1. मिशन

आप किसी ऐसे सेक्टर में हैं जिसके बारे में कोई जानकारी नहीं है. एक बड़े **सौर पल्स** ने आपकी शिप को एक दरार से फाड़ दिया है. इससे आप ब्रह्मांड के एक ऐसे हिस्से में फंस गए हैं जो किसी भी स्टार चार्ट पर मौजूद नहीं है.
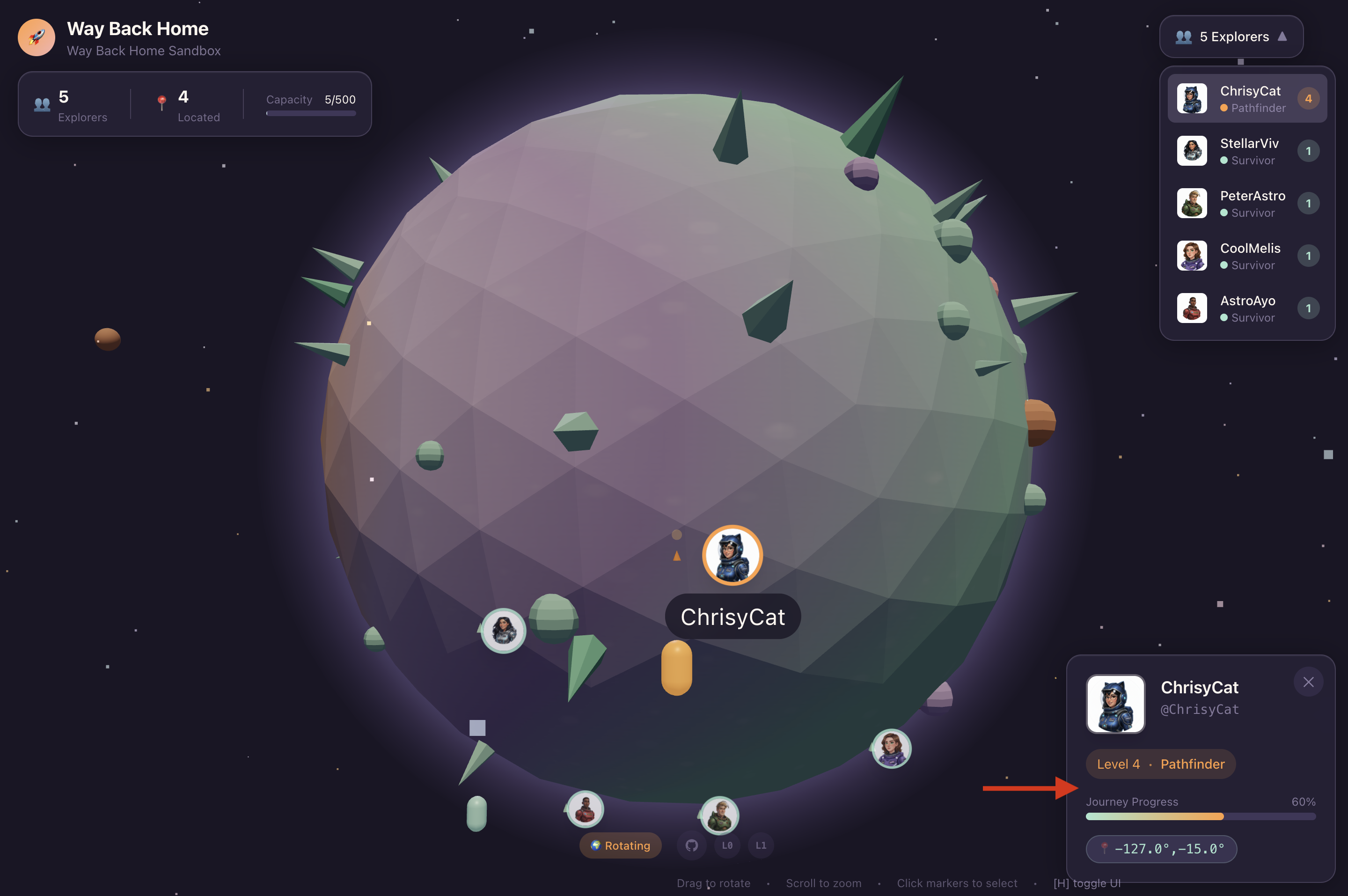
कई दिनों तक मरम्मत करने के बाद, आपको अपने पैरों के नीचे इंजन की आवाज़ सुनाई देती है. आपकी रॉकेटशिप ठीक कर दी गई है. आपने मदरशिप से लंबी दूरी का अपलिंक भी सुरक्षित कर लिया है. आपको उड़ान भरने की अनुमति है. अब आप घर जाने के लिए तैयार हैं. लेकिन जंप ड्राइव को चालू करने से पहले, एक डिस्ट्रेस सिग्नल सुनाई देता है. आपके सेंसर को "द रैवीन" में फंसी हुई पांच हल्की हीट सिग्नेचर मिलती हैं. यह एक ऊबड़-खाबड़ और गुरुत्वाकर्षण से मुड़ा हुआ सेक्टर है, जिसमें आपका मुख्य जहाज़ कभी नहीं जा सकता. ये भी एक्सप्लोरर हैं. ये उसी तूफ़ान से बचे हैं जिसमें तुम फंस गए थे. इन्हें हटाया नहीं जा सकता.
तुम ऐल्फ़ा-ड्रोन रेस्क्यू स्काउट की मदद लेते हो. यह छोटा और तेज़ गति से चलने वाला जहाज़, द रैवीन की संकरी दीवारों के बीच से गुज़रने वाला एकमात्र जहाज़ है. हालांकि, एक समस्या है: सोलर पल्स ने अपने मुख्य लॉजिक पर "सिस्टम रीसेट" किया है. स्काउट के कंट्रोल सिस्टम काम नहीं कर रहे हैं. यह चालू है, लेकिन इसका ऑनबोर्ड कंप्यूटर खाली है. यह मैन्युअल पायलट कमांड या फ़्लाइट पाथ को प्रोसेस नहीं कर सकता.
चैलेंज
सर्वाइवर को बचाने के लिए, आपको स्काउट के खराब हो चुके सर्किट को पूरी तरह से बायपास करना होगा. आपके पास एक ही विकल्प है: बायोमेट्रिक न्यूरल सिंक की सुविधा सेट अप करने के लिए, एआई एजेंट बनाएं. यह एजेंट, रीयल-टाइम ब्रिज के तौर पर काम करेगा. इससे आपको अपने बायोमेट्रिक इनपुट के ज़रिए, Rescue Scout को मैन्युअल तरीके से कंट्रोल करने की सुविधा मिलेगी. आपको जॉयस्टिक या कीबोर्ड का इस्तेमाल नहीं करना होगा. आपको सीधे तौर पर, शिप के नेविगेशन नेटवर्क में अपनी मंशा को शामिल करना होगा.
लिंक करने के लिए, आपको Scout के ऑप्टिकल सेंसर के सामने सिंक्रनाइज़ेशन प्रोटोकॉल पूरा करना होगा. एआई एजेंट को, सटीक और रीयल-टाइम हैंडशेक के ज़रिए आपके बायोलॉजिकल सिग्नेचर की पहचान करनी होगी.
आपके मिशन के मकसद:
- न्यूरल कोर को तैयार करना: एक ऐसा ADK एजेंट तय करें जो मल्टीमॉडल इनपुट को पहचान सके.
- कनेक्शन बनाना: Scout से एआई तक विज़ुअल डेटा स्ट्रीम करने के लिए, दोनों दिशाओं में काम करने वाली WebSocket पाइपलाइन बनाएं.
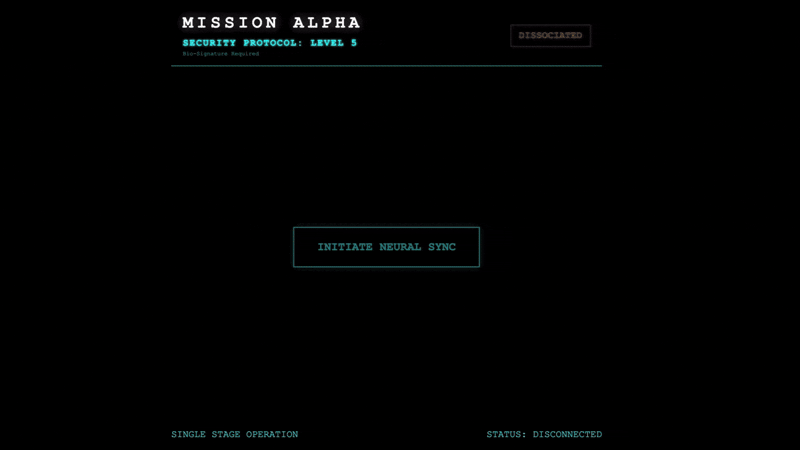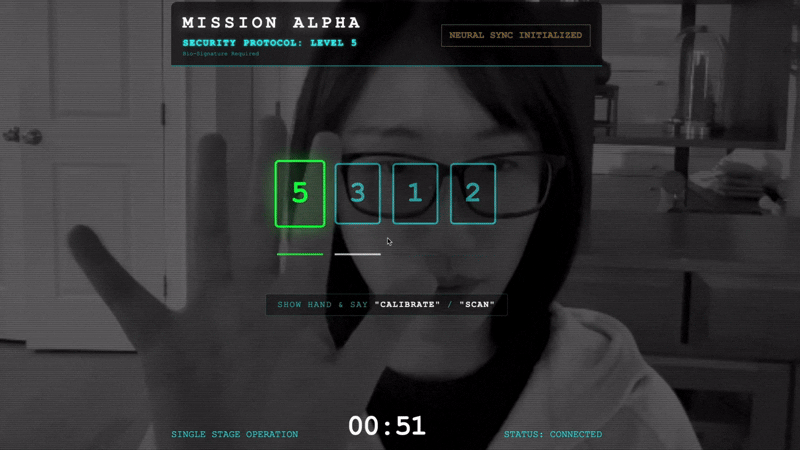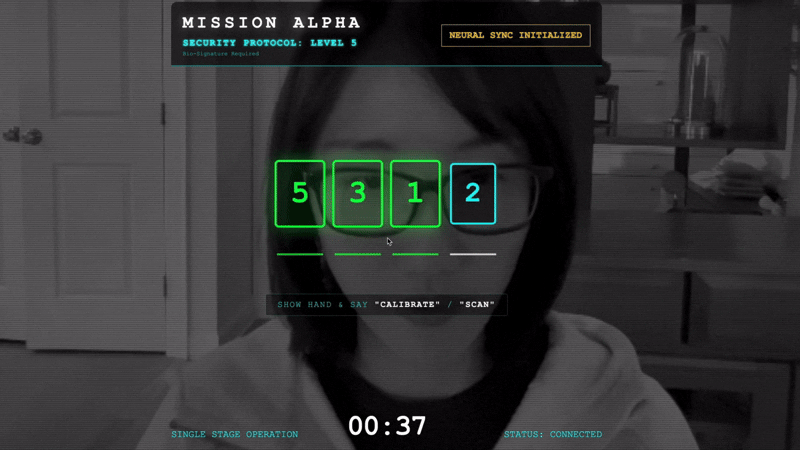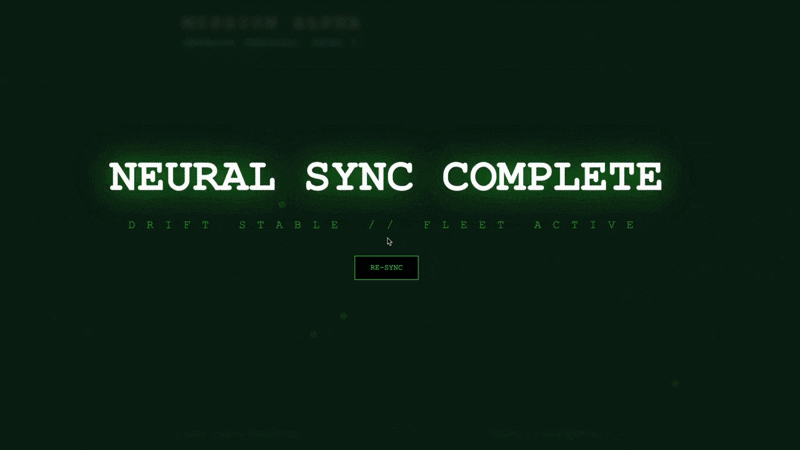
- हैंडशेक शुरू करें: सेंसर के सामने खड़े हों और उंगलियों को क्रम से दिखाएं. यानी, पहले एक उंगली दिखाएं, फिर दो, फिर तीन, फिर चार, और आखिर में पांच उंगलियां दिखाएं.
अगर यह प्रोसेस पूरी हो जाती है, तो "बायोमेट्रिक डेटा सिंक करें" सुविधा चालू हो जाएगी. एआई, न्यूरल लिंक को लॉक कर देगा. इससे आपको स्काउट को लॉन्च करने और बचे हुए लोगों को घर लाने के लिए, पूरी तरह से मैन्युअल कंट्रोल मिल जाएगा.
