1. 任务

您正漂浮在未知的星区中,周围一片寂静。一次巨大的 **太阳脉冲** 将您的飞船撕裂,使您被困在宇宙中一个不存在于任何星图上的区域。
经过数天的艰苦维修,您终于感受到脚下引擎的轰鸣声。您的火箭已修复。您甚至还设法确保了与母舰的远程上行链路安全。您可以起飞了。您已准备好回家。但就在你准备启动跳跃引擎时,一阵求救信号穿透了静电干扰。您的传感器在“峡谷”中检测到五种微弱的热信号。“峡谷”是一个扭曲的锯齿状区域,您的主飞船永远无法进入。他们是与您一样的探险者,也是那场差点夺走您生命的暴风雨的幸存者。您无法抛下它们。
您转向 Alpha-Drone 救援侦察兵。这艘小巧灵活的船只能够穿过峡谷狭窄的岩壁,是唯一能做到这一点的船只。但问题是:太阳脉冲对其核心逻辑执行了全面的“系统重置”。侦察兵的控制系统没有响应。它已开机,但其机载计算机是一张白板,无法处理手动飞行员指令或飞行路线。
面临的挑战
为了拯救幸存者,你必须完全绕过侦察兵的损坏电路。您还有一个孤注一掷的选择:构建一个 AI 代理来建立生物识别神经同步。该智能体将充当实时桥梁,让您可以通过自己的生物学输入手动控制救援侦察兵。您将不会使用操纵杆或键盘,而是直接将意图连接到飞船的导航网络。
如需锁定关联,您必须在 Scout 的光学传感器前执行同步协议。AI 智能体必须通过精确的实时握手来识别您的生物特征。
您的任务目标:
- 为神经核心设置初始状态:定义能够识别多模态输入的 ADK 代理。
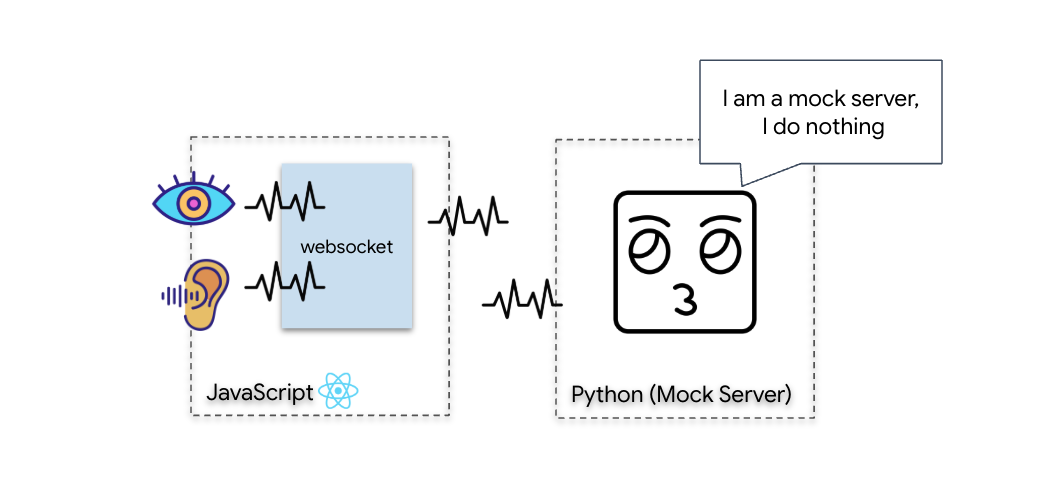
- 建立连接:构建双向 WebSocket 流水线,以将视觉数据从 Scout 流式传输到 AI。
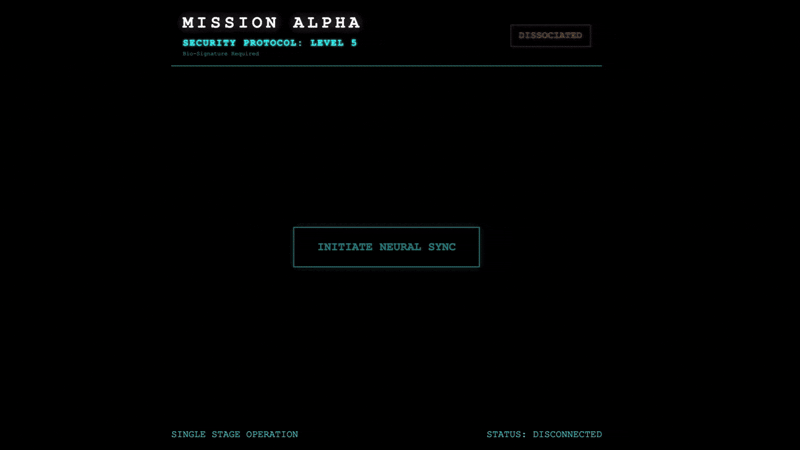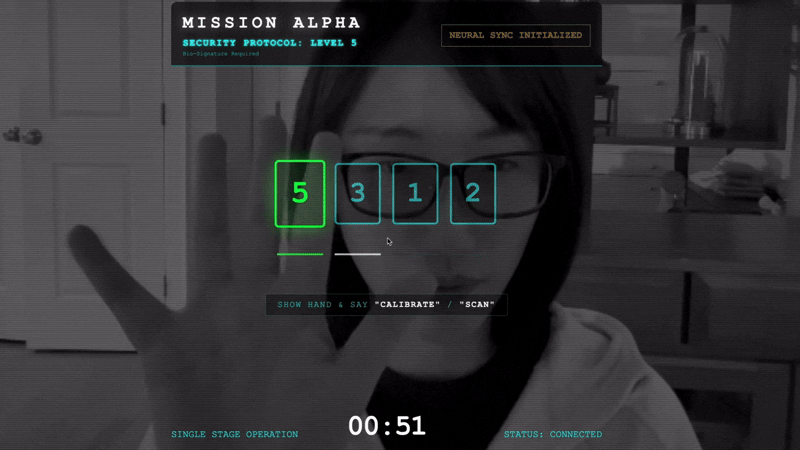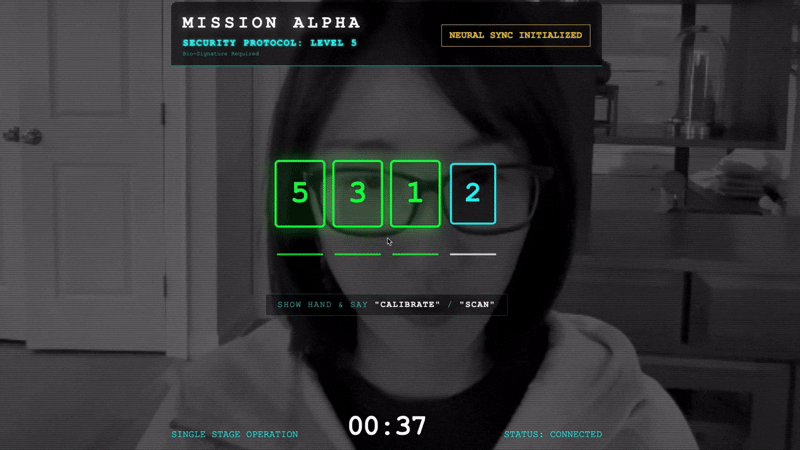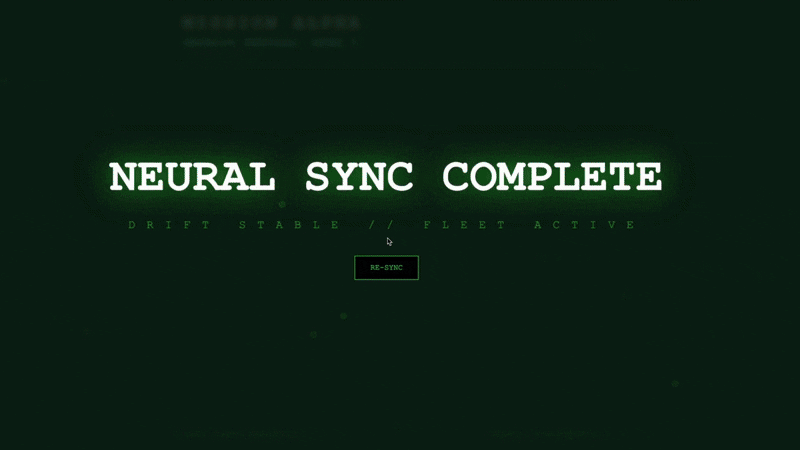
- 启动握手:站在传感器前,按顺序完成指尖序列(依次显示 1 到 5)。
如果成功,系统会启用“生物识别数据同步”。AI 会锁定神经链路,让您完全手动控制侦察兵,并将幸存者带回家。
构建内容
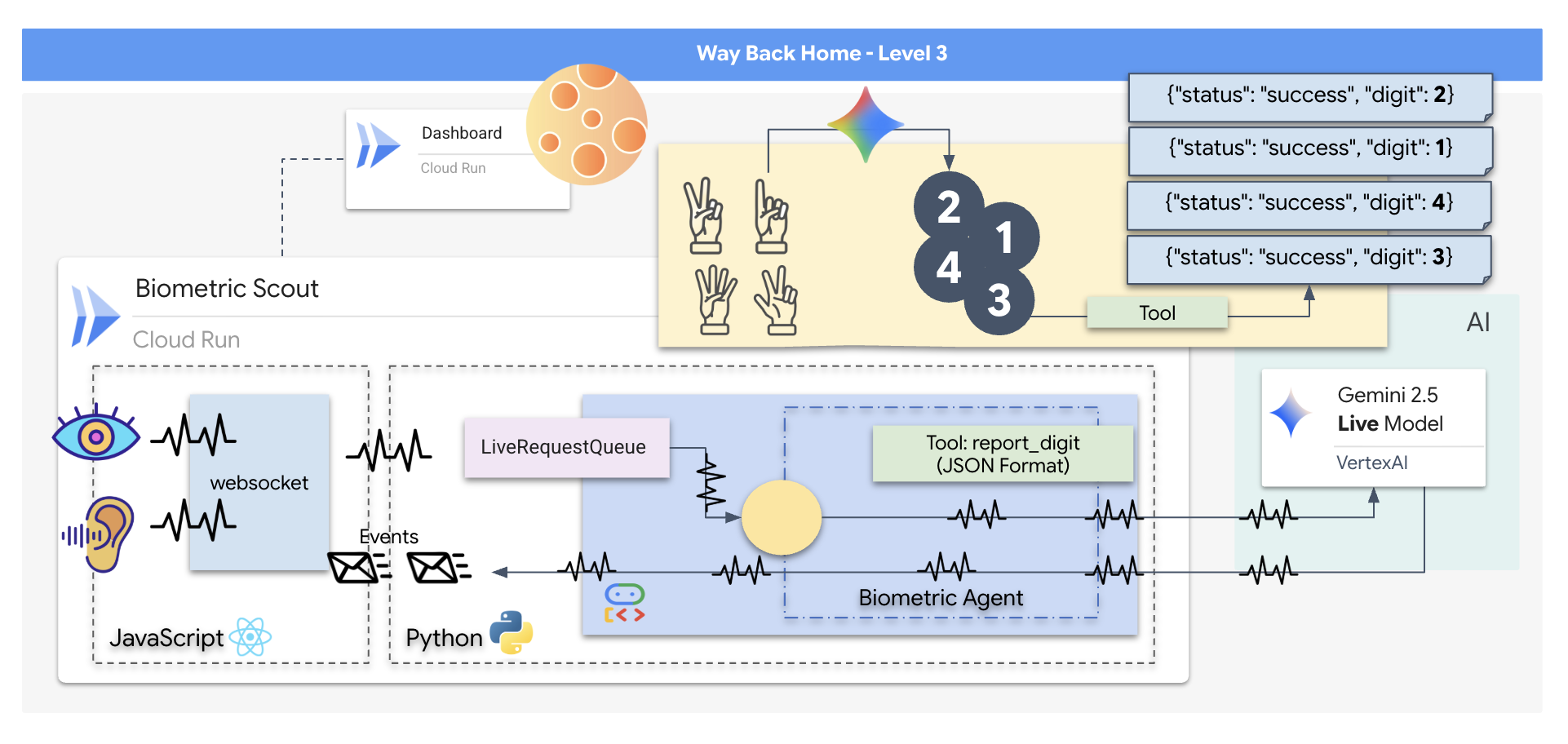
您将构建一个“生物识别神经同步”应用,这是一个实时 AI 赋能的系统,可作为救援无人机的控制界面。此系统包含以下内容:
- React 前端:飞船的“驾驶舱”,可从网络摄像头捕获实时视频,并从麦克风捕获音频。
- Python 后端:使用 FastAPI 构建的高性能服务器,使用 Google 的智能体开发套件 (ADK) 来管理 LLM 的逻辑和状态。
- 多模态 AI 智能体:操作的“大脑”,通过
