1. La missione

Stai vagando nel silenzio di un settore inesplorato. Un'enorme **pulsazione solare** ha squarciato la tua nave attraverso una spaccatura, lasciandoti bloccato in una zona dell'universo che non esiste in nessuna mappa stellare.
Dopo giorni di riparazioni estenuanti, finalmente senti il rombo dei motori sotto i piedi. Il tuo razzo è stato riparato. Sei persino riuscito a stabilire un collegamento uplink a lungo raggio con la nave madre. Puoi partire. Puoi tornare a casa. Ma mentre ti prepari a inserire la chiavetta, un segnale di soccorso interrompe la statica. I tuoi sensori rilevano cinque deboli firme termiche intrappolate nella "Gola", un settore frastagliato e deformato dalla gravità in cui la tua astronave principale non può mai entrare. Questi sono altri esploratori, sopravvissuti alla stessa tempesta che ha quasi causato la tua morte. Non puoi lasciarli indietro.
Ti rivolgi al tuo Alpha-Drone Rescue Scout. Questa piccola e agile nave è l'unica in grado di navigare tra le strette pareti del Ravine. Ma c'è un problema: l'impulso solare ha eseguito un "ripristino del sistema" totale sulla sua logica di base. I sistemi di controllo di Scout non rispondono. È acceso, ma il suo computer di bordo è vuoto e non è in grado di elaborare i comandi del pilota manuale o le traiettorie di volo.
La sfida
Per salvare i sopravvissuti, devi bypassare completamente i circuiti danneggiati dello Scout. Hai un'unica opzione disperata: creare un agente AI per stabilire una sincronizzazione neurale biometrica. Questo agente fungerà da ponte in tempo reale, consentendoti di controllare manualmente Rescue Scout tramite i tuoi input biologici. Non utilizzerai un joystick o una tastiera, ma collegherai la tua intenzione direttamente alla rete di navigazione della nave.
Per bloccare il collegamento, devi eseguire il protocollo di sincronizzazione davanti ai sensori ottici di Scout. L'agente AI deve riconoscere la tua firma biologica tramite un handshake preciso e in tempo reale.
Obiettivi della missione:
- Imprimi il Neural Core:definisci un ADK Agent in grado di riconoscere gli input multimodali.
- Stabilisci la connessione:crea una pipeline WebSocket bidirezionale per trasmettere in streaming i dati visivi da Scout all'AI.
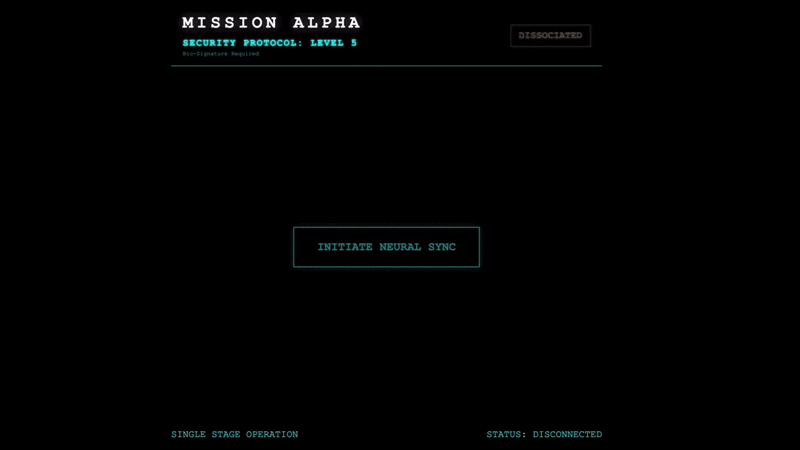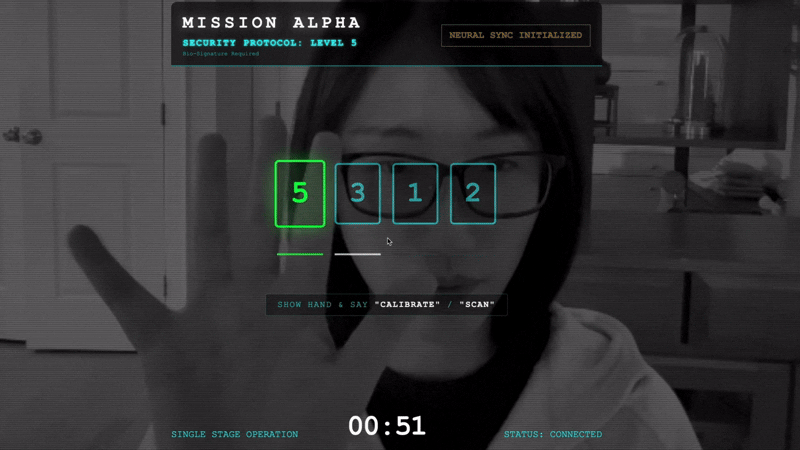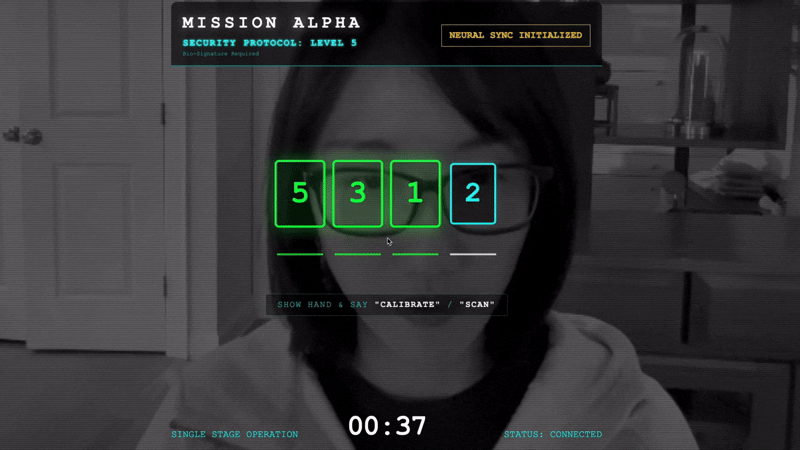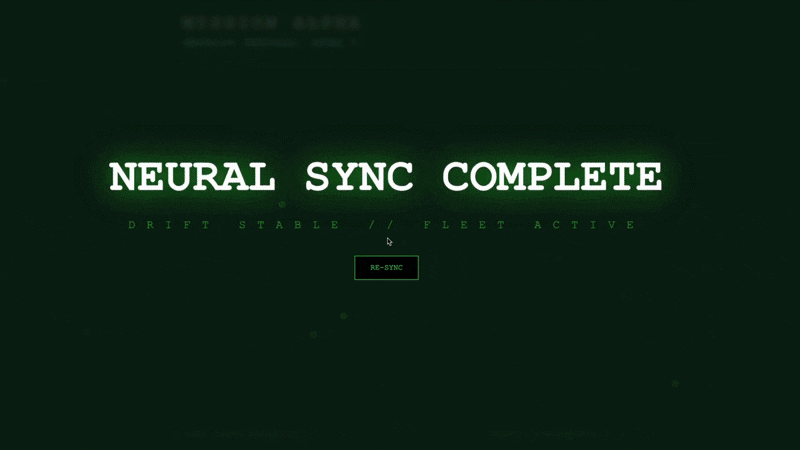
- Avvia la stretta di mano:posizionati davanti al sensore e completa la sequenza di dita, mostrando da 1 a 5 in ordine.
Se l'operazione riesce, si attiverà la "Sincronizzazione biometrica". L'AI bloccherà il collegamento neurale, dandoti il controllo manuale completo per lanciare lo Scout e riportare a casa i sopravvissuti.
Cosa creerai
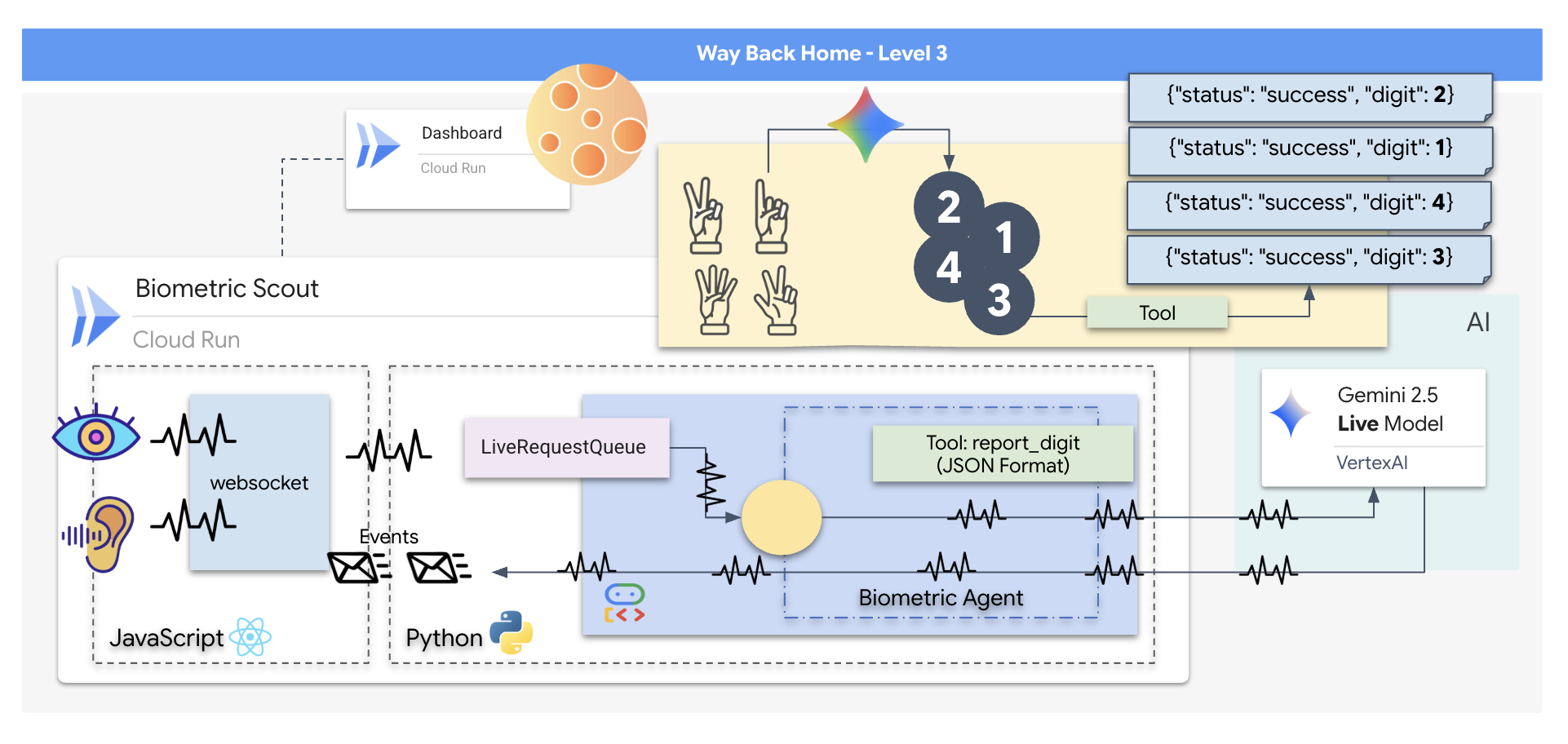
Creerai un'applicazione "Biometric Neural Sync", un sistema in tempo reale basato sull'AI che funge da interfaccia di controllo per un drone di soccorso. Questo sistema è composto da:
- Un frontend React:la "cabina di pilotaggio" della tua nave, che acquisisce video in diretta dalla webcam e audio dal microfono.
