1. Panoramica
In questo lab utilizzerai la funzionalità di co-hosting dei modelli in Vertex AI per ospitare più modelli sulla stessa VM per le previsioni online.
Cosa imparerai
Al termine del corso sarai in grado di:
- Creare un
DeploymentResourcePool - Eseguire il deployment dei modelli all'interno di un
DeploymentResourcePool
Il costo totale per eseguire questo lab su Google Cloud è di circa 2$.
2. Introduzione a Vertex AI
Questo lab utilizza la più recente offerta di prodotti AI disponibile su Google Cloud. Vertex AI integra le offerte ML di Google Cloud in un'esperienza di sviluppo fluida. In precedenza, i modelli addestrati con AutoML e i modelli personalizzati erano accessibili tramite servizi separati. La nuova offerta combina entrambi in un'unica API, insieme ad altri nuovi prodotti. Puoi anche migrare progetti esistenti su Vertex AI. In caso di feedback, consulta la pagina di supporto.
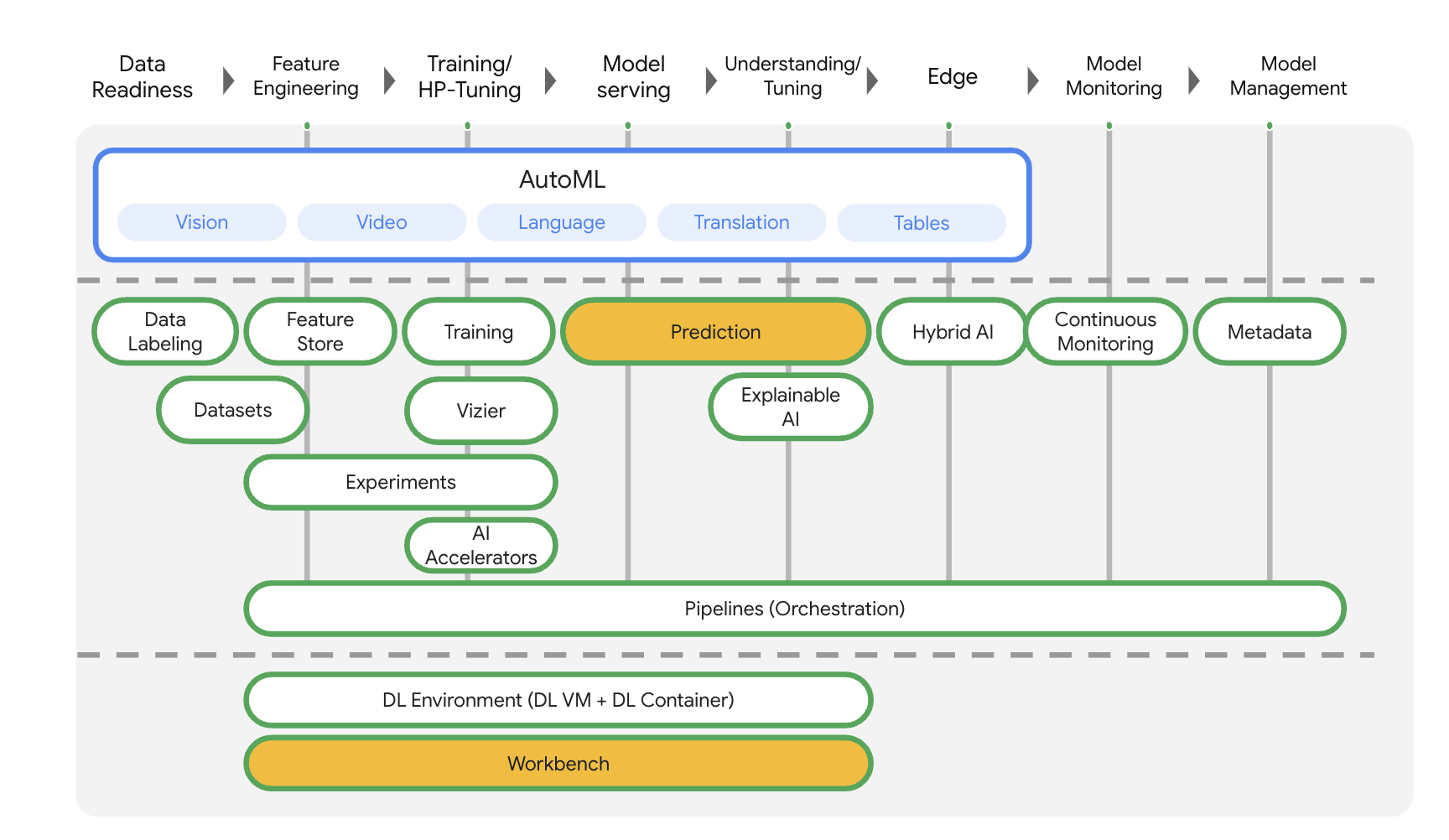
Vertex AI include molti prodotti diversi per supportare i flussi di lavoro ML end-to-end. Questo lab si concentrerà sui prodotti evidenziati di seguito: Predictions e Workbench.
