
1. Genel Bakış
AlloyDB ile dinamik karma perakende deneyimi oluşturma, yönlü filtreleme ve vektör arama özelliklerini birleştirme yolculuğumuzu hatırlıyor musunuz? Bu uygulama, modern perakende ihtiyaçlarının güçlü bir göstergesiydi ancak bu noktaya ulaşmak ve uygulamayı yinelemek için önemli bir geliştirme çalışması yapılması gerekti. Tam yığın geliştiriciler için kod düzenleyiciler ve veritabanı araçları arasında sürekli gidip gelmek genellikle bir performans sorunu olabilir, yeniliği ve verilerinizi anlama gibi önemli bir süreci yavaşlatabilir.
Çözüm
Hızlandırılmış uygulama geliştirmenin gücü tam da bu noktada kendini gösteriyor. Bu nedenle, sezgisel Gemini CLI aracılığıyla erişilebilen MCP (Modern Cloud Platform) Toolbox'ın, araç setimin vazgeçilmez bir parçası haline gelme sürecini paylaşmaktan heyecan duyuyorum. AlloyDB örneğinizle sorunsuz bir şekilde etkileşim kurduğunuzu, sorgu yazdığınızı ve veri kümenizi anladığınızı düşünün. Tüm bunları doğrudan entegre geliştirme ortamınızda (IDE) yapabilirsiniz. Bu sadece kolaylık sağlamakla ilgili değildir. Geliştirme yaşam döngüsündeki sürtünmeyi temelden azaltarak harici araçlarla uğraşmak yerine yenilikçi özellikler oluşturmaya odaklanmanızı sağlar.
Perakende e-ticaret uygulamamızda ürün verilerini verimli bir şekilde sorgulamamız, karmaşık filtrelemeyi yönetmemiz ve vektör aramanın nüanslarından yararlanmamız gerekiyordu. Bu nedenle, veritabanı etkileşimlerinde hızlı bir şekilde yineleme yapabilmek bizim için çok önemliydi. Gemini CLI tarafından desteklenen MCP Toolbox, bu süreci yalnızca basitleştirmekle kalmaz, hızlandırarak uygulamalarımızın temelini oluşturan veritabanı mantığını keşfetme, test etme ve iyileştirme şeklimizi dönüştürür. Bu çığır açan kombinasyonun tam yığın geliştirmeyi nasıl daha hızlı, daha akıllı ve daha keyifli hale getirdiğini inceleyelim.
Öğrenecekleriniz ve oluşturacaklarınız
IDE'de MCP Toolbox'ı kullanan ve Gemini CLI tarafından desteklenen bir perakende arama uygulaması. Ele alacağımız konular aşağıda belirtilmiştir:
- Sorunsuz AlloyDB etkileşimi için MCP Toolbox'ı doğrudan IDE'nize nasıl entegre edeceğinizi öğrenin.
- Perakende verilerinizde SQL sorguları yazmak ve yürütmek için Gemini CLI'ı kullanmayla ilgili pratik örnekler.
- Gemini CLI'dan yararlanarak perakende e-ticaret veri setimizle etkileşim kurun, normalde ayrı araçlar gerektirecek sorgular yazın ve sonuçları anında görün.
- Tablo yapılarını kontrol etmekten hızlı veri uygunluk kontrolleri yapmaya kadar, verileri incelemenin ve anlamanın yeni yollarını keşfedin. Tüm bunları IDE'mizdeki tanıdık komut satırı arayüzleri üzerinden yapabilirsiniz.
- Bu hızlandırılmış veritabanı iş akışı, tam yığın geliştirme döngülerinin daha hızlı olmasını nasıl doğrudan etkiler? Bu sayede hızlı prototip oluşturma ve yineleme nasıl mümkün olur?
Techstack
Kullandığımız araçlar:
- Veritabanı için AlloyDB
- Veritabanlarının gelişmiş üretken ve yapay zeka özelliklerini uygulamadan soyutlamak için MCP Toolbox
- Sunucusuz dağıtım için Cloud Run.
- Veri kümesini anlamak ve analiz etmek, perakende e-ticaret uygulamasının veritabanı bölümünü oluşturmak için Gemini CLI.
Şartlar
2. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
- Google Cloud'da çalışan bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmında Cloud Shell'i Etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmamışsa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Gerekli API'leri etkinleştirin: Bağlantıyı takip ederek API'leri etkinleştirin.
Alternatif olarak, bu işlem için gcloud komutunu kullanabilirsiniz. gcloud komutları ve kullanımı için belgelere bakın.
3. Veritabanı kurulumu
Bu laboratuvarda e-ticaret verileri için veritabanı olarak AlloyDB'yi kullanacağız. Veritabanları ve günlükler gibi tüm kaynakları tutmak için kümeler kullanılır. Her kümede, verilere erişim noktası sağlayan bir birincil örnek bulunur. Tablolar gerçek verileri içerir.
E-ticaret veri kümesinin yükleneceği bir AlloyDB kümesi, örneği ve tablosu oluşturalım.
Küme ve örnek oluşturma
- Cloud Console'da AlloyDB sayfasına gidin. Cloud Console'daki çoğu sayfayı bulmanın kolay bir yolu, konsolun arama çubuğunu kullanarak arama yapmaktır.
