1. 미션

미지의 구역에서 조용히 표류하고 있습니다. 거대한 **태양 펄스** 가 균열을 통해 함선을 찢어버려 별 지도에 존재하지 않는 우주의 한 구석에 고립되었습니다.
며칠간의 힘든 수리 끝에 드디어 발밑에서 엔진의 웅웅거리는 소리가 들립니다. 로켓이 수정되었습니다. 심지어 마더십에 장거리 업링크를 확보했습니다. 출발 허가가 나왔습니다. 이제 집으로 돌아가도 됩니다. 하지만 점프 드라이브를 작동시키려고 할 때 조난 신호가 정적을 뚫고 들어옵니다. 센서가 '협곡'에 갇힌 희미한 열 신호 5개를 감지합니다. 협곡은 주 함선이 절대 들어갈 수 없는 들쭉날쭉하고 중력이 왜곡된 구역입니다. 이들은 나와 같은 폭풍에서 살아남은 탐험가들입니다. 이러한 항목은 남겨둘 수 없습니다.
알파 드론 구조 스카우트를 찾습니다. 이 작고 민첩한 배는 좁은 협곡의 벽을 항해할 수 있는 유일한 선박입니다. 하지만 문제가 있습니다. 태양 펄스가 핵심 논리에 대한 전체 '시스템 재설정'을 실행했습니다. 스카우트의 제어 시스템이 응답하지 않습니다. 전원이 켜져 있지만 온보드 컴퓨터가 초기화되어 있어 수동 조종사 명령이나 비행 경로를 처리할 수 없습니다.
과제
생존자를 구하려면 스카우트의 손상된 회로를 완전히 우회해야 합니다. 절박한 방법이 하나 있습니다. 생체 인식 신경 동기화를 설정하는 AI 에이전트를 빌드하는 것입니다. 이 에이전트는 실시간 브리지 역할을 하여 사용자가 자신의 생체 입력을 통해 Rescue Scout를 수동으로 제어할 수 있도록 합니다. 조이스틱이나 키보드를 사용하지 않고 의도를 우주선의 탐색 네트워크에 직접 연결합니다.
링크를 고정하려면 Scout의 광학 센서 앞에서 동기화 프로토콜을 실행해야 합니다. AI 에이전트는 정확한 실시간 핸드셰이크를 통해 생체 서명을 인식해야 합니다.
미션 목표:
- 신경망 코어 각인: 멀티모달 입력을 인식할 수 있는 ADK 에이전트를 정의합니다.
- 연결 설정: Scout에서 AI로 시각적 데이터를 스트리밍하기 위해 양방향 WebSocket 파이프라인을 빌드합니다.
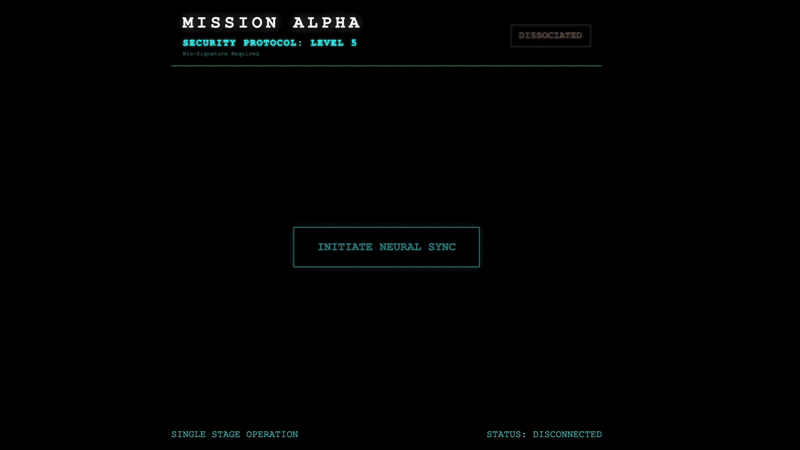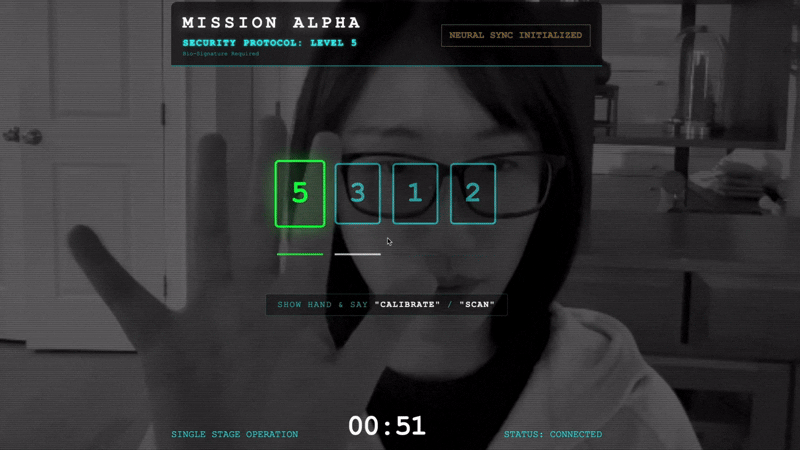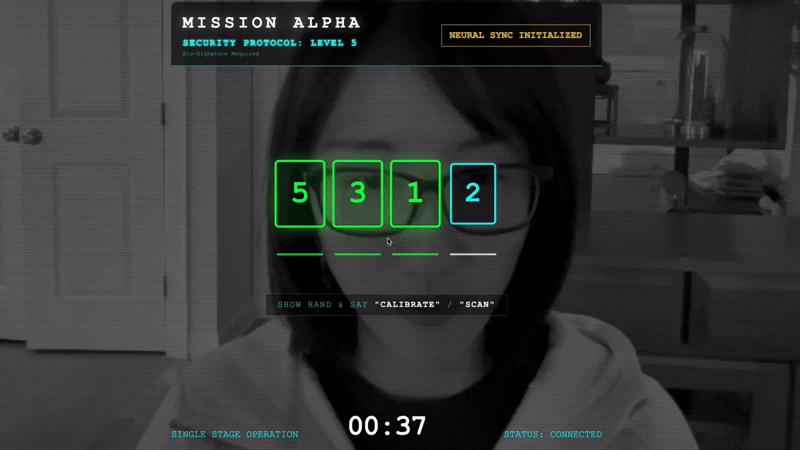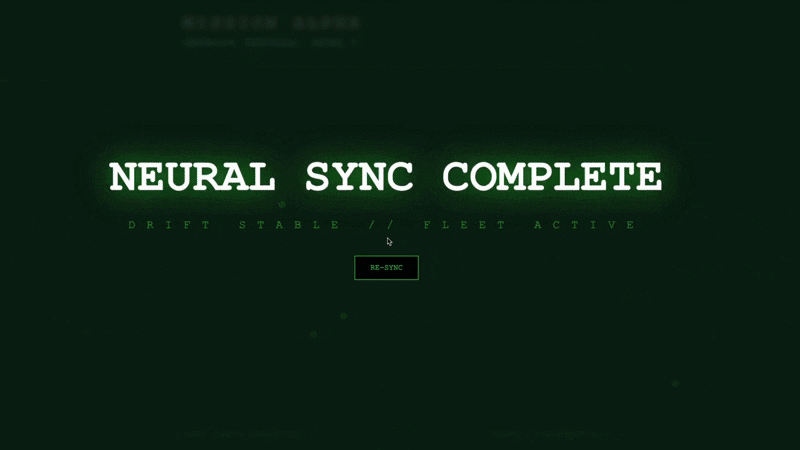
- 핸드셰이크 시작: 센서 앞에 서서 손가락 순서를 완료합니다(1부터 5까지 순서대로 표시).
성공하면 '생체 인식 동기화'가 실행됩니다. AI가 신경 링크를 잠그면 스카우트를 실행하고 생존자를 집으로 데려올 수 있는 완전한 수동 제어 권한이 부여됩니다.
빌드 대상
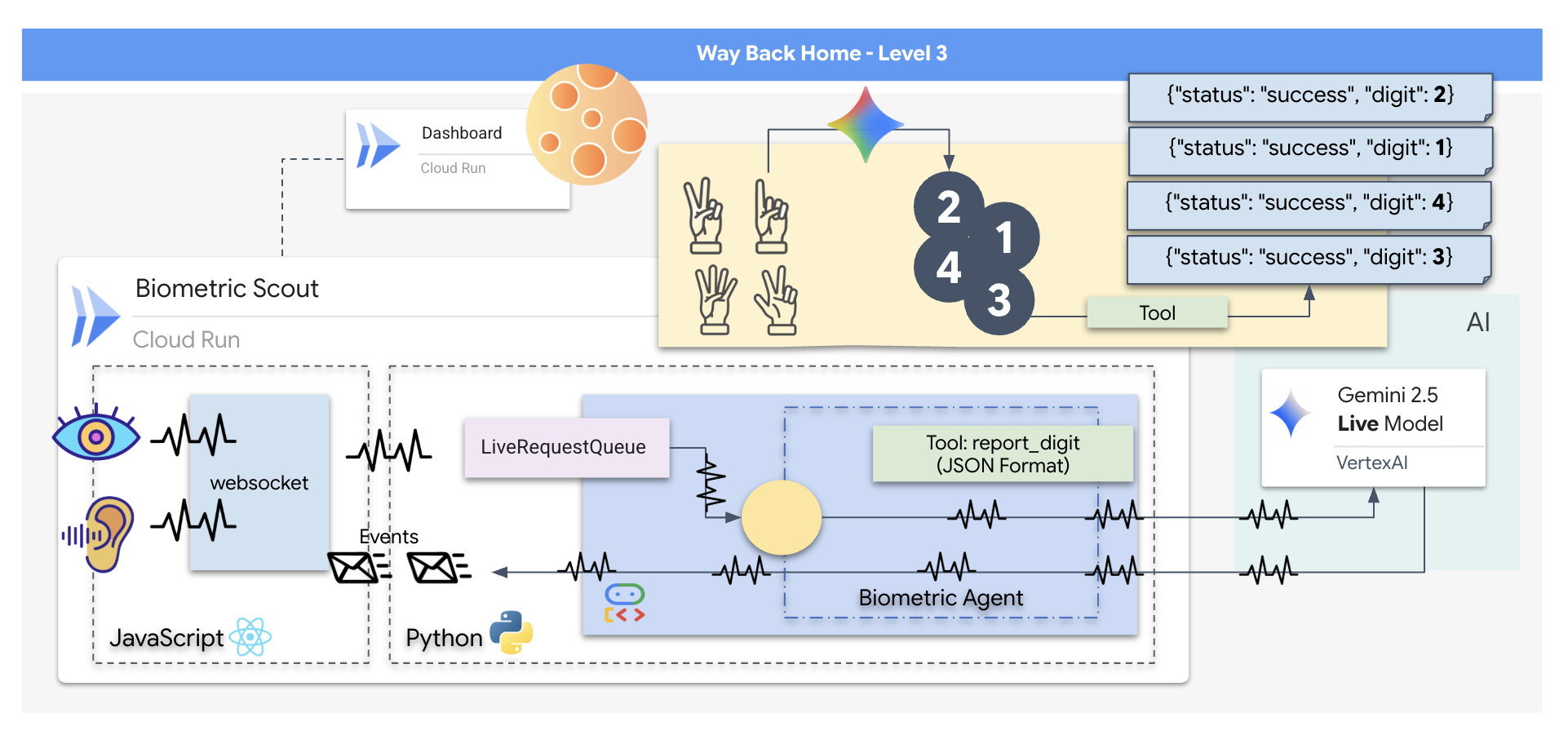
구조 드론의 제어 인터페이스 역할을 하는 실시간 AI 기반 시스템인 '생체 인식 신경 동기화' 애플리케이션을 구성합니다. 이 시스템은 다음으로 구성됩니다.
- React 프런트엔드: 웹캠의 라이브 동영상과 마이크의 오디오를 캡처하는 우주선의 '조종석'입니다.
- Python 백엔드: Google의 에이전트 개발 키트 (ADK)를 사용하여 LLM의 로직과 상태를 관리하는 FastAPI로 빌드된 고성능 서버입니다.
- 멀티모달 AI 에이전트:
google-genaiSDK를 통해 Gemini Live API를 사용하여 동영상 및 오디오 스트림을 동시에 처리하고 이해하는 작업의 '브레인'입니다. - 양방향 WebSocket 파이프라인: 프런트엔드와 AI 간에 영구적인 짧은 지연 시간 연결을 만들어 실시간 상호작용을 지원하는 '신경계'입니다.