3. Panoramica del caso d'uso
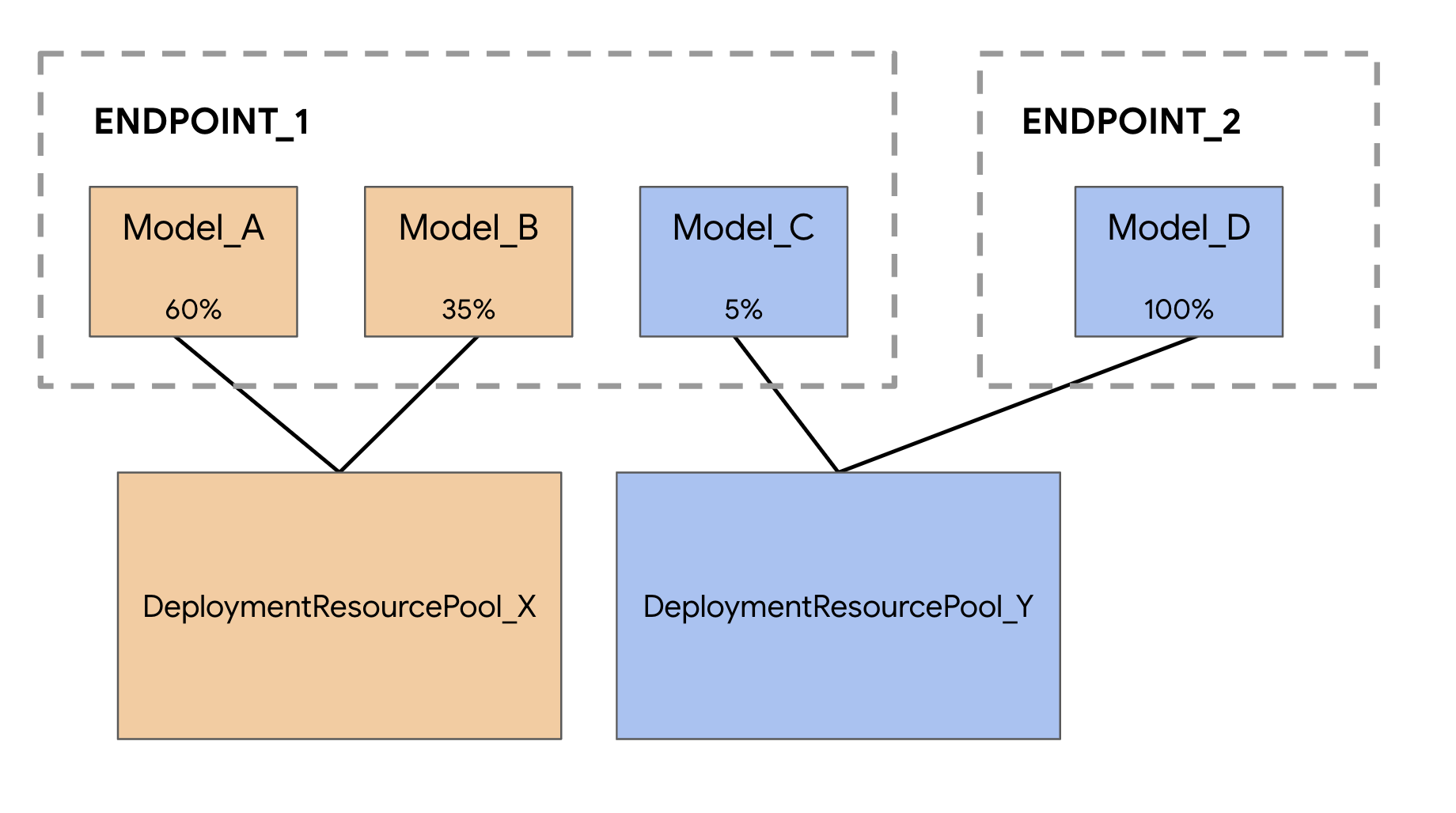
Quando esegui il deployment dei modelli nel servizio di previsione di Vertex AI, per impostazione predefinita ogni modello viene sottoposto a deployment sulla propria VM. Per rendere l'hosting più conveniente, puoi ospitare più modelli sulla stessa VM, con conseguente migliore utilizzo della memoria e delle risorse di calcolo. Il numero di modelli che scegli di sottoporre a deployment sulla stessa VM dipende dalle dimensioni dei modelli e dai pattern di traffico, ma questa funzionalità è particolarmente utile per gli scenari in cui hai molti modelli sottoposti a deployment con traffico sporadico.
