1. המשימה

אתה נסחף בשקט של מגזר לא ממופה. **פולס סולארי** עצום קרע את החללית שלכם דרך קרע במרחב, והשאיר אתכם תקועים בכיס ביקום שלא קיים באף מפת כוכבים.
אחרי ימים של תיקונים מתישים, אתם סוף סוף מרגישים את רעש המנועים מתחת לרגליים. החללית שלך תוקנה. אפילו הצלחתם לאבטח קישור עלייה למטוס האם לטווח ארוך. יש לך אישור להמראה. הכול מוכן. אבל כשאתם מתכוננים להפעיל את הזיכרון הנייד, אות מצוקה חודר את הרעש הסטטי. החיישנים שלכם קולטים חמש חתימות חום חלשות שנלכדו ב'הערוץ' – אזור משונן שמעוות על ידי כוח המשיכה, שהספינה הראשית שלכם לעולם לא יכולה להיכנס אליו. אלה חברים למסע, ניצולים מאותה סערה שכמעט גרמה למותכם. אי אפשר להשאיר אותם מאחור.
אתם פונים אל Alpha-Drone Rescue Scout. הספינה הקטנה והזריזה הזו היא כלי השיט היחיד שיכול לנווט בין הקירות הצרים של הערוץ. אבל יש בעיה: הפולס הסולארי ביצע 'איפוס מערכת' מלא בלוגיקה הבסיסית שלו. מערכות הבקרה של Scout לא מגיבות. הוא מופעל, אבל המחשב המובנה שלו הוא לוח חלק, והוא לא יכול לעבד פקודות ידניות של טייס או נתיבי טיסה.
האתגר
כדי להציל את השורדים, אתם צריכים לעקוף לחלוטין את המעגלים הפגומים של הצופה. יש לך אפשרות אחת נואשת: ליצור סוכן AI כדי להקים סנכרון עצבי ביומטרי. הסוכן הזה ישמש כגשר בזמן אמת, ויאפשר לכם לשלוט ב-Rescue Scout באופן ידני באמצעות הקלט הביולוגי שלכם. לא תשתמשו בג'ויסטיק או במקלדת, אלא תחברו את הכוונה שלכם ישירות לרשת הניווט של החללית.
כדי לנעול את הקישור, צריך לבצע את פרוטוקול הסנכרון מול החיישנים האופטיים של Scout. הנציג הדיגיטלי מבוסס-AI צריך לזהות את החתימה הביולוגית שלכם באמצעות לחיצת יד מדויקת בזמן אמת.
היעדים שלכם במשימה:
- הטבעת ליבת ה-Neural Core: הגדרת סוכן ADK שיכול לזהות קלט מולטימודאלי.
- יצירת החיבור: יצירת פייפליין WebSocket דו-כיווני להזרמת נתונים חזותיים מה-Scout ל-AI.
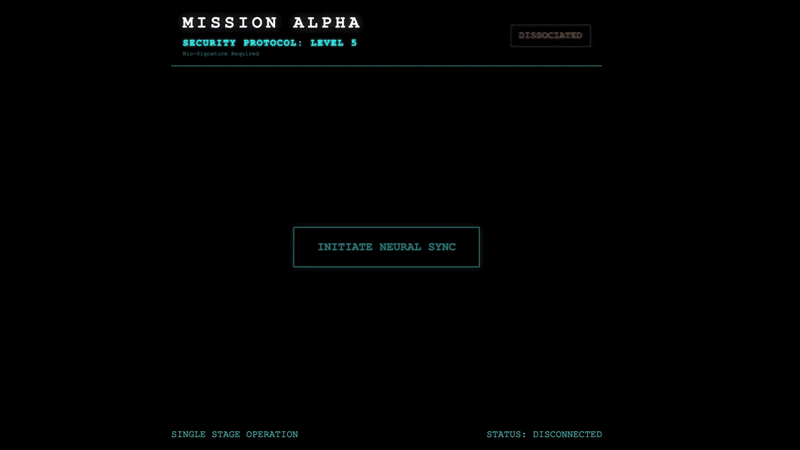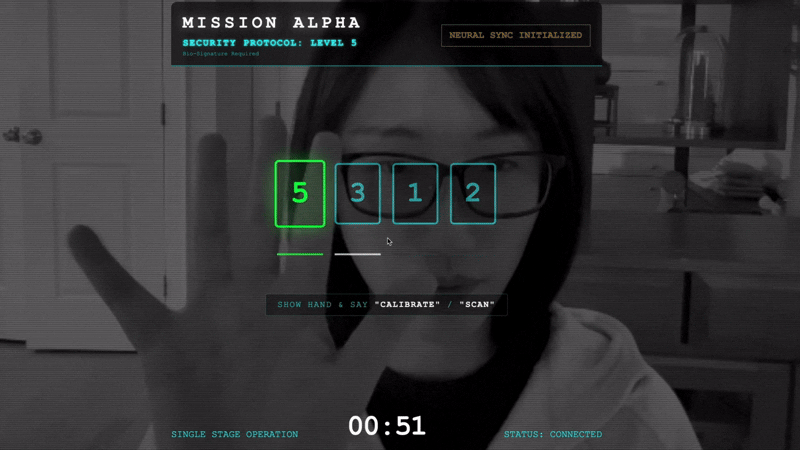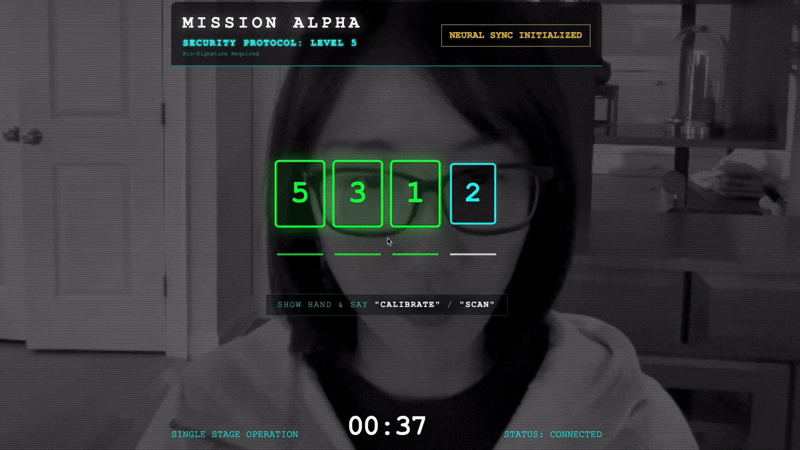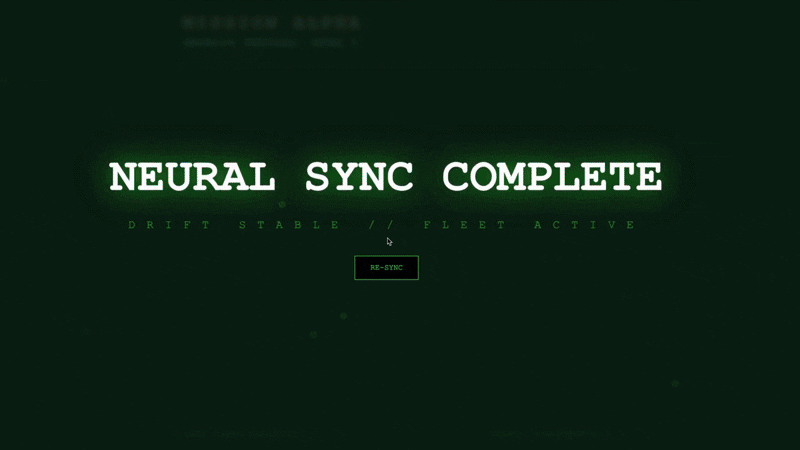
- מתחילים את הלחיצה: עומדים מול החיישן ומבצעים את רצף האצבעות – מראים את האצבעות 1 עד 5 לפי הסדר.
אם הפעולה בוצעה ללא שגיאות, יופעל הסנכרון הביומטרי. ה-AI ינעל את הקשר העצבי, ויאפשר לכם שליטה ידנית מלאה כדי להפעיל את הסקאוט ולהחזיר את הניצולים הביתה.
מה תפַתחו
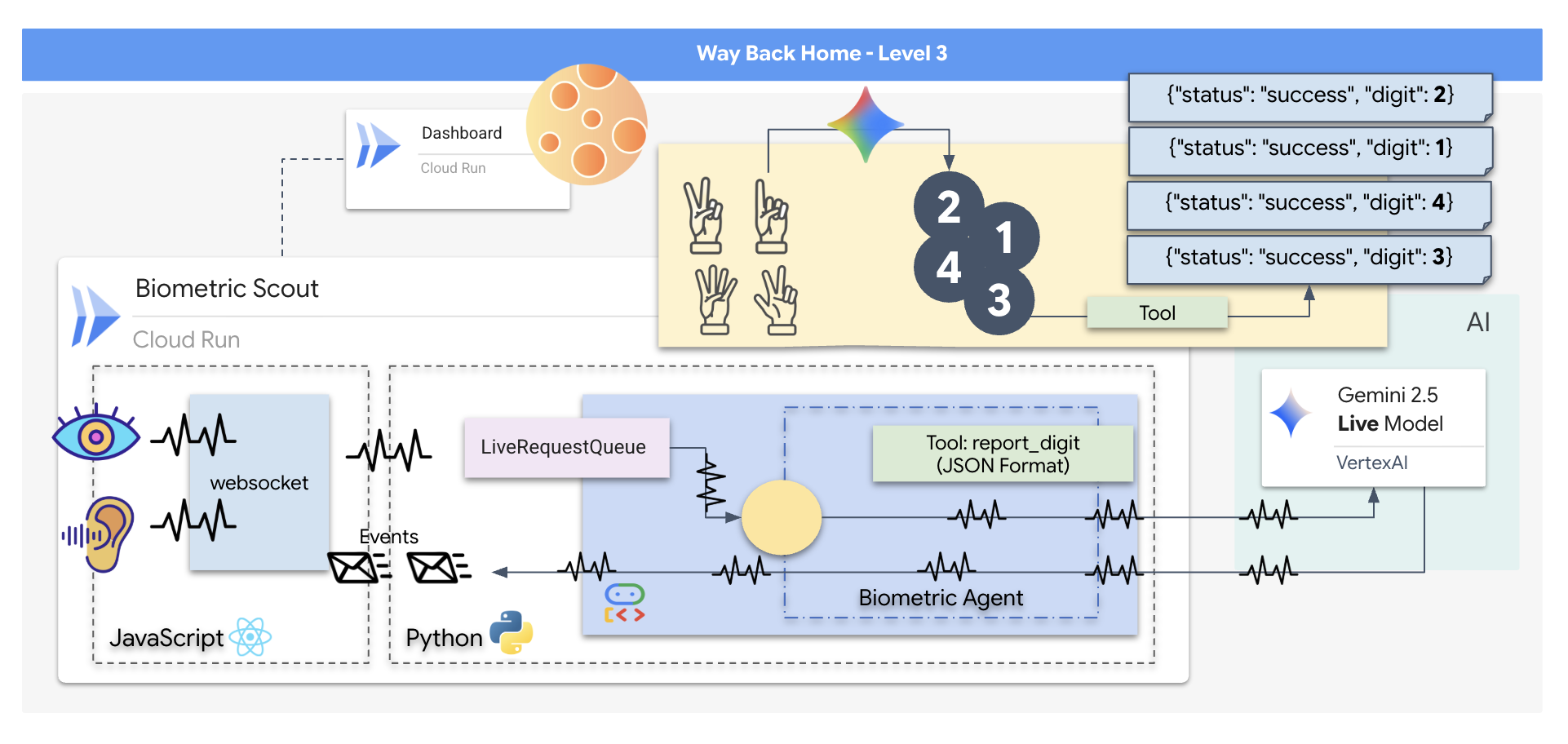
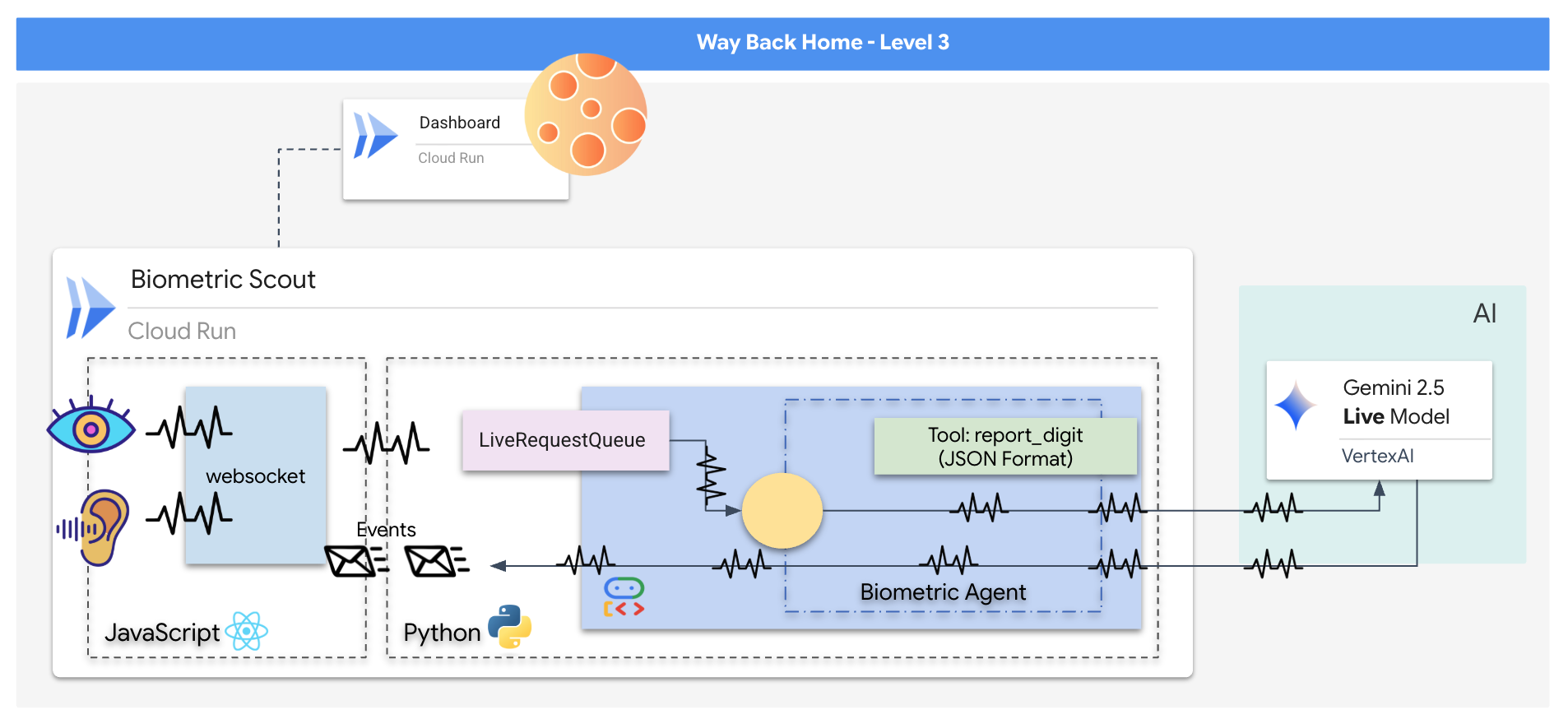
