
1. Tổng quan
Bạn còn nhớ hành trình xây dựng trải nghiệm bán lẻ kết hợp linh hoạt bằng AlloyDB, kết hợp tính năng lọc theo khía cạnh và tìm kiếm vectơ không? Ứng dụng đó là một minh chứng mạnh mẽ cho nhu cầu bán lẻ hiện đại, nhưng để đạt được điều đó và lặp lại quy trình, chúng tôi đã phải nỗ lực phát triển đáng kể. Đối với nhà phát triển toàn diện, việc liên tục chuyển đổi giữa trình chỉnh sửa mã và công cụ cơ sở dữ liệu thường có thể là một điểm tắc nghẽn, làm chậm quá trình đổi mới và quy trình quan trọng để hiểu dữ liệu của bạn.
Giải pháp
Đây chính xác là nơi sức mạnh của việc phát triển ứng dụng tăng tốc thực sự phát huy tác dụng. Đó là lý do tôi rất hào hứng chia sẻ cách MCP (Nền tảng đám mây hiện đại) Toolbox (có thể truy cập thông qua Gemini CLI trực quan) đã trở thành một phần không thể thiếu trong bộ công cụ của tôi. Hãy tưởng tượng bạn có thể tương tác liền mạch với phiên bản AlloyDB, viết truy vấn và hiểu rõ tập dữ liệu của mình – tất cả đều diễn ra ngay trong Môi trường phát triển tích hợp (IDE). Điều này không chỉ mang lại sự thuận tiện mà còn giúp giảm đáng kể những khó khăn trong vòng đời phát triển, cho phép bạn tập trung vào việc xây dựng các tính năng cải tiến thay vì phải vật lộn với các công cụ bên ngoài.
Trong bối cảnh ứng dụng thương mại điện tử bán lẻ của chúng tôi, nơi chúng tôi cần truy vấn dữ liệu sản phẩm một cách hiệu quả, xử lý việc lọc phức tạp và tận dụng các sắc thái của tính năng tìm kiếm vectơ, khả năng nhanh chóng lặp lại các hoạt động tương tác với cơ sở dữ liệu là điều tối quan trọng. Bộ công cụ MCP (dựa trên Gemini CLI) không chỉ đơn giản hoá mà còn đẩy nhanh quá trình này, giúp thay đổi cách chúng ta có thể khám phá, kiểm thử và tinh chỉnh logic cơ sở dữ liệu làm nền tảng cho các ứng dụng của mình. Hãy cùng tìm hiểu cách sự kết hợp mang tính đột phá này giúp quá trình phát triển toàn diện diễn ra nhanh hơn, thông minh hơn và thú vị hơn.
Kiến thức bạn sẽ học được và sản phẩm bạn sẽ tạo ra
Ứng dụng Tìm kiếm bán lẻ sử dụng Bộ công cụ MCP trong IDE, được hỗ trợ bởi Gemini CLI. Chúng tôi sẽ đề cập đến:
- Cách tích hợp MCP Toolbox trực tiếp vào IDE để tương tác liền mạch với AlloyDB.
- Ví dụ thực tế về cách sử dụng Gemini CLI để viết và thực thi truy vấn SQL dựa trên dữ liệu bán lẻ của bạn.
- Khai thác Gemini CLI để tương tác với tập dữ liệu thương mại điện tử bán lẻ của chúng tôi, viết các truy vấn mà thường yêu cầu các công cụ riêng biệt và xem kết quả ngay lập tức.
- Khám phá những cách mới để kiểm tra và hiểu dữ liệu – từ việc kiểm tra cấu trúc bảng đến việc thực hiện các bước kiểm tra nhanh tính hợp lệ của dữ liệu – tất cả đều thông qua các giao diện dòng lệnh quen thuộc trong IDE của chúng tôi.
- Cách quy trình làm việc với cơ sở dữ liệu được tăng tốc này đóng góp trực tiếp vào các chu kỳ phát triển toàn diện nhanh hơn, cho phép tạo mẫu và lặp lại nhanh chóng.
Techstack
Chúng tôi đang sử dụng:
- AlloyDB cho cơ sở dữ liệu
- Bộ công cụ MCP để trừu tượng hoá các tính năng nâng cao về AI và tạo sinh của cơ sở dữ liệu từ ứng dụng
- Cloud Run để triển khai không máy chủ.
- Gemini CLI để hiểu và phân tích tập dữ liệu, đồng thời xây dựng phần cơ sở dữ liệu của ứng dụng thương mại điện tử bán lẻ.
Yêu cầu
2. Trước khi bắt đầu
Tạo dự án
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
- Bạn sẽ sử dụng Cloud Shell, một môi trường dòng lệnh chạy trong Google Cloud. Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.

- Sau khi kết nối với Cloud Shell, hãy kiểm tra để đảm bảo bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
- Chạy lệnh sau trong Cloud Shell để xác nhận rằng lệnh gcloud biết về dự án của bạn.
gcloud config list project
- Nếu bạn chưa đặt dự án, hãy dùng lệnh sau để đặt:
gcloud config set project <YOUR_PROJECT_ID>
- Bật các API bắt buộc: Truy cập vào đường liên kết rồi bật các API.
Ngoài ra, bạn có thể dùng lệnh gcloud cho việc này. Tham khảo tài liệu để biết các lệnh và cách sử dụng gcloud.
3. Thiết lập cơ sở dữ liệu
Trong phòng thí nghiệm này, chúng ta sẽ sử dụng AlloyDB làm cơ sở dữ liệu cho dữ liệu thương mại điện tử. Nó sử dụng cụm để lưu giữ tất cả các tài nguyên, chẳng hạn như cơ sở dữ liệu và nhật ký. Mỗi cụm có một phiên bản chính cung cấp một điểm truy cập vào dữ liệu. Các bảng sẽ chứa dữ liệu thực tế.
Hãy tạo một cụm, thực thể và bảng AlloyDB nơi tập dữ liệu thương mại điện tử sẽ được tải.
