
1. ภาพรวม
คุณยังจำเส้นทางการสร้างประสบการณ์การค้าปลีกแบบไฮบริดแบบไดนามิกด้วย AlloyDB ซึ่งรวมการกรองแบบเจียระไนและการค้นหาเวกเตอร์ได้ไหม แอปพลิเคชันดังกล่าวแสดงให้เห็นถึงความต้องการของผู้ค้าปลีกสมัยใหม่ได้อย่างชัดเจน แต่การสร้างแอปพลิเคชันนี้และการทำซ้ำต้องใช้ความพยายามในการพัฒนาอย่างมาก สำหรับนักพัฒนาซอฟต์แวร์แบบฟูลสแต็ก การสลับไปมาระหว่างตัวแก้ไขโค้ดและเครื่องมือฐานข้อมูลอยู่เสมออาจเป็นจุดคอขวดที่ทำให้การสร้างสรรค์และกระบวนการสำคัญในการทำความเข้าใจข้อมูลช้าลง
โซลูชัน
นี่คือจุดที่การพัฒนาแอปพลิเคชันที่เร่งความเร็วแสดงให้เห็นถึงประสิทธิภาพอย่างแท้จริง และเป็นเหตุผลที่ฉันตื่นเต้นมากที่จะแชร์ว่า MCP (Modern Cloud Platform) Toolbox ซึ่งเข้าถึงได้ผ่าน Gemini CLI ที่ใช้งานง่ายได้กลายเป็นส่วนสำคัญในชุดเครื่องมือของฉัน ลองนึกภาพการโต้ตอบกับอินสแตนซ์ AlloyDB การเขียนคําค้นหา และการทําความเข้าใจชุดข้อมูลได้อย่างราบรื่น ทั้งหมดนี้ทําได้โดยตรงภายในสภาพแวดล้อมการพัฒนาแบบผสานรวม (IDE) ซึ่งไม่ได้เป็นเพียงความสะดวกสบาย แต่เป็นการลดอุปสรรคในวงจรการพัฒนาอย่างแท้จริง ทำให้คุณมุ่งเน้นที่การสร้างฟีเจอร์นวัตกรรมได้แทนที่จะต้องต่อสู้กับเครื่องมือภายนอก
ในบริบทของแอปอีคอมเมิร์ซค้าปลีกของเรา ซึ่งเราจำเป็นต้องค้นหาข้อมูลผลิตภัณฑ์อย่างมีประสิทธิภาพ จัดการการกรองที่ซับซ้อน และใช้ประโยชน์จากความแตกต่างของการค้นหาเวกเตอร์ ความสามารถในการทำซ้ำการโต้ตอบกับฐานข้อมูลอย่างรวดเร็วจึงมีความสำคัญอย่างยิ่ง MCP Toolbox ที่ขับเคลื่อนโดย Gemini CLI ไม่เพียงทำให้กระบวนการนี้ง่ายขึ้น แต่ยังช่วยเร่งความเร็วและเปลี่ยนวิธีที่เราสามารถสำรวจ ทดสอบ และปรับแต่งตรรกะของฐานข้อมูลที่รองรับแอปพลิเคชันของเรา มาดูกันว่าการผสมผสานที่พลิกโฉมนี้ช่วยให้การพัฒนาแบบฟูลสแต็กเร็วขึ้น ชาญฉลาดยิ่งขึ้น และสนุกมากขึ้นได้อย่างไร
สิ่งที่คุณจะได้เรียนรู้และสร้าง
แอปพลิเคชัน Retail Search ที่ใช้ MCP Toolbox ภายใน IDE ซึ่งขับเคลื่อนโดย Gemini CLI เราจะพูดถึงหัวข้อต่อไปนี้
- วิธีผสานรวม MCP Toolbox เข้ากับ IDE โดยตรงเพื่อให้การโต้ตอบกับ AlloyDB เป็นไปอย่างราบรื่น
- ตัวอย่างการใช้งานจริงของ Gemini CLI ในการเขียนและเรียกใช้การค้นหา SQL กับข้อมูลการค้าปลีก
- ใช้ประโยชน์จาก Gemini CLI เพื่อโต้ตอบกับชุดข้อมูลอีคอมเมิร์ซค้าปลีก เขียนคําค้นหาที่โดยปกติแล้วจะต้องใช้เครื่องมือแยกต่างหาก และดูผลลัพธ์ได้ทันที
- ค้นพบวิธีใหม่ๆ ในการตรวจสอบและทำความเข้าใจข้อมูล ตั้งแต่การตรวจสอบโครงสร้างตารางไปจนถึงการตรวจสอบความถูกต้องของข้อมูลอย่างรวดเร็ว ทั้งหมดนี้ผ่านอินเทอร์เฟซบรรทัดคำสั่งที่คุ้นเคยภายใน IDE ของเรา