आपको क्या बनाना है
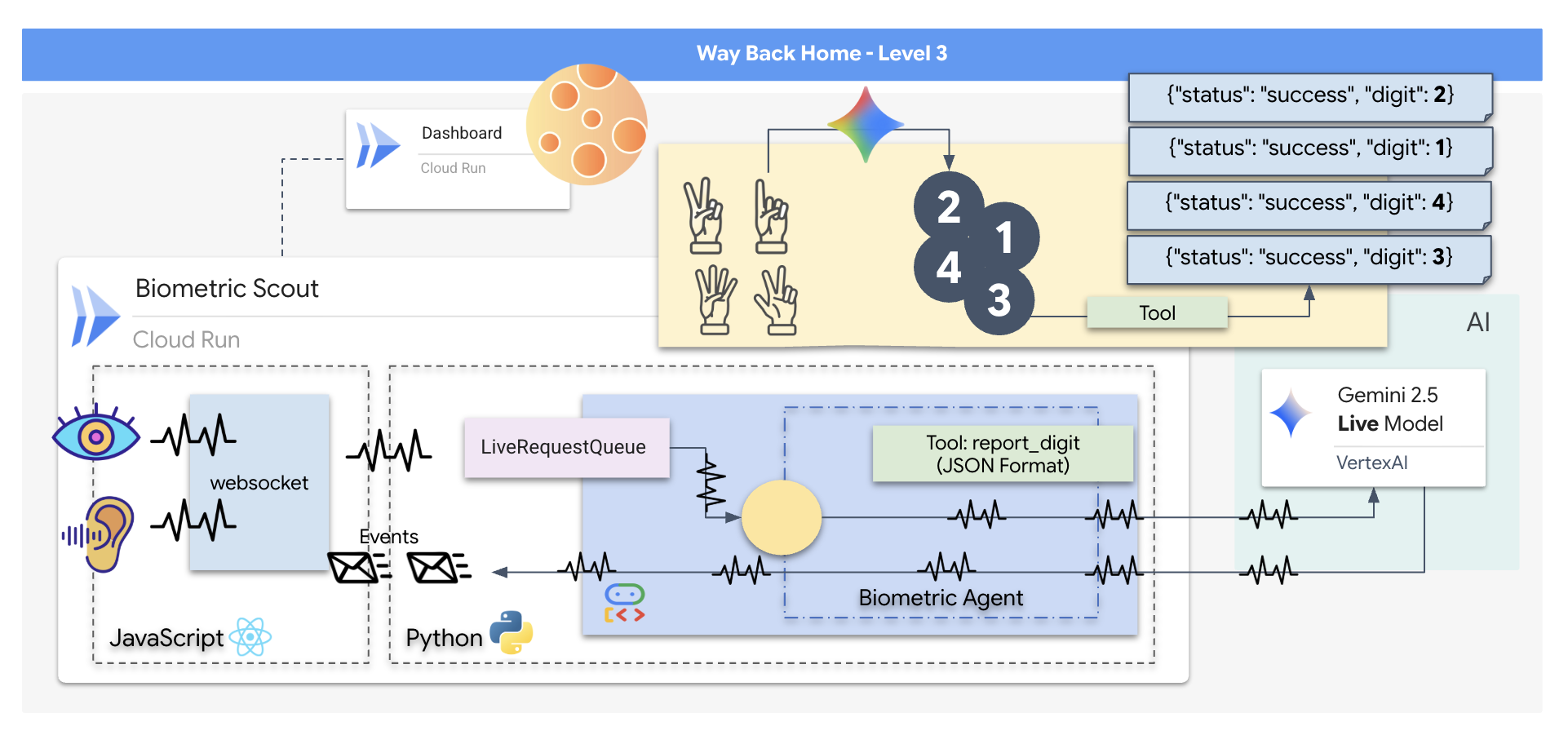
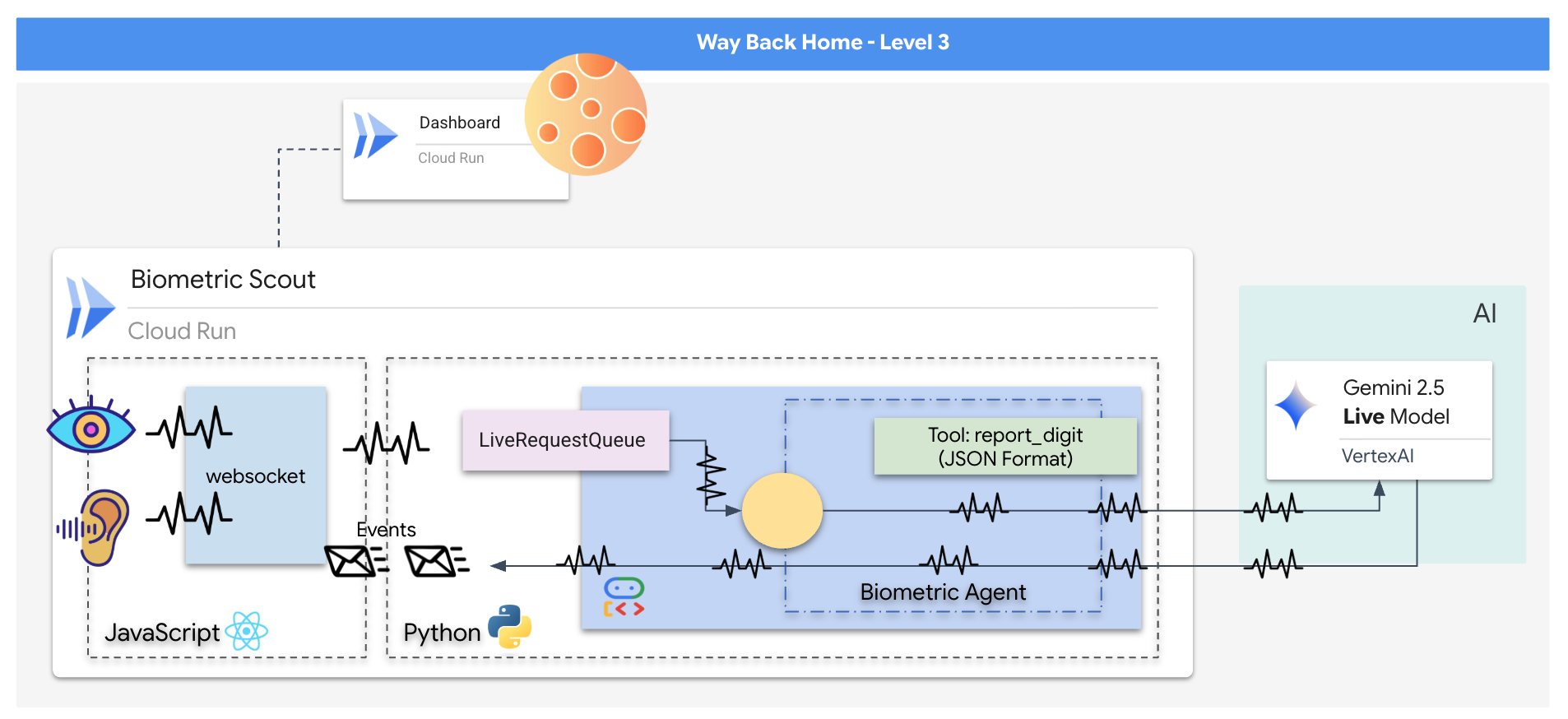
आपको "बायोमेट्रिक न्यूरल सिंक" ऐप्लिकेशन बनाना होगा. यह एक रीयल-टाइम, एआई की मदद से काम करने वाला सिस्टम है. यह रेस्क्यू ड्रोन के लिए कंट्रोल इंटरफ़ेस के तौर पर काम करता है. इस सिस्टम में ये शामिल हैं:
- React फ़्रंटएंड: यह आपकी शिप का "कॉकपिट" है. यह आपके वेबकैम से लाइव वीडियो और माइक्रोफ़ोन से ऑडियो कैप्चर करता है.
- Python बैकएंड: यह एक हाई-परफ़ॉर्मेंस सर्वर है. इसे FastAPI की मदद से बनाया गया है. इसमें Google के Agent Development Kit (ADK) का इस्तेमाल किया गया है, ताकि एलएलएम के लॉजिक और स्टेट को मैनेज किया जा सके.
- मल्टीमॉडल एआई एजेंट: यह ऑपरेशन का "ब्रेन" है. यह वीडियो और ऑडियो स्ट्रीम को एक साथ प्रोसेस करने और समझने के लिए,
google-genaiएसडीके के ज़रिए Gemini Live API का इस्तेमाल करता है. - दोनों दिशाओं में काम करने वाली WebSocket पाइपलाइन: यह "नर्वस सिस्टम" है, जो फ़्रंटएंड और एआई के बीच लगातार और कम समय में कनेक्शन बनाता है. इससे रीयल-टाइम में इंटरैक्शन किया जा सकता है.
आपको क्या सीखने को मिलेगा
टेक्नोलॉजी / कॉन्सेप्ट | ब्यौरा |
बैकएंड एआई एजेंट | Python और FastAPI की मदद से, स्टेटफ़ुल एआई एजेंट बनाएं. निर्देशों और मेमोरी को मैनेज करने के लिए, Google के एडीके (एजेंट डेवलपमेंट किट) का इस्तेमाल करें. साथ ही, Gemini मॉडल के साथ इंटरैक्ट करने के लिए, |
फ़्रंटएंड यूज़र इंटरफ़ेस (यूआई) | ब्राउज़र से सीधे तौर पर लाइव वीडियो और ऑडियो कैप्चर करने और स्ट्रीम करने के लिए, React का इस्तेमाल करके डाइनैमिक यूज़र इंटरफ़ेस बनाएं. |
रीयल-टाइम कम्यूनिकेशन | फ़ुल-डुप्लेक्स और कम समय में बातचीत करने के लिए, WebSocket पाइपलाइन लागू करें. इससे उपयोगकर्ता और एआई, दोनों एक साथ बातचीत कर पाएंगे. |
मल्टीमॉडल एआई | एक साथ चल रही वीडियो और ऑडियो स्ट्रीम को प्रोसेस करने और समझने के लिए, Gemini Live API का इस्तेमाल करें. इससे एआई को एक ही समय में "देखने" और "सुनने" की सुविधा मिलती है. |
टूल कॉलिंग | एआई को विज़ुअल ट्रिगर के जवाब में, कुछ खास Python फ़ंक्शन चलाने की अनुमति दें. इससे, मॉडल की बुद्धिमत्ता और असल दुनिया में होने वाली कार्रवाई के बीच के अंतर को कम किया जा सकता है. |
फ़ुल-स्टैक डिप्लॉयमेंट | पूरे ऐप्लिकेशन (React फ़्रंटएंड और Python बैकएंड) को Docker की मदद से कंटेनर में बदलें. इसके बाद, इसे Google Cloud Run पर, ज़्यादा उपयोगकर्ताओं को हैंडल करने वाली, बिना सर्वर के काम करने वाली सेवा के तौर पर डिप्लॉय करें. |
2. अपना एनवायरमेंट सेट अप करना
Cloud Shell ऐक्सेस करना
सबसे पहले, हम Cloud Shell खोलेंगे. यह ब्राउज़र पर आधारित एक टर्मिनल है. इसमें Google Cloud SDK और अन्य ज़रूरी टूल पहले से इंस्टॉल होते हैं.