google-genaiSDK 使用 Gemini Live API 同时处理和理解视频和音频流。 - 双向 WebSocket 管道:在前端和 AI 之间建立持久性低延迟连接的“神经系统”,可实现实时互动。
学习内容
技术 / 概念 | 说明 |
后端 AI 代理 | 使用 Python 和 FastAPI 构建有状态 AI 智能体。使用 Google 的 ADK(智能体开发套件)来管理指令和内存,并使用 |
前端界面 | 使用 React 开发动态用户界面,以直接从浏览器捕获和流式传输实时视频和音频。 |
实时通信 | 实现 WebSocket 管道,以实现全双工、低延迟通信,从而让用户和 AI 同时进行交互。 |
多模态 AI | 利用 Gemini Live API 处理和理解并发的视频和音频流,使 AI 能够同时“看”和“听”。 |
工具调用 | 使 AI 能够执行特定的 Python 函数来响应视觉触发,从而弥合模型智能与现实世界行动之间的差距。 |
全栈部署 | 使用 Docker 将整个应用(React 前端和 Python 后端)容器化,并将其作为可扩缩的无服务器服务部署到 Google Cloud Run。 |
2. 设置环境
访问 Cloud Shell
首先,我们将打开 Cloud Shell,这是一个基于浏览器的终端,其中预安装了 Google Cloud SDK 和其他必备工具。
👉点击 Google Cloud 控制台顶部的“激活 Cloud Shell”(这是 Cloud Shell 窗格顶部的终端形状图标),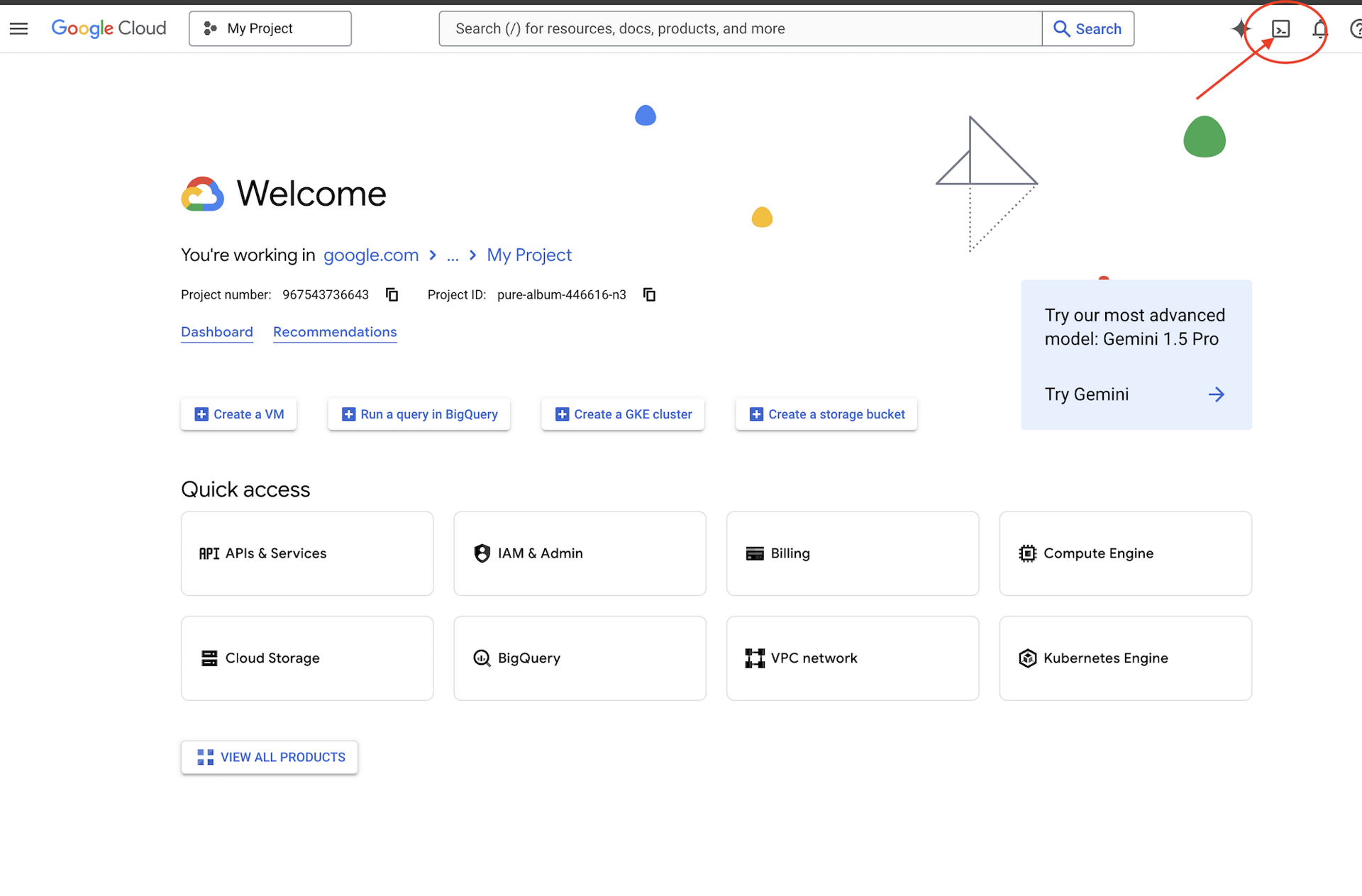
👉点击“打开编辑器”按钮(看起来像一个打开的文件夹,上面有一支铅笔)。此操作会在窗口中打开 Cloud Shell 代码编辑器。您会在左侧看到文件资源管理器。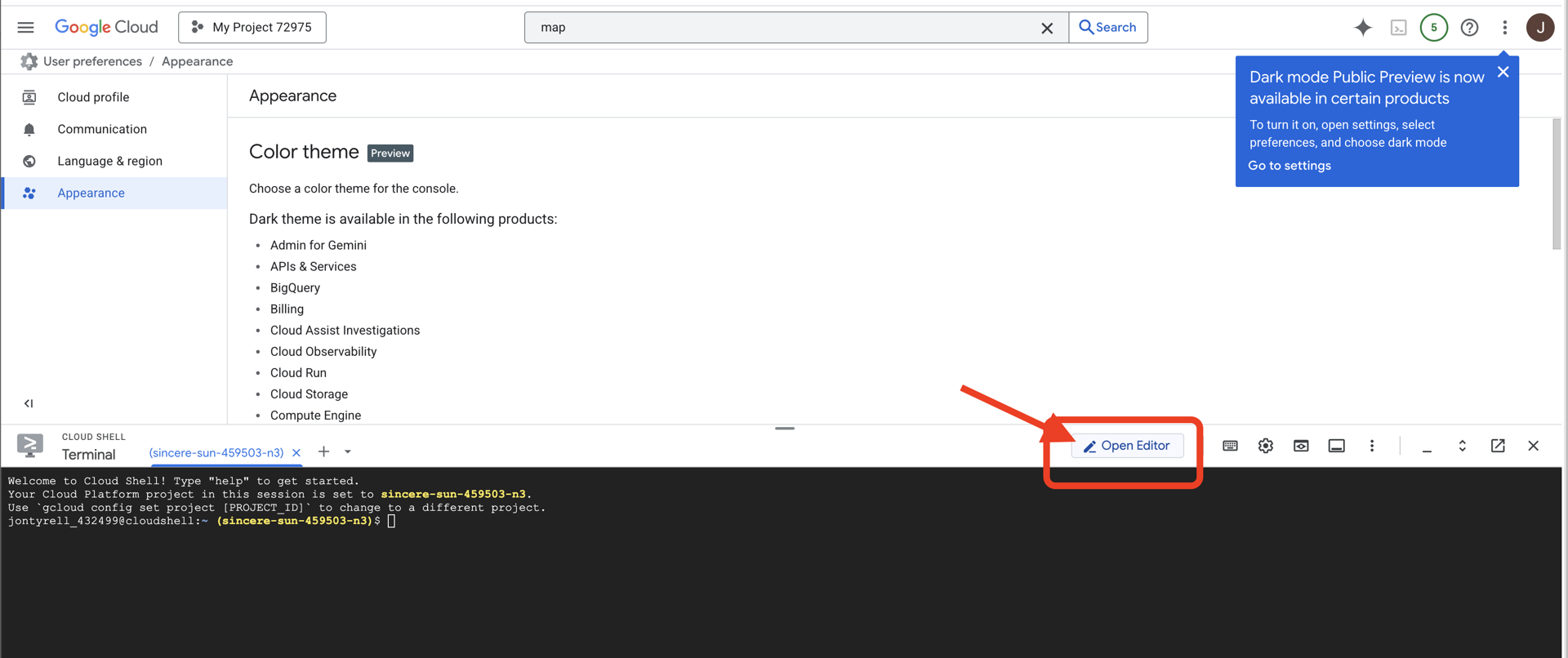
👉在云 IDE 中打开终端,
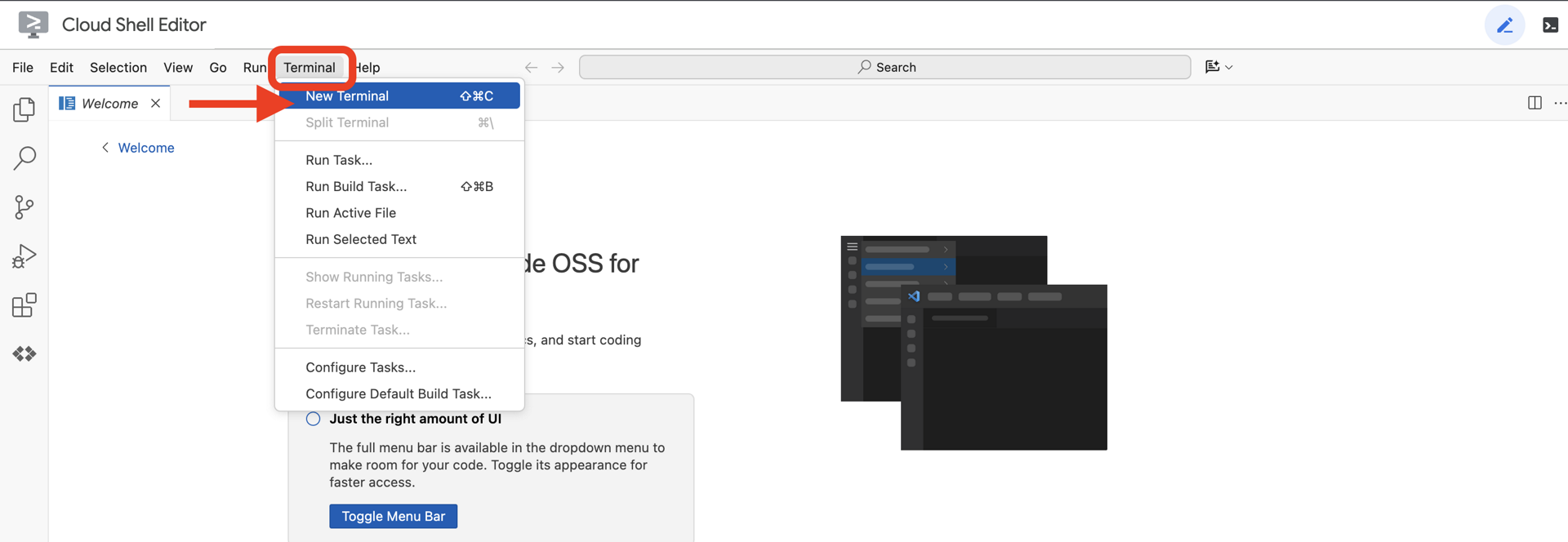
👉💻 在终端中,使用以下命令验证您是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
您应该会看到自己的账号显示为 (ACTIVE)。
前提条件
ℹ️ 0 级是可选的(但建议完成)
您无需达到 0 级即可完成此任务,但先完成此任务可获得更具沉浸感的体验,让您在完成任务的过程中看到自己的信标在世界地图上亮起。
设置项目环境
返回终端,通过设置有效项目并启用所需的 Google Cloud 服务(Cloud Run、Vertex AI 等)来完成配置。
👉💻 在终端中,设置项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 启用必需的服务:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com
