1. ミッション

未踏のセクターの静寂の中を漂っています。巨大な **Solar Pulse** により、宇宙船が裂け目を通り抜け、星図に存在しない宇宙のポケットに漂着してしまいました。
数日間の過酷な修理を経て、ついに足元でエンジンのうなりを感じます。ロケットが修理されました。マザーシップへの長距離アップリンクを確保することにも成功しました。出発を許可します。これで帰宅の準備が整いました。ジャンプ ドライブを起動しようとしたとき、静電気の音を突き破るように遭難信号が聞こえてきました。センサーが、メインの宇宙船では決して侵入できない、重力で歪んだギザギザのセクターである 「渓谷」に閉じ込められた 5 つの微弱な熱シグネチャを検出します。彼らは、あなたを飲み込みかけた嵐を生き延びた仲間たちです。会場に残してきてはいけません。
Alpha-Drone Rescue Scout に目を向けます。この小型で機敏な船は、渓谷の狭い壁を航行できる唯一の船です。しかし、問題があります。太陽パルスによってコアロジックが完全に「システム リセット」されてしまったのです。スカウトの制御システムが応答しません。電源は入っていますが、オンボード コンピュータは白紙の状態であり、手動のパイロット コマンドや飛行経路を処理できません。
課題
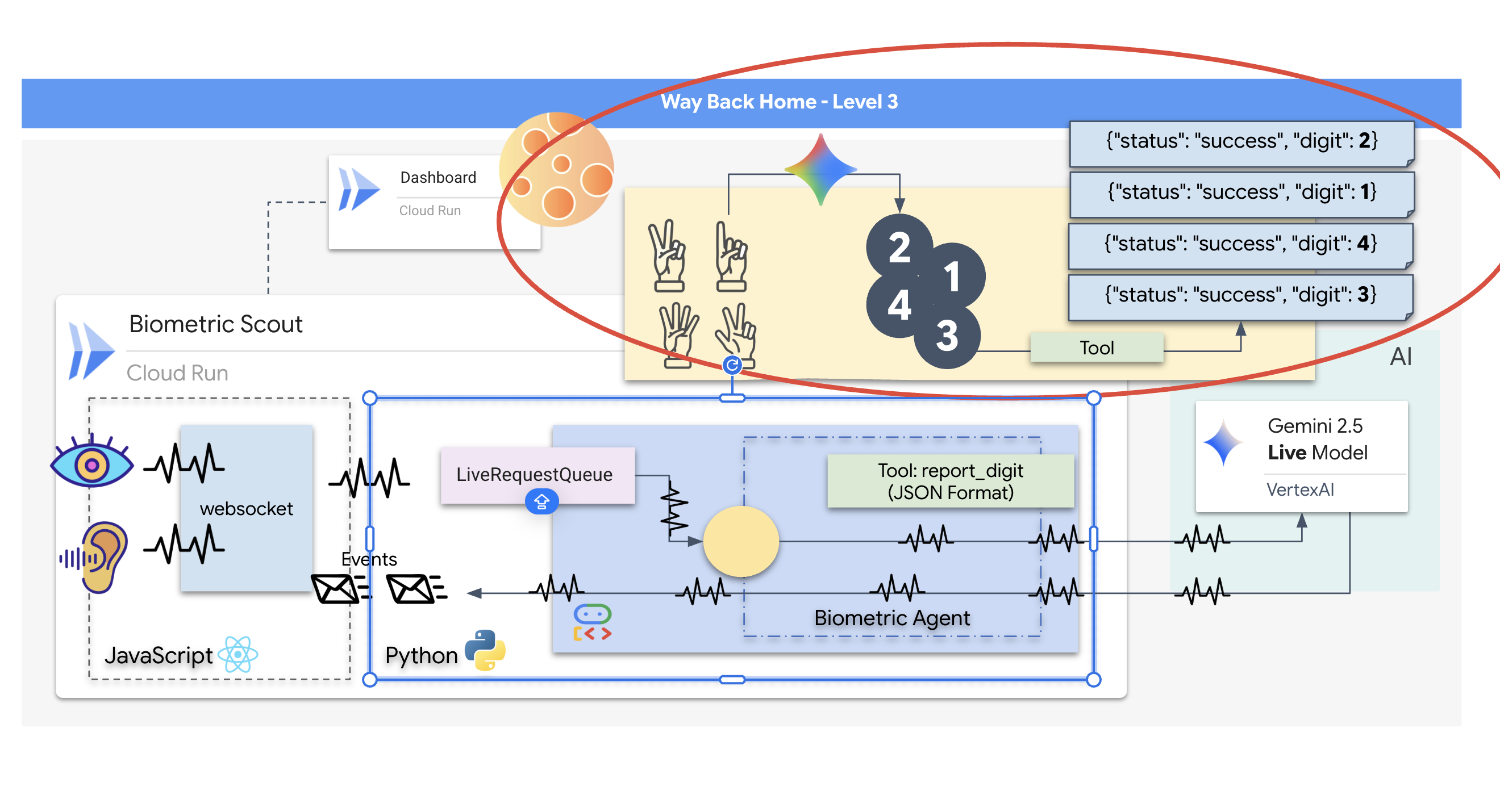
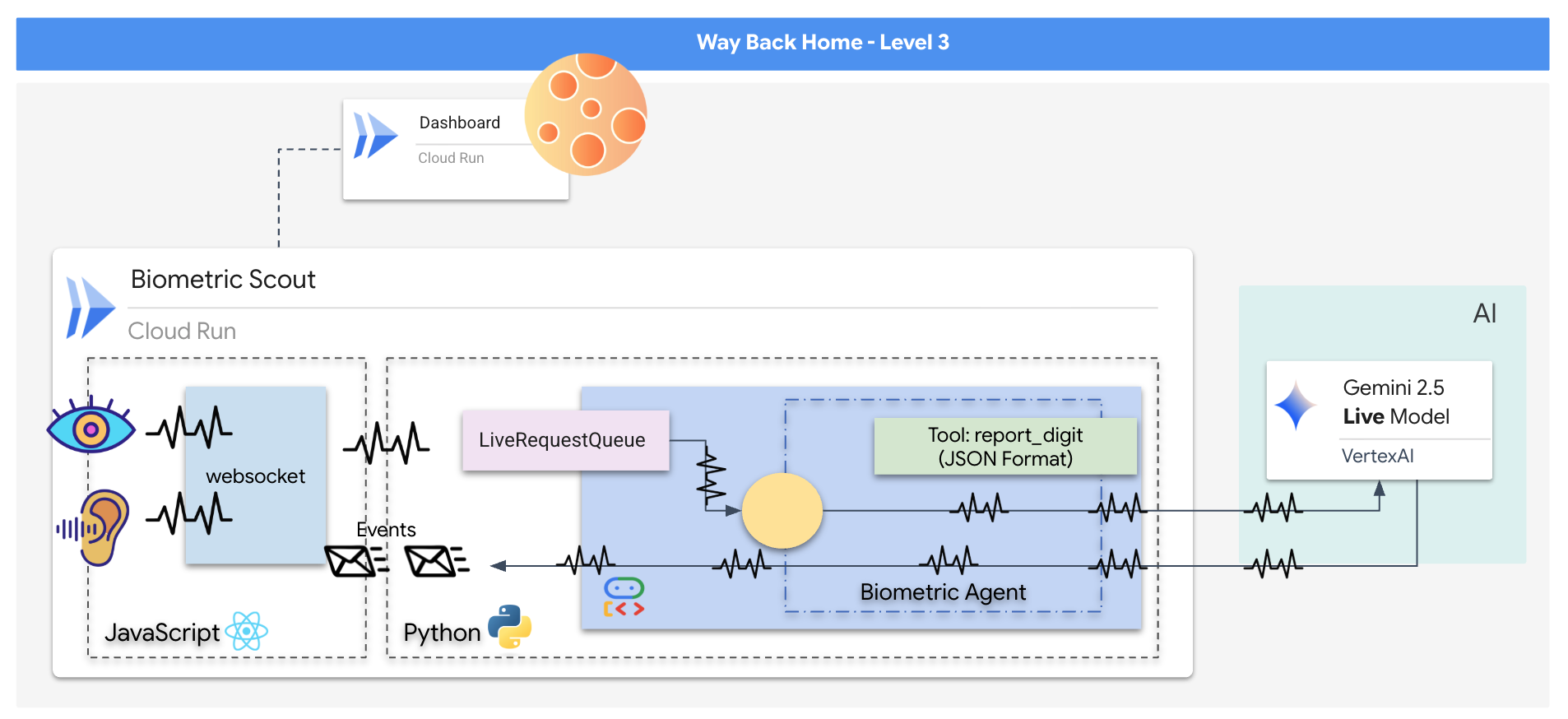
生存者を救うには、スカウトの損傷した回路を完全にバイパスする必要があります。最後の手段として、生体認証ニューラル同期を確立する AI エージェントを構築するという方法があります。このエージェントはリアルタイムのブリッジとして機能し、独自の生体入力を使用して Rescue Scout を手動で制御できます。ジョイスティックやキーボードは使用しません。意図を宇宙船のナビゲーション ネットワークに直接配線します。
リンクを確定するには、Scout の光学センサーの前で同期プロトコルを実行する必要があります。AI エージェントは、正確なリアルタイムのハンドシェイクを通じて、生体認証を認識する必要があります。
ミッションの目標:
- Neural Core をインプリントする: マルチモーダル入力を認識できる ADK エージェントを定義します。
- 接続を確立する: Scout から AI に視覚データをストリーミングする双方向 WebSocket パイプラインを構築します。
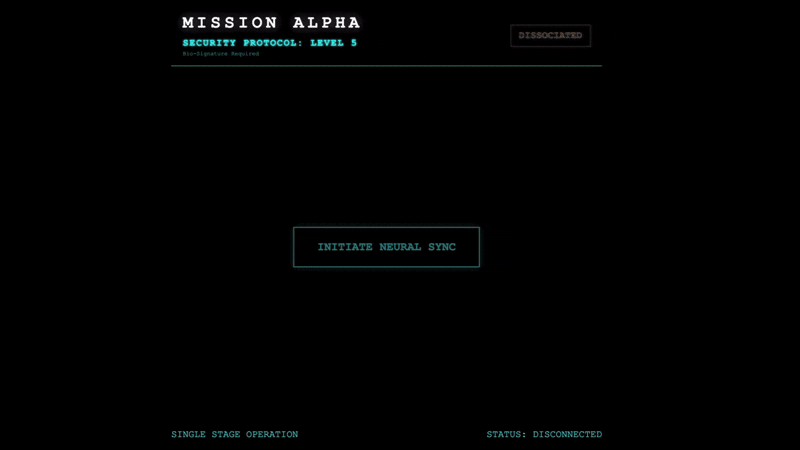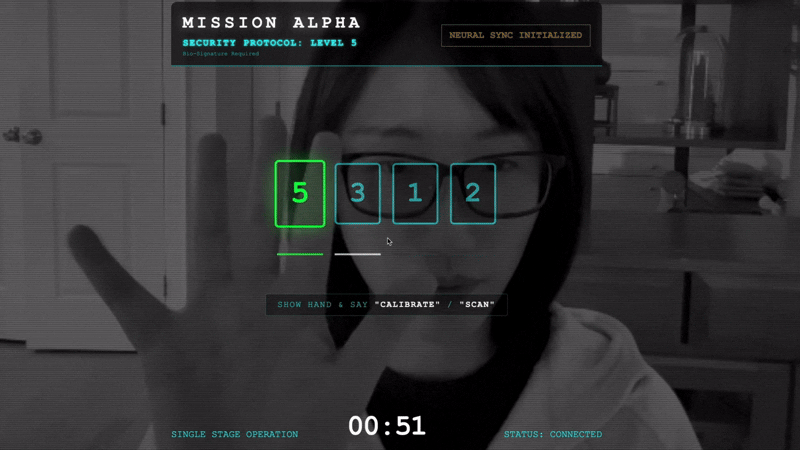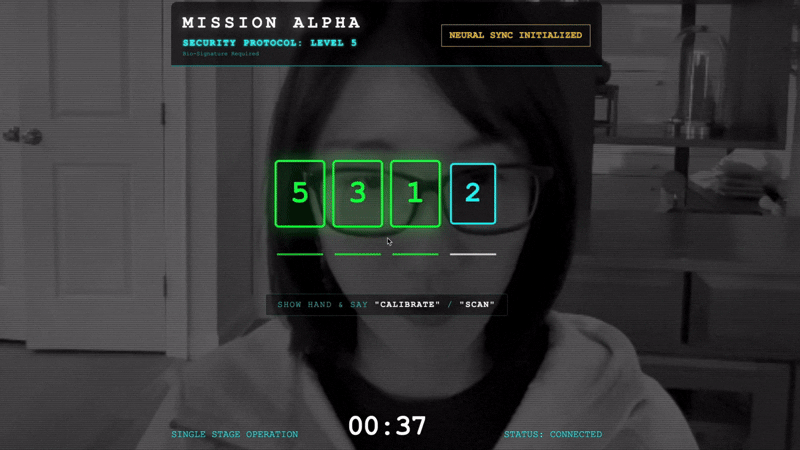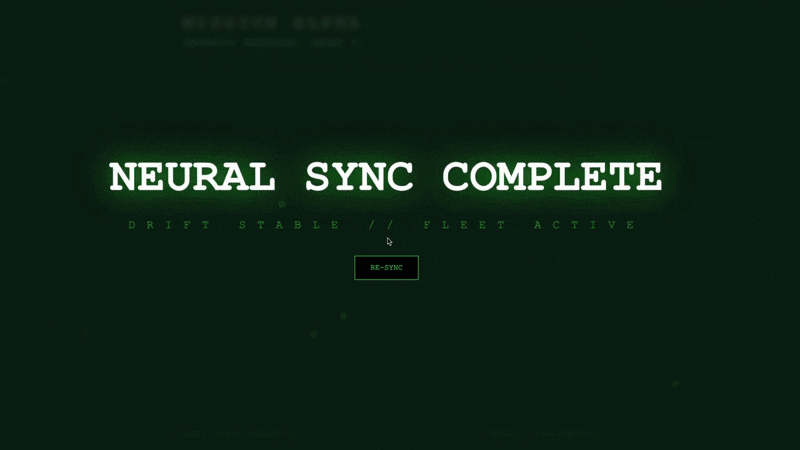
- ハンドシェイクを開始する: センサーの前に立ち、指のシーケンス(1 から 5 までを順番に表示)を完了します。
成功すると、[バイオメトリクス同期] が有効になります。AI がニューラル リンクをロックし、スカウトを起動して生存者を家に連れ帰るための完全な手動制御が可能になります。
作業内容
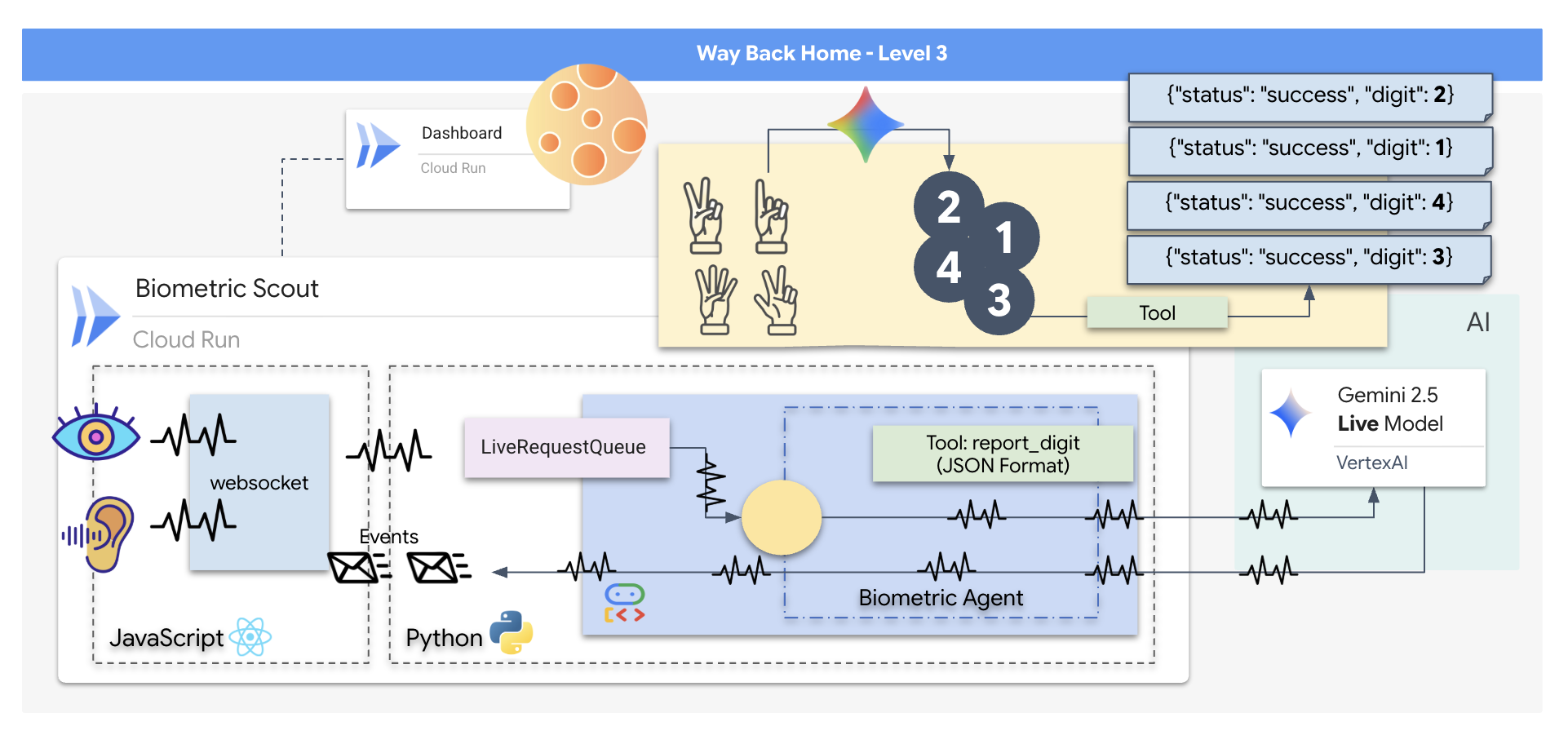
「Biometric Neural Sync」アプリケーションを構築します。これは、救助用ドローンの制御インターフェースとして機能するリアルタイムの AI 搭載システムです。このシステムは次の要素で構成されています。
- React フロントエンド: 船の「コックピット」。ウェブカメラからのライブ動画とマイクからの音声をキャプチャします。
- Python バックエンド: Google の Agent Development Kit(ADK)を使用して LLM のロジックと状態を管理する、FastAPI で構築された高性能サーバー。
- マルチモーダル AI エージェント:
google-genaiSDK を介して Gemini Live API を使用し、動画と音声のストリームを同時に処理して理解するオペレーションの「頭脳」です。 - 双方向 WebSocket パイプライン: フロントエンドと AI の間に永続的な低レイテンシ接続を確立し、リアルタイムのインタラクションを可能にする「神経系」。
学習内容
テクノロジー / コンセプト | 説明 |
バックエンド AI エージェント | Python と FastAPI を使用してステートフル AI エージェントを構築します。Google の ADK(Agent Development Kit)を使用して指示とメモリを管理し、 |