- เวิร์กโฟลว์ฐานข้อมูลที่รวดเร็วขึ้นนี้ช่วยให้วงจรการพัฒนาแบบฟูลสแต็กเร็วขึ้นได้อย่างไร ซึ่งช่วยให้การสร้างต้นแบบและการทำซ้ำเป็นไปอย่างรวดเร็ว
Techstack
เราใช้
- AlloyDB สำหรับฐานข้อมูล
- MCP Toolbox สำหรับการแยกฟีเจอร์ Generative และ AI ขั้นสูงของฐานข้อมูลออกจากแอปพลิเคชัน
- Cloud Run สำหรับการติดตั้งใช้งานแบบ Serverless
- Gemini CLI เพื่อทำความเข้าใจและวิเคราะห์ชุดข้อมูล รวมถึงสร้างส่วนฐานข้อมูลของแอปพลิเคชันอีคอมเมิร์ซค้าปลีก
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็น: ทำตามลิงก์และเปิดใช้ API
หรือจะใช้คำสั่ง gcloud สำหรับการดำเนินการนี้ก็ได้ โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
3. การตั้งค่าฐานข้อมูล
ในแล็บนี้ เราจะใช้ AlloyDB เป็นฐานข้อมูลสำหรับข้อมูลอีคอมเมิร์ซ โดยจะใช้คลัสเตอร์เพื่อจัดเก็บทรัพยากรทั้งหมด เช่น ฐานข้อมูลและบันทึก แต่ละคลัสเตอร์มีอินสแตนซ์หลักที่ให้จุดเข้าใช้งานข้อมูล ตารางจะเก็บข้อมูลจริง
มาสร้างคลัสเตอร์ อินสแตนซ์ และตาราง AlloyDB ที่จะโหลดชุดข้อมูลอีคอมเมิร์ซกัน
สร้างคลัสเตอร์และอินสแตนซ์
- ไปที่หน้า AlloyDB ใน Cloud Console วิธีง่ายๆ ในการค้นหาหน้าส่วนใหญ่ใน Cloud Console คือการค้นหาโดยใช้แถบค้นหาของคอนโซล
- เลือกสร้างคลัสเตอร์จากหน้านั้น

- คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง สร้างคลัสเตอร์และอินสแตนซ์ด้วยค่าต่อไปนี้ (ตรวจสอบว่าค่าตรงกันในกรณีที่คุณโคลนโค้ดของแอปพลิเคชันจากที่เก็บ)
- รหัสคลัสเตอร์: "
vector-cluster" - รหัสผ่าน: "
alloydb" - PostgreSQL 15 / ล่าสุดที่แนะนำ
- ภูมิภาค: "
us-central1" - เครือข่าย: "
default"
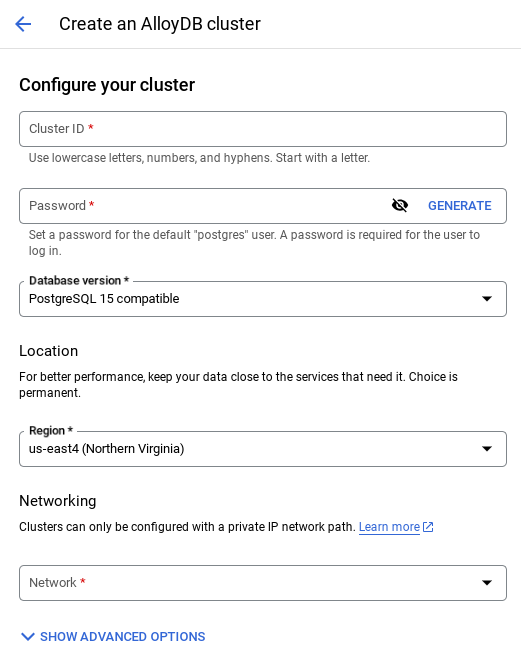
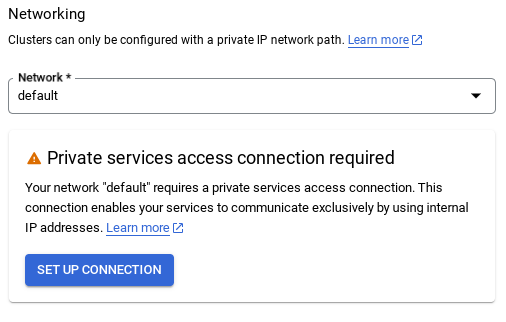
- เมื่อเลือกเครือข่ายเริ่มต้น คุณจะเห็นหน้าจอคล้ายกับหน้าจอด้านล่าง
เลือกตั้งค่าการเชื่อมต่อ
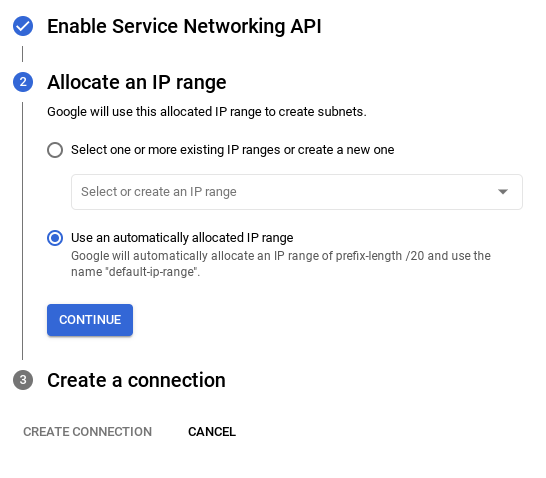
- จากนั้นเลือก "ใช้ช่วง IP ที่มีการจัดสรรโดยอัตโนมัติ" แล้วคลิก "ต่อไป" หลังจากตรวจสอบข้อมูลแล้ว ให้เลือกสร้างการเชื่อมต่อ
- เมื่อตั้งค่าเครือข่ายแล้ว คุณจะสร้างคลัสเตอร์ต่อไปได้ คลิกสร้างคลัสเตอร์เพื่อตั้งค่าคลัสเตอร์ให้เสร็จสมบูรณ์ตามที่แสดงด้านล่าง
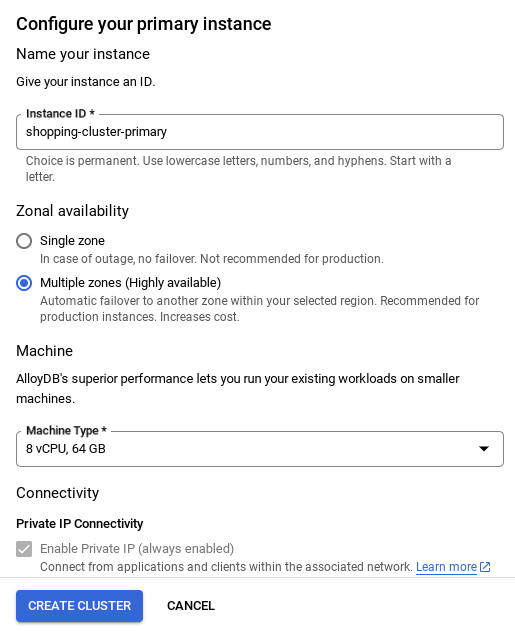
หมายเหตุสำคัญ:
- อย่าลืมเปลี่ยนรหัสอินสแตนซ์ (ซึ่งคุณดูได้ในขณะที่กำหนดค่าคลัสเตอร์ / อินสแตนซ์) เป็น **
vector-instance** หากเปลี่ยนไม่ได้ โปรดอย่าลืม **ใช้รหัสอินสแตนซ์** ในการอ้างอิงที่จะเกิดขึ้นทั้งหมด - โปรดทราบว่าการสร้างคลัสเตอร์จะใช้เวลาประมาณ 10 นาที เมื่อดำเนินการสำเร็จแล้ว คุณควรเห็นหน้าจอที่แสดงภาพรวมของคลัสเตอร์ที่เพิ่งสร้าง