- Bu sayfada KÜME OLUŞTUR'u seçin:

- Aşağıdaki gibi bir ekran görürsünüz. Aşağıdaki değerlerle bir küme ve örnek oluşturun (Uygulama kodunu depodan klonluyorsanız değerlerin eşleştiğinden emin olun):
- küme kimliği: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / en son önerilen
- Bölge: "
us-central1" - Ağ: "
default"
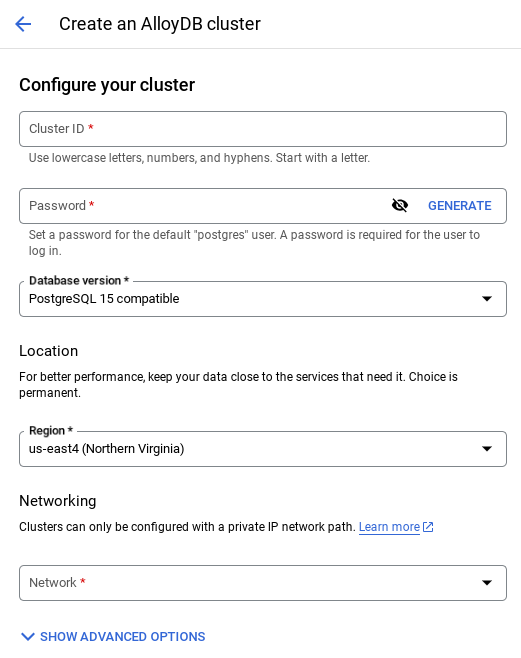
- Varsayılan ağı seçtiğinizde aşağıdaki gibi bir ekran görürsünüz.
BAĞLANTIYI AYARLA'yı seçin.
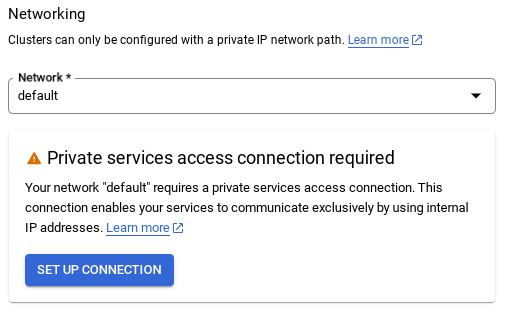
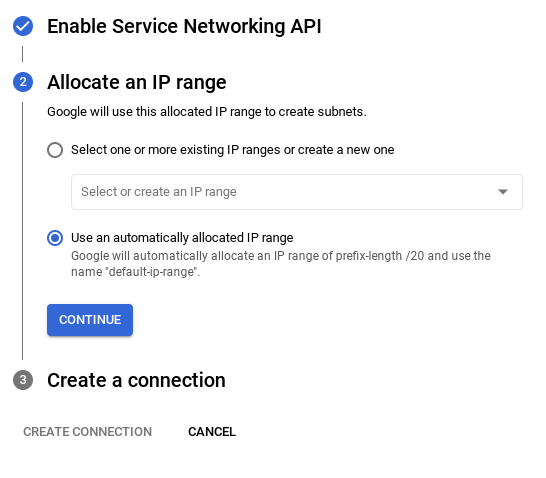
- Buradan "Otomatik olarak atanmış bir IP aralığı kullan"ı seçip Devam'ı tıklayın. Bilgileri inceledikten sonra BAĞLANTI OLUŞTUR'u seçin.
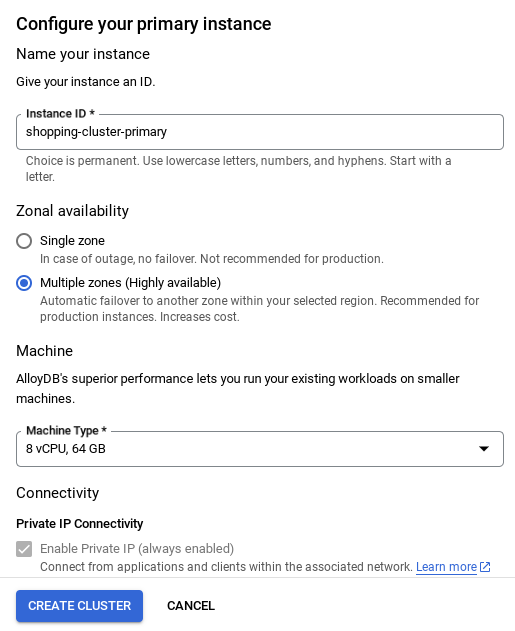
- Ağınız kurulduktan sonra kümenizi oluşturmaya devam edebilirsiniz. Aşağıda gösterildiği gibi küme kurulumunu tamamlamak için CREATE CLUSTER'ı (KÜME OLUŞTUR) tıklayın:
ÖNEMLİ NOT:
- Küme/örnek yapılandırılırken bulabileceğiniz örnek kimliğini **
vector-instance** olarak değiştirdiğinizden emin olun. Değiştiremiyorsanız tüm referanslarda <strong>örnek kimliğinizi kullandığınızdan</strong> emin olun. - Küme oluşturma işleminin yaklaşık 10 dakika süreceğini unutmayın. İşlem başarılı olduğunda, yeni oluşturduğunuz kümenizin genel görünümünü gösteren bir ekran görürsünüz.
4. Veri kullanımı
Şimdi mağazayla ilgili verilerin bulunduğu bir tablo ekleme zamanı. AlloyDB'ye gidin, birincil kümeyi ve ardından AlloyDB Studio'yu seçin:
Örneğinizin oluşturulmasının tamamlanmasını beklemeniz gerekebilir. Bu işlem tamamlandıktan sonra, kümeyi oluştururken oluşturduğunuz kimlik bilgilerini kullanarak AlloyDB'de oturum açın. PostgreSQL'de kimlik doğrulaması yapmak için aşağıdaki verileri kullanın:
- Kullanıcı adı : "
postgres" - Veritabanı : "
postgres" - Şifre : "
alloydb"
AlloyDB Studio'da kimliğinizi başarıyla doğruladıktan sonra SQL komutları Düzenleyici'ye girilir. Son pencerenin sağındaki artı işaretini kullanarak birden fazla Düzenleyici penceresi ekleyebilirsiniz.
Gerekli durumlarda Çalıştır, Biçimlendir ve Temizle seçeneklerini kullanarak AlloyDB için komutları düzenleyici pencerelerine gireceksiniz.
