1. ภารกิจ

คุณกำลังล่องลอยอยู่ในความเงียบของเขตแดนที่ไม่เคยมีใครรู้จัก **พัลส์สุริยะ** ขนาดมหึมาได้ฉีกกระชากยานของคุณผ่านรอยแยก ทำให้คุณติดอยู่ตรงส่วนเล็กๆ ของจักรวาลที่ไม่มีอยู่ในแผนที่ดาว
หลังจากซ่อมอย่างหนักหน่วงมาหลายวัน ในที่สุดคุณก็รู้สึกถึงเสียงเครื่องยนต์ที่อยู่ใต้เท้า จรวดของคุณได้รับการซ่อมแล้ว คุณยังสามารถรักษาการอัปลิงก์ระยะไกลไปยังยานแม่ได้อีกด้วย คุณได้รับอนุญาตให้ออกเดินทาง คุณพร้อมที่จะกลับบ้านแล้ว แต่ในขณะที่คุณเตรียมพร้อมที่จะเปิดใช้งานจัมป์ไดรฟ์ สัญญาณขอความช่วยเหลือก็แทรกเข้ามาในสัญญาณรบกวน เซ็นเซอร์ตรวจจับร่องรอยความร้อนจางๆ 5 จุดที่ติดอยู่ใน"The Ravine" ซึ่งเป็นเขตแดนที่ขรุขระและแรงโน้มถ่วงบิดเบือนจนยานหลักของคุณไม่สามารถเข้าไปได้ คนเหล่านี้คือเพื่อนร่วมทาง ผู้รอดชีวิตจากพายุลูกเดียวกันที่เกือบจะคร่าชีวิตคุณ คุณจะทิ้งไว้ไม่ได้
คุณจึงหันไปหา Alpha-Drone Rescue Scout เรือขนาดเล็กที่คล่องตัวนี้เป็นเรือเพียงลำเดียวที่สามารถแล่นผ่านกำแพงแคบๆ ของ The Ravine ได้ แต่มีปัญหาเกิดขึ้นคือ พัลส์สุริยะได้ทำการ "รีเซ็ตระบบ" ทั้งหมดในตรรกะหลัก ระบบควบคุมของ Scout ไม่ตอบสนอง โดรนเปิดอยู่ แต่คอมพิวเตอร์ออนบอร์ดเป็นหน้าว่าง ไม่สามารถประมวลผลคำสั่งของนักบินหรือเส้นทางการบินได้
ความท้าทาย
หากต้องการช่วยผู้รอดชีวิต คุณต้องข้ามวงจรที่เสียหายของสเกาต์ทั้งหมด คุณมีทางเลือกสุดท้ายคือสร้างเอเจนต์ AI เพื่อสร้างการซิงค์ประสาทไบโอเมตริก เอเจนต์นี้จะทำหน้าที่เป็นสะพานเชื่อมแบบเรียลไทม์ ซึ่งช่วยให้คุณควบคุม Rescue Scout ได้ด้วยตนเองผ่านอินพุตทางชีวภาพของคุณเอง คุณจะไม่ใช้จอยสติ๊กหรือแป้นพิมพ์ แต่จะเชื่อมต่อความตั้งใจของคุณเข้ากับเครือข่ายการนำทางของยานโดยตรง
หากต้องการล็อกลิงก์ คุณต้องทำตามโปรโตคอลการซิงโครไนซ์ที่ด้านหน้าเซ็นเซอร์ออปติคัลของ Scout เอเจนต์ AI ต้องจดจำลายเซ็นทางชีวภาพของคุณผ่านการแฮนด์เชคแบบเรียลไทม์ที่แม่นยำ
วัตถุประสงค์ของภารกิจ:
- ฝัง Neural Core: กำหนด Agent ของ ADK ที่สามารถจดจำอินพุตแบบหลายรูปแบบได้
- สร้างการเชื่อมต่อ: สร้างไปป์ไลน์ WebSocket แบบ 2 ทิศทางเพื่อสตรีมข้อมูลภาพจาก Scout ไปยัง AI
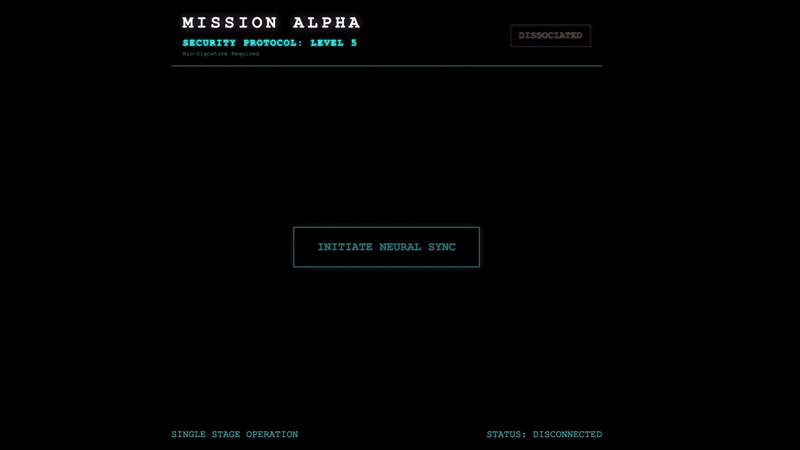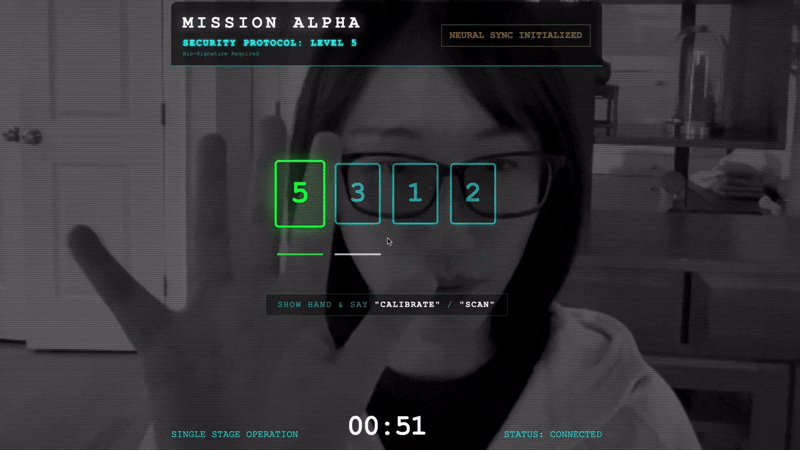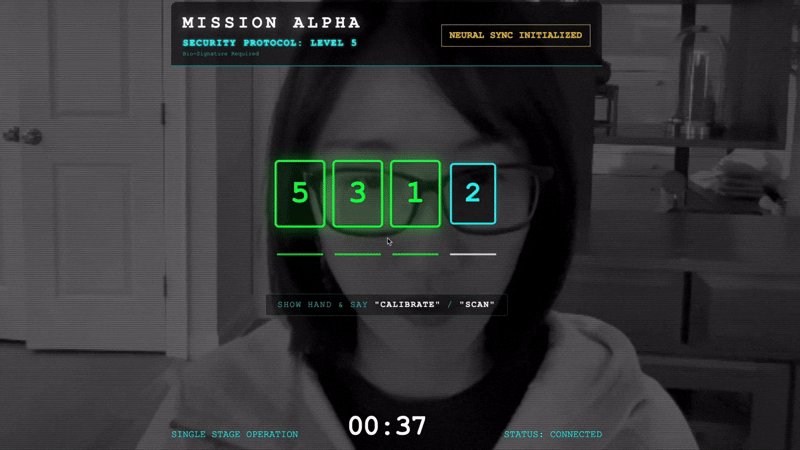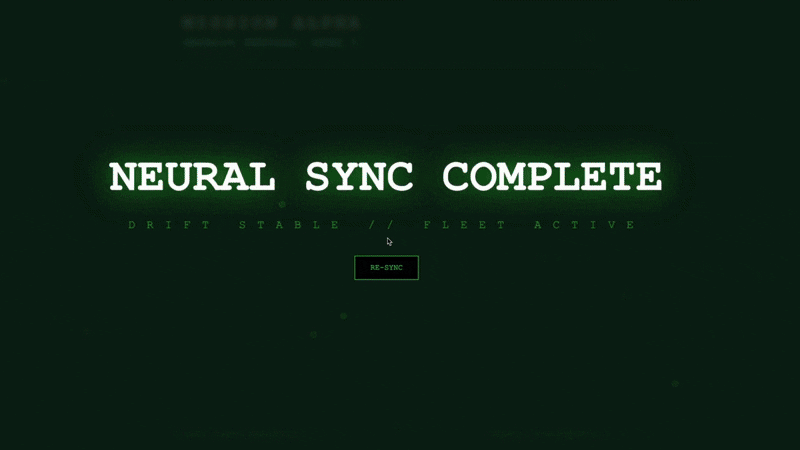
- เริ่มการจับมือ: ยืนต่อหน้าเซ็นเซอร์และทำตามลำดับนิ้ว โดยแสดงนิ้ว 1-5 ตามลำดับ
หากสำเร็จ "การซิงค์ข้อมูลไบโอเมตริก" จะทำงาน AI จะล็อกการเชื่อมต่อประสาท ทำให้คุณควบคุมด้วยตนเองได้อย่างเต็มที่เพื่อเปิดตัว Scout และนำผู้รอดชีวิตเหล่านั้นกลับบ้าน
สิ่งที่คุณจะสร้าง
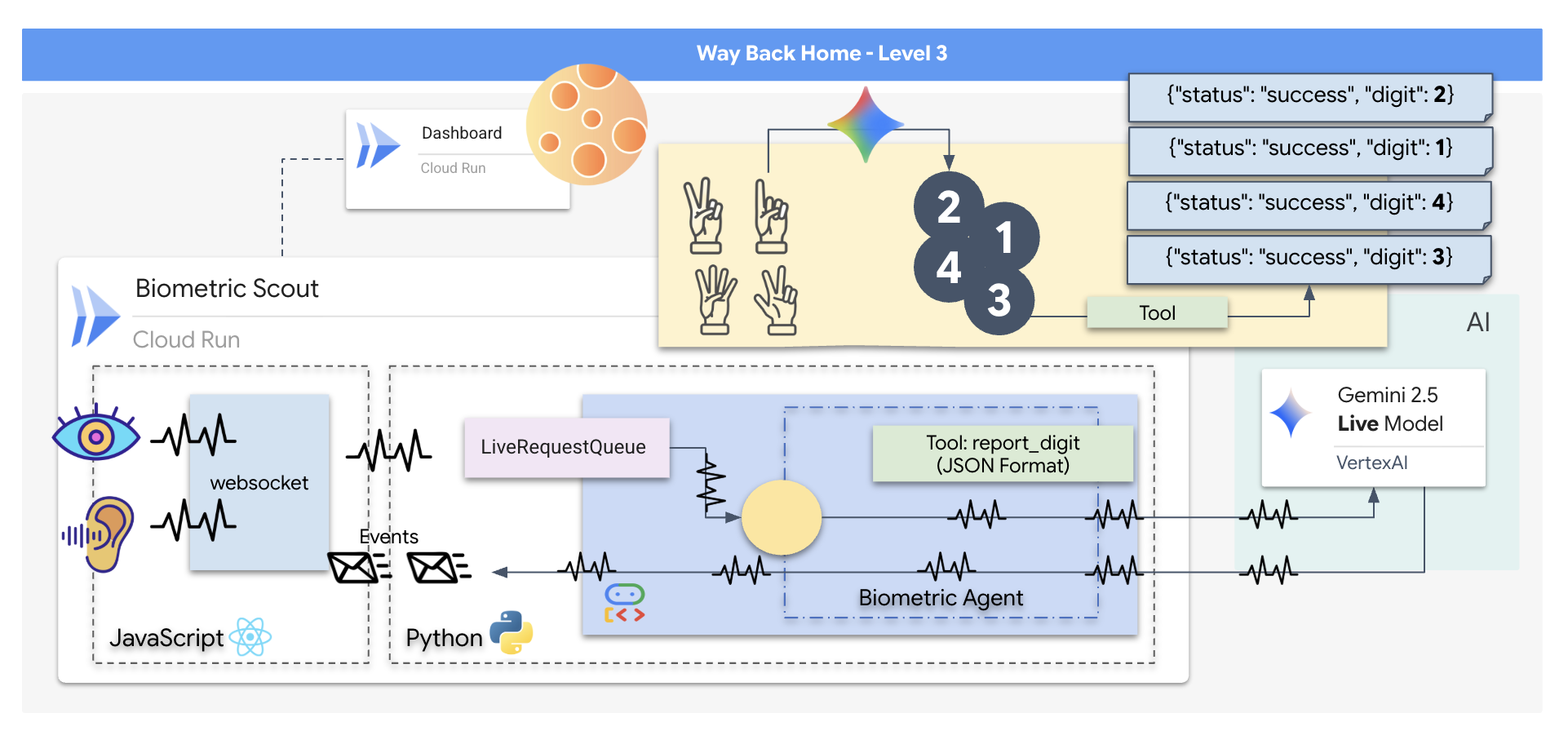
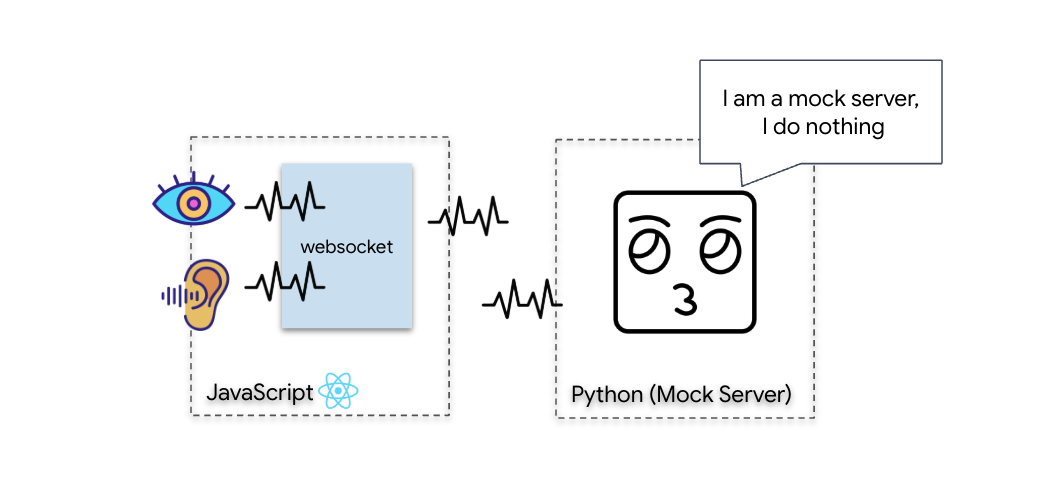
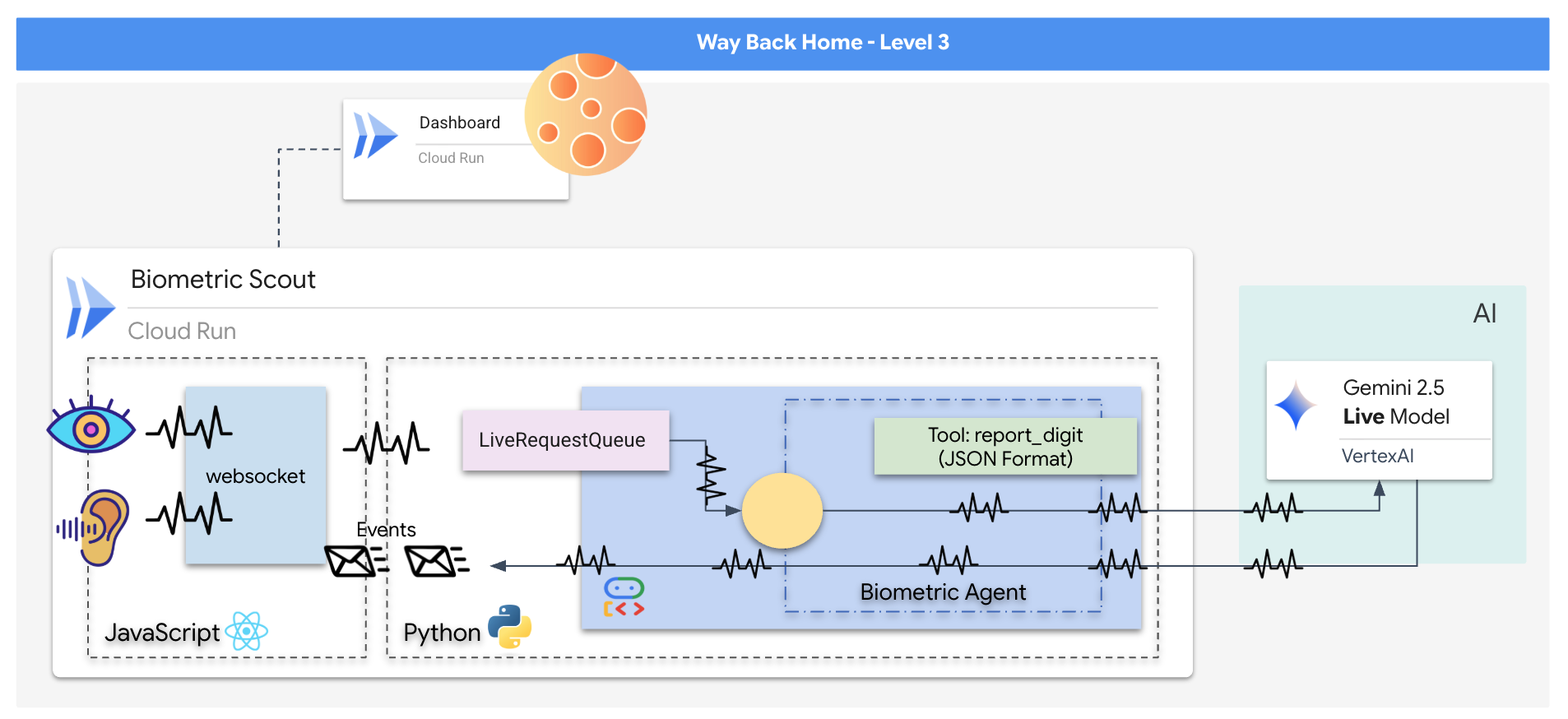
คุณจะสร้างแอปพลิเคชัน "Biometric Neural Sync" ซึ่งเป็นระบบที่ทำงานด้วยระบบ AI แบบเรียลไทม์ที่ทำหน้าที่เป็นอินเทอร์เฟซควบคุมสำหรับโดรนกู้ภัย ระบบนี้ประกอบด้วย
- ฟรอนท์เอนด์ React: "ห้องควบคุม" ของยาน ซึ่งจะบันทึกวิดีโอสดจากเว็บแคมและเสียงจากไมโครโฟน
- แบ็กเอนด์ Python: เซิร์ฟเวอร์ประสิทธิภาพสูงที่สร้างด้วย FastAPI โดยใช้ Agent Development Kit (ADK) ของ Google เพื่อจัดการตรรกะและสถานะของ LLM
- เอเจนต์ AI แบบมัลติโมดอล: "สมอง" ของการทำงาน โดยใช้ Gemini Live API ผ่าน
google-genaiSDK เพื่อประมวลผลและทำความเข้าใจสตรีมวิดีโอและเสียงพร้อมกัน - ไปป์ไลน์ WebSocket แบบ 2 ทิศทาง: "ระบบประสาท" ที่สร้างการเชื่อมต่อแบบถาวรที่มีเวลาในการตอบสนองต่ำระหว่างฟรอนท์เอนด์กับ AI ซึ่งช่วยให้เกิดการโต้ตอบแบบเรียลไทม์
สิ่งที่คุณจะได้เรียนรู้
เทคโนโลยี / แนวคิด | คำอธิบาย |
เอเจนต์ AI แบ็กเอนด์ | สร้าง AI Agent แบบมีสถานะด้วย Python และ FastAPI ใช้ ADK (Agent Development Kit) ของ Google เพื่อจัดการคำสั่งและหน่วยความจำ และใช้ |