4. การนำเข้าข้อมูล
ตอนนี้ได้เวลาเพิ่มตารางที่มีข้อมูลเกี่ยวกับร้านค้าแล้ว ไปที่ AlloyDB เลือกคลัสเตอร์หลัก แล้วเลือก AlloyDB Studio โดยทำดังนี้
คุณอาจต้องรอให้อินสแตนซ์สร้างเสร็จ เมื่อพร้อมแล้ว ให้ลงชื่อเข้าใช้ AlloyDB โดยใช้ข้อมูลเข้าสู่ระบบที่คุณสร้างขึ้นเมื่อสร้างคลัสเตอร์ ใช้ข้อมูลต่อไปนี้เพื่อตรวจสอบสิทธิ์ใน PostgreSQL
- ชื่อผู้ใช้ : "
postgres" - ฐานข้อมูล : "
postgres" - รหัสผ่าน : "
alloydb"
เมื่อตรวจสอบสิทธิ์เข้าสู่ AlloyDB Studio สำเร็จแล้ว ให้ป้อนคำสั่ง SQL ในเอดิเตอร์ คุณเพิ่มหน้าต่างเอดิเตอร์หลายหน้าต่างได้โดยใช้เครื่องหมายบวกทางด้านขวาของหน้าต่างสุดท้าย
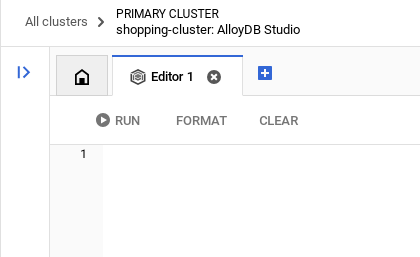
คุณจะป้อนคำสั่งสำหรับ AlloyDB ในหน้าต่างเอดิเตอร์ โดยใช้ตัวเลือกเรียกใช้ จัดรูปแบบ และล้างตามที่จำเป็น
เปิดใช้ส่วนขยาย
ในการสร้างแอปนี้ เราจะใช้ส่วนขยาย pgvector และ google_ml_integration ส่วนขยาย pgvector ช่วยให้คุณจัดเก็บและค้นหาการฝังเวกเตอร์ได้ ส่วนขยาย google_ml_integration มีฟังก์ชันที่คุณใช้เพื่อเข้าถึงปลายทางการคาดการณ์ของ Vertex AI เพื่อรับการคาดการณ์ใน SQL เปิดใช้ส่วนขยายเหล่านี้โดยเรียกใช้ DDL ต่อไปนี้
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
หากต้องการตรวจสอบส่วนขยายที่เปิดใช้ในฐานข้อมูล ให้เรียกใช้คำสั่ง SQL นี้
select extname, extversion from pg_extension;
สร้างตาราง
คุณสร้างตารางได้โดยใช้คำสั่ง DDL ด้านล่างใน AlloyDB Studio
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
คอลัมน์การฝังจะช่วยให้จัดเก็บค่าเวกเตอร์ของข้อความได้
ให้สิทธิ์
เรียกใช้คำสั่งด้านล่างเพื่อให้สิทธิ์ดำเนินการในฟังก์ชัน "ฝัง"
GRANT EXECUTE ON FUNCTION embedding TO postgres;
มอบบทบาทผู้ใช้ Vertex AI ให้กับบัญชีบริการ AlloyDB
จากคอนโซล Google Cloud IAM ให้สิทธิ์เข้าถึงบทบาท "ผู้ใช้ Vertex AI" แก่บัญชีบริการ AlloyDB (ซึ่งมีลักษณะดังนี้ service-<<PROJECT_NUMBER >>@gcp-sa-alloydb.iam.gserviceaccount.com) PROJECT_NUMBER จะมีหมายเลขโปรเจ็กต์ของคุณ
หรือคุณอาจเรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell ก็ได้
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
โหลดข้อมูลลงในฐานข้อมูล
- คัดลอก
insertคำสั่งการค้นหาจากinsert scripts sqlในชีตไปยังตัวแก้ไขตามที่กล่าวไว้ข้างต้น คุณสามารถคัดลอกคำสั่งแทรก 10-50 รายการเพื่อสาธิตกรณีการใช้งานนี้อย่างรวดเร็ว คุณดูรายการการแทรกที่เลือกได้ที่แท็บ "การแทรกที่เลือก 25-30 แถว" - คลิกเรียกใช้ ผลลัพธ์ของคำค้นหาจะปรากฏในตารางผลลัพธ์
