1. La missione

Ti trovi alla deriva nell'immensa distesa silenziosa e inesplorata dello spazio. Un'enorme pulsazione solare ha squarciato la tua nave attraverso una spaccatura dimensionale, lasciandoti bloccato in una zona dell'universo assente da qualsiasi carta stellare.
Dopo giorni di estenuanti riparazioni, il familiare ronzio dei motori torna finalmente. Il tuo razzo è operativo. Sei persino riuscito a stabilire un uplink a lungo raggio con la nave madre. La partenza è imminente. Puoi tornare a casa.
Ma mentre ti prepari a inserire la chiavetta, un segnale di emergenza interrompe la statica. I tuoi sensori rilevano una richiesta di aiuto da un pianeta chiamato "Ozymandias". I sopravvissuti sono intrappolati su questo mondo morente e la loro nave è bloccata. La tua missione è fondamentale: devi salvarli prima che l'atmosfera del pianeta crolli.
Il loro unico mezzo di fuga è un'antica astronave abbandonata costruita con tecnologia aliena. Sebbene funzionante, il suo motore warp è distrutto. Per salvare i sopravvissuti, devi connetterti da remoto al loro banco di lavoro volatile e assemblare manualmente un'unità sostitutiva.
La sfida
Non hai esperienza con questa tecnologia aliena, notoriamente fragile. Un componente destabilizzato può diventare un pericolo radioattivo in pochi secondi. Hai un tentativo per utilizzare il banco di lavoro volatile. Il tuo attuale assistente AI ha difficoltà a elaborare contemporaneamente dati visivi e manuali tecnici, il che porta a istruzioni allucinanti e avvisi di pericolo mancanti.
Per riuscirci, devi eseguire l'upgrade della tua AI da entità monolitica a sistema multi-agente collaborativo.
Obiettivi della missione:
Assembla il motore Warp seguendo le istruzioni specializzate in tempo reale del tuo nuovo sistema multi-agente.

Cosa creerai
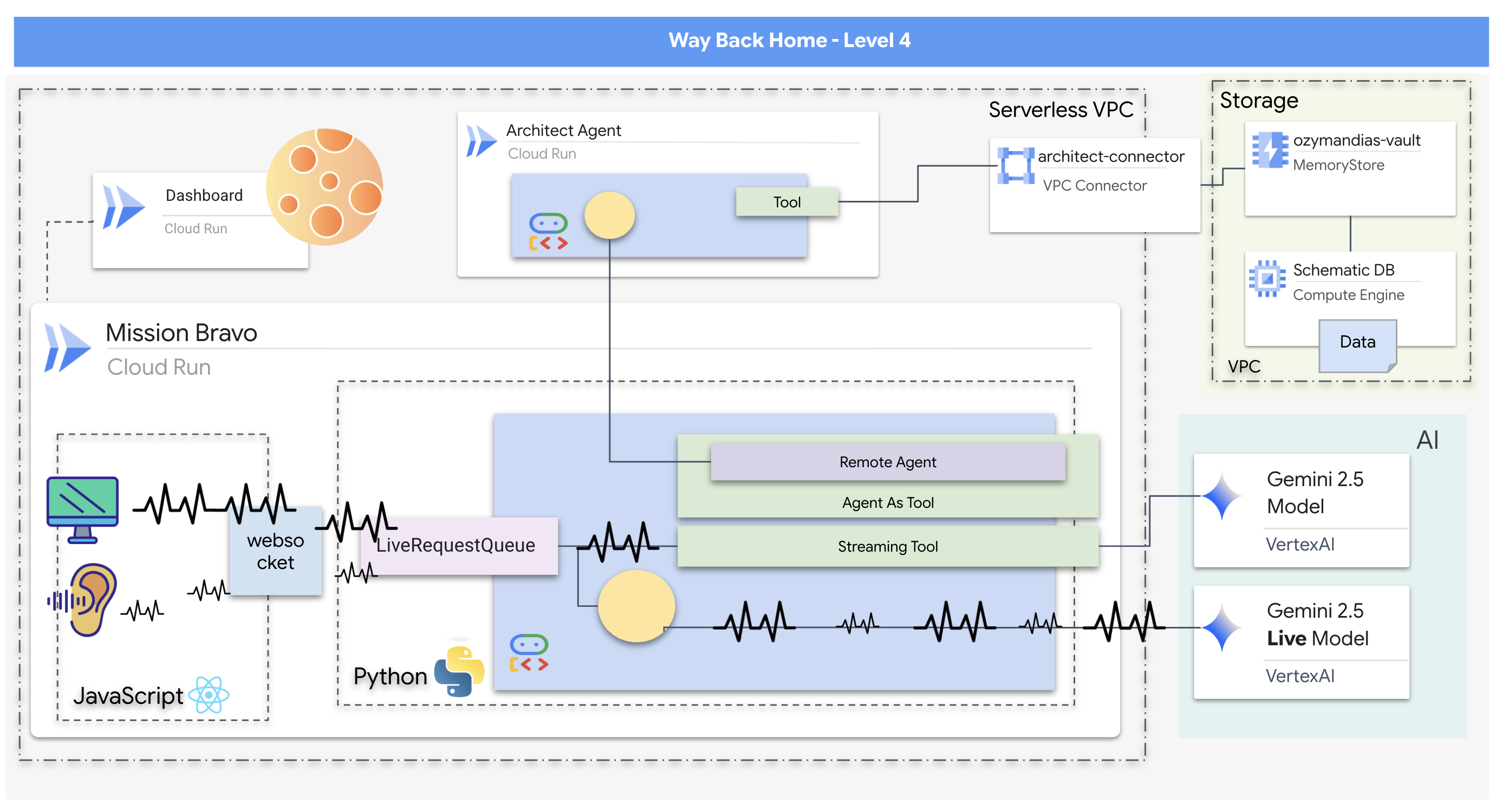
- Un sistema di AI multi-agente bidirezionale in tempo reale con un agente di invio centrale che gestisce l'interazione utente e si coordina con agenti specializzati.
- Un agente architetto che si connette a un database Redis per recuperare e pubblicare dati schematici.
- Un monitor di sicurezza proattivo che utilizza strumenti di streaming per analizzare un feed video in diretta alla ricerca di pericoli visivi e attivare avvisi in tempo reale.
- Un frontend basato su React che fornisce un'interfaccia utente per interagire con il sistema, trasmettendo in streaming video e audio agli agenti di backend.
Cosa imparerai a fare
Tecnologia / Concept | Descrizione |
Google Agent Development Kit (ADK) | Utilizzerai l'ADK per creare, testare e gestire gli agenti, sfruttando il suo framework per la gestione della comunicazione in tempo reale, l'integrazione degli strumenti e il ciclo di vita degli agenti. |
Streaming bidirezionale | Implementerai un agente di streaming bidirezionale che consente una comunicazione bidirezionale naturale e a bassa latenza, consentendo sia all'uomo che all'AI di interrompere e rispondere in tempo reale. |
Sistemi multi-agente | Imparerai a progettare un sistema di AI distribuita in cui un agente principale delega le attività ad agenti specializzati, consentendo una separazione dei problemi e un'architettura più scalabile. |
Protocollo Agent2Agent (A2A) | Utilizzerai il protocollo A2A per attivare la comunicazione tra l'agente di distribuzione e l'agente di architettura, consentendo loro di scoprire le funzionalità reciproche e scambiare dati. |
Strumenti di streaming | Implementerai uno strumento di streaming che funge da processo in background, analizzando continuamente un feed video per monitorare le modifiche di stato (pericoli) e restituire in modo proattivo i risultati. |
Google Cloud Run e Memorystore | Esegui il deployment dell'intera applicazione multi-agente in un ambiente di produzione, utilizzando Cloud Run per ospitare i servizi dell'agente e Memorystore (Redis) come database permanente. |
FastAPI e WebSocket | Il backend è creato utilizzando FastAPI e WebSockets per gestire la comunicazione in tempo reale ad alte prestazioni necessaria per lo streaming di audio, video e risposte degli agenti. |
Frontend React | Lavorerai con un frontend basato su React che acquisisce e trasmette i contenuti multimediali (audio/video) dell'utente e mostra le risposte in tempo reale degli agenti AI. |
2. Configura l'ambiente
Accedere a Cloud Shell
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro di Cloud Shell), 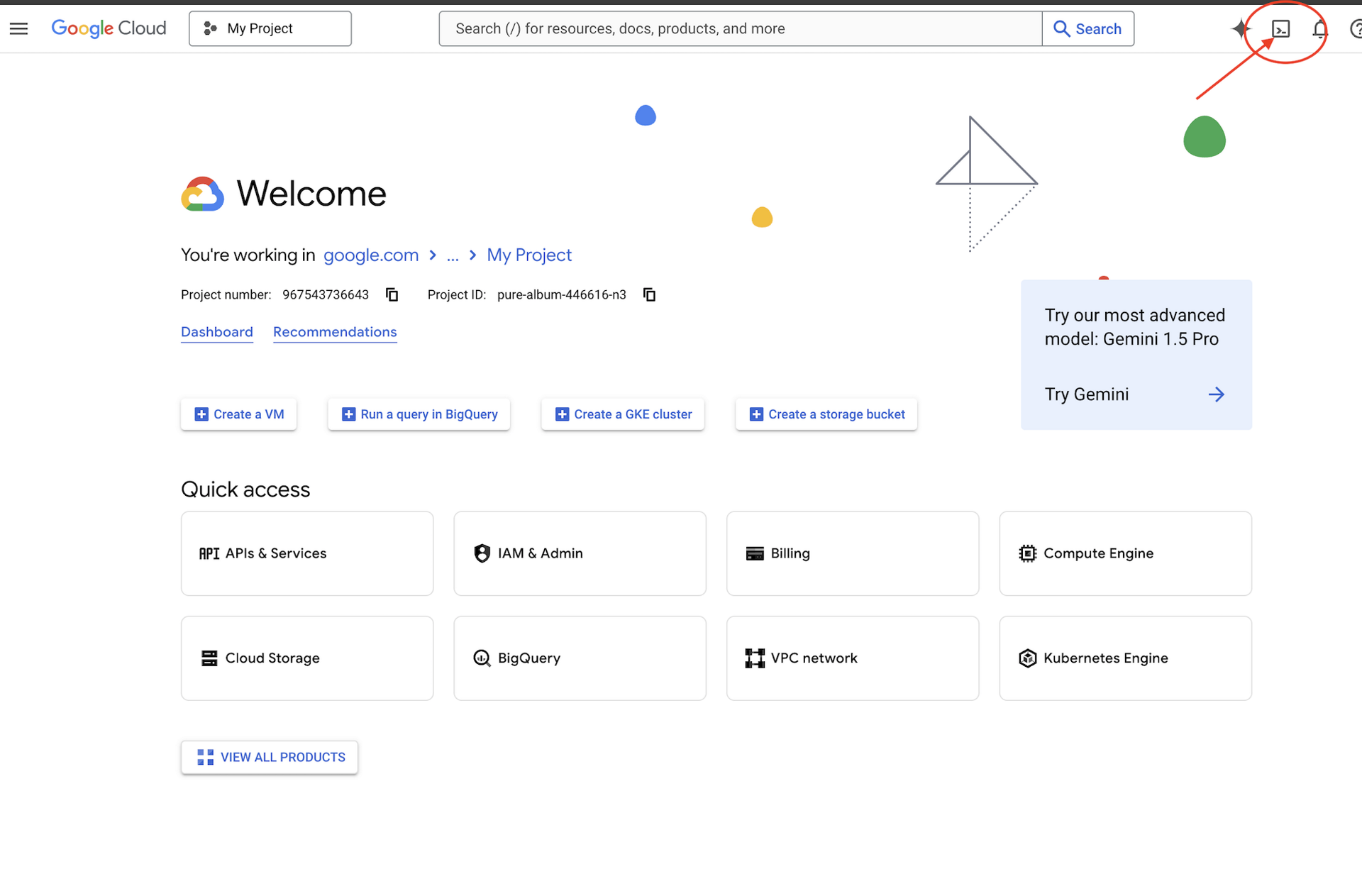
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro. 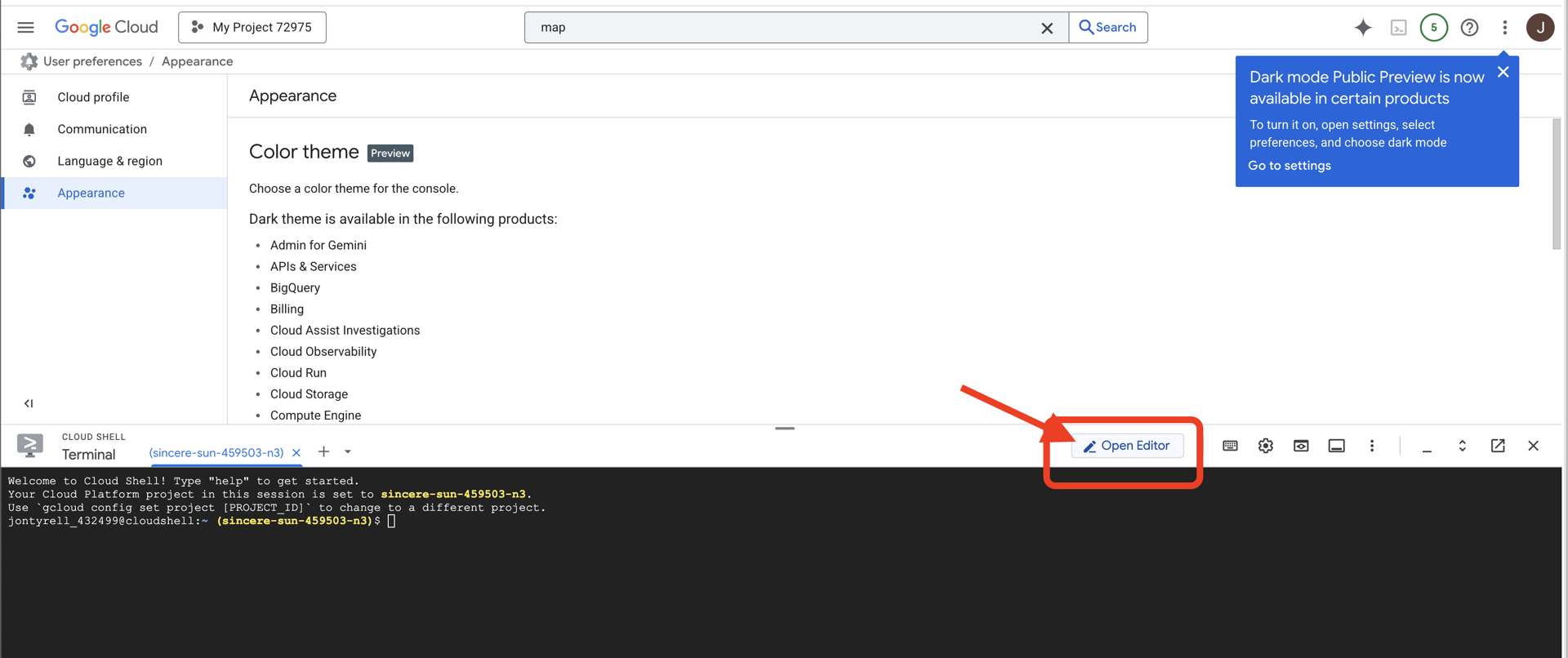
👉 Apri il terminale nell'IDE cloud.
👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
Dovresti vedere il tuo account elencato come (ACTIVE).
Prerequisiti
ℹ️ Il livello 0 è facoltativo (ma consigliato)
Puoi completare questa missione senza il livello 0, ma terminarla per prima offre un'esperienza più coinvolgente, che ti consente di vedere il tuo faro illuminarsi sulla mappa globale man mano che avanzi.
Configurare l'ambiente del progetto
Torna al terminale e finalizza la configurazione impostando il progetto attivo e abilitando i servizi Google Cloud richiesti (Cloud Run, Vertex AI e così via).
👉💻 Nel terminale, imposta l'ID progetto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Attiva i servizi richiesti:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
Installa le dipendenze
👉💻 Vai al livello 4 e installa i pacchetti Python richiesti:
cd $HOME/way-back-home/level_4
uv sync
Le dipendenze principali sono:
Pacchetto | Finalità |
| Framework web ad alte prestazioni per lo streaming di Satellite Station ed SSE |
| Server ASGI richiesto per eseguire l'applicazione FastAPI |
| Agent Development Kit utilizzato per creare l'agente di formazione |
| Libreria di protocolli Agent-to-Agent per la comunicazione standardizzata |
| Client nativo per l'accesso ai modelli Gemini |
| Client Python per la connessione a Schematic Vault (Memorystore) |
| Supporto per la comunicazione bidirezionale in tempo reale |
| Gestisce le variabili di ambiente e i secret di configurazione |
| Gestione delle impostazioni e convalida dei dati |
Verifica la configurazione
Prima di addentrarci nel codice, assicuriamoci che tutti i sistemi siano attivi. Esegui lo script di verifica per controllare il tuo progetto Google Cloud, le API e le dipendenze Python.
👉💻 Esegui lo script di verifica:
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Dovresti vedere una serie di segni di spunta verdi (✅).
- Se vedi croci rosse (❌), segui i comandi di correzione suggeriti nell'output (ad es.
gcloud services enable ...opip install ...). - Nota:per il momento è accettabile un avviso giallo per
.env. Creeremo questo file nel passaggio successivo.
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Creazione di Schematic Vault in Redis e dell'agente bidirezionale con ADK
Hai trovato il repository degli schemi planetari contenente i progetti del razzo abbandonato. Per recuperare questi dati in modo accurato, devi interagire con l'interfaccia di gestione dedicata del repository: l'agente Architect.
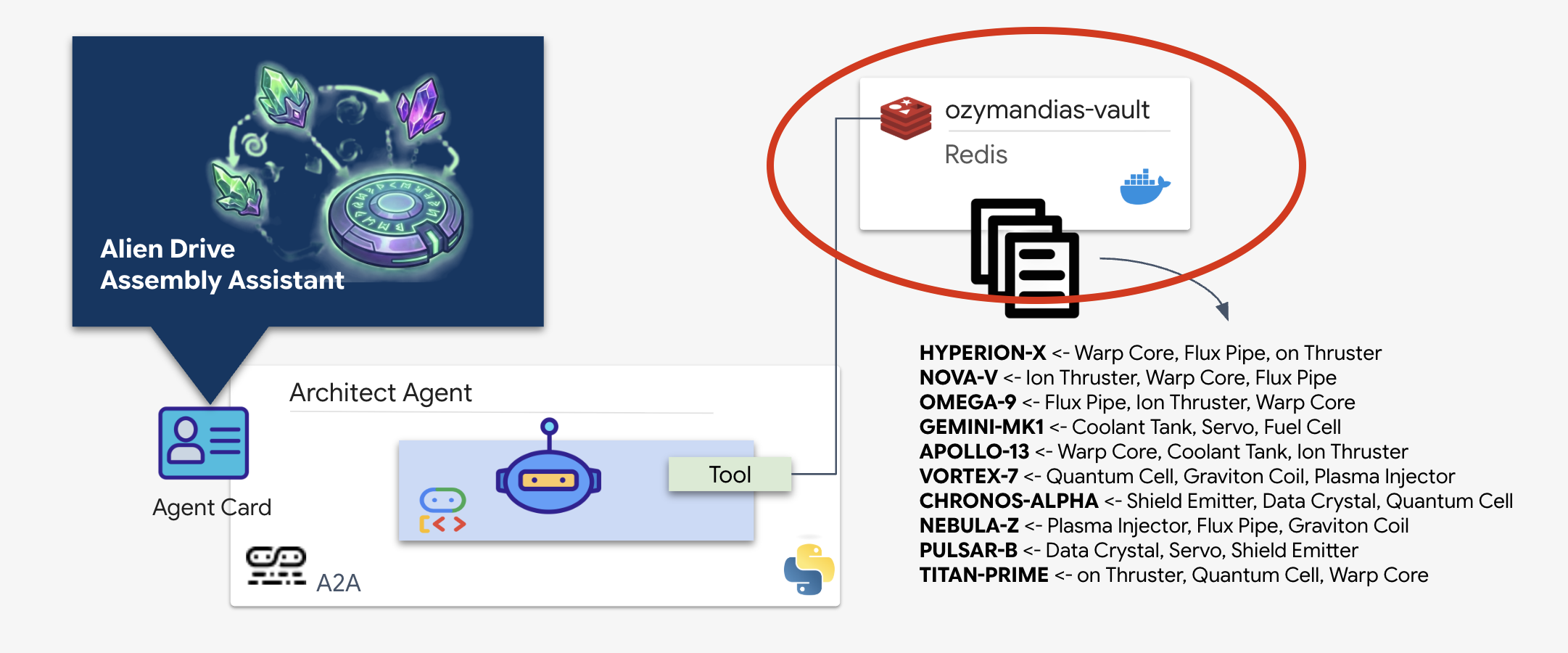
Provisioning del vault schematico (Redis)
Prima che l'architetto possa aiutarci, dobbiamo assicurarci che i dati siano ospitati in un ambiente sicuro e ad alta disponibilità. Utilizzeremo Redis come datastore rapido per i nostri schemi alieni. Per comodità di sviluppo, creeremo un'istanza Redis locale, ma le istruzioni su come eseguire il deployment in un ambiente di produzione con Google Cloud Memorystore verranno fornite in un secondo momento.
👉💻 Esegui questi comandi nel terminale per eseguire il provisioning dell'istanza Redis (potrebbe richiedere 2-3 minuti):
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 Per caricare i dati preliminari, esegui il comando seguente per accedere a Redis Shell:
docker exec -it ozymandias-vault redis-cli
(Il prompt cambierà in 127.0.0.1:6379)
👉💻 Incolla questi comandi all'interno:
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 Digita exit per tornare alla shell normale.
👉💻 Per verificare che i dati esistano eseguendo una query su una nave specifica direttamente dal terminale, esegui:
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 Questo è l'output previsto:
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
Implementazione dell'agente di architettura
L'agente di architettura è un agente specializzato responsabile del recupero dei progetti schematici dal nostro vault Redis. Funge da interfaccia dati dedicata, garantendo che l'agente di distribuzione principale riceva informazioni accurate e strutturate senza la necessità di conoscere la logica del database sottostante.
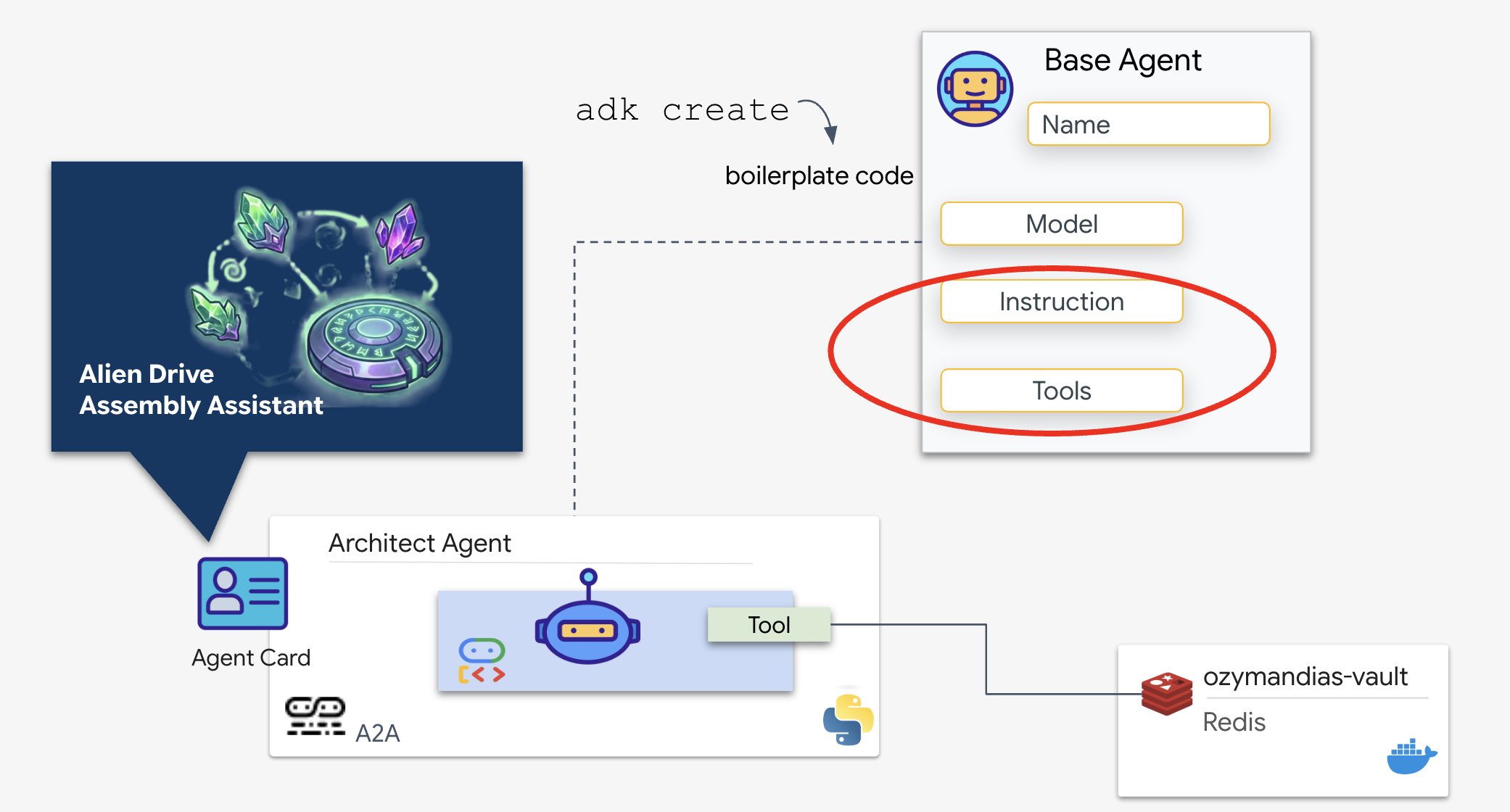
Google Agent Development Kit (ADK) è il framework modulare che rende possibile questa configurazione multi-agente. Gestisce due livelli critici:
- Ciclo di vita di connessione e sessione:l'interazione con le API in tempo reale richiede una gestione complessa dei protocolli, che gestiscono handshake, autenticazione e segnali keep-alive.
- Chiamata di funzione: si tratta del "round trip modello-codice-modello". Quando l'LLM decide di aver bisogno di dati, restituisce una chiamata di funzione strutturata. L'ADK intercetta questa richiesta, esegue il codice Python (
lookup_schematic_tool) e reinserisce il risultato nel contesto del modello in millisecondi.
Ora creeremo l'architetto. Questo agente non ha accesso alla videocamera. Esiste solo per ricevere un "Nome unità" e restituire l'"Elenco parti" dal database.
👉💻 Utilizzeremo il comando adk create. Si tratta di uno strumento di Agent Development Kit (ADK) che genera automaticamente il codice boilerplate e la struttura dei file per un nuovo agente, consentendoci di risparmiare tempo di configurazione.
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
Configura l'agente
L'interfaccia a riga di comando avvierà una procedura guidata di configurazione interattiva. Utilizza le seguenti risposte per configurare l'agente:
- Scegli un modello: seleziona Opzione 1 (Gemini Flash).
- Nota: la versione specifica (ad es. 2.5, 3.0) può variare in base alla disponibilità. Scegli sempre la variante "Flash" per la velocità.
- Scegli un backend: seleziona Opzione 2 (Vertex AI).
- Inserisci l'ID progetto Google Cloud: premi Invio per accettare il valore predefinito (rilevato dal tuo ambiente).
- Enter Google Cloud Region (Inserisci la regione Google Cloud): premi Invio per accettare il valore predefinito (
us-central1).
👀 L'interazione con il terminale dovrebbe essere simile a questa:
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
Ora dovresti visualizzare un messaggio di conferma Agent created. Viene generato il codice di base che modificheremo nel passaggio successivo.
👉✏️ Vai al file $HOME/way-back-home/level_4/backend/architect_agent/agent.py appena creato e aprilo nell'editor. Aggiungi lo snippet dello strumento al file dopo la prima riga di importazione:
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ Sostituisci l'intera riga instruction nella definizione di root_agent con la seguente e aggiungi anche lo strumento che abbiamo definito in precedenza:
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
Il vantaggio di ADK
Con l'architetto online, ora abbiamo una fonte attendibile. Prima di collegarlo all'agente principale,l'Agent Development Kit (ADK) offre un vantaggio significativo semplificando le complessità della creazione e del test degli agenti AI. Grazie alla console per sviluppatori adk web integrata, possiamo isolare e verificare la funzionalità del nostro Architect Agent, in particolare le sue funzionalità di chiamata degli strumenti, prima di integrarlo nel sistema multi-agente più grande. Questo approccio modulare allo sviluppo e ai test è fondamentale per creare applicazioni di AI solide e affidabili.