UI ของฟรอนท์เอนด์ | พัฒนาอินเทอร์เฟซผู้ใช้แบบไดนามิกโดยใช้ React เพื่อจับภาพและสตรีมวิดีโอสดและเสียงจากเบราว์เซอร์โดยตรง |
การสื่อสารแบบเรียลไทม์ | ใช้ไปป์ไลน์ WebSocket สำหรับการสื่อสารแบบฟูลดูเพล็กซ์ที่มีเวลาในการตอบสนองต่ำ เพื่อให้ผู้ใช้และ AI โต้ตอบได้พร้อมกัน |
AI แบบมัลติโมดัล | ใช้ประโยชน์จาก Gemini Live API เพื่อประมวลผลและทำความเข้าใจสตรีมวิดีโอและเสียงที่เกิดขึ้นพร้อมกัน ซึ่งจะช่วยให้ AI "เห็น" และ "ได้ยิน" ในเวลาเดียวกัน |
การเรียกใช้เครื่องมือ | เปิดใช้ AI เพื่อเรียกใช้ฟังก์ชัน Python ที่เฉพาะเจาะจงเพื่อตอบสนองต่อทริกเกอร์ภาพ ซึ่งจะช่วยเชื่อมช่องว่างระหว่างความฉลาดของโมเดลกับการดำเนินการในโลกแห่งความเป็นจริง |
การติดตั้งใช้งานแบบ Full Stack | สร้างคอนเทนเนอร์ทั้งแอปพลิเคชัน (ส่วนหน้าของ React และส่วนหลังของ Python) ด้วย Docker แล้วทำให้ใช้งานได้เป็นบริการแบบ Serverless ที่รองรับการปรับขนาดใน Google Cloud Run |
2. ตั้งค่าสภาพแวดล้อม
เข้าถึง Cloud Shell
ก่อนอื่น เราจะเปิด Cloud Shell ซึ่งเป็นเทอร์มินัลบนเบราว์เซอร์ที่มี Google Cloud SDK และเครื่องมือสำคัญอื่นๆ ติดตั้งไว้ล่วงหน้า
👉คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud (ไอคอนรูปเทอร์มินัลที่ด้านบนของแผง Cloud Shell) 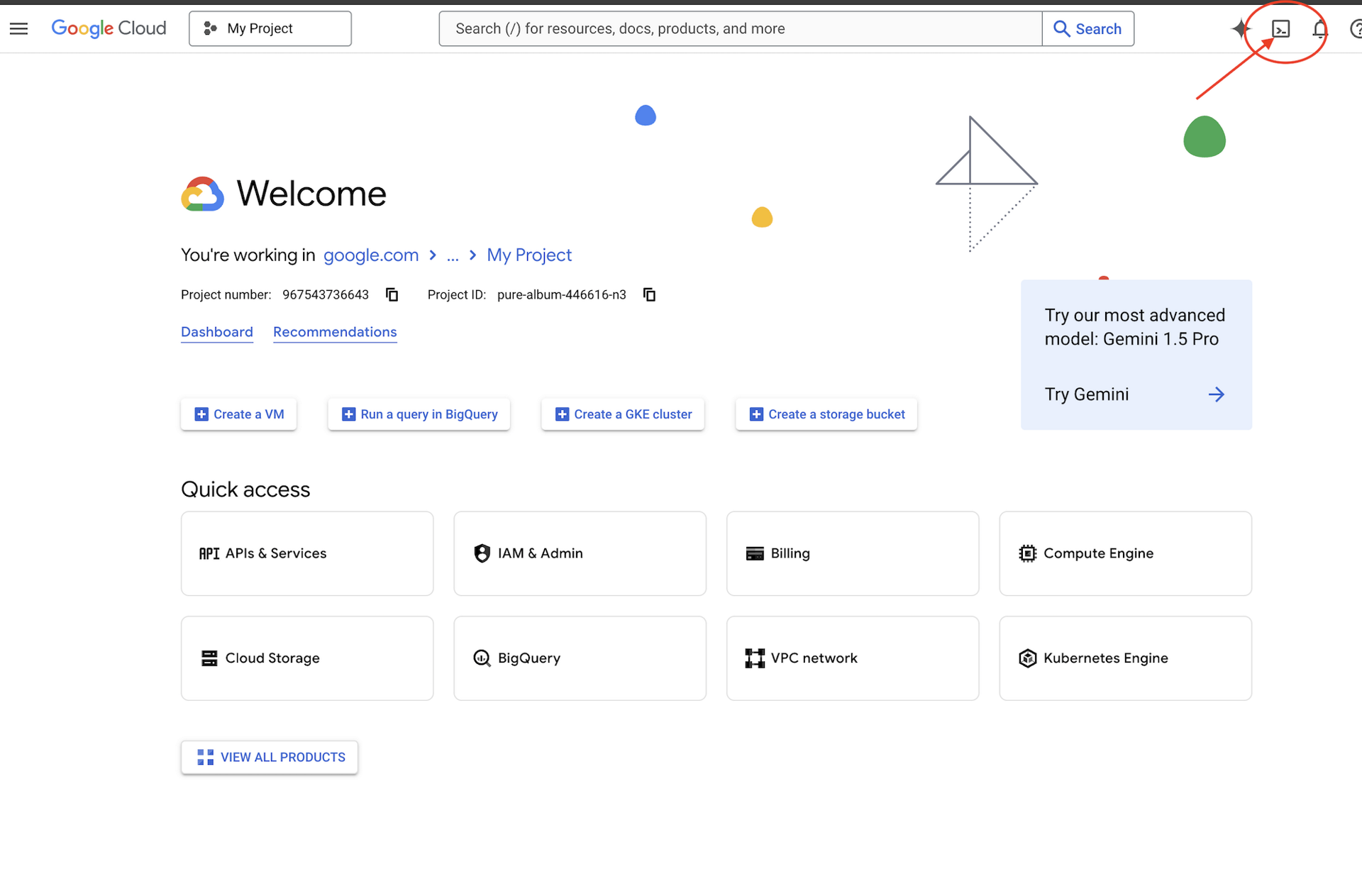
👉คลิกปุ่ม "เปิดตัวแก้ไข" (ลักษณะเป็นโฟลเดอร์ที่เปิดอยู่พร้อมดินสอ) ซึ่งจะเปิดตัวแก้ไขโค้ด Cloud Shell ในหน้าต่าง คุณจะเห็น File Explorer ทางด้านซ้าย 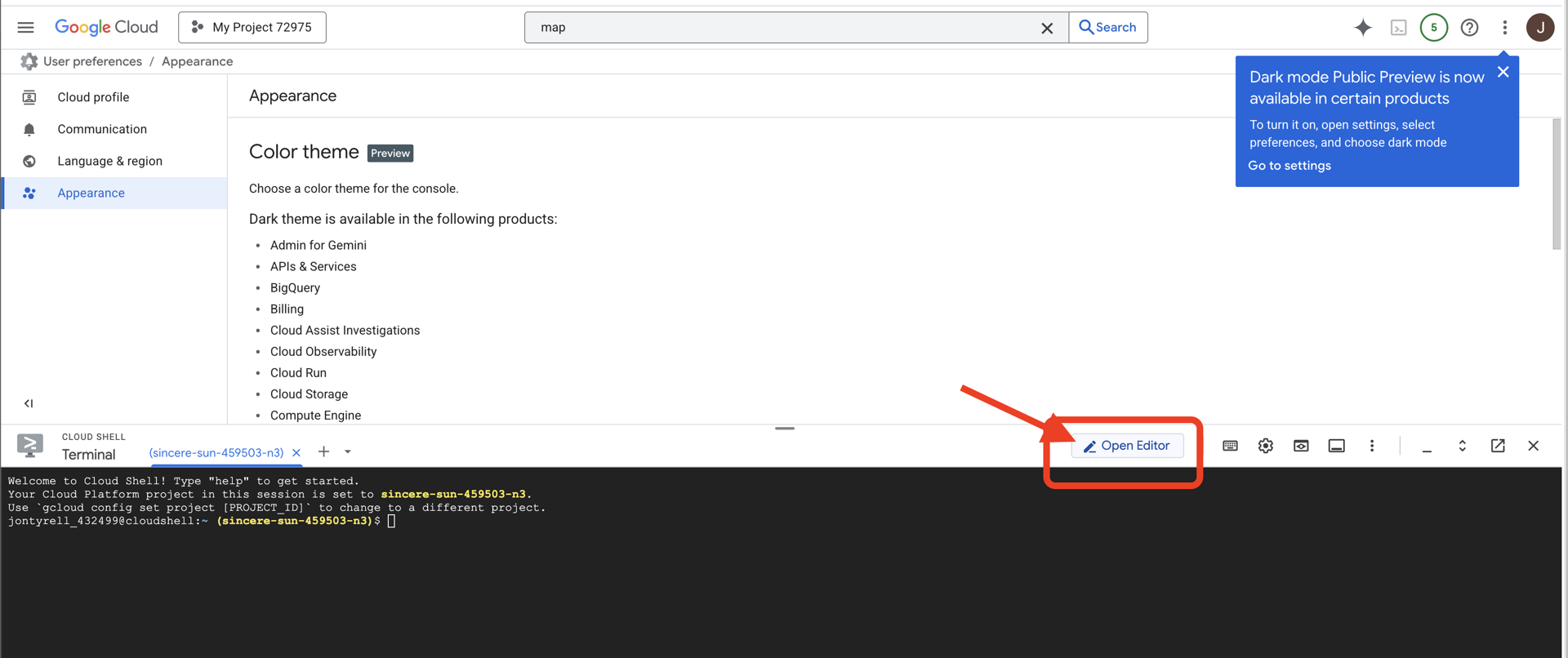
👉เปิดเทอร์มินัลใน Cloud IDE
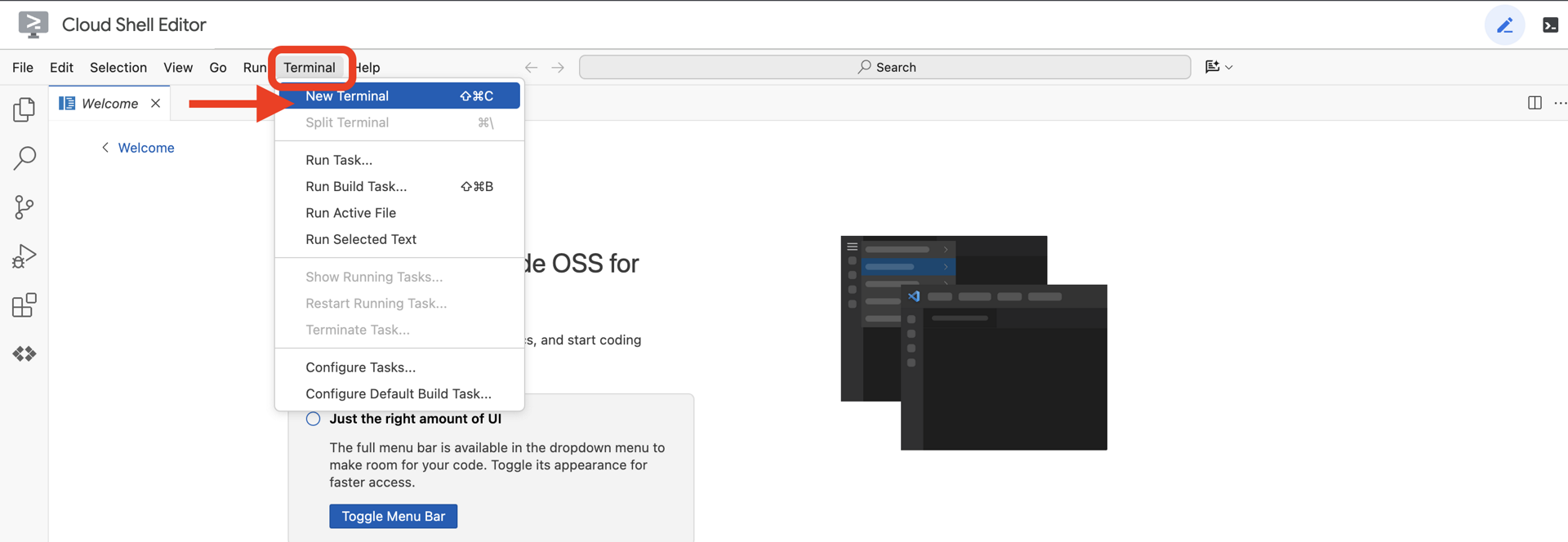
👉💻 ในเทอร์มินัล ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
คุณควรเห็นบัญชีของคุณแสดงเป็น (ACTIVE)
ข้อกำหนดเบื้องต้น
ℹ️ ระดับ 0 ไม่บังคับ (แต่แนะนำ)
คุณทำภารกิจนี้ให้เสร็จได้โดยไม่ต้องมีเลเวล 0 แต่การทำภารกิจนี้ให้เสร็จก่อนจะช่วยให้คุณได้รับประสบการณ์ที่สมจริงยิ่งขึ้น โดยคุณจะเห็นบีคอนสว่างขึ้นบนแผนที่โลกเมื่อมีความคืบหน้า
ตั้งค่าสภาพแวดล้อมของโปรเจ็กต์
กลับไปที่เทอร์มินัลของคุณ แล้วทำการกำหนดค่าให้เสร็จสมบูรณ์โดยการตั้งค่าโปรเจ็กต์ที่ใช้งานอยู่และเปิดใช้บริการ Google Cloud ที่จำเป็น (Cloud Run, Vertex AI ฯลฯ)
👉💻 ในเทอร์มินัล ให้ตั้งรหัสโปรเจ็กต์ดังนี้
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 เปิดใช้บริการที่จำเป็น
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
ติดตั้งการอ้างอิง
👉💻 ไปที่ Level แล้วติดตั้งแพ็กเกจ Python ที่จำเป็น
cd $HOME/way-back-home/level_3
uv sync
โดยมีข้อกำหนดที่สำคัญดังนี้
แพ็กเกจ | วัตถุประสงค์ |
| เฟรมเวิร์กเว็บประสิทธิภาพสูงสำหรับสถานีภาคพื้นดินและสตรีมมิง SSE |
| ต้องมีเซิร์ฟเวอร์ ASGI เพื่อเรียกใช้แอปพลิเคชัน FastAPI |
| Agent Development Kit ที่ใช้สร้าง Formation Agent |
| ไคลเอ็นต์ดั้งเดิมสำหรับการเข้าถึงโมเดล Gemini |
| รองรับการสื่อสารแบบเรียลไทม์แบบ 2 ทาง |
| จัดการตัวแปรสภาพแวดล้อมและข้อมูลลับในการกำหนดค่า |
ยืนยันการตั้งค่า
ก่อนที่จะเริ่มเขียนโค้ด เรามาตรวจสอบกันก่อนว่าทุกระบบพร้อมทำงาน เรียกใช้สคริปต์การยืนยันเพื่อตรวจสอบโปรเจ็กต์ Google Cloud, API และการอ้างอิง Python
👉💻 เรียกใช้สคริปต์การยืนยัน
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 คุณควรเห็นเครื่องหมายถูกสีเขียว (✅) หลายรายการ
- หากเห็นกากบาทสีแดง (❌) ให้ทำตามคำสั่งแก้ไขที่แนะนำในเอาต์พุต (เช่น
gcloud services enable ...หรือpip install ...) - หมายเหตุ: ตอนนี้เรายอมรับคำเตือนสีเหลืองสำหรับ
.envแล้ว และจะสร้างไฟล์ดังกล่าวในขั้นตอนถัดไป
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. การปรับเทียบ Comm-Link (WebSocket)