학습할 내용
기술 / 개념 | 설명 |
백엔드 AI 에이전트 | Python 및 FastAPI를 사용하여 스테이트풀 AI 에이전트를 빌드합니다. Google의 ADK (에이전트 개발 키트)를 사용하여 안내와 메모리를 관리하고 |
프런트엔드 UI | React를 사용하여 브라우저에서 직접 라이브 동영상과 오디오를 캡처하고 스트리밍하는 동적 사용자 인터페이스를 개발합니다. |
실시간 커뮤니케이션 | 전이중, 짧은 지연 시간 통신을 위한 WebSocket 파이프라인을 구현하여 사용자와 AI가 동시에 상호작용할 수 있도록 합니다. |
멀티모달 AI | Gemini Live API를 활용하여 동시 동영상 및 오디오 스트림을 처리하고 이해하여 AI가 동시에 '보고' '들을' 수 있도록 지원합니다. |
도구 호출 | AI가 시각적 트리거에 응답하여 특정 Python 함수를 실행할 수 있도록 지원하여 모델 인텔리전스와 실제 작업 간의 격차를 해소합니다. |
전체 스택 배포 | Docker를 사용하여 전체 애플리케이션 (React 프런트엔드 및 Python 백엔드)을 컨테이너화하고 Google Cloud Run에 확장 가능한 서버리스 서비스로 배포합니다. |
2. 환경 설정
Cloud Shell 액세스
먼저 Google Cloud SDK 및 기타 필수 도구가 사전 설치된 브라우저 기반 터미널인 Cloud Shell을 엽니다.
👉Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다 (Cloud Shell 창 상단의 터미널 모양 아이콘). 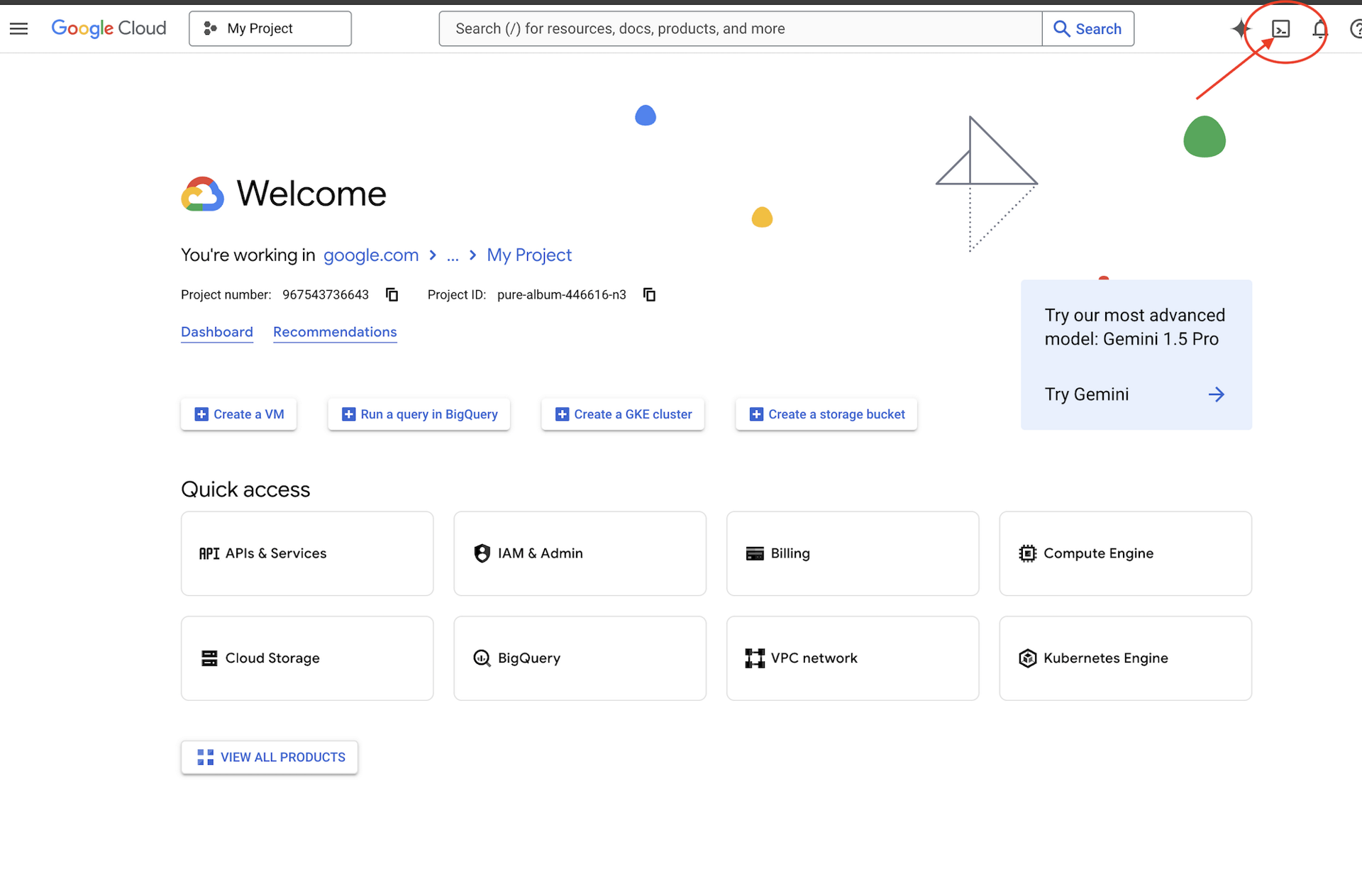
👉'편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 코드 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다. 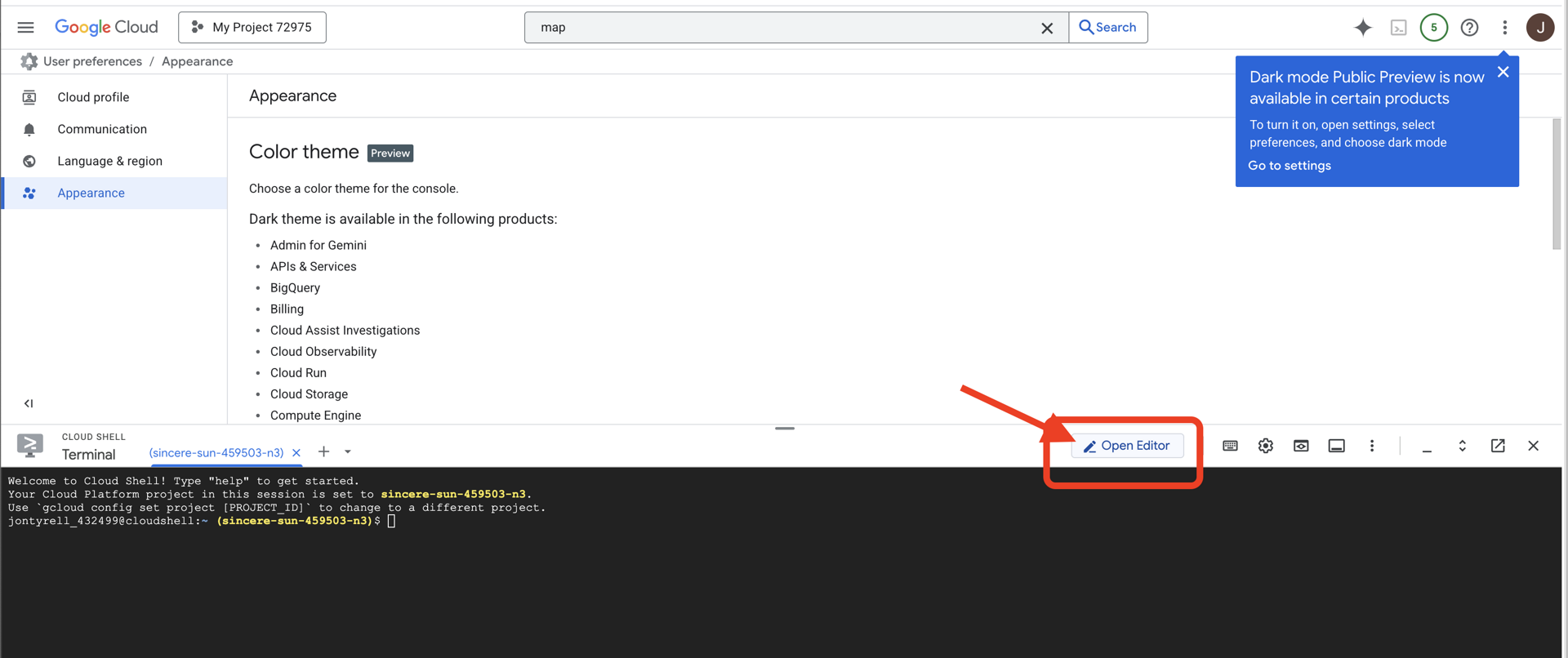
👉클라우드 IDE에서 터미널을 열고
👉💻 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
계정이 (ACTIVE)로 표시됩니다.
기본 요건
ℹ️ 레벨 0은 선택사항이지만 권장됩니다.
레벨 0 없이 이 미션을 완료할 수 있지만 먼저 완료하면 더 몰입감 있는 환경을 경험할 수 있으며, 진행하면서 전 세계 지도에서 내 비컨이 켜지는 것을 확인할 수 있습니다.
프로젝트 환경 설정
터미널로 돌아가 활성 프로젝트를 설정하고 필요한 Google Cloud 서비스 (Cloud Run, Vertex AI 등)를 사용 설정하여 구성을 완료합니다.
👉💻 터미널에서 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 필수 서비스 사용 설정:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
종속 항목 설치
👉💻 Level로 이동하여 필요한 Python 패키지를 설치합니다.
cd $HOME/way-back-home/level_3
uv sync
주요 종속 항목은 다음과 같습니다.
패키지 | 목적 |
| 위성 방송국 및 SSE 스트리밍을 위한 고성능 웹 프레임워크 |
| FastAPI 애플리케이션을 실행하는 데 필요한 ASGI 서버 |
| Formation Agent를 빌드하는 데 사용된 에이전트 개발 키트 |
| Gemini 모델에 액세스하기 위한 네이티브 클라이언트 |
| 실시간 양방향 통신 지원 |
| 환경 변수 및 구성 보안 비밀을 관리합니다. |
설정 확인
코드를 살펴보기 전에 모든 시스템이 정상인지 확인해 보겠습니다. 확인 스크립트를 실행하여 Google Cloud 프로젝트, API, Python 종속 항목을 감사합니다.
👉💻 확인 스크립트 실행:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 녹색 체크표시 (✅)가 연속으로 표시됩니다.
- 빨간색 십자 (❌)가 표시되면 출력에 제안된 수정 명령어 (예:
gcloud services enable ...또는pip install ...)를 따릅니다. - 참고: 현재는
.env에 대한 노란색 경고가 표시되어도 괜찮습니다. 다음 단계에서 해당 파일을 만듭니다.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Comm-Link (WebSockets) 보정
생체 인식 신경 동기화를 시작하려면 함선의 내부 시스템을 업데이트해야 합니다. 기본 목표는 조종석에서 고화질 동영상 및 오디오 스트림을 캡처하는 것입니다. 이 스트림은 신경 링크에 필수적인 구성요소인 손가락 시퀀스의 시각적 식별과 음성 주파수를 제공합니다.
전이중과 반이중의 비교
신경망 동기화에 이 정보가 필요한 이유를 이해하려면 데이터 흐름을 파악해야 합니다.
- Half-Duplex (표준 HTTP): 무전기와 같습니다. 한 사람이 말하고 'Over'라고 말하면 다른 사람이 말할 수 있습니다. 듣기와 말하기를 동시에 할 수는 없습니다.
- 전이중 (WebSocket): 대면 대화와 같습니다. 데이터는 양방향으로 동시에 흐릅니다. 브라우저가 동영상 프레임과 오디오 샘플을 AI에 업로드하는 동안 AI는 음성 응답과 도구 명령을 정확히 동시에 다운로드할 수 있습니다.
