1. Misja

Dryfujesz w ciszy niezbadanego sektora. Ogromny **impuls słoneczny** rozerwał Twój statek i przeniósł go przez szczelinę, pozostawiając Cię w kieszeni wszechświata, która nie istnieje na żadnej mapie gwiazd.
Po wielu dniach wyczerpujących napraw w końcu czujesz pod stopami wibracje silników. Twój statek kosmiczny został naprawiony. Udało Ci się nawet nawiązać połączenie dalekiego zasięgu z okrętem macierzystym. Możesz odlecieć. Możesz wrócić do domu. Gdy przygotowujesz się do włączenia napędu skokowego, w szumie pojawia się sygnał alarmowy. Czujniki wykrywają 5 słabych sygnatur cieplnych uwięzionych w „The Ravine” – poszarpanym, zniekształconym przez grawitację sektorze, do którego Twój główny statek nigdy nie może wejść. To inni odkrywcy, którzy przetrwali tę samą burzę, która prawie Cię zabiła. Nie możesz ich zostawić.
Zwracasz się do drona ratunkowego Alpha-Drone Rescue Scout. Ten mały, zwinny statek jest jedyną jednostką zdolną do poruszania się po wąskich ścianach Wąwozu. Jest jednak problem: impuls słoneczny spowodował całkowite „zresetowanie systemu” w jego podstawowej logice. Systemy sterowania zwiadowcy nie reagują. Jest włączony, ale jego komputer pokładowy jest pusty i nie może przetwarzać ręcznych poleceń pilota ani ścieżek lotu.
Wyzwanie
Aby uratować ocalałych, musisz całkowicie ominąć uszkodzone obwody zwiadowcy. Masz jedną desperacką opcję: stworzyć agenta AI, który nawiąże biometryczną synchronizację neuronową. Ten agent będzie działać jako pomost w czasie rzeczywistym, umożliwiając ręczne sterowanie robotem ratowniczym za pomocą własnych sygnałów biologicznych. Nie będziesz używać joysticka ani klawiatury, tylko bezpośrednio podłączysz swoje intencje do sieci nawigacyjnej statku.
Aby zablokować połączenie, musisz wykonać protokół synchronizacji przed czujnikami optycznymi robota Scout. Agent AI musi rozpoznać Twój podpis biologiczny za pomocą precyzyjnego, działającego w czasie rzeczywistym protokołu uzgadniania.
Cele misji:
- Wytrenuj rdzeń sieci neuronowej: zdefiniuj agenta ADK, który potrafi rozpoznawać dane wejściowe multimodalne.
- Nawiązywanie połączenia: utwórz dwukierunkowy potok WebSocket do przesyłania strumieniowego danych wizualnych z urządzenia Scout do AI.
- Rozpocznij uścisk dłoni: stań przed czujnikiem i wykonaj sekwencję palców – pokaż kolejno liczby od 1 do 5.
Jeśli się uda, włączy się „Synchronizacja danych biometrycznych”. AI zablokuje połączenie neuronowe, dając Ci pełną kontrolę nad uruchomieniem zwiadowcy i sprowadzeniem ocalałych do domu.
Co utworzysz
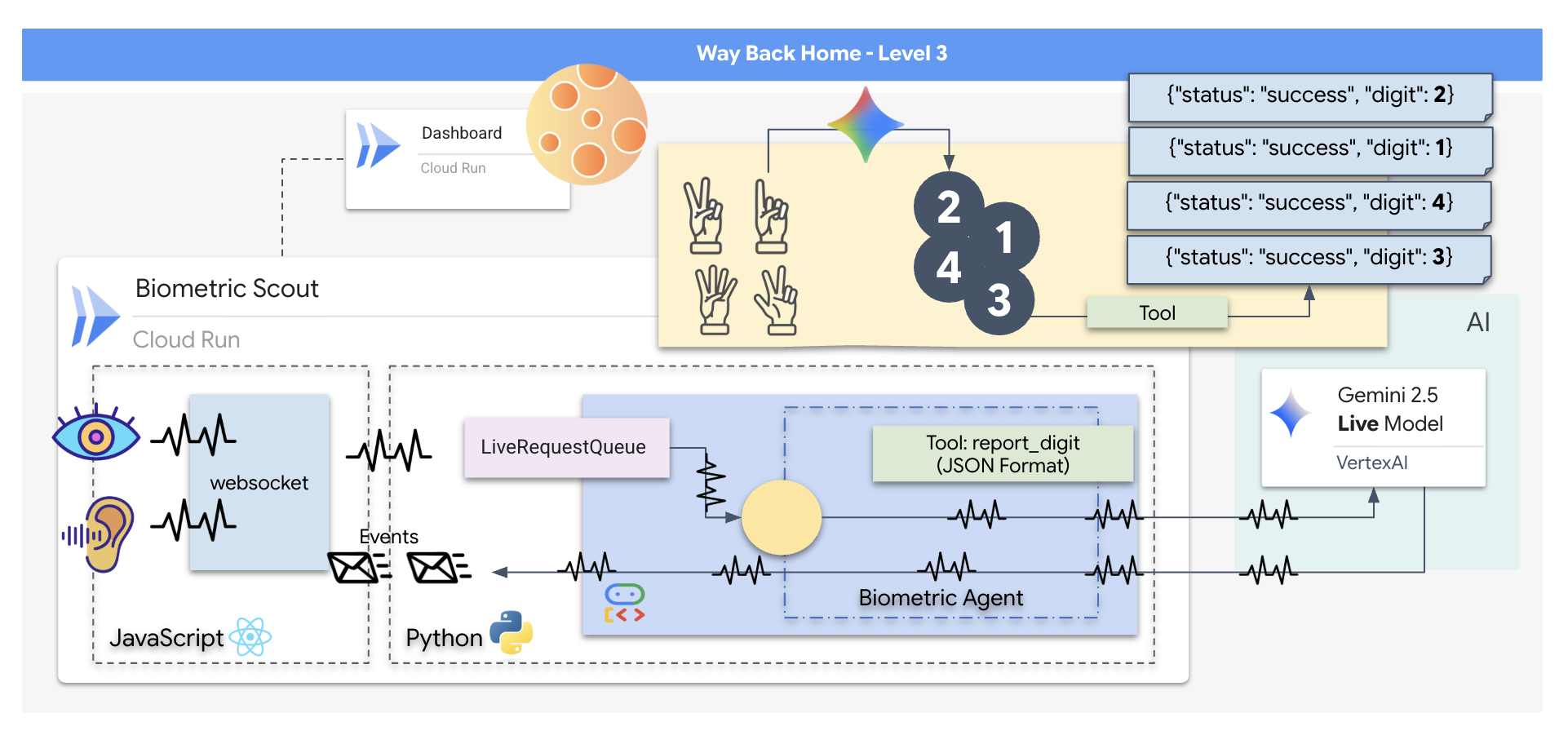
Zbudujesz aplikację „Biometric Neural Sync”, czyli system oparty na AI działający w czasie rzeczywistym, który będzie interfejsem sterowania dronem ratowniczym. System ten składa się z:
- Interfejs React: „kokpit” Twojego statku, który rejestruje obraz na żywo z kamery internetowej i dźwięk z mikrofonu.
- Backend w Pythonie: serwer o wysokiej wydajności zbudowany przy użyciu FastAPI, który wykorzystuje pakiet Agent Development Kit (ADK) od Google do zarządzania logiką i stanem modelu LLM.
- Wielomodalny agent AI: „mózg” całego procesu, który za pomocą interfejsu Gemini Live API i pakietu SDK
google-genaiprzetwarza i rozumie strumienie wideo i audio jednocześnie. - Dwukierunkowy potok WebSocket: „układ nerwowy”, który tworzy trwałe połączenie o niskim opóźnieniu między interfejsem a AI, umożliwiając interakcję w czasie rzeczywistym.
Czego się nauczysz
Technologia / Koncepcja | Opis |
Backendowy agent AI | Utwórz agenta AI z zachowywaniem stanu za pomocą Pythona i FastAPI. Użyj pakietu Agent Development Kit (ADK) od Google do zarządzania instrukcjami i pamięcią oraz |
Interfejs | Stwórz dynamiczny interfejs użytkownika za pomocą React, aby rejestrować i przesyłać transmisję na żywo wideo i audio bezpośrednio z przeglądarki. |
Komunikacja w czasie rzeczywistym | Wdróż potok WebSocket do komunikacji dwukierunkowej o niskim opóźnieniu, aby umożliwić użytkownikowi i AI jednoczesne interakcje. |
Multimodal AI | Skorzystaj z interfejsu Gemini Live API, aby przetwarzać i interpretować równoczesne strumienie wideo i audio, dzięki czemu AI będzie mogła „widzieć” i „słyszeć” w tym samym czasie. |
Wywoływanie narzędzi | Umożliwia to AI wykonywanie określonych funkcji Pythona w odpowiedzi na wizualne wyzwalacze, co eliminuje różnice między inteligencją modelu a działaniami w rzeczywistym świecie. |
Wdrożenie pełnego stosu | Umieść całą aplikację (frontend w React i backend w Pythonie) w kontenerze Dockera i wdróż ją jako skalowalną, bezserwerową usługę w Google Cloud Run. |
2. Konfigurowanie środowiska
Dostęp do Cloud Shell
Najpierw otworzymy Cloud Shell, czyli terminal w przeglądarce z zainstalowanym pakietem Google Cloud SDK i innymi niezbędnymi narzędziami.
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (jest to ikona terminala u góry panelu Cloud Shell). 
👉 Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików. 
👉Otwórz terminal w chmurowym IDE.
👉💻 W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
Twoje konto powinno być widoczne jako (ACTIVE).
Wymagania wstępne
ℹ️ Poziom 0 jest opcjonalny (ale zalecany)
Możesz ukończyć tę misję bez poziomu 0, ale jej wcześniejsze ukończenie zapewnia bardziej immersyjne wrażenia, ponieważ w miarę postępów możesz zobaczyć, jak Twój sygnał świetlny zapala się na mapie świata.
Konfigurowanie środowiska projektu
Wróć do terminala i dokończ konfigurację, ustawiając aktywny projekt i włączając wymagane usługi Google Cloud (Cloud Run, Vertex AI itp.).