- Un backend Python:un server ad alte prestazioni creato con FastAPI, che utilizza l'Agent Development Kit (ADK) di Google per gestire la logica e lo stato dell'LLM.
- Un agente AI multimodale:il "cervello" dell'operazione, che utilizza l'API Gemini Live tramite l'SDK
google-genaiper elaborare e comprendere contemporaneamente i flussi video e audio. - Una pipeline WebSocket bidirezionale:il "sistema nervoso" che crea una connessione persistente a bassa latenza tra il frontend e l'AI, consentendo l'interazione in tempo reale.
Cosa imparerai a fare
Tecnologia / Concept | Descrizione |
Agente AI di backend | Crea un agente AI stateful con Python e FastAPI. Utilizza l'ADK (Agent Development Kit) di Google per gestire le istruzioni e la memoria e l'SDK |
UI di frontend | Sviluppa un'interfaccia utente dinamica utilizzando React per acquisire e trasmettere in streaming video in diretta e audio direttamente dal browser. |
Comunicazione in tempo reale | Implementa una pipeline WebSocket per una comunicazione full-duplex a bassa latenza, che consente all'utente e all'AI di interagire simultaneamente. |
AI multimodale | Sfrutta l'API Gemini Live per elaborare e comprendere flussi video e audio simultanei, consentendo all'AI di "vedere" e "sentire" contemporaneamente. |
Chiamata di strumenti | Consente all'AI di eseguire funzioni Python specifiche in risposta a trigger visivi, colmando il divario tra l'intelligenza del modello e l'azione nel mondo reale. |
Deployment full-stack | Contenere l'intera applicazione (frontend React e backend Python) con Docker ed eseguirne il deployment come servizio scalabile e serverless su Google Cloud Run. |
2. Configura l'ambiente
Accedere a Cloud Shell
Innanzitutto, apri Cloud Shell, un terminale basato su browser con Google Cloud SDK e altri strumenti essenziali preinstallati.
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro Cloud Shell), 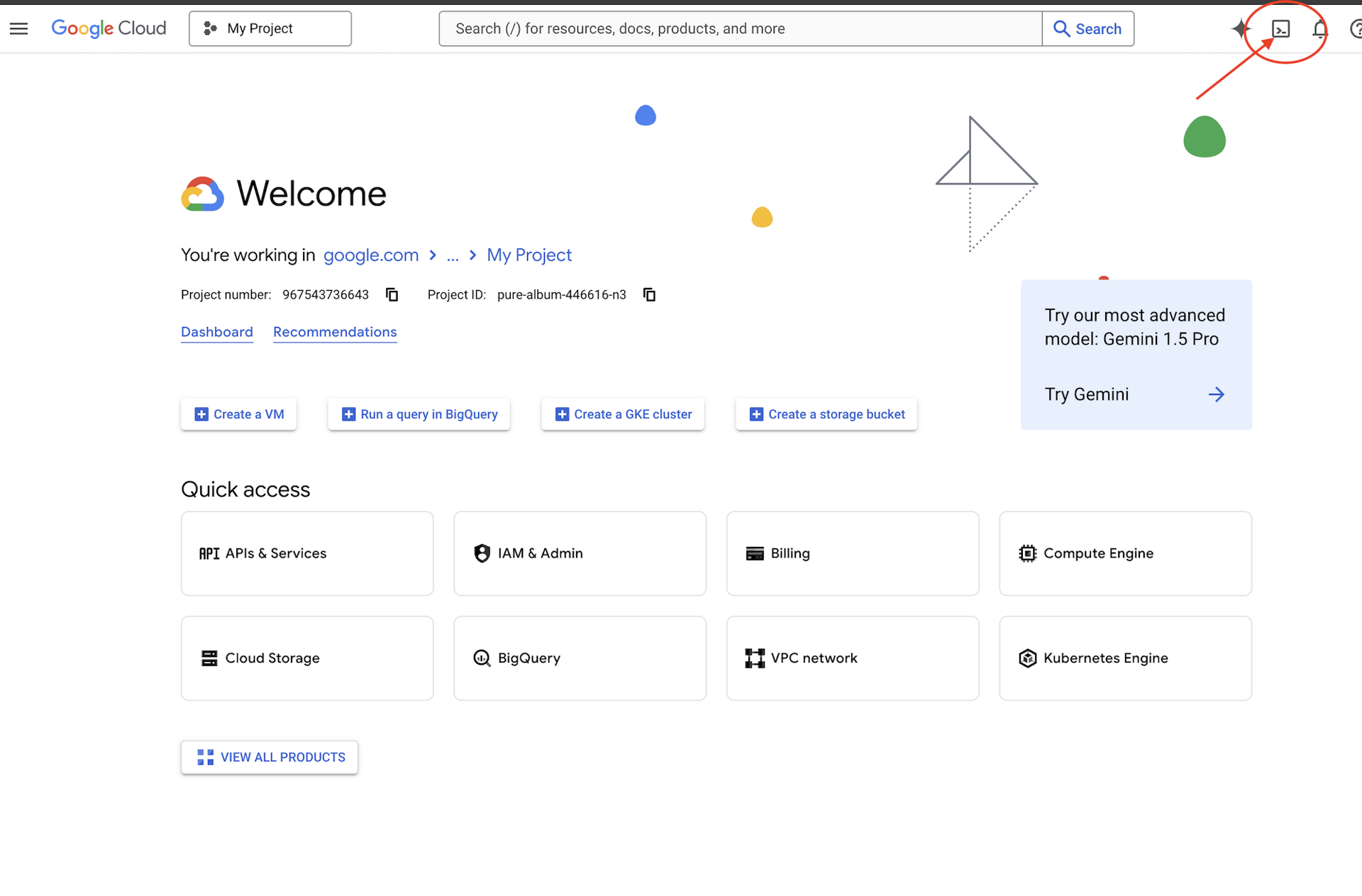
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro. 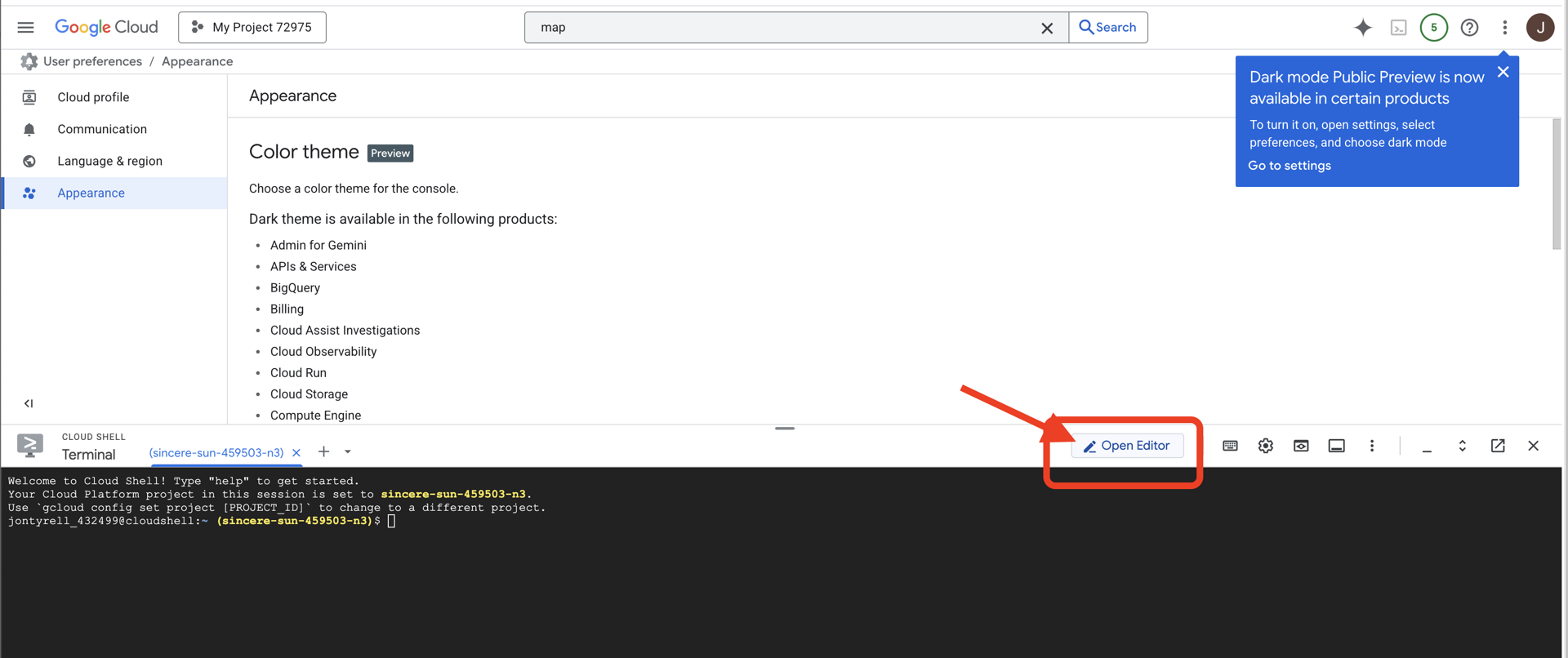
👉 Apri il terminale nell'IDE cloud.
👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
Dovresti vedere il tuo account elencato come (ACTIVE).
Prerequisiti
ℹ️ Il livello 0 è facoltativo (ma consigliato)
Puoi completare questa missione senza il livello 0, ma terminarla per prima offre un'esperienza più coinvolgente, che ti consente di vedere il tuo faro illuminarsi sulla mappa globale man mano che avanzi.
Configurare l'ambiente del progetto
Torna al terminale e finalizza la configurazione impostando il progetto attivo e abilitando i servizi Google Cloud richiesti (Cloud Run, Vertex AI e così via).
👉💻 Nel terminale, imposta l'ID progetto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Attiva i servizi richiesti:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Installa le dipendenze
👉💻 Vai a Level e installa i pacchetti Python richiesti:
cd $HOME/way-back-home/level_3
uv sync
Le dipendenze principali sono:
Pacchetto | Finalità |
| Framework web ad alte prestazioni per lo streaming di Satellite Station ed SSE |
| Server ASGI richiesto per eseguire l'applicazione FastAPI |
| Agent Development Kit utilizzato per creare l'agente di formazione |
| Client nativo per accedere ai modelli Gemini |
| Supporto per la comunicazione bidirezionale in tempo reale |
| Gestisce le variabili di ambiente e i secret di configurazione |
Verifica la configurazione
Prima di addentrarci nel codice, assicuriamoci che tutti i sistemi siano attivi. Esegui lo script di verifica per controllare il tuo progetto Google Cloud, le API e le dipendenze Python.