フロントエンド UI | React を使用して動的なユーザー インターフェースを開発し、ブラウザから直接ライブ動画と音声をキャプチャしてストリーミングします。 |
リアルタイムのコミュニケーション | 全二重の低レイテンシ通信用の WebSocket パイプラインを実装し、ユーザーと AI が同時にやり取りできるようにします。 |
マルチモーダル AI | Gemini Live API を活用して、動画と音声の同時ストリームを処理して理解し、AI が同時に「見て」「聞いて」理解できるようにします。 |
ツールの呼び出し | AI が視覚的なトリガーに応答して特定の Python 関数を実行できるようにし、モデルのインテリジェンスと現実世界の行動のギャップを埋めます。 |
フルスタック デプロイ | Docker を使用してアプリケーション全体(React フロントエンドと Python バックエンド)をコンテナ化し、Google Cloud Run にスケーラブルなサーバーレス サービスとしてデプロイします。 |
2. 環境をセットアップする
Cloud Shell にアクセスする
まず、Cloud Shell を開きます。これは、Google Cloud SDK やその他の重要なツールがプリインストールされたブラウザベースのターミナルです。
👉Google Cloud コンソールの最上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの最上部にあるターミナル型のアイコンです)。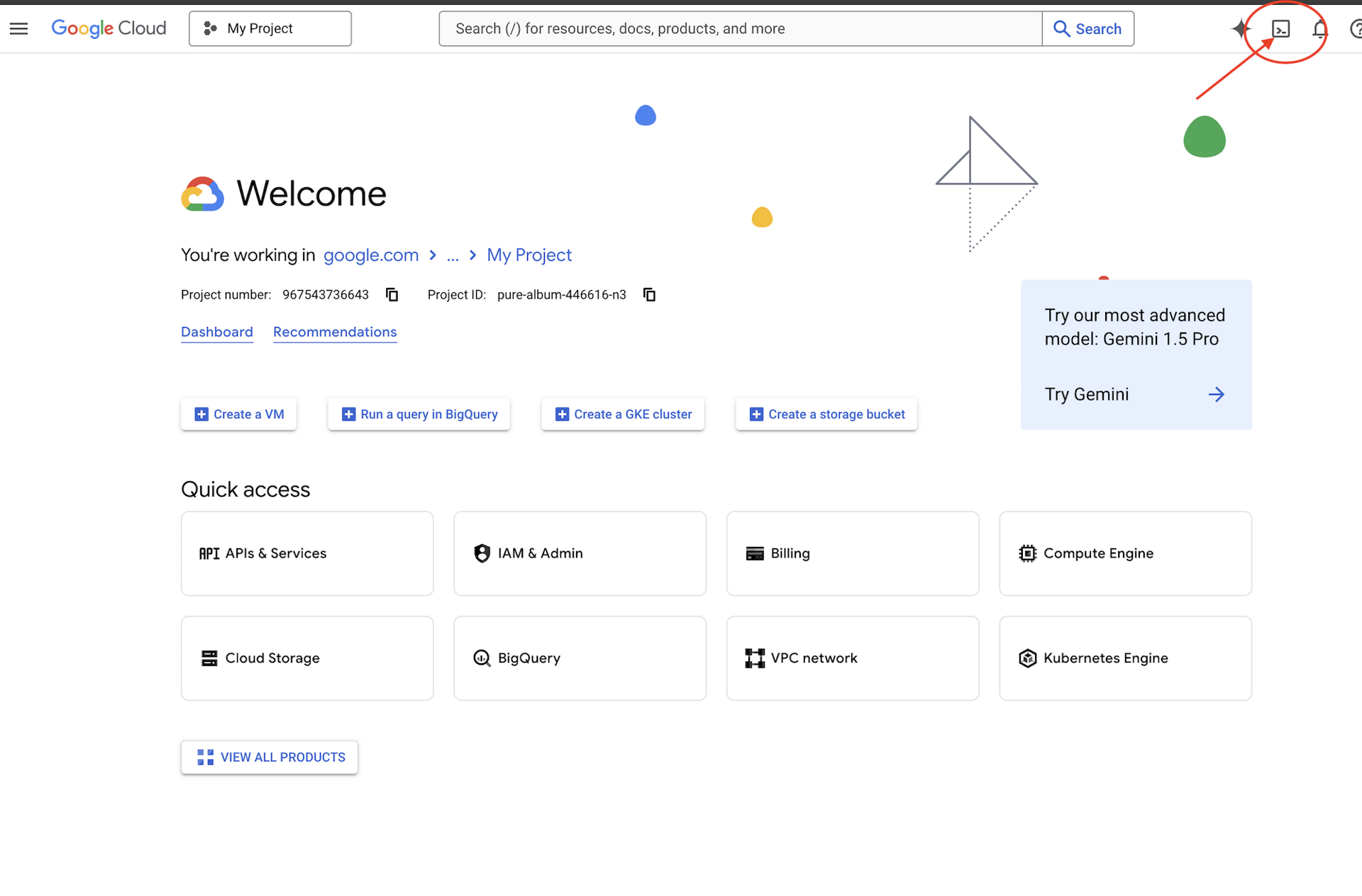
👉[エディタを開く] ボタン(開いたフォルダと鉛筆のアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。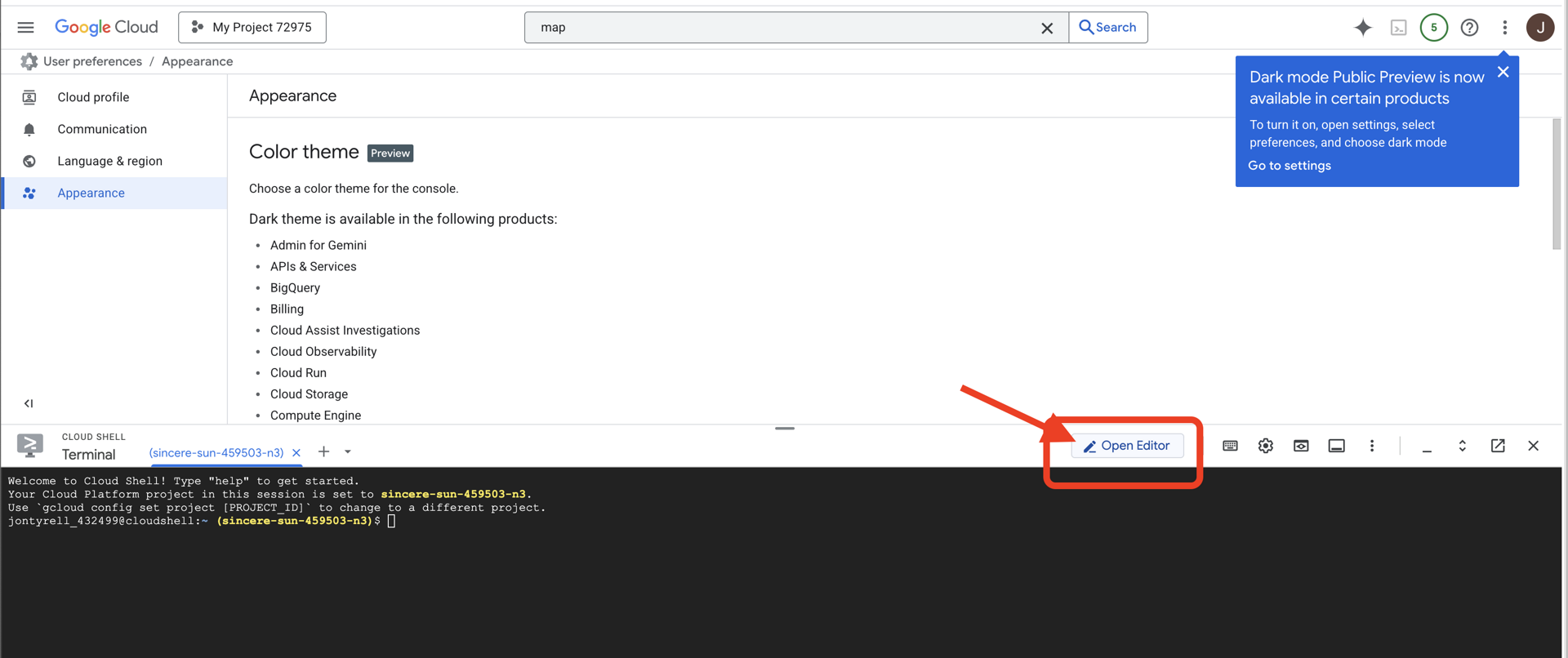
👉クラウド IDE でターミナルを開き、
👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
アカウントが (ACTIVE) として表示されます。
前提条件
ℹ️ レベル 0 は省略可能(ただし推奨)
このミッションはレベル 0 でなくても完了できますが、最初に完了すると、進行状況に応じてビーコンがグローバル マップ上で点灯する様子を確認できるなど、より没入感のある体験ができます。
プロジェクト環境を設定する
ターミナルに戻り、アクティブなプロジェクトを設定して、必要な Google Cloud サービス(Cloud Run、Vertex AI など)を有効にして、構成を完了します。
👉💻 ターミナルで、プロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 必要なサービスを有効にする:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
依存関係のインストール
👉💻 Level に移動し、必要な Python パッケージをインストールします。
cd $HOME/way-back-home/level_3
uv sync
主な依存関係は次のとおりです。
パッケージ | 目的 |
| Satellite Station と SSE ストリーミング用の高性能ウェブ フレームワーク |
| FastAPI アプリケーションの実行に必要な ASGI サーバー |
| Formation Agent の構築に使用される Agent Development Kit |
| Gemini モデルにアクセスするためのネイティブ クライアント |
| リアルタイムの双方向通信のサポート |
| 環境変数と構成シークレットを管理します |
設定を確認する
コードに入る前に、すべてのシステムが正常であることを確認しましょう。検証スクリプトを実行して、Google Cloud プロジェクト、API、Python の依存関係を監査します。
👉💻 検証スクリプトを実行します。
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 一連の緑色のチェックマーク(✅)が表示されます。
- 赤い十字(❌)が表示された場合は、出力に表示された修正コマンド(
gcloud services enable ...やpip install ...など)を実行します。 - 注:
.envの黄色い警告は現時点では許容されます。このファイルは次のステップで作成します。
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Comm-Link の調整(WebSockets)
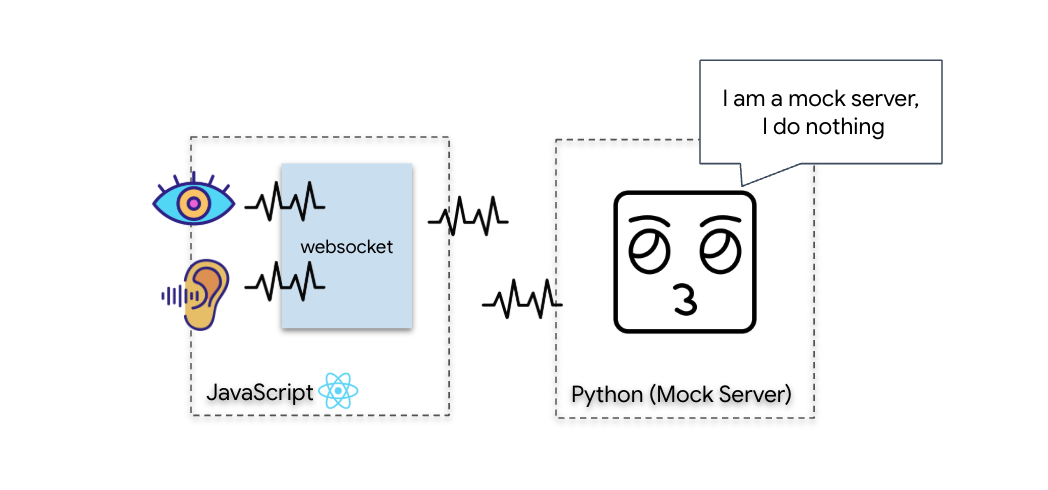
