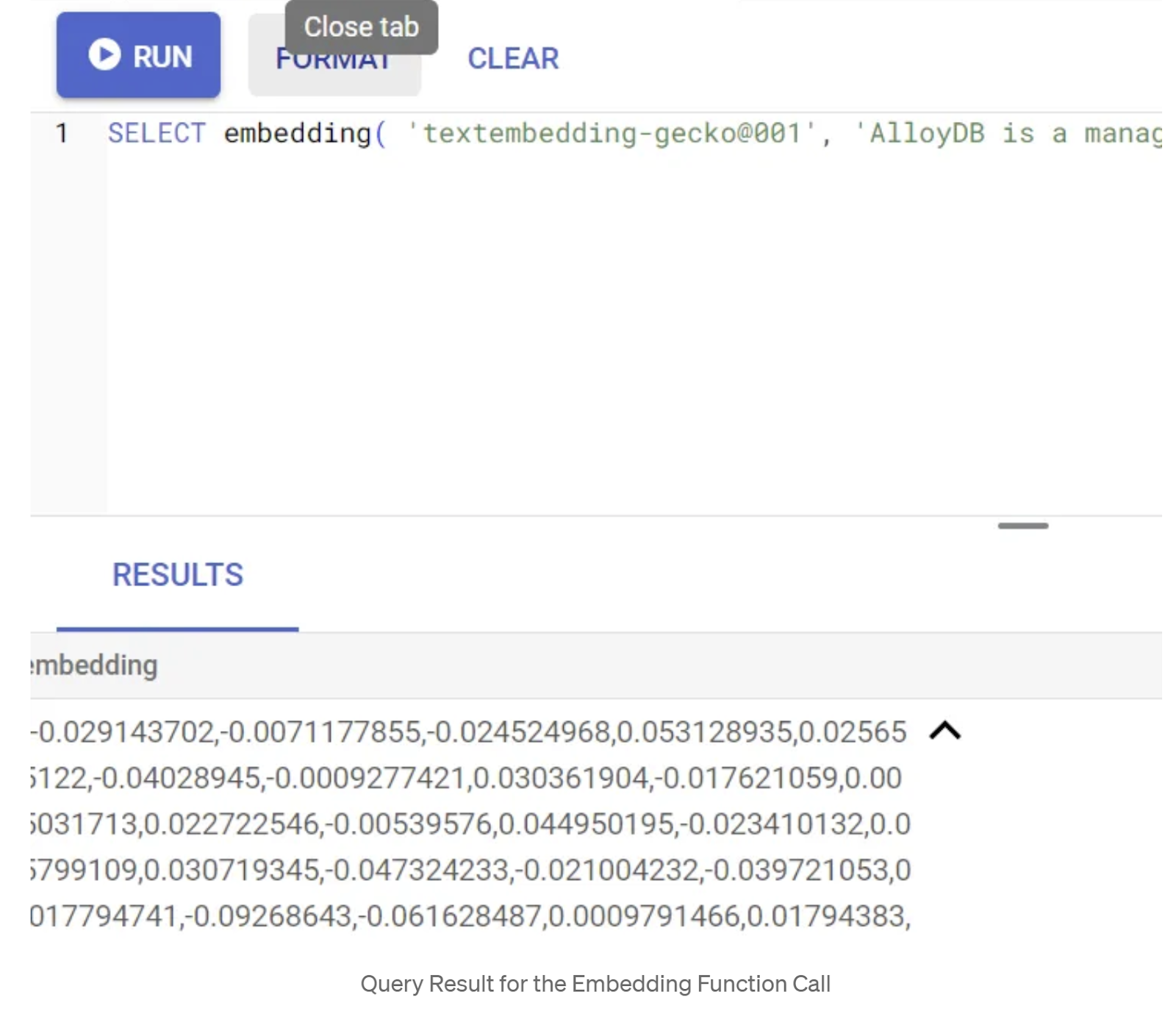
Обновите поле Abstract_Embeddings Vector.