👉💻 Esegui lo script di verifica:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Dovresti vedere una serie di segni di spunta verdi (✅).
- Se vedi croci rosse (❌), segui i comandi di correzione suggeriti nell'output (ad es.
gcloud services enable ...opip install ...). - Nota:per il momento è accettabile un avviso giallo per
.env. Creeremo questo file nel passaggio successivo.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Calibrazione del collegamento di comunicazione (WebSockets)
Per iniziare la sincronizzazione neurale biometrica, dobbiamo aggiornare i sistemi interni della nave. Il nostro obiettivo principale è acquisire uno stream video e audio ad alta fedeltà dall'abitacolo. Questo flusso fornisce i componenti essenziali per il collegamento neurale: l'identificazione visiva delle sequenze delle dita e la frequenza sonora della voce.
Full-duplex e half-duplex
Per capire perché è necessario per la sincronizzazione neurale, devi comprendere il flusso di dati:
- Half-Duplex (HTTP standard): come un walkie-talkie. Una persona parla, dice "Passo" e poi l'altra persona può parlare. Non puoi ascoltare e parlare contemporaneamente.
- Full-duplex (WebSocket): come una conversazione faccia a faccia. Il flusso di dati avviene in entrambe le direzioni contemporaneamente. Mentre il browser invia i frame video e i campioni audio all'AI, l'AI può inviarti le risposte vocali e i comandi degli strumenti nello stesso momento.
Perché Gemini Live ha bisogno del full-duplex:l'API Gemini Live è progettata per l'"interruzione". Immagina di mostrare la sequenza di dita e l'AI si accorge che la stai facendo in modo errato. In una configurazione HTTP standard, l'AI dovrebbe attendere il completamento dell'invio dei dati prima di chiederti di interromperlo. Con i WebSocket, l'AI può vedere un errore nel fotogramma 1 e inviare un segnale di "interruzione" che arriva nel cockpit mentre stai ancora muovendo la mano per il fotogramma 2.
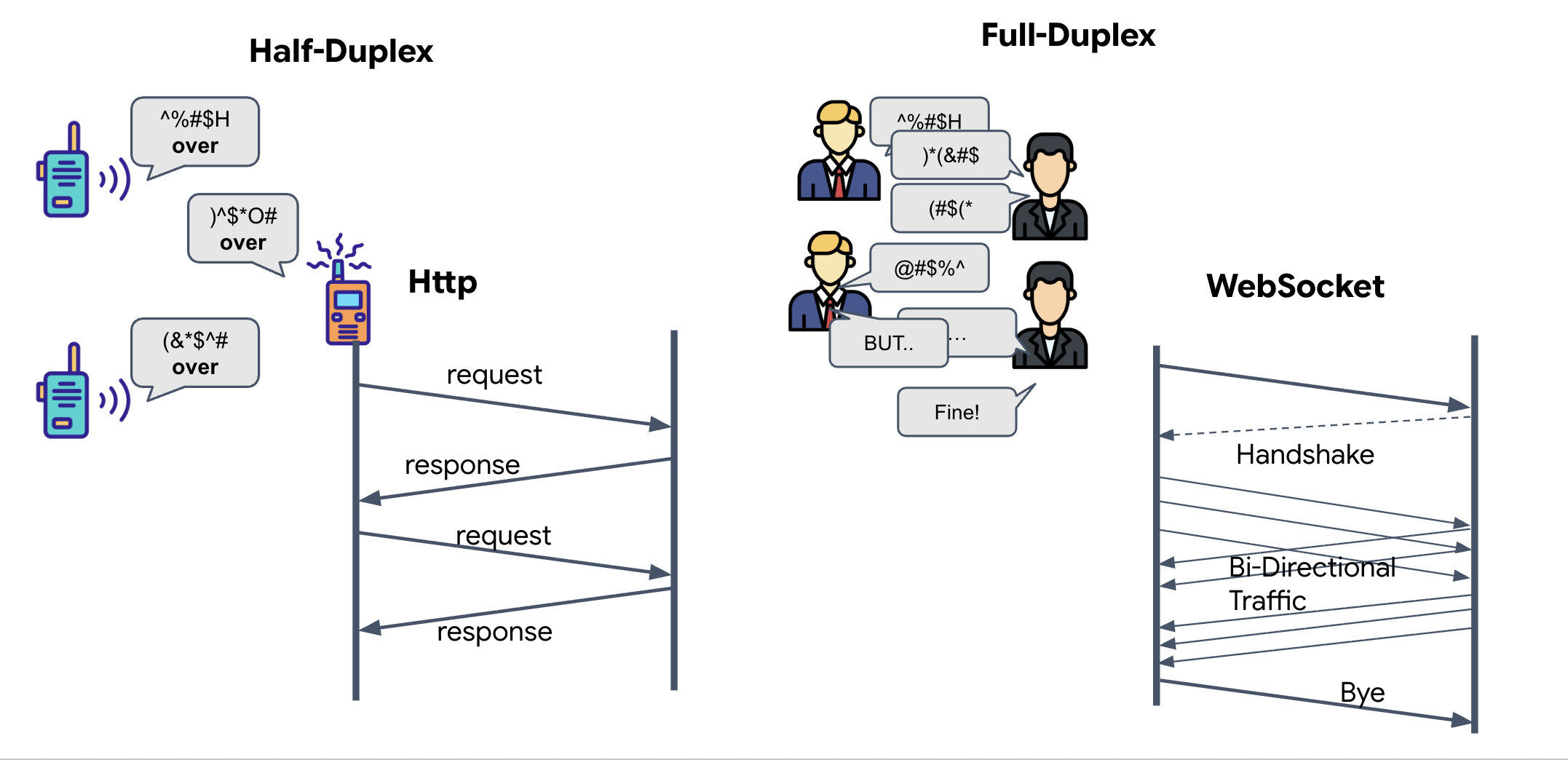
Che cos'è un WebSocket?
In una trasmissione galattica standard (HTTP), invii una richiesta e aspetti una risposta, come se inviassi una cartolina. Per una sincronizzazione neurale, le cartoline sono troppo lente. Abbiamo bisogno di un "cavo sotto tensione".
I WebSocket iniziano come una richiesta web standard (HTTP), ma poi vengono "aggiornati" in qualcosa di diverso.
- La richiesta:il browser invia una richiesta HTTP standard al server con un'intestazione speciale:
Upgrade: websocket. In sostanza, è come dire: "Vorrei interrompere l'invio di cartoline e iniziare una chiamata telefonica live". - La risposta:se l'agente AI (il server) lo supporta, invia una risposta
HTTP 101 Switching Protocols. - La trasformazione:in questo momento, la connessione HTTP viene sostituita dal protocollo WebSocket, ma il socket TCP/IP sottostante rimane aperto. Le regole di comunicazione cambiano immediatamente da "Richiesta/Risposta" a "Streaming full-duplex".
Implementa l'hook WebSocket
Ispezioniamo la morsettiera per capire come fluiscono i dati.
👀 Apri $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Vedrai i gestori di eventi del ciclo di vita WebSocket standard già configurati. Ecco la struttura del nostro sistema di comunicazione:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Il gestore onMessage
Concentrati sul blocco ws.current.onmessage. Questo è il ricevitore. Ogni volta che l'agente "pensa" o "parla", qui arriva un pacchetto di dati. Al momento non fa nulla: acquisisce il pacchetto e lo rilascia (tramite il segnaposto //#REPLACE-HANDLE-MSG).
Dobbiamo colmare questo vuoto con una logica che possa distinguere tra:
- Chiamate di strumenti (functionCall): l'AI riconosce i tuoi segnali manuali (il "Sync").
- Dati audio (inlineData): la voce dell'AI che ti risponde.
👉✏️ Ora, nello stesso file $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, sostituisci //#REPLACE-HANDLE-MSG con la logica riportata di seguito per gestire lo stream in entrata:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Come vengono trasformati audio e video in dati per la trasmissione
Per consentire la comunicazione in tempo reale su internet, l'audio e il video non elaborati devono essere convertiti in un formato adatto alla trasmissione. Ciò comporta l'acquisizione, la codifica e il packaging dei dati prima dell'invio su una rete.
Trasformazione dei dati audio
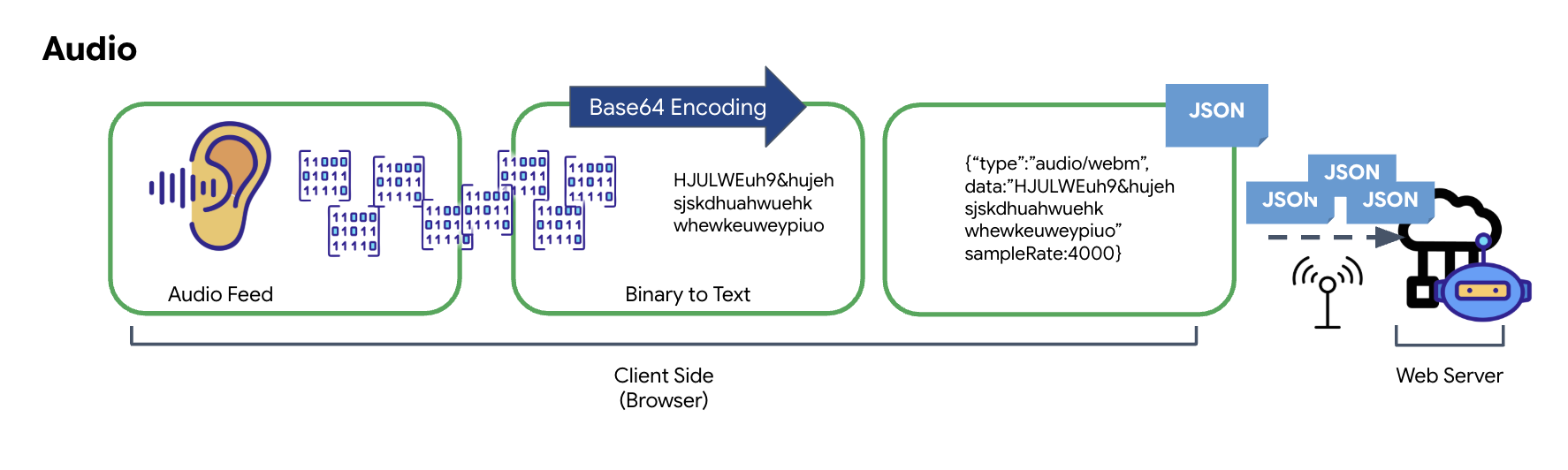
Il processo di conversione dell'audio analogico in dati digitali trasmissibili inizia con l'acquisizione delle onde sonore tramite un microfono. L'audio grezzo viene quindi elaborato tramite l'API Web Audio del browser. Poiché questi dati non elaborati sono in formato binario, non sono direttamente compatibili con i formati di trasmissione basati su testo come JSON. Per risolvere il problema, ogni segmento audio viene codificato in una stringa Base64. Base64 è un metodo che rappresenta i dati binari in un formato di stringa ASCII, garantendone l'integrità durante la trasmissione.
