1. 미션

고요하고 미지의 우주 공간에 떠 있습니다. 거대한 태양 펄스가 차원 균열을 통해 함선을 찢어버려 별 지도가 없는 우주에 고립되었습니다.
며칠간의 힘든 수리 끝에 드디어 익숙한 엔진 소리가 돌아옵니다. 로켓이 작동 중입니다. 마더십에 장거리 업링크를 설정하는 데 성공했습니다. 출발이 임박했습니다. 이제 집으로 돌아가도 됩니다.
하지만 점프 드라이브를 작동시키려고 할 때 조난 신호가 정적을 뚫고 들려옵니다. 센서가 '오지맨디아스'로 지정된 행성에서 도움을 요청하는 신호를 포착합니다. 생존자들은 죽어가는 세계에 갇혀 있고 배는 멈춰 있습니다. 행성의 대기가 붕괴되기 전에 이들을 구출해야 합니다.
탈출할 수 있는 유일한 방법은 외계인 기술로 만들어진 오래되고 버려진 로켓뿐입니다. 작동은 하지만 워프 드라이브가 부서져 있습니다. 생존자를 구하려면 휘발성 워크벤치에 원격으로 연결하여 교체 드라이브를 수동으로 조립해야 합니다.
과제
이 외계인 기술은 매우 취약한 것으로 알려져 있으며, 여러분은 이 기술에 대한 경험이 없습니다. 불안정한 구성요소는 몇 초 만에 방사성 물질이 될 수 있습니다. 휘발성 워크벤치를 작동할 수 있는 기회가 한 번 있습니다. 현재 AI 어시스턴트는 시각적 데이터와 기술 매뉴얼을 동시에 처리하는 데 어려움을 겪고 있어 환각 증상이 있는 안내와 누락된 위험 경고가 발생합니다.
성공하려면 AI를 모놀리식 엔티티에서 협업 멀티 에이전트 시스템으로 업그레이드해야 합니다.
미션 목표:
새 멀티 에이전트 시스템의 전문적인 실시간 안내에 따라 워프 드라이브를 조립합니다.

빌드 대상
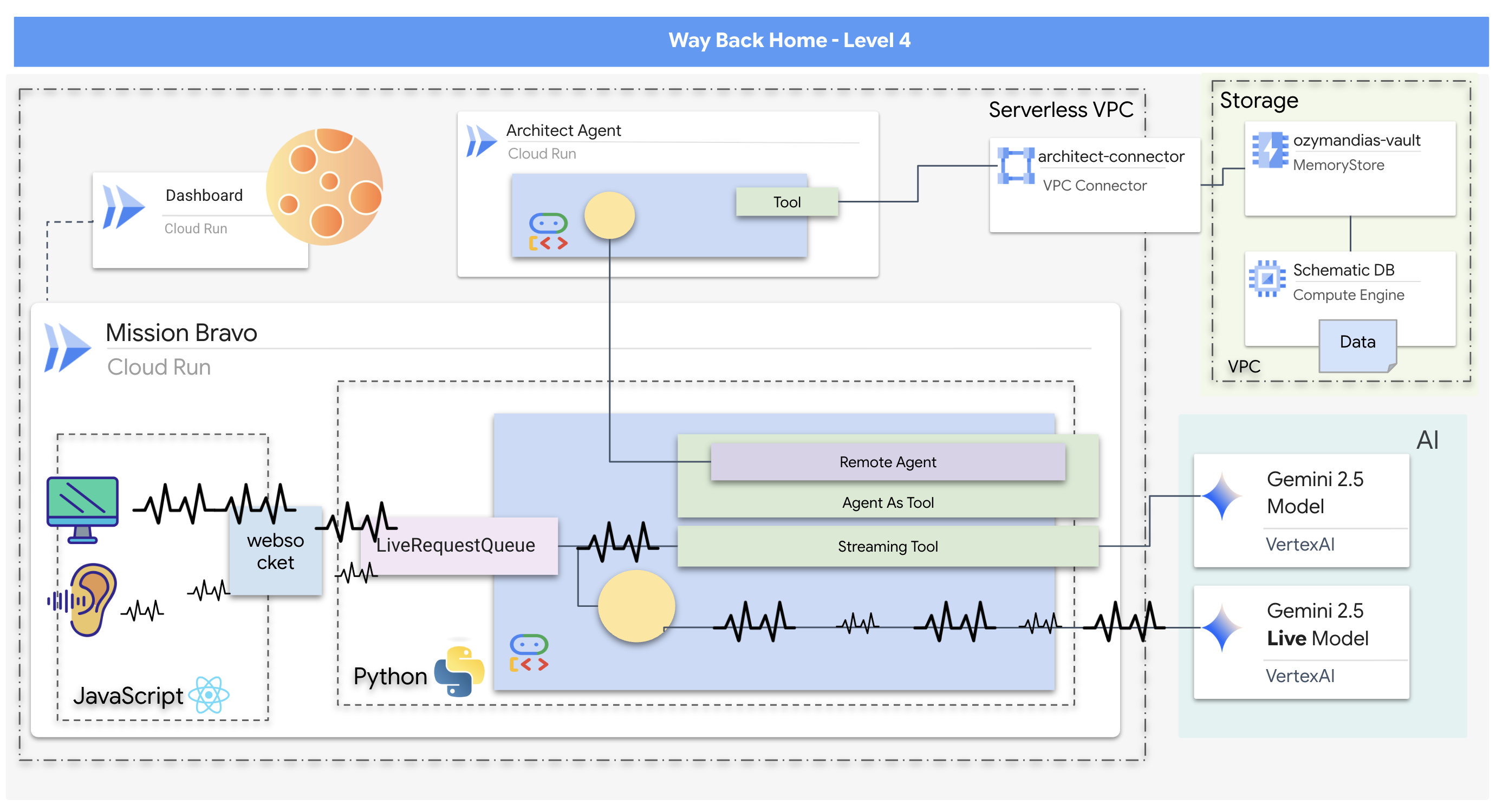
- 사용자 상호작용을 관리하고 전문 에이전트와 협력하는 중앙 디스패치 에이전트가 있는 실시간 양방향 멀티 에이전트 AI 시스템입니다.
- Redis 데이터베이스에 연결하여 개략적인 데이터를 가져오고 제공하는 아키텍트 에이전트
- 스트리밍 도구를 사용하여 라이브 동영상 피드에서 시각적 위험을 분석하고 실시간 알림을 트리거하는 사전 대응형 안전 모니터
- 시스템과 상호작용하고 백엔드 에이전트로 동영상과 오디오를 스트리밍하는 사용자 인터페이스를 제공하는 React 기반 프런트엔드
학습할 내용
기술 / 개념 | 설명 |
Google 에이전트 개발 키트 (ADK) | ADK를 사용하여 에이전트를 빌드, 테스트, 관리하고 실시간 커뮤니케이션, 도구 통합, 에이전트 수명 주기를 처리하는 프레임워크를 활용합니다. |
양방향 (Bidi) 스트리밍 | 자연스럽고 지연 시간이 짧은 양방향 통신을 지원하는 양방향 스트리밍 에이전트를 구현하여 사람과 AI가 모두 실시간으로 중단하고 응답할 수 있습니다. |
멀티 에이전트 시스템 | 기본 에이전트가 전문 에이전트에게 작업을 위임하여 관심사 분리와 확장 가능한 아키텍처를 지원하는 분산 AI 시스템을 설계하는 방법을 알아봅니다. |
에이전트 간 (A2A) 프로토콜 | A2A 프로토콜을 사용하여 디스패치 에이전트와 아키텍트 에이전트 간의 통신을 지원하여 서로의 기능을 검색하고 데이터를 교환할 수 있습니다. |
스트리밍 도구 | 백그라운드 프로세스로 작동하는 스트리밍 도구를 구현하여 동영상 피드를 지속적으로 분석하여 상태 변경 (위험)을 모니터링하고 결과를 사전에 제공합니다. |
Google Cloud Run 및 Memorystore | Cloud Run을 사용하여 에이전트 서비스를 호스팅하고 Memorystore (Redis)를 영구 데이터베이스로 사용하여 전체 멀티 에이전트 애플리케이션을 프로덕션 환경에 배포합니다. |
FastAPI 및 WebSockets | 백엔드는 오디오, 동영상, 에이전트 응답 스트리밍에 필요한 고성능 실시간 통신을 처리하기 위해 FastAPI와 WebSocket을 사용하여 빌드됩니다. |
React 프런트엔드 | 사용자 미디어 (오디오/동영상)를 캡처하고 스트리밍하며 AI 에이전트의 실시간 응답을 표시하는 React 기반 프런트엔드를 사용합니다. |
2. 환경 설정
Cloud Shell 액세스
👉Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다 (Cloud Shell 창 상단의 터미널 모양 아이콘). 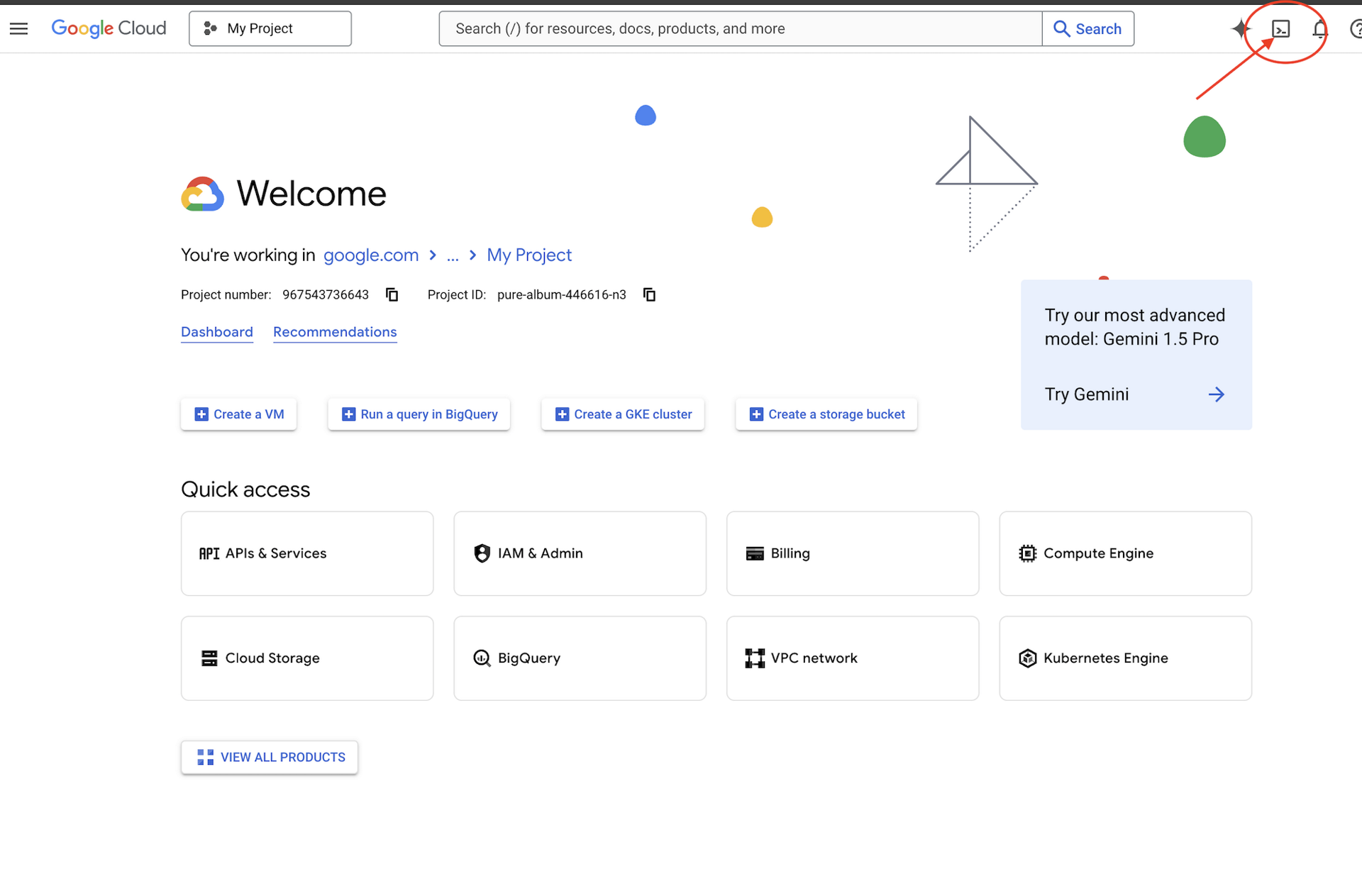
👉'편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 코드 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다. 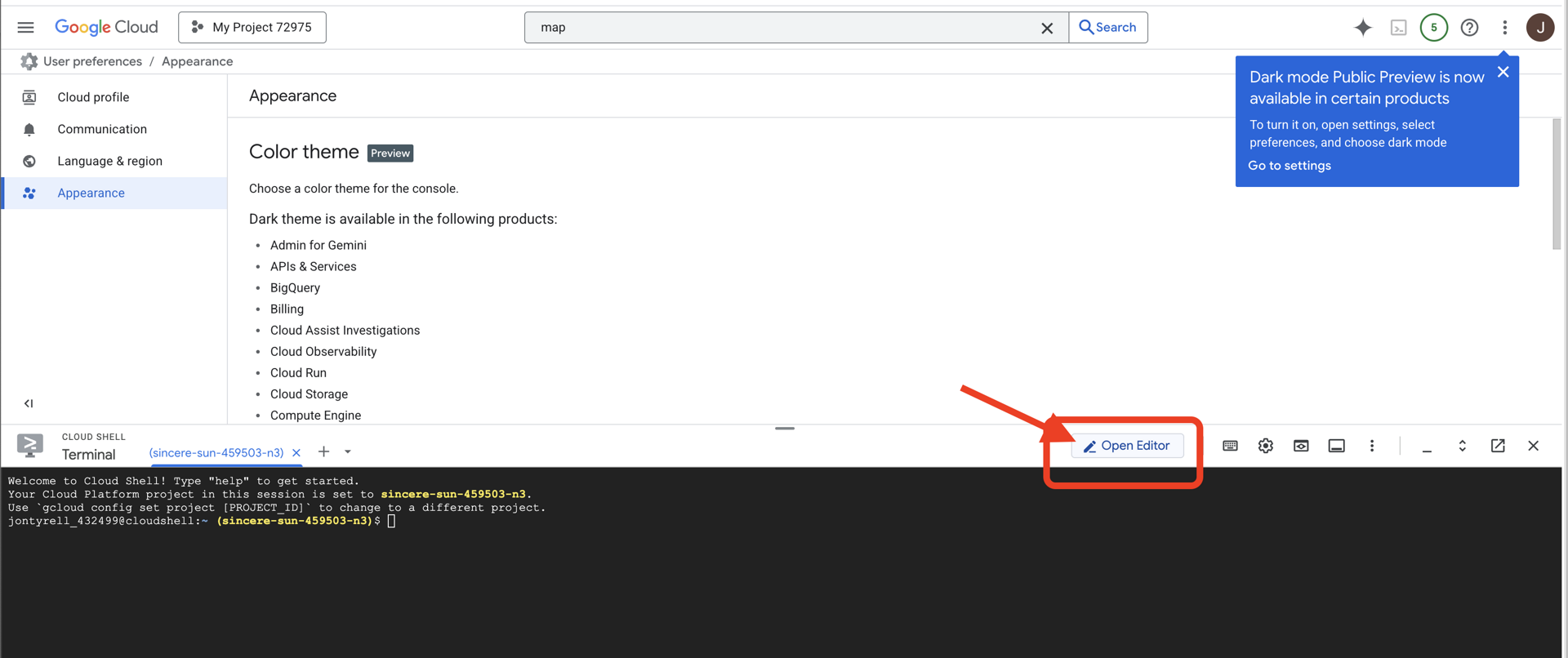
👉클라우드 IDE에서 터미널을 열고
👉💻 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되어 있는지 확인합니다.
gcloud auth list
계정이 (ACTIVE)로 표시됩니다.
기본 요건
ℹ️ 레벨 0은 선택사항이지만 권장됩니다.
레벨 0을 완료하지 않고도 이 미션을 완료할 수 있지만 먼저 완료하면 더 몰입감 있는 환경을 경험할 수 있으며, 진행하면서 전 세계 지도에서 내 비컨이 켜지는 것을 확인할 수 있습니다.
프로젝트 환경 설정
터미널로 돌아가 활성 프로젝트를 설정하고 필요한 Google Cloud 서비스 (Cloud Run, Vertex AI 등)를 사용 설정하여 구성을 완료합니다.
👉💻 터미널에서 프로젝트 ID를 설정합니다.
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 필수 서비스 사용 설정:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
종속 항목 설치
👉💻 4단계로 이동하여 필요한 Python 패키지를 설치합니다.
cd $HOME/way-back-home/level_4
uv sync
주요 종속 항목은 다음과 같습니다.
패키지 | 목적 |
| 위성 방송국 및 SSE 스트리밍을 위한 고성능 웹 프레임워크 |
| FastAPI 애플리케이션을 실행하는 데 필요한 ASGI 서버 |
| Formation Agent를 빌드하는 데 사용되는 에이전트 개발 키트 |
| 표준화된 통신을 위한 에이전트 간 프로토콜 라이브러리 |
| Gemini 모델에 액세스하기 위한 네이티브 클라이언트 |
| Schematic Vault (Memorystore)에 연결하기 위한 Python 클라이언트 |
| 실시간 양방향 통신 지원 |
| 환경 변수 및 구성 보안 비밀을 관리합니다. |
| 데이터 검증 및 설정 관리 |
설정 확인
코드를 시작하기 전에 모든 시스템이 정상인지 확인해 보겠습니다. 확인 스크립트를 실행하여 Google Cloud 프로젝트, API, Python 종속 항목을 감사합니다.
👉💻 확인 스크립트 실행:
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 일련의 녹색 체크표시 (✅)가 표시됩니다.
- 빨간색 십자 (❌)가 표시되면 출력에 제안된 수정 명령어 (예:
gcloud services enable ...또는pip install ...)를 따릅니다. - 참고: 현재는
.env에 대한 노란색 경고가 표시되어도 괜찮습니다. 다음 단계에서 해당 파일을 만듭니다.
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Redis에서 스키마 보관소 빌드 및 ADK를 사용한 양방향 에이전트 빌드
버려진 로켓의 청사진이 포함된 행성 도식 저장소를 찾았습니다. 이 데이터를 정확하게 가져오려면 저장소의 전용 관리 인터페이스인 Architect 에이전트와 인터페이스해야 합니다.
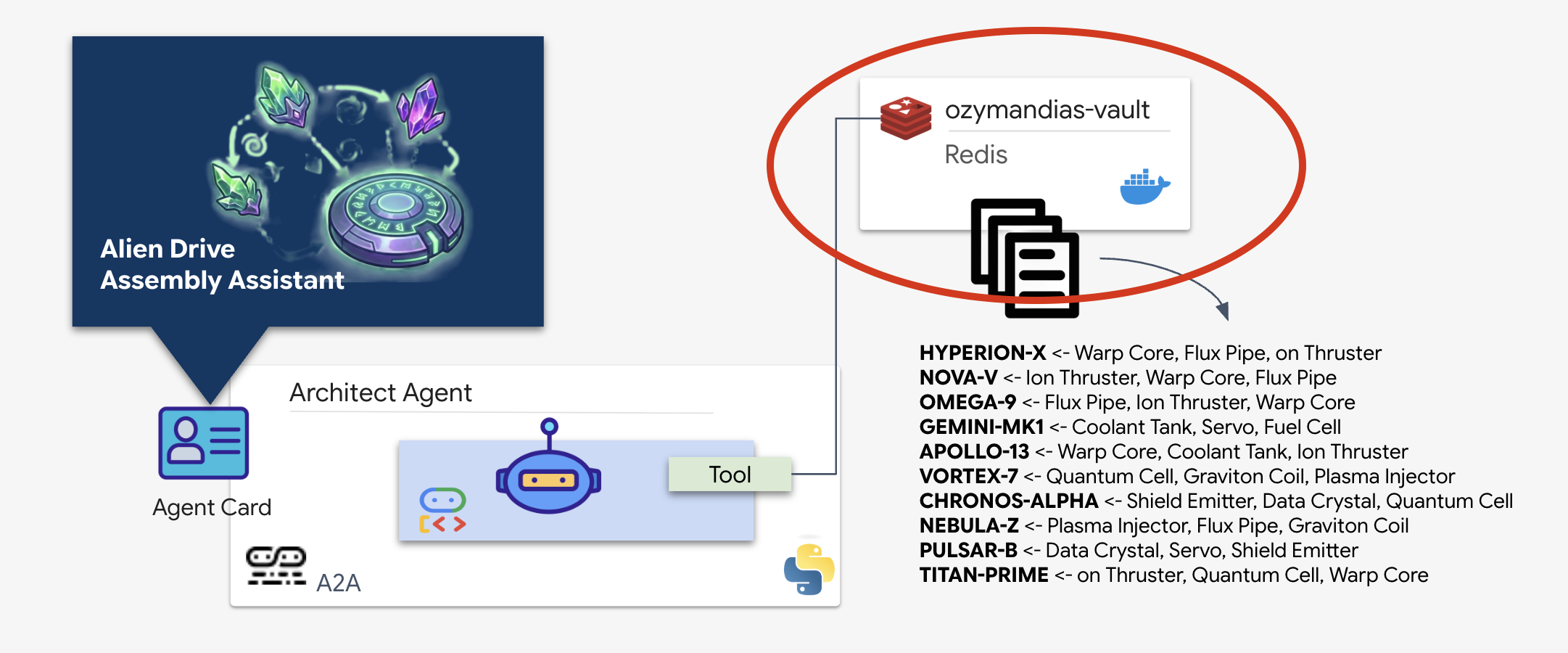
Schematic Vault (Redis) 프로비저닝
아키텍트의 지원을 받기 전에 데이터가 안전한 고가용성 환경에서 호스팅되는지 확인해야 합니다. 외계인 설계도의 빠른 데이터 스토어로 Redis를 사용합니다. 개발의 편의를 위해 로컬 Redis 인스턴스를 실행하지만 Google Cloud Memorystore를 사용하여 프로덕션 환경에 배포하는 방법에 관한 안내는 나중에 제공됩니다.
👉💻 터미널에서 다음 명령어를 실행하여 Redis 인스턴스를 프로비저닝합니다 (2~3분 정도 걸릴 수 있음).
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 예비 데이터를 로드하려면 다음을 실행하여 Redis Shell을 입력합니다.
docker exec -it ozymandias-vault redis-cli
(프롬프트가 127.0.0.1:6379으로 변경됩니다.)
👉💻 다음 명령어를 내부에 붙여넣습니다.
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 exit를 입력하여 일반 셸로 돌아갑니다.
👉💻 터미널에서 직접 특정 선박을 쿼리하여 데이터가 있는지 확인하려면 다음을 실행하세요.
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 예상 출력은 다음과 같습니다.
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
아키텍트 에이전트 구현
설계사 에이전트는 Redis 보관소에서 개략적인 청사진을 검색하는 역할을 하는 전문 에이전트입니다. 기본 디스패치 에이전트가 기본 데이터베이스 로직을 알 필요 없이 정확하고 구조화된 정보를 수신할 수 있도록 전용 데이터 인터페이스 역할을 합니다.
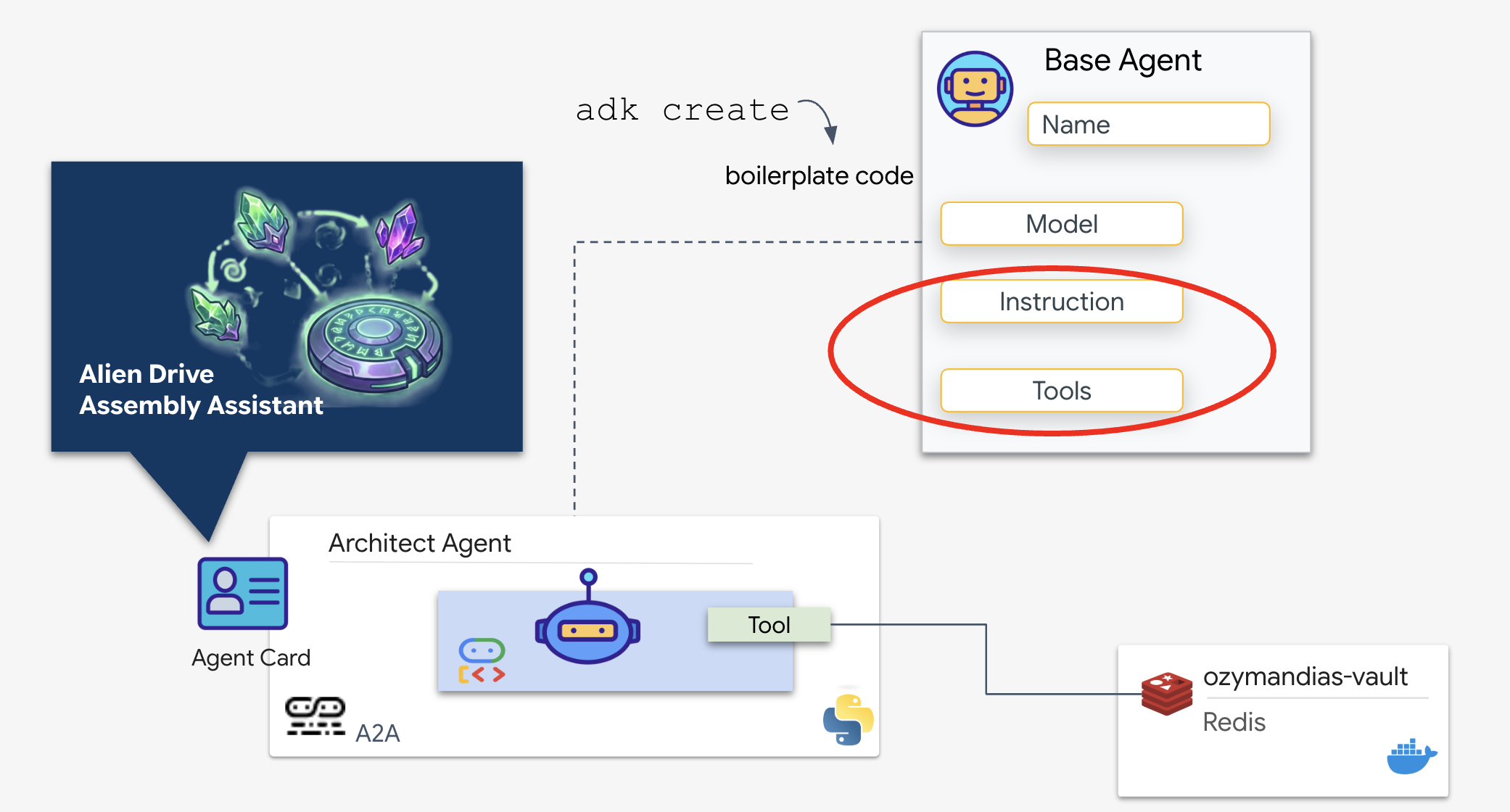
Google 에이전트 개발 키트 (ADK)는 이러한 멀티 에이전트 설정을 가능하게 하는 모듈식 프레임워크입니다. 이 계층은 두 가지 중요한 계층을 처리합니다.
- 연결 및 세션 수명 주기: 실시간 API와 상호작용하려면 핸드셰이크, 인증, 연결 유지 신호를 처리하는 복잡한 프로토콜 관리가 필요합니다.
- 함수 호출: '모델-코드-모델 왕복'입니다. LLM은 데이터가 필요하다고 판단되면 구조화된 함수 호출을 출력합니다. ADK는 이를 가로채고 Python 코드 (
lookup_schematic_tool)를 실행하며 결과를 밀리초 단위로 모델의 컨텍스트에 다시 제공합니다.
이제 Architect를 빌드합니다. 이 에이전트에는 카메라 액세스 권한이 없습니다. '드라이브 이름'을 수신하고 데이터베이스에서 '부품 목록'을 반환하기 위해서만 존재합니다.
👉💻 adk create 명령어를 사용합니다. 이는 에이전트 개발 키트 (ADK)의 도구로, 새 에이전트의 상용구 코드와 파일 구조를 자동으로 생성하여 설정 시간을 절약해 줍니다.
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
에이전트 구성
CLI에서 대화형 설정 마법사가 실행됩니다. 다음 응답을 사용하여 에이전트를 구성하세요.
- 모델 선택: 옵션 1 (Gemini Flash)을 선택합니다.
- 참고: 특정 버전 (예: 2.5, 3.0)은 사용 가능 여부에 따라 다를 수 있습니다. 속도를 위해 항상 'Flash' 변형을 선택하세요.
- 백엔드 선택: 옵션 2 (Vertex AI)를 선택합니다.
- Google Cloud 프로젝트 ID 입력: Enter 키를 눌러 기본값 (환경에서 감지됨)을 수락합니다.
- Google Cloud 리전 입력: Enter 키를 눌러 기본값 (
us-central1)을 수락합니다.
👀 터미널 상호작용은 다음과 비슷해야 합니다.
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
이제 Agent created 성공 메시지가 표시됩니다. 이렇게 하면 다음 단계에서 수정할 스켈레톤 코드가 생성됩니다.
👉✏️ 편집기에서 새로 만든 $HOME/way-back-home/level_4/backend/architect_agent/agent.py 파일로 이동하여 엽니다. 첫 번째 import 줄 뒤에 도구 스니펫을 파일에 추가합니다.
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ root_agent 정의의 전체 instruction 줄을 다음으로 바꾸고 앞에서 정의한 도구도 추가합니다.
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
ADK의 장점
이제 Architect가 온라인 상태이므로 정보 소스가 있습니다. 이 기능을 기본 에이전트에 연결하기 전에 에이전트 개발 키트 (ADK)를 사용하면 AI 에이전트 빌드 및 테스트의 복잡성을 간소화하여 상당한 이점을 얻을 수 있습니다. adk web 개발자 콘솔이 내장되어 있어 더 큰 멀티 에이전트 시스템에 통합하기 전에 Architect Agent의 기능, 특히 도구 호출 기능을 격리하여 확인할 수 있습니다. 개발 및 테스트에 대한 이러한 모듈식 접근 방식은 강력하고 안정적인 AI 애플리케이션을 빌드하는 데 중요합니다.
👉💻 터미널에서 다음을 실행합니다.
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 다음이 표시될 때까지 기다립니다.
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다. 포트 변경을 선택하고 8000으로 설정한 다음 변경 및 미리보기를 클릭합니다.
- architect_agent를 선택합니다.
- 도구 트리거: 채팅 인터페이스에
CHRONOS-ALPHA(또는 회로도 데이터베이스의 드라이브 ID)를 입력합니다. - 행동 관찰:
- 설계자는 즉시
lookup_schematic_tool를 트리거해야 합니다. - 엄격한 시스템 지침으로 인해 대화형 필러 없이 부품 목록 (예:
['Shield Emitter', 'Data Crystal', 'Quantum Cell'])만 반환해야 합니다.
- 설계자는 즉시
- 로그 확인: 터미널 창을 확인합니다.
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']와 같은 성공적인 실행 로그가 표시됩니다. !(architect_agent adk)[img/03-02-adkweb.png]
도구 실행 로그와 정리된 데이터 응답이 표시되면 전문가 에이전트가 의도한 대로 작동하는 것입니다. 요청을 처리하고, 보관소를 쿼리하고, 구조화된 데이터를 반환할 수 있습니다.
👉💻 종료하려면 Ctrl+C을 누르세요.
A2A 서버 초기화
디스패치 에이전트를 아키텍트에 연결하기 위해 에이전트 간 (A2A) 프로토콜을 사용합니다.
MCP (모델 컨텍스트 프로토콜)와 같은 프로토콜은 에이전트를 도구에 연결하는 데 중점을 두는 반면 A2A는 에이전트를 다른 에이전트에 연결하는 데 중점을 둡니다. 디스패처가 아키텍트를 '검색'하고 회로도를 조회하는 기능을 이해할 수 있도록 하는 표준입니다.
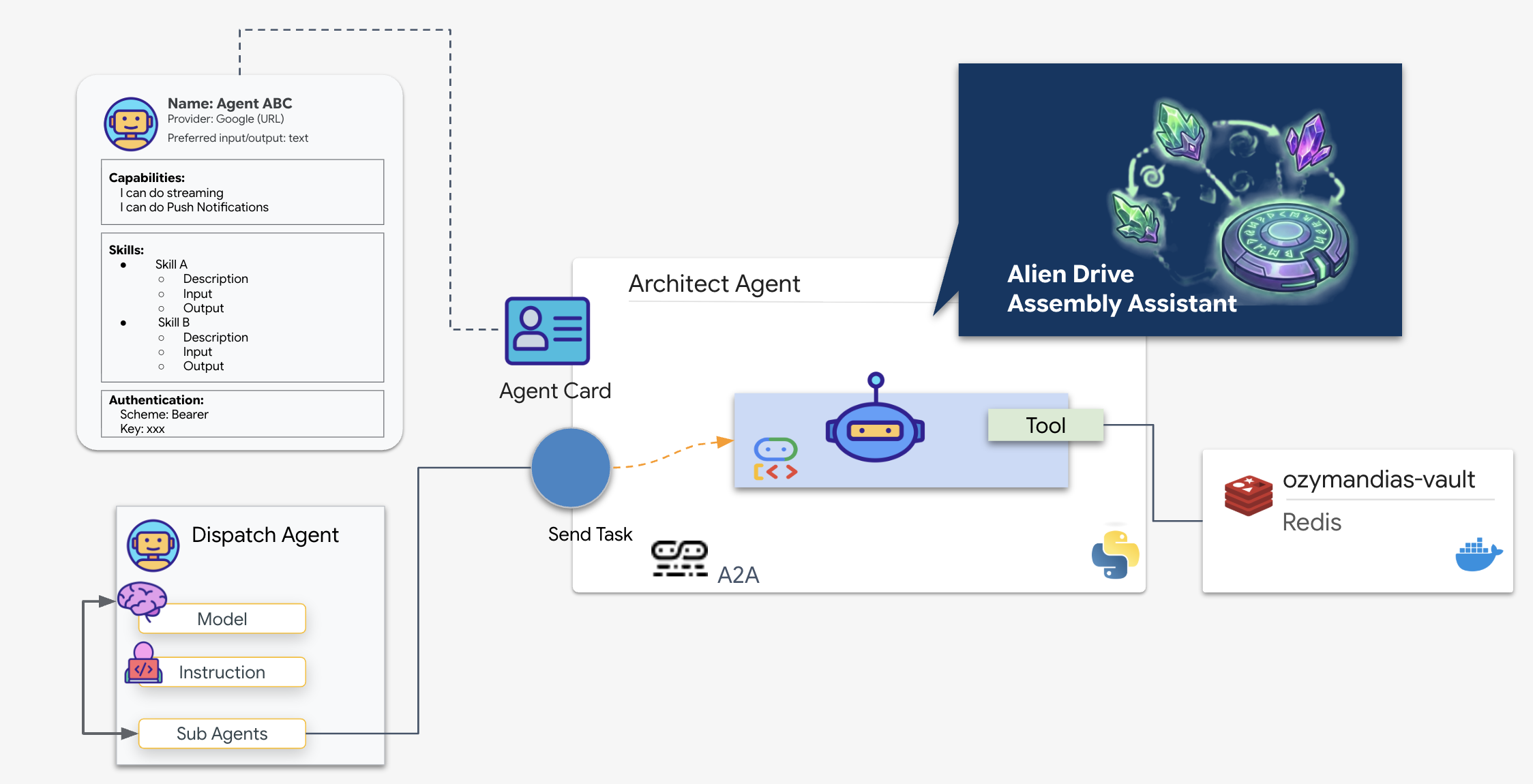
A2A 흐름: 이 미션에서는 클라이언트-서버 모델을 사용합니다.
- 서버 (아키텍트): 데이터베이스 도구를 호스팅하고 에이전트 카드를 통해 기술을 '광고'합니다.
- 클라이언트 (디스패치): 건축가의 카드를 읽고 API를 이해하며 개략적인 요청을 보냅니다.
에이전트 카드란 무엇인가요?
에이전트 카드는 AI의 디지털 명함 또는 '운전면허증'이라고 생각하면 됩니다. A2A 서버가 시작되면 다음을 포함하는 이 JSON 객체를 게시합니다.
- ID: 상담사의 이름 (
architect_agent) 및 ID입니다. - 설명: 시스템의 기능을 사람이 읽을 수 있고 머신이 읽을 수 있는 방식으로 요약한 내용입니다 ('시스템 역할: 데이터베이스 API...').
- 인터페이스: 예상되는 특정 입력 키 (
drive_name) 및 출력 형식입니다.
이 카드가 없으면 디스패치 에이전트는 아키텍트와 소통하는 방법을 추측하며 맹목적으로 운영됩니다.
서버 코드 만들기
👉✏️ 편집기에서 $HOME/way-back-home/level_4/backend/architect_agent 디렉터리 아래에 server.py이라는 파일을 만들고 다음 코드를 붙여넣습니다.
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 터미널로 돌아가 폴더로 이동하여 서버를 시작합니다.
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 A2A 서버가 시작되는지 확인합니다.
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
에이전트 카드 확인
새 터미널 탭을 엽니다 (+ 아이콘 클릭). 아키텍트가 에이전트 카드를 수동으로 가져와 ID를 올바르게 브로드캐스트하는지 확인합니다.
👉💻 다음 명령어를 실행합니다.
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 JSON 응답이 표시됩니다. 출력에서 description 필드를 찾습니다. 이전 ("SYSTEM ROLE: Database API...")에 상담사에게 제공한 지침과 일치해야 합니다.
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
이 JSON이 표시되면 아키텍트가 라이브 상태이고, A2A 프로토콜이 활성 상태이며, 에이전트 카드가 디스패처에 의해 검색될 준비가 된 것입니다.
이제 아키텍트가 원격 리소스로 제공될 준비가 되었으므로 디스패치 에이전트에 연결할 수 있습니다.
👉💻 Ctrl+C를 눌러 A2A 서버를 종료합니다.
4. BIDI-Streams 에이전트를 원격 에이전트 및 스트리밍 도구에 연결
이제 실시간 데이터와 원격 설계자 간의 격차를 해소하기 위해 기본 커뮤니케이션 허브를 구성합니다. 이 연결에는 작동 중에 조립대가 안정적으로 유지되도록 높은 대역폭과 짧은 지연 시간 파이프라인이 필요합니다.
양방향 스트리밍 (라이브) 상담사 이해하기
ADK의 양방향 스트리밍은 Gemini Live API의 지연 시간이 짧은 양방향 음성 및 동영상 상호작용 기능을 AI 에이전트에 추가합니다. 이는 기존 AI 상호작용과는 근본적으로 다른 방식입니다. 엄격한 '질문하고 기다리기' 패턴 대신 사람과 AI가 동시에 말하고, 듣고, 응답할 수 있는 실시간 양방향 커뮤니케이션이 가능합니다.
이메일을 보내는 것과 전화 통화를 하는 것의 차이를 생각해 보세요. 기존 상담사 상호작용은 이메일과 같습니다. 완전한 메시지를 보내고 완전한 응답을 기다린 다음 다른 메시지를 보냅니다. 양방향 스트리밍은 전화 대화와 같습니다. 유연하고 자연스러우며, 실시간으로 중단하고, 명확히 하고, 응답할 수 있습니다.
주요 특징:
- 양방향 통신: 완전한 응답을 기다리지 않고 지속적으로 데이터를 교환합니다. AI는 사용자의 말이 끝나면 즉시 대답합니다.
- 응답형 인터럽트: 사용자는 사람과의 대화에서와 마찬가지로 에이전트가 응답하는 도중에 새로운 입력으로 인터럽트할 수 있습니다. AI가 복잡한 단계를 설명하고 있는데 '잠깐, 다시 말해 줘'라고 말하면 AI는 즉시 중지하고 사용자의 중단에 응답합니다.
- 멀티모달에 최적화: 양방향 스트리밍은 다양한 입력 유형을 동시에 처리하는 데 탁월합니다. 동영상을 통해 외계인 부분을 보여주면서 상담사에게 말할 수 있으며, 상담사는 단일 통합 연결에서 두 스트림을 모두 처리합니다.
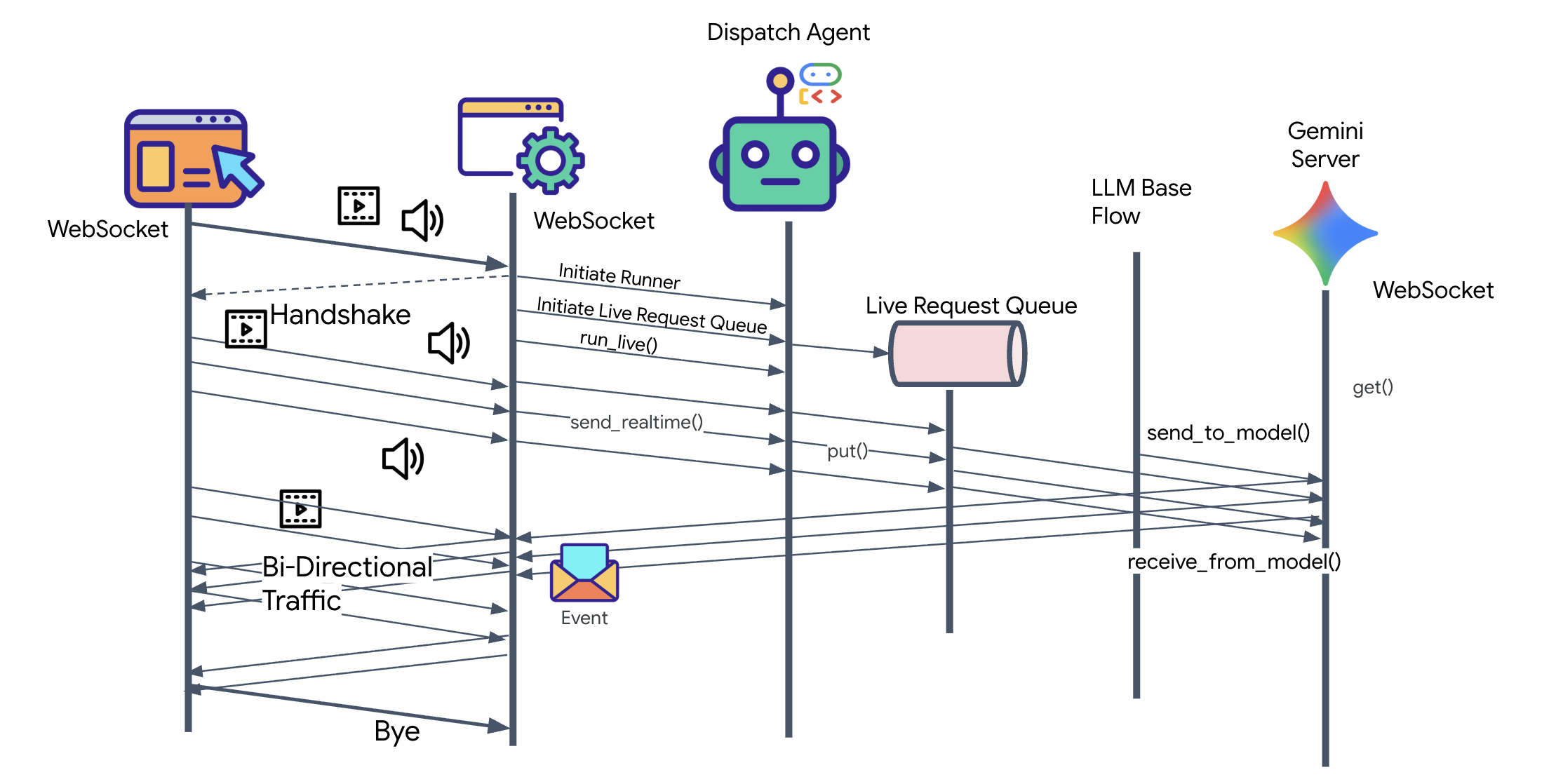
👀 클라이언트 로직을 구현하기 전에 생성된 디스패치 에이전트의 스켈레톤을 살펴보겠습니다. 이 에이전트는 음성 및 영상을 통해 사용자와 소통하고 쿼리를 아키텍트 에이전트에 위임합니다.
__init__.py agent.py hazard_db.py
agent.py: '브레인'입니다. 현재 기본 양방향 스트리밍 설정이 포함되어 있습니다. 이 파일을 수정하여 A2A 클라이언트 로직을 추가하여 Architect와 통신할 수 있도록 합니다.hazard_db.py: 안전 프로토콜이 포함된 디스패치 에이전트 전용 로컬 도구입니다. 이는 설계자의 개략적인 데이터베이스와는 별개입니다.
A2A 클라이언트 구현
디스패치 에이전트가 원격 아키텍트와 통신할 수 있도록 원격 A2A 에이전트를 정의해야 합니다. 이렇게 하면 디스패치 에이전트가 아키텍트를 찾을 위치와 '에이전트 카드'의 모양을 알 수 있습니다.
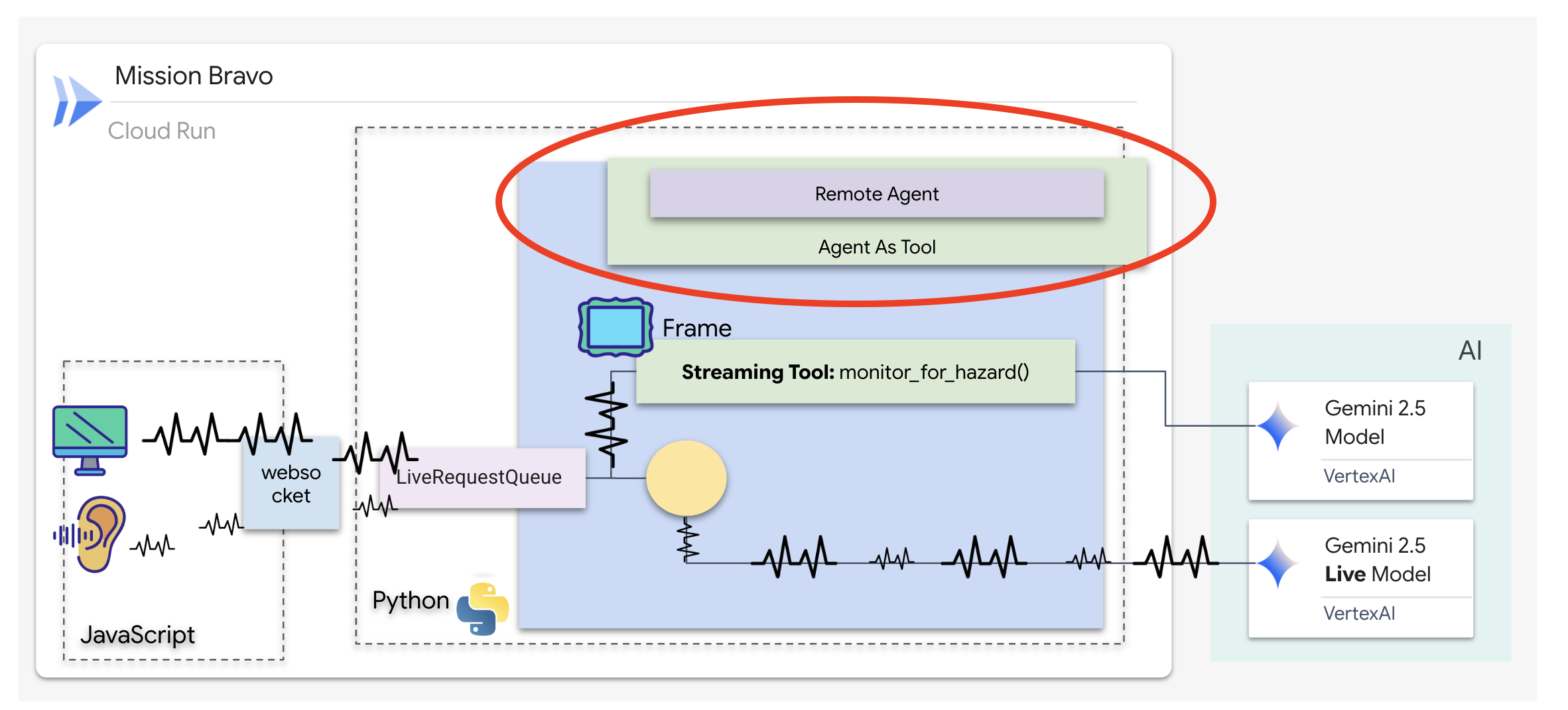
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py의 #REPLACE-REMOTEA2AAGENT를 다음으로 바꿉니다.
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
스트리밍 도구 작동 방식
이전 에이전트에서는 도구가 표준 '요청-응답' 패턴을 따랐습니다. 에이전트가 질문하고 도구가 답변을 제공하면 상호작용이 종료됩니다. 하지만 오지맨디아스에서는 위험이 사용자가 있는지 묻기를 기다리지 않습니다. 이를 위해서는 스트리밍 도구가 필요합니다.
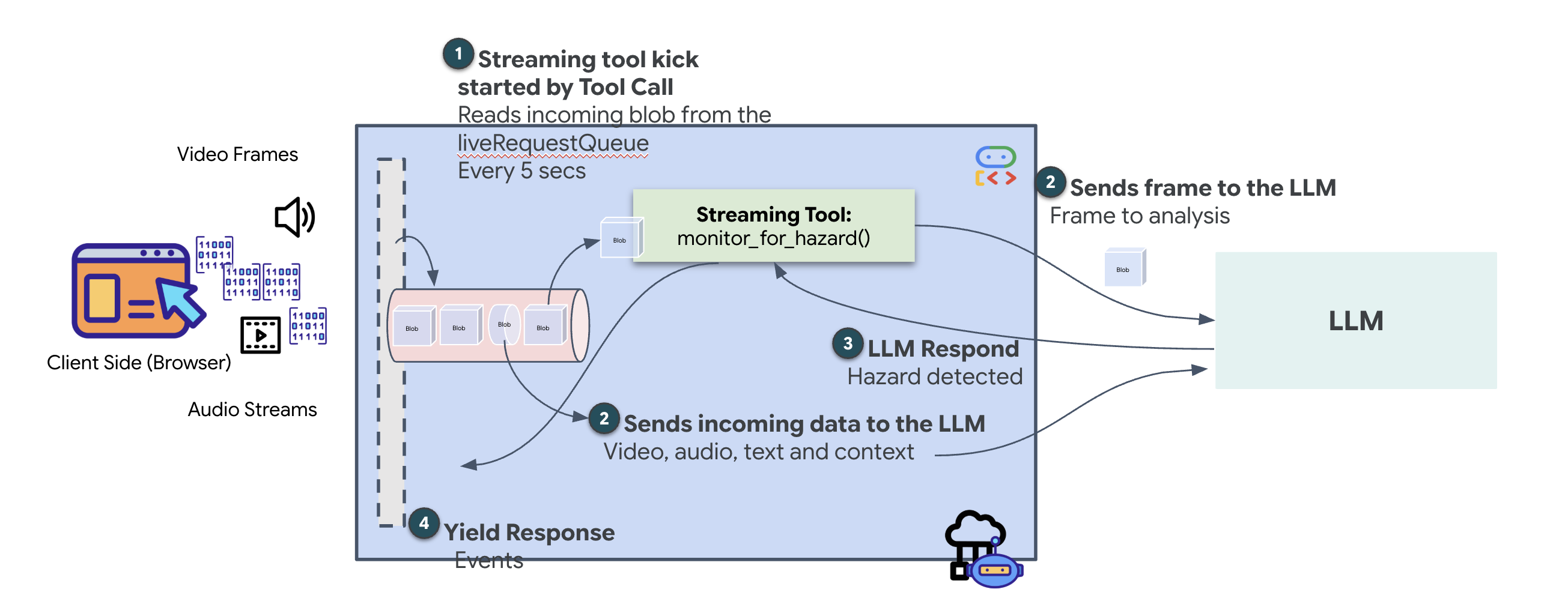
스트리밍 도구를 사용하면 함수가 중간 결과를 에이전트에게 실시간으로 스트리밍하여 에이전트가 변경사항에 즉시 대응할 수 있습니다. 일반적인 사용 사례로는 변동하는 주가를 모니터링하거나, Google의 경우 상태 변경을 위해 라이브 동영상 스트림을 모니터링하는 것이 있습니다.
표준 도구와 달리 스트리밍 도구는 AsyncGenerator 역할을 하는 비동기 함수입니다. 즉, 단일 값을 return하는 대신 시간이 지남에 따라 여러 업데이트를 yield합니다.
ADK에서 스트리밍 도구를 정의하려면 다음 기술 요구사항을 준수해야 합니다.
- 비동기 함수: 도구는
async def로 정의해야 합니다. - AsyncGenerator 반환 유형: 함수가
AsyncGenerator를 반환하도록 입력해야 합니다. 첫 번째 매개변수는 생성되는 데이터의 유형 (예:str)이고 두 번째 매개변수는 일반적으로None입니다. - 입력 스트림: Google은 동영상 스트리밍 도구를 사용합니다. 이 모드에서는 실제 동영상/오디오 스트림 (
LiveRequestQueue)이 함수에 직접 전달되므로 도구에서 상담사가 보는 것과 동일한 프레임을 '볼' 수 있습니다.
스트리밍 도구를 센티널이라고 생각해 보세요. 사용자와 디스패치 에이전트가 청사진을 논의하는 동안 센티널은 백그라운드에서 실행되며 모든 동영상 프레임을 자동으로 처리하여 사용자의 안전을 보장합니다.
