
1. 總覽
還記得我們運用 AlloyDB 建構動態混合型零售體驗,結合多面向篩選和向量搜尋的過程嗎?該應用程式充分展現了現代零售業的需求,但要達到這個目標並反覆改進,需要投入大量開發工作。對全端開發人員來說,程式碼編輯器和資料庫工具之間不斷來回切換,往往會成為瓶頸,拖慢創新速度和瞭解資料的重要程序。
解決方案
這正是加速應用程式開發的強大之處,因此我非常樂意分享 MCP (現代雲端平台) 工具箱如何透過直覺式的 Gemini CLI 存取,成為我工具箱中不可或缺的一部分。想像一下,您可以在整合式開發環境 (IDE) 中,直接與 AlloyDB 執行個體互動、撰寫查詢,以及瞭解資料集。這不僅是為了方便,更是為了從根本上減少開發生命週期中的摩擦,讓您專注於建構創新功能,而不是與外部工具搏鬥。
在零售電子商務應用程式的背景下,我們需要有效查詢產品資料、處理複雜的篩選條件,並運用向量搜尋的細微差異,因此快速疊代資料庫互動的能力至關重要。MCP Toolbox 採用 Gemini CLI,不僅簡化這項作業,還能加快速度,徹底改變我們探索、測試及調整應用程式基礎資料庫邏輯的方式。讓我們深入瞭解這項顛覆性的組合,如何讓全端開發變得更快、更聰明,也更有趣。
學習內容與建構項目
零售搜尋應用程式:在 IDE 中使用 MCP Toolbox,並透過 Gemini CLI 運作。說明涵蓋以下項目:
- 如何將 MCP Toolbox 直接整合至 IDE,順暢地與 AlloyDB 互動。
- 實用範例:使用 Gemini CLI 針對零售資料編寫及執行 SQL 查詢。
- 運用 Gemini CLI 與零售電子商務資料集互動,撰寫通常需要使用其他工具的查詢,並立即查看結果。
- 發掘探查及瞭解資料的新方式,包括檢查資料表結構和執行快速資料健全性檢查,所有操作都可在 IDE 內透過熟悉的指令列介面完成。
- 瞭解這個加速資料庫工作流程如何直接加快全端開發週期,進而實現快速原型設計和疊代。
Techstack
我們使用:
- AlloyDB for PostgreSQL
- MCP Toolbox:從應用程式中抽象化資料庫的進階生成式和 AI 功能
- Cloud Run,用於無伺服器部署作業。
- 使用 Gemini CLI 瞭解及分析資料集,並建構零售電子商務應用程式的資料庫部分。
需求條件
2. 事前準備
建立專案
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案。
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能。
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境。按一下 Google Cloud 控制台頂端的「啟用 Cloud Shell」。

- 連至 Cloud Shell 後,請使用下列指令確認驗證已完成,專案也已設為獲派的專案 ID:
gcloud auth list
- 在 Cloud Shell 中執行下列指令,確認 gcloud 指令已瞭解您的專案。
gcloud config list project
- 如果未設定專案,請使用下列指令來設定:
gcloud config set project <YOUR_PROJECT_ID>