Выполните приведенный ниже DML-запрос, чтобы обновить описание содержимого в таблице, добавив соответствующие векторные представления:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
При использовании пробного аккаунта Google Cloud у вас могут возникнуть проблемы с генерацией более чем нескольких встраиваний (например, максимум 20-25). Поэтому ограничьте количество строк в скрипте вставки.
Если вы хотите сгенерировать векторные представления изображений (для выполнения контекстного поиска в мультимодальной среде), выполните также следующее обновление:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
За кулисами надёжный инструментарий и хорошо структурированное приложение обеспечивают бесперебойную работу.
Инструментарий MCP (Model Context Protocol) для баз данных упрощает интеграцию инструментов генеративного ИИ и агентных систем с AlloyDB. Он выступает в качестве сервера с открытым исходным кодом, который оптимизирует объединение соединений, аутентификацию и безопасное предоставление доступа к функциям базы данных агентам ИИ или другим приложениям.
В нашем приложении мы использовали MCP Toolbox for Databases в качестве уровня абстракции для всех наших интеллектуальных гибридных поисковых запросов.
Для настройки и развертывания Toolbox в соответствии с нашим сценарием выполните следующие действия:
Как видите, одной из баз данных, поддерживаемых MCP Toolbox for Databases, является AlloyDB, и поскольку мы уже настроили её в предыдущем разделе, давайте перейдём к настройке Toolbox.
- Откройте терминал Cloud Shell и убедитесь, что ваш проект выбран и отображается в командной строке. Выполните следующую команду в терминале Cloud Shell, чтобы перейти в каталог вашего проекта:
mkdir gemini-cli-project
cd gemini-cli-project
- Выполните следующую команду, чтобы загрузить и установить Toolbox в новую папку:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Это создаст панель инструментов в текущей директории. Скопируйте путь к панели инструментов.
- Перейдите в редактор Cloud Shell (для режима редактирования кода) и в корневой папке проекта "gemini-cli-project" добавьте файл с именем "tools.yaml".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Давайте разберемся с файлом tools.yaml:
Источники представляют собой различные источники данных, с которыми может взаимодействовать инструмент. Источник — это источник данных, с которым может взаимодействовать инструмент. Вы можете определить источники в виде карты в разделе sources файла tools.yaml. Как правило, конфигурация источников содержит всю информацию, необходимую для подключения к базе данных и взаимодействия с ней.
Инструменты определяют действия, которые может выполнять агент, например, чтение и запись в источник. Инструмент представляет собой действие, которое может выполнить ваш агент, например, выполнение SQL-запроса. Вы можете определить инструменты в виде карты в разделе tools вашего файла tools.yaml. Как правило, для работы с инструментом требуется источник.
Для получения более подробной информации о настройке файла tools.yaml обратитесь к этой документации .
Как видно из файла Tools.yaml выше, инструмент "get-apparels" выводит подробную информацию обо всей одежде из базы данных.
7. Настройка Gemini CLI
В редакторе Cloud Shell создайте новую папку с именем .gemini внутри папки gemini-cli-project и создайте в ней новый файл с именем settings.json .
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
В разделе команд в приведенном выше фрагменте кода замените " /home/user/gemini-cli-project/toolbox " на свой путь к toolbox.
Установите Gemini CLI.