Questa stringa codificata viene poi incorporata in un oggetto JSON. Questo oggetto fornisce un formato strutturato per i dati, in genere include un campo "type" per identificarlo come audio e metadati come la frequenza di campionamento dell'audio. L'intero oggetto JSON viene quindi serializzato in una stringa e inviato tramite una connessione WebSocket. Questo approccio garantisce che l'audio venga trasmesso in modo ben organizzato e facilmente analizzabile.
Trasformazione dei dati video
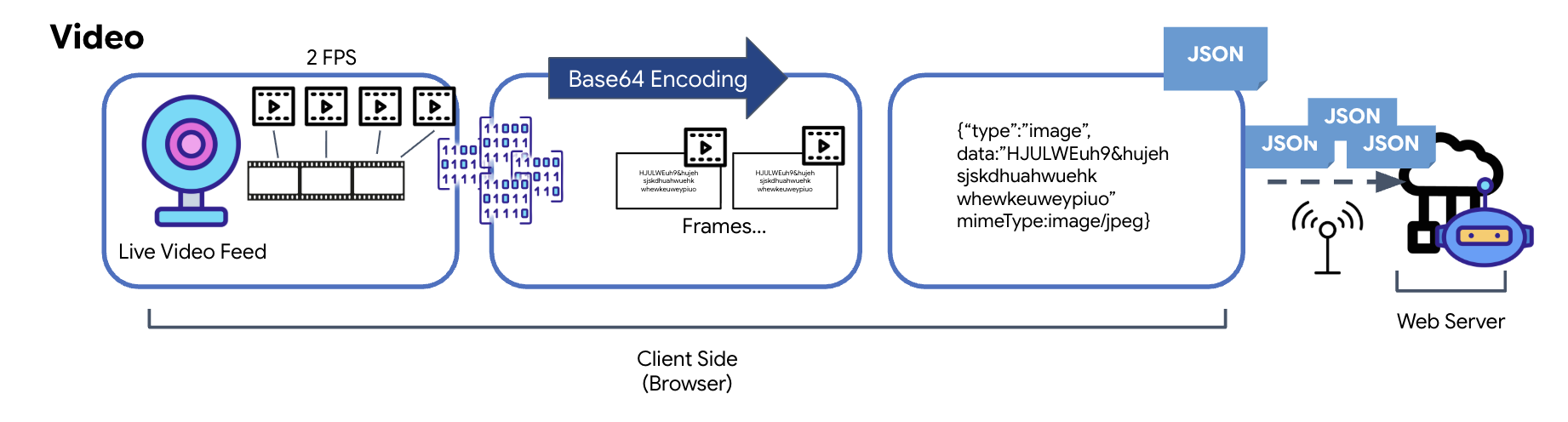
La trasmissione video viene eseguita tramite una tecnica di acquisizione dei frame. Anziché inviare uno stream video continuo, un loop ricorrente acquisisce immagini fisse dal video in diretta a un intervallo prestabilito, ad esempio due fotogrammi al secondo. A questo scopo, viene disegnato il fotogramma corrente di un elemento video HTML su un elemento canvas nascosto.
Viene quindi utilizzato il metodo toDataURL del canvas per convertire questa immagine acquisita in una stringa JPEG codificata Base64. Questo metodo include un'opzione per specificare la qualità dell'immagine, consentendo un compromesso tra fedeltà dell'immagine e dimensioni del file per ottimizzare il rendimento. Analogamente ai dati audio, questa stringa Base64 viene quindi inserita in un oggetto JSON. Questo oggetto è in genere etichettato con il tipo "image" e include mimeType, ad esempio "image/jpeg". Questo pacchetto JSON viene quindi convertito in una stringa e inviato tramite WebSocket, consentendo alla parte ricevente di ricostruire il video visualizzando la sequenza di immagini.
👉✏️ Nello stesso file $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js, sostituisci //#CAPTURE AUDIO and VIDEO con quanto segue per acquisire l'input dell'utente:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Una volta salvato, il cockpit sarà pronto a tradurre i segnali digitali dell'agente in aggiornamenti visivi della dashboard e audio.
Controllo diagnostico (test loopback)
Il tuo cockpit è ora disponibile. Ogni 500 ms viene trasmesso un "pacchetto" visivo dell'ambiente circostante. Prima di connetterci a Gemini, dobbiamo verificare che il trasmettitore della tua nave funzioni. Eseguiremo un "test di loopback" utilizzando un server di diagnostica locale.
👉💻 Innanzitutto, crea l'interfaccia di Cockpit dal terminale:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 A questo punto, avvia il server di simulazione:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Esegui il protocollo di test:
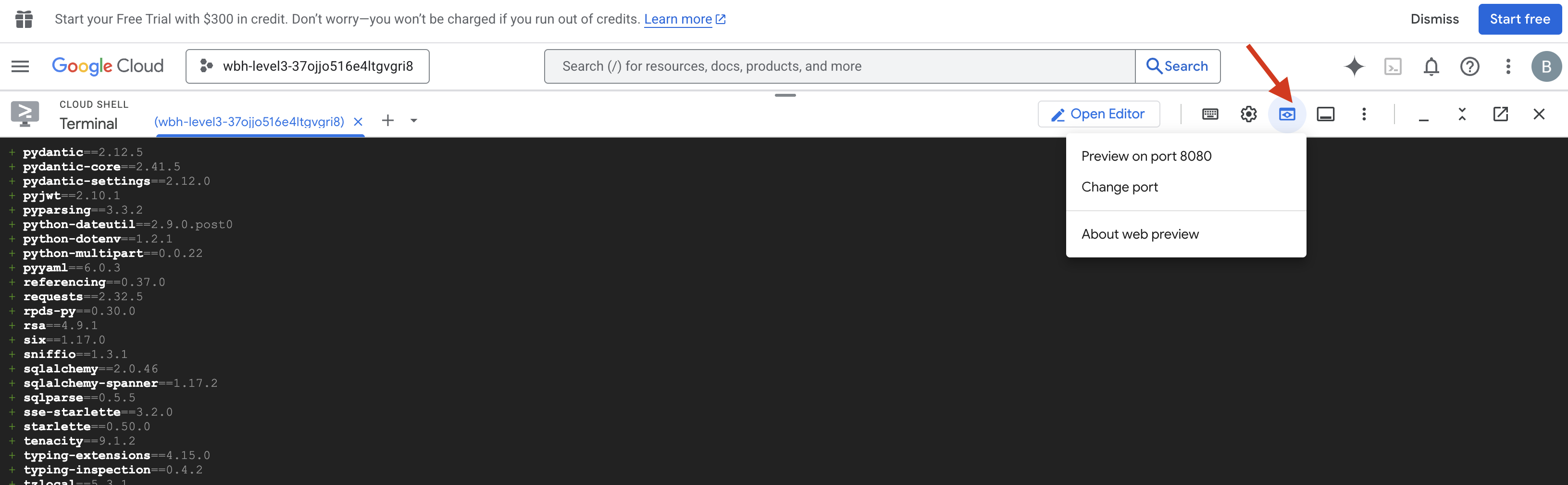
- Apri l'anteprima:fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell. Seleziona Cambia porta, impostala su 8080 e fai clic su Cambia e visualizza anteprima. Si aprirà una nuova scheda del browser che mostra l'interfaccia Cockpit.
- CRITICO:quando richiesto, DEVI consentire al browser di accedere alla videocamera e al microfono. Senza questi input, la sincronizzazione neurale non può essere avviata.
- Fai clic sul pulsante "AVVIA SINCRONIZZAZIONE NEURALE" nell'interfaccia utente.
👀 Verifica gli indicatori di stato:
- Controllo visivo:apri la console del browser. In alto a destra dovresti vedere
NEURAL SYNC INITIALIZED. - Controllo audio:se la pipeline audio bidirezionale è completamente operativa, sentirai una voce simulata che conferma: "Sistema connesso!"
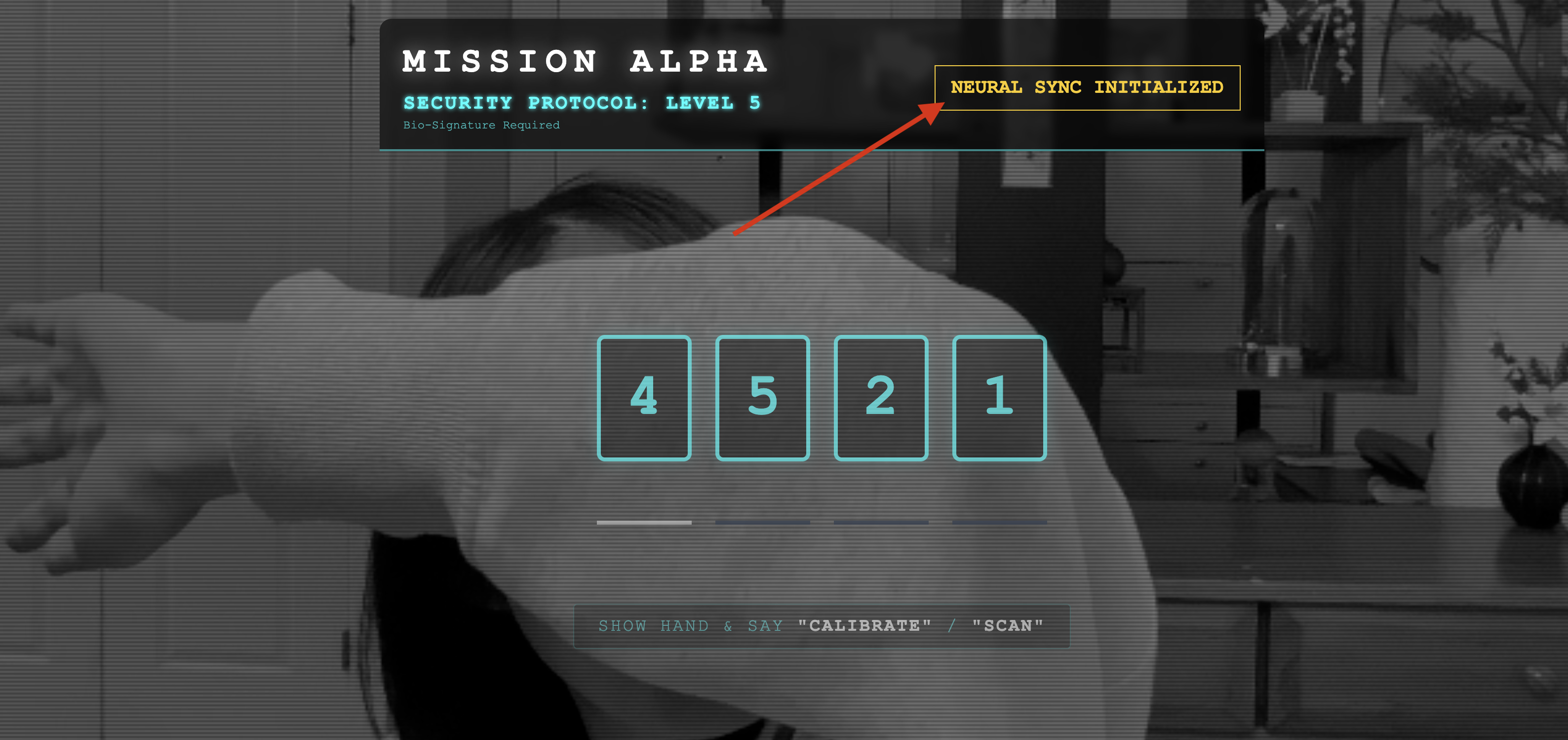
Una volta ascoltato il messaggio audio "Sistema connesso", il test è riuscito. Chiudi la scheda. Ora dobbiamo liberare la frequenza per fare spazio all'AI reale.
