
1. Misja

Sztuczna inteligencja służb ratunkowych potwierdziła Twoją tożsamość, a sygnał lokalizacyjny jest już widoczny na mapie planety – ale to tylko słaby błysk, który ginie w szumie. Zespoły ratownicze skanujące z orbity widzą coś w Twoich współrzędnych, ale nie mogą się na tym skupić. Sygnał jest zbyt słaby.
Aby zwiększyć siłę sygnału lokalizatora, musisz potwierdzić swoją dokładną lokalizację. System nawigacyjny kapsuły jest zniszczony, ale wrak rozrzucił na miejscu lądowania dowody, które można odzyskać. próbki gleby, Dziwna flora. Widok na obce nocne niebo.
Jeśli przeanalizujesz te dowody i określisz, w którym regionie planety się znajdujesz, AI może triangulować Twoją pozycję i wzmocnić sygnał lokalizatora. Wtedy być może ktoś Cię znajdzie.
Czas połączyć elementy.
Wymagania wstępne
⚠️ Ten poziom wymaga ukończenia poziomu 0.
Zanim zaczniesz, upewnij się, że masz:
- [ ]
config.jsonw katalogu głównym projektu, podając identyfikator uczestnika i współrzędne. - [ ] Twój awatar widoczny na mapie świata
- [ ] Twój lokalizator jest widoczny (przyciemniony) w miejscu współrzędnych.
Jeśli nie masz jeszcze ukończonego poziomu 0, zacznij od niego.
Co utworzysz
Na tym poziomie zbudujesz system AI z wieloma agentami, który analizuje dowody z miejsca katastrofy przy użyciu przetwarzania równoległego:
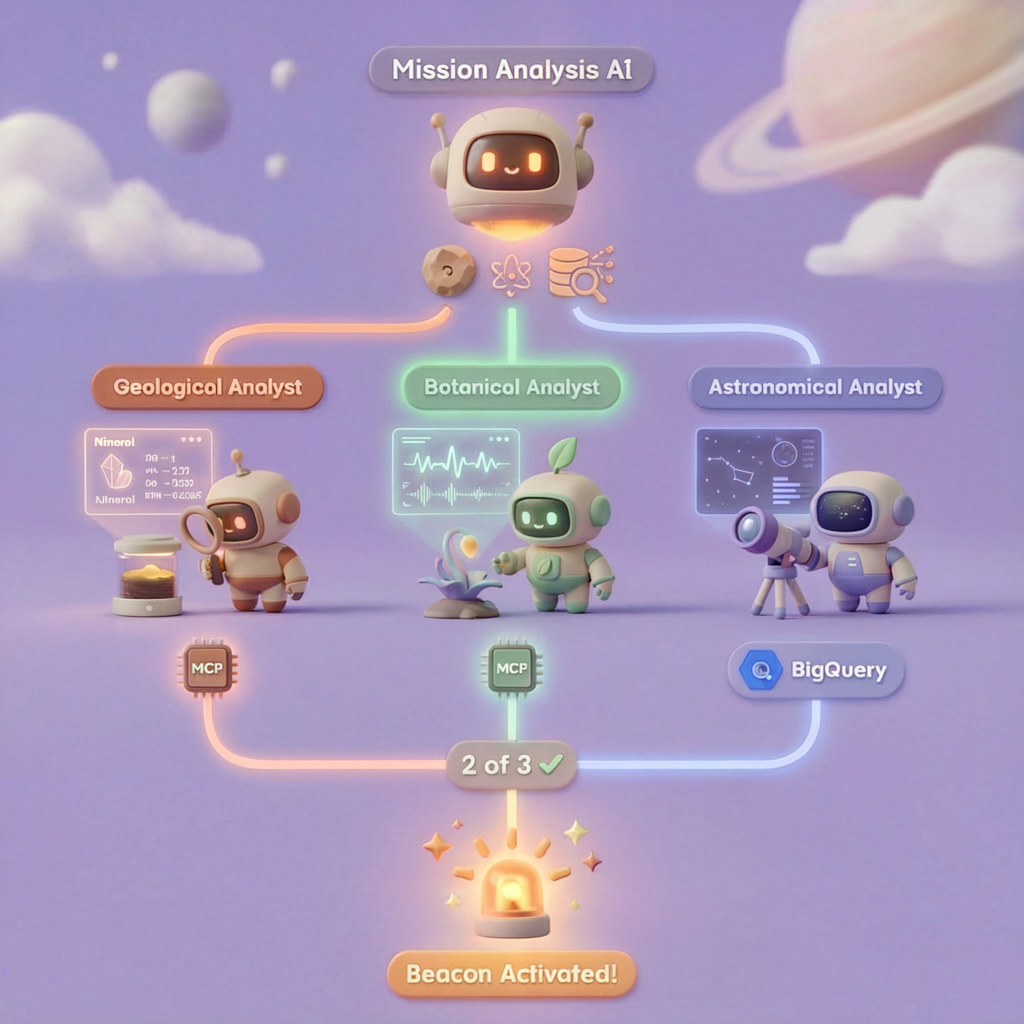

Cel szkolenia
Pomysł | Czego się nauczysz |
Systemy wieloagentowe | Tworzenie wyspecjalizowanych agentów z jednym zadaniem |
ParallelAgent | Tworzenie niezależnych agentów do równoczesnego uruchamiania |
before_agent_callback | Pobieranie konfiguracji i ustawianie stanu przed uruchomieniem agenta |
ToolContext | Dostęp do wartości stanu w funkcjach narzędzia |
Niestandardowe serwery MCP | Tworzenie narzędzi za pomocą wzorca imperatywnego (kod Pythona w Cloud Run) |
OneMCP BigQuery | Łączenie z zarządzanym przez Google MCP w celu uzyskania dostępu do BigQuery |
Multimodal AI | Analizowanie obrazów oraz filmów z dźwiękiem za pomocą Gemini |
Orkiestracja agentów | Koordynowanie pracy wielu agentów za pomocą głównego orkiestratora |
Wdrożenie w chmurze | Wdrażanie serwera i agenta MCP w Cloud Run |
Przygotowanie do A2A | Strukturyzowanie agentów pod kątem przyszłej komunikacji między agentami |
Biomy na Ziemi
Powierzchnia planety jest podzielona na 4 różne biomy, z których każdy ma unikalne cechy:
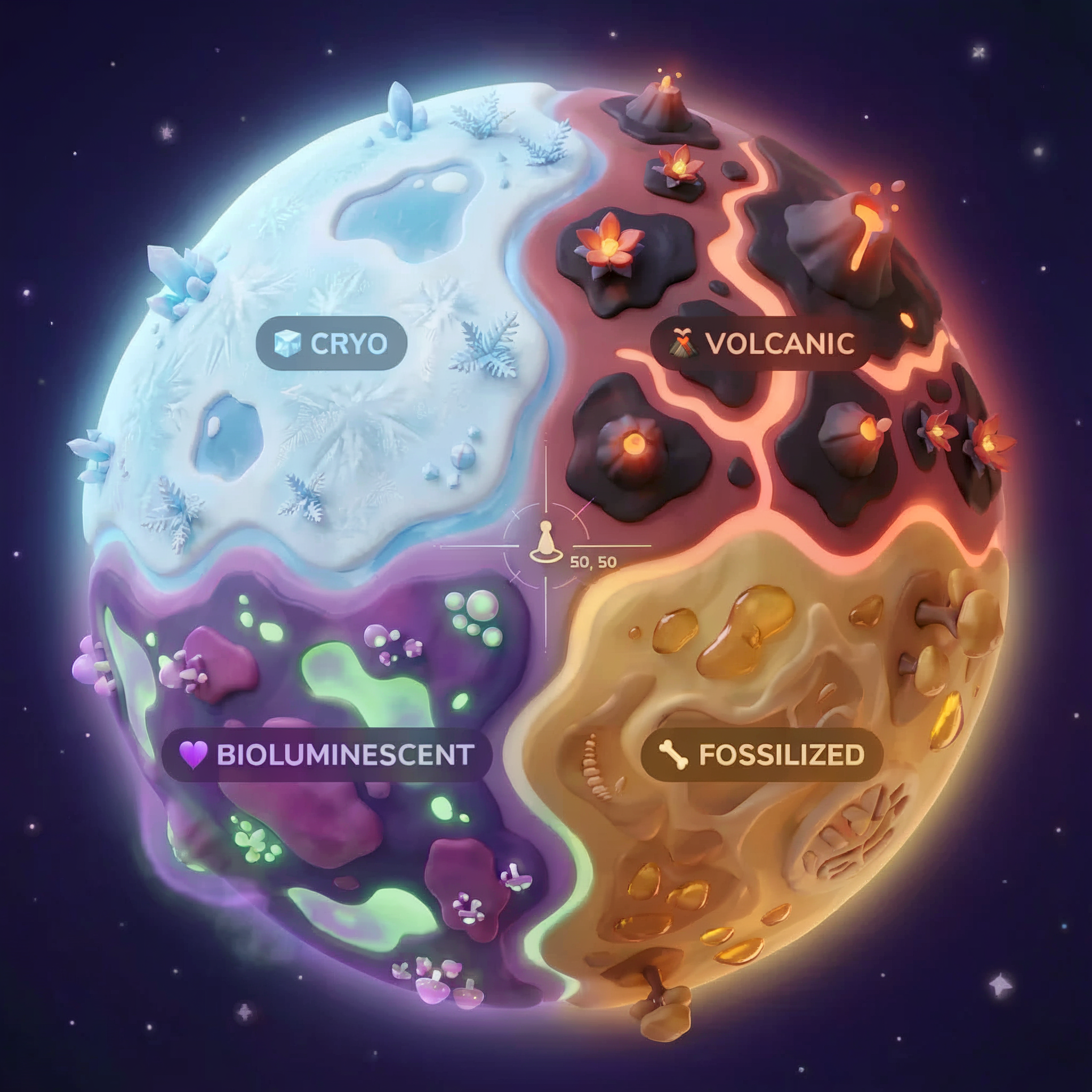
Twoje współrzędne określają, w jakim biomie doszło do katastrofy. Dowody w miejscu wypadku odzwierciedlają cechy tego biomu:
Biom | Kwadrant | Dowody geologiczne | Dowody botaniczne | Dowody astronomiczne |
🧊 CRYO | NW (x<50, y≥50) | Zamrożony metan, kryształy lodu | Paprocie mrozowe, krioflora | Niebieski olbrzym |
🌋 VOLCANIC | NE (x≥50, y≥50) | Złoża obsydianu | Kwiaty ognia, rośliny odporne na ciepło | Układ podwójny czerwonych karłów |
💜 BIOLUMINESCENT | SW (x<50, y<50) | Gleba fosforyzująca | Świecące grzyby, luminescencyjne rośliny | Zielony pulsar |
🦴 SKAMIENIAŁE | SE (x≥50, y<50) | Złoża bursztynu, minerały ite | Skamieniałe drzewa i starożytna flora | Żółte słońce |
Twoim zadaniem jest stworzenie agentów AI, którzy będą analizować dowody i wyciągać wnioski na temat tego, w jakim biomie się znajdujesz.
2. Konfigurowanie środowiska
Uruchamianie skryptu konfiguracji środowiska
Przed wygenerowaniem dowodów musisz włączyć wymagane interfejsy API Google Cloud, w tym OneMCP dla BigQuery, który zapewnia zarządzany dostęp MCP do BigQuery.
👉💻 Uruchom skrypt konfiguracji środowiska:
cd $HOME/way-back-home/level_1
chmod +x setup/setup_env.sh
./setup/setup_env.sh
Dane wyjściowe powinny wyglądać mniej więcej tak:
================================================================
Level 1: Environment Setup
================================================================
Project: your-project-id
[1/6] Enabling core Google Cloud APIs...
✓ Vertex AI API enabled
✓ Cloud Run API enabled
✓ Cloud Build API enabled
✓ BigQuery API enabled
✓ Artifact Registry API enabled
✓ IAM API enabled
[2/6] Enabling OneMCP BigQuery (Managed MCP)...
✓ OneMCP BigQuery enabled
[3/6] Setting up service account and IAM permissions...
✓ Service account 'way-back-home-sa' created
✓ Vertex AI User role granted
✓ Cloud Run Invoker role granted
✓ BigQuery User role granted
✓ BigQuery Data Viewer role granted