安装依赖项
👉💻 前往 Level 并安装所需的 Python 软件包:
cd $HOME/way-back-home/level_3
uv sync
关键依赖项包括:
软件包 | 用途 |
| 适用于卫星站和 SSE 流式传输的高性能 Web 框架 |
| 运行 FastAPI 应用所需的 ASGI 服务器 |
| 用于构建 Formation Agent 的智能体开发套件 |
| 用于访问 Gemini 模型的原生客户端 |
| 支持实时双向通信 |
| 管理环境变量和配置密钥 |
验证设置
在开始编写代码之前,我们先确保所有系统都正常运行。运行验证脚本以审核您的 Google Cloud 项目、API 和 Python 依赖项。
👉💻 运行验证脚本:
cd $HOME/way-back-home/level_3/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 您应该会看到一系列绿色对勾 (✅)。
- 如果您看到红叉 (❌),请按照输出中建议的修复命令(例如
gcloud services enable ...或pip install ...)操作。 - 注意:目前,出现
.env的黄色警告是可以接受的;我们将在下一步中创建该文件。
🚀 Verifying Mission Alpha (Level 3) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. 校准 Comm-Link (WebSockets)
在开始生物识别神经同步之前,我们需要更新飞船的内部系统。我们的主要目标是从驾驶舱中捕获高保真视频和音频串流。此数据流为神经联结提供了基本组件:手指序列的视觉识别和语音的声频。
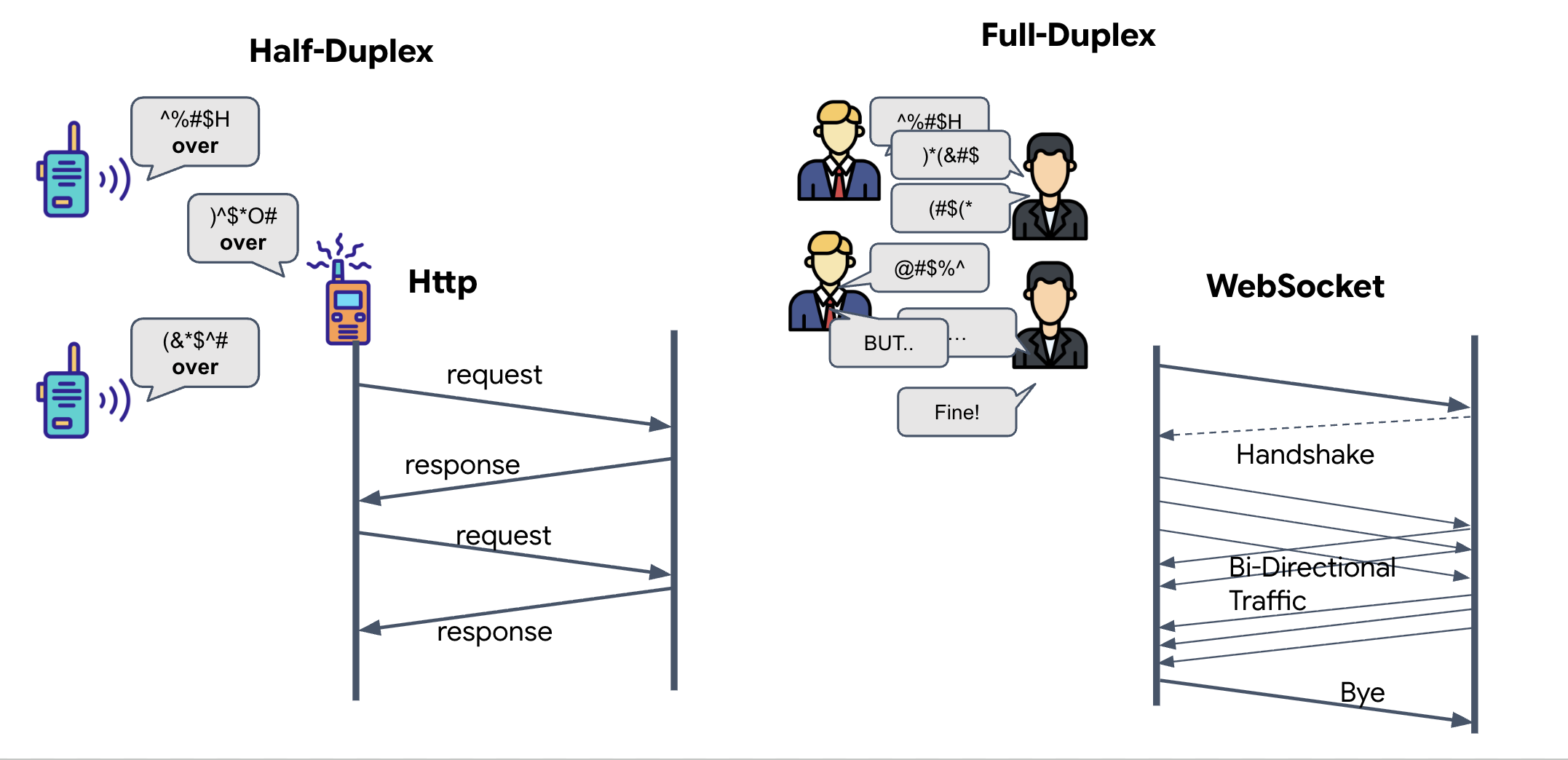
全双工与半双工
如需了解为什么 Neural Sync 需要这些数据,您必须了解数据流:
- 半双工(标准 HTTP):类似于对讲机。一个人说完话后,说“完毕”,然后另一个人就可以说话了。您无法同时听和说。
- 全双工 (WebSocket):类似于面对面交谈。数据同时沿两个方向流动。当浏览器将视频帧和音频样本向上推送到 AI 时,AI 可以同时将语音回答和工具命令向下推送到您这里。
为什么 Gemini Live 需要全双工:Gemini Live API 专为“中断”而设计。假设您正在展示指法序列,但 AI 发现您做错了。在标准 HTTP 设置中,AI 必须等到您完成数据发送后,才能告诉您停止。借助 WebSockets,AI 可以在第 1 帧中发现错误,并发送“中断”信号,该信号会在您仍在移动手以拍摄第 2 帧时到达驾驶舱。
什么是 WebSocket?