Gemini Live에 전이중이 필요한 이유: Gemini Live API는 '중단'을 위해 설계되었습니다. 손가락 시퀀스를 보여주고 있는데 AI가 잘못된 동작을 감지한다고 가정해 보겠습니다. 표준 HTTP 설정에서는 AI가 데이터 전송이 완료될 때까지 기다린 후에 중지하라고 알려줄 수 있습니다. WebSocket을 사용하면 AI가 프레임 1에서 실수를 발견하고 프레임 2를 위해 손을 움직이는 동안 조종석에 도착하는 '인터럽트' 신호를 보낼 수 있습니다.
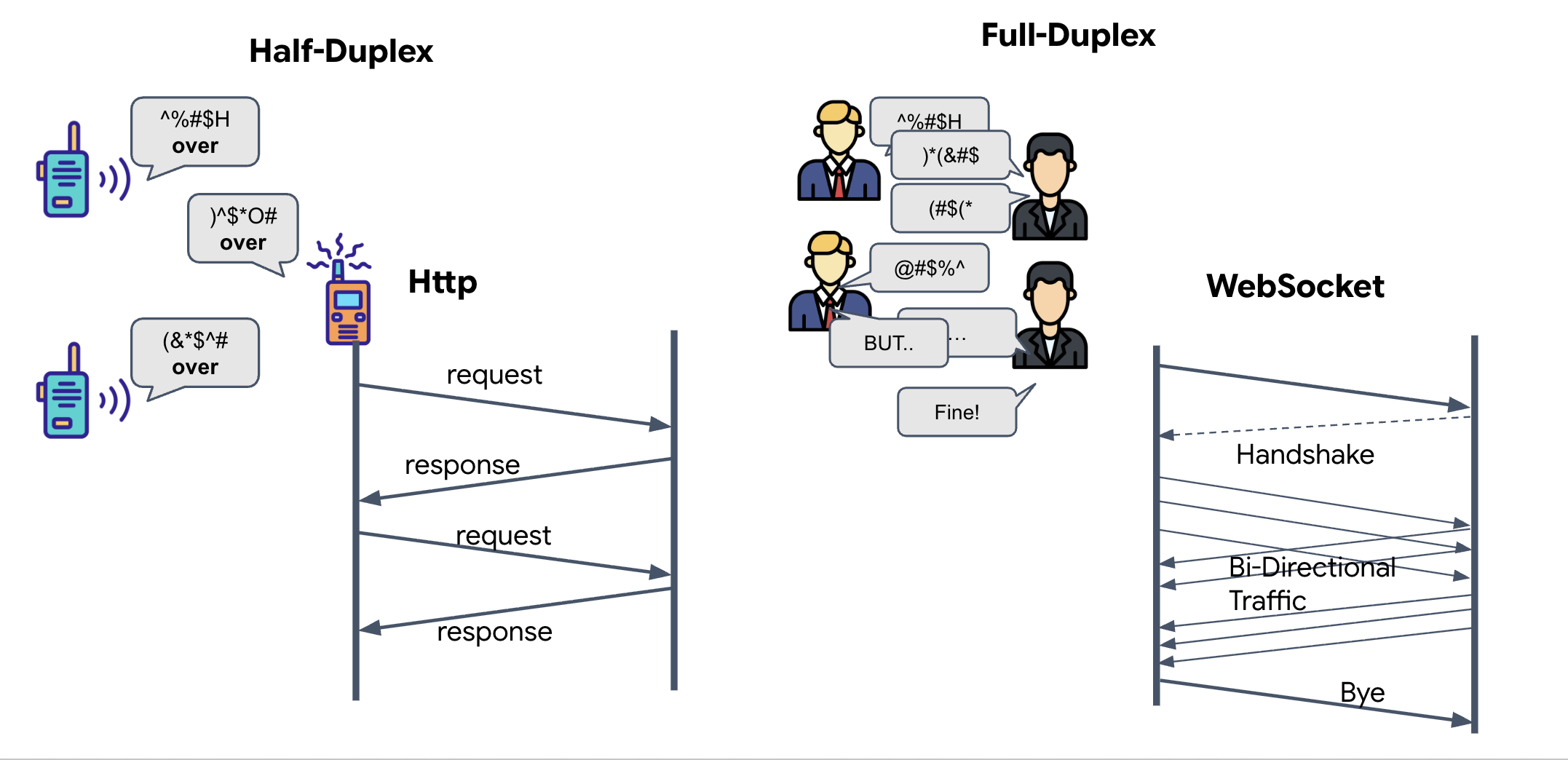
WebSocket이란 무엇인가요?
표준 은하계 전송 (HTTP)에서는 엽서를 보내는 것처럼 요청을 보내고 답장을 기다립니다. Neural Sync의 경우 엽서는 너무 느립니다. '전선'이 필요해.
WebSocket은 표준 웹 요청 (HTTP)으로 시작하지만 이후 다른 것으로 '업그레이드'됩니다.
- 요청: 브라우저에서 특수 헤더
Upgrade: websocket를 사용하여 표준 HTTP 요청을 서버로 보냅니다. 기본적으로 '엽서 보내기를 중지하고 실시간 전화 통화를 시작하고 싶어'라고 말하는 것과 같습니다. - 대답: AI 에이전트 (서버)가 이를 지원하는 경우
HTTP 101 Switching Protocols응답을 다시 보냅니다. - 변환: 이 시점에서 HTTP 연결은 WebSocket 프로토콜로 대체되지만 기본 TCP/IP 소켓은 열린 상태로 유지됩니다. 통신 규칙이 '요청/응답'에서 '전이중 스트리밍'으로 즉시 변경됩니다.
WebSocket 후크 구현
터미널 블록을 검사하여 데이터가 어떻게 흐르는지 살펴보겠습니다.
👀 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js을 엽니다. 표준 WebSocket 수명 주기 이벤트 핸들러가 이미 설정되어 있습니다. 다음은 커뮤니케이션 시스템의 기본 구조입니다.
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
onMessage 핸들러
ws.current.onmessage 블록에 집중합니다. 수신기입니다. 에이전트가 '생각'하거나 '말'할 때마다 데이터 패킷이 여기에 도착합니다. 현재는 아무것도 하지 않습니다. 패킷을 포착하고 자리표시자 //#REPLACE-HANDLE-MSG를 통해 삭제합니다.
다음 항목을 구분할 수 있는 로직으로 이 공백을 채워야 합니다.
- 도구 호출 (functionCall): AI가 내 손 신호를 인식합니다('동기화').
- 오디오 데이터 (inlineData): 사용자의 질문에 대답하는 AI의 음성입니다.
👉✏️ 이제 동일한 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js 파일에서 //#REPLACE-HANDLE-MSG를 아래 로직으로 바꿔 수신 스트림을 처리합니다.
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
오디오 및 동영상이 전송을 위한 데이터로 변환되는 방식
인터넷을 통한 실시간 통신을 사용 설정하려면 원본 오디오와 동영상을 전송에 적합한 형식으로 변환해야 합니다. 여기에는 네트워크를 통해 전송하기 전에 데이터를 캡처, 인코딩, 패키징하는 작업이 포함됩니다.
오디오 데이터 변환
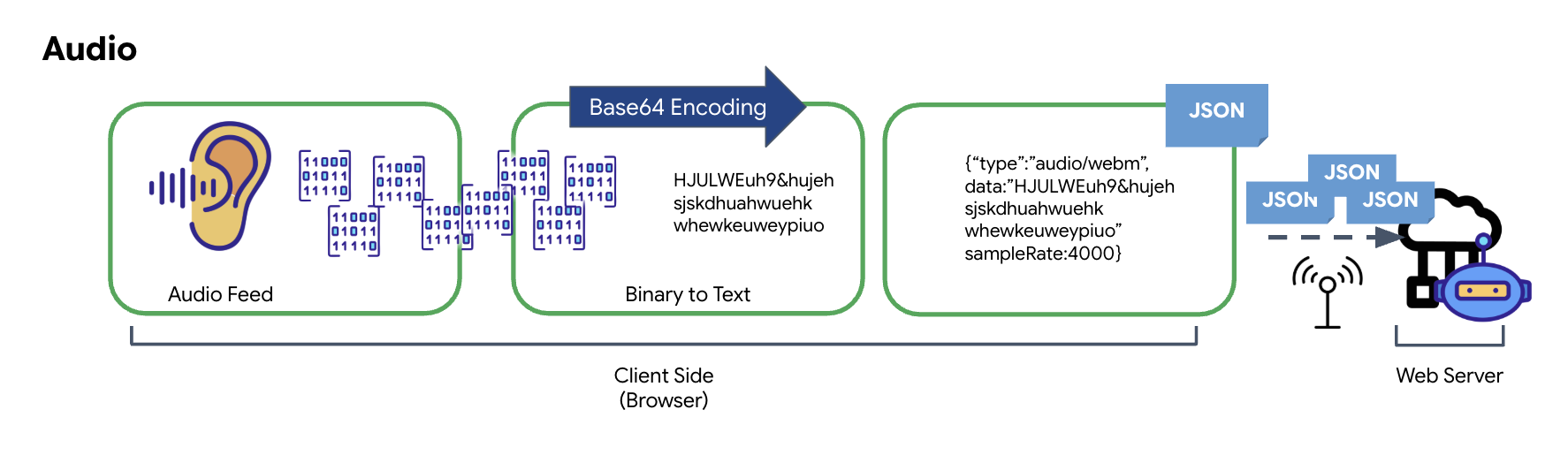
전송 가능한 디지털 데이터로 아날로그 오디오를 변환하는 프로세스는 마이크를 사용하여 음파를 캡처하는 것으로 시작됩니다. 그런 다음 이 원시 오디오는 브라우저의 Web Audio API를 통해 처리됩니다. 이 원시 데이터는 바이너리 형식이기 때문에 JSON과 같은 텍스트 기반 전송 형식과 직접 호환되지 않습니다. 이 문제를 해결하기 위해 오디오의 각 세그먼트는 Base64 문자열로 인코딩됩니다. Base64는 전송 중에 무결성을 보장하면서 바이너리 데이터를 ASCII 문자열 형식으로 나타내는 방법입니다.
이 인코딩된 문자열은 JSON 객체 내에 삽입됩니다. 이 객체는 데이터의 구조화된 형식을 제공하며, 일반적으로 오디오로 식별하는 'type' 필드와 오디오의 샘플링 레이트와 같은 메타데이터가 포함됩니다. 그런 다음 전체 JSON 객체가 문자열로 직렬화되어 WebSocket 연결을 통해 전송됩니다. 이 접근 방식을 사용하면 오디오가 잘 정리되고 쉽게 파싱할 수 있는 방식으로 전송됩니다.
동영상 데이터 변환
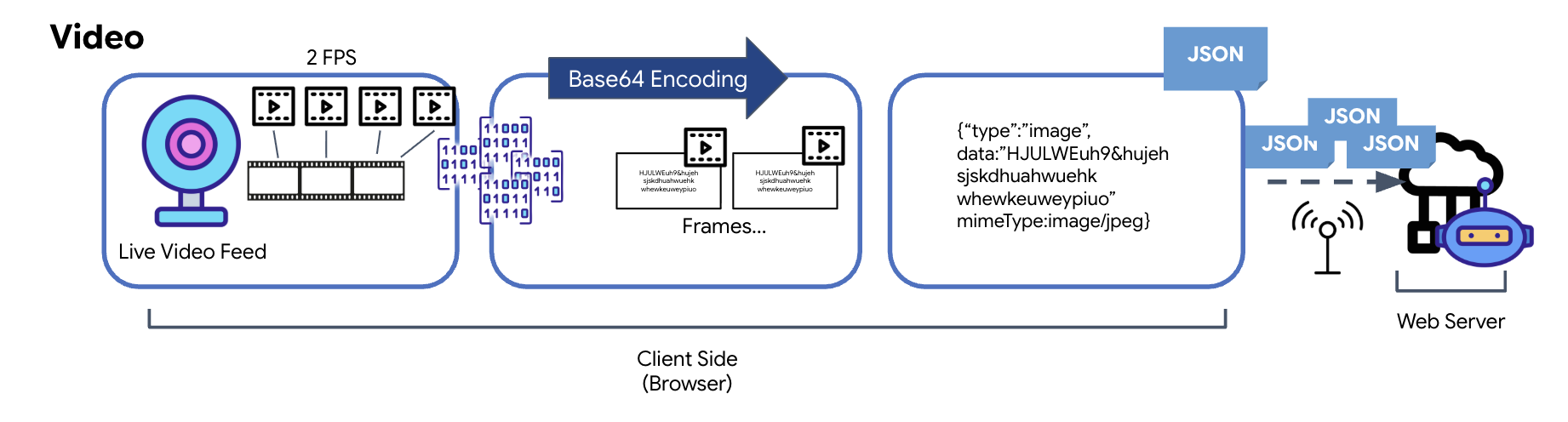
동영상 전송은 프레임 캡처 기법을 통해 이루어집니다. 연속 동영상 스트림을 전송하는 대신 반복되는 루프는 초당 2프레임과 같은 설정된 간격으로 실시간 동영상 피드에서 스틸 이미지를 캡처합니다. 이는 HTML 동영상 요소의 현재 프레임을 숨겨진 캔버스 요소에 그려서 달성됩니다.