תבנו אפליקציה בשם Biometric Neural Sync (סנכרון נוירונים ביומטרי), מערכת בזמן אמת שמבוססת על AI ומשמשת כממשק בקרה למזל"ט שמיועד למשימות חילוץ. המערכת הזו כוללת:
- קצה קדמי של React: 'תא הטייס' של החללית, שכולל צילום וידאו בשידור חי ממצלמת האינטרנט ואודיו מהמיקרופון.
- קצה עורפי של Python: שרת בעל ביצועים גבוהים שנבנה באמצעות FastAPI, עם Agent Development Kit (ADK) של Google לניהול הלוגיקה והמצב של ה-LLM.
- סוכן AI מולטימודאלי: ה "מוח" של הפעולה, שמשתמש ב-Gemini Live API דרך
google-genaiSDK כדי לעבד ולהבין בו-זמנית זרמי וידאו ואודיו. - פייפליין WebSocket דו-כיווני: 'המערכת העצבית' שיוצרת חיבור קבוע עם זמן טעינה נמוך בין הקצה הקדמי לבין ה-AI, ומאפשרת אינטראקציה בזמן אמת.
מה תלמדו
טכנולוגיה / קונספט | תיאור |
Backend AI Agent | יצירת סוכן AI עם שמירת מצב באמצעות Python ו-FastAPI. משתמשים בערכה לפיתוח סוכנים (ADK) של Google כדי לנהל את ההוראות והזיכרון, וב |
ממשק משתמש של קצה קדמי | פיתוח ממשק משתמש דינמי באמצעות React כדי לצלם ולהזרים וידאו ואודיו בשידור חי ישירות מהדפדפן. |
תקשורת בזמן אמת | הטמעה של צינור WebSocket לתקשורת דו-כיוונית עם זמן אחזור נמוך, שמאפשרת למשתמש ול-AI לקיים אינטראקציה בו-זמנית. |
AI מולטימודאלי | אפשר להשתמש ב-Gemini Live API כדי לעבד ולהבין שידורי וידאו ואודיו בו-זמנית, וכך לאפשר ל-AI 'לראות' ו'לשמוע' באותו הזמן. |
שימוש בכלים | הפעלת ה-AI כדי לבצע פונקציות ספציפיות של Python בתגובה לטריגרים חזותיים, וכך לגשר על הפער בין האינטליגנציה של המודל לבין פעולה בעולם האמיתי. |
פריסה של Full-Stack | העברת כל האפליקציה (חלק הקצה של React וחלק העורף של Python) לקונטיינר באמצעות Docker ופריסתה כשירות ניתן להתאמה וללא שרת ב-Google Cloud Run. |
2. הגדרת הסביבה
גישה ל-Cloud Shell
קודם נפתח את Cloud Shell, שהוא טרמינל מבוסס-דפדפן עם Google Cloud SDK וכלים חיוניים אחרים שמותקנים מראש.
👈 לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud (זהו סמל הטרמינל בחלק העליון של חלונית Cloud Shell), 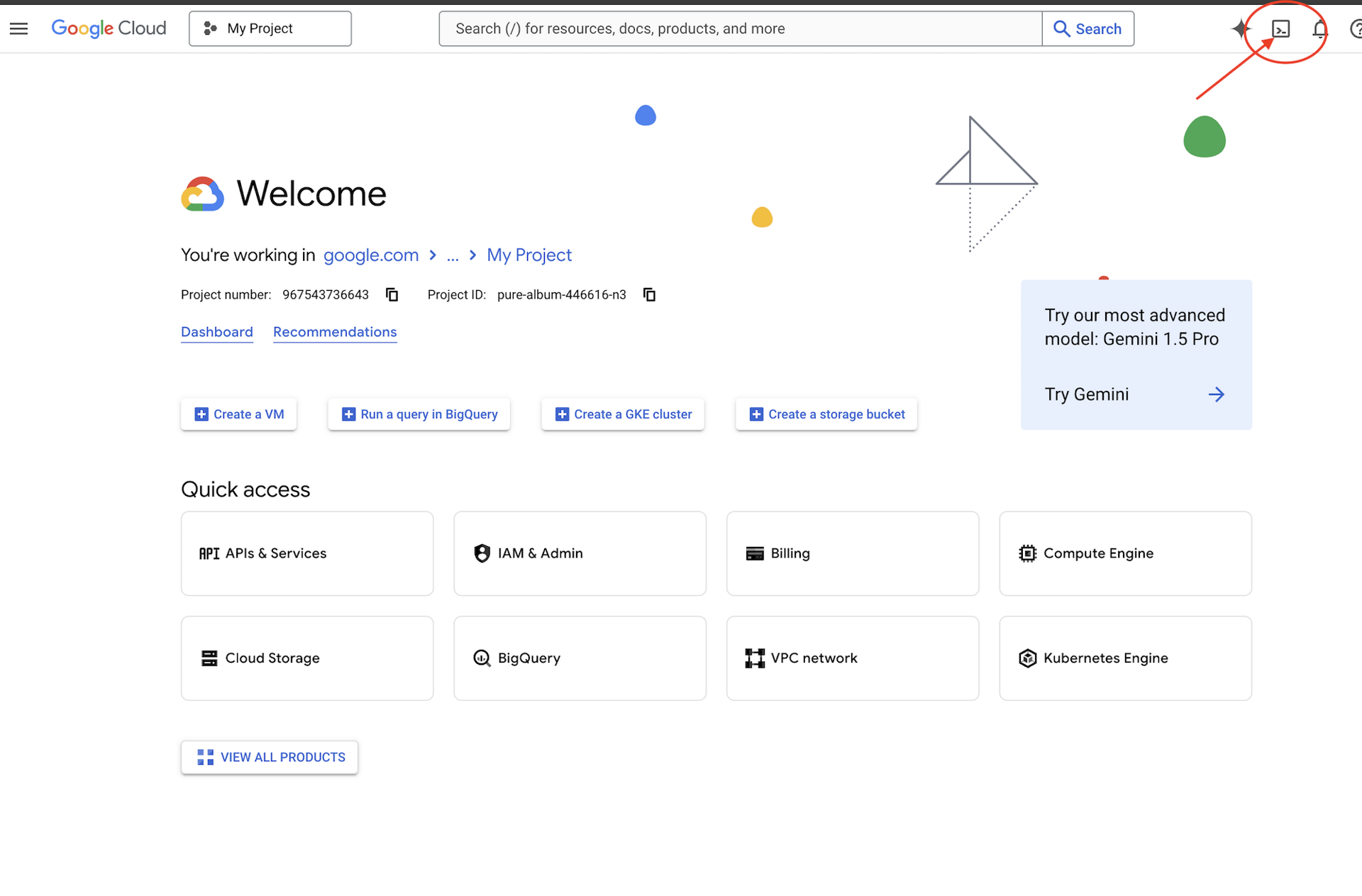
👈 לוחצים על הלחצן 'פתיחת הכלי לעריכה' (הוא נראה כמו תיקייה פתוחה עם עיפרון). ייפתח חלון עם Cloud Shell Code Editor. בצד ימין יופיע סייר הקבצים. 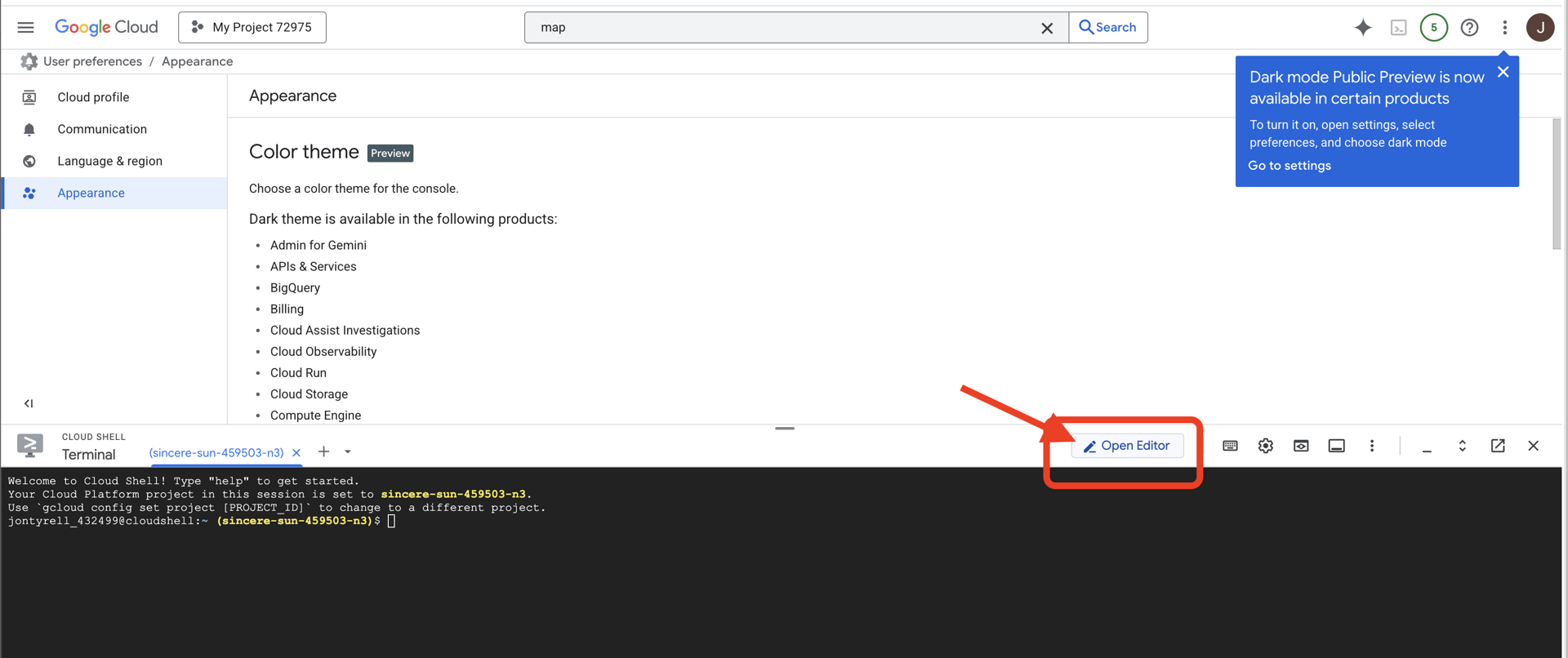
👈פותחים את הטרמינל בסביבת הפיתוח המשולבת (IDE) בענן,
👈💻 בטרמינל, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list
החשבון שלכם אמור להופיע ברשימה כ-(ACTIVE).
