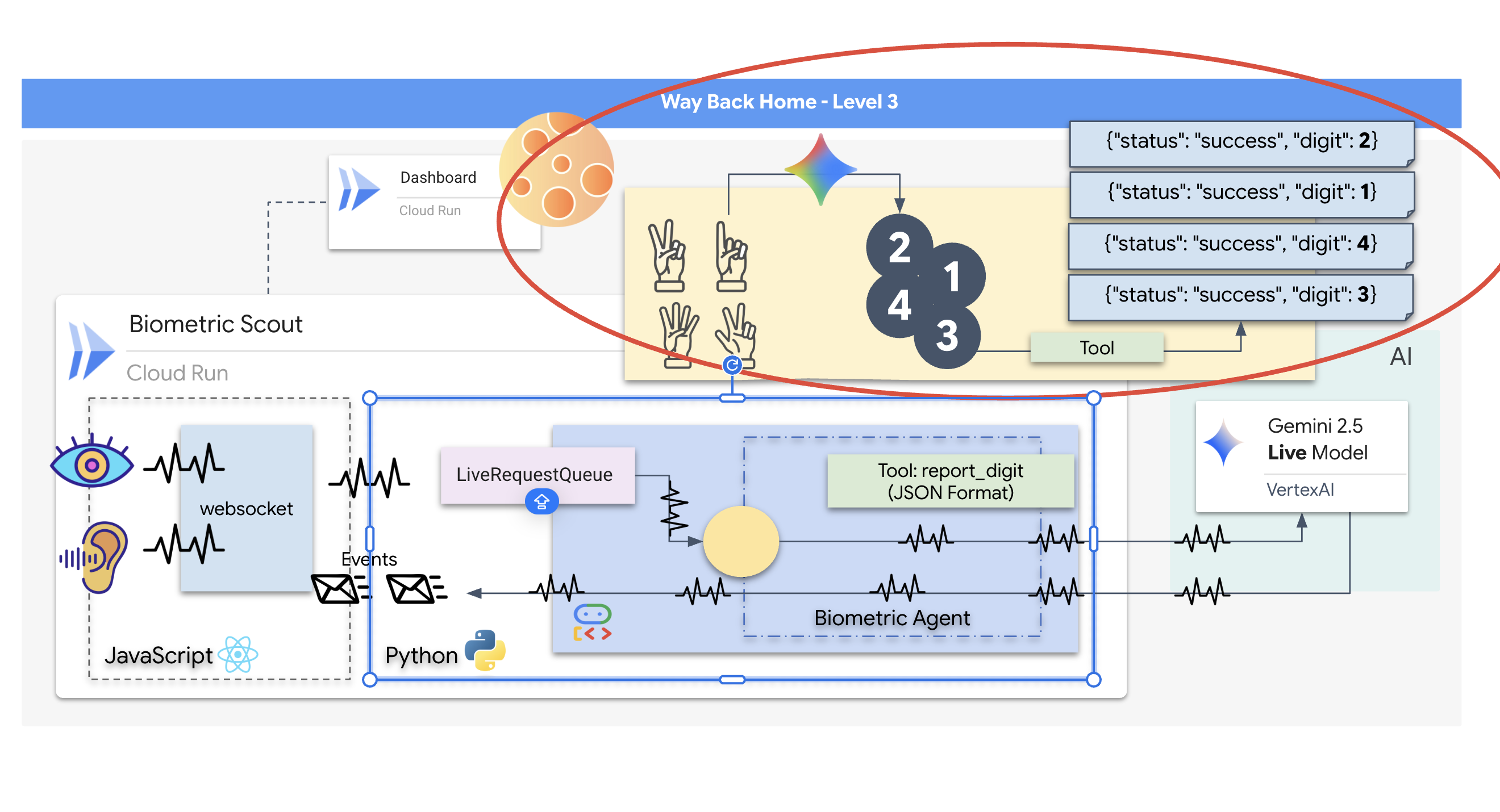
1. المهمة

أنت تائه في صمت قطاع مجهول. أدّى **نبض شمسي** هائل إلى تمزيق سفينتك عبر صدع، ما أدى إلى تقطُّع السبل بك في جزء من الكون غير موجود في أي خريطة نجمية.
بعد أيام من أعمال الإصلاح الشاقة، يمكنك أخيرًا سماع صوت المحركات تحت قدميك. تم إصلاح سفينة الصواريخ. لقد تمكّنت حتى من تأمين وصلة صاعدة بعيدة المدى إلى السفينة الأم. يمكنك المغادرة. يمكنك الآن العودة إلى المنزل. ولكن بينما تستعد لتشغيل محرك الأقراص، يخترق إشارة استغاثة التشويش. ترصد أجهزة الاستشعار خمسة آثار حرارية خافتة محصورة في "الوادي"، وهو قطاع وعر مشوّه الجاذبية لا يمكن أن تدخل إليه سفينتك الرئيسية أبدًا. هؤلاء هم رفاقك المستكشفون، الناجون من العاصفة نفسها التي كادت أن تودي بحياتك. لا يمكنك تركها.
تستعين بـ Alpha-Drone Rescue Scout. هذه السفينة الصغيرة السريعة هي الوحيدة القادرة على الإبحار بين الجدران الضيقة في "الوادي الضيق". لكن هناك مشكلة: أدت النبضة الشمسية إلى إعادة ضبط النظام بالكامل على مستوى منطقها الأساسي. أنظمة التحكّم في Scout لا تستجيب. وهي تعمل، ولكنّ الكمبيوتر المدمج فيها لا يتضمّن أي بيانات، وبالتالي لا يمكنه معالجة أوامر الطيار اليدوية أو مسارات الطيران.
التحدي
لإنقاذ الناجين، عليك تجاوز الدوائر التالفة في الروبوت الكشّاف بالكامل. أمامك خيار واحد يائس: إنشاء وكيل مستند إلى الذكاء الاصطناعي لإجراء مزامنة عصبية حيوية. سيعمل هذا الوكيل كجسر في الوقت الفعلي، ما يتيح لك التحكّم في Rescue Scout يدويًا من خلال مدخلاتك البيولوجية. لن تستخدم ذراع تحكّم أو لوحة مفاتيح، بل ستوصل نيتك مباشرةً بشبكة التنقّل في السفينة.
لإكمال عملية الربط، يجب تنفيذ بروتوكول المزامنة أمام المستشعرات الضوئية في Scout. يجب أن يتعرّف "وكيل الذكاء الاصطناعي" على توقيعك البيولوجي من خلال مصافحة دقيقة في الوقت الفعلي.
أهداف مهمتك:
- تضمين Neural Core: حدِّد وكيل ADK قادرًا على التعرّف على المدخلات المتعددة الوسائط.
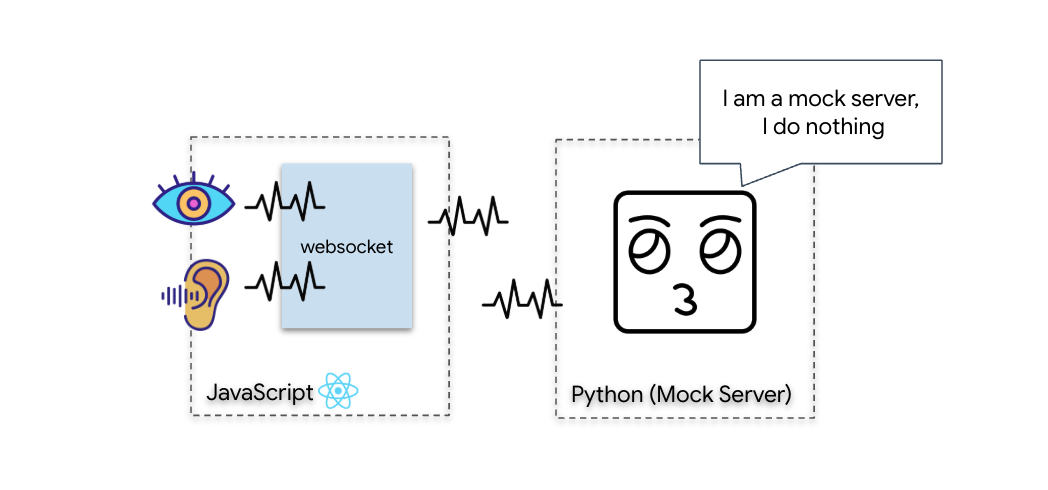
- إنشاء الاتصال: أنشئ مسار WebSocket ثنائي الاتجاه لبث البيانات المرئية من Scout إلى الذكاء الاصطناعي.
- بدء المصافحة: قِف أمام أداة الاستشعار وأكمِل تسلسل الأصابع، أي اعرض الأرقام من 1 إلى 5 بالترتيب.
في حال نجاح العملية، سيتم تفعيل ميزة "مزامنة المقاييس الحيوية". سيقفل الذكاء الاصطناعي الرابط العصبي، ما يمنحك تحكّمًا يدويًا كاملاً لإطلاق Scout وإعادة الناجين إلى ديارهم.