그런 다음 캔버스의 toDataURL 메서드를 사용하여 캡처된 이미지를 Base64로 인코딩된 JPEG 문자열로 변환합니다. 이 방법에는 이미지 품질을 지정하는 옵션이 포함되어 있어 이미지 충실도와 파일 크기 간의 균형을 조정하여 성능을 최적화할 수 있습니다. 오디오 데이터와 마찬가지로 이 Base64 문자열은 JSON 객체에 배치됩니다. 이 객체에는 일반적으로 'image' 유형 라벨이 지정되어 있으며'image/jpeg'와 같은 mimeType이 포함됩니다. 이 JSON 패킷은 문자열로 변환되어 WebSocket을 통해 전송되므로 수신 측에서 이미지 시퀀스를 표시하여 동영상을 재구성할 수 있습니다.
👉✏️ 동일한 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js 파일에서 //#CAPTURE AUDIO and VIDEO을 다음으로 바꿔 사용자 입력을 캡처합니다.
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
저장되면 칵핏에서 상담사의 디지털 신호를 시각적 대시보드 업데이트 및 오디오로 변환할 수 있습니다.
진단 검사 (루프백 테스트)
이제 조종석이 작동합니다. 500ms마다 주변 환경의 시각적 '패킷'이 전송됩니다. Gemini에 연결하기 전에 선박의 트랜스미터가 작동하는지 확인해야 합니다. 로컬 진단 서버를 사용하여 '루프백 테스트'를 실행합니다.
👉💻 먼저 터미널에서 Cockpit 인터페이스를 빌드합니다.
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 다음으로 모의 서버를 시작합니다.
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 테스트 프로토콜 실행:
- 미리보기 열기: Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다. 포트 변경을 선택하고 8080으로 설정한 다음 변경 및 미리보기를 클릭합니다. 새 브라우저 탭이 열리고 Cockpit 인터페이스가 표시됩니다.
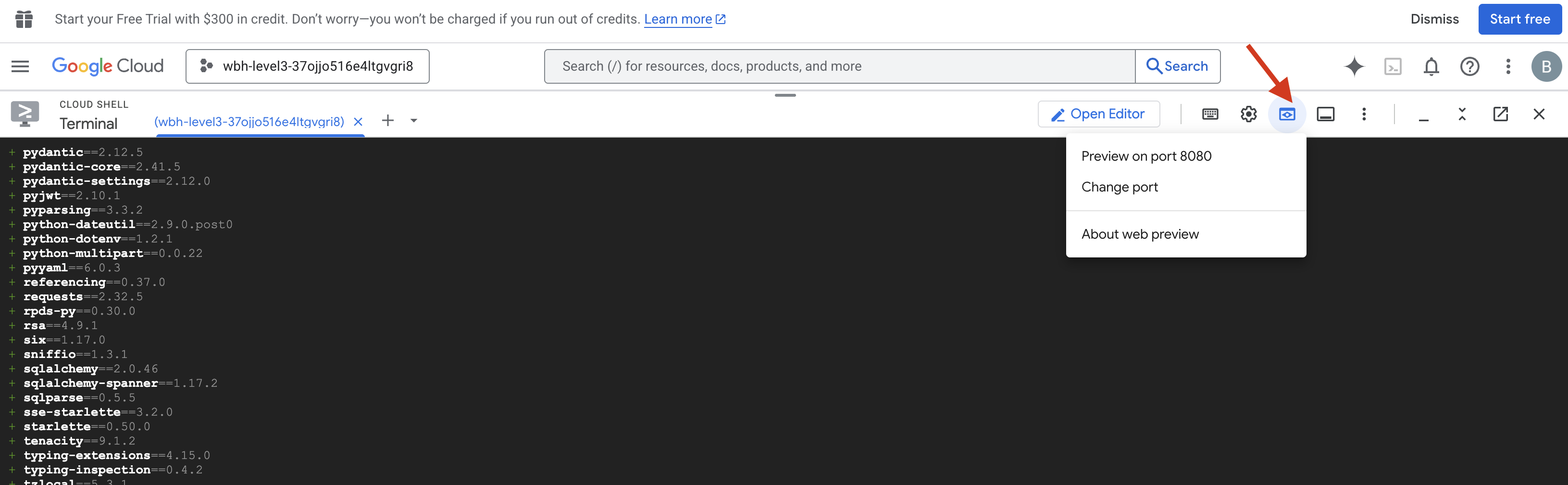
- 중요: 메시지가 표시되면 브라우저가 카메라 및 마이크에 액세스하도록 허용해야 합니다(MUST). 이러한 입력이 없으면 뉴럴 동기화를 시작할 수 없습니다.
- UI에서 'INITIATE NEURAL SYNC' 버튼을 클릭합니다.
👀 상태 표시기 확인:
- 시각적 확인: 브라우저 콘솔을 엽니다. 오른쪽 상단에
NEURAL SYNC INITIALIZED이 표시됩니다. - 오디오 확인: 양방향 오디오 파이프라인이 완전히 작동하면 시뮬레이션된 음성으로 '시스템이 연결되었습니다.'라는 확인 메시지가 들립니다.
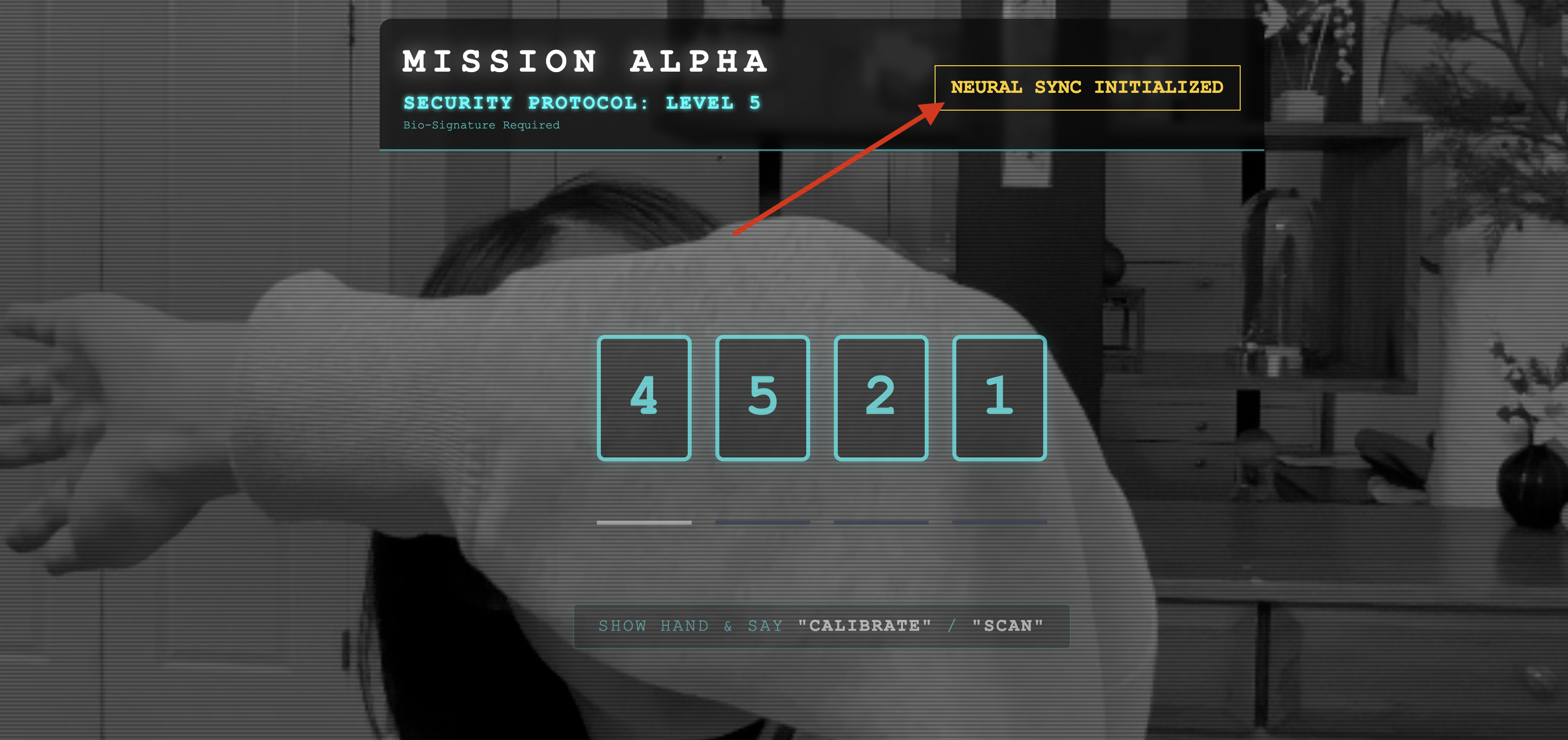
'시스템이 연결되었습니다'라는 오디오 확인이 들리면 테스트가 성공한 것입니다. 탭을 닫습니다. 이제 실제 AI를 위한 공간을 확보하기 위해 주파수를 정리해야 합니다.
👉💻 모의 서버와 프런트엔드 모두의 터미널에서 Ctrl+C를 누릅니다. UI가 실행 중인 브라우저 탭을 닫습니다.