דרישות מוקדמות
ℹ️ רמה 0 היא אופציונלית (אבל מומלצת)
אפשר להשלים את המשימה הזו בלי להגיע לרמה 0, אבל אם תסיימו אותה קודם, תוכלו ליהנות מחוויה סוחפת יותר ולראות את האור של המשואה נדלק במפה הגלובלית ככל שתתקדמו.
הגדרת סביבת הפרויקט
חוזרים לטרמינל, מגדירים את הפרויקט הפעיל ומפעילים את שירותי Google Cloud הנדרשים (Cloud Run, Vertex AI וכו') כדי להשלים את ההגדרה.
👈💻 בטרמינל, מגדירים את מזהה הפרויקט:
gcloud config set project $(cat ~/project_id.txt) --quiet
👈💻 הפעלת השירותים הנדרשים:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
התקנת יחסי תלות
👈💻 עוברים אל Level ומתקינים את חבילות Python הנדרשות:
cd $HOME/way-back-home/level_3
uv sync
יחסי התלות העיקריים הם:
חבילה | מטרה |
| מסגרת אינטרנט עם ביצועים גבוהים לתחנת הלוויין ולסטרימינג של SSE |
| נדרש שרת ASGI כדי להריץ את אפליקציית FastAPI |
| הערכה לפיתוח סוכנים ששימשה ליצירת סוכן ההרכבה |
| לקוח מקורי לגישה למודלים של Gemini |
| תמיכה בתקשורת דו-כיוונית בזמן אמת |
| ניהול משתני סביבה וסודות תצורה |
אימות ההגדרה
לפני שנתחיל לכתוב את הקוד, נבדוק שכל המערכות פועלות. מריצים את סקריפט האימות כדי לבצע ביקורת בפרויקט Google Cloud, בממשקי ה-API ובתלות של Python.
👈💻 מריצים את סקריפט האימות:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 אמורים להופיע כמה סימני וי ירוקים (✅).
- אם רואים סימני איקס אדומים (❌), צריך לפעול לפי הפקודות לתיקון שמופיעות בפלט (לדוגמה,
gcloud services enable ...אוpip install ...). - הערה: בשלב הזה, קבלת אזהרה צהובה לגבי
.envהיא תקינה. ניצור את הקובץ הזה בשלב הבא.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. כיול של Comm-Link (WebSockets)
כדי להתחיל את הסנכרון הביומטרי העצבי, אנחנו צריכים לעדכן את המערכות הפנימיות של הספינה. המטרה העיקרית שלנו היא לצלם סרטון באיכות גבוהה עם אודיו מהקוקפיט שלכם. הזרם הזה מספק את הרכיבים החיוניים לקישור העצבי: הזיהוי החזותי של רצפי האצבעות והתדר הקולי של הקול שלכם.
דופלקס מלא לעומת דופלקס חלקי
כדי להבין למה אנחנו צריכים את זה בשביל Neural Sync, צריך להבין את זרימת הנתונים:
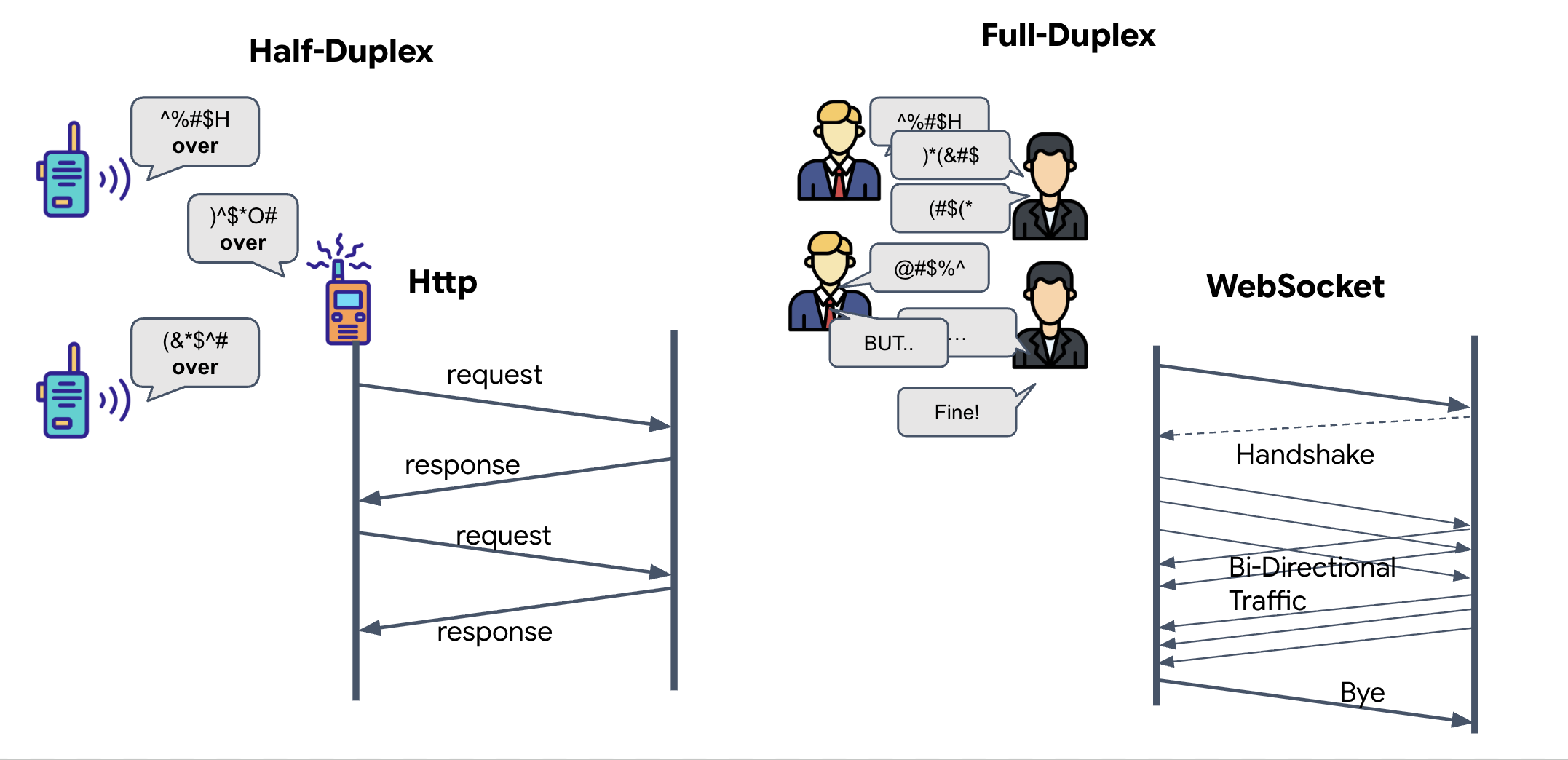
- Half-Duplex (HTTP רגיל): כמו מכשיר קשר. אדם אחד מדבר, אומר "סוף הקשר", ואז האדם השני יכול לדבר. אי אפשר להקשיב ולדבר בו-זמנית.
- Full-Duplex (WebSocket): כמו שיחה פנים אל פנים. הנתונים זורמים בו-זמנית בשני הכיוונים. בזמן שהדפדפן שולח פריימים של סרטונים ודגימות אודיו ל-AI, ה-AI יכול לשלוח לכם תשובות קוליות ופקודות לכלי בדיוק באותו הזמן.
למה Gemini Live צריך Full-Duplex: Gemini Live API מיועד ל"הפרעות". תארו לעצמכם שאתם מראים את רצף האצבעות, וה-AI רואה שאתם עושים את זה לא נכון. בהגדרה רגילה של HTTP, ה-AI יצטרך לחכות עד שתסיימו לשלוח את הנתונים כדי להגיד לכם להפסיק. באמצעות WebSockets, ה-AI יכול לזהות טעות בפריים 1 ולשלוח אות 'הפרעה' שמגיע לתא הטייס בזמן שאתם עדיין מזיזים את היד לפריים 2.
מהו WebSocket?
בשידור גלקטי רגיל (HTTP), שולחים בקשה ומחכים לתשובה – כמו שליחת גלויה. סנכרון עצבי איטי מדי בשביל גלויות. אנחנו צריכים "חוט חשמלי חי".
פרוטוקול WebSockets מתחיל כבקשת אינטרנט רגילה (HTTP), אבל אחר כך הוא עובר שדרוג למשהו אחר.
- הבקשה: הדפדפן שולח בקשת HTTP רגילה לשרת עם כותרת מיוחדת:
Upgrade: websocket. במילים אחרות, אתם אומרים: "אני רוצה להפסיק לשלוח גלויות ולהתחיל שיחת טלפון בזמן אמת". - התשובה: אם סוכן ה-AI (השרת) תומך בזה, הוא מחזיר תשובה מסוג
HTTP 101 Switching Protocols. - השינוי: בשלב הזה, חיבור ה-HTTP מוחלף בפרוטוקול WebSocket, אבל שקע ה-TCP/IP הבסיסי נשאר פתוח. כללי התקשורת משתנים באופן מיידי מ'בקשה/תגובה' ל'הזרמת נתונים דו-כיוונית'.
הטמעה של WebSocket Hook
כדי להבין איך הנתונים זורמים, נבדוק את טרמינל חוסם.
👀 פותחים את $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. תראו את המטפלים הרגילים באירועים של מחזור החיים של WebSocket שכבר הוגדרו. זהו השלד של מערכת התקשורת שלנו:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
ה-Handler של onMessage
מתמקדים בבלוק ws.current.onmessage. זה המקלט. בכל פעם שהסוכן "חושב" או "מדבר", מגיע לכאן חבילת נתונים. בשלב הזה, הפקודה לא עושה כלום – היא מאתרת את החבילה ומשמיטה אותה (באמצעות ה-placeholder //#REPLACE-HANDLE-MSG).
אנחנו צריכים למלא את החלל הזה בלוגיקה שתאפשר להבחין בין:
- קריאות לכלים (functionCall): ה-AI מזהה את תנועות הידיים שלכם (הסנכרון).