- 啟用必要的 API:按照這個連結啟用 API。
或者,您也可以使用 gcloud 指令執行這項操作。如要瞭解 gcloud 指令和用法,請參閱說明文件。
3. 資料庫設定
在本實驗室中,我們將使用 AlloyDB 做為電子商務資料的資料庫。並使用「叢集」保存所有資源,例如資料庫和記錄檔。每個叢集都有一個「主要執行個體」,可做為資料的存取點。資料表會保存實際資料。
我們來建立 AlloyDB 叢集、執行個體和資料表,以便載入電子商務資料集。
建立叢集和執行個體
- 在 Cloud 控制台中前往 AlloyDB 頁面。如要在 Cloud 控制台尋找大部分的頁面,只要使用控制台的搜尋列搜尋即可。
- 選取該頁面中的「建立叢集」:

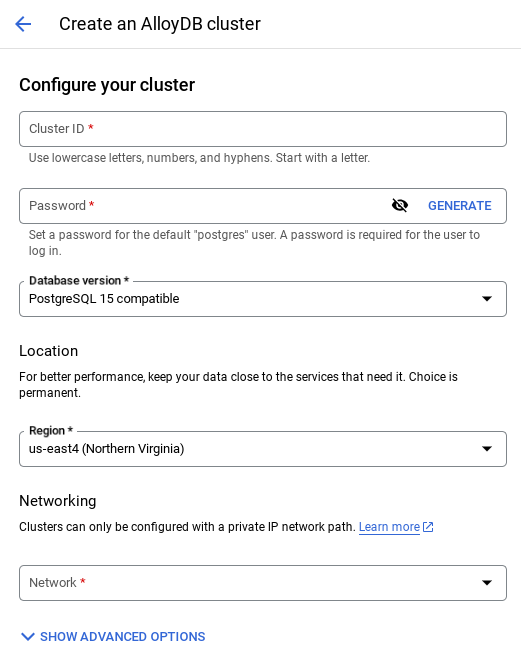
- 您會看到如下所示的畫面。使用下列值建立叢集和執行個體 (如果您要從存放區複製應用程式程式碼,請確保值相符):
- 叢集 ID:「
vector-cluster」 - password:「
alloydb」 - PostgreSQL 15 / 最新建議版本
- Region:「
us-central1」 - 網路:「
default」
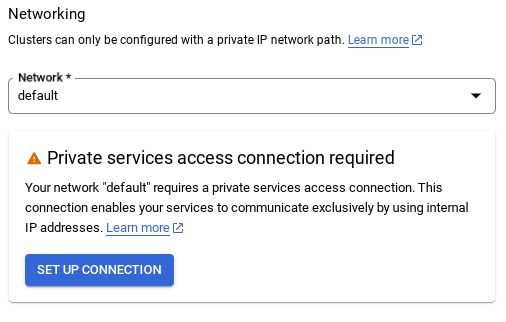
- 選取預設網路後,你會看到如下畫面。
選取「設定連線」。
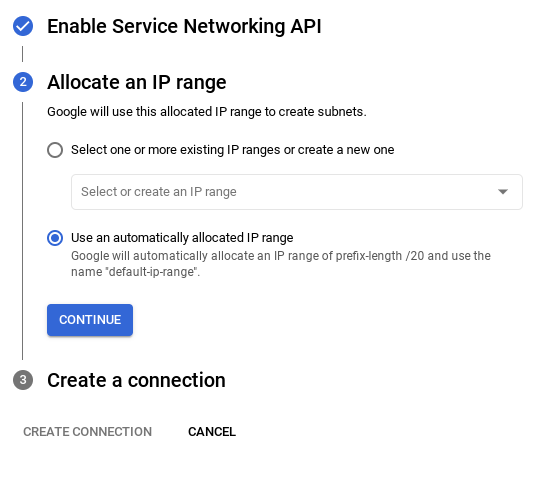
- 然後選取「使用系統自動分配的 IP 範圍」並繼續。確認資訊後,選取「建立連結」。
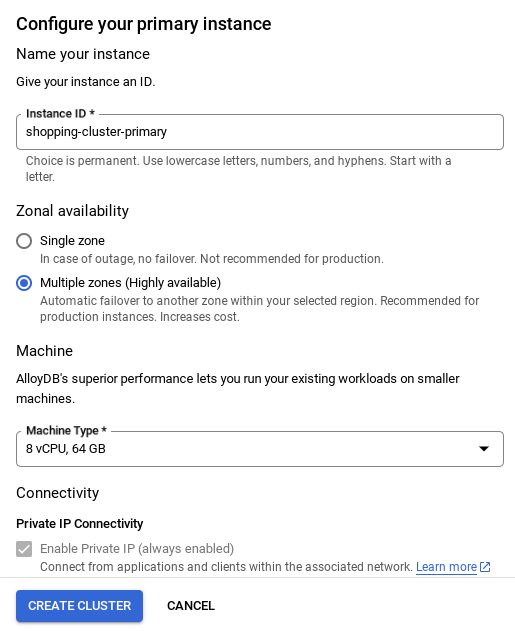
- 設定網路後,即可繼續建立叢集。按一下「CREATE CLUSTER」(建立叢集),完成叢集設定,如下所示:
重要注意事項:
- 請務必將執行個體 ID (可在設定叢集 / 執行個體時找到) 變更為**
vector-instance**。如果無法變更,請記得在所有後續參照中 **使用執行個體 ID**。 - 請注意,建立叢集約需 10 分鐘。成功後,畫面上會顯示您剛建立的叢集總覽。
4. 資料擷取
現在要新增包含商店資料的表格。前往 AlloyDB,選取主要叢集,然後選取 AlloyDB Studio:
您可能需要等待執行個體建立完成。完成後,請使用建立叢集時建立的憑證登入 AlloyDB。使用下列資料向 PostgreSQL 進行驗證:
- 使用者名稱:「
postgres」 - 資料庫:「
postgres」 - 密碼:「
alloydb」
成功驗證 AlloyDB Studio 後,即可在編輯器中輸入 SQL 指令。如要新增多個編輯器視窗,請按一下最後一個視窗右側的加號。
您會在編輯器視窗中輸入 AlloyDB 指令,並視需要使用「執行」、「格式化」和「清除」選項。
啟用擴充功能
我們會使用 pgvector 和 google_ml_integration 擴充功能建構這個應用程式。pgvector 擴充功能可讓您儲存及搜尋向量嵌入。google_ml_integration 擴充功能提供多種函式,可存取 Vertex AI 預測端點,在 SQL 中取得預測結果。執行下列 DDL,啟用這些擴充功能:
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector;