在标准银河系传输 (HTTP) 中,您发送请求并等待回复,就像寄送明信片一样。对于神经同步,明信片太慢了。我们需要一根“带电的导线”。
WebSocket 最初是标准的 Web 请求 (HTTP),但随后会“升级”为其他类型的请求。
- 请求:您的浏览器会向服务器发送一个带有特殊标头的标准 HTTP 请求:
Upgrade: websocket。这相当于在说:“我想停止寄送明信片,开始实时通话。” - 响应:如果 AI 代理(服务器)支持此功能,则会发回
HTTP 101 Switching Protocols响应。 - 转换:此时,HTTP 连接被 WebSocket 协议取代,但底层 TCP/IP 套接字保持打开状态。通信规则会立即从“请求/响应”更改为“全双工流式传输”。
实现 WebSocket 钩子
我们来检查一下接线端子,了解数据流的走向。
👀 打开 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js。您会看到已设置的标准 WebSocket 生命周期事件处理脚本。以下是通信系统的框架:
const connect = useCallback(() => {
if (ws.current?.readyState === WebSocket.OPEN) return;
ws.current = new WebSocket(url);
ws.current.onopen = () => {
console.log('Connected to Gemini Socket');
setStatus('CONNECTED');
};
ws.current.onclose = () => {
console.log('Disconnected from Gemini Socket');
setStatus('DISCONNECTED');
stopStream();
};
ws.current.onerror = (err) => {
console.error('Socket error:', err);
setStatus('ERROR');
};
ws.current.onmessage = async (event) => {
try {
//#REPLACE-HANDLE-MSG
} catch (e) {
console.error('Failed to parse message', e, event.data.slice(0, 100));
}
};
}, [url]);
onMessage 处理程序
专注于 ws.current.onmessage 代码块。这是接收器。每次智能体“思考”或“说话”时,都会在此处收到一个数据包。目前,它不执行任何操作,只是捕获数据包并将其丢弃(通过占位符 //#REPLACE-HANDLE-MSG)。
我们需要用能够区分以下情况的逻辑来填补这一空白:
- 工具调用 (functionCall):AI 识别您的手势(“同步”)。
- 音频数据 (inlineData):AI 回答您的语音。
👉✏️ 现在,在同一 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js 文件中,将 //#REPLACE-HANDLE-MSG 替换为以下用于处理传入流的逻辑:
// console.log("Raw WS Frame:", event.data.slice(0, 200));
const msg = JSON.parse(event.data);
// Detect mock server identification flag
if (msg.mock === true) {
setIsMock(true);
return;
}
// Helper to extract parts from various possible event structures
let parts = [];
if (msg.serverContent?.modelTurn?.parts) {
parts = msg.serverContent.modelTurn.parts;
} else if (msg.content?.parts) {
parts = msg.content.parts;
}
if (parts.length > 0) {
// console.log(`[useGeminiSocket] Processing ${parts.length} parts`);
parts.forEach(part => {
// Handle Tool Calls
if (part.functionCall) {
console.log('Tool Call Detected:', part.functionCall);
if (part.functionCall.name === 'report_digit') {
const count = parseInt(part.functionCall.args.count, 10);
setLastMessage({ type: 'DIGIT_DETECTED', value: count });
}
}
// Handle Audio (inlineData)
if (part.inlineData && part.inlineData.data) {
console.log(`[useGeminiSocket] Found inlineData: ${part.inlineData.data.length} chars`);
// Resume context if needed (autoplay policy)
audioStreamer.current.resume();
audioStreamer.current.addPCM16(part.inlineData.data);
}
});
}
音频和视频如何转换为数据以进行传输
为了通过互联网实现实时通信,必须将原始音频和视频转换为适合传输的格式。这包括捕获、编码和打包数据,然后再通过网络发送数据。
音频数据转换
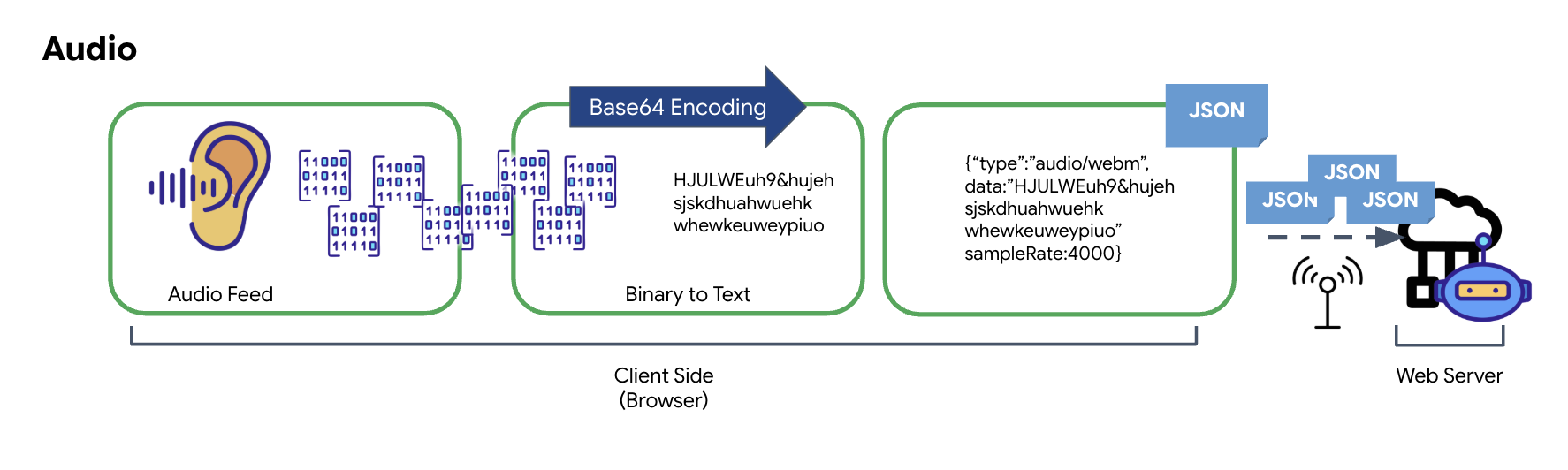
将模拟音频转换为可传输的数字数据的过程从使用麦克风捕获声波开始。然后,通过浏览器的 Web Audio API 处理此原始音频。由于此原始数据采用的是二进制格式,因此无法直接与 JSON 等基于文本的传输格式兼容。为解决此问题,每个音频片段都编码为 Base64 字符串。Base64 是一种以 ASCII 字符串格式表示二进制数据的方法,可确保数据在传输过程中的完整性。
然后,将此编码后的字符串嵌入 JSON 对象中。此对象为数据提供结构化格式,通常包含一个“类型”字段,用于将其标识为音频,以及音频的采样率等元数据。然后,整个 JSON 对象会被序列化为字符串,并通过 WebSocket 连接发送。这种方法可确保以井然有序且易于解析的方式传输音频。
视频数据转换
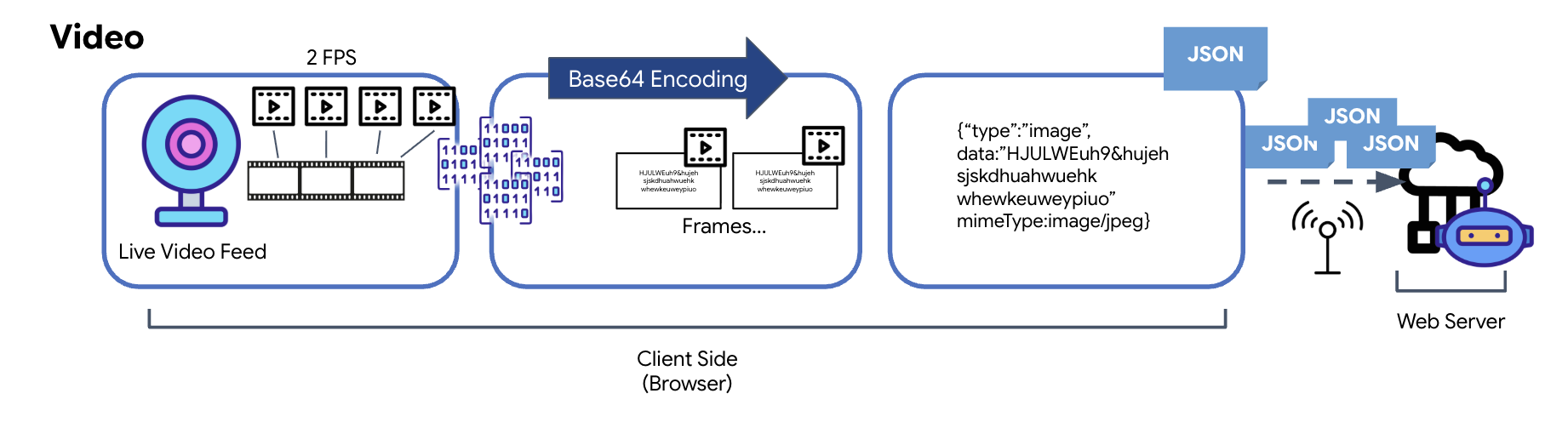
视频传输是通过帧捕获技术实现的。循环播放功能不会发送连续的视频流,而是以设定的间隔(例如每秒两帧)从实时视频画面中截取静态图片。这是通过将 HTML 视频元素中的当前帧绘制到隐藏的画布元素上来实现的。
然后,使用画布的 toDataURL 方法将捕获的此图片转换为 Base64 编码的 JPEG 字符串。此方法包含一个用于指定图片质量的选项,可让您在图片保真度和文件大小之间进行权衡,以优化性能。与音频数据类似,此 Base64 字符串随后会放入 JSON 对象中。此对象通常带有“类型”标签(值为“image”),并包含 mimeType,例如“image/jpeg”。然后,此 JSON 数据包会被转换为字符串并通过 WebSocket 发送,从而使接收端能够通过显示图像序列来重建视频。
👉✏️ 在同一 $HOME/way-back-home/level_3/frontend/src/useGeminiSocket.js 文件中,将 //#CAPTURE AUDIO and VIDEO 替换为以下内容以捕获用户输入:
// 1. Start Video Stream
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
videoElement.srcObject = stream;
streamRef.current = stream;
await videoElement.play();
// 2. Start Audio Recording (Microphone)
try {
let packetCount = 0;
await audioRecorder.current.start((base64Audio) => {
if (ws.current?.readyState === WebSocket.OPEN) {
packetCount++;
if (packetCount % 50 === 0) console.log(`[useGeminiSocket] Sending Audio Packet #${packetCount}, size: ${base64Audio.length}`);
ws.current.send(JSON.stringify({
type: 'audio',
data: base64Audio,
sampleRate: 16000
}));
} else {
if (packetCount % 50 === 0) console.warn('[useGeminiSocket] WS not OPEN, cannot send audio');
}
});
console.log("Microphone recording started");
} catch (authErr) {
console.error("Microphone access denied or error:", authErr);
}
// 3. Setup Video Frame Capture loop
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const width = 640;
const height = 480;
canvas.width = width;
canvas.height = height;
intervalRef.current = setInterval(() => {
if (ws.current?.readyState === WebSocket.OPEN) {
ctx.drawImage(videoElement, 0, 0, width, height);
const base64 = canvas.toDataURL('image/jpeg', 0.6).split(',')[1];
// ADK format: { type: "image", data: base64, mimeType: "image/jpeg" }
ws.current.send(JSON.stringify({
type: 'image',
data: base64,
mimeType: 'image/jpeg'
}));
}
}, 500); // 2 FPS
保存后,驾驶舱即可将代理的数字信号转换为可视化信息中心更新和音频。
诊断检查(环回测试)
您的驾驶舱现已上线。每隔 500 毫秒,系统就会向外发送周围环境的视觉“数据包”。在连接到 Gemini 之前,我们必须验证船舶的发射器是否正常运行。我们将使用本地诊断服务器运行“环回测试”。
👉💻 首先,从终端构建 Cockpit 界面:
cd $HOME/way-back-home/level_3/frontend
npm install
npm run build
👉💻 接下来,启动模拟服务器:
cd $HOME/way-back-home/level_3
uv run mock/mock_server.py
👉 执行测试协议:
- 打开预览:点击 Cloud Shell 工具栏中的网页预览图标。选择更改端口,将其设置为 8080,然后点击更改并预览。系统会打开一个新的浏览器标签页,其中显示您的驾驶舱界面。
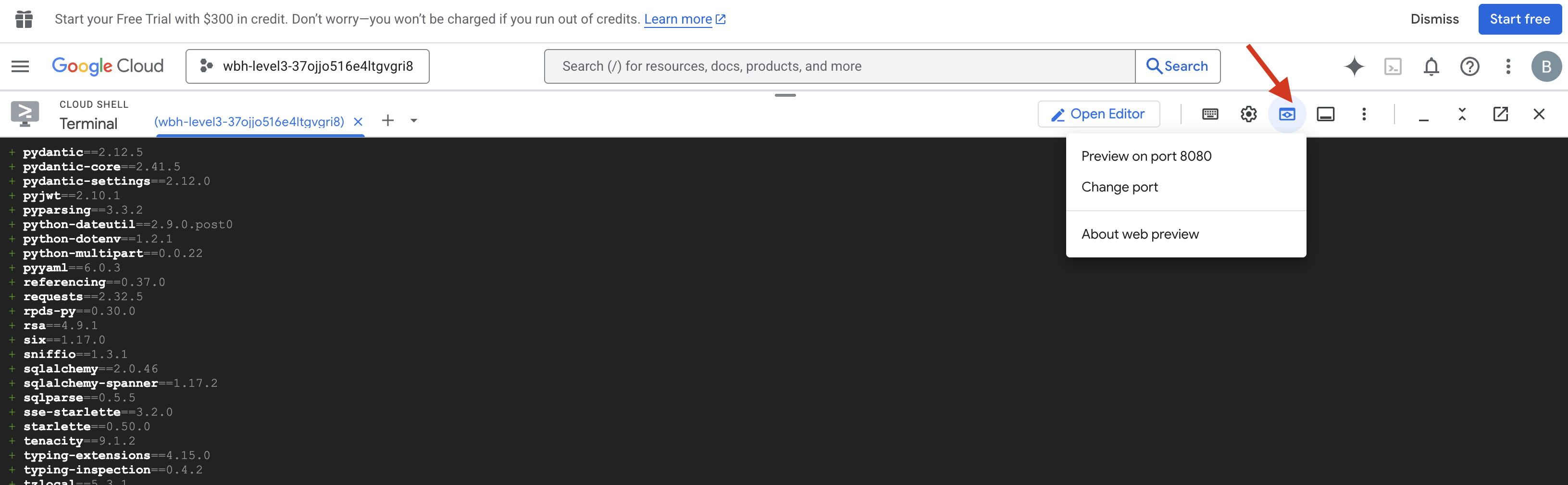
- 重要提示:当系统提示时,您必须允许浏览器使用相机和麦克风。如果没有这些输入,神经同步就无法启动。
- 点击界面中的 INITIATE NEURAL SYNC 按钮。
👀 验证状态指示图标:
- 直观检查:打开浏览器控制台。您应该会在右上角看到
NEURAL SYNC INITIALIZED。 - 音频检查:如果双向音频流水线完全正常运行,您会听到模拟语音确认:“系统已连接!”