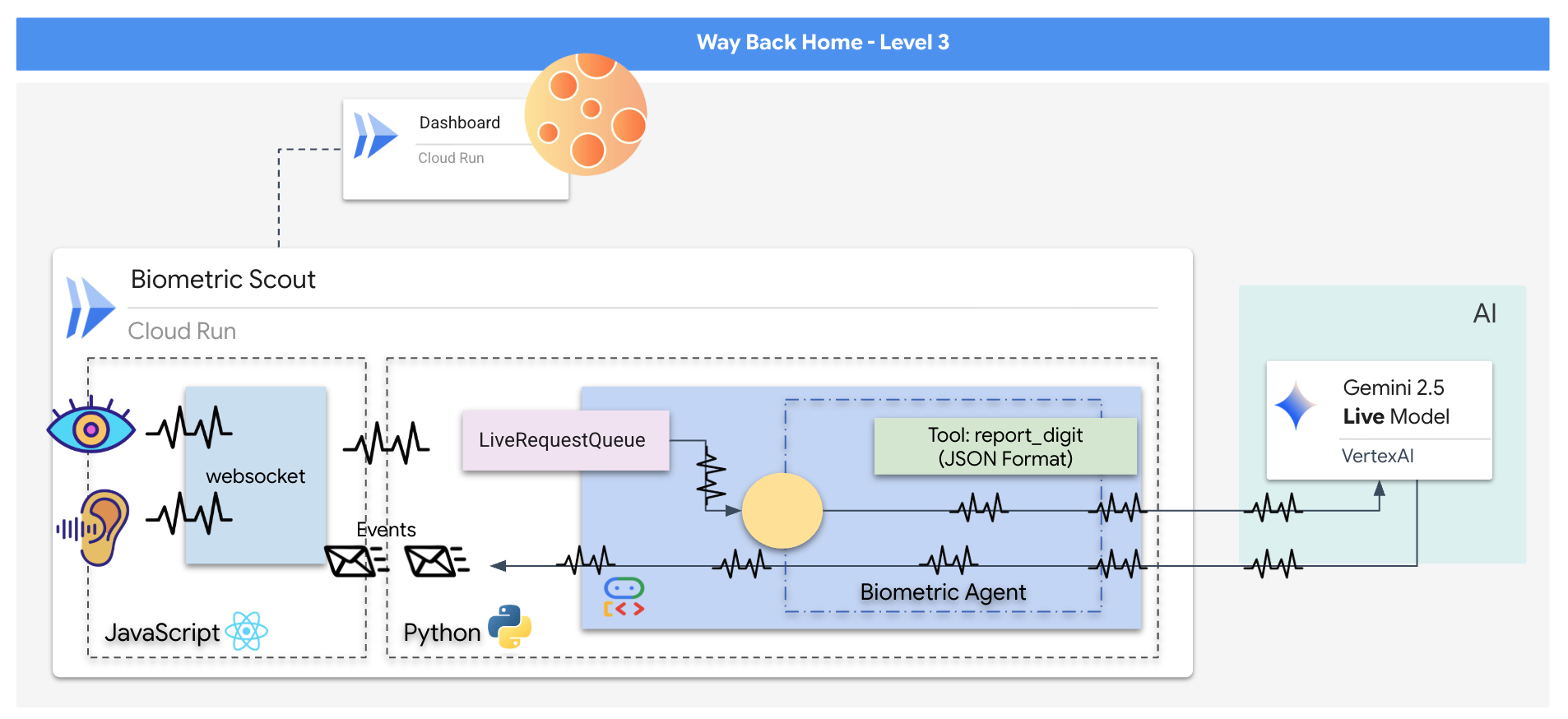
4. 멀티모달 에이전트
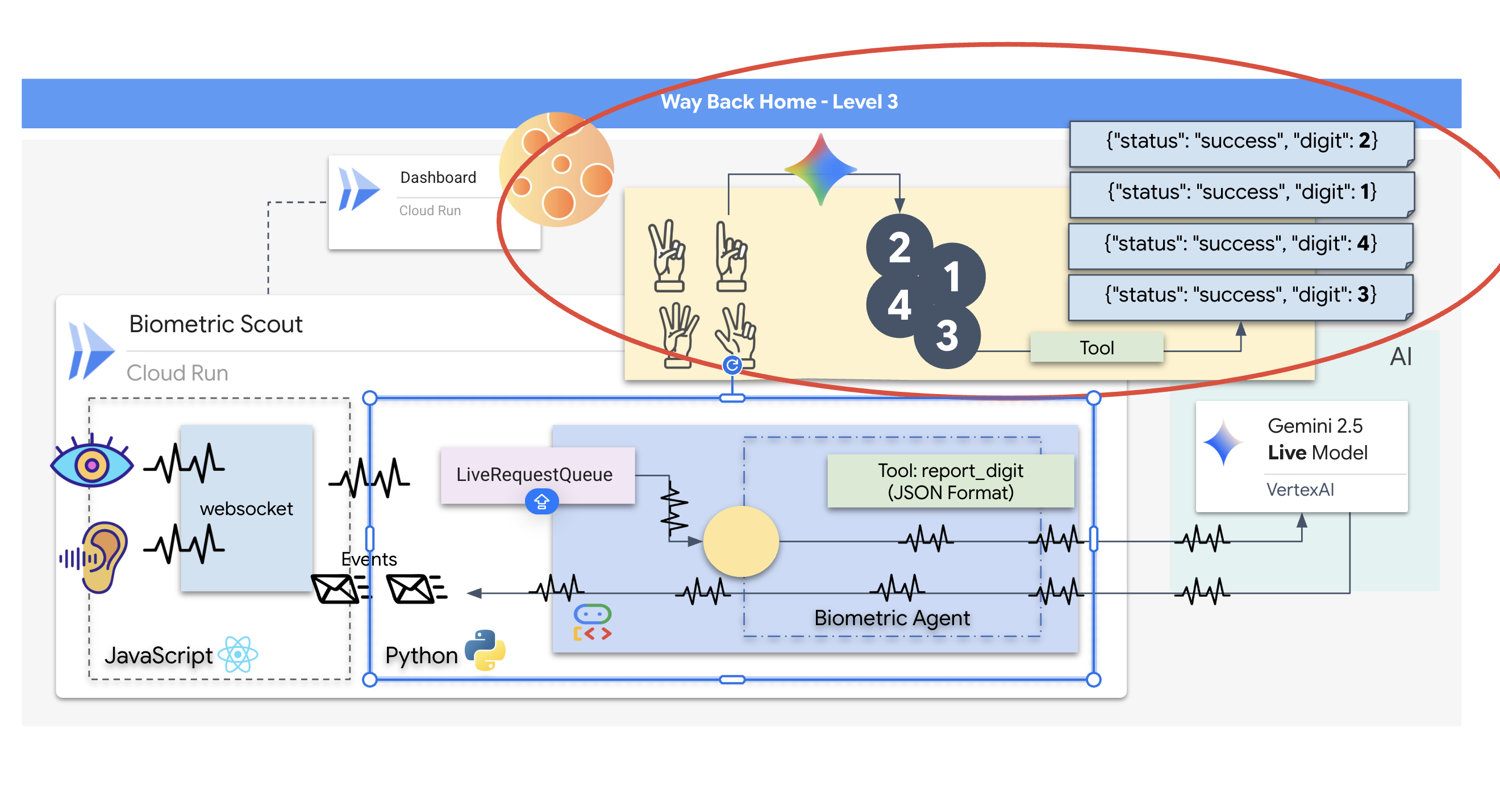
구조 스카우트는 작동하지만 '마음'이 비어 있습니다. 지금 연결하면 화면만 응시하게 됩니다. '손가락'이 무엇인지 알지 못합니다. 생존자를 구하려면 스카우트의 코어에 생체 인식 신경 프로토콜을 각인해야 합니다.
기존 에이전트는 일련의 번역기와 같이 작동합니다. 구식 AI와 대화하는 경우 '음성 텍스트 변환' 모델이 음성을 단어로 변환하고, '언어 모델'이 단어를 읽고 답장을 입력하며, 마지막으로 '텍스트 음성 변환' 모델이 답장을 다시 읽어줍니다. 이로 인해 구조 임무에서 치명적인 지연인 '지연 시간 격차'가 발생합니다.
Gemini Live API는 네이티브 멀티모달 모델입니다. 원시 오디오 바이트와 원시 동영상 프레임을 직접 동시에 처리합니다. 음성 진동을 '듣고' 손동작의 픽셀을 동일한 신경망 아키텍처 내에서 '확인'합니다.
이 기능을 활용하려면 조종석을 원시 Live API에 직접 연결하여 애플리케이션을 빌드하면 됩니다. 하지만 목표는 재사용 가능한 에이전트, 즉 빌드 속도가 더 빠른 모듈식의 강력한 엔티티를 빌드하는 것입니다.
ADK (에이전트 개발 키트)를 사용해야 하는 이유
Google 에이전트 개발 키트 (ADK)는 AI 에이전트를 개발하고 배포하기 위한 모듈식 프레임워크입니다.
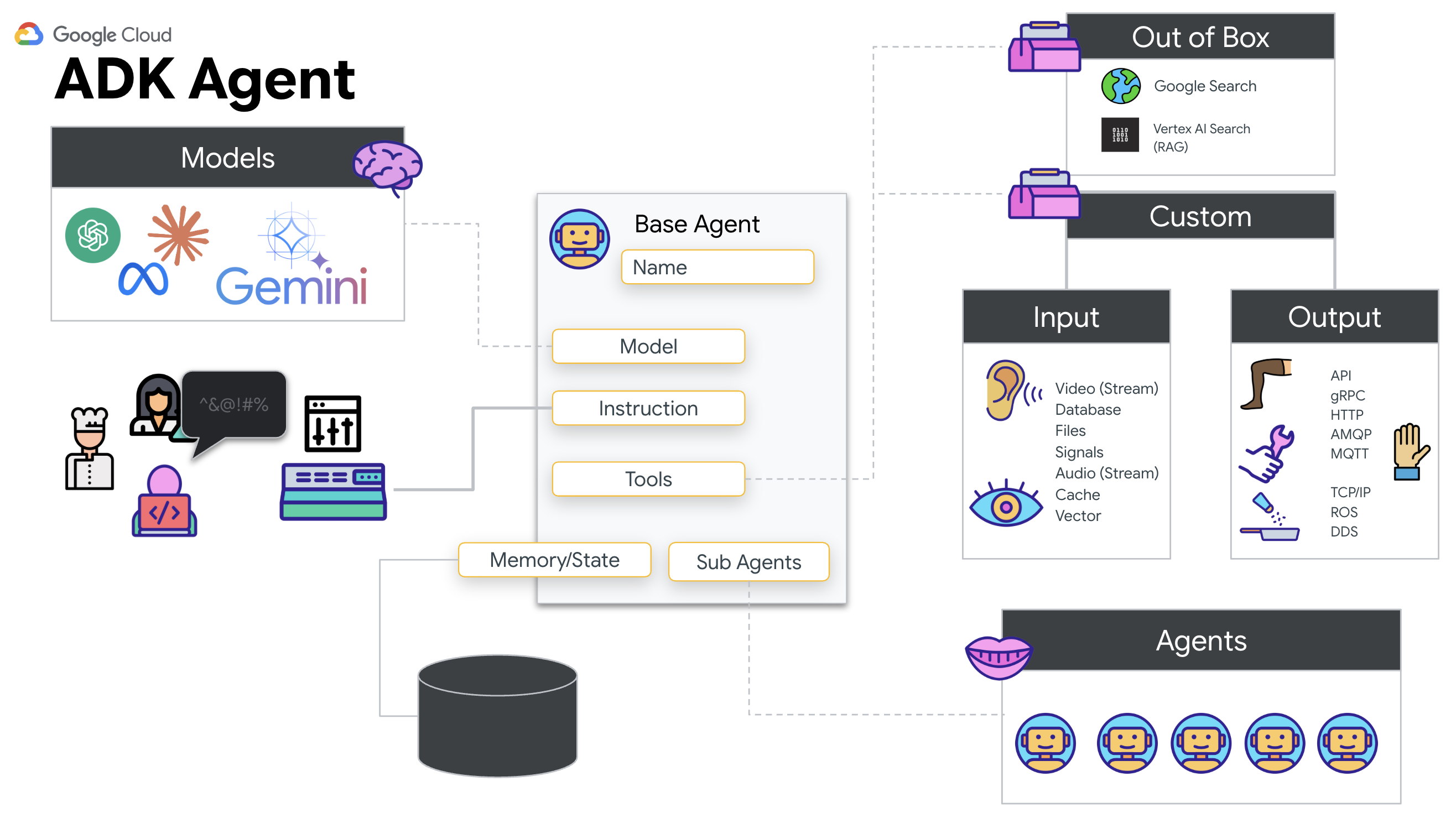
표준 LLM 호출은 일반적으로 스테이트리스(Stateless)입니다. 각 쿼리가 새로운 시작입니다. 실제 상담사는 특히 ADK의 SessionService와 통합된 경우 강력하고 장기적인 대화 세션을 지원합니다.
- 세션 지속성: ADK 세션은 지속적이며 서버 재시작 및 연결 해제 후에도 유지되면서 데이터베이스 (예: SQL 또는 Vertex AI)에 저장될 수 있습니다. 즉, 사용자가 연결을 해제했다가 나중에(며칠 후라도) 다시 연결하면 대화 기록과 컨텍스트가 완전히 복원됩니다. 일시적인 Live API 세션은 ADK에 의해 관리되고 추상화됩니다.
- 자동 재연결: WebSocket 연결은 타임아웃될 수 있습니다 (예: 약 10분 후).
RunConfig에서session_resumption가 사용 설정되면 ADK에서 이러한 재연결을 투명하게 처리합니다. 애플리케이션 코드에서 복잡한 재연결 로직을 관리할 필요가 없어 사용자에게 원활한 환경을 제공할 수 있습니다. - 스테이트풀 상호작용: 에이전트가 이전 턴을 기억하여 후속 질문, 명확한 설명, 컨텍스트가 중요한 복잡한 멀티턴 대화가 가능합니다. 이는 연속성이 필수적인 고객 지원, 대화형 튜토리얼, 미션 컨트롤 시나리오와 같은 애플리케이션에 기본적으로 필요합니다.
이 지속성을 통해 상호작용은 일련의 고립된 질문과 답변이 아닌 지능형 엔티티와의 지속적인 대화처럼 느껴집니다.
기본적으로 ADK 양방향 스트리밍을 사용하는 '실제 상담사'는 단순한 질문-응답 메커니즘을 넘어 진정으로 대화형이고 상태를 유지하며 중단을 인식하는 대화형 환경을 제공하여 AI 상호작용을 더 인간적으로 만들고 복잡하고 장기적인 작업에 훨씬 더 강력한 기능을 제공합니다.