如要查看資料庫已啟用的擴充功能,請執行下列 SQL 指令:
select extname, extversion from pg_extension;
建立資料表
您可以在 AlloyDB Studio 中使用下列 DDL 陳述式建立資料表:
CREATE TABLE apparels (
id BIGINT,
category VARCHAR(100),
sub_category VARCHAR(50),
uri VARCHAR(200),
gsutil_uri VARCHAR(200),
image VARCHAR(100),
content VARCHAR(2000),
pdt_desc VARCHAR(5000),
color VARCHAR(2000),
gender VARCHAR(200),
embedding vector(768),
img_embeddings vector(1408),
additional_specification VARCHAR(100000));
嵌入資料欄可儲存文字的向量值。
授予權限
執行下列陳述式,授予「embedding」函式的執行權:
GRANT EXECUTE ON FUNCTION embedding TO postgres;
為 AlloyDB 服務帳戶授予 Vertex AI 使用者角色
在 Google Cloud IAM 控制台中,將「Vertex AI 使用者」角色授予 AlloyDB 服務帳戶 (看起來像這樣:service-<<PROJECT_NUMBER>>@gcp-sa-alloydb.iam.gserviceaccount.com)。PROJECT_NUMBER 會顯示您的專案編號。
或者,您也可以從 Cloud Shell 終端機執行下列指令:
PROJECT_ID=$(gcloud config get-value project)
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:service-$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")@gcp-sa-alloydb.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
將資料載入資料庫
- 從工作表複製
insert查詢陳述式insert scripts sql,並貼到上述編輯器。您可以複製 10 到 50 個插入陳述式,快速展示這個用途。「Selected Inserts 25-30 rows」(選取的插入內容 25-30 列) 分頁中會列出選取的插入內容。 - 按一下「執行」。查詢結果會顯示在「結果」表格中。
重要注意事項:
請務必只複製 25 到 50 筆記錄來插入,並確認記錄來自類別、子類別、顏色和性別類型範圍。
5. 為資料建立嵌入
現代搜尋的真正創新之處在於理解意義,而不只是關鍵字。這時嵌入和向量搜尋技術就能派上用場。
我們使用預先訓練的語言模型,將產品說明和使用者查詢轉換為高維度數值表示法,也就是「嵌入」。這些嵌入會擷取語意,讓我們尋找「語意相似」的產品,而不只是包含相符的字詞。一開始,我們對這些嵌入內容進行直接向量相似度搜尋實驗,建立基準,展現語意理解的強大功能,即使在成效最佳化之前也是如此。