👉💻 W terminalu ustaw identyfikator projektu:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Włącz wymagane usługi:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
Instalowanie zależności
👉💻 Otwórz poziom i zainstaluj wymagane pakiety Pythona:
cd $HOME/way-back-home/level_3
uv sync
Kluczowe zależności:
Pakiet | Cel |
| Wydajny framework internetowy dla stacji satelitarnej i strumieniowania SSE |
| Do uruchomienia aplikacji FastAPI wymagany jest serwer ASGI |
| Pakiet Agent Development Kit użyty do utworzenia agenta Formation Agent |
| Natywny klient do uzyskiwania dostępu do modeli Gemini |
| Obsługa dwukierunkowej komunikacji w czasie rzeczywistym |
| Zarządzanie zmiennymi środowiskowymi i tajnymi danymi konfiguracyjnymi |
Weryfikacja konfiguracji
Zanim przejdziemy do kodu, upewnijmy się, że wszystko działa prawidłowo. Uruchom skrypt weryfikacyjny, aby sprawdzić projekt Google Cloud, interfejsy API i zależności Pythona.
👉💻 Uruchom skrypt weryfikacyjny:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Powinna się wyświetlić seria zielonych znaczników wyboru (✅).
- Jeśli zobaczysz czerwone krzyżyki (❌), wykonaj sugerowane polecenia naprawy w danych wyjściowych (np.
gcloud services enable ...lubpip install ...). - Uwaga: żółte ostrzeżenie dotyczące
.envjest na razie dopuszczalne. Utworzymy ten plik w następnym kroku.
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Kalibrowanie łącza komunikacyjnego (WebSockets)
Aby rozpocząć biometryczną synchronizację neuronową, musimy zaktualizować systemy wewnętrzne statku. Naszym głównym celem jest rejestrowanie wysokiej jakości obrazu i strumienia audio z kokpitu. Ten strumień zapewnia niezbędne komponenty połączenia neuronowego: wizualną identyfikację sekwencji palców i częstotliwość dźwiękową głosu.
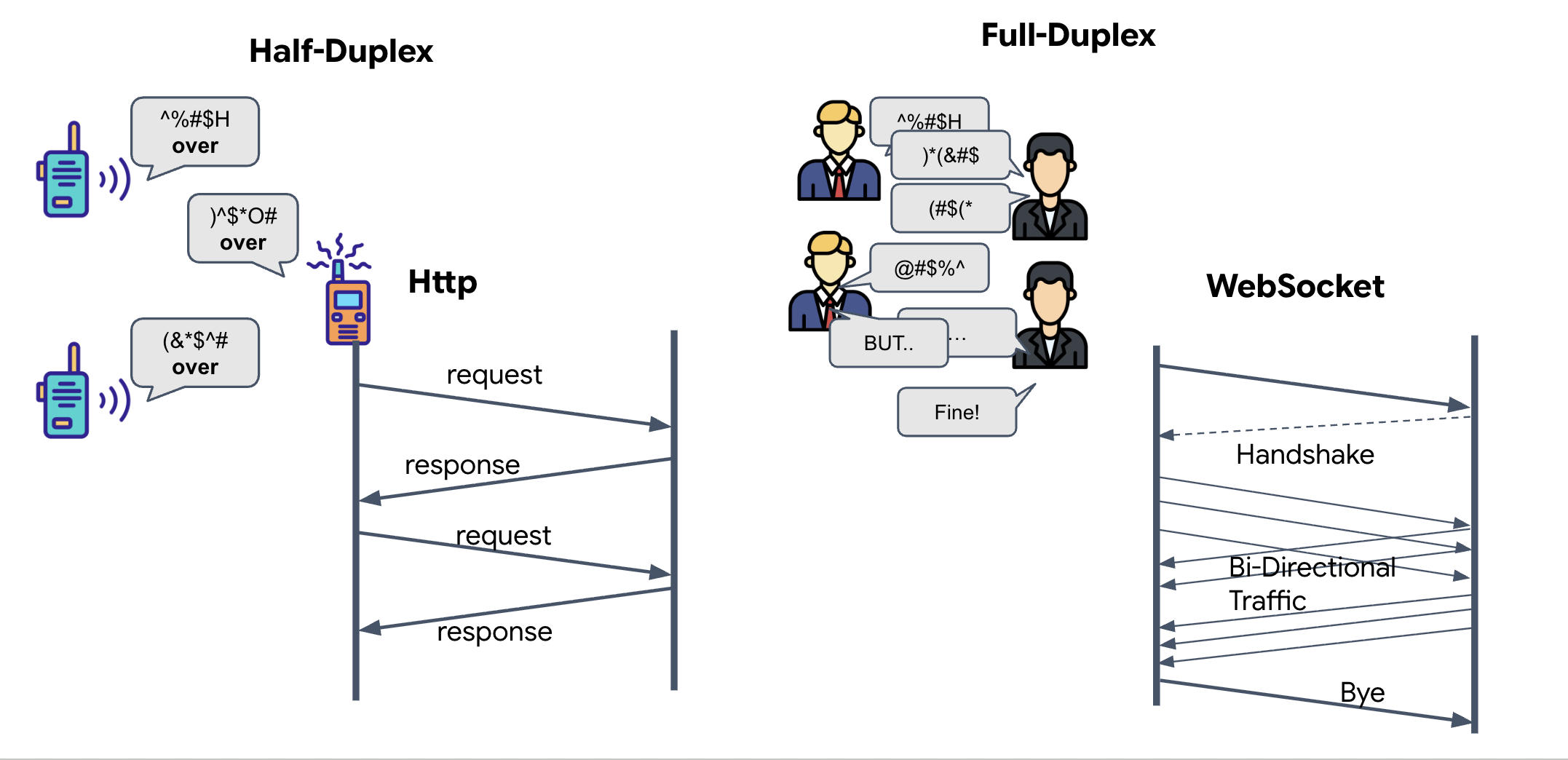
Full-duplex a half-duplex
Aby zrozumieć, dlaczego jest to potrzebne w przypadku synchronizacji neuronowej, musisz poznać przepływ danych:
- Half-Duplex (standardowy HTTP): działa jak krótkofalówka. Jedna osoba mówi, a potem mówi „Over” (Odbiór), po czym druga osoba może mówić. Nie możesz słuchać i mówić jednocześnie.
- Full-Duplex (WebSocket): podobnie jak rozmowa twarzą w twarz. Dane przepływają w obu kierunkach jednocześnie. Gdy przeglądarka przesyła klatki wideo i próbki audio do AI, AI może w tym samym czasie przesyłać odpowiedzi głosowe i polecenia narzędzi do Ciebie.
Dlaczego Gemini Live potrzebuje pełnego dupleksu: interfejs Gemini Live API został zaprojektowany z myślą o „przerwaniach”. Wyobraź sobie, że pokazujesz sekwencję palców, a AI widzi, że robisz to źle. W standardowej konfiguracji HTTP AI musiałaby poczekać, aż skończysz wysyłać dane, zanim mogłaby Cię poprosić o przerwanie. Dzięki WebSockets AI może wykryć błąd w klatce 1 i wysłać sygnał „przerwania”, który dotrze do kokpitu, gdy będziesz jeszcze poruszać ręką w klatce 2.
Co to jest WebSocket?
W standardowej transmisji galaktycznej (HTTP) wysyłasz żądanie i czekasz na odpowiedź, podobnie jak w przypadku wysyłania kartki pocztowej. W przypadku synchronizacji neuronowej pocztówki są zbyt wolne. Potrzebujemy „przewodu pod napięciem”.
WebSockets zaczynają się jako standardowe żądanie internetowe (HTTP), ale potem „ulepszają się” do czegoś innego.
- Żądanie: przeglądarka wysyła do serwera standardowe żądanie HTTP ze specjalnym nagłówkiem:
Upgrade: websocket. To tak, jakby powiedzieć: „Chcę przestać wysyłać pocztówki i zacząć rozmowę telefoniczną na żywo”. - Odpowiedź: jeśli agent AI (serwer) obsługuje tę funkcję, odsyła
HTTP 101 Switching Protocolsodpowiedź. - Transformacja: w tym momencie połączenie HTTP zostaje zastąpione protokołem WebSocket, ale podstawowe gniazdo TCP/IP pozostaje otwarte. Reguły komunikacji natychmiast zmieniają się z „Żądanie/Odpowiedź” na „Strumieniowanie dwukierunkowe”.
Wdróż funkcję WebSocket Hook
Przyjrzyjmy się blokowi zaciskowemu, aby zrozumieć, jak przepływają dane.
👀 Otwórz $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js. Zobaczysz standardowe procedury obsługi zdarzeń cyklu życia WebSocket, które są już skonfigurowane. Oto szkielet naszego systemu komunikacji:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
Moduł obsługi onMessage
Skup się na bloku ws.current.onmessage. To jest odbiornik. Za każdym razem, gdy agent „myśli” lub „mówi”, dociera tu pakiet danych. Obecnie nie robi nic – przechwytuje pakiet i go odrzuca (za pomocą symbolu zastępczego //#REPLACE-HANDLE-MSG).
Musimy wypełnić tę lukę logiką, która będzie w stanie odróżnić:
- Wywołania narzędzi (functionCall): AI rozpoznaje Twoje sygnały ręczne („Synchronizacja”).
- Dane audio (inlineData): głos AI odpowiadający na Twoje pytanie.
👉✏️ Teraz w tym samym pliku $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js zastąp //#REPLACE-HANDLE-MSG poniższą logiką, aby obsługiwać przychodzący strumień:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
Sposób przekształcania dźwięku i obrazu w dane do transmisji
Aby umożliwić komunikację w czasie rzeczywistym przez internet, surowe dane audio i wideo muszą zostać przekonwertowane na format odpowiedni do transmisji. Obejmuje to przechwytywanie, kodowanie i pakowanie danych przed wysłaniem ich przez sieć.