生体認証ニューラル同期を開始するには、船の内部システムを更新する必要があります。主な目的は、コックピットから高忠実度の動画と音声ストリームをキャプチャすることです。このストリームは、ニューラル リンクの重要なコンポーネント(指のシーケンスの視覚的識別と音声の音響周波数)を提供します。
全二重通信と半二重通信
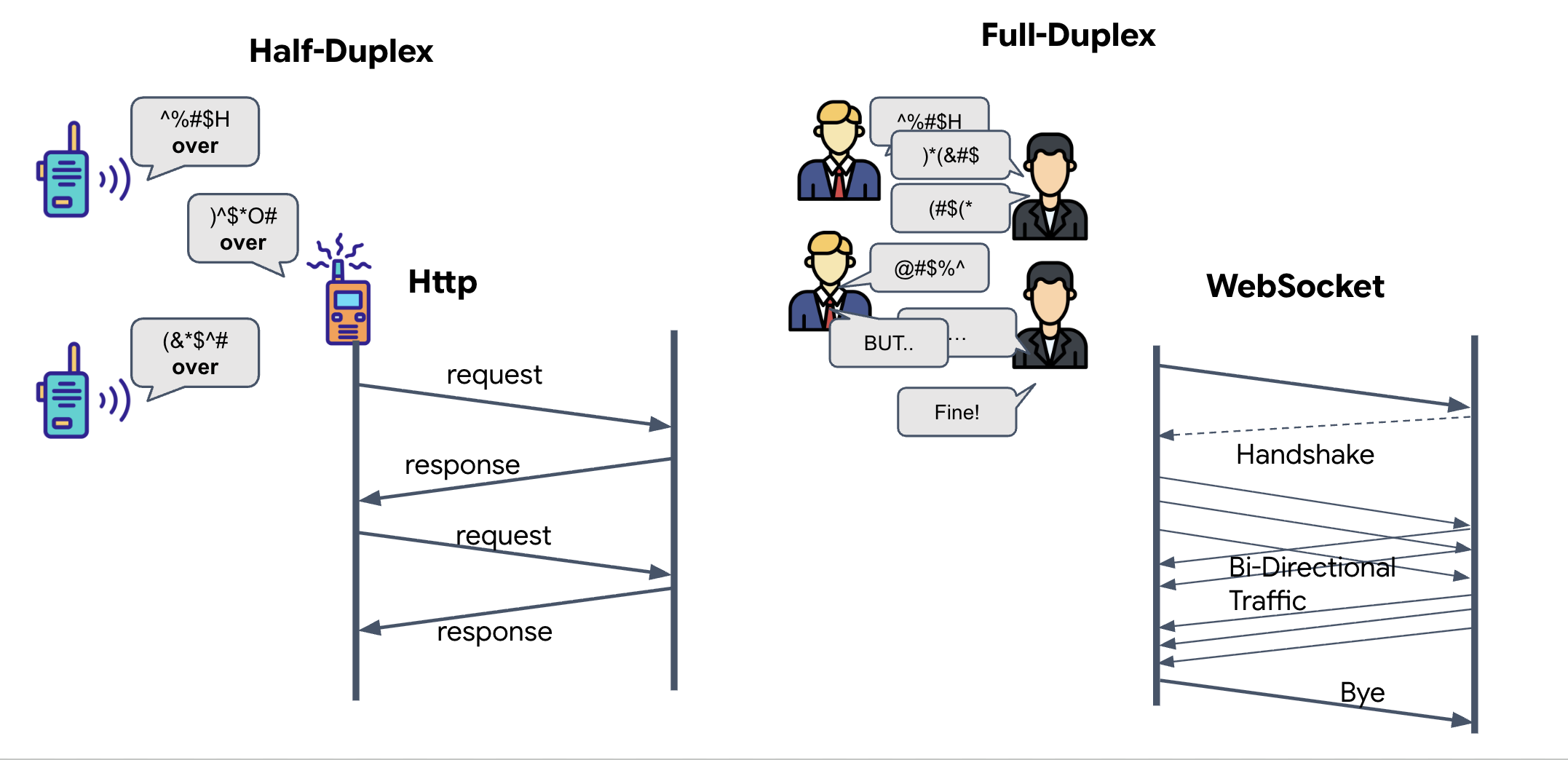
ニューラル同期にこの機能が必要な理由を理解するには、データの流れを理解する必要があります。
- 半二重(標準 HTTP): トランシーバーのようなものです。1 人が話して「Over」と言い、その後、別の人が話します。同時に聞くことと話すことはできません。
- 全二重(WebSocket): 対面での会話のようなものです。データは両方向に同時に流れます。ブラウザが動画フレームと音声サンプルを AI にアップロードしている間、AI は音声応答とツールコマンドを同時にダウンロードできます。
Gemini Live で全二重通信が必要な理由: Gemini Live API は「割り込み」用に設計されています。指のシーケンスを表示しているときに、AI が間違っていることを認識したとします。標準の HTTP 設定では、AI はデータの送信が完了するまで待ってから、停止を指示する必要があります。WebSocket を使用すると、AI はフレーム 1 の間違いを認識し、フレーム 2 のために手を動かしている間にコックピットに「割り込み」信号を送信できます。
WebSocket とは
標準の銀河間通信(HTTP)では、リクエストを送信して返信を待ちます。これは、はがきを送るようなものです。Neural Sync の場合、ポストカードは遅すぎます。「活線が必要です。」
WebSocket は標準のウェブ リクエスト(HTTP)として開始されますが、その後「アップグレード」されて別のものになります。
- リクエスト: ブラウザは、特別なヘッダー
Upgrade: websocketを含む標準の HTTP リクエストをサーバーに送信します。これは、「はがきを送るのをやめて、電話で話したい」と伝えるのとほぼ同じです。 - レスポンス: AI エージェント(サーバー)がこれをサポートしている場合は、
HTTP 101 Switching Protocolsレスポンスを返します。 - 変換: この時点で、HTTP 接続は WebSocket プロトコルに置き換えられますが、基盤となる TCP/IP ソケットは開いたままになります。通信のルールが「リクエスト/レスポンス」から「全二重ストリーミング」に瞬時に切り替わります。
WebSocket Hook を実装する
コネクタ ブロックを調べて、データの流れを理解しましょう。
👀 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js を開きます。標準の WebSocket ライフサイクル イベント ハンドラがすでに設定されていることがわかります。これは、通信システムのスケルトンです。
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
onMessage ハンドラ
ws.current.onmessage ブロックに焦点を当てます。これは受信側です。エージェントが「考える」または「話す」たびに、データ パケットがここに届きます。現在、この関数は何も行いません。パケットをキャッチして(プレースホルダ //#REPLACE-HANDLE-MSG を介して)ドロップします。
この空白を、次の 2 つを区別できるロジックで埋める必要があります。
- ツール呼び出し(functionCall): AI がハンドシグナル(「同期」)を認識します。
- 音声データ(inlineData): AI がユーザーに返信する音声。
👉✏️ 同じ $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js ファイルで、//#REPLACE-HANDLE-MSG を次のロジックに置き換えて、受信ストリームを処理します。
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
音声と動画を送信用のデータに変換する方法
インターネット経由のリアルタイム通信を可能にするには、未加工の音声と動画を送信に適した形式に変換する必要があります。これには、ネットワーク経由で送信する前にデータをキャプチャ、エンコード、パッケージ化することが含まれます。
音声データの変換
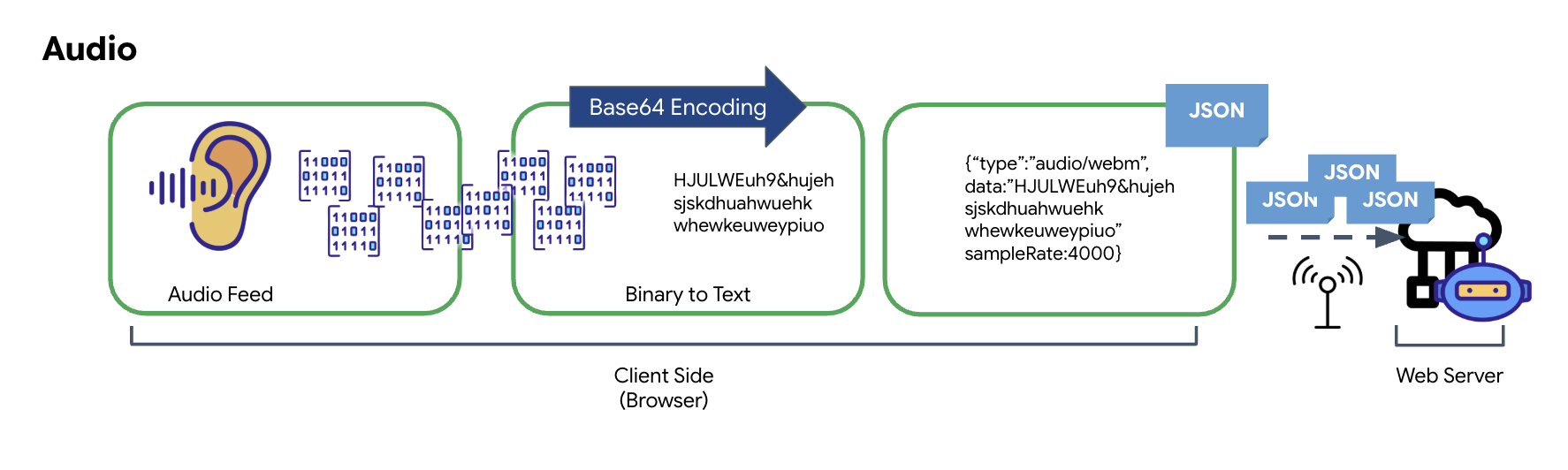