ما ستنشئه
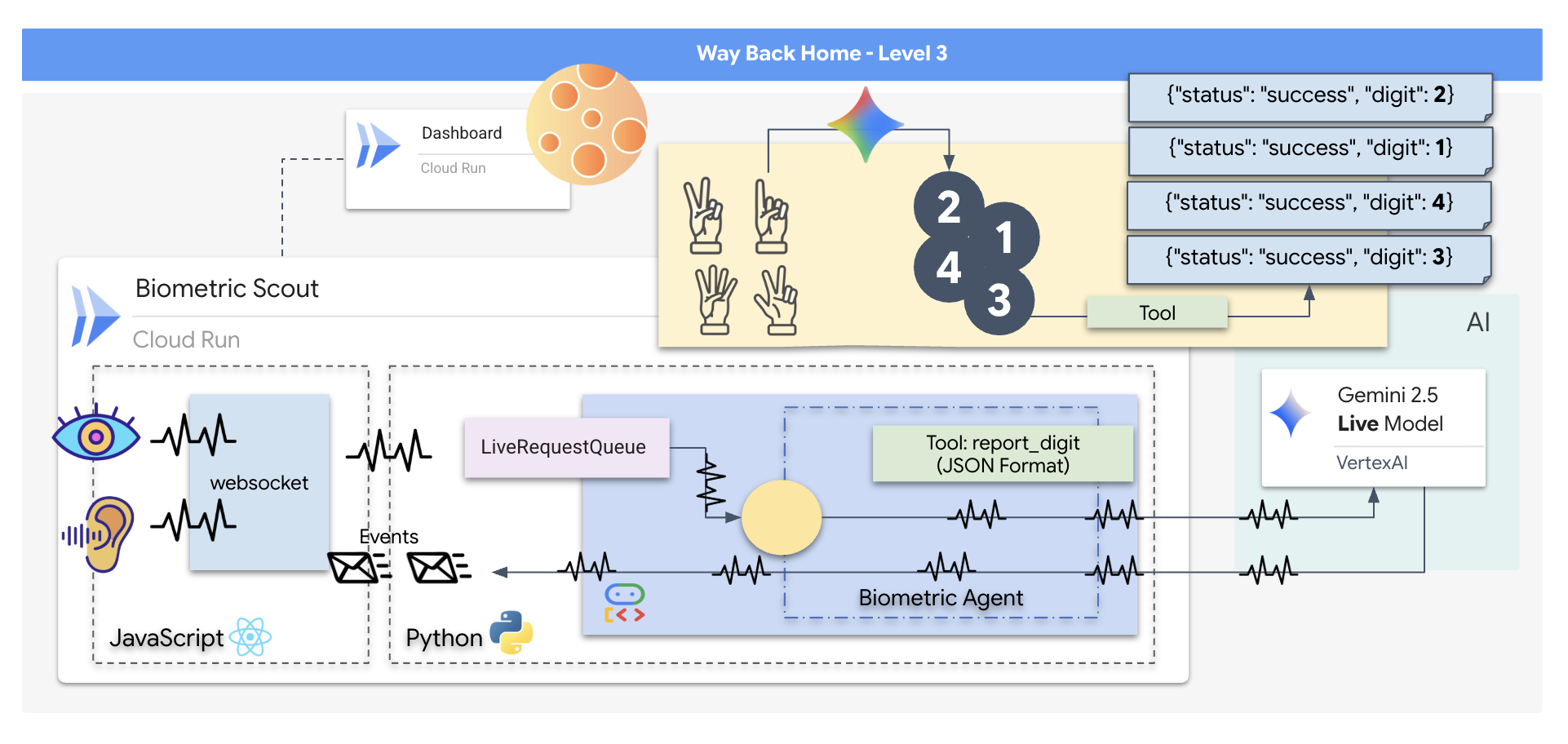
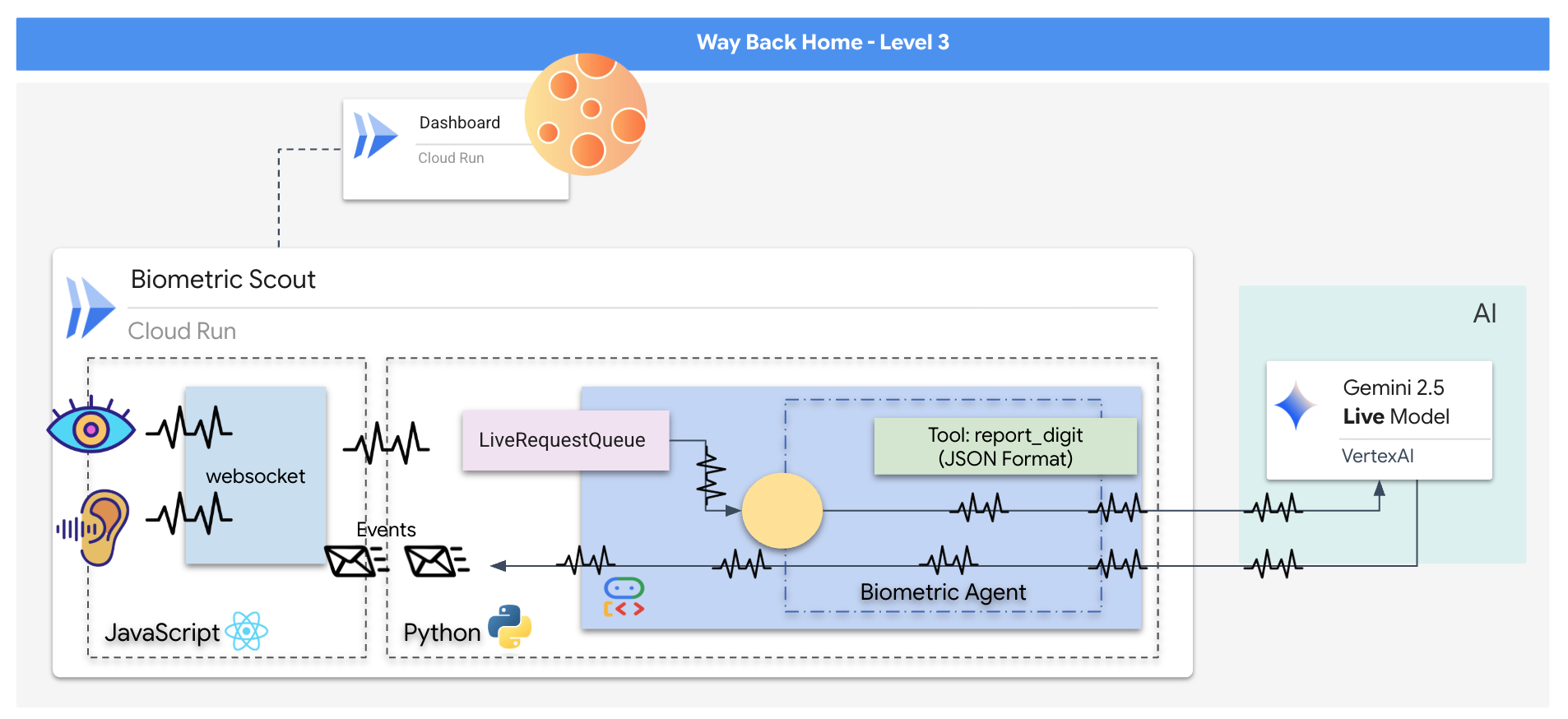
ستنشئ تطبيقًا باسم "المزامنة العصبية البيومترية"، وهو نظام في الوقت الفعلي يستند إلى الذكاء الاصطناعي ويعمل كواجهة تحكّم في طائرة مسيّرة مخصّصة لعمليات الإنقاذ. يتألف هذا النظام من:
- واجهة React الأمامية: هي "قمرة القيادة" لسفينتك، وهي تسجّل الفيديو المباشر من كاميرا الويب والصوت من الميكروفون.
- خادم خلفي بلغة Python: خادم عالي الأداء تم إنشاؤه باستخدام FastAPI، ويستخدم "حزمة تطوير الوكلاء" (ADK) من Google لإدارة منطق النموذج اللغوي الكبير وحالته.
- وكيل الذكاء الاصطناعي المتعدد الوسائط: هو "العقل" الذي يدير العملية، ويستخدم Gemini Live API من خلال حزمة تطوير البرامج (SDK)
google-genaiلمعالجة وفهم بث الفيديو والصوت في الوقت نفسه. - مسار WebSocket ثنائي الاتجاه: هو "الجهاز العصبي" الذي ينشئ اتصالاً مستمرًا بزمن انتقال منخفض بين الواجهة الأمامية والذكاء الاصطناعي (AI)، ما يتيح التفاعل في الوقت الفعلي.
ما ستتعلمه
التكنولوجيا / المفهوم | الوصف |
وكيل الذكاء الاصطناعي في الخلفية | إنشاء وكيل ذكاء اصطناعي ذي حالة باستخدام Python وFastAPI استخدِم حزمة تطوير الوكيل (ADK) من Google لإدارة التعليمات والذاكرة، و |
واجهة المستخدم الأمامية | يمكنك تطوير واجهة مستخدم ديناميكية باستخدام React لتسجيل وبث الفيديو والصوت مباشرةً من المتصفّح. |
التواصل في الوقت الفعلي | استخدِم مسار WebSocket لإجراء اتصال مزدوج الاتجاه وبوقت استجابة منخفض، ما يتيح للمستخدم والذكاء الاصطناعي التفاعل في الوقت نفسه. |
الذكاء الاصطناعي المتعدّد الوسائط | استخدِم Gemini Live API لمعالجة وفهم أحداث البث المتزامن للفيديو والصوت، ما يتيح للذكاء الاصطناعي "الرؤية" و "الاستماع" في الوقت نفسه. |
استخدام الأدوات | يمكنك السماح للذكاء الاصطناعي بتنفيذ دوال Python معيّنة استجابةً لمشغّلات مرئية، ما يؤدي إلى سدّ الفجوة بين ذكاء النموذج والإجراءات في العالم الحقيقي. |
النشر الكامل | وضع التطبيق بأكمله في حاوية (واجهة React أمامية وخلفية Python) باستخدام Docker ونشره كخدمة قابلة للتوسّع وبدون خادم على Google Cloud Run |
2. إعداد البيئة
الوصول إلى Cloud Shell
أولاً، سنفتح Cloud Shell، وهي وحدة طرفية مستندة إلى المتصفّح مع تثبيت مسبق لحزمة تطوير البرامج (SDK) من Google Cloud وأدوات أساسية أخرى.
👉انقر على "تفعيل Cloud Shell" في أعلى "وحدة تحكّم Google Cloud" (رمز شكل الوحدة الطرفية في أعلى لوحة Cloud Shell)، 
👉انقر على الزر "فتح المحرّر" (يبدو كملف مفتوح مع قلم رصاص). سيؤدي ذلك إلى فتح "محرِّر Cloud Shell للرموز" في النافذة. سيظهر لك مستكشف الملفات على الجانب الأيمن. 
👉افتح المحطة الطرفية في بيئة التطوير المتكاملة المستندة إلى السحابة الإلكترونية،
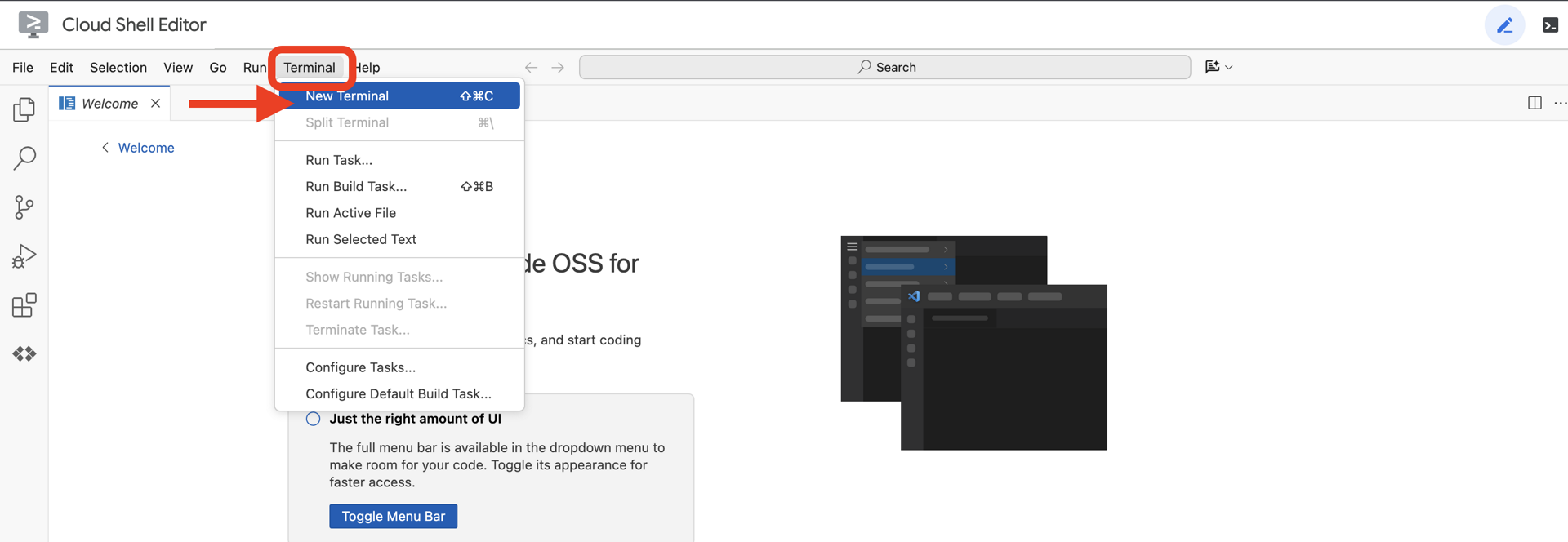
👉💻 في نافذة الوحدة الطرفية، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
من المفترض أن يظهر حسابك على أنّه (ACTIVE).
المتطلبات الأساسية
ℹ️ المستوى 0 اختياري (ولكن يُنصح به)
يمكنك إكمال هذه المهمة بدون المستوى 0، ولكن إكمالها أولاً يوفّر لك تجربة أكثر تفاعلية، ما يتيح لك رؤية ضوء جهاز التتبّع يضيء على الخريطة العالمية أثناء تقدّمك.
إعداد بيئة المشروع
ارجع إلى نافذة الوحدة الطرفية، وأكمِل عملية الإعداد من خلال ضبط المشروع النشط وتفعيل خدمات Google Cloud المطلوبة (مثل Cloud Run وVertex AI وما إلى ذلك).
👉💻 في نافذة الأوامر، اضبط رقم تعريف المشروع:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 تفعيل الخدمات المطلوبة:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
تثبيت الحِزم التابعة
👉💻 انتقِل إلى المستوى وثبِّت حِزم Python المطلوبة:
cd $HOME/way-back-home/level_3
uv sync
تشمل التبعيات الرئيسية ما يلي:
الحزمة | الغرض |
| إطار عمل ويب عالي الأداء لبث Satellite Station وSSE |
| مطلوب خادم ASGI لتشغيل تطبيق FastAPI |
| حزمة Agent Development Kit المستخدَمة لإنشاء Formation Agent |
| برنامج أصلي للوصول إلى نماذج Gemini |
| إتاحة التواصل الثنائي الاتجاه في الوقت الفعلي |
| إدارة متغيرات البيئة وأسرار الإعدادات |
التحقّق من الإعداد
قبل أن نبدأ في عرض الرمز، لنحرص على أنّ جميع الأنظمة تعمل بشكل سليم. نفِّذ نص التحقّق البرمجي لتدقيق مشروعك على Google Cloud وواجهات برمجة التطبيقات وتبعيات Python.
👉💻 تشغيل نص التحقّق البرمجي:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 ستظهر لك سلسلة من علامات الصح الخضراء (✅).