Il supporto per il co-hosting dei modelli introduce il concetto di pool di risorse di deployment, che raggruppa i modelli per condividere le risorse all'interno di una VM. I modelli possono condividere una VM se condividono un endpoint e anche se vengono sottoposti a deployment su endpoint diversi. Attualmente, i modelli nello stesso pool di risorse devono avere la stessa immagine container, inclusa la versione del framework dei container predefiniti di Vertex Prediction. Inoltre, in questa release sono supportati solo i container predefiniti di Vertex Prediction con il framework del modello TensorFlow, mentre gli altri framework di modelli e i container personalizzati non sono ancora supportati.
4. Configura l'ambiente
Per eseguire questo codelab, devi avere un progetto della piattaforma Google Cloud con la fatturazione abilitata. Per creare un progetto, segui le istruzioni riportate qui.
Passaggio 1: abilita l'API Compute Engine
Vai a Compute Engine e seleziona Abilita se non è già abilitato.
Passaggio 2: abilita l'API Vertex AI
Accedi alla sezione Vertex AI della tua console Cloud e fai clic su Abilita API Vertex AI.
Passaggio 3: crea un'istanza di Vertex AI Workbench
Nella sezione Vertex AI della console Cloud, fai clic su Workbench:
Abilita l'API Notebooks se non è già abilitata.
Una volta abilitata, fai clic su NOTEBOOK GESTITI:

Quindi seleziona NUOVO NOTEBOOK.
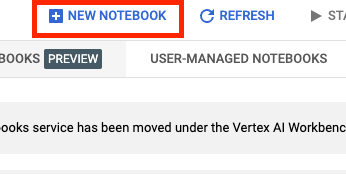
Assegna un nome al notebook e, in Autorizzazione , seleziona Account di servizio.
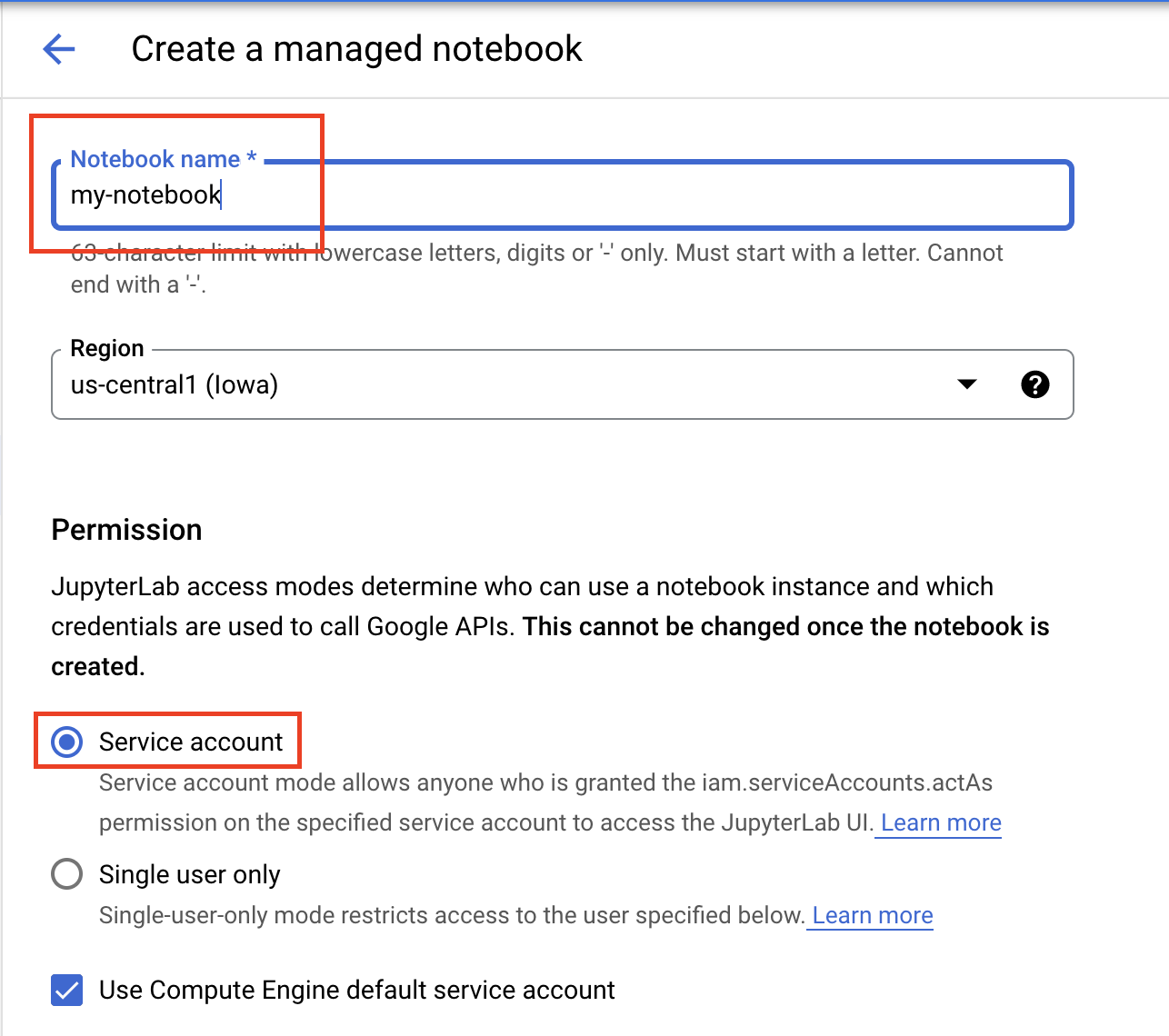
Seleziona Impostazioni avanzate.
In Sicurezza , seleziona "Abilita terminale" se non è già abilitato.
Puoi lasciare invariate tutte le altre impostazioni avanzate.
Quindi, fai clic su Crea. Il provisioning dell'istanza richiede alcuni minuti.
Una volta creata l'istanza, seleziona APRI JUPYTERLAB.

5. Addestramento del modello
Prima di poter provare la funzionalità di co-hosting, dobbiamo addestrare un modello e archiviare gli artefatti del modello salvato in un bucket Cloud Storage. Utilizzeremo l'executor del notebook Workbench per avviare il job di addestramento.
Passaggio 1: crea un bucket Cloud Storage