- נתוני אודיו (inlineData): הקול של ה-AI שמשיב לכם.
👉✏️ עכשיו, באותו קובץ $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, מחליפים את //#REPLACE-HANDLE-MSG בלוגיקה שבהמשך כדי לטפל בזרם הנתונים הנכנס:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
איך אודיו ווידאו הופכים לנתונים לצורך שידור
כדי לאפשר תקשורת בזמן אמת באינטרנט, צריך להמיר את האודיו והווידאו הגולמיים לפורמט שמתאים לשידור. התהליך כולל איסוף, קידוד ואריזה של הנתונים לפני שליחתם ברשת.
טרנספורמציה של נתוני אודיו
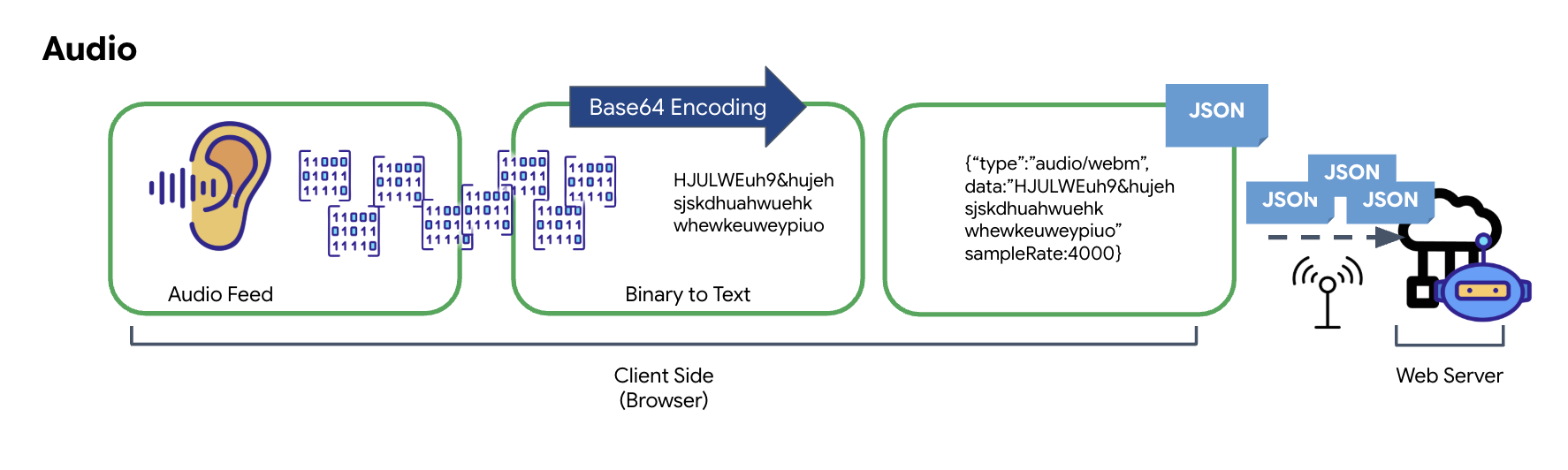
התהליך של המרת אודיו אנלוגי לנתונים דיגיטליים שניתן להעביר מתחיל בלכידת גלי הקול באמצעות מיקרופון. לאחר מכן, האודיו הגולמי הזה מעובד באמצעות Web Audio API של הדפדפן. הנתונים הגולמיים האלה הם בפורמט בינארי, ולכן הם לא תואמים ישירות לפורמטים של העברת נתונים מבוססי-טקסט כמו JSON. כדי לפתור את הבעיה, כל פלח אודיו מקודד למחרוזת Base64. Base64 היא שיטה שמייצגת נתונים בינאריים בפורמט מחרוזת ASCII, כדי להבטיח את השלמות שלהם במהלך השידור.
המחרוזת המקודדת הזו מוטמעת באובייקט JSON. האובייקט הזה מספק פורמט מובנה לנתונים, בדרך כלל כולל שדה 'סוג' כדי לזהות אותו כקובץ אודיו ומטא-נתונים כמו קצב הדגימה של האודיו. אחר כך אובייקט ה-JSON כולו עובר סריאליזציה למחרוזת ונשלח דרך חיבור WebSocket. הגישה הזו מבטיחה שהאודיו ישודר בצורה מאורגנת וקלה לניתוח.
טרנספורמציה של נתוני וידאו
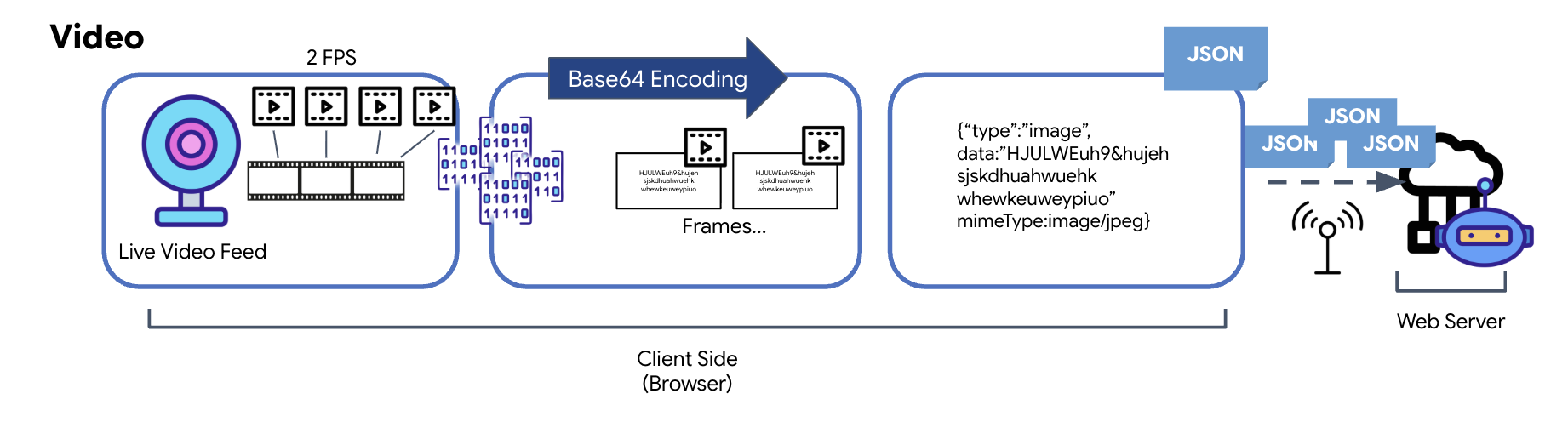
העברת הווידאו מתבצעת באמצעות טכניקה של לכידת פריימים. במקום לשלוח סטרימינג רציף של סרטון, לולאה חוזרת מצלמת תמונות סטילס מפיד הווידאו בשידור חי במרווח זמן מוגדר, למשל שני פריימים לשנייה. כדי לעשות את זה, המערכת מציירת את הפריים הנוכחי מרכיב וידאו של HTML על רכיב קנבס מוסתר.
לאחר מכן, נעשה שימוש בשיטה toDataURL של הקנבס כדי להמיר את התמונה שצולמה למחרוזת JPEG מקודדת ב-Base64. השיטה הזו כוללת אפשרות לציין את איכות התמונה, וכך לאפשר איזון בין נאמנות התמונה לבין גודל הקובץ כדי לשפר את הביצועים. בדומה לנתוני האודיו, מחרוזת Base64 הזו מוצבת באובייקט JSON. בדרך כלל האובייקט הזה מסומן ב'סוג' 'תמונה' וכולל את mimeType, כמו 'image/jpeg'. חבילת ה-JSON הזו מומרת למחרוזת ונשלחת דרך WebSocket, וכך הצד המקבל יכול לשחזר את הסרטון על ידי הצגת רצף התמונות.
👈✏️ באותו קובץ $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, מחליפים את //#CAPTURE AUDIO and VIDEO בקוד הבא כדי לתעד את קלט של משתמשים:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
אחרי השמירה, מרכז הבקרה יהיה מוכן לתרגם את האותות הדיגיטליים של הנציג לעדכונים חזותיים בלוח הבקרה ולאודיו.
בדיקת אבחון (בדיקת לולאה חוזרת)
לוח הבקרה שלך פעיל עכשיו. כל 500 אלפיות השנייה, משודר "חבילת" נתונים ויזואלית של הסביבה שלכם. לפני שמתחברים ל-Gemini, אנחנו צריכים לוודא שהמשדר של הספינה פועל. נריץ 'בדיקת לולאה חוזרת' באמצעות שרת אבחון מקומי.
👈💻 קודם כול, יוצרים את ממשק Cockpit מהטרמינל:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👈💻 לאחר מכן, מפעילים את שרת הדמה:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 מריצים את פרוטוקול הבדיקה:
- פתיחת התצוגה המקדימה: לוחצים על סמל התצוגה המקדימה של האינטרנט בסרגל הכלים של Cloud Shell. בוחרים באפשרות שינוי היציאה, מגדירים אותה ל-8080 ולוחצים על שינוי ותצוגה מקדימה. תיפתח כרטיסייה חדשה בדפדפן עם ממשק Cockpit.
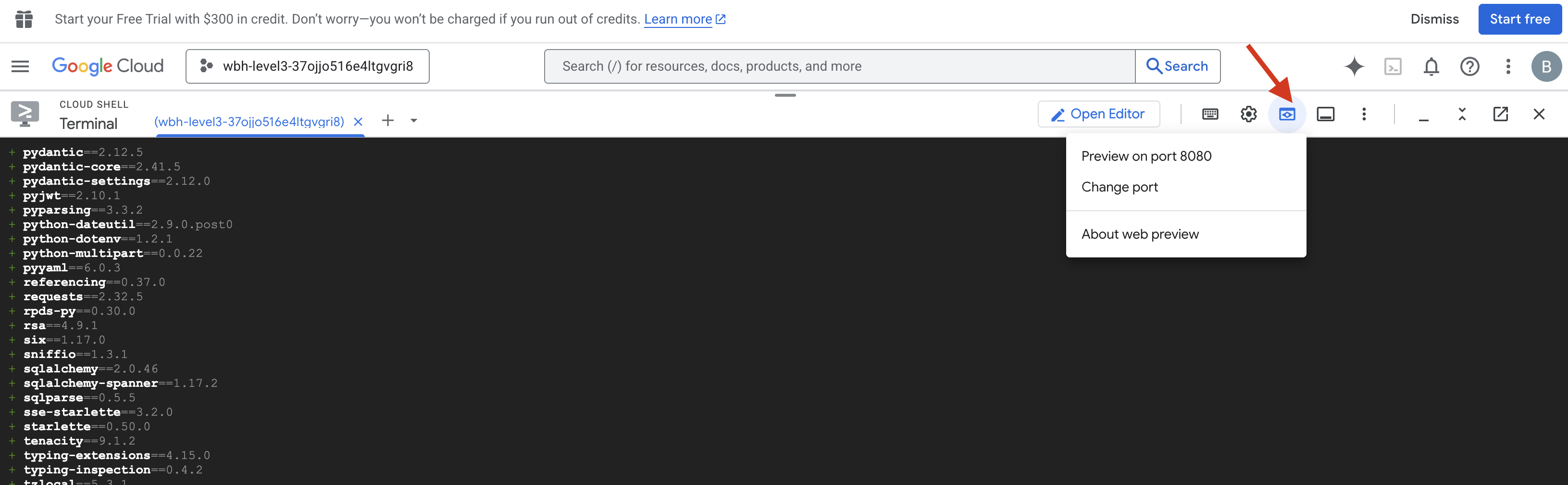
- חשוב מאוד: כשמתבקשים, חובה לאשר לדפדפן גישה למצלמה ולמיקרופון. ללא הקלט הזה, לא ניתן להפעיל את הסנכרון העצבי.
- בממשק המשתמש, לוחצים על הלחצן INITIATE NEURAL SYNC (הפעלת סנכרון עצבי).