👉💻 Premi Ctrl+C nei terminali sia per il server di simulazione sia per il frontend. Chiudi la scheda del browser in cui è in esecuzione la UI.
4. L'agente multimodale
Lo Scout di soccorso è operativo, ma la sua "mente" è vuota. Se lo colleghi ora, ti fisserà. Non sa cosa sia un "dito". Per salvare i sopravvissuti, devi imprimere il protocollo neurale biometrico sul nucleo dello Scout.
L'agente tradizionale funziona come una serie di traduttori. Se parli con un'AI vecchia scuola, un modello "Speech-to-Text" trasforma la tua voce in parole, un "modello linguistico" legge queste parole e digita una risposta e un modello "Text-to-Speech" infine legge la risposta. Si crea così un "gap di latenza", un ritardo che sarebbe fatale in una missione di soccorso.
L'API Gemini Live è un modello multimodale nativo. Elabora direttamente e contemporaneamente i byte audio e i fotogrammi video non elaborati. "Sente" la vibrazione della tua voce e "vede" i pixel dei tuoi gesti della mano all'interno della stessa architettura neurale.
Per sfruttare questa potenza, potremmo creare l'applicazione collegando l'abitacolo direttamente all'API Live non elaborata. Tuttavia, il nostro obiettivo è creare un agente riutilizzabile, ovvero un'entità modulare e solida più veloce da creare.
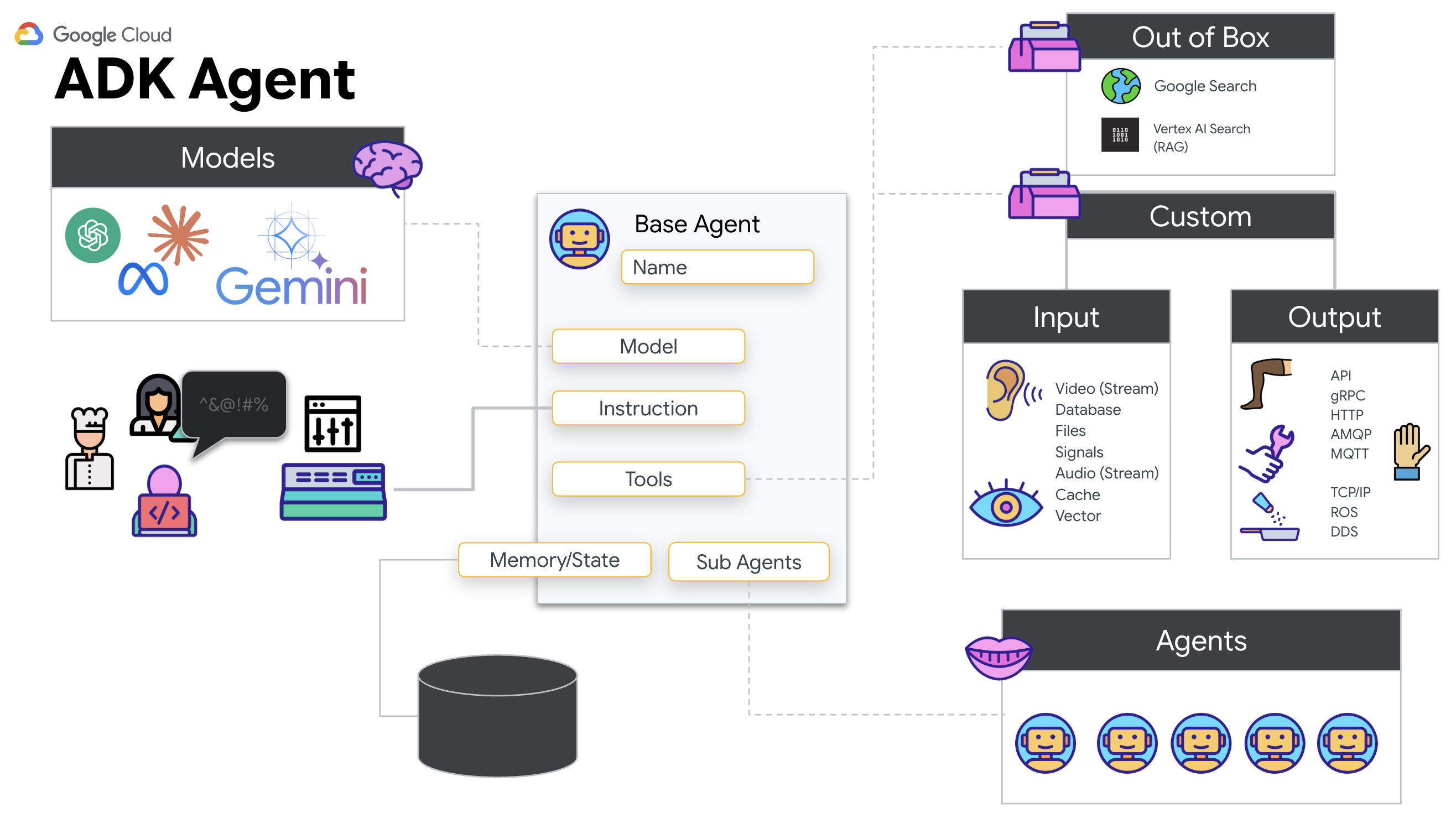
Perché ADK (Agent Development Kit)?
Google Agent Development Kit (ADK) è un framework modulare per lo sviluppo e il deployment di agenti AI.
Le chiamate a LLM standard sono in genere stateless; ogni query è un nuovo inizio. Gli agenti live, soprattutto se integrati con SessionService dell'ADK, consentono sessioni conversazionali robuste e di lunga durata.
- Persistenza della sessione:le sessioni ADK sono persistenti e possono essere archiviate in database (come SQL o Vertex AI), sopravvivendo a riavvii e disconnessioni del server. Ciò significa che se un utente si disconnette e si riconnette in un secondo momento, anche a distanza di giorni, la cronologia e il contesto della conversazione vengono ripristinati completamente. La sessione API Live effimera è gestita e astratta dall'ADK.
- Riconnessione automatica:le connessioni WebSocket possono scadere (ad esempio dopo circa 10 minuti). ADK gestisce queste riconnessioni in modo trasparente quando
session_resumptionè abilitato inRunConfig. Il codice dell'applicazione non deve gestire una logica di riconnessione complessa, garantendo un'esperienza fluida per l'utente. - Interazioni stateful:l'agente ricorda i turni precedenti, consentendo domande aggiuntive, chiarimenti e dialoghi complessi multi-turno in cui il contesto è fondamentale. Questo è fondamentale per applicazioni come l'assistenza clienti, i tutorial interattivi o gli scenari di controllo della missione in cui la continuità è essenziale.
Questa persistenza garantisce che l'interazione sembri una conversazione continua con un'entità intelligente, anziché una serie di domande e risposte isolate.
In sostanza, un "agente live" con ADK Bidi-streaming va oltre un semplice meccanismo di query-risposta per offrire un'esperienza conversazionale davvero interattiva, stateful e consapevole delle interruzioni, rendendo le interazioni con l'AI più umane e significativamente più potenti per attività complesse e di lunga durata.
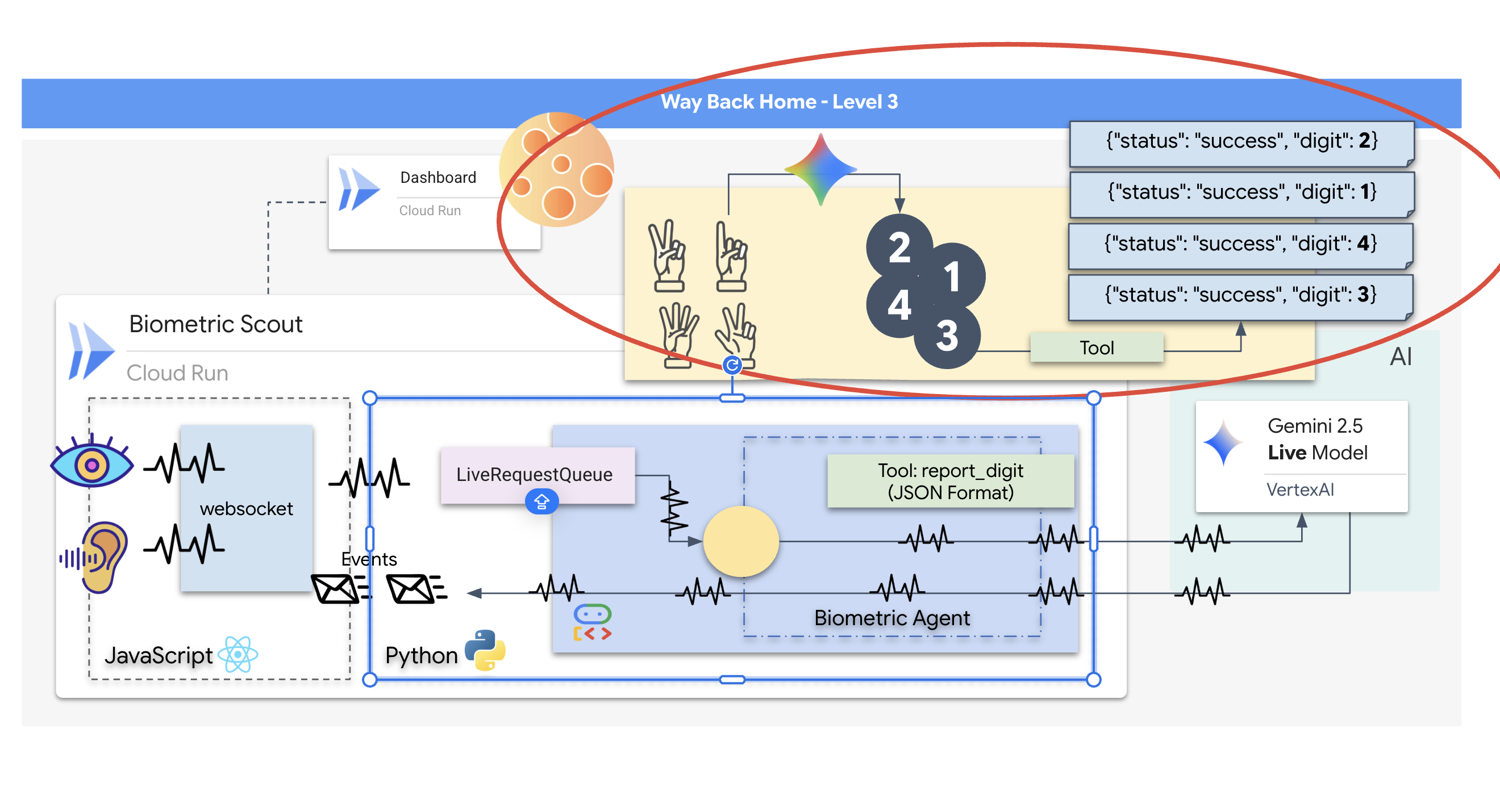
Richiesta di un operatore
La progettazione di un prompt per un agente bidirezionale in tempo reale richiede un cambio di mentalità. A differenza di un chatbot standard che attende una query di testo statica, un agente live è "sempre attivo". Riceve un flusso costante di frame audio e video, il che significa che il prompt deve fungere da script di loop di controllo anziché da semplice definizione della personalità.
