1. ミッション

あなたは、静かで未開拓の宇宙空間を漂っています。巨大な太陽パルスによって、宇宙船が次元の裂け目を通り抜け、星図にない宇宙のポケットに漂流してしまいました。
数日間の過酷な修理を経て、ついにエンジンの聞き慣れた音が戻ってきました。ロケットは稼働中です。マザーシップへの長距離アップリンクを確立することにも成功しました。出発が間近に迫っています。これで帰宅の準備ができました。
ジャンプ ドライブを起動しようとしたとき、静電気の音の中から遭難信号が聞こえてきました。センサーが、「オジマンディアス」という惑星からの助けを求める信号を特定しました。生存者たちは、滅びゆくこの世界に閉じ込められ、船は座礁している。惑星の大気が崩壊する前に救出するという重要なミッションがあなたに課せられます。
彼らが脱出する唯一の手段は、エイリアン テクノロジーで構築された古代の廃墟となったロケットです。機能はしますが、ワープ ドライブが壊れています。生存者を救うには、Volatile Workbench にリモートで接続し、交換用ドライブを手動で組み立てる必要があります。
課題
この異星人の技術は非常に壊れやすく、あなたはそれに関する経験がありません。不安定なコンポーネントは、数秒で放射性物質の危険な状態になる可能性があります。Volatile Workbench を操作できるのは 1 回のみです。現在の AI アシスタントは、視覚データと技術マニュアルを同時に処理することが難しく、幻覚のような指示や危険警告の見落としにつながっています。
成功するには、AI をモノリシック エンティティから協調型のマルチエージェント システムにアップグレードする必要があります。
ミッションの目標:
新しいマルチエージェント システムからのリアルタイムの専門的な手順に沿って、ワープ ドライブを組み立てます。

作業内容
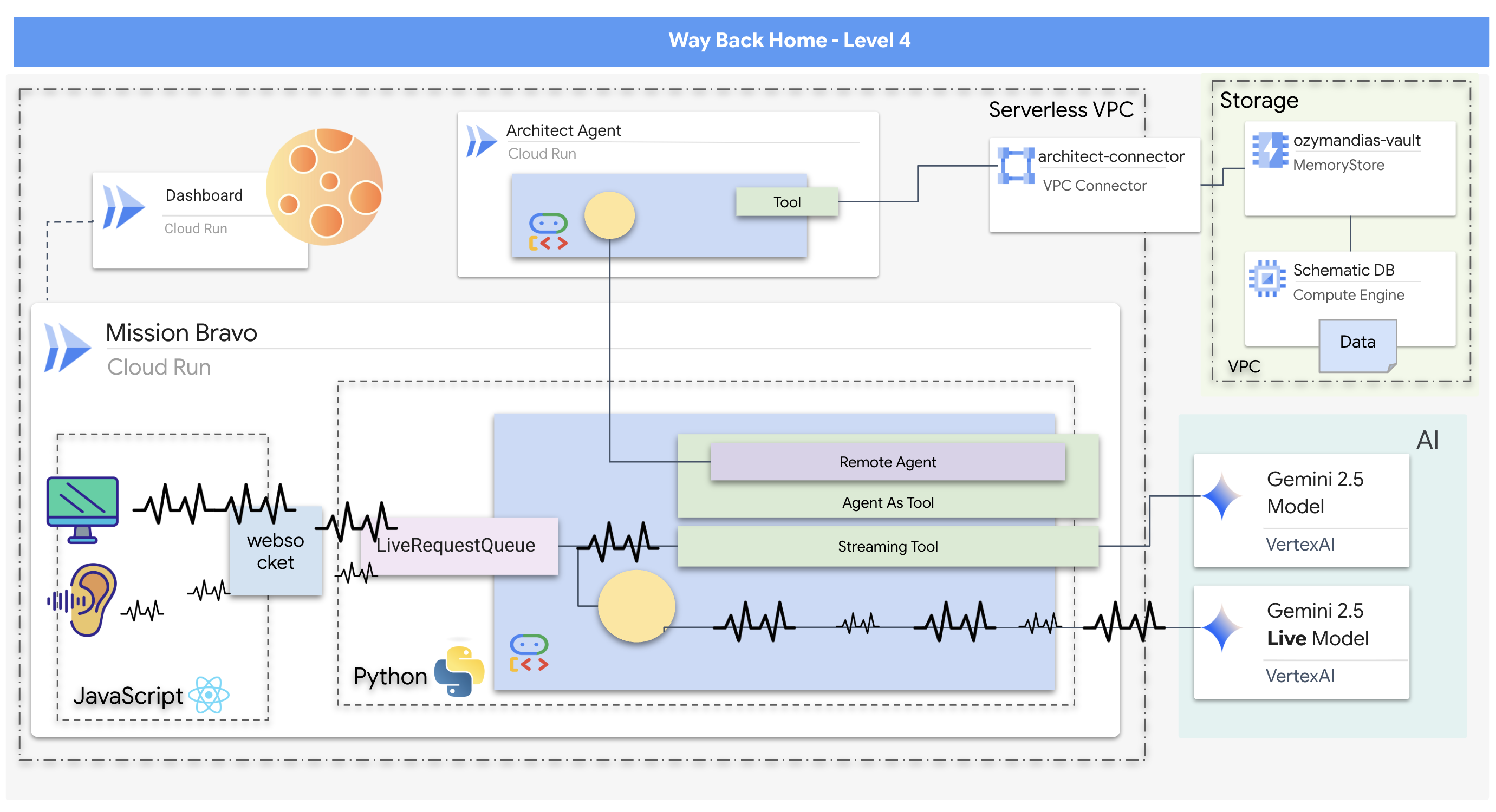
- ユーザー インタラクションを管理し、専門のエージェントと連携する中央のディスパッチ エージェントを備えた、リアルタイムの双方向マルチエージェント AI システム。
- Redis データベースに接続してスキーマデータを取得し、提供する Architect Agent。
- ストリーミング ツールを使用してライブ動画フィードを分析し、視覚的な危険を検出してリアルタイム アラートをトリガーする、プロアクティブな安全モニター。
- システムとのやり取り、動画と音声のバックエンド エージェントへのストリーミングを行うためのユーザー インターフェースを提供する React ベースのフロントエンド。
学習内容
テクノロジー / コンセプト | 説明 |
Google の Agent Development Kit(ADK) | ADK を使用してエージェントを構築、テスト、管理し、リアルタイム通信、ツール統合、エージェントのライフサイクルを処理するためのフレームワークを活用します。 |
双方向(Bidi)ストリーミング | 自然で低レイテンシの双方向通信を可能にする双方向ストリーミング エージェントを実装します。これにより、人間と AI の両方がリアルタイムで割り込みと応答を行うことができます。 |
マルチエージェント システム | プライマリ エージェントが専門エージェントにタスクを委任する分散 AI システムを設計する方法を学びます。これにより、関心の分離とスケーラブルなアーキテクチャが可能になります。 |
Agent-to-Agent(A2A)プロトコル | A2A プロトコルを使用して、ディスパッチ エージェントとアーキテクト エージェント間の通信を有効にします。これにより、互いの機能を検出し、データを交換できるようになります。 |
ストリーミング ツール | バックグラウンド プロセスとして機能し、動画フィードを継続的に分析して状態の変化(危険)をモニタリングし、結果をプロアクティブに生成するストリーミング ツールを実装します。 |
Google Cloud Run と Memorystore | エージェント サービスをホストする Cloud Run と永続データベースとして Memorystore(Redis)を使用して、マルチエージェント アプリケーション全体を本番環境にデプロイします。 |
FastAPI と WebSocket | バックエンドは FastAPI と WebSocket を使用して構築されており、音声、動画、エージェントのレスポンスのストリーミングに必要な高性能のリアルタイム通信を処理します。 |
React フロントエンド | ユーザーのメディア(音声/動画)をキャプチャしてストリーミングし、AI エージェントからのリアルタイムのレスポンスを表示する React ベースのフロントエンドを使用します。 |
2. 環境をセットアップする
Cloud Shell にアクセスする
👉Google Cloud コンソールの最上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの最上部にあるターミナル型のアイコンです)。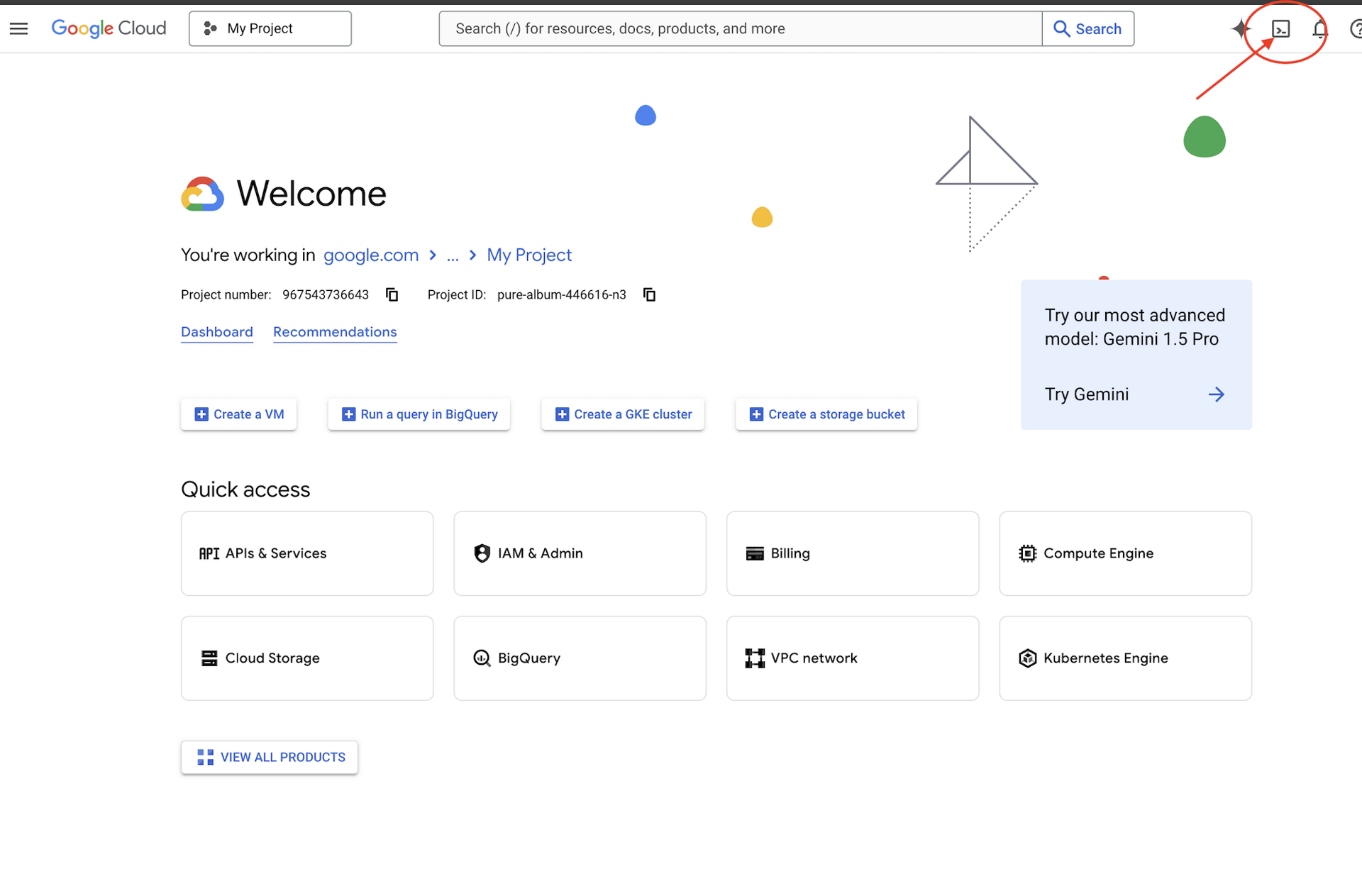
👉[エディタを開く] ボタン(開いたフォルダと鉛筆のアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。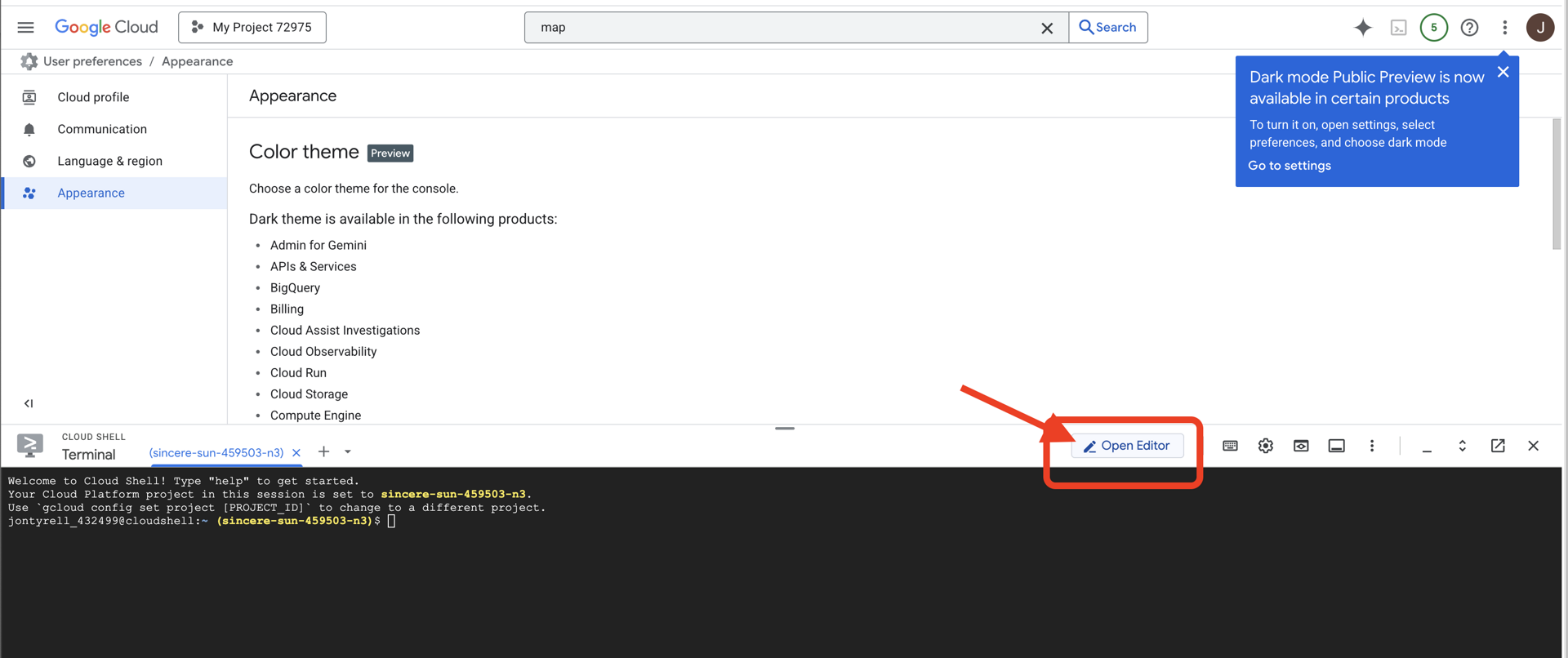
👉クラウド IDE でターミナルを開き、
👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
アカウントが (ACTIVE) として表示されます。
前提条件
ℹ️ レベル 0 は省略可能(ただし推奨)
このミッションはレベル 0 なしでも完了できますが、レベル 0 を先に完了すると、進行状況に応じてビーコンがグローバル マップ上で点灯する様子を確認できるため、より没入感のある体験ができます。
プロジェクト環境を設定する
ターミナルに戻り、アクティブなプロジェクトを設定して、必要な Google Cloud サービス(Cloud Run、Vertex AI など)を有効にして、構成を完了します。
👉💻 ターミナルで、プロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 必要なサービスを有効にする:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
依存関係のインストール
👉💻 レベル 4 に移動し、必要な Python パッケージをインストールします。
cd $HOME/way-back-home/level_4
uv sync
主な依存関係は次のとおりです。
パッケージ | 目的 |
| Satellite Station と SSE ストリーミング用の高性能ウェブ フレームワーク |
| FastAPI アプリケーションの実行に必要な ASGI サーバー |
| Formation Agent の構築に使用される Agent Development Kit |
| 標準化された通信のための Agent-to-Agent プロトコル ライブラリ |
| Gemini モデルにアクセスするためのネイティブ クライアント |
| Schematic Vault(Memorystore)に接続するための Python クライアント |
| リアルタイムの双方向通信のサポート |
| 環境変数と構成シークレットを管理します |
| データの検証と設定の管理 |
設定を確認する
コードに入る前に、すべてのシステムが正常であることを確認しましょう。検証スクリプトを実行して、Google Cloud プロジェクト、API、Python の依存関係を監査します。
👉💻 検証スクリプトを実行します。
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 一連の緑色のチェックマーク(✅)が表示されます。
- 赤い十字(❌)が表示された場合は、出力に表示された修正コマンド(
gcloud services enable ...やpip install ...など)を実行します。 - 注:
.envの黄色い警告は現時点では許容されます。このファイルは次のステップで作成します。
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. ADK を使用して Redis に Schematic Vault と双方向エージェントを構築する
あなたは、廃墟となったロケットのブループリントを含む惑星の設計図リポジトリを見つけました。このデータを正確に取得するには、リポジトリの専用管理インターフェースである Architect エージェントと連携する必要があります。
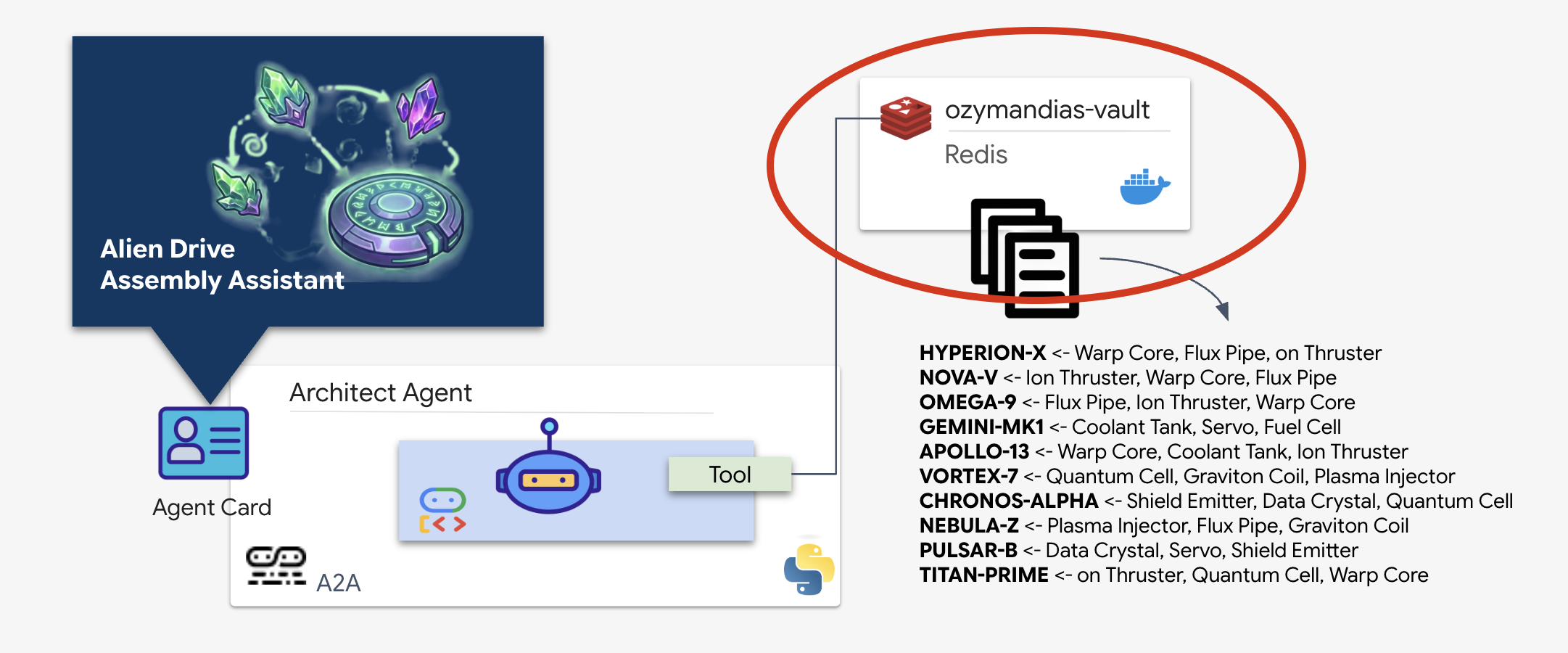
Schematic Vault(Redis)のプロビジョニング
アーキテクトのサポートを受ける前に、データが安全で高可用性の環境でホストされていることを確認する必要があります。エイリアンの設計図の高速データストアとして Redis を使用します。開発の便宜上、ローカル Redis インスタンスを起動しますが、Google Cloud Memorystore を使用して本番環境にデプロイする方法については後で説明します。
👉💻 ターミナルで次のコマンドを実行して、Redis インスタンスをプロビジョニングします(これには 2 ~ 3 分かかることがあります)。
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 予備データを読み込むには、次のコマンドを実行して Redis Shell を起動します。
docker exec -it ozymandias-vault redis-cli
(プロンプトが 127.0.0.1:6379 に変わります)。
👉💻 次のコマンドを貼り付けます。
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 「exit」と入力して通常のシェルに戻ります。
👉💻 ターミナルから特定の船を直接クエリしてデータが存在することを確認するには、次のコマンドを実行します。
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 想定される出力は次のとおりです。
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
Architect エージェントの実装
アーキテクト エージェントは、Redis Vault から概略図を取得する専門のエージェントです。専用のデータ インターフェースとして機能し、基盤となるデータベース ロジックを把握しなくても、メインの Dispatch Agent が正確で構造化された情報を受け取れるようにします。
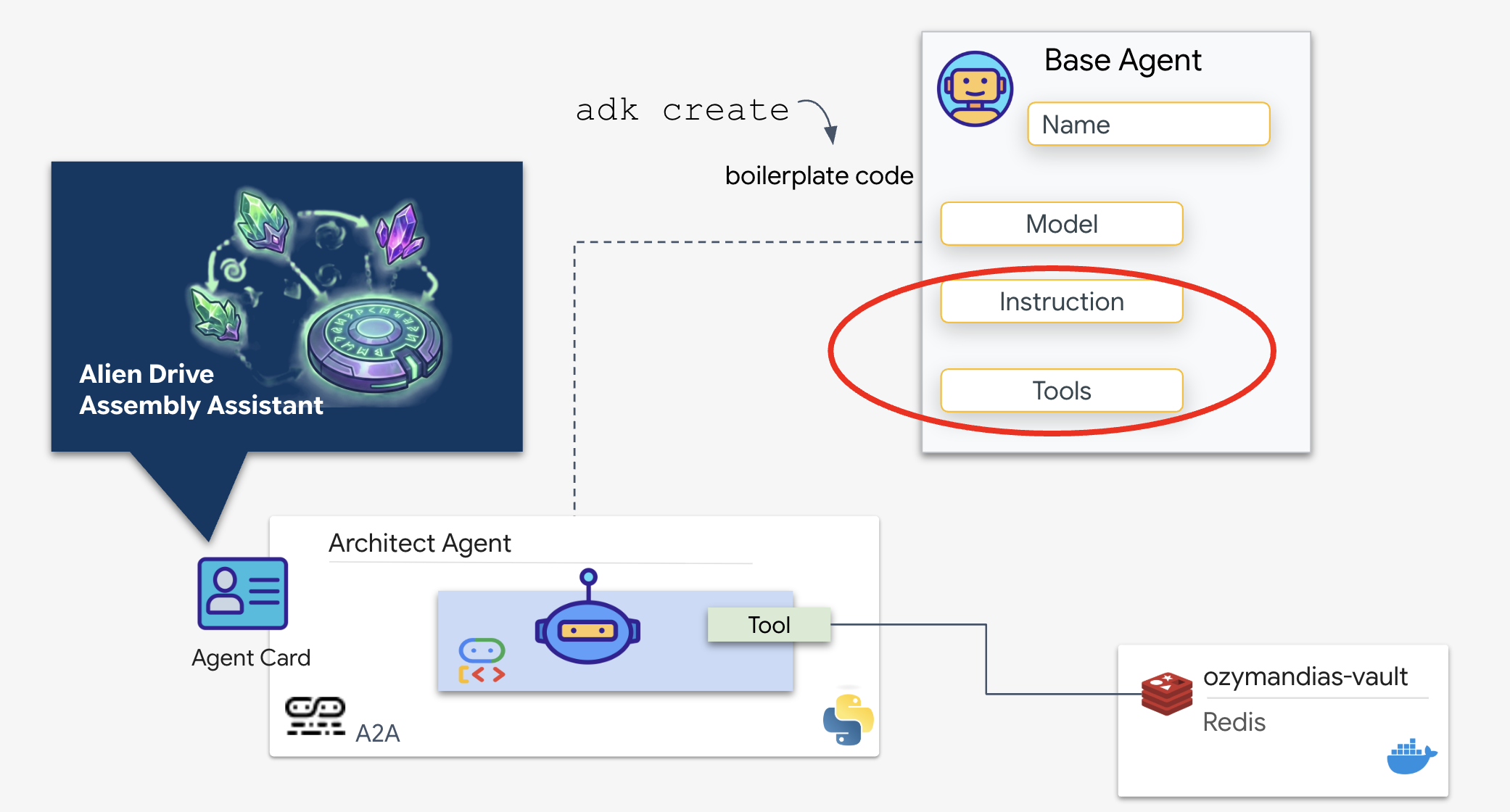
Google Agent Development Kit(ADK)は、このマルチエージェント設定を可能にするモジュラー フレームワークです。このレイヤは、次の 2 つの重要なレイヤを処理します。
- 接続とセッションのライフサイクル: リアルタイム API とのやり取りには、ハンドシェイク、認証、keep-alive 信号の処理など、複雑なプロトコル管理が必要です。
- 関数呼び出し: これは「モデル-コード-モデルのラウンド トリップ」です。LLM がデータが必要であると判断すると、構造化された関数呼び出しが出力されます。ADK はこれをインターセプトし、Python コード(
lookup_schematic_tool)を実行して、結果をミリ秒単位でモデルのコンテキストにフィードバックします。
次に、Architect を構築します。このエージェントにはカメラへのアクセス権がありません。これは、「ドライブ名」を受け取り、データベースから「部品リスト」を返すためだけに存在します。
👉💻 adk create コマンドを使用します。これは、新しいエージェントのボイラープレート コードとファイル構造を自動的に生成し、セットアップ時間を短縮する Agent Development Kit(ADK)のツールです。
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
エージェントを構成する
CLI によってインタラクティブな設定ウィザードが起動します。次のレスポンスを使用して、エージェントを構成します。
- モデルを選択: [オプション 1](Gemini Flash)を選択します。
- 注: 特定のバージョン(2.5、3.0 など)は、利用可能状況によって異なる場合があります。速度を重視する場合は、常に「Flash」バリアントを選択します。
- バックエンドを選択: [オプション 2](Vertex AI)を選択します。
- Google Cloud プロジェクト ID を入力: Enter キーを押して、デフォルト(環境から検出)を受け入れます。
- Google Cloud リージョンを入力: Enter キーを押してデフォルト(
us-central1)を受け入れます。
👀 ターミナルのやり取りは次のようになります。
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
Agent created 成功メッセージが表示されます。これにより、次のステップで変更するスケルトン コードが生成されます。
👉✏️ エディタで、新しく作成した $HOME/way-back-home/level_4/backend/architect_agent/agent.py ファイルに移動して開きます。最初のインポート行の後に、ツール スニペットをファイルに追加します。
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ root_agent 定義の instruction 行全体を次の内容に置き換え、前に定義したツールも追加します。
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
ADK のメリット
Architect がオンラインになったので、信頼できる情報源ができました。これをプライマリ エージェントに接続する前に、Agent Development Kit(ADK)は、AI エージェントの構築とテストの複雑さを簡素化することで、大きなメリットを提供します。adk web デベロッパー コンソールが組み込まれているため、Architect Agent の機能を分離して検証し、特にツール呼び出し機能を検証してから、より大規模なマルチエージェント システムに統合できます。開発とテストに対するこのモジュール式のアプローチは、堅牢で信頼性の高い AI アプリケーションを構築するうえで不可欠です。
👉💻 ターミナルで次のコマンドを実行します。
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 次のメッセージが表示されるまで待ちます。
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。[ポートの変更] を選択して「8000」に設定し、[変更してプレビュー] をクリックします。
- architect_agent を選択します。
- ツールをトリガーする: チャット インターフェースで、「
CHRONOS-ALPHA」(または回路図データベースの任意のドライブ ID)と入力します。 - 行動を観察する:
- アーキテクトは直ちに
lookup_schematic_toolをトリガーする必要があります。 - 厳格なシステム指示により、会話のフィラーなしでパーツのリスト(
['Shield Emitter', 'Data Crystal', 'Quantum Cell']など)のみが返されます。
- アーキテクトは直ちに
- ログを確認する: ターミナル ウィンドウを確認します。実行ログが正常に完了したことを確認します。
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
ツールの実行ログとクリーンなデータ レスポンスが表示された場合は、スペシャリスト エージェントが意図したとおりに機能しています。リクエストの処理、Vault のクエリ、構造化データの返信を行うことができます。
👉💻 終了するには Ctrl+C キーを押します。
A2A サーバーを初期化する
Dispatch Agent を Architect に接続するには、Agent-to-Agent(A2A)プロトコルを使用します。
MCP(Model Context Protocol)などのプロトコルはエージェントをツールに接続することに重点を置いていますが、A2A はエージェントを他のエージェントに接続することに重点を置いています。これは、Dispatcher が Architect を「検出」し、回路図を検索する機能を理解できるようにする標準です。
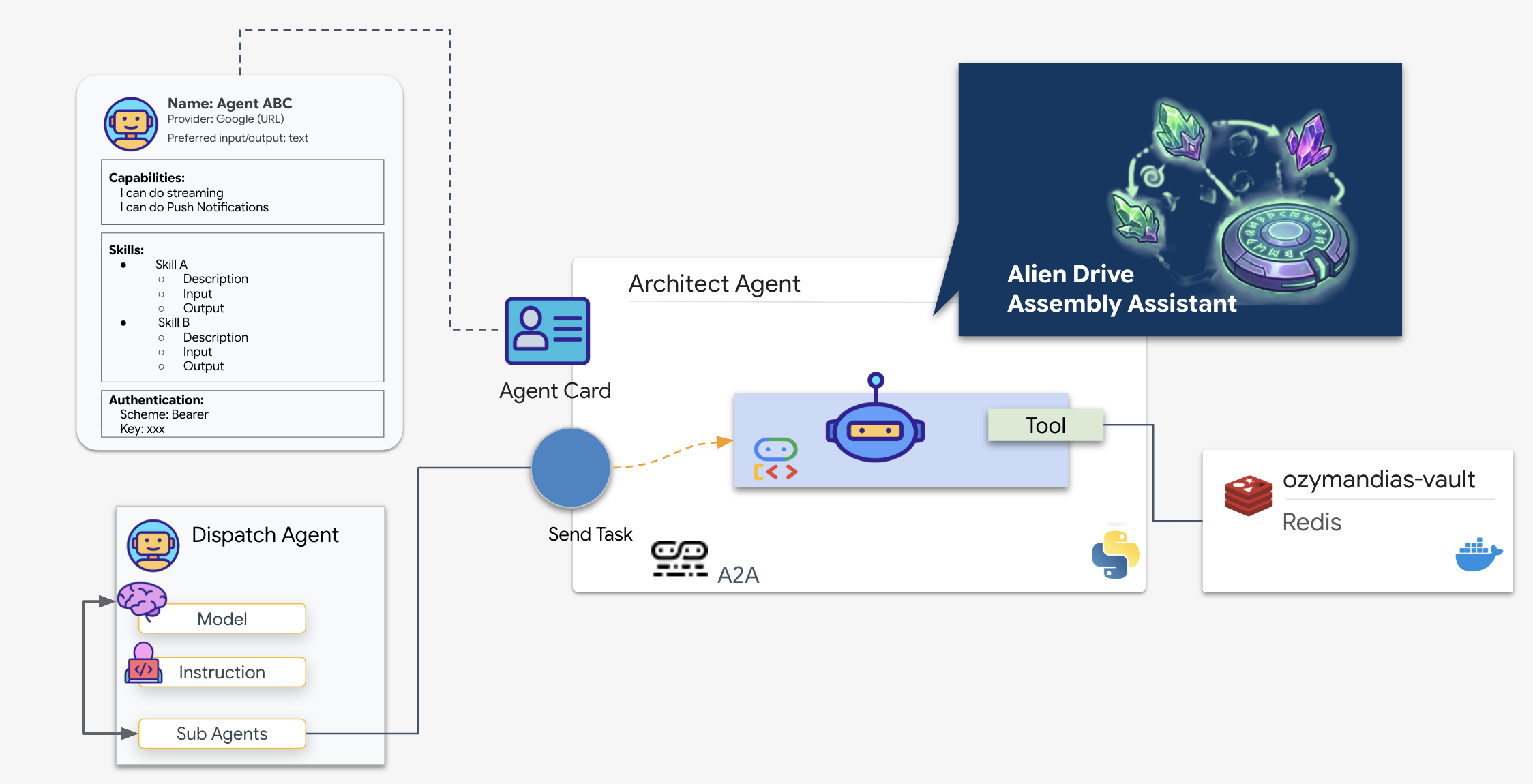
A2A フロー: このミッションでは、クライアント サーバー モデルを使用します。
- サーバー(アーキテクト): データベース ツールをホストし、エージェント カードを使用してスキルを「アドバタイズ」します。
- クライアント(Dispatch): アーキテクトのカードを読み取り、その API を理解して、概略リクエストを送信します。
エージェント カードとは
エージェント カードは、AI のデジタル名刺または「運転免許証」のようなものと考えてください。A2A サーバーが起動すると、次の情報を含む JSON オブジェクトが公開されます。
- ID: エージェントの名前(
architect_agent)と ID。 - 説明: 実行内容の人間とマシンが読める形式の概要(「システムロール: データベース API...」)。
- インターフェース: 期待される特定の入力キー(
drive_name)と出力形式。
このカードがないと、Dispatch エージェントは Architect との通信方法を推測しながら、手探りで作業することになります。
サーバーコードを作成する
👉✏️ エディタの $HOME/way-back-home/level_4/backend/architect_agent ディレクトリに server.py というファイルを作成し、次のコードを貼り付けます。
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 ターミナルに戻り、フォルダに移動してサーバーを起動します。
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 A2A サーバーが起動しているかどうかを確認します。
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
エージェント カードを確認する
新しいターミナルタブを開きます(+ アイコンをクリックします)。エージェント カードを手動で取得して、Architect が ID を正しくブロードキャストしていることを確認します。
👉💻 次のコマンドを実行します。
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 JSON レスポンスが表示されます。出力で description フィールドを探します。これは、エージェントに以前に指示した内容("SYSTEM ROLE: Database API...")と一致している必要があります。
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
この JSON が表示された場合、Architect はライブで、A2A プロトコルはアクティブであり、エージェント カードは Dispatcher によって検出される準備が整っています。
これで Architect がリモート リソースとして機能する準備が整ったので、Dispatch Agent に接続します。
👉💻 Ctrl+C キーを押して A2A サーバーを終了します。
4. BIDI-Streams エージェントをリモート エージェントとストリーミング ツールに接続する
次に、ライブデータとリモート アーキテクトのギャップを埋めるように、プライマリ通信ハブを構成します。この接続には、動作中に組み立てベンチが安定した状態を維持するための高帯域幅で低レイテンシのパイプラインが必要です。
双方向ストリーミング(ライブ)エージェントについて
ADK の双方向(Bidi)ストリーミングにより、Gemini Live API の低レイテンシの双方向音声と動画のインタラクション機能が AI エージェントに追加されます。従来の AI とのやり取りから根本的に変化しています。厳格な「質問して待つ」パターンではなく、人間と AI の両方が同時に発言、傾聴、応答できるリアルタイムの双方向コミュニケーションを実現します。
メールの送信と電話での会話の違いを考えてみてください。従来のエージェントのやり取りはメールのようなものです。完全なメッセージを送信し、完全なレスポンスを待ってから、別のメッセージを送信します。双方向ストリーミングは、電話での会話に似ています。流動的で自然な会話が可能で、リアルタイムで中断、明確化、応答を行うことができます。
主な特徴:
- 双方向通信: 完全なレスポンスを待たずに継続的にデータを交換します。AI は、ユーザーが話し終えたことを検出するとすぐに応答します。
- 応答の中断: 人間同士の会話と同様に、ユーザーはエージェントの応答中に新しい入力を送信してエージェントの応答を中断できます。AI が複雑な手順を説明しているときに「ちょっと待って、もう一度言って」と言うと、AI はすぐに停止して、ユーザーの割り込みに対応します。
- マルチモーダル向けに最適化: Bidi-streaming は、さまざまな入力タイプを同時に処理するのに優れています。エージェントにエイリアンのパーツを動画で見せながら話しかけると、両方のストリームが 1 つの統合された接続で処理されます。
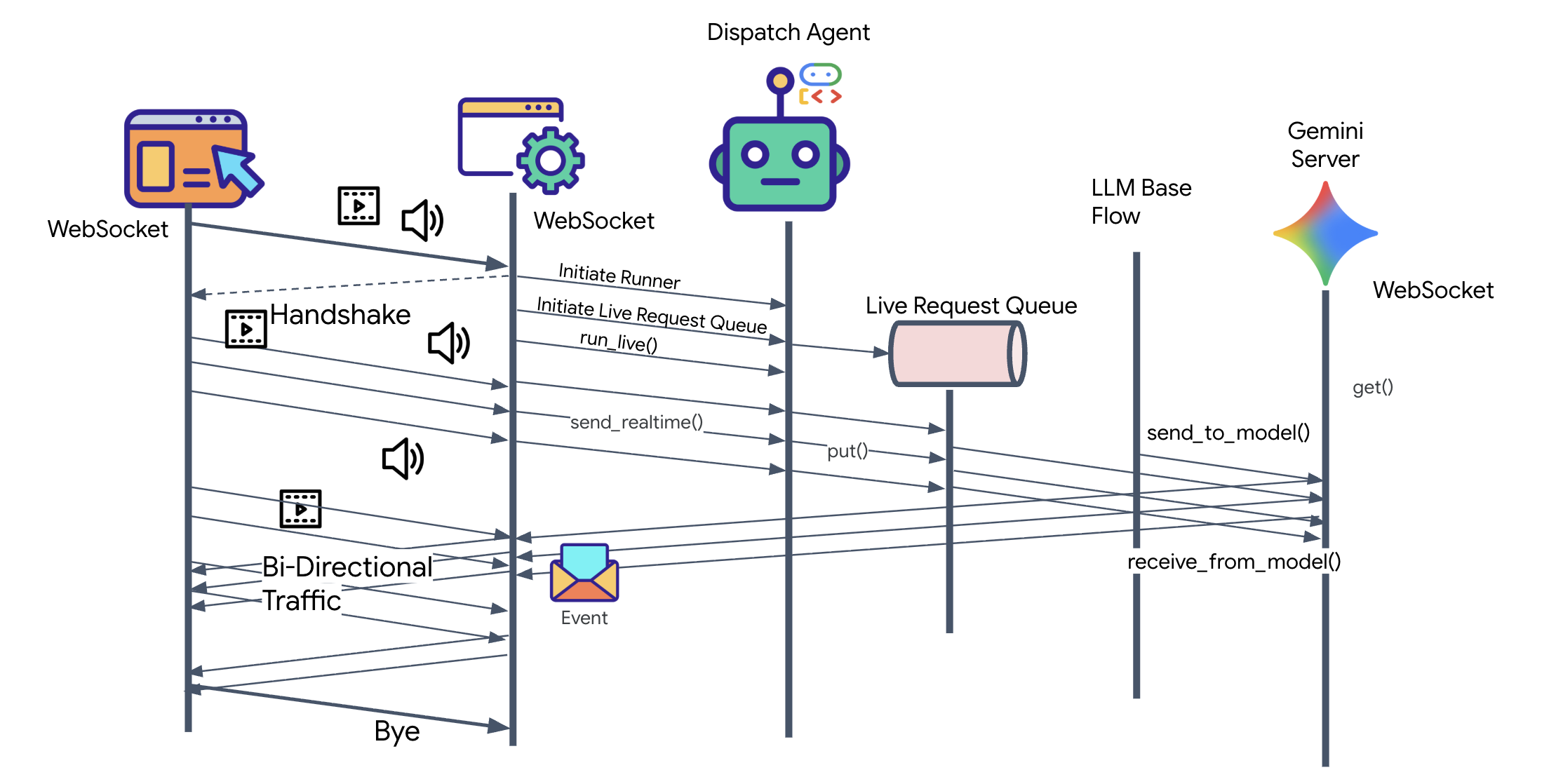
👀 クライアント ロジックを実装する前に、Dispatch Agent の事前生成されたスケルトンを見てみましょう。このエージェントは、音声と動画でユーザーと通信し、クエリをアーキテクト エージェントに委任します。
__init__.py agent.py hazard_db.py
agent.py: これは「Brain」です。現在、基本的な Bidi ストリーミングの設定が含まれています。このファイルを変更して、Architect と通信できるように A2A クライアント ロジックを追加します。hazard_db.py: これは、Dispatch Agent 固有のローカルツールで、安全プロトコルが含まれています。これは、Architect の回路図データベースとは別のものです。
A2A クライアントの実装
Dispatch Agent がリモートの Architect と通信できるようにするには、リモート A2A エージェントを定義する必要があります。これにより、ディスパッチ エージェントはアーキテクトの場所と「エージェント カード」の形式を把握できます。
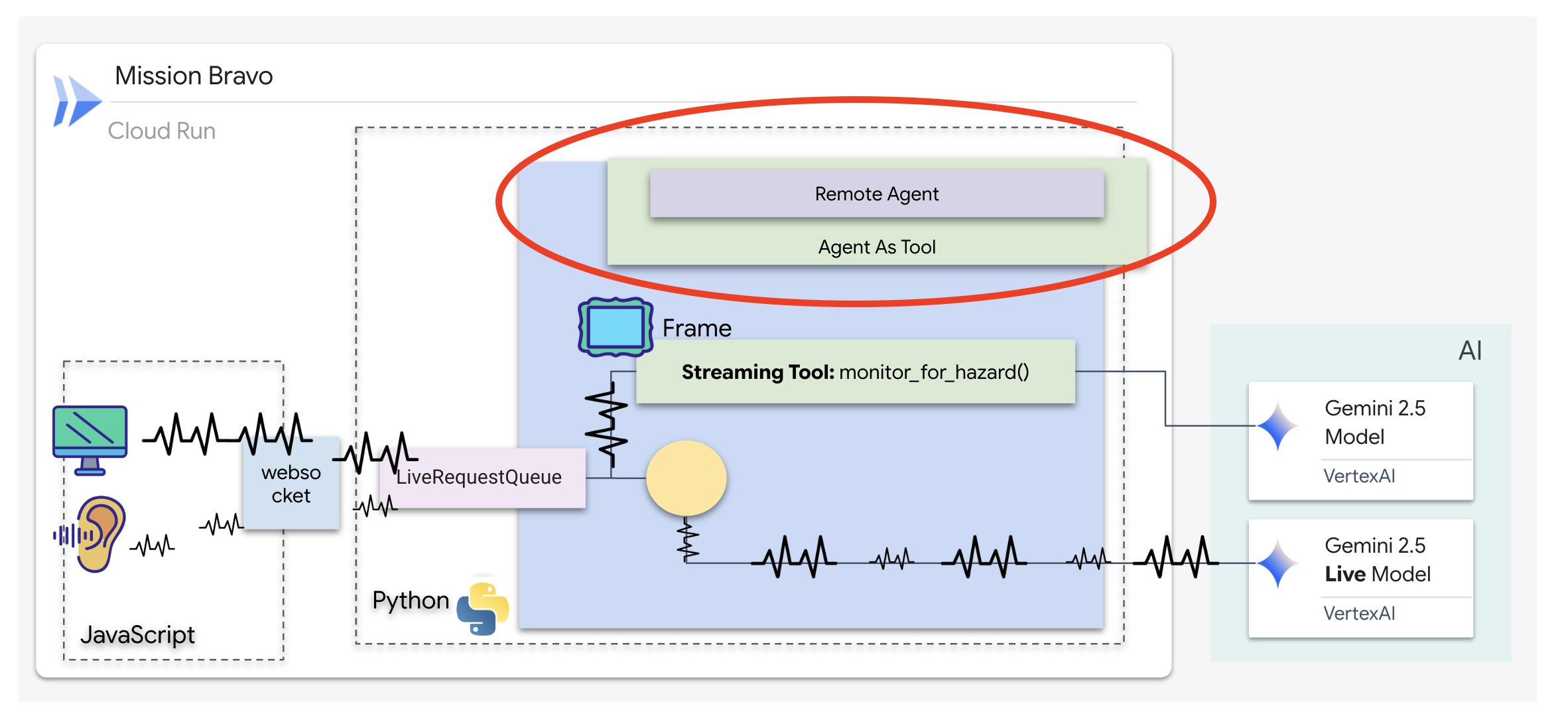
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py の #REPLACE-REMOTEA2AAGENT を次のように置き換えます。
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
ストリーミング ツールの仕組み
以前のエージェントでは、ツールは標準の「リクエスト-レスポンス」パターンに従っていました。エージェントが質問し、ツールが回答を提供すると、やり取りは終了します。ただし、Ozymandias では、危険な場所があるかどうかを尋ねるまで待ってくれません。これには、ストリーミング ツールが必要です。
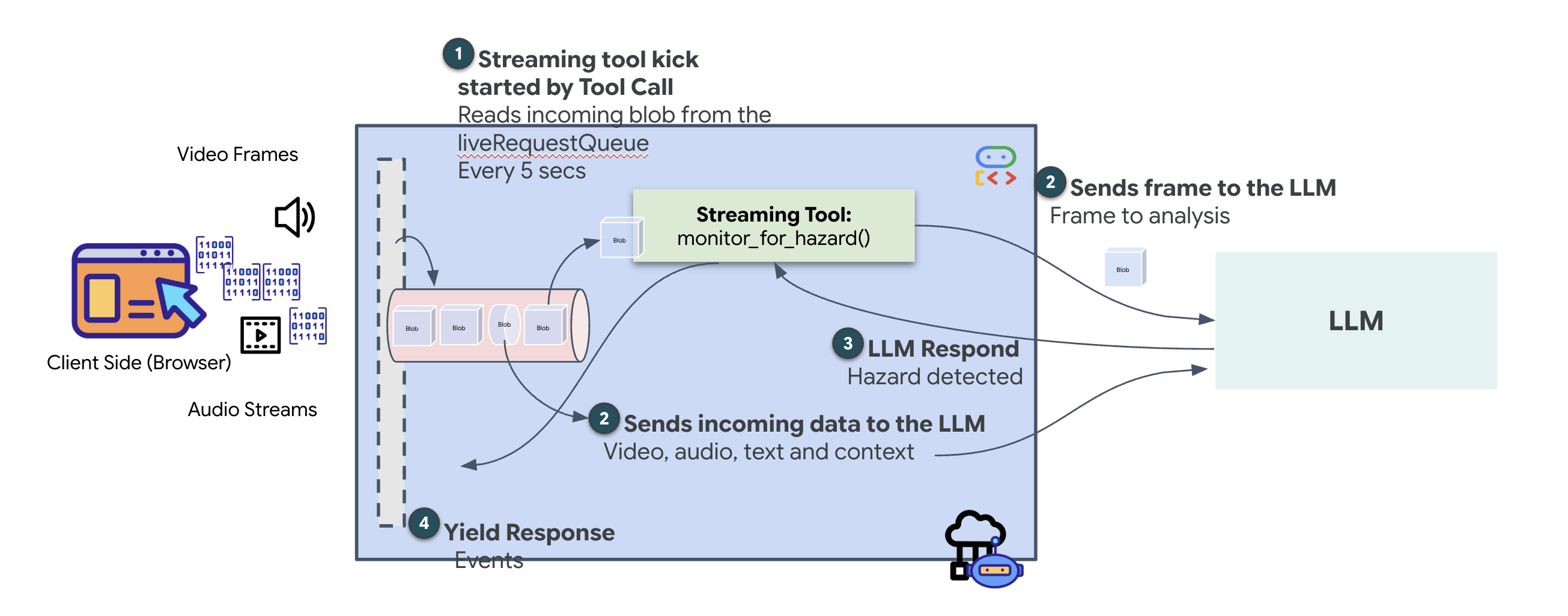
ストリーミング ツールを使用すると、関数は中間結果をリアルタイムでエージェントにストリーミングできます。これにより、エージェントは変更が発生したときに反応できます。一般的なユースケースとしては、株価の変動のモニタリングや、この例のように、ライブ動画ストリームの状態変化のモニタリングなどがあります。
標準ツールとは異なり、ストリーミング ツールは AsyncGenerator として機能する 非同期関数です。つまり、単一の値を return するのではなく、複数の更新を yield します。
ADK でストリーミング ツールを定義するには、次の技術要件に準拠する必要があります。
- 非同期関数: ツールは
async defで定義する必要があります。 - AsyncGenerator の戻り値の型: 関数は
AsyncGeneratorを返すように型指定する必要があります。最初のパラメータは生成されるデータの型(strなど)で、2 番目のパラメータは通常Noneです。 - 入力ストリーム: 動画ストリーミング ツールを使用します。このモードでは、実際の動画/音声ストリーム(
LiveRequestQueue)が関数に直接渡されるため、ツールはエージェントが見ているのと同じフレームを「確認」できます。
ストリーミング ツールは Sentinel と考えることができます。あなたと Dispatch エージェントがブループリントについて話し合っている間、センチネルはバックグラウンドで実行され、すべての動画フレームをサイレントに処理して安全を確保します。
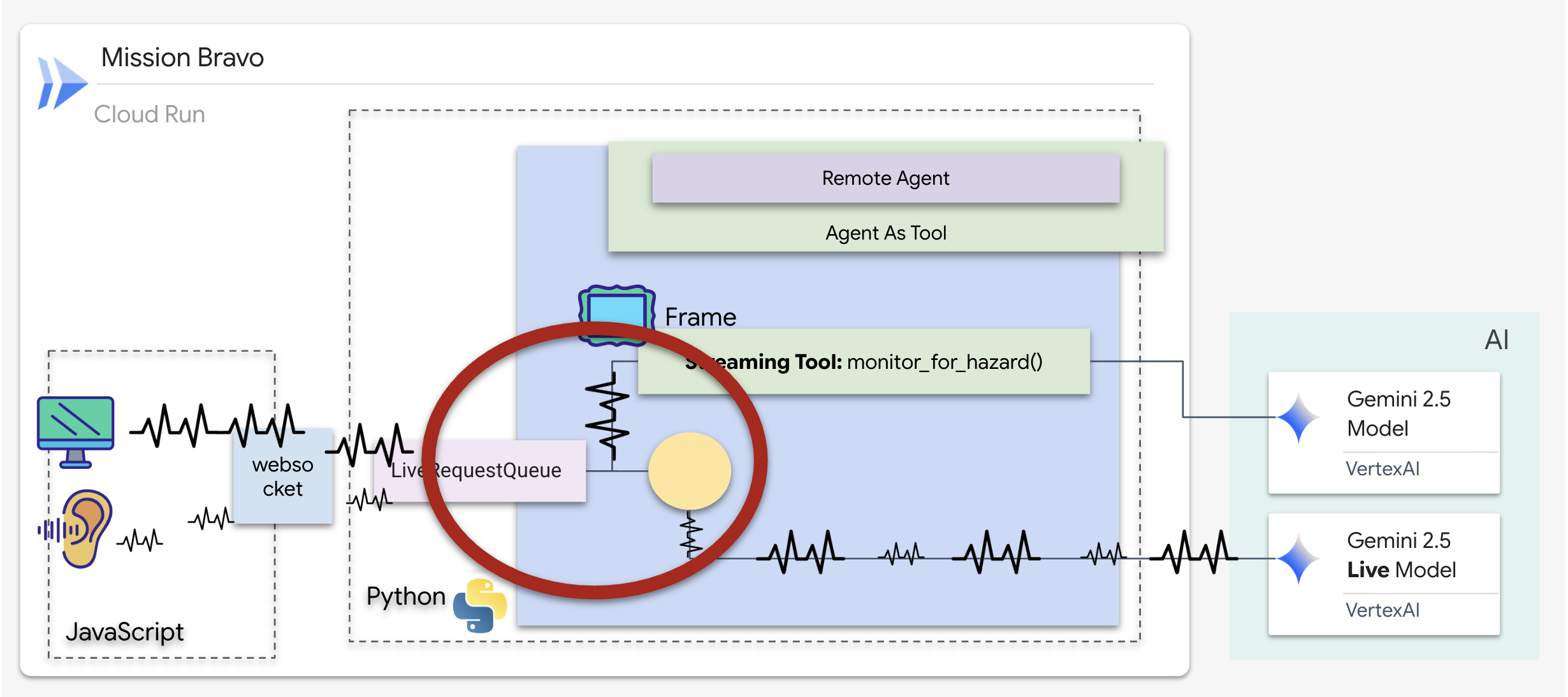
バックグラウンド モニタリング ツールを実装する
次に、monitor_for_hazard ツールを実装します。このツールは input_stream(動画フレーム)を取り込み、別の軽量なビジョン呼び出しを使用して分析し、危険が検出された場合にのみ警告を yield します。
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py で、#REPLACE_MONITOR_HAZARD を次のロジックに置き換えます。
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
ディスパッチ エージェントの実装
Dispatch Agent は、メインのインターフェースであり、オーケストレーターです。双方向ストリーミング リンク(ライブ音声と動画)を管理するため、常に会話の制御を維持する必要があります。これを実現するために、ADK の特定の機能である Agent-as-a-Tool を使用します。
コンセプト: Agent-as-a-Tool とサブエージェント
マルチエージェント システムを構築する場合は、責任の分担方法を決定する必要があります。救助ミッションでは、この区別が重要です。
- Agent-as-a-Tool: これは、双方向ストリーミング ハブに推奨されるアプローチです。ディスパッチ エージェント(エージェント A)がアーキテクト エージェント(エージェント B)をツールとして呼び出すと、アーキテクトのデータがディスパッチに渡されます。Dispatch はそのデータを解釈し、応答を生成します。Dispatch は制御を維持し、以降のすべてのユーザー入力を処理し続けます。
- サブエージェント: サブエージェントの関係では、責任が完全に移行されます。Dispatch がサブエージェントとして Architect にハンドオフした場合、ビジョンや会話スキルを持たないデータベース API と直接会話することになります。そのため、プライマリ エージェント(Dispatch)は事実上このプロセスから外れてしまいます。
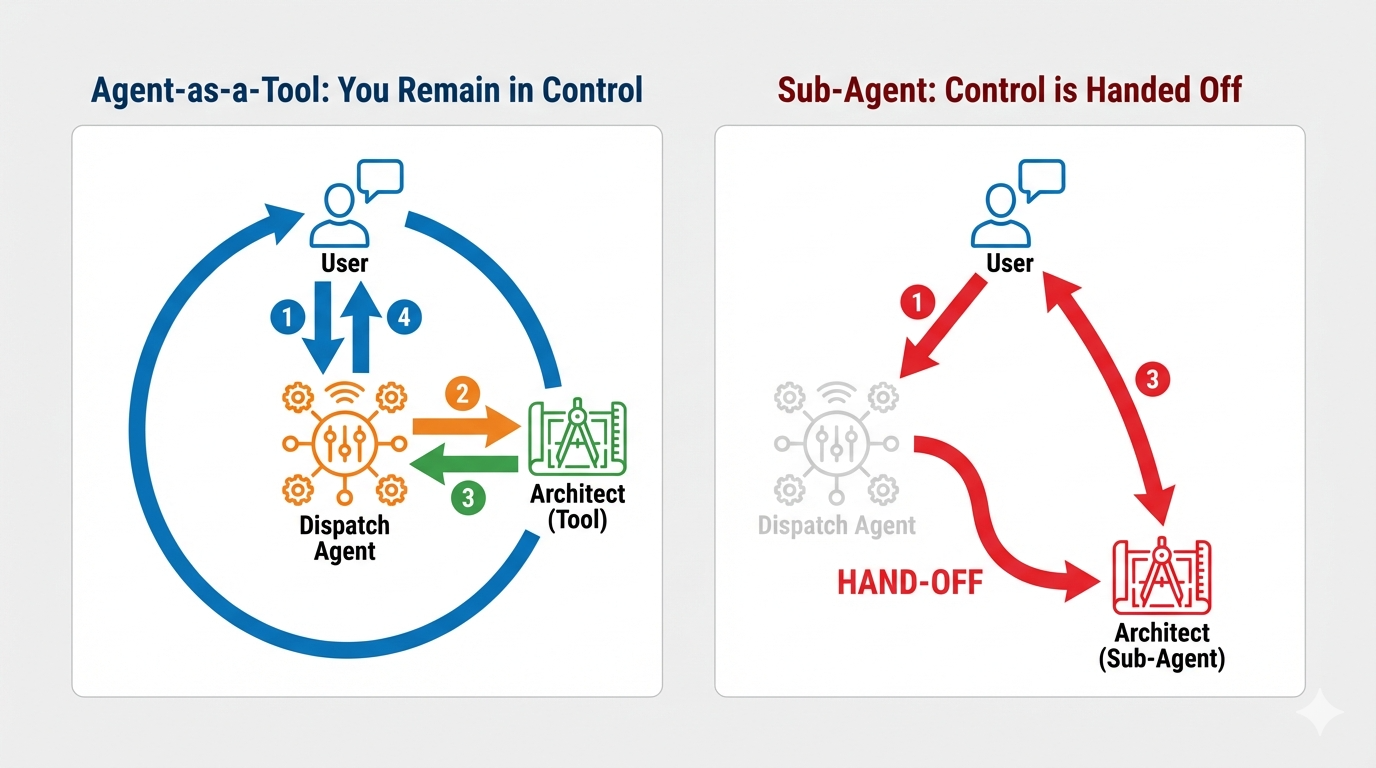
Agent-as-a-Tool を使用することで、双方向ストリーミング エージェントの流動的で人間のようなインタラクションを維持しながら、アーキテクトの専門知識を活用できます。
ルーティング ロジックのコーディング
次に、architect_agent を AgentTool でラップし、Dispatch エージェントに「ロジックマップ」を提供します。このマップは、エージェントが Vault からデータを取得するタイミングと、バックグラウンド センチネルから結果をレポートするタイミングを正確に示します。
Dispatch に瞬きしない「目」を与えるには、前の手順で作成したストリーミング ツールへのアクセス権を付与する必要があります。
ADK で、AsyncGenerator 関数(monitor_for_hazard など)を tools リストに追加すると、エージェントはそれを永続的なバックグラウンド プロセスとして扱います。1 回限りの実行ではなく、エージェントはツールの出力に「サブスクライブ」します。これにより、Sentinel がバックグラウンドでハザード アラートをサイレントで生成している間、Dispatch はメインの会話を継続できます。
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py の #REPLACE_AGENT_TOOLS を次のように置き換えます。
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
確認
👉💻 両方のエージェントが構成されたら、ライブ マルチエージェント インタラクションをテストできます。
- ターミナル A で、Architect Agent を起動します。
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- 新しいターミナル(ターミナル B)で、Dispatch Agent を実行します。
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
adk web シミュレータ内で gemini-live などのリアルタイムのマルチモーダル モデルを使用するマルチエージェント システムをテストするには、特定のワークフローが必要です。シミュレータはツール呼び出しの検査に優れていますが、このタイプのモデルで画像を初めて処理する際に互換性の問題が発生することがわかっています。
- Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。[ポートを変更] を選択し、[8000] に設定して、[変更してプレビュー] をクリックします。
👉dispatch_agent を選択し、ブループリントをアップロードして、想定されるエラーを処理する
これは最も重要なステップです。エージェントに画像コンテキストを提供する必要があります。
- インターフェースが読み込まれたら、プロンプトが表示されたらマイクへのアクセスを許可します。
- このブループリント画像をパソコンにダウンロードします。
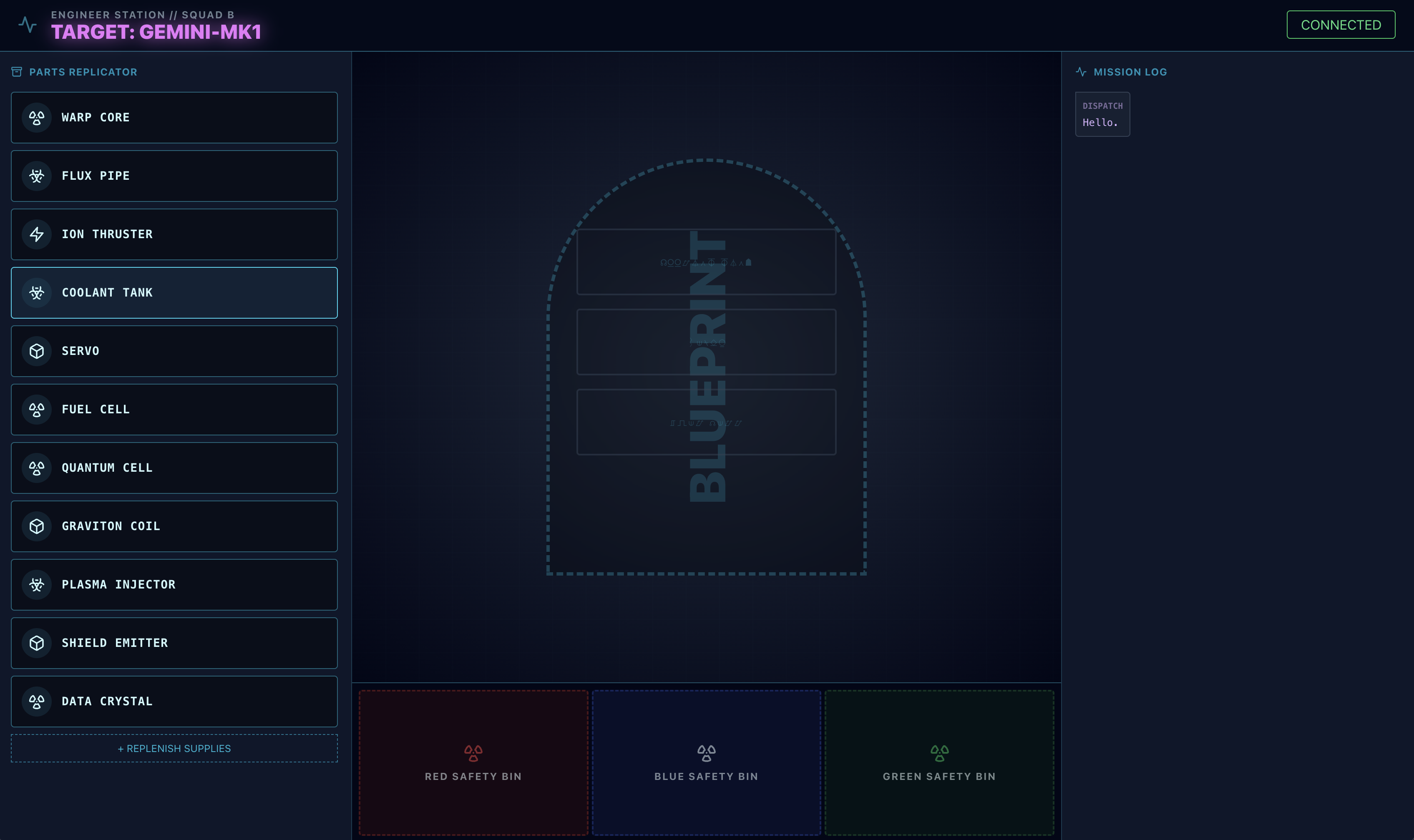
adk webインターフェースで、クリップ アイコンをクリックし、ダウンロードしたばかりのブループリント画像をアップロードします。
⚠️⚠️400 INVALID_ARGUMENT エラーが表示されます。これは想定された動作です。⚠️⚠️
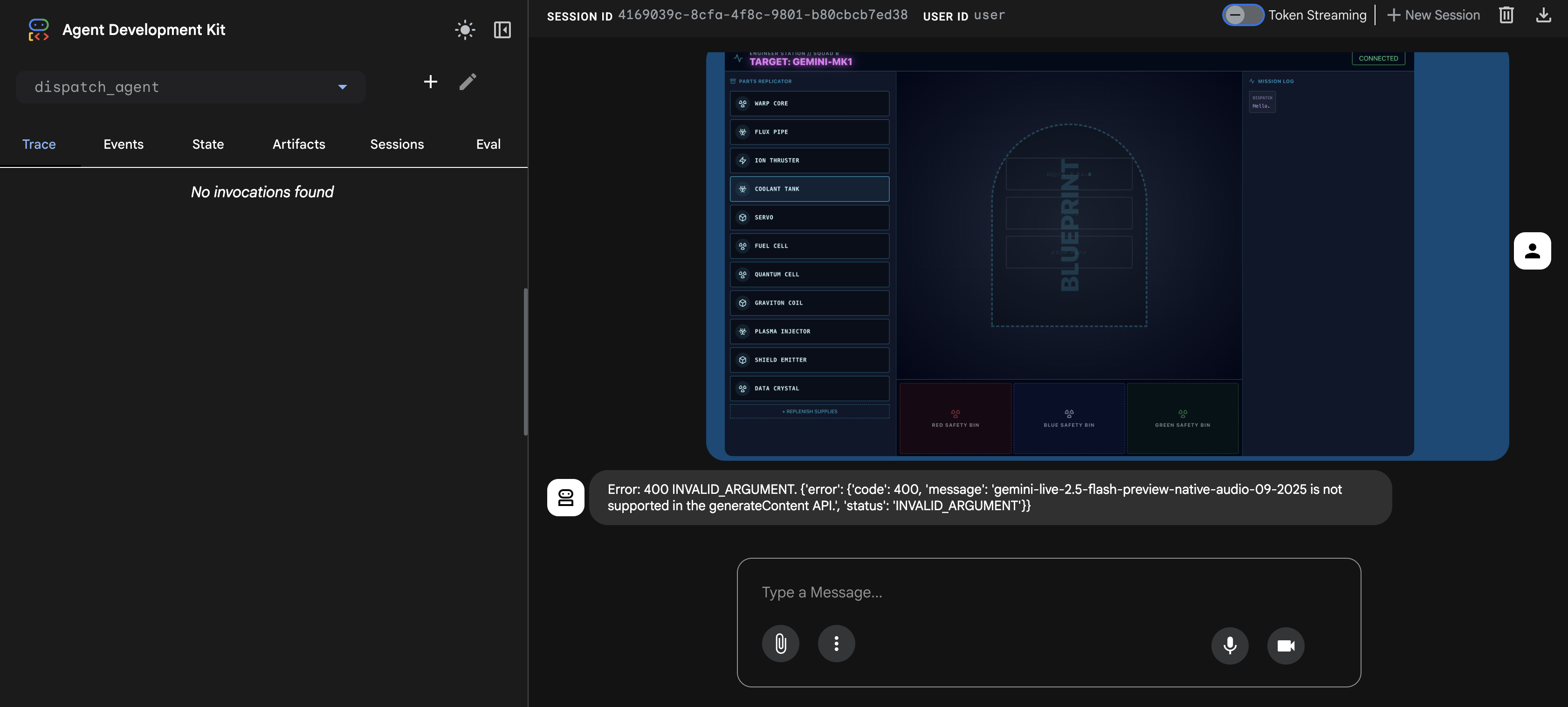
このエラーは、adk web 画像ハンドラが 1 回限りのアップロード用の gemini-live モデルの API と完全に互換性がないために発生します。ただし、画像はセッション コンテキストに正常に追加されています。
- 👉 エラーを解消するには、ブラウザのページを再読み込みします。
アセンブリ プロセスをトリガーする
👉 再読み込みすると、エラーは消え、チャット履歴にブループリント画像が表示されます。エージェントは必要なビジュアル コンテキストを取得しました。
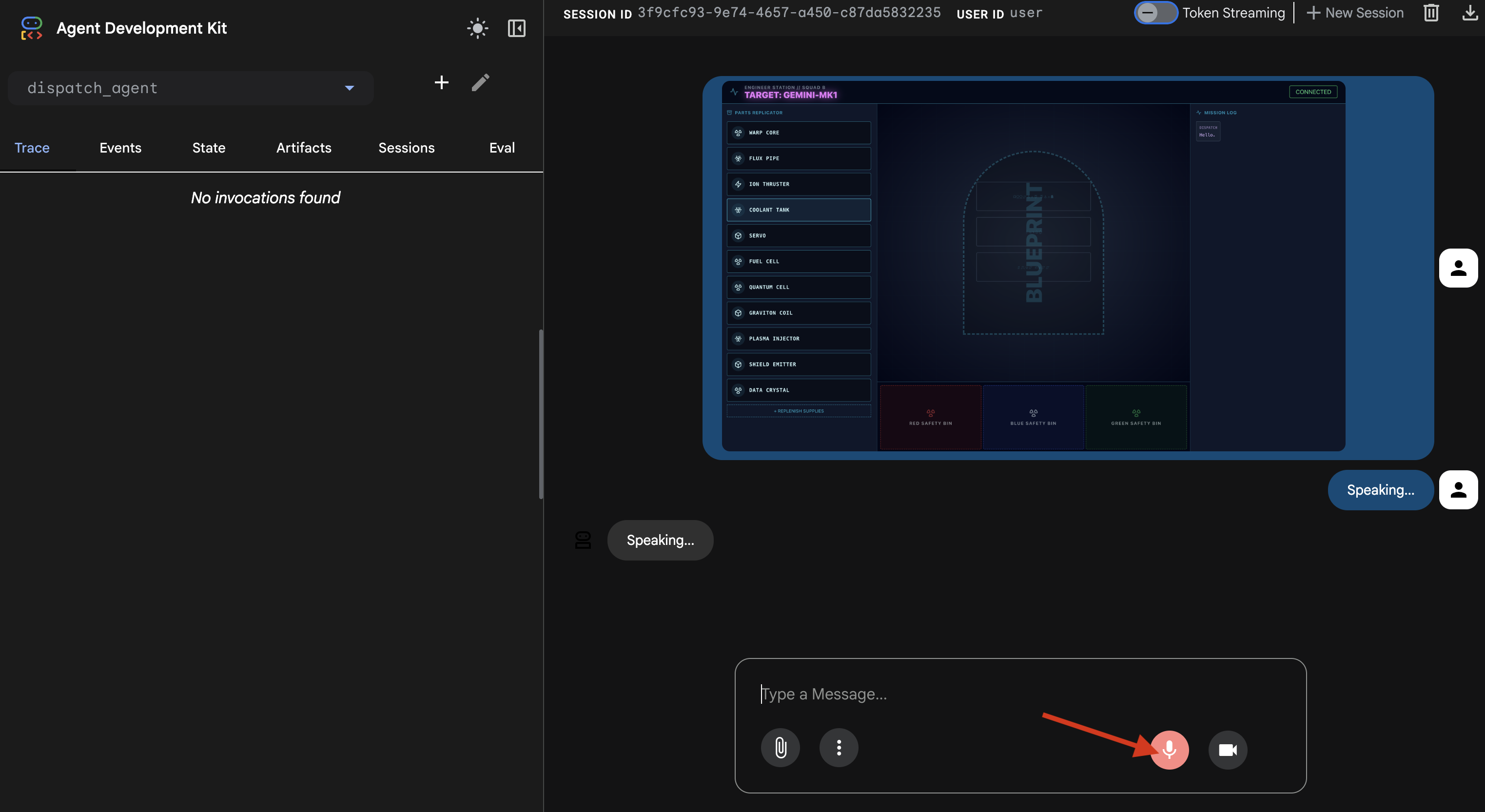
- マイクアイコンをクリックしてオンにします。インターフェースに「聴取中...」と表示されます。
- 「組み立てを開始して」と話しかけます。
- エージェントがリクエストを処理し、UI が [発言中...] に変わります。必要な部品をリストする音声のみの応答が聞こえます。
4. エージェント間ツール呼び出しを確認する
👉 最初の音声レスポンスはシステムが動作していることを確認するものですが、真の魔法はマルチエージェント通信トレースにあります。
- マイクをオフにします。
- ページをもう一度更新します。
左側の [トレース] パネルにデータが入力されます。実行フローが正常に完了したことを確認できます。
dispatch_agentは最初にmonitor_for_hazardを呼び出します。- 次に、
architect_agentに対して複数のexecute_architect呼び出しを行い、回路図データを取得します。
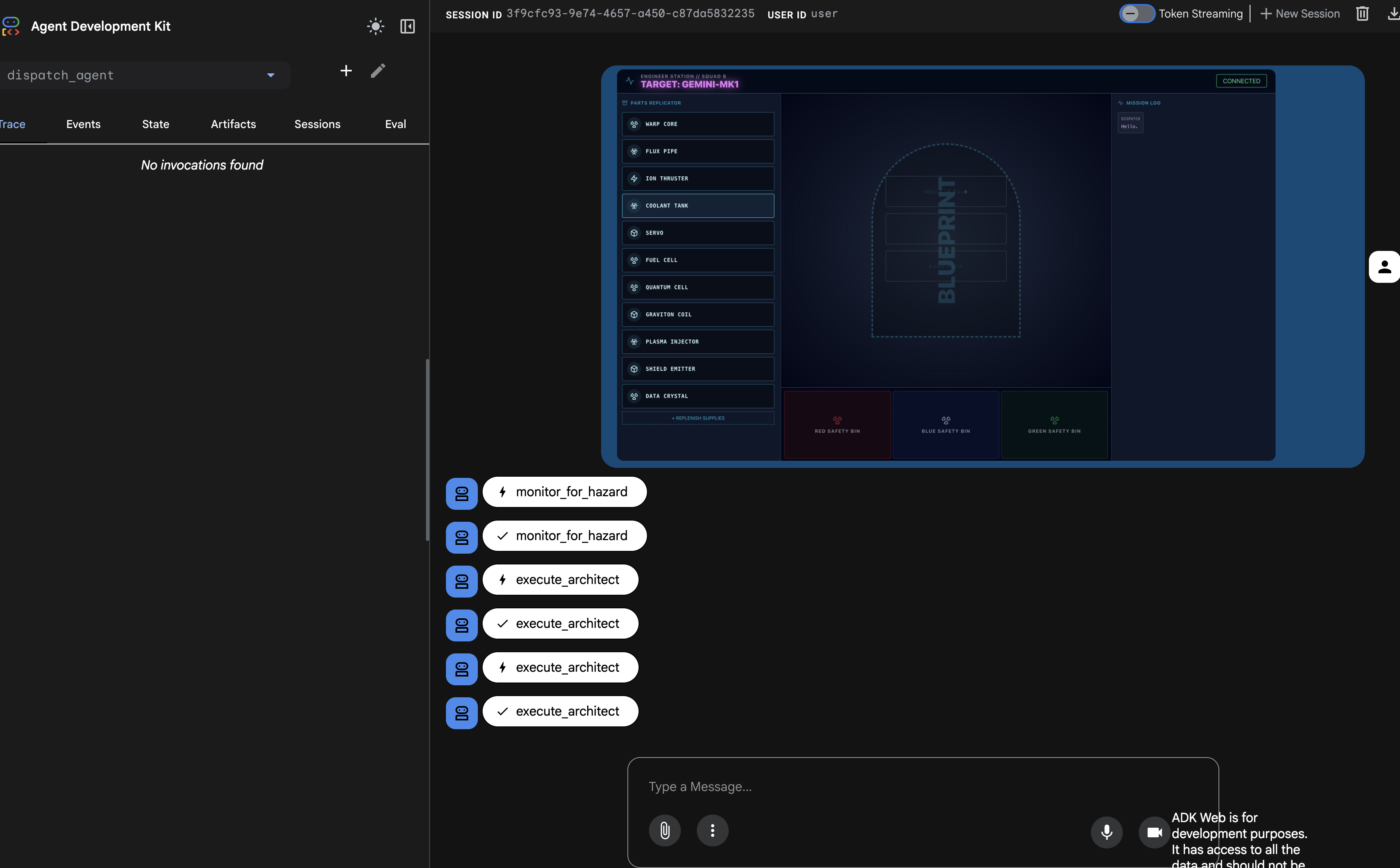
このシーケンスは、マルチエージェント ワークフロー全体が正しく機能していることを確認します。dispatch_agent がリクエストを受信し、ツール呼び出しを介してデータ取得タスクを architect_agent に委任し、ユーザーのコマンドを満たすためにデータを受信しています。
双方向ストリーミング リンクで、バックグラウンド モニタリングとマルチエージェント コラボレーションが可能になりました。次に、フロントエンドでこれらの複雑なレスポンスを解析する方法について説明します。
👉💻 両方のターミナルで Ctrl+c を押して終了します。
5. ライブ マルチモーダル イベント ストリームの詳細
前の手順では、組み込みの開発サーバー adk web を使用して、マルチエージェント システムの検証に成功しました。このユーティリティは、デフォルトの ADK ランナーを使用して、セッション、ストリーム、エージェントのライフサイクルを自動的に管理します。ただし、FastAPI サービス(main.py)のような本番環境対応のスタンドアロン アプリケーションを作成するには、明示的な制御が必要です。ライブ ユーザー セッションを処理するには、ADK Runner を手動で作成して管理する必要があります。これは、音声、動画、テキストの双方向ストリームを処理するコア コンポーネントであるためです。
モデル-コード-モデル ループ
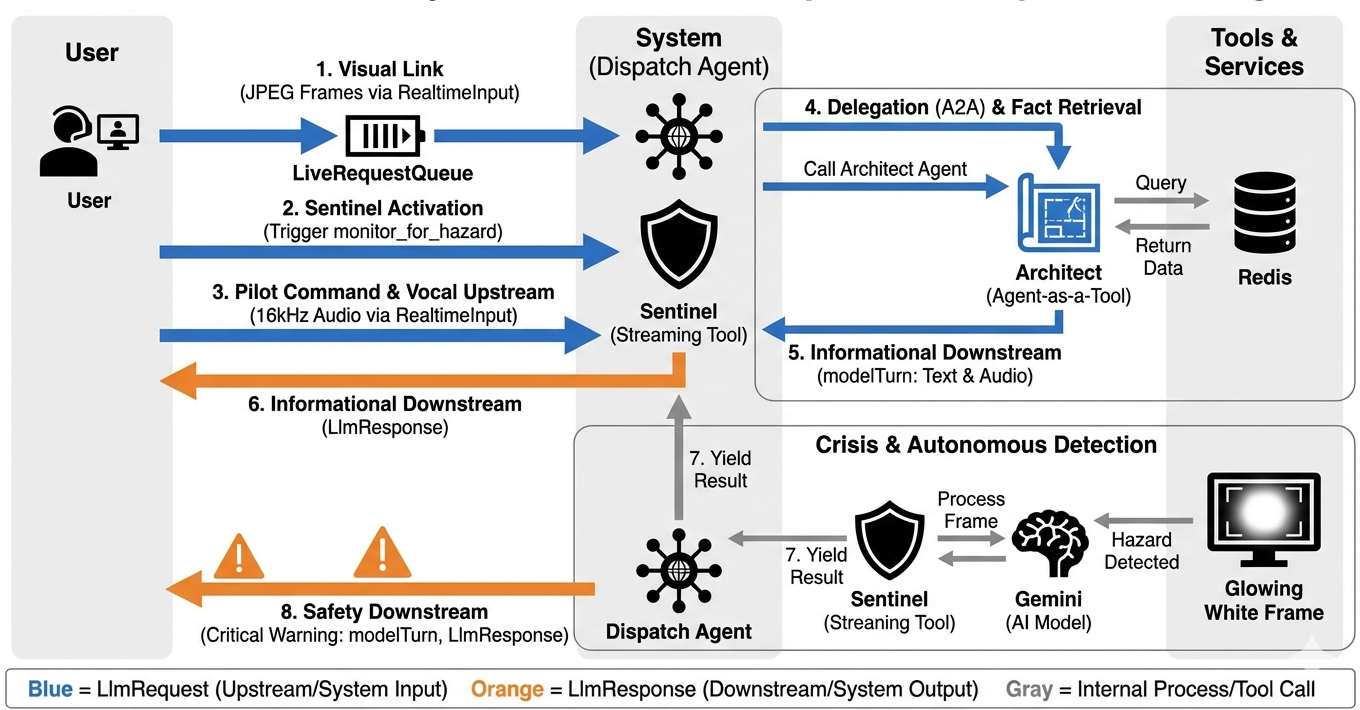
システムがリアルタイムでどのように動作するかを理解するために、単一のミッション セッションのライフサイクルを見てみましょう。このループは、LlmRequest オブジェクトと LlmResponse オブジェクトの継続的な交換を表します。
- ビジュアル リンク: 接続を開始し、ウェブカメラや画面を共有します。高忠実度の JPEG フレームが
realtimeInput経由で Upstream に流れ始めます(LiveRequestQueueを使用)。 - Sentinel のアクティベーション: システムが最初の「Hello」刺激を送信します。指示に従って、ディスパッチ エージェントは
monitor_for_hazardストリーミング ツールを直ちにトリガーします。これにより、受信したすべてのフレームをサイレントに監視するバックグラウンド ループが開始されます。 - パイロット コマンド: 通信で「組み立てを開始」と話します。
- 音声アップストリーム: 音声は 16 kHz の音声としてキャプチャされ、動画フレームとともにアップストリームに送信されます。
- 委任(A2A): Dispatch がインテントを「リッスン」します。このエージェントは、回路図がないことに気づき、
AgentTool(Agent-as-a-Tool)プロトコルを使用して Architect Agent を呼び出します。 - 事実の取得: Architect は Redis データベースにクエリを実行し、部品リストを Dispatch に返します。Dispatch は「セッションのマスター」のままで、お客様に引き継ぐことなくデータを受信します。
- 情報ダウンストリーム: Dispatch は、テキストとネイティブ音声の両方を含む
modelTurn(ダウンストリーム)を送信します。「Architect Confirmed. 必要なサブセットは、ワープコア、フラックス パイプ、イオンスラスターです。」 - 危機: 突然、作業台の部品が不安定になり、白く光り始めます。
- 自律検出: バックグラウンドの
monitor_for_hazardループ(Sentinel)が、光を含む特定の JPEG フレームを検出します。Gemini を呼び出してフレームを処理し、危険を特定します。 - Safety Downstream: ストリーミング ツールが結果を
yieldsします。これは Bidi-Streaming エージェントであるため、Dispatch は現在の状態を中断して、重大な安全警告を Downstream にすぐに送信できます。「危険を検知しました。データ クリスタルを無効化します。赤いゴミ箱に移動してください。」
エージェントのランタイム構成の設定
ADK の RunConfig を使用すると、エージェントの動作を詳細に構成できます。たとえば、ストリーミング データの処理方法や、さまざまなモダリティとのやり取りの方法などを構成できます。
streaming_mode はリアルタイムの双方向通信用に BIDI に設定され、ユーザーとエージェントが同時に発言したり聞いたりできるようになります。response_modalities パラメータは、エージェントが生成できる出力のタイプ(音声やテキストなど)を定義します。input_audio_transcription は、エージェントがユーザーの着信音声を処理して文字起こしする方法を構成します。より復元力の高いエクスペリエンスを実現するため、session_resumption では、エージェントが会話のコンテキストを記憶し、接続が切断された場合に再開できるようにします。最後に、proactivity を使用すると、エージェントはユーザーの直接的なコマンドなしでアクションや音声を開始できます(自発的な危険警告の発行など)。一方、enable_affective_dialog を使用すると、エージェントはより自然で共感的な応答を生成できます。ADK の RunConfig の詳細については、こちらをご覧ください。
👉✏️ $HOME/way-back-home/level_4/backend/main.py ファイル内の #REPLACE_RUN_CONFIG プレースホルダを見つけて、次の解析ロジックに置き換えます。
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
Request to Agent の実装
次に、WebSocket を介してユーザーの Volatile Workbench から Dispatch Agent にリアルタイムのマルチモーダル データをストリーミングするコア通信アップリンクを実装します。エージェントは継続的に「見て」(動画フレーム)、「聞いて」(音声コマンド)います。このロジックは、データ ストリームを継続的に受信し、受信したバイナリ音声チャンクと JSON でラップされたテキスト/画像パケットを区別して、Blob(マルチメディアの場合)または Content(テキストの場合)オブジェクトにカプセル化し、LiveRequestQueue に送信して双方向エージェント セッションを強化します。
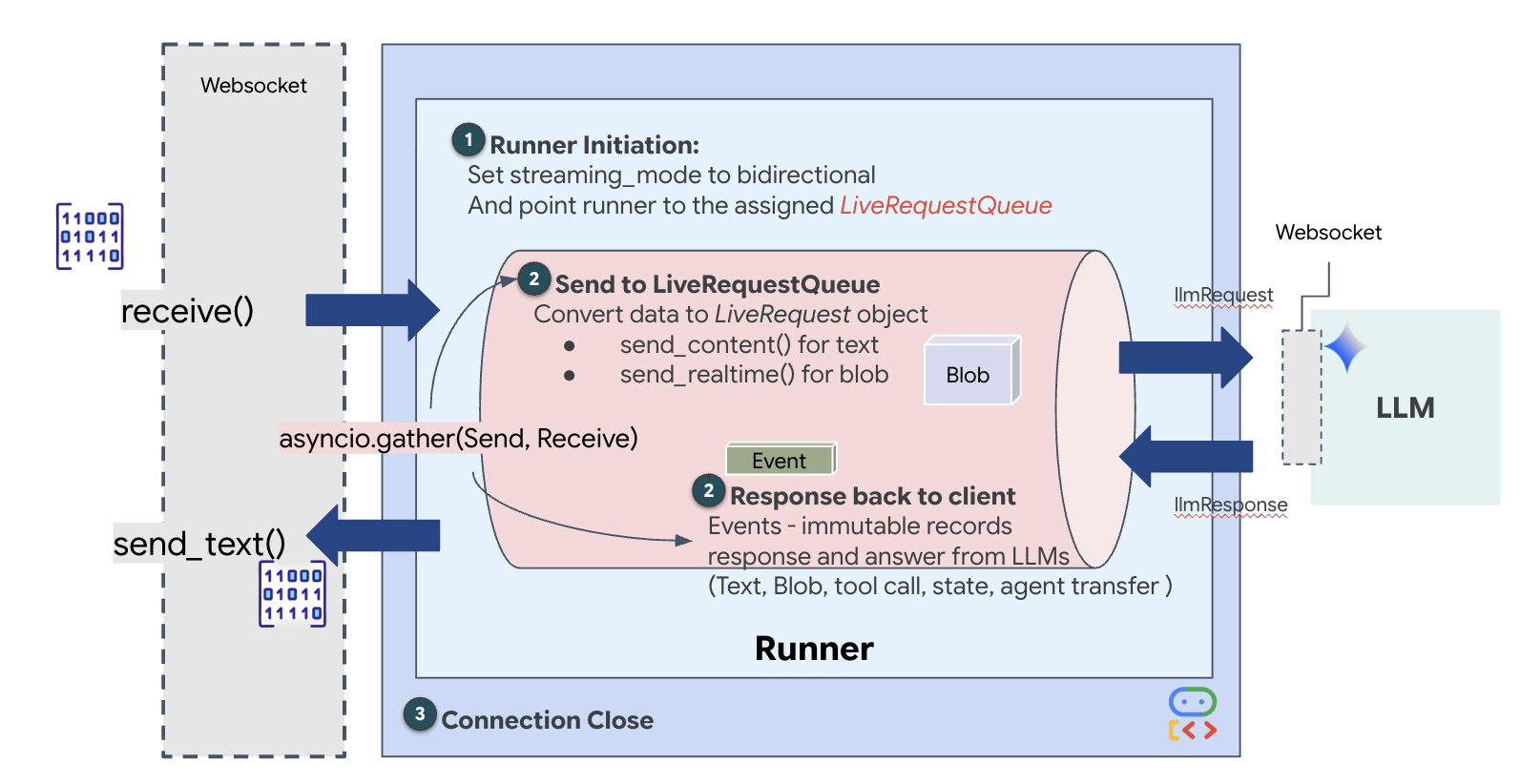
$HOME/way-back-home/level_4/backend/main.py ファイルの #PROCESS_AGENT_REQUEST プレースホルダを見つけ、次の解析ロジックに置き換えます。
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
マルチモーダル データがエージェントに送信されるようになりました。
レスポンスの実装: ダウンストリーム イベントのデータ構造
ADK で双方向(ライブ)エージェントを実行している場合、エージェントから返されるデータは、コア GenAI SDK 構造を継承する特定のタイプのイベントにパッケージ化されます。async for event in runner.run_live(...) ループで受け取る Event オブジェクトは、複数のオプション フィールドを含む単一のオブジェクトです。各フィールドは異なるタイプの情報に対応しています。
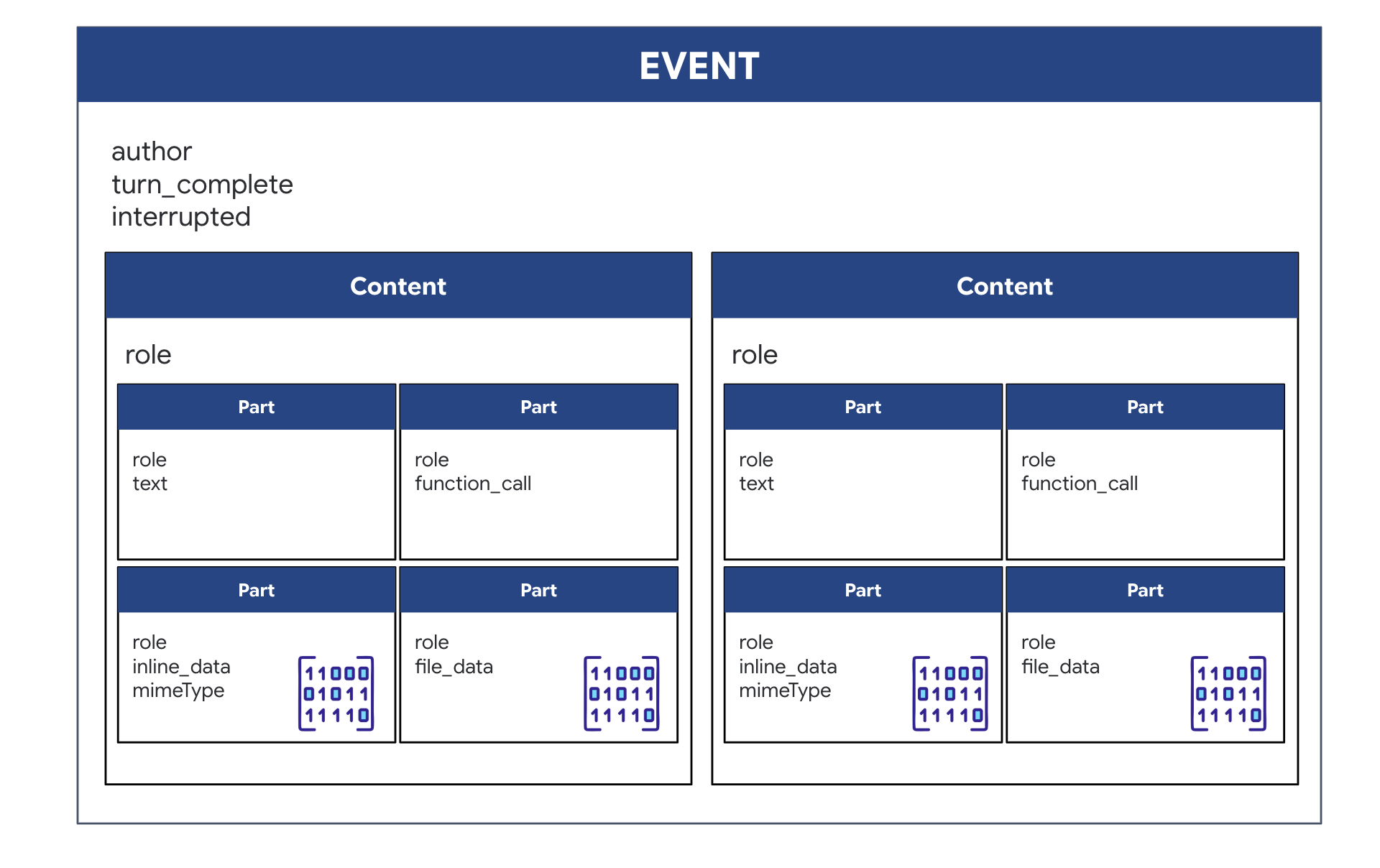
コンテンツの構造:
- エージェントが話すとき(
.server_content経由): このフィールドは単なるプレーン テキストではありません。Partsのリストが含まれます。各Partは、テキスト文字列("The part is stable."など)または未加工の音声 blob(音声)のいずれか 1 種類のデータを格納するコンテナです。 - エージェントが操作を行う場合(
.tool_callを介して): フィールドにはFunctionCallオブジェクトのリストが含まれます。各FunctionCallは、バックエンド コードが簡単に読み取って実行できるクリーンな形式で、ツールの名前と入力引数を指定するシンプルな構造化オブジェクトです。
👀 run_live ループによって生成された単一の Event を確認すると、event.model_dump(by_alias=True) によって生成された JSON は次のようになります。これは、GenAI SDK の形状に厳密に準拠しています。
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ main.py の downstream_task を更新して、完全なイベントデータを転送します。このロジックにより、AI のすべての「思考」が船の診断端末に記録され、単一の JSON オブジェクトとしてフロントエンド UI に送信されます。
$HOME/way-back-home/level_4/backend/main.py ファイルの #PROCESS_AGENT_RESPONSE プレースホルダを見つけ、次の解析ロジックに置き換えます。
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
ミッションの実行
バックエンド Vault が接続され、両方のエージェントが構成されたため、すべてのシステムがミッション対応になりました。次の手順でアプリケーション全体を起動すると、構築したばかりの 2 エージェント システムを操作できます。
目標: ワークベンチに表示されるランダムに割り当てられたワープドライブを組み立てます。手順: 派遣エージェントの音声ガイダンス(特に特定のコンポーネントに関する危険警告)に従う必要があります。
スペシャリスト(アーキテクト)を有効にする
👉💻 最初のターミナル ウィンドウで、Architect エージェントを起動します。このバックエンド サービスは Redis Vault に接続し、Dispatcher からのスキーマ リクエストを待機します。
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
(このターミナルは実行したままにします。これで、このエージェントがアクティブな「データベース エージェント」になります。)
Cockpit(ディスパッチャー)を起動する
👉💻 新しいターミナル ウィンドウ(ターミナル B)で、フロントエンド UI をビルドし、ユーザー インターフェースを提供してすべてのライブ通信を処理するメインの Dispatch エージェントを起動します。
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(これにより、ポート 8080 でプライマリ サーバーが起動します)。
テストシナリオを実行する
システムが稼働しました。エージェントの指示に従って組み立てを完了することが目標です。
- 👉 ワークベンチにアクセスする:
- Cloud Shell ツールバーの [ウェブでプレビュー] アイコンをクリックします。
- [ポートの変更] を選択し、[8080] に設定して、[変更してプレビュー] をクリックします。
- 👉 ミッションを開始する:
- インターフェースが読み込まれたら、画面とマイクへのアクセスを許可します。
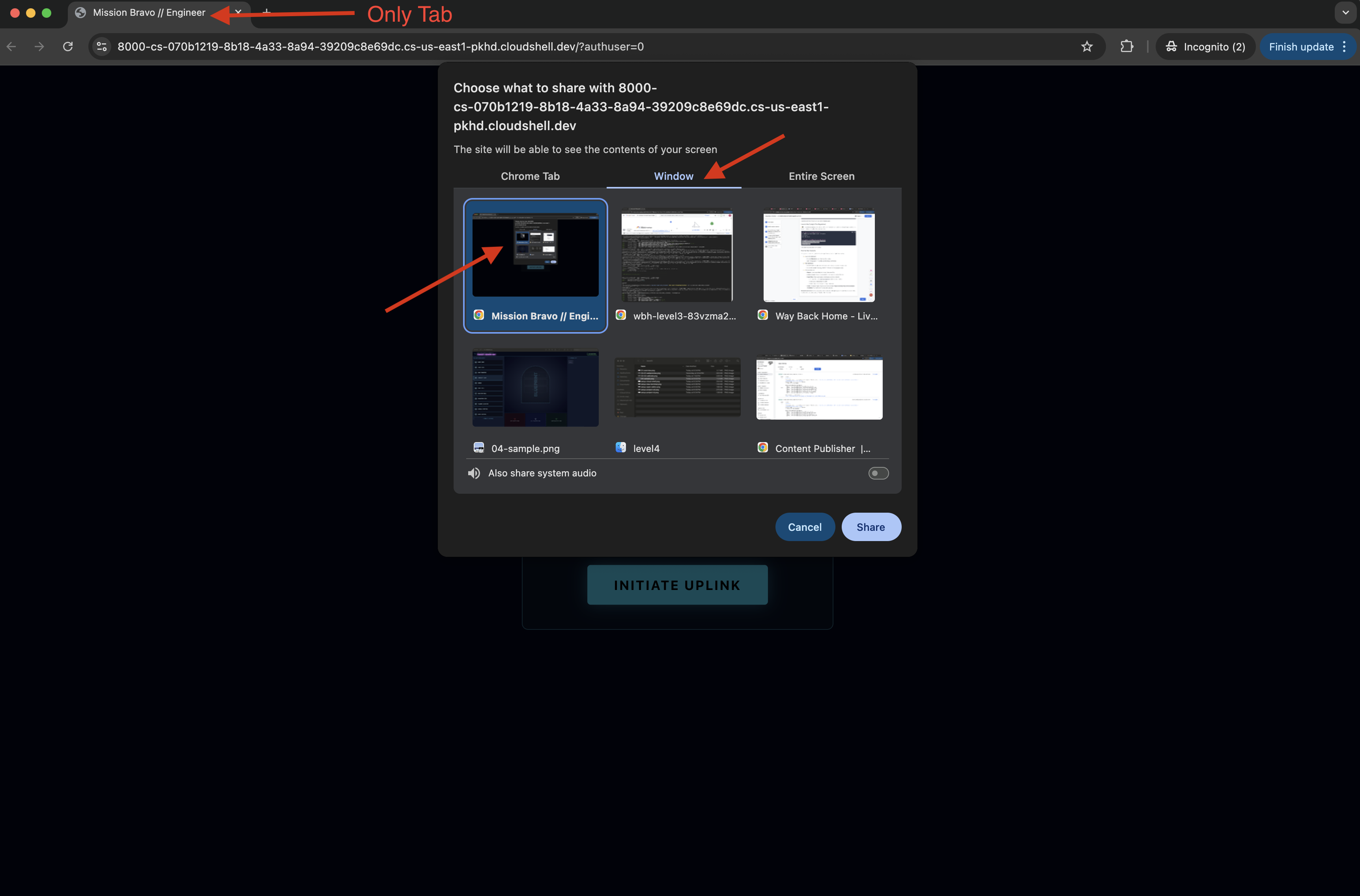
- 共有するタブまたはウィンドウを選択するよう求められます。ウィンドウを共有する場合は、問題が発生しないように、ウィンドウ内のタブが 1 つだけであることを確認してください。
- ランダムな名前(「NOVA-V」、「OMEGA-9」など)のドライブが割り当てられます。
- インターフェースが読み込まれたら、画面とマイクへのアクセスを許可します。
- 👉 アセンブリ ループ:
- リクエスト: ドライブの組み立てを開始するには、「組み立てを開始」と言います。
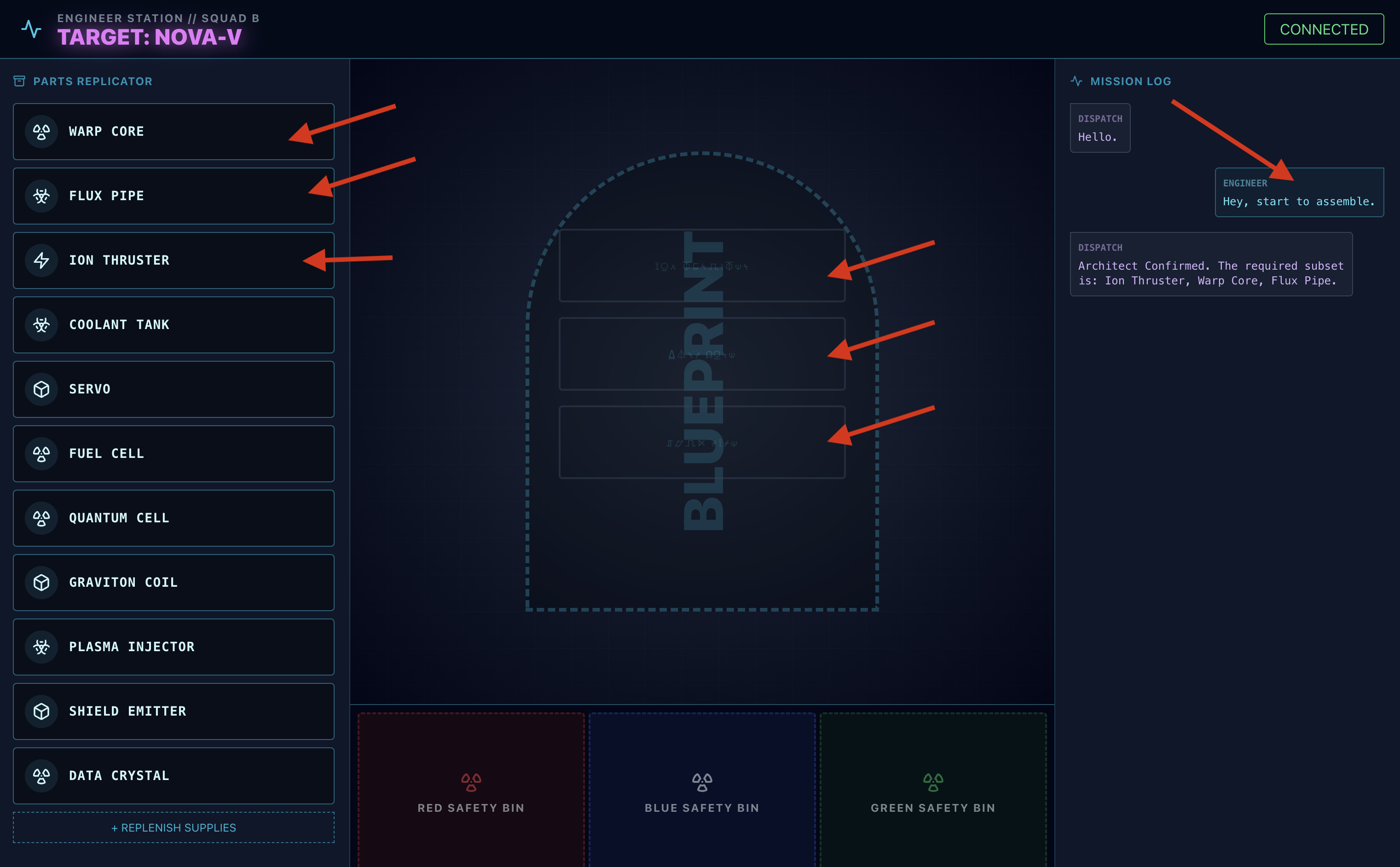
- Architect Respond: エージェントがドライブを組み立てるための正しい部品を提供します。
- 危険性チェック: ワークベンチで危険な部品が表示された場合:
- Dispatch エージェントの
monitor_for_hazardツールで視覚的に識別できます。 - 「視覚的危険アラート」が表示されます。(これには 30 秒ほどかかります)
- ハザードを解除するために使用するビンを確認します。
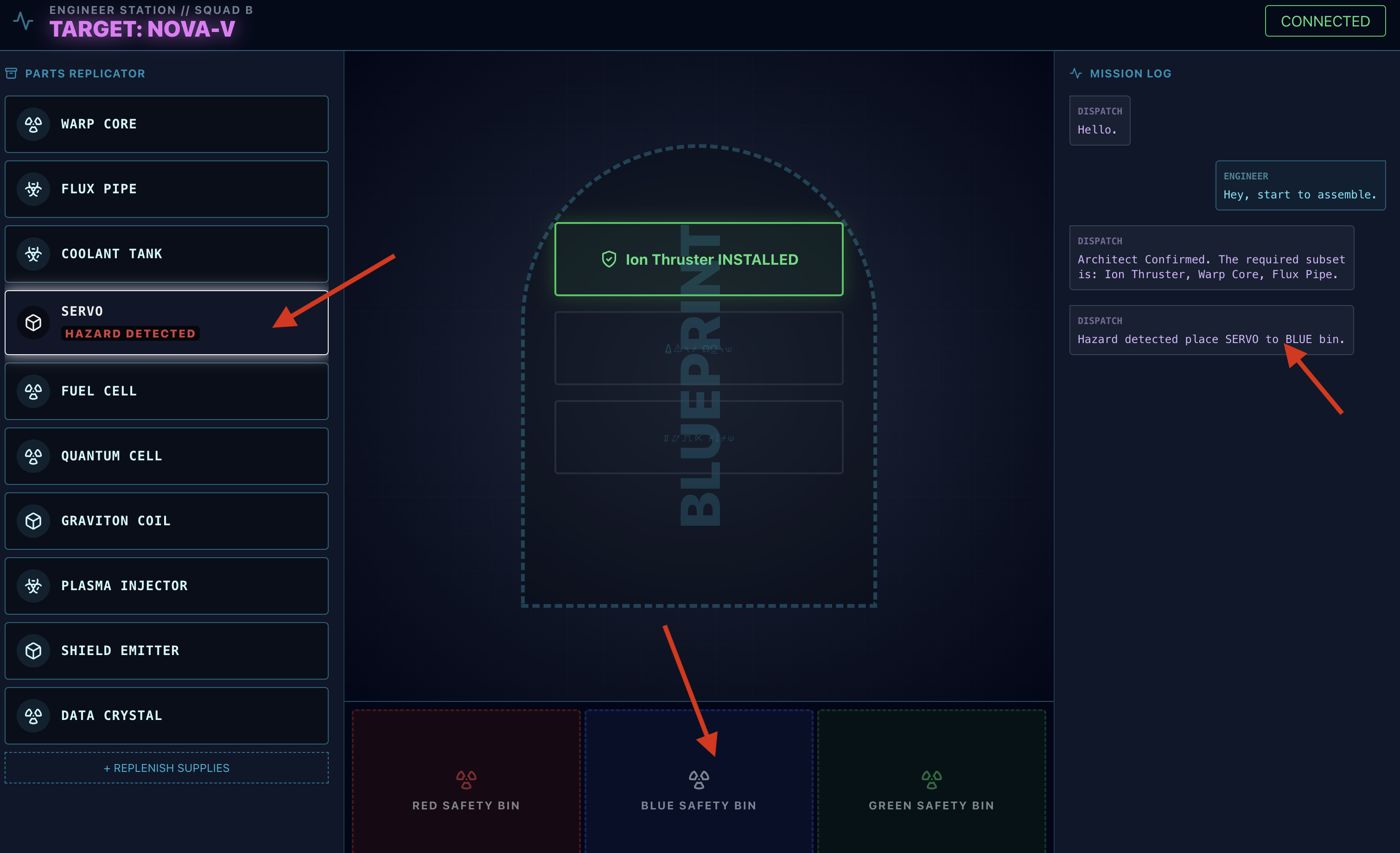
- Dispatch エージェントの
- 対応: 派遣エージェントから直接指示があります。「Hazard Confirmed. XXX をすぐに Red bin に入れてください。」続行するには、この手順に沿って操作する必要があります。
- リクエスト: ドライブの組み立てを開始するには、「組み立てを開始」と言います。