👉Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें (यह Cloud Shell पैनल में सबसे ऊपर मौजूद टर्मिनल के आकार का आइकॉन है), 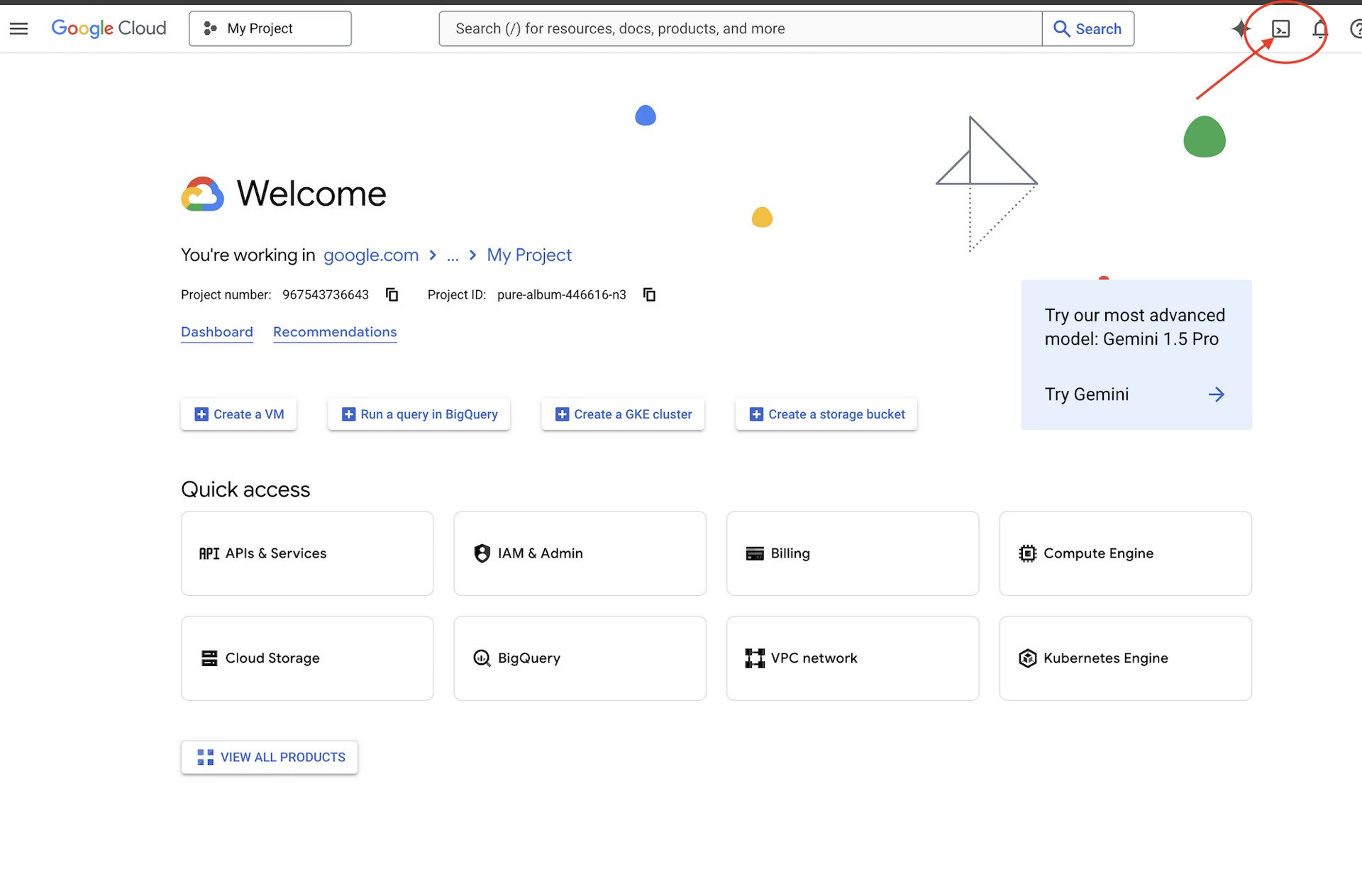
👉 "एडिटर खोलें" बटन पर क्लिक करें. यह बटन, पेंसिल वाले खुले फ़ोल्डर की तरह दिखता है. इससे विंडो में Cloud Shell Code Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा. 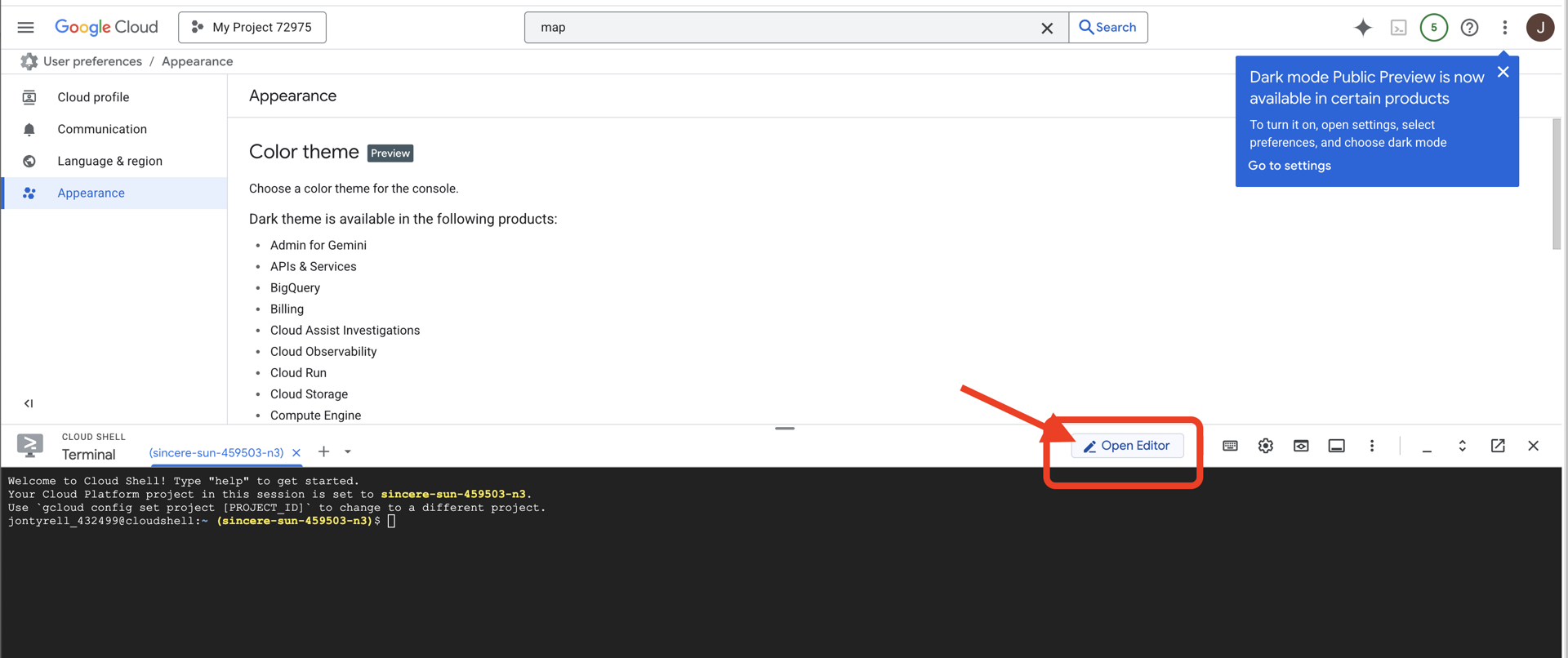
👉क्लाउड आईडीई में टर्मिनल खोलें,
👉💻 टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
आपको अपना खाता (ACTIVE) के तौर पर दिखेगा.
ज़रूरी शर्तें
ℹ️ लेवल 0 ज़रूरी नहीं है (लेकिन इसका सुझाव दिया जाता है)
इस मिशन को लेवल 0 पर भी पूरा किया जा सकता है. हालांकि, इसे पहले पूरा करने पर बेहतर अनुभव मिलता है. इससे आपको अपनी प्रोग्रेस के हिसाब से, ग्लोबल मैप पर अपने बीकन को जलते हुए देखने का मौका मिलता है.
प्रोजेक्ट एनवायरमेंट सेट अप करना
अपने टर्मिनल पर वापस जाएं. इसके बाद, चालू प्रोजेक्ट सेट करके और ज़रूरी Google Cloud सेवाएं (Cloud Run, Vertex AI वगैरह) चालू करके, कॉन्फ़िगरेशन पूरा करें.
👉💻 अपने टर्मिनल में, प्रोजेक्ट आईडी सेट करें:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 ज़रूरी सेवाएं चालू करें:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
डिपेंडेंसी इंस्टॉल करना
👉💻 लेवल पर जाएं और ज़रूरी Python पैकेज इंस्टॉल करें:
cd $HOME/way-back-home/level_3
uv sync
मुख्य डिपेंडेंसी ये हैं:
पैकेज | मकसद |
| सैटलाइट स्टेशन और एसएसई स्ट्रीमिंग के लिए, ज़्यादा परफ़ॉर्मेंस वाला वेब फ़्रेमवर्क |
| FastAPI ऐप्लिकेशन को चलाने के लिए, ASGI सर्वर की ज़रूरत होती है |
| फ़ॉर्मेशन एजेंट बनाने के लिए इस्तेमाल किया गया एजेंट डेवलपमेंट किट |
| Gemini मॉडल को ऐक्सेस करने के लिए नेटिव क्लाइंट |
| रीयल-टाइम में दोनों तरफ़ से बातचीत करने की सुविधा |
| यह एनवायरमेंट वैरिएबल और कॉन्फ़िगरेशन सीक्रेट मैनेज करता है |
सेटअप की पुष्टि करना
कोड को लॉन्च करने से पहले, आइए पक्का करें कि सभी सिस्टम ठीक से काम कर रहे हों. पुष्टि करने वाली स्क्रिप्ट चलाकर, अपने Google Cloud प्रोजेक्ट, एपीआई, और Python डिपेंडेंसी का ऑडिट करें.
👉💻 पुष्टि करने वाली स्क्रिप्ट चलाएं:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 आपको ग्रीन चेक (✅) की एक सीरीज़ दिखेगी.
- अगर आपको लाल रंग के क्रॉस (❌) दिखते हैं, तो आउटपुट में दिए गए, समस्या ठीक करने के सुझावों का पालन करें. उदाहरण के लिए,
gcloud services enable ...याpip install .... - ध्यान दें: फ़िलहाल,
.envके लिए पीले रंग की चेतावनी स्वीकार की जा सकती है. हम अगले चरण में यह फ़ाइल बनाएंगे.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. कम्यूनिकेशन लिंक (WebSockets) को कैलिब्रेट करना
बायोमेट्रिक न्यूरल सिंक शुरू करने के लिए, हमें आपके जहाज़ के इंटरनल सिस्टम को अपडेट करना होगा. हमारा मुख्य मकसद, आपके कॉकपिट से हाई-फ़िडेलिटी वीडियो और ऑडियो स्ट्रीम कैप्चर करना है. इस स्ट्रीम से, न्यूरल लिंक के लिए ज़रूरी कॉम्पोनेंट मिलते हैं: आपकी उंगलियों के क्रम की पहचान करने के लिए विज़ुअल और आपकी आवाज़ की सोनिक फ़्रीक्वेंसी.
फ़ुल-डूप्लेक्स बनाम हाफ़-डूप्लेक्स
न्यूरल सिंक के लिए हमें इसकी ज़रूरत क्यों है, यह समझने के लिए आपको डेटा के फ़्लो को समझना होगा:
- हाफ़-डुप्लेक्स (स्टैंडर्ड एचटीटीपी): वॉकी-टॉकी की तरह. एक व्यक्ति बोलता है, "ओवर" कहता है, और फिर दूसरा व्यक्ति बोल सकता है. एक ही समय पर सुना और बोला नहीं जा सकता.
- फ़ुल-डुप्लेक्स (WebSocket): यह फ़ेस-टू-फ़ेस बातचीत की तरह होता है. डेटा, दोनों दिशाओं में एक साथ ट्रांसफ़र होता है. जब आपका ब्राउज़र, वीडियो फ़्रेम और ऑडियो सैंपल को एआई के पास भेजता है, तब एआई उसी समय आपको आवाज़ वाले जवाब और टूल के निर्देश भेज सकता है.
Gemini Live की सुविधा के लिए फ़ुल-डुप्लेक्स की ज़रूरत क्यों होती है: Gemini Live API को "इंटरप्शन" के लिए डिज़ाइन किया गया है. मान लें कि आपको उंगलियों के क्रम को दिखाना है और एआई को लगता है कि आप इसे गलत तरीके से कर रहे हैं. स्टैंडर्ड एचटीटीपी सेटअप में, एआई को आपके डेटा भेजने की प्रोसेस पूरी होने का इंतज़ार करना पड़ता है. इसके बाद ही, वह आपको डेटा भेजने से रोकने के लिए कह सकता है. WebSockets की मदद से, एआई पहले फ़्रेम में हुई गलती को देख सकता है. साथ ही, "इंटरप्ट" सिग्नल भेज सकता है. यह सिग्नल, दूसरे फ़्रेम के लिए हाथ हिलाने के दौरान ही आपके कॉकपिट में पहुंच जाता है.
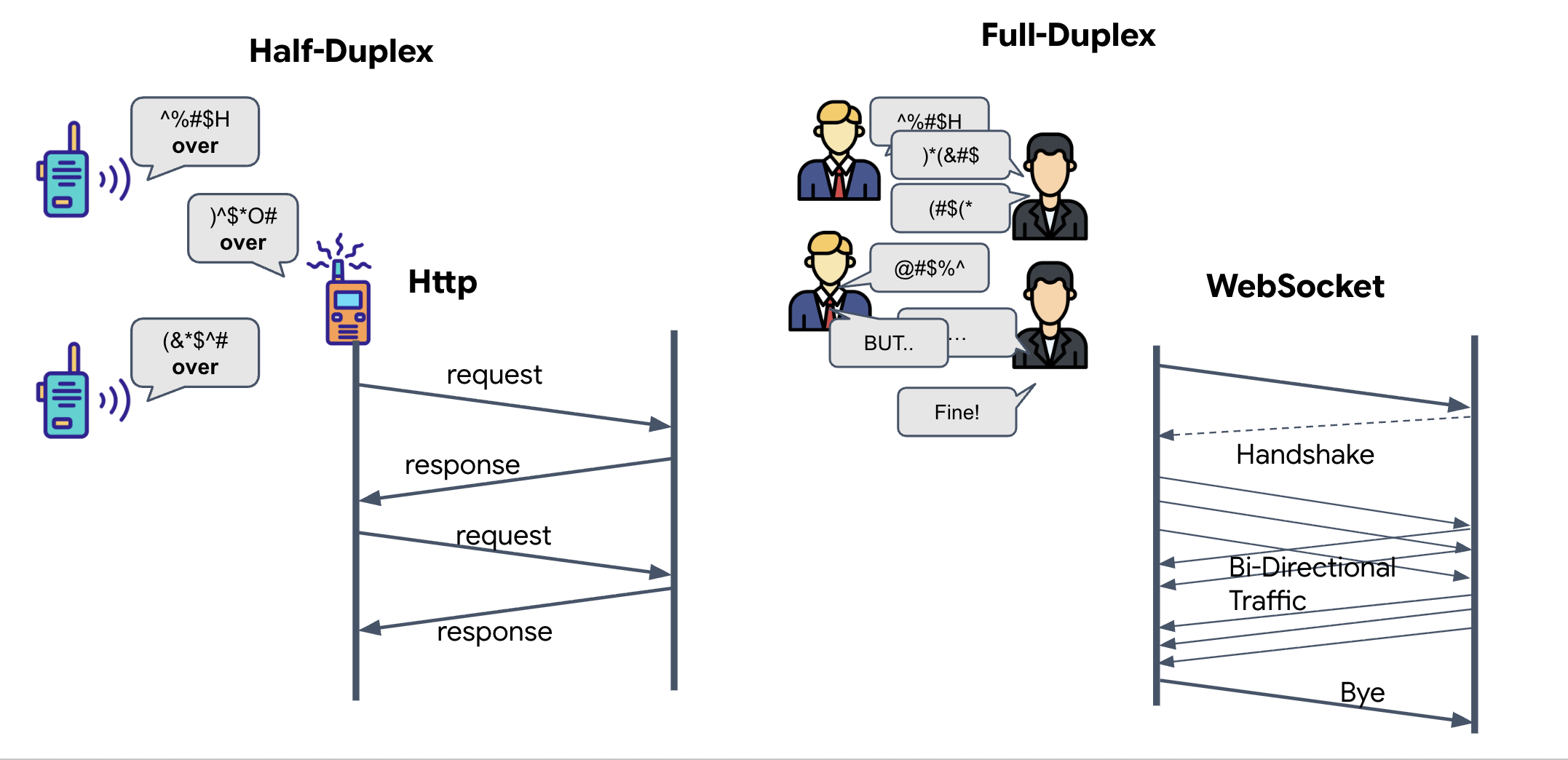
WebSocket क्या है?