Наконец, из терминала Cloud Shell установим Gemini CLI в ту же директорию gemini-cli-project, выполнив команду:
sudo npm install -g @google/gemini-cli
Укажите идентификатор вашего проекта
Убедитесь, что в настройках среды указан активный идентификатор проекта:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Начните работу с Gemini CLI
В командной строке введите команду:
gemini
Вы должны увидеть ответ, похожий на приведенный ниже:
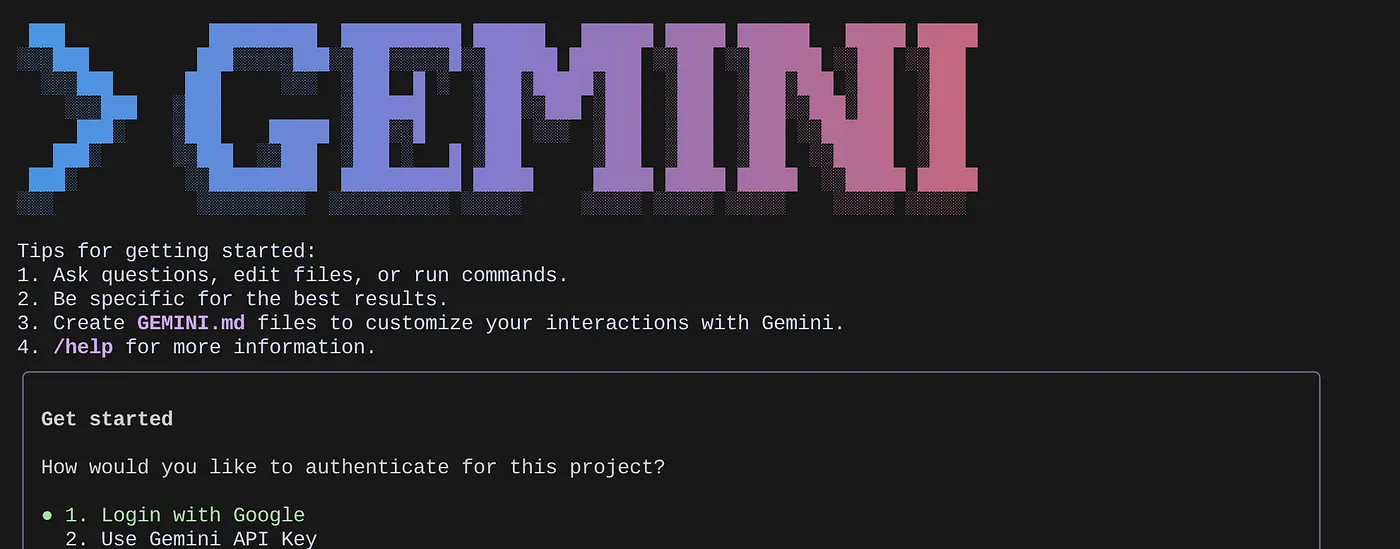
Пройдите аутентификацию и перейдите к следующему шагу.
8. Начните взаимодействовать с Gemini CLI.
Используйте команду /mcp для вывода списка настроенных MCP-серверов.
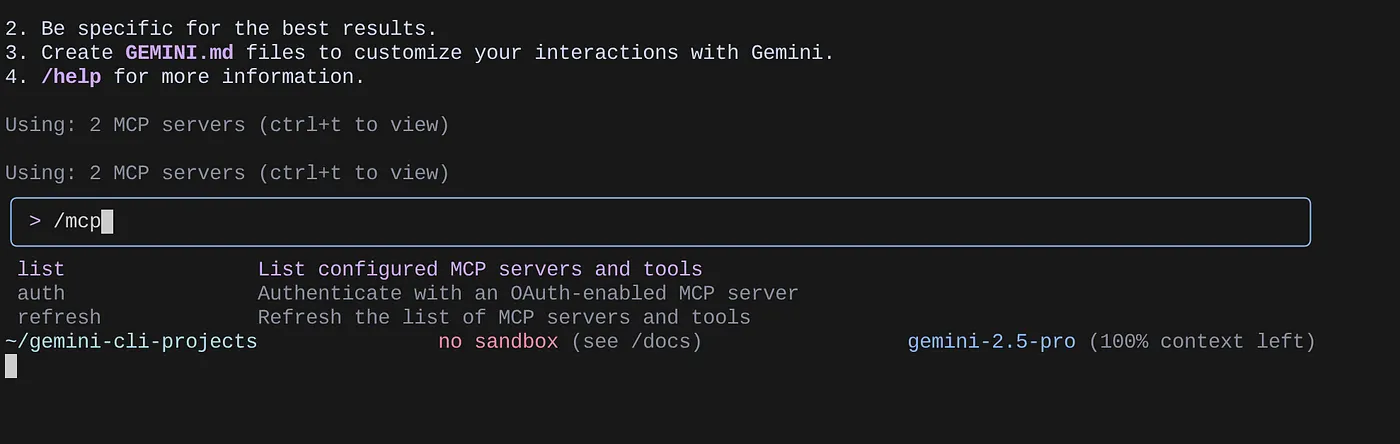
Вы должны увидеть список из двух настроенных нами серверов MCP: GitHub и MCP Toolbox for Databases, а также список используемых ими инструментов.