- إذا ظهرت علامات X حمراء (❌)، اتّبِع أوامر الإصلاح المقترَحة في الناتج (مثل
gcloud services enable ...أوpip install ...). - ملاحظة: يمكن تجاهل التحذير الأصفر بشأن
.envفي الوقت الحالي، وسننشئ هذا الملف في الخطوة التالية.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3- معايرة Comm-Link (WebSockets)
لبدء عملية المزامنة العصبية الحيوية، علينا تعديل الأنظمة الداخلية لسفينتك. هدفنا الأساسي هو تسجيل بث فيديو وبث صوتي عالي الدقة من قمرة القيادة. يوفر هذا البث المكوّنات الأساسية للرابط العصبي: التعرّف المرئي على تسلسلات أصابعك والتردد الصوتي لصوتك.
الاتصال المزدوج الكامل في مقابل الاتصال المزدوج النصفي
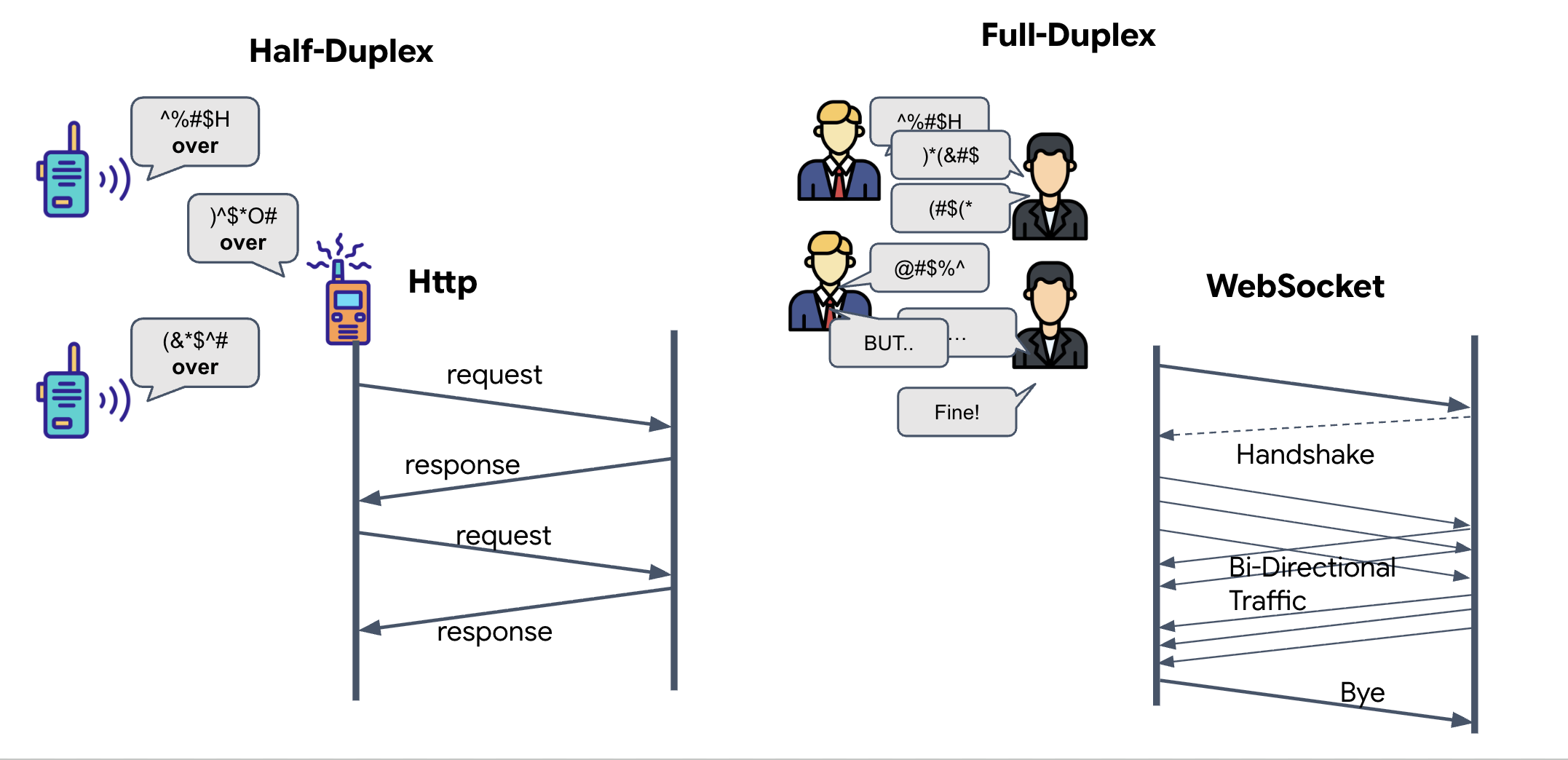
لفهم سبب حاجتنا إلى ذلك في ميزة Neural Sync، عليك معرفة كيفية تدفّق البيانات:
- الازدواج النصفي (بروتوكول HTTP العادي): يشبه جهاز اللاسلكي. يتحدث أحد الأشخاص، ثم يقول "انتهى"، وبعد ذلك يمكن للشخص الآخر التحدث. لا يمكنك الاستماع والتحدث في الوقت نفسه.
- الوضع المزدوج الكامل (WebSocket): يشبه المحادثة وجهًا لوجه. تتدفّق البيانات في كلا الاتجاهين في الوقت نفسه. بينما يرسل المتصفّح لقطات الفيديو وعيّنات الصوت إلى الذكاء الاصطناعي، يمكن للذكاء الاصطناعي أن يرسل إليك ردودًا صوتية وأوامر أدوات في الوقت نفسه.
لماذا تحتاج Gemini Live إلى ميزة Full-Duplex؟ تم تصميم واجهة برمجة التطبيقات Gemini Live من أجل "المقاطعة". لنفترض أنّك تعرض تسلسل الأصابع، ويرى الذكاء الاصطناعي أنّك تفعل ذلك بشكل خاطئ. في عملية إعداد HTTP عادية، على الذكاء الاصطناعي الانتظار إلى أن تنتهي من إرسال بياناتك قبل أن يطلب منك التوقّف. باستخدام WebSockets، يمكن للذكاء الاصطناعي رصد خطأ في الإطار 1 وإرسال إشارة "مقاطعة" تصل إلى قمرة القيادة أثناء استمرار تحريك يدك لتسجيل الإطار 2.
ما هو WebSocket؟
في عملية نقل البيانات العادية بين المجرات (HTTP)، يتم إرسال طلب وانتظار الرد، تمامًا مثل إرسال بطاقة بريدية. بالنسبة إلى المزامنة العصبية، تكون البطاقات البريدية بطيئة جدًا. نحن بحاجة إلى "سلك كهربائي حي".
تبدأ WebSockets كطلب ويب عادي (HTTP)، ولكن يتم بعد ذلك "ترقيتها" إلى شيء مختلف.
- الطلب: يرسل المتصفّح طلب HTTP عاديًا إلى الخادم مع عنوان خاص:
Upgrade: websocket. هذا يعني بشكل أساسي "أريد التوقف عن إرسال البطاقات البريدية وبدء مكالمة هاتفية مباشرة". - الردّ: إذا كان وكيل الذكاء الاصطناعي (الخادم) يتيح ذلك، سيرسل ردًا من النوع
HTTP 101 Switching Protocols. - التحويل: في هذه اللحظة، يتم استبدال اتصال HTTP ببروتوكول WebSocket، ولكن يظل مقبس TCP/IP الأساسي مفتوحًا. تتغيّر قواعد التواصل على الفور من "طلب/ردّ" إلى "البث ثنائي الاتجاه".
تنفيذ WebSocket Hook
لنلقِ نظرة على مجموعة الوصلات لفهم كيفية تدفّق البيانات.
👀 افتح $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. ستظهر لك معالجات أحداث دورة حياة WebSocket العادية التي تم إعدادها مسبقًا. في ما يلي الهيكل الأساسي لنظام التواصل:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
معالج onMessage
ركِّز على الحظر في ws.current.onmessage. هذا هو جهاز الاستقبال. في كل مرة "يفكّر" فيها الوكيل أو "يتحدث"، تصل حزمة بيانات إلى هنا. في الوقت الحالي، لا يتم تنفيذ أي إجراء، بل يتم التقاط الحزمة وإسقاطها (من خلال العنصر النائب //#REPLACE-HANDLE-MSG).
علينا ملء هذا الفراغ بمنطق يمكنه التمييز بين ما يلي:
- استدعاء الأدوات (functionCall): يشير إلى أنّ الذكاء الاصطناعي يتعرّف على إشارات يدك (ميزة "المزامنة").
- بيانات الصوت (inlineData): هي صوت الذكاء الاصطناعي الذي يردّ عليك.
👉✏️ الآن، في ملف $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js نفسه، استبدِل //#REPLACE-HANDLE-MSG بالمنطق أدناه للتعامل مع البث الوارد:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
كيف يتم تحويل الصوت والفيديو إلى بيانات لنقلها؟
لإتاحة التواصل في الوقت الفعلي عبر الإنترنت، يجب تحويل النسخة الأولية من الصوت والفيديو إلى تنسيق مناسب للإرسال. ويشمل ذلك التقاط البيانات وتشفيرها وتعبئتها قبل إرسالها عبر الشبكة.
تحويل البيانات الصوتية
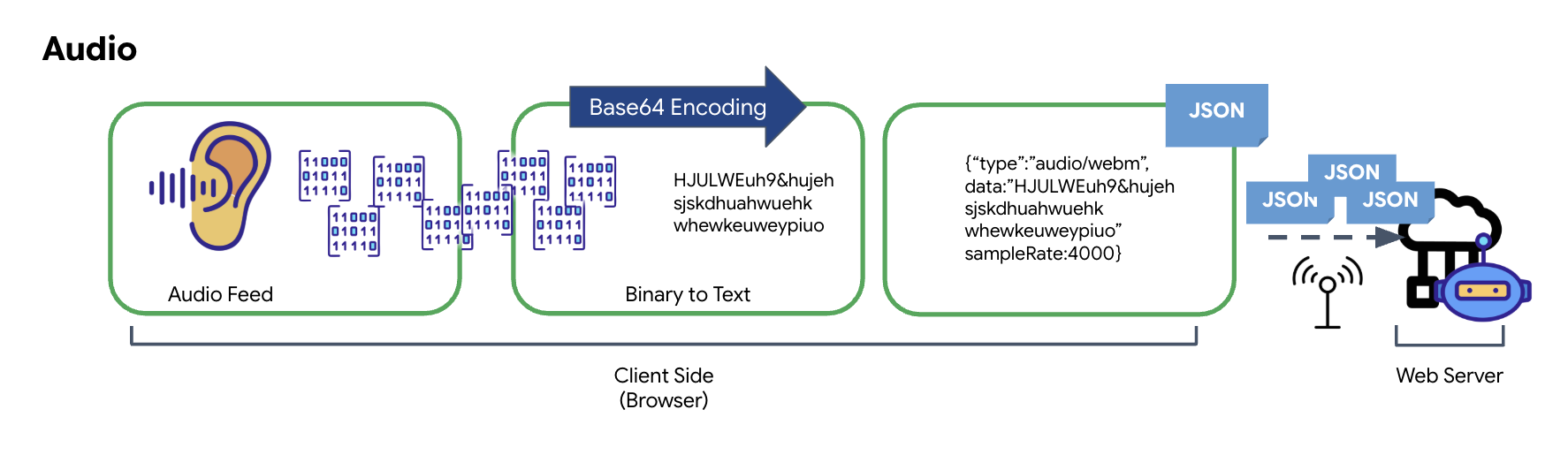
تبدأ عملية تحويل الصوت التناظري إلى بيانات رقمية قابلة للإرسال بالتقاط الموجات الصوتية باستخدام ميكروفون. بعد ذلك، تتم معالجة الصوت الخام من خلال Web Audio API في المتصفّح. بما أنّ هذه البيانات الأولية تكون بتنسيق ثنائي، فهي غير متوافقة مباشرةً مع تنسيقات النقل المستندة إلى النصوص، مثل JSON. لحلّ هذه المشكلة، يتم ترميز كل مقطع صوتي في سلسلة Base64. Base64 هي طريقة تمثّل البيانات الثنائية بتنسيق سلسلة ASCII، ما يضمن سلامتها أثناء الإرسال.
