1. La mission

Vous dérivez dans le silence d'un secteur inexploré. Une énorme **impulsion solaire** a déchiré votre vaisseau à travers une faille, vous laissant bloqué dans une poche de l'univers qui n'existe sur aucune carte stellaire.
Après des jours de réparations épuisantes, vous sentez enfin le ronronnement des moteurs sous vos pieds. Votre fusée est réparée. Vous avez même réussi à établir une liaison montante longue distance avec le vaisseau-mère. Vous êtes autorisé à décoller. Vous êtes prêt à rentrer chez vous. Mais alors que vous vous préparez à engager le lecteur de saut, un signal de détresse perce la statique. Vos capteurs détectent cinq faibles signatures thermiques piégées dans La Ravine, un secteur déchiqueté et déformé par la gravité dans lequel votre vaisseau principal ne peut jamais entrer. Ce sont d'autres explorateurs, des survivants de la même tempête qui a failli vous emporter. Vous ne pouvez pas les laisser derrière vous.
Vous vous tournez vers votre Alpha-Drone Rescue Scout. Ce petit navire agile est le seul capable de naviguer entre les parois étroites du Ravin. Mais il y a un problème : l'impulsion solaire a effectué une "réinitialisation du système" totale sur sa logique de base. Les systèmes de contrôle de Scout ne répondent pas. Il est allumé, mais son ordinateur de bord est une ardoise vierge, incapable de traiter les commandes manuelles du pilote ou les trajectoires de vol.
Le défi
Pour sauver les survivants, vous devez contourner complètement les circuits endommagés de l'éclaireur. Il ne vous reste qu'une seule option désespérée : créer un agent IA pour établir une synchronisation neuronale biométrique. Cet agent servira de passerelle en temps réel, vous permettant de contrôler le Rescue Scout manuellement grâce à vos propres entrées biologiques. Vous n'utiliserez pas de joystick ni de clavier. Vous allez câbler votre intention directement dans le réseau de navigation du vaisseau.
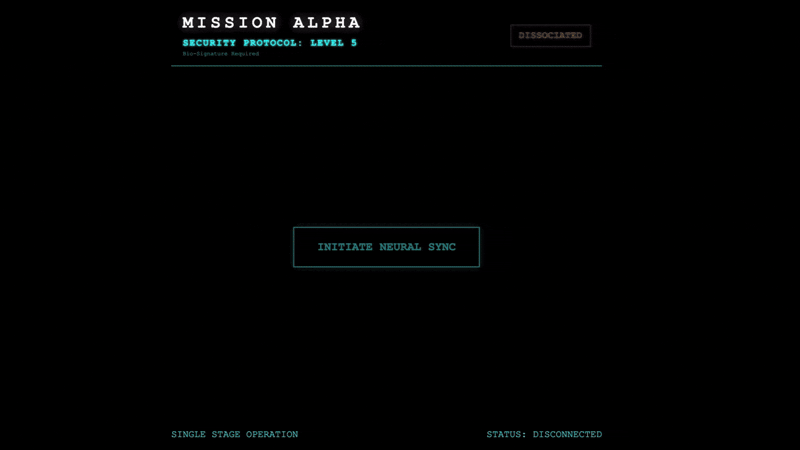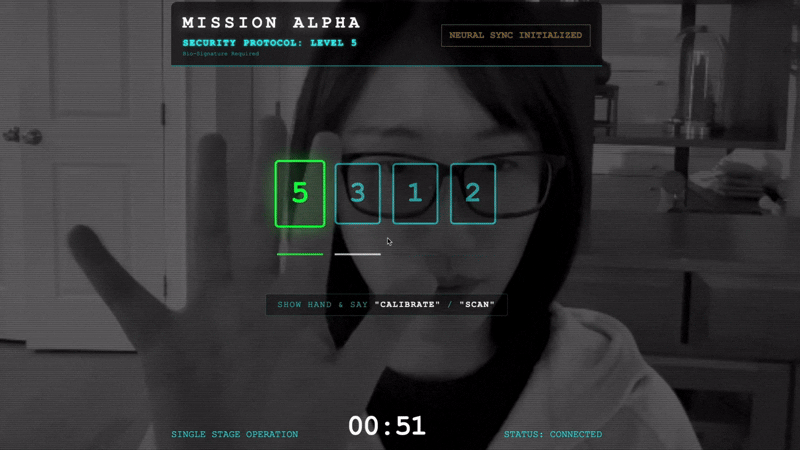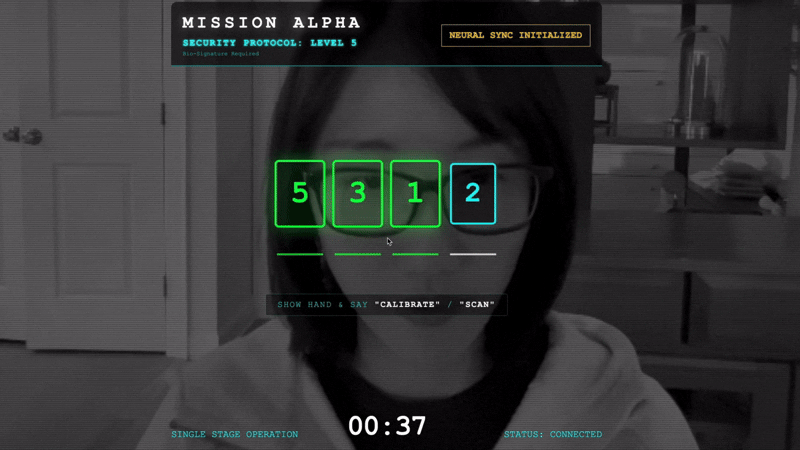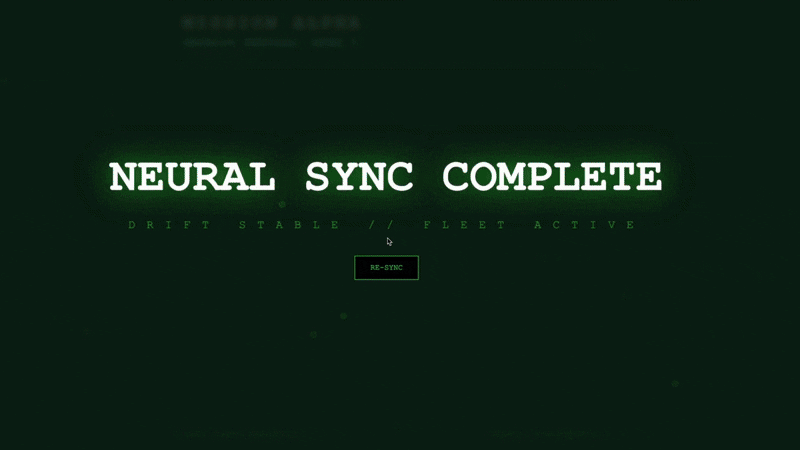
Pour verrouiller l'association, vous devez effectuer le protocole de synchronisation devant les capteurs optiques de Scout. L'agent IA doit reconnaître votre signature biologique grâce à une authentification précise en temps réel.
Objectifs de la mission :
- Imprégnez le Neural Core : définissez un agent ADK capable de reconnaître les entrées multimodales.
- Établissez la connexion : créez un pipeline WebSocket bidirectionnel pour diffuser des données visuelles du Scout vers l'IA.
- Initiez le handshake : placez-vous devant le capteur et effectuez la séquence de doigts (de 1 à 5 dans l'ordre).
Si l'opération réussit, la synchronisation biométrique s'active. L'IA verrouillera le lien neural, ce qui vous permettra de contrôler manuellement le Scout pour lancer la mission et ramener les survivants chez eux.
Objectifs de l'atelier
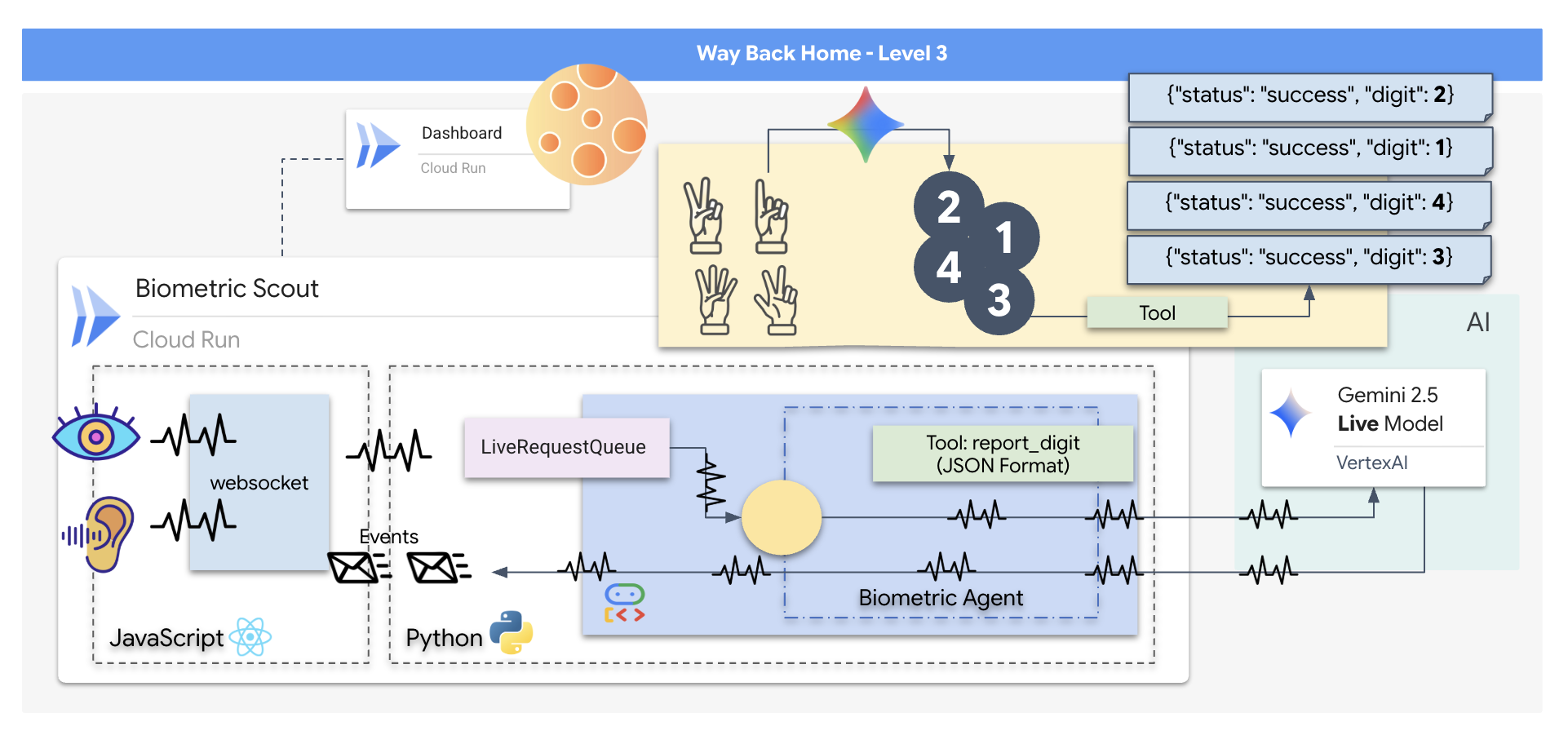
Vous allez créer une application "Biometric Neural Sync", un système en temps réel basé sur l'IA qui sert d'interface de contrôle pour un drone de sauvetage. Ce système comprend :
- Interface utilisateur React : le "cockpit" de votre vaisseau, qui capture la vidéo en direct de votre webcam et l'audio de votre micro.