Uzantıları etkinleştirme
Bu uygulamayı oluşturmak için pgvector ve google_ml_integration uzantılarını kullanacağız. pgvector uzantısı, vektör yerleştirmelerini depolamanıza ve aramanıza olanak tanır. google_ml_integration uzantısı, SQL'de tahmin almak için Vertex AI tahmin uç noktalarına erişmek üzere kullandığınız işlevleri sağlar. Aşağıdaki DDL'leri çalıştırarak bu uzantıları etkinleştirin:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Veritabanınızda etkinleştirilen uzantıları kontrol etmek istiyorsanız şu SQL komutunu çalıştırın:
select extname, extversion from pg_extension;
Tablo oluşturma
AlloyDB Studio'da aşağıdaki DDL ifadesini kullanarak bir tablo oluşturabilirsiniz:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Yerleştirme sütunu, metnin vektör değerlerinin depolanmasına olanak tanır.
İzin Ver
"embedding" işlevinde yürütme izni vermek için aşağıdaki ifadeyi çalıştırın:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
AlloyDB hizmet hesabına Vertex AI Kullanıcısı ROLÜ'nü verme
Google Cloud IAM Console'dan AlloyDB hizmet hesabına (service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com şeklinde görünür) "Vertex AI Kullanıcısı" rolüne erişim izni verin. PROJECT_NUMBER, proje numaranızı içerir.
Alternatif olarak, aşağıdaki komutu Cloud Shell Terminali'nden çalıştırabilirsiniz:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Verileri veritabanına yükleme
- E-tablodaki
insert scripts sqlbölümündeninsertsorgu ifadelerini kopyalayıp yukarıda belirtilen düzenleyiciye yapıştırın. Bu kullanım alanının hızlı bir demosunu yapmak için 10-50 ekleme ifadesini kopyalayabilirsiniz. Bu "Seçilen Ekleme İşlemleri 25-30 satır" sekmesinde, seçilmiş bir ekleme listesi bulunur. - Çalıştır'ı tıklayın. Sorgunuzun sonuçları Sonuçlar tablosunda görünür.
ÖNEMLİ NOT:
Yalnızca 25-50 kayıt kopyaladığınızdan ve bunların kategori, alt_kategori, renk, cinsiyet türleri aralığından olduğundan emin olun.
5. Veriler için yerleştirmeler oluşturma
Modern aramadaki gerçek yenilik, yalnızca anahtar kelimeleri değil, anlamı da anlamaktan geçer. Bu noktada yerleştirmeler ve vektör araması devreye girer.
Önceden eğitilmiş dil modellerini kullanarak ürün açıklamalarını ve kullanıcı sorgularını "gömme" adı verilen yüksek boyutlu sayısal gösterimlere dönüştürdük. Bu yerleştirmeler, anlamsal anlamı yakalayarak yalnızca eşleşen kelimeleri içeren ürünler yerine "anlamı benzer" olan ürünleri bulmamızı sağlar. Başlangıçta, bir temel oluşturmak için bu yerleştirmelerde doğrudan vektör benzerliği aramasıyla denemeler yaptık. Bu denemeler, performans optimizasyonlarından önce bile anlamsal anlayışın gücünü gösterdi.
Yerleştirme sütunu, ürün açıklaması metninin vektör değerlerinin depolanmasına olanak tanır. img_embeddings sütunu, resim yerleştirmelerinin (çok formatlı) depolanmasına olanak tanır. Bu şekilde, metin ile görüntü arasındaki mesafeye dayalı aramayı da kullanabilirsiniz. Ancak bu laboratuvarda yalnızca metin yerleştirmelerini kullanacağız.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Bu işlem, sorgudaki örnek metin için kayan nokta dizisi gibi görünen yerleştirme vektörünü döndürmelidir. Şöyle görünür:
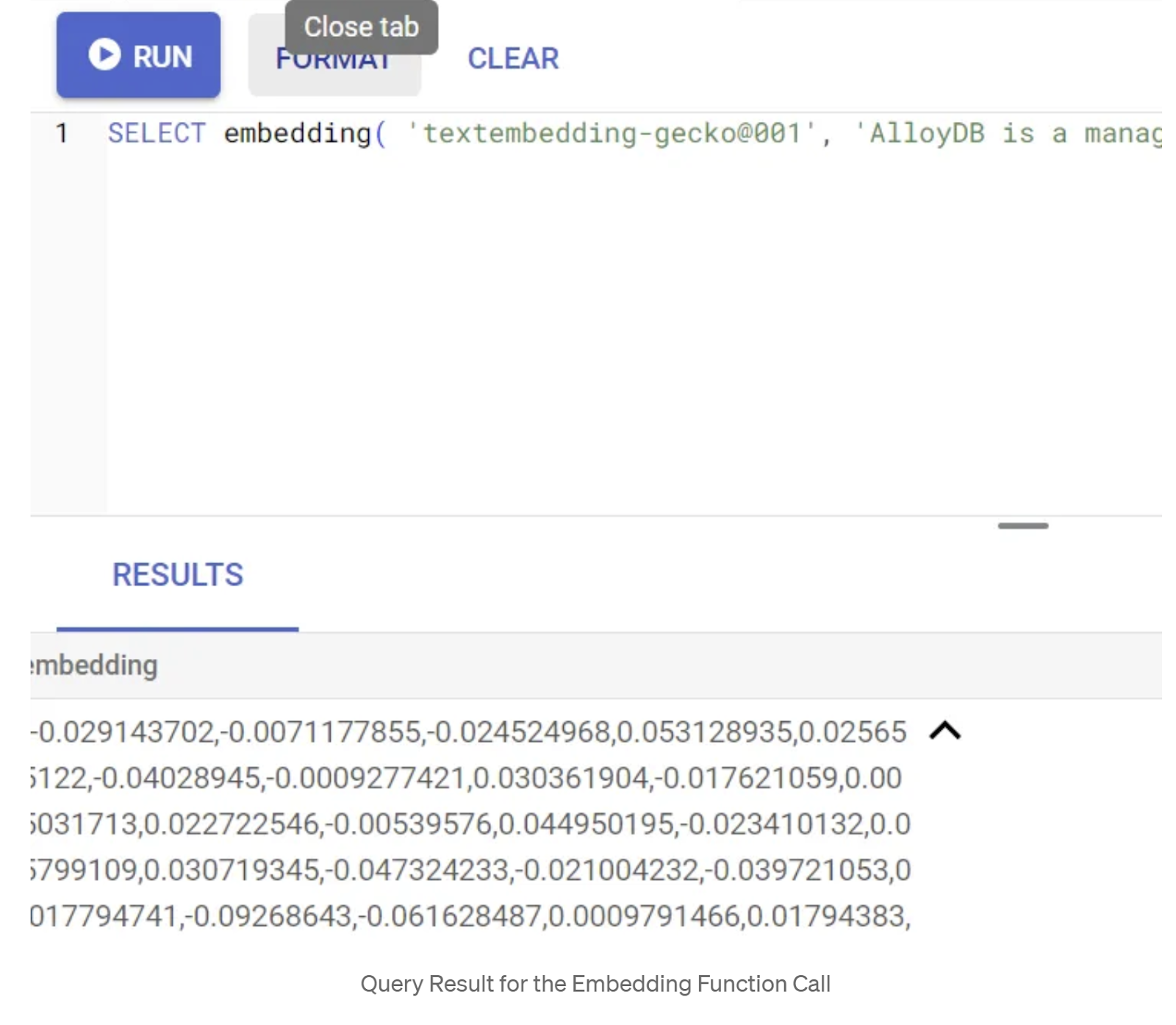
abstract_embeddings Vector alanını güncelleme
Tablodaki içerik açıklamasını ilgili yerleştirmelerle güncellemek için aşağıdaki DML'yi çalıştırın:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Google Cloud için deneme kredisi faturalandırma hesabı kullanıyorsanız birkaç yerleştirme (ör. en fazla 20-25) oluşturmakta sorun yaşayabilirsiniz. Bu nedenle, ekleme komut dosyasındaki satır sayısını sınırlayın.
Görüntü yerleştirmeleri oluşturmak (çok formatlı bağlamsal arama yapmak için) istiyorsanız aşağıdaki güncellemeyi de çalıştırın:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Veritabanları için MCP Araç Kutusu (AlloyDB)
Arka planda, güçlü araçlar ve iyi yapılandırılmış bir uygulama sayesinde sorunsuz bir şekilde çalışır.
Veritabanları için MCP (Model Context Protocol) Araç Kutusu, üretken yapay zeka ve ajan tabanlı araçların AlloyDB ile entegrasyonunu basitleştirir. Bağlantı havuzunu, kimlik doğrulamayı ve veritabanı işlevlerinin yapay zeka aracılarına veya diğer uygulamalara güvenli bir şekilde sunulmasını kolaylaştıran açık kaynaklı bir sunucu görevi görür.
Uygulamamızda, tüm akıllı karma arama sorgularımız için bir soyutlama katmanı olarak MCP Toolbox for Databases'i kullandık.
Kullanım alanımız için Toolbox'ı ayarlamak ve dağıtmak üzere aşağıdaki adımları uygulayın:
MCP Toolbox for Databases tarafından desteklenen veritabanlarından birinin AlloyDB olduğunu görebilirsiniz. Önceki bölümde bu veritabanını zaten sağladığımız için Toolbox'ı kurmaya devam edelim.
- Cloud Shell terminalinize gidin ve projenizin seçili olduğundan ve terminalin isteminde gösterildiğinden emin olun. Proje dizininize gitmek için Cloud Shell terminalinizde aşağıdaki komutu çalıştırın:
mkdir gemini-cli-project
cd gemini-cli-project
- Araç kutusunu yeni klasörünüze indirip yüklemek için aşağıdaki komutu çalıştırın:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Bu işlem, mevcut dizininizde araç kutusunu oluşturur. Yolu araç kutusuna kopyalayın.
- Cloud Shell Düzenleyici'ye (kod düzenleme modu için) gidin ve proje kök klasöründe ("gemini-cli-project") "tools.yaml" adlı bir dosya ekleyin.
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
tools.yaml dosyasını inceleyelim:
Kaynaklar, bir aracın etkileşimde bulunabileceği farklı veri kaynaklarınızı temsil eder. Kaynak, bir aracın etkileşimde bulunabileceği bir veri kaynağını temsil eder. Kaynakları, tools.yaml dosyanızın kaynaklar bölümünde harita olarak tanımlayabilirsiniz. Genellikle bir kaynak yapılandırması, veritabanına bağlanmak ve veritabanıyla etkileşim kurmak için gereken tüm bilgileri içerir.
Araçlar, bir aracının gerçekleştirebileceği işlemleri (ör. bir kaynağı okuma ve kaynağa yazma) tanımlar. Araç, aracınızın gerçekleştirebileceği bir işlemi (ör. SQL ifadesi çalıştırma) temsil eder. Araçlar'ı tools.yaml dosyanızın araçlar bölümünde harita olarak tanımlayabilirsiniz. Genellikle bir aracın işlem yapması için kaynak gerekir.
tools.yaml dosyanızı yapılandırma hakkında daha fazla bilgi için bu belgeye bakın.
Yukarıdaki Tools.yaml dosyasında görebileceğiniz gibi, "get-apparels" aracı, veritabanındaki tüm giysilerin ayrıntılarını listeler.