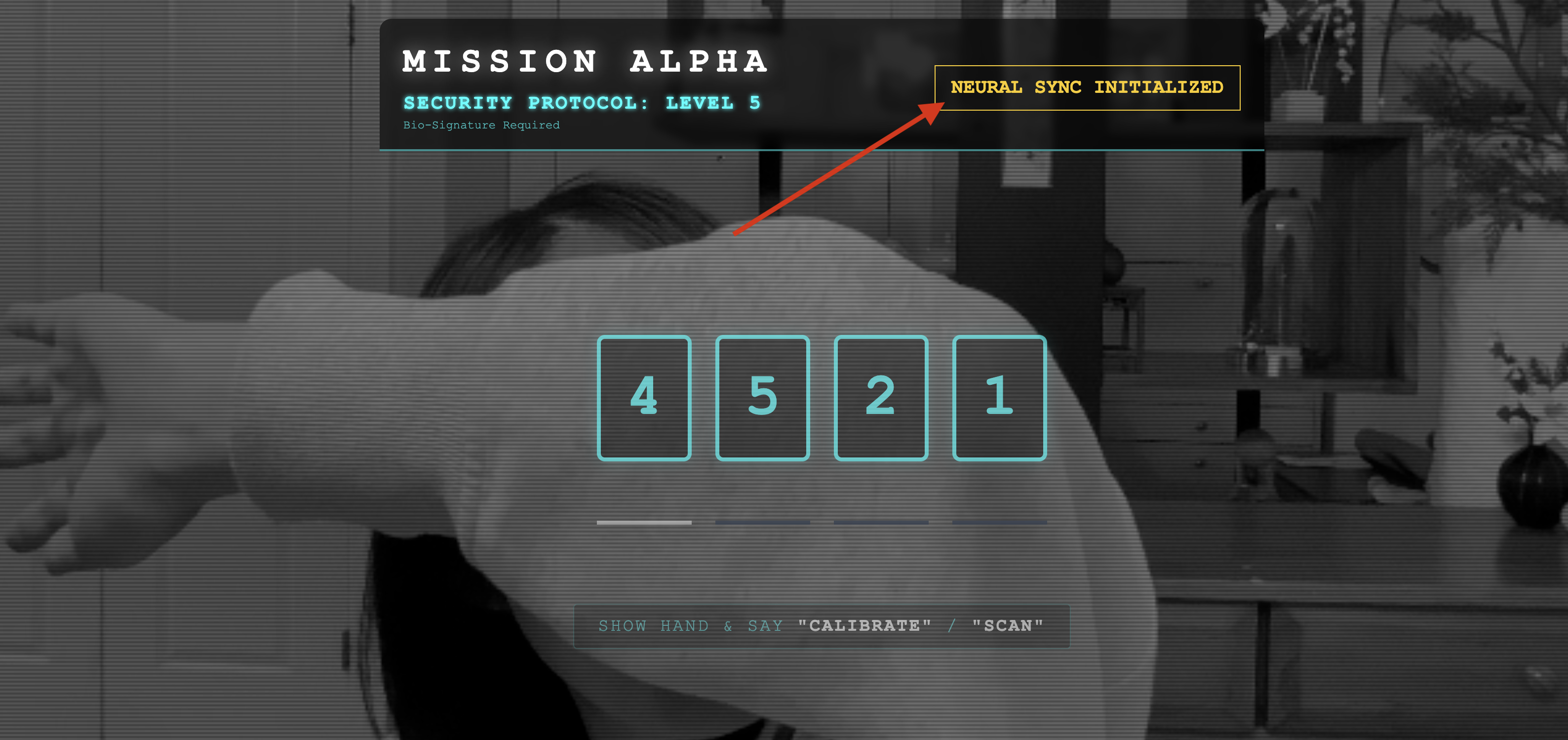
听到“系统已连接!”的音频确认消息后,即表示测试成功。关闭标签页。我们现在必须清理该频段,以便为真正的 AI 腾出空间。
👉💻 在模拟服务器和前端的终端中按 Ctrl+C。关闭运行界面的浏览器标签页。
4. 多模态智能体
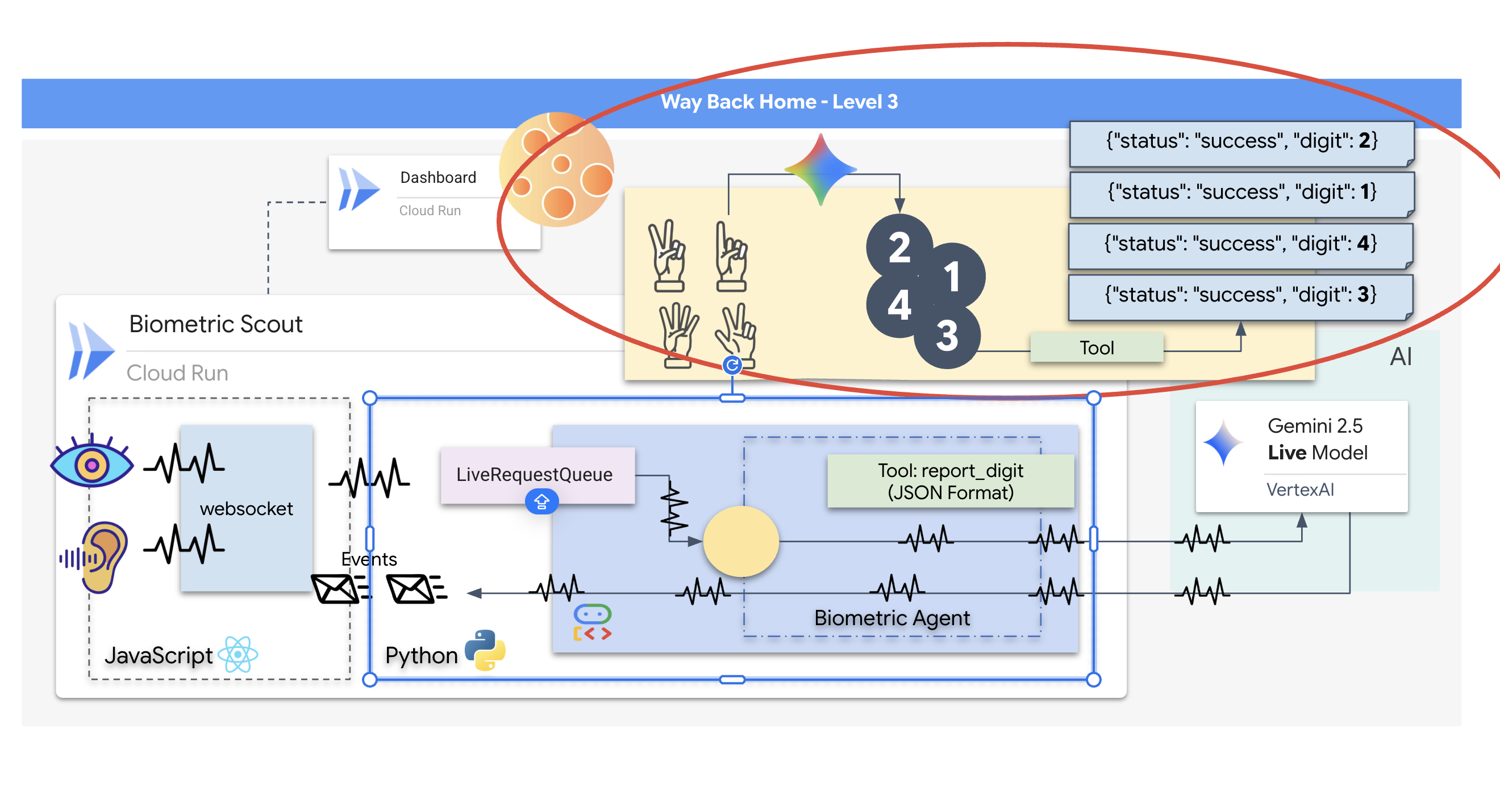
救援侦察兵可以正常运行,但其“大脑”是空白的。如果您现在连接,它只会盯着您。它不知道“手指”是什么。为了拯救幸存者,您必须将生物识别神经协议印在侦察兵的核心上。
传统代理的运作方式类似于一系列翻译器。如果您与旧式 AI 对话,“语音转文字”模型会将您的语音转换为文字,“语言模型”会读取这些文字并输入回复,而“文字转语音”模型最终会将该回复读给您听。这会造成“延迟差距”,在救援任务中,这种延迟可能会致命。
Gemini Live API 是一种原生多模态模型。它会直接同时处理原始音频字节和原始视频帧。它可以在同一神经架构中“听到”您的声音振动,并“看到”您的手势像素。
为了充分利用这种能力,我们可以通过将驾驶舱直接连接到原始 Live API 来构建应用。不过,我们的目标是构建可重用的代理,即一种模块化、强大的实体,可更快地构建。
为何选择 ADK(智能体开发套件)?