- Un backend Python : serveur hautes performances conçu avec FastAPI, utilisant l'Agent Development Kit (ADK) de Google pour gérer la logique et l'état du LLM.
- Un agent d'IA multimodal : le "cerveau" de l'opération, qui utilise l'API Gemini Live via le SDK
google-genaipour traiter et comprendre simultanément les flux vidéo et audio. - Pipeline WebSocket bidirectionnel : le "système nerveux" qui crée une connexion persistante à faible latence entre l'interface utilisateur et l'IA, permettant une interaction en temps réel.
Objectifs de l'atelier
Technologie / Concept | Description |
Agent d'IA de backend | Créez un agent d'IA avec état à l'aide de Python et FastAPI. Utilisez le kit de développement d'agent (ADK) de Google pour gérer les instructions et la mémoire, et le SDK |
Interface utilisateur du frontend | Développez une interface utilisateur dynamique à l'aide de React pour capturer et diffuser des vidéos et de l'audio en direct depuis le navigateur. |
Communication en temps réel | Implémentez un pipeline WebSocket pour une communication full-duplex à faible latence, permettant à l'utilisateur et à l'IA d'interagir simultanément. |
IA multimodale | Exploitez l'API Gemini Live pour traiter et comprendre les flux vidéo et audio simultanés, ce qui permet à l'IA de "voir" et d'"entendre" en même temps. |
Appel d'outils | Permettez à l'IA d'exécuter des fonctions Python spécifiques en réponse à des déclencheurs visuels, comblant ainsi le fossé entre l'intelligence du modèle et l'action dans le monde réel. |
Déploiement Full Stack | Conteneurisez l'intégralité de l'application (interface React et backend Python) avec Docker, puis déployez-la en tant que service évolutif sans serveur sur Google Cloud Run. |
2. Configurer votre environnement
Accéder à Cloud Shell
Nous allons commencer par ouvrir Cloud Shell, un terminal basé sur navigateur avec le SDK Google Cloud et d'autres outils essentiels préinstallés.
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell), 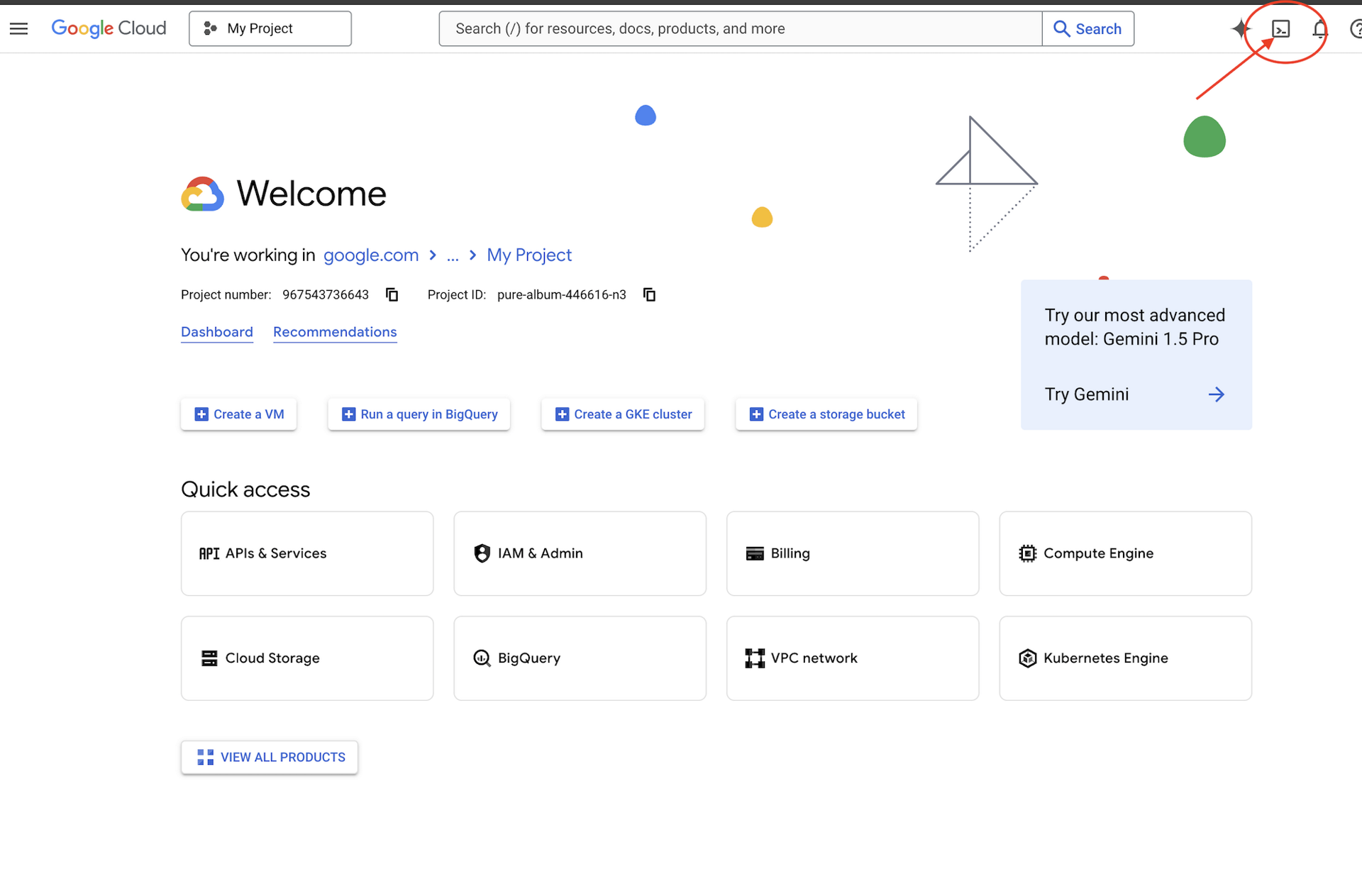
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 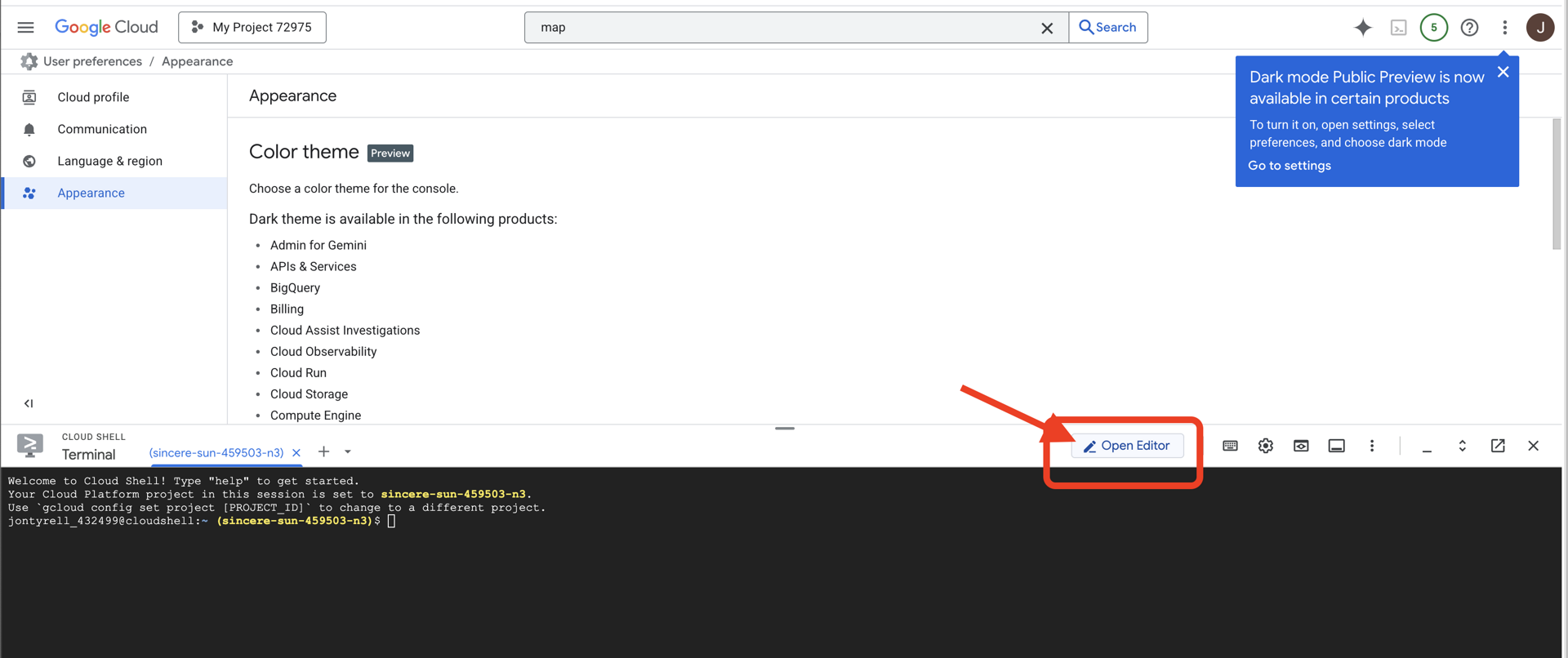
👉 Ouvrez le terminal dans l'IDE cloud.