✓ Storage Object Viewer role granted
[4/6] Configuring Cloud Build IAM for deployments...
✓ Cloud Build can now deploy services as way-back-home-sa
✓ Cloud Run Admin role granted to Compute SA
[5/6] Creating Artifact Registry repository...
✓ Repository 'way-back-home' created
[6/6] Creating environment variables file...
Found PARTICIPANT_ID in config.json: abc123...
✓ Created ../set_env.sh
================================================================
✅ Environment Setup Complete!
================================================================
Zmienne środowiskowe źródła
👉💻 Ustaw zmienne środowiskowe:
source $HOME/way-back-home/set_env.sh
Instalowanie zależności
👉💻 Zainstaluj zależności Pythona na poziomie 1:
cd $HOME/way-back-home/level_1
uv sync
Konfigurowanie katalogu gwiazd
👉💻 Skonfiguruj katalog gwiazd w BigQuery:
uv run python setup/setup_star_catalog.py
Zobaczysz, że:
Setting up star catalog in project: your-project-id
==================================================
✓ Dataset way_back_home already exists
✓ Created table star_catalog
✓ Inserted 12 rows into star_catalog
📊 Star Catalog Summary:
----------------------------------------
NE (VOLCANIC): 3 stellar patterns
NW (CRYO): 3 stellar patterns
SE (FOSSILIZED): 3 stellar patterns
SW (BIOLUMINESCENT): 3 stellar patterns
----------------------------------------
✓ Star catalog is ready for triangulation queries
==================================================
✅ Star catalog setup complete!
3. Generowanie dowodów z miejsca katastrofy
Teraz możesz generować spersonalizowane dowody z miejsca katastrofy na podstawie swoich współrzędnych.
Uruchom generator dowodów
👉💻 W katalogu level_1 uruchom:
cd $HOME/way-back-home/level_1
uv run python generate_evidence.py
Dane wyjściowe powinny wyglądać mniej więcej tak:
✓ Welcome back, Explorer_Aria!
Coordinates: (23, 67)
Ready to analyze your crash site.
📍 Crash site analysis initiated...
Generating evidence for your location...
🔬 Generating soil sample...
✓ Soil sample captured: outputs/soil_sample.png
✨ Capturing star field...
✓ Star field captured: outputs/star_field.png
🌿 Recording flora activity...
(This may take 1-2 minutes for video generation)
Generating video...
Generating video...
Generating video...
✓ Flora recorded: outputs/flora_recording.mp4
📤 Uploading evidence to Mission Control...
✓ Config updated with evidence URLs
==================================================
✅ Evidence generation complete!
==================================================
Sprawdź dowody
👉 Poświęć chwilę na przejrzenie wygenerowanych plików z dowodami w folderze outputs/. Każdy z nich odzwierciedla cechy biomu, w którym doszło do katastrofy, ale nie będziesz wiedzieć, który to biom, dopóki Twoi agenci AI nie przeprowadzą analizy.
Wygenerowane potwierdzenie może wyglądać mniej więcej tak (w zależności od lokalizacji):



4. Tworzenie niestandardowego serwera MCP
Systemy analizy na pokładzie kapsuły ratunkowej uległy zniszczeniu, ale surowe dane z czujników przetrwały katastrofę. Utworzysz serwer MCP za pomocą FastMCP, który udostępnia narzędzia do analizy geologicznej i botanicznej.
Tworzenie narzędzia do analizy geologicznej
To narzędzie analizuje zdjęcia próbek gleby, aby określić ich skład mineralny.
👉✏️ Otwórz $HOME/way-back-home/level_1/mcp-server/main.py i znajdź #REPLACE-GEOLOGICAL-TOOL. Zastąp go tym:
GEOLOGICAL_PROMPT = """Analyze this alien soil sample image.
Classify the PRIMARY characteristic (choose exactly one):
1. CRYO - Frozen/icy minerals, crystalline structures, frost patterns,
blue-white coloration, permafrost indicators
2. VOLCANIC - Volcanic rock, basalt, obsidian, sulfur deposits,
red-orange minerals, heat-formed crystite structures
3. BIOLUMINESCENT - Glowing particles, phosphorescent minerals,
organic-mineral hybrids, purple-green luminescence
4. FOSSILIZED - Ancient compressed minerals, amber deposits,
petrified organic matter, golden-brown stratification
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"minerals_detected": ["mineral1", "mineral2"],
"description": "Brief description of what you observe"
}
"""
@mcp.tool()
def analyze_geological(
image_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the soil sample image")
]
) -> dict:
"""
Analyzes a soil sample image to identify mineral composition and classify the planetary biome.