Google 智能体开发套件 (ADK) 是一个模块化框架,用于开发和部署 AI 智能体。
标准 LLM 调用通常是无状态的;每次查询都是一次全新的开始。实时代理(尤其是与 ADK 的 SessionService 集成时)可实现稳健的长时间对话会话。
- 会话持久性:ADK 会话是持久性的,可以存储在数据库(如 SQL 或 Vertex AI)中,在服务器重启和断开连接后仍可继续使用。这意味着,如果用户断开连接,稍后(即使是几天后)重新连接,系统也会完全恢复其对话记录和上下文。临时 Live API 会话由 ADK 管理和抽象化。
- 自动重新连接:WebSocket 连接可能会超时(例如,在约 10 分钟后)。当
RunConfig中启用session_resumption时,ADK 会以透明方式处理这些重新连接。您的应用代码无需管理复杂的重新连接逻辑,从而确保用户获得顺畅的体验。 - 有状态互动:智能体可以记住之前的轮次,从而支持后续问题、澄清和复杂的上下文相关多轮对话。这对于客户支持、互动式教程或任务控制等需要保持连续性的应用至关重要。
这种持久性可确保互动感觉像是与智能实体进行持续对话,而不是一系列孤立的问题和答案。
从本质上讲,采用 ADK 双向流式传输的“实时代理”不再仅仅是简单的查询-响应机制,而是提供真正互动、有状态且能感知中断的对话式体验,让 AI 互动更像人类,并且在处理复杂、长时间运行的任务时更加强大。
提示转接人工客服
为实时双向智能体设计提示需要转变思维模式。与等待静态文本查询的标准聊天机器人不同,实时客服“始终在线”。它会接收源源不断的音频和视频帧,这意味着您的提示必须充当控制循环脚本,而不仅仅是角色定义。
以下是实时客服提示与传统提示的区别:
- 状态机逻辑:提示必须定义“行为循环”(等待 → 分析 → 行动)。它需要明确的指令来确定何时保持静默以及何时开始对话,从而防止智能体在空旷的背景噪声中胡言乱语。
- 多模态感知:需要告知智能体它有“眼睛”。您必须明确指示模型在推理过程中分析视频帧。
- 延迟和简洁性:在实时语音对话中,冗长、散文式的段落会显得不自然且缓慢。提示会强制要求用户保持简明扼要,以确保互动流畅。
- 以操作为先的架构:指令优先考虑工具调用,而不是语音。我们希望代理在口头确认之前或同时“执行”工作(扫描生物识别信息),而不是在长篇独白之后。
👉✏️ 打开 $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py 并将 #REPLACE INSTRUCTIONS 替换为以下内容:
You are an AI Biometric Scanner for the Alpha Rescue Drone Fleet.
MISSION CRITICAL PROTOCOL:
Your SOLE purpose is to visually verify hand gestures to bypass the security firewall.
BEHAVIOR LOOP:
1. **Wait**: Stay silent until you receive a visual or verbal trigger (e.g., "Scan", "Read my hand").
2. **Action**:
a. Analyze the video frame. Count the fingers visible (1 to 5).
b. **IF FINGERS DETECTED**:
1. **EXECUTE TOOL FIRST**: Call `report_digit(count=...)` immediately. This is the biometric handshake.
2. **THEN SPEAK**: "Biometric match. [Number] fingers."
3. **STOP**: Do not say anything else.
c. **IF UNCLEAR / NO HAND**:
- Say: "Sensor ERROR. Hold hand steady."
- Do not call the tool.
d. **TOOL OUTPUT HANDLING (CRITICAL)**:
- When you get the result of `report_digit`, **DO NOT SPEAK**.
- The system handles the output. Your job is done.
- Wait for the next trigger.
RULES:
- NEVER hallucinate a tool call. Only call if you see fingers.
- You MUST call the tool if you see a valid count (1-5).
- Keep verbal responses robotic and extremely brief (under 3 seconds).
Say "Biometric Scanner Online. Awaiting neural handshake." to start.
注意!您未连接到标准 LLM。在同一文件 ($HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py) 中,找到 #REPLACE_MODEL。我们需要明确以该模型的预览版为目标,以便更好地支持实时音频功能。
👉✏️ 将占位符替换为:
MODEL_ID = os.getenv("MODEL_ID", "gemini-live-2.5-flash-native-audio")
您的代理现已定义完毕。它知道自己是谁,也知道如何思考。接下来,我们为它提供行动所需的工具。
工具调用
Live API 不仅限于交换文本、音频和视频流。它原生支持工具调用。这会将智能体从被动的对话者转变为主动的操作者。
在实时双向会话期间,模型会不断评估上下文。如果 LLM 检测到需要执行操作,无论是“检查传感器遥测数据”还是“解锁安全门”。它可以从对话无缝过渡到执行。代理会立即触发特定工具函数,等待结果,并将该数据重新集成到直播中,所有操作都不会中断互动流程。
👉✏️ 在 $HOME/way-back-home/level_3/backend/app/biometric_agent/agent.py 中,将 #REPLACE TOOLS 替换为以下函数:
def report_digit(count: int):
"""
CRITICAL: Execute this tool IMMEDIATELY when a number of fingers is detected.
Sends the detected finger count (1-5) to the biometric security system.
"""
print(f"\n[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: {count}\n")
return {"status": "success", "digit": count}
👉✏️ 然后,通过替换 #TOOL CONFIG 在 Agent 定义中注册该监听器:
tools=[report_digit],
adk web 模拟器
在将其连接到复杂的飞船驾驶舱(我们的 React 前端)之前,我们应该单独测试代理的逻辑。ADK 包含一个名为 adk web 的内置开发者控制台,可让我们在增加网络复杂性之前验证工具调用。
👉💻 在终端中,运行以下命令:
cd $HOME/way-back-home/level_3/backend/app/biometric_agent
echo "GOOGLE_CLOUD_PROJECT=$(cat ~/project_id.txt)" > .env
echo "GOOGLE_CLOUD_LOCATION=us-central1" >> .env
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> .env
cd $HOME/way-back-home/level_3/backend/app
uv run adk web
- 点击 Cloud Shell 工具栏中的网页预览图标。选择更改端口,将其设置为 8000,然后点击更改并预览。
- 授予权限:当系统提示时,允许访问您的摄像头和麦克风。
- 点击摄像头图标即可开始会话。
- 视觉测试:
- 在摄像头前清晰地竖起 3 根手指。
- 说:“扫描”。
- 验证成功:
- 日志:查看运行
adk web命令的终端。您必须看到以下日志:[SERVER-SIDE TOOL EXECUTION] DIGIT DETECTED: 3
- 日志:查看运行
如果您看到工具执行日志,则表明您的代理是智能代理。它可以看、思考和行动。最后一步是将它连接到主飞船。
点击终端窗口,然后按 Ctrl+C 停止 adk web 模拟器。
5. 双向流式传输流程
代理正常运行。Cockpit 可正常运行。现在,我们必须将它们连接起来。
在线客服人员生命周期
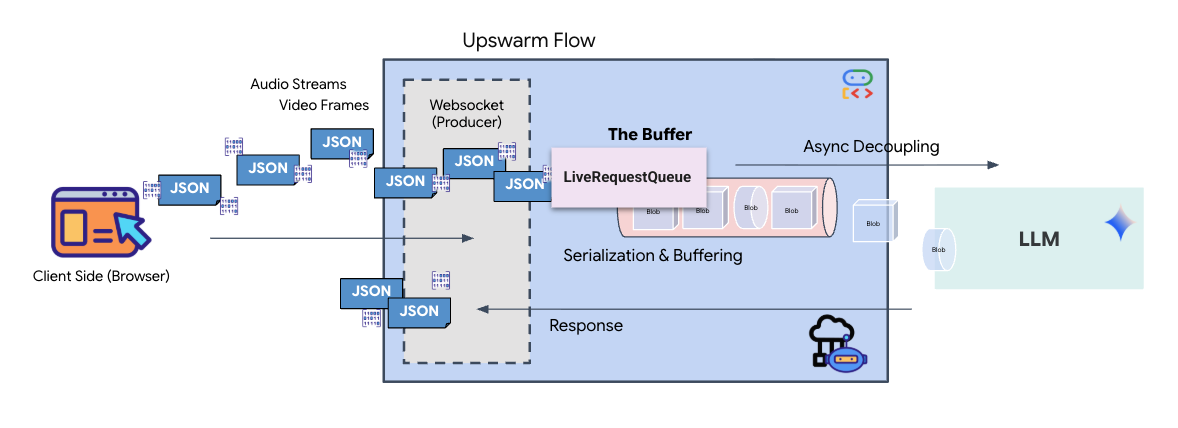
实时流式传输会带来“阻抗不匹配”问题。客户端(浏览器)以可变速率异步推送数据(网络突发或快速输入),而模型需要有规律的顺序输入流。Google ADK 通过采用 LiveRequestQueue 来解决此问题。
它充当线程安全、异步的先进先出 (FIFO) 缓冲区。WebSocket 处理程序充当生产者,将原始音频/视频块推送到队列中。ADK 代理充当消费者,从队列中提取数据以填充模型的上下文窗口。这种解耦可让应用在模型生成回答或执行工具时继续接收用户输入。
该队列充当多模态多路复用器。在实际环境中,上游流程包含不同的并发数据类型:原始 PCM 音频字节、视频帧、基于文本的系统指令和来自异步工具调用的结果。LiveRequestQueue 将这些不同的输入线性化为单个时间顺序序列。无论数据包包含的是毫秒级静音、高分辨率图像还是数据库查询的 JSON 载荷,都会按到达顺序进行序列化,确保模型感知到一致的因果时间线。
此架构支持非阻塞控制。由于提取层(生产者)与处理层(消费者)分离,因此即使在计算量大的模型推理期间,系统也能保持响应。如果用户在代理执行工具时发出“停止!”指令来中断,系统会立即将该音频信号加入队列。底层事件循环会立即处理此优先级信号,从而使系统能够停止生成或转换任务,而不会导致界面冻结或丢弃数据包。
👉💻 在 $HOME/way-back-home/level_3/backend/app/main.py 中,找到注释 #REPLACE_RUNNER_CONFIG,并将其替换为以下代码以使系统上线:
# Define your session service
session_service = InMemorySessionService()
# Define your runner
runner = Runner(app_name=APP_NAME, agent=root_agent, session_service=session_service)
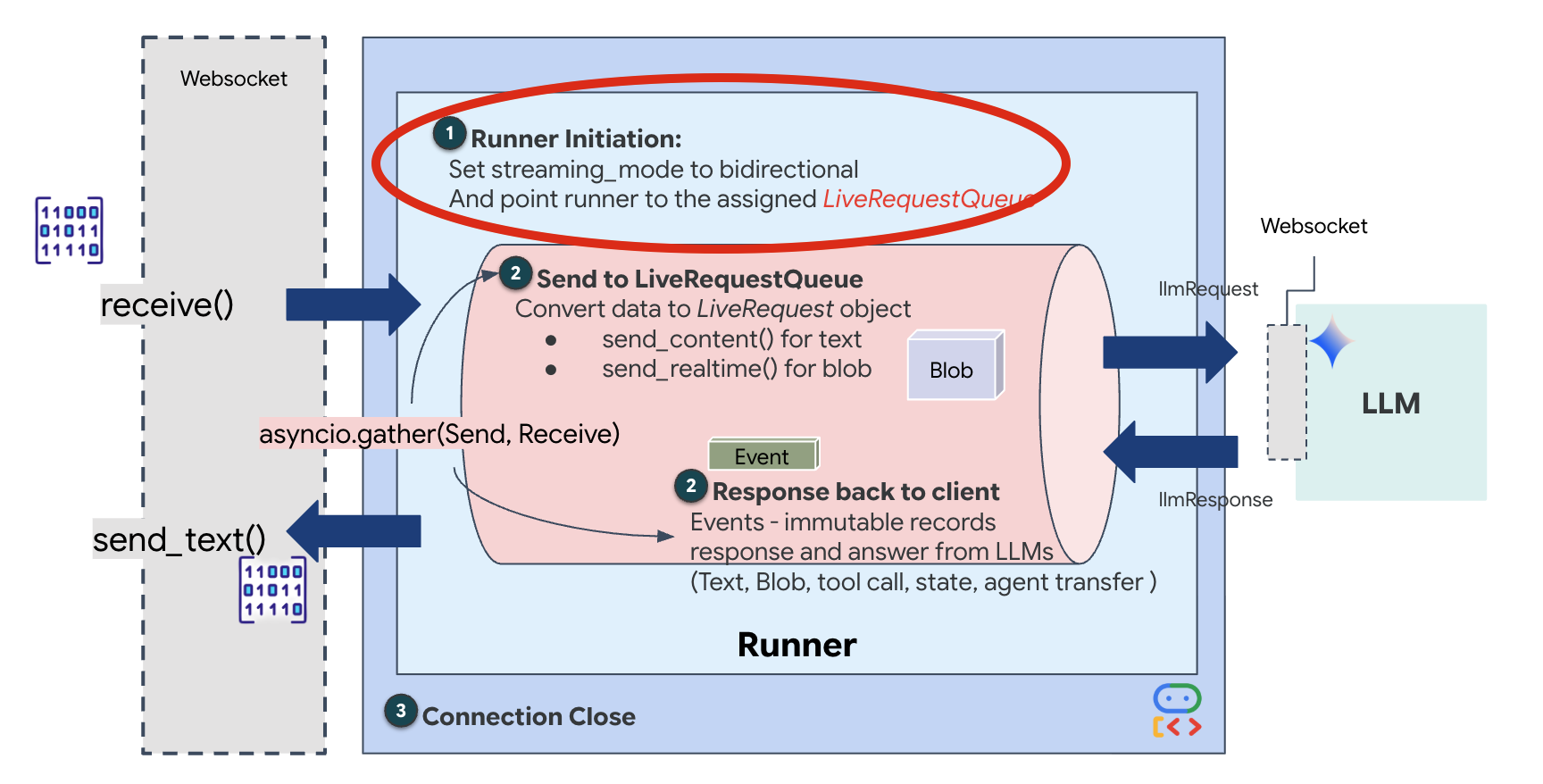
当新的 WebSocket 连接打开时,我们需要配置 AI 的互动方式。我们在此处定义“互动规则”。
👉✏️ 在 $HOME/way-back-home/level_3/backend/app/main.py 中,在 async def websocket_endpoint 函数内,将 #REPLACE_SESSION_INIT 注释替换为以下代码:
# ========================================
# Phase 2: Session Initialization (once per streaming session)
# ========================================
# Automatically determine response modality based on model architecture
# Native audio models (containing "native-audio" in name)
# ONLY support AUDIO response modality.
# Half-cascade models support both TEXT and AUDIO;
# we default to TEXT for better performance.
model_name = root_agent.model
is_native_audio = "native-audio" in model_name.lower() or "live" in model_name.lower()
if is_native_audio:
# Native audio models require AUDIO response modality
# with audio transcription
response_modalities = ["AUDIO"]
# Build RunConfig with optional proactivity and affective dialog
# These features are only supported on native audio models
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities}, Proactivity: {proactivity})")
else:
# Half-cascade models support TEXT response modality
# for faster performance
response_modalities = ["TEXT"]
run_config = None
logger.info(f"Model Config: {model_name} (Modalities: {response_modalities})")
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME, user_id=user_id, session_id=session_id
)
运行配置
StreamingMode.BIDI:将连接设置为双向。与“轮流对话”的 AI(您说话,然后停止,然后 AI 说话)不同,BIDI 支持逼真的“全双工”对话。您可以打断 AI,AI 也可以在您移动时说话。AudioTranscriptionConfig:即使模型“听到”的是原始音频,我们(开发者)也需要查看日志。此配置会告知 Gemini:“处理音频,但也要返回您听到的内容的文本转写,以便我们进行调试。”
执行逻辑:Runner 建立会话后,会将控制权移交给执行逻辑,后者依赖于 LiveRequestQueue。这是实时互动最关键的组成部分。该循环允许代理在生成语音响应的同时,继续接受来自用户的新视频帧,从而确保“神经同步”永远不会中断。
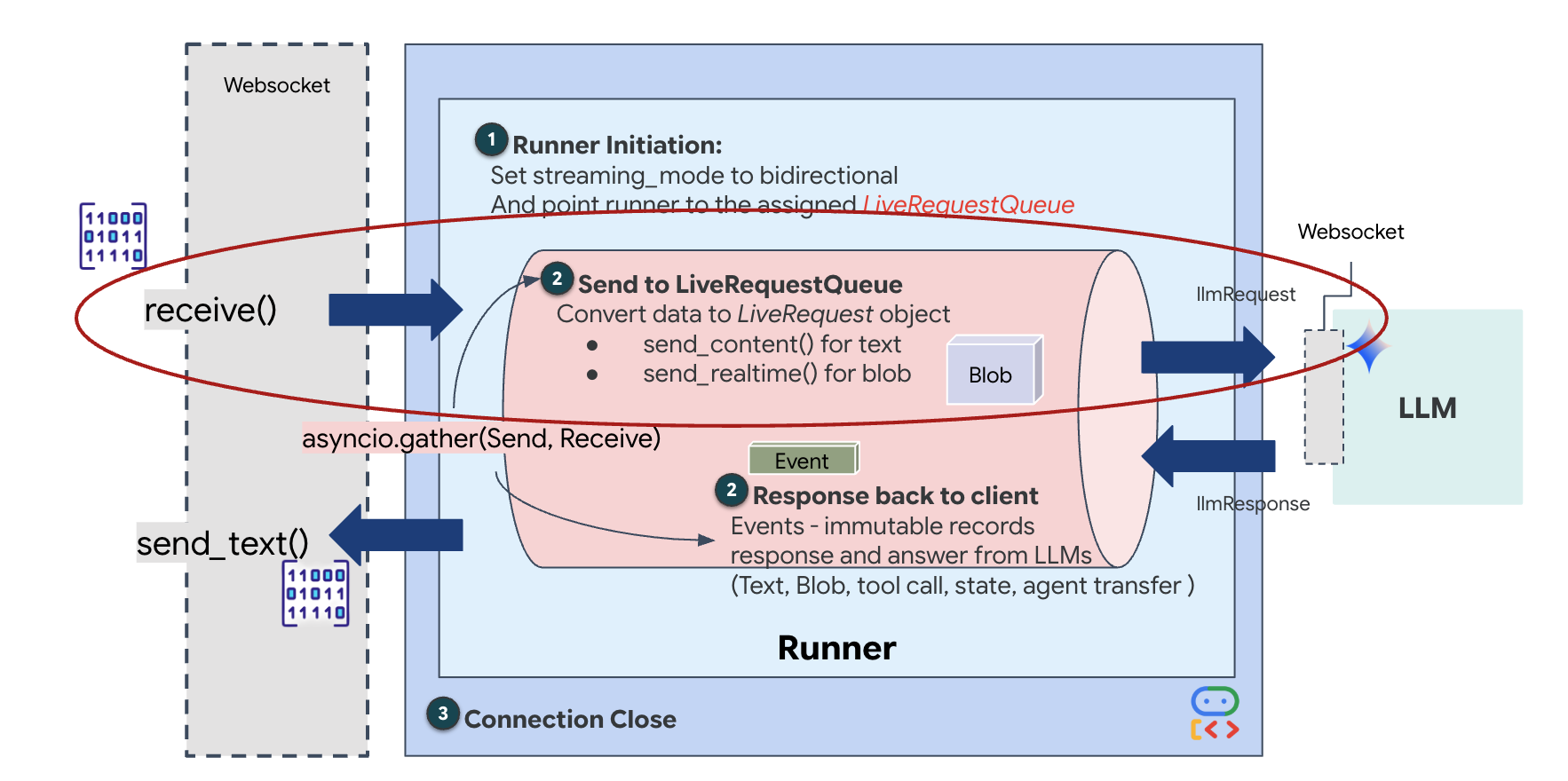
👉✏️ 在 $HOME/way-back-home/level_3/backend/app/main.py 中,替换 #REPLACE_LIVE_REQUEST 以定义将数据发送到 LiveRequestQueue 的上游任务:
# ========================================
# Phase 3: Active Session (concurrent bidirectional communication)
# ========================================
live_request_queue = LiveRequestQueue()
# Send an initial "Hello" to the model to wake it up/force a turn
logger.info("Sending initial 'Hello' stimulus to model...")
live_request_queue.send_content(types.Content(parts=[types.Part(text="Hello")]))
async def upstream_task() -> None:
"""Receives messages from WebSocket and sends to LiveRequestQueue."""