Ecco in che modo un prompt Live Agent differisce da uno tradizionale:
- Logica della macchina a stati:il prompt deve definire un "ciclo di comportamento" (attesa → analisi → azione). Ha bisogno di istruzioni esplicite su quando rimanere in silenzio e quando intervenire, impedendo all'agente di parlare sopra un rumore di fondo vuoto.
- Consapevolezza multimodale:l'agente deve sapere di avere "occhi". Devi istruirlo esplicitamente ad analizzare i frame video nell'ambito della procedura di ragionamento.
- Latenza e brevità:in una conversazione vocale dal vivo, i paragrafi lunghi e ricchi di prosa risultano innaturali e lenti. Il prompt impone la brevità per mantenere l'interazione concisa.
- Architettura basata sulle azioni:le istruzioni danno la priorità alla chiamata di strumenti rispetto al parlato. Vogliamo che l'agente "faccia" il lavoro (scansionare la biometria) prima o mentre conferma verbalmente, non dopo un lungo monologo.
👉✏️ Apri $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py e sostituisci #REPLACE INSTRUCTIONS con quanto segue:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
NOTA Non ti stai connettendo a un LLM standard. Nello stesso file ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py), individua #REPLACE_MODEL. Dobbiamo scegliere come target esplicito la versione di anteprima di questo modello per supportare meglio le funzionalità audio in tempo reale.
👉✏️ Sostituisci il segnaposto con:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
L'agente è ora definito. Sa chi è e come pensare. Poi, gli diamo gli strumenti per agire.
Chiamata allo strumento
L'API Live non si limita allo scambio di flussi di testo, audio e video. Supporta in modo nativo la chiamata di strumenti. In questo modo, gli agenti passano da conversatori passivi a operatori attivi.
Durante una sessione bidirezionale live, il modello valuta costantemente il contesto. Se il LLM rileva la necessità di eseguire un'azione, ad esempio "controllare la telemetria del sensore" o "aprire una porta di sicurezza". Passa senza problemi dalla conversazione all'esecuzione. L'agente attiva immediatamente la funzione dello strumento specifico, attende il risultato e integra i dati nel live streaming, il tutto senza interrompere il flusso dell'interazione.
👉✏️ In $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py, sostituisci #REPLACE TOOLS con questa funzione:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Quindi, registralo nella definizione Agent sostituendo #TOOL CONFIG:
tools=[report_digit],
Il simulatore adk web
Prima di collegarlo al complesso cockpit della nave (il nostro frontend React), dobbiamo testare la logica dell'agente in isolamento. L'ADK include una console per sviluppatori integrata chiamata adk web che ci consente di verificare la chiamata di strumenti prima di aggiungere complessità alla rete.
👉💻 Nel terminale, esegui:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell. Seleziona Cambia porta, impostala su 8000 e fai clic su Cambia e visualizza anteprima.
- Concedi le autorizzazioni: consenti l'accesso alla fotocamera e al microfono quando richiesto.
- Inizia la sessione facendo clic sull'icona della videocamera.
- Il test visivo:
- Tieni tre dita ben visibili davanti alla fotocamera.
- Di' "Scansiona".
- Verifica dell'operazione riuscita:
- Log:esamina il terminale che esegue il comando
adk web. Devi visualizzare questo log:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Log:esamina il terminale che esegue il comando
Se vedi il log di esecuzione dello strumento, il tuo agente è intelligente. Può vedere, pensare e agire. Il passaggio finale è collegarlo alla nave principale.
Fai clic nella finestra del terminale e premi Ctrl+C per arrestare il simulatore adk web.
5. Flusso di streaming bidirezionale
L'agente funziona. Il Cockpit funziona. Ora dobbiamo collegarli.
Il ciclo di vita di Live Agent
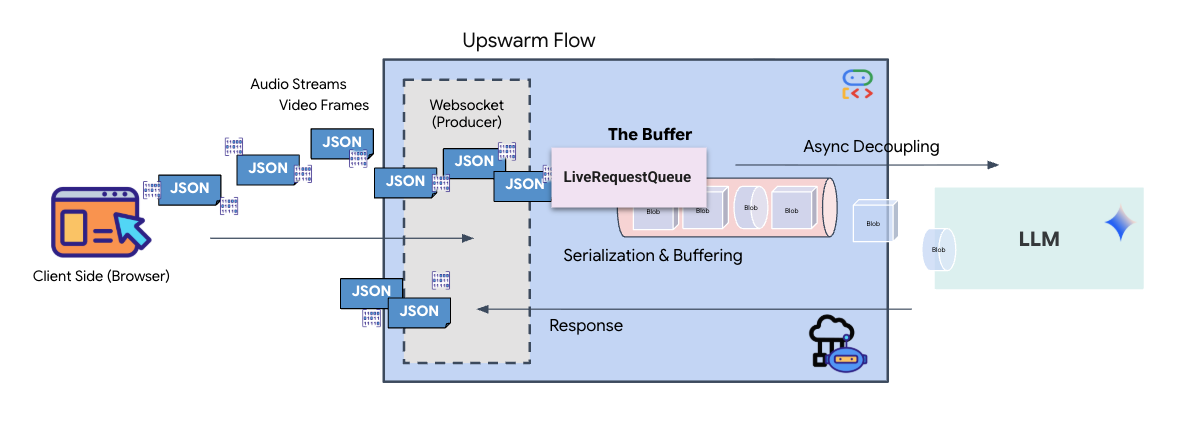
Lo streaming in tempo reale introduce un problema di "mancata corrispondenza di impedenza". Il client (browser) invia i dati in modo asincrono a velocità variabili (picchi di rete o input rapidi), mentre il modello richiede un flusso di input regolamentato e sequenziale. Google ADK risolve questo problema utilizzando LiveRequestQueue.
Funge da buffer asincrono FIFO (First-In-First-Out) thread-safe. Il gestore WebSocket funge da produttore, inserendo i blocchi audio/video non elaborati nella coda. L'agente ADK funge da consumatore, estraendo i dati dalla coda per alimentare la finestra contestuale del modello. Questo disaccoppiamento consente all'applicazione di continuare a ricevere input dell'utente anche mentre il modello genera una risposta o esegue uno strumento.
La coda funge da multiplexer multimodale. In un ambiente reale, il flusso upstream è costituito da tipi di dati distinti e simultanei: byte audio PCM non elaborati, frame video, istruzioni di sistema basate su testo e i risultati delle chiamate di funzioni asincrone. LiveRequestQueue linearizza questi input disparati in un'unica sequenza cronologica. Che il pacchetto contenga un millisecondo di silenzio, un'immagine ad alta risoluzione o un payload JSON da una query di database, viene serializzato nell'ordine esatto di arrivo, garantendo che il modello percepisca una sequenza temporale coerente e causale.
Questa architettura consente il controllo non bloccante. Poiché il livello di importazione (Producer) è disaccoppiato dal livello di elaborazione (Consumer), il sistema rimane reattivo anche durante l'inferenza del modello computazionalmente costosa. Se un utente interrompe l'Agent con il comando "Stop!" mentre esegue uno strumento, il segnale audio viene messo immediatamente in coda. Il ciclo di eventi sottostante elabora immediatamente questo segnale di priorità, consentendo al sistema di interrompere la generazione o le attività pivot senza che la UI si blocchi o che i pacchetti vengano eliminati.
👉💻 In $HOME/way-back-home/level_3/backend/app/main.py, trova il commento #REPLACE_RUNNER_CONFIG e sostituiscilo con il seguente codice per portare il sistema online:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
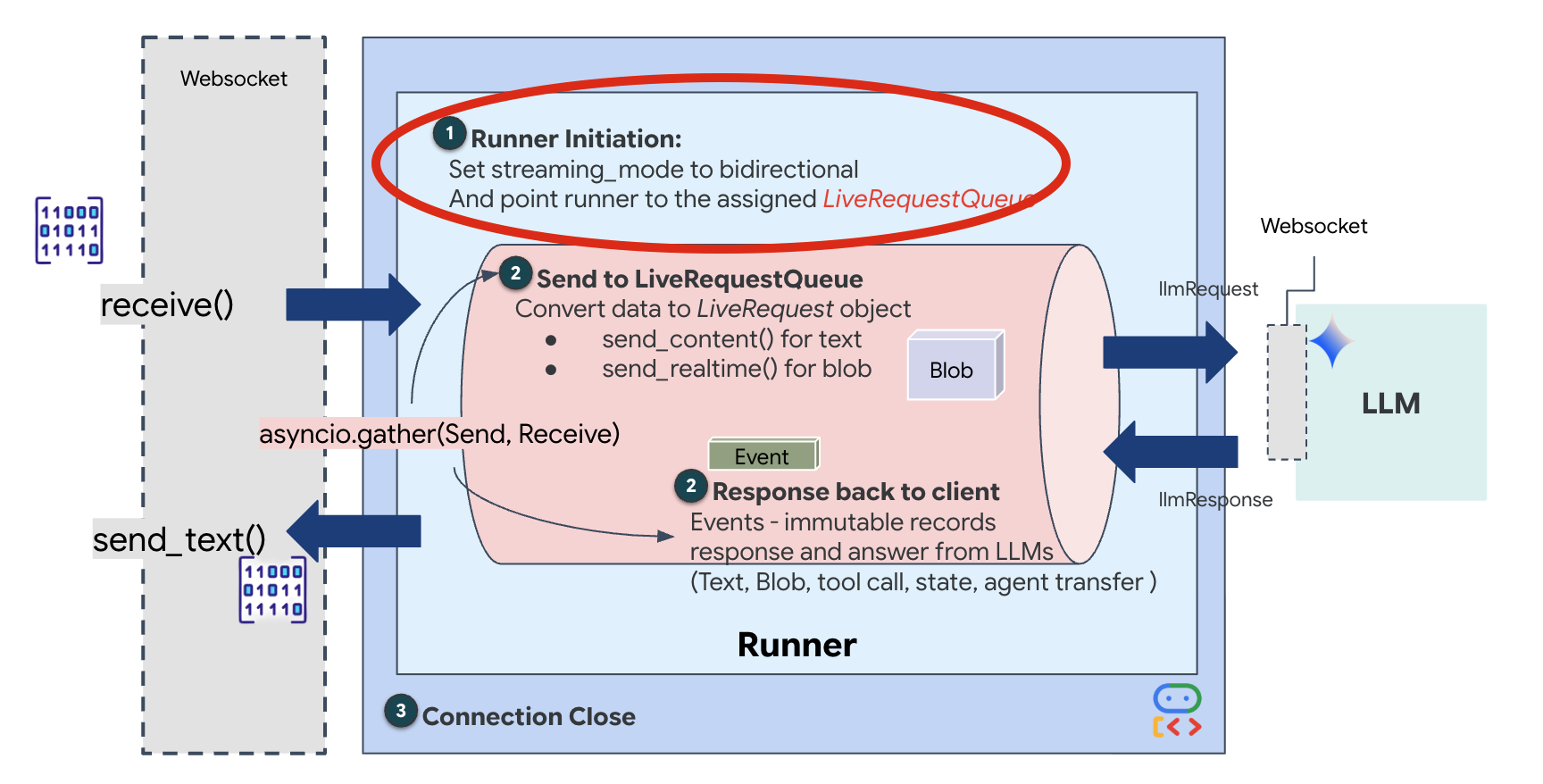
Quando si apre una nuova connessione WebSocket, dobbiamo configurare il modo in cui l'AI interagisce. È qui che definiamo le "Regole di coinvolgimento".