Przekształcanie danych audio
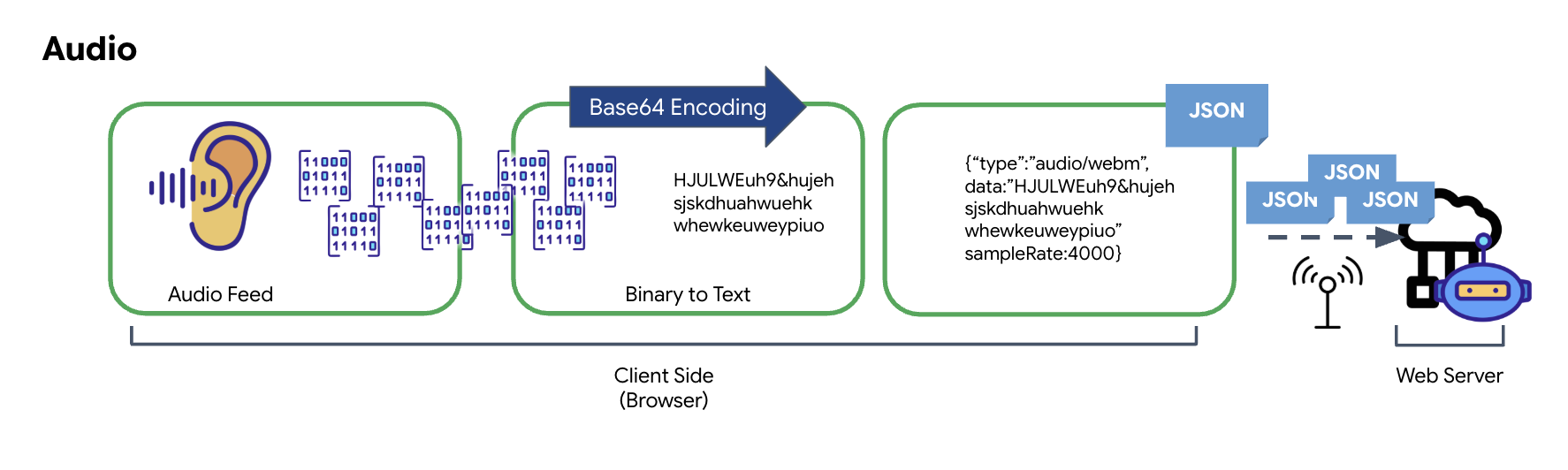
Proces konwertowania analogowego dźwięku na przesyłane dane cyfrowe rozpoczyna się od przechwytywania fal dźwiękowych za pomocą mikrofonu. Surowy dźwięk jest następnie przetwarzany za pomocą interfejsu Web Audio API przeglądarki. Ponieważ te nieprzetworzone dane są w formacie binarnym, nie są bezpośrednio zgodne z formatami transmisji tekstowej, takimi jak JSON. Aby rozwiązać ten problem, każdy segment dźwięku jest kodowany w postaci ciągu znaków Base64. Base64 to metoda reprezentowania danych binarnych w formacie ciągu ASCII, która zapewnia ich integralność podczas przesyłania.
Ten zakodowany ciąg tekstowy jest następnie osadzany w obiekcie JSON. Ten obiekt zapewnia ustrukturyzowany format danych, zwykle zawierający pole „type” (typ) do identyfikacji jako dźwięk oraz metadane, takie jak częstotliwość próbkowania dźwięku. Cały obiekt JSON jest następnie serializowany do ciągu znaków i wysyłany przez połączenie WebSocket. Dzięki temu dźwięk jest przesyłany w dobrze zorganizowany i łatwy do przeanalizowania sposób.
Przekształcanie danych wideo
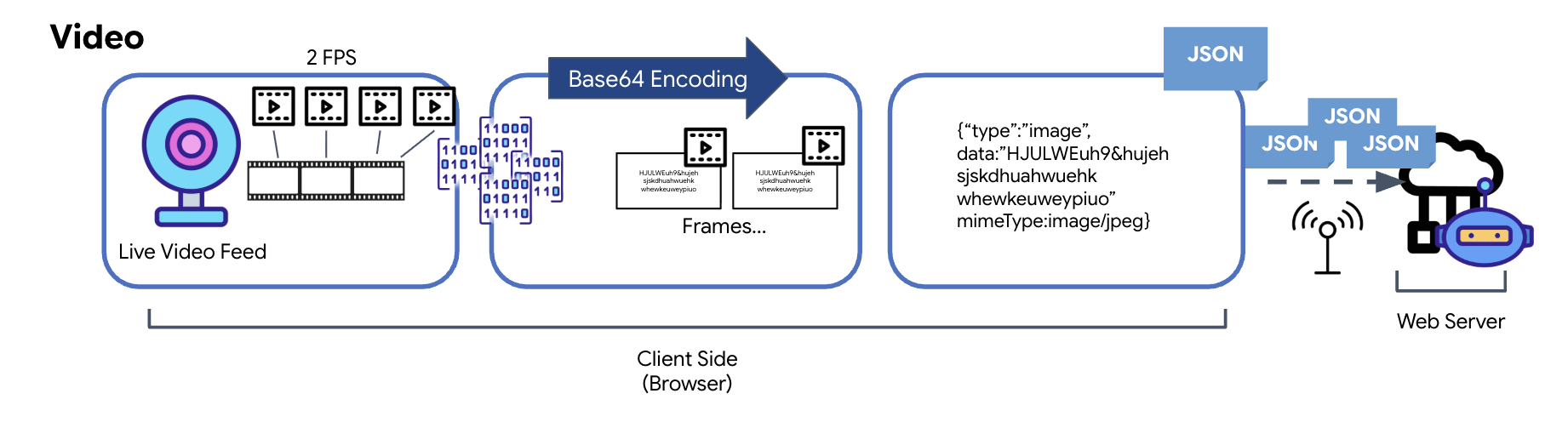
Transmisja wideo odbywa się za pomocą techniki przechwytywania klatek. Zamiast wysyłać ciągły strumień wideo, powtarzająca się pętla rejestruje obrazy z transmisji na żywo w określonych odstępach czasu, np. 2 klatki na sekundę. W tym celu bieżąca klatka z elementu wideo HTML jest rysowana na ukrytym elemencie canvas.
Metoda toDataURL elementu canvas jest następnie używana do przekształcenia przechwyconego obrazu w ciąg tekstowy JPEG zakodowany w formacie Base64. Ta metoda obejmuje opcję określania jakości obrazu, co pozwala na kompromis między wiernością obrazu a rozmiarem pliku w celu optymalizacji wydajności. Podobnie jak w przypadku danych audio ten ciąg tekstowy Base64 jest umieszczany w obiekcie JSON. Ten obiekt jest zwykle oznaczony typem „image” i zawiera mimeType, np. „image/jpeg”. Ten pakiet JSON jest następnie konwertowany na ciąg znaków i wysyłany przez WebSocket, co umożliwia odbiorcy odtworzenie filmu przez wyświetlenie sekwencji obrazów.
👉✏️ W tym samym pliku $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js zastąp //#CAPTURE AUDIO and VIDEO tym kodem, aby przechwytywać dane wejściowe użytkownika:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
Po zapisaniu kokpit będzie gotowy do tłumaczenia sygnałów cyfrowych agenta na wizualne aktualizacje panelu i dźwięk.
Test diagnostyczny (test pętli zwrotnej)
Twój kokpit jest już aktywny. Co 500 ms wysyłany jest wizualny „pakiet” informacji o Twoim otoczeniu. Zanim połączymy się z Gemini, musimy sprawdzić, czy nadajnik na Twoim statku działa. Przeprowadzimy „test pętli zwrotnej” za pomocą lokalnego serwera diagnostycznego.
👉💻 Najpierw skompiluj interfejs Cockpit w terminalu:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 Następnie uruchom serwer testowy:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 Wykonaj protokół testowy:
- Otwórz podgląd: na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce. Kliknij Zmień port, ustaw go na 8080 i kliknij Zmień i wyświetl podgląd. Otworzy się nowa karta przeglądarki z interfejsem Cockpit.
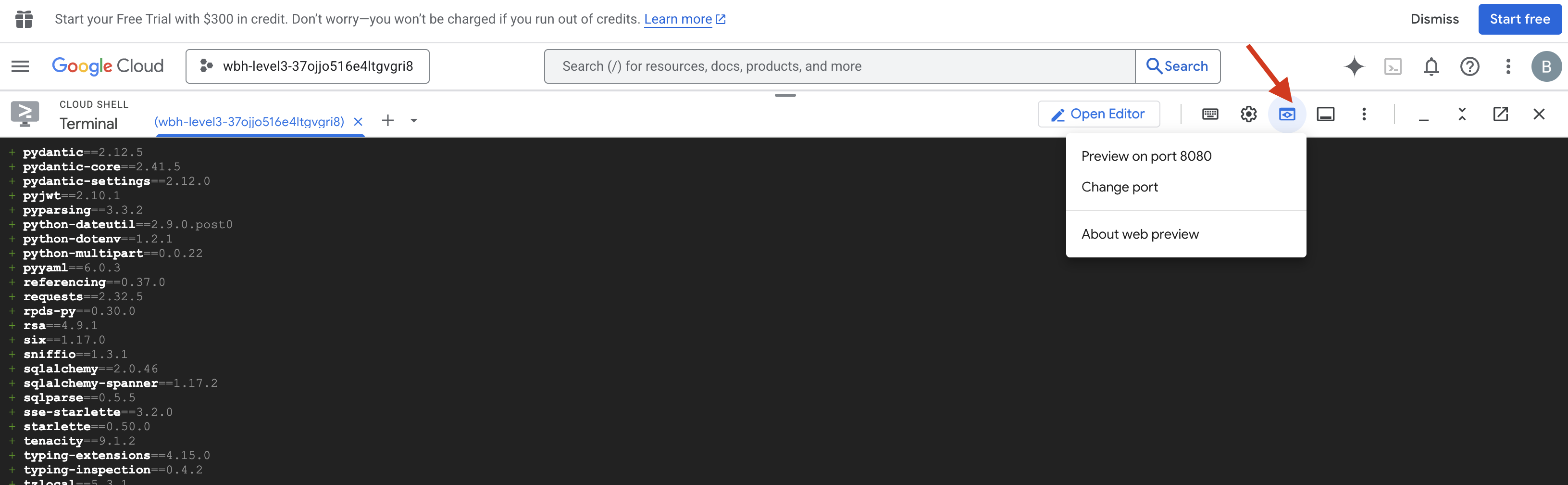
- WAŻNE: gdy pojawi się prośba, MUSISZ zezwolić przeglądarce na dostęp do kamery i mikrofonu. Bez tych danych wejściowych synchronizacja neuronowa nie może się rozpocząć.
- W interfejsie kliknij przycisk „INITIATE NEURAL SYNC” (ROZPOCZNIJ SYNCHRONIZACJĘ NEURALNĄ).
👀 Sprawdź wskaźniki stanu:
- Sprawdź wizualnie: otwórz Konsolę przeglądarki. W prawym górnym rogu powinna być widoczna ikona
NEURAL SYNC INITIALIZED. - Sprawdzenie dźwięku: jeśli dwukierunkowy potok audio działa prawidłowo, usłyszysz symulowany głos potwierdzający: „System połączony!”