嵌入資料欄可儲存產品說明文字的向量值。img_embeddings 欄可儲存圖片嵌入 (多模態)。這樣一來,您也可以使用以文字與圖片距離為依據的搜尋功能。但本實驗室只會使用文字嵌入。
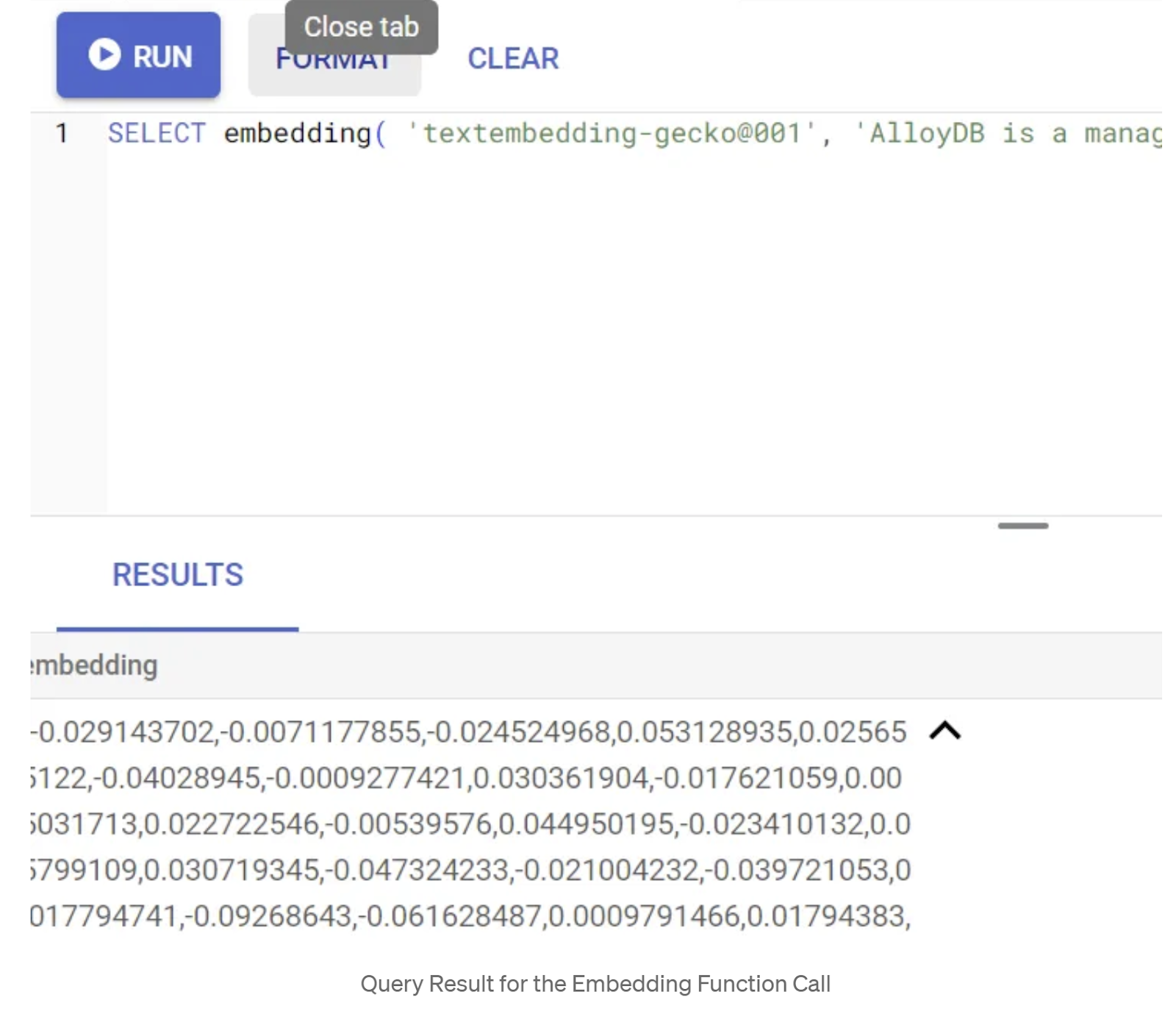
SELECT embedding('text-embedding-005', 'AlloyDB is a managed, cloud-hosted SQL database service.');
這應該會傳回嵌入向量 (看起來像是浮點數陣列),用於查詢中的範例文字。如下所示:
更新 abstract_embeddings 向量欄位
執行下列 DML,使用對應的嵌入內容更新資料表中的內容說明:
UPDATE apparels SET embedding = embedding('text-embedding-005',pdt_desc)::vector
WHERE pdt_desc IS NOT NULL;
如果您使用 Google Cloud 的試用額度帳單帳戶,可能無法產生超過幾個 (最多 20 到 25 個) 嵌入內容。因此請限制插入指令碼中的資料列數。
如要生成圖片嵌入 (用於執行多模態情境搜尋),請一併執行下列更新:
update apparels set img_embeddings = ai.image_embedding(
model_id => 'multimodalembedding@001',
image => gsutil_uri,
mimetype => 'image/jpg')
where gsutil_uri is not null
6. MCP Toolbox for Databases (AlloyDB)
在幕後,完善的工具和結構良好的應用程式可確保運作順暢。
MCP (Model Context Protocol) Toolbox for Databases 可簡化生成式 AI 和具備代理功能的工具與 AlloyDB 的整合程序。這項開放原始碼伺服器可簡化連線集區、驗證程序,並安全地向 AI 代理或其他應用程式公開資料庫功能。
在應用程式中,我們已將 MCP Toolbox for Databases 用於所有智慧混合搜尋查詢的抽象層。
如要設定及部署 Toolbox,請按照下列步驟操作:
您會看到 MCP Toolbox for Databases 支援的資料庫之一是 AlloyDB,由於我們已在上一節中佈建該資料庫,請繼續設定 Toolbox。
- 前往 Cloud Shell 終端機,確認已選取專案,且專案顯示在終端機的提示中。在 Cloud Shell 終端機執行下列指令,前往專案目錄:
mkdir gemini-cli-project
cd gemini-cli-project
- 執行下列指令,在新的資料夾中下載並安裝工具箱:
# see releases page for other versions
export VERSION=0.7.0
curl -O https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
這應該會在目前目錄中建立工具箱。複製工具箱的路徑。