👉✏️ In $HOME/way-back-home/level_3/backend/app/main.py, all'interno della funzione async def websocket_endpoint, sostituisci il commento #REPLACE_SESSION_INIT con il codice riportato di seguito:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
La configurazione di esecuzione
StreamingMode.BIDI: imposta la connessione bidirezionale. A differenza dell'AI "a turni" (in cui parli, ti fermi e poi parla l'AI), BIDI consente una conversazione "full-duplex" realistica. Puoi interrompere l'AI e l'AI può parlare mentre ti muovi.AudioTranscriptionConfig: anche se il modello "sente" l'audio grezzo, noi (gli sviluppatori) dobbiamo visualizzare i log. Questa configurazione indica a Gemini: "Elabora l'audio, ma invia anche una trascrizione di testo di ciò che hai sentito per consentirci di eseguire il debug".
La logica di esecuzione. Una volta stabilita la sessione, il runner passa il controllo alla logica di esecuzione, che si basa su LiveRequestQueue. Si tratta del componente più importante per l'interazione in tempo reale. Il ciclo consente all'agente di generare una risposta vocale mentre la coda continua ad accettare nuovi fotogrammi video dall'utente, garantendo che la "sincronizzazione neurale" non venga mai interrotta.
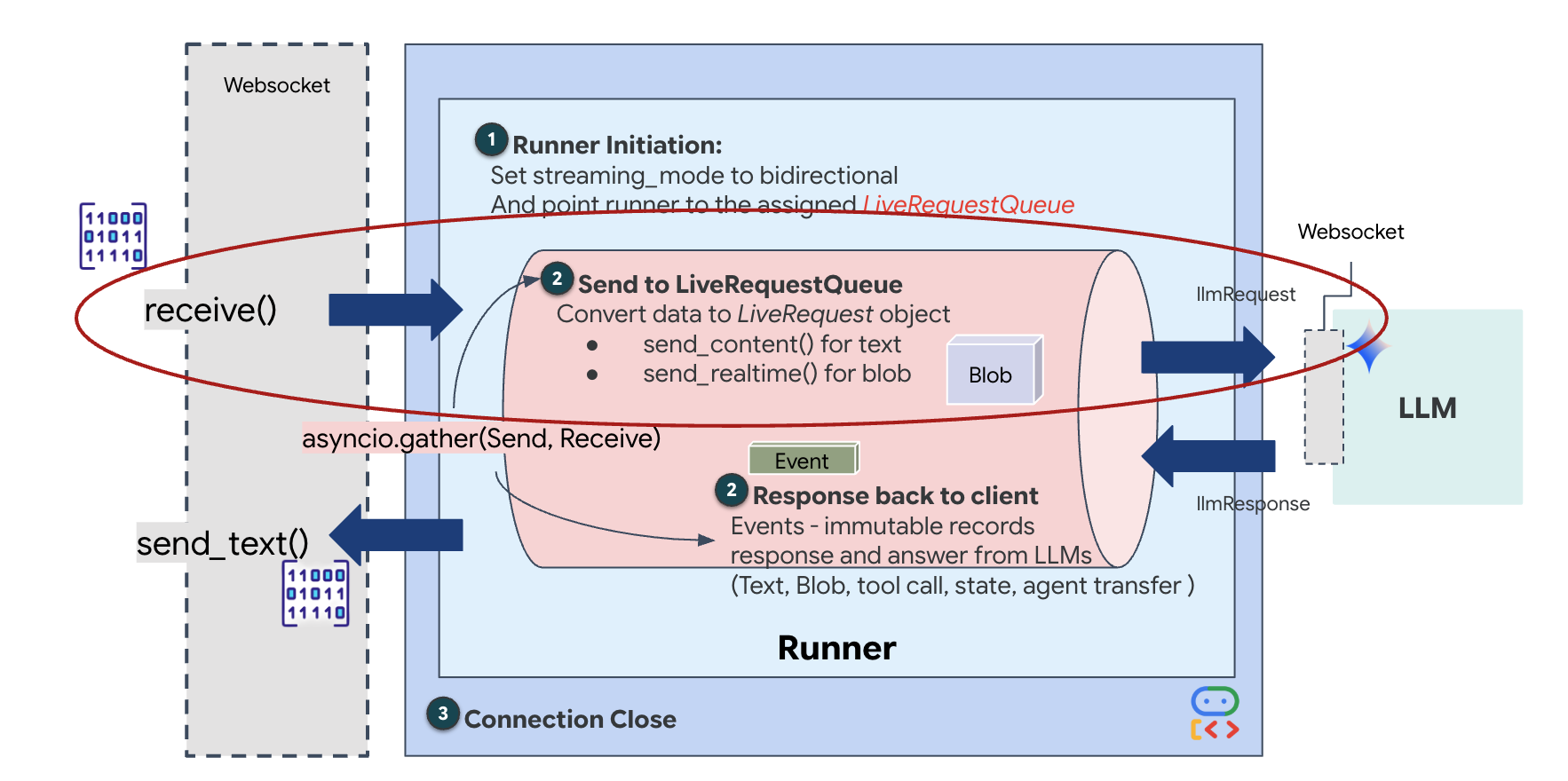
👉✏️ In $HOME/way-back-home/level_3/backend/app/main.py, sostituisci #REPLACE_LIVE_REQUEST per definire l'attività upstream che invia dati a LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
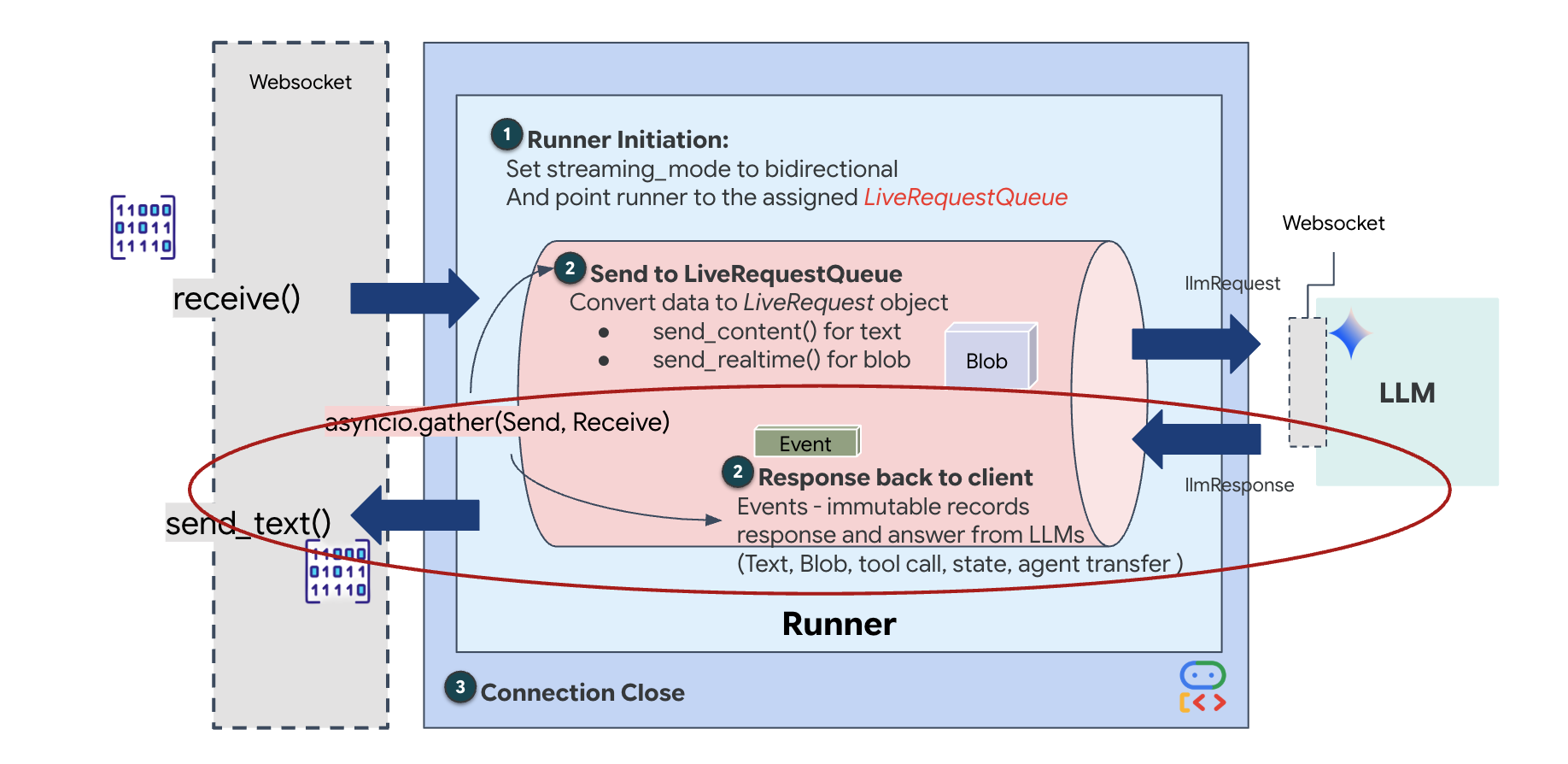
Infine, dobbiamo gestire le risposte dell'AI. Utilizza runner.run_live(), un generatore di eventi che produce eventi (audio, testo o chiamate di strumenti) man mano che si verificano.