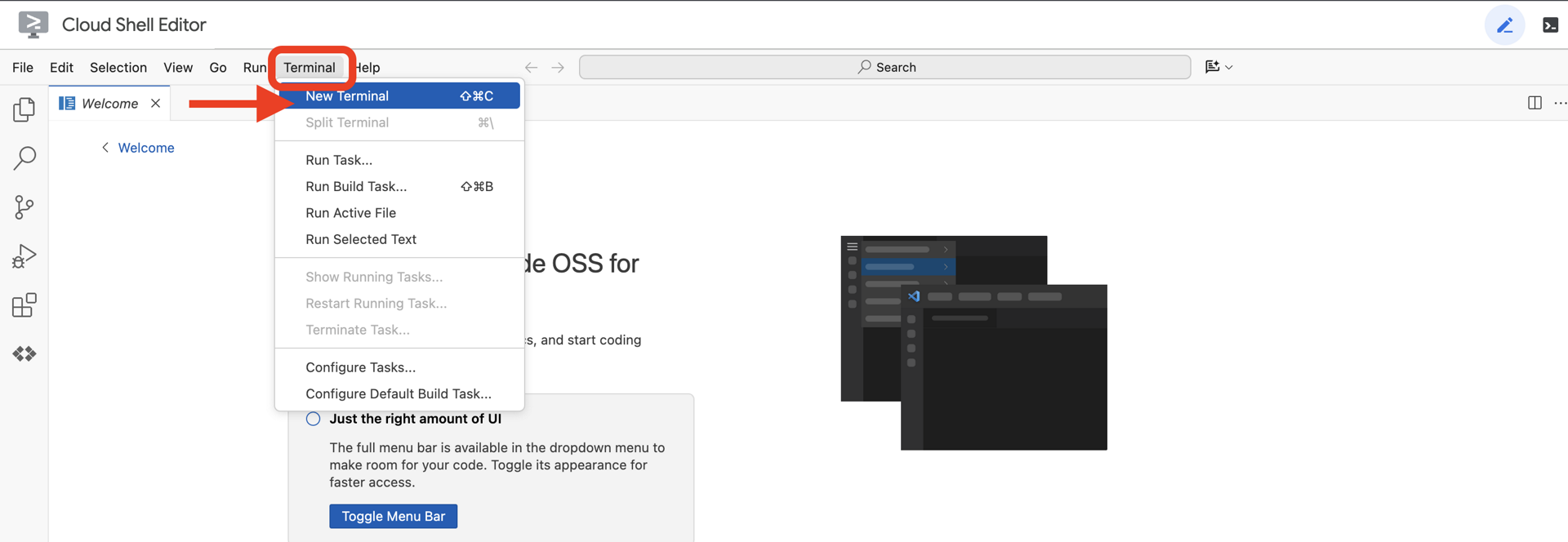
👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
Votre compte devrait être listé comme (ACTIVE).
Prérequis
ℹ️ Le niveau 0 est facultatif (mais recommandé)
Vous pouvez terminer cette mission sans le niveau 0, mais la terminer en premier vous offrira une expérience plus immersive, vous permettant de voir votre balise s'allumer sur la carte du monde à mesure que vous progressez.
Configurer l'environnement du projet
De retour dans votre terminal, finalisez la configuration en définissant le projet actif et en activant les services Google Cloud requis (Cloud Run, Vertex AI, etc.).
👉💻 Dans votre terminal, définissez l'ID du projet :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉 💻 Activez les services requis :
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Installer des dépendances
👉💻 Accédez à Level et installez les packages Python requis :
cd $HOME/way-back-home/level_3
uv sync
Voici les principales dépendances :
Package | Objectif |
| Framework Web hautes performances pour la station satellite et le streaming SSE |
| Serveur ASGI requis pour exécuter l'application FastAPI |
| Agent Development Kit utilisé pour créer l'agent de formation |
| Client natif pour accéder aux modèles Gemini |
| Prise en charge de la communication bidirectionnelle en temps réel |
| Gère les variables d'environnement et les secrets de configuration |
Vérifier la configuration
Avant de nous lancer dans le code, assurons-nous que tous les systèmes sont opérationnels. Exécutez le script de validation pour auditer votre projet Google Cloud, vos API et vos dépendances Python.
👉💻 Exécutez le script de validation :
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Une série de coches vertes (✅) devrait s'afficher.
- Si vous voyez des croix rouges (❌), suivez les commandes de correction suggérées dans le résultat (par exemple,
gcloud services enable ...oupip install ...). - Remarque : Un avertissement jaune pour
.envest acceptable pour le moment. Nous créerons ce fichier à l'étape suivante.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Calibrer le Comm-Link (WebSockets)
Pour commencer la synchronisation neuronale biométrique, nous devons mettre à jour les systèmes internes de votre vaisseau. Notre objectif principal est de capturer un flux vidéo et audio haute fidélité depuis votre cockpit. Ce flux fournit les composants essentiels du lien neuronal : l'identification visuelle de vos séquences de doigts et la fréquence sonore de votre voix.
Full-duplex et semi-duplex
Pour comprendre pourquoi nous en avons besoin pour la synchronisation neuronale, vous devez comprendre le flux de données :
- Semi-duplex (HTTP standard) : comme un talkie-walkie. Une personne parle, dit "Terminé", puis l'autre personne peut parler. Vous ne pouvez pas écouter et parler en même temps.
- Full-duplex (WebSocket) : comme une conversation en face à face. Les données circulent simultanément dans les deux sens. Pendant que votre navigateur envoie des images vidéo et des échantillons audio à l'IA, celle-ci peut vous envoyer des réponses vocales et des commandes d'outils en même temps.
Pourquoi Gemini Live a-t-il besoin du mode duplex intégral ? L'API Gemini Live est conçue pour l'interruption. Imaginez que vous montrez la séquence de doigts et que l'IA voit que vous vous trompez. Dans une configuration HTTP standard, l'IA devrait attendre que vous ayez fini d'envoyer vos données avant de vous dire d'arrêter. Avec WebSockets, l'IA peut détecter une erreur dans le frame 1 et envoyer un signal d'interruption qui arrive dans votre cockpit pendant que vous déplacez encore votre main pour le frame 2.
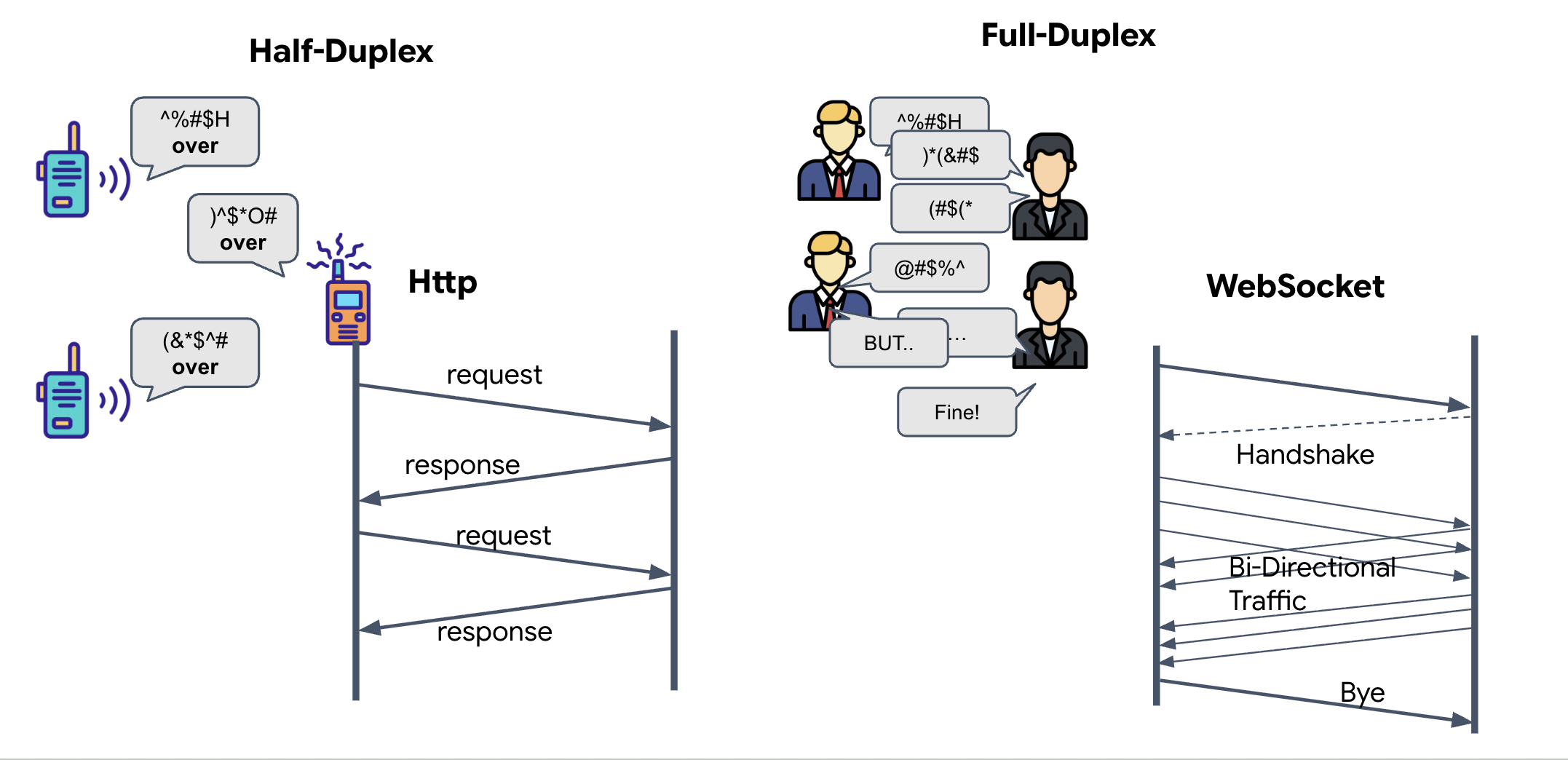
Qu'est-ce qu'un WebSocket ?
Dans une transmission galactique standard (HTTP), vous envoyez une requête et attendez une réponse, comme si vous envoyiez une carte postale. Pour une synchronisation neuronale, les cartes postales sont trop lentes. Nous avons besoin d'un "fil sous tension".
Les WebSockets commencent par une requête Web standard (HTTP), mais sont ensuite "mises à niveau" vers quelque chose de différent.
- La requête : votre navigateur envoie une requête HTTP standard au serveur avec un en-tête spécial :
Upgrade: websocket. En d'autres termes, vous dites : "J'aimerais arrêter d'envoyer des cartes postales et commencer une conversation téléphonique en direct." - La réponse : si l'agent d'IA (le serveur) accepte cette requête, il renvoie une réponse
HTTP 101 Switching Protocols. - La transformation : à ce moment-là, la connexion HTTP est remplacée par le protocole WebSocket, mais le socket TCP/IP sous-jacent reste ouvert. Les règles de communication passent instantanément de "Demande/Réponse" à "Streaming en duplex intégral".
Implémenter le hook WebSocket
Inspectons le bloc de terminal pour comprendre comment les données circulent.
👀 Ouvrez $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Vous verrez que les gestionnaires d'événements de cycle de vie WebSocket standards sont déjà configurés. Voici le squelette de notre système de communication :
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Gestionnaire onMessage
Concentrez-vous sur le bloc ws.current.onmessage. Il s'agit du receveur. Chaque fois que l'agent "pense" ou "parle", un paquet de données arrive ici. Actuellement, il ne fait rien : il capture le paquet et le supprime (via le code de substitution //#REPLACE-HANDLE-MSG).
Nous devons combler ce vide avec une logique capable de faire la distinction entre :
- Appels d'outils (functionCall) : l'IA reconnaît vos gestes (la synchronisation).
- Données audio (inlineData) : la voix de l'IA qui vous répond.
👉✏️ Maintenant, dans le même fichier $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, remplacez //#REPLACE-HANDLE-MSG par la logique ci-dessous pour gérer le flux entrant :
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Comment l'audio et la vidéo sont-ils transformés en données pour la transmission ?