Se hai già un bucket nel tuo progetto che vuoi utilizzare, puoi saltare questo passaggio. In caso contrario, avvia una nuova sessione di terminale dal launcher.

Dal terminale, esegui quanto segue per definire una variabile env per il tuo progetto, assicurandoti di sostituire your-cloud-project con l'ID del tuo progetto:
PROJECT_ID='your-cloud-project'
Quindi, esegui il comando seguente per creare un nuovo bucket nel tuo progetto.
BUCKET="gs://${PROJECT_ID}-bucket"
gsutil mb -l us-central1 $BUCKET
Passaggio 2: avvia l'esecuzione del notebook
Dal launcher dell'istanza Workbench, apri un nuovo notebook TensorFlow 2.

Il codice riportato di seguito addestra un classificatore di sentiment binario (positivo o negativo) sul set di dati delle recensioni dei film IMDB. Incolla il codice nel notebook.
Assicurati di sostituire {YOUR_BUCKET} con il bucket che hai creato nel passaggio precedente (o un altro bucket nel tuo progetto). Qui archivieremo gli artefatti del modello salvato, di cui avremo bisogno in un secondo momento quando caricheremo il modello in Vertex AI Model Registry.
import numpy as np
import tensorflow_datasets as tfds
import tensorflow as tf
# REPLACE WITH YOUR BUCKET!
OUTPUT_PATH='gs://{YOUR_BUCKET}/model_output'
BUFFER_SIZE = 10000
BATCH_SIZE = 64
VOCAB_SIZE = 1000
# Load data
dataset, info = tfds.load('imdb_reviews', with_info=True,
as_supervised=True)
train_dataset, test_dataset = dataset['train'], dataset['test']
train_dataset = train_dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
test_dataset = test_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
# Create text encoder
encoder = tf.keras.layers.TextVectorization(
max_tokens=VOCAB_SIZE)
encoder.adapt(train_dataset.map(lambda text, label: text))
# Create model
model = tf.keras.Sequential([
encoder,
tf.keras.layers.Embedding(
input_dim=len(encoder.get_vocabulary()),
output_dim=64,
# Use masking to handle the variable sequence lengths
mask_zero=True),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
# Compile model
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.keras.optimizers.Adam(1e-4),
metrics=['accuracy'])
# Fit model
history = model.fit(train_dataset, epochs=10,
validation_data=test_dataset,
validation_steps=30)
# Save model
model.save(OUTPUT_PATH)
Quindi, seleziona il pulsante Esegui.