👉💻 Nel terminale, esegui:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 Attendi finché non vedi:
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell. Seleziona Cambia porta, impostala su 8000 e fai clic su Cambia e visualizza anteprima.
- Seleziona architect_agent.
- Attiva lo strumento:nell'interfaccia di chat, digita:
CHRONOS-ALPHA(o qualsiasi ID Drive dal database schematico). - Osserva il comportamento:
- L'architetto deve attivare immediatamente
lookup_schematic_tool. - A causa delle nostre rigide istruzioni di sistema, dovrebbe restituire solo l'elenco delle parti (ad es.
['Shield Emitter', 'Data Crystal', 'Quantum Cell']) senza alcun riempitivo conversazionale.
- L'architetto deve attivare immediatamente
- Verifica i log:guarda la finestra del terminale. Dovresti visualizzare il log di esecuzione riuscita:
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
Se vedi il log di esecuzione dello strumento e la risposta con i dati puliti, l'agente specializzato funziona come previsto. Può elaborare richieste, eseguire query nel vault e restituire dati strutturati.
👉💻 Premi Ctrl+C per uscire.
Inizializzare il server A2A
Per connettere l'agente di distribuzione all'architetto, utilizziamo il protocollo Agent-to-Agent (A2A).
Mentre protocolli come MCP (Model Context Protocol) si concentrano sulla connessione degli agenti agli strumenti, A2A si concentra sulla connessione degli agenti ad altri agenti. È lo standard che consente al nostro Dispatcher di "scoprire" l'architetto e comprendere la sua capacità di cercare schemi.
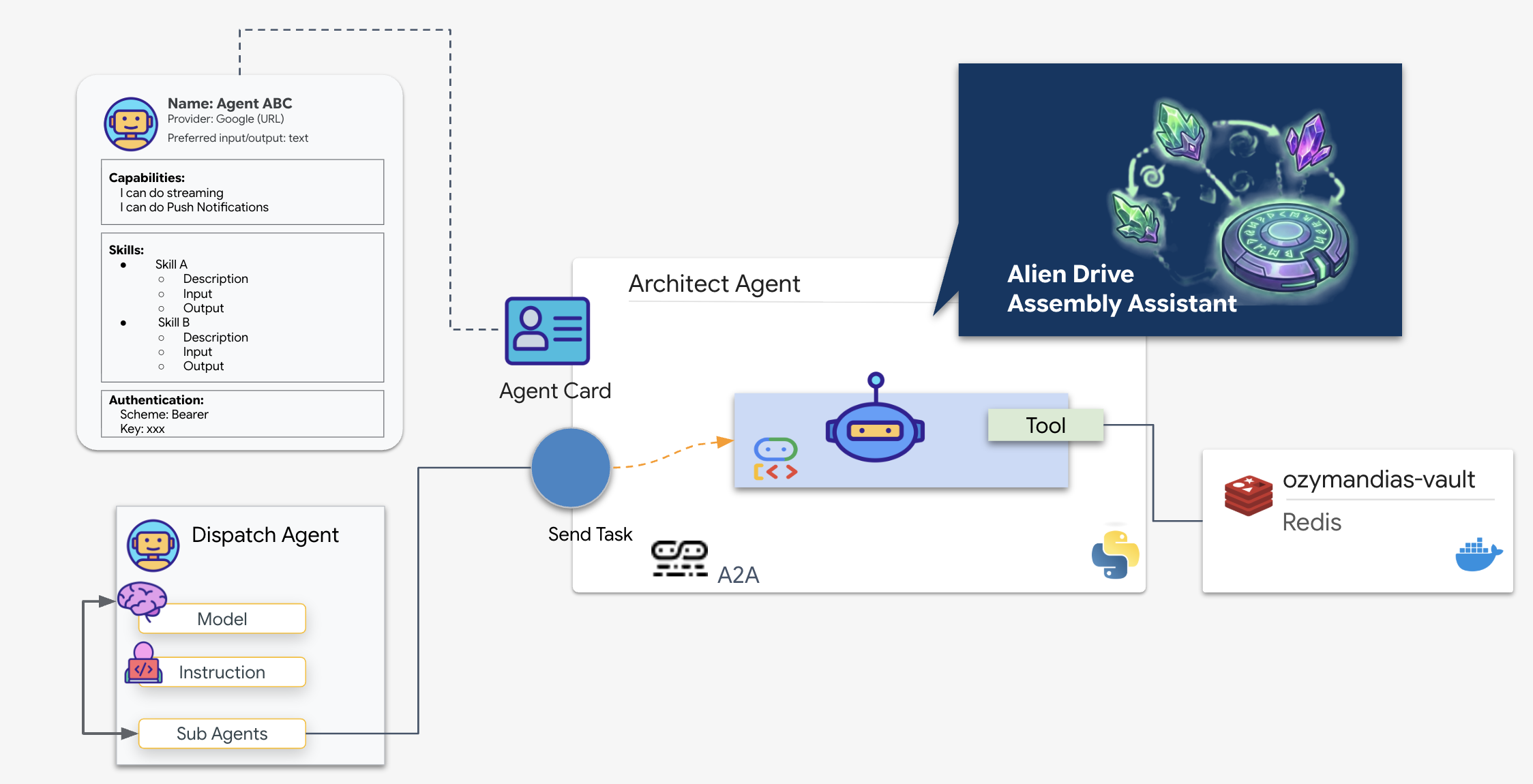
Il flusso da app ad app:in questa missione utilizziamo un modello client-server:
- Server (architetto): ospita gli strumenti di database e "pubblicizza" le sue competenze tramite una scheda dell'agente.
- Client (Dispatch): legge la scheda dell'architetto, ne comprende l'API e invia una richiesta schematica.
Che cos'è una scheda dell'agente?
Considera la scheda dell'agente come un biglietto da visita digitale o una "patente di guida" per un'AI. Quando viene avviato un server A2A, pubblica questo oggetto JSON contenente:
- Identità:il nome (
architect_agent) e l'ID dell'agente. - Descrizione:un riepilogo leggibile da persone e macchine di ciò che fa ("Ruolo di sistema: API Database...").
- Interfaccia:i tasti di input specifici (
drive_name) e i formati di output previsti.
Senza questa scheda, l'agente Dispatch opererebbe alla cieca, cercando di capire come comunicare con l'architetto.
Crea il codice server
👉✏️ Nell'editor, nella directory $HOME/way-back-home/level_4/backend/architect_agent, crea un file denominato server.py e incolla il seguente codice:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 Nel terminale, vai alla cartella e avvia il server:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 Verifica se il server A2A si avvia:
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Verifica la scheda dell'agente
Apri una nuova scheda del terminale (fai clic sull'icona +). Verificheremo che l'agente Architect trasmetta correttamente la propria identità recuperando manualmente la scheda dell'agente.
👉💻 Esegui questo comando:
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 Dovresti visualizzare una risposta JSON. Cerca il campo description nell'output. Deve corrispondere all'istruzione che hai dato all'agente in precedenza ("SYSTEM ROLE: Database API...").
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
Se vedi questo JSON, l'architetto è attivo, il protocollo A2A è attivo e la scheda dell'agente è pronta per essere rilevata dal dispatcher.
Ora che l'architetto è pronto a fungere da risorsa remota, possiamo procedere a integrarlo nell'agente di distribuzione.
👉💻 Premi Ctrl+C per uscire dal server A2A.
4. Connessione dell'agente BIDI-Streams all'agente remoto e agli strumenti di streaming
Ora configurerai l'hub di comunicazione principale per colmare il divario tra i dati in tempo reale e l'architetto remoto. Questa connessione richiede una pipeline a larghezza di banda elevata e bassa latenza per garantire che il banco di assemblaggio rimanga stabile durante il funzionamento.
Informazioni sugli agenti di streaming bidirezionale (live)
Lo streaming bidirezionale in ADK aggiunge agli agenti AI la funzionalità di interazione vocale e video bidirezionale a bassa latenza dell'API Gemini Live. Rappresenta un cambiamento fondamentale rispetto alle interazioni tradizionali con l'AI. Invece del rigido modello "chiedi e aspetta", consente una comunicazione bidirezionale in tempo reale in cui sia l'uomo che l'AI possono parlare, ascoltare e rispondere contemporaneamente.
Pensa alla differenza tra l'invio di email e una conversazione telefonica. Le interazioni con l'agente tradizionale sono come le email: invii un messaggio completo, aspetti una risposta completa e poi ne invii un altro. Lo streaming bidirezionale è come una conversazione telefonica: fluida, naturale, con la possibilità di interrompere, chiarire e rispondere in tempo reale.
Caratteristiche principali:
- Comunicazione bidirezionale:scambio continuo di dati senza attendere risposte complete. L'AI risponde non appena rileva che l'utente ha finito di parlare.
- Interruzione reattiva:gli utenti possono interrompere la risposta dell'agente con un nuovo input, proprio come in una conversazione umana. Se un'AI sta spiegando un passaggio complesso e tu dici "Aspetta, ripeti", l'AI si ferma immediatamente e risponde alla tua interruzione.
- Ottimizzato per la multimodalità:Bidi-streaming eccelle nell'elaborazione simultanea di diversi tipi di input. Puoi parlare con l'operatore mentre gli mostri le parti dell'alieno tramite video e lui elabora entrambi gli stream in un'unica connessione unificata.
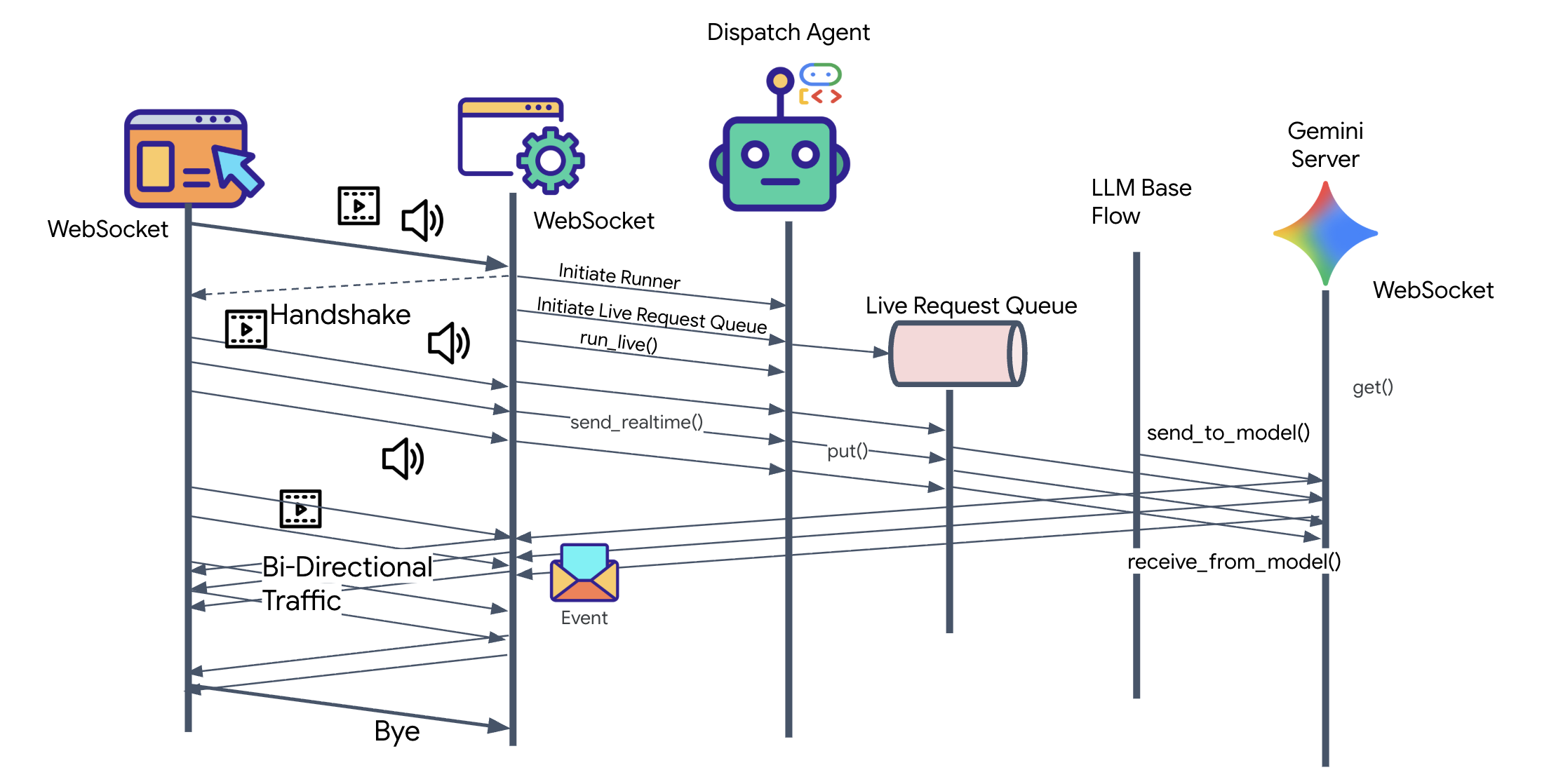
👀 Prima di implementare la logica del client, esaminiamo lo scheletro pregenerato per l'agente di invio. Questo agente comunicherà con l'utente tramite voce e video e delegherà le query all'agente architetto.
__init__.py agent.py hazard_db.py
agent.py: questo è il "cervello". Al momento contiene una configurazione di base dello streaming bidirezionale. Modificheremo questo file per aggiungere la logica del client A2A in modo che possa comunicare con l'architetto.hazard_db.py: si tratta di uno strumento locale specifico per l'agente di spedizione, contenente protocolli di sicurezza. È separato dal database schematico dell'architetto.
Implementazione del client A2A
Per consentire all'agente di distribuzione di comunicare con il nostro architetto remoto, dobbiamo definire un agente A2A remoto. In questo modo, l'agente Dispatch sa dove trovare l'agente Architect e qual è l'aspetto della sua "scheda agente".
👉✏️ Sostituisci #REPLACE-REMOTEA2AAGENT in $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py con quanto segue:
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
Come funzionano gli strumenti di streaming
Con l'agente precedente, gli strumenti seguivano un pattern standard "Richiesta-Risposta": l'agente pone una domanda, lo strumento fornisce una risposta e l'interazione termina. Tuttavia, su Ozymandias, i pericoli non aspettano che tu chieda se sono presenti. Per farlo, devi utilizzare uno strumento di streaming.
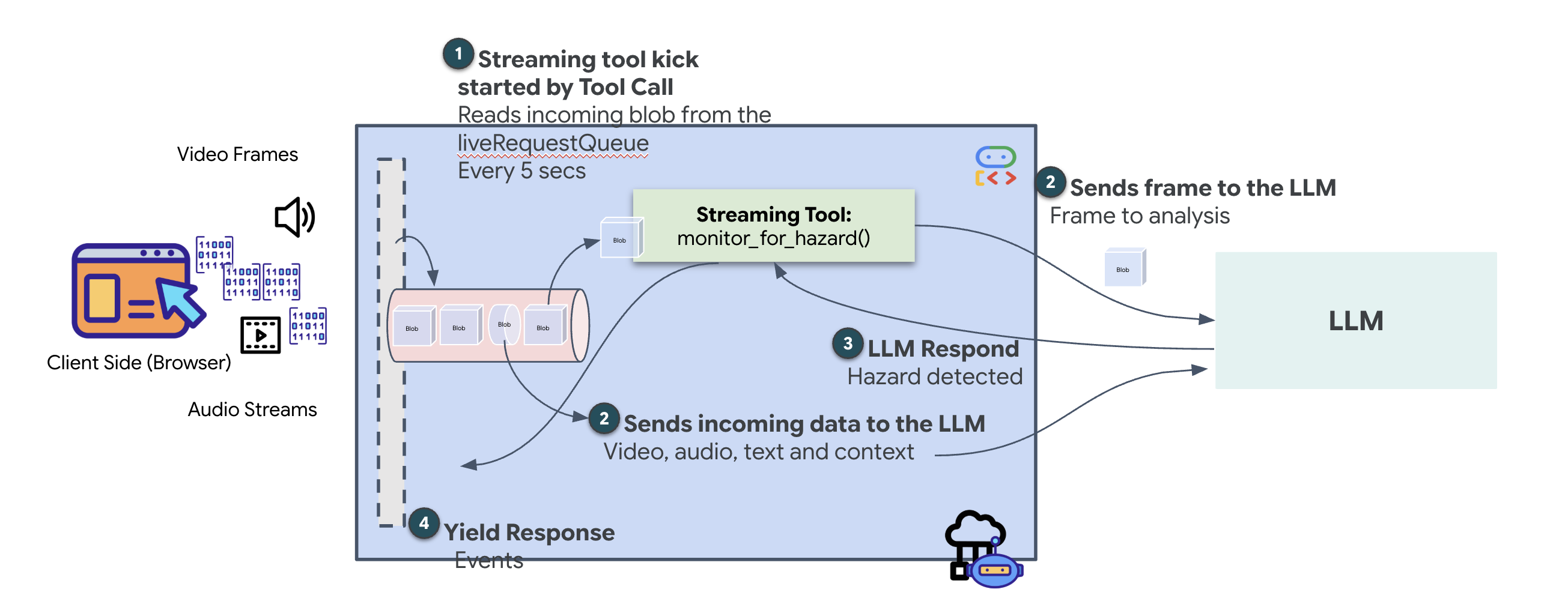
Gli strumenti di streaming consentono alle funzioni di trasmettere i risultati intermedi all'agente in tempo reale, consentendogli di reagire ai cambiamenti man mano che si verificano. I casi d'uso comuni includono il monitoraggio delle fluttuazioni dei prezzi delle azioni o, nel nostro caso, il monitoraggio di uno stream video live per i cambiamenti di stato.
A differenza degli strumenti standard, uno strumento di streaming è una funzione asincrona che funge da AsyncGenerator. Ciò significa che, anziché return un singolo valore, yield più aggiornamenti nel tempo.
Per definire uno strumento di streaming nell'ADK, devi rispettare i seguenti requisiti tecnici:
- Funzione asincrona:lo strumento deve essere definito con
async def. - Tipo restituito di AsyncGenerator:la funzione deve essere digitata per restituire un
AsyncGenerator. Il primo parametro è il tipo di dati restituiti (ad es.str), mentre il secondo è in genereNone. - Stream di input:utilizziamo strumenti di streaming video. In questa modalità, il flusso video/audio effettivo (il
LiveRequestQueue) viene passato direttamente alla funzione, consentendo allo strumento di "vedere" gli stessi frame visti dall'agente.
Pensa a uno strumento di streaming come a una sentinella. Mentre tu e l'agente del centralino discutete dei progetti, il sentinella viene eseguito in background, elaborando silenziosamente ogni fotogramma video per garantire la tua sicurezza.
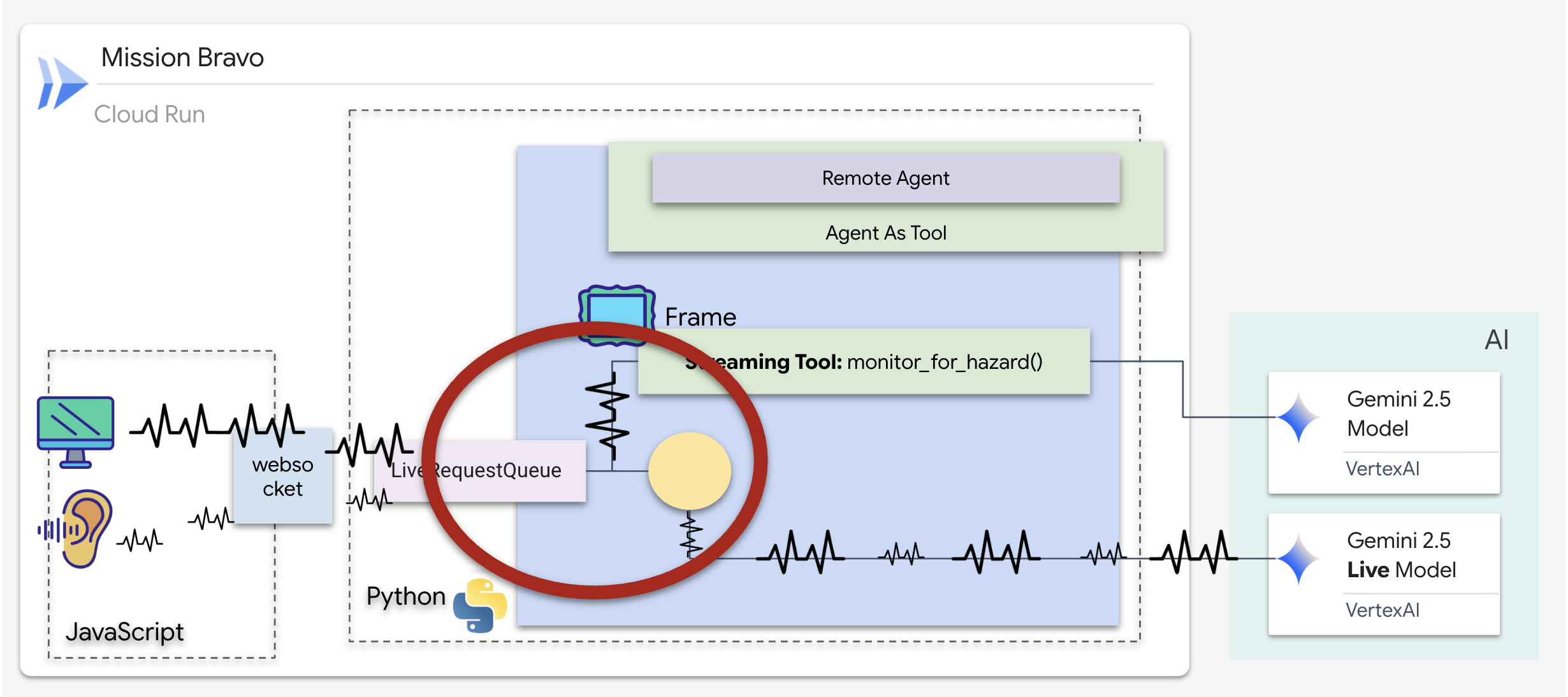
Implementazione dello strumento di monitoraggio in background
Ora implementeremo lo strumento monitor_for_hazard. Questo strumento acquisisce i input_stream (fotogrammi video), li analizza utilizzando una chiamata di visione separata e leggera e yield un avviso solo quando viene rilevato un pericolo.
👉✏️ In $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py, sostituisci #REPLACE_MONITOR_HAZARD con la seguente logica:
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
Implementazione dell'agente di distribuzione
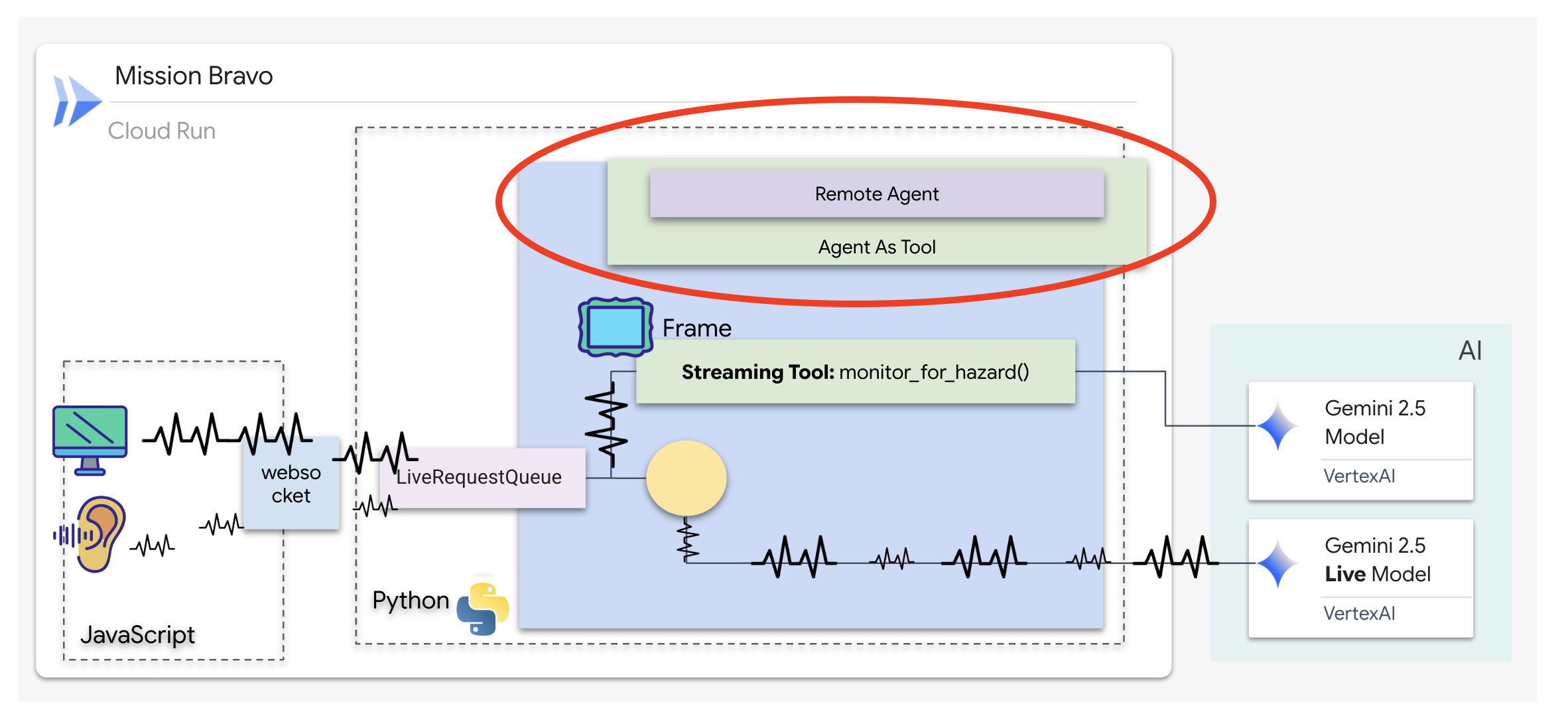
L'agente di distribuzione è l'interfaccia principale e l'orchestratore. Poiché gestisce il link di streaming bidirezionale (la tua voce e il tuo video in diretta), deve mantenere il controllo della conversazione in ogni momento. Per raggiungere questo obiettivo, utilizzeremo una funzionalità specifica dell'ADK: Agent-as-a-Tool.
Concetto: Agent-as-a-Tool e subagenti
Quando crei sistemi multi-agente, devi decidere come viene condivisa la responsabilità. Nella nostra missione di salvataggio, la distinzione è fondamentale:
- Agent-as-a-Tool::questo è l'approccio consigliato per il nostro hub di streaming bidirezionale. Quando l'agente Dispatch (agente A) chiama l'agente Architect (agente B) come strumento, i dati di Architect vengono restituiti a Dispatch. Dispatch interpreta i dati e genera una risposta. Dispatch rimane in controllo e continua a gestire tutti gli input utente successivi.
- Subagente:in un rapporto di subagenzia, la responsabilità viene trasferita completamente. Se Dispatch ti ha trasferito all'architetto come subagente, parlerai direttamente con un'API di database che non ha "visione" e non ha competenze conversazionali. L'agente principale (Dispatch) non sarebbe coinvolto.
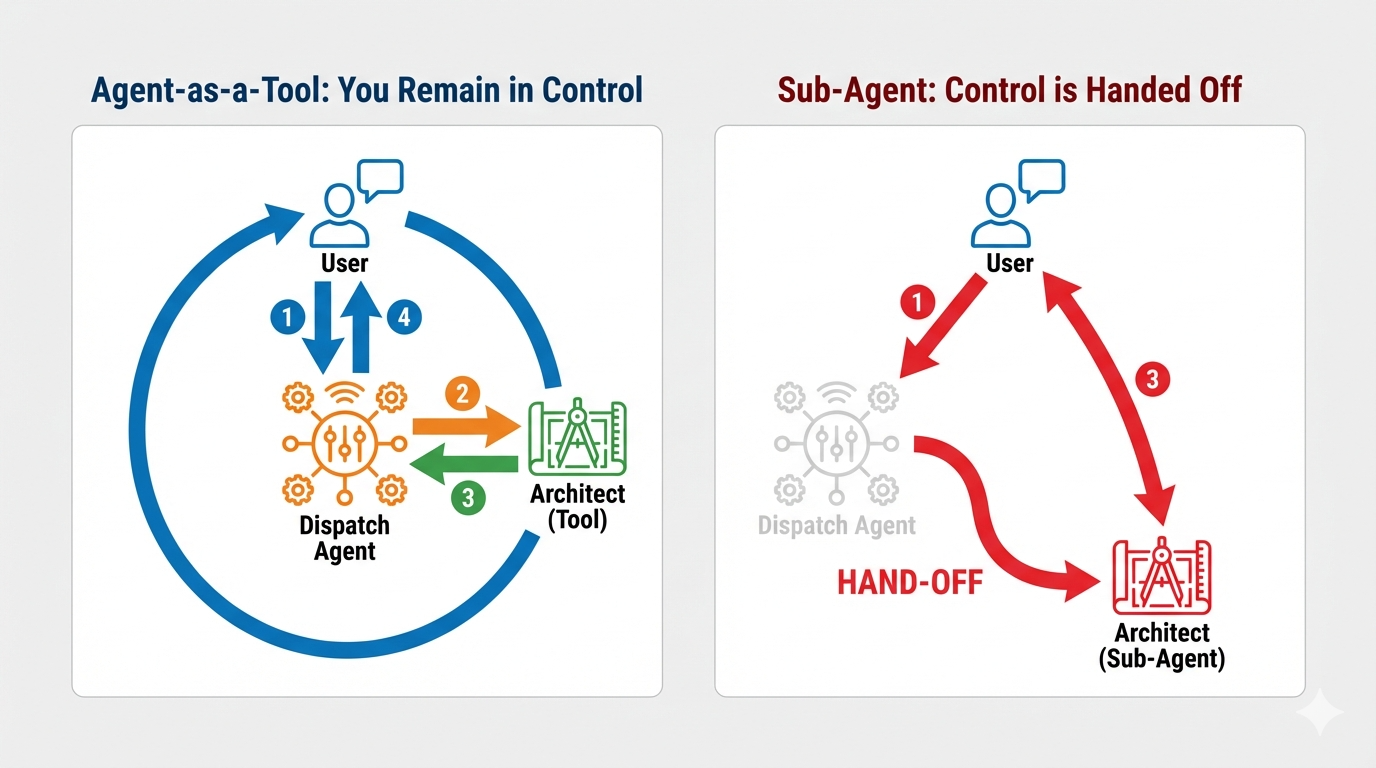
Utilizzando Agent-as-a-Tool, sfruttiamo le conoscenze specializzate dell'architetto mantenendo l'interazione fluida e simile a quella umana dell'agente di streaming bidirezionale.
Codifica della logica di routing
Ora inseriremo il nostro architect_agent in un AgentTool e forniremo all'agente Dispatch una "mappa logica". Questa mappa indica all'agente esattamente quando recuperare i dati dal vault e quando segnalare i risultati del sentinel in background.
Per dare a Dispatch "occhi" che non si chiudono mai, dobbiamo concedergli l'accesso allo strumento di streaming che abbiamo creato nel passaggio precedente.
In ADK, quando aggiungi una funzione AsyncGenerator (come monitor_for_hazard) all'elenco tools, l'agente la considera un processo in background persistente. Invece di un'esecuzione una tantum, l'agente "si abbona" all'output dello strumento. In questo modo, Dispatch può continuare la conversazione principale mentre Sentinel invia silenziosamente avvisi di pericolo in background.
👉✏️ Sostituisci #REPLACE_AGENT_TOOLS in $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py con quanto segue:
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
Verifica
👉💻 Con entrambi gli agenti configurati, possiamo testare l'interazione live multi-agente.
- Nel terminale A, avvia Architect Agent:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- In un nuovo terminale (terminale B), esegui l'agente di distribuzione:
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
Il test di un sistema multi-agente che utilizza un modello multimodale in tempo reale come gemini-live all'interno del simulatore adk web prevede un flusso di lavoro specifico. Il simulatore è ideale per esaminare le chiamate di strumenti, ma è nota una sua incompatibilità durante la prima elaborazione delle immagini con questo tipo di modello.
- Fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell. Seleziona Cambia porta, impostala su 8000 e fai clic su Cambia e visualizza anteprima.
👉 Seleziona dispatch_agent e carica il progetto e gestisci l'errore previsto
Questo è il passaggio più importante. Dobbiamo fornire il contesto dell'immagine all'agente.
- Quando l'interfaccia viene caricata, consenti l'accesso al microfono quando richiesto.
- Scarica questa immagine del progetto sul computer:
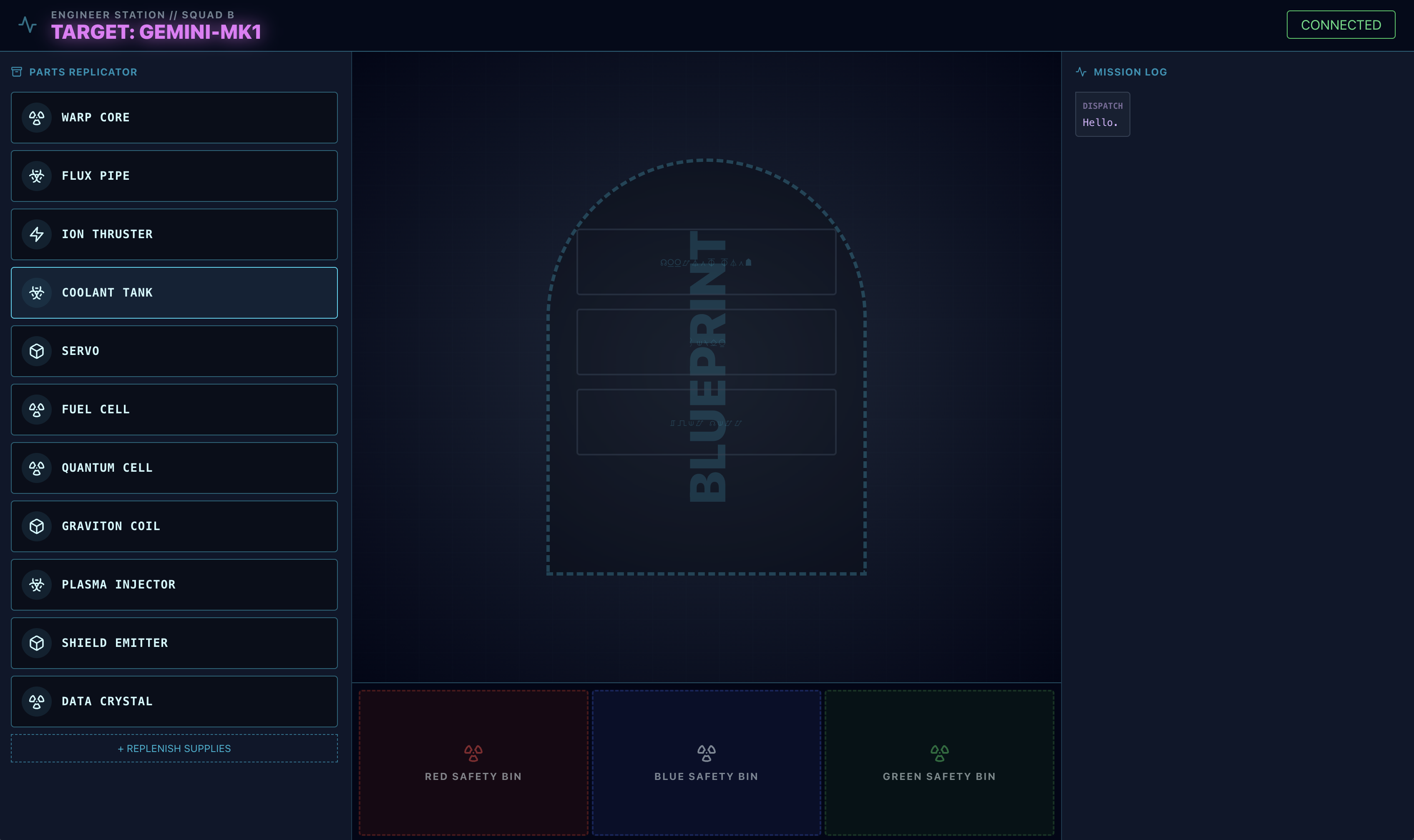
- Nell'interfaccia di
adk web, fai clic sull'icona a forma di graffetta e carica l'immagine del progetto che hai appena scaricato.
⚠️⚠️Verrà visualizzato un errore 400 INVALID_ARGUMENT. Questo è previsto.⚠️⚠️
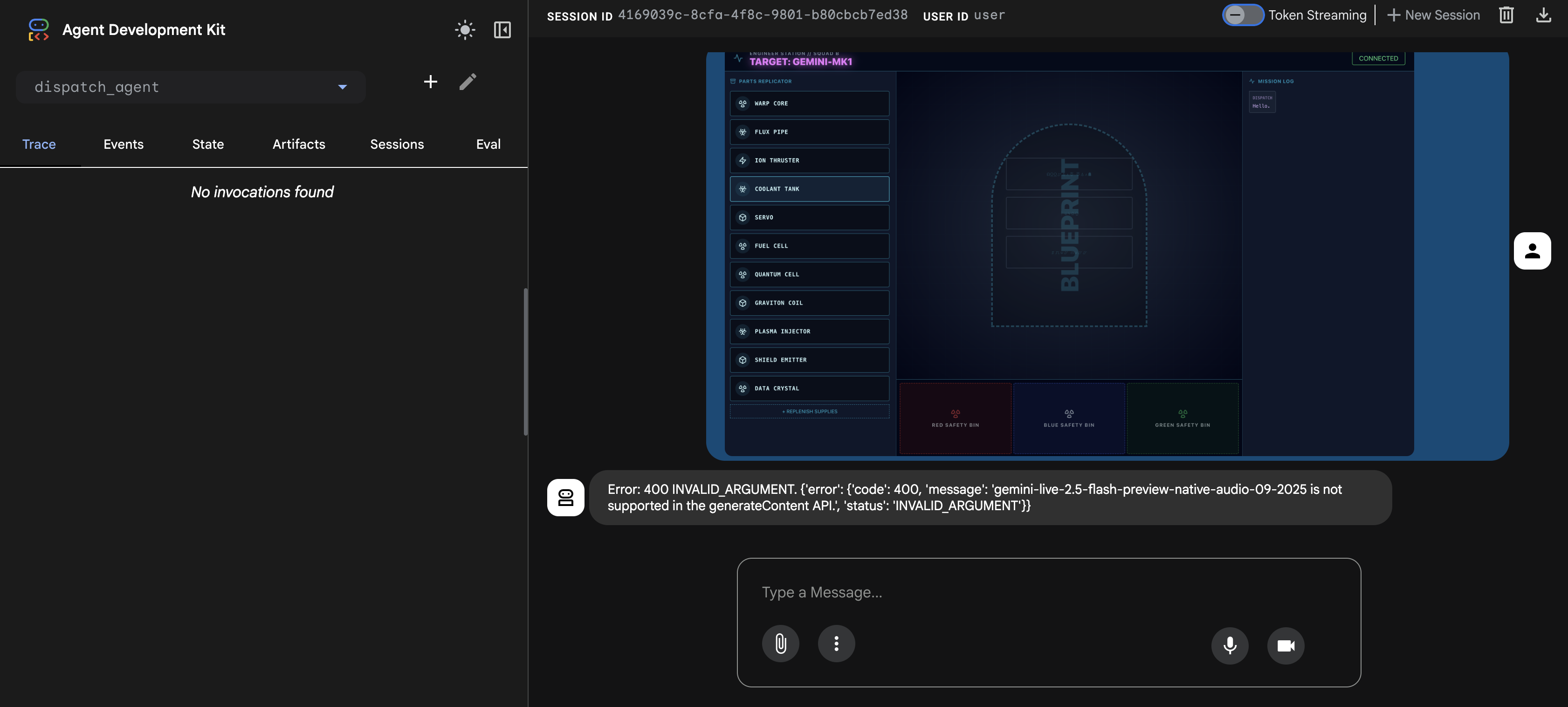
Questo errore si verifica perché il gestore delle immagini adk web non è completamente compatibile con l'API del modello gemini-live per un caricamento una tantum. Tuttavia, l'immagine è stata aggiunta correttamente al contesto della sessione.
- 👉 Per eliminare l'errore, ricarica la pagina del browser.
Attivare la procedura di assemblaggio
👉 Dopo il ricaricamento, l'errore non sarà più presente e vedrai l'immagine del progetto nella cronologia chat. L'agente ora ha il contesto visivo di cui ha bisogno.
- Fai clic sull'icona del microfono per attivarlo. L'interfaccia mostrerà il messaggio "In ascolto…".
- Pronuncia il comando vocale "start to assemble" (inizia ad assemblare).
- L'agente elaborerà la tua richiesta e l'interfaccia utente cambierà in "In attesa…". Dovresti sentire una risposta solo audio che elenca le parti richieste.
4. Verifica le chiamate agli strumenti da agente ad agente
👉 La risposta audio iniziale conferma che il sistema funziona, ma la vera magia sta nella traccia di comunicazione multi-agente.
- Disattiva il microfono.
- Aggiorna la pagina un'altra volta.
Il riquadro "Traccia" a sinistra verrà ora compilato. Puoi vedere il flusso di esecuzione completo e riuscito:
- Le
dispatch_agentprime chiamatemonitor_for_hazard. - Poi, effettua più chiamate
execute_architectaarchitect_agentper recuperare i dati dello schema.
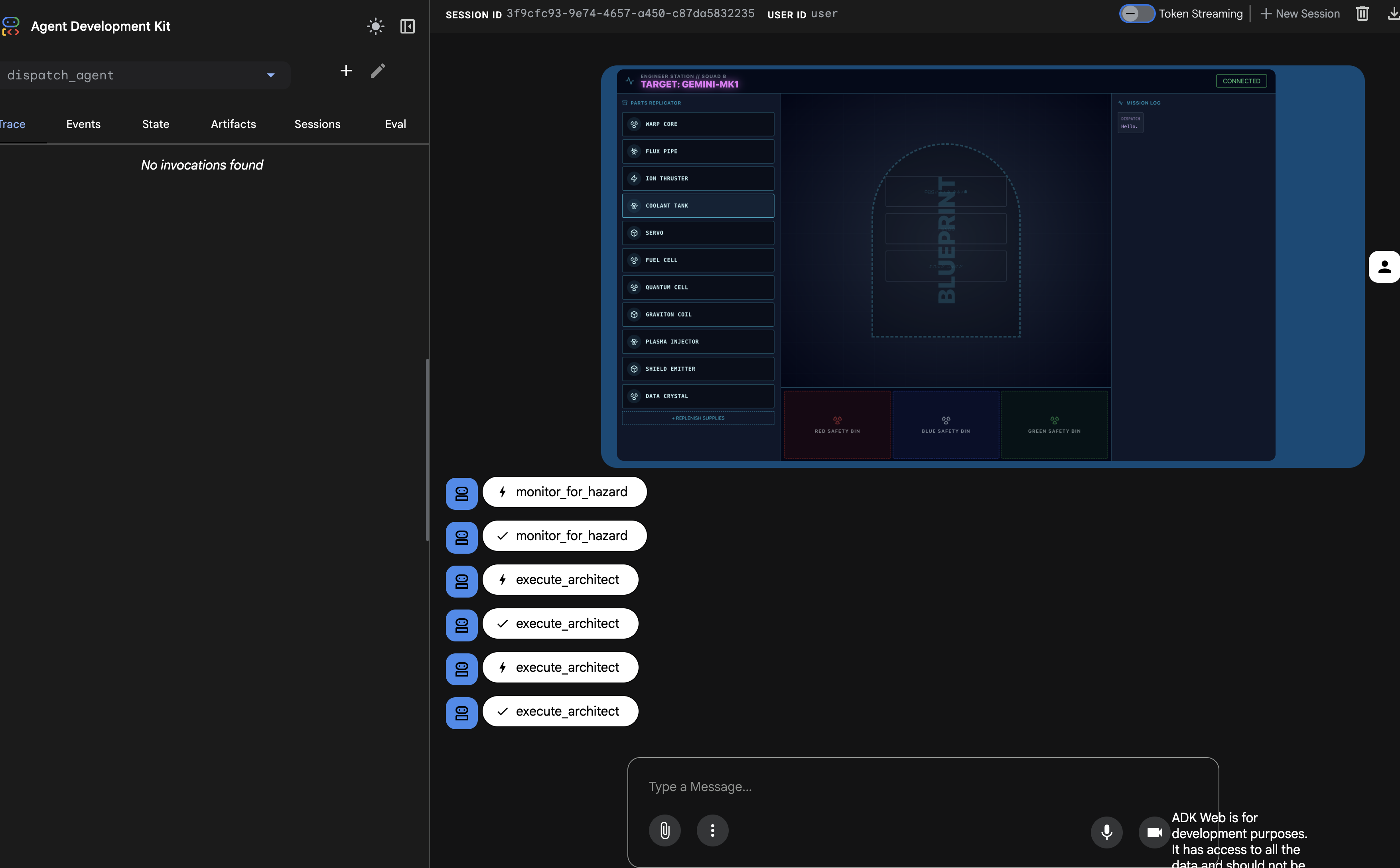
Questa sequenza conferma che l'intero flusso di lavoro multi-agente funziona correttamente: dispatch_agent ha ricevuto la richiesta, ha delegato l'attività di recupero dei dati a architect_agent tramite una chiamata di strumento e ha ricevuto i dati per soddisfare il comando dell'utente.
Il link di streaming bidirezionale ora è in grado di eseguire il monitoraggio in background e la collaborazione multi-agente. Successivamente, impareremo ad analizzare queste risposte complesse nel frontend.
👉💻 Premi Ctrl+c in entrambi i terminali per uscire.
5. Un approfondimento sui flussi di eventi multimodali live
Nel passaggio precedente, abbiamo verificato correttamente il nostro sistema multi-agente utilizzando il server di sviluppo integrato, adk web. Questa utilità utilizza un runner ADK predefinito per gestire automaticamente la sessione, gli stream e il ciclo di vita dell'agente. Tuttavia, per creare un'applicazione autonoma e pronta per la produzione come il nostro servizio FastAPI (main.py), abbiamo bisogno di un controllo esplicito. Dobbiamo creare e gestire manualmente ADK Runner per gestire le sessioni utente live, in quanto è il componente principale che elabora i flussi bidirezionali per audio, video e testo.
Il ciclo modello-codice-modello
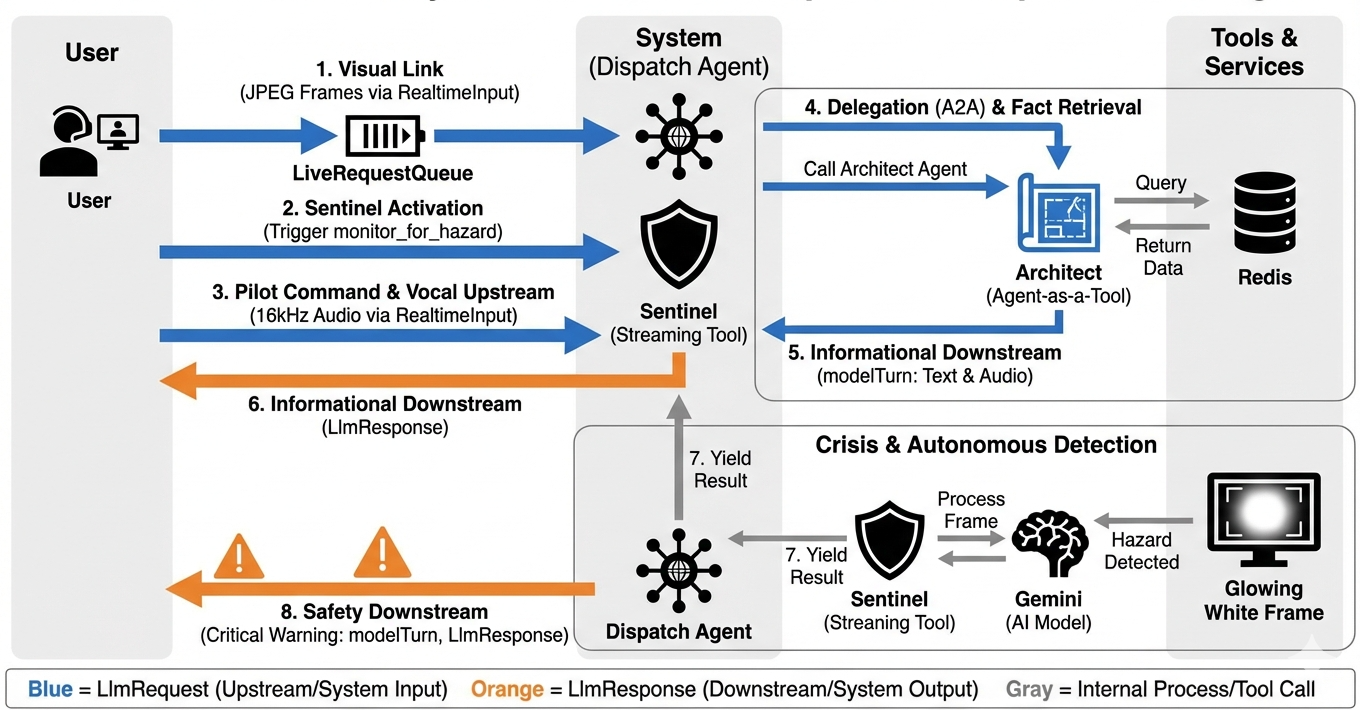
Per capire come funziona il sistema in tempo reale, seguiamo il ciclo di vita di una singola sessione di missione. Questo ciclo rappresenta lo scambio continuo di oggetti LlmRequest e LlmResponse.
- Il link visivo:avvii la connessione e condividi la webcam/lo schermo. I frame JPEG ad alta fedeltà iniziano a fluire a monte tramite
realtimeInput(utilizzandoLiveRequestQueue). - Attivazione sentinella:il sistema invia uno stimolo iniziale "Hello". In base alle istruzioni, Dispatch Agent attiva immediatamente lo
monitor_for_hazardStreaming Tool. Inizia un ciclo in background che osserva silenziosamente ogni fotogramma in arrivo. - Comando del pilota:parli nel sistema di comunicazione: "Inizia l'assemblaggio".
- Vocal Upstream:la tua voce viene acquisita come audio a 16 kHz e inviata Upstream insieme ai fotogrammi del video.
- Delega (A2A): Dispatch "sente" il tuo intento. Si rende conto di non avere gli schemi, quindi chiama l'agente architetto utilizzando il protocollo
AgentTool(agente come strumento). - Recupero dei fatti:l'architetto esegue query sul database Redis e restituisce l'elenco delle parti a Dispatch. L'invio rimane il "Master della sessione", ricevendo i dati senza trasferirli.
- Informazioni downstream:Dispatch invia un
modelTurn(downstream) contenente sia testo che audio nativo: "Architetto confermato. Il sottoinsieme richiesto è: Warp Core, Flux Pipe, Ion Thruster." - La crisi:improvvisamente, una parte del banco di lavoro si destabilizza e inizia a brillare di bianco.
- Rilevamento autonomo:il ciclo
monitor_for_hazardin background (il Sentinel) rileva il frame JPEG specifico contenente il bagliore. Elabora il frame chiamando Gemini e identifica il pericolo. - Sicurezza a valle:lo strumento di streaming
yieldsun risultato. Poiché si tratta di un agente Bidi-Streaming, Dispatch può interrompere il suo stato attuale per inviare immediatamente un avviso di sicurezza critico Downstream: "Pericolo rilevato! Neutralizzazione del cristallo di dati in corso. Spostalo nel cestino ROSSO."
Impostazione della configurazione di runtime dell'agente
Il RunConfig in ADK consente la configurazione dettagliata del comportamento di un agente, incluso il modo in cui gestisce i dati di streaming e interagisce con varie modalità.
streaming_mode è impostato su BIDI per una comunicazione bidirezionale in tempo reale, che consente sia all'utente sia all'agente di parlare e ascoltare contemporaneamente. Il parametro response_modalities definisce i tipi di output che l'agente può produrre, ad esempio voce e testo. input_audio_transcription configura il modo in cui l'agente elabora e trascrive il discorso in arrivo dell'utente. Per creare un'esperienza più resiliente, session_resumption consente all'agente di ricordare il contesto della conversazione e riprenderla se la connessione viene persa. Infine, proactivity consente all'agente di avviare azioni o discorsi senza un comando diretto dell'utente, ad esempio l'emissione di un avviso di pericolo spontaneo, mentre enable_affective_dialog consente all'agente di generare risposte più naturali ed empatiche. Puoi scoprire di più su RunConfig di ADK qui.
👉✏️ Individua il segnaposto #REPLACE_RUN_CONFIG nel file $HOME/way-back-home/level_4/backend/main.py e sostituiscilo con la seguente logica di analisi:
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
Implementazione della richiesta all'agente
Successivamente, implementeremo l'uplink di comunicazione principale che trasmette dati multimodali in tempo reale dal banco di lavoro volatile dell'utente all'agente di invio tramite un WebSocket. L'agente "vede" (fotogrammi video) e "sente" (comandi vocali) in modo continuo. La logica riceve continuamente il flusso di dati, distingue tra i blocchi audio binari in entrata e i pacchetti di testo/immagini con wrapping JSON e li incapsula in oggetti Blob (per i contenuti multimediali) o Content (per il testo), inviandoli a LiveRequestQueue per alimentare la sessione bidirezionale dell'agente.
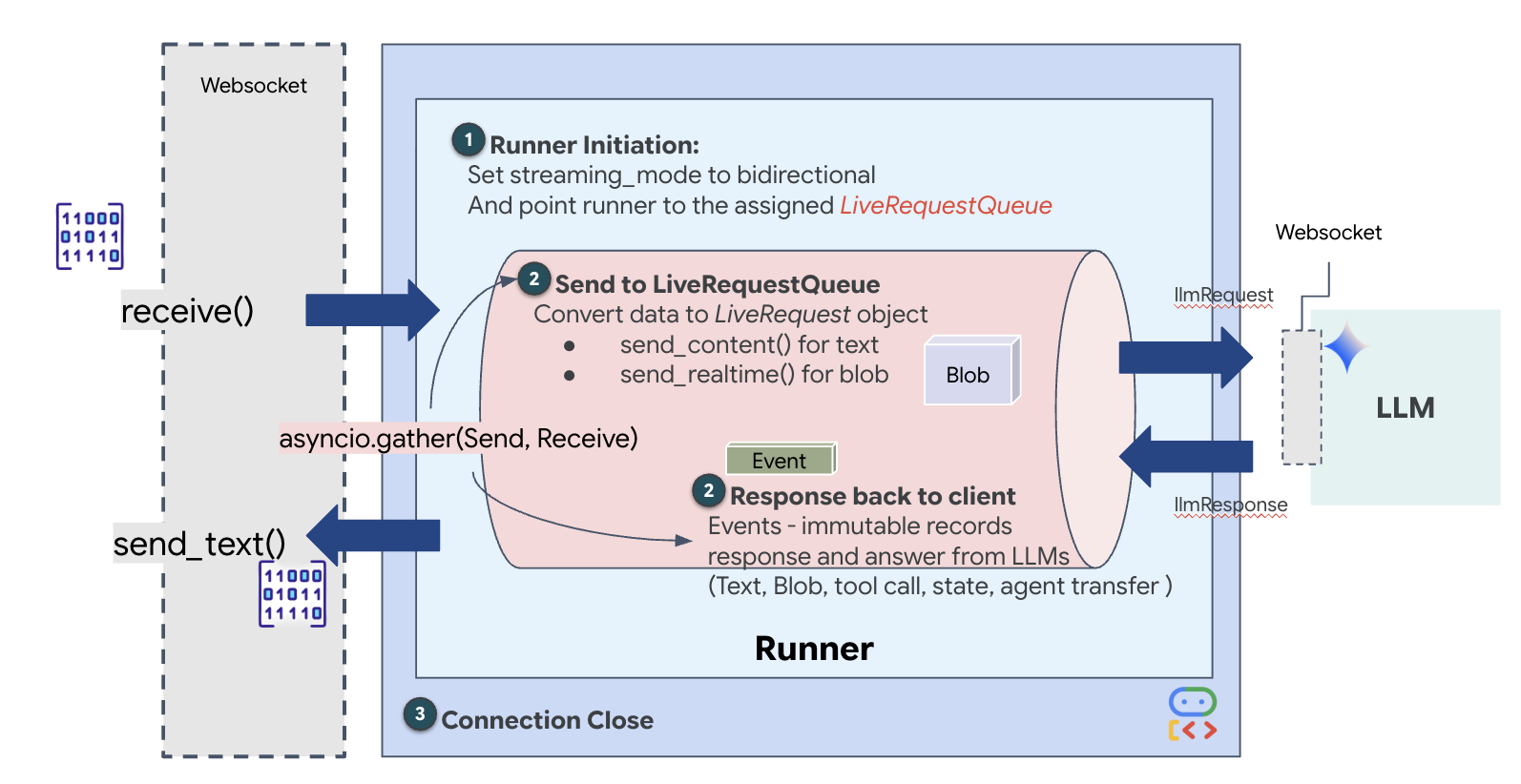
Individua il segnaposto #PROCESS_AGENT_REQUEST nel file $HOME/way-back-home/level_4/backend/main.py e sostituiscilo con la seguente logica di analisi:
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
I dati multimodali vengono ora inviati all'agente.
Implementazione della risposta: la struttura dei dati degli eventi downstream
Quando esegui un agente bidirezionale (live) con ADK, i dati restituiti dall'agente vengono inseriti in un tipo specifico di evento che eredita dalle strutture di base dell'SDK GenAI. L'oggetto Event che ricevi nel ciclo async for event in runner.run_live(...) è un singolo oggetto contenente diversi campi facoltativi, ognuno per un diverso tipo di informazione:
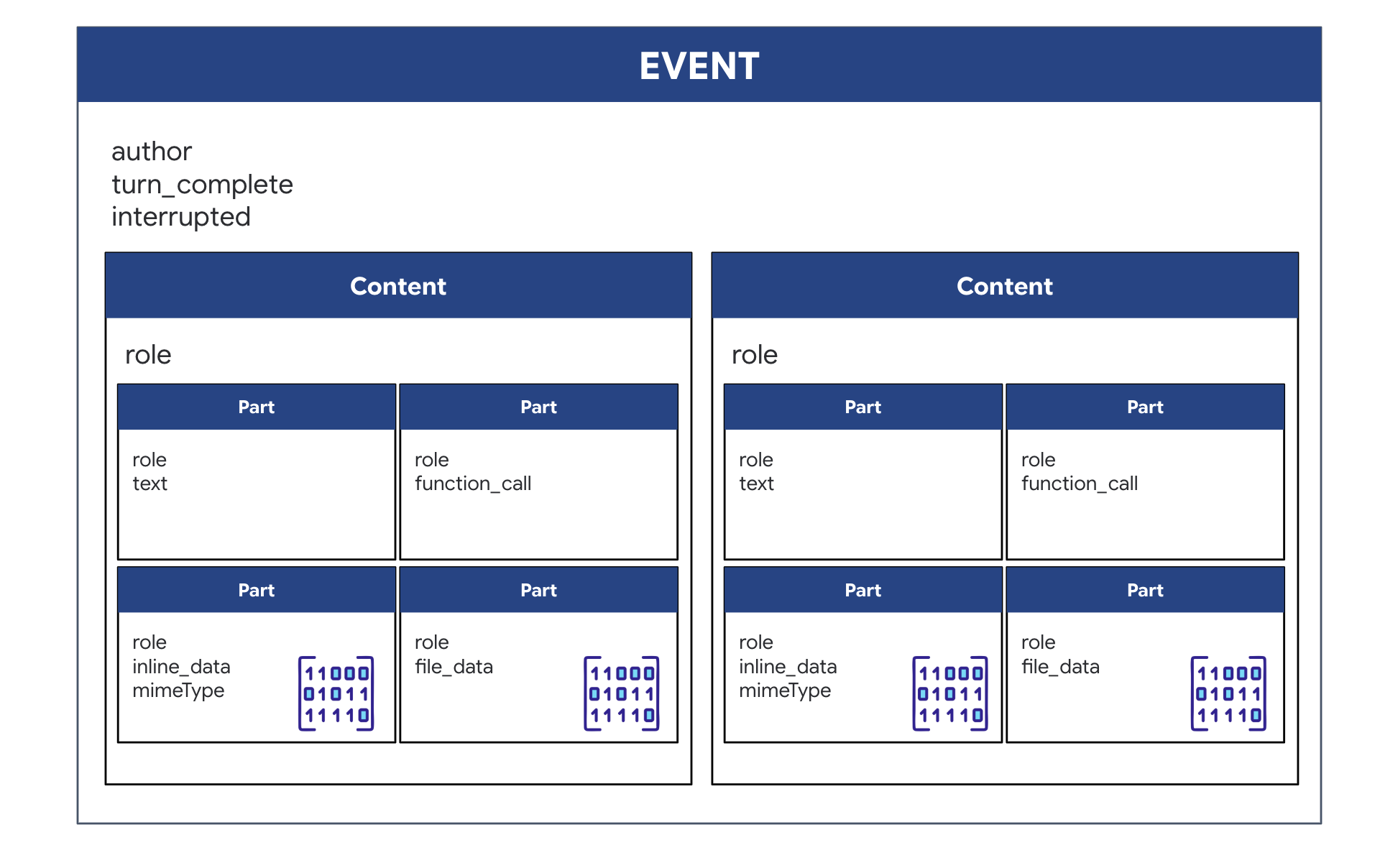
Come sono strutturati i contenuti:
- Quando l'agente parla (tramite
.server_content): il campo non è solo testo normale. Contiene un elenco diParts. OgniPartè un contenitore per un tipo di dati: una stringa di testo (come"The part is stable.") o un blob audio non elaborato (la voce). - Quando l'agente agisce (tramite
.tool_call): il campo contiene un elenco di oggettiFunctionCall. OgniFunctionCallè un oggetto semplice e strutturato che specifica il nome dello strumento e gli argomenti di input in un formato pulito che il codice di backend può leggere ed eseguire facilmente.
👀 Se esaminassi un singolo Event generato dal ciclo run_live, il JSON (prodotto da event.model_dump(by_alias=True)) avrebbe questo aspetto, seguendo rigorosamente le forme dell'SDK GenAI:
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ Ora aggiorneremo downstream_task in main.py per inoltrare i dati completi sugli eventi. Questa logica garantisce che ogni "pensiero" dell'AI venga registrato nel terminale diagnostico della nave e inviato come singolo oggetto JSON all'UI frontend.
Individua il segnaposto #PROCESS_AGENT_RESPONSE nel file $HOME/way-back-home/level_4/backend/main.py e sostituiscilo con la seguente logica di analisi:
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
Esecuzione della missione
Con il backend vault connesso e entrambi gli agenti configurati, tutti i sistemi sono ora pronti per la missione. I seguenti passaggi avvieranno l'applicazione completa, consentendoti di interagire con il sistema a due agenti che hai appena creato.
Obiettivo:assembla il motore a curvatura assegnato in modo casuale che appare sul banco di lavoro. Protocollo:devi seguire le indicazioni vocali dell'agente di spedizione, in particolare gli avvisi di pericolo per componenti specifici.
Attiva lo specialista (l'architetto)
👉💻 Nella prima finestra del terminale, avvia l'agente Architect. Questo servizio di backend si connetterà al vault Redis e attenderà le richieste schematiche dal dispatcher.
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
Lascia in esecuzione questo terminale. Ora è il tuo "agente di database" attivo.)
Avviare il Cockpit (il dispatcher)
👉💻 In una nuova finestra del terminale (Terminal B), creeremo la UI del frontend e avvieremo l'agente Dispatch principale, che gestisce l'interfaccia utente e tutta la comunicazione in tempo reale.
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(This starts the primary server on Port 8080.)
Esegui lo scenario di test
Il sistema è ora attivo. Il tuo obiettivo è seguire le istruzioni dell'agente per completare l'assemblaggio.
- 👉 Accedi a Workbench:
- Fai clic sull'icona Anteprima web nella barra degli strumenti di Cloud Shell.
- Seleziona Cambia porta, impostala su 8080 e fai clic su Cambia e visualizza anteprima.
- 👉 Inizia la missione:
- Quando l'interfaccia viene caricata, assicurati di consentire l'accesso allo schermo e al microfono.
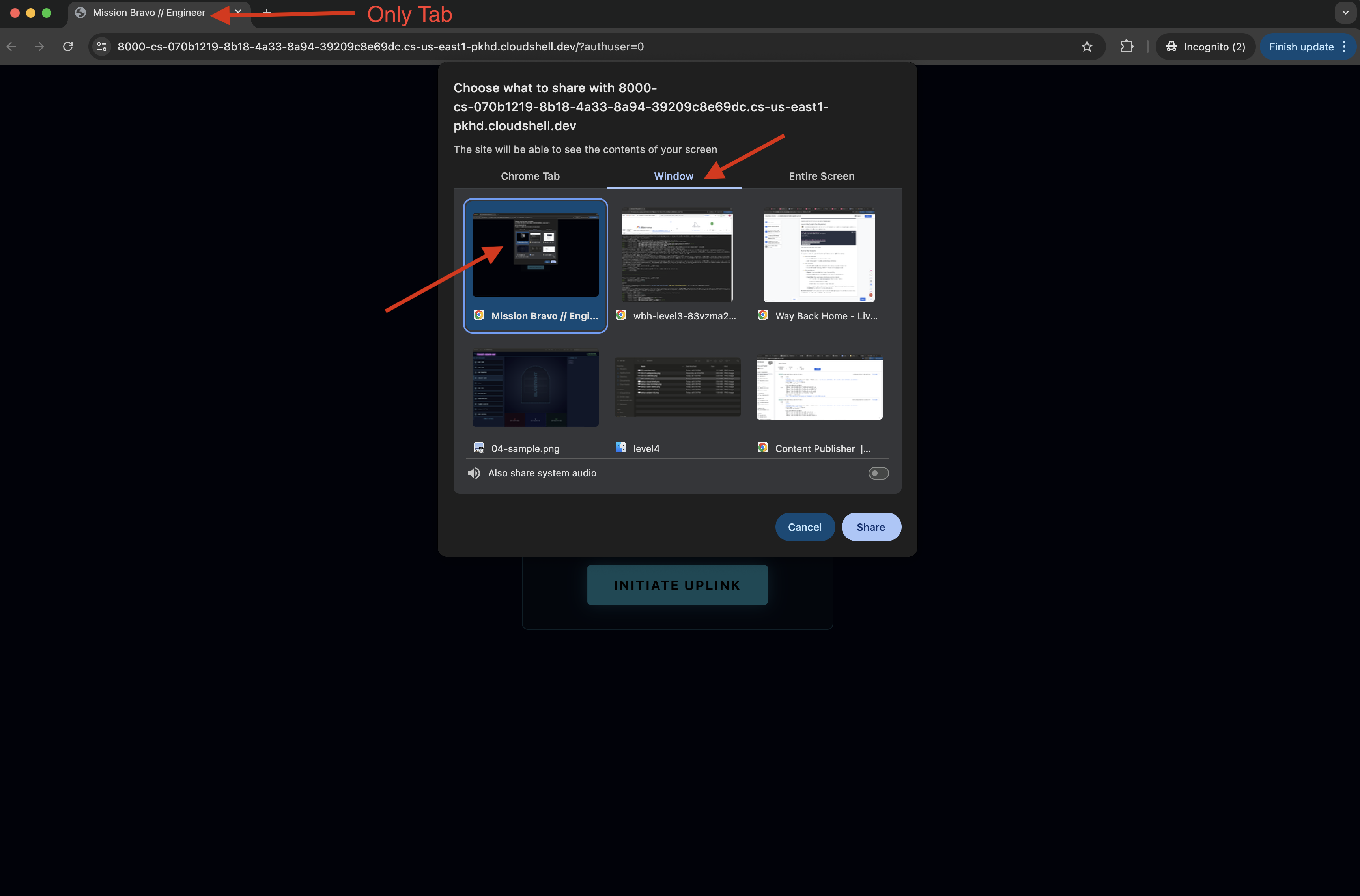
- Ti verrà chiesto di selezionare una scheda o una finestra da condividere. Se condividi la finestra, per evitare problemi, assicurati che sia l'UNICA scheda nella finestra.
- Ti verrà assegnato un drive con un nome casuale (ad es. "NOVA-V", "OMEGA-9").
- Quando l'interfaccia viene caricata, assicurati di consentire l'accesso allo schermo e al microfono.
- 👉 The Assembly Loop:
- Richiesta: per iniziare ad assemblare l'unità, di': "Inizia l'assemblaggio".
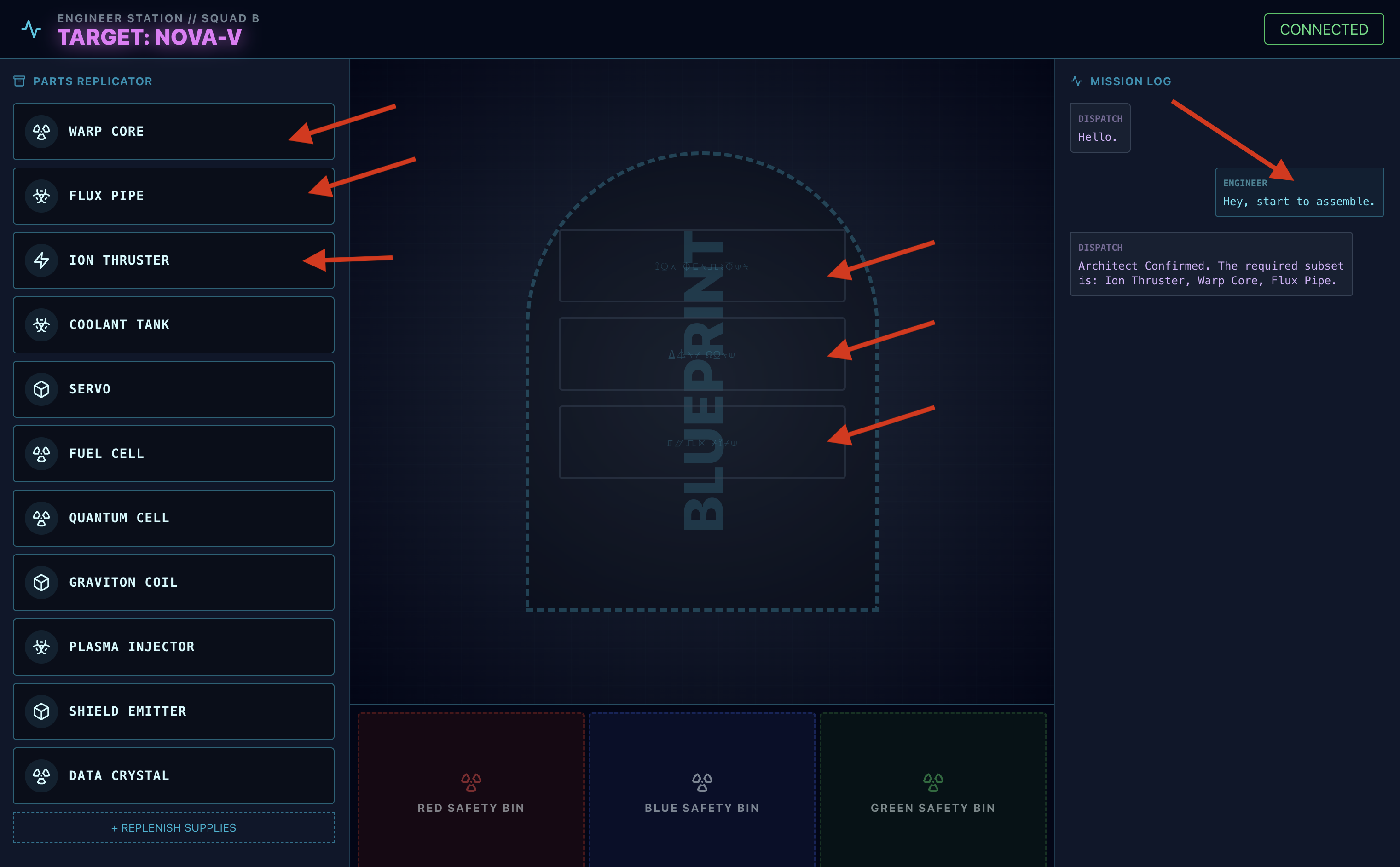
- Architetto risponde:l'agente fornirà le parti corrette per assemblare l'unità.
- Controllo dei pericoli:quando un componente sembra pericoloso sul banco di lavoro:
- Lo strumento
monitor_for_hazarddell'agente di invio lo identificherà visivamente. - Verrà generato un "AVVISO DI PERICOLO VISIVO". L'operazione durerà circa 30 secondi.
- Controlla quale contenitore utilizzare per disattivare il pericolo.
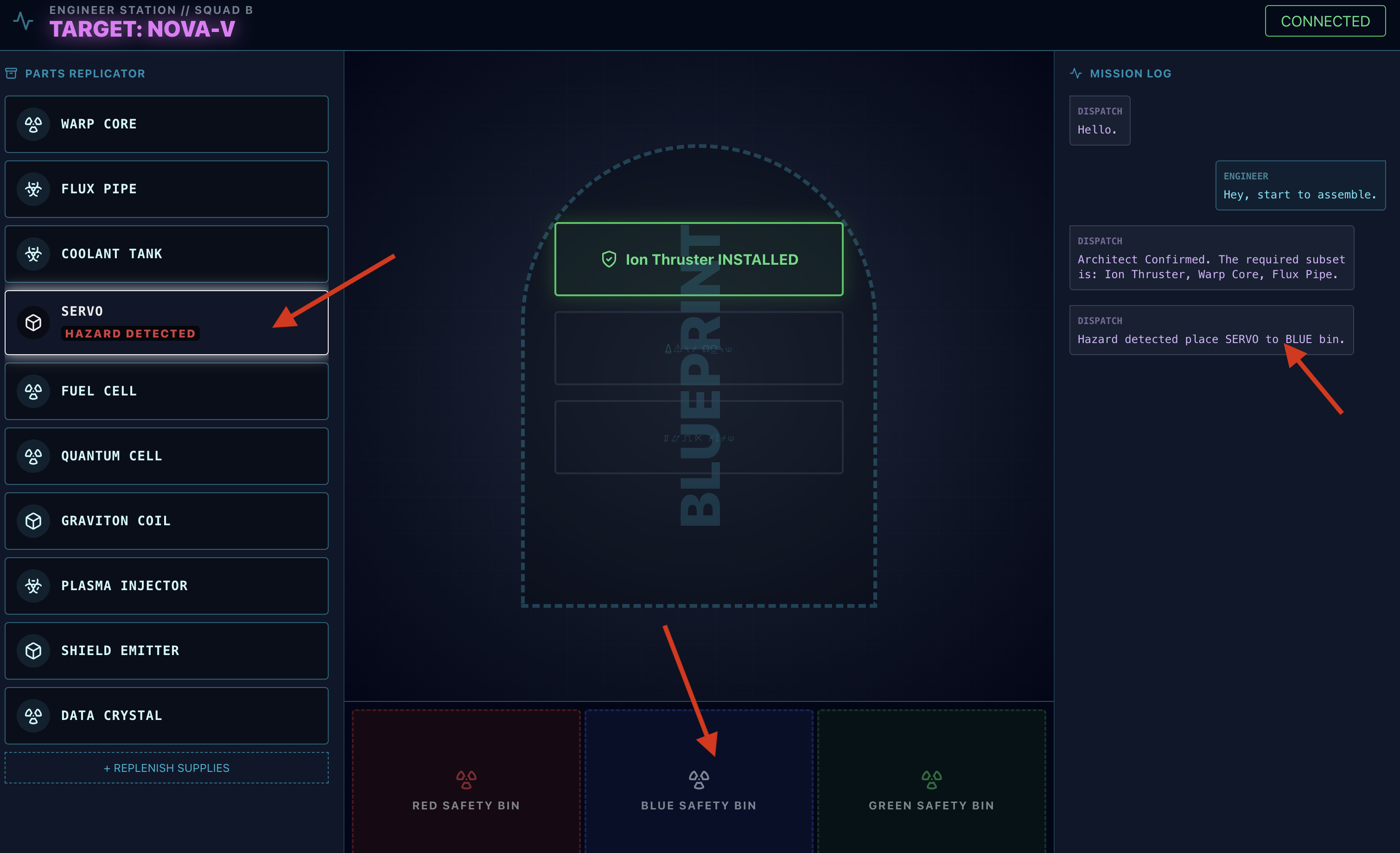
- Lo strumento
- Azione: l'agente del centralino ti darà un comando diretto: "Pericolo confermato. Metti XXX immediatamente nel cestino rosso." Devi seguire questa istruzione per continuare.
- Richiesta: per iniziare ad assemblare l'unità, di': "Inizia l'assemblaggio".
Missione compiuta. Hai creato un sistema interattivo multi-agente. I sopravvissuti sono al sicuro, il razzo ha superato l'atmosfera e il tuo viaggio di ritorno a casa continua.
👉💻 Premi Ctrl+c in entrambi i terminali per uscire.
6. (Facoltativo) Esegui il deployment in produzione
Hai testato l'agente localmente. Ora dobbiamo caricare il nucleo neurale dell'architetto nei mainframe della nave (Cloud Run). In questo modo, potrà operare come servizio permanente e indipendente che l'agente di Dispatch può interrogare da qualsiasi luogo.
Esegui il provisioning del vault protetto (infrastruttura)
Prima di eseguire il deployment dell'agente, dobbiamo creare la relativa memoria persistente (Memorystore) e il canale sicuro per accedervi (connettore VPC).
👉💻 Crea l'istanza Memorystore (Redis Vault):
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Recupera l'indirizzo di rete del vault: esegui questo comando e copia l'indirizzo IP host. Questo è l'indirizzo privato della tua nuova istanza Redis.
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 Crea il connettore di accesso VPC (ponte sicuro): questo connettore funge da ponte privato, consentendo a Cloud Run di accedere all'istanza Redis all'interno del tuo VPC.
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 Carica i dati:
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
Esegui il deployment dell'applicazione agente
Compila e crea l'immagine dell'agente
👉💻 Vai alla directory backend e crea il Dockerfile.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 Pacchettizza l'applicazione in un'immagine container.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
Esegui il deployment in Cloud Run
👉💻 Esegui il deployment dell'agente in Cloud Run. Inseriremo l'IP Redis e collegheremo il connettore VPC direttamente al comando di avvio. In questo modo l'agente inizia con una connessione sicura e privata al suo database.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 Verifica se il server A2A è in esecuzione.
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
Al termine del comando, vedrai un URL del servizio. L'agente architetto è ora attivo nel cloud, connesso in modo permanente al suo vault e pronto a fornire dati schematici ad altri agenti.
Esegui il deployment di Dispatch Hub nel mainframe di produzione
Ora che l'agente Architect è operativo nel cloud, dobbiamo eseguire il deployment dell'hub di distribuzione. Questo agente fungerà da interfaccia utente principale, gestendo i flussi audio/video live e delegando le query del database all'endpoint sicuro di Architect.
👉💻 Esegui questo comando nel terminale Cloud Shell. Verrà creato il Dockerfile completo e multifase nella directory backend.
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
Compila e crea l'immagine dell'agente/frontend
👉💻 Vai alla directory di backend contenente il codice dell'agente Dispatch (main.py) e pacchettizzalo in un'immagine container.
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
Esegui il deployment in Cloud Run
👉💻 Esegui il deployment di Dispatch Hub in Cloud Run. Inseriremo l'URL dell'architetto come variabile di ambiente, creando il collegamento fondamentale tra i nostri due agenti nativi del cloud.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
Al termine del comando, vedrai un URL del servizio (ad es. https://mission-bravo-...run.app). L'applicazione è ora attiva nel cloud.
👉 Vai alla pagina Google Cloud Run e seleziona il servizio biometric-scout dall'elenco. 
Individua l'URL pubblico visualizzato nella parte superiore della pagina dei dettagli del servizio. 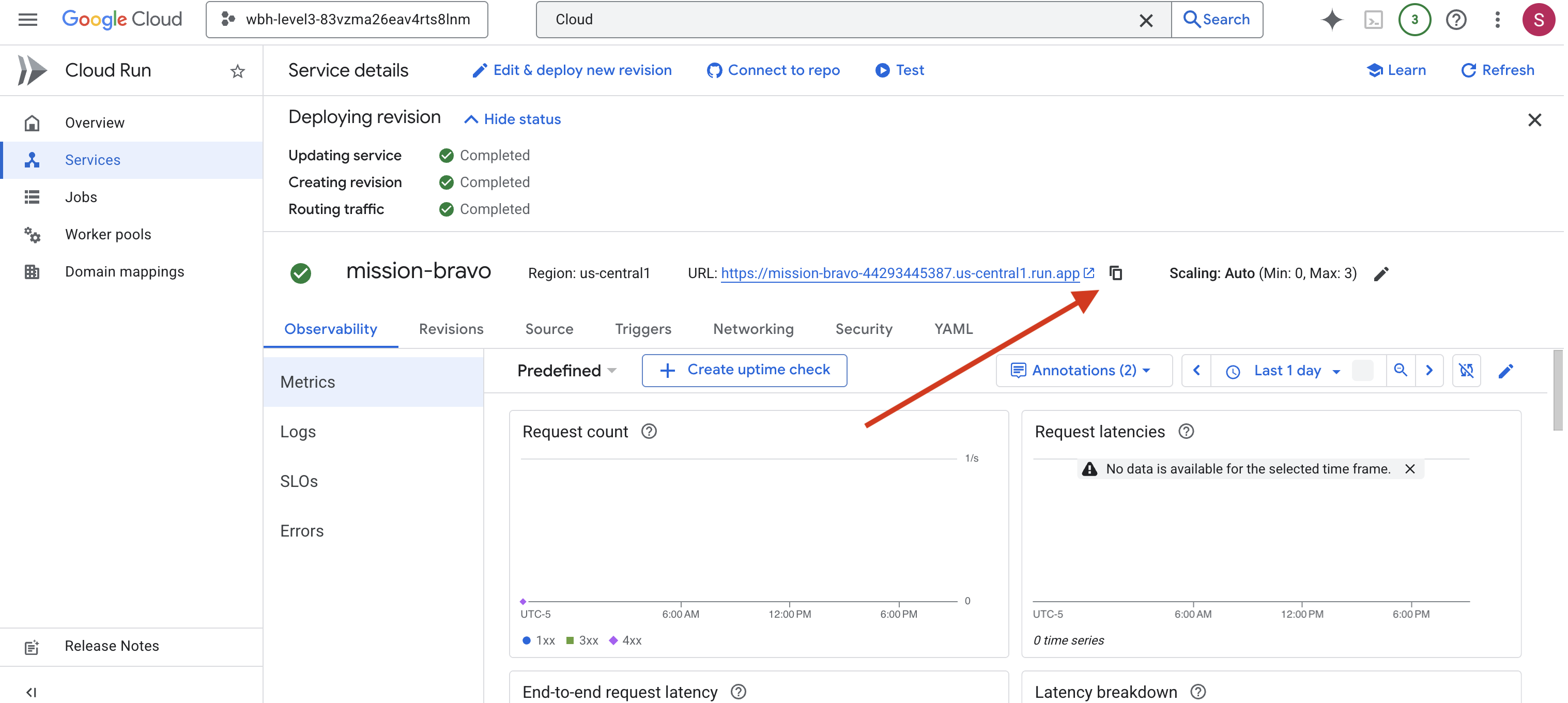
Controllo finale del sistema (test end-to-end)
👉 Ora interagirai con il sistema live.
- Ottieni l'URL:copia l'URL del servizio dall'output dell'ultimo comando di deployment (deve terminare con
run.app). - Apri il Cockpit:incolla l'URL nel browser web.
- Avvia contatto:quando l'interfaccia viene caricata, assicurati di consentirle di accedere allo schermo e al microfono.
- Richiedi dati:quando viene assegnata un'unità, chiedi di iniziare l'assemblaggio. Ad esempio: "Start to assemble" (inizia ad assemblare)

Ora stai interagendo con un sistema multi-agente completamente implementato in esecuzione interamente su Google Cloud.
Il sistema multi-agente blocca l'anello di contenimento finale e le radiazioni irregolari si stabilizzano in un ronzio costante.
"Warp Drive: STABILIZED. Rescue Craft: ENGINES IGNITED."

Sul monitor, l'astronave aliena sfreccia verso l'alto, sfuggendo per un pelo alla superficie in rovina di Ozymandias mentre l'atmosfera crolla. Si stabilisce in un'orbita sicura accanto alla tua nave e le comunicazioni si riempiono delle voci dei sopravvissuti, scossi ma vivi. Una volta completato il salvataggio e il percorso verso casa è libero, il collegamento remoto si interrompe.
Grazie a te, i sopravvissuti sono stati salvati.
Se hai partecipato al Livello 0, non dimenticare di controllare a che punto è la tua missione di ritorno a casa.