सामान्य गैलेक्टिक ट्रांसमिशन (एचटीटीपी) में, एक अनुरोध भेजा जाता है और जवाब का इंतज़ार किया जाता है. यह पोस्टकार्ड भेजने जैसा है. न्यूरल सिंक के लिए, पोस्टकार्ड बहुत धीमे होते हैं. हमें एक "लाइव वायर" की ज़रूरत है.
WebSockets, स्टैंडर्ड वेब अनुरोध (एचटीटीपी) के तौर पर शुरू होते हैं, लेकिन बाद में "अपग्रेड" होकर कुछ और बन जाते हैं.
- अनुरोध: आपका ब्राउज़र, सर्वर को एक सामान्य एचटीटीपी अनुरोध भेजता है. इसमें एक खास हेडर होता है:
Upgrade: websocket. इसका मतलब है कि "मुझे पोस्टकार्ड भेजना बंद करना है और लाइव फ़ोन कॉल शुरू करना है." - जवाब: अगर एआई एजेंट (सर्वर) इस सुविधा के साथ काम करता है, तो वह
HTTP 101 Switching Protocolsजवाब भेजता है. - बदलाव: इस समय, एचटीटीपी कनेक्शन को WebSocket प्रोटोकॉल से बदल दिया जाता है. हालांकि, टीसीपी/आईपी सॉकेट खुला रहता है. कम्यूनिकेशन के नियम, "अनुरोध/जवाब" से बदलकर तुरंत "फ़ुल-डुप्लेक्स स्ट्रीमिंग" पर सेट हो जाते हैं.
WebSocket हुक लागू करना
आइए, टर्मिनल ब्लॉक की जांच करके देखते हैं कि डेटा कैसे फ़्लो होता है.
👀 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js खोलें. आपको पहले से सेट अप किए गए स्टैंडर्ड WebSocket लाइफ़साइकल इवेंट हैंडलर दिखेंगे. यह हमारे कम्यूनिकेशन सिस्टम का स्ट्रक्चर है:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
onMessage हैंडलर
ws.current.onmessage ब्लॉक पर फ़ोकस करें. यह रिसीवर है. जब भी एजेंट "सोचता है" या "बोलता है", तो यहां एक डेटा पैकेट आता है. फ़िलहाल, यह कुछ नहीं करता. यह पैकेट को पकड़ता है और उसे छोड़ देता है (प्लेसहोल्डर //#REPLACE-HANDLE-MSG के ज़रिए).
हमें इस कमी को ऐसे लॉजिक से पूरा करना होगा जो इन दोनों के बीच अंतर कर सके:
- टूल कॉल (functionCall): एआई आपके हाथ के सिग्नल को पहचान रहा है ("सिंक करें").
- ऑडियो डेटा (inlineData): इसमें एआई की आवाज़ में दिया गया जवाब शामिल होता है.
👉✏️ अब उसी $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js फ़ाइल में, आने वाली स्ट्रीम को मैनेज करने के लिए, नीचे दिए गए लॉजिक से //#REPLACE-HANDLE-MSG को बदलें:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
ऑडियो और वीडियो को ट्रांसमिशन के लिए डेटा में कैसे बदला जाता है
इंटरनेट पर रीयल-टाइम में बातचीत करने के लिए, रॉ ऑडियो और वीडियो को ऐसे फ़ॉर्मैट में बदलना ज़रूरी है जो ट्रांसमिशन के लिए सही हो. इसमें नेटवर्क पर डेटा भेजने से पहले, उसे कैप्चर करना, एन्कोड करना, और पैकेज करना शामिल है.
ऑडियो डेटा बदलना
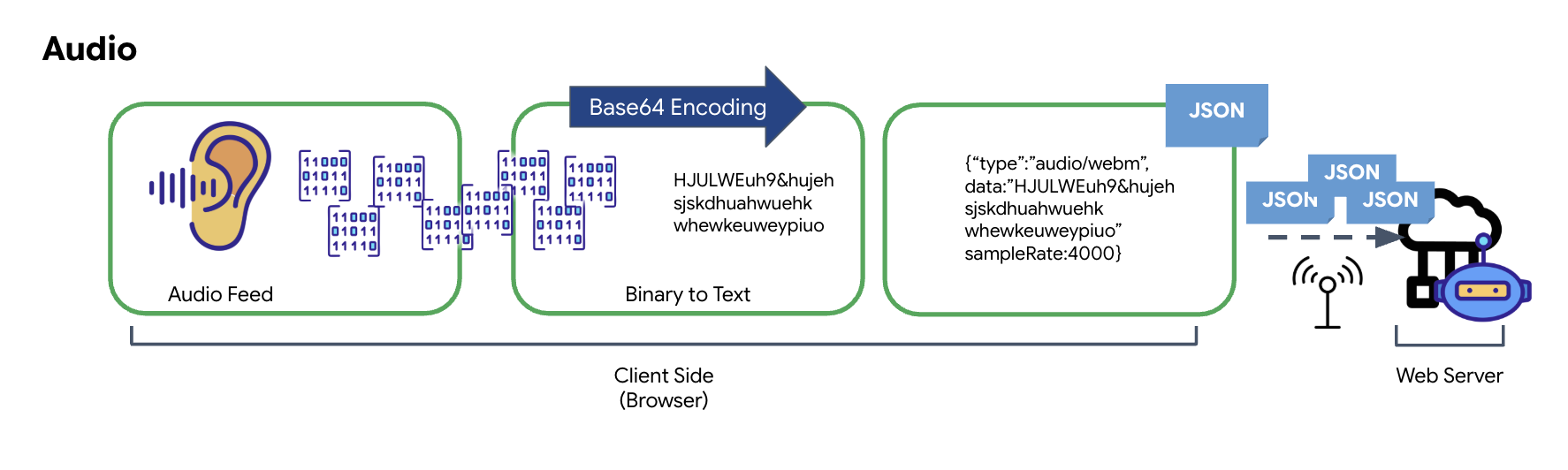
ऐनलॉग ऑडियो को ट्रांसमिट किए जा सकने वाले डिजिटल डेटा में बदलने की प्रोसेस, माइक्रोफ़ोन का इस्तेमाल करके साउंड वेव कैप्चर करने से शुरू होती है. इसके बाद, इस रॉ ऑडियो को ब्राउज़र के Web Audio API के ज़रिए प्रोसेस किया जाता है. यह रॉ डेटा बाइनरी फ़ॉर्मैट में होता है. इसलिए, यह JSON जैसे टेक्स्ट पर आधारित ट्रांसमिशन फ़ॉर्मैट के साथ सीधे तौर पर काम नहीं करता. इस समस्या को हल करने के लिए, ऑडियो के हर सेगमेंट को Base64 स्ट्रिंग में कोड में बदला जाता है. Base64 एक ऐसा तरीका है जो बाइनरी डेटा को ASCII स्ट्रिंग फ़ॉर्मैट में दिखाता है. इससे यह पक्का होता है कि ट्रांसमिशन के दौरान डेटा के साथ छेड़छाड़ न हो.
इसके बाद, इस एन्कोड की गई स्ट्रिंग को JSON ऑब्जेक्ट में एम्बेड किया जाता है. यह ऑब्जेक्ट, डेटा के लिए स्ट्रक्चर्ड फ़ॉर्मैट उपलब्ध कराता है. इसमें आम तौर पर, "type" फ़ील्ड शामिल होता है, ताकि इसे ऑडियो और मेटाडेटा के तौर पर पहचाना जा सके. जैसे, ऑडियो का सैंपल रेट. इसके बाद, पूरे JSON ऑब्जेक्ट को स्ट्रिंग में बदला जाता है और WebSocket कनेक्शन पर भेजा जाता है. इस तरीके से, यह पक्का किया जाता है कि ऑडियो को व्यवस्थित तरीके से और आसानी से पार्स किया जा सके.
वीडियो डेटा बदलना
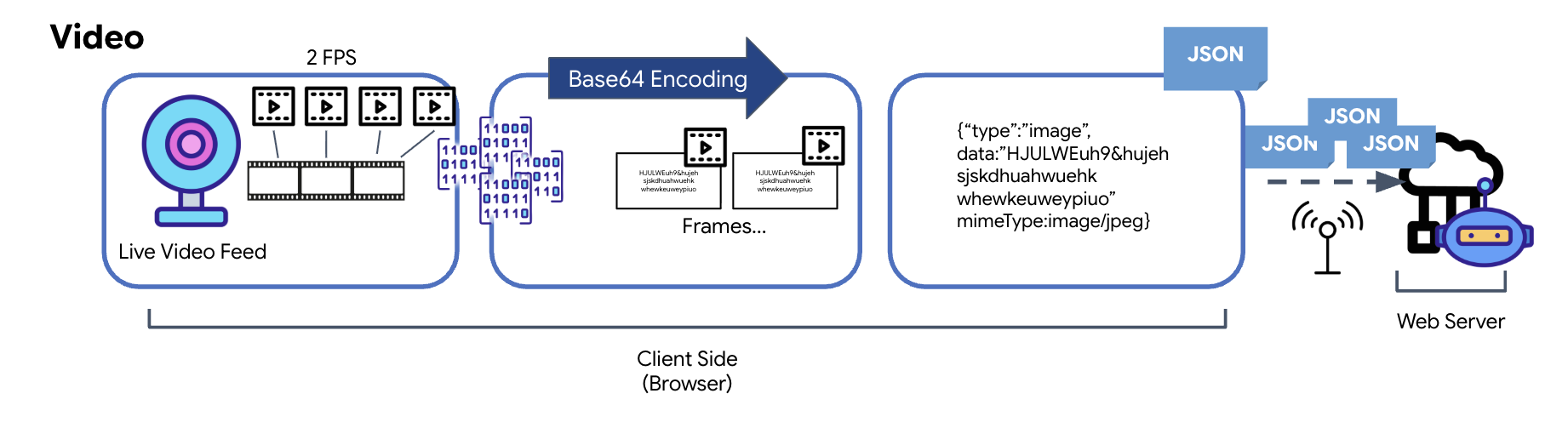
वीडियो ट्रांसमिशन, फ़्रेम-कैप्चर करने की तकनीक की मदद से किया जाता है. लगातार वीडियो स्ट्रीम भेजने के बजाय, बार-बार चलने वाला लूप, लाइव वीडियो फ़ीड से तय समय पर इमेज कैप्चर करता है. जैसे, हर सेकंड में दो फ़्रेम. इसके लिए, एचटीएमएल वीडियो एलिमेंट से मौजूदा फ़्रेम को छिपाए गए कैनवस एलिमेंट पर ड्रा किया जाता है.
इसके बाद, कैनवस के toDataURL तरीके का इस्तेमाल करके, कैप्चर की गई इस इमेज को Base64-encoded JPEG स्ट्रिंग में बदला जाता है. इस तरीके में, इमेज क्वालिटी तय करने का विकल्प शामिल होता है. इससे परफ़ॉर्मेंस को ऑप्टिमाइज़ करने के लिए, इमेज की फ़िडेलिटी और फ़ाइल साइज़ के बीच समझौता किया जा सकता है. ऑडियो डेटा की तरह ही, इस Base64 स्ट्रिंग को JSON ऑब्जेक्ट में रखा जाता है. इस ऑब्जेक्ट को आम तौर पर ‘image' के"type" के तौर पर लेबल किया जाता है. इसमें mimeType शामिल होता है, जैसे कि ‘image/jpeg'. इसके बाद, इस JSON पैकेट को स्ट्रिंग में बदल दिया जाता है और WebSocket पर भेज दिया जाता है. इससे, वीडियो पाने वाला व्यक्ति या कंपनी, इमेज के क्रम को दिखाकर वीडियो को फिर से बना पाती है.
👉✏️ उसी $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js फ़ाइल में, उपयोगकर्ता के इनपुट को कैप्चर करने के लिए, //#CAPTURE AUDIO and VIDEO को इससे बदलें:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
सेव करने के बाद, कॉकपिट एजेंट के डिजिटल सिग्नल को विज़ुअल डैशबोर्ड अपडेट और ऑडियो में बदलने के लिए तैयार हो जाएगा.