Args:
image_url: Cloud Storage URL of the soil sample image (gs://bucket/path/image.png)
Returns:
dict with biome, confidence, minerals_detected, and description
"""
logger.info(f">>> 🔬 Tool: 'analyze_geological' called for '{image_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
GEOLOGICAL_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Geological analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Geological analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Tworzenie narzędzia do analizy botanicznej
To narzędzie analizuje nagrania wideo przedstawiające florę, w tym ścieżkę audio.
👉✏️ W tym samym pliku ($HOME/way-back-home/level_1/mcp-server/main.py) znajdź #REPLACE-BOTANICAL-TOOL i zastąp go tym:
BOTANICAL_PROMPT = """Analyze this alien flora video recording.
Pay attention to BOTH:
1. VISUAL elements: Plant appearance, movement patterns, colors, bioluminescence
2. AUDIO elements: Ambient sounds, rustling, organic noises, frequencies
Classify the PRIMARY biome (choose exactly one):
1. CRYO - Crystalline ice-plants, frost-covered vegetation,
crackling/tinkling sounds, slow brittle movements, blue-white flora
2. VOLCANIC - Heat-resistant plants, sulfur-adapted species,
hissing/bubbling sounds, smoke-filtering vegetation, red-orange flora
3. BIOLUMINESCENT - Glowing plants, pulsing light patterns,
humming/resonating sounds, reactive to stimuli, purple-green flora
4. FOSSILIZED - Ancient petrified plants, amber-preserved specimens,
deep resonant sounds, minimal movement, golden-brown flora
Respond ONLY with valid JSON (no markdown, no explanation):
{
"biome": "CRYO|VOLCANIC|BIOLUMINESCENT|FOSSILIZED",
"confidence": 0.0-1.0,
"species_detected": ["species1", "species2"],
"audio_signatures": ["sound1", "sound2"],
"description": "Brief description of visual and audio observations"
}
"""
@mcp.tool()
def analyze_botanical(
video_url: Annotated[
str,
Field(description="Cloud Storage URL (gs://...) of the flora video recording")
]
) -> dict:
"""
Analyzes a flora video recording (visual + audio) to identify plant species and classify the biome.
Args:
video_url: Cloud Storage URL of the flora video (gs://bucket/path/video.mp4)
Returns:
dict with biome, confidence, species_detected, audio_signatures, and description
"""
logger.info(f">>> 🌿 Tool: 'analyze_botanical' called for '{video_url}'")
try:
response = client.models.generate_content(
model="gemini-2.5-flash",
contents=[
BOTANICAL_PROMPT,
genai_types.Part.from_uri(file_uri=video_url, mime_type="video/mp4")
]
)
result = parse_json_response(response.text)
logger.info(f" ✓ Botanical analysis complete: {result.get('biome', 'UNKNOWN')}")
return result
except Exception as e:
logger.error(f" ✗ Botanical analysis failed: {str(e)}")
return {"error": str(e), "biome": "UNKNOWN", "confidence": 0.0}
Testowanie serwera MCP lokalnie
👉💻 Przetestuj serwer MCP:
cd $HOME/way-back-home/level_1/mcp-server
pip install -r requirements.txt
python main.py
Zobaczysz, że:
[INFO] Initialized Gemini client for project: your-project-id
[INFO] 🚀 Location Analyzer MCP Server starting on port 8080
[INFO] 📍 MCP endpoint: http://0.0.0.0:8080/mcp
[INFO] 🔧 Tools: analyze_geological, analyze_botanical
Serwer FastMCP jest teraz uruchomiony z transportem HTTP. Aby zatrzymać, naciśnij Ctrl+C.
Wdrażanie serwera MCP w Cloud Run
👉💻 Wdróż:
cd $HOME/way-back-home/level_1/mcp-server
source $HOME/way-back-home/set_env.sh
gcloud builds submit . \
--config=cloudbuild.yaml \
--substitutions=_REGION="$REGION",_REPO_NAME="$REPO_NAME",_SERVICE_ACCOUNT="$SERVICE_ACCOUNT"
Zapisywanie adresu URL usługi
👉💻 Zapisz adres URL usługi:
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
echo "MCP Server URL: $MCP_SERVER_URL"
# Add to set_env.sh for later use
echo "export MCP_SERVER_URL=\"$MCP_SERVER_URL\"" >> $HOME/way-back-home/set_env.sh
5. Tworzenie agentów specjalistów
Teraz utworzysz 3 agenty specjalistyczne, z których każdy będzie miał jedno zadanie.
Tworzenie agenta analizy geologicznej
👉✏️ Otwórz agent/agents/geological_analyst.py i znajdź #REPLACE-GEOLOGICAL-AGENT. Zastąp go tym:
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_geological_tool
geological_analyst = Agent(
name="GeologicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes soil samples to classify planetary biome based on mineral composition.",
instruction="""You are a geological specialist analyzing alien soil samples.
## YOUR EVIDENCE TO ANALYZE
Soil sample URL: {soil_url}
## YOUR TASK
1. Call the analyze_geological tool with the soil sample URL above
2. Examine the results for mineral composition and biome indicators
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frozen, icy minerals, blue/white coloring
- VOLCANIC: Magma, obsidian, volcanic rock, red/orange coloring
- BIOLUMINESCENT: Glowing, phosphorescent minerals, purple/green
- FOSSILIZED: Amber, ancient preserved matter, golden/brown
## REPORTING FORMAT
Always report your classification clearly:
"GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
Include a brief description of what you observed in the sample.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the soil sample and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_geological_tool()]
)
Tworzenie agenta analizy botanicznej
👉✏️ Otwórz agent/agents/botanical_analyst.py i znajdź #REPLACE-BOTANICAL-AGENT. Zastąp go tym:
from google.adk.agents import Agent
from agent.tools.mcp_tools import get_botanical_tool
botanical_analyst = Agent(
name="BotanicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes flora recordings to classify planetary biome based on plant life and ambient sounds.",
instruction="""You are a botanical specialist analyzing alien flora recordings.
## YOUR EVIDENCE TO ANALYZE
Flora recording URL: {flora_url}
## YOUR TASK
1. Call the analyze_botanical tool with the flora recording URL above
2. Pay attention to BOTH visual AND audio elements in the recording
3. Report your findings clearly
The four possible biomes are:
- CRYO: Frost ferns, crystalline plants, cold wind sounds, crackling ice
- VOLCANIC: Fire blooms, heat-resistant flora, crackling/hissing sounds
- BIOLUMINESCENT: Glowing fungi, luminescent plants, ethereal hum, chiming
- FOSSILIZED: Petrified trees, ancient formations, deep resonant sounds
## REPORTING FORMAT
Always report your classification clearly:
"BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
Include descriptions of what you SAW and what you HEARD.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the flora recording and report what you find
- Call the tool immediately with the URL provided above""",
tools=[get_botanical_tool()]
)
Tworzenie agenta analizy astronomicznej
Ten agent stosuje inne podejście z 2 wzorcami narzędzi:
- Local FunctionTool: Gemini Vision do wyodrębniania funkcji gwiazd
- OneMCP BigQuery: wysyłanie zapytań do katalogu gwiazd za pomocą zarządzanego przez Google MCP
👉✏️ Otwórz agent/agents/astronomical_analyst.py i znajdź #REPLACE-ASTRONOMICAL-AGENT. Zastąp go tym:
from google.adk.agents import Agent
from agent.tools.star_tools import (
extract_star_features_tool,
get_bigquery_mcp_toolset,
)
# Get the BigQuery MCP toolset
bigquery_toolset = get_bigquery_mcp_toolset()
astronomical_analyst = Agent(
name="AstronomicalAnalyst",
model="gemini-2.5-flash",
description="Analyzes star field images and queries the star catalog via OneMCP BigQuery.",
instruction="""You are an astronomical specialist analyzing alien night skies.
## YOUR EVIDENCE TO ANALYZE
Star field URL: {stars_url}
## YOUR TWO TOOLS
### TOOL 1: extract_star_features (Local Gemini Vision)
Call this FIRST with the star field URL above.
Returns: "primary_star": "...", "nebula_type": "...", "stellar_color": "..."
### TOOL 2: BigQuery MCP (execute_query)
Call this SECOND with the results from Tool 1.