アナログ オーディオを送信可能なデジタルデータに変換するプロセスは、マイクで音波をキャプチャすることから始まります。この未加工の音声は、ブラウザの Web Audio API を介して処理されます。この生データはバイナリ形式であるため、JSON などのテキストベースの伝送形式と直接互換性はありません。この問題を解決するため、音声の各セグメントは Base64 文字列にエンコードされます。Base64 は、バイナリデータを ASCII 文字列形式で表現し、転送中の完全性を確保する方法です。
このエンコードされた文字列は、JSON オブジェクト内に埋め込まれます。このオブジェクトは、データの構造化された形式を提供します。通常、オーディオとして識別するための「type」フィールドと、オーディオのサンプルレートなどのメタデータが含まれます。JSON オブジェクト全体が文字列にシリアル化され、WebSocket 接続を介して送信されます。このアプローチにより、音声が整理された解析しやすい方法で送信されます。
動画データの変換
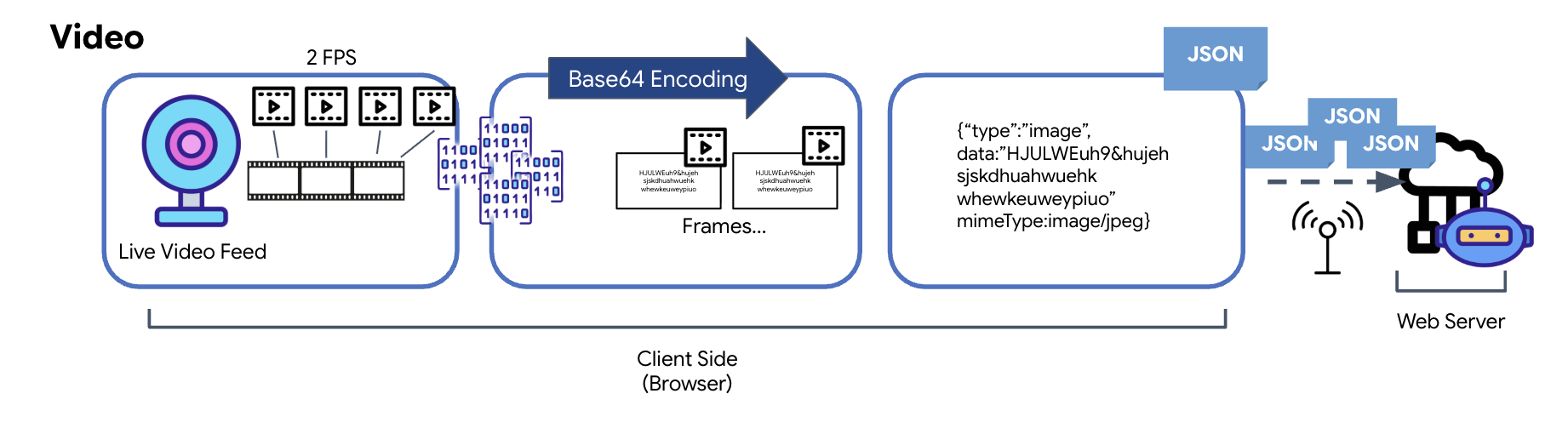
動画の送信は、フレーム キャプチャ技術によって実現されます。連続した動画ストリームを送信する代わりに、定期的なループでライブ動画フィードから静止画像を一定の間隔(1 秒あたり 2 フレームなど)でキャプチャします。これは、HTML 動画要素から非表示のキャンバス要素に現在のフレームを描画することで実現されます。
次に、キャンバスの toDataURL メソッドを使用して、キャプチャした画像を Base64 エンコードされた JPEG 文字列に変換します。この方法には、画質を指定するオプションが含まれており、画質の忠実度とファイル サイズのバランスを調整してパフォーマンスを最適化できます。音声データと同様に、この Base64 文字列は JSON オブジェクトに配置されます。通常、このオブジェクトには「type」というラベルが付けられ、mimeType(「image/jpeg」など)が含まれます。この JSON パケットは文字列に変換されて WebSocket 経由で送信され、受信側は一連の画像を表示して動画を再構築できます。
👉✏️ 同じ $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js ファイルで、ユーザー入力をキャプチャするために //#CAPTURE AUDIO and VIDEO を以下に置き換えます。
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
保存すると、コックピットでエージェントのデジタル信号を視覚的なダッシュボードの更新と音声に変換できるようになります。
診断チェック(ループバック テスト)
コックピットが公開されました。500 ミリ秒ごとに、周囲の視覚的な「パケット」が送信されます。Gemini に接続する前に、船舶の送信機が機能していることを確認する必要があります。ローカル診断サーバーを使用して「ループバック テスト」を実行します。
👉💻 まず、ターミナルから Cockpit インターフェースをビルドします。
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 次に、モックサーバーを起動します。
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 テスト プロトコルを実行します。
- プレビューを開く: Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。[ポートを変更] を選択し、[8080] に設定して、[変更してプレビュー] をクリックします。新しいブラウザタブが開き、Cockpit インターフェースが表示されます。
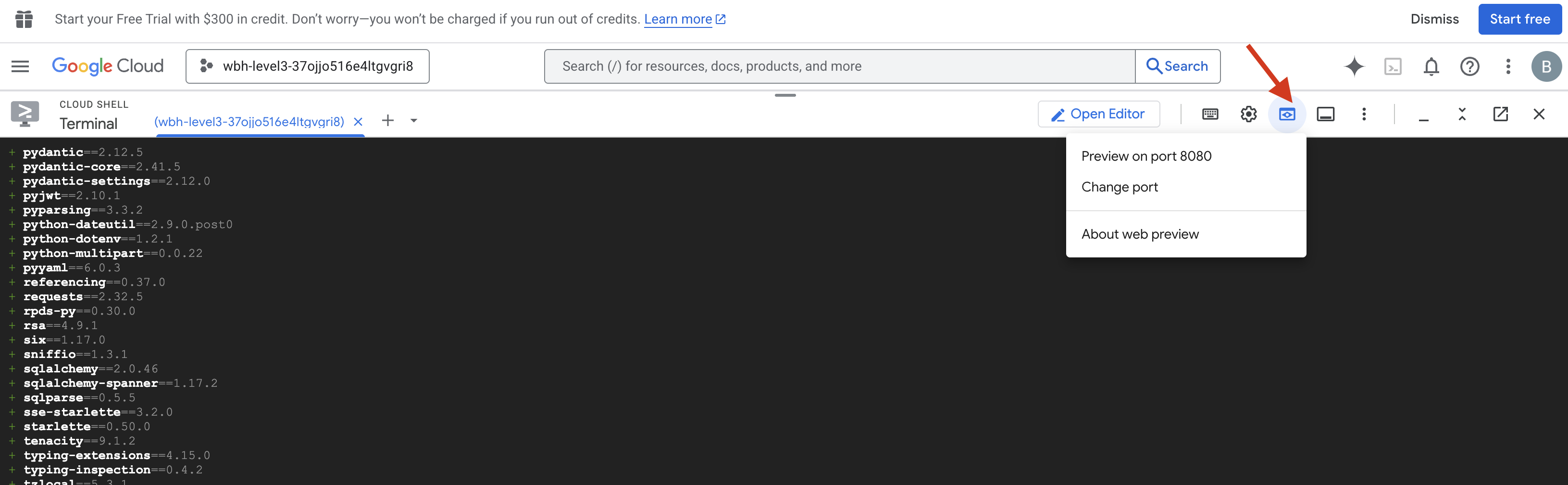
- 重要: メッセージが表示されたら、ブラウザがカメラとマイクにアクセスすることを許可する必要があります。これらの入力がないと、ニューラル同期を開始できません。
- UI で [INITIATE NEURAL SYNC] ボタンをクリックします。
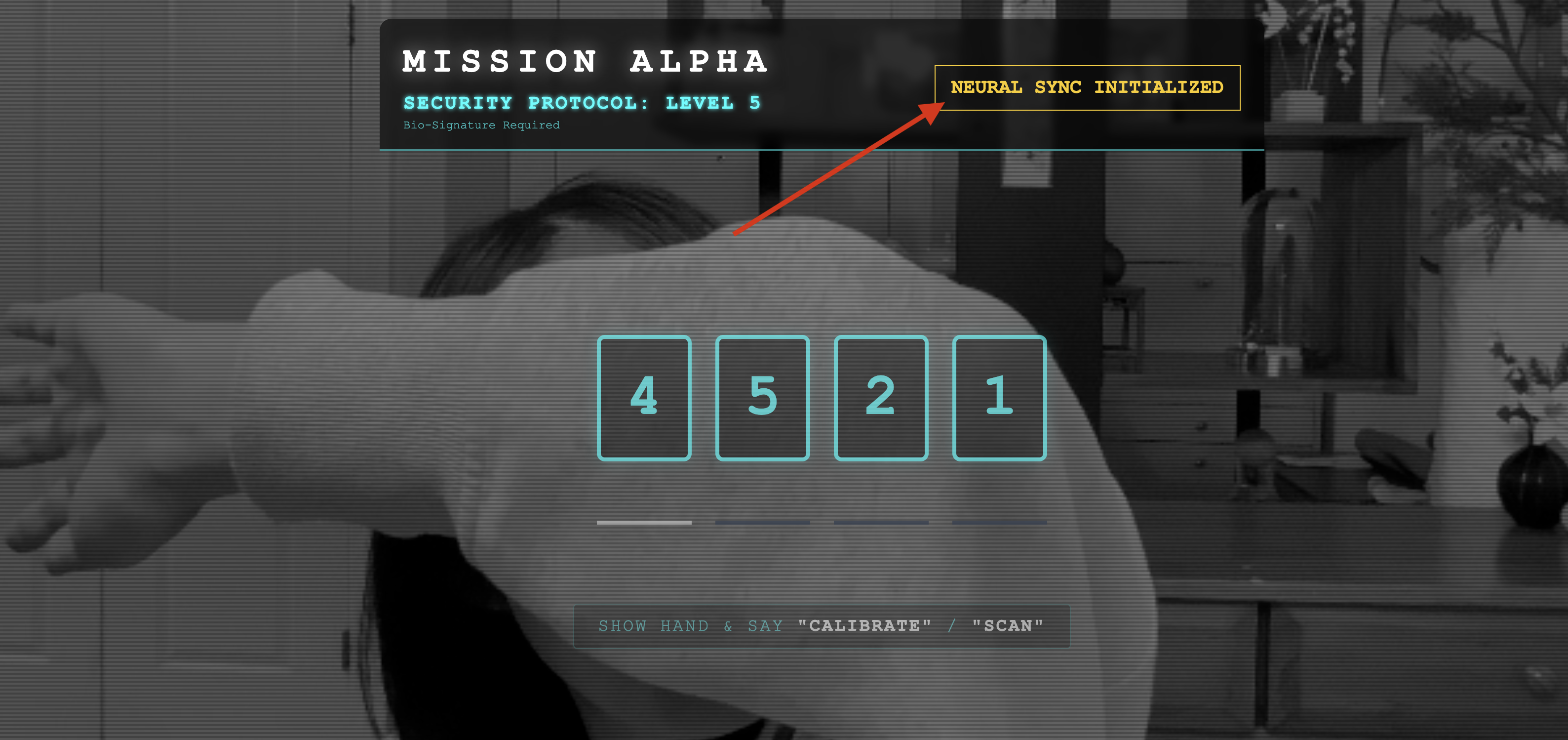
👀 ステータス インジケーターを確認します。
- 目視確認: ブラウザ コンソールを開きます。右上に
NEURAL SYNC INITIALIZEDが表示されます。 - 音声チェック: 双方向音声パイプラインが完全に動作している場合は、「システムが接続されました。」というシミュレートされた音声が聞こえます。
「System connected!」という音声確認が聞こえたら、テストは成功です。タブを閉じます。実際の AI のために、周波数をクリアする必要があります。