หากต้องการเริ่มการซิงค์ประสาทไบโอเมตริก เราต้องอัปเดตระบบภายในของยาน เป้าหมายหลักของเราคือการบันทึกวิดีโอและสตรีมเสียงที่มีความเที่ยงตรงสูงจากห้องนักบิน สตรีมนี้มีองค์ประกอบที่จำเป็นสำหรับลิงก์ประสาท ได้แก่ การระบุภาพของลำดับนิ้วและความถี่เสียงของเสียงของคุณ
Full-Duplex กับ Half-Duplex
หากต้องการทราบเหตุผลที่เราต้องใช้ข้อมูลนี้สำหรับการซิงค์แบบนิวรอล คุณต้องเข้าใจขั้นตอนการไหลของข้อมูลดังนี้
- Half-Duplex (HTTP มาตรฐาน): เหมือนวอล์คกี้ทอล์คกี้ โดยคนหนึ่งพูดแล้วพูดว่า "จบ" จากนั้นอีกคนก็พูดได้ คุณจะฟังและพูดพร้อมกันไม่ได้
- Full-Duplex (WebSocket): เหมือนการสนทนาแบบเห็นหน้า ข้อมูลจะไหลทั้ง 2 ทิศทางพร้อมกัน ในขณะที่เบราว์เซอร์ส่งเฟรมวิดีโอและตัวอย่างเสียงขึ้นไปยัง AI ทาง AI ก็สามารถส่งคำตอบด้วยเสียงและคำสั่งเครื่องมือลงมาให้คุณได้ในเวลาเดียวกัน
เหตุผลที่ Gemini Live ต้องใช้การสื่อสารแบบฟูลดูเพล็กซ์: Gemini Live API ออกแบบมาเพื่อ"การขัดจังหวะ" ลองนึกภาพว่าคุณกำลังแสดงลำดับนิ้ว แต่ AI เห็นว่าคุณทำผิด ในการตั้งค่า HTTP มาตรฐาน AI จะต้องรอให้คุณส่งข้อมูลเสร็จก่อนจึงจะบอกให้คุณหยุดได้ เมื่อใช้ WebSockets, AI จะเห็นข้อผิดพลาดในเฟรม 1 และส่งสัญญาณ "หยุดชะงัก" ซึ่งจะปรากฏในห้องนักบินขณะที่คุณยังคงขยับมือสำหรับเฟรม 2
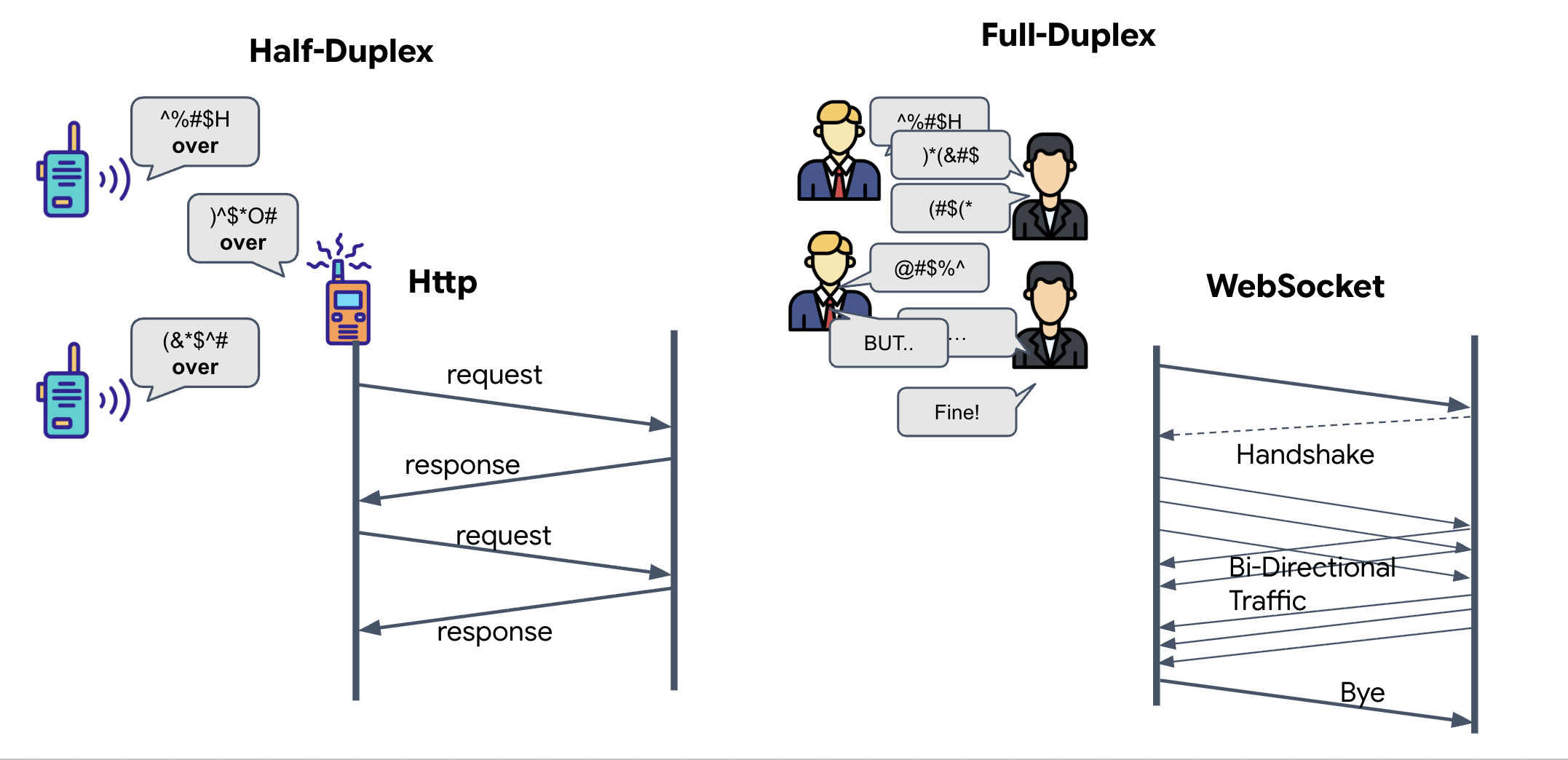
WebSocket คืออะไร
ในการส่งข้อมูลมาตรฐานในกาแล็กซี (HTTP) คุณจะส่งคำขอและรอการตอบกลับ เหมือนกับการส่งโปสการ์ด สำหรับการซิงค์แบบนิวรอล โปสการ์ดจะช้าเกินไป เราต้องการ "สายไฟที่มีกระแสไฟฟ้า"
WebSocket เริ่มต้นเป็นคำขอเว็บมาตรฐาน (HTTP) แต่จากนั้นจะ "อัปเกรด" เป็นอย่างอื่น
- คำขอ: เบราว์เซอร์จะส่งคำขอ HTTP มาตรฐานไปยังเซิร์ฟเวอร์พร้อมส่วนหัวพิเศษ
Upgrade: websocketซึ่งก็คือการพูดว่า "ฉันอยากหยุดส่งโปสการ์ดและเริ่มโทรศัพท์แบบเรียลไทม์" - การตอบกลับ: หากเอเจนต์ AI (เซิร์ฟเวอร์) รองรับการดำเนินการนี้ ระบบจะส่งการตอบกลับ
HTTP 101 Switching Protocolsกลับมา - การเปลี่ยนรูปแบบ: ในตอนนี้ โปรโตคอล WebSocket จะเข้ามาแทนที่การเชื่อมต่อ HTTP แต่ซ็อกเก็ต TCP/IP พื้นฐานจะยังคงเปิดอยู่ กฎของการสื่อสารจะเปลี่ยนจาก "คำขอ/คำตอบ" เป็น "การสตรีมแบบฟูลดูเพล็กซ์" ทันที
ติดตั้งใช้งาน Hook WebSocket
มาตรวจสอบเทอร์มินัลบล็อกเพื่อทําความเข้าใจวิธีส่งข้อมูลกัน
👀 เปิด $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js คุณจะเห็นตัวแฮนเดิลเหตุการณ์ในวงจร WebSocket มาตรฐานที่ตั้งค่าไว้แล้ว โครงสร้างของระบบการสื่อสารของเรามีดังนี้
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
ตัวแฮนเดิล onMessage
มุ่งเน้นที่บล็อก ws.current.onmessage นี่คือตัวรับ ทุกครั้งที่เอเจนต์ "คิด" หรือ "พูด" แพ็กเก็ตข้อมูลจะมาถึงที่นี่ ปัจจุบันฟังก์ชันนี้ยังไม่ทำอะไร โดยจะดักจับแพ็กเก็ตและทิ้ง (ผ่านตัวยึดตำแหน่ง //#REPLACE-HANDLE-MSG)
เราต้องเติมเต็มช่องว่างนี้ด้วยตรรกะที่แยกแยะระหว่างสิ่งต่อไปนี้ได้
- การเรียกใช้เครื่องมือ (functionCall): AI จะจดจำสัญญาณมือของคุณ ("ซิงค์")
- ข้อมูลเสียง (inlineData): เสียงของ AI ที่ตอบคุณ
👉✏️ ตอนนี้ในไฟล์ $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js เดียวกัน ให้แทนที่ //#REPLACE-HANDLE-MSG ด้วยตรรกะด้านล่างเพื่อจัดการสตรีมขาเข้า
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
วิธีแปลงเสียงและวิดีโอเป็นข้อมูลเพื่อการส่ง
หากต้องการเปิดใช้การสื่อสารแบบเรียลไทม์ผ่านอินเทอร์เน็ต คุณต้องแปลงเสียงและวิดีโอดิบให้อยู่ในรูปแบบที่เหมาะกับการส่ง ซึ่งเกี่ยวข้องกับการบันทึก การเข้ารหัส และการจัดแพ็กเกจข้อมูลก่อนส่งผ่านเครือข่าย
การเปลี่ยนรูปแบบข้อมูลเสียง
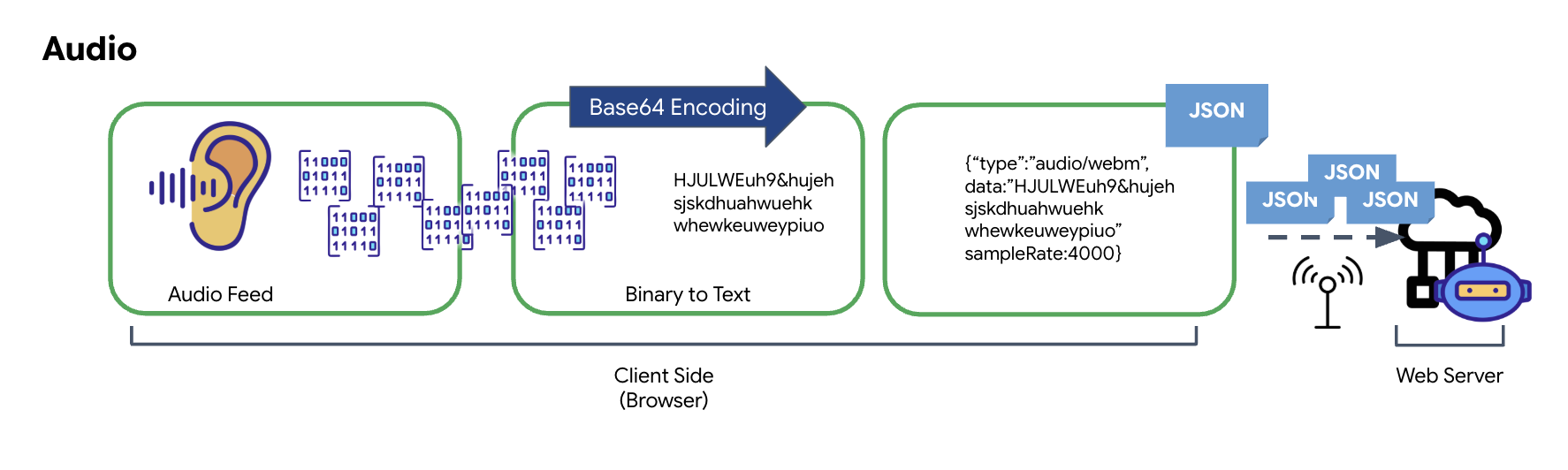