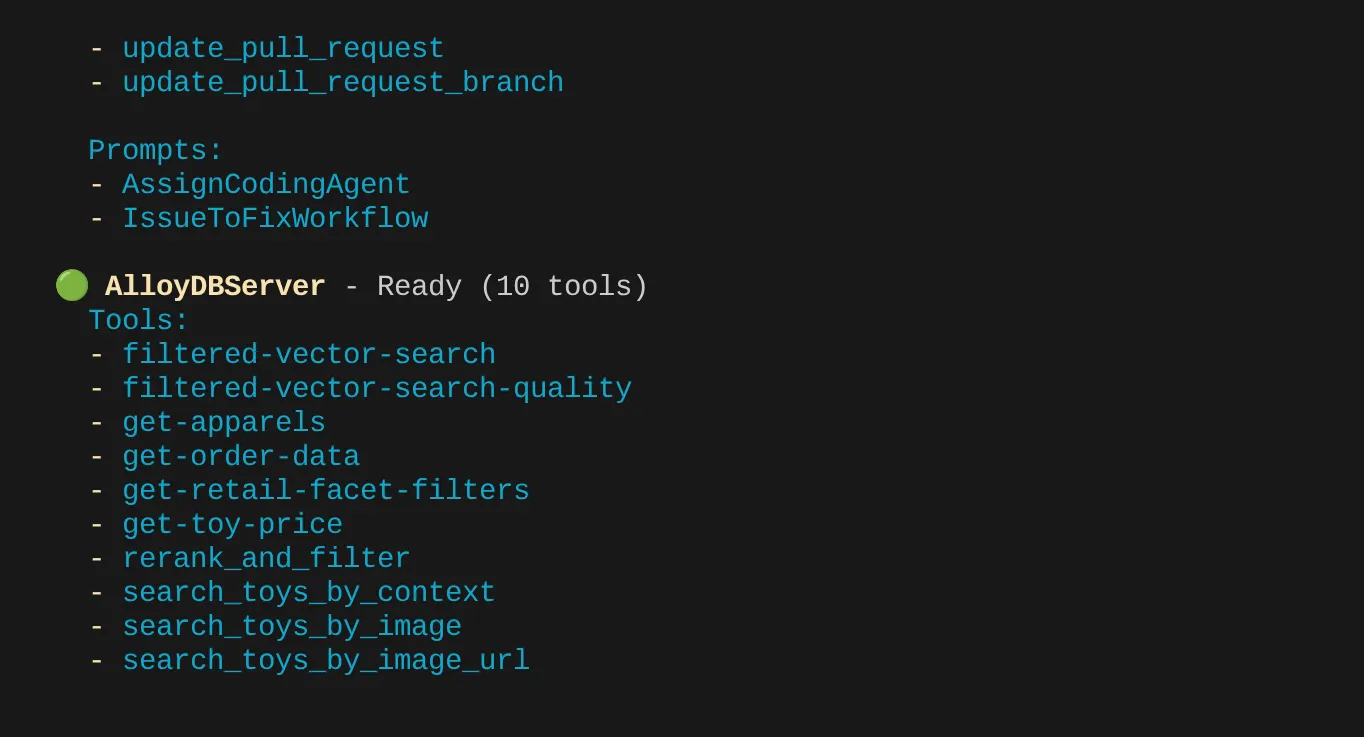
В моем случае у меня больше инструментов. Поэтому пока не обращайте на это внимания. Вы должны увидеть инструмент get-apparels на вашем сервере AlloyDB MCP.