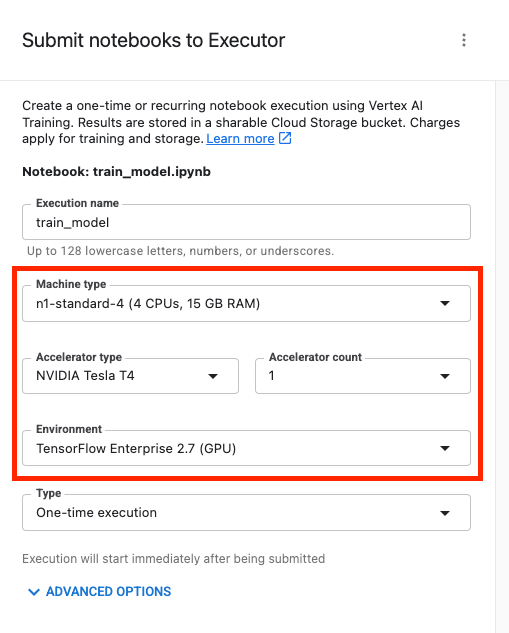
Quindi configura l'esecuzione come segue e fai clic su INVIA.
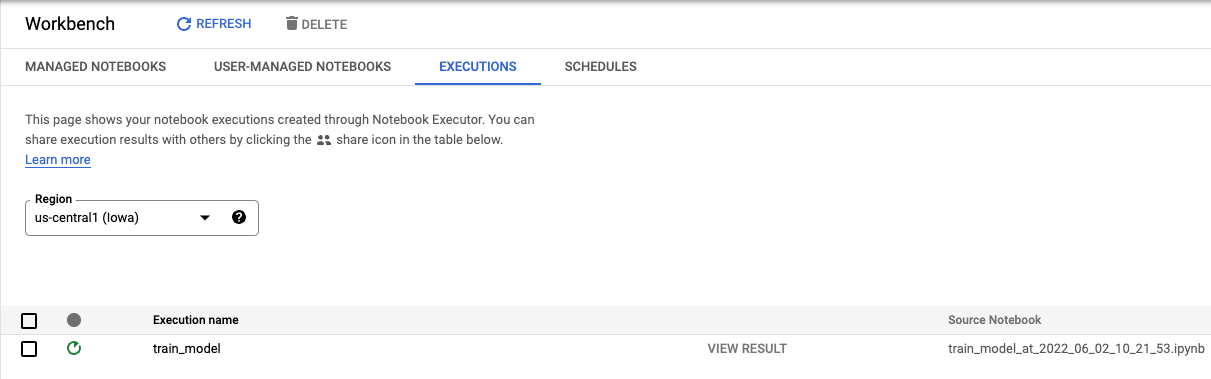
Nella scheda Esecuzioni della console puoi monitorare lo stato del job di addestramento.
6. Esegui il deployment del modello
Passaggio 1: carica il modello
Al termine dell'esecuzione, torna al notebook Workbench per caricare il modello. Crea un nuovo notebook TensorFlow.

Innanzitutto, importa l'SDK Vertex AI Python.
from google.cloud import aiplatform
Quindi carica il modello, sostituendo {YOUR_BUCKET} con il bucket che hai specificato nel codice di addestramento.
# replace {YOUR_BUCKET}
model_1 = aiplatform.Model.upload(display_name='text-model-1',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
A scopo dimostrativo, caricheremo questo modello due volte, creando due risorse modello diverse in Vertex AI. In questo modo possiamo testare il deployment di più modelli su un singolo endpoint all'interno di un pool di risorse di deployment. In uno scenario reale, avresti due modelli diversi anziché creare modelli dagli stessi artefatti salvati, ma questo è un modo più rapido per non dover avviare un'altra esecuzione di addestramento. Inoltre, puoi anche scegliere di eseguire il deployment dei due modelli su endpoint diversi all'interno dello stesso pool di risorse di deployment.
# replace {YOUR_BUCKET}
model_2 = aiplatform.Model.upload(display_name='text-model-2',
artifact_uri='gs://{YOUR_BUCKET}/model_output',
serving_container_image_uri='us-docker.pkg.dev/vertex-ai/prediction/tf2-cpu.2-8:latest')
In Vertex AI Model Registry dovresti ora vedere entrambi i modelli. Lo stato del deployment è vuoto perché non abbiamo ancora eseguito il deployment dei modelli.