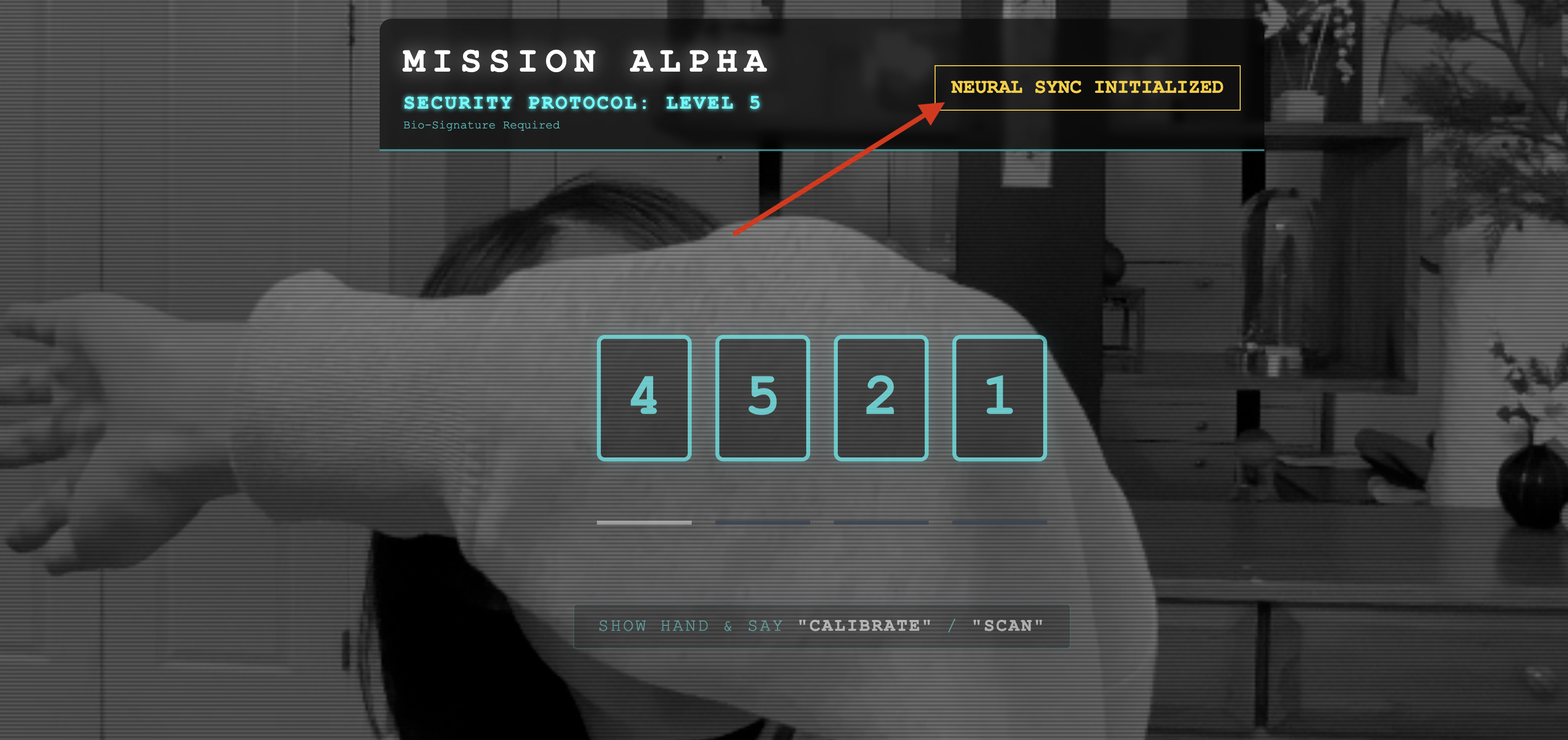
Gdy usłyszysz potwierdzenie dźwiękowe „System connected!” (System połączony!), test zakończy się sukcesem. Zamknij kartę. Musimy teraz oczyścić częstotliwość, aby zrobić miejsce dla prawdziwej AI.
👉💻 W terminalach zarówno serwera testowego, jak i frontendu naciśnij Ctrl+C. Zamknij kartę przeglądarki, na której działa interfejs.
4. Agent multimodalny
Ratownik jest sprawny, ale jego „umysł” jest pusty. Jeśli teraz się połączysz, będzie tylko na Ciebie patrzeć. Nie wie, czym jest „palec”. Aby uratować ocalałych, musisz wgrać do rdzenia zwiadowcy biometryczny protokół neuronowy.
Tradycyjny agent działa jak seria tłumaczy. Jeśli rozmawiasz ze starszą wersją AI, model „zamiany mowy na tekst” przekształca Twój głos w słowa, „model językowy” odczytuje te słowa i wpisuje odpowiedź, a model „zamiany tekstu na mowę” odczytuje ją na głos. Powoduje to „lukę w opóźnieniu”, czyli opóźnienie, które w misji ratunkowej mogłoby mieć fatalne skutki.
Gemini Live API to natywny model multimodalny. Przetwarza bezpośrednio i jednocześnie nieprzetworzone bajty audio i nieprzetworzone klatki wideo. „Słyszy” wibracje Twojego głosu i „widzi” piksele gestów dłoni w ramach tej samej architektury sieci neuronowej.
Aby wykorzystać tę moc, możemy zbudować aplikację, łącząc kokpit bezpośrednio z interfejsem Live API. Naszym celem jest jednak stworzenie agenta wielokrotnego użytku – modułowego, solidnego podmiotu, który można szybciej zbudować.
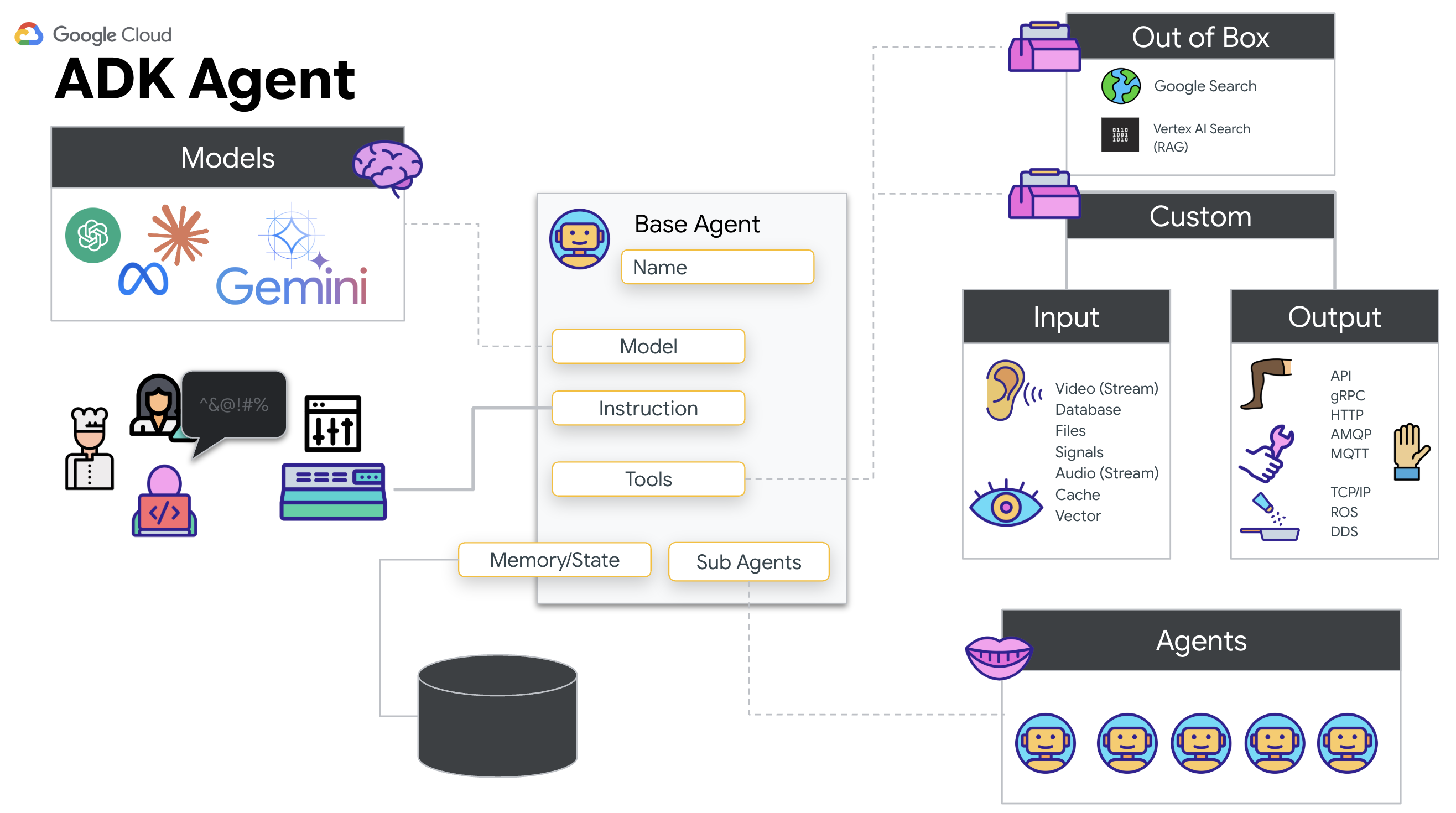
Dlaczego warto używać pakietu ADK (Agent Development Kit)?
Pakiet Google Agent Development Kit (ADK) to modułowa platforma do tworzenia i wdrażania agentów AI.
Wywołania standardowych modeli LLM są zwykle bezstanowe – każde zapytanie to nowy początek. Pracownicy obsługi klienta na żywo, zwłaszcza gdy są zintegrowani z usługą SessionService w ADK, umożliwiają prowadzenie długich sesji rozmów.
- Trwałość sesji: sesje ADK są trwałe i można je przechowywać w bazach danych (np. SQL lub Vertex AI), dzięki czemu przetrwają ponowne uruchomienie serwera i rozłączenia. Oznacza to, że jeśli użytkownik odłączy się i połączy ponownie później – nawet po kilku dniach – jego historia rozmów i kontekst zostaną w pełni przywrócone. Sesją Live API o krótkim czasie trwania zarządza ADK, który ją też abstrahuje.
- Automatyczne ponowne łączenie: połączenia WebSocket mogą wygasnąć (np. po około 10 minutach). Gdy
session_resumptionjest włączony wRunConfig, ADK obsługuje te ponowne połączenia w sposób niewidoczny dla użytkownika. Kod aplikacji nie musi zarządzać złożoną logiką ponownego łączenia, co zapewnia użytkownikowi płynne działanie. - Interakcje z zachowaniem stanu: agent zapamiętuje poprzednie tury, co umożliwia zadawanie kolejnych pytań, wyjaśnianie wątpliwości i prowadzenie złożonych dialogów wieloetapowych, w których kontekst ma kluczowe znaczenie. Jest to kluczowe w przypadku aplikacji takich jak obsługa klienta, interaktywne samouczki czy scenariusze kontroli misji, w których ciągłość jest niezbędna.
Dzięki temu interakcja przypomina ciągłą rozmowę z inteligentnym podmiotem, a nie serię odrębnych pytań i odpowiedzi.