- 前往 Cloud Shell 編輯器 (程式碼編輯模式),在專案根資料夾「gemini-cli-project」中新增名為「tools.yaml」的檔案。
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
讓我們瞭解 tools.yaml:
來源代表工具可互動的不同資料來源。來源代表工具可互動的資料來源。您可以在 tools.yaml 檔案的來源區段中,將來源定義為對應。一般來說,來源設定會包含連線及與資料庫互動所需的任何資訊。
工具會定義代理可執行的動作,例如讀取及寫入來源。工具代表代理程式可執行的動作,例如執行 SQL 陳述式。您可以在 tools.yaml 檔案的 tools 區段中,將工具定義為對應。一般來說,工具需要來源才能執行動作。
如要進一步瞭解如何設定 tools.yaml,請參閱這份說明文件。
如上方的 Tools.yaml 檔案所示,「get-apparels」工具會列出資料庫中所有服飾的詳細資料。
7. 設定 Gemini CLI
在 Cloud Shell 編輯器中,於 gemini-cli-project 資料夾內建立名為 .gemini 的新資料夾,並在其中建立名為 settings.json 的新檔案。
{
"mcpServers": {
"AlloyDBServer": {
"command": "/home/user/gemini-cli-project/toolbox",
"args": ["--tools-file", "tools.yaml", "--stdio"]
}
}
}
在上述程式碼片段的指令部分,將「/home/user/gemini-cli-project/toolbox」替換為工具箱的路徑。
安裝 Gemini CLI
最後,請在 Cloud Shell 終端機中,執行下列指令,在相同目錄 gemini-cli-project 中安裝 Gemini CLI:
sudo npm install -g @google/gemini-cli
設定專案 ID
確認您已在環境中設定有效專案 ID:
export GOOGLE_CLOUD_PROJECT=<<YOUR_PROJECT_ID>>
開始使用 Gemini CLI
在指令列中輸入下列指令:
gemini
畫面會顯示類似下列內容的回應:
完成驗證並繼續進行下一個步驟。
8. 開始與 Gemini CLI 互動
使用 /mcp 指令列出已設定的 MCP 伺服器。
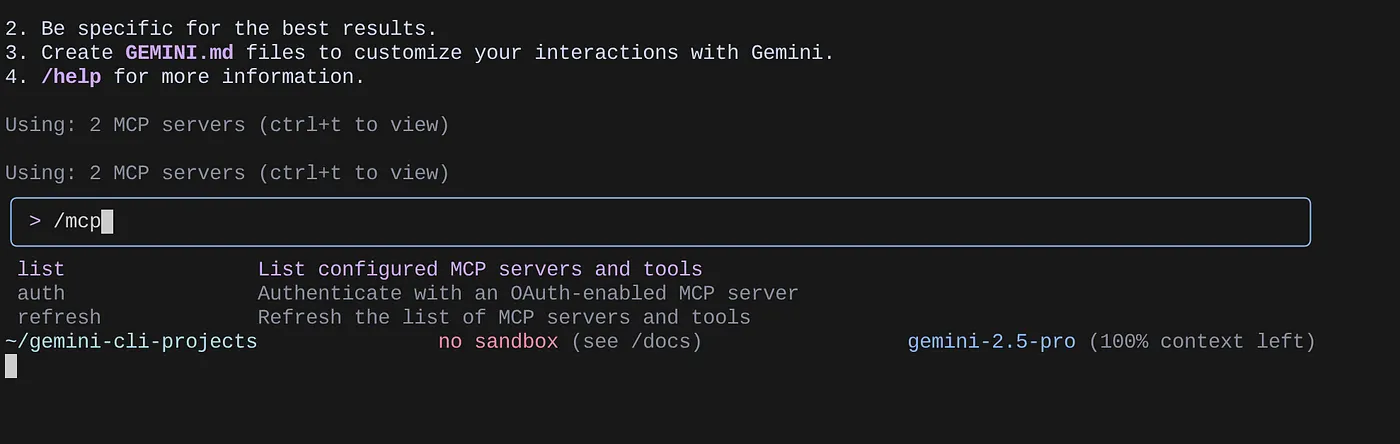
您應該會看到我們設定的 2 個 MCP 伺服器:GitHub 和 MCP Toolbox for Databases,以及列出的工具。
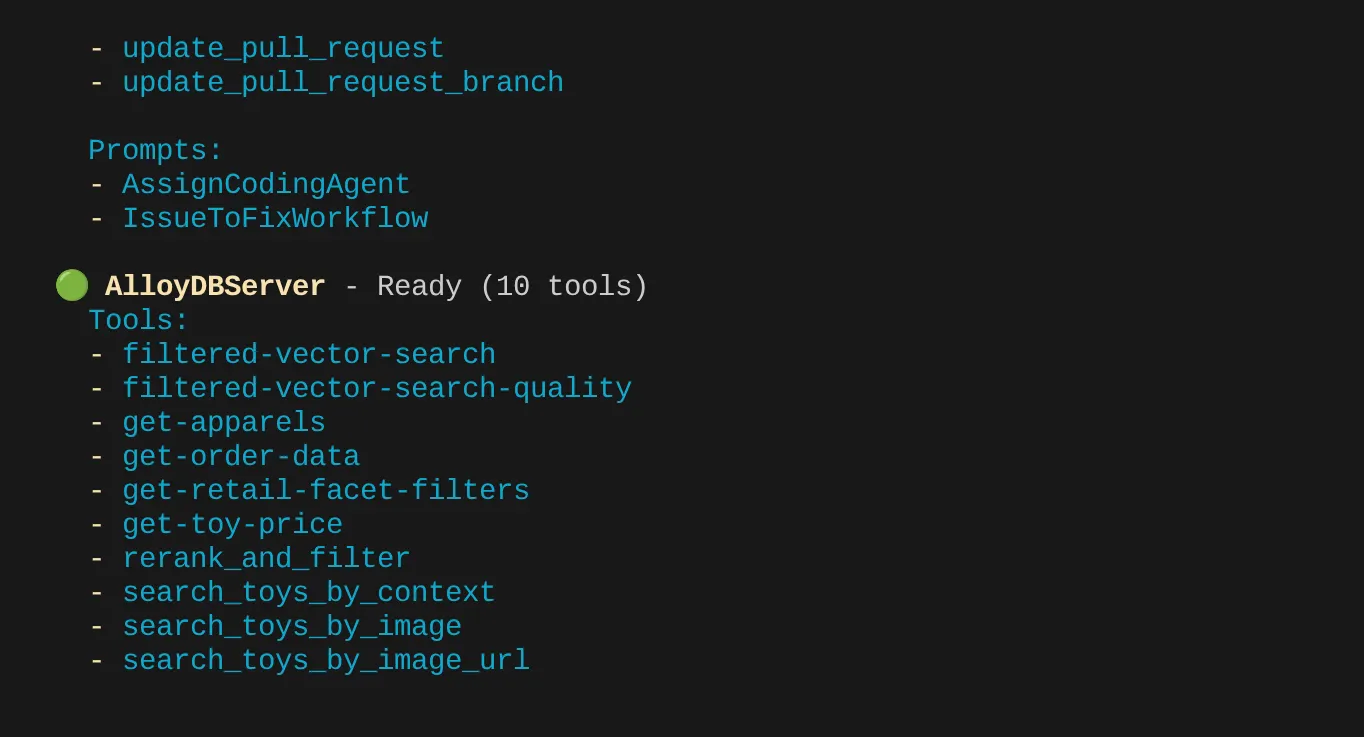
就我而言,我還有更多工具。因此請暫時忽略。您應該會在 AlloyDB MCP 伺服器中看到 get-apparels 工具。
透過 MCP Toolbox 開始查詢資料庫
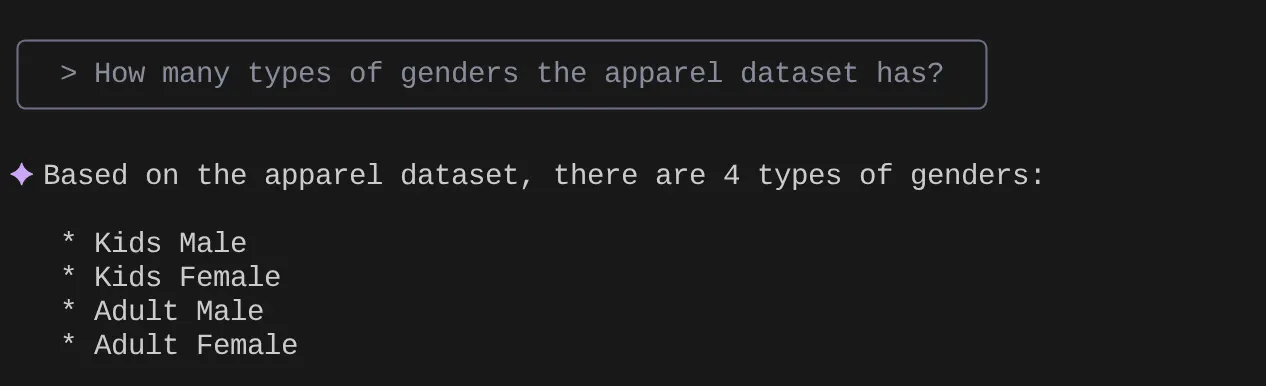
現在請嘗試提出自然語言問題,擷取我們正在使用的資料集的回應和查詢:
> How many types of genders the apparel dataset has?