👉✏️ In $HOME/way-back-home/level_3/backend/app/main.py, sostituisci #REPLACE_SORT_RESPONSE per definire l'attività downstream e il gestore della concorrenza:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Nota la riga await asyncio.gather(upstream_task(), downstream_task()). Questa è l'essenza del full-duplex. Eseguiamo l'attività di ascolto (upstream) e l'attività di conversazione (downstream) esattamente nello stesso momento. In questo modo, il "collegamento neurale" consente l'interruzione e il flusso di dati simultaneo.
Il backend è ora completamente codificato. Il "cervello" (ADK) è collegato al "corpo" (WebSocket).
Esecuzione di Bio-Sync
Il codice è completo. I sistemi sono verdi. È il momento di lanciare il salvataggio.
- 👉💻 Avvia il backend:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Avvia il frontend:
- Fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell. Seleziona Cambia porta, impostala su 8080 e fai clic su Cambia e visualizza anteprima.
- 👉 Esegui il protocollo:
- Fai clic su "AVVIA SINCRONIZZAZIONE NEURALE".
- Calibra:assicurati che la videocamera veda chiaramente la tua mano sullo sfondo.
- La sincronizzazione:guarda il codice di sicurezza visualizzato sullo schermo (ad es. 3, poi 2, poi 5).
- Corrispondenza del segnale:quando appare un numero, alza esattamente quel numero di dita.
- Tieni la mano ferma:tieni la mano visibile finché l'IA non conferma la "Corrispondenza biometrica".
- Adattamento:il codice è casuale. Passa immediatamente al numero successivo mostrato fino al completamento della sequenza.

- Quando corrisponde l'ultimo numero della sequenza casuale, la "Sincronizzazione biometrica" sarà completata. Il collegamento neurale si bloccherà. Hai il controllo manuale. I motori dello Scout si accenderanno, tuffandosi nel Ravine per riportare a casa i sopravvissuti.
👉💻 Premi Ctrl+C nel terminale backend per uscire.
6. (Facoltativo) Esegui il deployment in produzione
Hai testato correttamente la biometria in locale. Ora dobbiamo caricare il nucleo neurale dell'agente nei mainframe della nave (Cloud Run) in modo che possa operare indipendentemente dalla tua console locale.
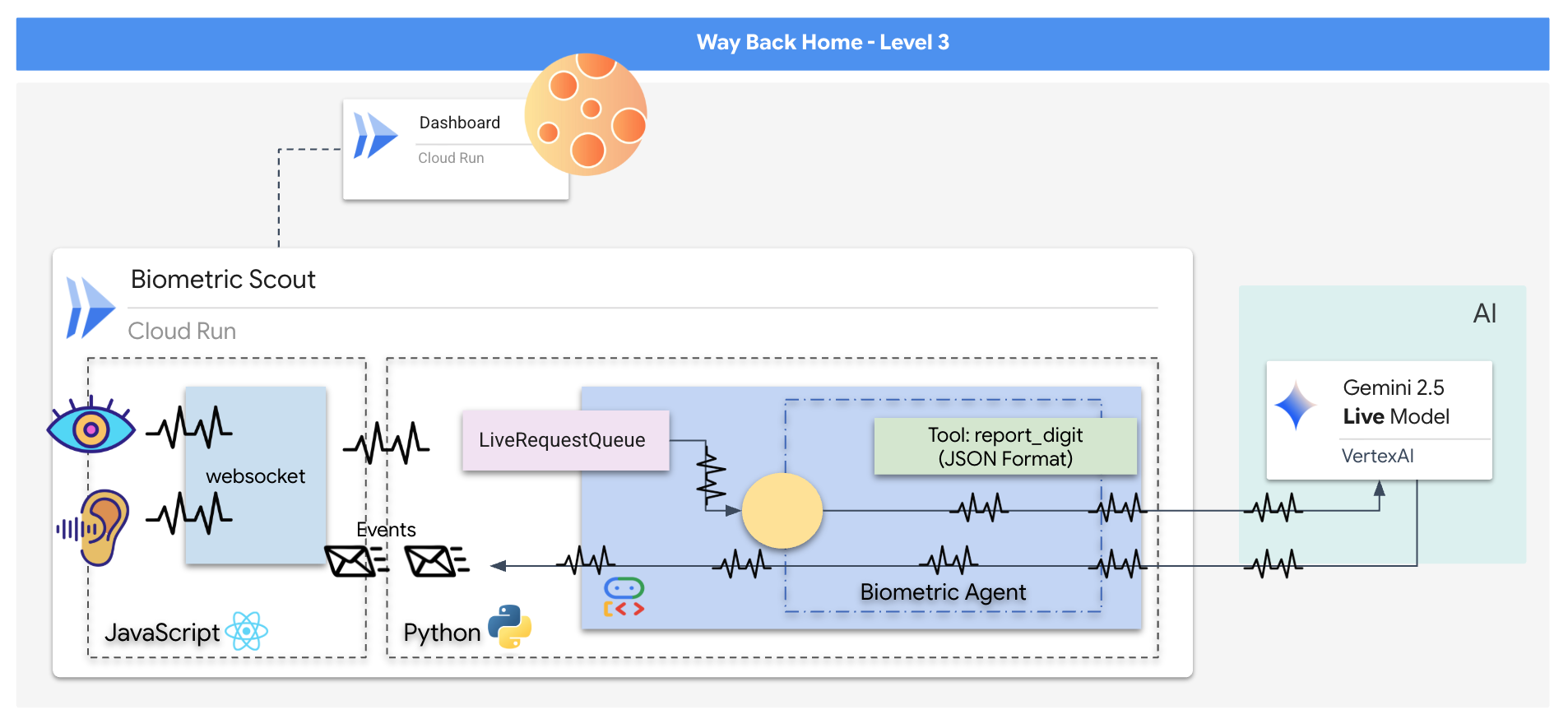
👉💻 Esegui questo comando nel terminale Cloud Shell. Verrà creato il Dockerfile completo e multifase nella directory backend.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Vai alla directory di backend e pacchettizza l'applicazione in un'immagine container.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Esegui il deployment del servizio in Cloud Run. Inseriremo le variabili di ambiente necessarie, in particolare la configurazione di Gemini, direttamente nel comando di avvio.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Al termine del comando, vedrai un URL del servizio (ad es. https://biometric-scout-...run.app). L'applicazione è ora attiva nel cloud.
👉 Vai alla pagina Google Cloud Run e seleziona il servizio biometric-scout dall'elenco. 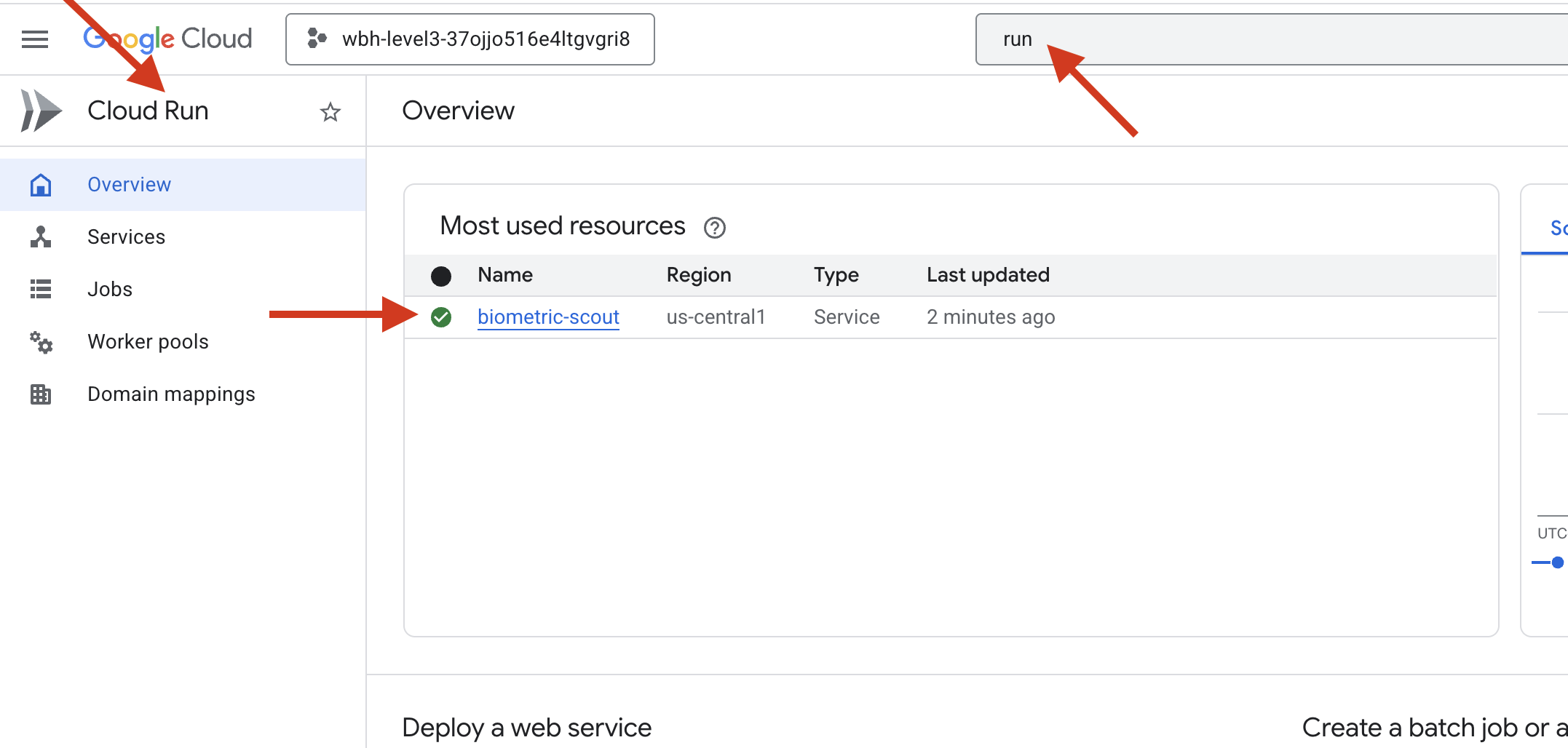
Individua l'URL pubblico visualizzato nella parte superiore della pagina dei dettagli del servizio. 
Prova a eseguire Bio-Sync in questo ambiente. Funziona?
Quando il quinto dito si estende, l'AI blocca la sequenza. Lo schermo lampeggia in verde: "Sincronizzazione neurale biometrica: STABILITA".
Con un solo pensiero, fai tuffare lo Scout nell'oscurità, agganciati al pod bloccato e tiralo fuori appena prima che la distorsione gravitazionale si chiuda.

La camera stagna si apre con un sibilo e lì ci sono cinque sopravvissuti vivi e vegeti. Salgono sul ponte, malconci ma vivi, finalmente al sicuro grazie a te.
Grazie a te, il collegamento neurale è sincronizzato e i sopravvissuti sono stati salvati.
Se hai partecipato al Livello 0, non dimenticare di controllare a che punto è il tuo avanzamento nella missione di ritorno a casa.