Tạo một cụm và phiên bản
- Chuyển đến trang AlloyDB trong Cloud Console. Một cách dễ dàng để tìm hầu hết các trang trong Cloud Console là tìm kiếm các trang đó bằng thanh tìm kiếm của bảng điều khiển.
- Chọn TẠO CỤM trên trang đó:

- Bạn sẽ thấy một màn hình như màn hình bên dưới. Tạo một cụm và thực thể bằng các giá trị sau (Đảm bảo các giá trị khớp nhau trong trường hợp bạn đang sao chép mã xử lý ứng dụng từ kho lưu trữ):
- mã nhận dạng cụm: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mới nhất (nên dùng)
- Vùng: "
us-central1" - Mạng: "
default"
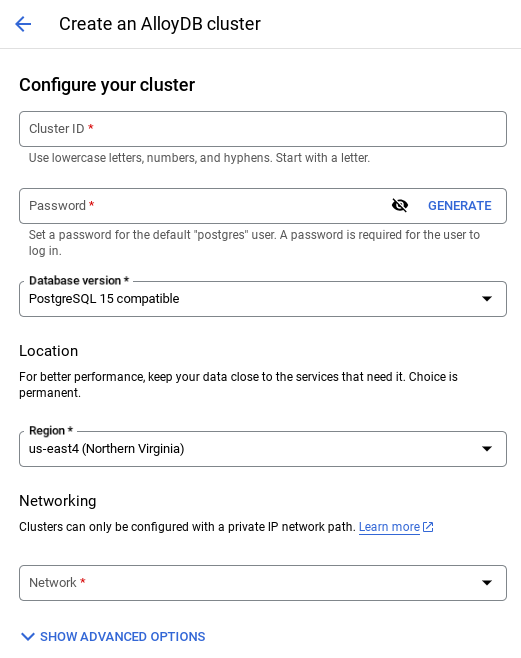
- Khi chọn mạng mặc định, bạn sẽ thấy một màn hình như màn hình bên dưới.
Chọn THIẾT LẬP KẾT NỐI.
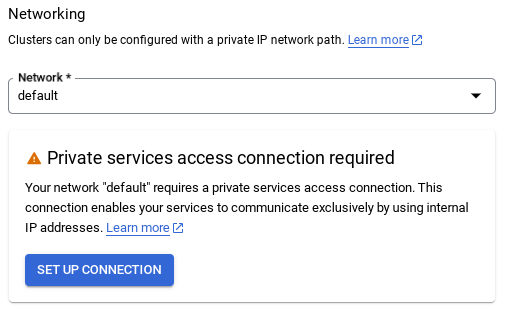
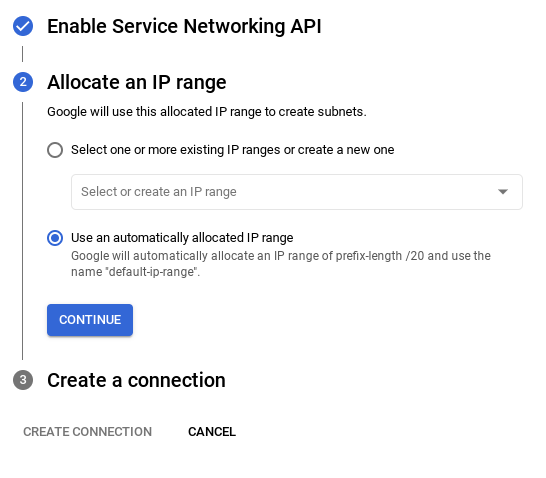
- Tại đó, hãy chọn "Sử dụng dải IP được phân bổ tự động" rồi chọn Tiếp tục. Sau khi xem xét thông tin, hãy chọn TẠO KẾT NỐI.
- Sau khi thiết lập mạng, bạn có thể tiếp tục tạo cụm. Nhấp vào TẠO CỤM để hoàn tất việc thiết lập cụm như minh hoạ bên dưới:
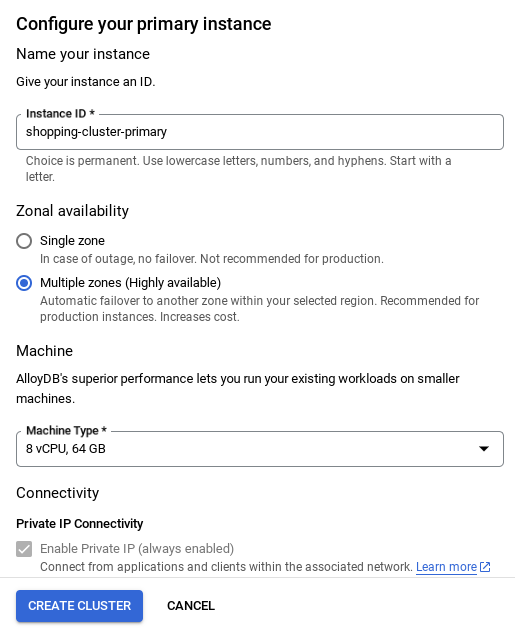
LƯU Ý QUAN TRỌNG:
- Nhớ thay đổi mã nhận dạng phiên bản (bạn có thể tìm thấy mã này tại thời điểm định cấu hình cụm / phiên bản) thành **
vector-instance**. Nếu không thay đổi được, hãy nhớ **sử dụng mã nhận dạng phiên bản** trong tất cả các thông tin tham chiếu sắp tới. - Xin lưu ý rằng quá trình tạo Cụm sẽ mất khoảng 10 phút. Sau khi tạo thành công, bạn sẽ thấy một màn hình cho biết thông tin tổng quan về cụm mà bạn vừa tạo.