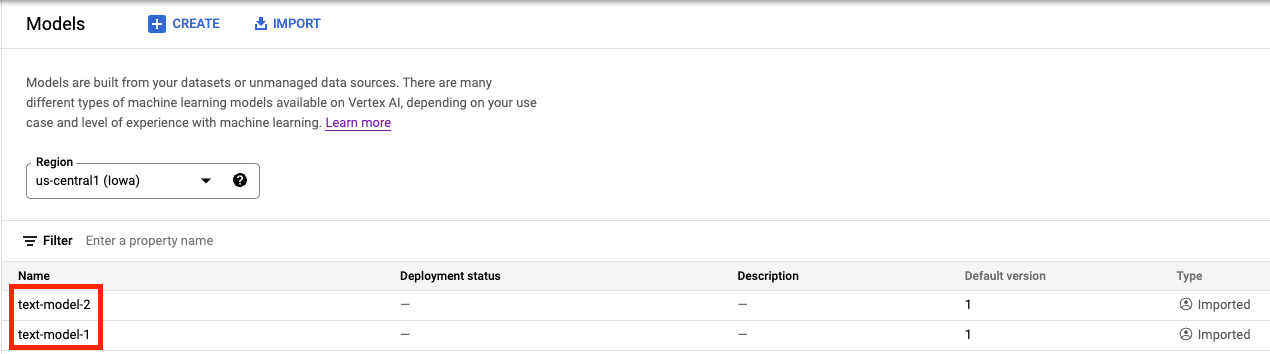
Passaggio 2: crea un endpoint
Crea un endpoint. Tieni presente che questa operazione è diversa dal deployment di un modello su un endpoint.
endpoint = aiplatform.Endpoint.create('cohost-endpoint')
Una volta creato l'endpoint, lo vedrai nella console.
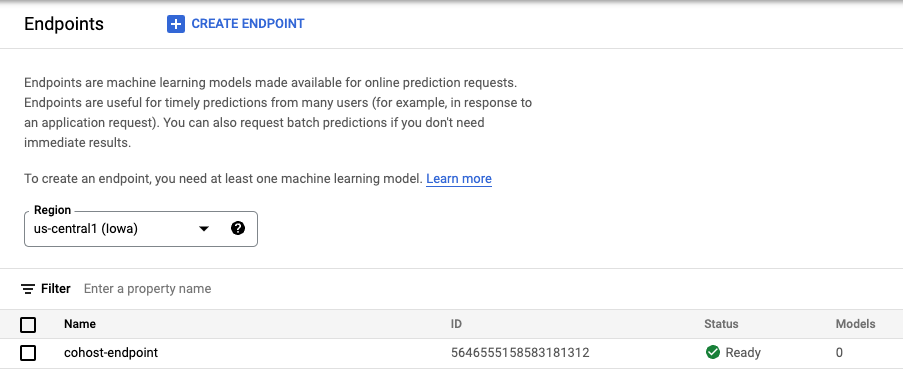
Passaggio 3: crea il DeploymentResourcePool
Puoi creare il DeploymentResourcePool con il seguente comando. Assicurati di sostituire {YOUR_PROJECT} con l'ID progetto.
# replace {YOUR_PROJECT}
PROJECT_ID={YOUR_PROJECT}
REGION="us-central1"
VERTEX_API_URL=REGION + "-aiplatform.googleapis.com"
VERTEX_PREDICTION_API_URL=REGION + "-prediction-aiplatform.googleapis.com"
MULTI_MODEL_API_VERSION="v1beta1"
# Give the pool a name
DEPLOYMENT_RESOURCE_POOL_ID="my-resource-pool"
import json
import pprint
pp = pprint.PrettyPrinter(indent=4)
CREATE_RP_PAYLOAD = {
"deployment_resource_pool":{
"dedicated_resources":{
"machine_spec":{
"machine_type":"n1-standard-4"
},
"min_replica_count":1,
"max_replica_count":2
}
},
"deployment_resource_pool_id":DEPLOYMENT_RESOURCE_POOL_ID
}
CREATE_RP_REQUEST=json.dumps(CREATE_RP_PAYLOAD)
pp.pprint("CREATE_RP_REQUEST: " + CREATE_RP_REQUEST)
!curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools \
-d '{CREATE_RP_REQUEST}'
Puoi visualizzare il pool eseguendo
!curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/deploymentResourcePools/{DEPLOYMENT_RESOURCE_POOL_ID}
Passaggio 4: esegui il deployment dei modelli sull'endpoint
Ora che il pool di risorse è stato creato, possiamo eseguire il deployment dei modelli all'interno del pool di risorse.