หมายเหตุสำคัญ:
โปรดคัดลอกเฉพาะระเบียน 25-50 รายการเพื่อแทรก และตรวจสอบว่ามาจากช่วงของหมวดหมู่ หมวดหมู่ย่อย สี ประเภทเพศ
5. สร้างการฝังสำหรับข้อมูล
นวัตกรรมที่แท้จริงในการค้นหาในปัจจุบันอยู่ที่การทำความเข้าใจความหมาย ไม่ใช่แค่คีย์เวิร์ด ซึ่งเป็นจุดที่การฝังและการค้นหาเวกเตอร์เข้ามามีบทบาท
เราแปลงคำอธิบายผลิตภัณฑ์และคำค้นหาของผู้ใช้ให้เป็นการแสดงตัวเลขแบบหลายมิติที่เรียกว่า "การฝัง" โดยใช้โมเดลภาษาที่ฝึกไว้ล่วงหน้า การฝังเหล่านี้จะบันทึกความหมายเชิงความหมาย ซึ่งช่วยให้เราค้นหาผลิตภัณฑ์ที่ "มีความหมายคล้ายกัน" แทนที่จะมีเพียงคำที่ตรงกัน ในตอนแรก เราได้ทดลองใช้การค้นหาความคล้ายคลึงของเวกเตอร์โดยตรงในการฝังเหล่านี้เพื่อสร้างพื้นฐาน ซึ่งแสดงให้เห็นถึงพลังของการทำความเข้าใจเชิงความหมายแม้ก่อนการเพิ่มประสิทธิภาพ
คอลัมน์การฝังจะช่วยให้จัดเก็บค่าเวกเตอร์ของข้อความคำอธิบายผลิตภัณฑ์ได้ คอลัมน์ img_embeddings จะช่วยให้จัดเก็บการฝังรูปภาพ (มัลติโมดัล) ได้ ด้วยวิธีนี้ คุณยังใช้การค้นหาตามระยะห่างของข้อความกับรูปภาพได้ด้วย แต่เราจะใช้เฉพาะการฝังข้อความในห้องทดลองนี้
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
ซึ่งควรแสดงผลเวกเตอร์การฝังที่มีลักษณะคล้ายอาร์เรย์ของจำนวนทศนิยมสำหรับข้อความตัวอย่างในการค้นหา มีลักษณะดังนี้
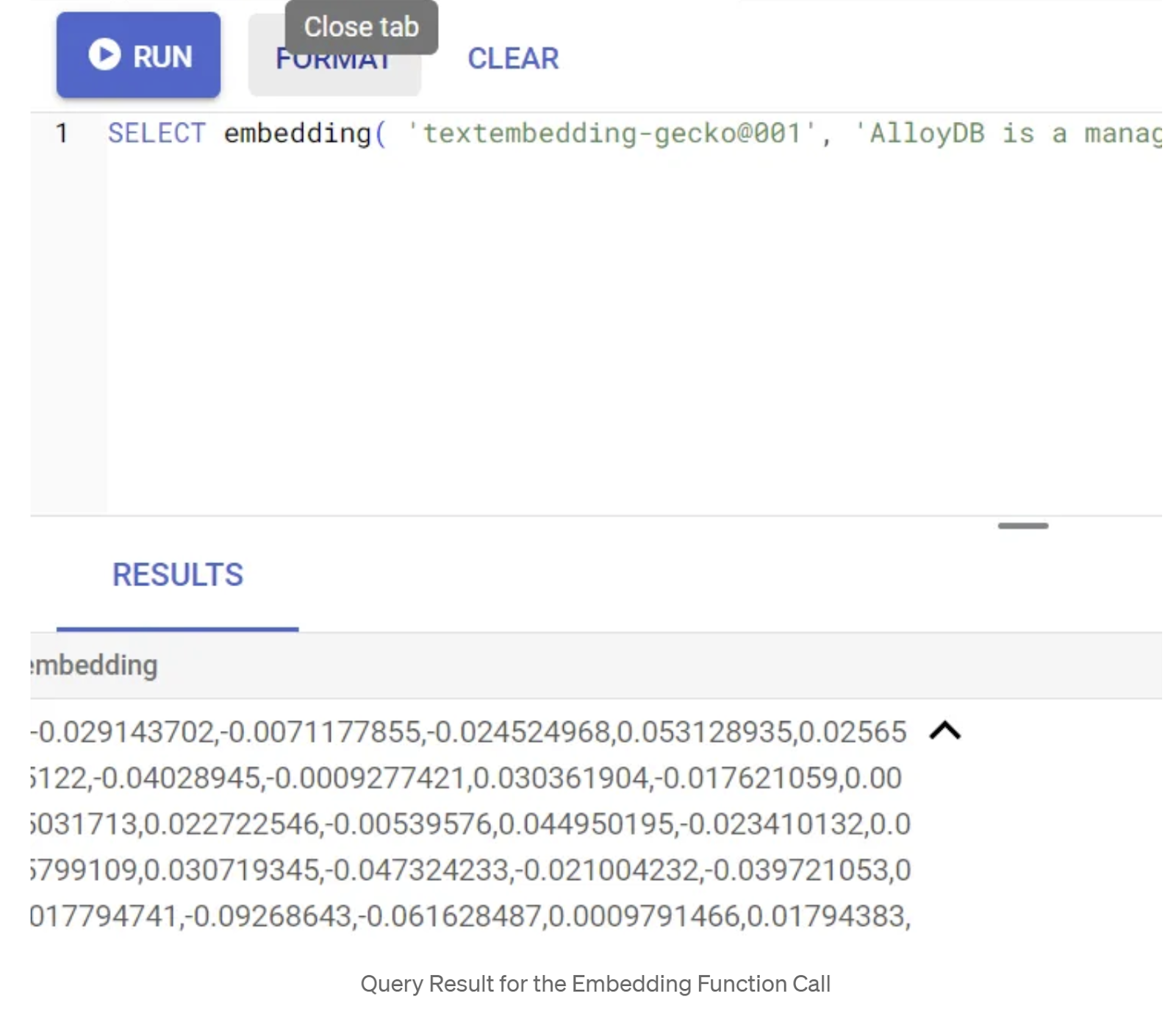
อัปเดตฟิลด์เวกเตอร์ abstract_embeddings
เรียกใช้ DML ด้านล่างเพื่ออัปเดตคำอธิบายเนื้อหาในตารางด้วยการฝังที่เกี่ยวข้อง
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
คุณอาจพบปัญหาในการสร้าง Embedding มากกว่า 2-3 รายการ (เช่น สูงสุด 20-25 รายการ) หากใช้บัญชีสำหรับการเรียกเก็บเงินเครดิตทดลองใช้สำหรับ Google Cloud ดังนั้นให้จำกัดจำนวนแถวในสคริปต์การแทรก
หากต้องการสร้างการฝังรูปภาพ (เพื่อทำการค้นหาตามบริบทแบบมัลติโมดัล) ให้เรียกใช้การอัปเดตด้านล่างด้วย
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox สำหรับฐานข้อมูล (AlloyDB)
เบื้องหลัง เครื่องมือที่มีประสิทธิภาพและแอปพลิเคชันที่มีโครงสร้างดีช่วยให้การทำงานเป็นไปอย่างราบรื่น
กล่องเครื่องมือ MCP (Model Context Protocol) สำหรับฐานข้อมูลช่วยให้การผสานรวมเครื่องมือ Generative AI และเครื่องมือแบบเป็น Agent กับ AlloyDB เป็นเรื่องง่าย โดยจะทำหน้าที่เป็นเซิร์ฟเวอร์โอเพนซอร์สที่เพิ่มประสิทธิภาพการจัดกลุ่มการเชื่อมต่อ การตรวจสอบสิทธิ์ และการเปิดเผยฟังก์ชันฐานข้อมูลอย่างปลอดภัยต่อ Agent AI หรือแอปพลิเคชันอื่นๆ