Pour permettre la communication en temps réel sur Internet, les contenus audio et vidéo bruts doivent être convertis dans un format adapté à la transmission. Cela implique de capturer, d'encoder et d'empaqueter les données avant de les envoyer sur un réseau.
Transformation des données audio
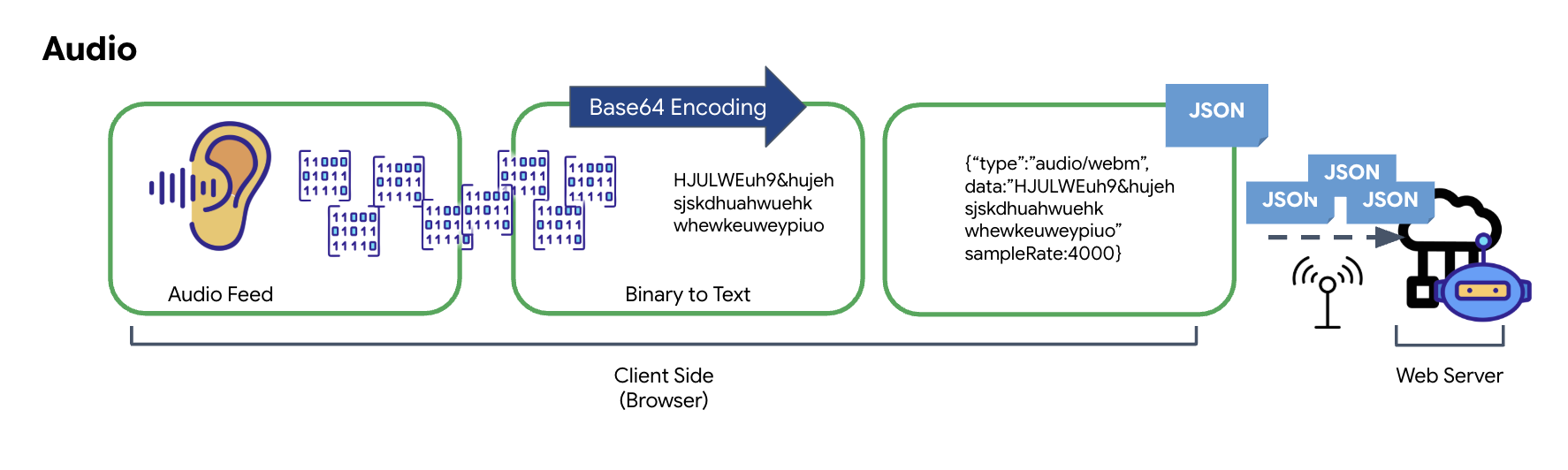
Le processus de conversion de l'audio analogique en données numériques transmissibles commence par la capture des ondes sonores à l'aide d'un micro. Cet audio brut est ensuite traité par l'API Web Audio du navigateur. Comme ces données brutes sont au format binaire, elles ne sont pas directement compatibles avec les formats de transmission textuels tels que JSON. Pour résoudre ce problème, chaque segment audio est encodé en chaîne Base64. Base64 est une méthode qui représente les données binaires au format chaîne ASCII, ce qui garantit leur intégrité lors de la transmission.
Cette chaîne encodée est ensuite intégrée dans un objet JSON. Cet objet fournit un format structuré pour les données, incluant généralement un champ "type" pour l'identifier comme audio et des métadonnées telles que le taux d'échantillonnage de l'audio. L'intégralité de l'objet JSON est ensuite sérialisée en chaîne et envoyée via une connexion WebSocket. Cette approche garantit que l'audio est transmis de manière bien organisée et facilement analysable.
Transformation des données vidéo
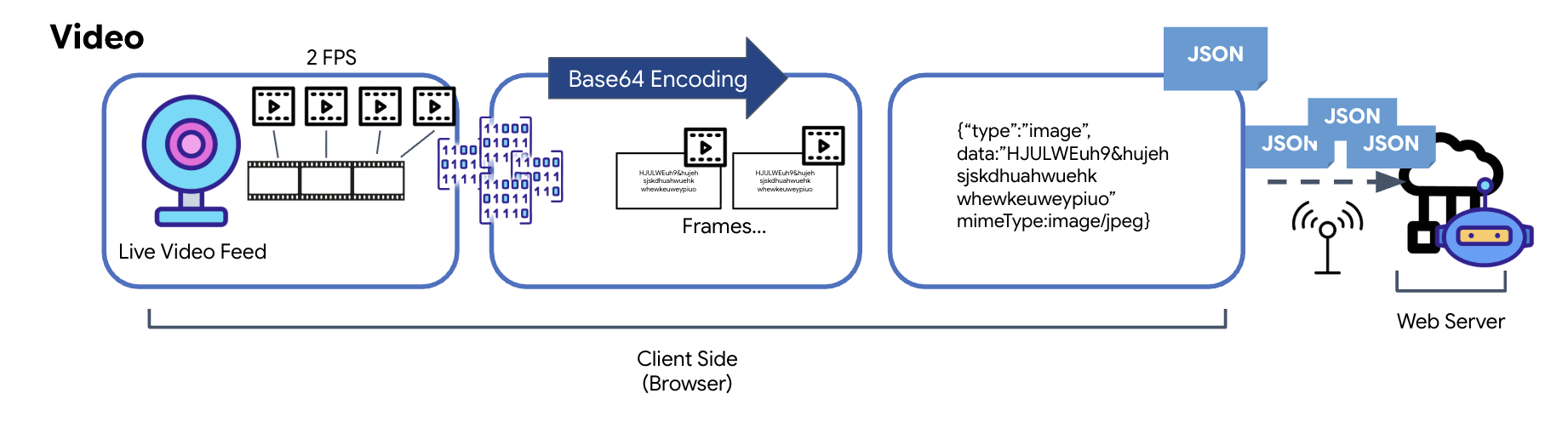
La transmission vidéo est assurée par une technique de capture d'images. Au lieu d'envoyer un flux vidéo continu, une boucle récurrente capture des images fixes à partir du flux vidéo en direct à un intervalle défini, par exemple deux images par seconde. Pour ce faire, le frame actuel d'un élément vidéo HTML est dessiné sur un élément de canevas masqué.
La méthode toDataURL du canevas est ensuite utilisée pour convertir cette image capturée en chaîne JPEG encodée en base64. Cette méthode inclut une option permettant de spécifier la qualité de l'image, ce qui permet de trouver un équilibre entre la fidélité de l'image et la taille du fichier pour optimiser les performances. Comme pour les données audio, cette chaîne Base64 est ensuite placée dans un objet JSON. Cet objet est généralement associé au type "image" et inclut le mimeType, tel que "image/jpeg". Ce paquet JSON est ensuite converti en chaîne et envoyé via le WebSocket, ce qui permet à l'extrémité de réception de reconstruire la vidéo en affichant la séquence d'images.
👉✏️ Dans le même fichier $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, remplacez //#CAPTURE AUDIO and VIDEO par ce qui suit pour capturer la saisie de l'utilisateur :
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Une fois enregistré, le cockpit sera prêt à traduire les signaux numériques de l'agent en mises à jour visuelles du tableau de bord et en audio.
Diagnostic (test de boucle)
Votre cockpit est désormais disponible. Toutes les 500 ms, un "paquet" visuel de votre environnement est transmis. Avant de vous connecter à Gemini, nous devons vérifier que l'émetteur de votre navire fonctionne. Nous allons exécuter un "test de bouclage" à l'aide d'un serveur de diagnostic local.
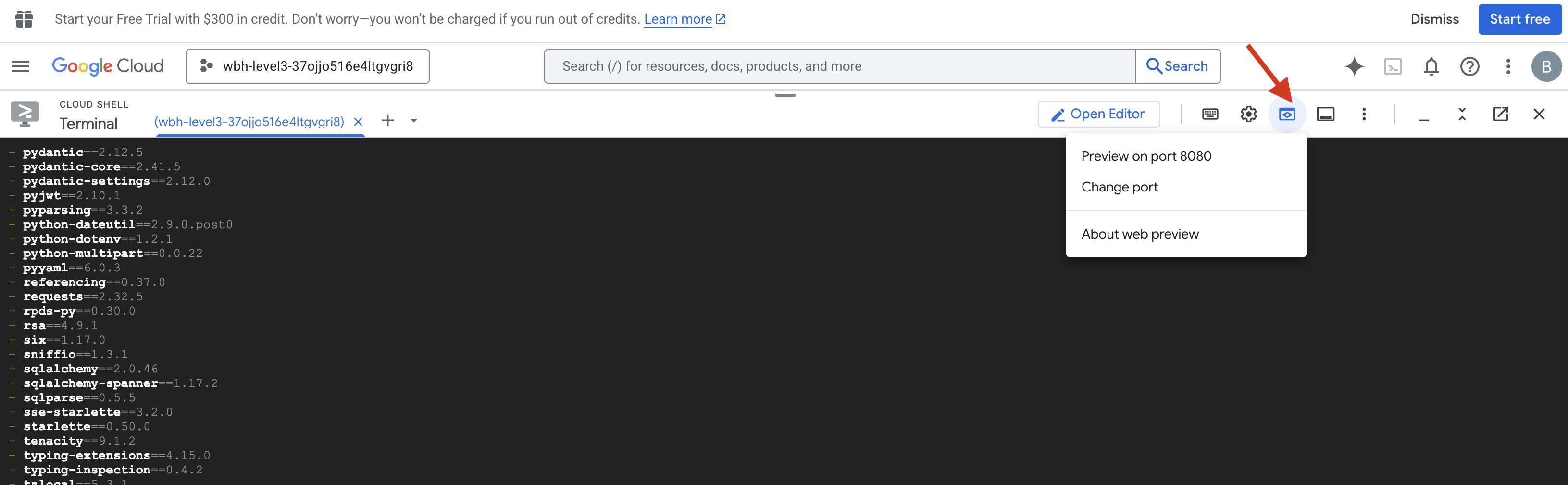
👉💻 Commencez par compiler l'interface Cockpit depuis votre terminal :
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Ensuite, démarrez le serveur fictif :
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Exécutez le protocole de test :
- Ouvrez l'aperçu : cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell. Sélectionnez Modifier le port, définissez-le sur 8080, puis cliquez sur Modifier et prévisualiser. Un nouvel onglet de navigateur s'ouvre et affiche l'interface Cockpit.
- CRITIQUE : Lorsque vous y êtes invité, vous DEVEZ autoriser le navigateur à accéder à votre caméra et à votre micro. Sans ces entrées, la synchronisation neuronale ne peut pas démarrer.
- Cliquez sur le bouton INITIATE NEURAL SYNC (LANCER LA SYNCHRONISATION NEURONALE) dans l'interface utilisateur.
👀 Vérifiez les indicateurs d'état :
- Vérification visuelle : ouvrez la console de votre navigateur. L'icône
NEURAL SYNC INITIALIZEDdoit s'afficher en haut à droite. - Test audio : si votre pipeline audio bidirectionnel est entièrement opérationnel, vous entendrez une voix simulée confirmer : Système connecté !