Начните выполнять запросы к базе данных через панель инструментов MCP.
Теперь попробуйте задавать вопросы на естественном языке, чтобы получить ответы и выполнить запросы к набору данных, с которым мы работаем:
> How many types of genders the apparel dataset has?
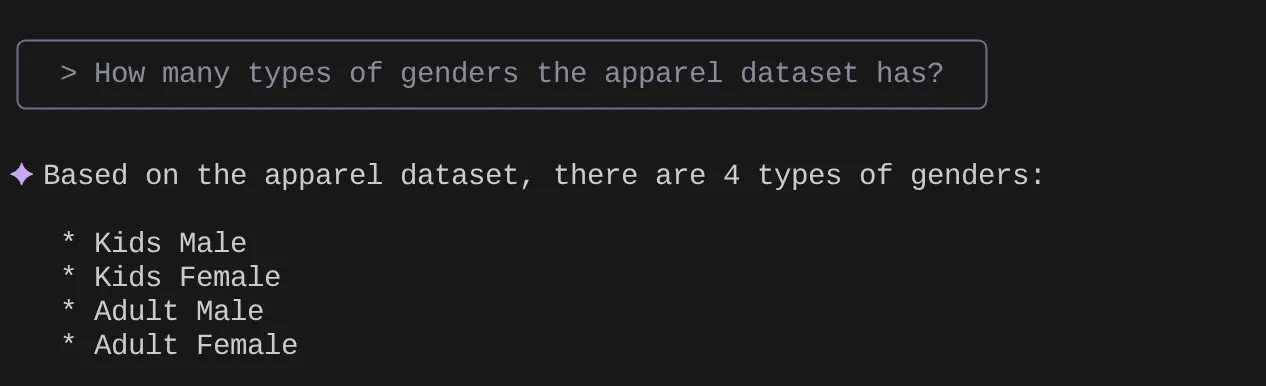
> Give me the SQL that I can use to find the number of apparels that are footwear
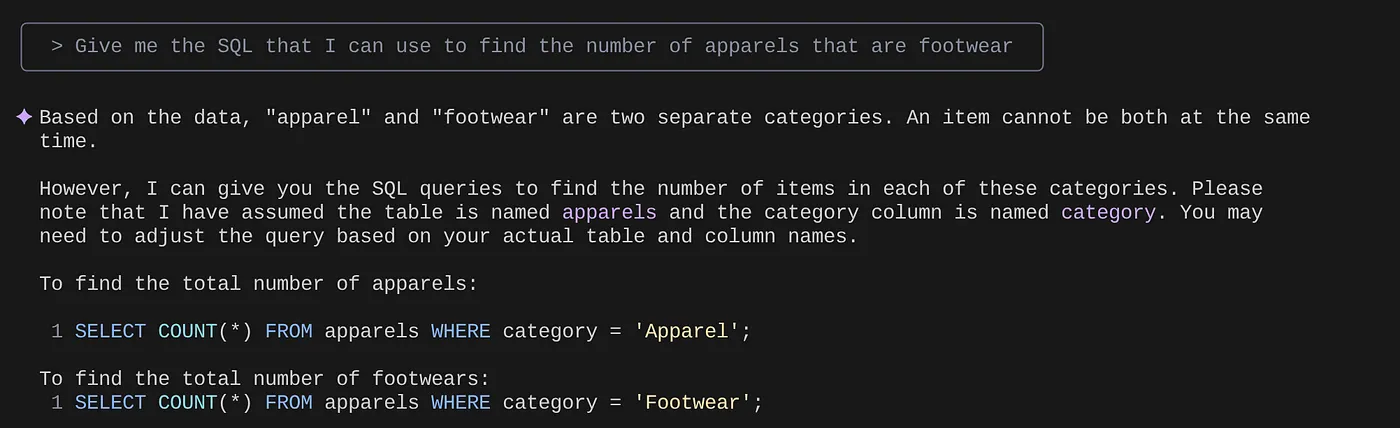