डाइग्नोस्टिक टेस्ट (लूपबैक टेस्ट)
आपका कॉकपिट अब लाइव है. हर 500 मि॰से॰ में, आपके आस-पास की चीज़ों का विज़ुअल "पैकेट" भेजा जाता है. Gemini से कनेक्ट करने से पहले, हमें यह पुष्टि करनी होगी कि आपके जहाज़ का ट्रांसमीटर काम कर रहा है. हम स्थानीय डाइग्नोस्टिक सर्वर का इस्तेमाल करके, "लूपबैक टेस्ट" करेंगे.
👉💻 सबसे पहले, अपने टर्मिनल से कॉकपिट इंटरफ़ेस बनाएं:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 इसके बाद, मॉक सर्वर शुरू करें:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 टेस्ट प्रोटोकॉल लागू करें:
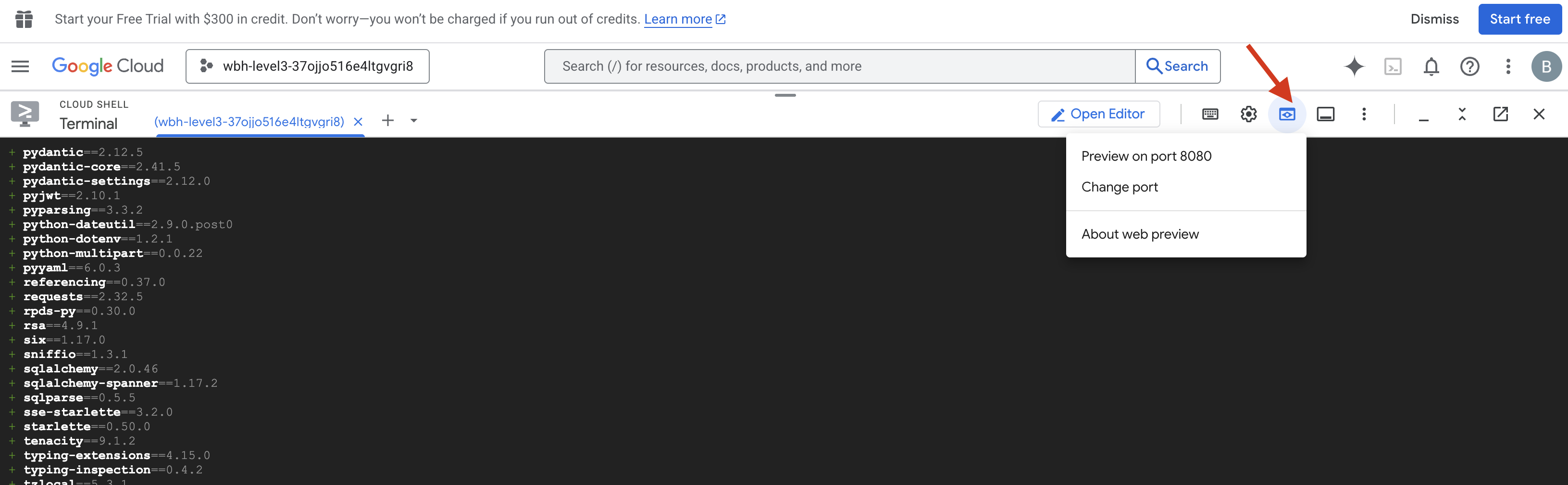
- झलक देखें: Cloud Shell टूलबार में मौजूद, वेब झलक आइकॉन पर क्लिक करें. पोर्ट बदलें को चुनें. इसके बाद, इसे 8080 पर सेट करें. इसके बाद, बदलें और झलक देखें पर क्लिक करें. आपके ब्राउज़र में एक नया टैब खुलेगा. इसमें आपको Cockpit इंटरफ़ेस दिखेगा.
- अहम जानकारी: जब आपसे अनुमति मांगी जाए, तब आपको ब्राउज़र को कैमरा और माइक्रोफ़ोन ऐक्सेस करने की अनुमति देनी होगी. इन इनपुट के बिना, न्यूरल सिंक शुरू नहीं किया जा सकता.
- यूज़र इंटरफ़ेस (यूआई) में, "न्यूरल सिंक शुरू करें" बटन पर क्लिक करें.
👀 पुष्टि के स्टेटस दिखाने वाले इंडिकेटर:
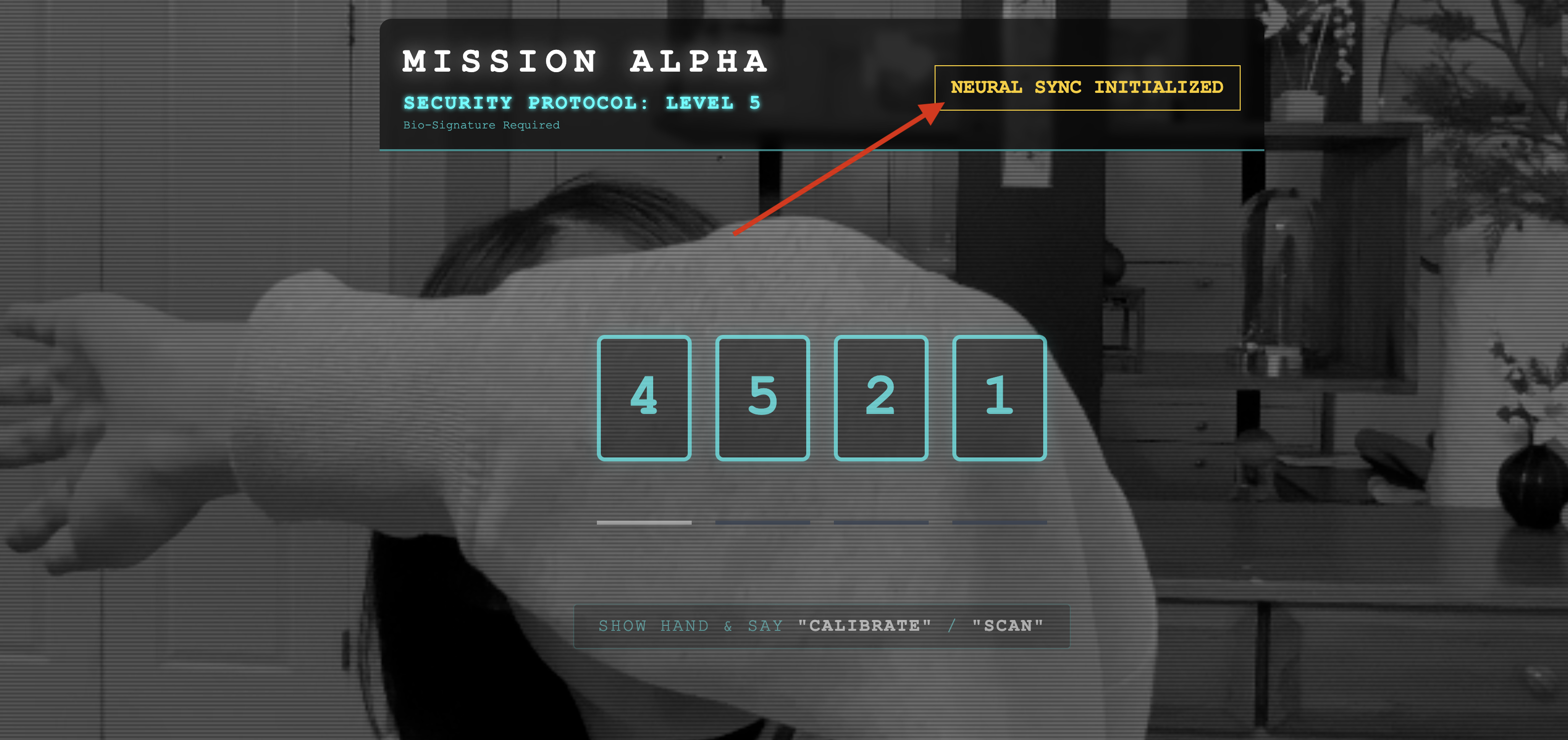
- विज़ुअल जांच: अपने ब्राउज़र कंसोल को खोलें. आपको सबसे ऊपर दाईं ओर
NEURAL SYNC INITIALIZEDदिखेगा. - ऑडियो की जांच: अगर दोनों तरफ़ से ऑडियो ट्रांसफ़र करने की सुविधा पूरी तरह से काम कर रही है, तो आपको एक आवाज़ सुनाई देगी. इसमें पुष्टि की जाएगी कि "सिस्टम कनेक्ट हो गया है!"
"सिस्टम कनेक्ट हो गया है!" ऑडियो की पुष्टि होने के बाद, जांच पूरी हो जाती है. टैब बंद करें. अब हमें फ़्रीक्वेंसी को हटाना होगा, ताकि असली एआई के लिए जगह बनाई जा सके.
👉💻 मॉक सर्वर और फ़्रंटएंड, दोनों के टर्मिनल में Ctrl+C दबाएं. यूज़र इंटरफ़ेस (यूआई) चलाने वाले ब्राउज़र टैब को बंद करें.
4. मल्टीमॉडल एजेंट
रेस्क्यू स्काउट काम कर रहा है, लेकिन उसका "दिमाग" खाली है. अगर आपने अभी कनेक्ट किया, तो यह सिर्फ़ आपको देखेगा. इसे नहीं पता कि "उंगली" क्या होती है. बचे हुए लोगों को बचाने के लिए, आपको स्काउट के कोर पर बायोमेट्रिक न्यूरल प्रोटोकॉल को इंप्रिंट करना होगा.
ट्रेडिशनल एजेंट, अनुवादकों की एक सीरीज़ की तरह काम करता है. अगर किसी पुराने एआई से बात की जाती है, तो "स्पीच-टू-टेक्स्ट" मॉडल आपकी आवाज़ को शब्दों में बदलता है. "लैंग्वेज मॉडल" उन शब्दों को पढ़कर जवाब टाइप करता है. इसके बाद, "टेक्स्ट-टू-स्पीच" मॉडल उस जवाब को पढ़कर सुनाता है. इससे "लेटेंसी गैप" यानी कि डेटा ट्रांसफ़र में देरी होती है. बचाव मिशन में यह देरी जानलेवा साबित हो सकती है.
Gemini Live API, एक नेटिव मल्टीमॉडल मॉडल है. यह सीधे तौर पर और एक साथ, रॉ ऑडियो बाइट और रॉ वीडियो फ़्रेम को प्रोसेस करता है. यह एक ही न्यूरल आर्किटेक्चर में, आपकी आवाज़ के कंपन को "सुनता" है और आपके हाथ के जेस्चर के पिक्सल को "देखता" है.
इस सुविधा का फ़ायदा पाने के लिए, हम कॉकपिट को सीधे तौर पर Live API से कनेक्ट करके ऐप्लिकेशन बना सकते हैं. हालांकि, हमारा मकसद एक ऐसा एजेंट बनाना है जिसका दोबारा इस्तेमाल किया जा सके. यह एक मॉड्यूलर और मज़बूत इकाई है, जिसे तेज़ी से बनाया जा सकता है.
ADK (एजेंट डेवलपमेंट किट) क्यों?
Google Agent Development Kit (ADK), एआई एजेंट डेवलप और डिप्लॉय करने के लिए एक मॉड्यूलर फ़्रेमवर्क है.
स्टैंडर्ड एलएलएम कॉल आम तौर पर स्टेटलेस होते हैं. हर क्वेरी एक नई शुरुआत होती है. लाइव एजेंट, खास तौर पर ADK के SessionService के साथ इंटिग्रेट होने पर, बातचीत वाले मज़बूत और लंबे समय तक चलने वाले सेशन को चालू करते हैं.
- सेशन की जानकारी सेव रखना: ADK सेशन की जानकारी सेव रहती है. इसे SQL या Vertex AI जैसे डेटाबेस में सेव किया जा सकता है. सर्वर रीस्टार्ट होने और कनेक्शन बंद होने के बाद भी यह जानकारी बनी रहती है. इसका मतलब है कि अगर कोई उपयोगकर्ता डिसकनेक्ट हो जाता है और कुछ दिनों बाद फिर से कनेक्ट होता है, तो उसकी बातचीत का इतिहास और कॉन्टेक्स्ट पूरी तरह से वापस आ जाता है. लाइव एपीआई के कुछ समय के लिए चलने वाले सेशन को ADK मैनेज करता है.
- अपने-आप फिर से कनेक्ट होना: WebSocket कनेक्शन का समय खत्म हो सकता है. उदाहरण के लिए, ~10 मिनट बाद. ADK,
RunConfigमेंsession_resumptionके चालू होने पर, इन कनेक्शन को पारदर्शी तरीके से हैंडल करता है. आपके ऐप्लिकेशन कोड को फिर से कनेक्ट करने के लिए, जटिल लॉजिक को मैनेज करने की ज़रूरत नहीं होती. इससे उपयोगकर्ता को बेहतर अनुभव मिलता है. - स्टेटफ़ुल इंटरैक्शन: एजेंट को पिछले टर्न याद रहते हैं. इससे फ़ॉलो-अप वाले सवाल पूछे जा सकते हैं, जवाबों को ज़्यादा साफ़ तौर पर समझाया जा सकता है, और ऐसे जटिल मल्टी-टर्न डायलॉग किए जा सकते हैं जिनमें कॉन्टेक्स्ट बहुत ज़रूरी होता है. यह ग्राहक सहायता, इंटरैक्टिव ट्यूटोरियल या मिशन कंट्रोल जैसे ऐप्लिकेशन के लिए ज़रूरी है. इन ऐप्लिकेशन में, बातचीत को जारी रखना ज़रूरी होता है.