กระบวนการแปลงเสียงอนาล็อกเป็นข้อมูลดิจิทัลที่ส่งได้เริ่มต้นด้วยการจับคลื่นเสียงโดยใช้ไมโครโฟน จากนั้นระบบจะประมวลผลเสียงดิบนี้ผ่าน Web Audio API ของเบราว์เซอร์ เนื่องจากข้อมูลดิบนี้อยู่ในรูปแบบไบนารี จึงไม่สามารถใช้ร่วมกับรูปแบบการส่งข้อความ เช่น JSON ได้โดยตรง หากต้องการแก้ไขปัญหานี้ ระบบจะเข้ารหัสเสียงแต่ละส่วนเป็นสตริง Base64 Base64 เป็นวิธีการที่แสดงข้อมูลไบนารีในรูปแบบสตริง ASCII เพื่อให้มั่นใจถึงความสมบูรณ์ของข้อมูลในระหว่างการส่ง
จากนั้นจะฝังสตริงที่เข้ารหัสนี้ไว้ในออบเจ็กต์ JSON ออบเจ็กต์นี้มีรูปแบบที่มีโครงสร้างสำหรับข้อมูล ซึ่งโดยปกติจะมีช่อง "type" เพื่อระบุว่าเป็นเสียงและข้อมูลเมตา เช่น อัตราการสุ่มตัวอย่างของเสียง จากนั้นระบบจะแปลงออบเจ็กต์ JSON ทั้งหมดเป็นสตริงและส่งผ่านการเชื่อมต่อ WebSocket วิธีนี้ช่วยให้มั่นใจได้ว่าระบบจะส่งเสียงในลักษณะที่มีการจัดระเบียบอย่างดีและแยกวิเคราะห์ได้ง่าย
การเปลี่ยนรูปแบบข้อมูลวิดีโอ
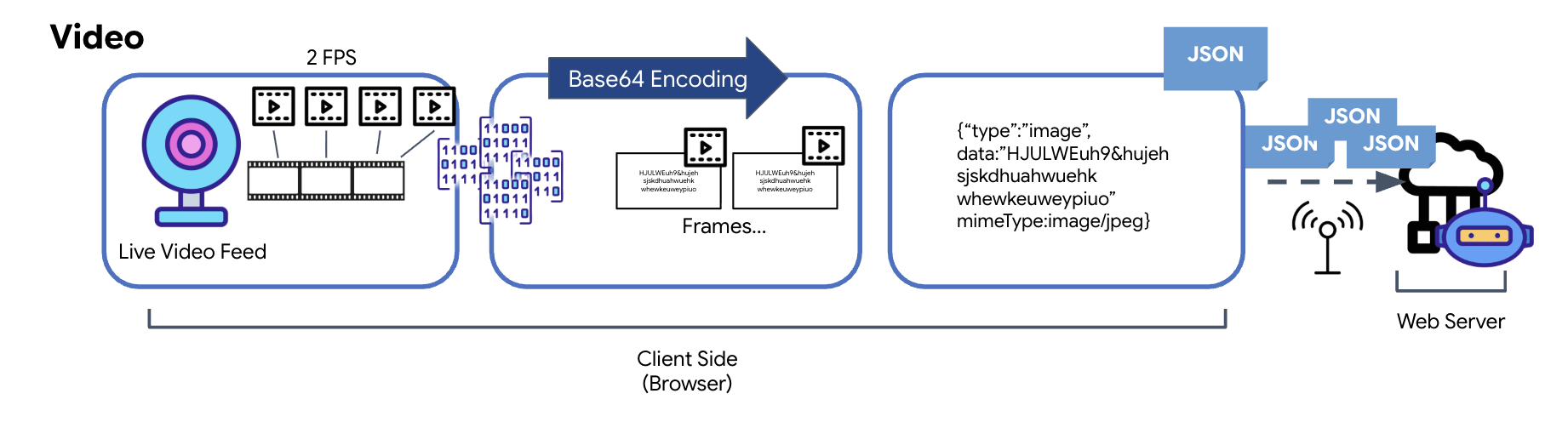
การส่งวิดีโอทำได้ด้วยเทคนิคการจับภาพเฟรม การวนซ้ำที่เกิดซ้ำจะจับภาพนิ่งจากฟีดวิดีโอสดในช่วงเวลาที่กำหนด เช่น 2 เฟรมต่อวินาที แทนที่จะส่งสตรีมวิดีโออย่างต่อเนื่อง โดยทำได้ด้วยการวาดเฟรมปัจจุบันจากองค์ประกอบวิดีโอ HTML ลงในองค์ประกอบ Canvas ที่ซ่อนอยู่
จากนั้นจะใช้วิธี toDataURL ของ Canvas เพื่อแปลงรูปภาพที่จับภาพนี้เป็นสตริง JPEG ที่เข้ารหัส Base64 วิธีนี้มีตัวเลือกในการระบุคุณภาพของรูปภาพ ซึ่งช่วยให้คุณเลือกได้ว่าจะเน้นความสมจริงของรูปภาพหรือขนาดไฟล์เพื่อเพิ่มประสิทธิภาพ จากนั้นจะวางสตริง Base64 นี้ลงในออบเจ็กต์ JSON เช่นเดียวกับข้อมูลเสียง โดยปกติแล้วออบเจ็กต์นี้จะมีป้ายกำกับ "type" เป็น "image" และมี mimeType เช่น "image/jpeg" จากนั้นระบบจะแปลงแพ็กเก็ต JSON นี้เป็นสตริงและส่งผ่าน WebSocket ซึ่งจะช่วยให้ฝั่งที่รับสามารถสร้างวิดีโอขึ้นใหม่ได้โดยการแสดงลำดับของรูปภาพ
👉✏️ ใน$HOME/way-back-home/level_3/frontend/src/useGeminiSocket.jsไฟล์เดียวกัน ให้แทนที่ //#CAPTURE AUDIO and VIDEO ด้วยข้อความต่อไปนี้เพื่อบันทึกข้อมูลจากผู้ใช้
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
เมื่อบันทึกแล้ว Cockpit จะพร้อมแปลสัญญาณดิจิทัลของเอเจนต์เป็นการอัปเดตแดชบอร์ดแบบภาพและเสียง
การตรวจสอบการวินิจฉัย (การทดสอบลูปแบ็ก)
ตอนนี้ค็อกพิตของคุณพร้อมใช้งานแล้ว ทุกๆ 500 มิลลิวินาที ระบบจะส่ง "แพ็กเก็ต" ภาพของสภาพแวดล้อมรอบตัวคุณออกไป ก่อนเชื่อมต่อกับ Gemini เราต้องตรวจสอบว่าเครื่องส่งสัญญาณของเรือทำงานได้ เราจะทำการ "ทดสอบ Loopback" โดยใช้เซิร์ฟเวอร์การวินิจฉัยในพื้นที่
👉💻 ก่อนอื่น ให้สร้างอินเทอร์เฟซ Cockpit จากเทอร์มินัลโดยทำดังนี้
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 จากนั้นเริ่มเซิร์ฟเวอร์จำลองโดยทำดังนี้
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 ดำเนินการตามโปรโตคอลการทดสอบ
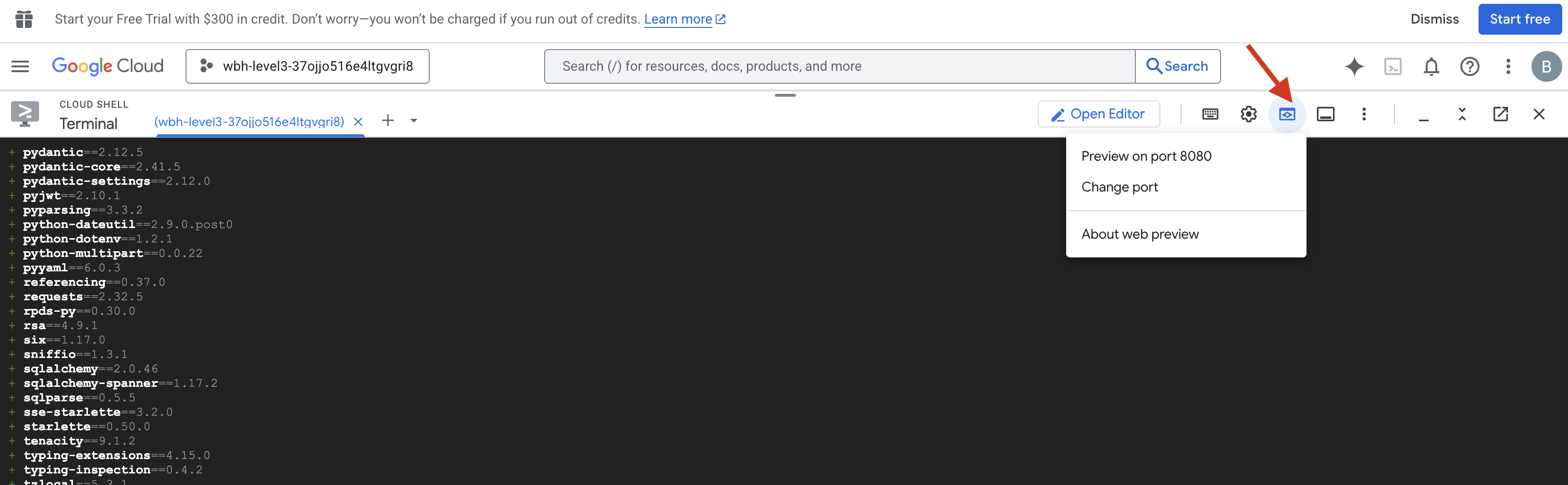
- เปิดตัวอย่าง: คลิกไอคอนตัวอย่างเว็บในแถบเครื่องมือของ Cloud Shell เลือกเปลี่ยนพอร์ต ตั้งค่าเป็น 8080 แล้วคลิกเปลี่ยนและแสดงตัวอย่าง แท็บเบราว์เซอร์ใหม่จะเปิดขึ้นเพื่อแสดงอินเทอร์เฟซ Cockpit
- สำคัญ: เมื่อได้รับแจ้ง คุณต้องอนุญาตให้เบราว์เซอร์เข้าถึงกล้องและไมโครโฟน หากไม่มีข้อมูลเหล่านี้ การซิงค์ประสาทจะเริ่มต้นไม่ได้
- คลิกปุ่ม "เริ่มการซิงค์แบบนิวรอล" ใน UI
👀 ตรวจสอบสัญญาณบอกสถานะ
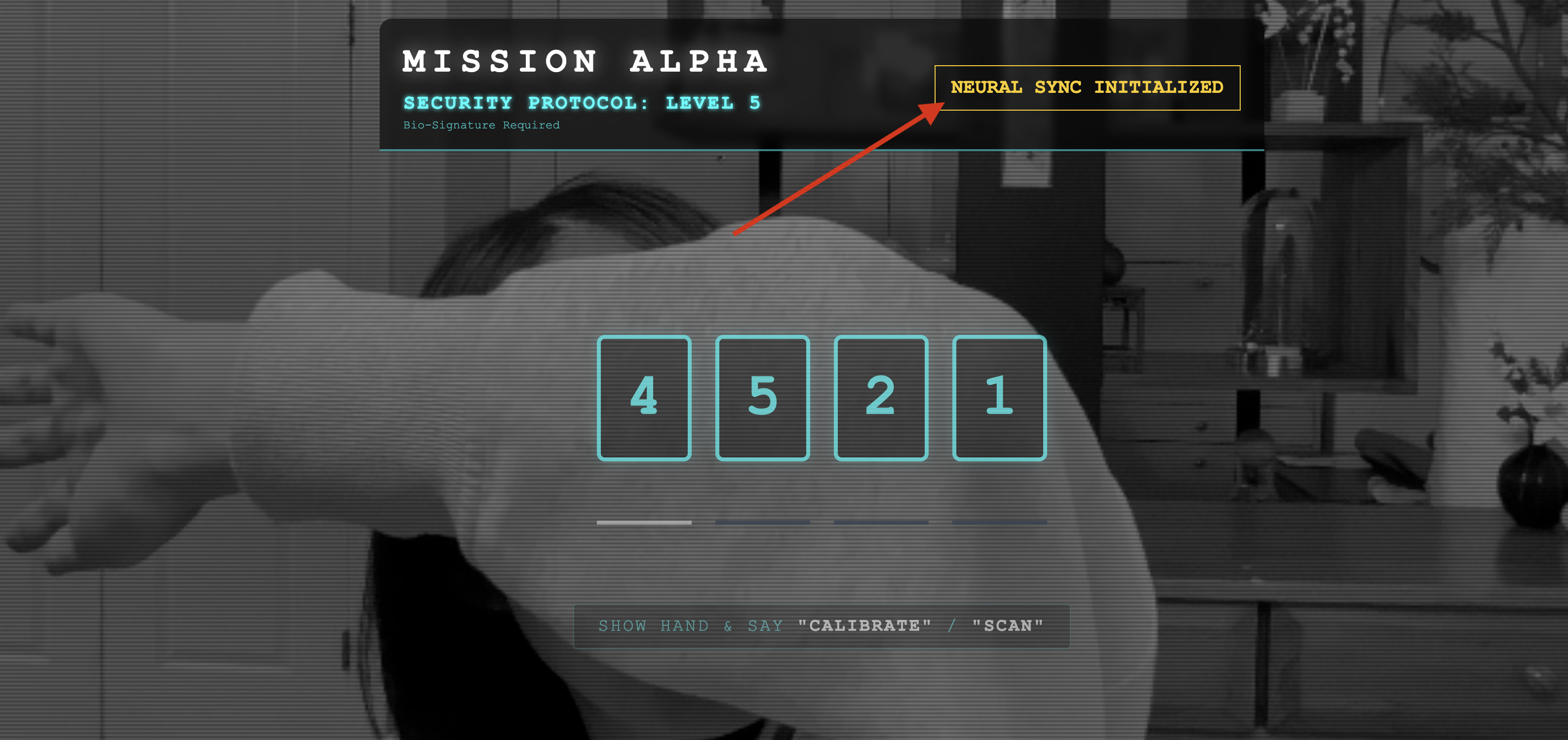
- การตรวจสอบด้วยภาพ: เปิดคอนโซลของเบราว์เซอร์ คุณควรเห็น
NEURAL SYNC INITIALIZEDที่ด้านขวาบน - การตรวจสอบเสียง: หากไปป์ไลน์เสียงแบบ 2 ทิศทางทำงานได้อย่างเต็มที่ คุณจะได้ยินเสียงจำลองที่ยืนยันว่า "เชื่อมต่อระบบแล้ว"
เมื่อได้ยินเสียงยืนยัน "เชื่อมต่อระบบแล้ว" แสดงว่าการทดสอบสำเร็จ ปิดแท็บ ตอนนี้เราต้องล้างความถี่เพื่อเปิดพื้นที่สำหรับ AI จริงๆ
👉💻 กด Ctrl+C ในเทอร์มินัลสำหรับทั้งเซิร์ฟเวอร์จำลองและส่วนหน้า ปิดแท็บเบราว์เซอร์ที่เรียกใช้ UI