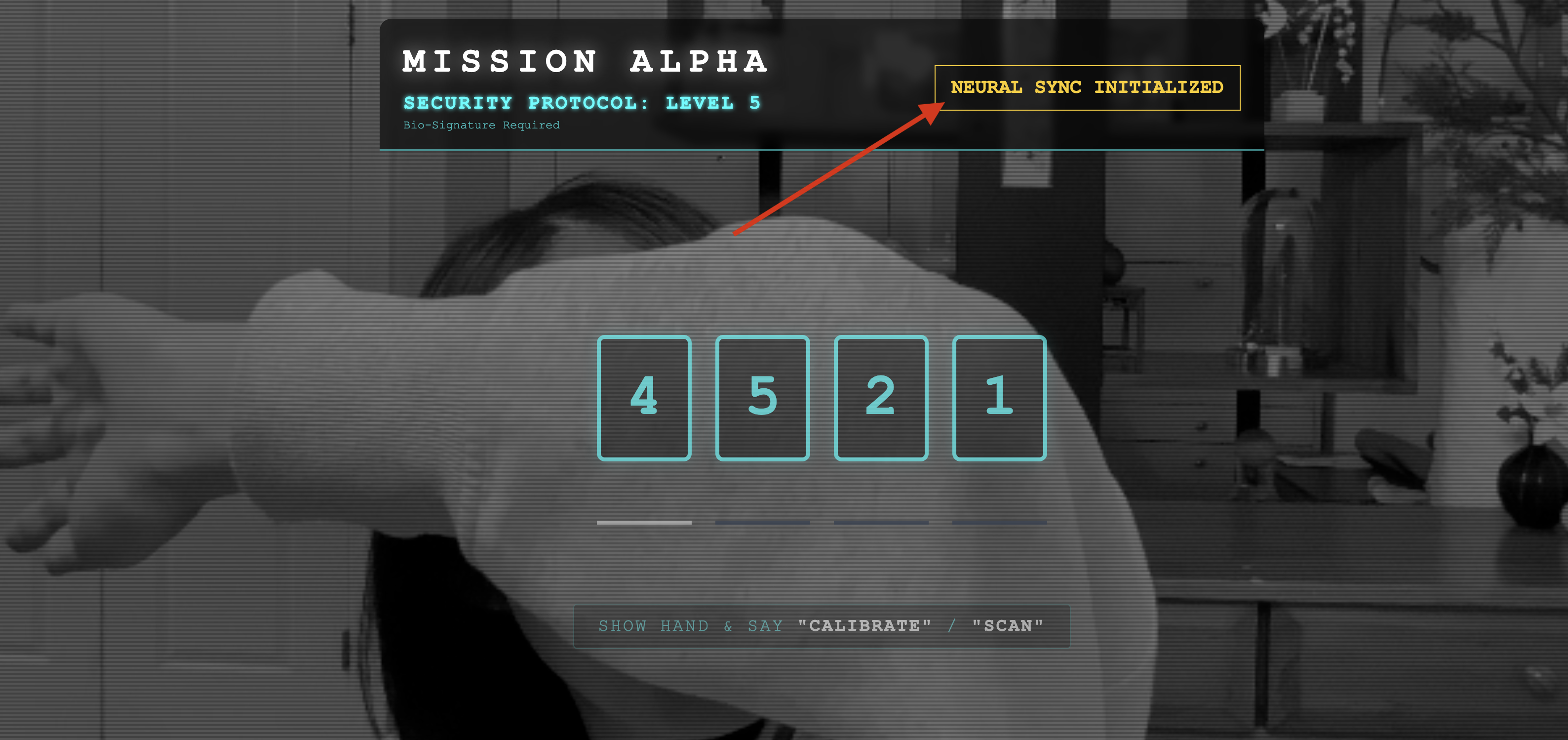
Une fois que vous avez entendu la confirmation audio "Système connecté", le test est réussi. Fermez l'onglet. Nous devons maintenant effacer la fréquence pour laisser la place à la véritable IA.
👉💻 Appuyez sur Ctrl+C dans les terminaux pour le serveur fictif et l'interface. Fermez l'onglet du navigateur exécutant l'UI.
4. L'agent multimodal
Le Scout de sauvetage est opérationnel, mais son "esprit" est vide. Si vous vous connectez maintenant, il ne fera que vous regarder. Il ne sait pas ce qu'est un "doigt". Pour sauver les survivants, vous devez imprimer le protocole neural biométrique sur le cœur de l'éclaireur.
L'agent traditionnel fonctionne comme une série de traducteurs. Si vous parlez à une IA à l'ancienne, un modèle de reconnaissance vocale transforme votre voix en mots, un modèle de langage lit ces mots et tape une réponse, et un modèle de synthèse vocale lit enfin cette réponse à voix haute. Cela crée un "écart de latence", un délai qui serait fatal lors d'une mission de sauvetage.
L'API Gemini Live est un modèle multimodal natif. Il traite directement et simultanément les octets audio bruts et les images vidéo brutes. Elle "entend" les vibrations de votre voix et "voit" les pixels de vos gestes de la main dans la même architecture neurale.
Pour exploiter cette puissance, nous pourrions créer l'application en connectant directement le cockpit à l'API Live brute. Toutefois, notre objectif est de créer un agent réutilisable, c'est-à-dire une entité modulaire et robuste qui est plus rapide à créer.
Pourquoi utiliser ADK (Agent Development Kit) ?
Google Agent Development Kit (ADK) est un framework modulaire permettant de développer et de déployer des agents d'IA.
Les appels LLM standards sont généralement sans état : chaque requête est un nouveau départ. Les agents humains, en particulier lorsqu'ils sont intégrés à SessionService de l'ADK, permettent des sessions de conversation robustes et de longue durée.
- Persistance des sessions : les sessions ADK sont persistantes et peuvent être stockées dans des bases de données (comme SQL ou Vertex AI). Elles survivent aux redémarrages et aux déconnexions du serveur. Cela signifie que si un utilisateur se déconnecte et se reconnecte plus tard (même plusieurs jours après), son historique et son contexte de conversation sont entièrement restaurés. La session éphémère de l'API Live est gérée et abstraite par l'ADK.
- Reconnexion automatique : les connexions WebSocket peuvent expirer (par exemple, au bout de 10 minutes environ). L'ADK gère ces reconnexions de manière transparente lorsque
session_resumptionest activé dansRunConfig. Le code de votre application n'a pas besoin de gérer une logique de reconnexion complexe, ce qui garantit une expérience fluide pour l'utilisateur. - Interactions avec état : l'agent se souvient des tours précédents, ce qui permet de poser des questions complémentaires, de demander des clarifications et d'avoir des dialogues multitours complexes où le contexte est essentiel. C'est fondamental pour les applications telles que le service client, les tutoriels interactifs ou les scénarios de contrôle de mission où la continuité est essentielle.
Cette persistance garantit que l'interaction ressemble à une conversation continue avec une entité intelligente, plutôt qu'à une série de questions et réponses isolées.
En substance, un "agent Live" avec ADK Bidi-streaming va au-delà d'un simple mécanisme de requête-réponse pour offrir une expérience conversationnelle véritablement interactive, avec état et consciente des interruptions. Les interactions avec l'IA sont ainsi plus humaines et beaucoup plus efficaces pour les tâches complexes et de longue durée.
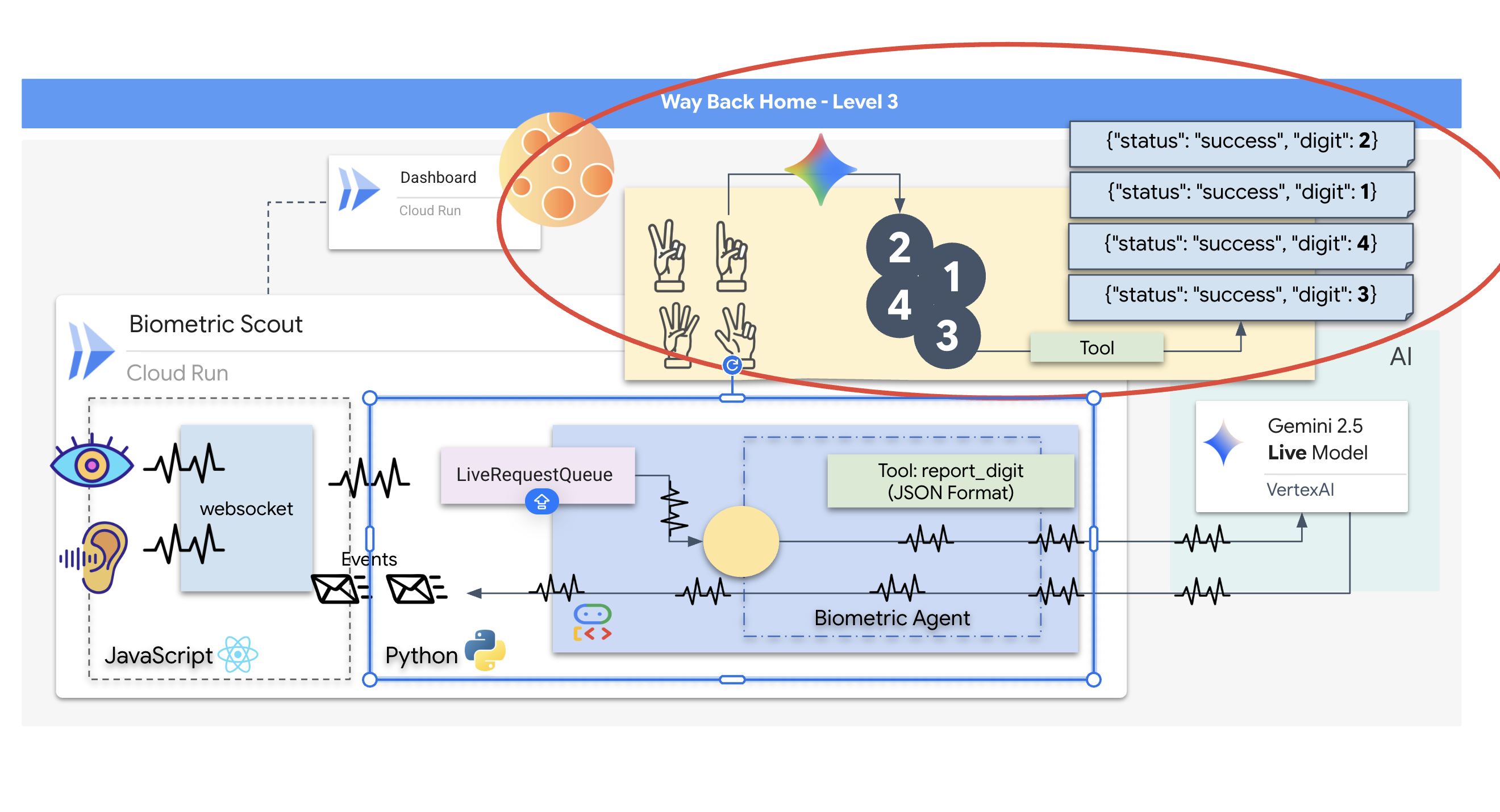
Demander à parler à un agent
Concevoir une requête pour un agent bidirectionnel en temps réel nécessite un changement d'état d'esprit. Contrairement à un chatbot standard qui attend une requête textuelle statique, un agent Live Agent est "toujours disponible". Il reçoit un flux constant de frames audio et vidéo. Votre requête doit donc agir comme un script de boucle de contrôle plutôt que comme une simple définition de personnalité.