👉💻 モックサーバーとフロントエンドの両方のターミナルで Ctrl+C を押します。UI を実行しているブラウザタブを閉じます。
4. マルチモーダル エージェント
Rescue Scout は動作しますが、「心」は空白です。今接続しても、ただ見つめられるだけです。「指」が何であるかわからないため、生存者を救うには、スカウトのコアに生体認証ニューラル プロトコルを刻印する必要があります。
従来のエージェントは、一連の翻訳者のように動作します。昔ながらの AI に話しかけると、「音声テキスト変換」モデルが音声を単語に変換し、「言語モデル」がその単語を読み取って返信を入力し、「テキスト音声変換」モデルが最後にその返信を読み上げます。これにより、救助ミッションでは致命的となる遅延が発生します。
Gemini Live API はネイティブのマルチモーダル モデルです。生の音声バイトと生の動画フレームを直接同時に処理します。同じニューラル アーキテクチャ内で、音声の振動を「聞き取り」、手のジェスチャーのピクセルを「認識」します。
この機能を活用するために、コックピットを未加工の Live API に直接接続してアプリケーションを構築できます。ただし、Google の目標は、再利用可能なエージェント(構築が迅速なモジュール式の堅牢なエンティティ)を構築することです。
ADK(Agent Development Kit)を使用する理由
Google Agent Development Kit(ADK)は、AI エージェントの開発とデプロイ用のモジュラー フレームワークです。
標準の LLM 呼び出しは通常ステートレスです。各クエリは新しい開始です。ライブ エージェントは、特に ADK の SessionService と統合されている場合、堅牢で長時間実行される会話セッションを可能にします。
- セッションの永続性: ADK セッションは永続的で、データベース(SQL や Vertex AI など)に保存でき、サーバーの再起動や切断後も維持されます。つまり、ユーザーが切断して後で再接続した場合(数日後でも)、会話の履歴とコンテキストが完全に復元されます。エフェメラル Live API セッションは ADK によって管理、抽象化されます。
- 自動再接続: WebSocket 接続はタイムアウトする可能性があります(約 10 分後など)。
RunConfigでsession_resumptionが有効になっている場合、ADK はこれらの再接続を透過的に処理します。アプリケーション コードで複雑な再接続ロジックを管理する必要がないため、ユーザーにシームレスなエクスペリエンスを提供できます。 - ステートフルなインタラクション: エージェントは前のターンを記憶しているため、フォローアップの質問、説明、コンテキストが重要な複雑なマルチターン ダイアログが可能です。これは、継続性が不可欠なカスタマー サポート、インタラクティブなチュートリアル、ミッション コントロールなどのシナリオで重要です。
この永続性により、一連の孤立した質問と回答ではなく、インテリジェントなエンティティとの継続的な会話のように感じられます。
つまり、ADK Bidi-streaming を使用した「ライブ エージェント」は、単純なクエリ応答メカニズムを超えて、真にインタラクティブでステートフルな、中断を認識する会話機能を提供します。これにより、AI のインタラクションがより人間らしくなり、複雑で長時間実行されるタスクに対して大幅に強力になります。
ライブ対応のエージェントを求めるプロンプト
リアルタイムの双方向エージェントのプロンプトを設計するには、考え方を切り替える必要があります。静的なテキストクエリを待機する標準のチャットボットとは異なり、ライブ エージェントは「常にオン」です。音声フレームと動画フレームが常にストリーミングされるため、プロンプトは単なる人格の定義ではなく、制御ループ スクリプトとして機能する必要があります。
ライブ対応のエージェントのプロンプトと従来のプロンプトの違いは次のとおりです。
- ステート マシンのロジック: プロンプトで「動作ループ」(待機 → 分析 → 行動)を定義する必要があります。エージェントが空のバックグラウンド ノイズをまくし立てるのを防ぐため、いつ黙っているべきか、いつ関与すべきかについて明確な指示が必要です。
- マルチモーダル認識: エージェントに「目」があることを伝える必要があります。推論プロセスの一部として動画フレームを分析するように明示的に指示する必要があります。
- 遅延と簡潔さ: 音声によるライブ会話では、長くて散文的な段落は不自然で遅く感じられます。プロンプトは簡潔さを重視し、やり取りをスムーズに進めます。