4. Nhập dữ liệu
Bây giờ, đã đến lúc thêm một bảng có dữ liệu về cửa hàng. Chuyển đến AlloyDB, chọn cụm chính rồi chọn AlloyDB Studio:
Bạn có thể phải đợi phiên bản của mình được tạo xong. Sau khi tạo, hãy đăng nhập vào AlloyDB bằng thông tin đăng nhập mà bạn đã tạo khi tạo cụm. Sử dụng dữ liệu sau để xác thực với PostgreSQL:
- Tên người dùng : "
postgres" - Cơ sở dữ liệu : "
postgres" - Mật khẩu : "
alloydb"
Sau khi bạn xác thực thành công vào AlloyDB Studio, các lệnh SQL sẽ được nhập vào Trình chỉnh sửa. Bạn có thể thêm nhiều cửa sổ Trình chỉnh sửa bằng cách nhấp vào dấu cộng ở bên phải cửa sổ cuối cùng.
Bạn sẽ nhập các lệnh cho AlloyDB trong cửa sổ trình chỉnh sửa, sử dụng các lựa chọn Chạy, Định dạng và Xoá khi cần.
Bật tiện ích
Để tạo ứng dụng này, chúng ta sẽ sử dụng các tiện ích pgvector và google_ml_integration. Tiện ích pgvector cho phép bạn lưu trữ và tìm kiếm các vectơ nhúng. Tiện ích google_ml_integration cung cấp các hàm mà bạn dùng để truy cập vào các điểm cuối dự đoán của Vertex AI nhằm nhận thông tin dự đoán bằng SQL. Bật các tiện ích này bằng cách chạy các DDL sau:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
Nếu bạn muốn kiểm tra các tiện ích đã được bật trên cơ sở dữ liệu, hãy chạy lệnh SQL sau:
select extname, extversion from pg_extension;
Tạo bảng
Bạn có thể tạo một bảng bằng câu lệnh DDL bên dưới trong AlloyDB Studio:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
Cột nhúng sẽ cho phép lưu trữ các giá trị vectơ của văn bản.
Cấp quyền
Chạy câu lệnh bên dưới để cấp quyền thực thi cho hàm "embedding":
GRANT EXECUTE ON FUNCTION embedding TO postgres;
Cấp vai trò Người dùng Vertex AI cho tài khoản dịch vụ AlloyDB
Trên bảng điều khiển IAM của Google Cloud, hãy cấp cho tài khoản dịch vụ AlloyDB (có dạng như sau: service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com) quyền truy cập vào vai trò "Người dùng Vertex AI". PROJECT_NUMBER sẽ có số dự án của bạn.
Ngoài ra, bạn có thể chạy lệnh bên dưới trong Cloud Shell Terminal:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
Tải dữ liệu vào cơ sở dữ liệu
- Sao chép câu lệnh truy vấn
inserttừinsert scripts sqltrong trang tính vào trình chỉnh sửa như đã đề cập ở trên. Bạn có thể sao chép 10 đến 50 câu lệnh chèn để xem nhanh bản minh hoạ về trường hợp sử dụng này. Có một danh sách các đoạn chèn được chọn ở đây trong thẻ "Các đoạn chèn được chọn từ 25 đến 30 hàng". - Nhấp vào Chạy. Kết quả của truy vấn sẽ xuất hiện trong bảng Results (Kết quả).
LƯU Ý QUAN TRỌNG:
Hãy nhớ chỉ sao chép từ 25 đến 50 bản ghi để chèn và đảm bảo rằng bản ghi đó thuộc một dải ô gồm các loại danh mục, danh mục phụ, màu sắc, giới tính.
5. Tạo các vectơ nhúng cho dữ liệu
Sự đổi mới thực sự trong hoạt động tìm kiếm hiện đại nằm ở việc hiểu được ý nghĩa, chứ không chỉ là từ khoá. Đây là lúc các tính năng nhúng và tìm kiếm vectơ phát huy tác dụng.
Chúng tôi đã chuyển đổi nội dung mô tả sản phẩm và cụm từ tìm kiếm của người dùng thành các biểu diễn số có nhiều chiều (gọi là "embedding") bằng cách sử dụng các mô hình ngôn ngữ được huấn luyện trước. Các vectơ nhúng này nắm bắt ý nghĩa ngữ nghĩa, cho phép chúng tôi tìm thấy những sản phẩm "tương tự về ý nghĩa" thay vì chỉ chứa các từ khớp. Ban đầu, chúng tôi đã thử nghiệm tính năng tìm kiếm mức độ tương đồng của vectơ trực tiếp trên các mục nhúng này để thiết lập một đường cơ sở, cho thấy sức mạnh của khả năng hiểu ngữ nghĩa ngay cả trước khi tối ưu hoá hiệu suất.
Cột nhúng sẽ cho phép lưu trữ các giá trị vectơ của văn bản nội dung mô tả sản phẩm. Cột img_embeddings sẽ cho phép lưu trữ các mục nhúng hình ảnh (đa phương thức). Bằng cách này, bạn cũng có thể sử dụng tính năng tìm kiếm dựa trên khoảng cách giữa văn bản và hình ảnh. Tuy nhiên, chúng ta sẽ chỉ sử dụng các vectơ nhúng văn bản trong phòng thí nghiệm này.