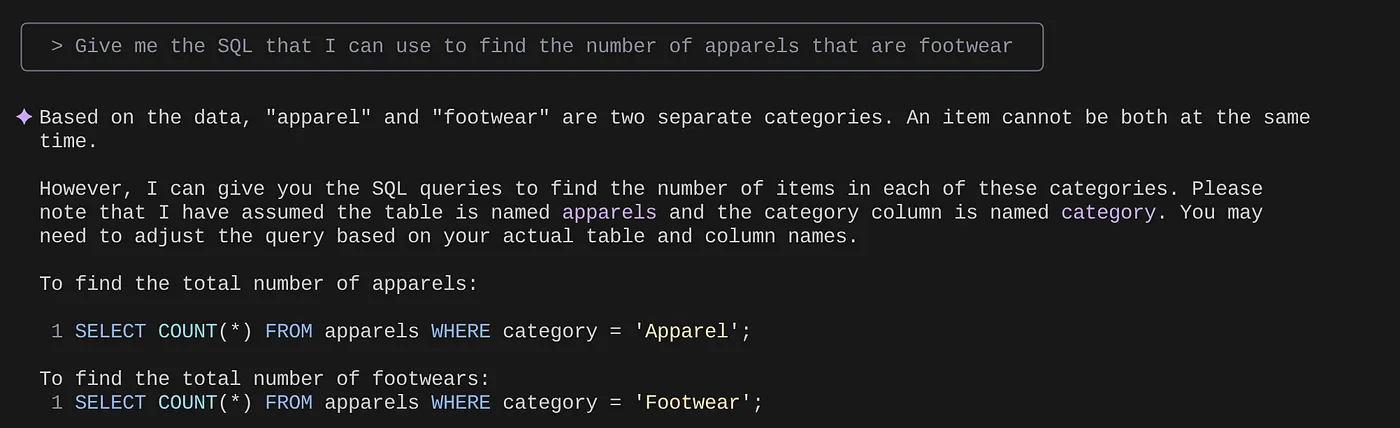
> Give me the SQL that I can use to find the number of apparels that are footwear
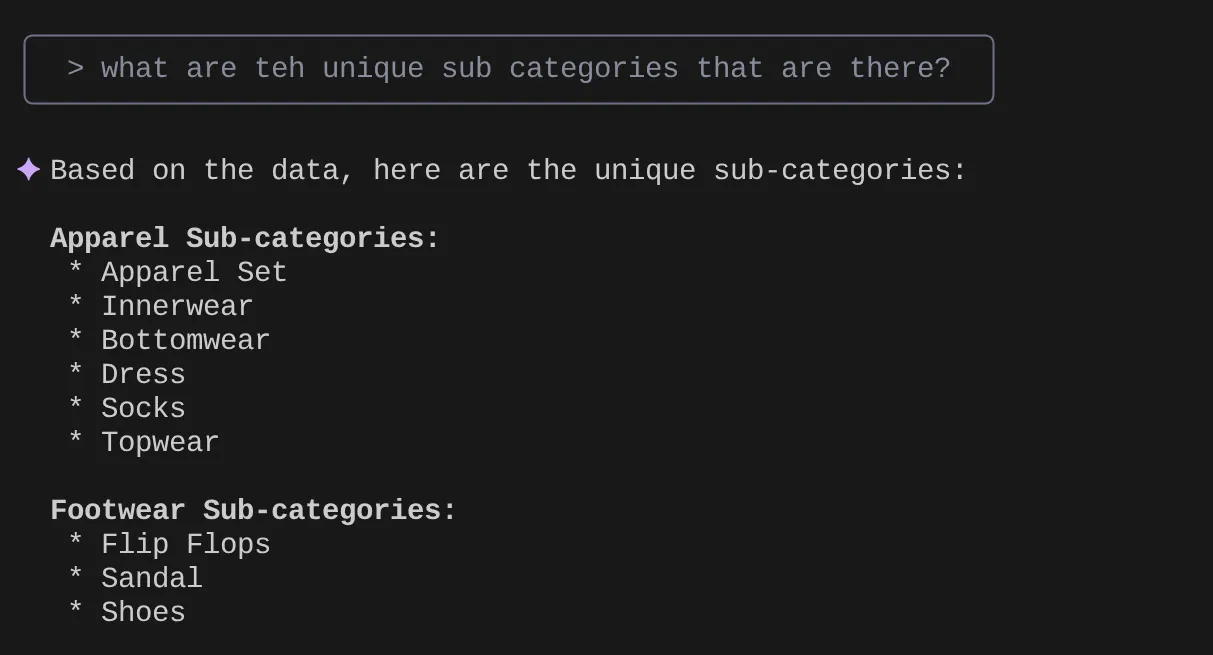
> What are the unique sub categories that are there?