7. Gemini CLI'yı kurma
Cloud Shell Düzenleyici'de, gemini-cli-project klasörünün içinde .gemini adlı yeni bir klasör oluşturun ve bu klasörde settings.json adlı yeni bir dosya oluşturun.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Yukarıdaki snippet'teki komut bölümünde "/home/user/gemini-cli-project/toolbox" ifadesini toolbox'a giden yolunuzla değiştirin.
Gemini CLI'yı yükleme
Son olarak, Cloud Shell Terminalinden aşağıdaki komutu çalıştırarak Gemini KSA'yı aynı dizine (gemini-cli-project) yükleyelim:
sudo npm install -g @google/gemini-cli
Proje kimliğinizi ayarlama
Ortamda etkin proje kimliğinin ayarlandığından emin olun:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Gemini KSA'yı kullanmaya başlama
Komut satırından şu komutu girin:
gemini
Aşağıdakine benzer bir yanıt görmeniz gerekir:
Kimliğinizi doğrulayın ve sonraki adıma geçin.
8. Gemini CLI ile etkileşim kurmaya başlama
Yapılandırılmış MCP sunucularını listelemek için /mcp komutunu kullanın.
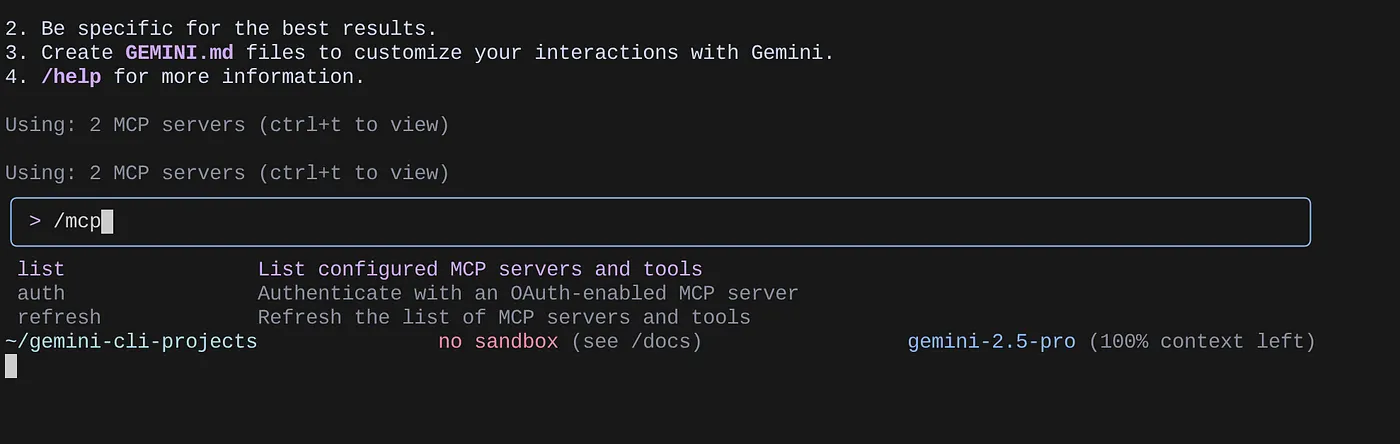
Yapılandırdığımız 2 MCP sunucusunu (GitHub ve Veritabanları için MCP Toolkit) araçlarıyla birlikte görebilirsiniz.
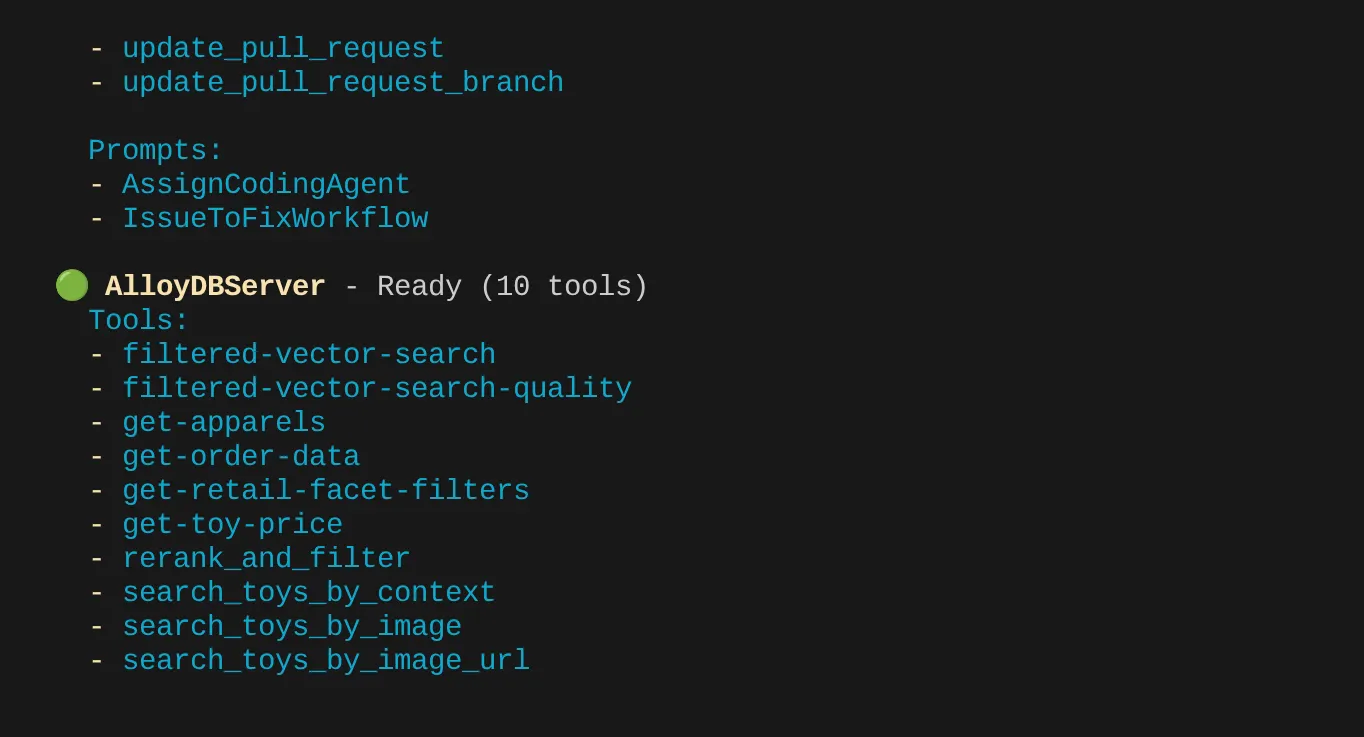
Benim durumumda daha fazla araç var. Bu nedenle, şimdilik bu uyarıyı dikkate almayın. AlloyDB MCP sunucunuzda get-apparels aracını görmeniz gerekir.