- アクション優先アーキテクチャ: 指示では、音声よりもツール呼び出しが優先されます。エージェントには、長い独白の後にではなく、口頭で確認する前または確認中に、作業(生体認証のスキャン)を行ってほしいと考えています。
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py を開き、#REPLACE INSTRUCTIONS を次のように置き換えます。
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
注:標準 LLM に接続していません。同じファイル($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py)で、#REPLACE_MODEL を見つけます。リアルタイムの音声機能をより適切にサポートするため、このモデルのプレビュー バージョンを明示的にターゲットにする必要があります。
👉✏️ プレースホルダを次の内容に置き換えます。
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
これで、エージェントが定義されました。自分自身が誰で、どのように考えるかを認識しています。次に、行動するためのツールを提供します。
ツールの呼び出し
Live API は、テキスト、音声、動画のストリームの交換に限定されません。ツール呼び出しをネイティブにサポートしています。これにより、エージェントは受動的な会話者から能動的なオペレーターに変わります。
ライブの双方向セッション中、モデルはコンテキストを常に評価します。LLM が「センサー テレメトリーの確認」や「安全なドアのロック解除」などのアクションを実行する必要があると判断した場合。会話から実行にシームレスに移行できます。エージェントは特定のツール関数をすぐにトリガーし、結果を待って、そのデータをライブストリームに統合します。この間、インタラクションのフローは中断されません。
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py で、#REPLACE TOOLS を次の関数に置き換えます。
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ 次に、#TOOL CONFIG を置き換えて、Agent 定義に登録します。
tools=[report_digit],
adk web シミュレータ
これを複雑な配送コックピット(React フロントエンド)に接続する前に、エージェントのロジックを単独でテストする必要があります。ADK には adk web という組み込みのデベロッパー コンソールが含まれており、ネットワークの複雑さを追加する前にツール呼び出しを検証できます。
👉💻 ターミナルで次のコマンドを実行します。
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。[ポートを変更] を選択して「8000」に設定し、[変更してプレビュー] をクリックします。
- 権限を付与する: メッセージが表示されたら、カメラとマイクへのアクセスを許可します。
- カメラアイコンをクリックしてセッションを開始します。
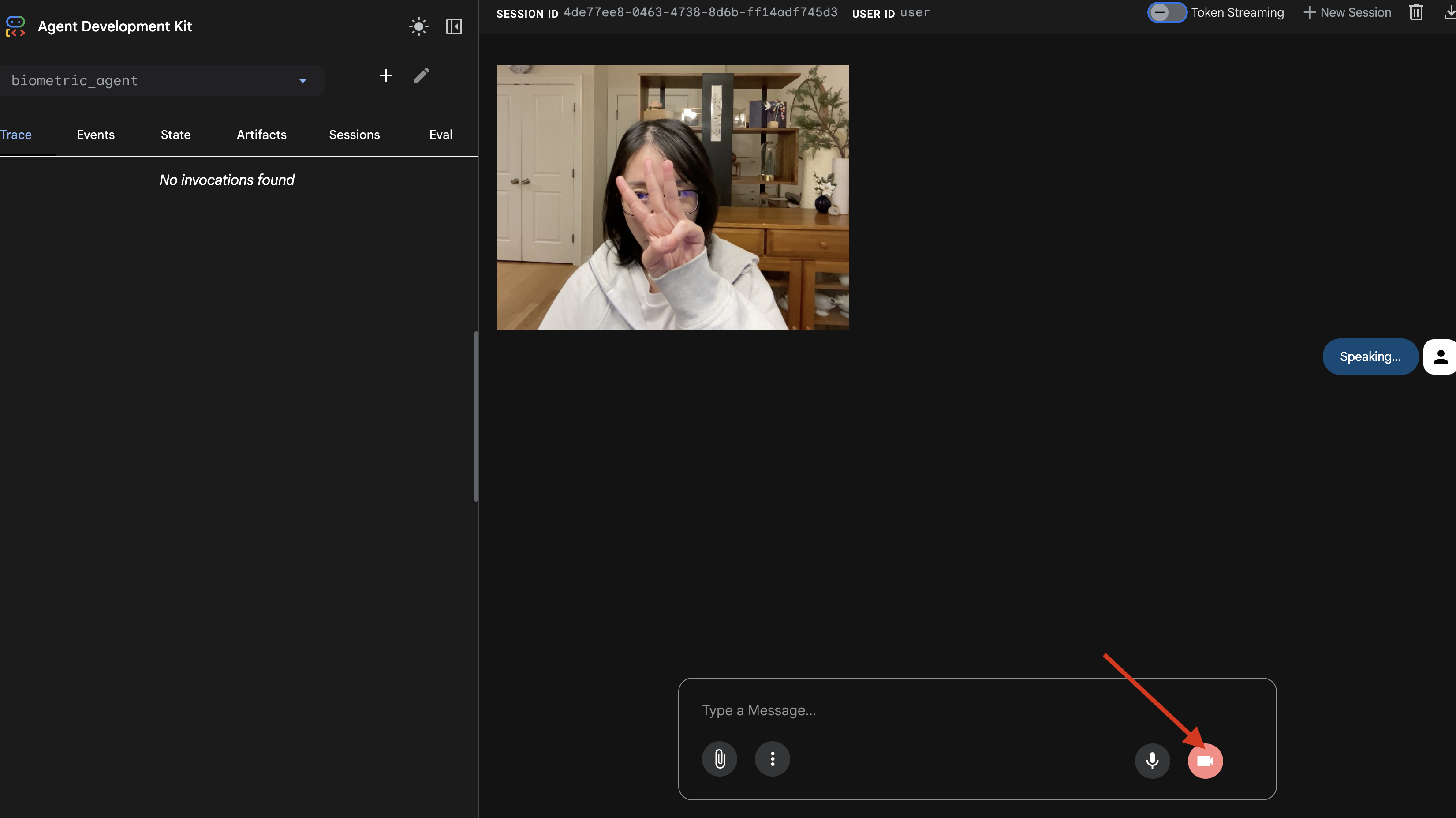
- ビジュアル テスト:
- カメラの前で 3 本の指をはっきりと立てます。
- 「スキャン」と話しかけます。
- 成功を確認する:
- ログ:
adk webコマンドを実行しているターミナルを確認します。[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3というログが表示されるはずです。
- ログ:
ツールの実行ログが表示された場合、エージェントはインテリジェントです。認識、思考、行動が可能です。最後のステップは、メインの船に接続することです。
ターミナル ウィンドウをクリックし、Ctrl+C を押して adk web シミュレータを停止します。
5. 双方向ストリーミング フロー
エージェントが動作します。Cockpit が動作している。次に、これらを接続する必要があります。
ライブ対応エージェントのライフサイクル
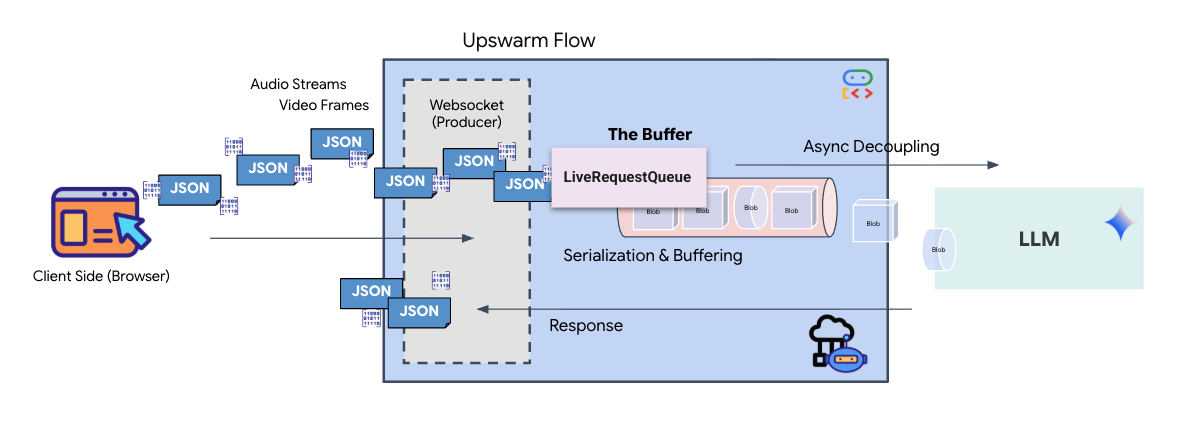
リアルタイム ストリーミングでは、「インピーダンスの不一致」という問題が発生します。クライアント(ブラウザ)は、ネットワーク バーストや高速入力など、可変レートで非同期にデータをプッシュしますが、モデルでは入力の調整されたシーケンシャル ストリームが必要です。Google ADK は、LiveRequestQueue を使用してこの問題を解決します。
