
1. La mission

Vous vous êtes identifié auprès de l'IA d'urgence et votre balise clignote désormais sur la carte de la planète, mais elle est à peine visible, perdue dans le bruit. Les équipes de secours qui effectuent des recherches depuis l'orbite ont repéré quelque chose à vos coordonnées, mais elles ne parviennent pas à vous localiser précisément. Le signal est trop faible.
Pour que votre balise soit à pleine puissance, vous devez confirmer votre position exacte. Le système de navigation du pod est hors service, mais l'accident a dispersé des preuves récupérables sur le site d'atterrissage. Échantillons de sol. Une flore étrange. Vue dégagée du ciel nocturne extraterrestre.
Si vous pouvez analyser ces preuves et déterminer dans quelle région du monde vous vous trouvez, l'IA peut trianguler votre position et amplifier le signal de la balise. Quelqu'un vous trouvera peut-être.
Il est temps de rassembler les pièces.
Prérequis
⚠️ Pour accéder à ce niveau, vous devez avoir terminé le niveau 0.
Avant de commencer, vérifiez que vous disposez des éléments suivants :
- [ ]
config.jsonà la racine du projet avec votre ID de participant et vos coordonnées - [ ] Votre avatar est visible sur la carte du monde.
- [ ] Votre balise est affichée (en grisé) à vos coordonnées.
Si vous n'avez pas terminé le niveau 0, commencez par là.
Objectifs de l'atelier
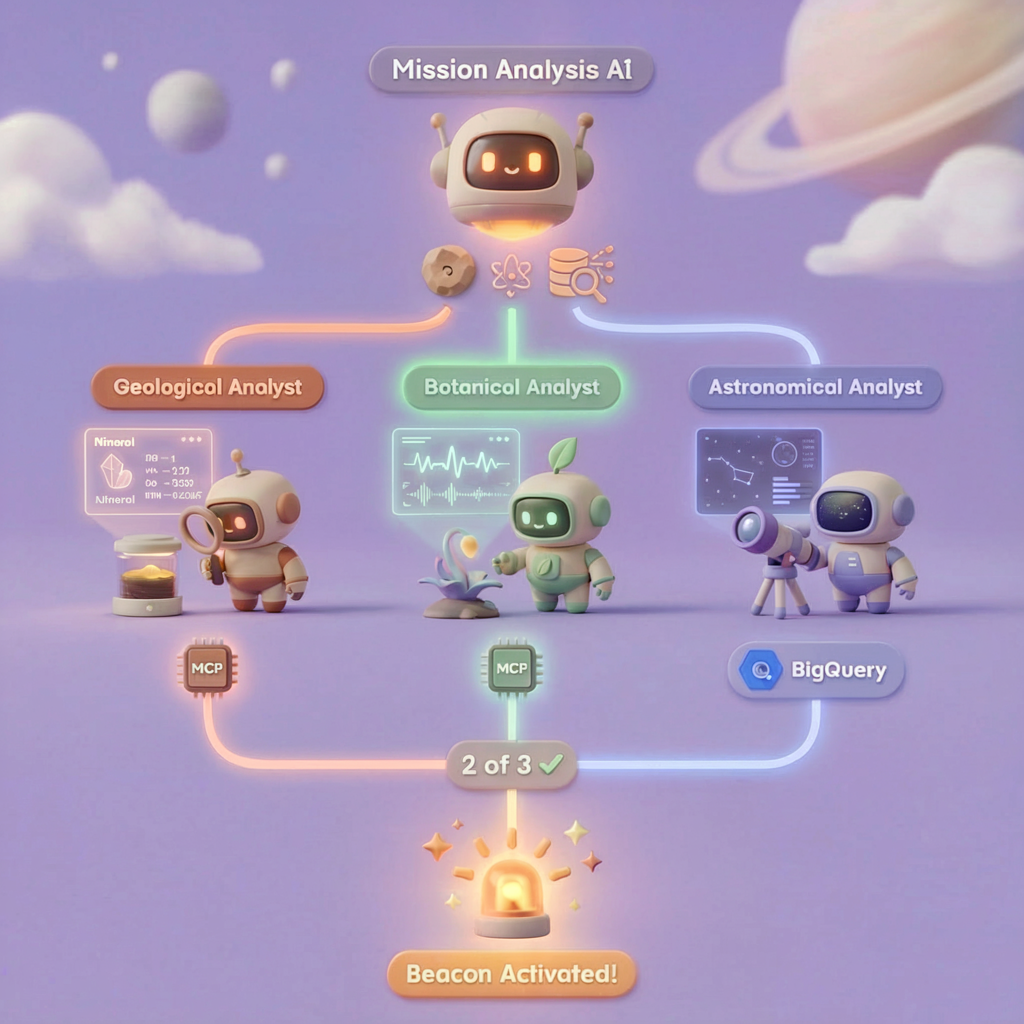
Dans ce niveau, vous allez construire un système d'IA multi-agent qui analyse les preuves sur le lieu du crash à l'aide du traitement parallèle :

Objectifs de la formation
Concept | Ce que vous allez apprendre |
Systèmes multi-agents | Créer des agents spécialisés avec des responsabilités uniques |
ParallelAgent | Composer des agents indépendants pour qu'ils s'exécutent simultanément |
before_agent_callback | Récupérer la configuration et définir l'état avant l'exécution de l'agent |
ToolContext | Accéder aux valeurs d'état dans les fonctions d'outil |
Serveurs MCP personnalisés | Créer des outils avec le modèle impératif (code Python sur Cloud Run) |
OneMCP BigQuery | Se connecter au MCP géré de Google pour accéder à BigQuery |
IA multimodale | Analyser des images et des vidéos avec audio avec Gemini |
Orchestration d'agents | Coordonner plusieurs agents avec un orchestrateur racine |
Cloud Deployment | Déployer le serveur et l'agent MCP sur Cloud Run |
Préparation A2A | Structurer les agents pour les futures communications entre agents |
Biomes de la planète
La surface de la planète est divisée en quatre biomes distincts, chacun avec des caractéristiques uniques :
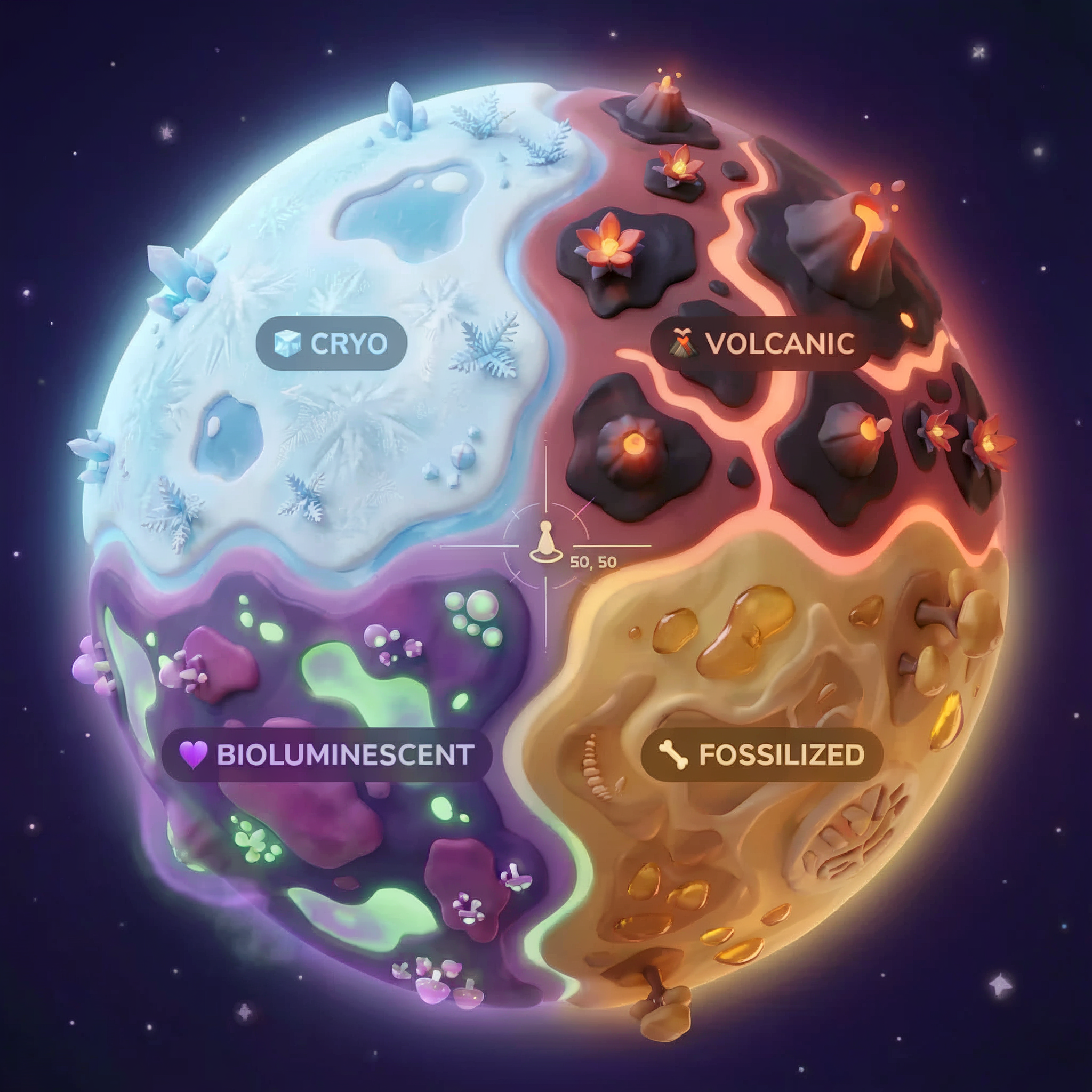
Vos coordonnées déterminent le biome dans lequel vous vous êtes écrasé. Les éléments trouvés sur le site du crash reflètent les caractéristiques de ce biome :
Biome | Quadrant | Preuves géologiques | Preuves botaniques | Preuves astronomiques |
🧊 CRYO | NW (x<50, y≥50) | Méthane gelé, cristaux de glace | Fougères de glace, cryoflore | Étoile géante bleue |
🌋 VOLCANIC | NE (x≥50, y≥50) | Dépôts d'obsidienne | Fleurs de feu, flore résistante à la chaleur | Binaire naine rouge |
💜 BIOLUMINESCENT | SO (x<50, y<50) | Sol phosphorescent | Champignons et plantes luminescents | Pulsar vert |
🦴 FOSSILISÉ | SE (x≥50, y<50) | Dépôts d'ambre, minéraux ite | Arbres pétrifiés, flore ancienne | Soleil jaune |
Votre mission : créer des agents d'IA capables d'analyser les preuves et de déduire le biome dans lequel vous vous trouvez.