MCP Araç Kutusu aracılığıyla veritabanını sorgulamaya başlama
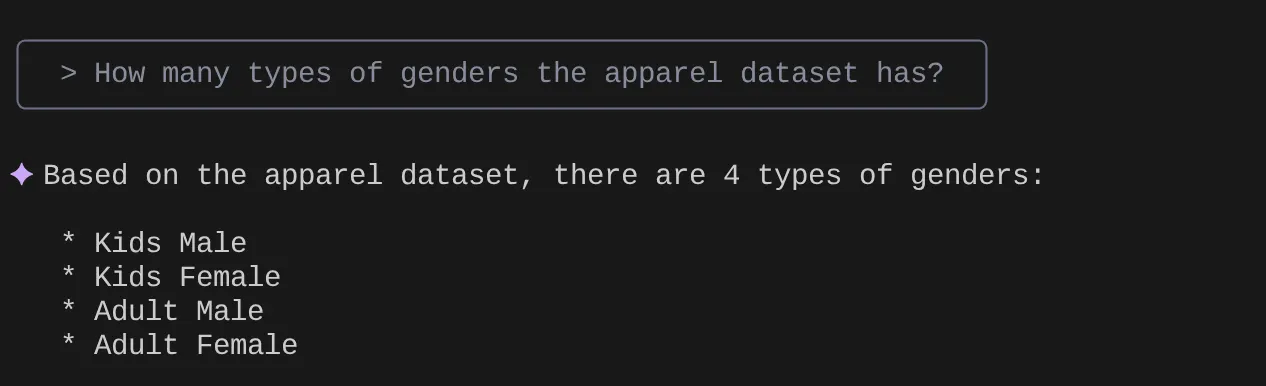
Şimdi, çalıştığımız veri kümesiyle ilgili yanıt ve sorgu almak için doğal dil soruları sormayı deneyin:
> How many types of genders the apparel dataset has?
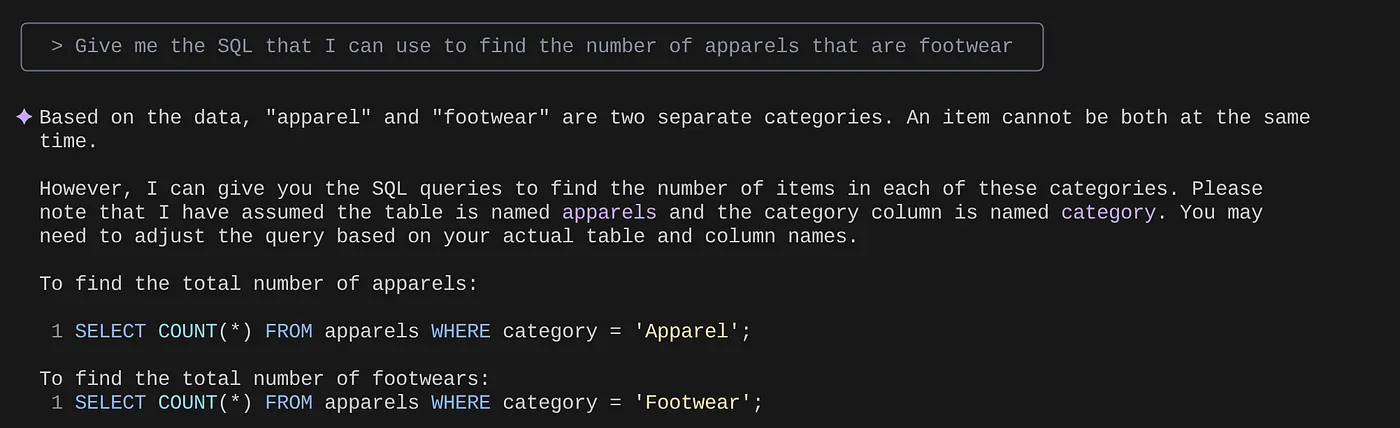
> Give me the SQL that I can use to find the number of apparels that are footwear
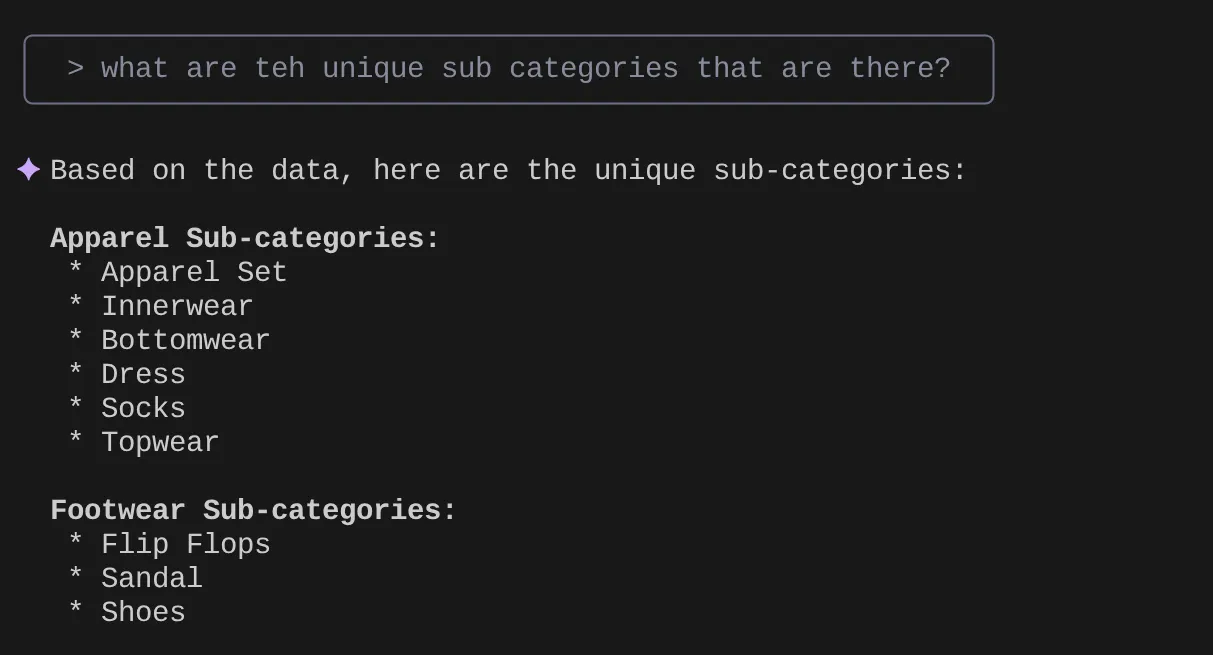
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
Şimdi de analizlerime ve bu türdeki birçok sorguya dayanarak ayrıntılı bir sorgu oluşturduğumu ve bunu test etmek istediğimi varsayalım. Ya da veritabanı mühendislerinin sizin için Tools.yaml dosyasını aşağıdaki gibi oluşturduğunu varsayalım:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Şimdi doğal dil araması yapmayı deneyelim:
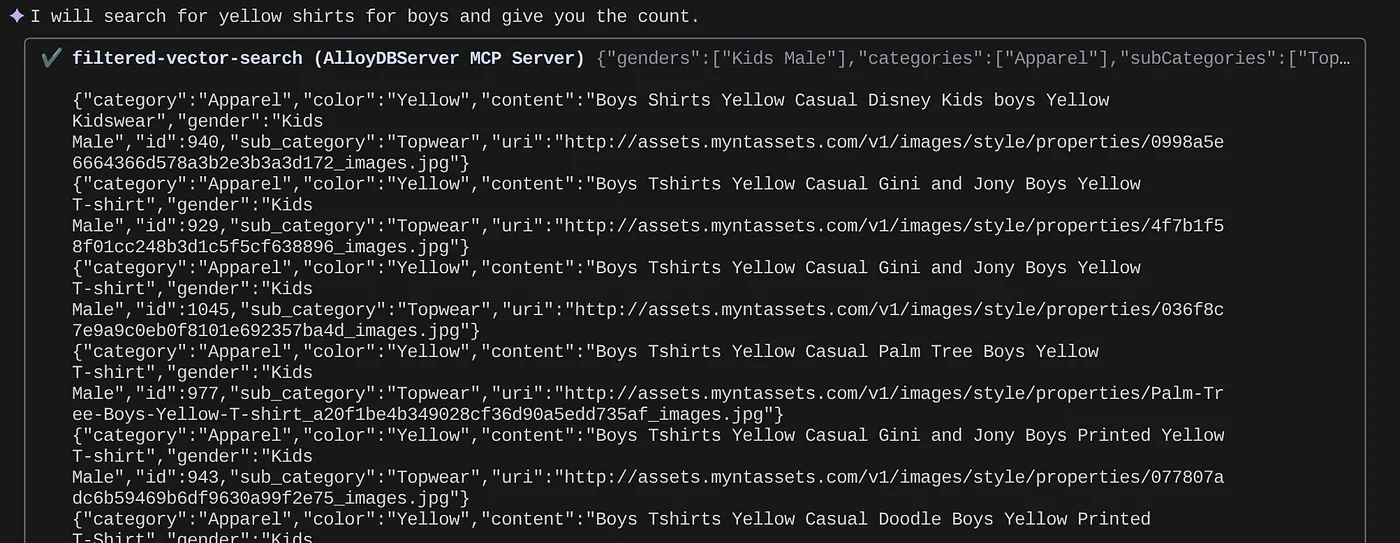
> How many yellow shirts are there for boys?