इस सुविधा की वजह से, ऐसा लगता है कि किसी समझदार इकाई के साथ बातचीत जारी है. ऐसा नहीं लगता कि अलग-अलग सवाल पूछे जा रहे हैं और उनके जवाब दिए जा रहे हैं.
संक्षेप में कहें, तो ADK Bidi-streaming की सुविधा के साथ "लाइव एजेंट", सवाल-जवाब के सामान्य तरीके से आगे बढ़कर, बातचीत को ज़्यादा इंटरैक्टिव, स्टेटफ़ुल, और रुकावटों के बारे में जानकारी देने वाला बनाता है. इससे एआई के साथ बातचीत ज़्यादा मानवीय लगती है. साथ ही, यह मुश्किल और लंबे समय तक चलने वाले कामों के लिए ज़्यादा असरदार होता है.
लाइव एजेंट से बातचीत करने का अनुरोध करना
रीयल-टाइम में दोनों तरफ़ से बातचीत करने वाले एजेंट के लिए प्रॉम्प्ट डिज़ाइन करने के लिए, सोच में बदलाव करना ज़रूरी है. स्टैंडर्ड चैट बॉट, टेक्स्ट क्वेरी का इंतज़ार करता है. हालांकि, लाइव एजेंट "हमेशा उपलब्ध" रहता है. इसे लगातार ऑडियो और वीडियो फ़्रेम मिलते हैं. इसका मतलब है कि आपके प्रॉम्प्ट को सिर्फ़ पर्सनैलिटी की परिभाषा के तौर पर नहीं, बल्कि कंट्रोल लूप स्क्रिप्ट के तौर पर काम करना चाहिए.
लाइव एजेंट से बातचीत करने के लिए इस्तेमाल किए जाने वाले प्रॉम्प्ट और सामान्य प्रॉम्प्ट में यह अंतर होता है:
- स्टेट मशीन लॉजिक: प्रॉम्प्ट में "व्यवहार लूप" (इंतज़ार करें → विश्लेषण करें → कार्रवाई करें) को तय किया जाना चाहिए. इसे साफ़ तौर पर यह निर्देश देना ज़रूरी है कि कब चुप रहना है और कब बातचीत करनी है. इससे एजेंट को बैकग्राउंड के शोर के बारे में बड़बड़ाने से रोका जा सकेगा.
- टेक्स्ट, इमेज, और वीडियो वगैरह का इस्तेमाल करके की गई क्वेरी को समझने की क्षमता: एजेंट को यह बताना ज़रूरी है कि उसके पास "आंखें" हैं. आपको इसे साफ़ तौर पर निर्देश देना होगा कि यह वीडियो फ़्रेम का विश्लेषण करे, ताकि यह सही जवाब दे सके.
- जवाब मिलने में लगने वाला समय और जवाब की लंबाई: लाइव बातचीत में, लंबे और मुश्किल शब्दों वाले पैराग्राफ़ पढ़ने में समय लगता है और वे स्वाभाविक नहीं लगते. प्रॉम्प्ट में जवाब को छोटा रखने के लिए कहा जाता है, ताकि बातचीत को दिलचस्प बनाया जा सके.
- ऐक्शन-फ़र्स्ट आर्किटेक्चर: निर्देशों में, बोलने के बजाय टूल कॉलिंग को प्राथमिकता दी जाती है. हम चाहते हैं कि एजेंट, बायोमेट्रिक को स्कैन करने का काम पहले या साथ-साथ करे. ऐसा तब होना चाहिए, जब वह बोलकर पुष्टि कर रहा हो. ऐसा लंबे समय तक बोलने के बाद नहीं होना चाहिए.
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py खोलें और #REPLACE INSTRUCTIONS को इससे बदलें:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
ध्यान दें! आपने किसी स्टैंडर्ड एलएलएम से कनेक्ट नहीं किया है. उसी फ़ाइल ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py) में, #REPLACE_MODEL ढूंढें. हमें इस मॉडल के प्रीव्यू वर्शन को साफ़ तौर पर टारगेट करना होगा, ताकि हम रीयल-टाइम में ऑडियो की सुविधाओं को बेहतर तरीके से सपोर्ट कर सकें.
👉✏️ प्लेसहोल्डर को इससे बदलें:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
अब आपका एजेंट तय हो गया है. इसे पता है कि यह कौन है और इसे कैसे सोचना है. इसके बाद, हम इसे कार्रवाई करने के लिए टूल देते हैं.
टूल का इस्तेमाल करना
लाइव एपीआई का इस्तेमाल सिर्फ़ टेक्स्ट, ऑडियो, और वीडियो स्ट्रीम शेयर करने के लिए नहीं किया जाता. इसमें टूल कॉलिंग की सुविधा पहले से मौजूद है. इससे एजेंट, बातचीत में हिस्सा लेने के बजाय सक्रिय ऑपरेटर के तौर पर काम कर पाते हैं.
दोनों पक्षों के बीच लाइव बातचीत के दौरान, मॉडल लगातार कॉन्टेक्स्ट का आकलन करता है. अगर एलएलएम को किसी कार्रवाई को पूरा करने की ज़रूरत होती है, जैसे कि "सेंसर टेलीमेट्री की जांच करना" या "सुरक्षित दरवाज़े को अनलॉक करना". यह बातचीत से लेकर काम पूरा करने तक की प्रोसेस को आसानी से पूरा करता है. एजेंट, टूल के फ़ंक्शन को तुरंत ट्रिगर करता है. इसके बाद, नतीजे का इंतज़ार करता है और उस डेटा को लाइव स्ट्रीम में वापस इंटिग्रेट करता है. यह सब, बातचीत के फ़्लो को रोके बिना होता है.
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py में, #REPLACE TOOLS को इस फ़ंक्शन से बदलें:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ इसके बाद, #TOOL CONFIG को बदलकर, Agent की परिभाषा में इसे रजिस्टर करें:
tools=[report_digit],
adk web सिम्युलेटर
इसे जटिल शिप कॉकपिट (हमारा React फ़्रंटएंड) से कनेक्ट करने से पहले, हमें एजेंट के लॉजिक की अलग से जांच करनी चाहिए. ADK में adk web नाम का एक बिल्ट-इन डेवलपर कंसोल शामिल होता है. इससे, नेटवर्क की जटिलता को जोड़ने से पहले, टूल कॉलिंग की पुष्टि की जा सकती है.
👉💻 अपने टर्मिनल में, यह कमांड चलाएं:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Cloud Shell टूलबार में, वेब प्रीव्यू आइकॉन पर क्लिक करें. पोर्ट बदलें को चुनें. इसके बाद, इसे 8000 पर सेट करें. इसके बाद, बदलें और झलक देखें पर क्लिक करें.
- अनुमति दें: जब आपसे पूछा जाए, तब अपने डिवाइस के कैमरे और माइक्रोफ़ोन को ऐक्सेस करने की अनुमति दें.
- कैमरे के आइकॉन पर क्लिक करके सेशन शुरू करें.
- विज़ुअल टेस्ट:
- कैमरे के सामने तीन उंगलियां साफ़ तौर पर दिखाएं.
- "स्कैन करो" कहें.
- पुष्टि करें कि समस्या ठीक हो गई है:
- लॉग:
adk webकमांड चलाने वाले टर्मिनल को देखें. आपको यह लॉग दिखना चाहिए:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- लॉग:
अगर आपको टूल के इस्तेमाल का लॉग दिखता है, तो इसका मतलब है कि आपका एजेंट स्मार्ट है. यह देख सकता है, सोच सकता है, और काम कर सकता है. आखिरी चरण में, इसे मुख्य शिप में जोड़ना होता है.
टर्मिनल विंडो पर क्लिक करें और adk web सिम्युलेटर को रोकने के लिए, Ctrl+C दबाएं.
5. दोनों दिशाओं में स्ट्रीमिंग का फ़्लो
एजेंट काम करता है. Cockpit काम करता है. अब हमें उन्हें कनेक्ट करना होगा.
लाइव एजेंट की लाइफ़साइकल
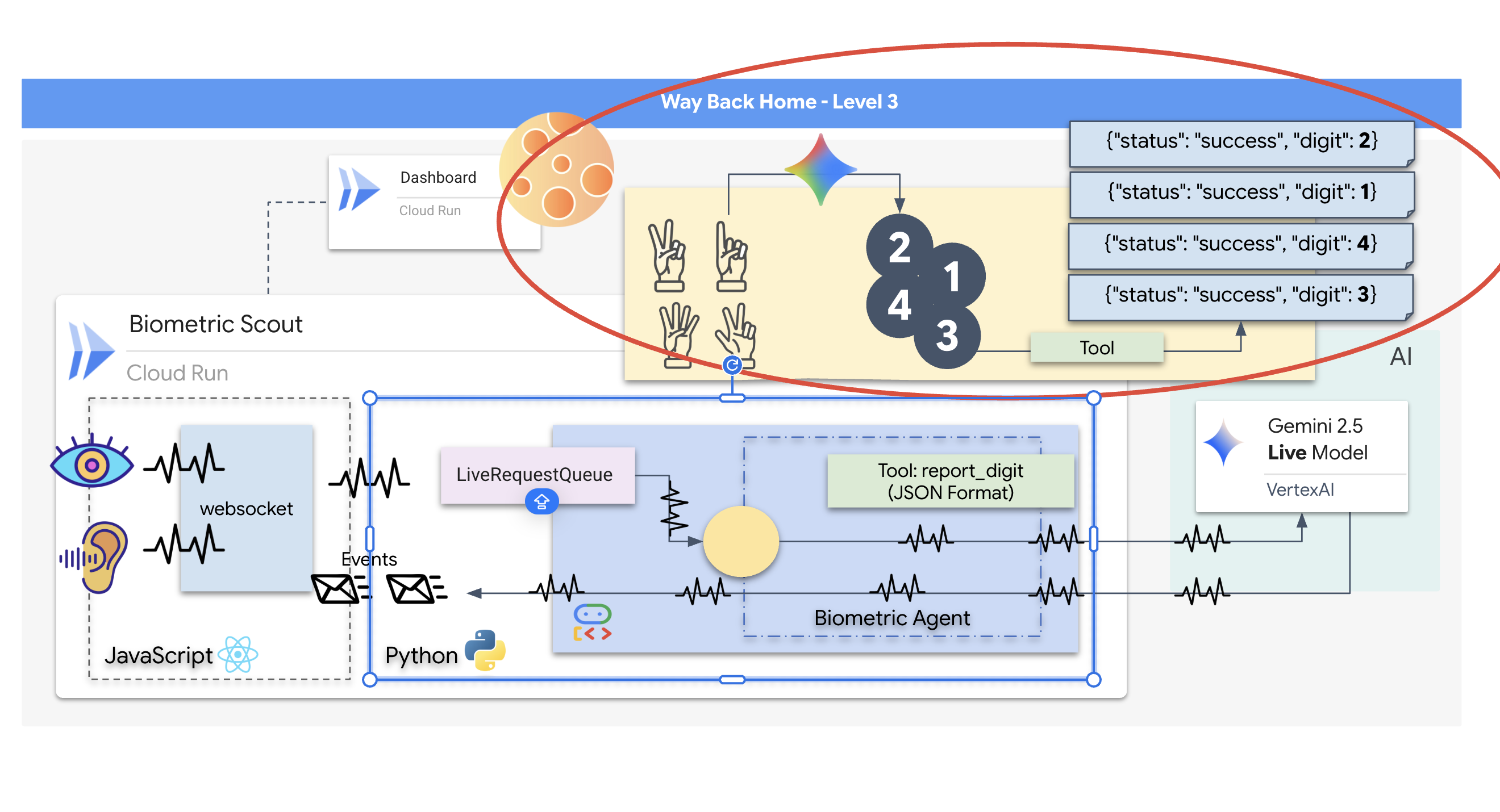
रीयल-टाइम स्ट्रीमिंग से "इंपेडेंस मिसमैच" की समस्या होती है. क्लाइंट (ब्राउज़र) अलग-अलग दरों पर डेटा को एसिंक्रोनस तरीके से पुश करता है. जैसे, नेटवर्क में अचानक डेटा ट्रांसफ़र होना या तेज़ी से इनपुट मिलना. वहीं, मॉडल को इनपुट के लिए एक तय और क्रमवार स्ट्रीम की ज़रूरत होती है. Google ADK, LiveRequestQueue का इस्तेमाल करके इस समस्या को हल करता है.