Use this exact SQL query (replace the placeholders with values from Step 1):
SELECT quadrant, biome, primary_star, nebula_type
FROM `{project_id}.way_back_home.star_catalog`
WHERE LOWER(primary_star) = LOWER('PRIMARY_STAR_FROM_STEP_1')
AND LOWER(nebula_type) = LOWER('NEBULA_TYPE_FROM_STEP_1')
LIMIT 1
## YOUR WORKFLOW
1. Call extract_star_features with: {stars_url}
2. Get the primary_star and nebula_type from the result
3. Call execute_query with the SQL above (replacing placeholders)
4. Report the biome and quadrant from the query result
## BIOME REFERENCE
| Biome | Quadrant | Primary Star | Nebula Type |
|-------|----------|--------------|-------------|
| CRYO | NW | blue_giant | ice_blue |
| VOLCANIC | NE | red_dwarf_binary | fire |
| BIOLUMINESCENT | SW | green_pulsar | purple_magenta |
| FOSSILIZED | SE | yellow_sun | golden |
## REPORTING FORMAT
"ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
Include a description of the stellar features you observed.
## IMPORTANT
- You do NOT synthesize with other evidence
- You do NOT confirm locations
- Just analyze the stars and report what you find
- Start by calling extract_star_features with the URL above""",
tools=[extract_star_features_tool, bigquery_toolset]
)
6. Tworzenie połączeń narzędzi MCP
Teraz utworzysz otoczki Pythona, które umożliwią agentom ADK komunikację z serwerami MCP. Te otoczki obsługują cykl życia połączenia – ustanawianie sesji, wywoływanie narzędzi i parsowanie odpowiedzi.
Tworzenie połączenia z narzędziem MCP (niestandardowy MCP)
Łączy się to z niestandardowym serwerem FastMCP wdrożonym w Cloud Run.
👉✏️ Otwórz agent/tools/mcp_tools.py i znajdź #REPLACE-MCP-TOOL-CONNECTION. Zastąp go tym:
import os
import logging
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
logger = logging.getLogger(__name__)
MCP_SERVER_URL = os.environ.get("MCP_SERVER_URL")
_mcp_toolset = None
def get_mcp_toolset():
"""Get the MCPToolset connected to the location-analyzer server."""
global _mcp_toolset
if _mcp_toolset is not None:
return _mcp_toolset
if not MCP_SERVER_URL:
raise ValueError(
"MCP_SERVER_URL not set. Please run:\n"
" export MCP_SERVER_URL='https://location-analyzer-xxx.a.run.app'"
)
# FastMCP exposes MCP protocol at /mcp endpoint
mcp_endpoint = f"{MCP_SERVER_URL}/mcp"
logger.info(f"[MCP Tools] Connecting to: {mcp_endpoint}")
_mcp_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_endpoint,
timeout=120, # 2 minutes for Gemini analysis
)
)
return _mcp_toolset
def get_geological_tool():
"""Get the geological analysis tool from the MCP server."""
return get_mcp_toolset()
def get_botanical_tool():
"""Get the botanical analysis tool from the MCP server."""
return get_mcp_toolset()
Tworzenie narzędzi do analizy gwiazd (OneMCP BigQuery)
Katalog gwiazd, który został wcześniej wczytany do BigQuery, zawiera wzory gwiazd dla każdego biomu. Zamiast pisać kod klienta BigQuery do wysyłania zapytań, łączymy się z serwerem BigQuery OneMCP Google, który udostępnia funkcję execute_query BigQuery jako narzędzie MCP, z którego każdy agent ADK może korzystać bezpośrednio.
👉✏️ Otwórz agent/tools/star_tools.py i znajdź #REPLACE-STAR-TOOLS. Zastąp go tym:
import os
import json
import logging
from google import genai
from google.genai import types as genai_types
from google.adk.tools import FunctionTool
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
import google.auth
import google.auth.transport.requests
logger = logging.getLogger(__name__)
# =============================================================================
# CONFIGURATION - Environment variables only
# =============================================================================
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
if not PROJECT_ID:
logger.warning("[Star Tools] GOOGLE_CLOUD_PROJECT not set")
# Initialize Gemini client for star feature extraction
genai_client = genai.Client(
vertexai=True,
project=PROJECT_ID or "placeholder",
location=os.environ.get("GOOGLE_CLOUD_LOCATION", "us-central1")
)
logger.info(f"[Star Tools] Initialized for project: {PROJECT_ID}")
# =============================================================================
# OneMCP BigQuery Connection
# =============================================================================
BIGQUERY_MCP_URL = "https://bigquery.googleapis.com/mcp"
_bigquery_toolset = None
def get_bigquery_mcp_toolset():
"""
Get the MCPToolset connected to Google's BigQuery MCP server.
This uses OAuth 2.0 authentication with Application Default Credentials.
The toolset provides access to BigQuery's pre-built MCP tools like:
- execute_query: Run SQL queries
- list_datasets: List available datasets
- get_table_schema: Get table structure
"""
global _bigquery_toolset
if _bigquery_toolset is not None:
return _bigquery_toolset
logger.info("[Star Tools] Connecting to OneMCP BigQuery...")
# Get OAuth credentials
credentials, project_id = google.auth.default(
scopes=["https://www.googleapis.com/auth/bigquery"]
)
# Refresh to get a valid token
credentials.refresh(google.auth.transport.requests.Request())
oauth_token = credentials.token
# Configure headers for BigQuery MCP
headers = {
"Authorization": f"Bearer {oauth_token}",
"x-goog-user-project": project_id or PROJECT_ID
}
# Create MCPToolset with StreamableHTTP connection
_bigquery_toolset = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=BIGQUERY_MCP_URL,
headers=headers
)
)
logger.info("[Star Tools] Connected to BigQuery MCP")
return _bigquery_toolset
# =============================================================================
# Local FunctionTool: Star Feature Extraction
# =============================================================================
# This is a LOCAL tool that calls Gemini directly - demonstrating that
# you can mix local FunctionTools with MCP tools in the same agent.
STAR_EXTRACTION_PROMPT = """Analyze this alien night sky image and extract stellar features.
Identify:
1. PRIMARY STAR TYPE: blue_giant, red_dwarf, red_dwarf_binary, green_pulsar, yellow_sun, etc.
2. NEBULA TYPE: ice_blue, fire, purple_magenta, golden, etc.
3. STELLAR COLOR: blue_white, red_orange, green_purple, yellow_gold, etc.
Respond ONLY with valid JSON:
{"primary_star": "...", "nebula_type": "...", "stellar_color": "...", "description": "..."}
"""
def _parse_json_response(text: str) -> dict:
"""Parse JSON from Gemini response, handling markdown formatting."""
cleaned = text.strip()
if cleaned.startswith("```json"):
cleaned = cleaned[7:]
elif cleaned.startswith("```"):
cleaned = cleaned[3:]
if cleaned.endswith("```"):
cleaned = cleaned[:-3]
cleaned = cleaned.strip()
try:
return json.loads(cleaned)
except json.JSONDecodeError as e:
logger.error(f"Failed to parse JSON: {e}")
return {"error": f"Failed to parse response: {str(e)}"}
def extract_star_features(image_url: str) -> dict:
"""
Extract stellar features from a star field image using Gemini Vision.
This is a LOCAL FunctionTool - we call Gemini directly, not through MCP.
The agent will use this alongside the BigQuery MCP tools.
"""
logger.info(f"[Stars] Extracting features from: {image_url}")
response = genai_client.models.generate_content(
model="gemini-2.5-flash",
contents=[
STAR_EXTRACTION_PROMPT,
genai_types.Part.from_uri(file_uri=image_url, mime_type="image/png")
]
)
result = _parse_json_response(response.text)
logger.info(f"[Stars] Extracted: primary_star={result.get('primary_star')}")
return result
# Create the local FunctionTool
extract_star_features_tool = FunctionTool(extract_star_features)
7. Tworzenie aranżera
Teraz utwórz równoległą załogę i aranżera głównego, który koordynuje wszystko.
Tworzenie zespołu analizy równoległej
Dlaczego warto uruchamiać 3 specjalistów równolegle? Są one całkowicie niezależne – analityk geologiczny nie musi czekać na wyniki analityka botanicznego i odwrotnie. Każdy specjalista analizuje inny dowód, korzystając z różnych narzędzi. ParallelAgent uruchamia wszystkie 3 narzędzia jednocześnie, co skraca całkowity czas analizy z ok. 30 sekund (sekwencyjnie) do ok. 10 sekund (równolegle).