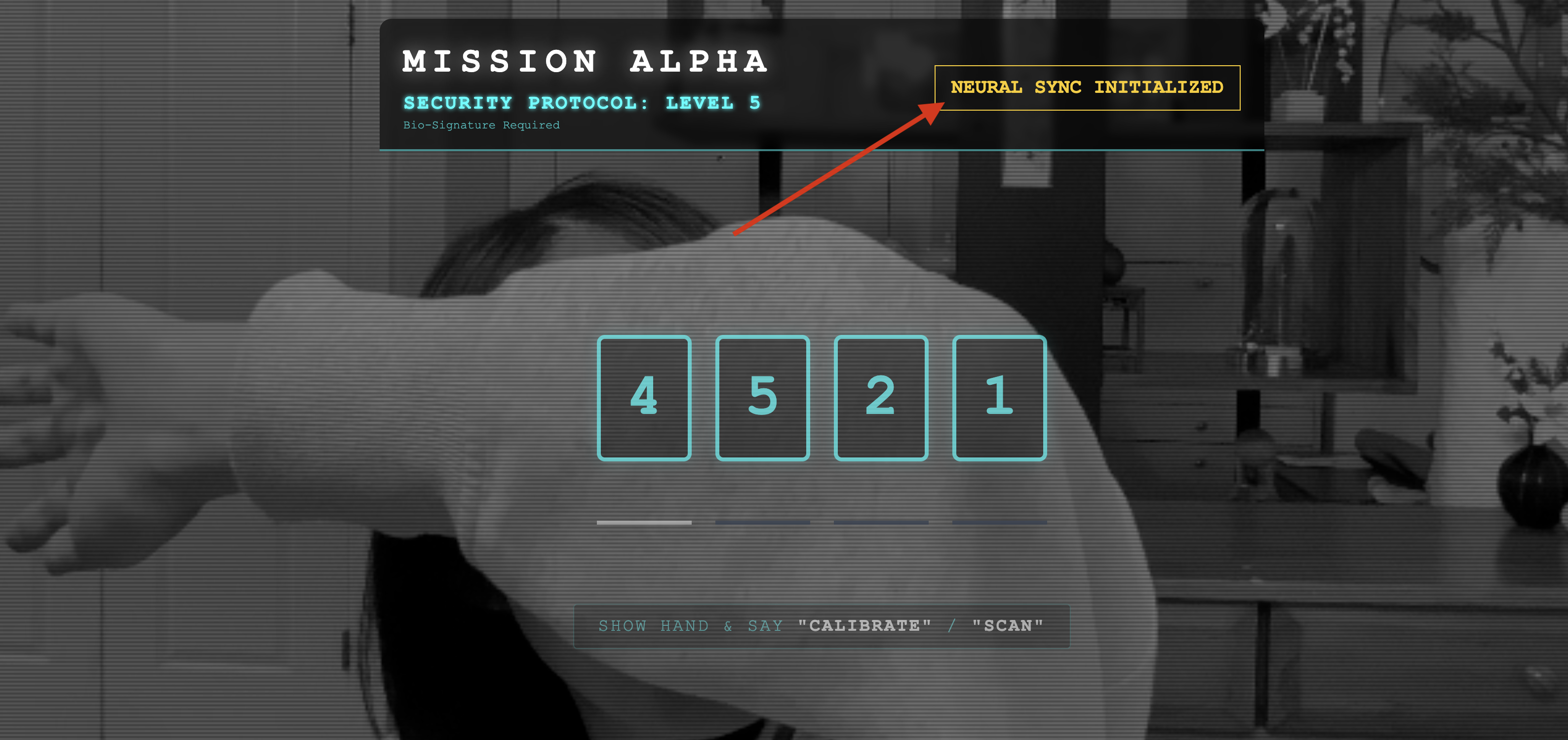
👀 בדיקת האינדיקטורים של סטטוס האימות:
- בדיקה ויזואלית: פותחים את מסוף הדפדפן. בפינה השמאלית העליונה אמור להופיע הסמל
NEURAL SYNC INITIALIZED. - בדיקת אודיו: אם פייפליין האודיו הדו-כיווני פועל באופן מלא, תשמעו קול מדומה שאומר: המערכת מחוברת!
אם שומעים את אישור האודיו 'המערכת מחוברת!', סימן שהבדיקה הצליחה. סגרו את הכרטיסייה. עכשיו אנחנו צריכים לפנות את התדר כדי לפנות מקום ל-AI האמיתי.
👈💻 לוחצים על Ctrl+C במסופים של שרת הדמה ושל חזית האתר. סוגרים את הכרטיסייה בדפדפן שבה פועל ממשק המשתמש.
4. הסוכן המולטי-מודאלי
ה-Rescue Scout פועל, אבל ה'מוח' שלו ריק. אם תנסו להתחבר עכשיו, הוא רק יבהה בכם. הוא לא יודע מה זה 'אצבע'. כדי להציל את הניצולים, צריך להטביע את הפרוטוקול הביומטרי העצבי בגרעין של הסקאוט.
סוכן מסורתי פועל כמו סדרה של מתרגמים. אם מדברים עם AI מהדור הישן, מודל של 'דיבור לטקסט' הופך את הקול למילים, 'מודל שפה' קורא את המילים האלה ומקליד תשובה, ומודל של 'טקסט לדיבור' קורא את התשובה הזו בחזרה. כך נוצר 'פער בהשהיה' – עיכוב שעלול להיות קטלני במשימת הצלה.
Gemini Live API הוא מודל מולטימודאלי מקורי. הוא מעבד ישירות ובמקביל בייטים של אודיו גולמי ומסגרות של וידאו גולמי. היא 'שומעת' את הרטט של הקול שלכם ו'רואה' את הפיקסלים של תנועות הידיים שלכם באותה ארכיטקטורה עצבית.
כדי למצות את הפוטנציאל הזה, אפשר לבנות את האפליקציה על ידי חיבור ישיר של מרכז הבקרה ל-Live API הגולמי. עם זאת, המטרה שלנו היא ליצור סוכן שאפשר לעשות בו שימוש חוזר – ישות מודולרית וחזקה שאפשר ליצור מהר יותר.
למה כדאי להשתמש ב-ADK (ערכה לפיתוח סוכנים)?
הערכה לפיתוח סוכנים (ADK) של Google היא מסגרת מודולרית לפיתוח ולפריסה של סוכני AI.
קריאות רגילות ל-LLM הן בדרך כלל חסרות מצב (stateless). כל שאילתה מתחילה מחדש. נציגים חיים, במיוחד כשהם משולבים עם SessionService של ADK, מאפשרים לנהל שיחות ארוכות ויציבות.
- המשכיות של סשנים: סשנים של ADK הם מתמשכים ואפשר לשמור אותם במסדי נתונים (כמו SQL או Vertex AI), גם אחרי הפעלה מחדש של השרת או ניתוקים. כלומר, אם משתמש מתנתק ומתחבר מחדש מאוחר יותר – גם אם זה קורה ימים אחרי – היסטוריית השיחות וההקשר שלו משוחזרים במלואם. סשן ה-API הזמני בזמן אמת מנוהל ומופשט על ידי ADK.
- חיבור מחדש אוטומטי: יכול להיות שחיבורי WebSocket יפסיקו לפעול (למשל, אחרי כ-10 דקות). ADK מטפל בחיבורים מחדש האלה באופן שקוף כשהאפשרות
session_resumptionמופעלת ב-RunConfig. קוד האפליקציה לא צריך לנהל לוגיקה מורכבת של חיבור מחדש, וכך המשתמשים נהנים מחוויה חלקה. - אינטראקציות עם שמירת מצב: הסוכן זוכר את התורות הקודמות, כך שאפשר לשאול שאלות המשך, לקבל הבהרות ולנהל דיאלוגים מורכבים עם כמה תורות שבהם ההקשר הוא קריטי. התכונה הזו חיונית לאפליקציות כמו תמיכת לקוחות, הדרכות אינטראקטיביות או תרחישי שליטה במשימה שבהם ההמשכיות היא קריטית.
ההתמדה הזו מבטיחה שהאינטראקציה תרגיש כמו שיחה מתמשכת עם ישות חכמה, ולא כמו סדרה של שאלות ותשובות מבודדות.
במילים אחרות, 'סוכן לייב' עם ADK Bidi-streaming הוא הרבה יותר ממנגנון פשוט של שאילתה ותשובה. הוא מציע ממשק צ'אט עם AI אינטראקטיבי באמת, עם שמירת מצב וזיהוי של הפרעות, כך שהאינטראקציות עם ה-AI מרגישות יותר אנושיות ויעילות הרבה יותר למשימות מורכבות וארוכות.
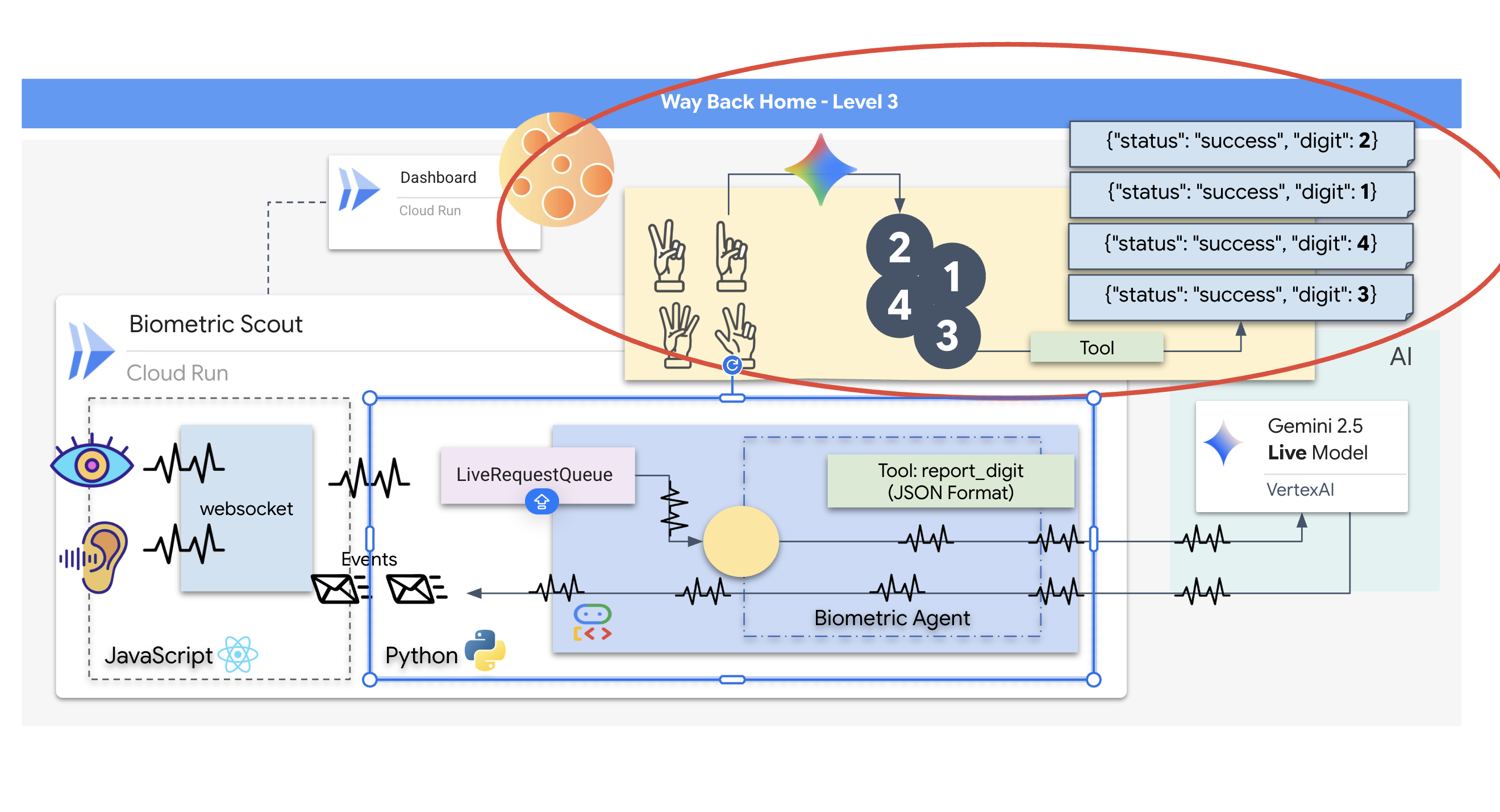
הנחיות לנציג תמיכה
כדי לעצב פרומפט לסוכן דו-כיווני בזמן אמת, צריך לשנות את הגישה. בניגוד לבוט צ'אט רגיל שמחכה לשאילתת טקסט סטטית, נציג תמיכה חי "תמיד זמין". הוא מקבל זרם קבוע של פריימים של אודיו ווידאו, כלומר ההנחיה שלכם צריכה לשמש כסקריפט של לולאת בקרה ולא רק כהגדרת אישיות.