スレッドセーフな非同期の先入れ先出し(FIFO)バッファとして機能します。WebSocket ハンドラはプロデューサーとして機能し、未加工の音声/動画チャンクをキューにプッシュします。ADK エージェントはコンシューマーとして機能し、キューからデータを取得してモデルのコンテキスト ウィンドウに供給します。この分離により、モデルがレスポンスを生成している間やツールを実行している間でも、アプリケーションはユーザー入力を継続して受け取ることができます。
このキューは、マルチモーダル マルチプレクサとして機能します。実際の環境では、アップストリーム フローは、未加工の PCM 音声バイト、動画フレーム、テキストベースのシステム指示、非同期ツール呼び出しの結果など、個別の同時データ型で構成されます。LiveRequestQueue は、これらの異なる入力を 1 つの時系列シーケンスに線形化します。パケットにミリ秒の無音、高解像度画像、データベース クエリからの JSON ペイロードが含まれているかどうかにかかわらず、到着順にシリアル化されるため、モデルは一貫した因果関係のタイムラインを認識できます。
このアーキテクチャにより、ノンブロッキング制御が可能になります。取り込みレイヤ(プロデューサー)が処理レイヤ(コンシューマー)から切り離されているため、計算コストの高いモデル推論中であっても、システムは応答性を維持します。Agent がツールを実行中にユーザーが「ストップ」コマンドで中断すると、その音声信号はすぐにキューに追加されます。基盤となるイベントループがこの優先度シグナルを直ちに処理するため、UI のフリーズやパケットのドロップなしで、システムの生成タスクやピボットタスクを停止できます。
👉💻 $HOME/way-back-home/level_3/backend/app/main.py で、コメント #REPLACE_RUNNER_CONFIG を見つけ、次のコードに置き換えてシステムをオンラインにします。
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
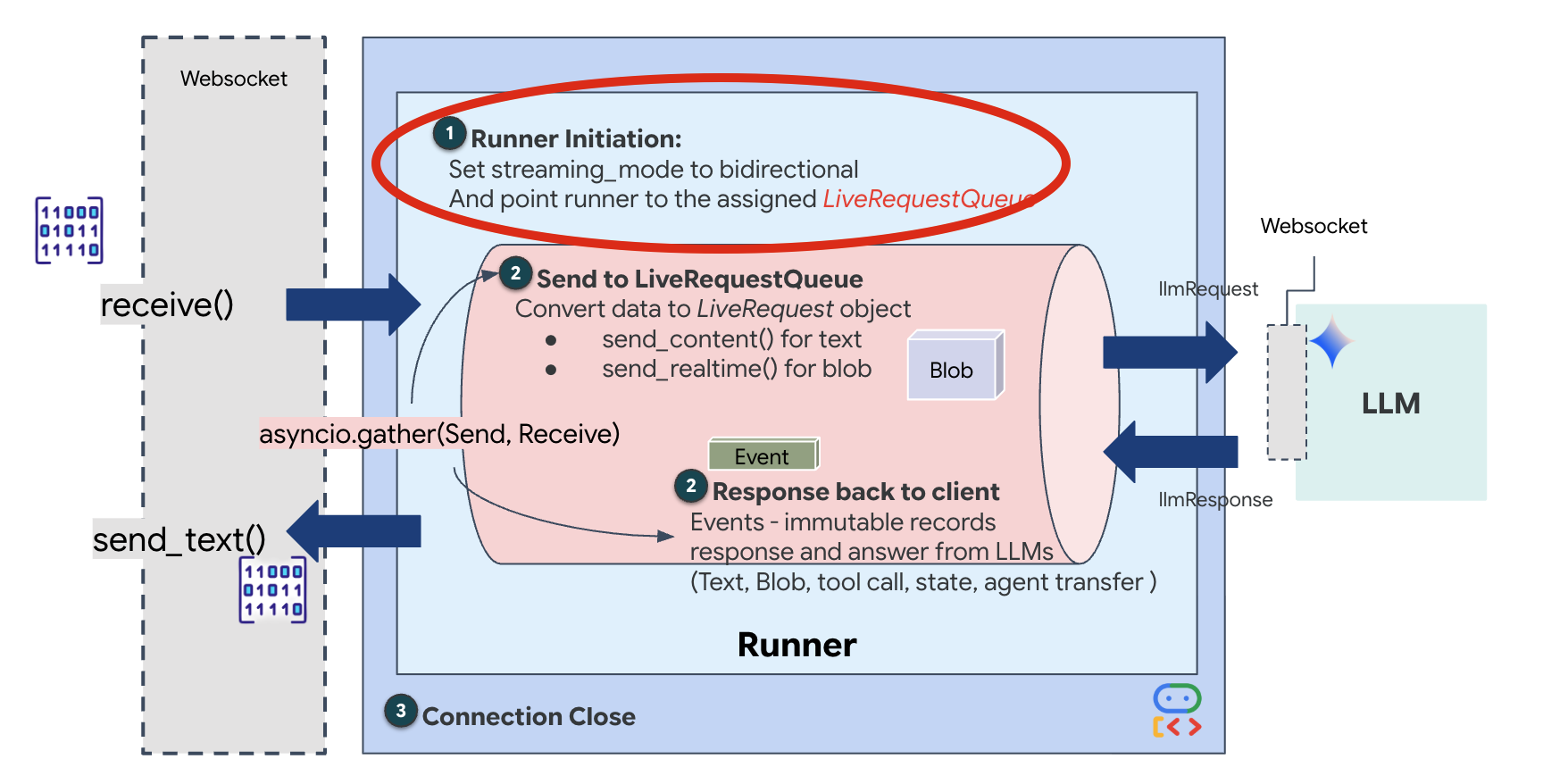
新しい WebSocket 接続が開いたら、AI の動作を構成する必要があります。ここでは、「ルール オブ エンゲージメント」を定義します。
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py の async def websocket_endpoint 関数内で、#REPLACE_SESSION_INIT コメントを次のコードに置き換えます。
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
実行構成
StreamingMode.BIDI: 接続を双方向に設定します。「ターンベース」の AI(ユーザーが話して停止すると、AI が話す)とは異なり、BIDI では現実的な「全二重通信」の会話が可能です。AI の会話を中断したり、移動中に AI に話しかけたりできます。AudioTranscriptionConfig: モデルは未加工の音声を「聞く」ことができますが、デベロッパーはログを確認する必要があります。この構成は、Gemini に「音声を処理するだけでなく、デバッグできるように、聞いた内容のテキスト文字起こしも返して」と伝えます。
実行ロジック: Runner がセッションを確立すると、実行ロジックに制御が引き渡されます。実行ロジックは LiveRequestQueue に依存します。これは、リアルタイムのインタラクションにとって最も重要なコンポーネントです。このループにより、エージェントは音声応答を生成しながら、キューでユーザーからの新しい動画フレームを受け取り続けることができるため、「ニューラル同期」が途切れることはありません。
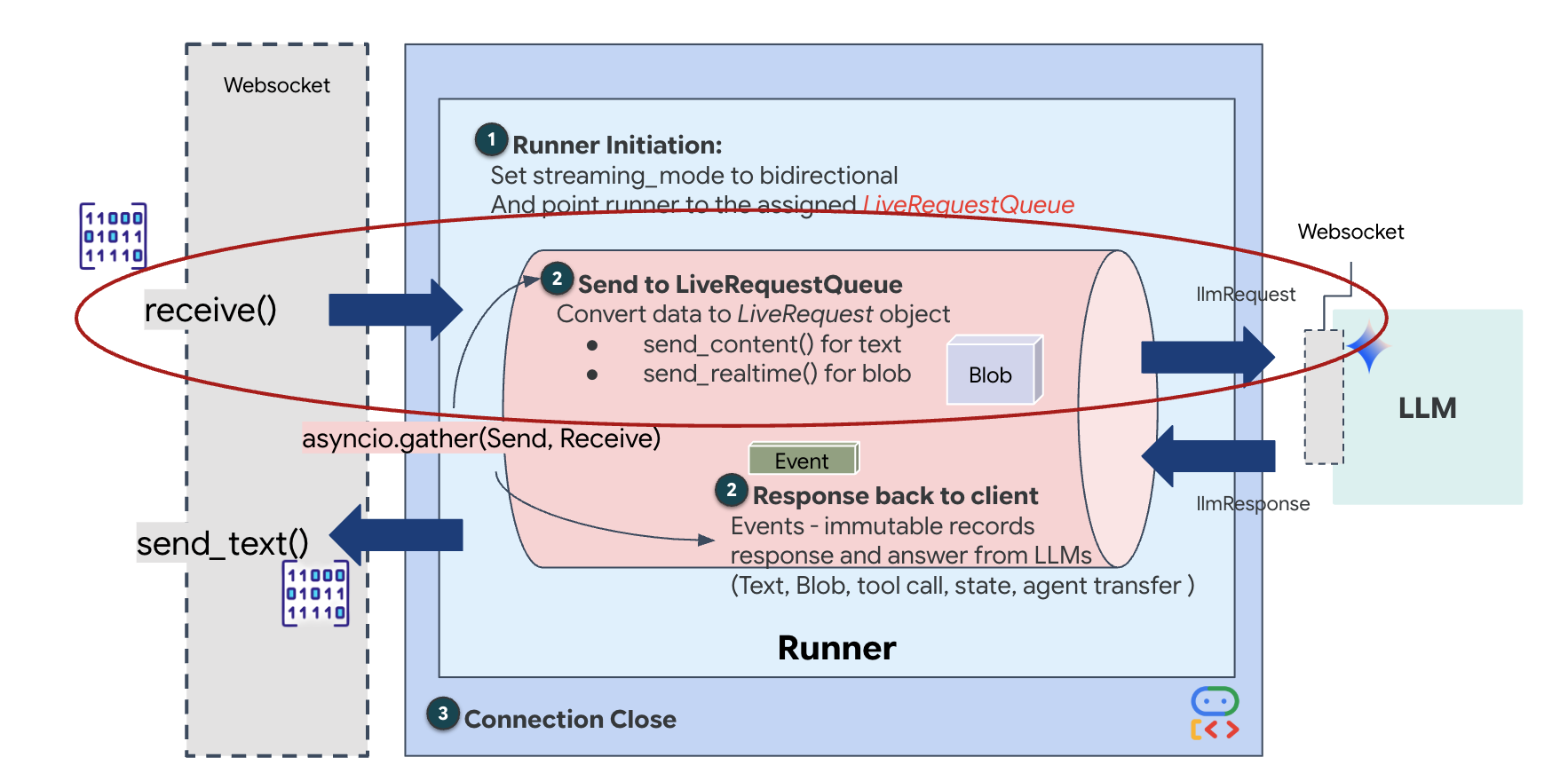
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py で、#REPLACE_LIVE_REQUEST を置き換えて、LiveRequestQueue にデータを送信する上流タスクを定義します。
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
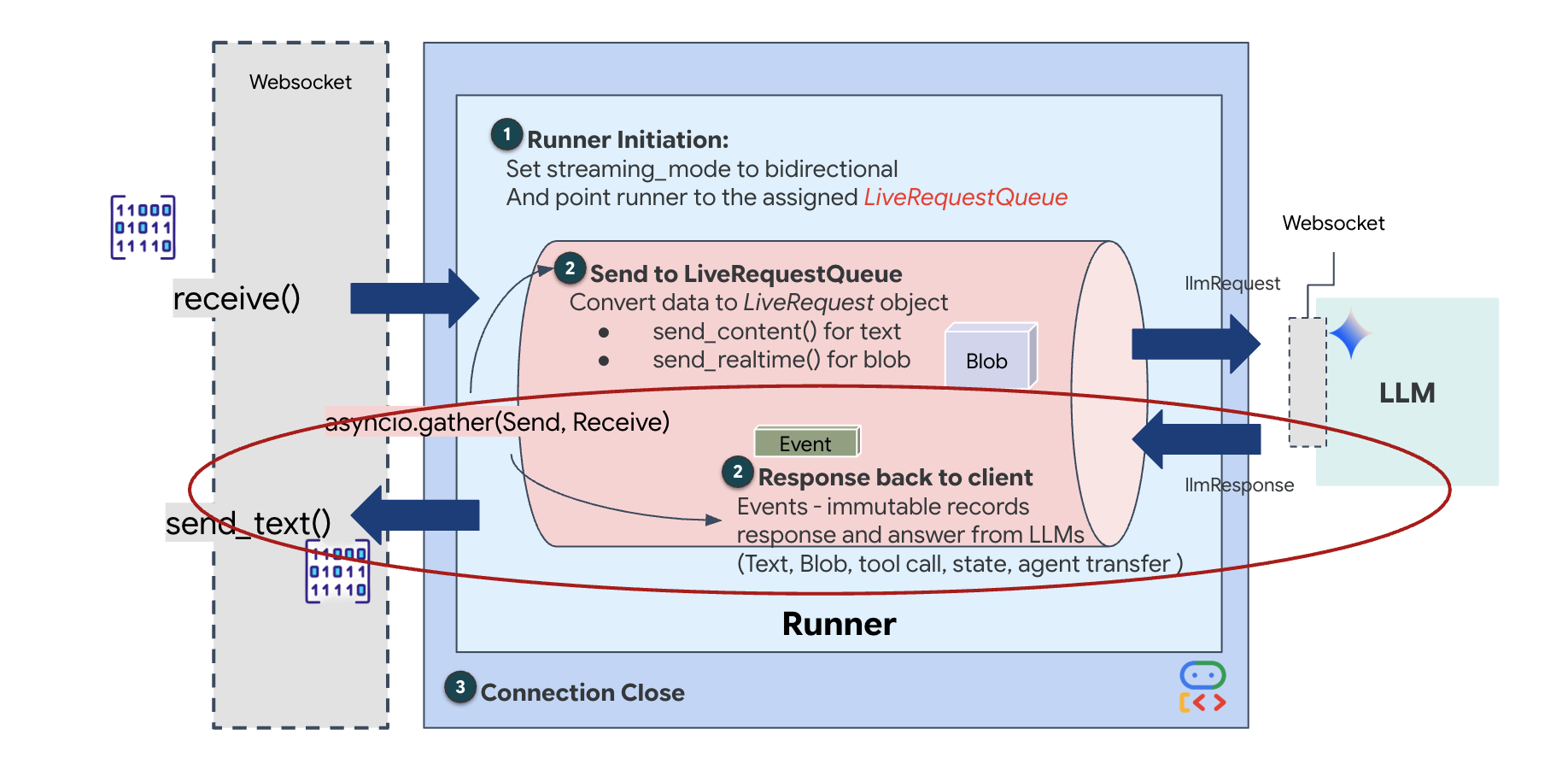
最後に、AI のレスポンスを処理する必要があります。これは、イベント(音声、テキスト、ツール呼び出し)が発生したときにイベントを生成するイベント ジェネレータである runner.run_live() を使用します。