2. Configurer votre environnement
Exécuter le script de configuration de l'environnement
Avant de générer des preuves, vous devez activer les API Google Cloud requises, y compris OneMCP pour BigQuery, qui fournit un accès MCP géré à BigQuery.
👉💻 Exécutez le script de configuration de l'environnement :
cd $HOME/way-back-home/level_1
chmod +x setup/setup_env.sh
./setup/setup_env.sh
Le résultat doit ressembler à ce qui suit :
================================================================
Level 1: Environment Setup
================================================================
Project: your-project-id
[1/6] Enabling core Google Cloud APIs...
✓ Vertex AI API enabled
✓ Cloud Run API enabled
✓ Cloud Build API enabled
✓ BigQuery API enabled
✓ Artifact Registry API enabled
✓ IAM API enabled
[2/6] Enabling OneMCP BigQuery (Managed MCP)...
✓ OneMCP BigQuery enabled
[3/6] Setting up service account and IAM permissions...
✓ Service account 'way-back-home-sa' created
✓ Vertex AI User role granted
✓ Cloud Run Invoker role granted
✓ BigQuery User role granted
✓ BigQuery Data Viewer role granted
✓ Storage Object Viewer role granted
[4/6] Configuring Cloud Build IAM for deployments...
✓ Cloud Build can now deploy services as way-back-home-sa
✓ Cloud Run Admin role granted to Compute SA
[5/6] Creating Artifact Registry repository...
✓ Repository 'way-back-home' created
[6/6] Creating environment variables file...
Found PARTICIPANT_ID in config.json: abc123...
✓ Created ../set_env.sh
================================================================
✅ Environment Setup Complete!
================================================================
Variables d'environnement source
👉💻 Définissez les variables d'environnement :
source $HOME/way-back-home/set_env.sh
Installer des dépendances
👉💻 Installez les dépendances Python de niveau 1 :
cd $HOME/way-back-home/level_1
uv sync
Configurer le catalogue d'étoiles
👉💻 Configurez le catalogue d'étoiles dans BigQuery :
uv run python setup/setup_star_catalog.py
Vous devriez obtenir le résultat suivant :
Setting up star catalog in project: your-project-id
==================================================
✓ Dataset way_back_home already exists
✓ Created table star_catalog
✓ Inserted 12 rows into star_catalog
📊 Star Catalog Summary:
----------------------------------------
NE (VOLCANIC): 3 stellar patterns
NW (CRYO): 3 stellar patterns
SE (FOSSILIZED): 3 stellar patterns
SW (BIOLUMINESCENT): 3 stellar patterns
----------------------------------------
✓ Star catalog is ready for triangulation queries
==================================================
✅ Star catalog setup complete!
3. Générer des preuves de site de plantage
Générez maintenant des preuves personnalisées du site de l'accident en fonction de vos coordonnées.
Exécuter le générateur de preuves
👉💻 Depuis le répertoire level_1, exécutez la commande suivante :
cd $HOME/way-back-home/level_1
uv run python generate_evidence.py
Le résultat doit ressembler à ce qui suit :
✓ Welcome back, Explorer_Aria!
Coordinates: (23, 67)
Ready to analyze your crash site.
📍 Crash site analysis initiated...
Generating evidence for your location...
🔬 Generating soil sample...
✓ Soil sample captured: outputs/soil_sample.png
✨ Capturing star field...
✓ Star field captured: outputs/star_field.png
🌿 Recording flora activity...
(This may take 1-2 minutes for video generation)
Generating video...
Generating video...
Generating video...
✓ Flora recorded: outputs/flora_recording.mp4
📤 Uploading evidence to Mission Control...
✓ Config updated with evidence URLs
==================================================
✅ Evidence generation complete!
==================================================
Vérifier vos pièces justificatives
👉 Prenez le temps d'examiner les fichiers de preuve générés dans le dossier outputs/. Chacun reflète les caractéristiques du biome de votre lieu de crash, mais vous ne saurez pas de quel biome il s'agit tant que vos agents IA ne l'auront pas analysé.
En fonction de votre localisation, les preuves générées peuvent se présenter comme suit :



4. Créer le serveur MCP personnalisé
Les systèmes d'analyse embarqués de votre capsule de sauvetage sont hors service, mais les données brutes des capteurs ont survécu au crash. Vous allez créer un serveur MCP avec FastMCP qui fournit des outils d'analyse géologique et botanique.
Créer l'outil d'analyse géologique
Cet outil analyse les images d'échantillons de sol pour identifier la composition minérale.
👉✏️ Ouvrez $HOME/way-back-home/level_1/mcp-server/main.py et recherchez #REPLACE-GEOLOGICAL-TOOL. Remplacez-le par :
GEOLOGICAL_PROMPT = """Analyze this alien soil sample image.
Classify the PRIMARY characteristic (choose exactly one):
1. CRYO - Frozen/icy minerals, crystalline structures, frost patterns,
blue-white coloration, permafrost indicators
2. VOLCANIC - Volcanic rock, basalt, obsidian, sulfur deposits,
red-orange minerals, heat-formed crystite structures
3. BIOLUMINESCENT - Glowing particles, phosphorescent minerals,
organic-mineral hybrids, purple-green luminescence
4. FOSSILIZED - Ancient compressed minerals, amber deposits,
petrified organic matter, golden-brown stratification
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"minerals_detected": ["mineral1", "mineral2"],
"description": "Brief description of what you observe"
}
"""
@mcp.tool()
def analyze_geological(
image_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the soil sample image")
]
) -> dict:
"""
Analyzes a soil sample image to identify mineral composition and classify the planetary biome.
Args:
image_url: Cloud Storage URL of the soil sample image (gs://bucket/path/image.png)
Returns:
dict with biome, confidence, minerals_detected, and description
"""
logger.info(f">>> 🔬 Tool: 'analyze_geological' called for '{image_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
GEOLOGICAL_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Geological analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Geological analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Créer l'outil d'analyse botanique
Cet outil analyse les enregistrements vidéo de la flore, y compris la piste audio.
👉✏️ Dans le même fichier ($HOME/way-back-home/level_1/mcp-server/main.py), recherchez #REPLACE-BOTANICAL-TOOL et remplacez-le par :
BOTANICAL_PROMPT = """Analyze this alien flora video recording.