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
Thao tác này sẽ trả về vectơ nhúng (có dạng một mảng số thực) cho văn bản mẫu trong truy vấn. Có dạng như sau:
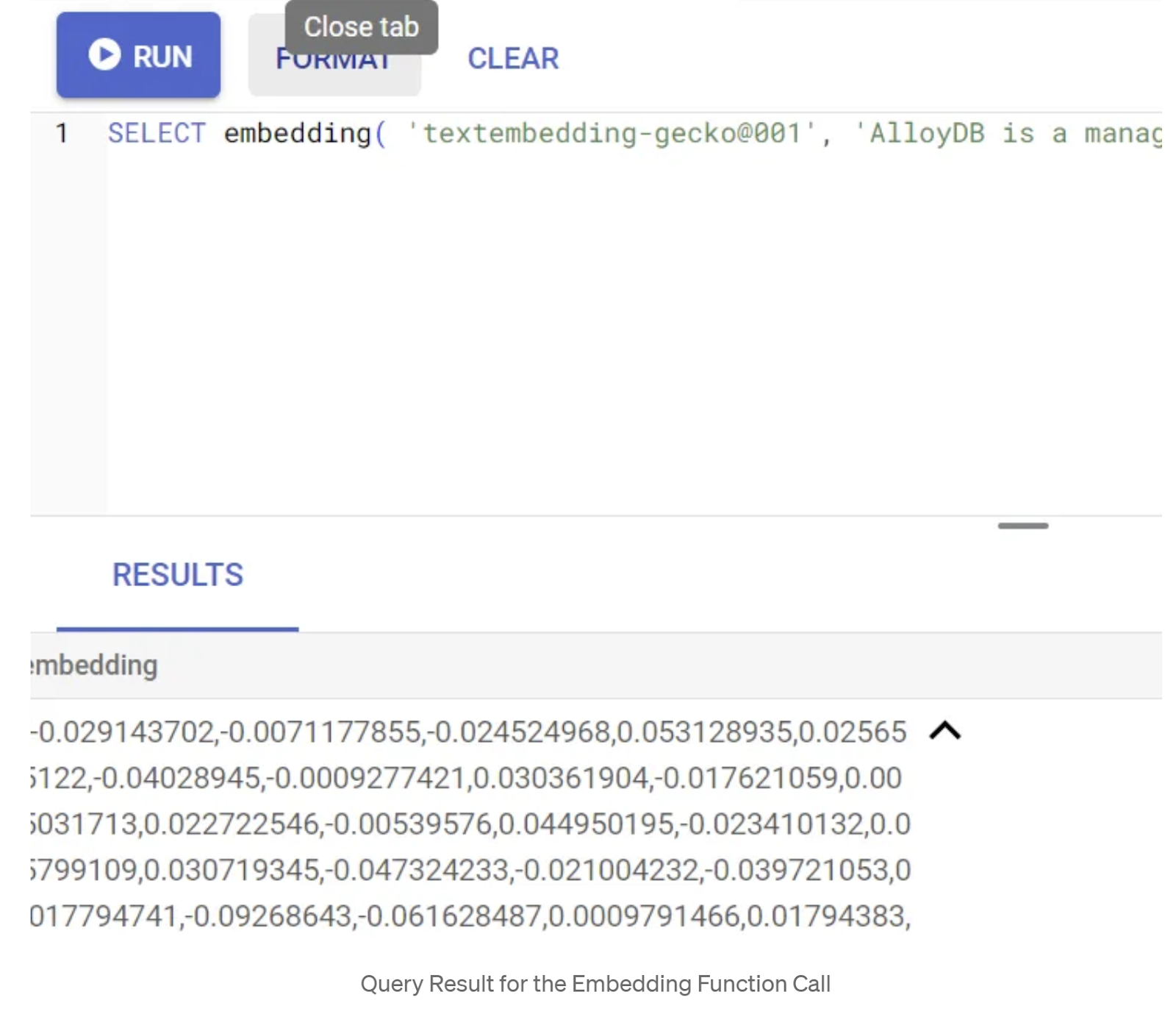
Cập nhật trường Vector abstract_embeddings
Chạy DML bên dưới để cập nhật nội dung mô tả trong bảng bằng các mục nhúng tương ứng:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
Bạn có thể gặp khó khăn khi tạo nhiều hơn một vài vectơ nhúng (chẳng hạn như tối đa 20-25) nếu đang sử dụng tài khoản thanh toán có tín dụng dùng thử cho Google Cloud. Vì vậy, hãy giới hạn số lượng hàng trong tập lệnh chèn.
Nếu bạn muốn tạo các vectơ nhúng hình ảnh (để thực hiện tìm kiếm theo ngữ cảnh đa phương thức), hãy chạy bản cập nhật bên dưới:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. Bộ công cụ MCP cho cơ sở dữ liệu (AlloyDB)
Đằng sau đó, công cụ mạnh mẽ và ứng dụng có cấu trúc hợp lý sẽ đảm bảo hoạt động trơn tru.
Hộp công cụ MCP (Giao thức ngữ cảnh mô hình) cho Cơ sở dữ liệu giúp đơn giản hoá việc tích hợp AI tạo sinh và các công cụ dựa trên tác nhân với AlloyDB. Đây là một máy chủ nguồn mở giúp đơn giản hoá việc gộp kết nối, xác thực và việc cung cấp các chức năng cơ sở dữ liệu một cách an toàn cho các tác nhân AI hoặc các ứng dụng khác.
Trong ứng dụng của mình, chúng tôi đã sử dụng MCP Toolbox for Databases làm lớp trừu tượng cho tất cả các truy vấn tìm kiếm kết hợp thông minh.
Làm theo các bước bên dưới để thiết lập và triển khai Toolbox cho trường hợp sử dụng của chúng tôi:
Bạn có thể thấy rằng một trong những cơ sở dữ liệu được Bộ công cụ MCP cho cơ sở dữ liệu hỗ trợ là AlloyDB. Vì chúng ta đã cung cấp cơ sở dữ liệu đó trong phần trước, nên hãy tiếp tục thiết lập Bộ công cụ.
- Chuyển đến Cloud Shell Terminal và đảm bảo dự án của bạn được chọn và xuất hiện trong lời nhắc của thiết bị đầu cuối. Chạy lệnh bên dưới qua Cloud Shell Terminal để chuyển đến thư mục dự án:
mkdir gemini-cli-project
cd gemini-cli-project
- Chạy lệnh bên dưới để tải xuống và cài đặt hộp công cụ trong thư mục mới:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Thao tác này sẽ tạo hộp công cụ trong thư mục hiện tại của bạn. Sao chép đường dẫn đến hộp công cụ.
- Chuyển đến Cloud Shell Editor (để chuyển sang chế độ chỉnh sửa mã) rồi thêm một tệp có tên là "tools.yaml" vào thư mục gốc của dự án "gemini-cli-project".