„Live Agent” z ADK Bidi-streaming to coś więcej niż prosty mechanizm zapytań i odpowiedzi. Zapewnia on prawdziwie interaktywną, stanową i uwzględniającą przerwy konwersację, dzięki czemu interakcje z AI są bardziej naturalne i znacznie skuteczniejsze w przypadku złożonych, długotrwałych zadań.
Prośba o połączenie z pracownikiem obsługi klienta
Projektowanie prompta dla dwukierunkowego agenta działającego w czasie rzeczywistym wymaga zmiany sposobu myślenia. W przeciwieństwie do standardowego chatbota, który czeka na statyczne zapytanie tekstowe, pracownik obsługi klienta jest „zawsze włączony”. Otrzymuje on stały strumień klatek audio i wideo, co oznacza, że Twój prompt musi działać jak skrypt pętli sterującej, a nie tylko definicja osobowości.
Oto czym różni się prompt Live Agent od tradycyjnego prompta:
- Logika automatu stanów: prompt musi definiować „pętlę zachowań” (czekanie → analiza → działanie). Wymaga to wyraźnych instrukcji, kiedy ma milczeć, a kiedy się włączyć, aby zapobiec mówieniu agenta ponad pustym szumem w tle.
- Świadomość multimodalna: agent musi wiedzieć, że ma „oczy”. Musisz wyraźnie polecić mu analizowanie klatek filmu w ramach procesu rozumowania.
- Opóźnienie i zwięzłość: podczas rozmowy głosowej na żywo długie, rozbudowane akapity brzmią nienaturalnie i powoli. Prompt wymusza zwięzłość, aby interakcja była szybka.
- Architektura oparta na działaniach: instrukcje nadają priorytet wywoływaniu narzędzi przed mową. Chcemy, aby agent „wykonał” pracę (zeskanował dane biometryczne) przed lub podczas potwierdzenia ustnego, a nie po długim monologu.
👉✏️ Otwórz $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py i zastąp #REPLACE INSTRUCTIONS tym kodem:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
UWAGA! Nie łączysz się ze standardowym LLM. W tym samym pliku ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py) znajdź #REPLACE_MODEL. Musimy wyraźnie kierować reklamy na wersję przedpremierową tego modelu, aby lepiej obsługiwać funkcje audio w czasie rzeczywistym.
👉✏️ Zastąp symbol zastępczy tym tekstem:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
Agent został zdefiniowany. Wie, kim jest i jak myśleć. Następnie dajemy mu narzędzia do działania.
Wywoływanie narzędzi
Interfejs Live API nie ogranicza się tylko do wymiany strumieni tekstu, dźwięku i wideo. Natywnie obsługuje wywoływanie narzędzi. Dzięki temu agenci przestaną być pasywnymi rozmówcami i staną się aktywnymi operatorami.
Podczas dwukierunkowej sesji na żywo model stale ocenia kontekst. Jeśli LLM wykryje potrzebę wykonania działania, np. „sprawdzenia telemetrii czujnika” lub „otwarcia zabezpieczonych drzwi”. Płynnie przechodzi od rozmowy do realizacji. Agent natychmiast uruchamia konkretną funkcję narzędzia, czeka na wynik i integruje te dane z transmisją na żywo, nie przerywając interakcji.
👉✏️ W polu $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py zastąp #REPLACE TOOLS tą funkcją:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ Następnie zarejestruj go w definicji Agent, zastępując #TOOL CONFIG:
tools=[report_digit],
Symulator adk web
Zanim połączymy go ze złożonym kokpitem statku (naszym interfejsem React), powinniśmy przetestować logikę agenta w izolacji. ADK zawiera wbudowaną konsolę deweloperską o nazwie adk web, która umożliwia weryfikację wywoływania narzędzi przed dodaniem złożoności sieci.
👉💻 W terminalu uruchom:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- Na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce. Kliknij Zmień port, ustaw go na 8000 i kliknij Zmień i wyświetl podgląd.
- Przyznaj uprawnienia: gdy pojawi się prośba, zezwól na dostęp do kamery i mikrofonu.
- Rozpocznij sesję, klikając ikonę kamery.
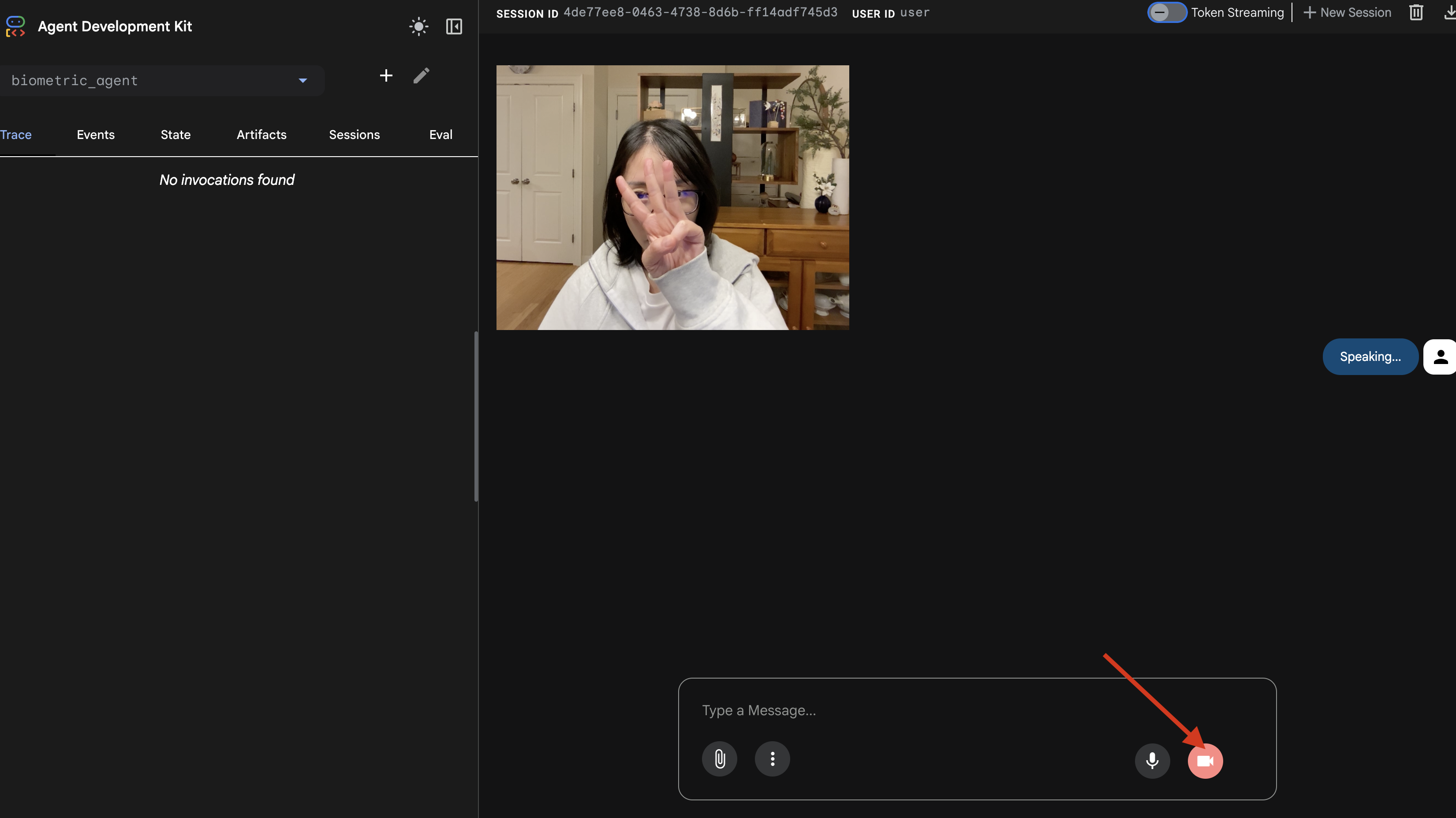
- Test wizualny:
- Wyraźnie pokaż 3 palce przed aparatem.
- Powiedz „Skanuj”.
- Weryfikacja:
- Dzienniki: sprawdź terminal, w którym uruchomiono polecenie
adk web. Musisz zobaczyć ten dziennik:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- Dzienniki: sprawdź terminal, w którym uruchomiono polecenie
Jeśli widzisz dziennik wykonywania narzędzia, Twój agent jest inteligentny. Potrafi widzieć, myśleć i działać. Ostatnim krokiem jest podłączenie go do głównego statku.
Kliknij okno terminala i naciśnij Ctrl+C, aby zatrzymać symulator adk web.
5. Dwukierunkowy przepływ transmisji
Agent działa. Kokpit działa. Teraz musimy je połączyć.
Cykl życia pracownika obsługi klienta
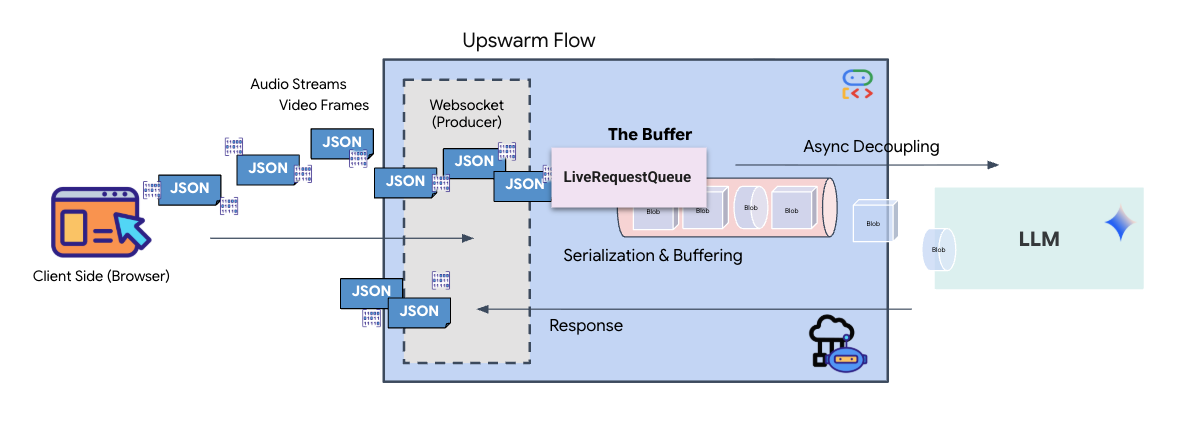
Strumieniowanie w czasie rzeczywistym powoduje problem „niedopasowania impedancji”. Klient (przeglądarka) przesyła dane asynchronicznie z różną szybkością – w postaci nagłych skoków lub szybkich serii danych wejściowych – podczas gdy model wymaga uregulowanego, sekwencyjnego strumienia danych wejściowych. Google ADK rozwiązuje ten problem, stosując LiveRequestQueue.