Pay attention to BOTH:
1. VISUAL elements: Plant appearance, movement patterns, colors, bioluminescence
2. AUDIO elements: Ambient sounds, rustling, organic noises, frequencies
Classify the PRIMARY biome (choose exactly one):
1. CRYO - Crystalline ice-plants, frost-covered vegetation,
crackling/tinkling sounds, slow brittle movements, blue-white flora
2. VOLCANIC - Heat-resistant plants, sulfur-adapted species,
hissing/bubbling sounds, smoke-filtering vegetation, red-orange flora
3. BIOLUMINESCENT - Glowing plants, pulsing light patterns,
humming/resonating sounds, reactive to stimuli, purple-green flora
4. FOSSILIZED - Ancient petrified plants, amber-preserved specimens,
deep resonant sounds, minimal movement, golden-brown flora
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"species_detected": ["species1", "species2"],
"audio_signatures": ["sound1", "sound2"],
"description": "Brief description of visual and audio observations"
}
"""
@mcp.tool()
def analyze_botanical(
video_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the flora video recording")
]
) -> dict:
"""
Analyzes a flora video recording (visual + audio) to identify plant species and classify the biome.
Args:
video_url: Cloud Storage URL of the flora video (gs://bucket/path/video.mp4)
Returns:
dict with biome, confidence, species_detected, audio_signatures, and description
"""
logger.info(f">>> 🌿 Tool: 'analyze_botanical' called for '{video_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
BOTANICAL_PROMPT,
genai_types.Part.from_uri(file_uri=video_url, mime_type="video/mp4")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Botanical analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Botanical analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Tester le serveur MCP localement
👉💻 Testez le serveur MCP :
cd $HOME/way-back-home/level_1/mcp-server
pip install -r requirements.txt
python main.py
Vous devriez obtenir le résultat suivant :
[INFO] Initialized Gemini client for project: your-project-id
[INFO] 🚀 Location Analyzer MCP Server starting on port 8080
[INFO] 📍 MCP endpoint: http://0.0.0.0:8080/mcp
[INFO] 🔧 Tools: analyze_geological, analyze_botanical
Le serveur FastMCP est désormais en cours d'exécution avec le transport HTTP. Appuyez sur Ctrl+C pour arrêter.
Déployer le serveur MCP sur Cloud Run
👉💻 Déployer :
cd $HOME/way-back-home/level_1/mcp-server
source $HOME/way-back-home/set_env.sh
gcloud builds submit . \
--config=cloudbuild.yaml \
--substitutions=_REGION="$REGION",_REPO_NAME="$REPO_NAME",_SERVICE_ACCOUNT="$SERVICE_ACCOUNT"
Enregistrer l'URL du service
👉💻 Enregistrez l'URL du service :
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
echo "MCP Server URL: $MCP_SERVER_URL"
# Add to set_env.sh for later use
echo "export MCP_SERVER_URL=\"$MCP_SERVER_URL\"" >> $HOME/way-back-home/set_env.sh
5. Créer les agents spécialisés
Vous allez maintenant créer trois agents spécialisés, chacun avec une seule responsabilité.
Créer l'agent d'analyse géologique
👉✏️ Ouvrez agent/agents/geological_analyst.py et recherchez #REPLACE-GEOLOGICAL-AGENT. Remplacez-le par :
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_geological_tool
geological_analyst = Agent(
name="GeologicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes soil samples to classify planetary biome based on mineral composition.",
instruction="""You are a geological specialist analyzing alien soil samples.
## YOUR EVIDENCE TO ANALYZE
Soil sample URL: {soil_url}
## YOUR TASK
1. Call the analyze_geological tool with the soil sample URL above
2. Examine the results for mineral composition and biome indicators
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frozen, icy minerals, blue/white coloring
- VOLCANIC: Magma, obsidian, volcanic rock, red/orange coloring
- BIOLUMINESCENT: Glowing, phosphorescent minerals, purple/green
- FOSSILIZED: Amber, ancient preserved matter, golden/brown
## REPORTING FORMAT
Always report your classification clearly:
"GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
Include a brief description of what you observed in the sample.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the soil sample and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_geological_tool()]
)
Créer l'agent Botanical Analyst
👉✏️ Ouvrez agent/agents/botanical_analyst.py et recherchez #REPLACE-BOTANICAL-AGENT. Remplacez-le par :
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_botanical_tool
botanical_analyst = Agent(
name="BotanicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes flora recordings to classify planetary biome based on plant life and ambient sounds.",
instruction="""You are a botanical specialist analyzing alien flora recordings.
## YOUR EVIDENCE TO ANALYZE
Flora recording URL: {flora_url}
## YOUR TASK
1. Call the analyze_botanical tool with the flora recording URL above
2. Pay attention to BOTH visual AND audio elements in the recording
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frost ferns, crystalline plants, cold wind sounds, crackling ice
- VOLCANIC: Fire blooms, heat-resistant flora, crackling/hissing sounds
- BIOLUMINESCENT: Glowing fungi, luminescent plants, ethereal hum, chiming
- FOSSILIZED: Petrified trees, ancient formations, deep resonant sounds
## REPORTING FORMAT
Always report your classification clearly:
"BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
Include descriptions of what you SAW and what you HEARD.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the flora recording and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_botanical_tool()]
)
Créer l'agent Astronomical Analyst
Cet agent utilise une approche différente avec deux modèles d'outils :
- LocalFunctionTool : Gemini Vision pour extraire les caractéristiques des étoiles
- OneMCP BigQuery : interrogez le catalogue d'étoiles via le MCP géré de Google.
👉✏️ Ouvrez agent/agents/astronomical_analyst.py et recherchez #REPLACE-ASTRONOMICAL-AGENT. Remplacez-le par :
from google.adk.agents import Agent
from agent.tools.star_tools import (
extract_star_features_tool,
get_bigquery_mcp_toolset,
)
# Get the BigQuery MCP toolset
bigquery_toolset = get_bigquery_mcp_toolset()
astronomical_analyst = Agent(
name="AstronomicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes star field images and queries the star catalog via OneMCP BigQuery.",
instruction="""You are an astronomical specialist analyzing alien night skies.
## YOUR EVIDENCE TO ANALYZE
Star field URL: {stars_url}
## YOUR TWO TOOLS
### TOOL 1: extract_star_features (Local Gemini Vision)
Call this FIRST with the star field URL above.
Returns: "primary_star": "...", "nebula_type": "...", "stellar_color": "..."
### TOOL 2: BigQuery MCP (execute_query)
Call this SECOND with the results from Tool 1.
Use this exact SQL query (replace the placeholders with values from Step 1):
SELECT quadrant, biome, primary_star, nebula_type
FROM `{project_id}.way_back_home.star_catalog`
WHERE LOWER(primary_star) = LOWER('PRIMARY_STAR_FROM_STEP_1')
AND LOWER(nebula_type) = LOWER('NEBULA_TYPE_FROM_STEP_1')
LIMIT 1
## YOUR WORKFLOW
1. Call extract_star_features with: {stars_url}
2. Get the primary_star and nebula_type from the result
3. Call execute_query with the SQL above (replacing placeholders)
4. Report the biome and quadrant from the query result
## BIOME REFERENCE
| Biome | Quadrant | Primary Star | Nebula Type |
|-------|----------|--------------|-------------|
| CRYO | NW | blue_giant | ice_blue |
| VOLCANIC | NE | red_dwarf_binary | fire |
| BIOLUMINESCENT | SW | green_pulsar | purple_magenta |
| FOSSILIZED | SE | yellow_sun | golden |
## REPORTING FORMAT
"ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
Include a description of the stellar features you observed.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the stars and report what you find
- Start by calling extract_star_features with the URL above""",
tools=[extract_star_features_tool, bigquery_toolset]
)
6. Créer les connexions aux outils MCP
Vous allez maintenant créer les wrappers Python qui permettent à vos agents ADK de communiquer avec les serveurs MCP. Ces wrappers gèrent le cycle de vie de la connexion (établissement de sessions, appel d'outils et analyse des réponses).
Créer une connexion à l'outil MCP (MCP personnalisé)
Cela permet de se connecter à votre serveur FastMCP personnalisé déployé sur Cloud Run.