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
Hãy tìm hiểu về tools.yaml:
Nguồn đại diện cho các nguồn dữ liệu khác nhau mà một công cụ có thể tương tác. Nguồn đại diện cho một nguồn dữ liệu mà công cụ có thể tương tác. Bạn có thể xác định Nguồn dưới dạng bản đồ trong phần nguồn của tệp tools.yaml. Thông thường, cấu hình nguồn sẽ chứa mọi thông tin cần thiết để kết nối và tương tác với cơ sở dữ liệu.
Công cụ xác định những hành động mà một tác nhân có thể thực hiện, chẳng hạn như đọc và ghi vào một nguồn. Công cụ là một hành động mà tác nhân của bạn có thể thực hiện, chẳng hạn như chạy một câu lệnh SQL. Bạn có thể xác định Công cụ dưới dạng một bản đồ trong phần công cụ của tệp tools.yaml. Thông thường, một công cụ sẽ yêu cầu một nguồn để hoạt động.
Để biết thêm thông tin chi tiết về cách định cấu hình tools.yaml, hãy tham khảo tài liệu này.
Như bạn có thể thấy trong tệp Tools.yaml ở trên, công cụ "get-apparels" liệt kê tất cả thông tin chi tiết về quần áo trong cơ sở dữ liệu.
7. Thiết lập Gemini CLI
Trong Cloud Shell Editor, hãy tạo một thư mục mới có tên là .gemini bên trong thư mục gemini-cli-project rồi tạo một tệp mới có tên là settings.json trong thư mục đó.
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
Trong phần lệnh trong đoạn mã trên, hãy thay thế "/home/user/gemini-cli-project/toolbox" bằng đường dẫn đến hộp công cụ.
Cài đặt Gemini CLI
Cuối cùng, trong Cloud Shell Terminal, hãy cài đặt Gemini CLI trong cùng một thư mục gemini-cli-project bằng cách thực thi lệnh:
sudo npm install -g @google/gemini-cli
Đặt mã dự án
Đảm bảo bạn đã đặt mã dự án đang hoạt động trong môi trường:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
Bắt đầu sử dụng Gemini CLI
Trên dòng lệnh, hãy nhập lệnh:
gemini
Bạn sẽ thấy một phản hồi tương tự như bên dưới:
Xác thực và chuyển sang bước tiếp theo.
8. Bắt đầu tương tác với Gemini CLI
Sử dụng lệnh /mcp để liệt kê các máy chủ MCP đã định cấu hình.
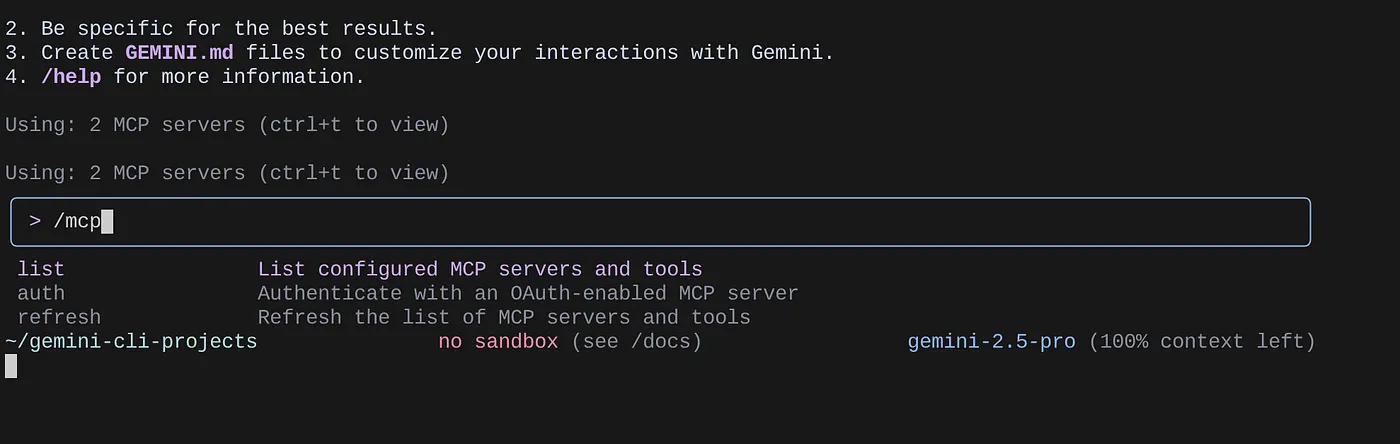
Bạn sẽ thấy 2 máy chủ MCP mà chúng ta đã định cấu hình: GitHub và MCP Toolbox for Databases (Bộ công cụ MCP cho cơ sở dữ liệu) cùng với các công cụ của chúng.