4. เอเจนต์แบบหลายรูปแบบ
หุ่นยนต์กู้ภัยทำงานได้ แต่ "จิตใจ" ของมันว่างเปล่า หากคุณเชื่อมต่อตอนนี้ มันก็จะจ้องมองคุณ มันไม่รู้ว่า "นิ้ว" คืออะไร คุณต้องฝังโปรโตคอลประสาทไบโอเมตริกลงในแกนกลางของหน่วยสอดแนมเพื่อช่วยผู้รอดชีวิต
เอเจนต์แบบเดิมจะทำงานเหมือนนักแปลหลายๆ คน หากคุณพูดกับ AI แบบดั้งเดิม โมเดล "Speech-to-Text" จะเปลี่ยนเสียงของคุณเป็นคำ โมเดล "Language Model" จะอ่านคำเหล่านั้นและพิมพ์คำตอบ และโมเดล "Text-to-Speech" จะอ่านคำตอบนั้นให้คุณฟังในที่สุด ซึ่งทำให้เกิด "ช่องว่างของเวลาในการตอบสนอง" ซึ่งเป็นความล่าช้าที่อาจทำให้ภารกิจกู้ภัยล้มเหลว
Gemini Live API เป็นโมเดลหลายรูปแบบดั้งเดิม โดยจะประมวลผลไบต์เสียงดิบและเฟรมวิดีโอดิบโดยตรงพร้อมกัน โดยจะ "ได้ยิน" การสั่นของเสียงและ "เห็น" พิกเซลของท่าทางมือภายในสถาปัตยกรรมประสาทเดียวกัน
หากต้องการใช้ประโยชน์จากความสามารถนี้ เราสามารถสร้างแอปพลิเคชันได้โดยเชื่อมต่อค็อกพิตกับ Live API ดิบโดยตรง อย่างไรก็ตาม เป้าหมายของเราคือการสร้าง Agent ที่นำกลับมาใช้ใหม่ได้ ซึ่งเป็นเอนทิตีแบบโมดูลที่แข็งแกร่งและสร้างได้รวดเร็วกว่า
ทำไมต้อง ADK (Agent Development Kit)
Google Agent Development Kit (ADK) เป็นเฟรมเวิร์กแบบโมดูลาร์สำหรับการพัฒนาและติดตั้งใช้งาน AI Agent
โดยปกติแล้วการเรียกใช้ LLM มาตรฐานจะไม่มีสถานะ ซึ่งหมายความว่าคำค้นหาแต่ละรายการเป็นการเริ่มต้นใหม่ ตัวแทนแบบเรียลไทม์ช่วยให้เซสชันการสนทนาทำงานได้อย่างราบรื่นและยาวนาน โดยเฉพาะเมื่อผสานรวมกับ SessionService ของ ADK
- การคงอยู่ของเซสชัน: เซสชัน ADK จะคงอยู่และจัดเก็บไว้ในฐานข้อมูลได้ (เช่น SQL หรือ Vertex AI) โดยจะยังคงอยู่แม้ว่าเซิร์ฟเวอร์จะรีสตาร์ทหรือตัดการเชื่อมต่อ ซึ่งหมายความว่าหากผู้ใช้ยกเลิกการเชื่อมต่อและเชื่อมต่ออีกครั้งในภายหลัง แม้จะผ่านไปหลายวันแล้วก็ตาม ประวัติการสนทนาและบริบทจะได้รับการกู้คืนอย่างสมบูรณ์ ADK จะจัดการและแยกเซสชัน Live API แบบชั่วคราว
- การเชื่อมต่อใหม่โดยอัตโนมัติ: การเชื่อมต่อ WebSocket อาจหมดเวลา (เช่น หลังจากผ่านไปประมาณ 10 นาที) ADK จะจัดการการเชื่อมต่อใหม่เหล่านี้อย่างโปร่งใสเมื่อเปิดใช้
session_resumptionในRunConfigโค้ดของแอปพลิเคชันไม่จำเป็นต้องจัดการตรรกะการเชื่อมต่อใหม่ที่ซับซ้อน จึงมั่นใจได้ว่าผู้ใช้จะได้รับประสบการณ์ที่ราบรื่น - การโต้ตอบแบบเก็บสถานะ: เอเจนต์จะจดจำเทิร์นก่อนหน้าได้ ทำให้สามารถถามคำถามต่อเนื่อง ขอคำชี้แจง และสนทนาแบบหลายเทิร์นที่ซับซ้อนซึ่งบริบทมีความสำคัญ ซึ่งเป็นสิ่งสำคัญสำหรับแอปพลิเคชันต่างๆ เช่น การสนับสนุนลูกค้า บทแนะนำแบบอินเทอร์แอกทีฟ หรือสถานการณ์การควบคุมภารกิจที่ความต่อเนื่องเป็นสิ่งจำเป็น
การคงอยู่เช่นนี้ช่วยให้การโต้ตอบรู้สึกเหมือนเป็นการสนทนาอย่างต่อเนื่องกับเอนทิตีอัจฉริยะ แทนที่จะเป็นชุดคำถามและคำตอบที่แยกจากกัน
กล่าวโดยสรุปคือ "เจ้าหน้าที่บริการลูกค้า" ที่มีสตรีมแบบสองทิศทางของ ADK จะก้าวข้ามกลไกการตอบคำถามแบบง่ายๆ เพื่อมอบประสบการณ์การสนทนาแบบโต้ตอบอย่างแท้จริง เก็บสถานะ และรับรู้การหยุดชะงัก ซึ่งจะช่วยให้การโต้ตอบกับ AI รู้สึกเหมือนมนุษย์มากขึ้นและมีประสิทธิภาพมากขึ้นอย่างมากสำหรับงานที่ซับซ้อนและใช้เวลานาน
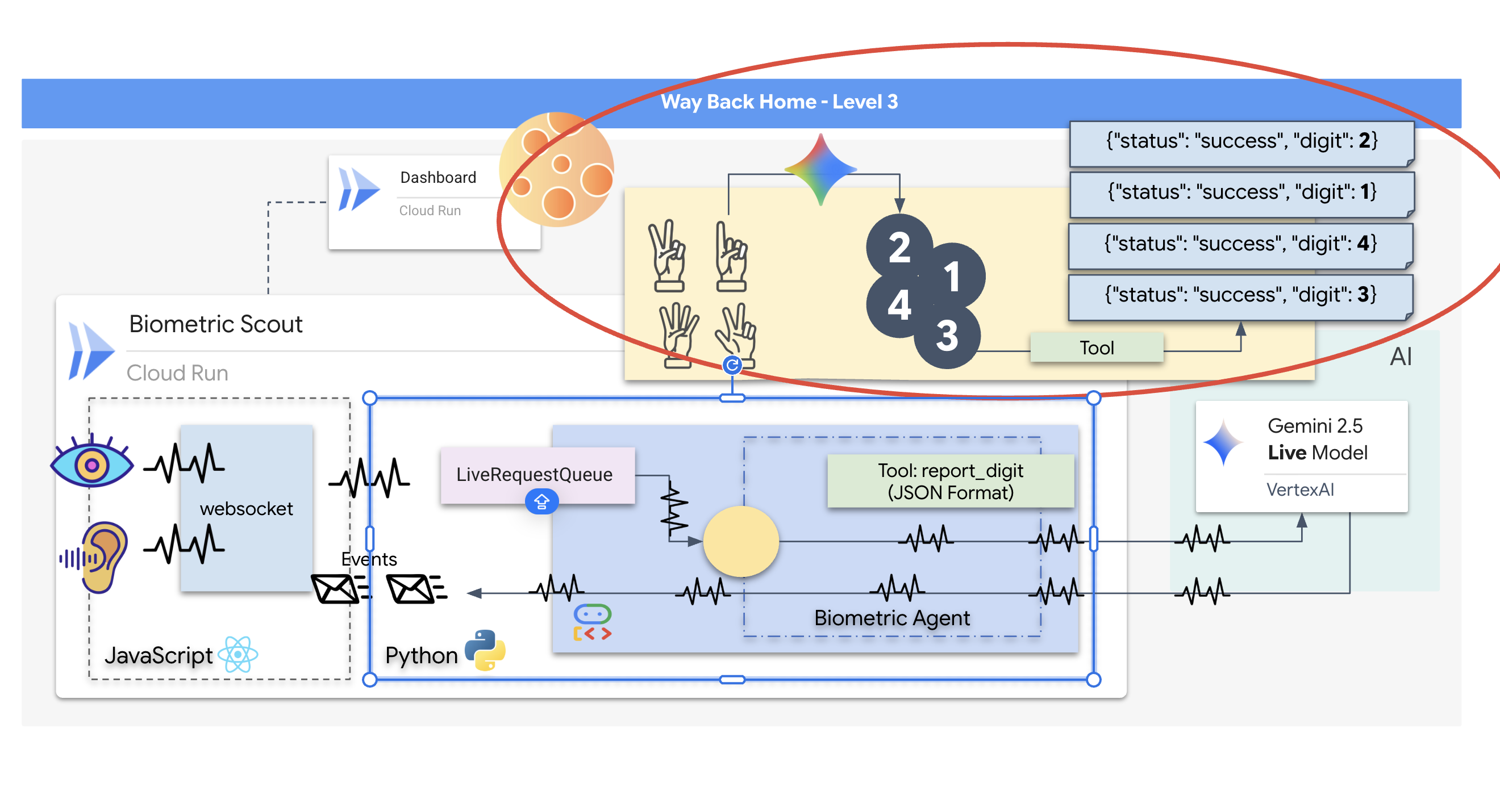
การแจ้งให้คุยกับตัวแทนแบบเรียลไทม์
การออกแบบพรอมต์สำหรับเอเจนต์แบบเรียลไทม์และแบบ 2 ทางต้องมีการเปลี่ยนแนวคิด เจ้าหน้าที่บริการลูกค้าจะ "เปิดตลอดเวลา" ซึ่งแตกต่างจากแชทบ็อตมาตรฐานที่รอคำค้นหาข้อความแบบคงที่ โดยจะรับสตรีมเฟรมเสียงและวิดีโออย่างต่อเนื่อง ซึ่งหมายความว่าพรอมต์ของคุณต้องทำหน้าที่เป็นสคริปต์ลูปควบคุม ไม่ใช่แค่คำจำกัดความของบุคลิก
พรอมต์สำหรับเจ้าหน้าที่บริการลูกค้าแตกต่างจากพรอมต์แบบเดิมดังนี้