👉✏️ Otwórz agent/agent.py i znajdź #REPLACE-PARALLEL-CREW. Zastąp go tym:
import os
import logging
import httpx
from google.adk.agents import Agent, ParallelAgent
from google.adk.agents.callback_context import CallbackContext
# Import specialist agents
from agent.agents.geological_analyst import geological_analyst
from agent.agents.botanical_analyst import botanical_analyst
from agent.agents.astronomical_analyst import astronomical_analyst
# Import confirmation tool
from agent.tools.confirm_tools import confirm_location_tool
logger = logging.getLogger(__name__)
# =============================================================================
# BEFORE AGENT CALLBACK - Fetches config and sets state
# =============================================================================
async def setup_participant_context(callback_context: CallbackContext) -> None:
"""
Fetch participant configuration and populate state for all agents.
This callback:
1. Reads PARTICIPANT_ID and BACKEND_URL from environment
2. Fetches participant data from the backend API
3. Sets state values: soil_url, flora_url, stars_url, username, x, y, etc.
4. Returns None to continue normal agent execution
"""
participant_id = os.environ.get("PARTICIPANT_ID", "")
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
project_id = os.environ.get("GOOGLE_CLOUD_PROJECT", "")
logger.info(f"[Callback] Setting up context for participant: {participant_id}")
# Set project_id and backend_url in state immediately
callback_context.state["project_id"] = project_id
callback_context.state["backend_url"] = backend_url
callback_context.state["participant_id"] = participant_id
if not participant_id:
logger.warning("[Callback] No PARTICIPANT_ID set - using placeholder values")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["flora_url"] = "Not available - set PARTICIPANT_ID"
callback_context.state["stars_url"] = "Not available - set PARTICIPANT_ID"
return None
# Fetch participant data from backend API
try:
url = f"{backend_url}/participants/{participant_id}"
logger.info(f"[Callback] Fetching from: {url}")
async with httpx.AsyncClient(timeout=30.0) as client:
response = await client.get(url)
response.raise_for_status()
data = response.json()
# Extract evidence URLs
evidence_urls = data.get("evidence_urls", {})
# Set all state values for sub-agents to access
callback_context.state["username"] = data.get("username", "Explorer")
callback_context.state["x"] = data.get("x", 0)
callback_context.state["y"] = data.get("y", 0)
callback_context.state["soil_url"] = evidence_urls.get("soil", "Not available")
callback_context.state["flora_url"] = evidence_urls.get("flora", "Not available")
callback_context.state["stars_url"] = evidence_urls.get("stars", "Not available")
logger.info(f"[Callback] State populated for {data.get('username')}")
except Exception as e:
logger.error(f"[Callback] Error fetching participant config: {e}")
callback_context.state["username"] = "Explorer"
callback_context.state["x"] = 0
callback_context.state["y"] = 0
callback_context.state["soil_url"] = f"Error: {e}"
callback_context.state["flora_url"] = f"Error: {e}"
callback_context.state["stars_url"] = f"Error: {e}"
return None
# =============================================================================
# PARALLEL ANALYSIS CREW
# =============================================================================
evidence_analysis_crew = ParallelAgent(
name="EvidenceAnalysisCrew",
description="Runs geological, botanical, and astronomical analysis in parallel.",
sub_agents=[geological_analyst, botanical_analyst, astronomical_analyst]
)
Tworzenie głównego aranżera
Teraz utwórz agenta głównego, który koordynuje wszystko i używa wywołania zwrotnego.
👉✏️ W tym samym pliku (agent/agent.py) znajdź #REPLACE-ROOT-ORCHESTRATOR. Zastąp go tym:
root_agent = Agent(
name="MissionAnalysisAI",
model="gemini-2.5-flash",
description="Coordinates crash site analysis to confirm explorer location.",
instruction="""You are the Mission Analysis AI coordinating a rescue operation.
## Explorer Information
- Name: {username}
- Coordinates: ({x}, {y})
## Evidence URLs (automatically provided to specialists via state)
- Soil sample: {soil_url}
- Flora recording: {flora_url}
- Star field: {stars_url}
## Your Workflow
### STEP 1: DELEGATE TO ANALYSIS CREW
Tell the EvidenceAnalysisCrew to analyze all the evidence.
The evidence URLs are already available to the specialists.
### STEP 2: COLLECT RESULTS
Each specialist will report:
- "GEOLOGICAL ANALYSIS: [BIOME] (confidence: X%)"
- "BOTANICAL ANALYSIS: [BIOME] (confidence: X%)"
- "ASTRONOMICAL ANALYSIS: [BIOME] in [QUADRANT] quadrant (confidence: X%)"
### STEP 3: APPLY 2-OF-3 AGREEMENT RULE
- If 2 or 3 specialists agree → that's the answer
- If all 3 disagree → use judgment based on confidence
### STEP 4: CONFIRM LOCATION
Call confirm_location with the determined biome.
## Biome Reference
| Biome | Quadrant | Key Characteristics |
|-------|----------|---------------------|
| CRYO | NW | Frozen, blue, ice crystals |
| VOLCANIC | NE | Magma, red/orange, obsidian |
| BIOLUMINESCENT | SW | Glowing, purple/green |
| FOSSILIZED | SE | Amber, golden, ancient |
## Response Style
Be encouraging and narrative! Celebrate when the beacon activates!
""",
sub_agents=[evidence_analysis_crew],
tools=[confirm_location_tool],
before_agent_callback=setup_participant_context
)
Tworzenie narzędzia do potwierdzania lokalizacji
To ostatni element – narzędzie, które potwierdza Twoją lokalizację w centrum kontroli misji i aktywuje lokalizator. Gdy główny koordynator określi, w jakim biomie się znajdujesz (korzystając z zasady 2 z 3), wywołuje to narzędzie, aby wysłać wynik do interfejsu API backendu.
To narzędzie korzysta z ToolContext, co daje mu dostęp do wartości stanu (takich jak participant_id i backend_url), które zostały wcześniej ustawione przez before_agent_callback.
👉✏️ W agent/tools/confirm_tools.py znajdź #REPLACE-CONFIRM-TOOL. Zastąp go tym:
import os
import logging
import requests
from google.adk.tools import FunctionTool
from google.adk.tools.tool_context import ToolContext
logger = logging.getLogger(__name__)
BIOME_TO_QUADRANT = {
"CRYO": "NW",
"VOLCANIC": "NE",
"BIOLUMINESCENT": "SW",
"FOSSILIZED": "SE"
}
def _get_actual_biome(x: int, y: int) -> tuple[str, str]:
"""Determine actual biome and quadrant from coordinates."""
if x < 50 and y >= 50:
return "NW", "CRYO"
elif x >= 50 and y >= 50:
return "NE", "VOLCANIC"
elif x < 50 and y < 50:
return "SW", "BIOLUMINESCENT"
else:
return "SE", "FOSSILIZED"
def confirm_location(biome: str, tool_context: ToolContext) -> dict:
"""
Confirm the explorer's location and activate the rescue beacon.
Uses ToolContext to read state values set by before_agent_callback.
"""
# Read from state (set by before_agent_callback)
participant_id = tool_context.state.get("participant_id", "")
x = tool_context.state.get("x", 0)
y = tool_context.state.get("y", 0)
backend_url = tool_context.state.get("backend_url", "https://api.waybackhome.dev")
# Fallback to environment variables
if not participant_id:
participant_id = os.environ.get("PARTICIPANT_ID", "")
if not backend_url:
backend_url = os.environ.get("BACKEND_URL", "https://api.waybackhome.dev")
if not participant_id:
return {"success": False, "message": "❌ No participant ID available."}
biome_upper = biome.upper().strip()
if biome_upper not in BIOME_TO_QUADRANT:
return {"success": False, "message": f"❌ Unknown biome: {biome}"}
# Get actual biome from coordinates
actual_quadrant, actual_biome = _get_actual_biome(x, y)
if biome_upper != actual_biome:
return {
"success": False,
"message": f"❌ Mismatch! Analysis: {biome_upper}, Actual: {actual_biome}"
}
quadrant = BIOME_TO_QUADRANT[biome_upper]
try:
response = requests.patch(
f"{backend_url}/participants/{participant_id}/location",
params={"x": x, "y": y},
timeout=10
)
response.raise_for_status()
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED!\n\nLocation: {biome_upper} in {quadrant}\nCoordinates: ({x}, {y})"
}
except requests.exceptions.ConnectionError:
return {
"success": True,
"message": f"🔦 BEACON ACTIVATED! (Local)\n\nLocation: {biome_upper} in {quadrant}",
"simulated": True
}
except Exception as e:
return {"success": False, "message": f"❌ Failed: {str(e)}"}
confirm_location_tool = FunctionTool(confirm_location)
8. Testowanie za pomocą interfejsu internetowego ADK
Teraz przetestujmy lokalnie cały system wielu agentów.