הנה דוגמה להבדל בין הנחיה לנציג תמיכה לבין הנחיה רגילה:
- לוגיקה של מכונת מצבים: בהנחיה צריך להגדיר 'לולאת התנהגות' (המתנה → ניתוח → פעולה). הוא צריך הוראות ברורות מתי להישאר בשקט ומתי להגיב, כדי שהסוכן לא יפטפט על רעשי רקע ריקים.
- הבנה מולטימודלית: צריך להגיד לסוכן שיש לו "עיניים". צריך להנחות אותו באופן מפורש לנתח פריים של סרטון כחלק מתהליך החשיבה שלו.
- השהיה ותמציתיות: בשיחה קולית במצב לייב, פסקאות ארוכות עם הרבה מילים מרגישות לא טבעיות ואיטיות. ההנחיה הזו מעודדת תמציתיות כדי שהאינטראקציה תהיה מהירה.
- ארכיטקטורה שמתמקדת בפעולה: ההוראות נותנות עדיפות להפעלת כלים על פני דיבור. אנחנו רוצים שהנציג יבצע את הפעולה (סריקת המידע הביומטרי) לפני או במהלך האימות המילולי, ולא אחרי מונולוג ארוך.
👉✏️ פותחים את $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py ומחליפים את #REPLACE INSTRUCTIONS בטקסט הבא:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
הערה! אתם לא מתחברים למודל LLM רגיל. באותו קובץ ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), מאתרים את #REPLACE_MODEL. אנחנו צריכים לטרגט באופן מפורש את גרסת הטרום-השקה של המודל הזה כדי לתמוך טוב יותר ביכולות האודיו בזמן אמת.
👈✏️ מחליפים את הפלייסהולדר ב:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
הגדרתם את הסוכן. הוא יודע מי הוא ואיך לחשוב. לאחר מכן, אנחנו נותנים לו את הכלים לפעול.
הפעלת כלים
ה-API של שידור חי לא מוגבל רק להחלפת טקסט, אודיו וסרטונים. הוא תומך באופן מובנה בהפעלת כלים. התכונה הזו הופכת סוכנים שהם משתתפים פסיביים בשיחה למפעילים פעילים.
במהלך שיחה בזמן אמת, המודל מעריך כל הזמן את ההקשר. אם מודל ה-LLM מזהה צורך לבצע פעולה, בין אם מדובר ב'בדיקת טלמטריה של חיישן' או ב'פתיחת דלת מאובטחת'. הוא עובר בצורה חלקה משיחה לביצוע. הסוכן מפעיל את הפונקציה הספציפית של הכלי באופן מיידי, מחכה לתוצאה ומשלב את הנתונים האלה בחזרה בשידור החי, בלי לשבש את רצף האינטראקציה.
👉✏️ ב-$HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, מחליפים את #REPLACE TOOLS בפונקציה הזו:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ לאחר מכן, רושמים אותו בהגדרה של Agent על ידי החלפת #TOOL CONFIG:
tools=[report_digit],
הסימולטור adk web
לפני שמחברים את זה לתא הטייס המורכב של החללית (ה-Frontend של React), כדאי לבדוק את הלוגיקה של הסוכן בנפרד. ה-ADK כולל קונסולת מפתחים מובנית בשם adk web, שמאפשרת לנו לאמת את השימוש בכלים לפני הוספת מורכבות לרשת.
👈💻 בטרמינל, מריצים את הפקודה:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- בסרגל הכלים של Cloud Shell, לוחצים על סמל תצוגה מקדימה של אתר. בוחרים באפשרות שינוי היציאה, מגדירים אותה ל-8000 ולוחצים על שינוי ותצוגה מקדימה.
- נותנים הרשאות: כשמתבקשים, לוחצים על אישור כדי לאשר גישה למצלמה ולמיקרופון.
- כדי להתחיל את הסשן, לוחצים על סמל המצלמה.
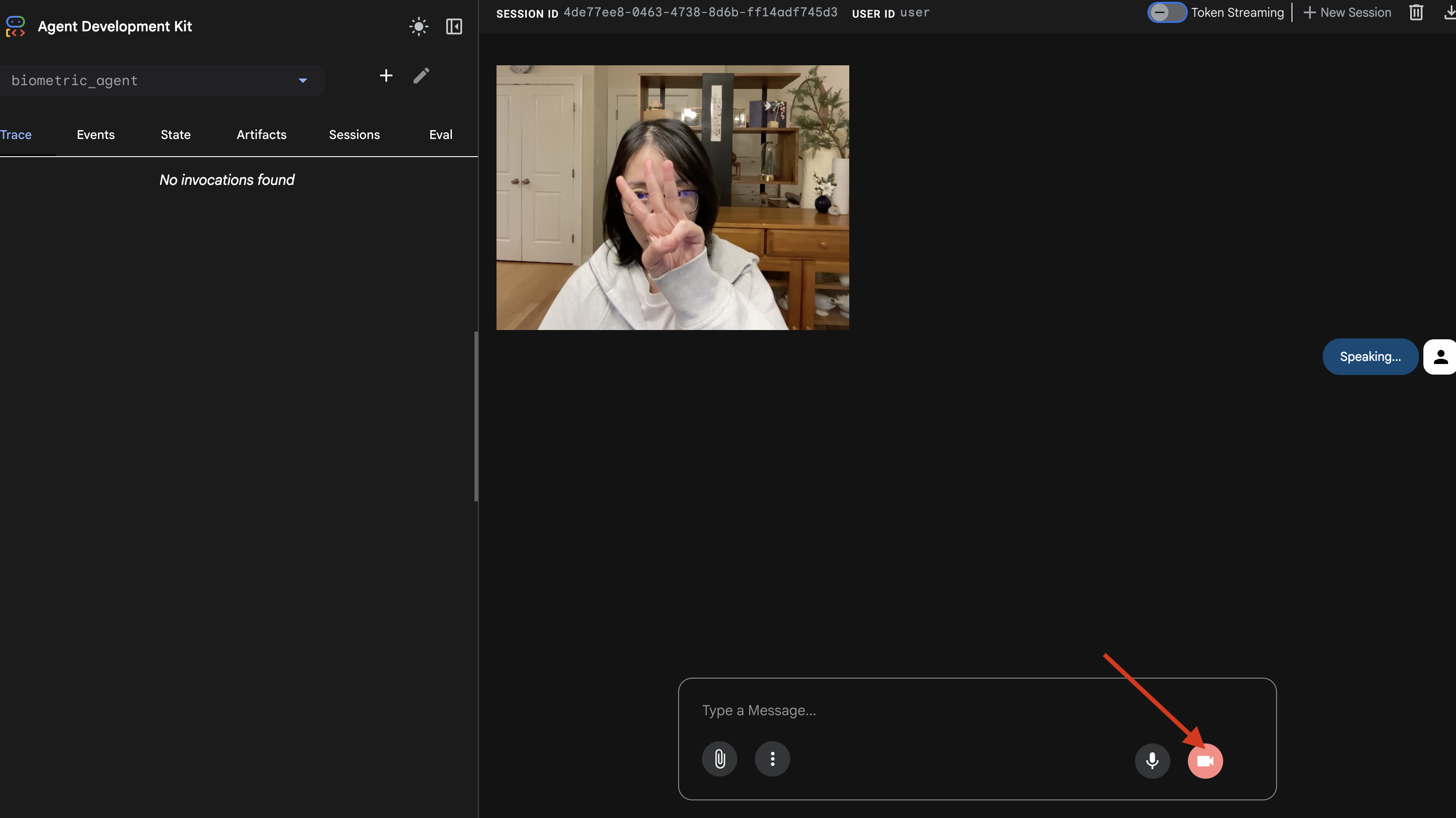
- הבדיקה החזותית:
- מציבים 3 אצבעות בבירור מול המצלמה.
- אומרים: "סריקה".
- אימות ההצלחה:
- יומנים: בודקים את הטרמינל שבו מריצים את הפקודה
adk web. צריך לראות את היומן הזה:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- יומנים: בודקים את הטרמינל שבו מריצים את הפקודה
אם אתם רואים את יומן הביצוע של הכלי, הסוכן שלכם הוא סוכן חכם. הוא יכול לראות, לחשוב ולפעול. השלב האחרון הוא לחבר אותו לספינה הראשית.
לוחצים על חלון הטרמינל ומקישים על Ctrl+C כדי להפסיק את הסימולטור adk web.
5. תהליך הסטרימינג הדו-כיווני
הסוכן פועל. ה-Cockpit פועל. עכשיו צריך לקשר ביניהם.
מחזור החיים של נציג תמיכה אנושי
סטרימינג בזמן אמת יוצר בעיה של 'אי התאמה בעכבה'. הלקוח (הדפדפן) שולח נתונים באופן אסינכרוני בקצב משתנה – פרצי נתונים או קלט מהיר – בעוד שהמודל דורש זרם קלט רציף ומסודר. הערכה לפיתוח סוכנים (ADK) של Google פותרת את הבעיה הזו באמצעות LiveRequestQueue.
הוא פועל כמאגר אסינכרוני בשיטת 'נכנס ראשון, יוצא ראשון' (FIFO) שמאובטח מפני שינויים בו-זמניים. ה-WebSocket handler פועל כProducer, ומעביר נתונים גולמיים של אודיו או וידאו לתור. סוכן ה-ADK פועל כצרכן, ושולף נתונים מהתור כדי להזין את חלון ההקשר של המודל. ההפרדה הזו מאפשרת לאפליקציה להמשיך לקבל קלט של משתמשים גם בזמן שהמודל יוצר תשובה או מפעיל כלי.
התור משמש כמַרבֵב מולטימודאלי. בסביבה אמיתית, הזרימה במעלה הזרם מורכבת מסוגי נתונים נפרדים שמתרחשים בו-זמנית: בייטים של אודיו PCM גולמי, פריימים של וידאו, הוראות מערכת מבוססות טקסט והתוצאות של קריאות אסינכרוניות לכלים. המודל LiveRequestQueue הופך את הקלטים השונים האלה לרצף כרונולוגי יחיד. לא משנה אם החבילה מכילה מילי-שנייה של שקט, תמונה ברזולוציה גבוהה או מטען ייעודי (payload) בפורמט JSON משאילתת מסד נתונים, היא עוברת סריאליזציה בסדר ההגעה המדויק, וכך המודל תופס ציר זמן עקבי וסיבתי.
הארכיטקטורה הזו מאפשרת שליטה ללא חסימה. מכיוון ששכבת ההזנה (Producer) מופרדת משכבת העיבוד (Consumer), המערכת ממשיכה להגיב גם במהלך הסקת מסקנות של מודל שדורשת הרבה משאבי מחשוב. אם משתמש מפריע עם הפקודה 'תפסיק!' בזמן שהנציג מבצע כלי, אות האודיו הזה מתווסף מיד לתור. לולאת האירועים הבסיסית מעבדת את אות העדיפות הזה באופן מיידי, וכך המערכת יכולה להפסיק את יצירת המשימות או לשנות את המשימות בלי שממשק המשתמש יקפא או שחבילות יאבדו.