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
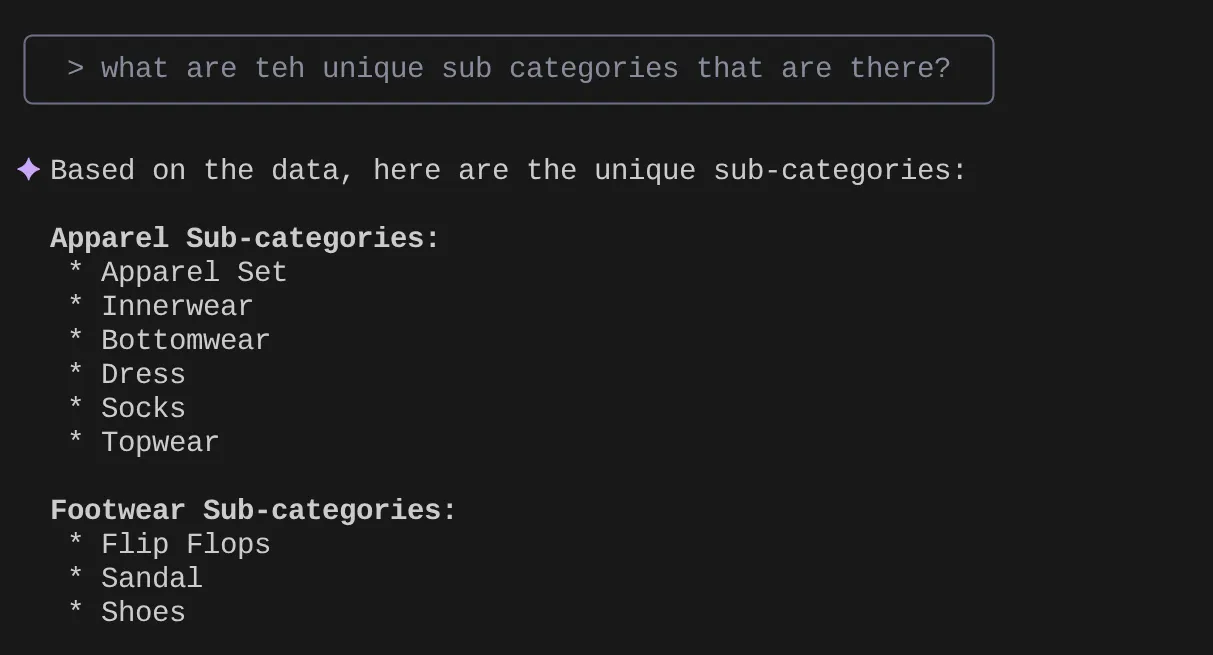
Допустим, на основе моих наблюдений и множества подобных запросов я составил подробный запрос и хочу его протестировать. Или, допустим, инженеры баз данных уже создали для вас файл Tools.yaml, как показано ниже:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Теперь давайте попробуем поиск на естественном языке:
> How many yellow shirts are there for boys?