ในแอปพลิเคชัน เราใช้ MCP Toolbox สำหรับฐานข้อมูลเป็นเลเยอร์แอบสแตรกชันสำหรับการค้นหาแบบไฮบริดอัจฉริยะทั้งหมด
ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าและติดตั้งใช้งานกล่องเครื่องมือสำหรับกรณีการใช้งานของเรา
คุณจะเห็นว่าฐานข้อมูลอย่างหนึ่งที่ MCP Toolbox สำหรับฐานข้อมูลรองรับคือ AlloyDB และเนื่องจากเราได้จัดสรรฐานข้อมูลดังกล่าวในส่วนก่อนหน้าแล้ว เราจึงมาตั้งค่า Toolbox กันเลย
- ไปที่เทอร์มินัล Cloud Shell และตรวจสอบว่าได้เลือกโปรเจ็กต์และแสดงในพรอมต์ของเทอร์มินัลแล้ว เรียกใช้คำสั่งด้านล่างจากเทอร์มินัล Cloud Shell เพื่อไปยังไดเรกทอรีโปรเจ็กต์
mkdir gemini-cli-project
cd gemini-cli-project
- เรียกใช้คำสั่งด้านล่างเพื่อดาวน์โหลดและติดตั้งกล่องเครื่องมือในโฟลเดอร์ใหม่
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
ซึ่งควรสร้างกล่องเครื่องมือในไดเรกทอรีปัจจุบัน คัดลอกเส้นทางไปยังกล่องเครื่องมือ
- ไปที่ Cloud Shell Editor (สำหรับโหมดแก้ไขโค้ด) และในโฟลเดอร์รูทของโปรเจ็กต์ "gemini-cli-project" ให้เพิ่มไฟล์ชื่อ "tools.yaml"
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
มาทำความเข้าใจ tools.yaml กัน
แหล่งข้อมูลแสดงถึงแหล่งข้อมูลต่างๆ ที่เครื่องมือสามารถโต้ตอบด้วย แหล่งที่มาแสดงถึงแหล่งข้อมูลที่เครื่องมือโต้ตอบด้วยได้ คุณกำหนดแหล่งข้อมูลเป็นแผนที่ได้ในส่วนแหล่งข้อมูลของไฟล์ tools.yaml โดยปกติแล้ว การกำหนดค่าแหล่งที่มาจะมีข้อมูลที่จำเป็นต่อการเชื่อมต่อและโต้ตอบกับฐานข้อมูล
เครื่องมือกำหนดการดำเนินการที่ Agent สามารถทำได้ เช่น การอ่านและเขียนไปยังแหล่งที่มา เครื่องมือแสดงถึงการดำเนินการที่เอเจนต์ทำได้ เช่น การเรียกใช้คำสั่ง SQL คุณกำหนดเครื่องมือเป็นแผนที่ได้ในส่วนเครื่องมือของไฟล์ tools.yaml โดยปกติแล้ว เครื่องมือจะต้องมีแหล่งข้อมูลเพื่อดำเนินการ
ดูรายละเอียดเพิ่มเติมเกี่ยวกับการกำหนดค่า tools.yaml ได้ในเอกสารประกอบนี้
ดังที่เห็นในไฟล์ Tools.yaml ด้านบน เครื่องมือ "get-apparels" จะแสดงรายละเอียดเครื่องแต่งกายทั้งหมดจากฐานข้อมูล
7. ตั้งค่า Gemini CLI
จากโปรแกรมแก้ไข Cloud Shell ให้สร้างโฟลเดอร์ใหม่ชื่อ .gemini ภายในโฟลเดอร์ gemini-cli-project แล้วสร้างไฟล์ใหม่ชื่อ settings.json ในโฟลเดอร์ดังกล่าว
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
ในส่วนคำสั่งในข้อมูลโค้ดด้านบน ให้แทนที่ "/home/user/gemini-cli-project/toolbox" ด้วยเส้นทางไปยังกล่องเครื่องมือ
ติดตั้ง Gemini CLI