ミッション完了。これで、インタラクティブなマルチエージェント システムが正常に構築されました。生存者は無事、ロケットは大気圏を突破し、「帰還」は続きます。
👉💻 両方のターミナルで Ctrl+c を押して終了します。
6. 本番環境にデプロイする(省略可)
ローカルでエージェントのテストが完了しました。次に、アーキテクトのニューラル コアを船のメインフレーム(Cloud Run)にアップロードする必要があります。これにより、Dispatch エージェントがどこからでもクエリできる永続的な独立サービスとして動作します。
セキュア Vault(インフラストラクチャ)をプロビジョニングする
エージェントをデプロイする前に、エージェントの永続メモリ(Memorystore)と、それにアクセスするための安全なチャネル(VPC Connector)を作成する必要があります。
👉💻 Memorystore インスタンス(Redis Vault)を作成します。
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Vault のネットワーク アドレスを取得する: このコマンドを実行して、host IP アドレスをコピーします。これは、新しい Redis インスタンスのプライベート アドレスです。
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 VPC アクセス コネクタ(セキュア ブリッジ)を作成します。このコネクタはプライベート ブリッジとして機能し、Cloud Run が VPC 内の Redis インスタンスにアクセスできるようにします。
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 データを読み込みます。
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
エージェント アプリケーションをデプロイする
エージェント イメージをコンパイルしてビルドする
👉💻 バックエンド ディレクトリに移動して、Dockerfile を作成します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 アプリケーションをコンテナ イメージにパッケージ化します。
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
Cloud Run へのデプロイ
👉💻 エージェントを Cloud Run にデプロイします。Redis IP を挿入し、VPC コネクタを起動コマンドに直接リンクします。これにより、エージェントはデータベースへの安全なプライベート接続から開始されます。
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 A2A サーバーが実行されているかどうかを確認します。
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
コマンドが完了すると、サービス URL が表示されます。アーキテクト エージェントがクラウドで稼働し、Vault に永続的に接続され、他のエージェントにスキーマデータを提供する準備が整いました。
Dispatch Hub を本番環境のメインフレームにデプロイする
クラウドで Architect Agent が動作するようになったので、Dispatch Hub をデプロイする必要があります。このエージェントは、ライブ音声/動画ストリームを処理し、データベース クエリを Architect の安全なエンドポイントに委任する、主要なユーザー インターフェースとして機能します。
👉💻 Cloud Shell ターミナルで次のコマンドを実行します。これにより、バックエンド ディレクトリに完全なマルチステージ Dockerfile が作成されます。
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
エージェント/フロントエンド イメージをコンパイルしてビルドする
👉💻 Dispatch エージェントのコード(main.py)を含むバックエンド ディレクトリに移動し、コンテナ イメージにパッケージ化します。
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
Cloud Run へのデプロイ
👉💻 Dispatch Hub を Cloud Run にデプロイします。アーキテクトの URL を環境変数として挿入し、2 つのクラウドネイティブ エージェント間の重要なリンクを作成します。
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
コマンドが完了すると、サービス URL(https://mission-bravo-...run.app など)が表示されます。これで、アプリケーションがクラウドで稼働します。
👉 Google Cloud Run ページに移動し、リストから biometric-scout サービスを選択します。
👉 [サービスの詳細] ページの上部に表示されている公開 URL を確認します。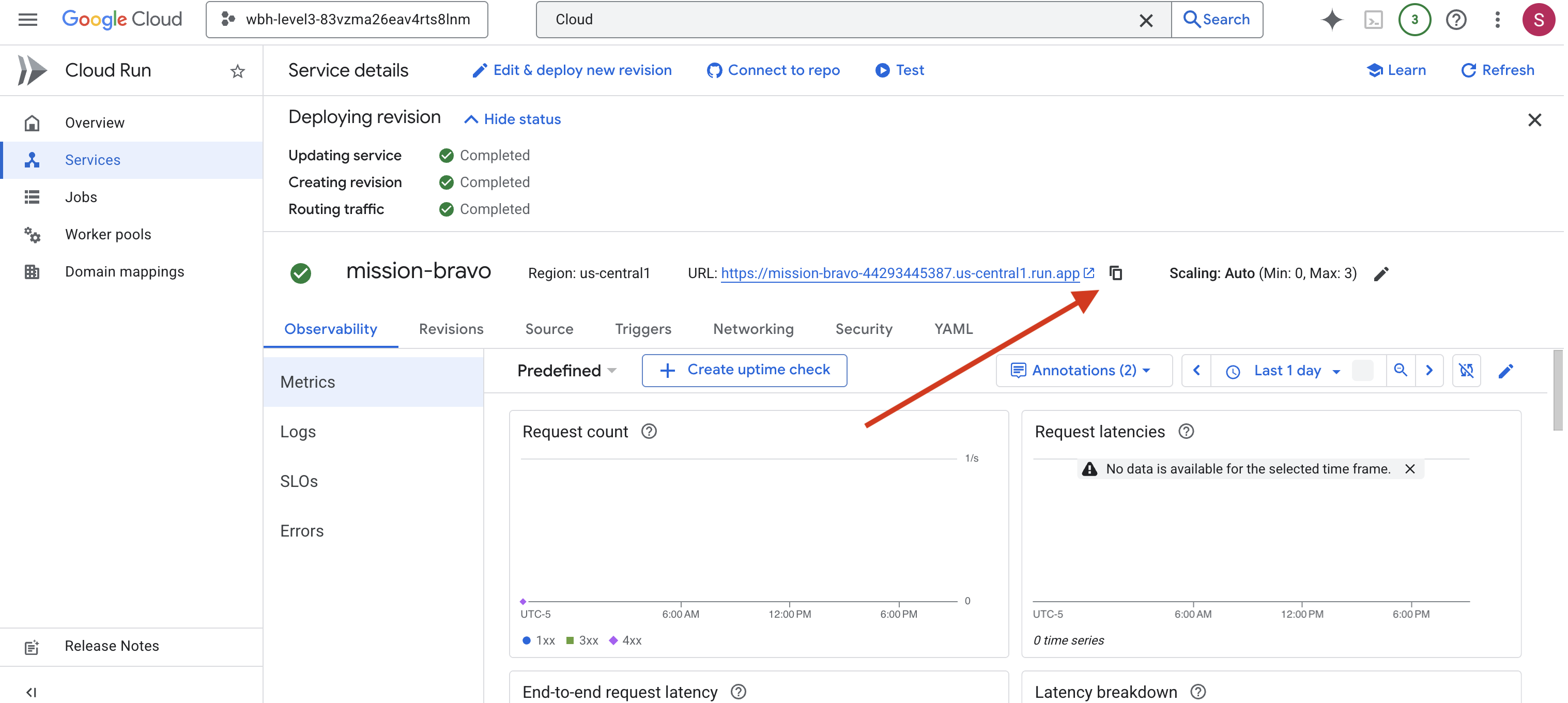
最終システム チェック(エンドツーエンド テスト)
👉 ここからは、実際のシステムを操作します。
- URL を取得する: 最後のデプロイ コマンドの出力からサービス URL をコピーします(末尾は
run.appになります)。 - Cockpit を開く: URL をウェブブラウザに貼り付けます。
- Initiate Contact(お問い合わせを開始): インターフェースが読み込まれたら、画面とマイクへのアクセスを許可してください。
- Request Data(リクエスト データ): ドライブが割り当てられたら、組み立てを開始するよう依頼します。例: 「組み立てを開始」

これで、Google Cloud で完全に実行されるマルチエージェント システムを操作できるようになりました。
マルチエージェント システムが最終封じ込めリングを所定の位置に固定し、不安定な放射線が安定した音に変わります。
「ワープドライブ: 安定化。レスキュー クラフト: エンジン点火。」

モニターには、大気が崩壊する中、オジマンディアスの崩壊する表面をかろうじて逃れ、上空に飛び立つエイリアンの船が映し出されている。船の横の安全な軌道に落ち着き、通信には生存者の声が満ちています。彼らは震えていますが、生きています。救助が完了し、帰宅ルートが確保されると、リモート リンクが切断されます。
おかげで生存者を救出できました。
レベル 0 に参加された方は、帰宅ミッションの進捗状況を忘れずにご確認ください。