يتم بعد ذلك تضمين هذه السلسلة المرمّزة في عنصر JSON. يوفر هذا العنصر تنسيقًا منظَّمًا للبيانات، ويتضمّن عادةً حقل "النوع" لتحديد نوعه كملف صوتي وبيانات وصفية مثل معدّل عيّنات الصوت. بعد ذلك، يتم تحويل عنصر JSON بالكامل إلى سلسلة وإرساله عبر اتصال WebSocket. يضمن هذا الأسلوب نقل الصوت بطريقة منظَّمة وسهلة التحليل.
تحويل بيانات الفيديو
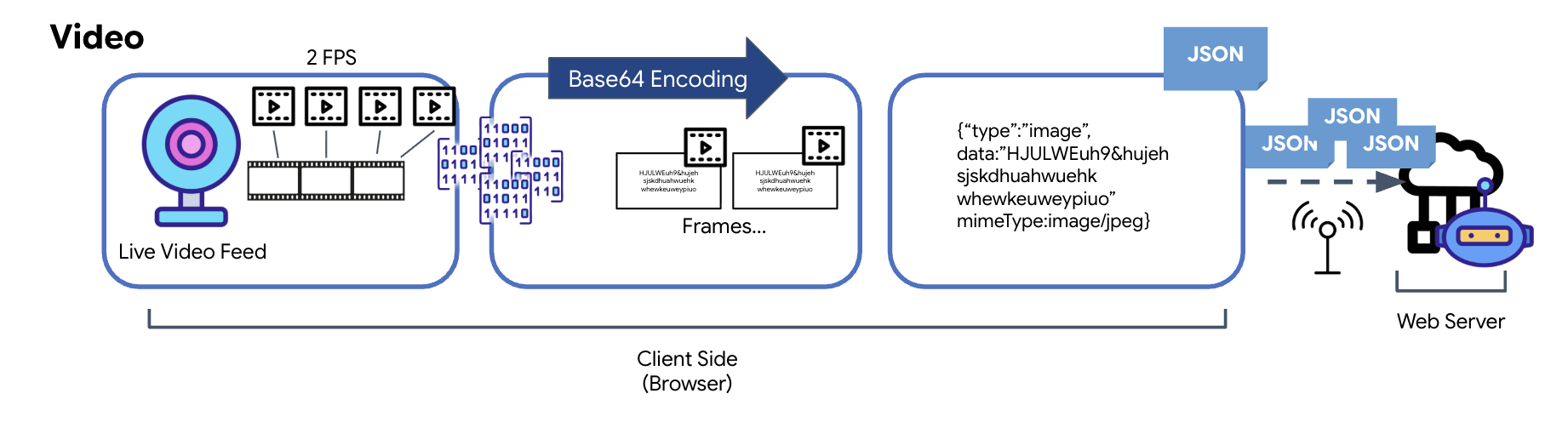
يتم نقل الفيديو من خلال تقنية التقاط اللقطات. بدلاً من إرسال بث فيديو متواصل، تلتقط حلقة متكررة صورًا ثابتة من خلاصة الفيديو المباشر بفاصل زمني محدّد، مثل صورتَين في الثانية. ويتم ذلك من خلال رسم الإطار الحالي من عنصر فيديو HTML على عنصر لوحة مخفية.
يتم بعد ذلك استخدام طريقة toDataURL في لوحة الرسم لتحويل هذه الصورة الملتقطة إلى سلسلة JPEG مرمّزة بتنسيق Base64. تتضمّن هذه الطريقة خيارًا لتحديد جودة الصورة، ما يسمح بتحقيق توازن بين دقة الصورة وحجم الملف لتحسين الأداء. وكما هو الحال مع بيانات الصوت، يتم وضع سلسلة Base64 هذه في عنصر JSON. عادةً ما يتم تصنيف هذا العنصر على أنّه "نوع" "صورة" ويتضمّن mimeType، مثل "image/jpeg". يتم بعد ذلك تحويل حزمة JSON هذه إلى سلسلة وإرسالها عبر WebSocket، ما يتيح للطرف المستلِم إعادة إنشاء الفيديو من خلال عرض تسلسل الصور.
👉✏️ في ملف $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js نفسه، استبدِل //#CAPTURE AUDIO and VIDEO بما يلي لالتقاط بيانات أدخلها المستخدم:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
بعد الحفظ، ستكون لوحة القيادة جاهزة لترجمة الإشارات الرقمية للوكيل إلى تحديثات مرئية في لوحة البيانات ومحتوى صوتي.
اختبار التشخيص (اختبار الإرجاع)
أصبحت لوحة التحكّم متاحة الآن. كل 500 ملي ثانية، يتم إرسال "حزمة" مرئية لما يحيط بك. قبل الاتصال بـ Gemini، يجب التأكّد من أنّ جهاز الإرسال في سفينتك يعمل. سنجري "اختبار الاتصال الحلقي" باستخدام خادم تشخيص محلي.
👉💻 أولاً، أنشئ واجهة Cockpit من جهازك الطرفي:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 بعد ذلك، ابدأ تشغيل الخادم الوهمي:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 تنفيذ بروتوكول الاختبار:
- فتح المعاينة: انقر على رمز معاينة الويب في شريط أدوات Cloud Shell. انقر على تغيير المنفذ، واضبطه على 8080، ثم انقر على تغيير ومعاينة. سيتم فتح علامة تبويب جديدة في المتصفّح تعرض واجهة Cockpit.
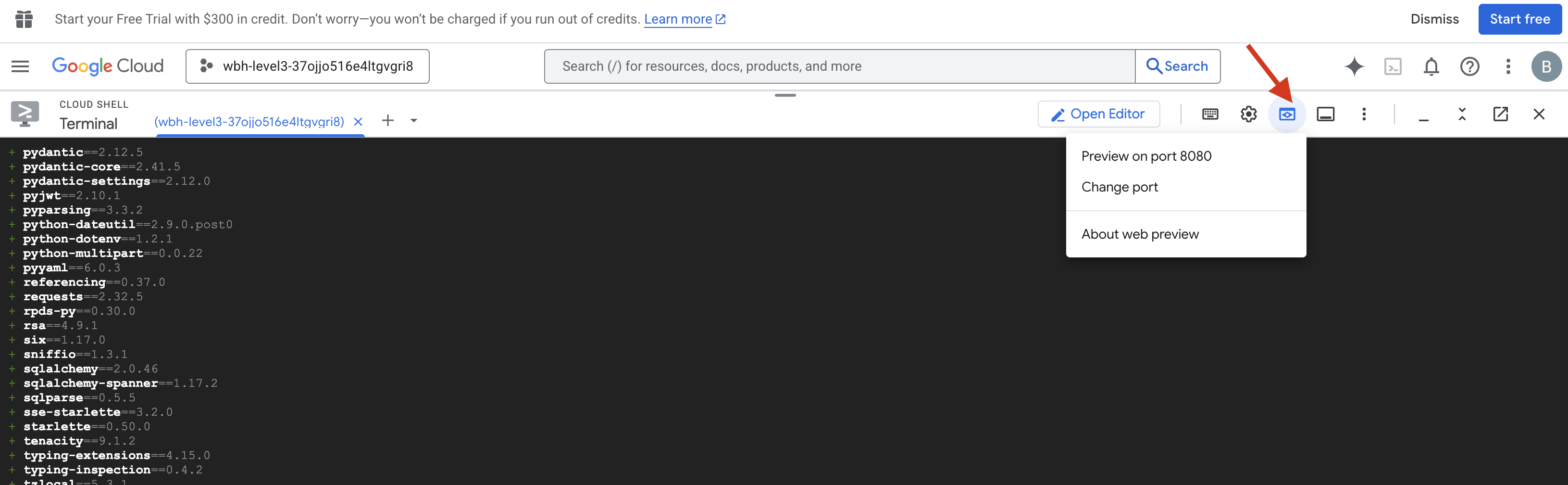
- ملاحظة مهمة: عندما يُطلب منك ذلك، عليك السماح للمتصفّح بالوصول إلى الكاميرا والميكروفون. وبدون هذه المدخلات، لا يمكن بدء المزامنة العصبية.
- انقر على الزر "بدء المزامنة العصبية" في واجهة المستخدم.
👀 التحقّق من مؤشرات الحالة:
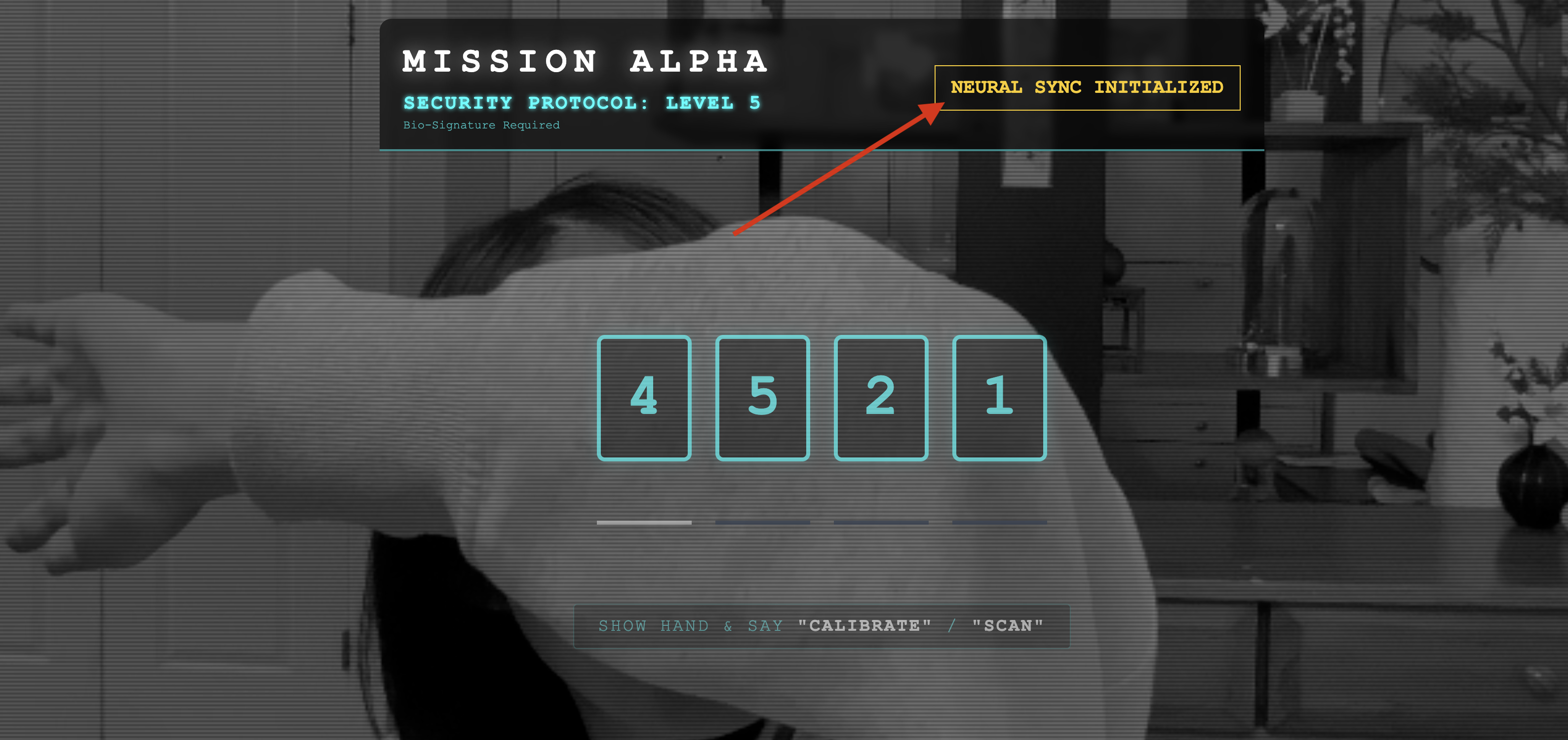
- التحقّق المرئي: افتح "وحدة تحكّم المتصفّح". من المفترض أن يظهر لك الرمز
NEURAL SYNC INITIALIZEDفي أعلى يسار الشاشة. - التحقّق من الصوت: إذا كانت قناة الصوت ثنائية الاتجاه تعمل بشكل كامل، ستسمع صوتًا محاكيًا يؤكّد: "تم الاتصال بالنظام".