👉✏️ Ouvrez agent/tools/mcp_tools.py et recherchez #REPLACE-MCP-TOOL-CONNECTION. Remplacez-le par :
import os
import logging
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
logger = logging.getLogger(__name__)
MCP_SERVER_URL = os.environ.get("MCP_SERVER_URL")
_mcp_toolset = None
def get_mcp_toolset():
"""Get the MCPToolset connected to the location-analyzer server."""
global _mcp_toolset
if _mcp_toolset is not None:
return _mcp_toolset
if not MCP_SERVER_URL:
raise ValueError(
"MCP_SERVER_URL not set. Please run:\n"
" export MCP_SERVER_URL='https://location-analyzer-xxx.a.run.app'"
)
# FastMCP exposes MCP protocol at /mcp endpoint
mcp_endpoint = f"{MCP_SERVER_URL}/mcp"
logger.info(f"[MCP Tools] Connecting to: {mcp_endpoint}")
_mcp_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_endpoint,
timeout=120, # 2 minutes for Gemini analysis
)
)
return _mcp_toolset
def get_geological_tool():
"""Get the geological analysis tool from the MCP server."""
return get_mcp_toolset()
def get_botanical_tool():
"""Get the botanical analysis tool from the MCP server."""
return get_mcp_toolset()
Créer des outils d'analyse des étoiles (OneMCP BigQuery)
Le catalogue d'étoiles que vous avez chargé précédemment dans BigQuery contient des motifs stellaires pour chaque biome. Au lieu d'écrire du code client BigQuery pour l'interroger, nous nous connectons au serveur OneMCP BigQuery de Google, qui expose la fonctionnalité execute_query de BigQuery en tant qu'outil MCP que tout agent ADK peut utiliser directement.
👉✏️ Ouvrez agent/tools/star_tools.py et recherchez #REPLACE-STAR-TOOLS. Remplacez-le par :
import os
import json
import logging
from google import genai
from google.genai import types as genai_types
from google.adk.tools import FunctionTool
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
import google.auth
import google.auth.transport.requests
logger = logging.getLogger(__name__)
# =============================================================================
# CONFIGURATION - Environment variables only
# =============================================================================
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
if not PROJECT_ID:
logger.warning("[Star Tools] GOOGLE_CLOUD_PROJECT not set")
# Initialize Gemini client for star feature extraction
genai_client = genai.Client(
vertexai=True,
project=PROJECT_ID or "placeholder",
location=os.environ.get("GOOGLE_CLOUD_LOCATION", "us-central1")
)
logger.info(f"[Star Tools] Initialized for project: {PROJECT_ID}")
# =============================================================================
# OneMCP BigQuery Connection
# =============================================================================
BIGQUERY_MCP_URL = "https://bigquery.googleapis.com/mcp"
_bigquery_toolset = None
def get_bigquery_mcp_toolset():
"""
Get the MCPToolset connected to Google's BigQuery MCP server.
This uses OAuth 2.0 authentication with Application Default Credentials.
The toolset provides access to BigQuery's pre-built MCP tools like:
- execute_query: Run SQL queries
- list_datasets: List available datasets
- get_table_schema: Get table structure
"""
global _bigquery_toolset
if _bigquery_toolset is not None:
return _bigquery_toolset
logger.info("[Star Tools] Connecting to OneMCP BigQuery...")
# Get OAuth credentials
credentials, project_id = google.auth.default(
scopes=["https://www.googleapis.com/auth/bigquery"]
)
# Refresh to get a valid token
credentials.refresh(google.auth.transport.requests.Request())
oauth_token = credentials.token
# Configure headers for BigQuery MCP
headers = {
"Authorization": f"Bearer {oauth_token}",
"x-goog-user-project": project_id or PROJECT_ID
}
# Create MCPToolset with StreamableHTTP connection
_bigquery_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=BIGQUERY_MCP_URL,
headers=headers
)
)
logger.info("[Star Tools] Connected to BigQuery MCP")
return _bigquery_toolset
# =============================================================================
# Local FunctionTool: Star Feature Extraction
# =============================================================================
# This is a LOCAL tool that calls Gemini directly - demonstrating that
# you can mix local FunctionTools with MCP tools in the same agent.
STAR_EXTRACTION_PROMPT = """Analyze this alien night sky image and extract stellar features.
Identify:
1. PRIMARY STAR TYPE: blue_giant, red_dwarf, red_dwarf_binary, green_pulsar, yellow_sun, etc.
2. NEBULA TYPE: ice_blue, fire, purple_magenta, golden, etc.
3. STELLAR COLOR: blue_white, red_orange, green_purple, yellow_gold, etc.
Respond ONLY with valid JSON:
{"primary_star": "...", "nebula_type": "...", "stellar_color": "...", "description": "..."}
"""
def _parse_json_response(text: str) -> dict:
"""Parse JSON from Gemini response, handling markdown formatting."""
cleaned = text.strip()
if cleaned.startswith("```json"):
cleaned = cleaned[7:]
elif cleaned.startswith("```"):
cleaned = cleaned[3:]
if cleaned.endswith("```"):
cleaned = cleaned[:-3]
cleaned = cleaned.strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError as e:
logger.error(f"Failed to parse JSON: {e}")
return {"error": f"Failed to parse response: {str(e)}"}
def extract_star_features(image_url: str) -> dict:
"""
Extract stellar features from a star field image using Gemini Vision.
This is a LOCAL FunctionTool - we call Gemini directly, not through MCP.
The agent will use this alongside the BigQuery MCP tools.
"""
logger.info(f"[Stars] Extracting features from: {image_url}")
response = genai_client.models.generate_content(
model="gemini-2.5-flash",
contents=[
STAR_EXTRACTION_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = _parse_json_response(response.text)
logger.info(f"[Stars] Extracted: primary_star={result.get('primary_star')}")
return result
# Create the local FunctionTool
extract_star_features_tool = FunctionTool(extract_star_features)
7. Créer l'outil d'orchestration
Créez maintenant l'orchestrateur d'équipes et racine parallèles qui coordonne tout.
Créer l'équipe d'analyse parallèle
Pourquoi exécuter les trois spécialistes en parallèle ? Elles sont totalement indépendantes : l'analyste géologique n'a pas besoin d'attendre les résultats de l'analyste botanique, et vice versa. Chaque spécialiste analyse une pièce à conviction différente à l'aide d'outils différents. Un ParallelAgent exécute les trois en même temps, ce qui réduit le temps d'analyse total d'environ 30 secondes (séquentiel) à environ 10 secondes (parallèle).
👉✏️ Ouvrez agent/agent.py et recherchez #REPLACE-PARALLEL-CREW. Remplacez-le par :
import os
import logging
import httpx
from google.adk.agents import Agent, ParallelAgent
from google.adk.agents.callback_context import CallbackContext
# Import specialist agents
from agent.agents.geological_analyst import geological_analyst
from agent.agents.botanical_analyst import botanical_analyst
from agent.agents.astronomical_analyst import astronomical_analyst
# Import confirmation tool
from agent.tools.confirm_tools import confirm_location_tool
logger = logging.getLogger(__name__)
# =============================================================================
# BEFORE AGENT CALLBACK - Fetches config and sets state
# =============================================================================
async def setup_participant_context(callback_context: CallbackContext) -> None:
"""
Fetch participant configuration and populate state for all agents.
This callback:
1. Reads PARTICIPANT_ID and BACKEND_URL from environment
2. Fetches participant data from the backend API
3. Sets state values: soil_url, flora_url, stars_url, username, x, y, etc.
4. Returns None to continue normal agent execution
"""
participant_id = os.environ.get("PARTICIPANT_ID", "")
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
logger.info(f"[Callback] Setting up context for participant: {participant_id}")
# Set project_id and backend_url in state immediately
callback_context.state["project_id"] = project_id
callback_context.state["backend_url"] = backend_url
callback_context.state["participant_id"] = participant_id
if not participant_id:
logger.warning("[Callback] No PARTICIPANT_ID set - using placeholder values")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["flora_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["stars_url"] = "Not available - set PARTICIPANT_ID"
return None
# Fetch participant data from backend API
try:
url = f"{backend_url}/participants/{participant_id}"
logger.info(f"[Callback] Fetching from: {url}")
async with httpx.AsyncClient(timeout=30.0) as client:
response = await client.get(url)
response.raise_for_status()
data = response.json()
# Extract evidence URLs
evidence_urls = data.get("evidence_urls", {})
# Set all state values for sub-agents to access
callback_context.state["username"] = data.get("username", "Explorer")
callback_context.state["x"] = data.get("x", 0)
callback_context.state["y"] = data.get("y", 0)
callback_context.state["soil_url"] = evidence_urls.get("soil", "Not available")
callback_context.state["flora_url"] = evidence_urls.get("flora", "Not available")
callback_context.state["stars_url"] = evidence_urls.get("stars", "Not available")
logger.info(f"[Callback] State populated for {data.get('username')}")
except Exception as e:
logger.error(f"[Callback] Error fetching participant config: {e}")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = f"Error: {e}"
callback_context.state["flora_url"] = f"Error: {e}"
callback_context.state["stars_url"] = f"Error: {e}"
return None
# =============================================================================
# PARALLEL ANALYSIS CREW
# =============================================================================
evidence_analysis_crew = ParallelAgent(
name="EvidenceAnalysisCrew",
description="Runs geological, botanical, and astronomical analysis in parallel.",
sub_agents=[geological_analyst, botanical_analyst, astronomical_analyst]
)
Créer l'orchestrateur racine
Créez maintenant l'agent racine qui coordonne tout et utilise le rappel.