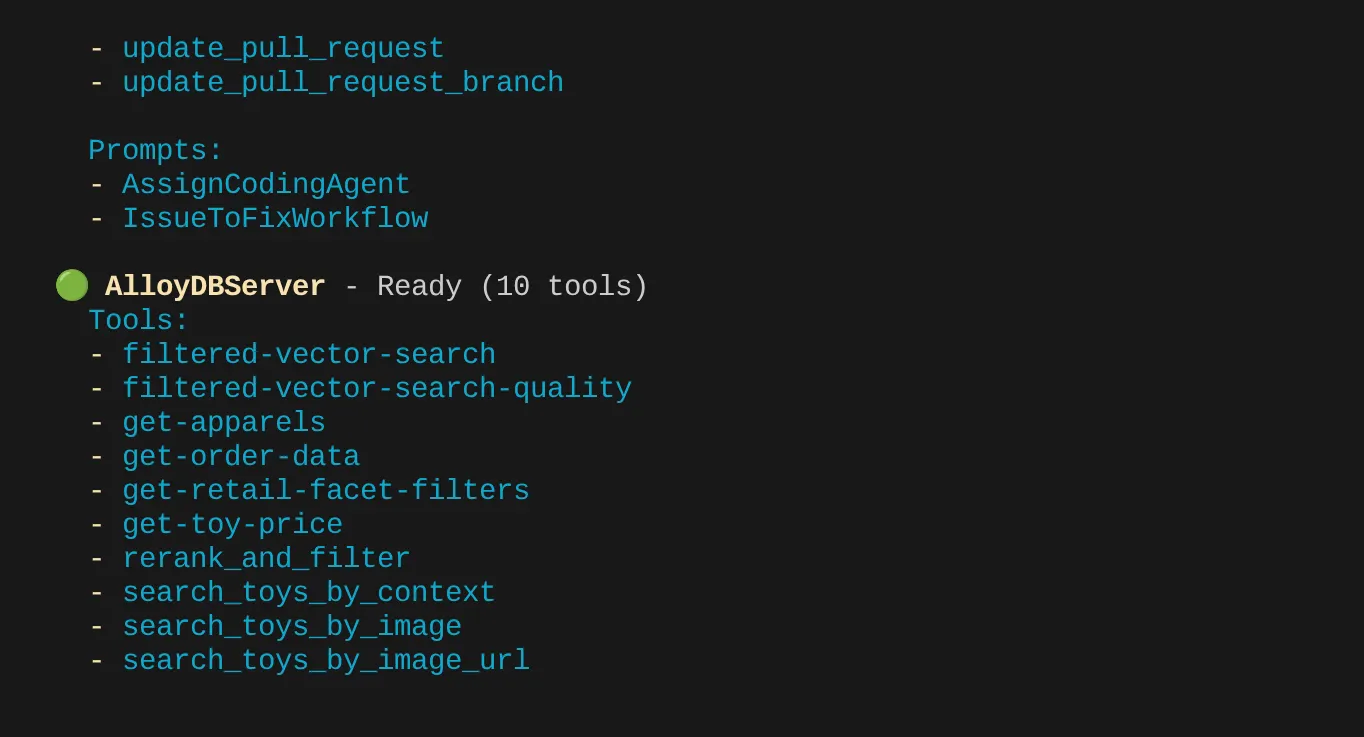
Trong trường hợp của tôi, tôi có nhiều công cụ hơn. Vậy nên tạm thời bỏ qua cảnh báo này. Bạn sẽ thấy công cụ get-apparels trong máy chủ AlloyDB MCP.
Bắt đầu truy vấn cơ sở dữ liệu thông qua Bộ công cụ MCP
Bây giờ, hãy thử đặt câu hỏi bằng ngôn ngữ tự nhiên để tìm nạp câu trả lời và truy vấn cho tập dữ liệu mà chúng ta đang làm việc:
> How many types of genders the apparel dataset has?
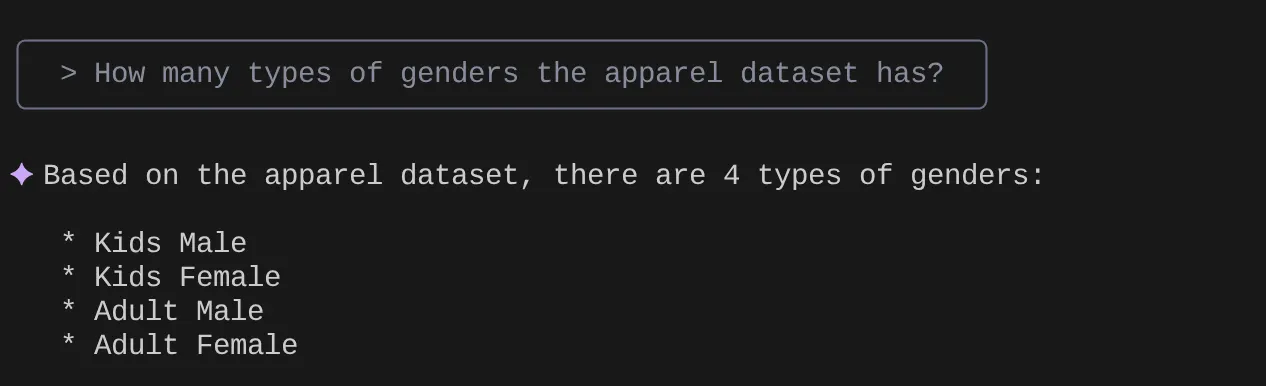
> Give me the SQL that I can use to find the number of apparels that are footwear
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
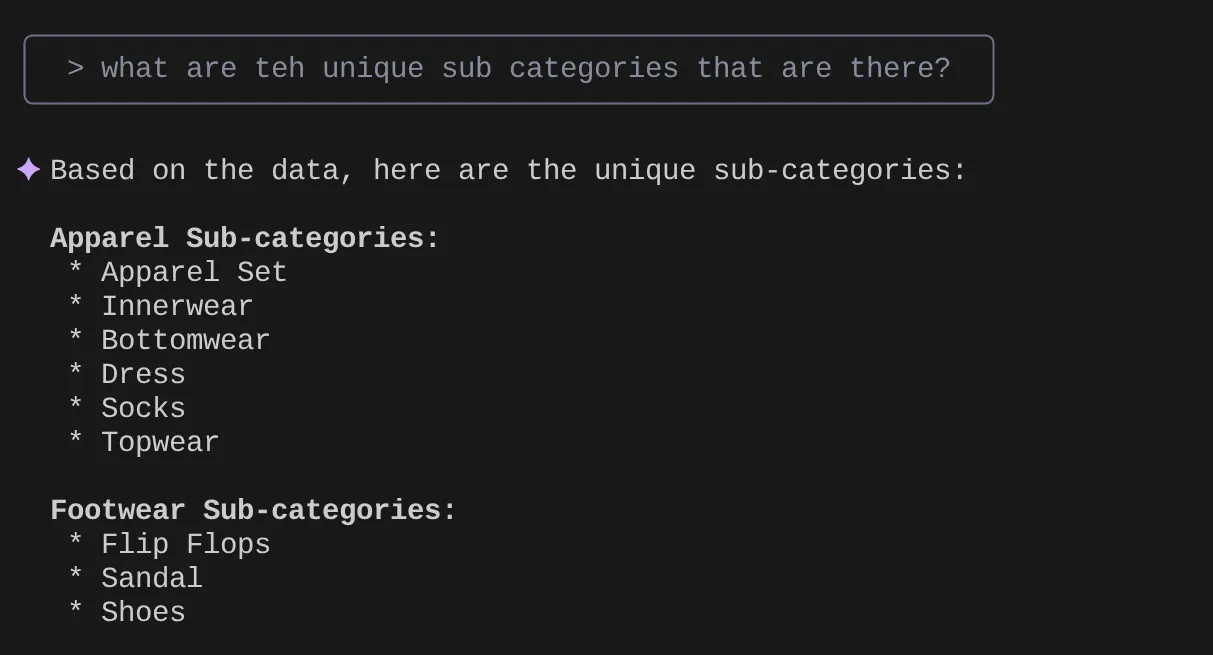
Giả sử dựa trên thông tin chi tiết và nhiều truy vấn như vậy, tôi đã nghĩ ra một truy vấn chi tiết và muốn kiểm thử truy vấn đó. Hoặc giả sử các kỹ sư cơ sở dữ liệu đã tạo Tools.yaml cho bạn như sau:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
Bây giờ, hãy thử tìm kiếm bằng ngôn ngữ tự nhiên:
> How many yellow shirts are there for boys?