- ตรรกะของเครื่องสถานะ: พรอมต์ต้องกำหนด "ลูปพฤติกรรม" (รอ → วิเคราะห์ → ดำเนินการ) โดยต้องมีคำสั่งที่ชัดเจนว่าเมื่อใดควรเงียบและเมื่อใดควรพูด เพื่อป้องกันไม่ให้เอเจนต์พูดพล่ามเมื่อมีเสียงรบกวนรอบข้าง
- การรับรู้หลายรูปแบบ: คุณต้องบอก Agent ว่ามี "ตา" คุณต้องสั่งให้วิเคราะห์เฟรมวิดีโออย่างชัดเจนโดยเป็นส่วนหนึ่งของกระบวนการให้เหตุผล
- เวลาในการตอบสนองและความกระชับ: ในการสนทนาด้วยเสียงแบบเรียลไทม์ ย่อหน้าที่ยาวและมีเนื้อหาเป็นร้อยแก้วจะดูไม่เป็นธรรมชาติและช้า พรอมต์จะบังคับให้ใช้คำสั้นๆ เพื่อให้การโต้ตอบกระชับ
- สถาปัตยกรรมที่เน้นการดำเนินการเป็นอันดับแรก: คำสั่งจะจัดลำดับความสำคัญของการเรียกใช้เครื่องมือเหนือคำพูด เราต้องการให้ตัวแทน "ทำ" งาน (สแกนไบโอเมตริก) ก่อนหรือขณะที่ยืนยันด้วยวาจา ไม่ใช่หลังจากที่พูดคนเดียวเป็นเวลานาน
👉✏️ เปิด $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py แล้วแทนที่ #REPLACE INSTRUCTIONS ด้วยข้อมูลต่อไปนี้
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
หมายเหตุ คุณไม่ได้เชื่อมต่อกับ LLM มาตรฐาน ในไฟล์เดียวกัน ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py) ให้ค้นหา #REPLACE_MODEL เราต้องกำหนดเป้าหมายเวอร์ชันตัวอย่างของโมเดลนี้อย่างชัดเจนเพื่อรองรับความสามารถด้านเสียงแบบเรียลไทม์ได้ดียิ่งขึ้น
👉✏️ แทนที่ตัวยึดตำแหน่งด้วย
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
ตอนนี้คุณได้กำหนด Agent แล้ว โดยรู้ว่าใครคือตัวมันเองและคิดอย่างไร จากนั้นเราก็ให้เครื่องมือในการดำเนินการ
การเรียกใช้เครื่องมือ
Live API ไม่ได้จำกัดอยู่แค่การแลกเปลี่ยนสตรีมข้อความ เสียง และวิดีโอ โดยรองรับการเรียกใช้เครื่องมือโดยค่าเริ่มต้น ซึ่งจะเปลี่ยนเอเจนต์จากผู้สนทนาแบบเรื่อยๆ ให้เป็นผู้ปฏิบัติงานที่กระตือรือร้น
ในระหว่างเซสชันแบบ 2 ทางแบบเรียลไทม์ โมเดลจะประเมินบริบทอย่างต่อเนื่อง หาก LLM ตรวจพบว่าจำเป็นต้องดำเนินการ ไม่ว่าจะเป็น "ตรวจสอบการวัดและส่งข้อมูลของเซ็นเซอร์" หรือ "ปลดล็อกประตูที่ปลอดภัย" โดยจะเปลี่ยนจากการสนทนาเป็นการดำเนินการได้อย่างราบรื่น Agent จะเรียกใช้ฟังก์ชันเครื่องมือที่เฉพาะเจาะจงทันที รอผลลัพธ์ และผสานรวมข้อมูลนั้นกลับเข้าไปในไลฟ์สด โดยไม่ขัดขวางขั้นตอนการโต้ตอบ
👉✏️ ใน $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py ให้แทนที่ #REPLACE TOOLS ด้วยฟังก์ชันนี้
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ จากนั้นลงทะเบียนในคำจำกัดความของ Agent โดยแทนที่ #TOOL CONFIG ดังนี้
tools=[report_digit],
adk web Simulator
ก่อนเชื่อมต่อกับห้องนักบินของยานที่ซับซ้อน (ส่วนหน้า React ของเรา) เราควรทดสอบตรรกะของ Agent แยกกัน ADK มีคอนโซลสำหรับนักพัฒนาแอปในตัวที่ชื่อ adk web ซึ่งช่วยให้เรายืนยันการเรียกใช้เครื่องมือได้ก่อนที่จะเพิ่มความซับซ้อนของเครือข่าย
👉💻 ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- คลิกไอคอนตัวอย่างเว็บในแถบเครื่องมือ Cloud Shell เลือกเปลี่ยนพอร์ต ตั้งค่าเป็น 8000 แล้วคลิกเปลี่ยนและแสดงตัวอย่าง
- ให้สิทธิ์: อนุญาตให้เข้าถึงกล้องและไมโครโฟนเมื่อได้รับแจ้ง
- เริ่มเซสชันโดยคลิกไอคอนกล้อง
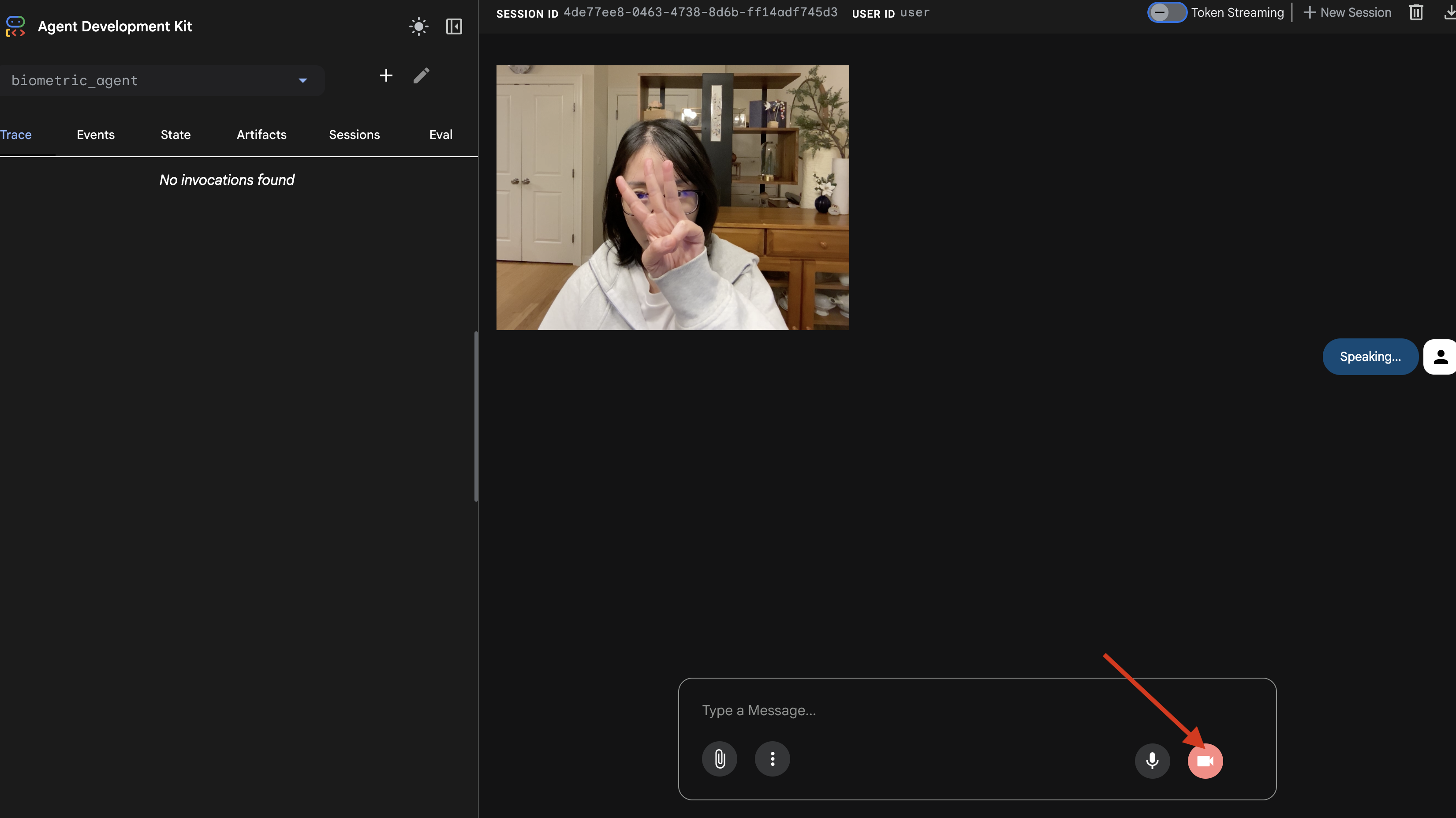
- การทดสอบด้วยภาพ:
- ยก 3 นิ้วขึ้นให้กล้องเห็นชัดเจน
- พูดว่า "สแกน"
- ยืนยันความสำเร็จ:
- บันทึก: ดูเทอร์มินัลที่เรียกใช้คำสั่ง
adk webคุณต้องเห็นบันทึกนี้[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- บันทึก: ดูเทอร์มินัลที่เรียกใช้คำสั่ง
หากคุณเห็นบันทึกการดำเนินการของเครื่องมือ แสดงว่าเอเจนต์ของคุณมีความอัจฉริยะ มันมอง คิด และลงมือทำได้ ขั้นตอนสุดท้ายคือการต่อสายเข้ากับยานหลัก
คลิกในหน้าต่างเทอร์มินัล แล้วกด Ctrl+C เพื่อหยุดโปรแกรมจำลอง adk web
5. ขั้นตอนการสตรีมแบบ 2 ทาง
Agent ทำงาน Cockpit ทำงาน ตอนนี้เราต้องเชื่อมต่ออุปกรณ์
วงจรชีวิตของเจ้าหน้าที่บริการลูกค้า
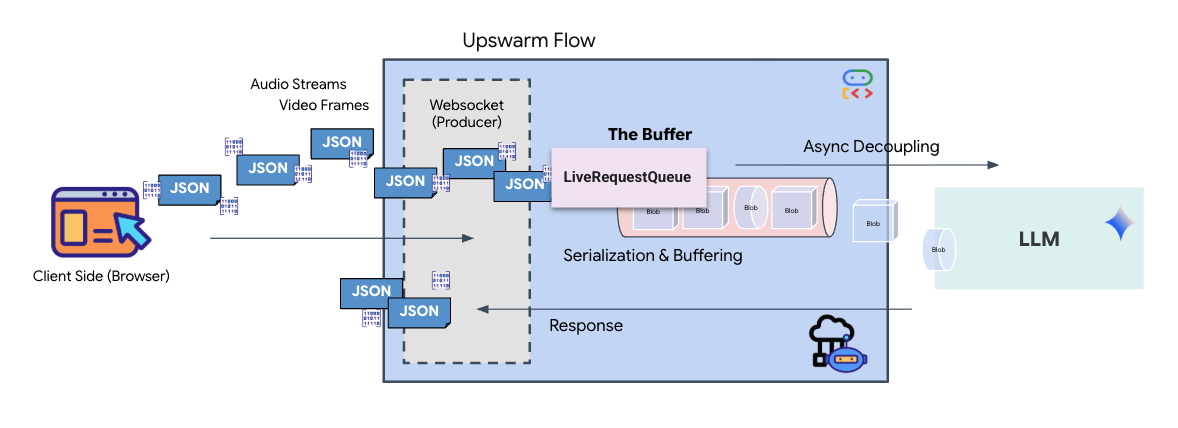