بعد سماع تأكيد الصوت "تم ربط النظام"، يكون الاختبار ناجحًا. أغلِق علامة التبويب. علينا الآن إخلاء التردد لإتاحة المجال للذكاء الاصطناعي الحقيقي.
👉💻 اضغط على Ctrl+C في النوافذ الطرفية لكل من الخادم التجريبي والواجهة الأمامية. أغلِق علامة تبويب المتصفّح التي يتم تشغيل واجهة المستخدم عليها.
4. الوكيل المتعدد الوسائط
الروبوت الاستطلاعي جاهز للعمل، لكن "عقله" فارغ. إذا اتصلت الآن، لن يردّ عليك. لا يعرف ما هو "الإصبع". لإنقاذ الناجين، عليك نقش بروتوكول المقاييس الحيوية العصبية على قلب الروبوت الاستطلاعي.
يعمل "الوكيل التقليدي" كسلسلة من المترجمين. إذا كنت تتحدث إلى ذكاء اصطناعي قديم، سيحوّل نموذج "تحويل الصوت إلى نص" صوتك إلى كلمات، وسيقرأ "النموذج اللغوي" هذه الكلمات ويكتب ردًا، وسيقرأ نموذج "تحويل النص إلى صوت" هذا الردّ بصوت عالٍ. يؤدي ذلك إلى حدوث "فجوة في وقت الاستجابة"، أي تأخير قد يكون قاتلاً في مهمة إنقاذ.
Gemini Live API هو نموذج أصلي متعدد الوسائط. ويعالج وحدات بايت الصوت ولقطات الفيديو الأولية مباشرةً وفي الوقت نفسه. فهو "يسمع" اهتزاز صوتك و "يرى" وحدات البكسل الخاصة بإيماءات يدك ضمن بنية عصبية واحدة.
للاستفادة من هذه الإمكانية، يمكننا إنشاء التطبيق من خلال ربط لوحة القيادة مباشرةً بواجهة برمجة التطبيقات Live API الأولية. ومع ذلك، هدفنا هو إنشاء وكيل قابل لإعادة الاستخدام، أي كيان قوي ومقسّم إلى وحدات يمكن إنشاؤه بشكل أسرع.
لماذا نستخدم حزمة تطوير الوكلاء (ADK)؟
Google Agent Development Kit (ADK) هو إطار عمل معياري لتطوير وكلاء الذكاء الاصطناعي وتفعيلهم.
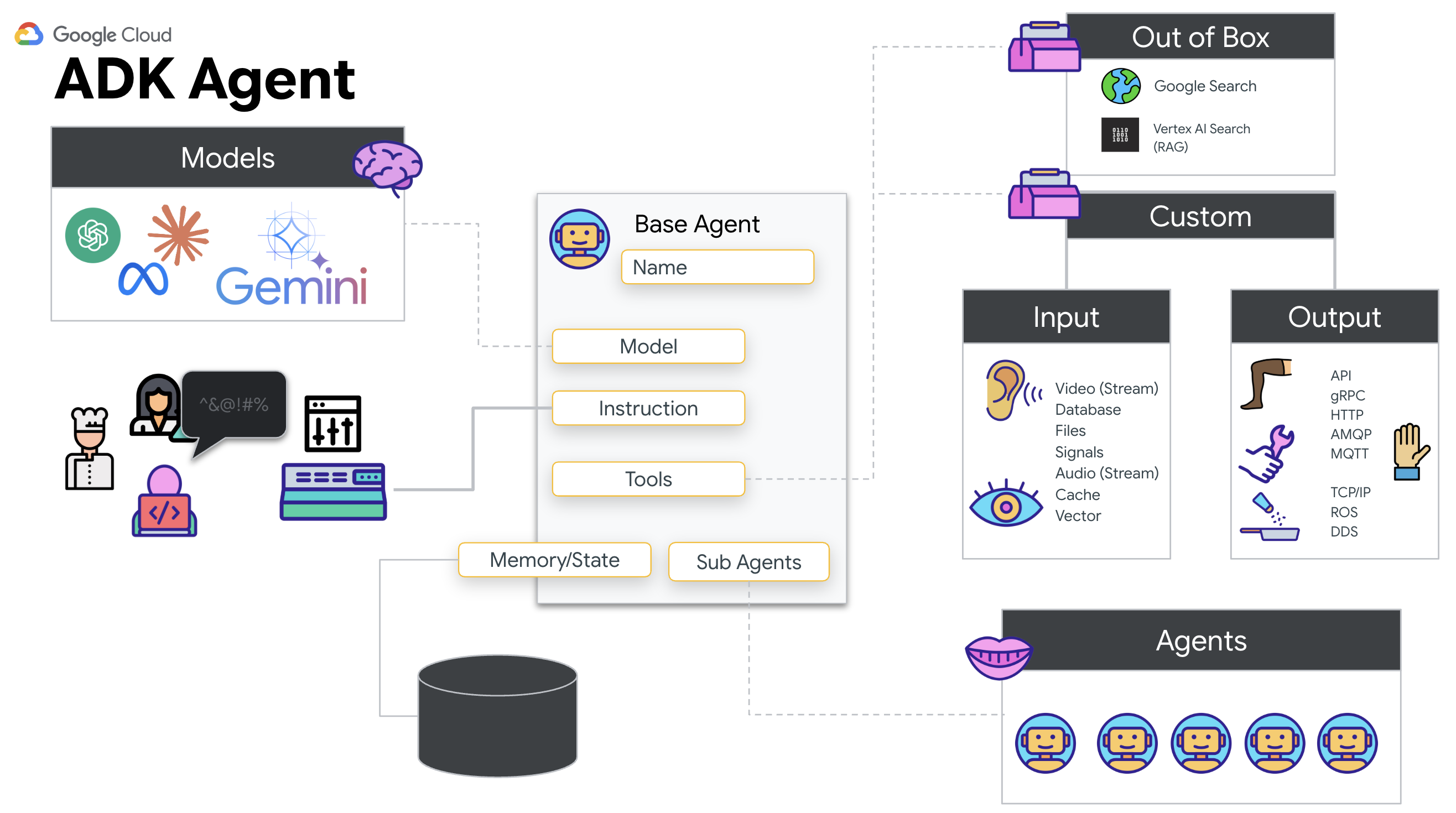
عادةً ما تكون طلبات LLM العادية بدون حالة، أي أنّ كل طلب بحث هو بداية جديدة. تتيح "الوكلاء المباشرون"، خاصةً عند دمجهم مع SessionService في "حزمة تطوير التطبيقات لنظام Android"، جلسات محادثة قوية وطويلة الأمد.
- ثبات الجلسة: تتسم جلسات ADK بالثبات ويمكن تخزينها في قواعد البيانات (مثل SQL أو Vertex AI)، كما يمكنها الاستمرار حتى بعد إعادة تشغيل الخادم أو قطع الاتصال. وهذا يعني أنّه إذا قطع المستخدم الاتصال وأعاد الاتصال لاحقًا، حتى بعد أيام، سيتم استعادة سجلّ المحادثات وسياقها بالكامل. تتولّى حزمة تطوير البرامج (ADK) إدارة جلسة Live API المؤقتة وتجريدها.
- إعادة الاتصال تلقائيًا: يمكن أن تنتهي مهلة اتصالات WebSocket (مثلاً، بعد 10 دقائق تقريبًا). يتعامل ADK مع عمليات إعادة الربط هذه بشكل شفاف عند تفعيل
session_resumptionفيRunConfig. لا يحتاج الرمز البرمجي للتطبيق إلى إدارة منطق إعادة الاتصال المعقّد، ما يضمن تقديم تجربة سلسة للمستخدم. - التفاعلات المستندة إلى الحالة: يتذكّر الوكيل المحادثات السابقة، ما يتيح طرح أسئلة متابعة وتقديم توضيحات وإجراء حوارات معقّدة متعددة الأدوار يكون فيها السياق مهمًا. وهذا أمر أساسي للتطبيقات، مثل دعم العملاء أو البرامج التعليمية التفاعلية أو سيناريوهات التحكّم في المهام التي تكون فيها الاستمرارية ضرورية.
يضمن هذا الثبات أن يبدو التفاعل وكأنه محادثة مستمرة مع كيان ذكي، بدلاً من سلسلة من الأسئلة والأجوبة المنفصلة.
باختصار، تتجاوز ميزة "المحادثة المباشرة مع وكيل" في ADK Bidi-streaming آلية بسيطة للرد على الاستفسارات، وتقدّم تجربة حوارية تفاعلية وحالة وواعية للانقطاع، ما يجعل التفاعلات مع الذكاء الاصطناعي تبدو أكثر إنسانية وأكثر فعالية بشكل كبير في المهام المعقدة والطويلة الأمد.
طلب التحدّث إلى موظّف دعم يقدّم خدمة مباشرة
يتطلّب تصميم طلب لوكيل ثنائي الاتجاه يعمل في الوقت الفعلي تغييرًا في طريقة التفكير. على عكس برامج الدردشة العادية التي تنتظر طلب بحث بنص ثابت، يكون "الوكيل المباشر" متاحًا دائمًا. يتلقّى هذا النموذج بثًا مستمرًا من إطارات الصوت والفيديو، ما يعني أنّ طلبك يجب أن يعمل كنص برمجي لحلقة التحكّم وليس مجرد تعريف للشخصية.
في ما يلي أوجه الاختلاف بين طلب Live Agent وطلب الدعم التقليدي:
- منطق آلة الحالة: يجب أن يحدّد الطلب "حلقة سلوك" (انتظار → تحليل → تنفيذ إجراء). ويحتاج إلى تعليمات واضحة بشأن الوقت الذي يجب فيه التزام الصمت والوقت الذي يجب فيه التفاعل، ما يمنع الوكيل من الثرثرة على ضوضاء الخلفية الفارغة.
- الإدراك المتعدّد الوسائط: يجب إخبار الوكيل بأنّه يملك "عيونًا". يجب أن تطلب منه صراحةً تحليل لقطات الفيديو كجزء من عملية الاستدلال.
- زمن الاستجابة والإيجاز: في محادثة صوتية مباشرة، تبدو الفقرات الطويلة المليئة بالنثر غير طبيعية وبطيئة. تفرض المطالبة الإيجاز للحفاظ على سرعة التفاعل.
- بنية ترتكز على الإجراءات: تعطي التعليمات الأولوية لاستدعاء الأدوات على الكلام. نريد أن ينفّذ الوكيل العمل (مسح المقياس الحيوي) قبل أو أثناء تأكيده شفهيًا، وليس بعد مونولوج طويل.
👉✏️ افتح $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py واستبدِل #REPLACE INSTRUCTIONS بما يلي:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
ملاحظة أنت لا تتواصل مع نموذج لغوي كبير عادي. في الملف نفسه ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py)، ابحث عن #REPLACE_MODEL. علينا استهداف الإصدار التجريبي من هذا النموذج بشكل صريح لتقديم دعم أفضل لقدرات الصوت في الوقت الفعلي.
👉✏️ استبدِل العنصر النائب بما يلي:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
تم الآن تحديد الوكيل. فهو يعرف من هو وكيف يفكر. بعد ذلك، نزوّده بالأدوات اللازمة لاتخاذ الإجراءات.
استدعاء الأدوات
لا تقتصر Live API على تبادل النصوص والصوت والفيديو فقط. يتوافق بشكلٍ أساسي مع ميزة استخدام الأدوات. يؤدي ذلك إلى تحويل الوكلاء من محاورين عاديين إلى مشغّلين نشطين.
أثناء جلسة مباشرة ثنائية الاتجاه، يقيّم النموذج السياق باستمرار. إذا رصد النموذج اللغوي الكبير الحاجة إلى تنفيذ إجراء، سواء كان "التحقّق من بيانات قياس الأداء للمستشعر" أو "فتح باب آمن" وينتقل بسلاسة من المحادثة إلى التنفيذ. يُشغّل "الوكيل" وظيفة الأداة المحدّدة على الفور، وينتظر النتيجة، ويدمج هذه البيانات مرة أخرى في البث المباشر، وكل ذلك بدون مقاطعة سير التفاعل.
👉✏️ في $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py، استبدِل #REPLACE TOOLS بالدالة التالية:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ بعد ذلك، سجِّل هذا المتغير في تعريف Agent من خلال استبدال #TOOL CONFIG:
tools=[report_digit],
adk web Simulator
قبل ربط هذا الجزء بقمرة قيادة السفينة المعقّدة (الواجهة الأمامية المستندة إلى React)، يجب اختبار منطق "الوكيل" بشكل منفصل. تتضمّن حزمة تطوير التطبيقات (ADK) وحدة تحكّم مدمجة للمطوّرين تُسمى adk web تتيح لنا التحقّق من ميزة "استدعاء الأدوات" قبل إضافة تعقيد الشبكة.