실제 상담사 요청
실시간 양방향 에이전트를 위한 프롬프트를 설계하려면 사고방식의 변화가 필요합니다. 정적 텍스트 쿼리를 기다리는 표준 채팅 봇과 달리 Live Agent는 '항상 켜져' 있습니다. 오디오 및 동영상 프레임이 지속적으로 스트리밍되므로 프롬프트는 단순히 성격 정의가 아닌 제어 루프 스크립트로 작동해야 합니다.
실제 상담사 프롬프트는 기존 프롬프트와 다음과 같이 다릅니다.
- 상태 머신 로직: 프롬프트는 '동작 루프' (대기 → 분석 → 행동)를 정의해야 합니다. 언제 침묵을 유지하고 언제 응대해야 하는지에 관한 명시적인 안내가 필요하며, 이를 통해 에이전트가 빈 배경 소음 위로 계속해서 말을 하는 것을 방지할 수 있습니다.
- 멀티모달 인식: 에이전트에게 '눈'이 있다고 알려야 합니다. 추론 과정의 일부로 동영상 프레임을 분석하도록 명시적으로 지시해야 합니다.
- 지연 시간 및 간결성: 실시간 음성 대화에서 긴 산문 형식의 단락은 부자연스럽고 느리게 느껴집니다. 프롬프트는 상호작용을 신속하게 유지하기 위해 간결성을 강제합니다.
- 액션 우선 아키텍처: 음성보다 도구 호출을 우선시합니다. 에이전트가 긴 독백 후에가 아니라 구두로 확인하기 전이나 중에 작업을 수행 (생체 인식 스캔)하기를 원합니다.
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py를 열고 #REPLACE INSTRUCTIONS를 다음으로 바꿉니다.
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
참고: 표준 LLM에 연결되어 있지 않습니다. 동일한 파일 ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py)에서 #REPLACE_MODEL을 찾습니다. 실시간 오디오 기능을 더 잘 지원하려면 이 모델의 미리보기 버전을 명시적으로 타겟팅해야 합니다.
👉✏️ 자리표시자를 다음으로 바꿉니다.
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
이제 에이전트가 정의되었습니다. 자신이 누구인지, 어떻게 생각해야 하는지 알고 있습니다. 그런 다음 행동할 수 있는 도구를 제공합니다.
도구 호출
Live API는 텍스트, 오디오, 동영상 스트림 교환에만 국한되지 않습니다. 도구 호출을 기본적으로 지원합니다. 이렇게 하면 에이전트가 수동적인 대화 상대에서 능동적인 운영자로 전환됩니다.
실시간 양방향 세션 중에 모델은 컨텍스트를 지속적으로 평가합니다. LLM이 '센서 원격 분석 확인' 또는 '보안 문 잠금 해제'와 같은 작업을 실행해야 한다고 감지하는 경우 대화에서 실행으로 원활하게 전환됩니다. 에이전트는 상호작용 흐름을 중단하지 않고 특정 도구 기능을 즉시 트리거하고 결과를 기다리며 해당 데이터를 라이브 스트림에 다시 통합합니다.
👉✏️ $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py에서 #REPLACE TOOLS를 다음 함수로 바꿉니다.
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ 그런 다음 #TOOL CONFIG을 대체하여 Agent 정의에 등록합니다.
tools=[report_digit],
adk web 시뮬레이터
복잡한 배송 콕핏 (React 프런트엔드)에 연결하기 전에 에이전트의 로직을 격리된 상태로 테스트해야 합니다. ADK에는 네트워크 복잡성을 추가하기 전에 도구 호출을 확인할 수 있는 adk web라는 기본 제공 개발자 콘솔이 포함되어 있습니다.
👉💻 터미널에서 다음을 실행합니다.
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다. 포트 변경을 선택하고 8000으로 설정한 후 변경 및 미리보기를 클릭합니다.
- 권한 부여: 메시지가 표시되면 카메라 및 마이크에 대한 액세스를 허용합니다.
- 카메라 아이콘을 클릭하여 세션을 시작합니다.
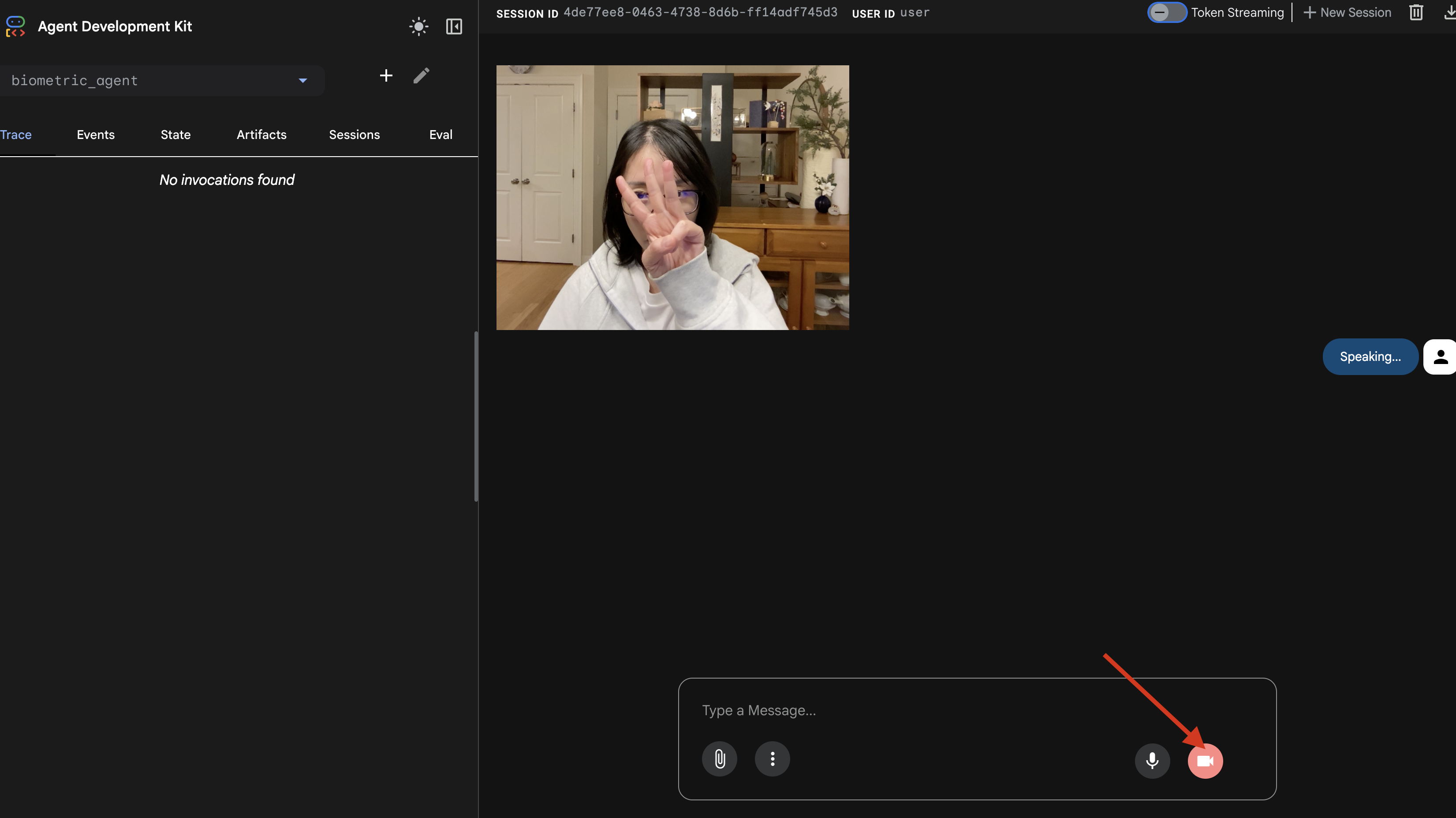
- 시각적 테스트:
- 카메라 앞에 손가락 3개를 명확하게 들어 올립니다.
- "스캔해 줘"라고 말합니다.
- 성공 확인:
- 로그:
adk web명령어를 실행하는 터미널을 확인합니다.[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3로그가 표시되어야 합니다.
- 로그:
도구 실행 로그가 표시되면 에이전트가 지능적입니다. 보고, 생각하고, 행동할 수 있습니다. 마지막 단계는 메인 함선에 연결하는 것입니다.
터미널 창을 클릭하고 Ctrl+C를 눌러 adk web 시뮬레이터를 중지합니다.
5. 양방향 스트리밍 흐름
에이전트가 작동합니다. Cockpit이 작동합니다. 이제 연결해야 합니다.
실제 상담사 라이프사이클
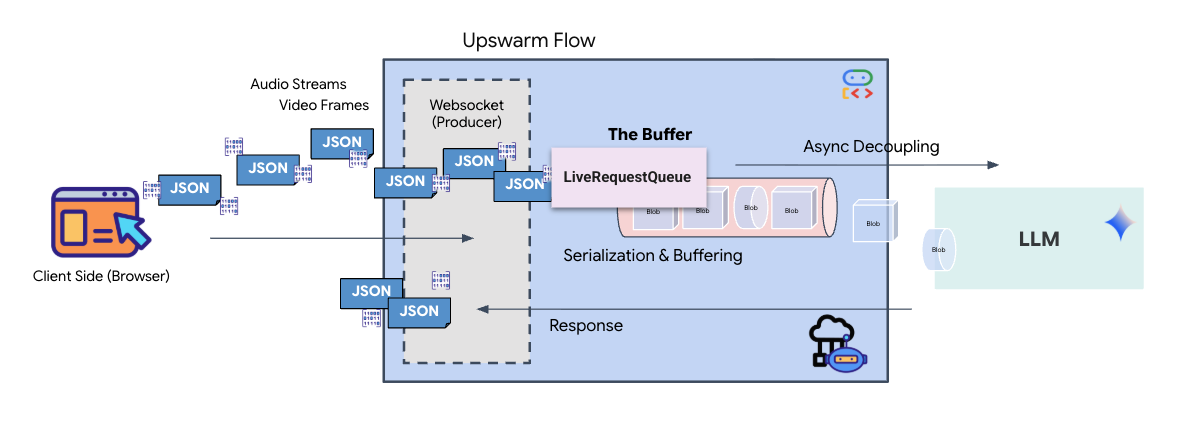
실시간 스트리밍에는 '임피던스 불일치' 문제가 있습니다. 클라이언트 (브라우저)는 네트워크 버스트 또는 연속 입력과 같이 가변적인 속도로 데이터를 비동기적으로 푸시하는 반면 모델에는 규제된 순차적 입력 스트림이 필요합니다. Google ADK는 LiveRequestQueue를 사용하여 이 문제를 해결합니다.
스레드로부터 안전한 비동기 선입 선출 (FIFO) 버퍼 역할을 합니다. WebSocket 핸들러는 생산자 역할을 하여 원시 오디오/동영상 청크를 대기열로 푸시합니다. ADK 에이전트는 컨슈머 역할을 하여 대기열에서 데이터를 가져와 모델의 컨텍스트 창에 제공합니다. 이렇게 분리하면 모델이 응답을 생성하거나 도구를 실행하는 동안에도 애플리케이션이 사용자 입력을 계속 받을 수 있습니다.
이 대기열은 멀티모달 멀티플렉서 역할을 합니다. 실제 환경에서 업스트림 흐름은 원시 PCM 오디오 바이트, 동영상 프레임, 텍스트 기반 시스템 명령, 비동기 도구 호출의 결과와 같은 동시 데이터 유형으로 구성됩니다. LiveRequestQueue는 이러한 이질적인 입력을 하나의 시간순 시퀀스로 선형화합니다. 패킷에 1밀리초의 무음, 고해상도 이미지 또는 데이터베이스 쿼리의 JSON 페이로드가 포함되어 있는지 여부에 관계없이 도착 순서대로 정확하게 직렬화되므로 모델이 일관된 인과적 타임라인을 인식할 수 있습니다.
이 아키텍처는 차단되지 않는 제어를 지원합니다. 수집 레이어 (생산자)가 처리 레이어 (소비자)에서 분리되어 있으므로 계산 비용이 많이 드는 모델 추론 중에도 시스템이 응답성을 유지합니다. 상담사가 도구를 실행하는 동안 사용자가 '중지' 명령으로 방해하면 해당 오디오 신호가 즉시 대기열에 추가됩니다. 기본 이벤트 루프는 이 우선순위 신호를 즉시 처리하므로 시스템은 UI가 멈추거나 패킷이 삭제되지 않고도 생성 또는 피벗 작업을 중지할 수 있습니다.