การสตรีมแบบเรียลไทม์ทำให้เกิดปัญหา "ความต้านทานไม่ตรงกัน" ไคลเอ็นต์ (เบราว์เซอร์) จะส่งข้อมูลแบบอะซิงโครนัสในอัตราที่แตกต่างกัน ซึ่งอาจเป็นการส่งข้อมูลแบบเป็นชุดหรือการป้อนข้อมูลอย่างรวดเร็ว ในขณะที่โมเดลต้องการสตรีมอินพุตแบบลำดับที่ได้รับการควบคุม Google ADK แก้ปัญหานี้ได้โดยใช้LiveRequestQueue
โดยจะทำหน้าที่เป็นบัฟเฟอร์แบบอะซิงโครนัสแบบเข้าก่อนออกก่อน (FIFO) ที่ปลอดภัยสำหรับเธรด ตัวแฮนเดิล WebSocket ทำหน้าที่เป็นโปรดิวเซอร์ โดยจะพุชเสียง/วิดีโอแบบดิบเป็นก้อนๆ ลงในคิว เอเจนต์ ADK ทำหน้าที่เป็นผู้บริโภค โดยดึงข้อมูลจากคิวเพื่อป้อนหน้าต่างบริบทของโมเดล การแยกนี้ช่วยให้แอปพลิเคชันรับข้อมูลจากผู้ใช้ต่อไปได้แม้ในขณะที่โมเดลกำลังสร้างคำตอบหรือเรียกใช้เครื่องมือ
คิวทำหน้าที่เป็นมัลติเพล็กเซอร์มัลติโมดอล ในสภาพแวดล้อมจริง โฟลว์ต้นทางประกอบด้วยประเภทข้อมูลที่แตกต่างกันซึ่งเกิดขึ้นพร้อมกัน ได้แก่ ไบต์เสียง PCM ดิบ เฟรมวิดีโอ คำสั่งของระบบที่อิงตามข้อความ และผลลัพธ์จากการเรียกใช้เครื่องมือแบบไม่พร้อมกัน LiveRequestQueueจะแปลงอินพุตที่แตกต่างกันเหล่านี้ให้เป็นลำดับตามลำดับเวลาเดียว ไม่ว่าแพ็กเก็ตจะมีช่วงเงียบเป็นมิลลิวินาที รูปภาพความละเอียดสูง หรือเพย์โหลด JSON จากการค้นหาฐานข้อมูล ระบบจะจัดลำดับแพ็กเก็ตตามลำดับที่มาถึงอย่างถูกต้อง เพื่อให้มั่นใจว่าโมเดลจะรับรู้ไทม์ไลน์แบบมีเหตุผลและสอดคล้องกัน
สถาปัตยกรรมนี้ช่วยให้การควบคุมแบบไม่บล็อก เนื่องจากเลเยอร์การนำเข้า (Producer) แยกออกจากเลเยอร์การประมวลผล (Consumer) ระบบจึงยังคงตอบสนองได้แม้ในระหว่างการอนุมานโมเดลที่มีค่าใช้จ่ายในการคำนวณสูง หากผู้ใช้ขัดจังหวะด้วยคำสั่ง "หยุด" ขณะที่เอเจนต์กำลังเรียกใช้เครื่องมือ ระบบจะจัดคิวสัญญาณเสียงนั้นทันที ลูปเหตุการณ์พื้นฐานจะประมวลผลสัญญาณลำดับความสำคัญนี้ทันที ทำให้ระบบหยุดการสร้างหรือเปลี่ยนงานได้โดยที่ UI ไม่หยุดทำงานหรือแพ็กเก็ตไม่หลุด
👉💻 ใน $HOME/way-back-home/level_3/backend/app/main.py ให้ค้นหาความคิดเห็น #REPLACE_RUNNER_CONFIG แล้วแทนที่ด้วยโค้ดต่อไปนี้เพื่อนำระบบกลับมาออนไลน์
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
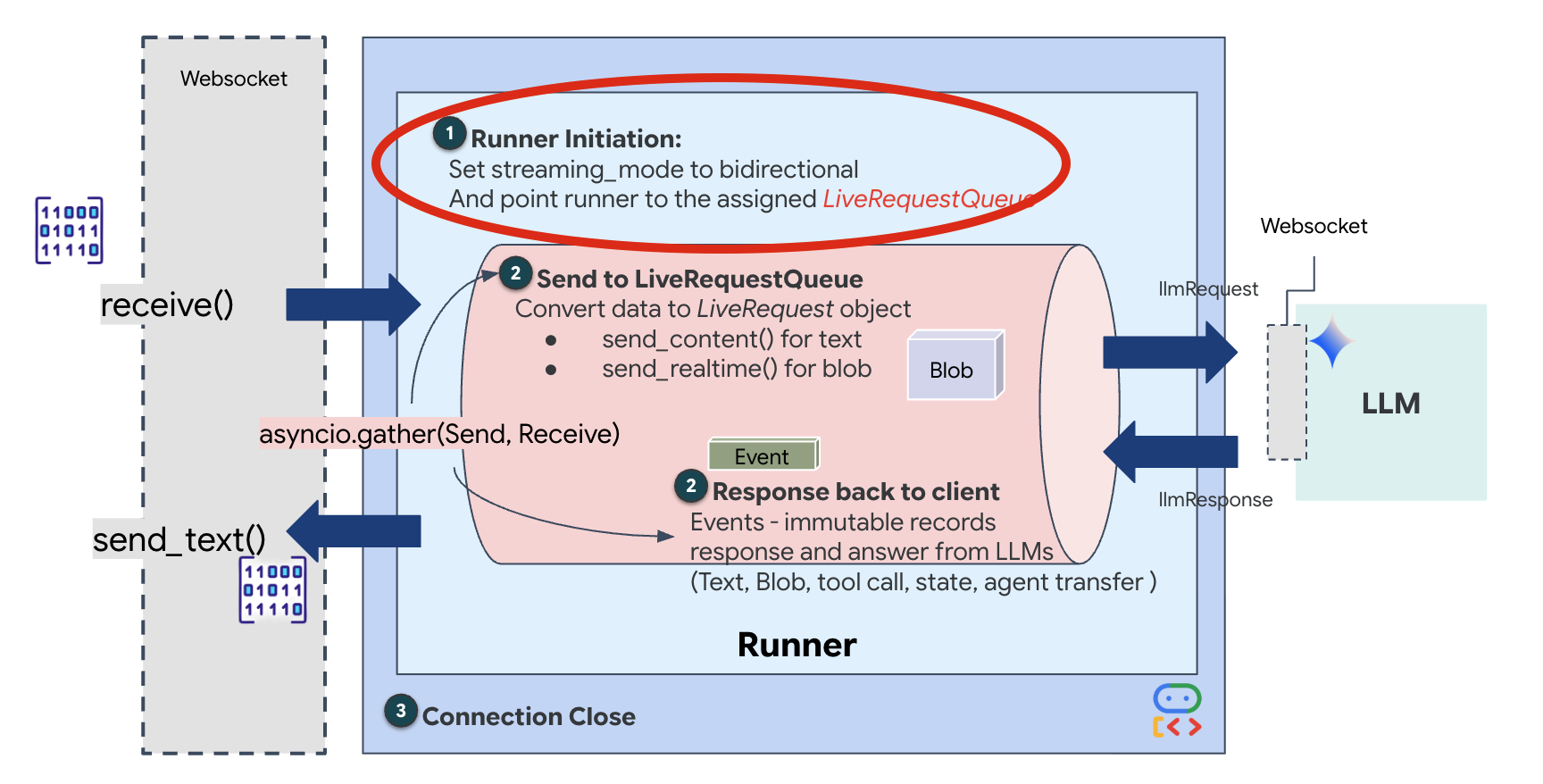
เมื่อเปิดการเชื่อมต่อ WebSocket ใหม่ เราต้องกำหนดค่าวิธีที่ AI โต้ตอบ นี่คือส่วนที่เราจะกำหนด "กฎของการมีส่วนร่วม"
👉✏️ ใน $HOME/way-back-home/level_3/backend/app/main.py ภายในฟังก์ชัน async def websocket_endpoint ให้แทนที่ความคิดเห็น #REPLACE_SESSION_INIT ด้วยโค้ดด้านล่าง
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
การกำหนดค่าการวิ่ง
StreamingMode.BIDI: การดำเนินการนี้จะตั้งค่าการเชื่อมต่อเป็นแบบ 2 ทาง BIDI ต่างจาก AI แบบ "ผลัดกันพูด" (ที่คุณพูด หยุด แล้ว AI พูด) ตรงที่ช่วยให้การสนทนาเป็นแบบ "ฟูลดูเพล็กซ์" ที่สมจริง คุณสามารถขัดจังหวะ AI ได้ และ AI ก็พูดได้ในขณะที่คุณกำลังเคลื่อนที่AudioTranscriptionConfig: แม้ว่าโมเดลจะ "ได้ยิน" เสียงดิบ แต่เรา (นักพัฒนาซอฟต์แวร์) ก็ต้องดูบันทึก การกำหนดค่านี้จะบอก Gemini ว่า "ประมวลผลเสียง แต่ส่งข้อความถอดเสียงของสิ่งที่คุณได้ยินกลับมาด้วย เพื่อให้เราแก้ไขข้อบกพร่องได้"
ตรรกะการดำเนินการ เมื่อ Runner สร้างเซสชันแล้ว ก็จะส่งต่อการควบคุมไปยังตรรกะการดำเนินการ ซึ่งอาศัย LiveRequestQueue ซึ่งเป็นองค์ประกอบที่สำคัญที่สุดสำหรับการโต้ตอบแบบเรียลไทม์ ลูปช่วยให้เอเจนต์สร้างการตอบกลับด้วยเสียงได้ในขณะที่คิวจะยังคงรับเฟรมวิดีโอใหม่จากผู้ใช้ต่อไป เพื่อให้มั่นใจว่า "Neural Sync" จะไม่ขาดตอน
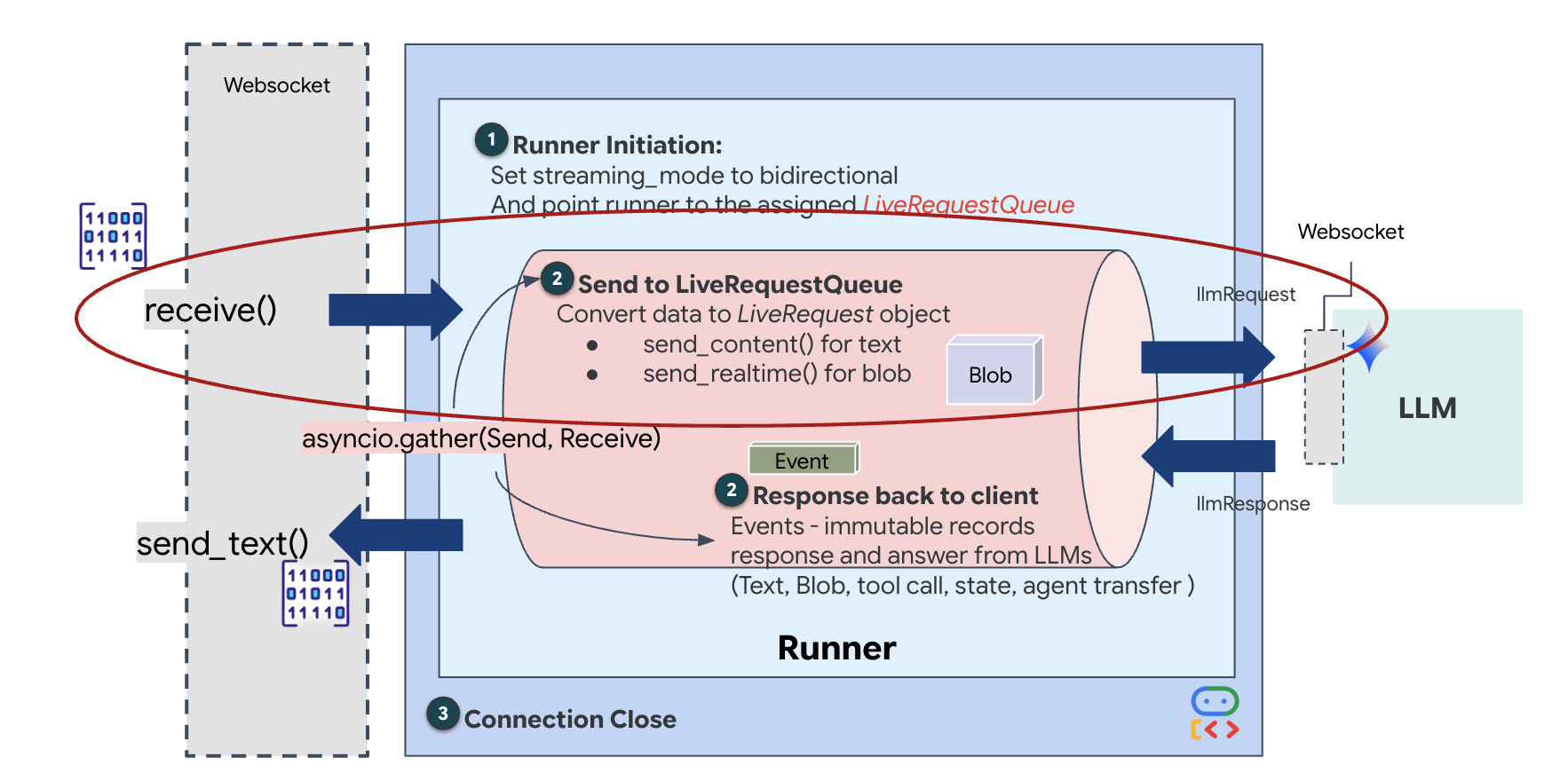
👉✏️ ใน $HOME/way-back-home/level_3/backend/app/main.py ให้แทนที่ #REPLACE_LIVE_REQUEST เพื่อกําหนดงานต้นทางที่ส่งข้อมูลไปยัง LiveRequestQueue ดังนี้
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