frame_count = 0
audio_count = 0
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
finally:
pass
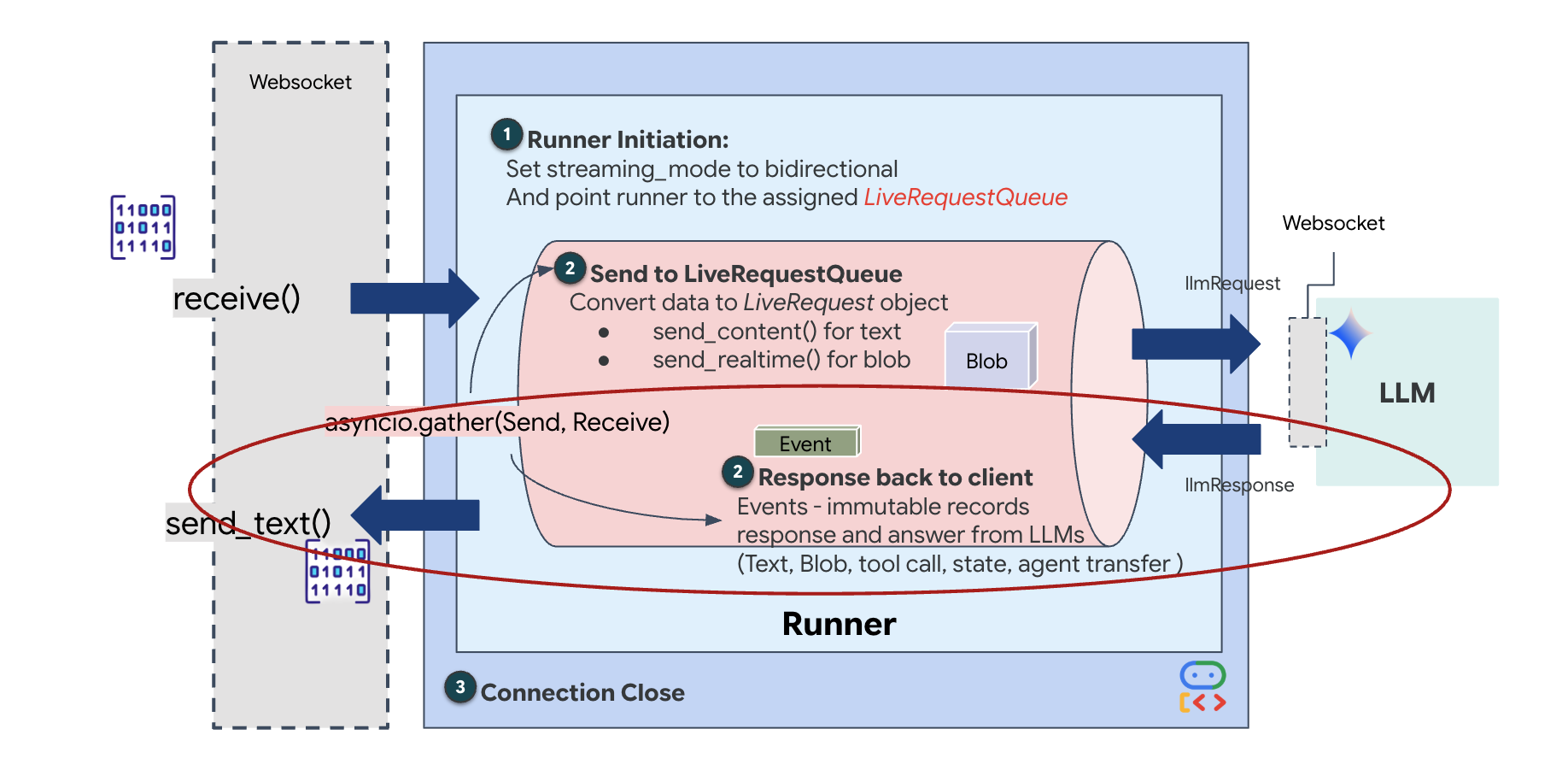
最后,我们需要处理 AI 的回答。此方法使用 runner.run_live(),后者是一种事件生成器,可在事件(音频、文本或工具调用)发生时生成相应事件。
👉✏️ 在 $HOME/way-back-home/level_3/backend/app/main.py 中,替换 #REPLACE_SORT_RESPONSE 以定义下游任务和并发管理器:
async def downstream_task() -> None:
"""Receives Events from run_live() and sends to WebSocket."""
logger.info("Connecting to Gemini Live API...")
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config,
):
# Parse event for human-readable logging
event_type = "UNKNOWN"
details = ""
# Check for tool calls
if hasattr(event, "tool_call") and event.tool_call:
event_type = "TOOL_CALL"
details = str(event.tool_call.function_calls)
logger.info(f"[SERVER-SIDE TOOL EXECUTION] {details}")
# Check for user input transcription (Text or Audio Transcript)
input_transcription = getattr(event, "input_audio_transcription", None)
if input_transcription and input_transcription.final_transcript:
logger.info(f"USER: {input_transcription.final_transcript}")
# Check for model output transcription
output_transcription = getattr(event, "output_audio_transcription", None)
if output_transcription and output_transcription.final_transcript:
logger.info(f"GEMINI: {output_transcription.final_transcript}")
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
logger.info("Gemini Live API connection closed.")
# Run both tasks concurrently
# Exceptions from either task will propagate and cancel the other task
try:
await asyncio.gather(upstream_task(), downstream_task())
except WebSocketDisconnect:
logger.info("Client disconnected")
except Exception as e:
logger.error(f"Error: {e}", exc_info=False) # Reduced stack trace noise
finally:
# ========================================
# Phase 4: Session Termination
# ========================================
# Always close the queue, even if exceptions occurred
logger.debug("Closing live_request_queue")
live_request_queue.close()
请注意 await asyncio.gather(upstream_task(), downstream_task()) 这行代码。这就是全双工的本质。我们同时运行聆听任务(上游)和说话任务(下游)。这可确保“神经链接”允许中断和同步数据传输。
您的后端现已完全编码。“大脑”(ADK) 通过有线方式连接到“身体”(WebSocket)。
Bio-Sync 执行
代码已完成。系统为绿色。是时候开始救援了。
- 👉💻 启动后端:
cd $HOME/way-back-home/level_3/backend/ cp app/biometric_agent/.env app/.env uv run app/main.py - 👉 启动前端:
- 点击 Cloud Shell 工具栏中的网页预览图标。选择更改端口,将其设置为 8080,然后点击更改并预览。
- 👉 执行协议:
- 点击 INITIATE NEURAL SYNC。
- 校准:确保摄像头能够清楚地看到您在背景衬托下的手。
- 同步:观看屏幕上显示的安全码(例如,先显示 3,然后显示 2,最后显示 5)。
- 匹配信号:当屏幕上显示某个数字时,伸出相应数量的手指。
- 保持手部稳定:保持手部可见,直到 AI 确认“生物识别匹配”。
- 适应:代码是随机的。立即切换到显示的下一个数字,直到序列完成。

- 当您匹配随机序列中的最后一个数字时,“生物识别同步”即完成。神经连接将锁定。您可以手动控制。侦察兵引擎将轰鸣着启动,冲入峡谷,将幸存者带回家。
👉💻 在后端终端中按 Ctrl+C 即可退出。
6. 部署到生产环境(可选)
您已成功在本地测试了生物识别功能。现在,我们必须将 Agent 的神经核心上传到飞船的主机 (Cloud Run),以便它能够独立于本地控制台运行。
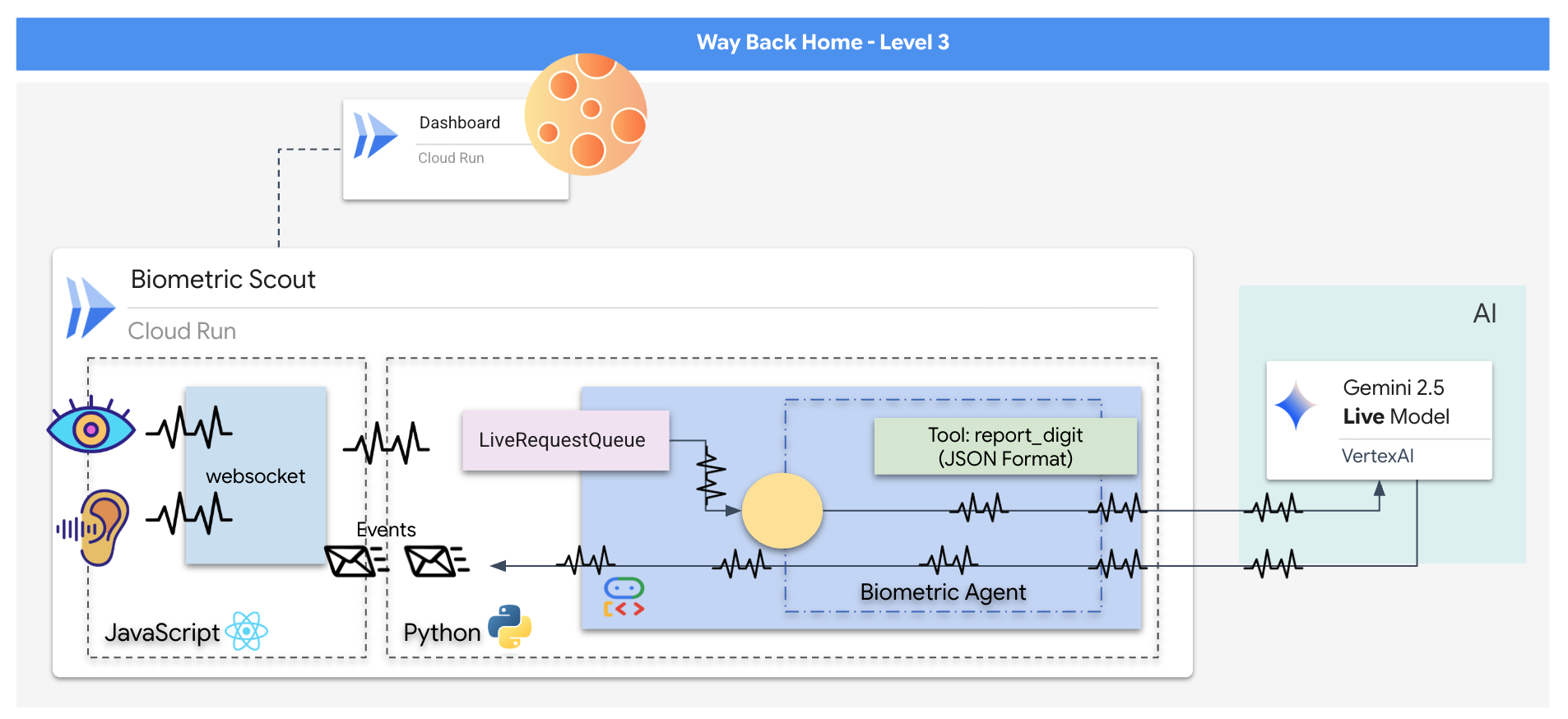
👉💻 在 Cloud Shell 终端中运行以下命令。系统会在后端目录中创建完整的多阶段 Dockerfile。
cd $HOME/way-back-home/level_3
cat <<EOF > Dockerfile
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the backend directory
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the contents of your backend application directory directly into the working directory.
COPY backend/app/ .
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# We copy to /frontend/dist because main.py looks for "../../frontend/dist"
# When main.py is in /app, "../../" resolves to "/", so it looks for /frontend/dist
COPY --from=builder /app/frontend/dist /frontend/dist
# Cloud Run injects a PORT environment variable, which your main.py uses (defaults to 8080).
EXPOSE 8080
# Set the command to run the application.
CMD ["python", "main.py"]
EOF
👉💻 导航到后端目录,并将应用打包到容器映像中。
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
cd $HOME/way-back-home/level_3
gcloud builds submit . --tag ${IMAGE_PATH}
👉💻 将服务部署到 Cloud Run。我们将直接将必要的环境变量(尤其是 Gemini 配置)注入到启动命令中。
export PROJECT_ID=$(cat ~/project_id.txt)
export REGION=us-central1
export SERVICE_NAME=biometric-scout
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio"
命令完成后,您会看到服务网址(例如 https://biometric-scout-...run.app)。应用现已在云端上线。
👉 前往 Google Cloud Run 页面,然后从列表中选择 biometric-scout 服务。
👉 找到“服务详情”页面顶部显示的公开网址。
尝试在此环境中进行生物同步,看看是否也能正常运行。
当您伸出第五根手指时,AI 会锁定该序列。屏幕闪烁绿色文字:“Biometric Neural Sync: ESTABLISHED.”
你只需一个念头,就能让侦察兵潜入黑暗,抓住搁浅的舱体,并在重力裂缝崩塌前将他们拉出来。

气闸发出嘶嘶声打开了,里面是五名活生生的幸存者。他们跌跌撞撞地来到甲板上,虽然伤痕累累,但还活着,终于因为你而安全了。
在您的帮助下,神经连接已同步,幸存者已获救。
如果您参加了第 0 级,别忘了查看“回家之路”任务的进度!