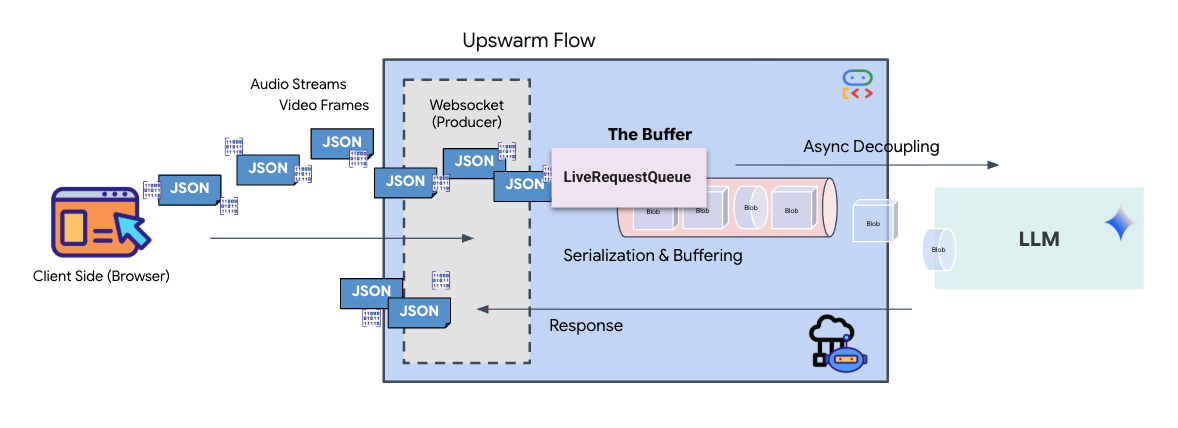
👉💻 ב-$HOME/way-back-home/level_3/backend/app/main.py, מחפשים את ההערה #REPLACE_RUNNER_CONFIG ומחליפים אותה בקוד הבא כדי להעלות את המערכת לאונליין:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
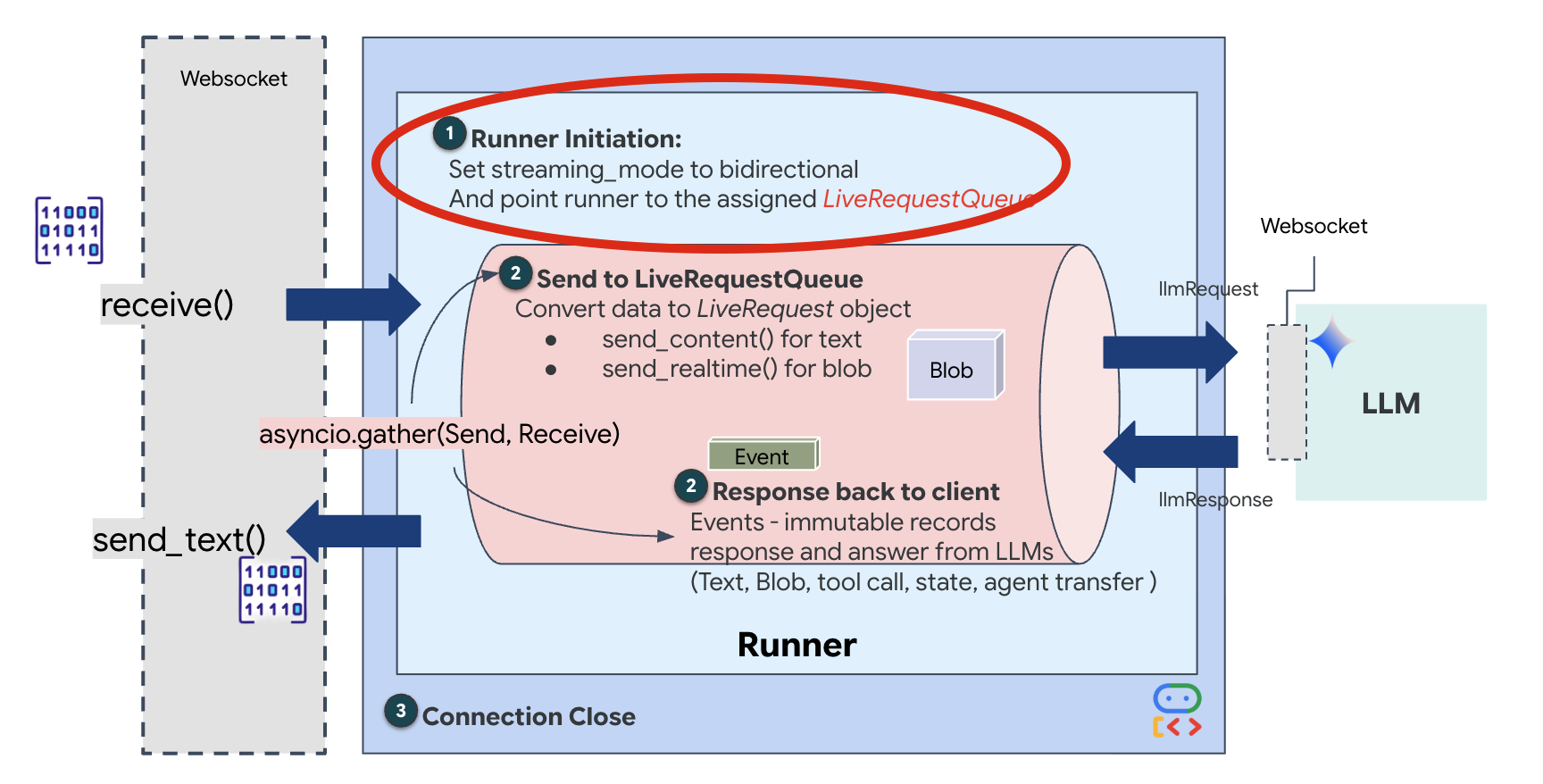
כשנפתח חיבור WebSocket חדש, צריך להגדיר את אופן האינטראקציה של ה-AI. בשלב הזה אנחנו מגדירים את "כללי ההתנהלות".
👈✏️ ב-$HOME/way-back-home/level_3/backend/app/main.py, בתוך הפונקציה async def websocket_endpoint, מחליפים את ההערה #REPLACE_SESSION_INIT בקוד הבא:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
הגדרות ההרצה
-
StreamingMode.BIDI: הגדרה זו קובעת שהחיבור יהיה דו-כיווני. בניגוד ל-AI שפועל בשיטת "תורות" (אתם מדברים, מפסיקים, ואז הוא מדבר), BIDI מאפשר שיחה ריאליסטית בשיטת "דיבור דו-כיווני". אתם יכולים להפריע ל-AI, וה-AI יכול לדבר בזמן שאתם זזים. -
AudioTranscriptionConfig: למרות שהמודל 'שומע' אודיו גולמי, אנחנו (המפתחים) צריכים לראות יומנים. ההגדרה הזו אומרת ל-Gemini: "תעבד את האודיו, אבל גם תחזיר תמליל טקסט של מה ששמעת כדי שנוכל לבצע ניפוי באגים".
לוגיקת ההפעלה אחרי שה-Runner יוצר את הסשן, הוא מעביר את השליטה ללוגיקת ההפעלה, שמסתמכת על LiveRequestQueue. זהו הרכיב הכי חשוב לאינטראקציה בזמן אמת. הלופ מאפשר לסוכן ליצור תגובה קולית בזמן שהתור ממשיך לקבל פריימים חדשים של סרטונים מהמשתמש, וכך לוודא שהסנכרון העצבי אף פעם לא נקטע.
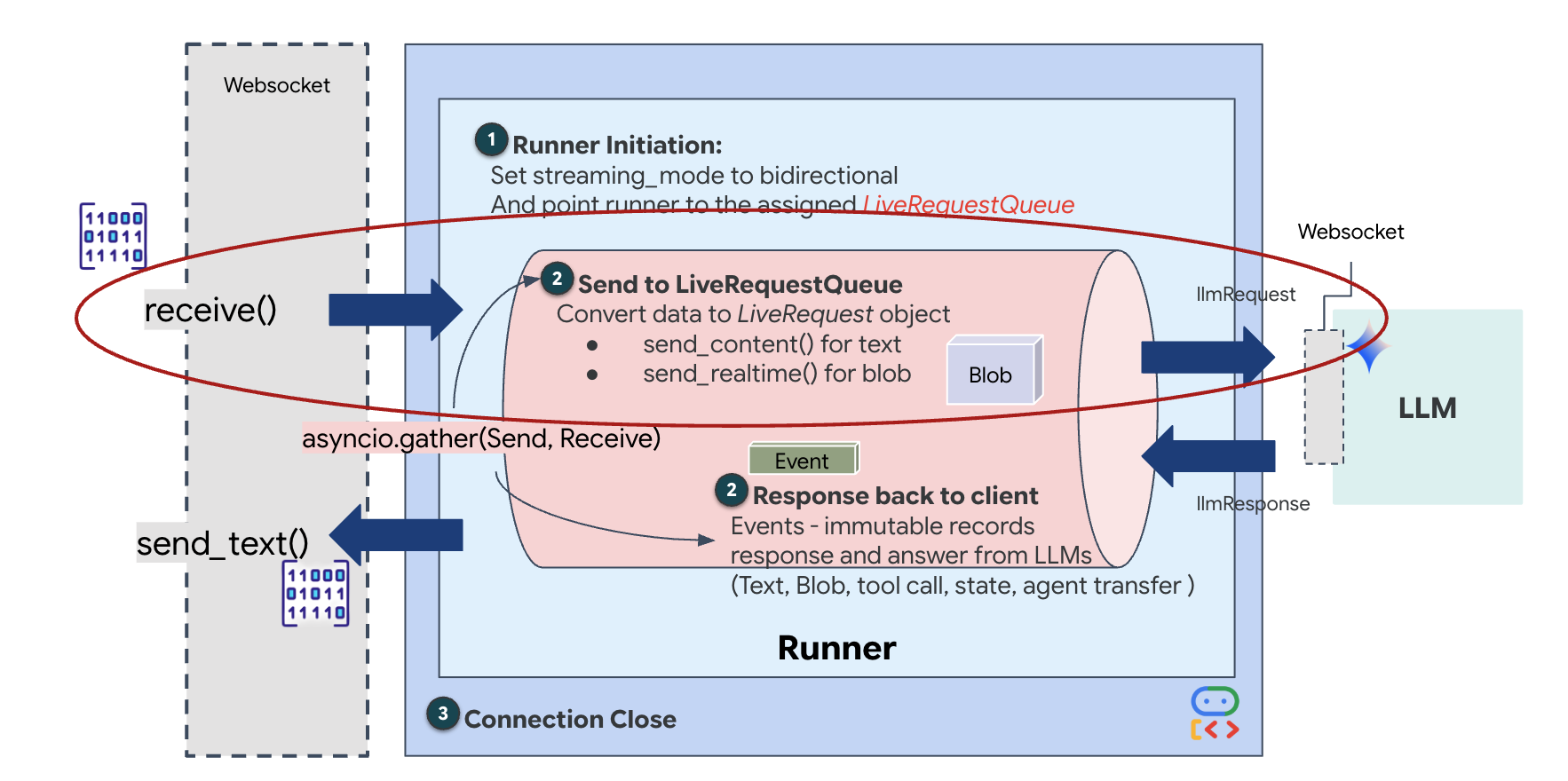
👉✏️ ב-$HOME/way-back-home/level_3/backend/app/main.py, מחליפים את #REPLACE_LIVE_REQUEST כדי להגדיר את המשימה במעלה הזרם ששולחת נתונים אל LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
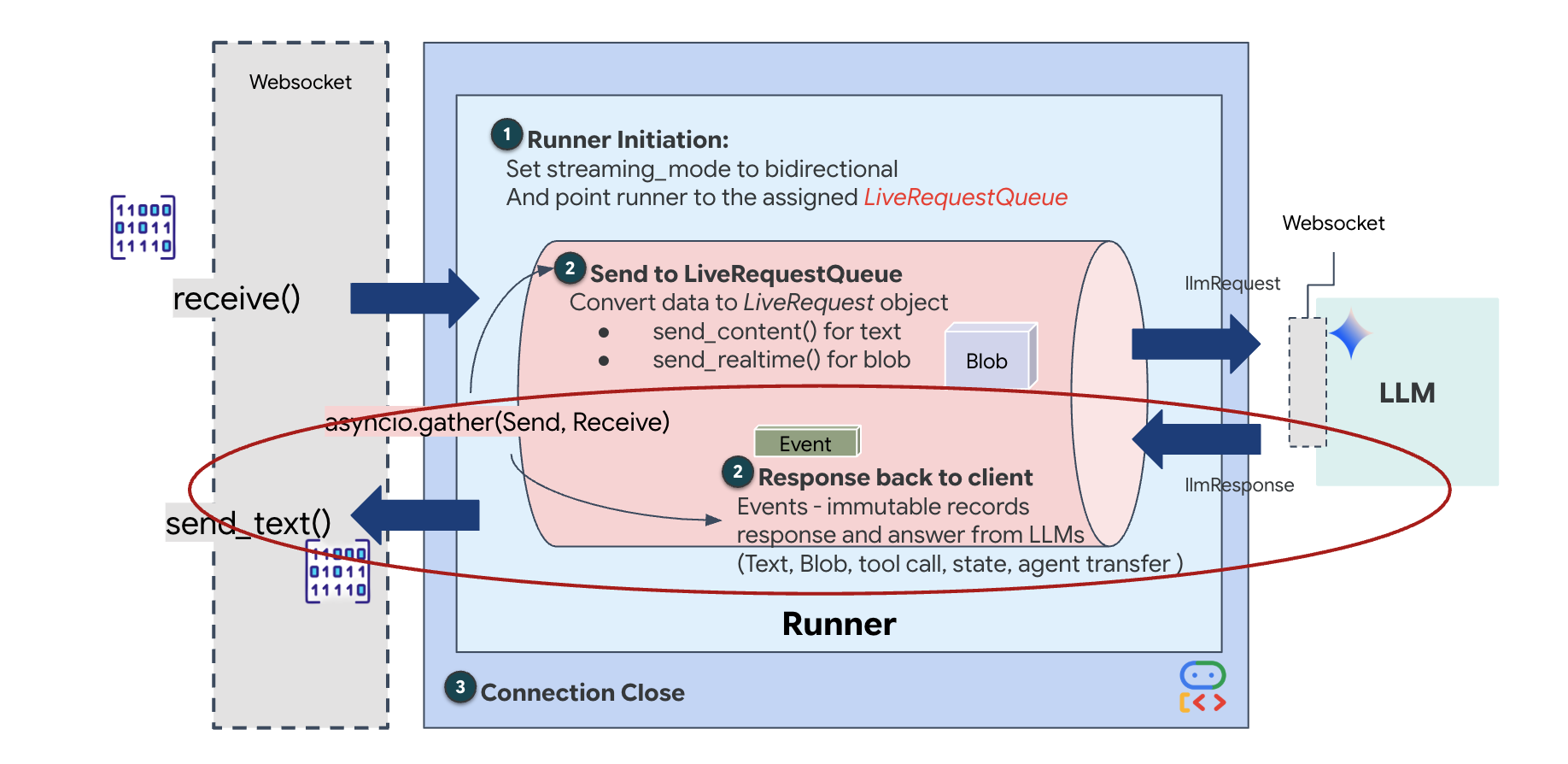
לבסוף, צריך לטפל בתשובות של ה-AI. הפעולה הזו מתבצעת באמצעות runner.run_live(), שהוא מחולל אירועים שמפיק אירועים (אודיו, טקסט או קריאות לכלים) בזמן שהם מתרחשים.
👉✏️ ב-$HOME/way-back-home/level_3/backend/app/main.py, מחליפים את #REPLACE_SORT_RESPONSE כדי להגדיר את המשימה הבאה ואת מנהל המקביליות:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
שימו לב לשורה await asyncio.gather(upstream_task(), downstream_task()). זהו העיקרון של דופלקס מלא. אנחנו מריצים את משימת ההאזנה (upstream) ואת משימת הדיבור (downstream) בדיוק באותו הזמן. כך אפשר לוודא ש'הקשר העצבי' מאפשר הפרעה וזרימת נתונים בו-זמנית.
הקוד של ה-Backend הושלם. ה'מוח' (ADK) מחובר ל'גוף' (WebSocket).
ביצוע Bio-Sync
הקוד שלם. המערכות ירוקות. הגיע הזמן להתחיל את המבצע.