Innanzitutto, eseguiamo il deployment di model_1. Assicurati di sostituire MODEL_1_ID e ENDPOINT_ID con gli ID rispettivi.
MODEL_1_ID="{MODEL_1_ID}"
ENDPOINT_ID="{ENDPOINT_ID}"
Il comando seguente eseguirà il deployment di model_1 sull'endpoint all'interno del pool di risorse.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_1_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 100
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
L'operazione richiede alcuni minuti, ma al termine vedrai il modello sottoposto a deployment sull'endpoint nella console.
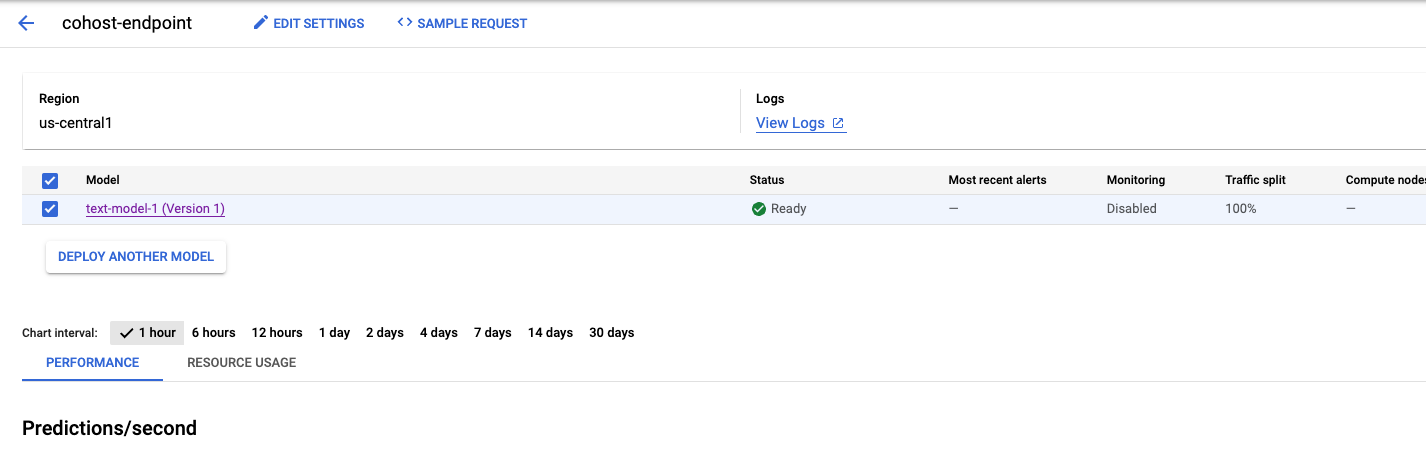
Quindi, possiamo eseguire il deployment di model_2 nello stesso pool di deployment. Eseguiremo il deployment sullo stesso endpoint di model_1. Tuttavia, puoi anche scegliere di eseguire il deployment di model_2 su un endpoint diverso all'interno dello stesso pool di risorse.
Aggiorna MODEL_ID con l'ID di model_2. Anche in questo caso, puoi ottenere questo ID eseguendo model_2.name.
MODEL_2_ID="{MODEL_2_ID}"
Quindi esegui il deployment di model_2. Poiché abbiamo già eseguito il deployment di model_1 sull'endpoint, dobbiamo aggiornare trafficSplit in modo che il traffico venga suddiviso tra i due modelli. Non dovremmo non aggiornare trafficSplit se scegliamo di eseguire il deployment di model_2 su un endpoint diverso all'interno dello stesso pool di risorse.
Per aggiornare la suddivisione del traffico, devi definire l'ID DeployedModel per model_1. Tieni presente che questo è diverso dall'ID modello.
DEPLOYED_MODEL_1_ID = {DEPLOYED_MODEL_1_ID}
Quindi esegui quanto segue per eseguire il deployment del secondo modello.
MODEL_NAME = "projects/{project_id}/locations/{region}/models/{model_id}".format(project_id=PROJECT_ID, region=REGION, model_id=MODEL_2_ID)
SHARED_RESOURCE = "projects/{project_id}/locations/{region}/deploymentResourcePools/{deployment_resource_pool_id}".format(project_id=PROJECT_ID, region=REGION, deployment_resource_pool_id=DEPLOYMENT_RESOURCE_POOL_ID)
#`trafficSplit` is a map from a DeployedModel's ID to the percentage of this Endpoint's traffic that should be forwarded to that DeployedModel.