สุดท้ายจากเทอร์มินัล Cloud Shell ให้ติดตั้ง Gemini CLI ในไดเรกทอรีเดียวกัน gemini-cli-project โดยเรียกใช้คำสั่งต่อไปนี้
sudo npm install -g @google/gemini-cli
ตั้งค่ารหัสโปรเจ็กต์
ตรวจสอบว่าคุณได้ตั้งค่ารหัสโปรเจ็กต์ที่ใช้งานอยู่ในสภาพแวดล้อมแล้ว
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
เริ่มต้นใช้งาน Gemini CLI
จากบรรทัดคำสั่ง ให้ป้อนคำสั่งต่อไปนี้
gemini
คุณควรเห็นคำตอบที่คล้ายกับด้านล่างนี้
ตรวจสอบสิทธิ์และไปยังขั้นตอนถัดไป
8. เริ่มโต้ตอบกับ Gemini CLI
ใช้คำสั่ง /mcp เพื่อแสดงรายการเซิร์ฟเวอร์ MCP ที่กำหนดค่าไว้
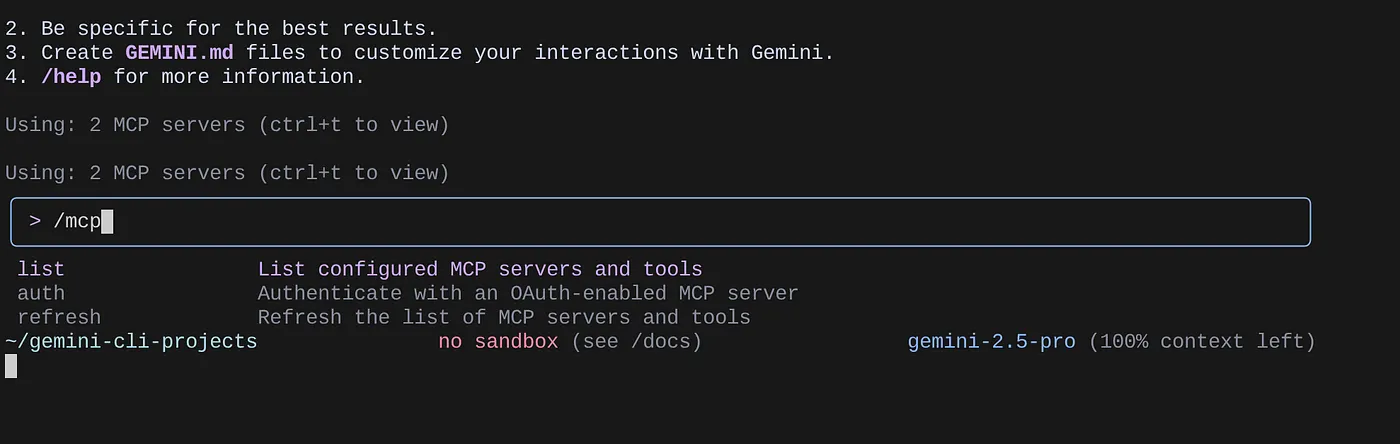
คุณควรจะเห็นเซิร์ฟเวอร์ MCP 2 เครื่องที่เรากำหนดค่าไว้ ได้แก่ GitHub และ MCP Toolbox สำหรับฐานข้อมูลที่แสดงพร้อมกับเครื่องมือของเซิร์ฟเวอร์
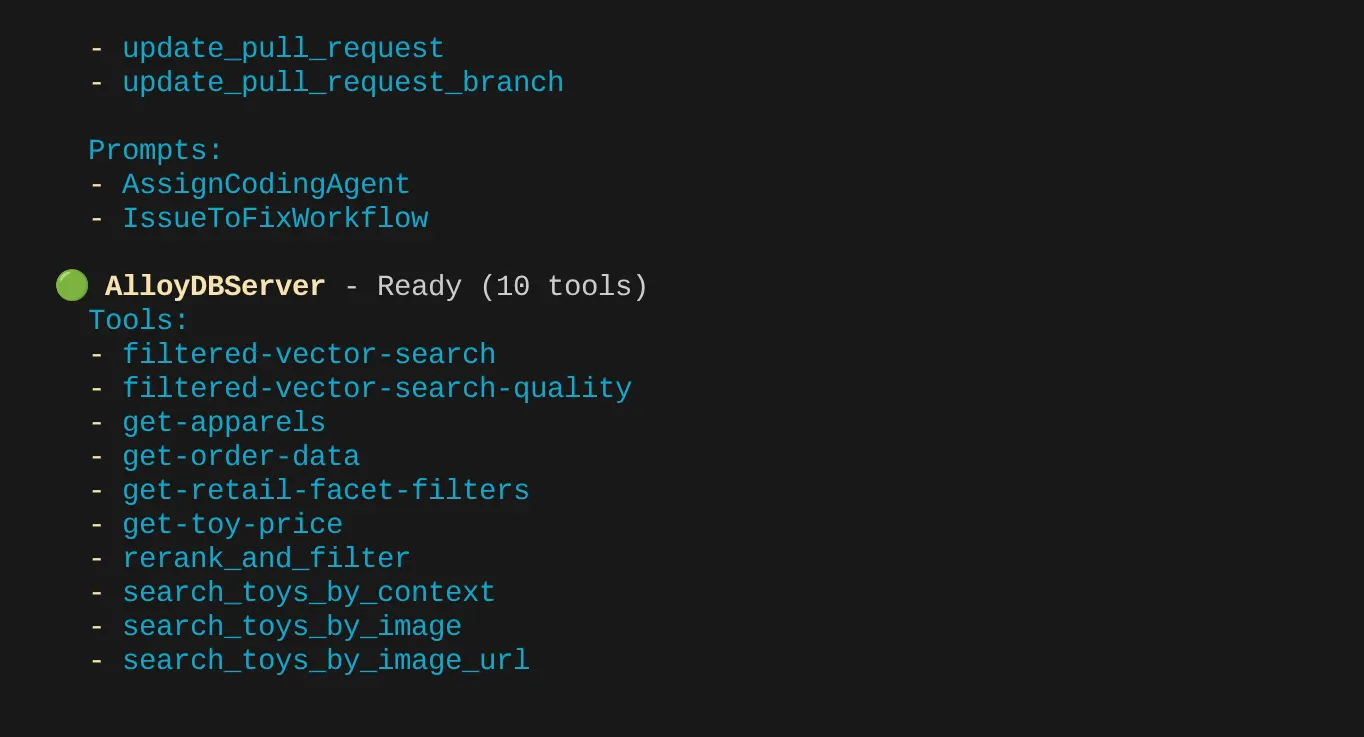
ในกรณีของฉัน ฉันมีเครื่องมือมากกว่านี้ ดังนั้นตอนนี้คุณไม่ต้องสนใจ คุณควรเห็นเครื่องมือ get-apparels ในเซิร์ฟเวอร์ MCP ของ AlloyDB
เริ่มค้นหาฐานข้อมูลผ่าน MCP Toolbox
ตอนนี้ลองถามคำถามในภาษาง่ายๆ เพื่อดึงคำตอบและคำค้นหาสำหรับชุดข้อมูลที่เรากำลังทำงานด้วย
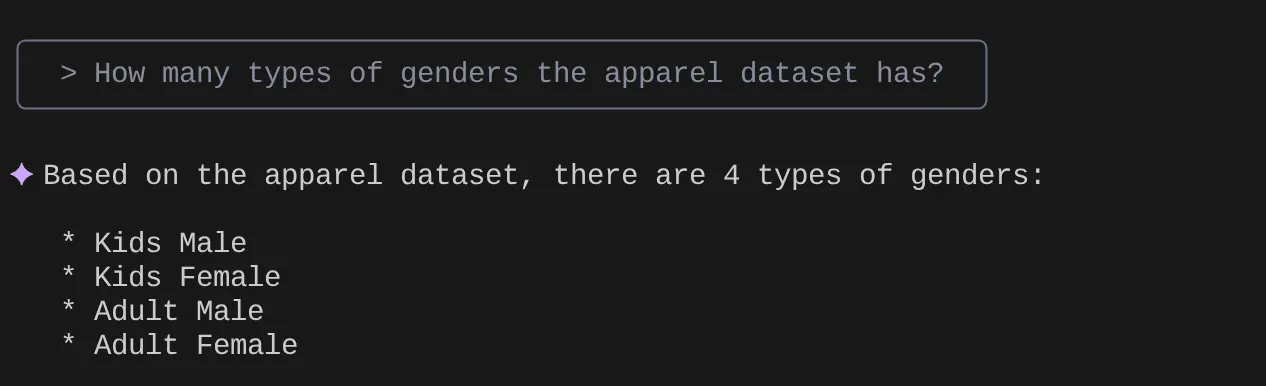
> How many types of genders the apparel dataset has?
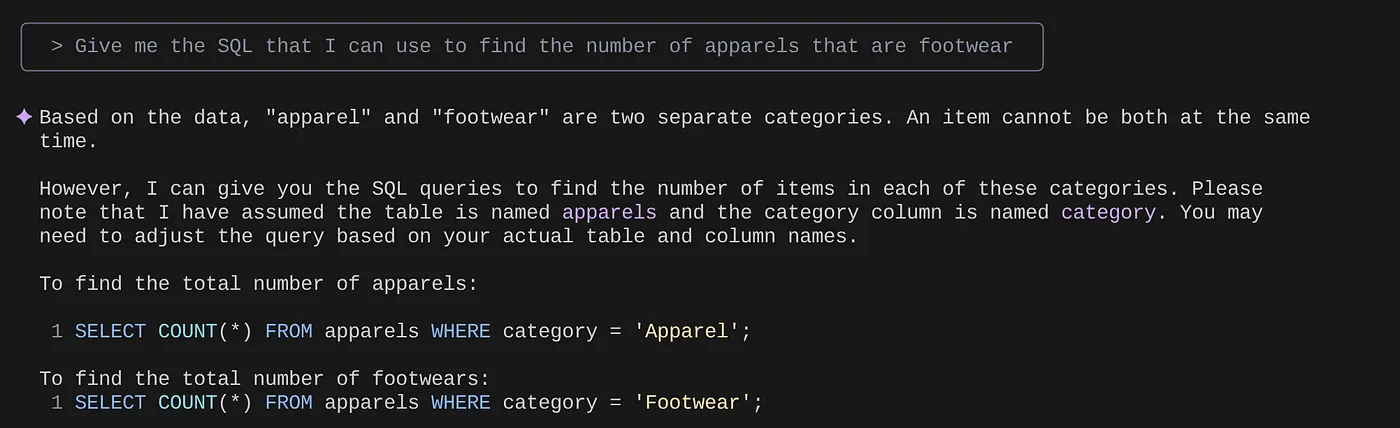
> Give me the SQL that I can use to find the number of apparels that are footwear
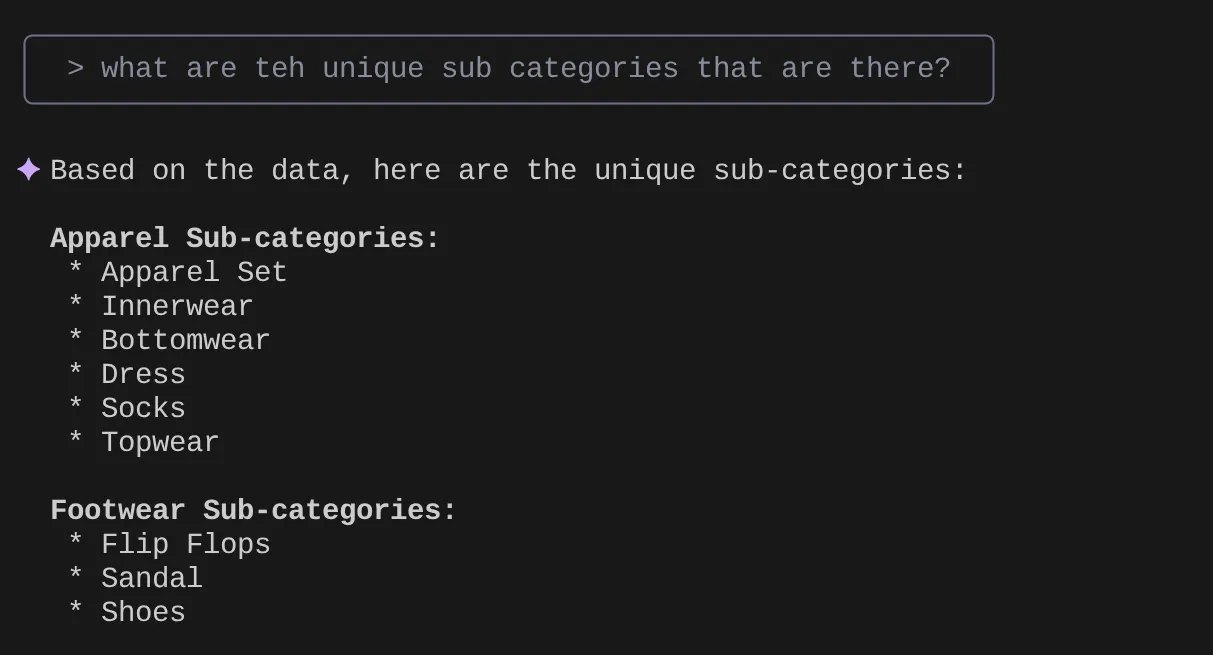
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
สมมติว่าจากข้อมูลเชิงลึกของฉันและคำค้นหาอื่นๆ ที่คล้ายกัน ฉันได้คำค้นหาโดยละเอียดและต้องการทดสอบ หรือสมมติว่าวิศวกรฐานข้อมูลสร้าง Tools.yaml ให้คุณแล้วดังนี้
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
คราวนี้มาลองค้นหาโดยใช้ภาษาที่เป็นธรรมชาติกัน
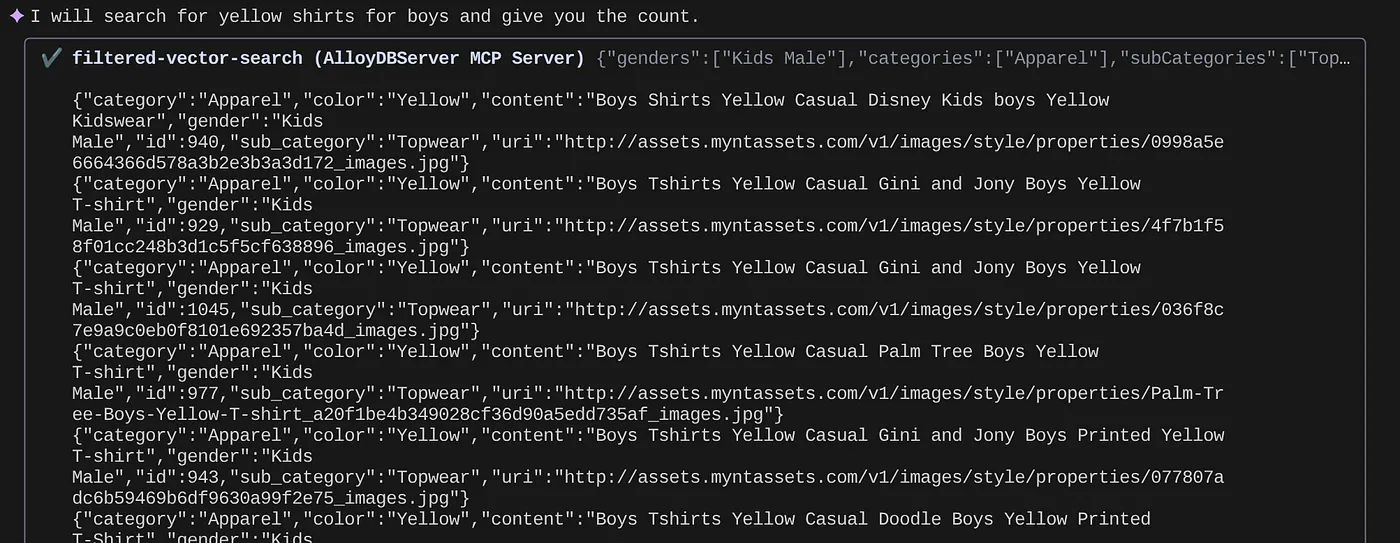
> How many yellow shirts are there for boys?

เจ๋งไปเลยใช่ไหมล่ะ ตอนนี้ฉันสามารถแก้ไขไฟล์ YAML เพื่อให้การค้นหามีความก้าวหน้ามากขึ้นได้ในขณะที่ยังคงส่งมอบฟังก์ชันใหม่ๆ ในแอปพลิเคชันของฉันต่อไปในไทม์ไลน์ที่เร่งด่วน
9. การพัฒนาแอปที่รวดเร็ว
ความยอดเยี่ยมของการนำความสามารถของฐานข้อมูลมาไว้ใน IDE โดยตรงผ่าน Gemini CLI และ MCP Toolbox ไม่ได้เป็นเพียงทฤษฎีเท่านั้น ซึ่งจะช่วยให้เวิร์กโฟลว์มีความรวดเร็วและจับต้องได้ โดยเฉพาะอย่างยิ่งสำหรับแอปพลิเคชันที่ซับซ้อน เช่น ประสบการณ์การค้าปลีกแบบไฮบริดของเรา มาดูสถานการณ์จำลองกัน
1. การวนซ้ำตรรกะการกรองผลิตภัณฑ์อย่างรวดเร็ว