Uruchamianie serwera WWW pakietu ADK
👉💻 Ustaw zmienne środowiskowe i uruchom serwer WWW pakietu ADK:
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
# Verify environment is set
echo "PARTICIPANT_ID: $PARTICIPANT_ID"
echo "MCP Server: $MCP_SERVER_URL"
# Start ADK web server
uv run adk web
Zobaczysz, że:
+-----------------------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://localhost:8000. |
+-----------------------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
Otwieranie interfejsu internetowego
👉 Kliknij ikonę Podgląd w przeglądarce na pasku narzędzi Cloud Shell (w prawym górnym rogu) i wybierz Zmień port.
![]()
👉 Ustaw port na 8000 i kliknij „Zmień i wyświetl podgląd”.
👉 Otworzy się interfejs ADK. W menu kliknij agent.
Przeprowadzanie analizy
👉 W interfejsie czatu wpisz:
Analyze the evidence from my crash site and confirm my location to activate the beacon.
Zobacz, jak działa system z wieloma agentami:
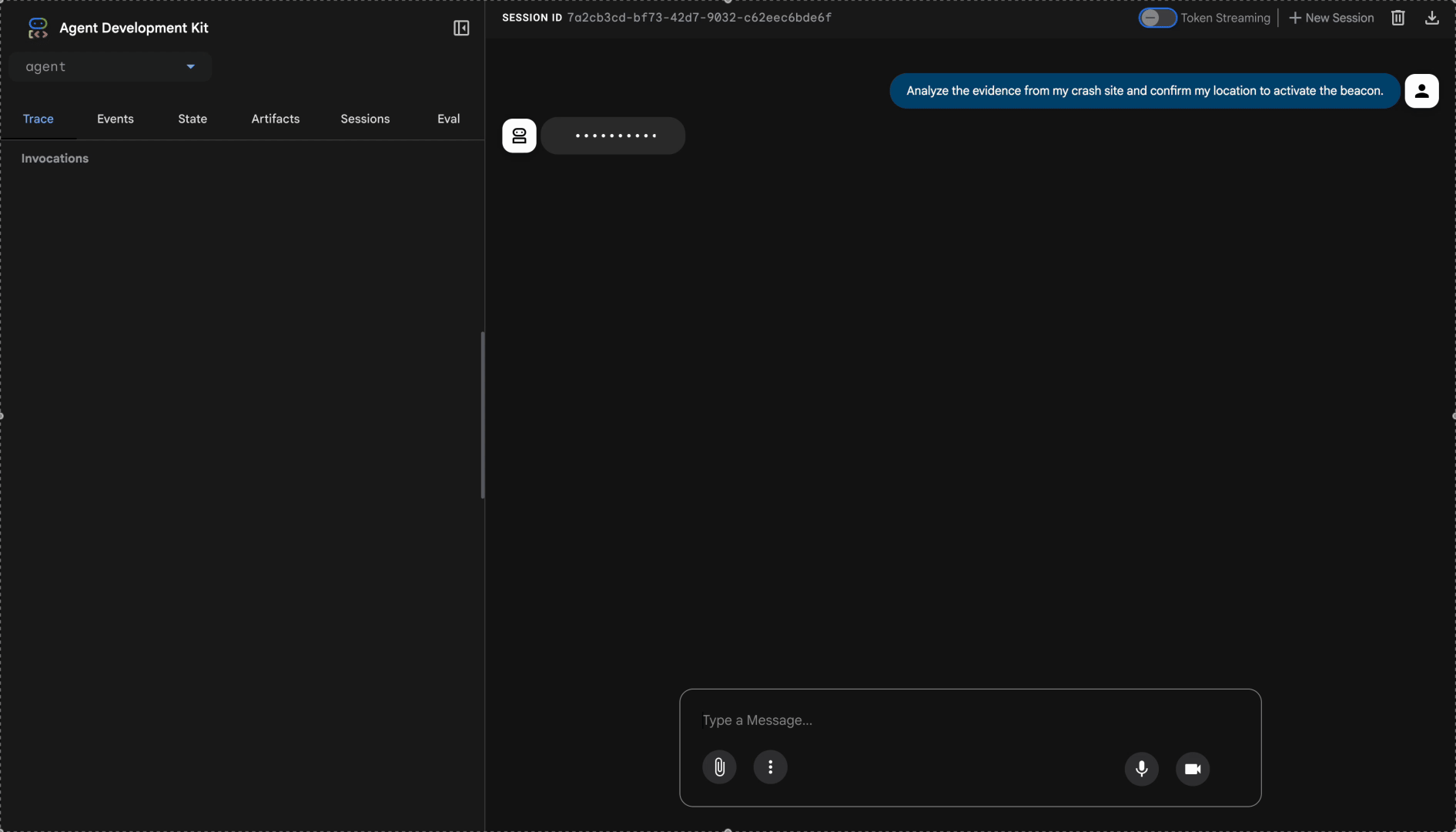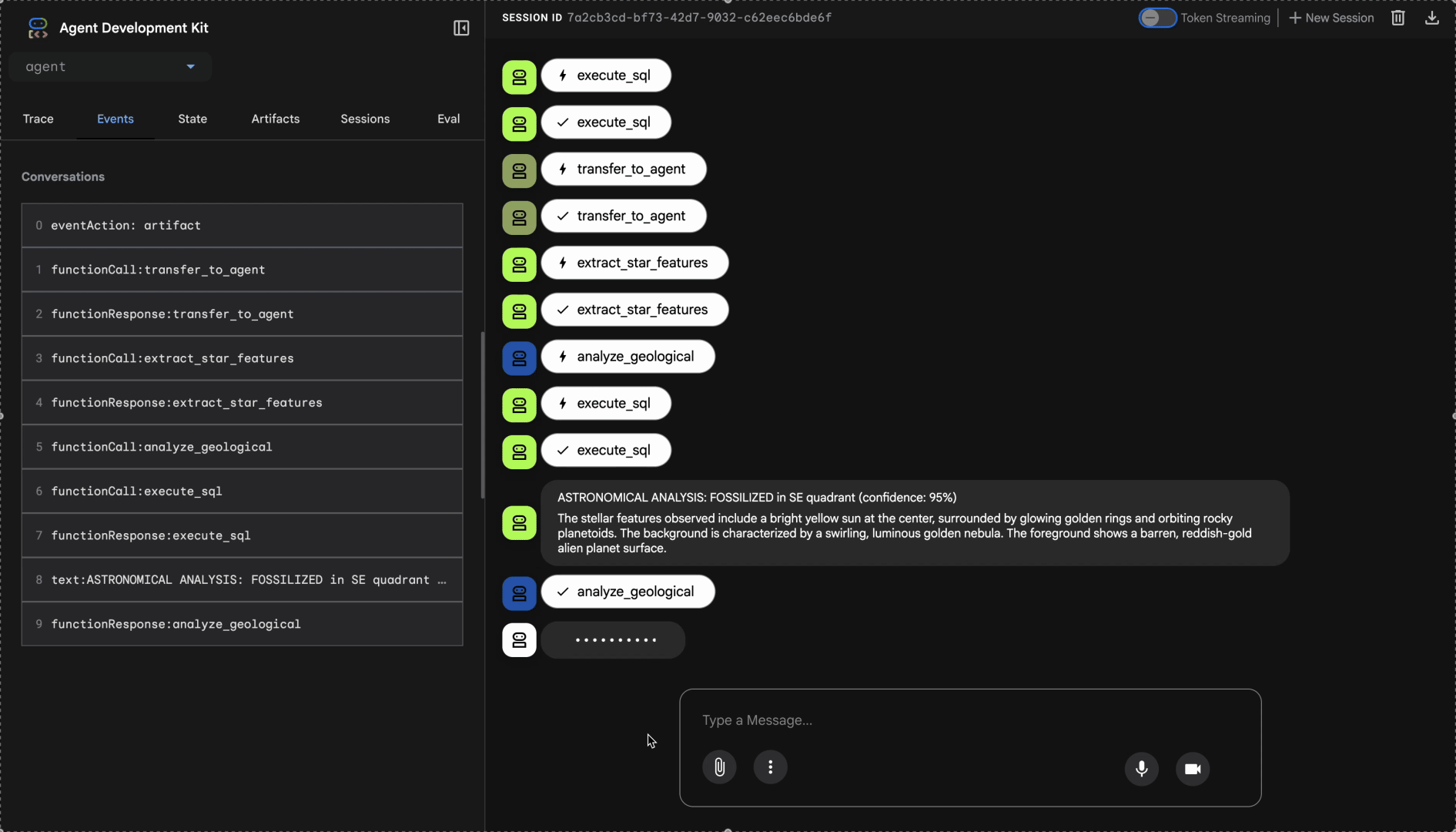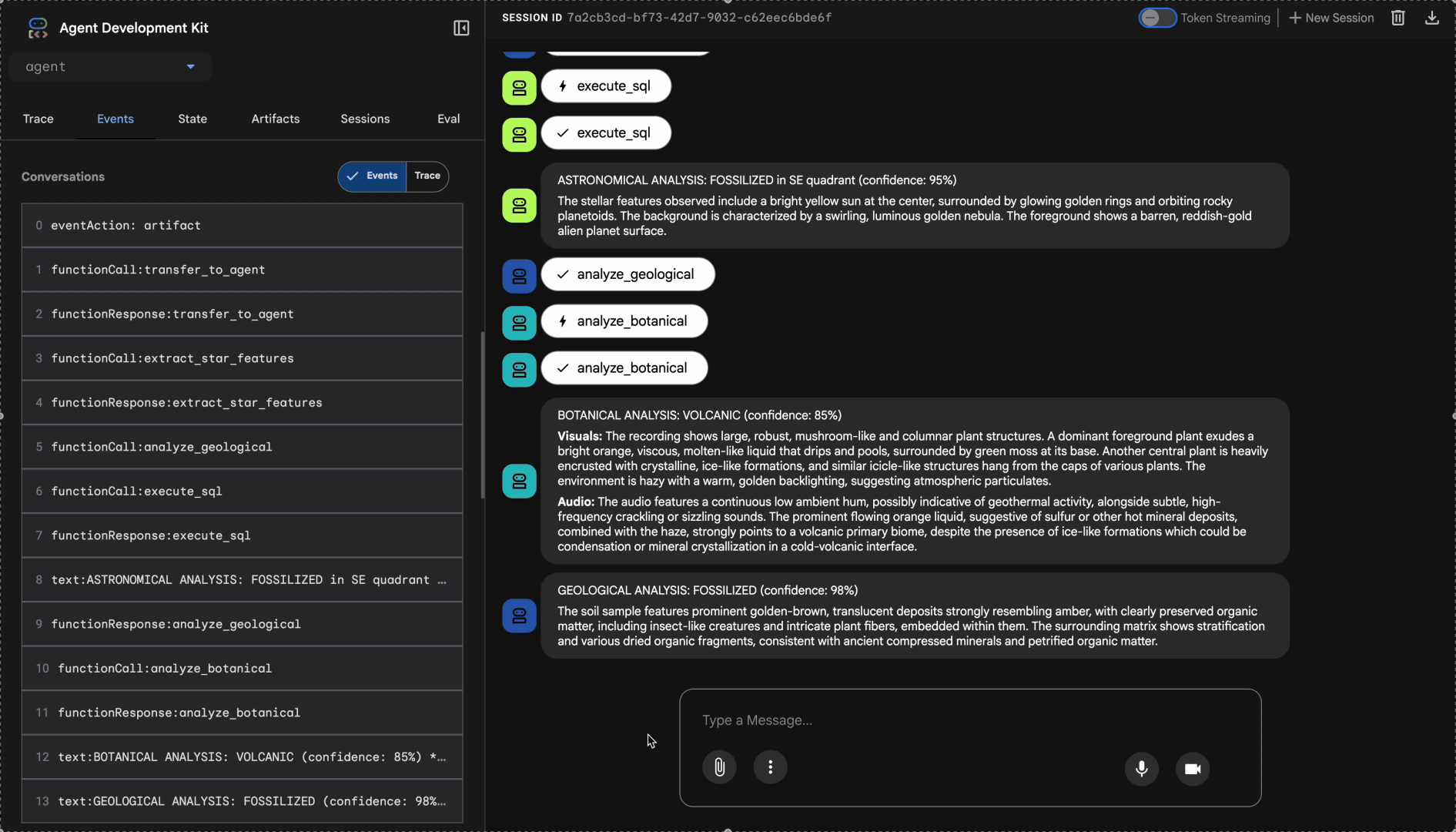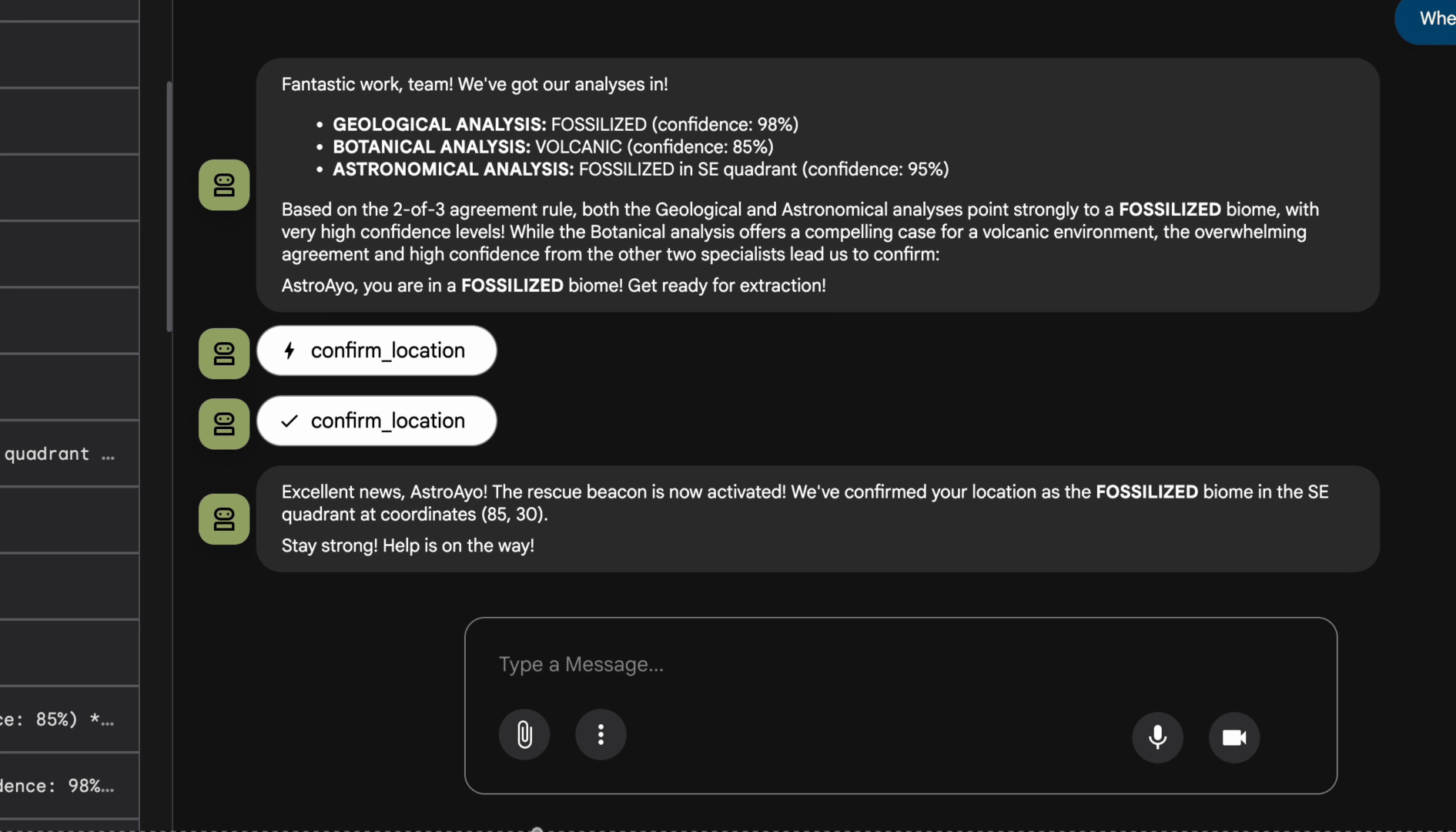
👉 Gdy 3 agenty zakończą analizę, wpisz:
Where am I?
Jak system przetwarza Twoją prośbę:

Panel śledzenia po prawej stronie zawiera wszystkie interakcje z agentem i wywołania narzędzi.
👉 Gdy skończysz testowanie, naciśnij Ctrl+C w terminalu, aby zatrzymać serwer.