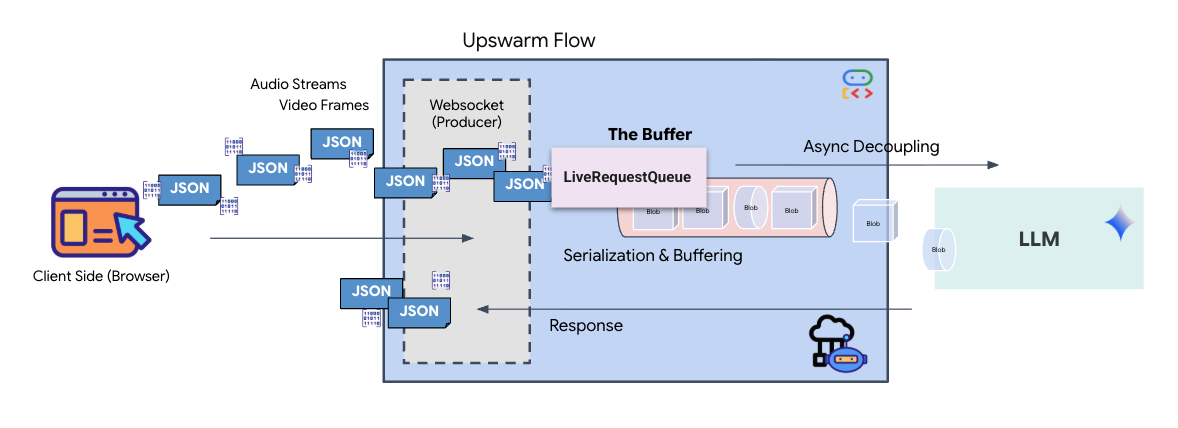
यह थ्रेड-सेफ़, एसिंक्रोनस फ़र्स्ट-इन-फ़र्स्ट-आउट (एफ़आईएफ़ओ) बफ़र के तौर पर काम करता है. WebSocket हैंडलर, प्रोड्यूसर के तौर पर काम करता है. यह ऑडियो/वीडियो के रॉ डेटा को क्यू में भेजता है. ADK एजेंट, उपयोगकर्ता के तौर पर काम करता है. यह मॉडल की कॉन्टेक्स्ट विंडो में डेटा डालने के लिए, डेटा को क्यू से खींचता है. इस तरह, ऐप्लिकेशन को उपयोगकर्ता का इनपुट मिलता रहता है. भले ही, मॉडल जवाब जनरेट कर रहा हो या किसी टूल का इस्तेमाल कर रहा हो.
यह कतार, मल्टीमॉडल मल्टीप्लेक्सर के तौर पर काम करती है. असल एनवायरमेंट में, अपस्ट्रीम फ़्लो में अलग-अलग तरह के डेटा होते हैं. जैसे, रॉ पीसीएम ऑडियो बाइट, वीडियो फ़्रेम, टेक्स्ट पर आधारित सिस्टम के निर्देश, और एसिंक्रोनस टूल कॉल के नतीजे. LiveRequestQueue इन अलग-अलग इनपुट को, समय के हिसाब से एक ही क्रम में व्यवस्थित करता है. पैकेट में मिलीसेकंड की चुप्पी, हाई रिज़ॉल्यूशन वाली इमेज या डेटाबेस क्वेरी से मिला JSON पेलोड, कुछ भी हो सकता है. इसे उसी क्रम में सीरियल किया जाता है जिस क्रम में यह आता है. इससे यह पक्का होता है कि मॉडल को एक जैसी और वजह के साथ टाइमलाइन दिखे.
इस आर्किटेक्चर की मदद से, नॉन-ब्लॉकिंग कंट्रोल को चालू किया जा सकता है. डेटा इकट्ठा करने वाली लेयर (प्रोड्यूसर) को प्रोसेसिंग लेयर (कंज्यूमर) से अलग किया जाता है. इसलिए, कंप्यूटेशनल रूप से मुश्किल मॉडल इन्फ़्रेंस के दौरान भी सिस्टम काम करता रहता है. अगर कोई उपयोगकर्ता, एजेंट के टूल का इस्तेमाल करते समय "बंद करो!" निर्देश देता है, तो उस ऑडियो सिग्नल को तुरंत कतार में लगा दिया जाता है. इवेंट लूप, इस प्राथमिकता वाले सिग्नल को तुरंत प्रोसेस करता है. इससे सिस्टम, यूज़र इंटरफ़ेस (यूआई) के फ़्रीज़ होने या पैकेट के ड्रॉप होने के बिना, जनरेशन या पिवट टास्क को रोक सकता है.
👉💻 सिस्टम को ऑनलाइन लाने के लिए, $HOME/way-back-home/level_3/backend/app/main.py में जाकर #REPLACE_RUNNER_CONFIG टिप्पणी ढूंढें और उसे इस कोड से बदलें:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
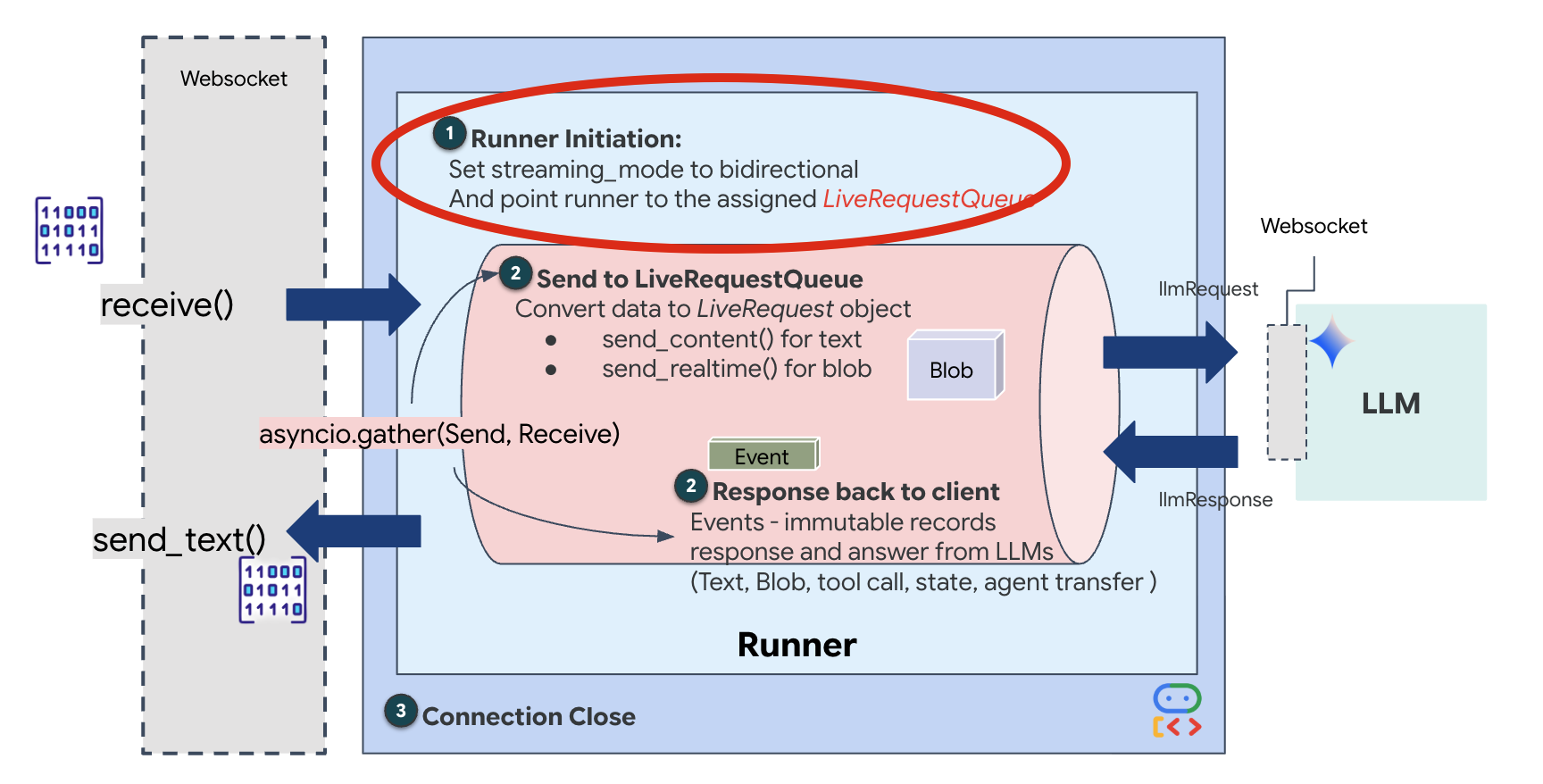
जब कोई नया WebSocket कनेक्शन खुलता है, तो हमें यह कॉन्फ़िगर करना होता है कि एआई कैसे इंटरैक्ट करेगा. यहां हम "रूल ऑफ़ एंगेजमेंट" तय करते हैं.
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py में, async def websocket_endpoint फ़ंक्शन के अंदर, #REPLACE_SESSION_INIT टिप्पणी को यहां दिए गए कोड से बदलें:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
रन कॉन्फ़िगरेशन
StreamingMode.BIDI: इससे कनेक्शन को दोनों दिशाओं में सेट किया जाता है. "बारी-बारी से" बातचीत करने वाले एआई (जिसमें आप बोलते हैं, रुकते हैं, और फिर एआई बोलता है) के उलट, BIDI की मदद से "फ़ुल-डुप्लेक्स" बातचीत की जा सकती है. एआई को रोका जा सकता है. साथ ही, चलते-फिरते एआई से बातचीत की जा सकती है.AudioTranscriptionConfig: मॉडल, रॉ ऑडियो को "सुनता" है. हालांकि, हमें (डेवलपर) लॉग देखने की ज़रूरत होती है. इस कॉन्फ़िगरेशन से Gemini को यह निर्देश मिलता है: "ऑडियो को प्रोसेस करो. साथ ही, हमें यह भी बताओ कि तुमने क्या सुना, ताकि हम गड़बड़ी को ठीक कर सकें."
एक्ज़ीक्यूशन लॉजिक जब रनर सेशन बना लेता है, तो वह कंट्रोल को एक्ज़ीक्यूशन लॉजिक को सौंप देता है. यह LiveRequestQueue पर निर्भर करता है. रीयल-टाइम में इंटरैक्शन करने के लिए, यह सबसे अहम कॉम्पोनेंट है. लूप की मदद से, एजेंट बोलकर जवाब दे पाता है. वहीं, कतार में उपयोगकर्ता से नए वीडियो फ़्रेम मिलते रहते हैं. इससे यह पक्का होता है कि "न्यूरल सिंक" कभी बंद न हो.