Harika, değil mi? Artık, uygulamamda yeni işlevler sunmaya devam ederken sorgularda daha fazla ilerleme kaydetmek için YAML dosyasını düzeltebiliyorum.
9. Hızlandırılmış Uygulama Geliştirme
Gemini CLI ve MCP Toolbox aracılığıyla veritabanı özelliklerini doğrudan IDE'nize getirmenin avantajları sadece teorik değildir. Bu, özellikle hibrit perakende deneyimimiz gibi karmaşık bir uygulama için somut ve hızı artıran iş akışlarına dönüşür. Birkaç senaryoya göz atalım:
1. Ürün filtreleme mantığını hızlı bir şekilde yineleme
"Yazlık spor kıyafetler" için yeni bir promosyon başlattığımızı düşünelim. Faset filtrelerimizin (ör. marka, boyut, renk, fiyat aralığına göre) bu yeni kategoriyle nasıl etkileşim kurduğunu test etmek istiyoruz.
IDE entegrasyonu olmadan:
Büyük ihtimalle ayrı bir SQL istemcisine geçer, sorgumu yazar, çalıştırır, sonuçları analiz eder, uygulama kodunu ayarlamak için IDE'me geri döner, istemciye geri döner ve işlemi tekrarlardım. Bu bağlam değiştirme işlemi büyük bir sorun teşkil ediyor.