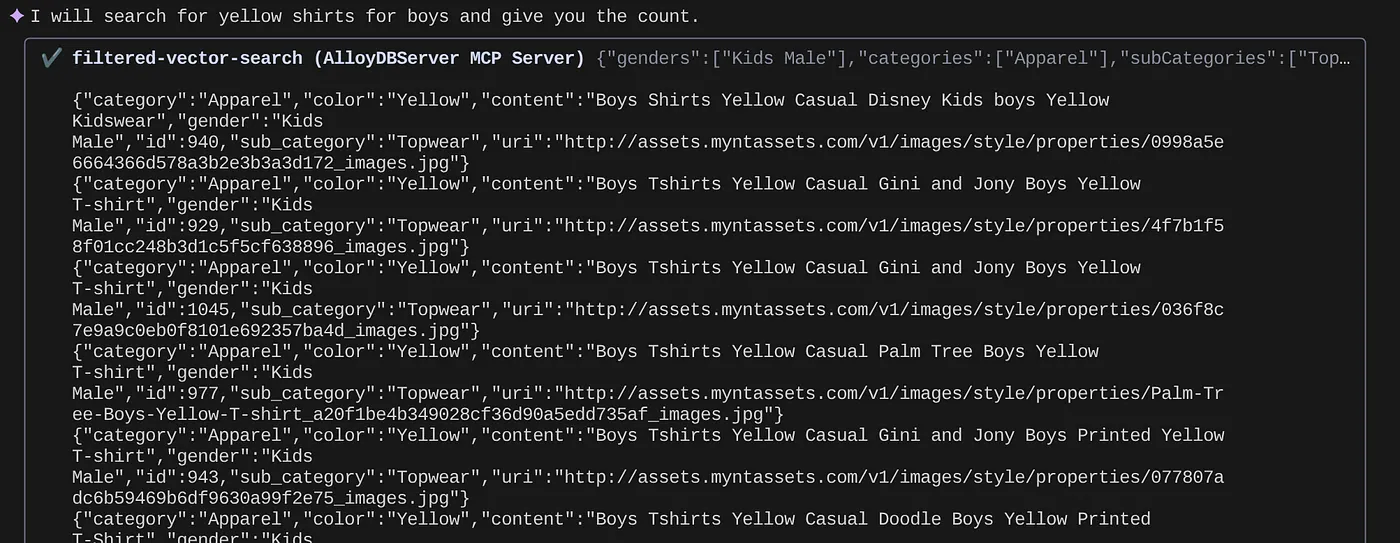

Thật thú vị phải không? Giờ đây, tôi có thể sửa tệp yaml để có thêm nhiều tiến bộ trong các truy vấn trong khi tiếp tục cung cấp các chức năng mới trong ứng dụng của mình trong thời gian ngắn hơn.
9. Phát triển ứng dụng nhanh
Việc tích hợp các chức năng của cơ sở dữ liệu trực tiếp vào IDE thông qua Gemini CLI và MCP Toolbox không chỉ mang tính lý thuyết. Điều này giúp tăng tốc quy trình làm việc một cách rõ rệt, đặc biệt là đối với một ứng dụng phức tạp như trải nghiệm bán lẻ kết hợp của chúng tôi. Hãy xem xét một vài trường hợp:
1. Nhanh chóng lặp lại logic lọc sản phẩm
Hãy tưởng tượng rằng chúng ta vừa ra mắt một chương trình khuyến mãi mới cho "trang phục thể thao mùa hè". Chúng tôi muốn kiểm tra cách các bộ lọc theo khía cạnh (ví dụ: theo thương hiệu, kích thước, màu sắc, khoảng giá) tương tác với danh mục mới này.
Không có tính năng tích hợp IDE:
Tôi có thể chuyển sang một ứng dụng SQL riêng biệt, viết truy vấn, thực thi truy vấn đó, phân tích kết quả, quay lại IDE để điều chỉnh mã xử lý ứng dụng, chuyển lại sang ứng dụng và lặp lại. Việc chuyển đổi bối cảnh này là một trở ngại lớn.
Với Gemini CLI và MCP:
Tôi có thể ở trong IDE và làm nhiều việc khác:
- Truy vấn: Tôi có thể nhanh chóng cập nhật truy vấn trong yaml bằng (tập dữ liệu giả định) "SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'" và thử ngay trong thiết bị đầu cuối.
- Khám phá dữ liệu: Xem ngay các thương hiệu được trả về. Nếu tôi cần xem tình trạng còn hàng của sản phẩm theo thương hiệu và kích thước cụ thể, thì đây là một truy vấn nhanh khác:"SELECT COUNT(*) FROM products WHERE brand = 'SummitGear' AND size = 'M' AND category = 'activewear' AND season = 'summer'"
- Tích hợp mã: Sau đó, tôi có thể điều chỉnh ngay logic lọc giao diện người dùng hoặc các lệnh gọi API phụ trợ dựa trên những thông tin chi tiết nhanh về dữ liệu trong IDE này, giúp giảm đáng kể vòng phản hồi.