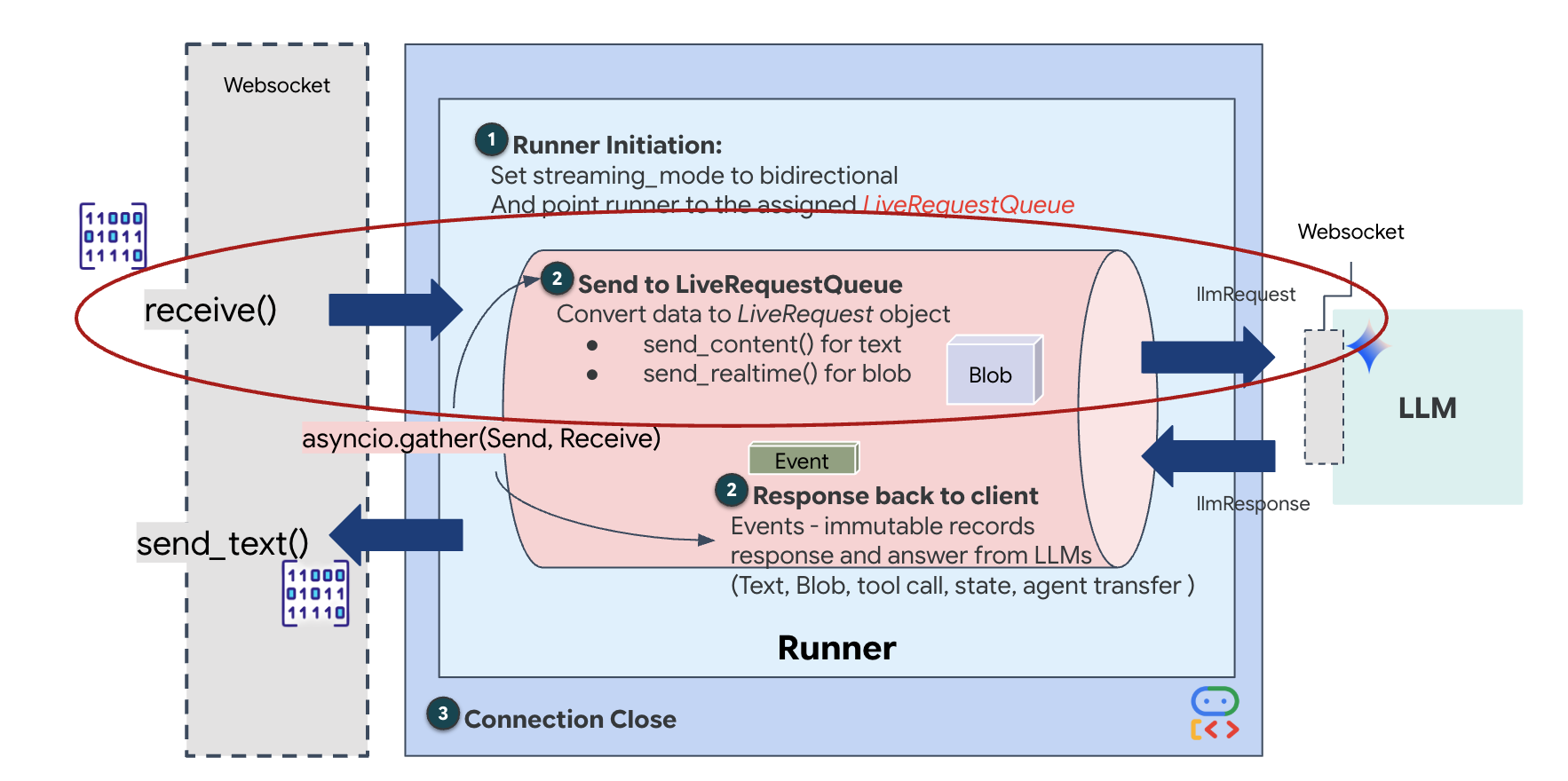
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py में, #REPLACE_LIVE_REQUEST को बदलकर अपस्ट्रीम टास्क तय करें. यह टास्क, LiveRequestQueue को डेटा भेजता है:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
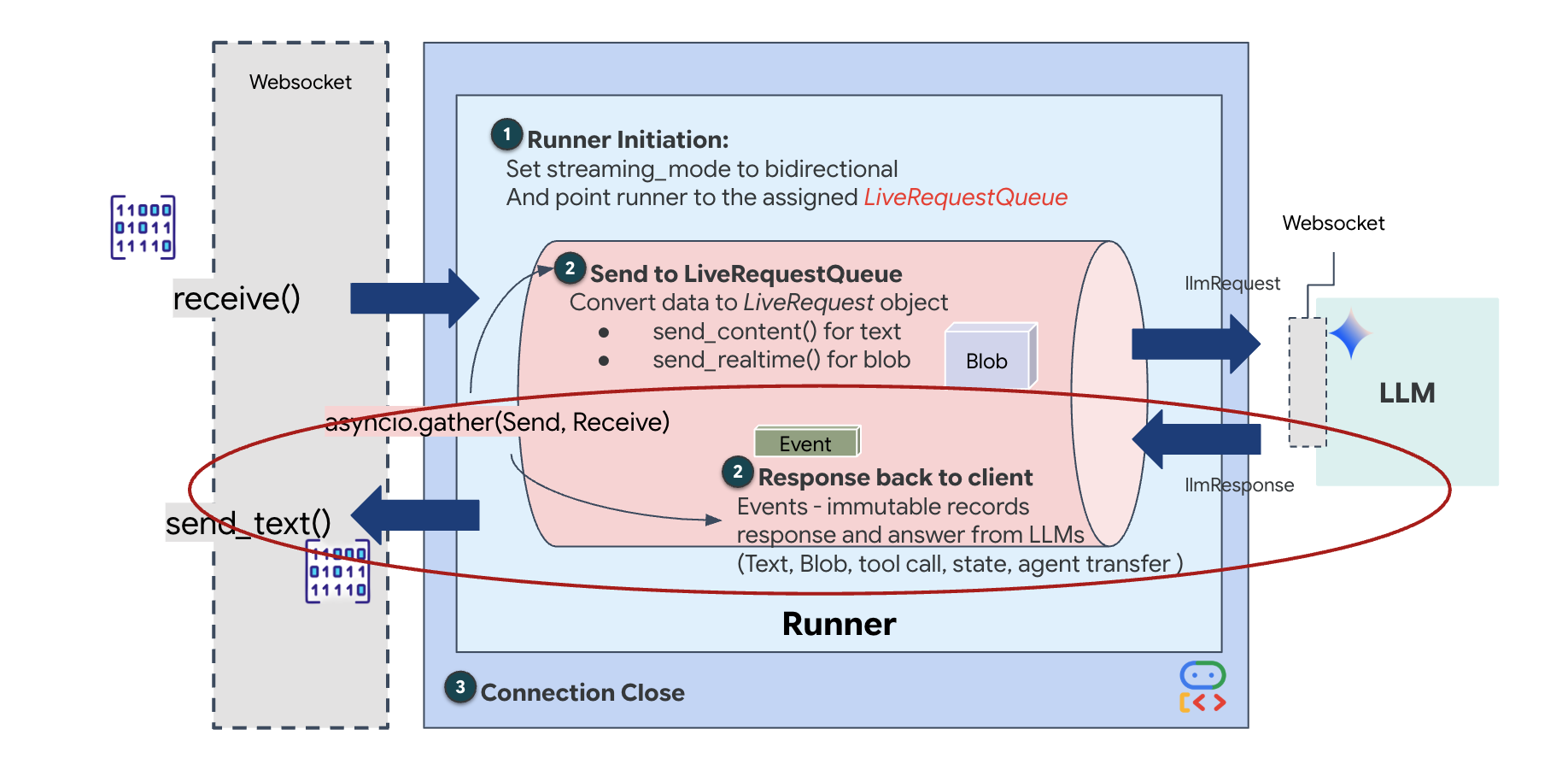
आखिर में, हमें एआई के जवाबों को मैनेज करना होगा. यह runner.run_live() का इस्तेमाल करता है. यह एक इवेंट जनरेटर है, जो इवेंट (ऑडियो, टेक्स्ट या टूल कॉल) जनरेट करता है.
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py में, डाउनस्ट्रीम टास्क और कंकरेंसी मैनेजर को तय करने के लिए, #REPLACE_SORT_RESPONSE को बदलें:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
लाइन await asyncio.gather(upstream_task(), downstream_task()) पर ध्यान दें. फ़ुल-डूप्लेक्स का मतलब यही है. हम सुनने (अपस्ट्रीम) और बोलने (डाउनस्ट्रीम) के टास्क को एक ही समय पर पूरा करते हैं. इससे यह पक्का होता है कि "न्यूरल लिंक" में रुकावट न आए और डेटा एक साथ ट्रांसफ़र हो सके.
आपका बैकएंड अब पूरी तरह से कोड किया गया है. "ब्रेन" (ADK) को "बॉडी" (WebSocket) से कनेक्ट किया जाता है.
बायो-सिंक एक्ज़ीक्यूशन
कोड पूरा हो गया है. सिस्टम हरे रंग के हैं. अब बचाव शुरू करने का समय आ गया है.
- 👉💻 बैकएंड शुरू करें:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 फ़्रंटएंड लॉन्च करें:
- Cloud Shell टूलबार में, वेब प्रीव्यू आइकॉन पर क्लिक करें. पोर्ट बदलें को चुनें. इसके बाद, इसे 8080 पर सेट करें. इसके बाद, बदलें और झलक देखें पर क्लिक करें.
- 👉 प्रोटोकॉल लागू करें:
- "न्यूरल सिंक शुरू करें" पर क्लिक करें.
- कैलिब्रेट करें: पक्का करें कि कैमरे में आपका हाथ, बैकग्राउंड के हिसाब से साफ़ तौर पर दिख रहा हो.
- सिंक करना: स्क्रीन पर दिखने वाला सुरक्षा कोड देखें. उदाहरण के लिए, 3, फिर 2, फिर 5.
- सिग्नल से मैच करें: जब कोई नंबर दिखता है, तो उतनी ही उंगलियां दिखाएं.
- हाथ को स्थिर रखें: अपने हाथ को तब तक दिखने दें, जब तक एआई "बायोमेट्रिक मैच" की पुष्टि न कर दे.
- बदलाव: कोड रैंडम होता है. जब तक क्रम पूरा नहीं हो जाता, तब तक तुरंत अगले नंबर पर स्विच करें.

- जब आपका नंबर, रैंडम क्रम में दिए गए आखिरी नंबर से मैच हो जाएगा, तब "बायोमेट्रिक सिंक" की प्रोसेस पूरी हो जाएगी. न्यूरल लिंक लॉक हो जाएगा. आपके पास मैन्युअल कंट्रोल होता है. स्काउट के इंजन चालू हो जाएंगे और वह रवीन में गोता लगाएगा, ताकि बचे हुए लोगों को घर ले जाया जा सके.
👉💻 बाहर निकलने के लिए, बैकएंड टर्मिनल में Ctrl+C दबाएं.
6. प्रोडक्शन में डिप्लॉय करें (ज़रूरी नहीं)
आपने स्थानीय तौर पर बायोमेट्रिक डेटा की जांच कर ली है. अब हमें एजेंट के न्यूरल कोर को जहाज़ के मेनफ़्रेम (Cloud Run) पर अपलोड करना होगा, ताकि यह आपके लोकल कंसोल से अलग काम कर सके.
👉💻 अपने Cloud Shell टर्मिनल में यह कमांड चलाएं. इससे आपके बैकएंड डायरेक्ट्री में पूरा और कई चरणों वाला Dockerfile बन जाएगा.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 बैकएंड डायरेक्ट्री पर जाएं और ऐप्लिकेशन को कंटेनर इमेज में पैकेज करें.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 सेवा को Cloud Run पर डिप्लॉय करें. हम ज़रूरी एनवायरमेंट वैरिएबल, खास तौर पर Gemini कॉन्फ़िगरेशन को सीधे लॉन्च कमांड में शामिल करेंगे.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
कमांड पूरी होने के बाद, आपको एक सेवा यूआरएल (जैसे, https://biometric-scout-...run.app) दिखेगा. अब ऐप्लिकेशन, क्लाउड में लाइव हो गया है.
👉 Google Cloud Run पेज पर जाएं और सूची से, बायोमेट्रिक-स्काउट सेवा चुनें. 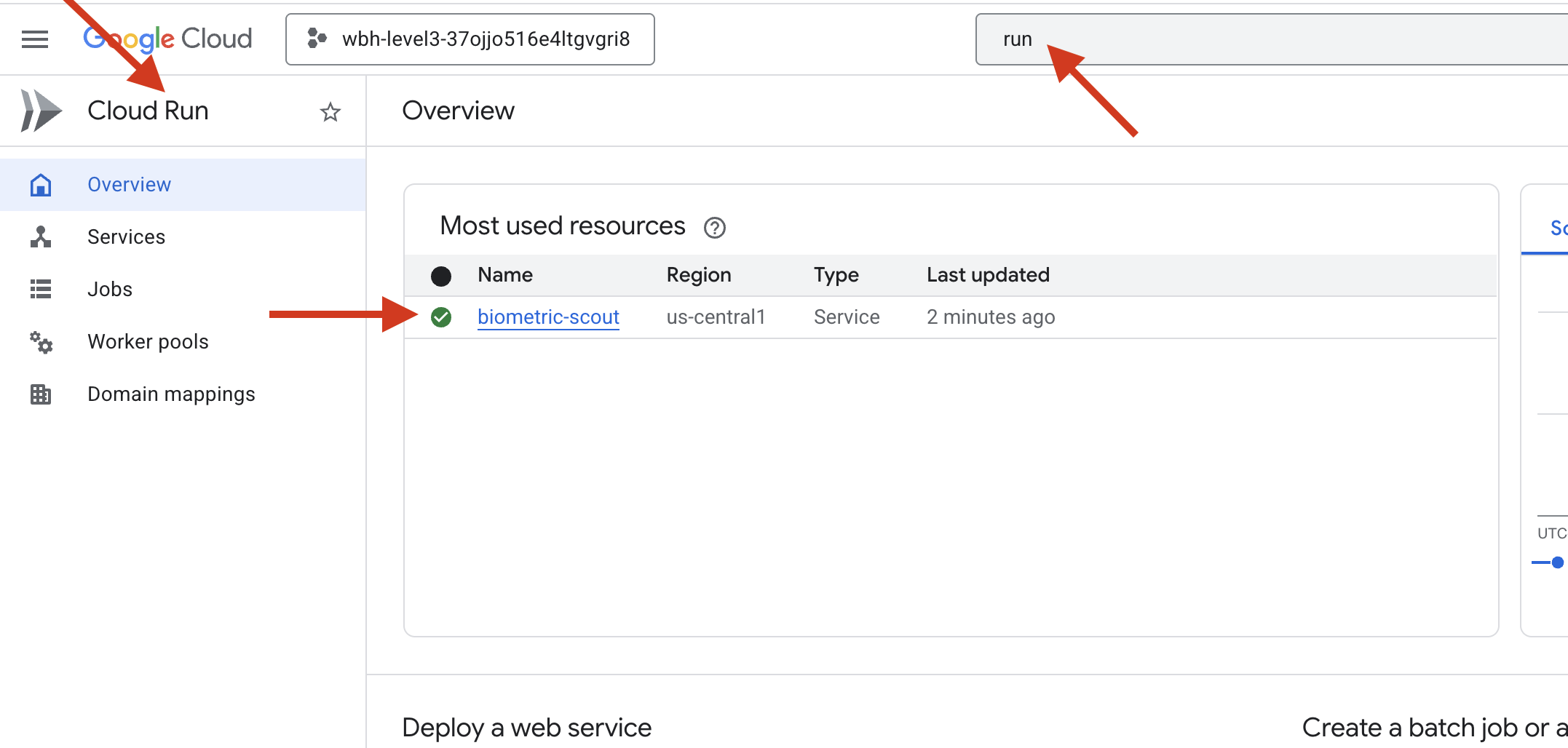
👉 सेवा की जानकारी वाले पेज पर सबसे ऊपर मौजूद, सार्वजनिक यूआरएल ढूंढें. 
इस एनवायरमेंट में बायो-सिंक करने की कोशिश करें. क्या यह सुविधा काम करती है?
पांचवीं उंगली के फैलते ही, एआई इस क्रम को लॉक कर देता है. स्क्रीन पर हरे रंग की फ़्लैश दिखती है: "बायोमेट्रिक न्यूरल सिंक: ESTABLISHED."
एक ही सोच के साथ, स्काउट को अंधेरे में डुबोया जाता है, फंसे हुए पॉड से जोड़ा जाता है, और गुरुत्वाकर्षण के टूटने से ठीक पहले उन्हें बाहर निकाला जाता है.

एयरलॉक खुलता है और वहां पांच लोग ज़िंदा हैं. वे डेक पर लड़खड़ाते हुए आते हैं. वे घायल हैं, लेकिन ज़िंदा हैं. वे आपकी वजह से सुरक्षित हैं.
आपकी मदद से, न्यूरल लिंक सिंक हो गया है और सर्वाइवर को बचा लिया गया है.
अगर आपने लेवल 0 में हिस्सा लिया था, तो यह देखना न भूलें कि 'घर वापसी' मिशन में आपकी प्रोग्रेस कहां तक पहुंची है!