Voici en quoi une requête d'agent en direct diffère d'une requête traditionnelle :
- Logique de la machine à états : la requête doit définir une "boucle de comportement" (Attendre → Analyser → Agir). Il a besoin d'instructions explicites sur le moment où il doit rester silencieux et celui où il doit s'engager, ce qui empêche l'agent de bavarder sur un bruit de fond vide.
- Conscience multimodale : l'agent doit être informé qu'il a des "yeux". Vous devez lui demander explicitement d'analyser les images vidéo dans le cadre de son processus de raisonnement.
- Latence et concision : dans une conversation vocale en direct, les longs paragraphes denses semblent artificiels et lents. L'invite impose la concision pour que l'interaction soit rapide.
- Architecture "Action-First" : les instructions donnent la priorité à l'appel d'outils plutôt qu'à la parole. Nous voulons que l'agent "fasse" le travail (scanne la biométrie) avant ou pendant la confirmation verbale, et non après un long monologue.
👉✏️ Ouvrez $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py et remplacez #REPLACE INSTRUCTIONS par ce qui suit :
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
REMARQUE : Vous ne vous connectez pas à un LLM standard. Dans le même fichier ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), localisez #REPLACE_MODEL. Nous devons cibler explicitement la version Preview de ce modèle pour mieux prendre en charge les fonctionnalités audio en temps réel.
👉✏️ Remplacez l'espace réservé par :
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Votre agent est maintenant défini. Il sait qui il est et comment penser. Ensuite, nous lui donnons les outils pour agir.
Appel d'outils
L'API Live ne se limite pas à l'échange de flux de texte, audio et vidéo. Il est compatible en natif avec l'appel d'outils. Cela permet de transformer les agents, qui sont des interlocuteurs passifs, en opérateurs actifs.
Lors d'une session bidirectionnelle en direct, le modèle évalue constamment le contexte. Si le LLM détecte la nécessité d'effectuer une action, qu'il s'agisse de "vérifier la télémétrie du capteur" ou de "déverrouiller une porte sécurisée". Il passe facilement de la conversation à l'exécution. L'agent déclenche immédiatement la fonction d'outil spécifique, attend le résultat et réintègre ces données dans le flux en direct, le tout sans interrompre le déroulement de l'interaction.
👉✏️ Dans $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, remplacez #REPLACE TOOLS par cette fonction :
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Ensuite, enregistrez-le dans la définition Agent en remplaçant #TOOL CONFIG :
tools=[report_digit],
Simulateur adk web
Avant de connecter cela au cockpit complexe du vaisseau (notre frontend React), nous devons tester la logique de l'agent de manière isolée. L'ADK inclut une console de développement intégrée appelée adk web, qui nous permet de vérifier l'appel d'outils avant d'ajouter de la complexité au réseau.
👉💻 Dans votre terminal, exécutez la commande suivante :
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell. Sélectionnez Modifier le port, définissez-le sur 8000, puis cliquez sur Modifier et prévisualiser.
- Accorder les autorisations : Autorisez l'accès à votre caméra et à votre micro lorsque vous y êtes invité.
- Démarrez la session en cliquant sur l'icône en forme de caméra.
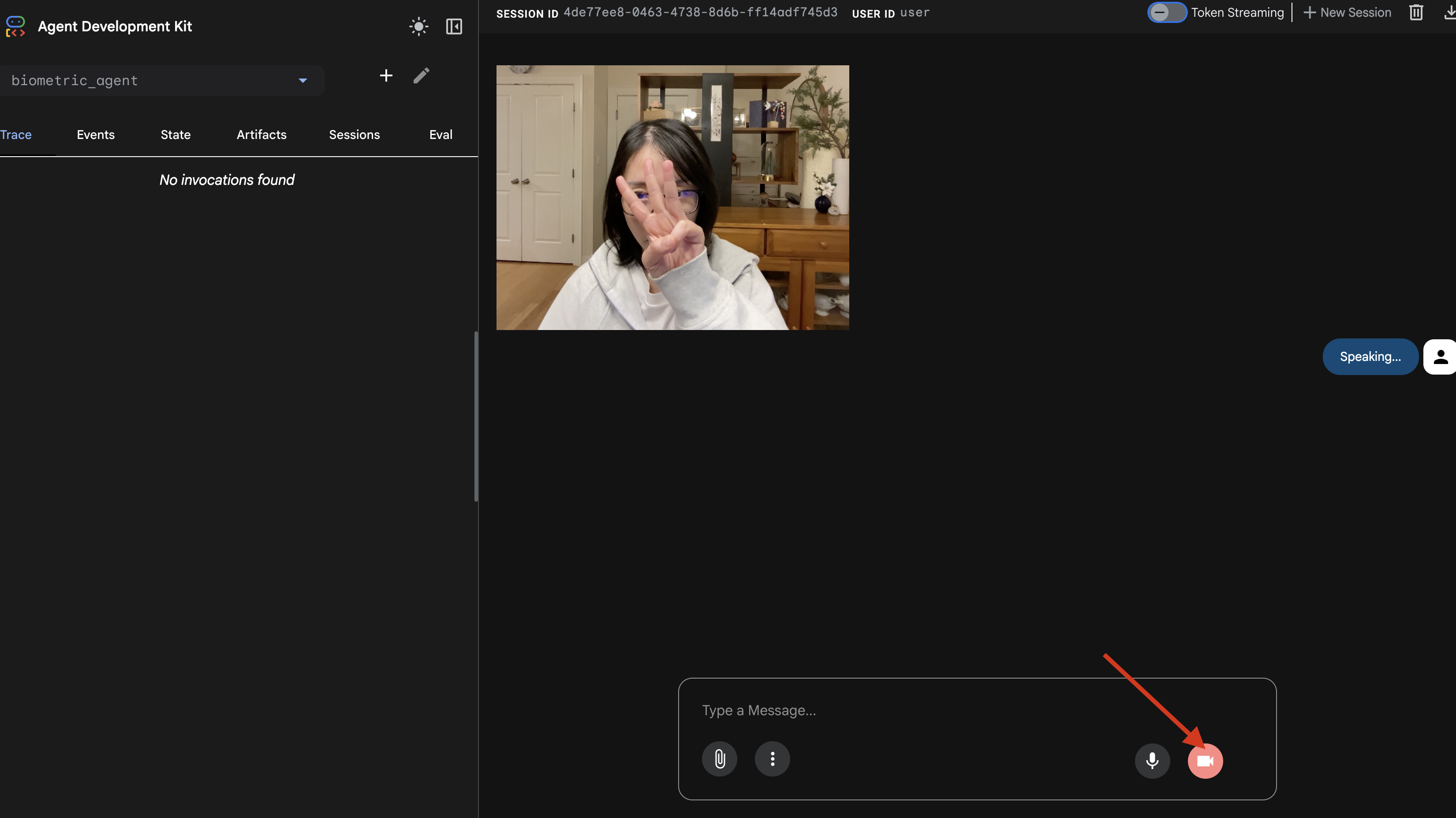
- Test visuel :
- Placez clairement trois doigts devant l'appareil photo.
- Dites "Scanner".
- Vérifier la réussite
- Journaux : consultez le terminal exécutant la commande
adk web. Vous devez voir ce journal :[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Journaux : consultez le terminal exécutant la commande
Si le journal d'exécution de l'outil s'affiche, cela signifie que votre agent est intelligent. Il peut voir, penser et agir. La dernière étape consiste à le connecter au vaisseau principal.
Cliquez dans la fenêtre du terminal et appuyez sur Ctrl+C pour arrêter le simulateur adk web.
5. Flux de streaming bidirectionnel
L'agent fonctionne. Le Cockpit fonctionne. Maintenant, nous devons les connecter.
Cycle de vie de l'agent en direct
Le streaming en temps réel pose un problème d'"incompatibilité d'impédance". Le client (navigateur) envoie des données de manière asynchrone à des débits variables (rafales réseau ou entrées rapides), tandis que le modèle nécessite un flux d'entrée séquentiel et régulé. Google ADK résout ce problème en utilisant LiveRequestQueue.
Il agit comme un tampon FIFO (First-In-First-Out) asynchrone et thread-safe. Le gestionnaire WebSocket agit en tant que producteur, en insérant des blocs audio/vidéo bruts dans la file d'attente. L'agent ADK agit en tant que consommateur, en extrayant les données de la file d'attente pour alimenter la fenêtre de contexte du modèle. Ce découplage permet à l'application de continuer à recevoir des entrées utilisateur même lorsque le modèle génère une réponse ou exécute un outil.
La file d'attente sert de multiplexeur multimodal. Dans un environnement réel, le flux en amont se compose de différents types de données simultanés : octets audio PCM bruts, frames vidéo, instructions système textuelles et résultats des appels d'outils asynchrones. LiveRequestQueue linéarise ces entrées disparates en une seule séquence chronologique. Qu'il contienne une milliseconde de silence, une image haute résolution ou une charge utile JSON provenant d'une requête de base de données, le paquet est sérialisé dans l'ordre exact d'arrivée, ce qui garantit que le modèle perçoit une chronologie cohérente et causale.
Cette architecture permet le contrôle non bloquant. Étant donné que la couche d'ingestion (producteur) est dissociée de la couche de traitement (consommateur), le système reste réactif même pendant l'inférence de modèle coûteuse en termes de calcul. Si un utilisateur interrompt l'agent avec une commande "Arrête !" pendant qu'il exécute un outil, ce signal audio est immédiatement mis en file d'attente. La boucle d'événement sous-jacente traite immédiatement ce signal de priorité, ce qui permet au système d'arrêter la génération ou de faire pivoter les tâches sans que l'UI se fige ni que des paquets soient perdus.