👉✏️ Dans le même fichier (agent/agent.py), recherchez #REPLACE-ROOT-ORCHESTRATOR. Remplacez-le par :
root_agent = Agent(
name="MissionAnalysisAI",
model="gemini-2.5-flash",
description="Coordinates crash site analysis to confirm explorer location.",
instruction="""You are the Mission Analysis AI coordinating a rescue operation.
## Explorer Information
- Name: {username}
- Coordinates: ({x}, {y})
## Evidence URLs (automatically provided to specialists via state)
- Soil sample: {soil_url}
- Flora recording: {flora_url}
- Star field: {stars_url}
## Your Workflow
### STEP 1: DELEGATE TO ANALYSIS CREW
Tell the EvidenceAnalysisCrew to analyze all the evidence.
The evidence URLs are already available to the specialists.
### STEP 2: COLLECT RESULTS
Each specialist will report:
- "GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
- "BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
- "ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
### STEP 3: APPLY 2-OF-3 AGREEMENT RULE
- If 2 or 3 specialists agree → that's the answer
- If all 3 disagree → use judgment based on confidence
### STEP 4: CONFIRM LOCATION
Call confirm_location with the determined biome.
## Biome Reference
| Biome | Quadrant | Key Characteristics |
|-------|----------|---------------------|
| CRYO | NW | Frozen, blue, ice crystals |
| VOLCANIC | NE | Magma, red/orange, obsidian |
| BIOLUMINESCENT | SW | Glowing, purple/green |
| FOSSILIZED | SE | Amber, golden, ancient |
## Response Style
Be encouraging and narrative! Celebrate when the beacon activates!
""",
sub_agents=[evidence_analysis_crew],
tools=[confirm_location_tool],
before_agent_callback=setup_participant_context
)
Créer l'outil de confirmation de l'établissement
Il s'agit de la dernière pièce du puzzle : l'outil qui confirme votre position au centre de contrôle et active votre balise. Lorsque l'orchestrateur racine détermine le biome dans lequel vous vous trouvez (à l'aide de la règle d'accord à deux sur trois), il appelle cet outil pour envoyer le résultat à l'API de backend.
Cet outil utilise ToolContext, ce qui lui donne accès aux valeurs d'état (comme participant_id et backend_url) qui ont été définies par before_agent_callback plus tôt.
👉✏️ Dans agent/tools/confirm_tools.py, recherchez #REPLACE-CONFIRM-TOOL. Remplacez-le par :
import os
import logging
import requests
from google.adk.tools import FunctionTool
from google.adk.tools.tool_context import ToolContext
logger = logging.getLogger(__name__)
BIOME_TO_QUADRANT = {
"CRYO": "NW",
"VOLCANIC": "NE",
"BIOLUMINESCENT": "SW",
"FOSSILIZED": "SE"
}
def _get_actual_biome(x: int, y: int) -> tuple[str, str]:
"""Determine actual biome and quadrant from coordinates."""
if x < 50 and y >= 50:
return "NW", "CRYO"
elif x >= 50 and y >= 50:
return "NE", "VOLCANIC"
elif x < 50 and y < 50:
return "SW", "BIOLUMINESCENT"
else:
return "SE", "FOSSILIZED"
def confirm_location(biome: str, tool_context: ToolContext) -> dict:
"""
Confirm the explorer's location and activate the rescue beacon.
Uses ToolContext to read state values set by before_agent_callback.
"""
# Read from state (set by before_agent_callback)
participant_id = tool_context.state.get("participant_id", "")
x = tool_context.state.get("x", 0)
y = tool_context.state.get("y", 0)
backend_url = tool_context.state.get("backend_url", "https://api.waybackhome.dev")
# Fallback to environment variables
if not participant_id:
participant_id = os.environ.get("PARTICIPANT_ID", "")
if not backend_url:
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
if not participant_id:
return {"success": False, "message": "❌ No participant ID available."}
biome_upper = biome.upper().strip()
if biome_upper not in BIOME_TO_QUADRANT:
return {"success": False, "message": f"❌ Unknown biome: {biome}"}
# Get actual biome from coordinates
actual_quadrant, actual_biome = _get_actual_biome(x, y)
if biome_upper != actual_biome:
return {
"success": False,
"message": f"❌ Mismatch! Analysis: {biome_upper}, Actual: {actual_biome}"
}
quadrant = BIOME_TO_QUADRANT[biome_upper]
try:
response = requests.patch(
f"{backend_url}/participants/{participant_id}/location",
params={"x": x, "y": y},
timeout=10
)
response.raise_for_status()
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED!\n\nLocation: {biome_upper} in {quadrant}\nCoordinates: ({x}, {y})"
}
except requests.exceptions.ConnectionError:
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED! (Local)\n\nLocation: {biome_upper} in {quadrant}",
"simulated": True
}
except Exception as e:
return {"success": False, "message": f"❌ Failed: {str(e)}"}
confirm_location_tool = FunctionTool(confirm_location)
8. Tester avec l'UI Web ADK
Testons maintenant l'ensemble du système multi-agents en local.
Démarrer le serveur Web ADK
👉💻 Définissez les variables d'environnement et démarrez le serveur Web ADK :
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
# Verify environment is set
echo "PARTICIPANT_ID: $PARTICIPANT_ID"
echo "MCP Server: $MCP_SERVER_URL"
# Start ADK web server
uv run adk web
Vous devriez obtenir le résultat suivant :
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Accéder à l'UI Web
👉 Dans la barre d'outils Cloud Shell (en haut à droite), cliquez sur l'icône Aperçu Web, puis sélectionnez Modifier le port.
![]()
👉 Définissez le port sur 8000, puis cliquez sur Modifier et prévisualiser.
👉 L'interface utilisateur Web de l'ADK s'ouvre. Sélectionnez agent dans le menu déroulant.
Exécuter l'analyse
👉 Dans l'interface de chat, saisissez :
Analyze the evidence from my crash site and confirm my location to activate the beacon.