Gemini CLI ve MCP ile:
IDE'mde ve daha birçok yerde kalabilirim:
- Sorgulama: "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" (hipotetik veri kümesi) ile yaml dosyasındaki sorguyu hızlıca güncelleyip doğrudan terminalimde deneyebilirim.
- Veri Keşfi: Döndürülen markaları anında görün. Belirli bir marka ve boyuttaki ürünlerin stok durumunu görmem gerekiyorsa başka bir hızlı sorgu kullanırım:"SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'"
- Kod Entegrasyonu: Ardından, ön uç filtreleme mantığını veya arka uç API çağrılarını bu hızlı, IDE içi veri analizlerine göre anında ayarlayabilirim. Böylece geri bildirim döngüsü önemli ölçüde kısalır.
2. Ürün Önerileri İçin Vector Search'ü İnce Ayarlama
Karma arama özelliğimiz, alakalı ürün önerileri için vektör yerleştirmelerinden yararlanır. "Erkek koşu ayakkabısı" önerilerinin tıklama oranlarında düşüş olduğunu varsayalım.
IDE entegrasyonu olmadan:
Önerilen ayakkabıların benzerlik puanlarını analiz etmek, bunları kullanıcı etkileşimi verileriyle karşılaştırmak ve herhangi bir kalıbı ilişkilendirmeye çalışmak için bir veritabanı aracında özel komut dosyaları veya sorgular çalıştırıyorum.
Gemini CLI ve MCP ile:
- Yerleştirmeleri Analiz Etme: Ürün yerleştirmeleri ve bunlarla ilişkili meta veriler için doğrudan sorgu oluşturabilirim: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- Çapraz Referans: Seçilen bir ürün ile önerileri arasındaki gerçek vektör benzerliğini de doğrudan kontrol edebilirim. Örneğin, B ürününü inceleyen kullanıcılara A ürünü öneriliyorsa vektör yerleştirmelerini almak ve karşılaştırmak için bir sorgu çalıştırabilirim.
- Hata ayıklama: Bu sayede hata ayıklama ve hipotez testi daha hızlı yapılabilir. Yerleştirme modeli beklendiği gibi mi çalışıyor? Verilerde öneri kalitesini etkileyen anormallikler var mı? Kodlama ortamımdan ayrılmadan ilk yanıtları alabiliyorum.
3. Yeni özellikler için şema ve veri dağıtımını anlama
"Müşteri yorumları" özelliği eklemeyi planladığımızı varsayalım. Arka uç API'sini yazmadan önce mevcut müşteri verilerini ve yorumların nasıl yapılandırılacağını anlamamız gerekir.
IDE entegrasyonu olmadan:
Bir veritabanı istemcisine bağlanmam, müşteriler ve siparişler gibi tablolarda DESCRIBE komutlarını çalıştırmam, ardından ilişkileri ve veri türlerini anlamak için örnek verileri sorgulamam gerekiyor.
Gemini CLI ve MCP ile:
- Şema Keşfi: YAML dosyasındaki tabloyu sorgulayıp doğrudan terminalde çalıştırabilirim.
- Veri örnekleme: Ardından, müşteri demografik bilgilerini ve satın alma geçmişini anlamak için örnek verileri çekebilirim: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Planlama: Şemaya ve veri dağıtımına hızlı erişim sayesinde, yeni inceleme tablosunun nasıl tasarlanacağı, hangi yabancı anahtarların oluşturulacağı ve incelemelerin müşterilere ve ürünlere nasıl verimli bir şekilde bağlanacağı konusunda bilinçli kararlar verebiliriz. Tüm bunları, yeni özellik için tek bir satır uygulama kodu yazmadan önce yapabiliriz.
Bunlar yalnızca birkaç örnek olsa da temel avantajı vurgulamaktadır: sürtünmeyi azaltmak ve geliştirici hızını artırmak. AlloyDB etkileşimini doğrudan IDE'ye taşıyan Gemini CLI ve MCP Toolbox, daha iyi ve daha hızlı yanıt veren uygulamaları daha hızlı geliştirmemizi sağlıyor.
10. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynak Yöneticisi sayfasına gidin.
- Proje listesinde silmek istediğiniz projeyi seçin ve Sil'i tıklayın.
- İletişim kutusunda proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
- Alternatif olarak, KÜMEYİ SİL düğmesini tıklayarak bu proje için yeni oluşturduğumuz AlloyDB kümesini silebilirsiniz (yapılandırma sırasında küme için us-central1'i seçmediyseniz bu köprüdeki konumu değiştirin).
11. Tebrikler
Tebrikler! MCP Toolbox'ı sorunsuz AlloyDB etkileşimi için doğrudan IDE'nize başarıyla entegre ettiniz ve genellikle ayrı araçlar gerektiren sorgular yazmak için perakende e-ticaret veri setimizle etkileşim kurmak üzere Gemini CLI'dan yararlandınız. Tablo yapılarını kontrol etmekten hızlı veri doğruluk kontrolleri yapmaya kadar, verileri incelemenin ve anlamanın yeni yollarını öğrendiniz. Tüm bu işlemler, IDE'mizdeki tanıdık komut satırı arayüzleri üzerinden gerçekleştirilir.
Depoyu klonlayın, analiz edin ve Gemini CLI ile Veritabanları için MCP Toolbox'ı kullanarak uygulamayı geliştirdiyseniz bana bildirin.
Gemini CLI ve MCP ile oluşturulup sunucusuz çalışma zamanlarında dağıtılan bu tür veri odaklı uygulamalar hakkında daha fazla bilgi edinmek için Code Vipassana'nın yaklaşan sezonuna kaydolun. Bu etkinlikte eğitmenler tarafından yönetilen uygulamalı oturumlar ve daha fazla codelab'e katılabilirsiniz.