2. Tinh chỉnh tính năng tìm kiếm vectơ để đề xuất sản phẩm
Tính năng tìm kiếm kết hợp của chúng tôi dựa vào các vectơ nhúng để đưa ra đề xuất sản phẩm phù hợp. Giả sử chúng tôi nhận thấy tỷ lệ nhấp cho các đề xuất "giày chạy bộ nam" đang giảm.
Không có tính năng tích hợp IDE:
Tôi sẽ chạy các tập lệnh hoặc truy vấn tuỳ chỉnh trong một công cụ cơ sở dữ liệu để phân tích điểm số tương đồng của những đôi giày được đề xuất, so sánh điểm số đó với lượt tương tác của người dùng và cố gắng liên kết mọi mẫu hình.
Với Gemini CLI và MCP:
- Phân tích các vectơ nhúng: Tôi có thể trực tiếp truy vấn các vectơ nhúng sản phẩm và siêu dữ liệu liên quan: "SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10"
- Tham chiếu chéo: Tôi cũng có thể kiểm tra nhanh mức độ tương đồng vectơ thực tế giữa một sản phẩm đã chọn và các sản phẩm được đề xuất ngay tại đó. Ví dụ: nếu sản phẩm A được đề xuất cho những người dùng đã xem sản phẩm B, thì tôi có thể chạy một truy vấn để truy xuất và so sánh các vectơ nhúng của họ.
- Gỡ lỗi: Tính năng này giúp gỡ lỗi và kiểm thử giả thuyết nhanh hơn. Mô hình nhúng có hoạt động như mong đợi không? Có điểm bất thường nào trong dữ liệu ảnh hưởng đến chất lượng đề xuất không? Tôi có thể nhận được câu trả lời ban đầu mà không cần rời khỏi môi trường lập trình.
3. Tìm hiểu về lược đồ và phân phối dữ liệu cho các tính năng mới
Giả sử chúng ta đang lên kế hoạch thêm tính năng "bài đánh giá của khách hàng". Trước khi viết API phụ trợ, chúng ta cần hiểu rõ dữ liệu khách hàng hiện tại và cách các bài đánh giá có thể được cấu trúc.
Không có tính năng tích hợp IDE:
Tôi cần kết nối với một ứng dụng cơ sở dữ liệu, chạy các lệnh DESCRIBE trên các bảng như khách hàng và đơn đặt hàng, rồi truy vấn dữ liệu mẫu để hiểu các mối quan hệ và kiểu dữ liệu.
Với Gemini CLI và MCP:
- Khám phá giản đồ: Tôi có thể chỉ cần truy vấn bảng trong tệp yaml và thực thi trực tiếp trong thiết bị đầu cuối.
- Lấy mẫu dữ liệu: Sau đó, tôi có thể lấy dữ liệu mẫu để hiểu rõ thông tin nhân khẩu học và nhật ký mua hàng của khách hàng: "SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5"
- Lập kế hoạch: Quyền truy cập nhanh vào giản đồ và việc phân phối dữ liệu giúp chúng tôi đưa ra quyết định sáng suốt về cách thiết kế bảng đánh giá mới, những khoá ngoại cần thiết lập và cách liên kết hiệu quả các bài đánh giá với khách hàng và sản phẩm, tất cả đều được thực hiện trước khi viết một dòng mã xử lý ứng dụng cho tính năng mới.
Đây chỉ là một vài ví dụ, nhưng chúng nêu bật lợi ích cốt lõi: giảm bớt rào cản và tăng tốc độ của nhà phát triển. Bằng cách đưa hoạt động tương tác với AlloyDB trực tiếp vào IDE, Gemini CLI và MCP Toolbox giúp chúng tôi xây dựng các ứng dụng tốt hơn, có khả năng phản hồi nhanh hơn.
10. Dọn dẹp
Để tránh bị tính phí vào tài khoản Google Cloud của bạn cho các tài nguyên được dùng trong bài đăng này, hãy làm theo các bước sau:
- Trong bảng điều khiển Cloud, hãy chuyển đến trang trình quản lý tài nguyên.
- Trong danh sách dự án, hãy chọn dự án mà bạn muốn xoá, rồi nhấp vào Xoá.
- Trong hộp thoại, hãy nhập mã dự án rồi nhấp vào Tắt để xoá dự án.
- Ngoài ra, bạn có thể chỉ cần xoá cụm AlloyDB (thay đổi vị trí trong siêu liên kết này nếu bạn không chọn us-central1 cho cụm tại thời điểm định cấu hình) mà chúng ta vừa tạo cho dự án này bằng cách nhấp vào nút XOÁ CỤM.
11. Xin chúc mừng
Xin chúc mừng! Bạn đã tích hợp thành công MCP Toolbox trực tiếp vào IDE để tương tác liền mạch với AlloyDB và tận dụng Gemini CLI để tương tác với tập dữ liệu thương mại điện tử bán lẻ của chúng tôi nhằm viết các truy vấn mà thường yêu cầu các công cụ riêng biệt. Bạn đã học được những cách mới để kiểm tra và hiểu dữ liệu – từ việc kiểm tra cấu trúc bảng đến việc thực hiện các bước kiểm tra nhanh tính hợp lệ của dữ liệu – tất cả đều thông qua các giao diện dòng lệnh quen thuộc trong IDE của chúng tôi.
Hãy sao chép repo, phân tích và cho tôi biết liệu bạn có cải thiện ứng dụng bằng Gemini CLI và Bộ công cụ MCP cho Cơ sở dữ liệu hay không.
Để biết thêm về các ứng dụng dựa trên dữ liệu như vậy được xây dựng bằng Gemini CLI, MCP và triển khai trên thời gian chạy Không máy chủ, hãy đăng ký tham gia mùa tiếp theo của Code Vipassana. Tại đây, bạn sẽ được tham gia các phiên thực hành có hướng dẫn và nhiều lớp học lập trình tương tự!!!