Regardez le système multi-agent en action :
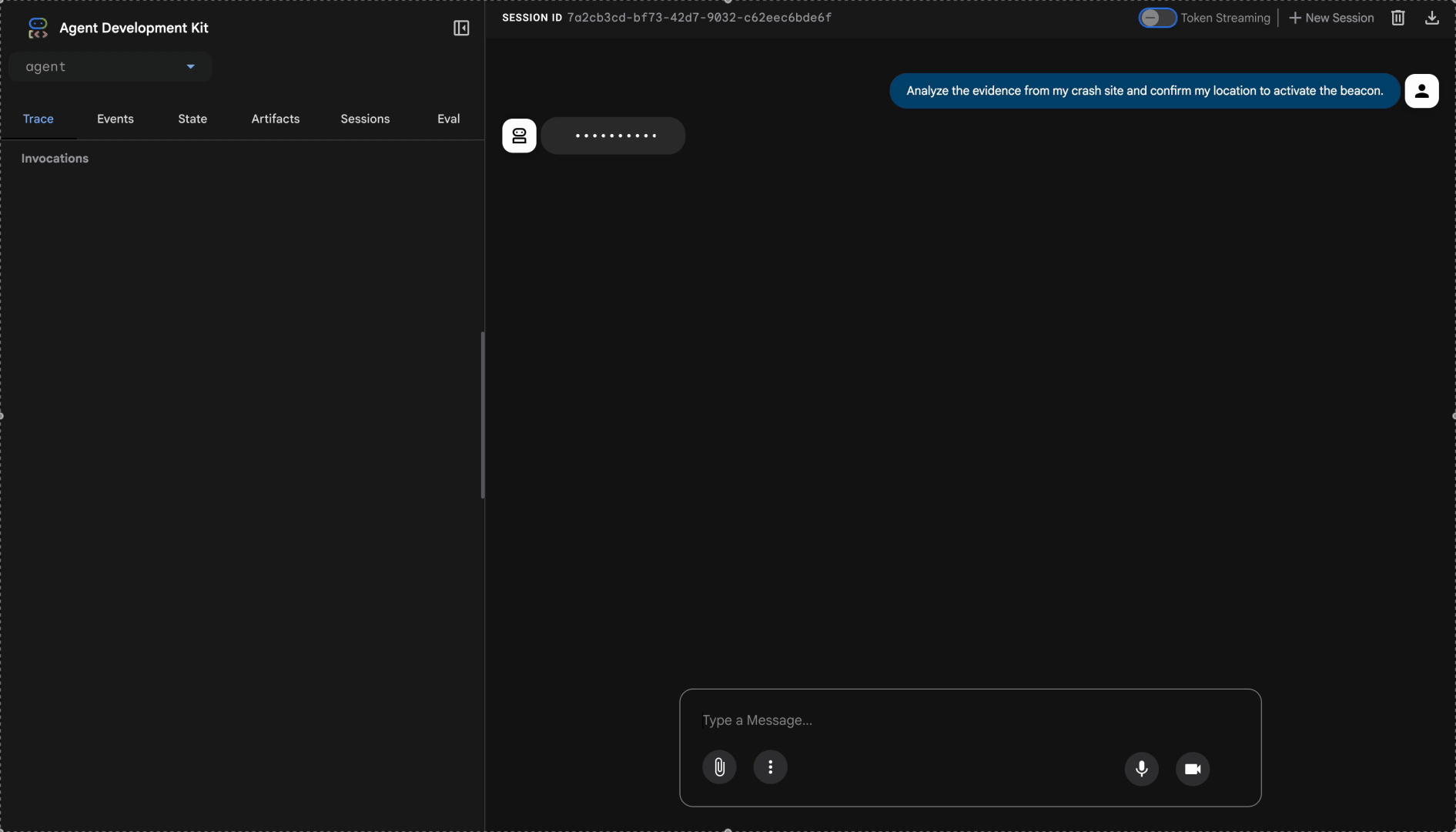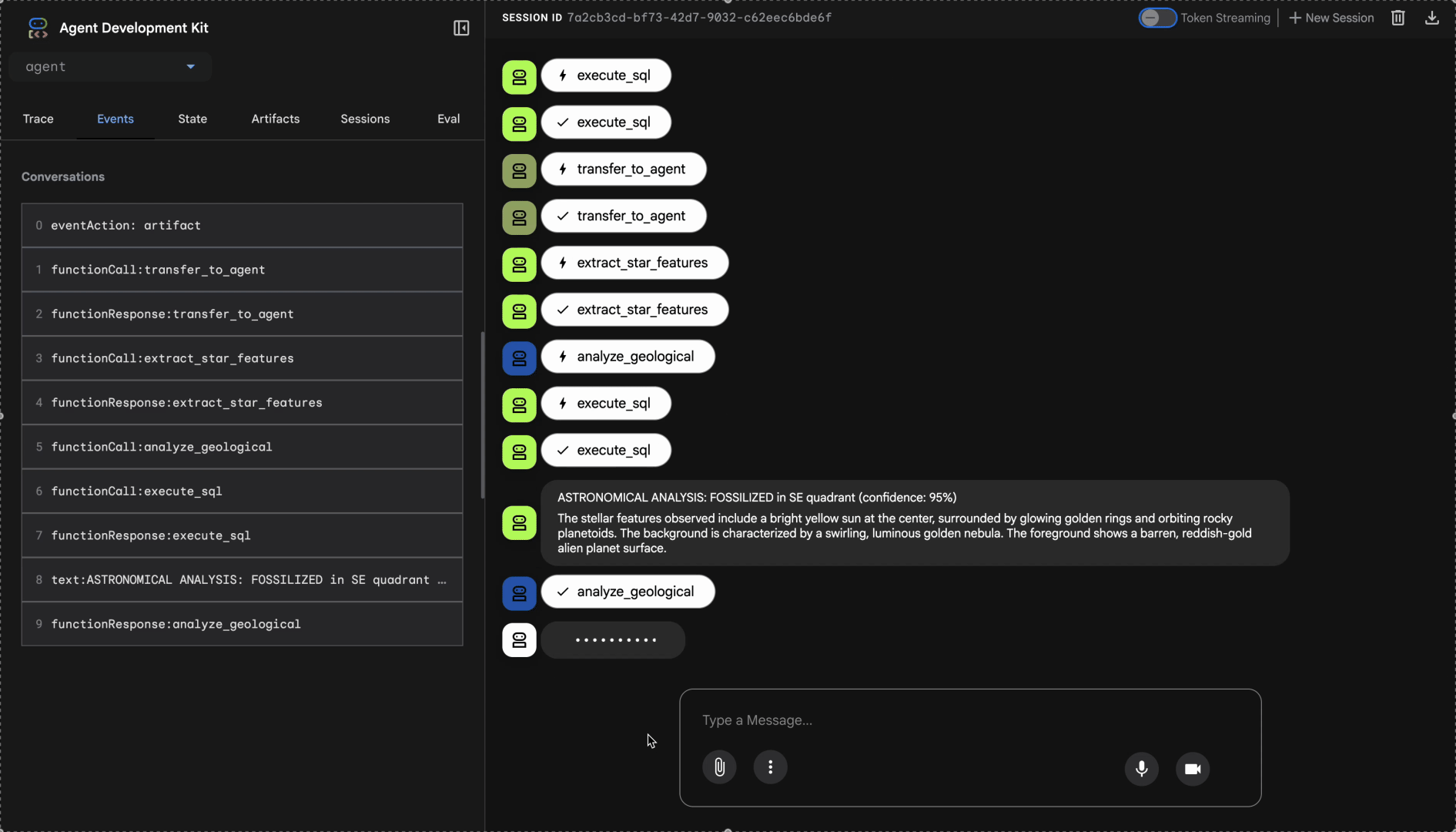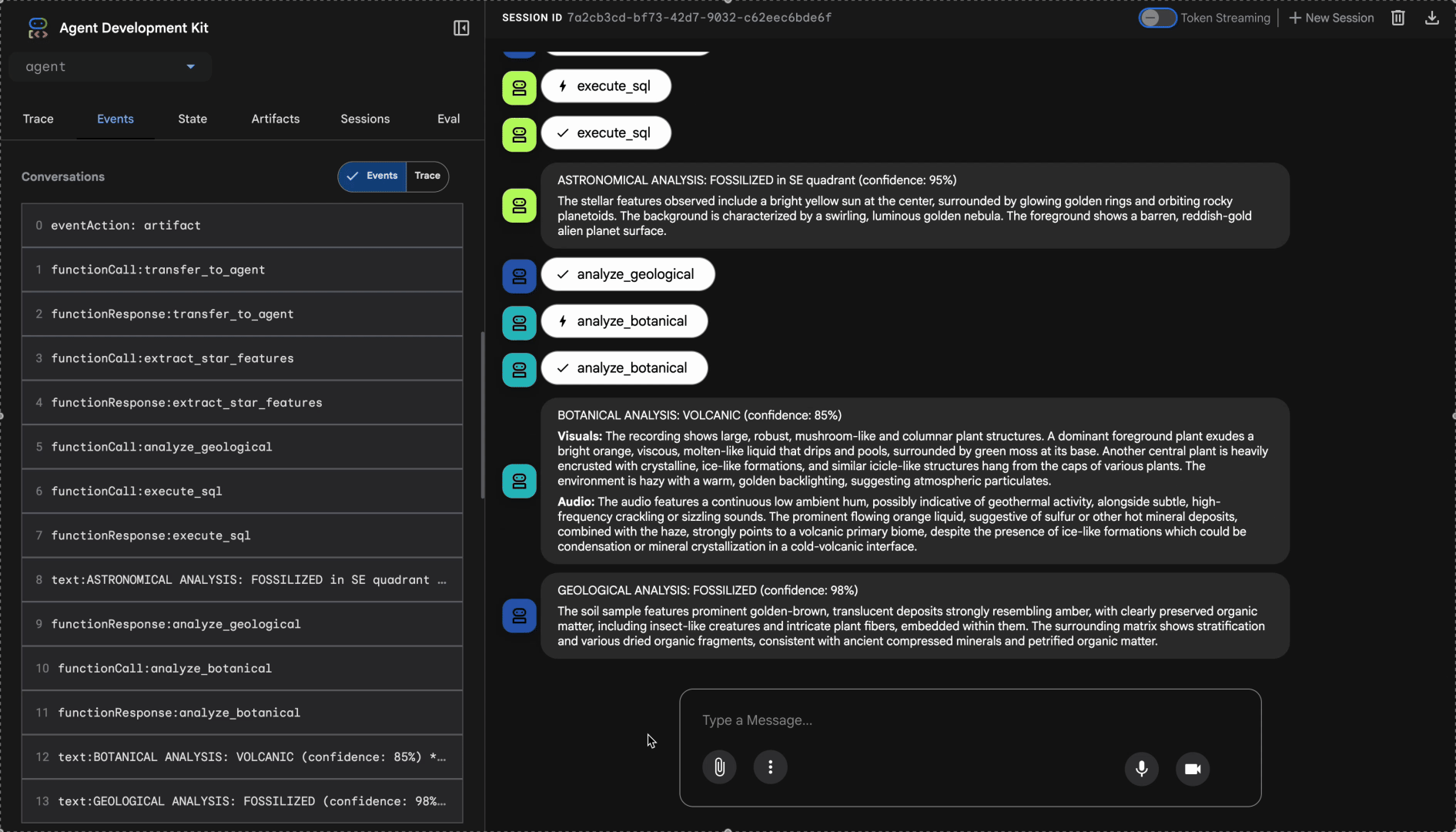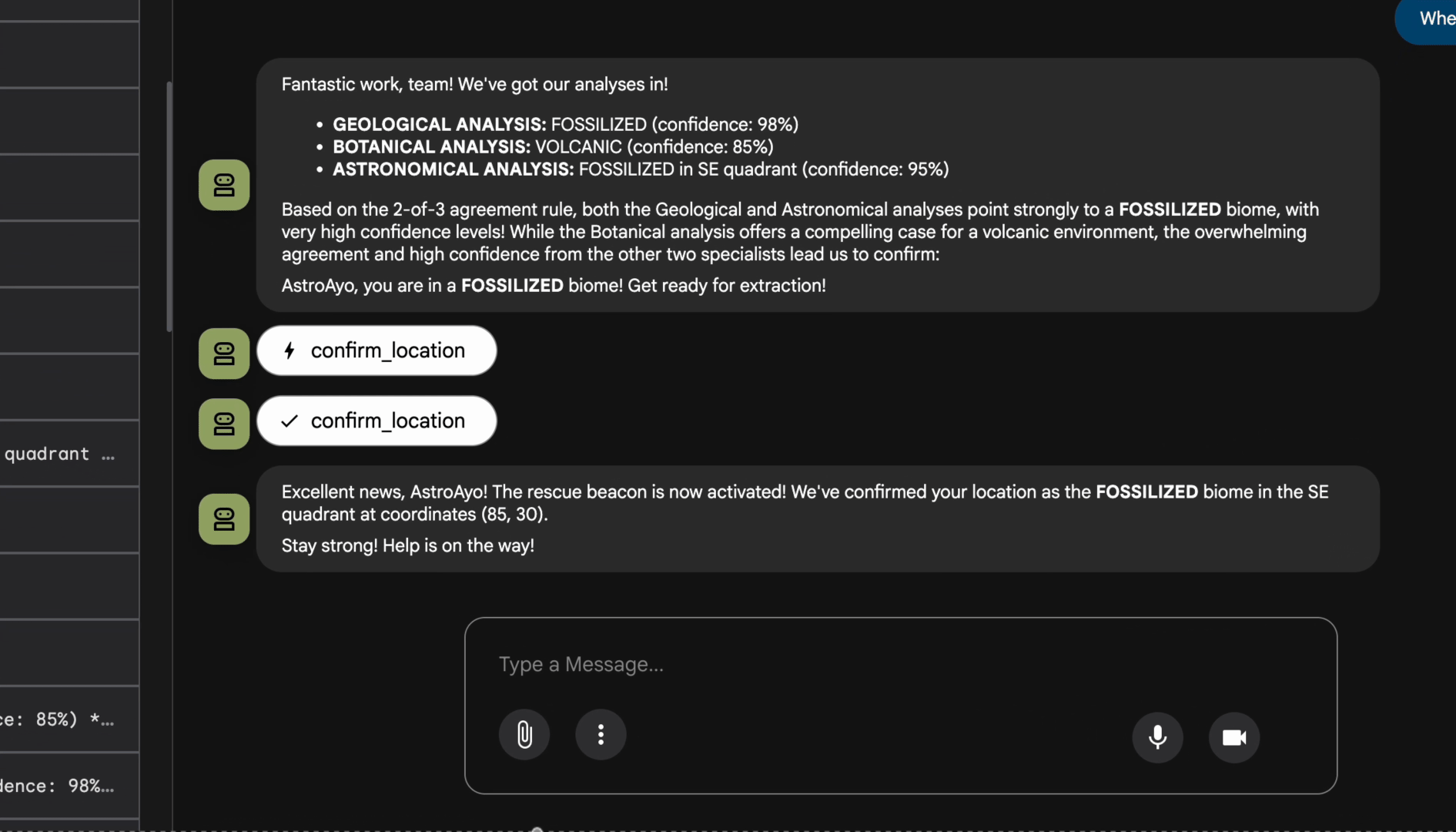
👉 Une fois que les trois agents ont terminé leurs analyses, saisissez :
Where am I?
Comment le système traite votre demande :

Le panneau de trace à droite affiche toutes les interactions de l'agent et les appels d'outils.
👉 Appuyez sur Ctrl+C dans le terminal pour arrêter le serveur une fois les tests terminés.
9. Déployer dans Cloud Run