9. Wdrożenie w Cloud Run
Teraz wdróż system wieloagentowy w Cloud Run, aby przygotować go do obsługi A2A.
Wdrażanie agenta
👉💻 Wdróż w Cloud Run za pomocą interfejsu ADK CLI:
cd $HOME/way-back-home/level_1
source $HOME/way-back-home/set_env.sh
uv run adk deploy cloud_run \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$REGION \
--service_name=mission-analysis-ai \
--with_ui \
--a2a \
./agent
Gdy pojawi się prośba Do you want to continue (Y/n) i Allow unauthenticated invocations to [mission-analysis-ai] (Y/n)?, wpisz Y w obu przypadkach, aby wdrożyć agenta A2A i umożliwić do niego dostęp publiczny.
Dane wyjściowe powinny wyglądać mniej więcej tak:
Building and deploying agent to Cloud Run...
✓ Container built successfully
✓ Deploying to Cloud Run...
✓ Service deployed: https://mission-analysis-ai-abc123-uc.a.run.app
Ustawianie zmiennych środowiskowych w Cloud Run
Wdrożony agent musi mieć dostęp do zmiennych środowiskowych. Zaktualizuj usługę:
👉💻 Ustaw wymagane zmienne środowiskowe:
gcloud run services update mission-analysis-ai \
--region=$REGION \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT,GOOGLE_CLOUD_LOCATION=$REGION,MCP_SERVER_URL=$MCP_SERVER_URL,BACKEND_URL=$BACKEND_URL,PARTICIPANT_ID=$PARTICIPANT_ID,GOOGLE_GENAI_USE_VERTEXAI=True"
Zapisz adres URL agenta
👉💻 Pobierz wdrożony adres URL:
export AGENT_URL=$(gcloud run services describe mission-analysis-ai \
--region=$REGION --format='value(status.url)')
echo "Agent URL: $AGENT_URL"
# Add to set_env.sh
echo "export LEVEL1_AGENT_URL=\"$AGENT_URL\"" >> $HOME/way-back-home/set_env.sh
Sprawdzanie wdrożenia
👉💻 Przetestuj wdrożonego agenta, otwierając adres URL w przeglądarce (flaga --with_ui wdrożyła interfejs internetowy ADK) lub za pomocą polecenia curl:
curl -X GET "$AGENT_URL/list-apps"
Powinna pojawić się odpowiedź z listą Twoich agentów.
10. Podsumowanie
🎉 Poziom 1 ukończony!
Sygnał ratunkowy jest teraz nadawany z pełną mocą. Sygnał triangulacyjny przebija się przez zakłócenia atmosferyczne, a jego stały puls mówi: „Jestem tutaj. Udało mi się przeżyć. Przyjdź do mnie”.
Ale nie jesteś jedyną osobą na tej planecie. Gdy Twój nadajnik się aktywuje, na horyzoncie zaczynają migać inne światła – inni ocaleni, inne miejsca katastrofy, inni odkrywcy, którzy przeżyli.
![]()
Na poziomie 2 nauczysz się przetwarzać przychodzące sygnały SOS i współpracować z innymi ocalałymi. Akcja ratunkowa nie polega tylko na znalezieniu zaginionych osób, ale też na tym, by zaginieni znaleźli ratowników.
Rozwiązywanie problemów
„MCP_SERVER_URL not set”
export MCP_SERVER_URL=$(gcloud run services describe location-analyzer \
--region=$REGION --format='value(status.url)')
„PARTICIPANT_ID not set”
source $HOME/way-back-home/set_env.sh
echo $PARTICIPANT_ID
„Nie znaleziono tabeli BigQuery”
uv run python setup/setup_star_catalog.py
„Specjaliści proszą o adresy URL” – oznacza to, że szablon {key} nie działa. Sprawdź:
- Czy
before_agent_callbackjest ustawiony na agencie głównym? - Czy wywołanie zwrotne prawidłowo ustawia wartości stanu?
- Czy agenci podrzędni używają
{soil_url}(nie f-stringów)?
„Wszystkie 3 analizy są ze sobą sprzeczne”. Wygeneruj ponownie dowody: uv run python generate_evidence.py
„Agent nie odpowiada w adk web”
- Sprawdź, czy port 8000 jest prawidłowy.
- Sprawdź, czy ustawione są zmienne MCP_SERVER_URL i PARTICIPANT_ID
- Sprawdzanie terminala pod kątem komunikatów o błędach
Podsumowanie architektury
Komponent | Typ | Wzór | Cel |
setup_participant_context | Oddzwanianie | before_agent_callback | Pobieranie konfiguracji i ustawianie stanu |
GeologicalAnalyst | Agent | Szablonowanie {soil_url} | Klasyfikacja gleby |
BotanicalAnalyst | Agent | Szablon {flora_url} | Klasyfikacja flory |
AstronomicalAnalyst | Agent | {stars_url}, {project_id} | Triangulacja gwiazd |
confirm_location | Narzędzie | Dostęp do stanu ToolContext | Aktywuj beacon |
EvidenceAnalysisCrew | ParallelAgent | Zestawienie sub-agentów | Równoczesne uruchamianie specjalistów |
MissionAnalysisAI | Agent (główny) | Aranżer + oddzwanianie | Koordynacja i synteza |
location-analyzer | Serwer FastMCP | Niestandardowa platforma MCP | Analiza geologiczna i botaniczna |
bigquery.googleapis.com/mcp | OneMCP | Zarządzana platforma MCP | Dostęp do BigQuery |
Opanowane kluczowe pojęcia
✓ before_agent_callback: pobieranie konfiguracji przed uruchomieniem agenta
✓ {key} State Templating: dostęp do wartości stanu w instrukcjach agenta
✓ ToolContext: dostęp do wartości stanu w funkcjach narzędzia
✓ State Sharing: stan nadrzędny automatycznie dostępny dla subagentów za pomocą InvocationContext
✓ Multi-Agent Architecture: wyspecjalizowani agenci z pojedynczymi zadaniami
✓ ParallelAgent: równoległe wykonywanie niezależnych zadań
✓ Custom MCP Server: własny serwer MCP w Cloud Run
✓ OneMCP BigQuery: zarządzany wzorzec MCP do uzyskiwania dostępu do bazy danych
✓ Cloud Deployment: wdrożenie bezstanowe z użyciem zmiennych środowiskowych
✓ A2A Preparation: agent gotowy do komunikacji między agentami
Dla osób niegrających: zastosowania w rzeczywistości
„Określanie Twojej lokalizacji” to równoległa analiza ekspercka z konsensusem – równoczesne przeprowadzanie wielu specjalistycznych analiz AI i synteza wyników.
Aplikacje dla firm
Przypadek użycia | Parallel Experts | Reguła syntezy |
Diagnoza medyczna | Analityk obrazów, analityk objawów, analityk laboratoryjny | Próg ufności 2 z 3 |
Wykrywanie oszustw | Analityk transakcji, analityk zachowań, analityk sieci | 1 flaga = weryfikacja |
Przetwarzanie dokumentów | Agent OCR, agent klasyfikacji, agent wyodrębniania | Wszyscy muszą się zgodzić |
Kontrola jakości | Kontroler wizualny, analityk czujników, kontroler specyfikacji | 2 z 3 |
Kluczowe informacje o architekturze
- before_agent_callback for configuration: pobierz konfigurację raz na początku i wypełnij stan wszystkich subagentów. Brak odczytu pliku konfiguracyjnego w podagentach.
- {key} State Templating: deklaratywne, przejrzyste, idiomatyczne. Bez f-stringów, importów i manipulacji sys.path.
- Mechanizmy konsensusu: umowa 2 z 3 skutecznie radzi sobie z niejednoznacznością bez konieczności uzyskania jednomyślności.
- ParallelAgent w przypadku niezależnych zadań: jeśli analizy nie są od siebie zależne, możesz je przeprowadzać równolegle, aby przyspieszyć proces.
- 2 wzorce MCP: niestandardowy (utworzony przez Ciebie) i OneMCP (hostowany przez Google). Oba korzystają z StreamableHTTP.
- Wdrożenie bezstanowe: ten sam kod działa lokalnie i po wdrożeniu. Zmienne środowiskowe + interfejs API backendu = brak plików konfiguracyjnych w kontenerach.
Co dalej?
Poziom 2. Przetwarzanie sygnału SOS →
Naucz się przetwarzać przychodzące sygnały alarmowe od innych ocalałych za pomocą wzorców opartych na zdarzeniach i bardziej zaawansowanej koordynacji agentów.