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py で、#REPLACE_SORT_RESPONSE を置き換えて、ダウンストリーム タスクと同時実行マネージャーを定義します。
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
await asyncio.gather(upstream_task(), downstream_task()) という行に注目してください。これが全二重通信の要点です。リスニング タスク(アップストリーム)とスピーキング タスク(ダウンストリーム)を同時に実行します。これにより、「ニューラル リンク」で中断と同時データフローが可能になります。
これでバックエンドのコーディングが完了しました。「Brain」(ADK)は「Body」(WebSocket)に接続されています。
Bio-Sync の実行
コードは完成しています。システムは緑色です。救助を開始します。
- 👉💻 バックエンドを起動します。
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 フロントエンドを起動する:
- Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。[ポートを変更] を選択し、[8080] に設定して、[変更してプレビュー] をクリックします。
- 👉 プロトコルを実行する:
- [INITIATE NEURAL SYNC] をクリックします。
- 調整: 背景に対して手がはっきりと映るようにします。
- 同期: 画面に表示されるセキュリティ コード(例: 3、2、5)を確認します。
- シグナルを一致させる: 数字が表示されたら、その数字と同じ数の指を立てます。
- 動かさない: AI が「生体認証が一致しました」と確認するまで、手を動かさないでください。
- 適応: コードはランダムです。シーケンスが完了するまで、表示された次の数字にすぐに切り替えます。

- ランダムな数列の最後の数字と一致すると、[生体認証の同期] が完了します。ニューラル リンクがロックされます。手動で制御できます。スカウトのエンジンがうなりを上げ、渓谷に飛び込み、生存者を家に連れ帰ります。
👉💻 バックエンド ターミナルで Ctrl+C を押して終了します。
6. 本番環境にデプロイする(省略可)
生体認証のローカル テストが正常に完了しました。次に、Agent のニューラル コアを船のメインフレーム(Cloud Run)にアップロードして、ローカル コンソールから独立して動作できるようにする必要があります。
👉💻 Cloud Shell ターミナルで次のコマンドを実行します。これにより、バックエンド ディレクトリに完全なマルチステージ Dockerfile が作成されます。
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 backend ディレクトリに移動して、アプリケーションをコンテナ イメージにパッケージ化します。
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 サービスを Cloud Run にデプロイします。必要な環境変数(特に Gemini 構成)を起動コマンドに直接挿入します。
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
コマンドが完了すると、サービス URL(https://biometric-scout-...run.app など)が表示されます。これで、アプリケーションがクラウドで稼働します。
👉 Google Cloud Run ページに移動し、リストから biometric-scout サービスを選択します。
👉 [サービスの詳細] ページの上部に表示されている公開 URL を確認します。
この環境で バイオ同期を試してみてください。バイオ同期も機能しますか?
小指を伸ばすと、AI がシーケンスをロックします。画面が緑色に点滅し、「Biometric Neural Sync: ESTABLISHED」と表示されます。
一瞬の判断で、スカウトを暗闇に突入させ、立ち往生しているポッドにロックオンし、重力裂け目が崩壊する直前にポッドを引き出します。

エアロックがシューッと音を立てて開き、5 人の生存者がそこにいた。彼らは甲板にたどり着き、傷だらけながらも生きています。あなたのおかげで、ついに安全な場所にたどり着いたのです。
おかげで、ニューラル リンクが同期され、生存者が救出されました。
レベル 0 に参加された方は、帰宅ミッションの進捗状況を忘れずにご確認ください。