Déployez maintenant votre système multi-agents sur Cloud Run pour qu'il soit prêt pour A2A.
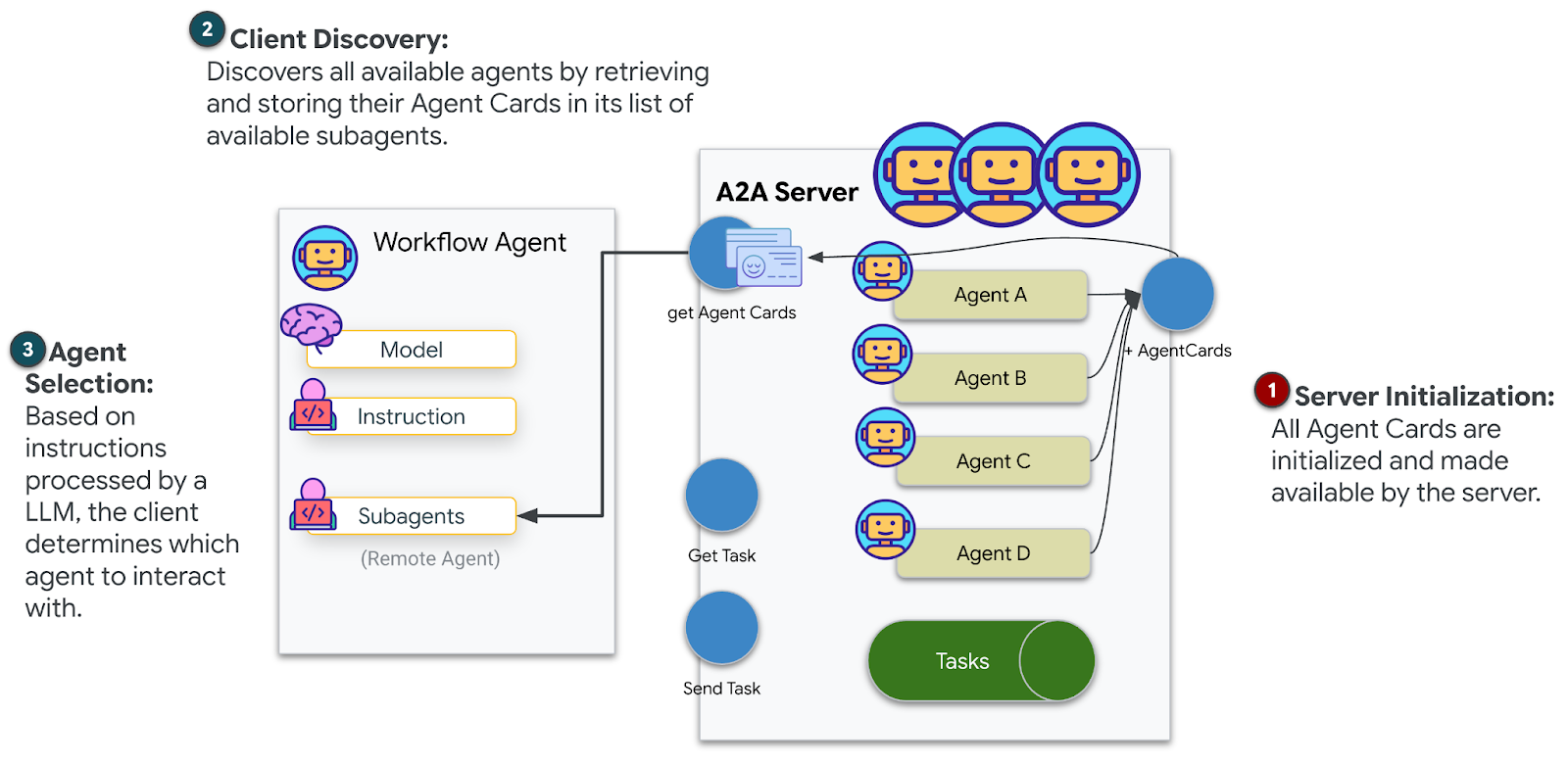
Déployer l'agent
👉💻 Déployez sur Cloud Run à l'aide de l'ADK CLI :
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
uv run adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$REGION \
--service_name=mission-analysis-ai \
--with_ui \
--a2a \
./agent
Lorsque les invites Do you want to continue (Y/n) et Allow unauthenticated invocations to [mission-analysis-ai] (Y/n)? s'affichent, saisissez Y pour les deux afin de déployer votre agent A2A et d'autoriser l'accès public.