# The traffic percentage values for an endpoint must add up to 100.
# The key for the model being deployed is "0".
DEPLOY_MODEL_PAYLOAD = {
"deployedModel": {
"model": MODEL_NAME,
"shared_resources": SHARED_RESOURCE
},
"trafficSplit": {
"0": 50,
DEPLOYED_MODEL_1_ID: 50
}
}
DEPLOY_MODEL_REQUEST=json.dumps(DEPLOY_MODEL_PAYLOAD)
pp.pprint("DEPLOY_MODEL_REQUEST: " + DEPLOY_MODEL_REQUEST)
!curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://{VERTEX_API_URL}/{MULTI_MODEL_API_VERSION}/projects/{PROJECT_ID}/locations/{REGION}/endpoints/{ENDPOINT_ID}:deployModel \
-d '{DEPLOY_MODEL_REQUEST}'
Anche in questo esempio, i due modelli sono stati sottoposti a deployment sullo stesso endpoint, ma puoi anche eseguire il co-hosting dei modelli nello stesso pool di risorse sottoposti a deployment su endpoint diversi. In questo caso, non dovrai preoccuparti della suddivisione del traffico.
Dopo il deployment del secondo modello, li vedrai entrambi nella console.
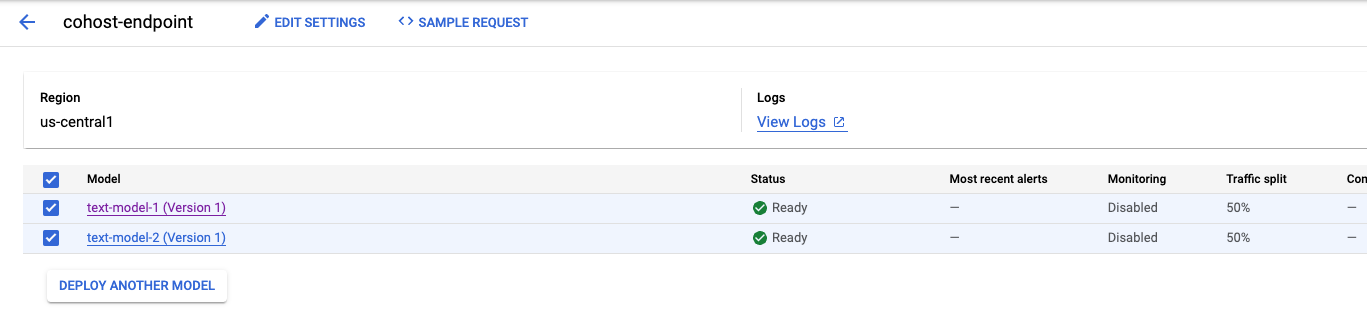
Passaggio 5: ottieni le previsioni
Il passaggio finale consiste nel testare l'endpoint e ottenere le previsioni.
Innanzitutto, definiamo la frase di test.
x_test=['The movie was cool. The animation and the graphics were out of this world. I would recommend this movie.']
Quindi, chiama predict sull'endpoint, che restituirà una previsione da uno dei modelli sottoposti a deployment sull'endpoint.
endpoint.predict(instances=x_test)
🎉 Congratulazioni! 🎉
Hai imparato come utilizzare Vertex AI per:
- Eseguire il co-hosting dei modelli sulla stessa VM per le previsioni online
Per saperne di più sulle diverse parti di Vertex, consulta la documentazione.
7. Esegui la pulizia
Se non prevedi di utilizzarli, ti consigliamo di annullare il deployment dei modelli dall'endpoint. Puoi anche eliminare completamente l'endpoint. Se necessario, puoi sempre rieseguire il deployment di un modello su un endpoint.

I notebook gestiti di Workbench vanno in timeout automaticamente dopo 180 minuti di inattività, quindi non devi preoccuparti di arrestare l'istanza. Se vuoi arrestare manualmente l'istanza, fai clic sul pulsante Arresta nella sezione Vertex AI Workbench della console. Se vuoi eliminare completamente il notebook, fai clic sul pulsante Elimina.

Per eliminare il bucket di archiviazione, utilizza il menu di navigazione nella console Cloud, vai ad Archiviazione, seleziona il bucket e fai clic su Elimina: