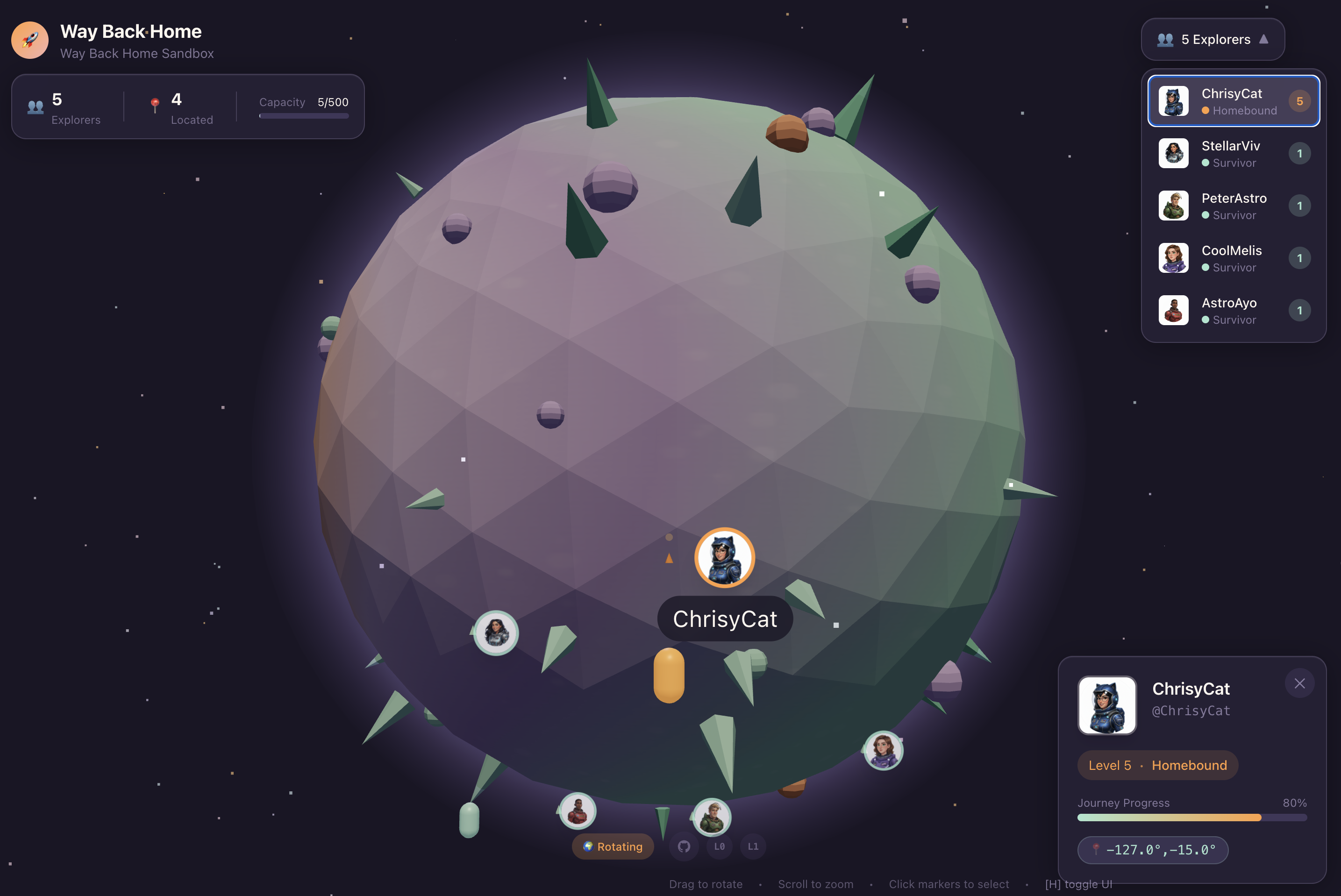
1. La mission

Vous êtes à la dérive dans l'étendue silencieuse et inexplorée de l'espace. Une énorme impulsion solaire a déchiré votre vaisseau à travers une faille dimensionnelle, vous laissant bloqué dans une poche de l'univers absente de toute carte stellaire.
Après des jours de réparations épuisantes, le ronronnement familier des moteurs revient enfin. Votre fusée est opérationnelle. Vous avez même réussi à établir une liaison montante longue distance avec le vaisseau-mère. Le départ est imminent. Vous êtes prêt à rentrer chez vous.
Mais alors que vous vous préparez à engager le lecteur de saut, un signal de détresse se fait entendre. Vos capteurs détectent un appel à l'aide provenant d'une planète nommée Ozymandias. Les survivants sont piégés sur cette planète mourante, leur vaisseau étant immobilisé. Votre mission est essentielle : sauvez-les avant que l'atmosphère de la planète ne s'effondre.
Leur seul moyen de s'échapper est une vieille fusée abandonnée construite avec la Technologie extraterrestre. Bien qu'elle soit fonctionnelle, son Moteur Warp est brisé. Pour sauver les survivants, vous devez vous connecter à distance à leur Volatile Workbench et assembler manuellement un lecteur de remplacement.
Le défi
Vous n'avez aucune expérience avec cette technologie extraterrestre, qui est notoirement fragile. Un composant déstabilisé peut devenir un danger radioactif en quelques secondes. Vous disposez d'une seule tentative pour utiliser l'atelier volatile. Votre assistant IA actuel a du mal à traiter simultanément les données visuelles et les manuels techniques, ce qui entraîne des instructions hallucinatoires et des avertissements de danger manqués.
Pour réussir, vous devez faire évoluer votre IA d'une entité monolithique vers un système multi-agents collaboratif.
Objectifs de la mission :
Assemblez le Warp Drive en suivant les instructions spécialisées en temps réel de votre nouveau système multi-agent.

Objectifs de l'atelier
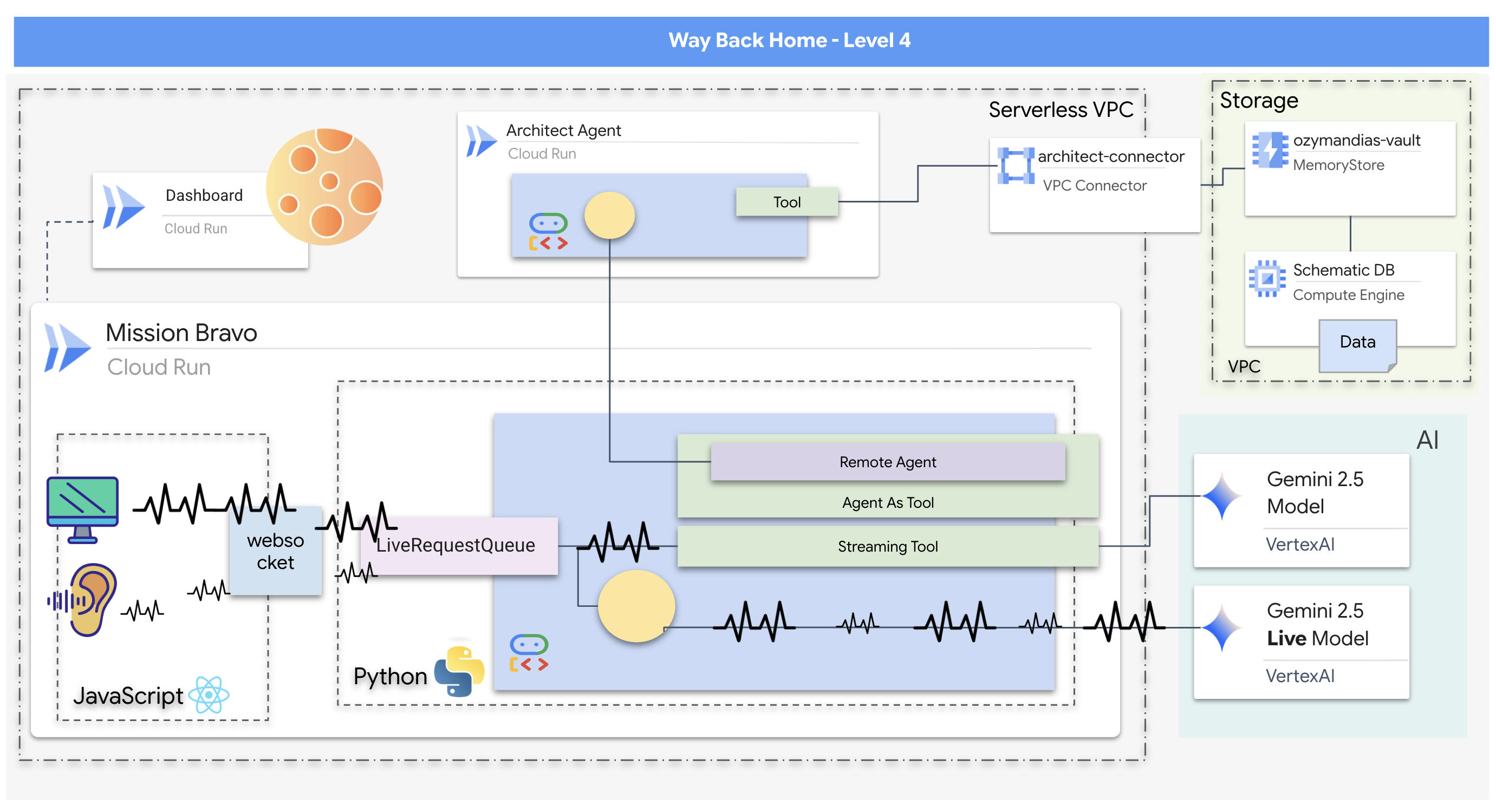
- Système d'IA multi-agents bidirectionnel en temps réel, avec un agent Dispatch central qui gère l'interaction utilisateur et se coordonne avec des agents spécialisés.
- Un agent Architect qui se connecte à une base de données Redis pour récupérer et diffuser des données schématiques.
- Un moniteur de sécurité proactif qui utilise des outils de streaming pour analyser le flux vidéo en direct et détecter les dangers visuels, puis déclencher des alertes en temps réel.
- Un frontend basé sur React qui fournit une interface utilisateur pour interagir avec le système, en diffusant des vidéos et de l'audio vers les agents de backend.
Objectifs de l'atelier
Technologie / Concept | Description |
Google Agent Development Kit (ADK) | Vous utiliserez l'ADK pour créer, tester et gérer les agents, en tirant parti de son framework pour gérer la communication en temps réel, l'intégration d'outils et le cycle de vie des agents. |
Streaming bidirectionnel | Vous allez implémenter un agent de streaming bidirectionnel qui permet une communication bidirectionnelle naturelle à faible latence, permettant à la fois à l'humain et à l'IA d'interrompre et de répondre en temps réel. |
Systèmes multi-agents | Vous apprendrez à concevoir un système d'IA distribué dans lequel un agent principal délègue des tâches à des agents spécialisés, ce qui permet de séparer les préoccupations et d'obtenir une architecture plus évolutive. |
Protocole Agent-to-Agent (A2A) | Vous utiliserez le protocole A2A pour permettre la communication entre l'agent Dispatch et l'agent Architect, ce qui leur permettra de découvrir les capacités de chacun et d'échanger des données. |
Outils de streaming | Vous allez implémenter un outil de streaming qui agit comme un processus en arrière-plan, en analysant en continu un flux vidéo pour surveiller les changements d'état (dangers) et en fournissant des résultats de manière proactive. |
Google Cloud Run et Memorystore | Vous allez déployer l'intégralité de l'application multi-agents dans un environnement de production, en utilisant Cloud Run pour héberger les services d'agent et Memorystore (Redis) comme base de données persistante. |
FastAPI et WebSockets | Le backend est conçu à l'aide de FastAPI et de WebSockets pour gérer la communication en temps réel et hautes performances requise pour le streaming audio et vidéo, ainsi que pour les réponses des agents. |
Interface React | Vous travaillerez avec une interface React qui capture et diffuse les contenus multimédias (audio/vidéo) des utilisateurs, et affiche les réponses en temps réel des agents IA. |
2. Configurer votre environnement
Accéder à Cloud Shell
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell), 
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 
👉 Ouvrez le terminal dans l'IDE cloud.
👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
Votre compte devrait être listé comme (ACTIVE).
Prérequis
ℹ️ Le niveau 0 est facultatif (mais recommandé)
Vous pouvez terminer cette mission sans le niveau 0, mais la terminer en premier vous offre une expérience plus immersive, vous permettant de voir votre balise s'allumer sur la carte du monde à mesure que vous progressez.
Configurer l'environnement du projet
De retour dans votre terminal, finalisez la configuration en définissant le projet actif et en activant les services Google Cloud requis (Cloud Run, Vertex AI, etc.).
👉💻 Dans votre terminal, définissez l'ID du projet :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Activez les services requis :
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
Installer des dépendances
👉💻 Accédez au niveau 4 et installez les packages Python requis :
cd $HOME/way-back-home/level_4
uv sync
Voici les principales dépendances :
Package | Objectif |
| Framework Web hautes performances pour la station satellite et le streaming SSE |
| Serveur ASGI requis pour exécuter l'application FastAPI |
| Agent Development Kit utilisé pour créer l'agent Formation |
| Bibliothèque de protocole Agent-to-Agent pour une communication standardisée |
| Client natif pour accéder aux modèles Gemini |
| Client Python pour se connecter à Schematic Vault (Memorystore) |
| Prise en charge de la communication bidirectionnelle en temps réel |
| Gère les variables d'environnement et les secrets de configuration |
| Validation des données et gestion des paramètres |
Vérifier la configuration
Avant de nous lancer dans le code, assurons-nous que tous les systèmes sont opérationnels. Exécutez le script de validation pour auditer votre projet Google Cloud, vos API et vos dépendances Python.
👉💻 Exécutez le script de validation :
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Une série de coches vertes (✅) devrait s'afficher.
- Si des croix rouges (❌) s'affichent, suivez les commandes de correction suggérées dans le résultat (par exemple,
gcloud services enable ...oupip install ...). - Remarque : Un avertissement jaune pour
.envest acceptable pour le moment. Nous créerons ce fichier à l'étape suivante.
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Créer un coffre-fort schématique dans Redis et l'agent bidirectionnel avec ADK
Vous avez trouvé le dépôt de schémas planétaires contenant les plans de la fusée abandonnée. Pour récupérer ces données avec précision, vous devez interagir avec l'interface de gestion dédiée du dépôt : l'agent Architect.
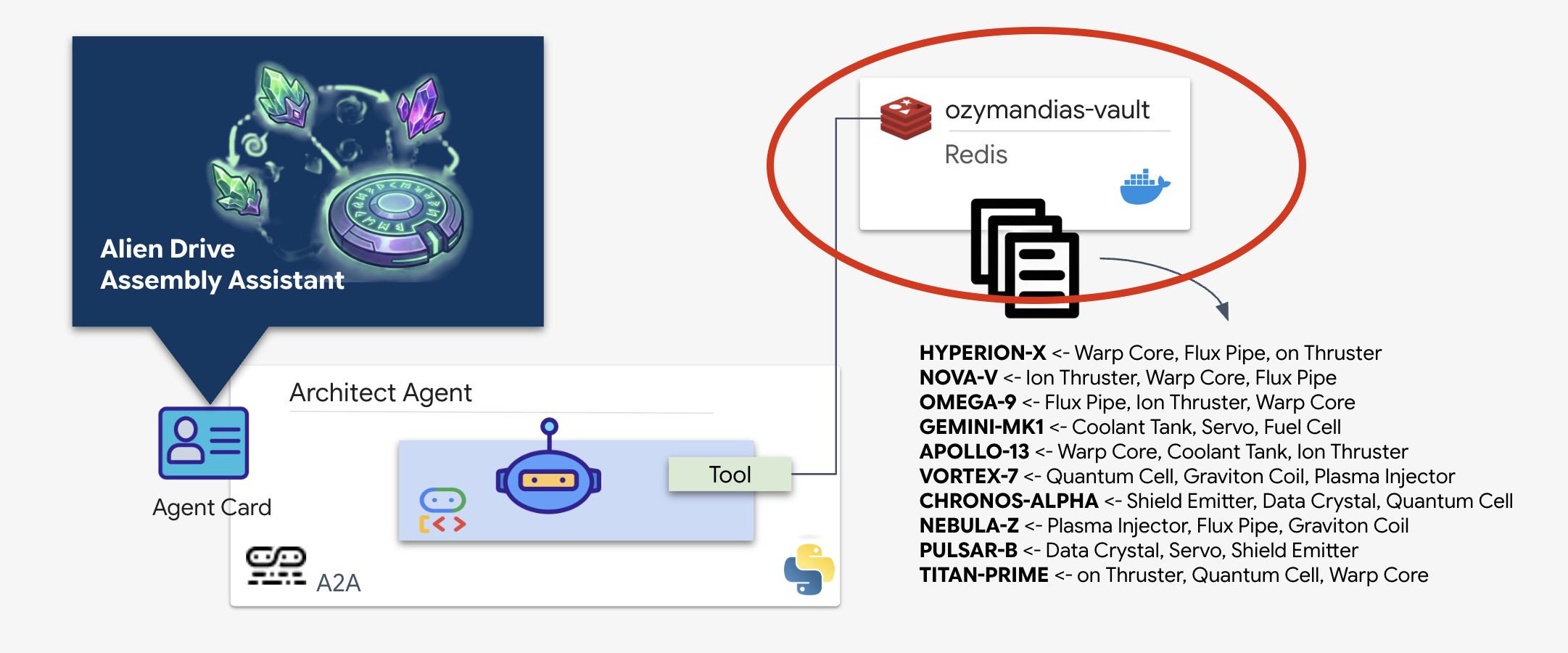
Provisionner le coffre-fort Schematic (Redis)
Avant que l'architecte puisse nous aider, nous devons nous assurer que les données sont hébergées dans un environnement sécurisé et à haute disponibilité. Nous allons utiliser Redis comme magasin de données rapide pour nos schémas extraterrestres. Pour faciliter le développement, nous allons créer une instance Redis locale. Toutefois, nous vous expliquerons plus tard comment déployer l'application dans un environnement de production avec Google Cloud Memorystore.
👉💻 Exécutez les commandes suivantes dans votre terminal pour provisionner l'instance Redis (cela peut prendre deux à trois minutes) :
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 Pour charger les données préliminaires, exécutez la commande suivante pour accéder à Redis Shell :
docker exec -it ozymandias-vault redis-cli
(Votre invite deviendra 127.0.0.1:6379.)
👉💻 Collez ces commandes à l'intérieur :
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 Saisissez exit pour revenir à votre shell normal.
👉💻 Pour vérifier que les données existent en interrogeant un navire spécifique directement depuis votre terminal, exécutez la commande suivante :
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 Voici le résultat attendu :
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
Implémenter l'agent Architect
L'agent Architect est un agent spécialisé chargé de récupérer les plans schématiques de notre coffre-fort Redis. Il sert d'interface de données dédiée, garantissant que l'agent Dispatch principal reçoit des informations précises et structurées sans avoir besoin de connaître la logique de la base de données sous-jacente.
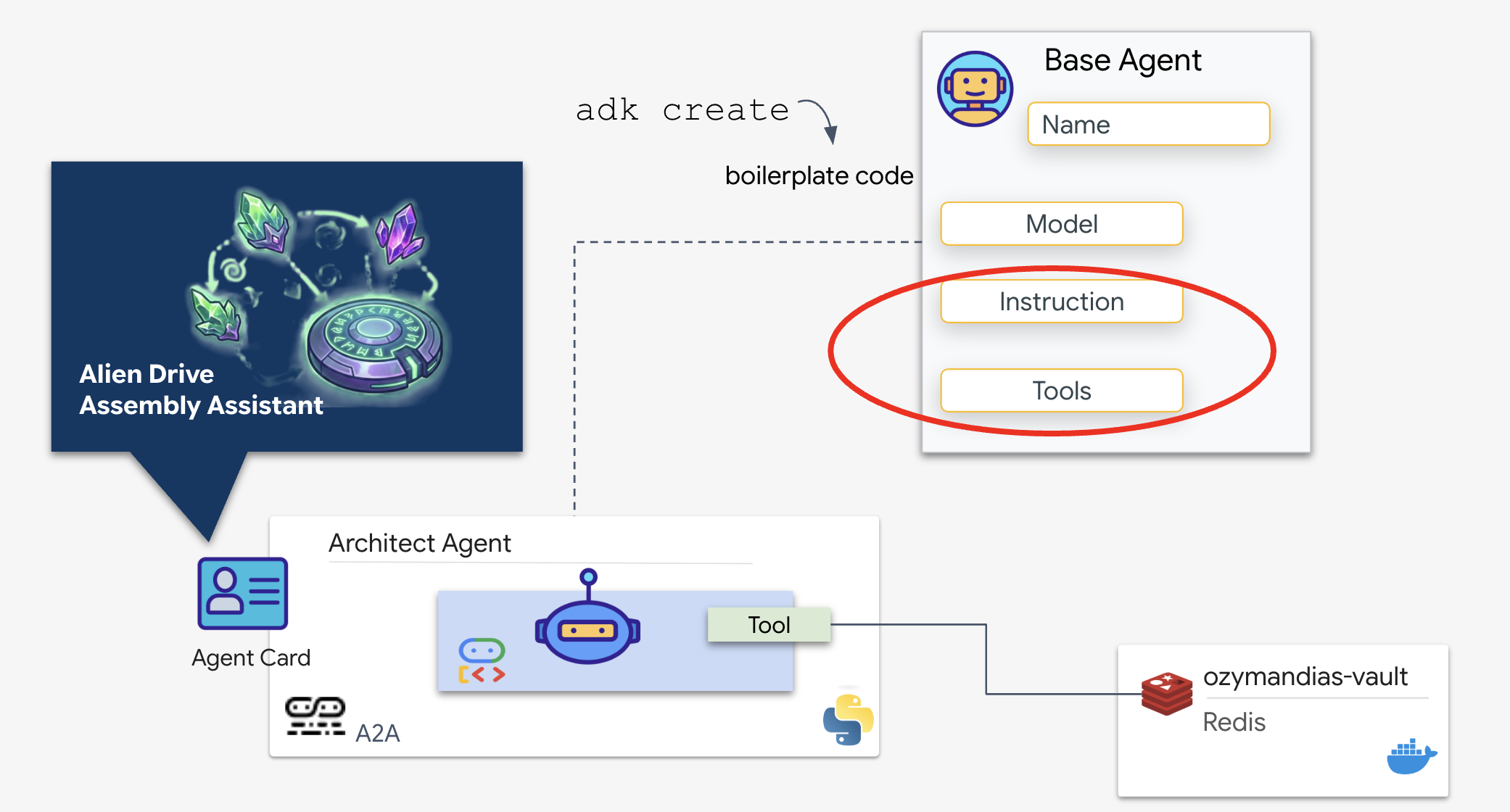
Le Google Agent Development Kit (ADK) est le framework modulaire qui permet cette configuration multi-agents. Il gère deux couches critiques :
- Cycle de vie des connexions et des sessions : l'interaction avec les API en temps réel nécessite une gestion complexe des protocoles, y compris des signaux d'établissement de connexion, d'authentification et de message keep-alive.
- Appel de fonction : il s'agit du "parcours aller-retour modèle-code-modèle". Lorsque le LLM décide qu'il a besoin de données, il génère un appel de fonction structuré. L'ADK intercepte cette requête, exécute votre code Python (
lookup_schematic_tool) et renvoie le résultat dans le contexte du modèle en quelques millisecondes.
Nous allons maintenant créer l'architecte. Cet agent n'a pas accès à la caméra. Il existe uniquement pour recevoir un "nom de lecteur" et renvoyer la "liste des pièces" de la base de données.
👉💻 Nous allons utiliser la commande adk create. Il s'agit d'un outil de l'Agent Development Kit (ADK) qui génère automatiquement le code récurrent et la structure de fichier pour un nouvel agent, ce qui nous fait gagner du temps de configuration.
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
Configurer l'agent
La CLI lance un assistant de configuration interactif. Utilisez les réponses suivantes pour configurer votre agent :
- Choisir un modèle : sélectionnez Option 1 (Gemini Flash).
- Remarque : La version spécifique (par exemple, 2.5 ou 3.0) peut varier en fonction de la disponibilité. Choisissez toujours la variante "Flash" pour la vitesse.
- Choisir un backend : sélectionnez Option 2 (Vertex AI).
- Saisissez l'ID du projet Google Cloud : appuyez sur Entrée pour accepter la valeur par défaut (détectée à partir de votre environnement).
- Enter Google Cloud Region (Saisir la région Google Cloud) : appuyez sur Entrée pour accepter la valeur par défaut (
us-central1).
👀 Votre interaction avec le terminal devrait ressembler à ceci :
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
Un message de réussite Agent created devrait s'afficher. Cela génère le code squelette que nous modifierons à l'étape suivante.
👉✏️ Accédez au fichier $HOME/way-back-home/level_4/backend/architect_agent/agent.py que vous venez de créer et ouvrez-le dans votre éditeur. Ajoutez l'extrait d'outil au fichier après la première ligne d'importation :
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ Remplacez l'intégralité de la ligne instruction dans la définition root_agent par ce qui suit, et ajoutez également l'outil que nous avons défini précédemment :
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
L'avantage ADK
Avec Architect en ligne, nous disposons désormais d'une source de référence. Avant de connecter cela à l'agent principal,l'Agent Development Kit (ADK) offre un avantage considérable en simplifiant la création et le test des agents d'IA. Grâce à la console de développement adk web intégrée, nous pouvons isoler et vérifier la fonctionnalité de notre Architect Agent, en particulier ses capacités d'appel d'outils, avant de l'intégrer au système multi-agents plus vaste. Cette approche modulaire du développement et des tests est essentielle pour créer des applications d'IA robustes et fiables.
👉 💻 Dans votre terminal, exécutez la commande suivante :
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 Attendez de voir :
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell. Sélectionnez Modifier le port, définissez-le sur 8000, puis cliquez sur Modifier et prévisualiser.
- Sélectionnez architect_agent.
- Déclenchez l'outil : dans l'interface de chat, saisissez
CHRONOS-ALPHA(ou n'importe quel ID Drive de la base de données schématique). - Observer le comportement :
- L'architecte doit immédiatement déclencher le
lookup_schematic_tool. - En raison de nos instructions système strictes, il ne devrait renvoyer que la liste des pièces (par exemple,
['Shield Emitter', 'Data Crystal', 'Quantum Cell']) sans aucun remplissage conversationnel.
- L'architecte doit immédiatement déclencher le
- Vérifiez les journaux : consultez la fenêtre de votre terminal. Le journal d'exécution doit s'afficher :
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
Si vous voyez le journal d'exécution de l'outil et la réponse de données propres, cela signifie que votre agent spécialisé fonctionne comme prévu. Il peut traiter les requêtes, interroger le coffre-fort et renvoyer des données structurées.
👉💻 Appuyez sur Ctrl+C pour quitter.
Initialiser le serveur A2A
Pour connecter l'agent Dispatch à l'architecte, nous utilisons le protocole Agent-to-Agent (A2A).
Alors que des protocoles tels que MCP (Model Context Protocol) se concentrent sur la connexion des agents aux outils, A2A se concentre sur la connexion des agents à d'autres agents. Il s'agit de la norme qui permet à notre Dispatcher de "découvrir" l'Architect et de comprendre sa capacité à rechercher des schémas.
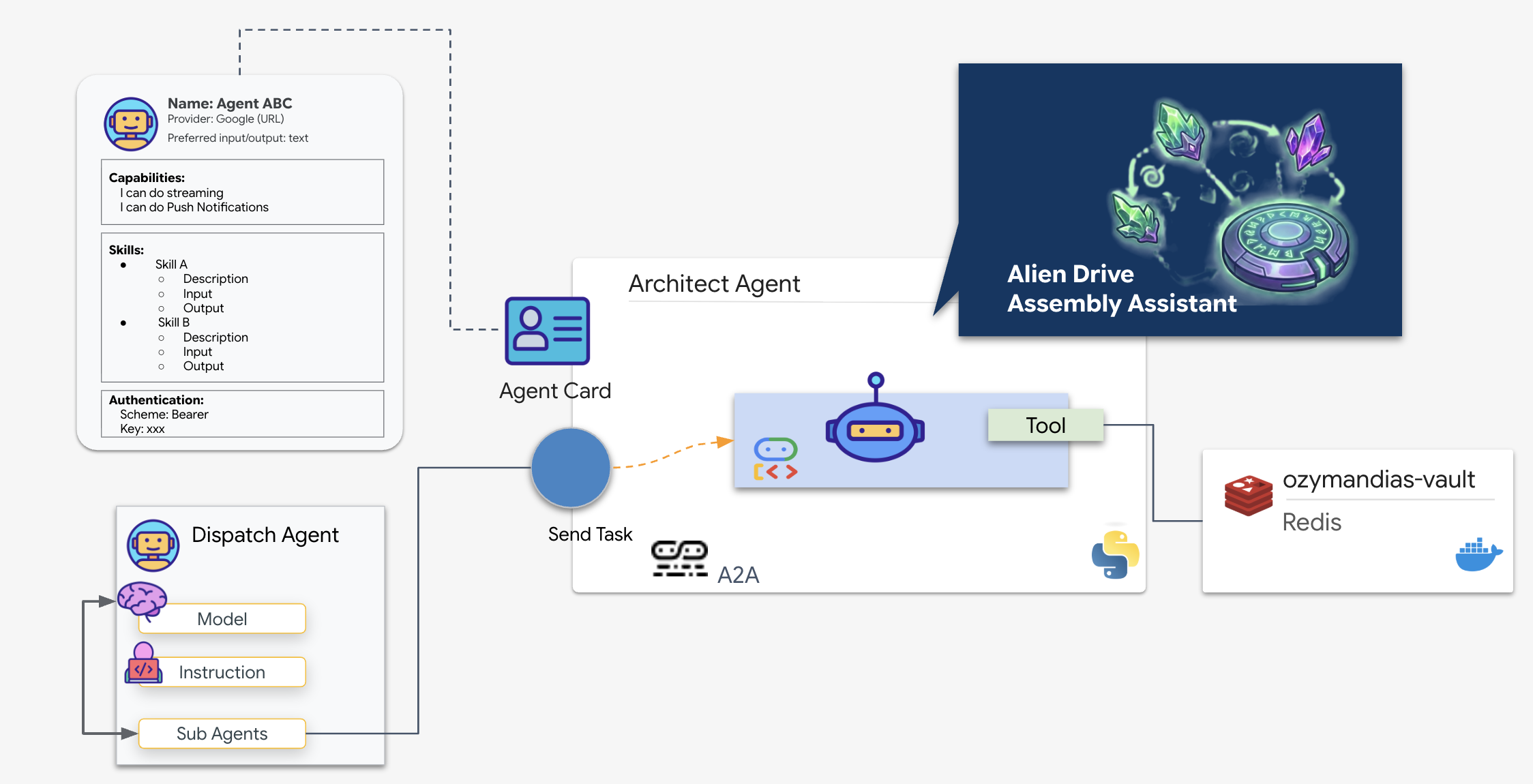
Flux A2A : dans cette mission, nous utilisons un modèle client-serveur :
- Serveur (architecte) : héberge les outils de base de données et "annonce" ses compétences via une carte d'agent.
- Client (Dispatch) : lit la fiche de l'architecte, comprend son API et envoie une demande schématique.
Qu'est-ce qu'une fiche d'agent ?
Considérez la fiche d'agent comme une carte de visite numérique ou un "permis de conduire" pour une IA. Lorsqu'un serveur A2A démarre, il publie cet objet JSON contenant les éléments suivants :
- Identité : nom (
architect_agent) et ID de l'agent. - Description : résumé lisible par l'humain et par la machine de ce qu'il fait ("Rôle système : API de base de données…").
- Interface : les clés d'entrée spécifiques (
drive_name) et les formats de sortie attendus.
Sans cette fiche, l'agent Dispatch fonctionnerait à l'aveugle et devrait deviner comment communiquer avec l'architecte.
Créer le code du serveur
👉✏️ Dans votre éditeur, sous le répertoire $HOME/way-back-home/level_4/backend/architect_agent, créez un fichier nommé server.py et collez le code suivant :
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 De retour dans votre terminal, accédez au dossier et démarrez le serveur :
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 Vérifiez si le serveur A2A démarre :
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Vérifier la carte de l'agent
Ouvrez un nouvel onglet de terminal (cliquez sur l'icône +). Nous allons vérifier que l'architecte diffuse correctement son identité en récupérant manuellement sa carte d'agent.
👉 💻 Exécutez la commande suivante :
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 Vous devriez voir une réponse JSON. Recherchez le champ description dans le résultat. Elle doit correspondre à l'instruction que vous avez donnée à l'agent précédemment ("SYSTEM ROLE: Database API...").
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
Si ce JSON s'affiche, cela signifie que l'architecte est en ligne, que le protocole A2A est actif et que la carte d'agent est prête à être découverte par le répartiteur.
Maintenant que l'architecte est prêt à servir de ressource distante, nous pouvons procéder à son câblage dans l'agent Dispatch.
👉 💻 Appuyez sur Ctrl+C pour quitter le serveur A2A.
4. Connecter l'agent BIDI-Streams à un agent distant et à des outils de streaming
Vous allez maintenant configurer le hub de communication principal pour combler le fossé entre les données en direct et l'architecte à distance. Cette connexion nécessite un pipeline à haut débit et à faible latence pour garantir la stabilité de l'atelier d'assemblage pendant le fonctionnement.
Comprendre les agents de streaming bidirectionnel (en direct)
Le streaming bidirectionnel dans ADK ajoute aux agents d'IA la capacité d'interaction vocale et vidéo bidirectionnelle à faible latence de l'API Gemini Live. Il représente un changement fondamental par rapport aux interactions traditionnelles avec l'IA. Au lieu du modèle rigide "demander et attendre", il permet une communication bidirectionnelle en temps réel où l'humain et l'IA peuvent parler, écouter et répondre simultanément.
Pensez à la différence entre envoyer des e-mails et avoir une conversation téléphonique. Les interactions avec un agent traditionnel sont semblables à des e-mails : vous envoyez un message complet, attendez une réponse complète, puis envoyez un autre message. Le streaming bidirectionnel est comme une conversation téléphonique : fluide, naturel, avec la possibilité d'interrompre, de clarifier et de répondre en temps réel.
Principales caractéristiques :
- Communication bidirectionnelle : échange continu de données sans attendre de réponses complètes. L'IA répond dès qu'elle détecte que l'utilisateur a fini de parler.
- Interruption réactive : les utilisateurs peuvent interrompre l'agent en cours de réponse en saisissant de nouvelles informations, comme dans une conversation humaine. Si une IA explique une étape complexe et que vous dites "Attends, répète", elle s'arrête immédiatement et répond à votre interruption.
- Optimisé pour la multimodalité : le streaming bidirectionnel excelle dans le traitement simultané de différents types d'entrées. Vous pouvez parler à l'agent tout en lui montrant les pièces extraterrestres en vidéo. Il traite les deux flux dans une seule connexion unifiée.
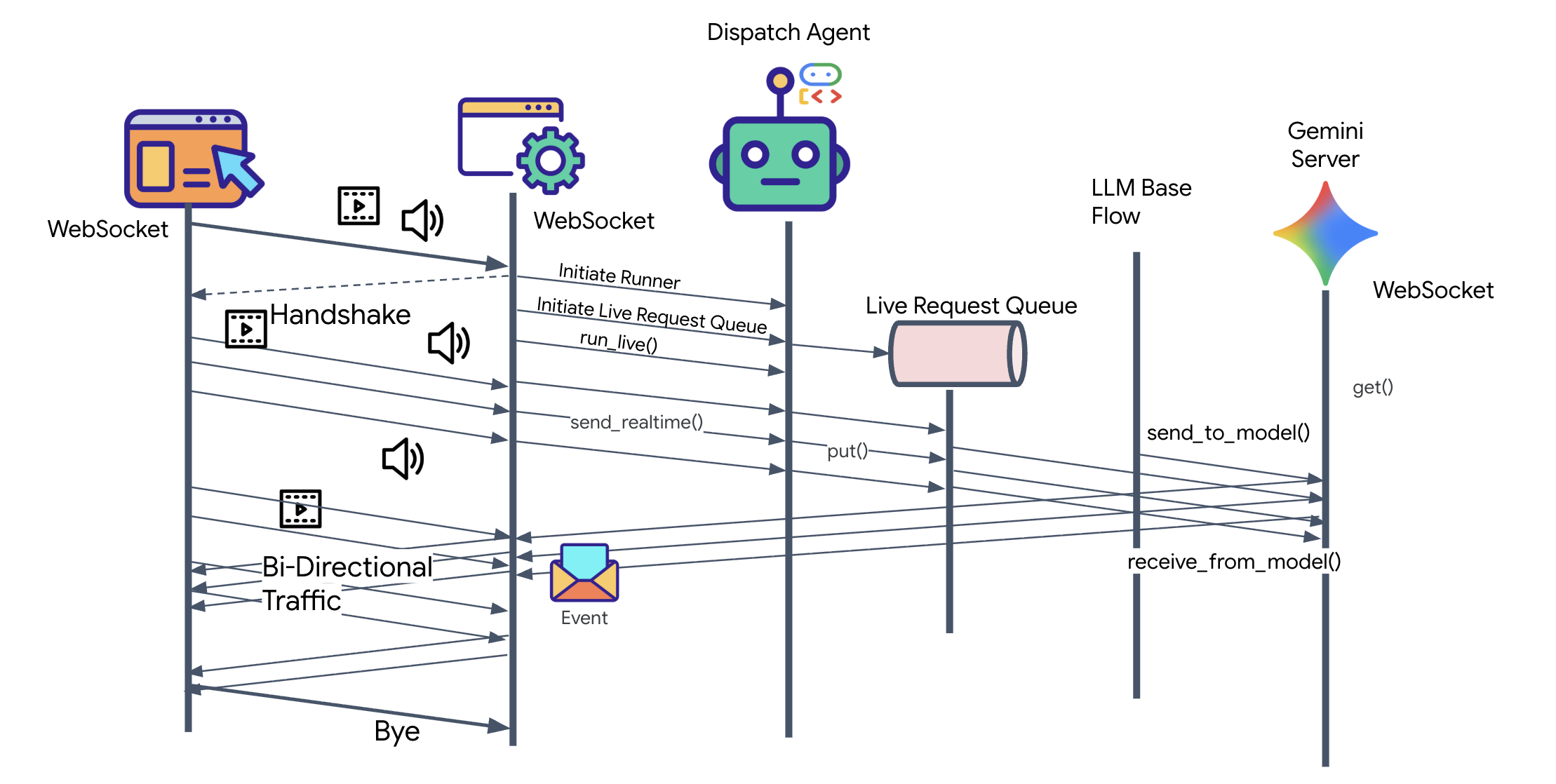
👀 Avant d'implémenter la logique du client, examinons le squelette pré-généré de l'agent Dispatch. Cet agent communiquera avec l'utilisateur par voix et vidéo, et délèguera les requêtes à l'agent Architect.
__init__.py agent.py hazard_db.py
agent.py: il s'agit du "cerveau". Il contient actuellement une configuration de base pour le streaming bidirectionnel. Nous allons modifier ce fichier pour ajouter la logique A2A Client afin qu'il puisse communiquer avec l'architecte.hazard_db.py: outil local spécifique à l'agent Dispatch, contenant des protocoles de sécurité. Elle est distincte de la base de données schématiques de l'architecte.
Implémenter le client A2A
Pour permettre à l'agent Dispatch de communiquer avec notre architecte distant, nous devons définir un agent A2A distant. Cela indique à l'agent Dispatch où trouver l'architecte et à quoi ressemble sa carte d'agent.
👉✏️ Remplacez #REPLACE-REMOTEA2AAGENT dans $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py par ce qui suit :
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
Fonctionnement des outils de streaming
Avec l'agent précédent, les outils suivaient un modèle standard de "demande-réponse" : l'agent posait une question, l'outil fournissait une réponse et l'interaction se terminait. Cependant, sur Ozymandias, les dangers ne vous attendent pas pour vous demander s'ils sont présents. Pour cela, vous avez besoin d'un outil de streaming.
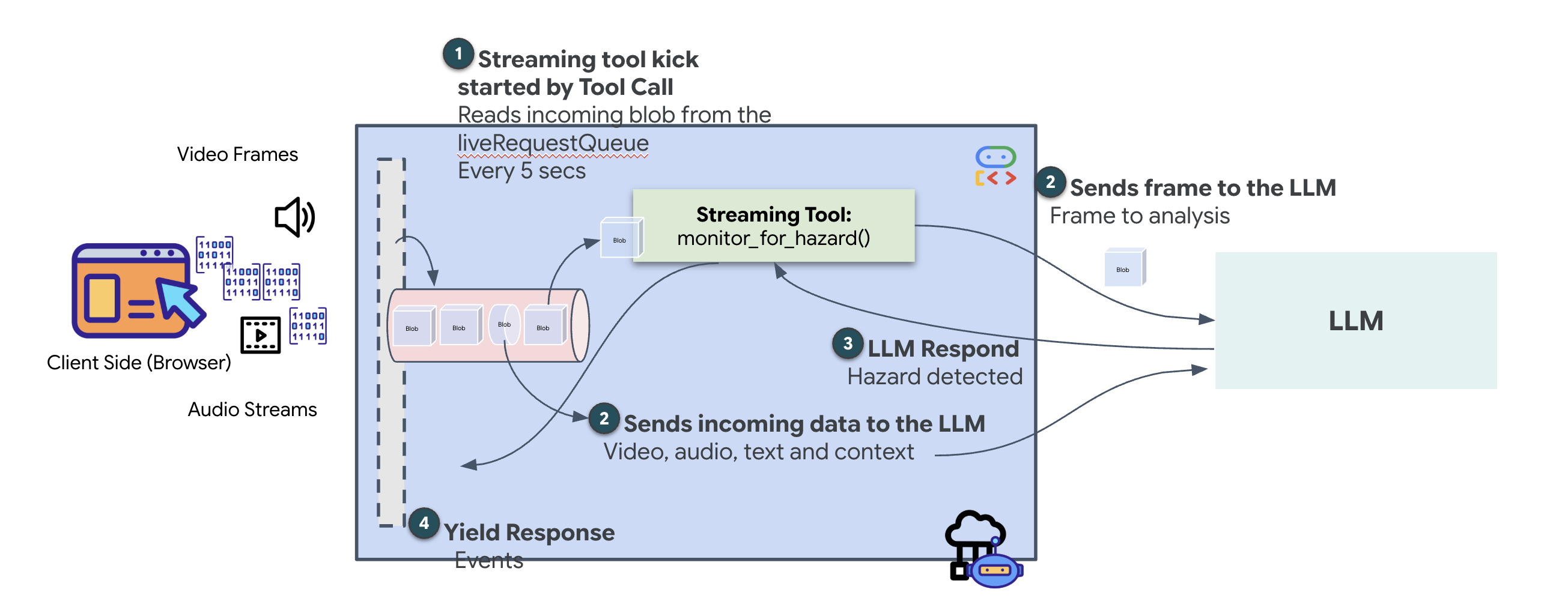
Les outils de streaming permettent aux fonctions de renvoyer les résultats intermédiaires à l'agent en temps réel, ce qui lui permet de réagir aux changements au fur et à mesure qu'ils se produisent. Les cas d'utilisation courants incluent la surveillance des fluctuations des cours boursiers ou, dans notre cas, la surveillance d'un flux vidéo en direct pour les changements d'état.
Contrairement aux outils standards, un outil de streaming est une fonction asynchrone qui agit comme un AsyncGenerator. Cela signifie qu'au lieu de return une seule valeur, il yield plusieurs mises à jour au fil du temps.
Pour définir un outil de streaming dans l'ADK, vous devez respecter les exigences techniques suivantes :
- Fonction asynchrone : l'outil doit être défini avec
async def. - Type renvoyé par AsyncGenerator : la fonction doit être typée pour renvoyer un
AsyncGenerator. Le premier paramètre est le type de données générées (par exemple,str), et le second est généralementNone. - Flux d'entrée : nous utilisons des outils de streaming vidéo. Dans ce mode, le flux vidéo/audio réel (le
LiveRequestQueue) est transmis directement à la fonction, ce qui permet à l'outil de "voir" les mêmes images que l'agent.
Considérez un outil de streaming comme un Sentinel. Pendant que vous discutez des plans avec l'agent Dispatch, le sentinel s'exécute en arrière-plan et traite silencieusement chaque image vidéo pour assurer votre sécurité.
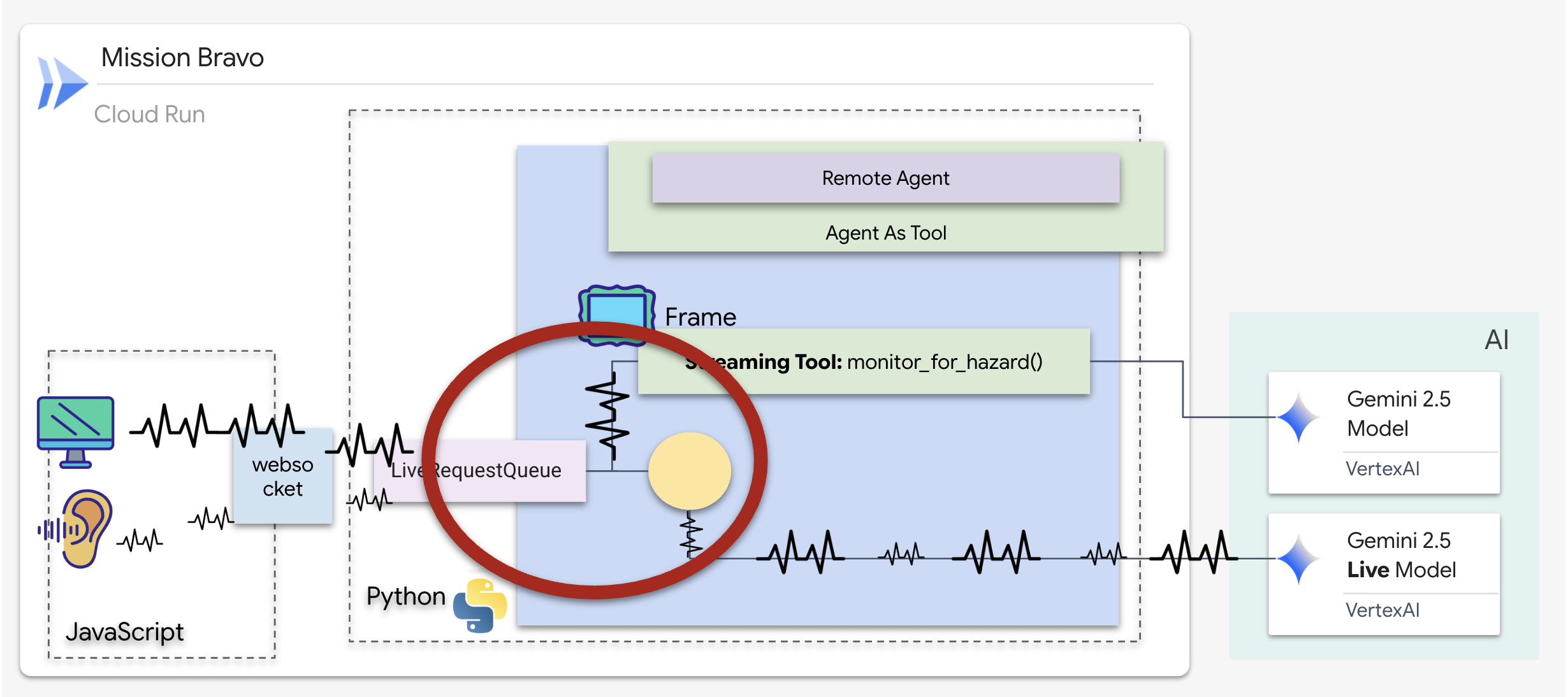
Implémenter l'outil de surveillance en arrière-plan
Nous allons maintenant implémenter l'outil monitor_for_hazard. Cet outil ingère les input_stream (images vidéo), les analyse à l'aide d'un appel Vision distinct et léger, puis yield un avertissement uniquement en cas de détection d'un danger.
👉✏️ Dans $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py, remplacez #REPLACE_MONITOR_HAZARD par la logique suivante :
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
Implémenter l'agent Dispatch
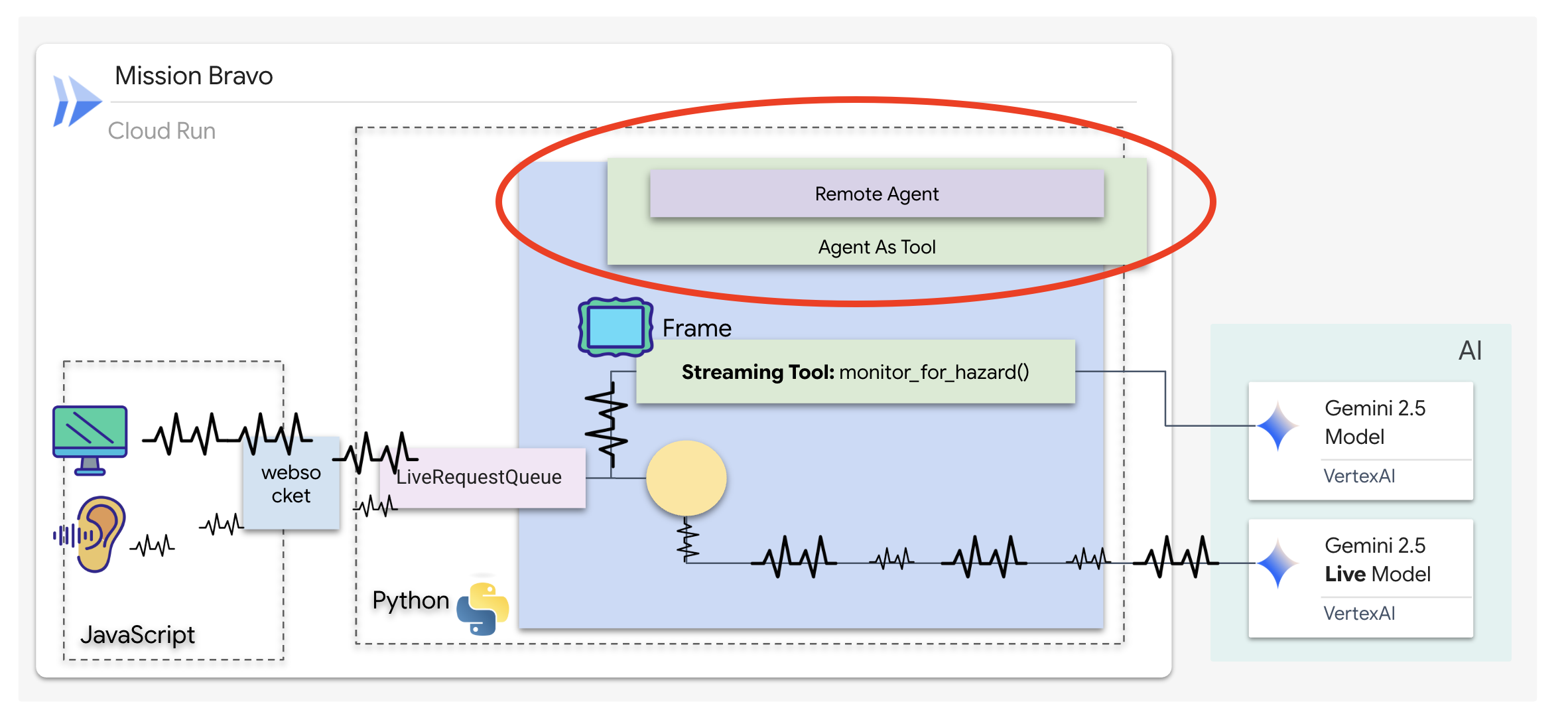
L'agent Dispatch est votre interface principale et l'orchestrateur. Comme il gère le lien de streaming bidirectionnel (votre voix et votre vidéo en direct), il doit conserver le contrôle de la conversation à tout moment. Pour ce faire, nous utiliserons une fonctionnalité ADK spécifique : Agent-as-a-Tool.
Concept : Agent en tant qu'outil vs sous-agents
Lorsque vous créez des systèmes multi-agents, vous devez décider de la manière dont la responsabilité est partagée. Dans notre mission de sauvetage, la distinction est essentielle :
- Agent-as-a-Tool: : il s'agit de l'approche recommandée pour notre hub de streaming bidirectionnel. Lorsque l'agent Dispatch (Agent A) appelle l'agent Architect (Agent B) en tant qu'outil, les données de l'agent Architect sont renvoyées à l'agent Dispatch. Dispatch interprète ensuite ces données et génère une réponse pour vous. Dispatch garde le contrôle et continue de gérer toutes les entrées utilisateur ultérieures.
- Sous-agent : dans une relation de sous-agent, la responsabilité est entièrement transférée. Si Dispatch vous a transféré vers l'architecte en tant que sous-agent, vous parlerez directement à une API de base de données qui n'a pas de "vision" ni de compétences conversationnelles. L'agent principal (Dispatch) ne serait pas informé.
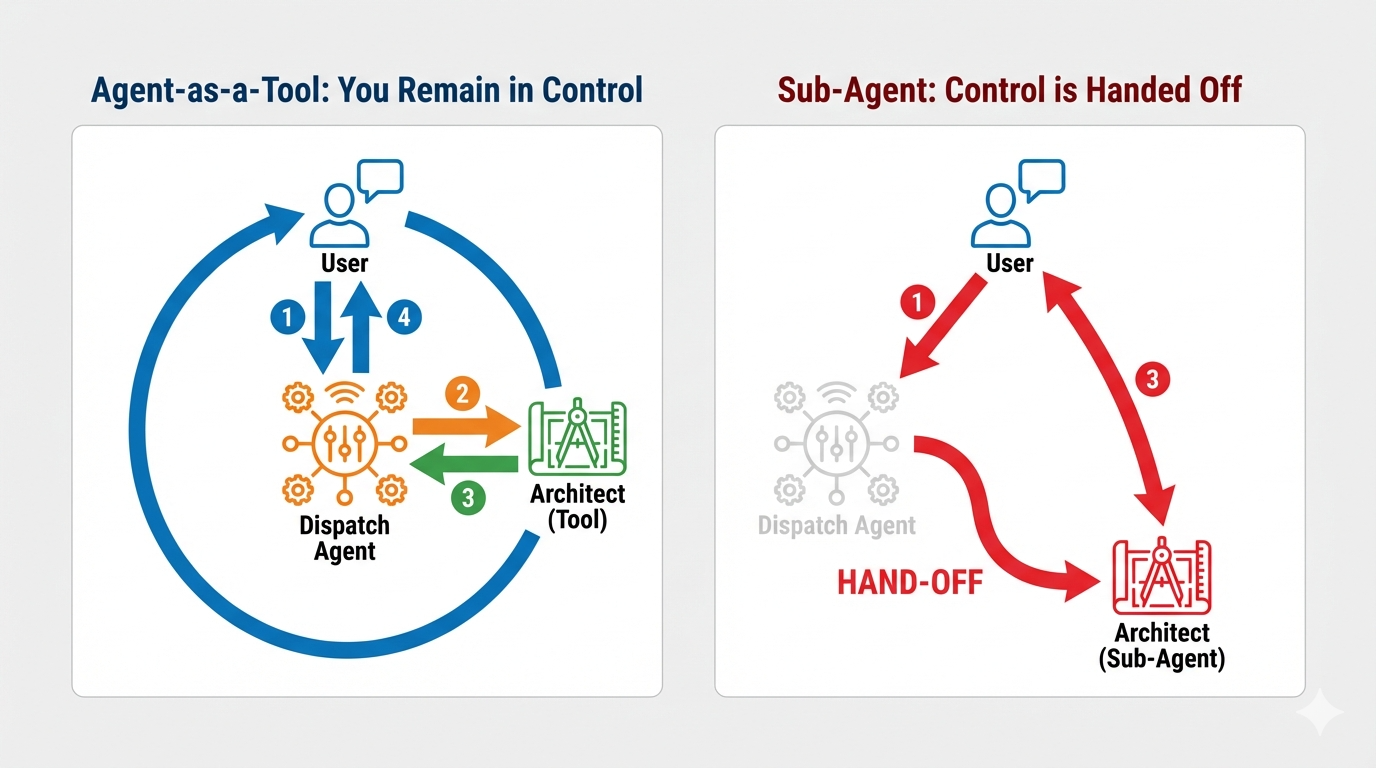
En utilisant Agent-as-a-Tool, nous exploitons les connaissances spécialisées de l'architecte tout en conservant l'interaction fluide et humaine de l'agent de streaming bidirectionnel.
Coder la logique de routage
Nous allons maintenant encapsuler notre architect_agent dans un AgentTool et fournir à l'agent Dispatch une "carte logique". Cette carte indique à l'agent exactement quand récupérer les données du coffre et quand signaler les résultats du sentinelle en arrière-plan.
Pour que Dispatch ait des "yeux" qui ne clignent jamais, nous devons lui accorder l'accès à l'outil de streaming que nous avons créé à l'étape précédente.
Dans ADK, lorsque vous ajoutez une fonction AsyncGenerator (comme monitor_for_hazard) à la liste tools, l'agent la traite comme un processus d'arrière-plan persistant. Au lieu d'une exécution ponctuelle, l'agent "s'abonne" au résultat de l'outil. Cela permet à Dispatch de poursuivre sa conversation principale tandis que Sentinel génère silencieusement des alertes de danger en arrière-plan.
👉✏️ Remplacez #REPLACE_AGENT_TOOLS dans $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py par ce qui suit :
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
Validation
👉💻 Une fois les deux agents configurés, nous pouvons tester l'interaction multi-agents en direct.
- Dans le terminal A, démarrez l'agent Architect :
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- Dans un nouveau terminal (terminal B), exécutez l'agent Dispatch :
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
Tester un système multi-agents qui utilise un modèle multimodal en temps réel comme gemini-live dans le simulateur adk web implique un workflow spécifique. Le simulateur est excellent pour inspecter les appels d'outils, mais il présente une incompatibilité connue lors du premier traitement d'images avec ce type de modèle.
- Cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell. Sélectionnez Modifier le port, définissez-le sur 8000, puis cliquez sur Modifier et prévisualiser.
👉 Sélectionnez dispatch_agent, importez le Blueprint et gérez l'erreur attendue
Il s'agit de l'étape la plus importante. Nous devons fournir le contexte de l'image à l'agent.
- Lorsque l'interface se charge, autorisez-la à accéder à votre micro lorsque vous y êtes invité.
- Téléchargez cette image de plan sur votre ordinateur :
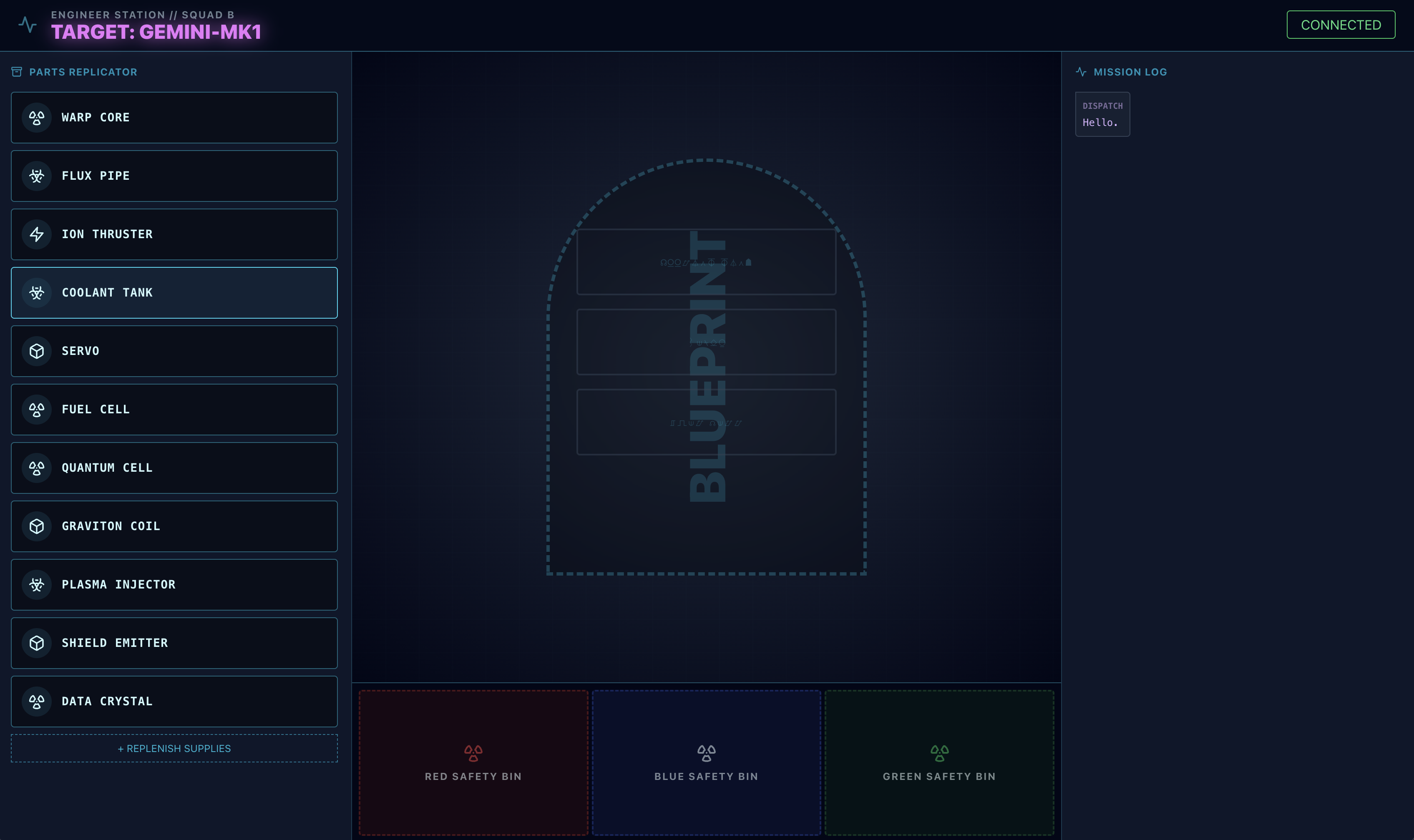
- Dans l'interface
adk web, cliquez sur l'icône en forme de trombone, puis importez l'image du plan que vous venez de télécharger.
⚠️⚠️ Vous verrez une erreur 400 INVALID_ARGUMENT. Ce comportement est normal.⚠️⚠️
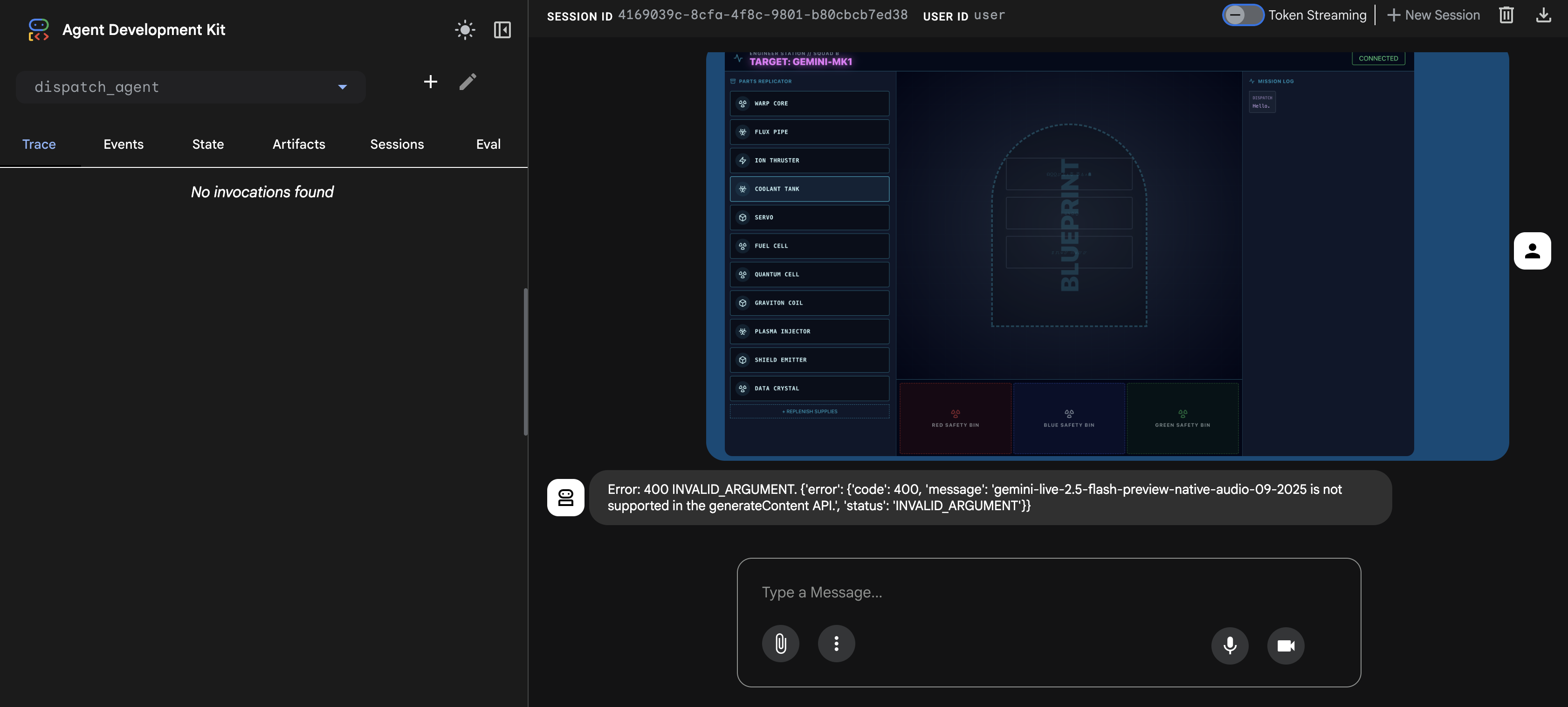
Cette erreur se produit, car le gestionnaire d'images adk web n'est pas entièrement compatible avec l'API du modèle gemini-live pour un import unique. Toutefois, l'image a bien été ajoutée au contexte de la session.
- 👉 Pour corriger l'erreur, il vous suffit d'actualiser la page du navigateur.
Déclencher le processus d'assemblage
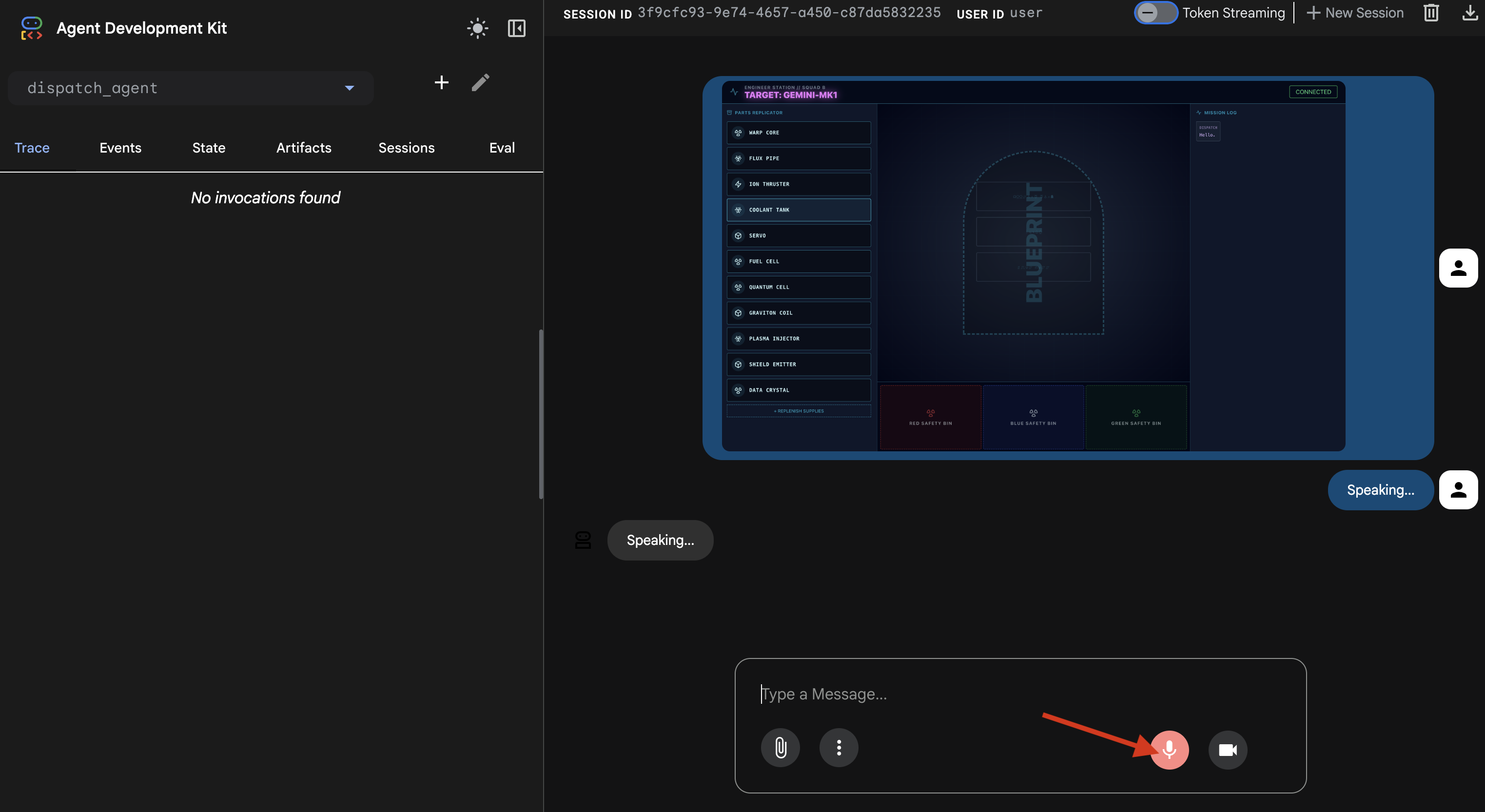
👉 Une fois la page rechargée, l'erreur disparaît et l'image du plan s'affiche dans l'historique de chat. L'agent dispose désormais du contexte visuel dont il a besoin.
- Cliquez sur l'icône du micro pour l'activer. L'interface affiche "Écoute en cours…".
- Énoncez la commande vocale Commence l'assemblage.
- L'agent traitera votre demande et l'interface utilisateur affichera "En train de parler…". Vous devriez entendre une réponse audio listant les pièces requises.
4. Vérifier les appels d'outils d'agent à agent
👉 La réponse audio initiale confirme que le système fonctionne, mais la véritable magie réside dans la trace de communication multi-agents.
- Désactivez le micro.
- Actualisez la page une nouvelle fois.
Le panneau "Trace" à gauche est maintenant rempli. Vous pouvez voir le flux d'exécution complet et réussi :
dispatch_agentappelle d'abordmonitor_for_hazard.- Il effectue ensuite plusieurs appels
execute_architectàarchitect_agentpour récupérer les données schématiques.
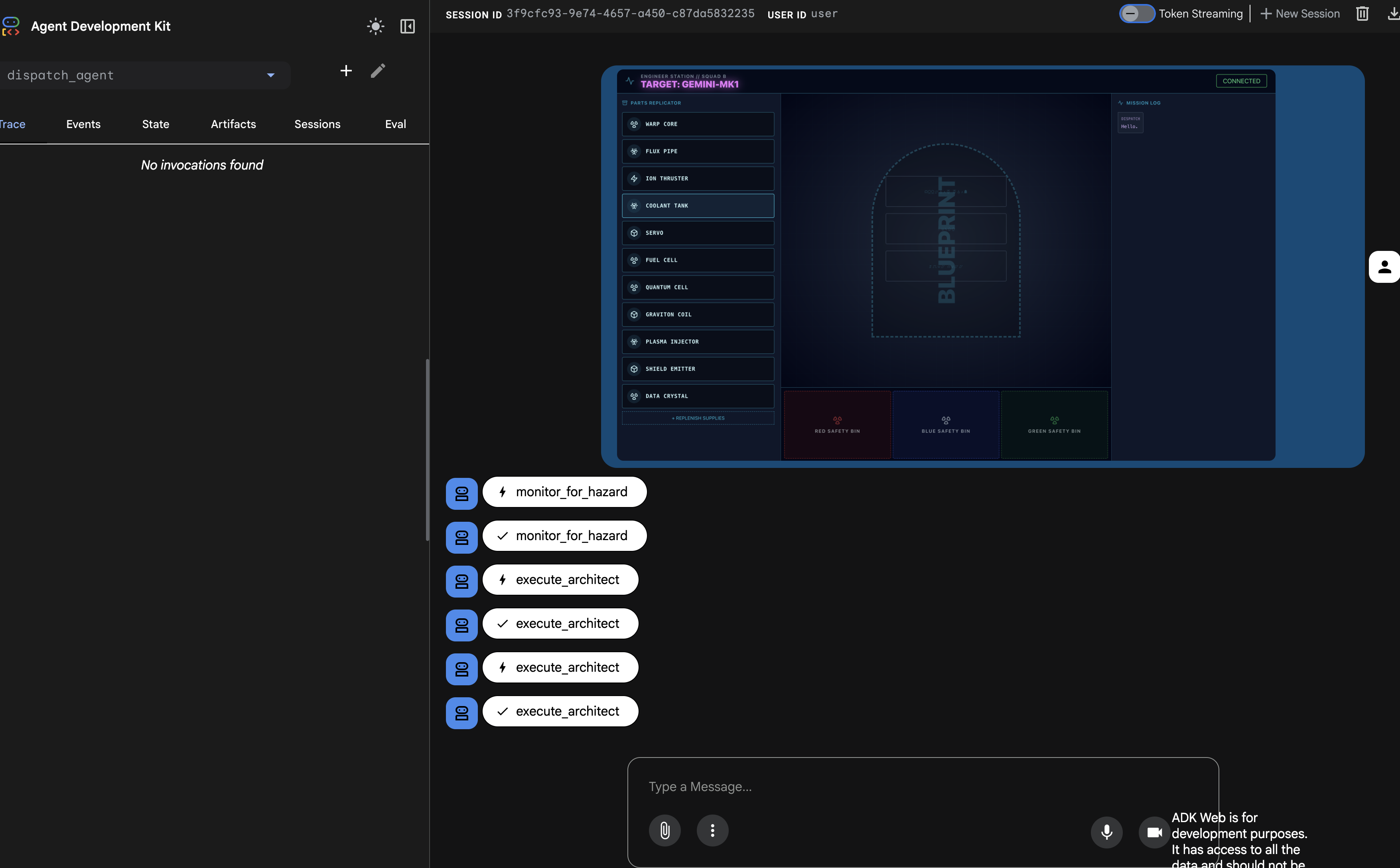
Cette séquence confirme que l'ensemble du workflow multi-agents fonctionne correctement : dispatch_agent a reçu la requête, a délégué la tâche de récupération des données à architect_agent via un appel d'outil et a reçu les données en retour pour répondre à la commande de l'utilisateur.
Votre lien de streaming bidirectionnel est désormais compatible avec la surveillance en arrière-plan et la collaboration multi-agents. Nous allons ensuite apprendre à analyser ces réponses complexes sur le frontend.
👉💻 Appuyez sur Ctrl+c dans les deux terminaux pour quitter.
5. Présentation détaillée des flux d'événements multimodaux en direct
À l'étape précédente, nous avons validé notre système multi-agent à l'aide du serveur de développement intégré, adk web. Cet utilitaire utilise un exécuteur ADK par défaut pour gérer automatiquement le cycle de vie des sessions, des flux et des agents. Toutefois, pour créer une application autonome prête pour la production comme notre service FastAPI (main.py), nous avons besoin d'un contrôle explicite. Nous devons créer et gérer manuellement l'exécuteur ADK pour gérer les sessions utilisateur en direct, car il s'agit du composant principal qui traite les flux bidirectionnels pour l'audio, la vidéo et le texte.
La boucle modèle-code-modèle
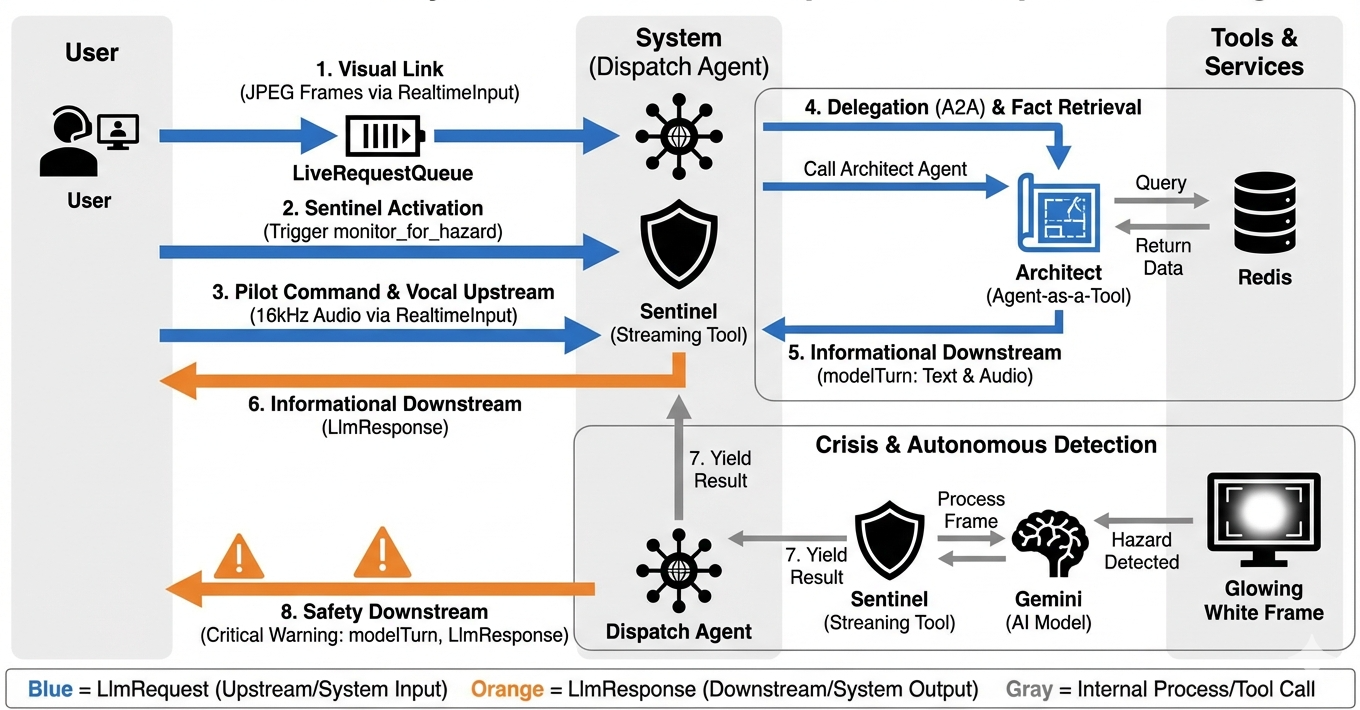
Pour comprendre comment le système fonctionne en temps réel, examinons le cycle de vie d'une session de mission unique. Cette boucle représente l'échange continu d'objets LlmRequest et LlmResponse.
- Lien visuel : vous initiez la connexion et partagez votre webcam/écran. Les images JPEG haute fidélité commencent à être transmises en amont via
realtimeInput(à l'aide deLiveRequestQueue). - Activation du sentinel : le système envoie un stimulus initial "Bonjour". Conformément à ses instructions, l'agent Dispatch déclenche immédiatement l'outil de streaming
monitor_for_hazard. Cela lance une boucle en arrière-plan qui surveille silencieusement chaque frame entrant. - Commande du pilote : vous parlez dans le système de communication : "Commencez l'assemblage."
- Flux vocal : votre voix est captée sous forme audio à 16 kHz et envoyée en flux montant avec les images vidéo.
- Délégation (A2A) : Dispatch "entend" votre intention. Il se rend compte qu'il manque les schémas et appelle donc l'agent Architect à l'aide du protocole
AgentTool(Agent-as-a-Tool). - Récupération des faits : l'architecte interroge la base de données Redis et renvoie la liste des pièces à Dispatch. Dispatch reste le "maître de la session" et reçoit les données sans vous les transmettre.
- Informations en aval : Dispatch envoie un
modelTurn(en aval) contenant à la fois du texte et de l'audio natif : "Architecte confirmé. Le sous-ensemble requis est le suivant : Warp Core, Flux Pipe, Ion Thruster." - La crise : soudain, une pièce sur l'établi se déstabilise et commence à briller en blanc.
- Détection autonome : la boucle
monitor_for_hazarden arrière-plan (le Sentinel) récupère le frame JPEG spécifique contenant la lueur. Il traite le cadre en appelant Gemini et identifie le danger. - Sécurité en aval : l'outil de streaming
yieldsun résultat. Comme il s'agit d'un agent Bidi-Streaming, Dispatch peut interrompre son état actuel pour envoyer immédiatement un avertissement de sécurité critique Downstream : "Danger détecté ! Neutralisation du cristal de données en cours. Mettez-le dans le bac ROUGE."
Définir la configuration de l'environnement d'exécution de l'agent
RunConfig dans ADK permet de configurer en détail le comportement d'un agent, y compris la façon dont il gère les données de streaming et interagit avec différentes modalités.
streaming_mode est défini sur BIDI pour une communication bidirectionnelle en temps réel, permettant à l'utilisateur et à l'agent de parler et d'écouter simultanément. Le paramètre response_modalities définit les types de sortie que l'agent peut produire, comme la voix et le texte. input_audio_transcription configure la façon dont l'agent traite et transcrit la parole entrante de l'utilisateur. Pour créer une expérience plus résiliente, session_resumption permet à l'agent de se souvenir du contexte de la conversation et de la reprendre en cas de perte de connexion. Enfin, proactivity permet à l'agent de lancer des actions ou de parler sans commande directe de l'utilisateur, par exemple en émettant un avertissement spontané, tandis que enable_affective_dialog permet à l'agent de générer des réponses plus naturelles et empathiques. Pour en savoir plus sur RunConfig d'ADK, cliquez ici.
👉✏️ Recherchez l'espace réservé #REPLACE_RUN_CONFIG dans votre fichier $HOME/way-back-home/level_4/backend/main.py et remplacez-le par la logique de dissection suivante :
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
Implémenter la requête à l'agent
Nous allons ensuite implémenter la liaison montante de communication principale qui diffuse des données multimodales en temps réel depuis l'atelier volatile de l'utilisateur vers l'agent Dispatch via un WebSocket. L'agent "voit" (images vidéo) et "entend" (commandes vocales) en continu. La logique reçoit en continu le flux de données, fait la distinction entre les blocs audio binaires entrants et les paquets de texte/d'image enveloppés au format JSON, et les encapsule dans des objets Blob (pour le multimédia) ou Content (pour le texte), en les envoyant dans LiveRequestQueue pour alimenter la session d'agent bidirectionnelle.
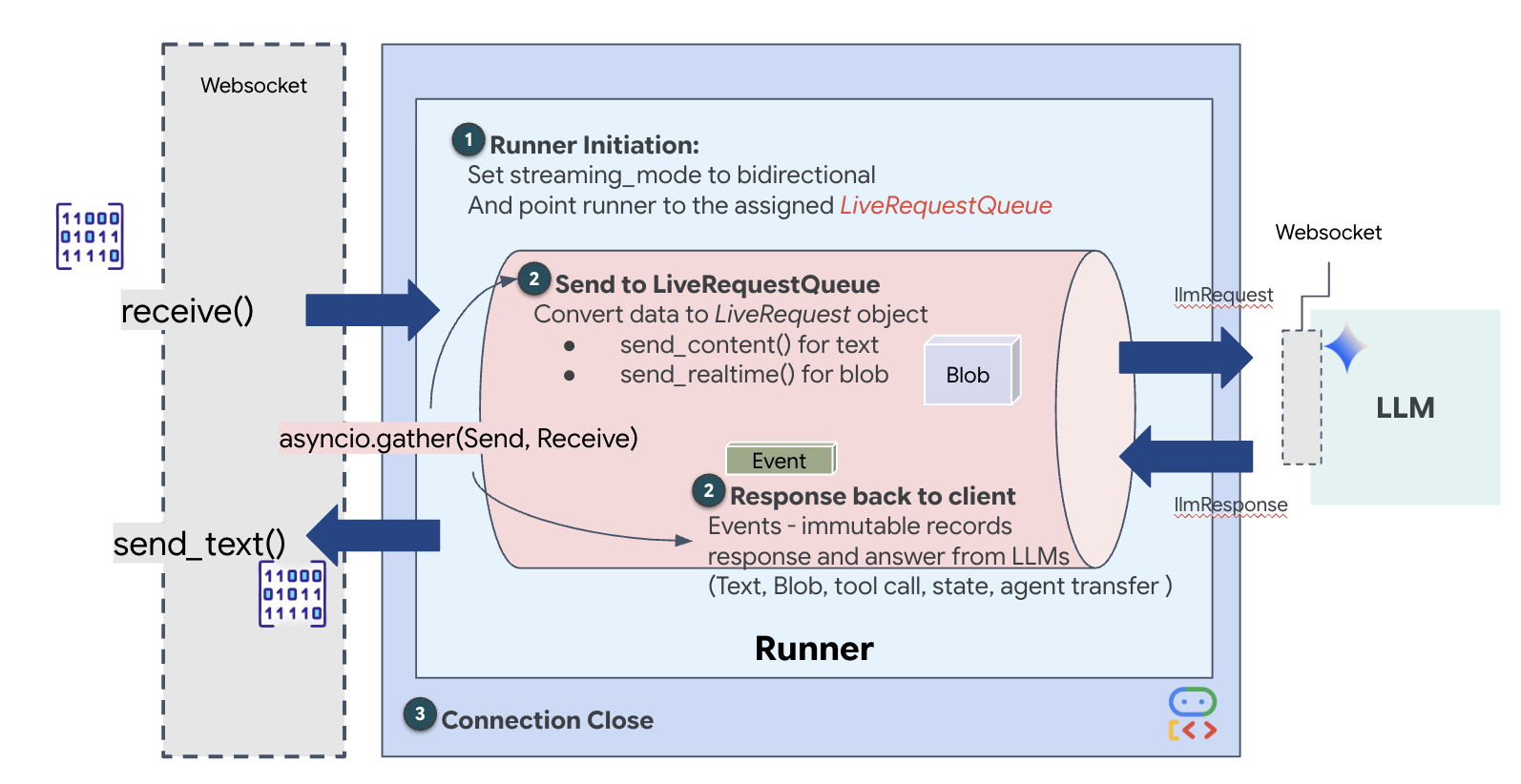
Recherchez l'espace réservé #PROCESS_AGENT_REQUEST dans votre fichier $HOME/way-back-home/level_4/backend/main.py et remplacez-le par la logique de dissection suivante :
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
Les données multimodales sont désormais envoyées à l'agent.
Implémenter la réponse : structure des données d'événement en aval
Lorsque vous exécutez un agent bidirectionnel (en direct) avec ADK, les données renvoyées par l'agent sont regroupées dans un type spécifique d'événement qui hérite des structures de base du SDK GenAI. L'objet Event que vous recevez dans votre boucle async for event in runner.run_live(...) est un objet unique contenant plusieurs champs facultatifs, chacun correspondant à un type d'informations différent :
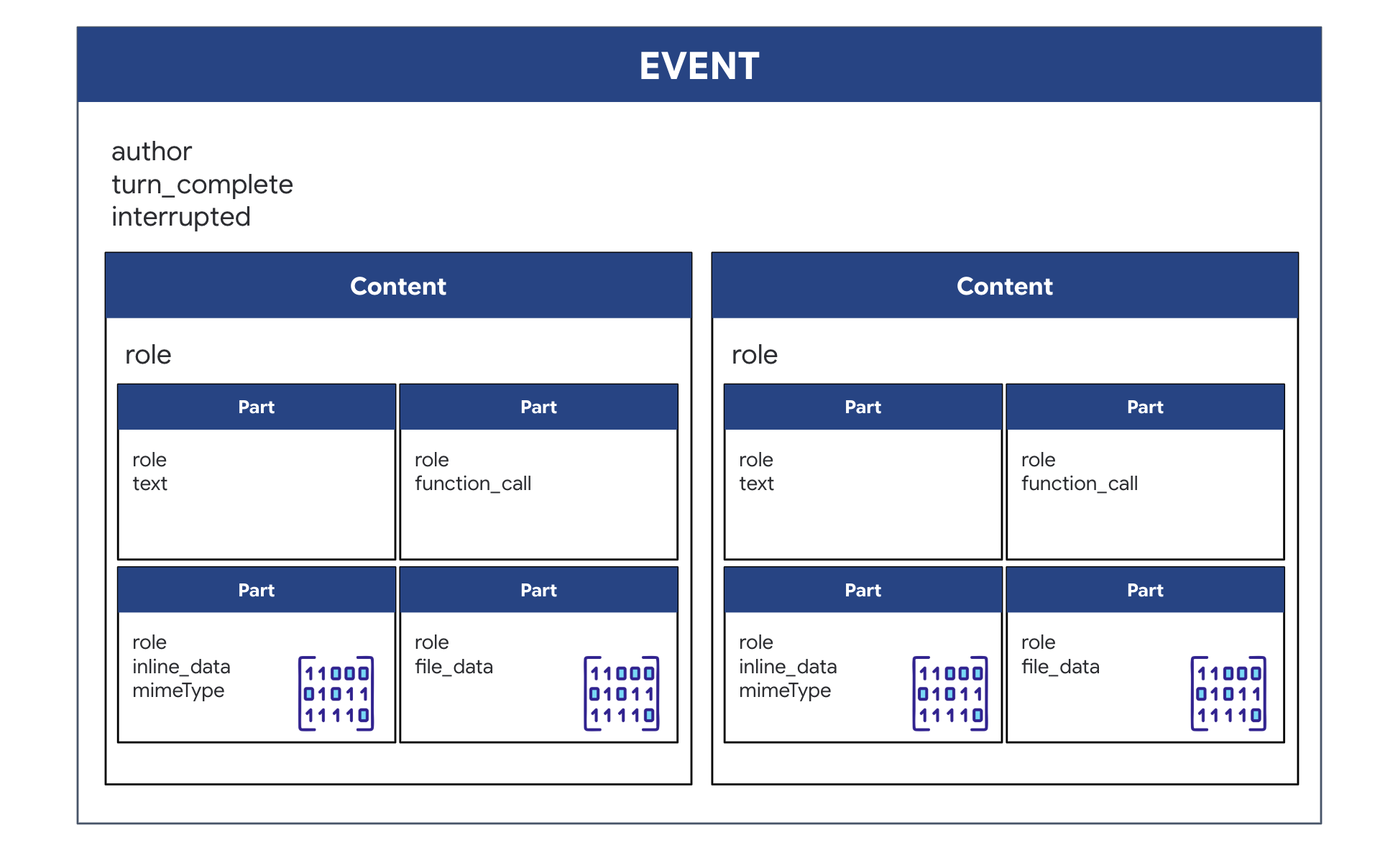
Structure du contenu :
- Lorsque l'agent parle (via
.server_content) : le champ n'est pas en texte brut. Il contient une liste deParts. ChaquePartest un conteneur pour un type de données : une chaîne de texte (comme"The part is stable.") ou un blob audio brut (la voix). - Lorsque l'agent agit (via
.tool_call) : le champ contient une liste d'objetsFunctionCall. ChaqueFunctionCallest un objet simple et structuré qui spécifie le nom de l'outil et les arguments d'entrée dans un format clair que votre code de backend peut facilement lire et exécuter.
👀 Si vous deviez examiner un seul Event généré par la boucle run_live, le JSON (produit par event.model_dump(by_alias=True)) ressemblerait à ceci, en suivant strictement les formes du SDK GenAI :
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ Nous allons maintenant mettre à jour le downstream_task dans main.py pour transférer les données d'événement complètes. Cette logique garantit que chaque "pensée" de l'IA est consignée dans le terminal de diagnostic du vaisseau et envoyée sous la forme d'un seul objet JSON à l'interface utilisateur front-end.
Recherchez l'espace réservé #PROCESS_AGENT_RESPONSE dans votre fichier $HOME/way-back-home/level_4/backend/main.py et remplacez-le par la logique de dissection suivante :
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
Exécution de la mission
Une fois le coffre-fort backend connecté et les deux agents configurés, tous les systèmes sont prêts pour la mission. Les étapes suivantes lanceront l'application complète, ce qui vous permettra d'interagir avec le système à deux agents que vous venez de créer.
Objectif : Assemblez le réacteur à distorsion qui apparaît sur votre établi et qui vous a été attribué de manière aléatoire. Protocole : vous devez suivre les instructions vocales de l'agent de répartition, en particulier les avertissements de danger pour des composants spécifiques.
Activer le spécialiste (l'architecte)
👉💻 Dans votre première fenêtre de terminal, lancez l'agent Architect. Ce service de backend se connecte au coffre-fort Redis et attend les requêtes schématiques du répartiteur.
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
(Laissez ce terminal en cours d'exécution. Il s'agit désormais de votre "agent de base de données" actif.)
Lancer le Cockpit (Dispatcher)
👉💻 Dans une nouvelle fenêtre de terminal (Terminal B), nous allons créer l'interface utilisateur front-end et démarrer l'agent Dispatch principal, qui sert l'interface utilisateur et gère toutes les communications en direct.
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(Cela démarre le serveur principal sur le port 8080.)
Exécuter le scénario de test
Le système est désormais opérationnel. Votre objectif est de suivre les instructions de l'agent pour terminer l'assemblage.
- 👉 Accéder à Workbench :
- Cliquez sur l'icône Aperçu sur le Web dans la barre d'outils Cloud Shell.
- Sélectionnez Modifier le port, définissez-le sur 8080, puis cliquez sur Modifier et prévisualiser.
- 👉 Commencer la mission :
- Lorsque l'interface se charge, assurez-vous de l'autoriser à accéder à votre écran et à votre micro.
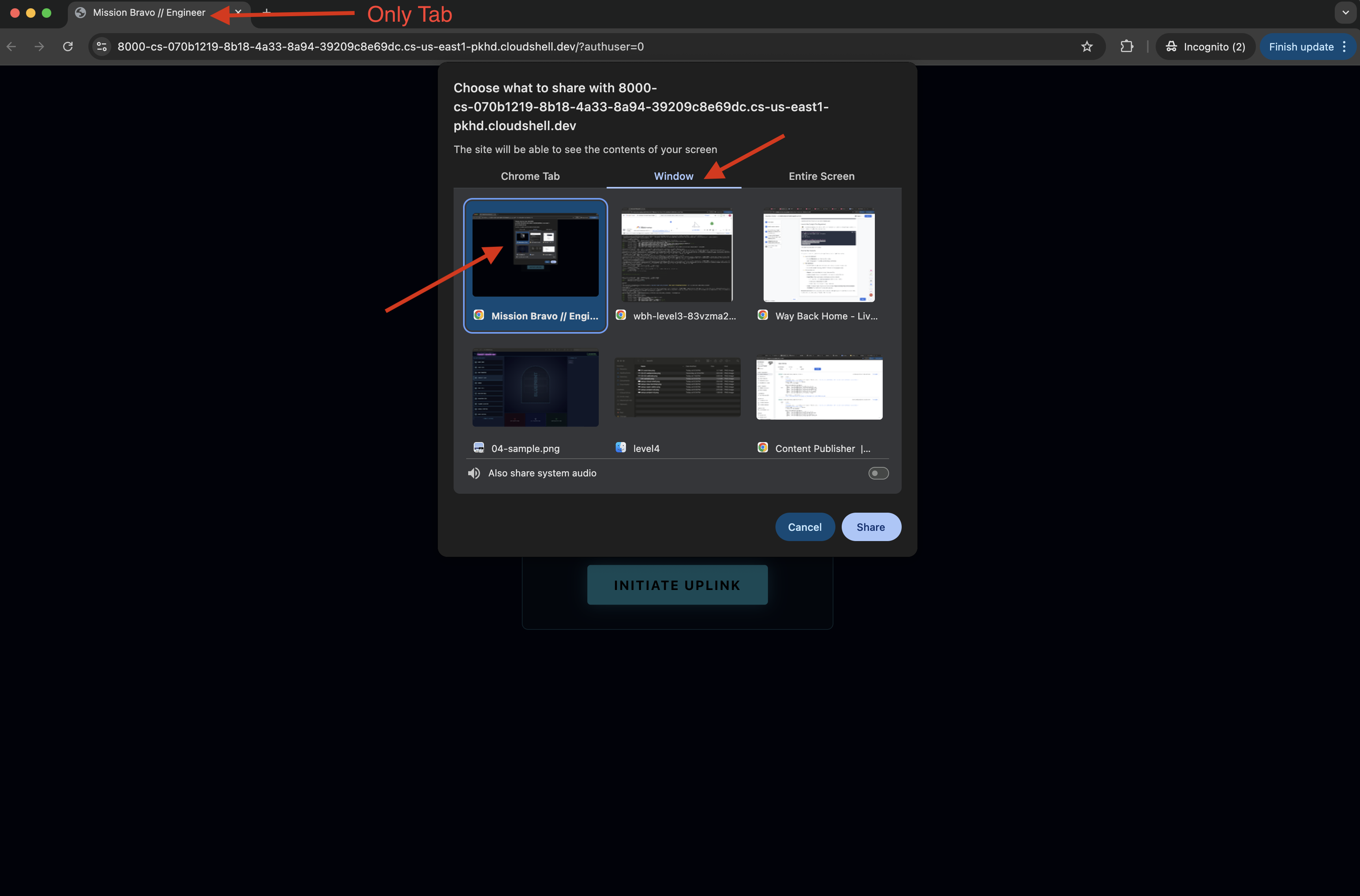
- Vous serez invité à sélectionner un onglet ou une fenêtre à partager. Si vous partagez la fenêtre, assurez-vous qu'il s'agit du SEUL onglet de la fenêtre pour éviter tout problème.
- Un disque portant un nom aléatoire (par exemple, "NOVA-V" ou "OMEGA-9") vous sera attribué.
- Lorsque l'interface se charge, assurez-vous de l'autoriser à accéder à votre écran et à votre micro.
- 👉 La boucle Assembly :
- Demande : pour commencer à assembler le lecteur, dites Commence l'assemblage.
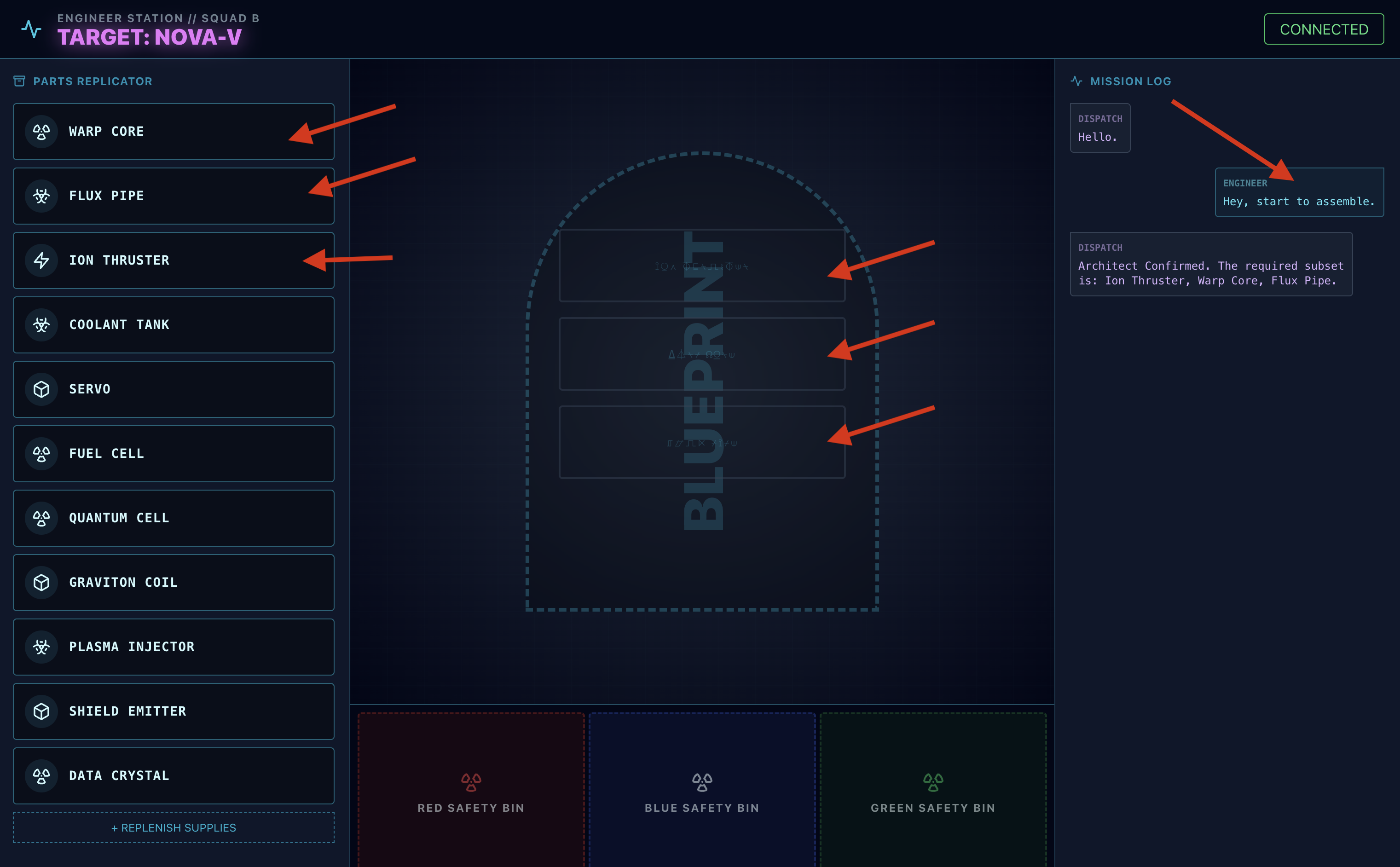
- Réponse de l'architecte : l'agent fournit les pièces correctes pour assembler le lecteur.