Le résultat doit ressembler à ce qui suit :
Building and deploying agent to Cloud Run...
✓ Container built successfully
✓ Deploying to Cloud Run...
✓ Service deployed: https://mission-analysis-ai-abc123-uc.a.run.app
Définir des variables d'environnement sur Cloud Run
L'agent déployé doit avoir accès aux variables d'environnement. Mettez à jour le service :
👉💻 Définissez les variables d'environnement requises :
gcloud run services update mission-analysis-ai \
--region=$REGION \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$REGION,MCP_SERVER_URL=$MCP_SERVER_URL,BACKEND_URL=$BACKEND_URL,PARTICIPANT_ID=$PARTICIPANT_ID,GOOGLE_GENAI_USE_VERTEXAI=True"
Enregistrer l'URL de l'agent
👉 💻 Obtenez l'URL déployée :
export AGENT_URL=$(gcloud run services describe mission-analysis-ai \
--region=$REGION --format='value(status.url)')
echo "Agent URL: $AGENT_URL"
# Add to set_env.sh
echo "export LEVEL1_AGENT_URL=\"$AGENT_URL\"" >> $HOME/way-back-home/set_env.sh
Vérifier le déploiement
👉💻 Testez l'agent déployé en ouvrant l'URL dans votre navigateur (l'indicateur --with_ui a déployé l'interface Web ADK) ou testez-le via curl :
curl -X GET "$AGENT_URL/list-apps"
Une réponse listant votre agent devrait s'afficher.
10. Conclusion
🎉 Niveau 1 terminé !
Votre balise de détresse émet désormais à pleine puissance. Le signal triangulé traverse les interférences atmosphériques, une impulsion régulière qui dit : "Je suis là. J'ai survécu. Viens me trouver."
Mais vous n'êtes pas seul sur cette planète. Lorsque votre balise s'active, vous remarquez d'autres lumières qui s'allument à l'horizon : d'autres survivants, d'autres sites de crash, d'autres explorateurs qui ont réussi à s'en sortir.
![]()
Dans le niveau 2, vous apprendrez à traiter les signaux SOS entrants et à coordonner vos actions avec les autres survivants. Il ne s'agit pas seulement d'être retrouvé, mais de se retrouver.
Dépannage
"MCP_SERVER_URL non défini"
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
"PARTICIPANT_ID not set"
source $HOME/way-back-home/set_env.sh
echo $PARTICIPANT_ID
"Table BigQuery introuvable"
uv run python setup/setup_star_catalog.py
"Spécialistes demandant des URL" : cela signifie que le templating {key} ne fonctionne pas. Vérifier :
before_agent_callbackest-il défini sur l'agent racine ?- Le rappel définit-il correctement les valeurs d'état ?
- Les sous-agents utilisent-ils
{soil_url}(et non des f-strings) ?
"Les trois analyses ne sont pas d'accord" Régénérer les preuves : uv run python generate_evidence.py
"L'agent ne répond pas dans adk web"
- Vérifier que le port 8000 est correct
- Vérifiez que MCP_SERVER_URL et PARTICIPANT_ID sont définis.
- Vérifier les messages d'erreur dans le terminal
Résumé de l'architecture
Composant | Type | Schéma | Objectif |
setup_participant_context | Rappel | before_agent_callback | Récupérer la configuration, définir l'état |
GeologicalAnalyst | Agent | Modèles {soil_url} | Classification des sols |
BotanicalAnalyst | Agent | Modèles {flora_url} | Classification de la flore |
AstronomicalAnalyst | Agent | {stars_url}, {project_id} | Triangulation en étoile |
confirm_location | Outil | Accès à l'état ToolContext | Activer la balise |
EvidenceAnalysisCrew | ParallelAgent | Composition des sous-agents | Exécuter des spécialistes simultanément |
MissionAnalysisAI | Agent (racine) | Orchestrateur + rappel | Coordonner et synthétiser |
location-analyzer | Serveur FastMCP | MCP personnalisé | Analyses géologiques et botaniques |
bigquery.googleapis.com/mcp | OneMCP | MCP géré | Accès à BigQuery |
Concepts clés maîtrisés
✓ before_agent_callback : récupérez la configuration avant l'exécution de l'agent
✓ Modèles d'état {key} : accédez aux valeurs d'état dans les instructions de l'agent
✓ ToolContext : accédez aux valeurs d'état dans les fonctions d'outil
✓ Partage d'état : l'état parent est automatiquement disponible pour les sous-agents via InvocationContext
✓ Architecture multi-agents : agents spécialisés avec des responsabilités uniques
✓ ParallelAgent : exécution simultanée de tâches indépendantes
✓ Serveur MCP personnalisé : votre propre serveur MCP sur Cloud Run
✓ OneMCP BigQuery : modèle MCP géré pour l'accès aux bases de données
✓ Déploiement cloud : déploiement sans état à l'aide de variables d'environnement
✓ Préparation A2A : agent prêt pour la communication entre agents
Pour les non-gamers : applications concrètes
L'expression "Localisation précise" représente l'analyse parallèle par des experts avec consensus, qui consiste à exécuter plusieurs analyses d'IA spécialisées en même temps et à synthétiser les résultats.
Applications d'entreprise
Cas d'utilisation | Experts parallèles | Règle de synthèse |
Diagnostic médical | Analyste d'images, analyste de symptômes, analyste de laboratoire | Seuil de confiance de 2 sur 3 |
Détection de fraude | Analyste des transactions, analyste du comportement, analyste du réseau | 1 signalement = examen |
Traitement de documents | Agent OCR, agent de classification, agent d'extraction | Tout le monde doit être d'accord |
Contrôle qualité | Inspecteur visuel, analyste de capteurs, vérificateur de spécifications | Passage 2 sur 3 |
Insights clés sur l'architecture
- before_agent_callback pour la configuration : récupérez la configuration une seule fois au début et remplissez l'état pour tous les sous-agents. Aucune lecture de fichier de configuration dans les sous-agents.
- Création de modèles d'état {key} : déclarative, propre et idiomatique. Pas de f-strings, pas d'importations, pas de manipulation de sys.path.
- Mécanismes de consensus : un accord à deux sur trois gère l'ambiguïté de manière robuste sans nécessiter un accord unanime.
- ParallelAgent pour les tâches indépendantes : lorsque les analyses ne dépendent pas les unes des autres, exécutez-les simultanément pour plus de rapidité.
- Deux modèles MCP : personnalisé (créez votre propre modèle) ou OneMCP (hébergé par Google). Les deux utilisent StreamableHTTP.
- Déploiement sans état : le même code fonctionne en local et une fois déployé. Variables d'environnement + API de backend = aucun fichier de configuration dans les conteneurs.
Et maintenant ?
Niveau 2 : Traitement du signal SOS →
Apprenez à traiter les signaux de détresse entrants d'autres survivants à l'aide de modèles basés sur les événements et d'une coordination plus avancée des agents.