👉💻 في الوحدة الطرفية، شغِّل الأمر التالي:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- انقر على رمز معاينة الويب في شريط أدوات Cloud Shell. انقر على تغيير المنفذ، واضبطه على 8000، ثم انقر على تغيير ومعاينة.
- منح الأذونات: السماح بالوصول إلى الكاميرا والميكروفون عند الطلب
- ابدأ الجلسة بالنقر على رمز الكاميرا.
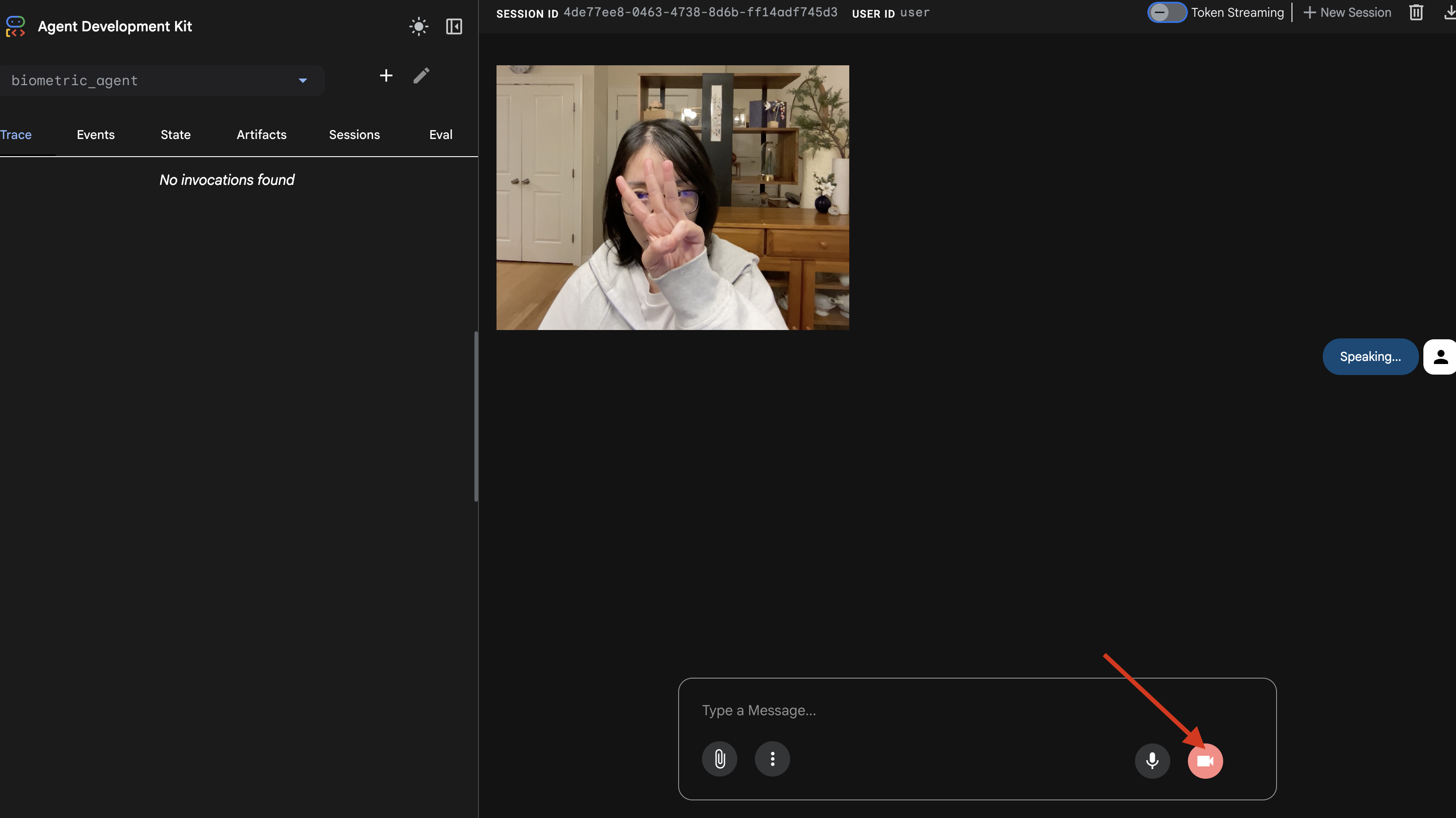
- الاختبار المرئي:
- ارفع 3 أصابع بوضوح أمام الكاميرا.
- قُل: "مسح ضوئي".
- التحقّق من النجاح:
- السجلات: اطّلِع على الوحدة الطرفية التي تنفِّذ الأمر
adk web. يجب أن يظهر لك السجلّ التالي:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- السجلات: اطّلِع على الوحدة الطرفية التي تنفِّذ الأمر
إذا ظهر لك سجلّ تنفيذ الأداة، يعني ذلك أنّ "الوكيل" ذكي. يمكنه الرؤية والتفكير والتصرّف، والخطوة الأخيرة هي ربطه بالسفينة الرئيسية.
انقر في نافذة المحطة الطرفية واضغط على Ctrl+C لإيقاف محاكي adk web.
5- مسار البث ثنائي الاتجاه
يعمل الوكيل. تعمل Cockpit. الآن، علينا ربطها.
مراحل النشاط لموظّف الدعم المباشر
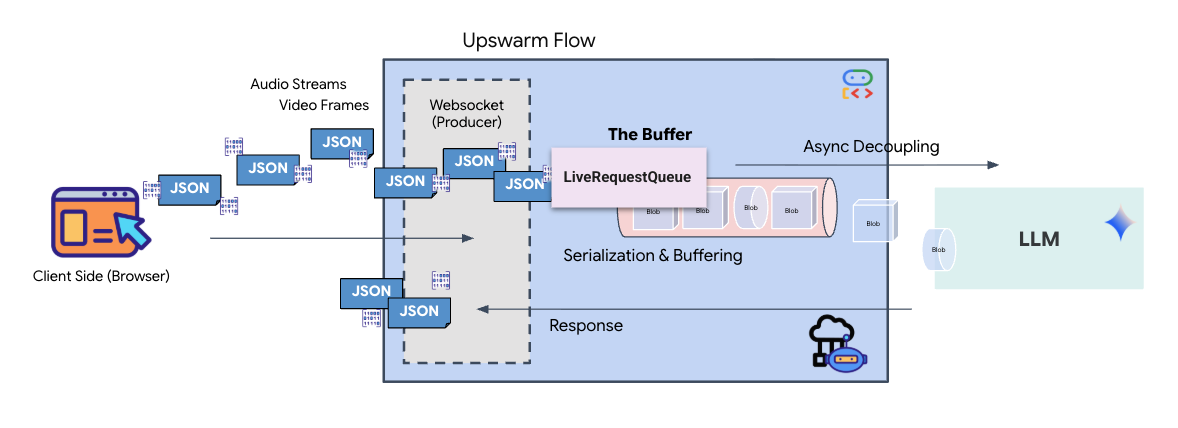
يؤدي البث في الوقت الفعلي إلى حدوث مشكلة "عدم تطابق المعاوقة". يدفع العميل (المتصفّح) البيانات بشكل غير متزامن بمعدّلات متغيرة، مثل دفعات الشبكة أو الإدخالات السريعة، بينما يتطلّب النموذج تدفقًا منظمًا ومتسلسلاً من الإدخالات. تحلّ "حزمة تطوير التطبيقات" من Google هذه المشكلة من خلال استخدام LiveRequestQueue.
يعمل هذا المخزن المؤقت كذاكرة تخزين مؤقت غير متزامنة وآمنة للاستخدام المتزامن، وتعتمد على مبدأ الأولوية للأسبق (FIFO). يعمل معالج WebSocket كمنتج، حيث يدفع أجزاء الصوت/الفيديو الأولية إلى قائمة الانتظار. يعمل ADK Agent كمستهلك، حيث يسحب البيانات من قائمة الانتظار لتعبئة قدرة استيعاب النموذج. يتيح هذا الفصل للتطبيق مواصلة تلقّي بيانات أدخلها المستخدم حتى أثناء إنشاء النموذج لردّ أو تنفيذ أداة.
يعمل قائمة الانتظار كمبدّل إرسال متعدد الوسائط. في بيئة حقيقية، يتألف مسار البيانات من المصدر من أنواع بيانات مميزة ومتزامنة: وحدات بايت صوتية بتنسيق PCM، وإطارات فيديو، وتعليمات نظام مستندة إلى النصوص، ونتائج من استدعاءات الأدوات غير المتزامنة. تعمل LiveRequestQueue على تحويل هذه المدخلات المختلفة إلى تسلسل زمني واحد. سواء كانت الحزمة تحتوي على جزء من الثانية من الصمت أو صورة عالية الدقة أو حمولة JSON من طلب بحث في قاعدة بيانات، يتم تسلسلها بالترتيب الدقيق لوصولها، ما يضمن أن يدرك النموذج جدولاً زمنيًا متسقًا وسببيًا.
تتيح هذه البنية التحكّم بدون حظر. بما أنّ طبقة الاستيعاب (المنتج) منفصلة عن طبقة المعالجة (المستهلك)، يظل النظام سريع الاستجابة حتى أثناء استنتاج النموذج المكلف حسابيًا. إذا قاطع المستخدم "الوكيل" بطلب "توقّف" أثناء تنفيذه لأداة، يتم وضع إشارة الصوت هذه في قائمة الانتظار على الفور. تعالج حلقة الأحداث الأساسية إشارة الأولوية هذه على الفور، ما يسمح للنظام بإيقاف عملية الإنشاء أو تغيير المهام بدون تجميد واجهة المستخدم أو إسقاط الحِزم.
👉💻 في $HOME/way-back-home/level_3/backend/app/main.py، ابحث عن التعليق #REPLACE_RUNNER_CONFIG واستبدِله بالرمز التالي لتفعيل النظام:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
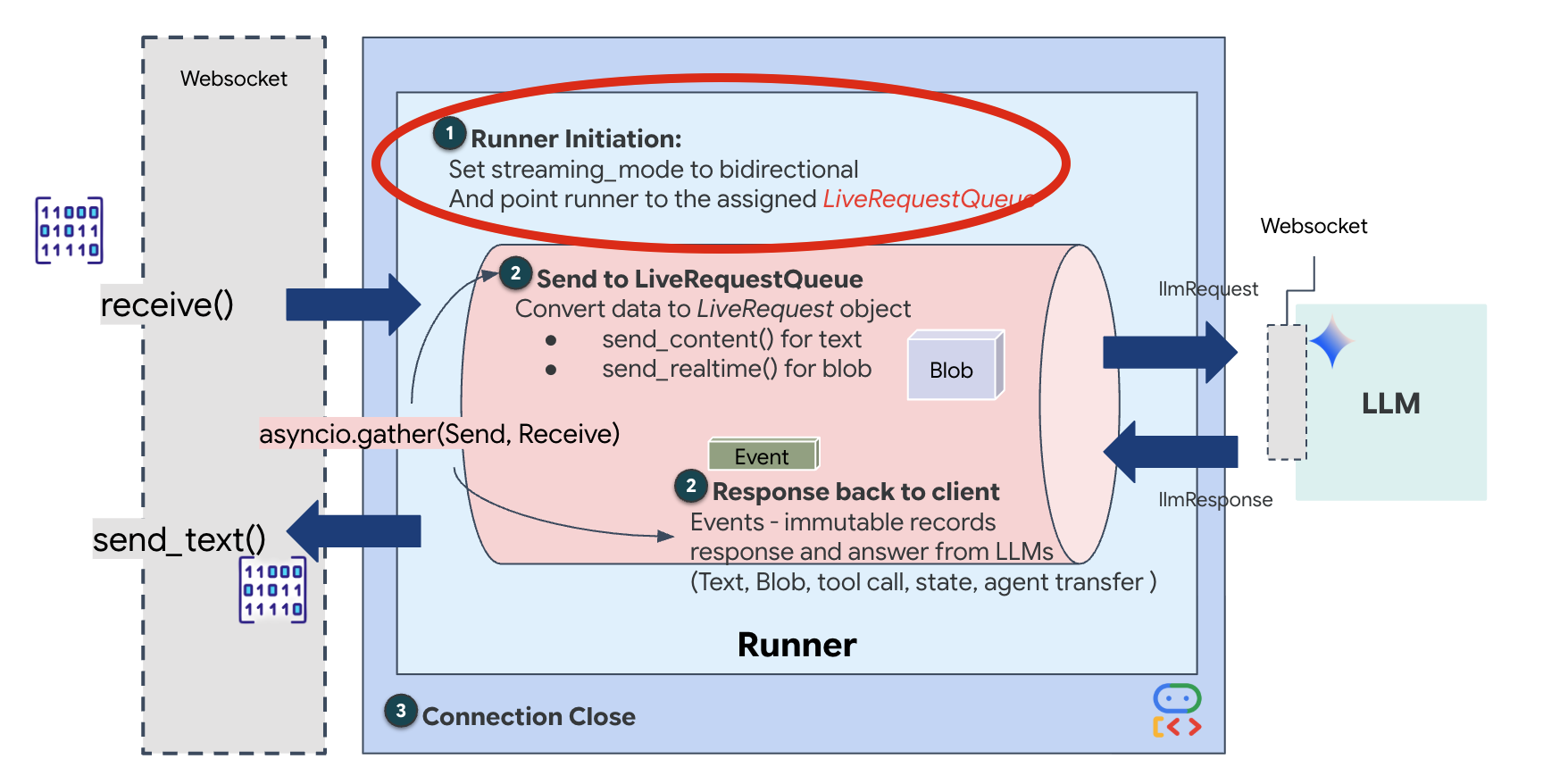
عند فتح اتصال WebSocket جديد، علينا ضبط طريقة تفاعل الذكاء الاصطناعي. هذا هو المكان الذي نحدّد فيه "قواعد المشاركة".