that I can use to find the number of apparels that are footwear
假設我根據洞察資料和許多類似查詢,擬定了一項詳細查詢,並想進行測試。假設資料庫工程師已為您建構 Tools.yaml,如下所示:
sources:
alloydb:
kind: "alloydb-postgres"
project: "<<YOUR_PROJECT_ID>>"
region: "us-central1"
cluster: "vector-cluster"
instance: "vector-instance"
database: "postgres"
user: "postgres"
password: "alloydb"
tools:
get-apparels:
kind: postgres-sql
source: alloydb
description: Get all apparel data.
statement: |
select id, content, uri, category, sub_category,color,gender from apparels;
filtered-vector-search:
kind: postgres-sql
source: alloydb
description: Get the list of facet filter values from the retail dataset.
parameters:
- name: categories
type: array
description: List of categories preferred by the user.
items:
name: category
type: string
description: Category value.
- name: subCategories
type: array
description: List of sub-categories preferred by the user.
items:
name: subCategory
type: string
description: Sub-Category value.
- name: colors
type: array
description: List of colors preferred by the user.
items:
name: color
type: string
description: Color value.
- name: genders
type: array
description: List of genders preferred by the user for apparel fitting.
items:
name: gender
type: string
description: Gender name.
- name: searchtext
type: string
description: Description of the product that the user wants to find database matches for.
statement: |
SELECT id, content, uri, category, sub_category,color,gender FROM apparels
where category = ANY($1) and sub_Category = ANY($2) and color = ANY($3) and gender = ANY($4)
order by embedding <=> embedding('text-embedding-005',$5)::vector limit 10
現在來試試自然語言搜尋:
> How many yellow shirts are there for boys?
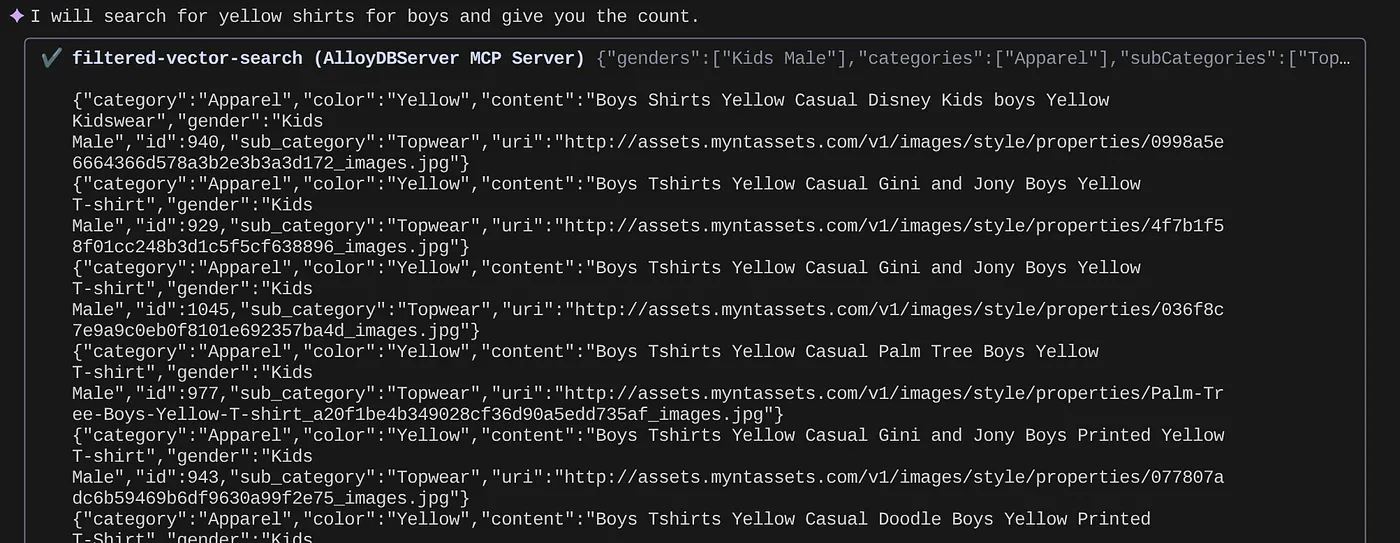

很酷吧?現在我可以修正 YAML 檔案,進一步提升查詢功能,同時繼續在應用程式中提供新功能,並加快時程。
9. 加速應用程式開發
透過 Gemini CLI 和 MCP Toolbox,直接在 IDE 中使用資料庫功能,不僅是理論上的優勢,這可轉換為實際的加速工作流程,特別是對於混合式零售體驗等複雜應用程式。以下列舉幾個情境:
1. 快速疊代產品篩選邏輯
假設我們剛推出「夏季運動服」的新促銷活動,我們想測試多面向篩選器 (例如依品牌、尺寸、顏色、價格範圍) 與這個新類別的互動方式。
不整合 IDE:
我可能會切換到另一個 SQL 用戶端,編寫查詢、執行查詢、分析結果、返回 IDE 調整應用程式程式碼、切換回用戶端,然後重複上述步驟。這種情境切換會造成重大阻礙。