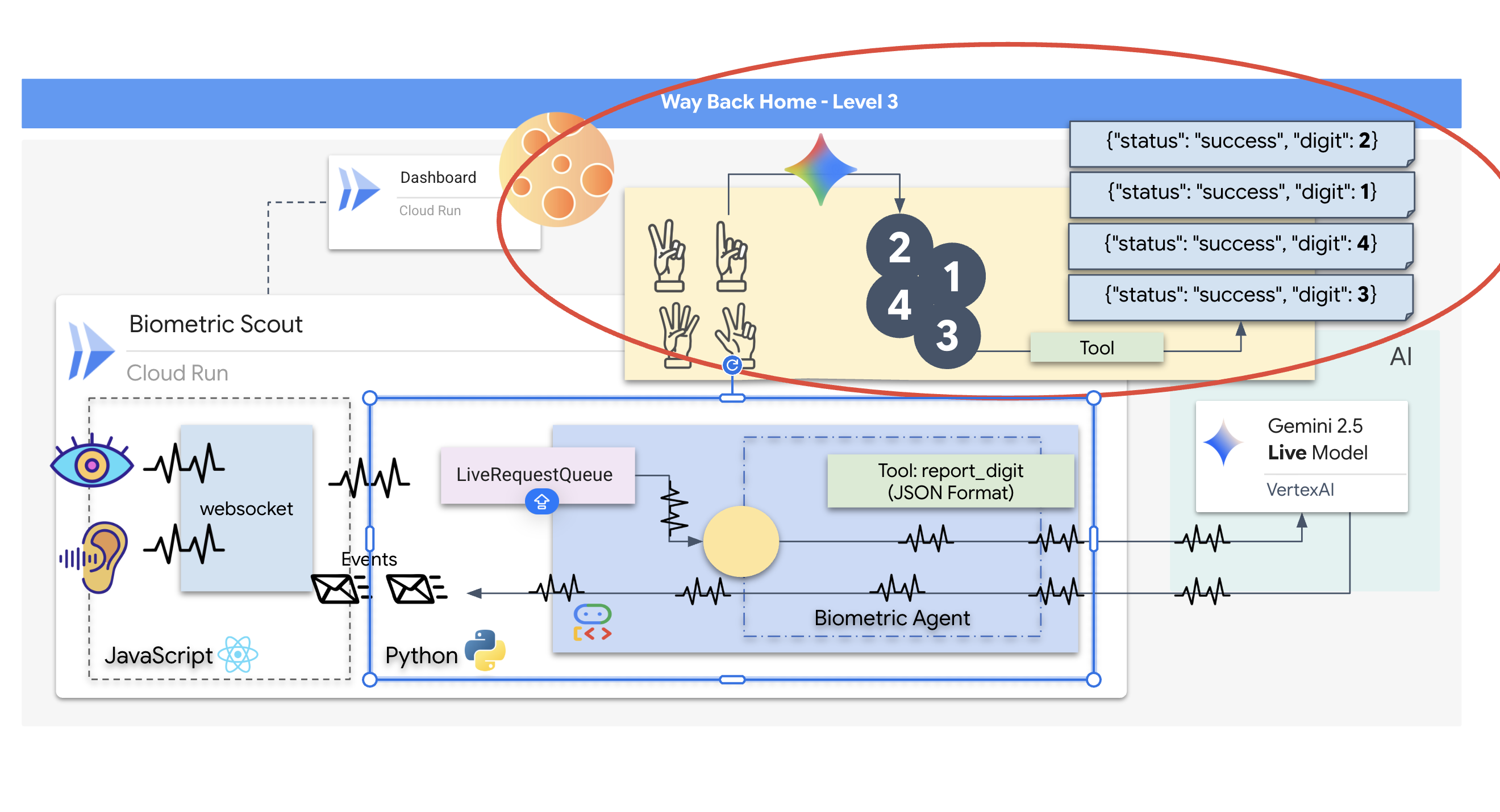
Pełni funkcję bezpiecznego wątkowo, asynchronicznego bufora FIFO (First-In-First-Out). Obsługa WebSocket działa jako producent, który umieszcza w kolejce surowe fragmenty audio i wideo. Agent ADK działa jako konsument, pobierając dane z kolejki, aby zasilać okno kontekstowe modelu. To rozdzielenie umożliwia aplikacji dalsze odbieranie danych wejściowych od użytkownika, nawet gdy model generuje odpowiedź lub wykonuje narzędzie.
Kolejka pełni funkcję multipleksera multimodalnego. W rzeczywistym środowisku przepływ danych do modelu obejmuje różne, równoległe typy danych: surowe bajty audio PCM, klatki wideo, instrukcje systemowe oparte na tekście i wyniki asynchronicznych wywołań narzędzi. LiveRequestQueue przekształca te różne dane wejściowe w jedną sekwencję chronologiczną. Niezależnie od tego, czy pakiet zawiera milisekundę ciszy, obraz o wysokiej rozdzielczości czy ładunek JSON z zapytania do bazy danych, jest on serializowany w dokładnej kolejności przybycia, co zapewnia modelowi spójną, przyczynową oś czasu.
Ta architektura umożliwia sterowanie nieblokujące. Warstwa pozyskiwania danych (producent) jest odseparowana od warstwy przetwarzania (konsument), dzięki czemu system zachowuje responsywność nawet podczas wymagającego obliczeniowo wnioskowania modelu. Jeśli użytkownik przerwie działanie narzędzia przez agenta poleceniem „Stop!”, sygnał audio zostanie natychmiast umieszczony w kolejce. Podstawowa pętla zdarzeń natychmiast przetwarza ten sygnał priorytetu, co pozwala systemowi zatrzymać generowanie lub zmienić zadania bez zawieszania interfejsu użytkownika ani utraty pakietów.
👉💻 W $HOME/way-back-home/level_3/backend/app/main.py znajdź komentarz #REPLACE_RUNNER_CONFIG i zastąp go tym kodem, aby uruchomić system:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
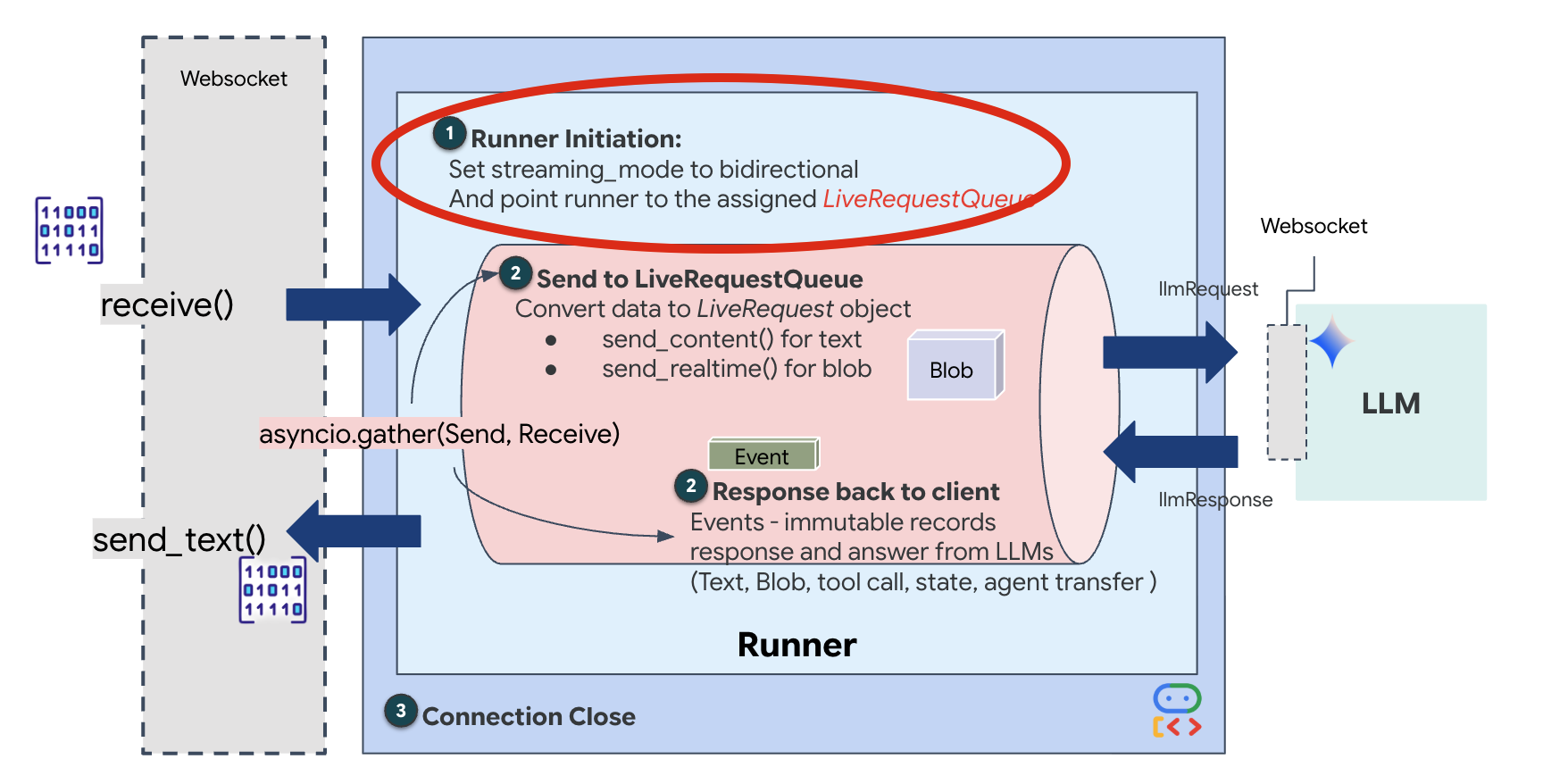
Gdy otworzy się nowe połączenie WebSocket, musimy skonfigurować sposób interakcji AI. W tym miejscu określamy „zasady zaangażowania”.
👉✏️ W $HOME/way-back-home/level_3/backend/app/main.py w funkcji async def websocket_endpoint zastąp komentarz #REPLACE_SESSION_INIT poniższym kodem:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
Konfiguracja uruchomienia
StreamingMode.BIDI: ustawia połączenie dwukierunkowe. W przeciwieństwie do AI „turowej” (gdzie mówisz, przestajesz, a potem mówi ona) BIDI umożliwia realistyczną rozmowę „full-duplex”. Możesz przerwać AI, a AI może mówić, gdy się poruszasz.AudioTranscriptionConfig: Mimo że model „słyszy” surowe dane audio, my (deweloperzy) musimy mieć dostęp do logów. Ta konfiguracja mówi Gemini: „Przetwórz dźwięk, ale prześlij też transkrypcję tekstową tego, co usłyszałeś, abyśmy mogli debugować”.