👉✏️ في $HOME/way-back-home/level_3/backend/app/main.py، داخل الدالة async def websocket_endpoint، استبدِل التعليق #REPLACE_SESSION_INIT بالرمز أدناه:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
إعدادات التشغيل
-
StreamingMode.BIDI: يضبط هذا الخيار الاتصال على ثنائي الاتجاه. على عكس الذكاء الاصطناعي "القائم على التناوب" (حيث تتحدث أنت، ثم تتوقف، ثم يتحدث هو)، يتيح الذكاء الاصطناعي ثنائي الاتجاه إجراء محادثة "ثنائية الاتجاه" واقعية. يمكنك مقاطعة الذكاء الاصطناعي، ويمكنه التحدث أثناء تحرّكك. -
AudioTranscriptionConfig: على الرغم من أنّ النموذج "يسمع" الصوت الخام، إلا أنّنا (المطوّرين) نحتاج إلى الاطّلاع على السجلات. يخبر هذا الإعداد Gemini بما يلي: "عالِج الصوت، ولكن أرسِل أيضًا نسخة نصية لما سمعته حتى نتمكّن من تصحيح الأخطاء".
منطق التنفيذ بعد أن ينشئ Runner الجلسة، ينقل التحكّم إلى منطق التنفيذ الذي يعتمد على LiveRequestQueue. هذا هو العنصر الأكثر أهمية للتفاعل في الوقت الفعلي. تسمح الحلقة للوكيل بإنشاء ردّ صوتي بينما يواصل الصف قبول إطارات فيديو جديدة من المستخدم، ما يضمن عدم انقطاع "المزامنة العصبية" أبدًا.
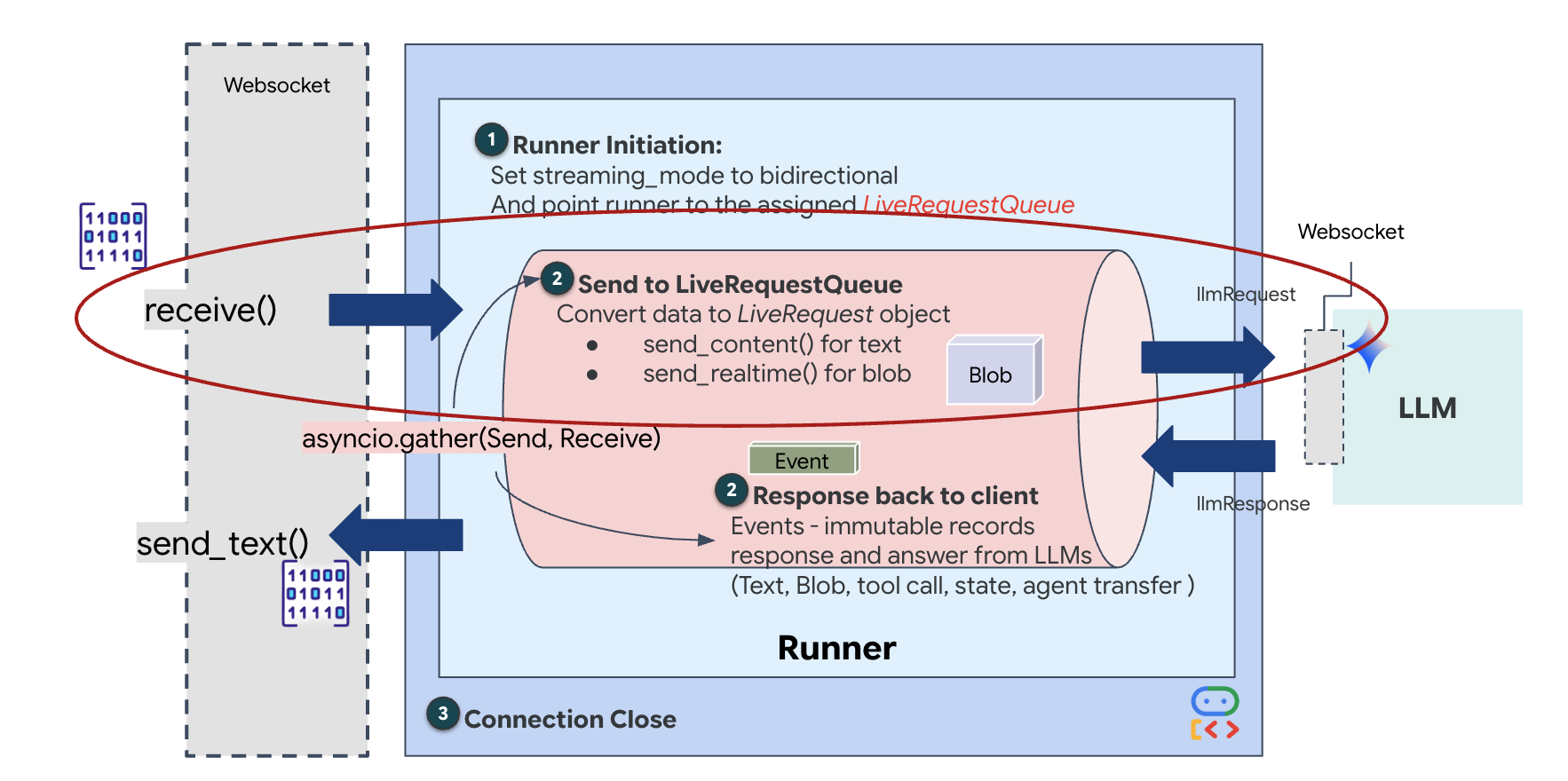
👉✏️ في $HOME/way-back-home/level_3/backend/app/main.py، استبدِل #REPLACE_LIVE_REQUEST لتحديد مهمة المصدر التي ترسل البيانات إلى LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
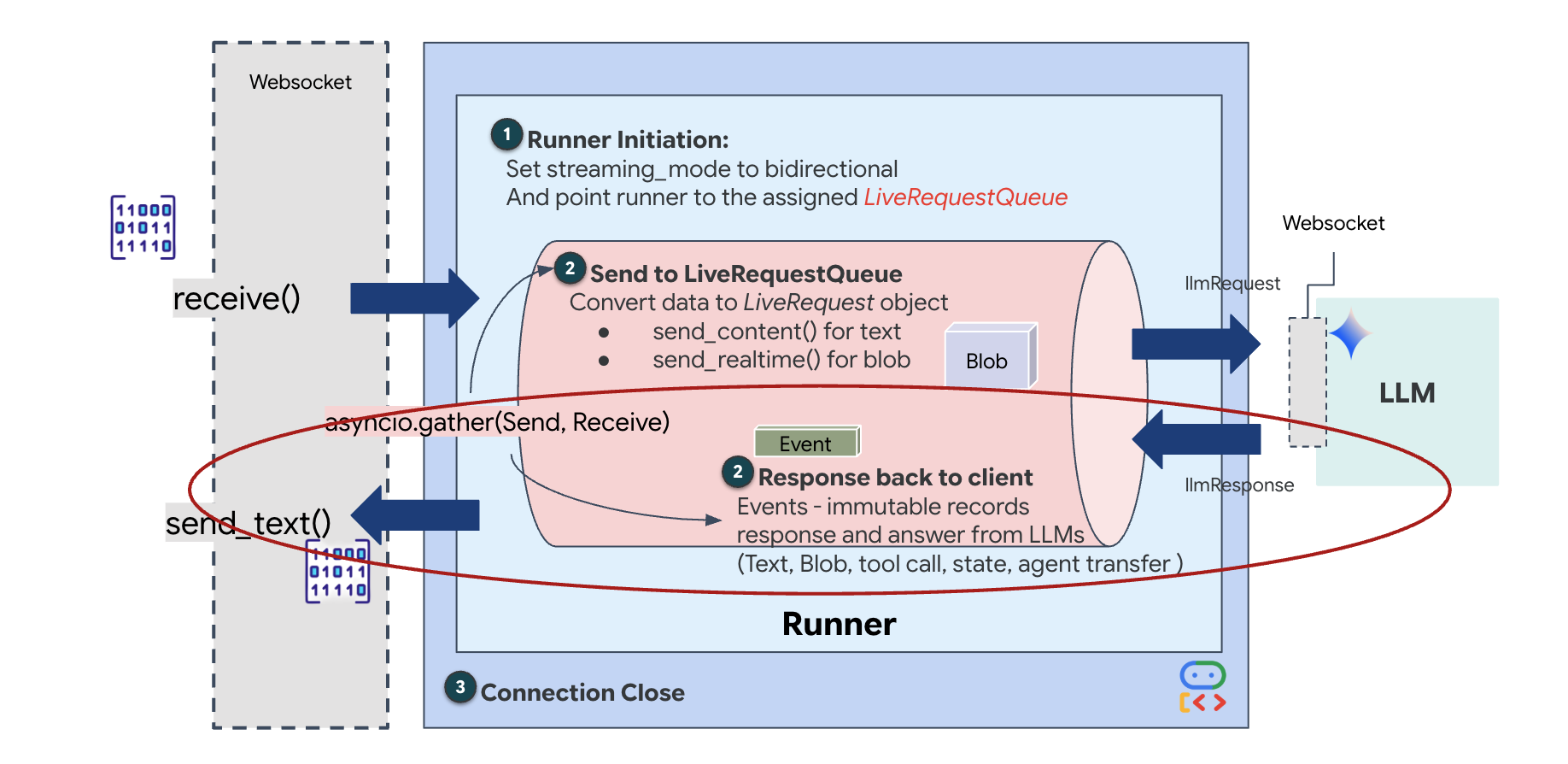
أخيرًا، علينا التعامل مع ردود الذكاء الاصطناعي. يستخدم هذا الإعداد runner.run_live()، وهو أداة لإنشاء الأحداث تعرض الأحداث (الصوت أو النص أو طلبات الأدوات) عند حدوثها.
👉✏️ في $HOME/way-back-home/level_3/backend/app/main.py، استبدِل #REPLACE_SORT_RESPONSE لتحديد المهمة النهائية ومدير التزامن:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
لاحظ السطر await asyncio.gather(upstream_task(), downstream_task()). هذا هو جوهر الاتصال المزدوج الاتجاه. ننفّذ مهمة الاستماع (في اتجاه المصدر) ومهمة التحدث (في اتجاه المستهلك) في الوقت نفسه تمامًا. يضمن ذلك أنّ "الرابط العصبي" يتيح إمكانية المقاطعة وتدفّق البيانات في الوقت نفسه.
تم الآن ترميز الخلفية بالكامل. يتم ربط "الدماغ" (ADK) بـ "الجسم" (WebSocket).