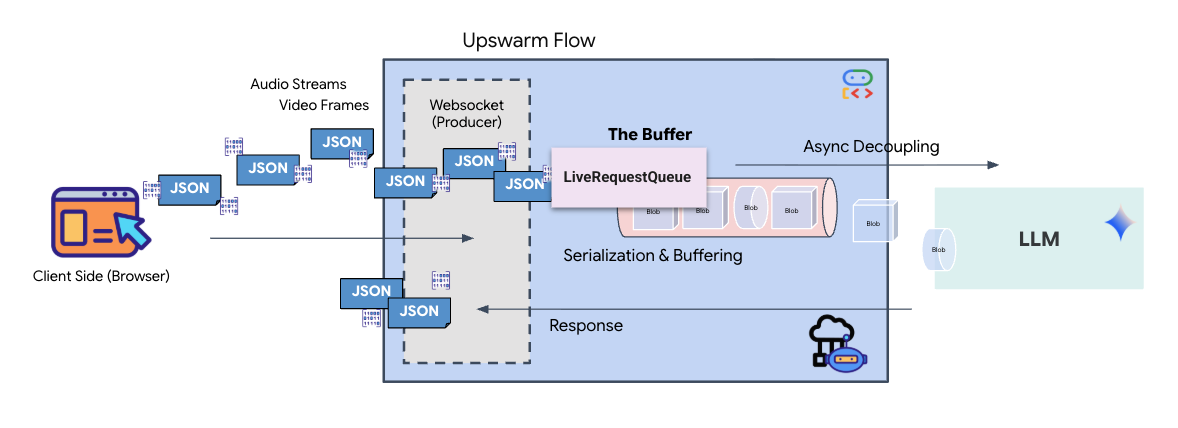
👉💻 Dans $HOME/way-back-home/level_3/backend/app/main.py, recherchez le commentaire #REPLACE_RUNNER_CONFIG et remplacez-le par le code suivant pour mettre le système en ligne :
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
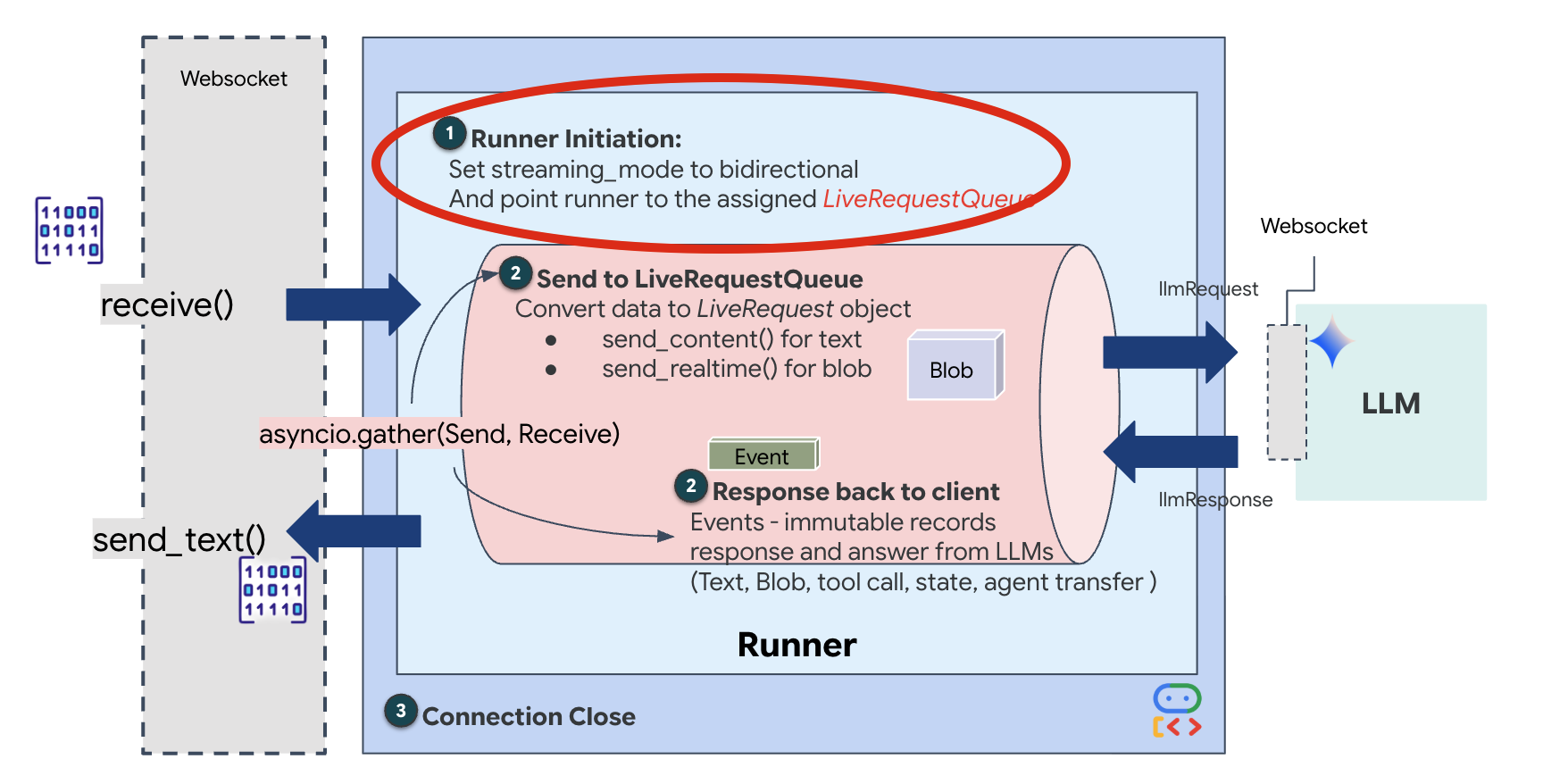
Lorsqu'une nouvelle connexion WebSocket s'ouvre, nous devons configurer la façon dont l'IA interagit. C'est là que nous définissons les "règles d'engagement".
👉✏️ Dans $HOME/way-back-home/level_3/backend/app/main.py, dans la fonction async def websocket_endpoint, remplacez le commentaire #REPLACE_SESSION_INIT par le code ci-dessous :
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
Configuration d'exécution
StreamingMode.BIDI: définit la connexion sur bidirectionnelle. Contrairement à l'IA "tour par tour" (où vous parlez, vous vous arrêtez, puis elle parle), BIDI permet une conversation "full duplex" réaliste. Vous pouvez interrompre l'IA, et l'IA peut parler pendant que vous vous déplacez.AudioTranscriptionConfig: même si le modèle "entend" l'audio brut, nous (les développeurs) avons besoin de voir les journaux. Cette configuration indique à Gemini : "Traite l'audio, mais renvoie également une transcription textuelle de ce que tu as entendu pour que nous puissions déboguer."
Logique d'exécution : une fois que le Runner a établi la session, il transmet le contrôle à la logique d'exécution, qui s'appuie sur LiveRequestQueue. Il s'agit du composant le plus important pour les interactions en temps réel. La boucle permet à l'agent de générer une réponse vocale pendant que la file d'attente continue d'accepter de nouvelles images vidéo de l'utilisateur, ce qui garantit que la "synchronisation neuronale" n'est jamais interrompue.
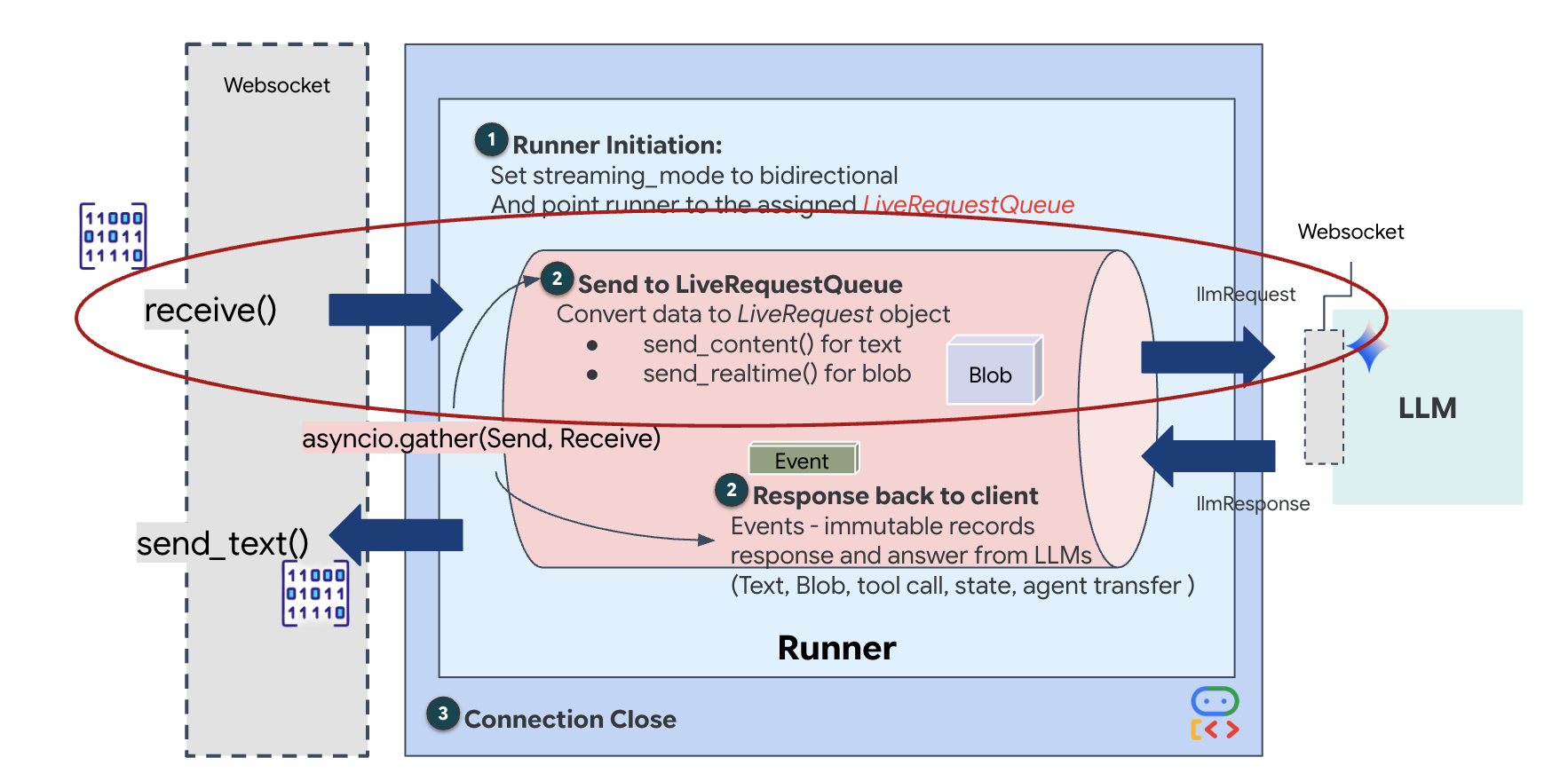
👉✏️ Dans $HOME/way-back-home/level_3/backend/app/main.py, remplacez #REPLACE_LIVE_REQUEST pour définir la tâche en amont qui envoie des données à LiveRequestQueue :
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
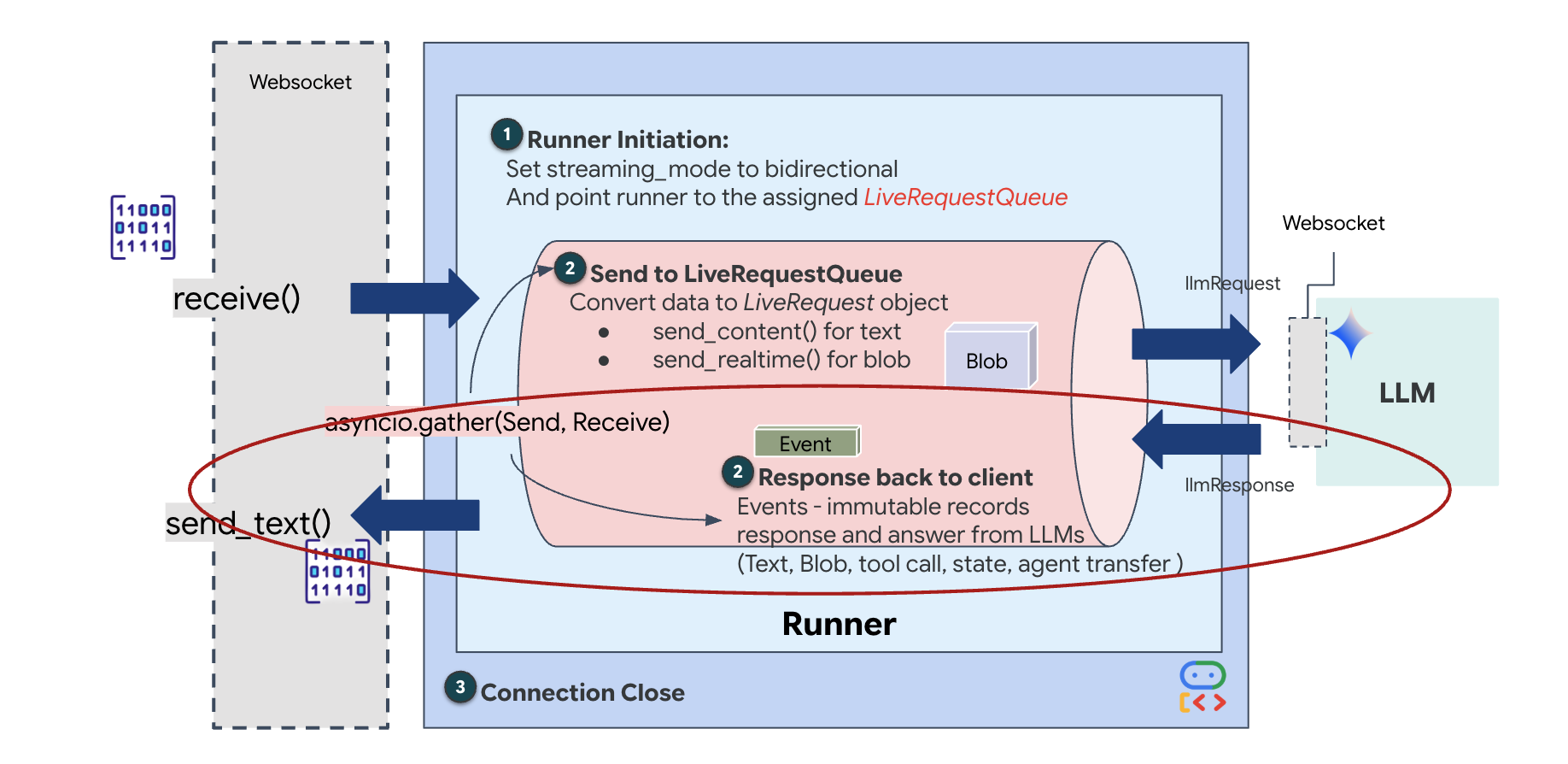
Enfin, nous devons gérer les réponses de l'IA. Il utilise runner.run_live(), qui est un générateur d'événements qui génère des événements (audio, texte ou appels d'outils) au fur et à mesure qu'ils se produisent.
👉✏️ Dans $HOME/way-back-home/level_3/backend/app/main.py, remplacez #REPLACE_SORT_RESPONSE pour définir la tâche en aval et le gestionnaire de simultanéité :
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Notez la ligne await asyncio.gather(upstream_task(), downstream_task()). C'est l'essence du duplex intégral. Nous exécutons la tâche d'écoute (en amont) et la tâche d'expression orale (en aval) exactement en même temps. Cela garantit que le "lien neural" permet l'interruption et le flux de données simultané.
Votre backend est désormais entièrement codé. Le "cerveau" (ADK) est connecté au "corps" (WebSocket).
Exécution de la synchronisation biologique
Le code est complet. Les systèmes sont verts. Il est temps de lancer le sauvetage.
- 👉💻 Démarrez le backend :
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Lancez l'interface :
- Cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell. Sélectionnez Modifier le port, définissez-le sur 8080, puis cliquez sur Modifier et prévisualiser.
- 👉 Exécutez le protocole :
- Cliquez sur INITIATE NEURAL SYNC (DÉMARRER LA SYNCHRONISATION NEURONALE).
- Calibrer : assurez-vous que la caméra voit clairement votre main sur le fond.
- La synchronisation : regardez le code de sécurité affiché à l'écran (par exemple, 3, puis 2, puis 5).
- Faites correspondre le signal : lorsqu'un nombre apparaît, levez le nombre exact de doigts.
- Restez immobile : gardez votre main visible jusqu'à ce que l'IA confirme la "Correspondance biométrique".
- Adaptation : le code est aléatoire. Passez immédiatement au nombre suivant affiché jusqu'à ce que la séquence soit terminée.

- Une fois que vous avez trouvé le dernier chiffre de la séquence aléatoire, la synchronisation biométrique est terminée. Le lien neuronal se verrouille. Vous avez le contrôle manuel. Les moteurs du Scout rugissent et le véhicule plonge dans le Ravin pour ramener les survivants chez eux.
👉💻 Appuyez sur Ctrl+C dans le terminal backend pour quitter.
6. Déployer en production (facultatif)
Vous avez testé les données biométriques en local. Nous devons maintenant importer le cœur neuronal de l'agent dans les ordinateurs centraux du vaisseau (Cloud Run) afin qu'il puisse fonctionner indépendamment de votre console locale.
👉💻 Exécutez la commande suivante dans votre terminal Cloud Shell. Il créera le fichier Dockerfile complet en plusieurs étapes dans votre répertoire backend.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Accédez au répertoire backend et empaquetez l'application dans une image de conteneur.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Déployez le service sur Cloud Run. Nous injecterons les variables d'environnement nécessaires (en particulier la configuration Gemini) directement dans la commande de lancement.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Une fois la commande terminée, une URL de service s'affiche (par exemple, https://biometric-scout-...run.app). L'application est désormais en ligne dans le cloud.
👉 Accédez à la page Google Cloud Run et sélectionnez le service biometric-scout dans la liste. 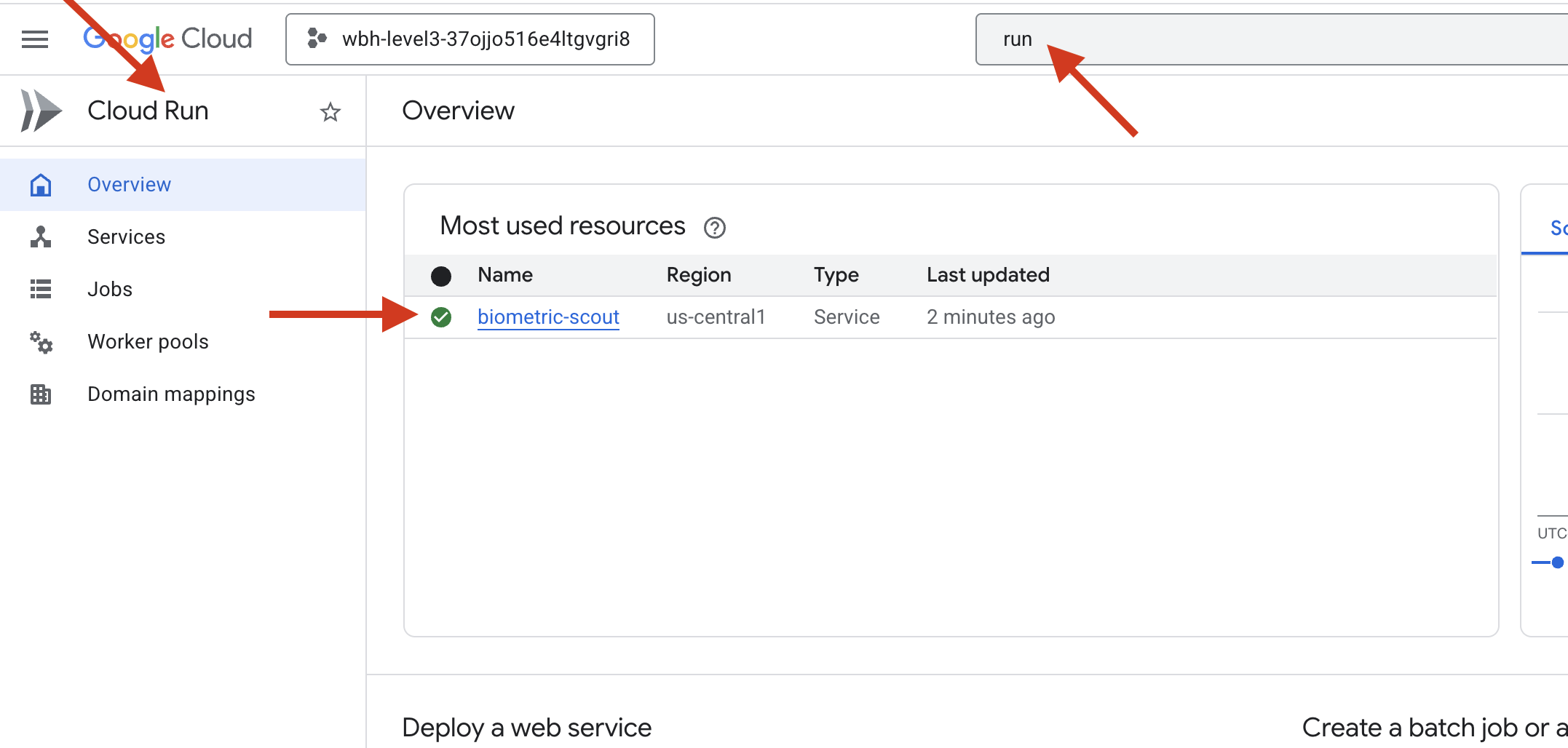
👉 Recherchez l'URL publique affichée en haut de la page "Informations sur le service". 
Essayez d'effectuer une synchronisation biologique dans cet environnement. Est-ce que cela fonctionne ?
Lorsque votre auriculaire est tendu, l'IA verrouille la séquence. L'écran clignote en vert : "Synchronisation neuronale biométrique : ÉTABLIE."
D'une simple pensée, vous plongez le Scout dans l'obscurité, vous accrochez à la capsule échouée et vous la sortez juste avant que la déchirure gravitationnelle ne s'effondre.

Le sas s'ouvre en sifflant, et voilà cinq survivants bien vivants. Ils trébuchent sur le pont, battus mais vivants, enfin en sécurité grâce à vous.
Grâce à vous, le lien neural est synchronisé et les survivants sont sauvés.
Si vous avez participé au niveau 0, n'oubliez pas de vérifier où vous en êtes dans la mission "Retour à la maison" !