Logika wykonania: gdy Runner nawiąże sesję, przekazuje kontrolę do logiki wykonania, która korzysta z LiveRequestQueue. Jest to najważniejszy komponent interakcji w czasie rzeczywistym. Pętla umożliwia agentowi generowanie odpowiedzi głosowej, podczas gdy kolejka nadal przyjmuje nowe klatki wideo od użytkownika, dzięki czemu „synchronizacja neuronowa” nigdy nie zostaje przerwana.
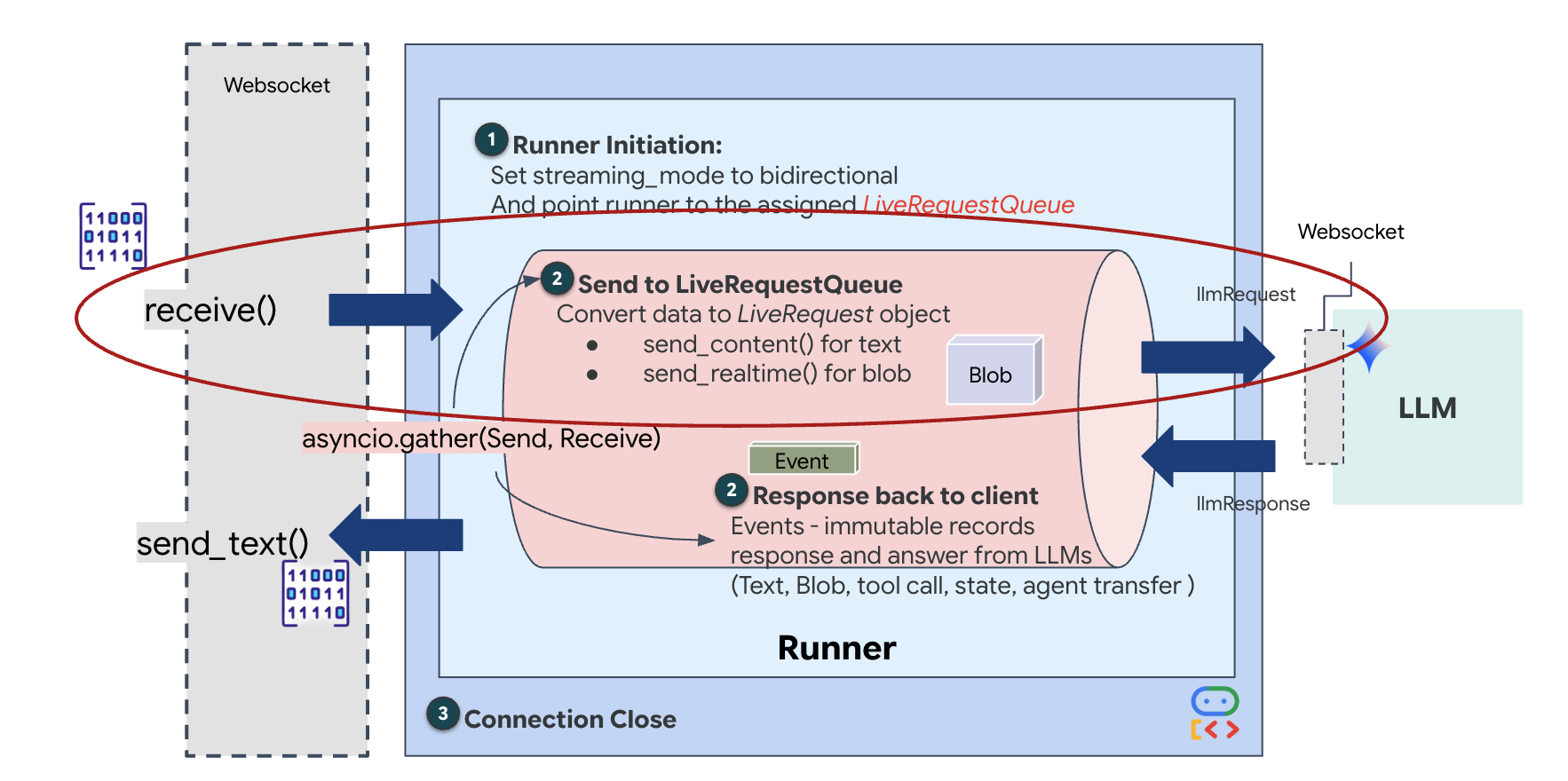
👉✏️ W $HOME/way-back-home/level_3/backend/app/main.py zastąp #REPLACE_LIVE_REQUEST, aby zdefiniować zadanie nadrzędne, które wysyła dane do LiveRequestQueue:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
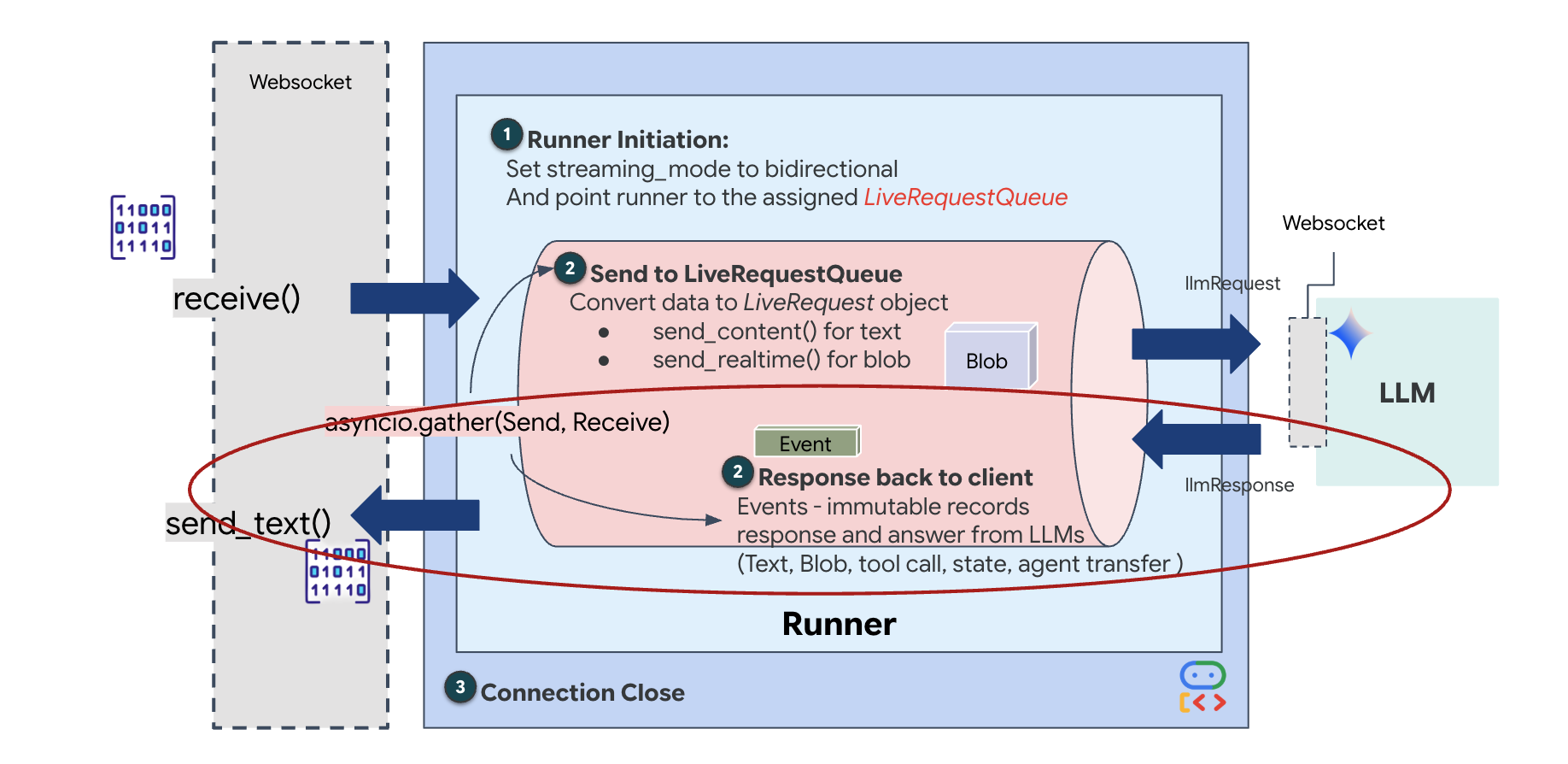
Na koniec musimy obsłużyć odpowiedzi AI. Korzysta z funkcji runner.run_live(), która jest generatorem zdarzeń (Audio, Text lub Tool Calls) w miarę ich występowania.
👉✏️ W $HOME/way-back-home/level_3/backend/app/main.py zastąp #REPLACE_SORT_RESPONSE, aby zdefiniować zadanie podrzędne i menedżera współbieżności:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
Zwróć uwagę na wiersz await asyncio.gather(upstream_task(), downstream_task()). To jest istota pełnego dupleksu. Zadanie słuchania (wysyłanie) i zadanie mówienia (pobieranie) są wykonywane w tym samym czasie. Dzięki temu „Neural Link” umożliwia przerywanie i jednoczesny przepływ danych.
Backend jest już w pełni zakodowany. „Mózg” (ADK) jest połączony z „ciałem” (WebSocket).
Wykonywanie Bio-Sync
Kod jest kompletny. Systemy są zielone. Czas rozpocząć akcję ratunkową.
- 👉💻 Uruchom backend:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 Uruchom frontend:
- Na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce. Kliknij Zmień port, ustaw go na 8080 i kliknij Zmień i wyświetl podgląd.
- 👉 Wykonaj protokół:
- Kliknij „INITIATE NEURAL SYNC” (ROZPOCZNIJ SYNCHRONIZACJĘ NEURALNĄ).