สมมติว่าเราเพิ่งเปิดตัวโปรโมชันใหม่สำหรับ "ชุดออกกำลังกายสำหรับฤดูร้อน" เราต้องการทดสอบว่าตัวกรองแบบเจียระไน (เช่น ตามแบรนด์ ขนาด สี ช่วงราคา) จะทำงานร่วมกับหมวดหมู่ใหม่นี้อย่างไร
หากไม่มีการผสานรวม IDE
ฉันอาจเปลี่ยนไปใช้ไคลเอ็นต์ SQL แยกต่างหาก เขียนคําค้นหา ดําเนินการ วิเคราะห์ผลลัพธ์ กลับไปที่ IDE เพื่อปรับโค้ดของแอปพลิเคชัน กลับไปที่ไคลเอ็นต์ แล้วทําซ้ำ การสลับบริบทนี้เป็นอุปสรรคสำคัญ
ด้วย Gemini CLI และ MCP:
ฉันสามารถทำงานใน IDE และทำสิ่งอื่นๆ ได้ ดังนี้
- การค้นหา: ฉันอัปเดตการค้นหาใน yaml ได้อย่างรวดเร็วด้วย (ชุดข้อมูลสมมติ) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" และลองใช้ในเทอร์มินัลได้เลย
- การสํารวจข้อมูล: ดูแบรนด์ที่แสดงผลได้ทันที หากต้องการดูความพร้อมจำหน่ายสินค้าสำหรับแบรนด์และขนาดที่เฉพาะเจาะจง คุณสามารถใช้คำค้นหาแบบรวดเร็วอีกคำสั่งหนึ่งได้ดังนี้ "SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- การผสานรวมโค้ด: จากนั้นฉันจะปรับตรรกะการกรองส่วนหน้าหรือการเรียก API ส่วนหลังได้ทันทีตามข้อมูลเชิงลึกเกี่ยวกับข้อมูลใน IDE อย่างรวดเร็ว ซึ่งจะช่วยลดวงจรความคิดเห็นได้อย่างมาก
2. การปรับแต่งการค้นหาเวกเตอร์สำหรับสินค้าแนะนำ
การค้นหาแบบไฮบริดของเราใช้การฝังเวกเตอร์เพื่อแสดงคำแนะนำผลิตภัณฑ์ที่เกี่ยวข้อง สมมติว่าเราเห็นอัตราการคลิกผ่านของคำแนะนำ "รองเท้าวิ่งผู้ชาย" ลดลง
หากไม่มีการผสานรวม IDE
ฉันจะเรียกใช้สคริปต์หรือการค้นหาที่กำหนดเองในเครื่องมือฐานข้อมูลเพื่อวิเคราะห์คะแนนความคล้ายคลึงของรองเท้าที่แนะนำ เปรียบเทียบกับข้อมูลการโต้ตอบของผู้ใช้ และพยายามหาความสัมพันธ์ของรูปแบบต่างๆ
ด้วย Gemini CLI และ MCP:
- การวิเคราะห์การฝัง: ฉันสามารถค้นหาการฝังผลิตภัณฑ์และข้อมูลเมตาที่เกี่ยวข้องได้โดยตรง: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- การอ้างอิงโยง: ฉันยังตรวจสอบความคล้ายคลึงของเวกเตอร์จริงระหว่างผลิตภัณฑ์ที่เลือกกับผลิตภัณฑ์ที่แนะนำได้อย่างรวดเร็วในที่นั้นด้วย เช่น หากระบบแนะนำผลิตภัณฑ์ ก ให้กับผู้ใช้ที่ดูผลิตภัณฑ์ ข ฉันก็สามารถเรียกใช้การค้นหาเพื่อดึงและเปรียบเทียบการฝังเวกเตอร์ของผลิตภัณฑ์ทั้ง 2 ได้
- การแก้ไขข้อบกพร่อง: ช่วยให้แก้ไขข้อบกพร่องและทดสอบสมมติฐานได้เร็วขึ้น โมเดลการฝังทำงานตามที่คาดไว้หรือไม่ ข้อมูลมีความผิดปกติที่ส่งผลต่อคุณภาพของคำแนะนำไหม ฉันสามารถรับคำตอบเบื้องต้นได้โดยไม่ต้องออกจากสภาพแวดล้อมการเขียนโค้ด
3. ทำความเข้าใจสคีมาและการกระจายข้อมูลสำหรับฟีเจอร์ใหม่
สมมติว่าเราวางแผนที่จะเพิ่มฟีเจอร์ "รีวิวจากลูกค้า" ก่อนที่จะเขียน API แบ็กเอนด์ เราต้องทำความเข้าใจข้อมูลลูกค้าเดิมและโครงสร้างของรีวิว