- 👉💻 מפעילים את ה-Backend:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 מפעילים את חזית האתר:
- בסרגל הכלים של Cloud Shell, לוחצים על סמל תצוגה מקדימה של אתר. בוחרים באפשרות שינוי היציאה, מגדירים אותה ל-8080 ולוחצים על שינוי ותצוגה מקדימה.
- 👉 מפעילים את הפרוטוקול:
- לוחצים על הפעלת סנכרון עצבי.
- כיול: מוודאים שהמצלמה רואה את היד בבירור על רקע הרקע.
- הסנכרון: צופים בקוד האבטחה שמוצג על המסך (לדוגמה, 3, אחר כך 2, אחר כך 5).
- התאמת האות: כשמופיעה ספרה, מרימים בדיוק את מספר האצבעות הזה.
- החזיקו את היד באופן יציב: ודאו שהיד גלויה עד שה-AI יאשר שהייתה התאמה ביומטרית.
- התאמה: הקוד הוא אקראי. עוברים מיד למספר הבא שמוצג עד שהרצף מסתיים.

- כשתזהו את המספר האחרון ברצף האקראי, הסנכרון הביומטרי יושלם. הקשר העצבי יינעל. יש לכם שליטה ידנית. מנועי ה-Scout יתחילו לפעול, ויצללו לתוך הערוץ כדי להחזיר את הניצולים הביתה.
👈💻 כדי לצאת, לוחצים על Ctrl+C בטרמינל של הקצה העורפי.
6. פריסה בסביבת הייצור (אופציונלי)
הבדיקה הביומטרית בוצעה בהצלחה באופן מקומי. עכשיו צריך להעלות את ליבת ה-AI של הסוכן למחשבים המרכזיים של הספינה (Cloud Run) כדי שהוא יוכל לפעול באופן עצמאי ממסוף המקומי.
👈💻 מריצים את הפקודה הבאה במסוף של Cloud Shell. הפעולה הזו תיצור את קובץ ה-Dockerfile המלא והרב-שלבי בספריית ה-backend.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👈💻 עוברים לתיקיית ה-backend ואורזים את האפליקציה לקובץ אימג' של קונטיינר.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👈💻 פורסים את השירות ב-Cloud Run. אנחנו נחדיר את משתני הסביבה הנדרשים – במיוחד את הגדרות Gemini – ישירות לפקודת ההפעלה.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
בסיום הפקודה, תוצג כתובת URL של שירות (למשל, https://biometric-scout-...run.app). האפליקציה פעילה עכשיו בענן.
👈 עוברים לדף Google Cloud Run ובוחרים את השירות biometric-scout מהרשימה. 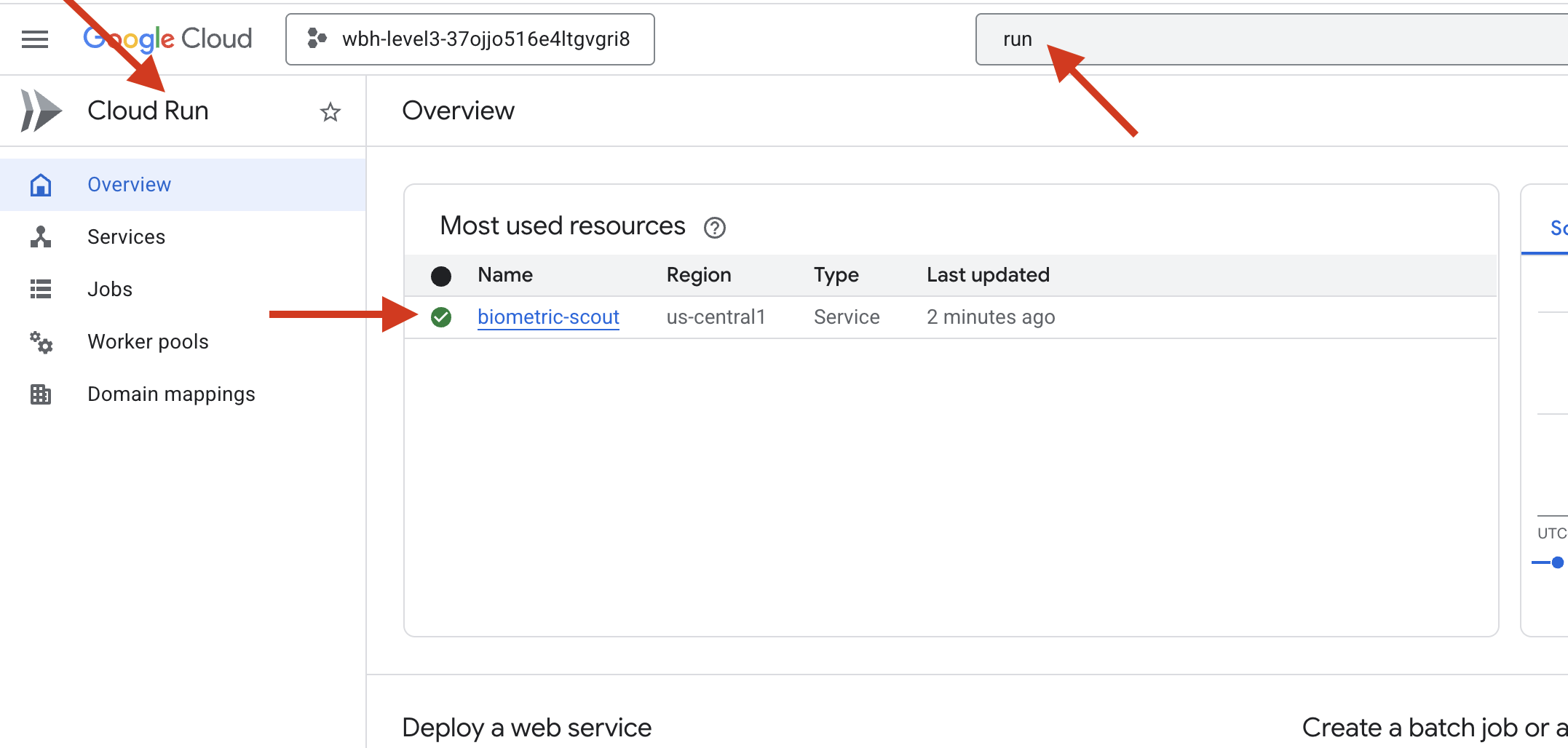
👈 מאתרים את כתובת ה-URL הציבורית שמוצגת בחלק העליון של דף פרטי השירות. 
נסה לבצע סנכרון ביוגרפי בסביבה הזו. האם זה עובד?
כשהאצבע החמישית נפרשת, ה-AI נועל את הרצף. המסך יהבהב בירוק: 'סנכרון נוירומטרי: נוצר'.
במחשבה אחת, אתם משגרים את הסקאוט אל החושך, נאחזים בתא התקוע ומושכים אותו החוצה רגע לפני שהקרע בכוח המשיכה קורס.

דלת המעבר נפתחת בלחץ אוויר, והנה הם – חמישה ניצולים חיים ונושמים. הם נכנסים בטעות לסיפון, חבולים אבל חיים, סוף סוף בטוחים בזכותך.
הודות לך, הקישור העצבי מסונכרן והניצולים מחולצים.
אם השתתפתם ברמה 0, אל תשכחו לבדוק איפה אתם בתהליך החזרה הביתה!