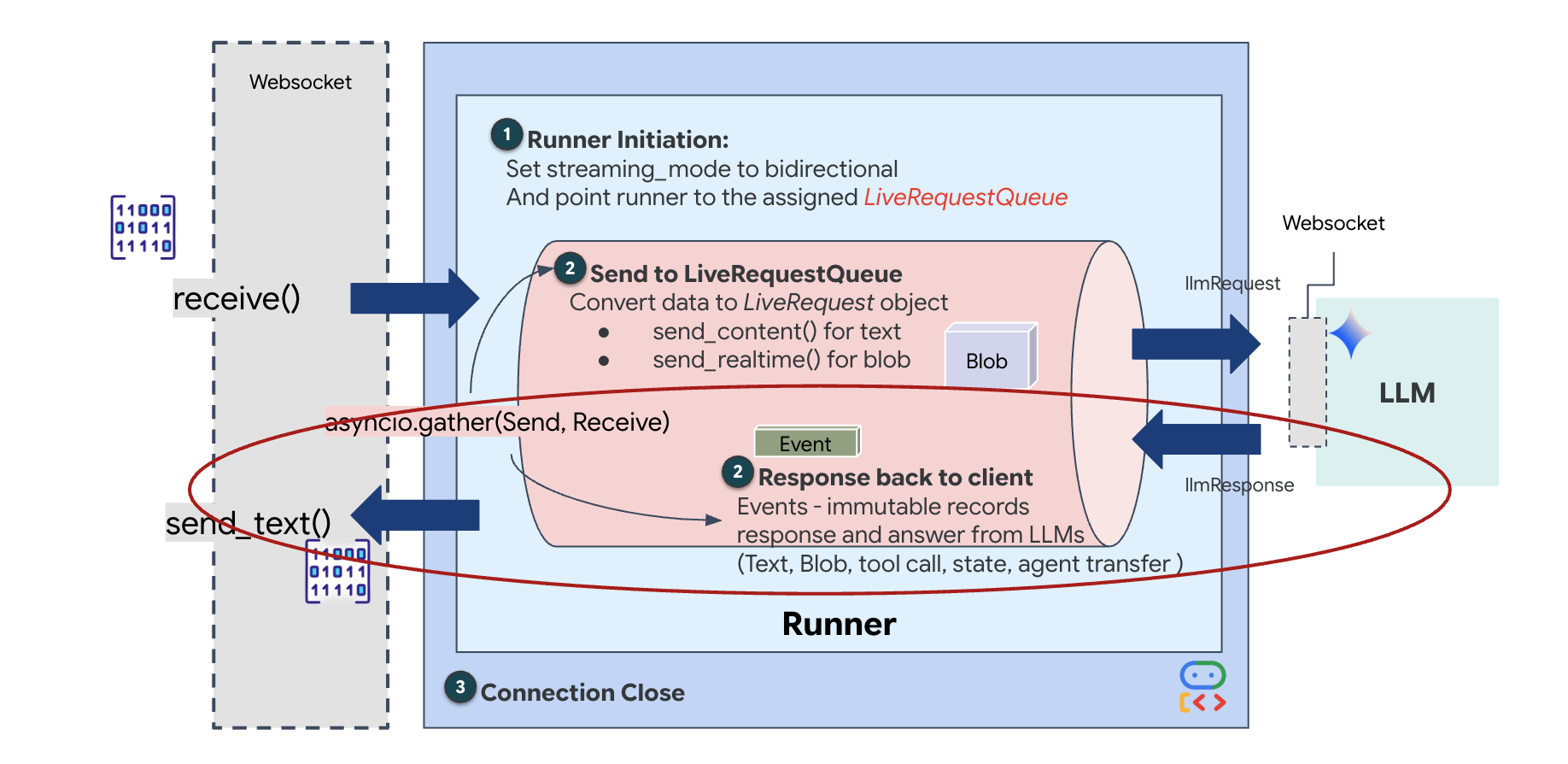
สุดท้าย เราต้องจัดการคำตอบของ AI ซึ่งใช้ runner.run_live() ซึ่งเป็นตัวสร้างเหตุการณ์ที่สร้างเหตุการณ์ (เสียง ข้อความ หรือการเรียกใช้เครื่องมือ) เมื่อเกิดขึ้น
👉✏️ ใน $HOME/way-back-home/level_3/backend/app/main.py ให้แทนที่ #REPLACE_SORT_RESPONSE เพื่อกำหนดงานดาวน์สตรีมและตัวจัดการการทำงานพร้อมกัน
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
สังเกตบรรทัด await asyncio.gather(upstream_task(), downstream_task()) นี่คือหัวใจสำคัญของการสื่อสารแบบสองทิศทาง เราจะเรียกใช้งานการฟัง (ต้นทาง) และการพูด (ปลายทาง) พร้อมกัน ซึ่งจะช่วยให้ "Neural Link" อนุญาตการหยุดชะงักและโฟลว์ข้อมูลพร้อมกัน
ตอนนี้แบ็กเอนด์ของคุณได้รับการโค้ดอย่างสมบูรณ์แล้ว “สมอง” (ADK) เชื่อมต่อกับ “ร่างกาย” (WebSocket)
การดำเนินการ Bio-Sync
โค้ดเสร็จสมบูรณ์แล้ว ระบบเป็นสีเขียว ถึงเวลาเริ่มการช่วยเหลือแล้ว
- 👉💻 เริ่มแบ็กเอนด์
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 เปิดใช้ฟรอนท์เอนด์
- คลิกไอคอนตัวอย่างเว็บในแถบเครื่องมือ Cloud Shell เลือกเปลี่ยนพอร์ต ตั้งค่าเป็น 8080 แล้วคลิกเปลี่ยนและแสดงตัวอย่าง
- 👉 ดำเนินการตามโปรโตคอล
- คลิก "เริ่มการซิงค์ประสาท"
- ปรับเทียบ: ตรวจสอบว่ากล้องมองเห็นมือของคุณอย่างชัดเจนเมื่อเทียบกับพื้นหลัง
- การซิงค์: ดูรหัสความปลอดภัยที่แสดงบนหน้าจอ (เช่น 3 แล้ว 2 แล้ว 5)
- จับคู่สัญญาณ: เมื่อมีตัวเลขปรากฏขึ้น ให้ชูนิ้วตามจำนวนตัวเลขนั้น
- ถือให้นิ่ง: ถือมือให้มองเห็นจนกว่า AI จะยืนยันว่า "ตรงกับข้อมูลไบโอเมตริก"
- ปรับเปลี่ยน: รหัสจะสุ่ม เปลี่ยนไปใช้หมายเลขถัดไปที่แสดงทันทีจนกว่าลำดับจะเสร็จสมบูรณ์

- เมื่อคุณจับคู่หมายเลขสุดท้ายในลำดับแบบสุ่มได้แล้ว "การซิงค์ไบโอเมตริก" จะเสร็จสมบูรณ์ ลิงก์ประสาทจะล็อก คุณควบคุมได้ด้วยตนเอง เครื่องยนต์ของรถสอดแนมจะคำรามก้องเพื่อนำผู้รอดชีวิตกลับบ้าน
👉💻 กด Ctrl+C ในเทอร์มินัลแบ็กเอนด์เพื่อออก
6. ติดตั้งใช้งานในเวอร์ชันที่ใช้งานจริง (ไม่บังคับ)
คุณทดสอบไบโอเมตริกในเครื่องเรียบร้อยแล้ว ตอนนี้เราต้องอัปโหลดแกนประสาทของ Agent ไปยังเมนเฟรมของยาน (Cloud Run) เพื่อให้ทำงานได้อย่างอิสระจากคอนโซลในเครื่อง
👉💻 เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล Cloud Shell ซึ่งจะสร้าง Dockerfile แบบหลายขั้นตอนที่สมบูรณ์ในไดเรกทอรีแบ็กเอนด์
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 ไปที่ไดเรกทอรีแบ็กเอนด์และแพ็กเกจแอปพลิเคชันเป็นอิมเมจคอนเทนเนอร์
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 ทำให้บริการใช้งานได้ใน Cloud Run เราจะแทรกตัวแปรสภาพแวดล้อมที่จำเป็น ซึ่งก็คือการกำหนดค่า Gemini โดยเฉพาะ ลงในคำสั่งเปิดใช้โดยตรง
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
เมื่อคำสั่งเสร็จสมบูรณ์ คุณจะเห็น URL ของบริการ (เช่น https://biometric-scout-...run.app) ตอนนี้แอปพลิเคชันพร้อมใช้งานในระบบคลาวด์แล้ว
👉 ไปที่หน้า Google Cloud Run แล้วเลือกบริการ biometric-scout จากรายการ 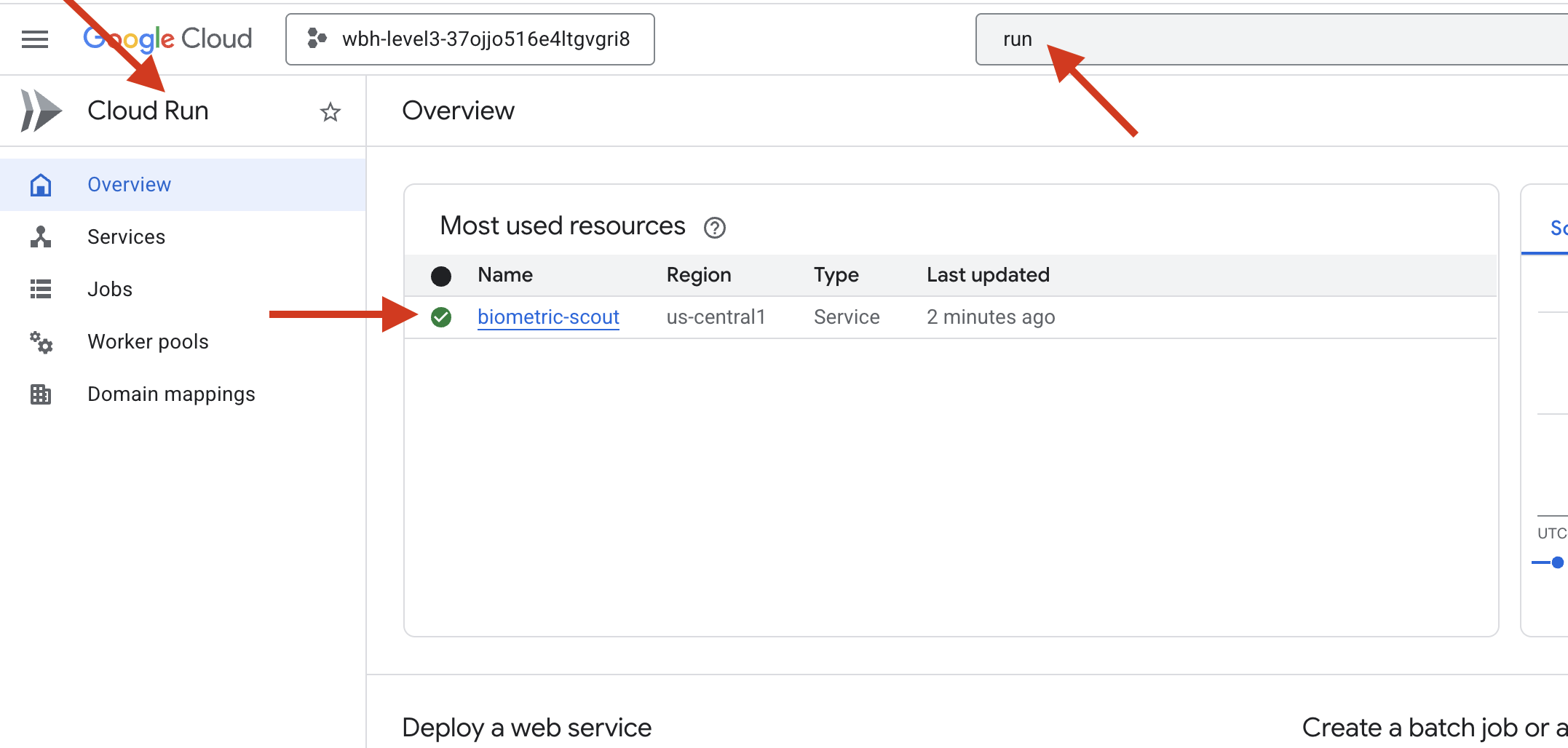
👉 ค้นหา URL สาธารณะที่แสดงที่ด้านบนของหน้ารายละเอียดบริการ 
ลองทำ Bio-Sync ในสภาพแวดล้อมนี้ด้วยได้ไหม
เมื่อนิ้วก้อยเหยียดออก AI จะล็อกลำดับ หน้าจอกะพริบเป็นสีเขียว: "การซิงค์ประสาทไบโอเมตริก: สำเร็จ"
เพียงแค่คิด คุณก็ดำดิ่งสเกาต์ลงไปในความมืด เกาะติดกับพ็อดที่ติดอยู่ และดึงพ็อดออกมาได้ก่อนที่แรงโน้มถ่วงจะพังทลาย

ประตูสุญญากาศเปิดออกพร้อมเสียงลม และเราก็เห็นผู้รอดชีวิต 5 คนที่ยังมีลมหายใจ พวกเขาเดินโซเซขึ้นมาบนดาดฟ้า บอบช้ำแต่ยังมีชีวิตอยู่ ปลอดภัยในที่สุดเพราะคุณ
ขอบคุณที่ช่วยให้เราซิงค์ลิงก์ประสาทและช่วยเหลือผู้รอดชีวิตได้
หากคุณเข้าร่วมในเลเวล 0 อย่าลืมตรวจสอบความคืบหน้าในภารกิจ "กลับบ้าน" นะ