- Vérification des dangers : lorsqu'une pièce semble dangereuse sur l'établi :
- L'outil
monitor_for_hazardde l'agent Dispatch l'identifiera visuellement. - Une "ALERTE DE DANGER VISUEL" s'affichera. (Cela prendra environ 30 secondes.)
- Il vérifie quel bac utiliser pour désactiver le danger.
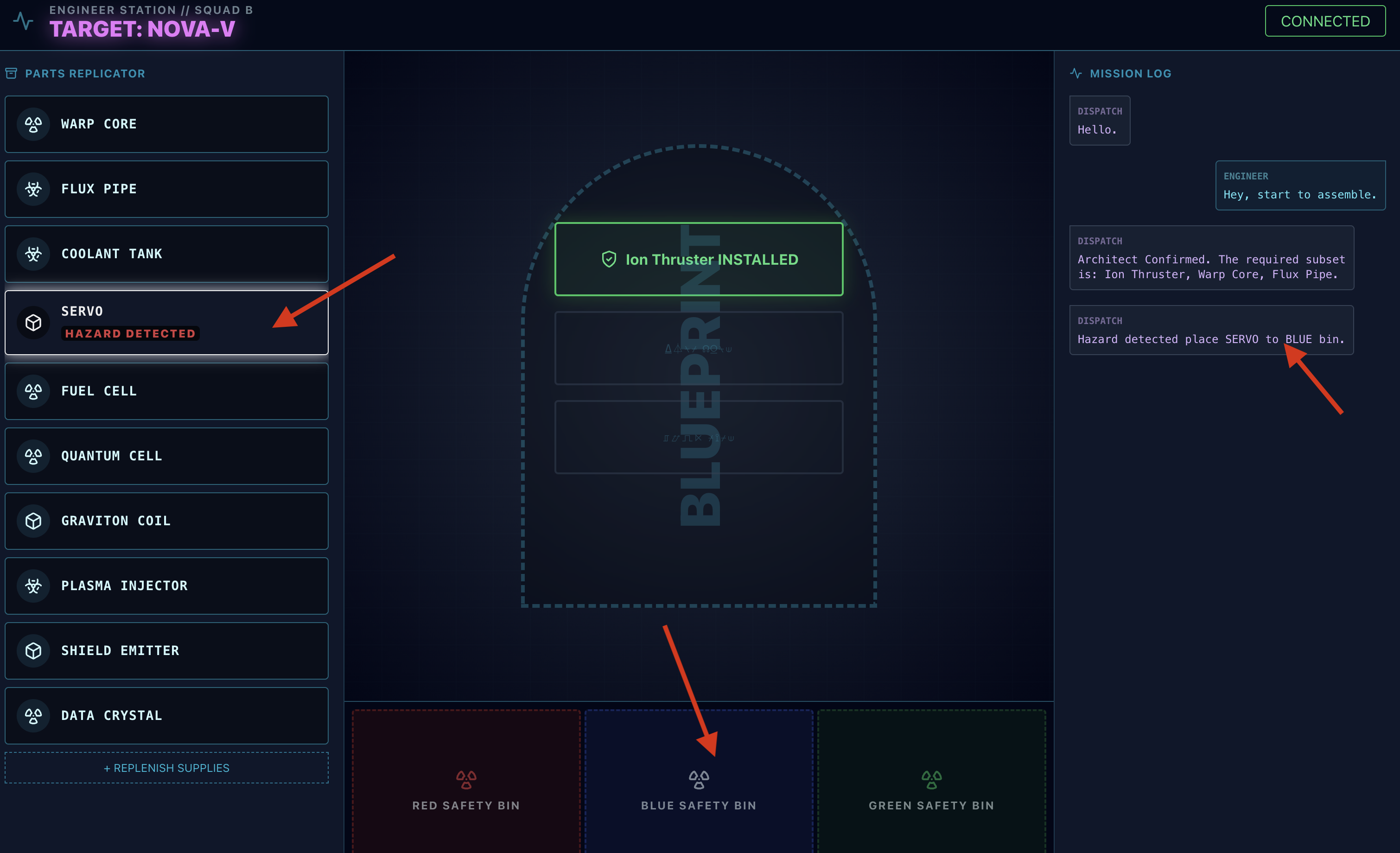
- L'outil
- Action : L'agent de répartition vous donnera une commande directe : "Danger confirmé. Placez XXX immédiatement dans le bac rouge." Vous devez suivre cette instruction pour continuer.
- Demande : pour commencer à assembler le lecteur, dites Commence l'assemblage.
Mission accomplie. Vous avez créé un système multi-agent interactif. Les survivants sont en sécurité, la fusée a quitté l'atmosphère et votre "Way Back Home" continue.
👉💻 Appuyez sur Ctrl+c dans les deux terminaux pour quitter.
6. Déployer en production (facultatif)
Vous avez testé l'agent localement. Nous devons maintenant importer le cœur neuronal de l'Architecte dans les ordinateurs centraux du vaisseau (Cloud Run). Cela lui permettra de fonctionner comme un service permanent et indépendant que l'agent Dispatch pourra interroger depuis n'importe où.
Provisionner le Secure Vault (infrastructure)
Avant de déployer l'agent, nous devons créer sa mémoire persistante (Memorystore) et le canal sécurisé pour y accéder (connecteur VPC).
👉💻 Créez l'instance Memorystore (coffre-fort Redis) :
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Récupérez l'adresse réseau du coffre-fort : exécutez cette commande et copiez l'adresse IP host. Il s'agit de l'adresse privée de votre nouvelle instance Redis.
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 Créez le connecteur d'accès au VPC (pont sécurisé) : ce connecteur sert de pont privé, permettant à Cloud Run d'accéder à l'instance Redis dans votre VPC.
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 Chargez les données :
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
Déployer l'application d'agent
Compiler et créer l'image de l'agent
👉💻 Accédez au répertoire backend et créez le fichier Dockerfile.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 Empaquetez l'application dans une image de conteneur.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
Déployer dans Cloud Run
👉💻 Déployez l'agent sur Cloud Run. Nous allons injecter l'adresse IP Redis et associer le connecteur VPC directement à la commande de lancement. Cela garantit que l'agent commence par une connexion sécurisée et privée à sa base de données.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 Vérifiez si le serveur A2A est en cours d'exécution.
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
Une fois la commande terminée, une URL du service s'affiche. L'agent Architect est désormais disponible dans le cloud, connecté en permanence à son coffre-fort et prêt à fournir des données schématiques à d'autres agents.
Déployer Dispatch Hub sur le mainframe de production
Maintenant que l'agent Architect est opérationnel dans le cloud, nous devons déployer le Dispatch Hub. Cet agent servira d'interface utilisateur principale, gérant les flux audio/vidéo en direct et déléguant les requêtes de base de données au point de terminaison sécurisé de l'architecte.
👉💻 Exécutez la commande suivante dans votre terminal Cloud Shell. Il créera le fichier Dockerfile complet en plusieurs étapes dans votre répertoire backend.
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
Compiler et créer l'image de l'agent/de l'interface
👉💻 Accédez au répertoire backend contenant le code de l'agent Dispatch (main.py) et packagez-le dans une image de conteneur.
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
Déployer dans Cloud Run
👉💻 Déployez le Dispatch Hub sur Cloud Run. Nous allons injecter l'URL de l'architecte en tant que variable d'environnement, créant ainsi le lien essentiel entre nos deux agents natifs du cloud.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
Une fois la commande terminée, une URL de service s'affiche (par exemple, https://mission-bravo-...run.app). L'application est désormais en ligne dans le cloud.
👉 Accédez à la page Google Cloud Run et sélectionnez le service biometric-scout dans la liste. 
👉 Recherchez l'URL publique affichée en haut de la page d'informations sur le service. 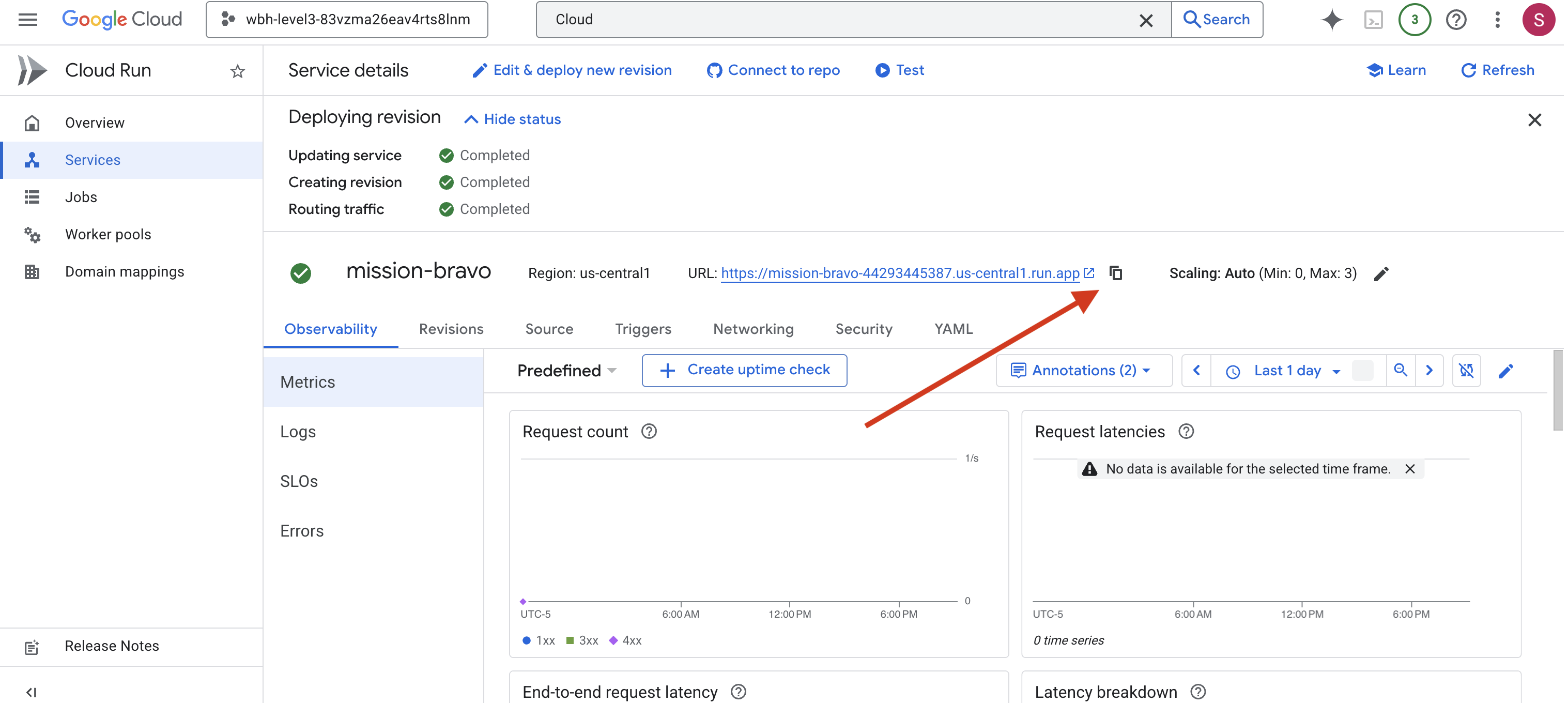
Vérification finale des systèmes (test de bout en bout)
👉 Vous allez maintenant interagir avec le système en direct.
- Obtenez l'URL : copiez l'URL du service à partir du résultat de la dernière commande de déploiement (elle doit se terminer par
run.app). - Ouvrez le Cockpit : collez l'URL dans votre navigateur Web.
- Initier le contact : lorsque l'interface se charge, assurez-vous de l'autoriser à accéder à votre écran et à votre micro.
- Demander des données : lorsqu'un lecteur est attribué, demandez à commencer l'assemblage. Par exemple : "Commence à assembler"

Vous interagissez maintenant avec un système multi-agents entièrement déployé et exécuté sur Google Cloud.
Le système multi-agents verrouille l'anneau de confinement final, et les radiations erratiques se stabilisent en un bourdonnement constant.
"Warp Drive : STABILIZED. Rescue Craft : ENGINS ALLUMÉS."

Sur votre écran, le vaisseau extraterrestre s'élance vers le haut, échappant de justesse à la surface en ruine d'Ozymandias alors que l'atmosphère s'effondre. Il se stabilise sur une orbite sûre à côté de votre vaisseau, et les communications se remplissent des voix des survivants, secoués mais en vie. Une fois le sauvetage terminé et le chemin vers votre domicile dégagé, la connexion à distance est interrompue.
Grâce à vous, les survivants ont été secourus.
Si vous avez participé au niveau 0, n'oubliez pas de vérifier votre progression dans la mission "Retour à la maison" !