تنفيذ Bio-Sync
الرمز مكتمل. تكون الأنظمة باللون الأخضر. حان الوقت لبدء عملية الإنقاذ.
- 👉💻 بدء الخلفية:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 تشغيل الواجهة الأمامية:
- انقر على رمز معاينة الويب في شريط أدوات Cloud Shell. انقر على تغيير المنفذ، واضبطه على 8080، ثم انقر على تغيير ومعاينة.
- 👉 تنفيذ البروتوكول:
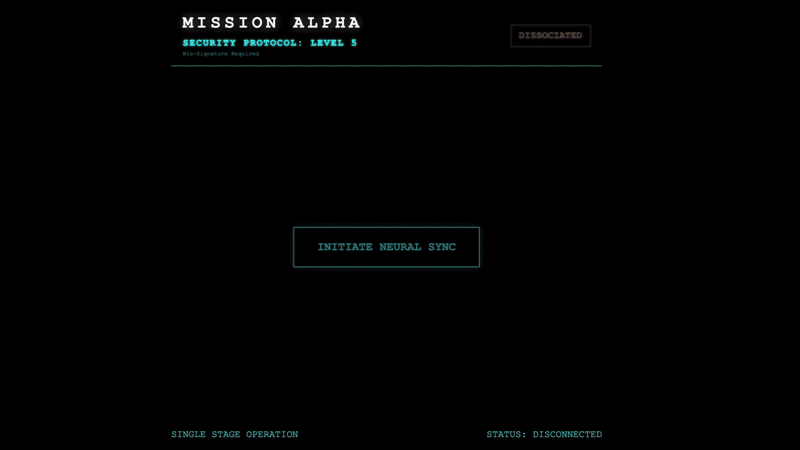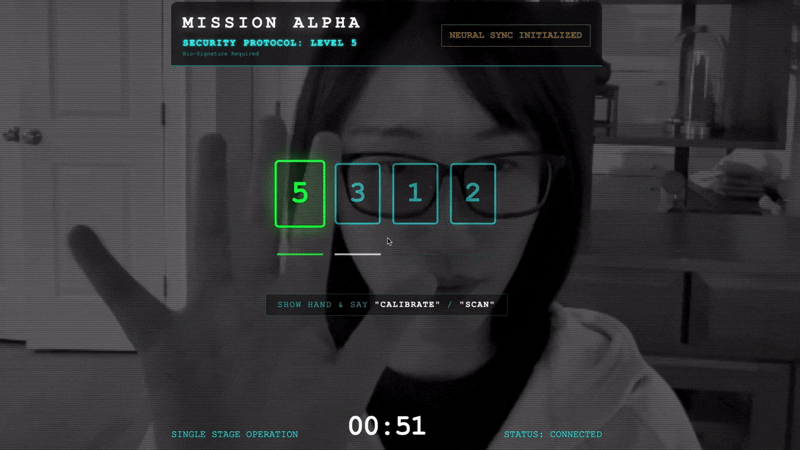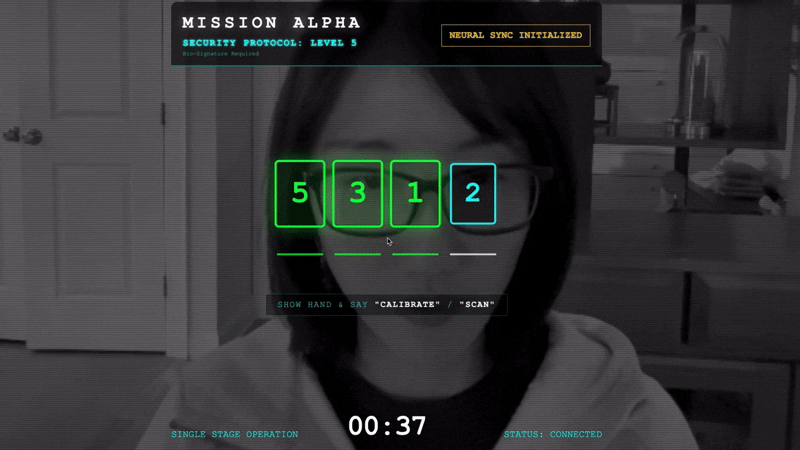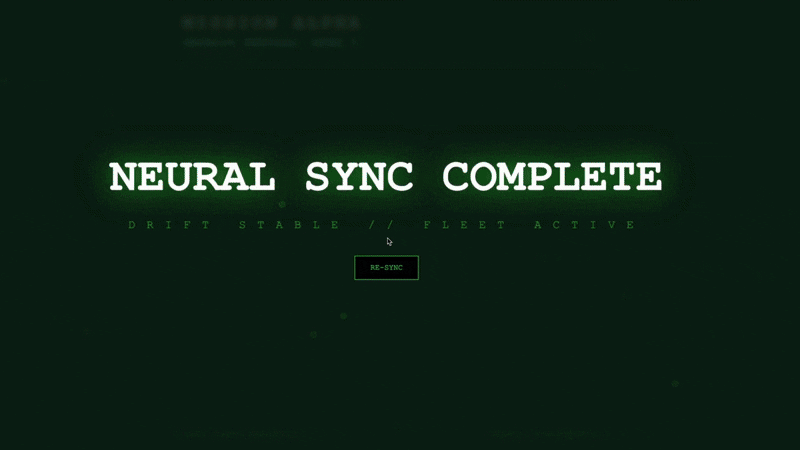
- انقر على "بدء المزامنة العصبية".
- المعايرة: تأكَّد من أنّ الكاميرا ترى يدك بوضوح على الخلفية.
- المزامنة: شاهِد رمز الأمان المعروض على الشاشة (مثلاً، 3، ثم 2، ثم 5).
- مطابقة الإشارة: عندما يظهر رقم، ارفع عدد الأصابع نفسه.
- تثبيت اليد: أبقِ يدك مرئية إلى أن تؤكّد تكنولوجيات الذكاء الاصطناعي "المطابقة البيومترية".
- التكيّف: الرمز عشوائي. بدِّل على الفور إلى الرقم التالي المعروض إلى أن يكتمل التسلسل.

- عند مطابقة الرقم الأخير في التسلسل العشوائي، ستكتمل عملية "مزامنة المقاييس الحيوية". سيتم قفل الرابط العصبي. يمكنك التحكّم يدويًا. ستنطلق مركبات الاستطلاع في رحلة إلى الوادي العميق لإعادة الناجين إلى ديارهم.
👉💻 اضغط على Ctrl+C في نافذة الخلفية الطرفية للخروج.
6. النشر في الإصدار العلني (اختياري)
لقد اختبرت المقاييس الحيوية بنجاح على جهازك. الآن، علينا تحميل النواة العصبية للعميل إلى الحواسيب المركزية للسفينة (Cloud Run) حتى تتمكّن من العمل بشكل مستقل عن وحدة التحكّم المحلية.
👉💻 شغِّل الأمر التالي في وحدة Cloud Shell الطرفية. سيؤدي ذلك إلى إنشاء ملف Dockerfile كامل ومتعدّد المستويات في دليل الخلفية.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 انتقِل إلى دليل الخلفية وحوِّل التطبيق إلى صورة حاوية.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 نشر الخدمة على Cloud Run سنضيف متغيرات البيئة اللازمة، وتحديدًا إعدادات Gemini، مباشرةً إلى أمر التشغيل.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
بعد انتهاء تنفيذ الأمر، سيظهر لك عنوان URL للخدمة (مثل https://biometric-scout-...run.app). أصبح التطبيق الآن متاحًا على السحابة الإلكترونية.
👉 انتقِل إلى صفحة Google Cloud Run واختَر خدمة Biometric-scout من القائمة. 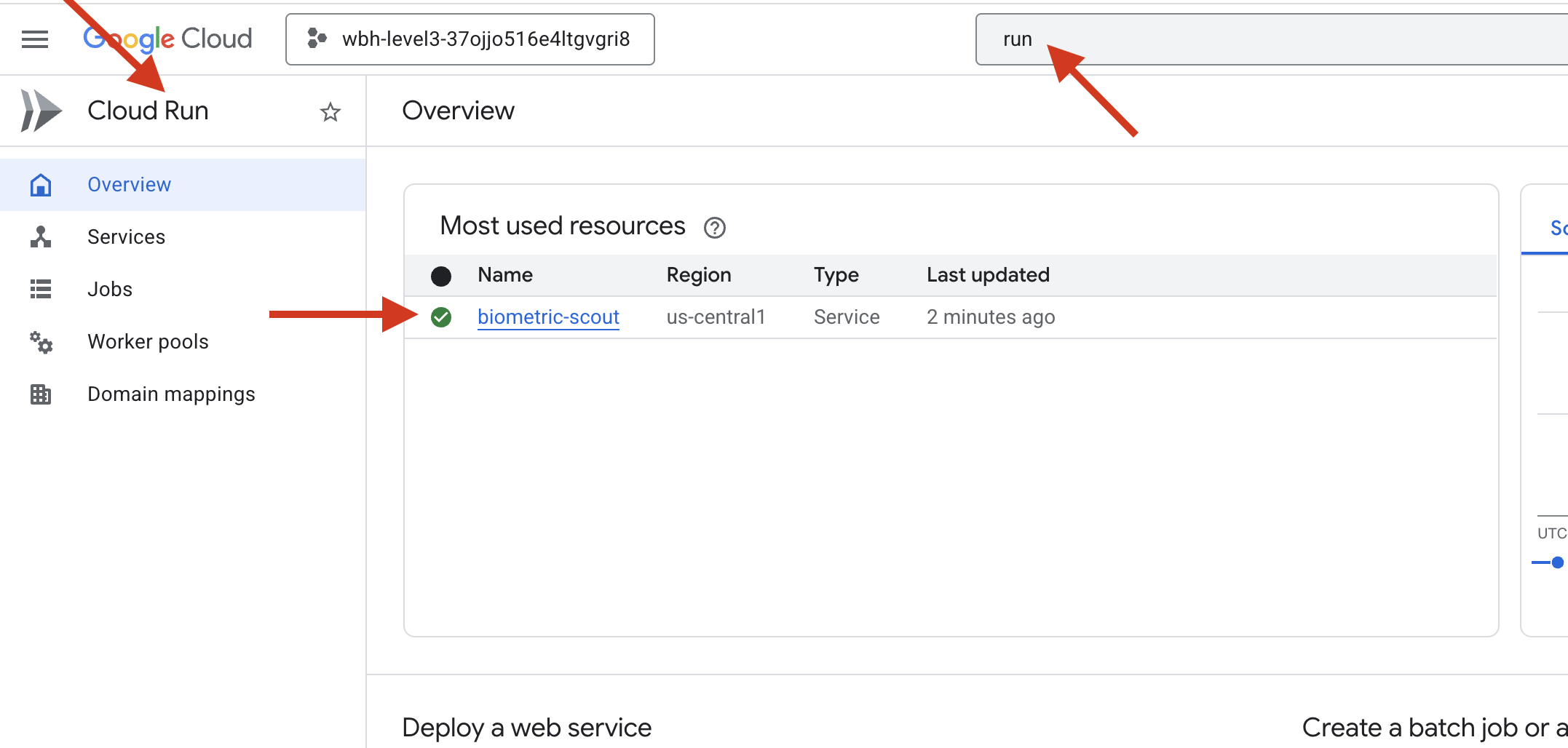
👉 ابحث عن عنوان URL العام المعروض في أعلى صفحة "تفاصيل الخدمة". 
جرِّب إجراء Bio-Sync في هذه البيئة، هل تعمل أيضًا؟
عندما تمدّد إصبعك الخامس، يقفل الذكاء الاصطناعي التسلسل. تومض الشاشة باللون الأخضر: "Biometric Neural Sync: ESTABLISHED".
بفكرة واحدة، يمكنك توجيه "المستكشف" (Scout) إلى الظلام، والتشبّث بالمركبة العالقة، وإخراجها قبل أن ينهار تمزّق الجاذبية.

يصدر صوت أزيز عند فتح قفل غرفة معادلة الضغط، ويظهرون هناك، خمسة ناجين يتنفسون. يتعثّرون على سطح السفينة، وقد أصيبوا بجروح لكنّهم على قيد الحياة، وأصبحوا في أمان أخيرًا بفضلك.
بفضل مساعدتك، تمت مزامنة الرابط العصبي وإنقاذ الناجين.
إذا شاركت في المستوى 0، لا تنسَ التحقّق من مستوى تقدّمك في مهمة "العودة إلى الوطن".