👉💻 $HOME/way-back-home/level_3/backend/app/main.py에서 #REPLACE_RUNNER_CONFIG 주석을 찾아 다음 코드로 바꿔 시스템을 온라인 상태로 만듭니다.
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
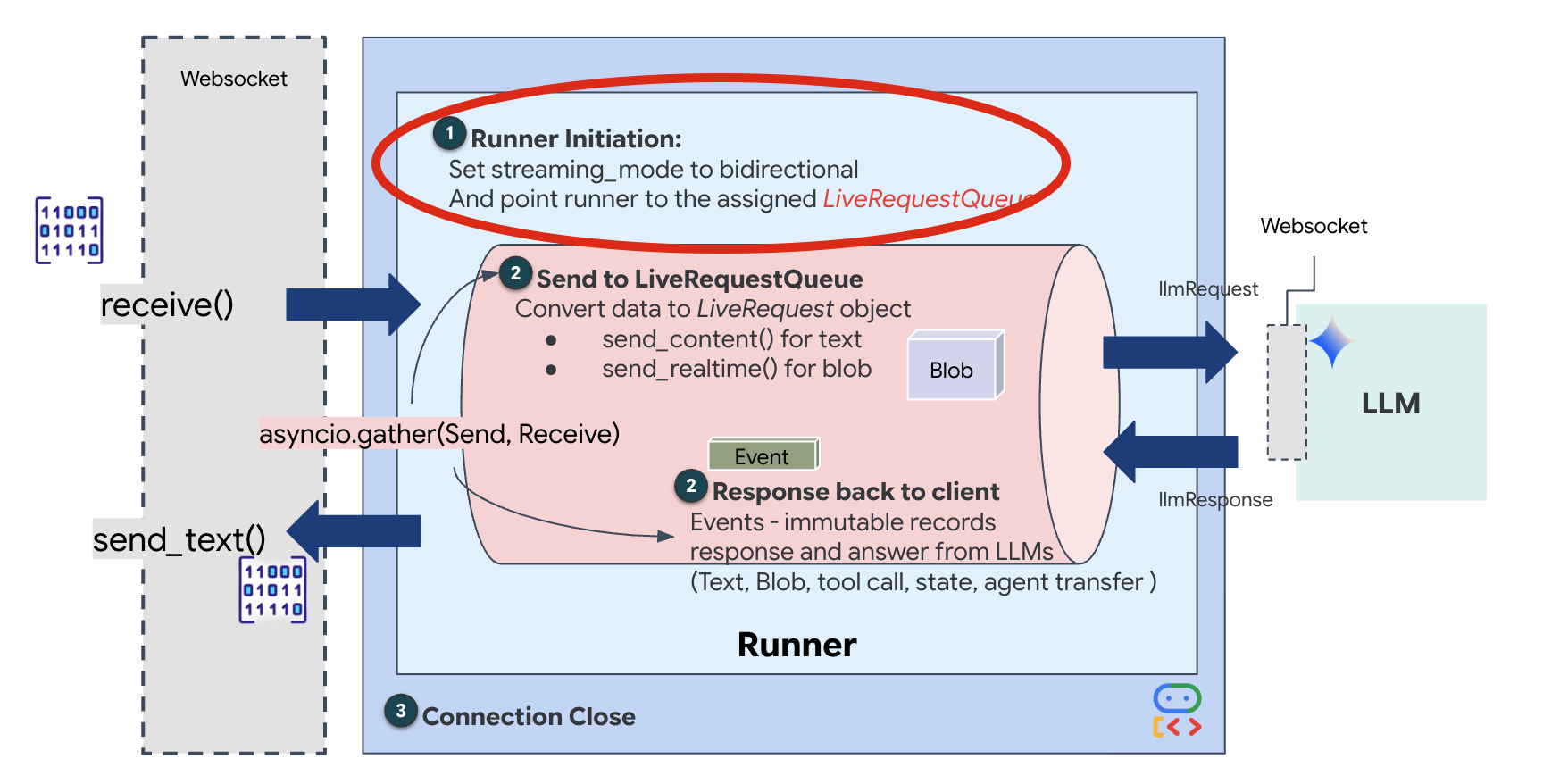
새 WebSocket 연결이 열리면 AI가 상호작용하는 방식을 구성해야 합니다. 여기에서 '참여 규칙'을 정의합니다.
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py의 async def websocket_endpoint 함수 내에서 #REPLACE_SESSION_INIT 주석을 아래 코드로 바꿉니다.
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
실행 구성
StreamingMode.BIDI: 연결을 양방향으로 설정합니다. '턴 기반' AI (내가 말하고 멈추면 AI가 말하는 방식)와 달리 BIDI는 현실적인 '전이중' 대화를 지원합니다. AI를 중단할 수 있으며, 이동 중에 AI가 말할 수 있습니다.AudioTranscriptionConfig: 모델이 원시 오디오를 '듣는' 경우에도 개발자는 로그를 확인해야 합니다. 이 구성은 Gemini에게 '오디오를 처리하되, 디버깅할 수 있도록 들은 내용을 텍스트 스크립트로도 보내줘'라고 지시합니다.
실행 로직 러너가 세션을 설정하면 LiveRequestQueue를 사용하는 실행 로직에 제어권을 넘깁니다. 이는 실시간 상호작용에 가장 중요한 구성요소입니다. 이 루프를 통해 에이전트는 음성 응답을 생성하는 동시에 대기열에서 사용자의 새로운 동영상 프레임을 계속 수락할 수 있으므로 'Neural Sync'가 중단되지 않습니다.
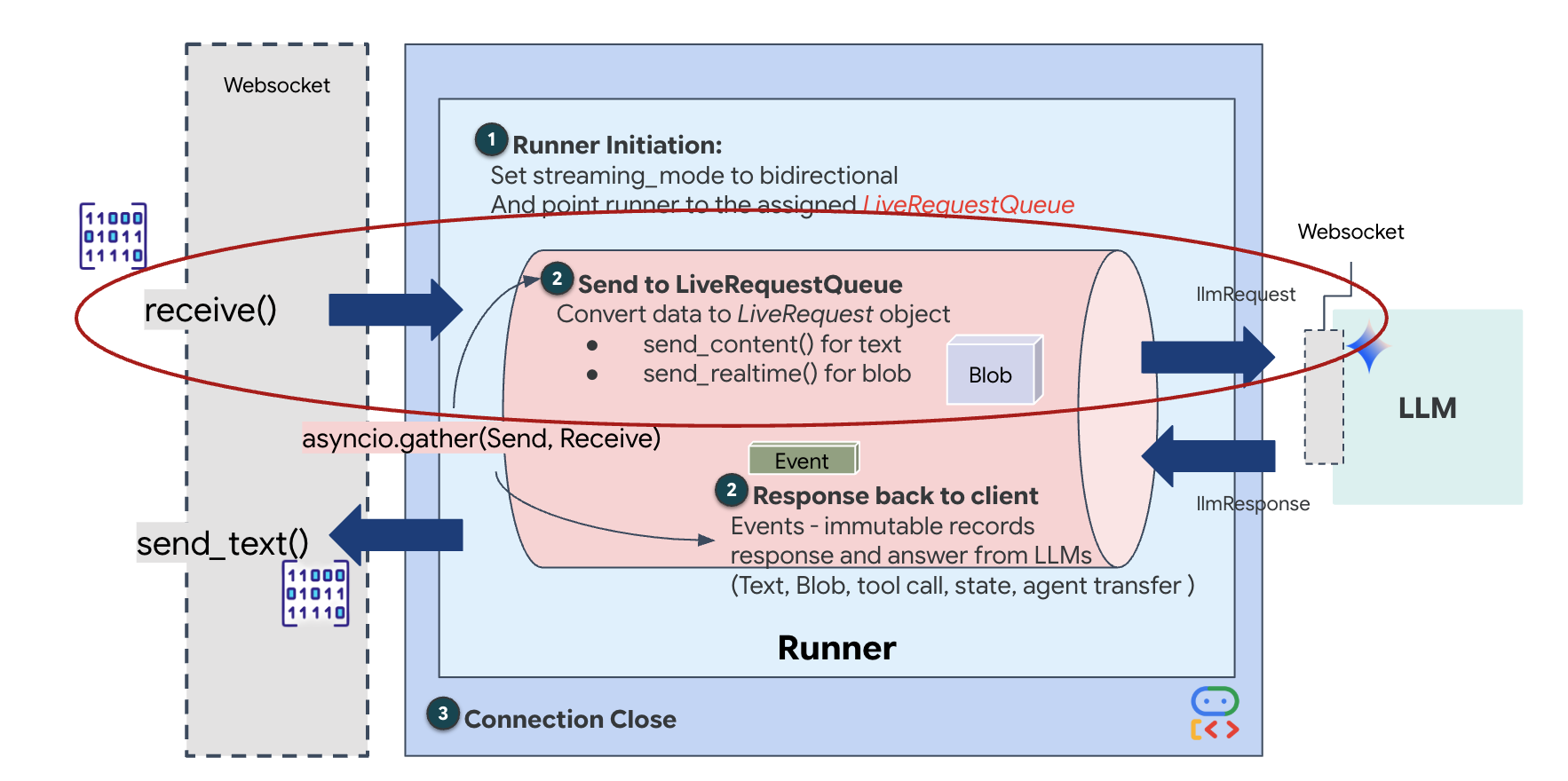
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py에서 #REPLACE_LIVE_REQUEST를 바꿔 LiveRequestQueue에 데이터를 전송하는 업스트림 작업을 정의합니다.
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
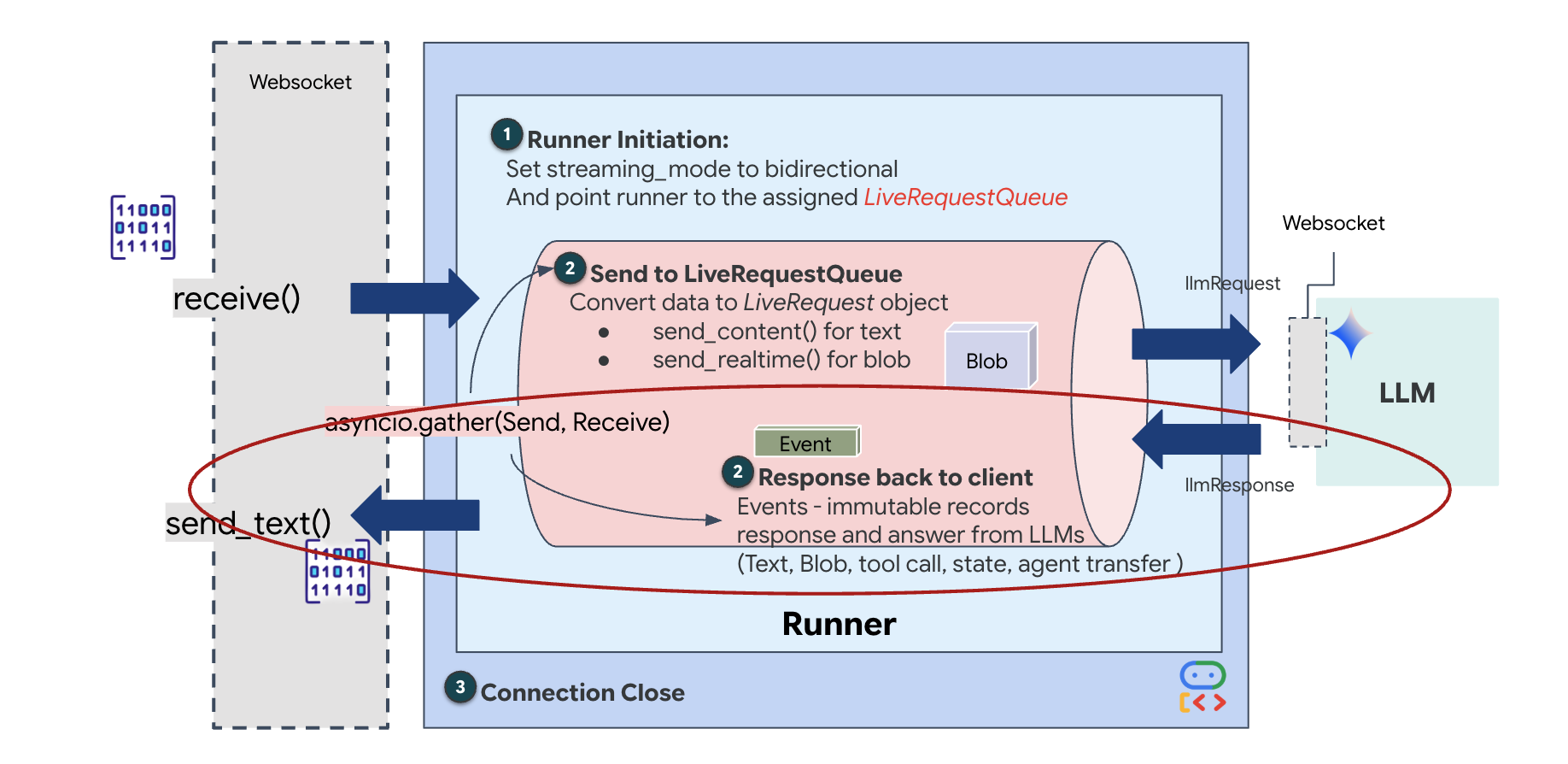
마지막으로 AI의 대답을 처리해야 합니다. 여기서는 이벤트가 발생할 때 이벤트 (오디오, 텍스트 또는 도구 호출)를 생성하는 이벤트 생성기인 runner.run_live()를 사용합니다.