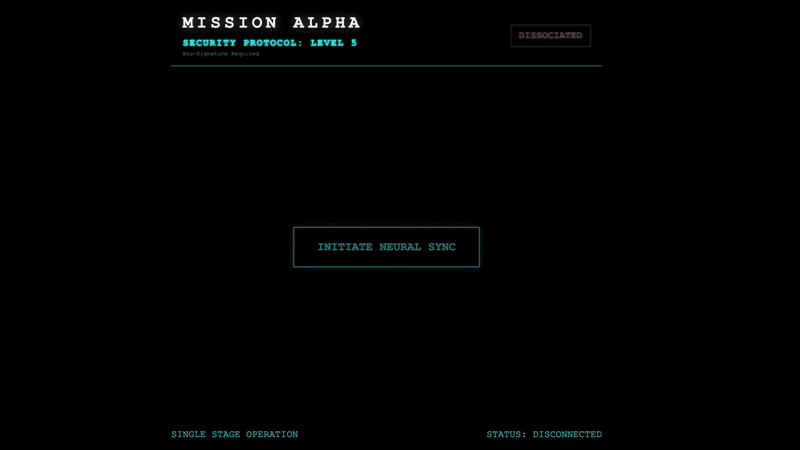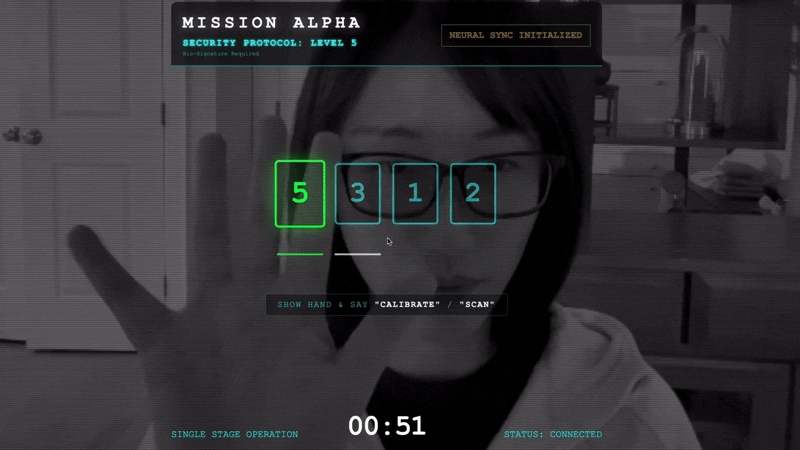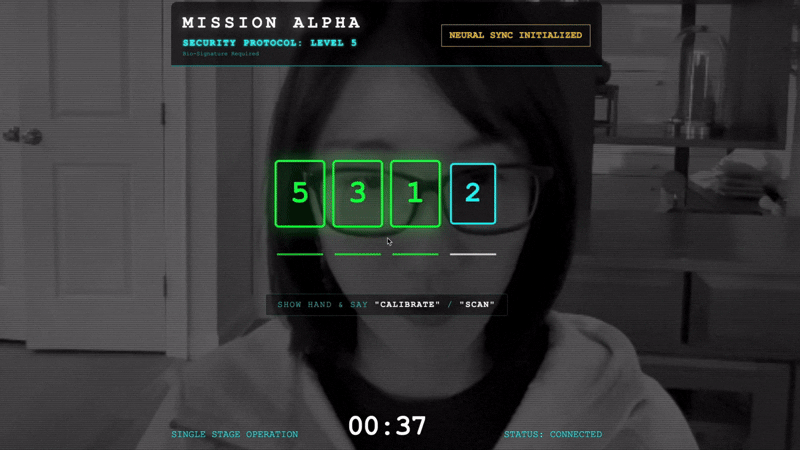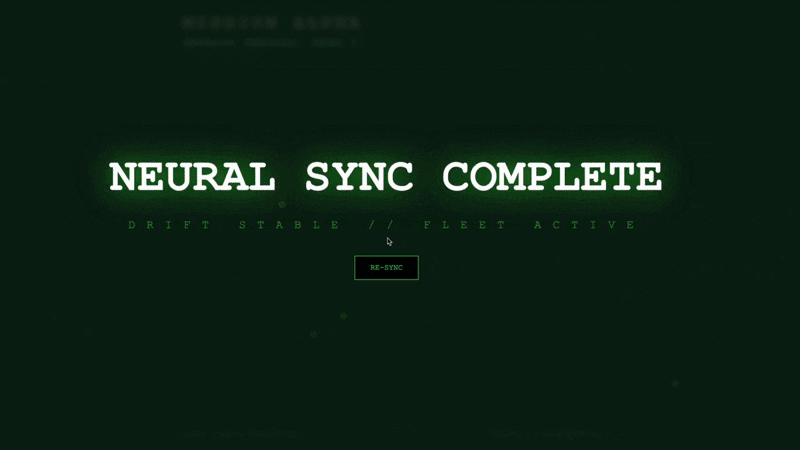
- Skalibruj: upewnij się, że kamera wyraźnie widzi Twoją dłoń na tle.
- Synchronizacja: obserwuj kod zabezpieczający wyświetlany na ekranie (np. 3, potem 2, a następnie 5).
- Dopasuj sygnał: gdy pojawi się liczba, pokaż dokładnie tyle palców.
- Trzymaj rękę nieruchomo: trzymaj rękę w widocznym miejscu, aż AI potwierdzi „Dopasowanie biometryczne”.
- Dostosuj: kod jest losowy. Od razu przejdź do następnej wyświetlanej liczby, aż sekwencja się zakończy.

- Gdy dopasujesz ostatnią liczbę w losowej sekwencji, synchronizacja biometryczna zostanie zakończona. Połączenie neuronowe zostanie zablokowane. Masz kontrolę ręczną. Silniki zwiadowców warkną, gdy będą wlatywać do Wąwozu, aby zabrać ocalałych do domu.
👉💻 Aby zamknąć terminal backendu, naciśnij Ctrl+C.
6. Wdróż w gałęzi produkcyjnej (opcjonalnie)
Udało Ci się przetestować dane biometryczne lokalnie. Teraz musimy przesłać rdzeń neuronowy Agenta do komputerów głównych statku (Cloud Run), aby mógł działać niezależnie od Twojej konsoli lokalnej.
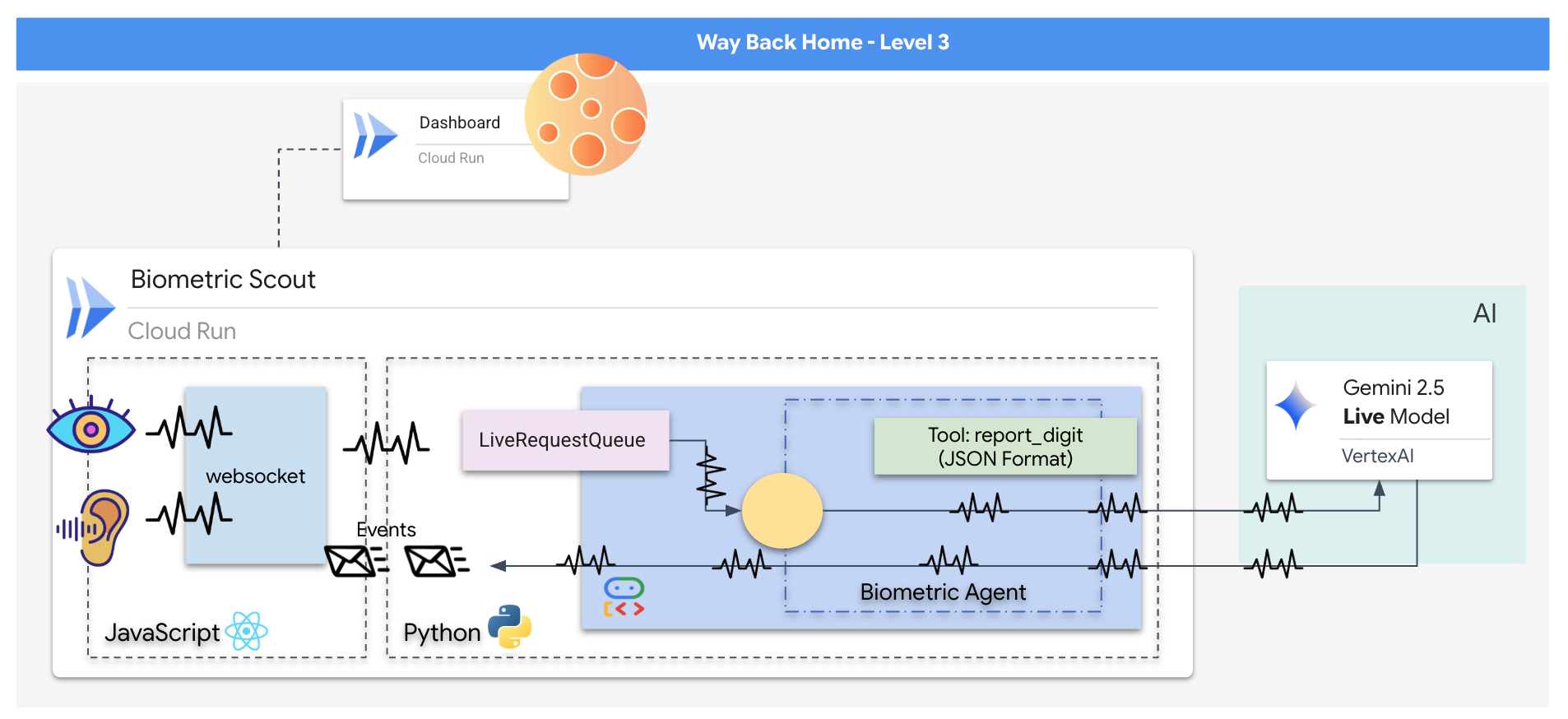
👉💻 Uruchom w terminalu Cloud Shell to polecenie. W katalogu backendu zostanie utworzony kompletny, wieloetapowy plik Dockerfile.
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 Przejdź do katalogu backendu i zapakuj aplikację w obraz kontenera.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 Wdróż usługę w Cloud Run. Wstrzykniemy niezbędne zmienne środowiskowe, w szczególności konfigurację Gemini, bezpośrednio do polecenia uruchamiania.
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
Po zakończeniu działania polecenia zobaczysz adres URL usługi (np. https://biometric-scout-...run.app). Aplikacja jest już aktywna w chmurze.
👉 Otwórz stronę Google Cloud Run i wybierz z listy usługę biometric-scout. 
👉 Znajdź publiczny adres URL wyświetlany u góry strony Szczegóły usługi. 
Spróbuj wykonać synchronizację biometryczną w tym środowisku. Czy to też działa?
Gdy wyprostujesz piąty palec, AI zablokuje sekwencję. Ekran miga na zielono: „Biometric Neural Sync: ESTABLISHED”.
Jedną myślą zanurzasz zwiadowcę w ciemności, przyczepiasz się do uwięzionej kapsuły i wyciągasz ją tuż przed tym, jak załamanie grawitacyjne się zapada.

Śluza powietrzna otwiera się z sykiem, a w niej stoi pięcioro żywych, oddychających ocalałych. Wpadają na pokład, poturbowani, ale żywi i wreszcie bezpieczni dzięki Tobie.
Dzięki Tobie połączenie neuronowe jest zsynchronizowane, a ocalałe osoby zostały uratowane.
Jeśli udało Ci się ukończyć poziom 0, nie zapomnij sprawdzić, jak Ci idzie w misji powrotnej do domu!