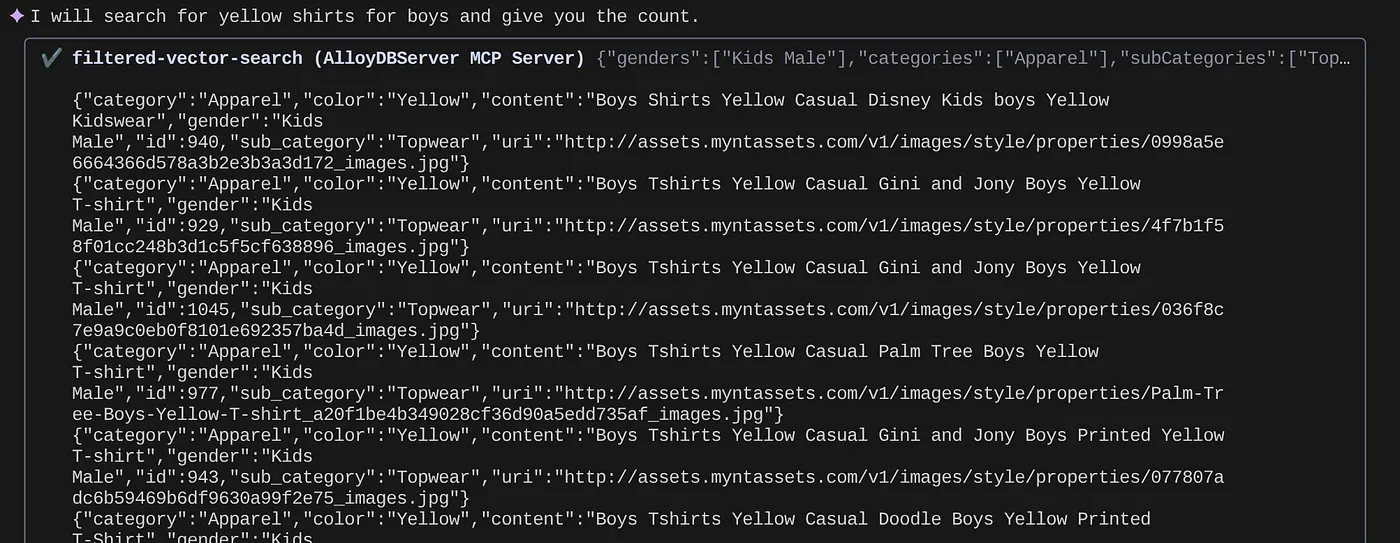

Здорово, правда? Теперь я могу исправлять YAML-файл для дальнейшего совершенствования запросов, одновременно ускоряя разработку новых функций для своего приложения.
9. Ускоренная разработка приложений
Преимущество интеграции возможностей баз данных непосредственно в вашу IDE через Gemini CLI и MCP Toolbox заключается не только в теории. Это приводит к ощутимому повышению скорости рабочих процессов, особенно для такого сложного приложения, как наш гибридный розничный сервис. Рассмотрим несколько сценариев:
1. Быстрое совершенствование логики фильтрации товаров.
Представьте, что мы только что запустили новую акцию по продаже «летней спортивной одежды». Мы хотим проверить, как наши фильтры (например, по бренду, размеру, цвету, ценовому диапазону) взаимодействуют с этой новой категорией.
Без интеграции с IDE:
Скорее всего, я бы переключился на отдельный SQL-клиент, написал запрос, выполнил его, проанализировал результаты, вернулся бы в свою IDE, чтобы внести изменения в код приложения, снова переключился бы на клиент и повторил бы всё сначала. Такое переключение контекста — большая проблема.
С помощью Gemini CLI и MCP:
Я могу оставаться в своей IDE и многое другое:
- Запрос: Я могу быстро обновить запрос в YAML, добавив (гипотетический набор данных) "SELECT DISTINCT brand FROM products WHERE category = 'activewear' AND season = 'summer'", и попробовать его прямо в терминале.
- Анализ данных: Мгновенно просматривайте возвращаемые бренды. Если мне нужно узнать наличие товара определенного бренда и размера, достаточно выполнить еще один быстрый запрос: "SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'"
- Интеграция кода: На основе этих быстрых данных, полученных непосредственно в IDE, я могу немедленно скорректировать логику фильтрации на стороне клиента или вызовы API на стороне бэкэнда, что значительно сокращает цикл обратной связи.
2. Тонкая настройка векторного поиска для рекомендаций товаров.
Наш гибридный поиск использует векторные представления для предоставления релевантных рекомендаций по товарам. Допустим, мы наблюдаем снижение коэффициента кликабельности по рекомендациям типа «мужские беговые кроссовки».