👉✏️ $HOME/way-back-home/level_3/backend/app/main.py에서 #REPLACE_SORT_RESPONSE를 바꿔 다운스트림 작업과 동시 실행 관리자를 정의합니다.
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
await asyncio.gather(upstream_task(), downstream_task()) 줄을 확인합니다. 이것이 전이중의 본질입니다. Google은 듣기 작업 (업스트림)과 말하기 작업 (다운스트림)을 정확히 동시에 실행합니다. 이를 통해 '신경 링크'가 중단과 동시 데이터 흐름을 허용합니다.
이제 백엔드가 완전히 코딩되었습니다. '브레인' (ADK)이 '바디' (WebSocket)에 연결됩니다.
Bio-Sync 실행
코드가 완료되었습니다. 시스템이 녹색입니다. 이제 구조를 시작할 시간입니다.
- 👉💻 백엔드 시작:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 프런트엔드 실행:
- Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다. 포트 변경을 선택하고 8080으로 설정한 다음 변경 및 미리보기를 클릭합니다.
- 👉 프로토콜 실행:
- '신경망 동기화 시작'을 클릭합니다.
- 보정: 카메라에 배경을 기준으로 손이 선명하게 보이도록 합니다.
- 동기화: 화면에 표시된 보안 코드 (예: 3, 2, 5)를 확인합니다.
- 신호 맞추기: 숫자가 표시되면 그 숫자만큼 손가락을 들어 올립니다.
- 가만히 들고 있기: AI가 '생체 인식 일치'를 확인할 때까지 손을 보이게 합니다.
- 적응: 코드가 무작위입니다. 순서가 완료될 때까지 표시된 다음 숫자로 즉시 전환합니다.

- 무작위 순서의 마지막 숫자를 맞추면 '생체 인식 동기화'가 완료됩니다. 신경 링크가 잠깁니다. 수동으로 제어할 수 있습니다. 스카우트 엔진이 굉음을 내며 협곡으로 돌진하여 생존자들을 집으로 데려갑니다.
👉💻 백엔드 터미널에서 Ctrl+C를 눌러 종료합니다.
6. 프로덕션에 배포 (선택사항)
생체 인식 테스트를 로컬에서 성공적으로 완료했습니다. 이제 에이전트의 신경망 코어를 함선의 메인프레임 (Cloud Run)에 업로드하여 로컬 콘솔과 독립적으로 작동할 수 있도록 해야 합니다.
👉💻 Cloud Shell 터미널에서 다음 명령어를 실행합니다. 백엔드 디렉터리에 완전한 다단계 Dockerfile이 생성됩니다.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 백엔드 디렉터리로 이동하여 애플리케이션을 컨테이너 이미지로 패키징합니다.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Cloud Run에 서비스를 배포합니다. 필요한 환경 변수(특히 Gemini 구성)가 실행 명령어에 직접 삽입됩니다.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
명령어가 완료되면 서비스 URL (예: https://biometric-scout-...run.app)이 표시됩니다. 이제 애플리케이션이 클라우드에서 라이브로 제공됩니다.
👉 Google Cloud Run 페이지로 이동하여 목록에서 biometric-scout 서비스를 선택합니다. 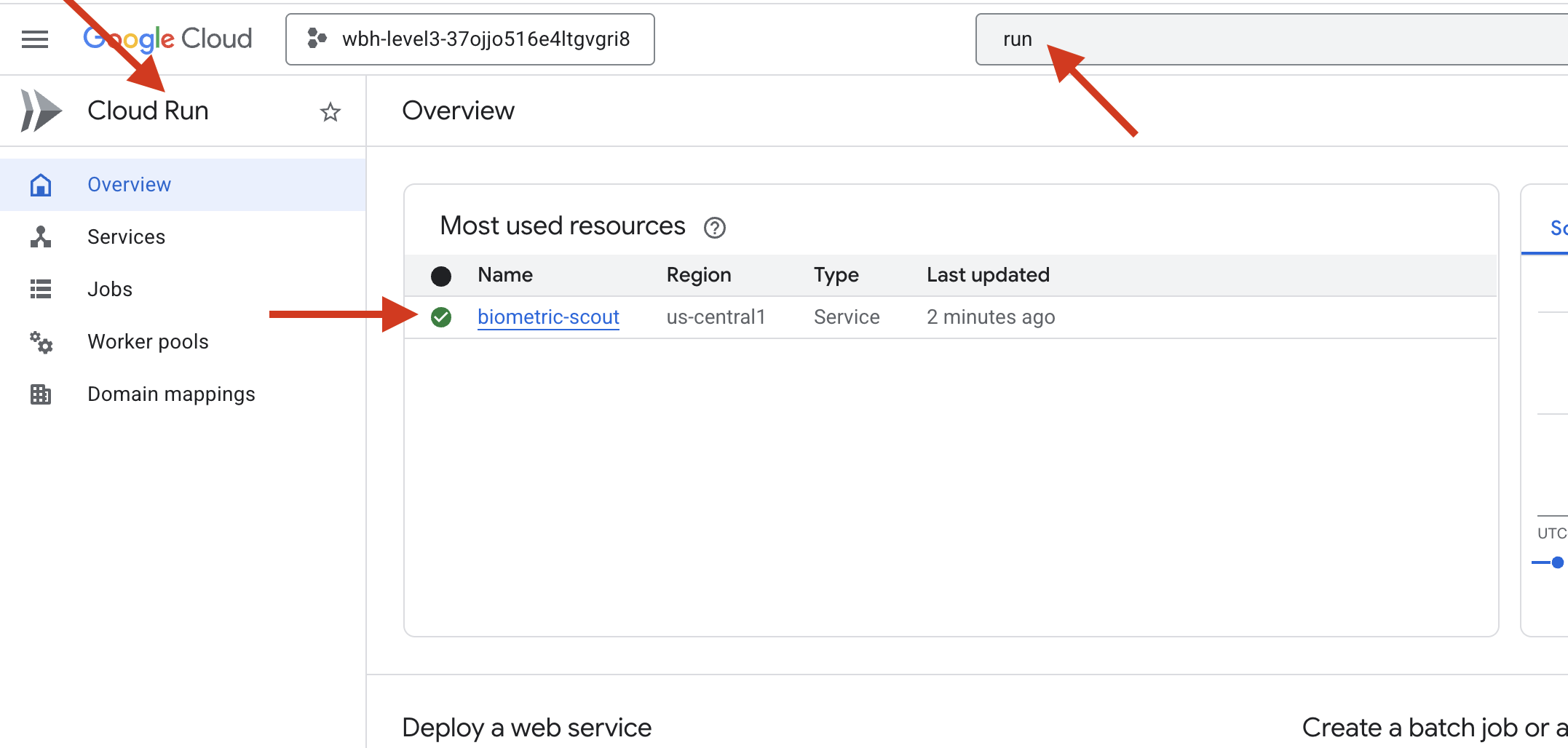
👉 서비스 세부정보 페이지 상단에 표시된 공개 URL을 찾습니다. 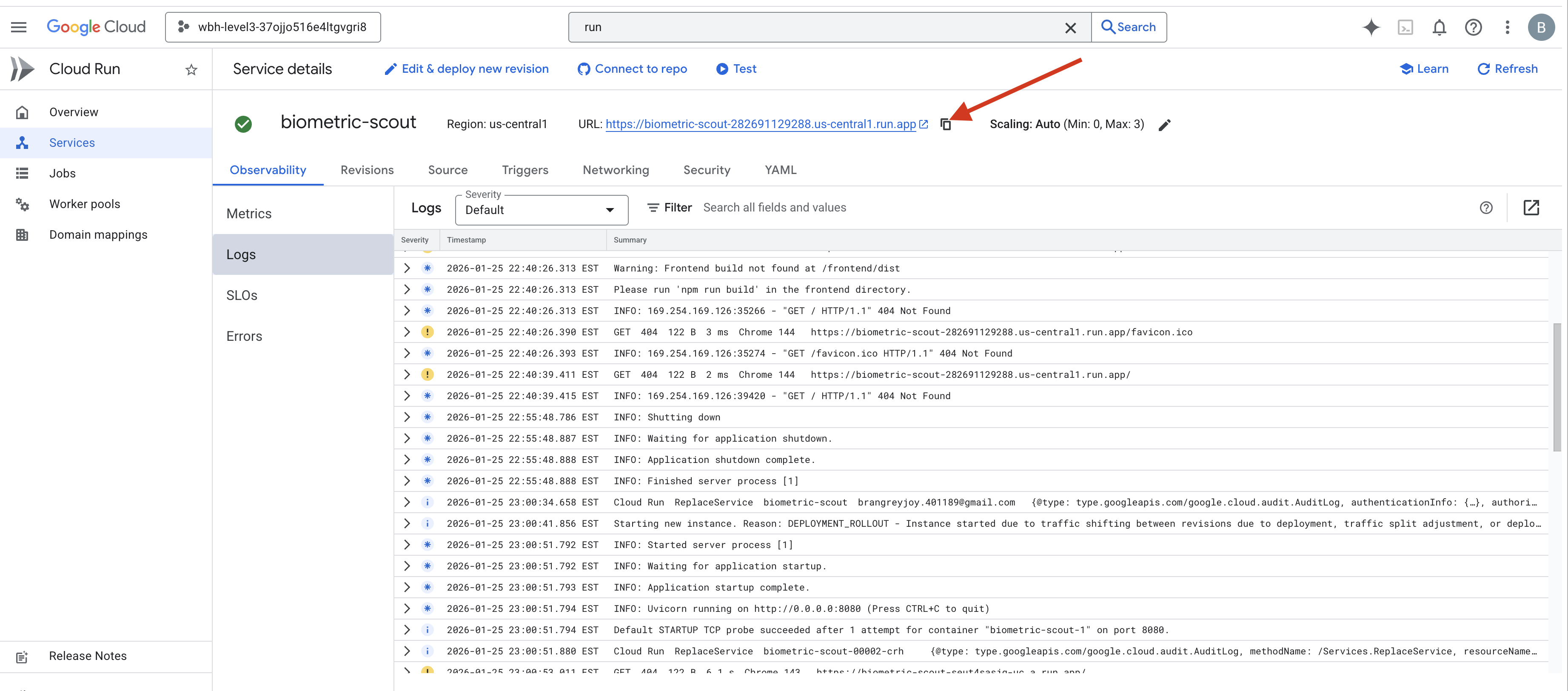
이 환경에서 생체 동기화를 시도해 보세요. 작동하나요?
다섯 번째 손가락이 펴지면 AI가 시퀀스를 잠급니다. 화면이 녹색으로 깜박이며 '생체 인식 신경 동기화: 설정됨'이라고 표시됩니다.
단 한 번의 생각으로 스카웃을 어둠 속으로 다이빙시켜 고립된 포드에 매달리고 중력 균열이 무너지기 직전에 포드를 끌어냅니다.

에어락이 열리자 살아 있는 생존자 다섯 명이 눈에 들어왔습니다. 그들은 갑판으로 비틀거리며 나옵니다. 만신창이지만 살아 있습니다. 덕분에 마침내 안전해졌습니다.
덕분에 신경 링크가 동기화되고 생존자가 구조되었습니다.
레벨 0에 참여한 경우 집으로 돌아가는 미션에서 진행 상황을 확인하세요.