使用 Gemini CLI 和 MCP:
我可以在 IDE 中執行更多操作:
- 查詢:我可以在 yaml 中快速更新查詢 (假設的資料集)「SELECT DISTINCT brand FROM products WHERE category = ‘activewear' AND season = ‘summer'」,並直接在終端機中嘗試。
- 資料探索:立即查看傳回的品牌。如果需要查看特定品牌和尺寸的產品供應情形,可以執行另一個快速查詢:「SELECT COUNT(*) FROM products WHERE brand = ‘SummitGear' AND size = ‘M' AND category = ‘activewear' AND season = ‘summer'」。
- 整合程式碼:根據這些快速的 IDE 內資料洞察,我隨即調整前端篩選邏輯或後端 API 呼叫,大幅縮短意見回饋循環。
2. 微調 Vector Search,提供產品建議
我們的混合搜尋功能會根據向量嵌入,提供相關的產品建議。假設「男士慢跑鞋」建議的點閱率下降。
不整合 IDE:
我會在資料庫工具中執行自訂指令碼或查詢,分析建議鞋款的相似度分數、與使用者互動資料進行比較,並嘗試找出任何關聯模式。
使用 Gemini CLI 和 MCP:
- 分析嵌入:我可以直接查詢產品嵌入及其相關聯的中繼資料:「SELECT product_id, name, vector_embedding FROM products WHERE category = ‘running shoes' AND gender = ‘male' LIMIT 10」
- 交叉參照:我也可以直接快速檢查所選產品與建議之間的實際向量相似度。舉例來說,如果系統向看過產品 B 的使用者推薦產品 A,我可以執行查詢來擷取並比較這兩項產品的向量嵌入。
- 偵錯:可加快偵錯和假設測試的速度。嵌入模型是否如預期運作?資料中是否有異常情形,導致推薦內容品質不佳?不必離開程式碼環境,就能取得初步解答。
3. 瞭解新功能的結構定義和資料分布
假設我們打算新增「顧客評論」功能,撰寫後端 API 之前,我們需要瞭解現有的顧客資料,以及評論的結構。
不整合 IDE:
我需要連線至資料庫用戶端,對 customers 和 orders 等資料表執行 DESCRIBE 指令,然後查詢範例資料,瞭解關係和資料類型。
使用 Gemini CLI 和 MCP:
- 結構定義探索:我只要查詢 YAML 檔案中的表格,就能直接在終端機中執行。
- 資料取樣:接著,我可以提取樣本資料,瞭解顧客的人口統計資料和購買記錄:「SELECT customer_id, name, signup_date, total_orders FROM customers ORDER BY signup_date DESC LIMIT 5」
- 規劃:快速存取結構定義和資料分配情形,有助於我們做出明智決策,決定如何設計新的評論表格、要建立哪些外部鍵,以及如何有效將評論連結至顧客和產品,完全不必為新功能編寫任何應用程式程式碼。
以上僅列舉幾個例子,但都突顯了核心優點:減少摩擦並提高開發人員速度。Gemini CLI 和 MCP Toolbox 可直接在 IDE 中與 AlloyDB 互動,讓我們更快建構出更優質、更靈敏的應用程式。
10. 清理
如要避免系統向您的 Google Cloud 帳戶收取本文章所用資源的費用,請按照下列步驟操作:
- 前往 Google Cloud 控制台的資源管理員頁面。
- 在專案清單中選取要刪除的專案,然後點按「刪除」。
- 在對話方塊中輸入專案 ID,然後按一下「Shut down」(關機) 即可刪除專案。
- 或者,您也可以點選「DELETE CLUSTER」按鈕,刪除我們剛為這個專案建立的 AlloyDB 叢集 (如果您在設定叢集時未選擇 us-central1,請變更這個超連結中的位置)。
11. 恭喜
恭喜!您已成功將 MCP Toolbox 直接整合至 IDE,順暢地與 AlloyDB 互動,並運用 Gemini CLI 與零售電子商務資料集互動,撰寫通常需要使用其他工具的查詢。您已學會探查及瞭解資料的新方法,包括檢查資料表結構和執行快速資料健全性檢查,而且全都在 IDE 內透過熟悉的指令列介面完成。
請複製 repo,並分析您是否使用 Gemini CLI 和 MCP Toolbox for Databases 強化應用程式。
如要進一步瞭解如何採用 Gemini 技術建構這類資料驅動應用程式,並使用 Gemini CLI 和 MCP 部署至無伺服器執行階段,請報名參加即將推出的 Code Vipassana 課程,透過講師帶領的實作課程和更多程式碼研究室,深入瞭解相關知識!