หากไม่มีการผสานรวม IDE
ฉันจะต้องเชื่อมต่อกับไคลเอ็นต์ฐานข้อมูล เรียกใช้คำสั่ง DESCRIBE ในตารางต่างๆ เช่น ลูกค้าและคำสั่งซื้อ แล้วจึงค้นหาข้อมูลตัวอย่างเพื่อทำความเข้าใจความสัมพันธ์และประเภทข้อมูล
ด้วย Gemini CLI และ MCP:
- การสำรวจสคีมา: ฉันสามารถค้นหาตารางในไฟล์ YAML และเรียกใช้ในเทอร์มินัลได้โดยตรง
- การสุ่มตัวอย่างข้อมูล: จากนั้นฉันจะดึงข้อมูลตัวอย่างเพื่อทําความเข้าใจข้อมูลประชากรของลูกค้าและประวัติการซื้อได้โดยใช้คำสั่ง "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- การวางแผน: การเข้าถึงสคีมาและการกระจายข้อมูลอย่างรวดเร็วนี้ช่วยให้เราตัดสินใจได้อย่างชาญฉลาดเกี่ยวกับวิธีออกแบบตารางรีวิวใหม่ คีย์นอกที่จะสร้าง และวิธีลิงก์รีวิวกับลูกค้าและผลิตภัณฑ์อย่างมีประสิทธิภาพ ทั้งหมดนี้ก่อนที่จะเขียนโค้ดของแอปพลิเคชันแม้แต่บรรทัดเดียวสำหรับฟีเจอร์ใหม่
ตัวอย่างเหล่านี้เป็นเพียงส่วนหนึ่ง แต่ก็แสดงให้เห็นถึงประโยชน์หลัก นั่นคือการลดอุปสรรคและเพิ่มความเร็วของนักพัฒนาแอป การนำการโต้ตอบกับ AlloyDB มาไว้ใน IDE โดยตรงทำให้ Gemini CLI และ MCP Toolbox ช่วยให้เราสร้างแอปพลิเคชันที่ดีขึ้นและตอบสนองได้ดียิ่งขึ้นได้เร็วขึ้น
10. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าResource Manager
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
- หรือคุณจะลบคลัสเตอร์ AlloyDB ที่เราเพิ่งสร้างขึ้นสำหรับโปรเจ็กต์นี้ก็ได้ (เปลี่ยนตำแหน่งในไฮเปอร์ลิงก์นี้หากคุณไม่ได้เลือก us-central1 สำหรับคลัสเตอร์ในขณะที่กำหนดค่า) โดยคลิกปุ่มลบคลัสเตอร์
11. ขอแสดงความยินดี
ยินดีด้วย คุณผสานรวม MCP Toolbox เข้ากับ IDE โดยตรงเรียบร้อยแล้วเพื่อการโต้ตอบกับ AlloyDB ที่ราบรื่น และใช้ประโยชน์จาก Gemini CLI เพื่อโต้ตอบกับชุดข้อมูลอีคอมเมิร์ซค้าปลีกของเราเพื่อเขียนคําค้นหาที่ปกติแล้วจะต้องใช้เครื่องมือแยกต่างหาก คุณได้เรียนรู้วิธีใหม่ๆ ในการตรวจสอบและทําความเข้าใจข้อมูล ตั้งแต่การตรวจสอบโครงสร้างตารางไปจนถึงการตรวจสอบความถูกต้องของข้อมูลอย่างรวดเร็ว ทั้งหมดนี้ผ่านอินเทอร์เฟซบรรทัดคำสั่งที่คุ้นเคยภายใน IDE ของเรา
โปรดโคลนที่เก็บ วิเคราะห์ และแจ้งให้เราทราบหากคุณปรับปรุงแอปพลิเคชันโดยใช้ Gemini CLI และ MCP Toolbox สำหรับฐานข้อมูล
หากต้องการดูแอปพลิเคชันที่ขับเคลื่อนด้วยข้อมูลดังกล่าวที่สร้างขึ้นด้วย Gemini CLI, MCP และทำให้ใช้งานได้ในรันไทม์แบบ Serverless โปรดลงทะเบียนเข้าร่วมซีซันถัดไปของ Code Vipassana ซึ่งคุณจะได้รับเซสชันแบบลงมือปฏิบัติจริงที่นำโดยผู้สอนและ Codelab อื่นๆ ที่คล้ายกัน!!!