Без интеграции с IDE:
Я бы запускал пользовательские скрипты или запросы в инструменте для работы с базами данных, чтобы анализировать показатели сходства рекомендованной обуви, сравнивать их с данными о взаимодействии пользователей и пытаться выявить закономерности.
С помощью Gemini CLI и MCP:
- Анализ векторных представлений: Я могу напрямую запрашивать векторные представления товаров и связанные с ними метаданные: "SELECT product_id, name, vector_embedding FROM products WHERE category = 'running shoes' AND gender = 'male' LIMIT 10"
- Перекрестная сверка: Я также могу быстро проверить фактическое векторное сходство между выбранным продуктом и его рекомендациями прямо на месте. Например, если продукт A рекомендуется пользователям, которые просматривали продукт B, я могу выполнить запрос для получения и сравнения их векторных представлений.
- Отладка: Это позволяет быстрее проводить отладку и проверку гипотез. Ведет ли себя модель встраивания так, как ожидается? Есть ли аномалии в данных, влияющие на качество рекомендаций? Я могу получить предварительные ответы, не покидая среду программирования.
3. Понимание схемы и распределения данных для новых функций.
Допустим, мы планируем добавить функцию «отзывы клиентов». Прежде чем писать API для бэкэнда, нам нужно понять, какие данные о клиентах уже существуют и как могут быть структурированы отзывы.
Без интеграции с IDE:
Мне потребуется подключиться к клиенту базы данных, выполнить команды DESCRIBE для таких таблиц, как customers и orders, а затем запросить примеры данных, чтобы понять взаимосвязи и типы данных.
С помощью Gemini CLI и MCP:
- Исследование схемы: я могу просто сделать запрос к таблице в YAML-файле и выполнить его непосредственно в терминале.
- Выборка данных: Затем я могу получить выборочные данные, чтобы понять демографические характеристики клиентов и историю покупок: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Планирование: Быстрый доступ к схеме и распределению данных помогает нам принимать обоснованные решения о том, как спроектировать новую таблицу отзывов, какие внешние ключи установить и как эффективно связать отзывы с клиентами и продуктами, и все это до написания хотя бы одной строки кода приложения для новой функции.
Это лишь несколько примеров, но они подчеркивают главное преимущество: снижение трения и повышение скорости разработки. Благодаря интеграции взаимодействия с AlloyDB непосредственно в IDE, Gemini CLI и MCP Toolbox позволяют нам быстрее создавать более качественные и отзывчивые приложения.
10. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу управления ресурсами .
- В списке проектов выберите проект, который хотите удалить, и нажмите кнопку «Удалить» .
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить» , чтобы удалить проект.
- В качестве альтернативы вы можете просто удалить кластер AlloyDB (измените местоположение по этой гиперссылке, если вы не выбрали us-central1 для кластера во время настройки), который мы только что создали для этого проекта, нажав кнопку «УДАЛИТЬ КЛАСТЕР».
11. Поздравляем!
Поздравляем! Вы успешно интегрировали MCP Toolbox непосредственно в свою IDE для бесперебойного взаимодействия с AlloyDB и использовали Gemini CLI для работы с нашим набором данных по розничной электронной коммерции, чтобы писать запросы, которые обычно требуют отдельных инструментов. Вы освоили новые способы анализа и понимания данных — от проверки структуры таблиц до быстрой проверки корректности данных — и все это с помощью привычных интерфейсов командной строки в нашей IDE.
Пожалуйста, клонируйте репозиторий , проанализируйте его и сообщите мне, если вы улучшили приложение, используя Gemini CLI и MCP Toolbox for Databases.
Чтобы узнать больше о подобных приложениях, основанных на обработке данных и созданных с помощью Gemini CLI, MCP и развернутых на бессерверных средах выполнения, зарегистрируйтесь на наш предстоящий сезон Code Vipassana, где вас ждут практические занятия под руководством инструктора и множество других мастер-классов!