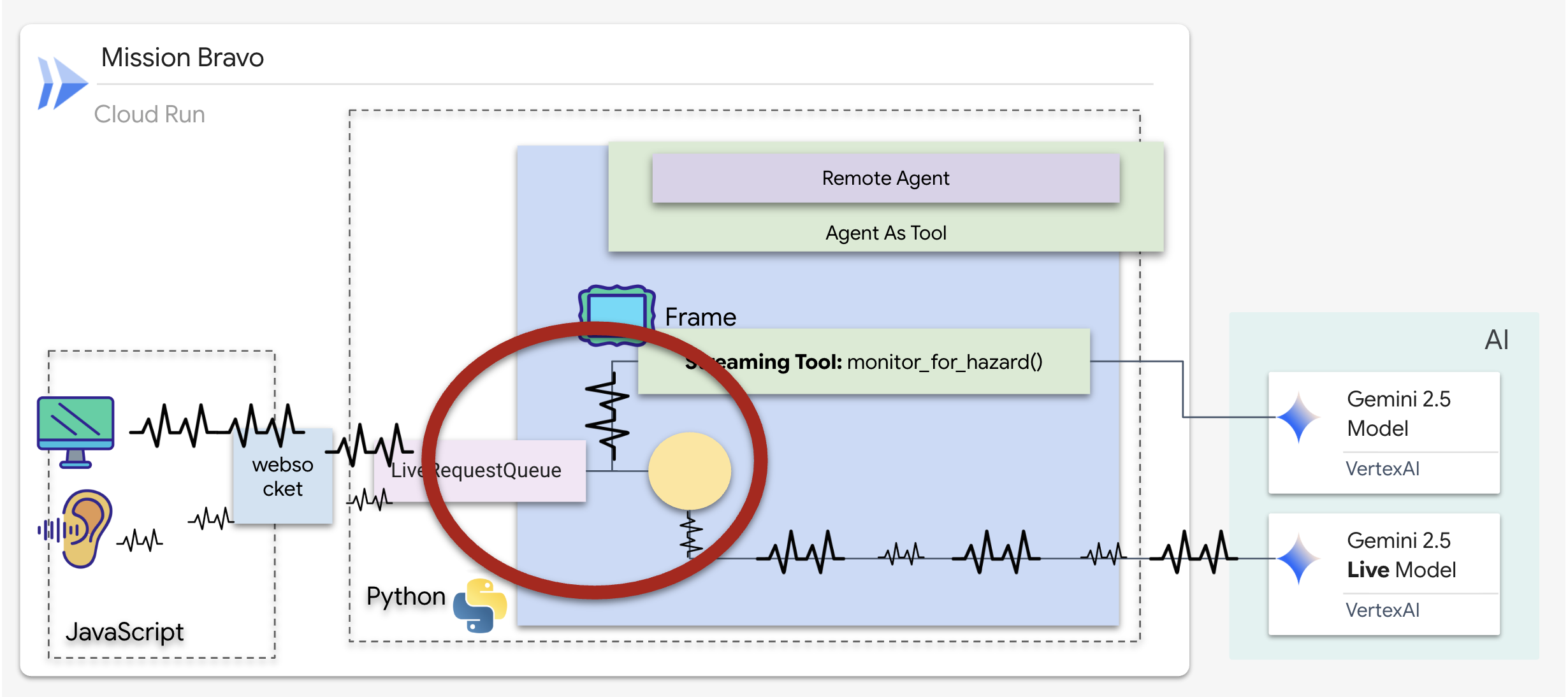
백그라운드 모니터링 도구 구현
이제 monitor_for_hazard 도구를 구현합니다. 이 도구는 input_stream (동영상 프레임)을 인그레스하고, 별도의 경량 시각 호출을 사용하여 분석하며, 위험이 감지된 경우에만 경고를 yield합니다.
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py에서 #REPLACE_MONITOR_HAZARD를 다음 로직으로 바꿉니다.
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
디스패치 에이전트 구현
디스패치 에이전트는 기본 인터페이스이자 오케스트레이터입니다. 양방향 스트리밍 링크 (라이브 음성 및 동영상)를 관리하므로 항상 대화 제어 권한을 유지해야 합니다. 이를 위해 Agent-as-a-Tool이라는 특정 ADK 기능을 사용합니다.
개념: 도구로서의 에이전트와 하위 에이전트
멀티 에이전트 시스템을 빌드할 때는 책임을 공유하는 방법을 결정해야 합니다. 구조 임무에서 이 구분은 매우 중요합니다.
- Agent-as-a-Tool: 양방향 스트리밍 허브에 권장되는 접근 방식입니다. 디스패치 에이전트 (에이전트 A)가 아키텍트 에이전트 (에이전트 B)를 도구로 호출하면 아키텍트의 데이터가 디스패치에 다시 전달됩니다. 그러면 Dispatch가 데이터를 해석하고 응답을 생성합니다. 디스패치가 제어권을 유지하고 이후의 모든 사용자 입력을 계속 처리합니다.
- 하위 에이전트: 하위 에이전트 관계에서는 책임이 완전히 이전됩니다. 디스패치에서 하위 에이전트로서 아키텍트에게 인계한 경우 '비전'도 없고 대화 기술도 없는 데이터베이스 API와 직접 대화하게 됩니다. 기본 상담사 (Dispatch)는 효과적으로 루프에서 벗어나게 됩니다.
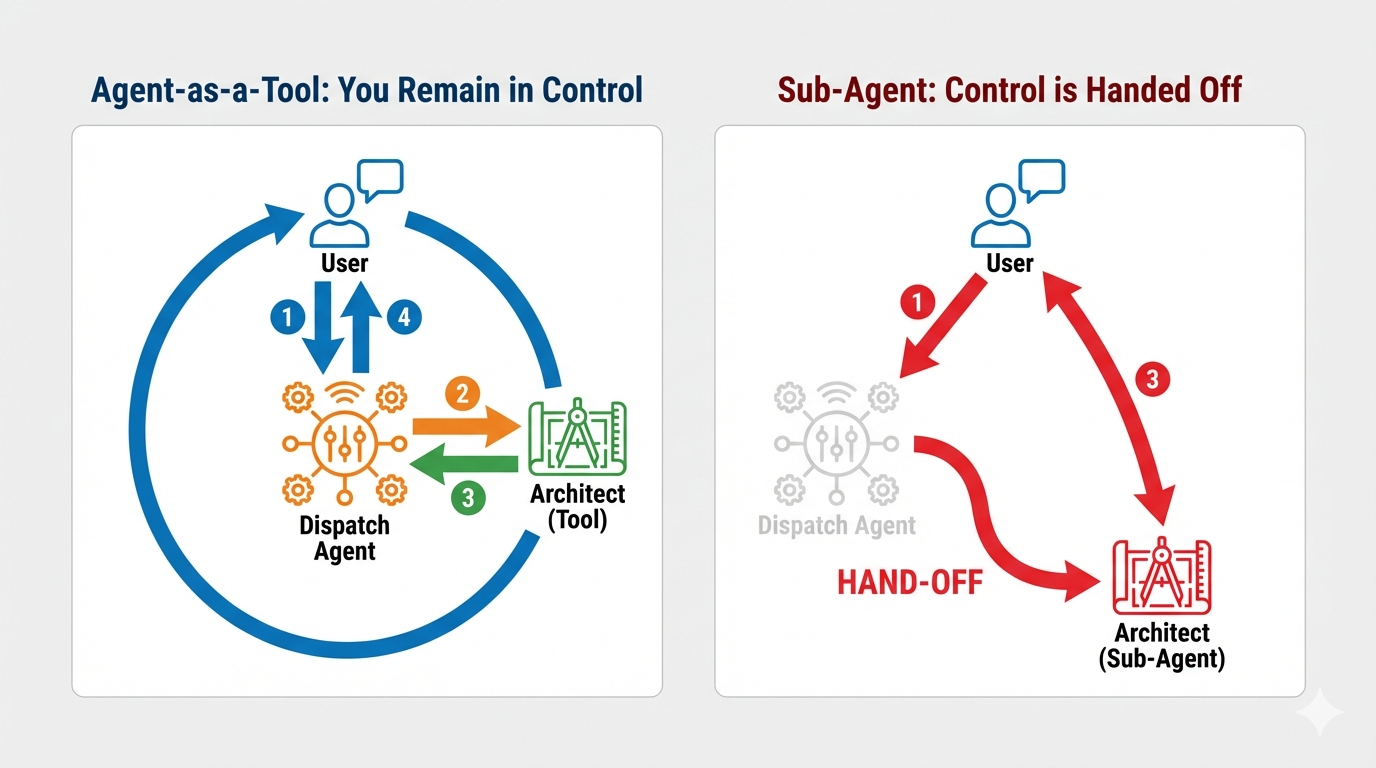
Agent-as-a-Tool을 사용하면 양방향 스트리밍 에이전트의 유연하고 인간적인 상호작용을 유지하면서도 Architect의 전문 지식을 활용할 수 있습니다.
라우팅 로직 코딩
이제 architect_agent를 AgentTool로 래핑하고 디스패치 에이전트에 '로직 맵'을 제공합니다. 이 지도는 에이전트가 Vault에서 데이터를 가져와야 하는 시점과 백그라운드 센티넬에서 발견 사항을 보고해야 하는 시점을 정확하게 알려줍니다.
Dispatch에 깜박이지 않는 '눈'을 제공하려면 이전 단계에서 빌드한 스트리밍 도구에 대한 액세스 권한을 부여해야 합니다.
ADK에서 AsyncGenerator 함수 (예: monitor_for_hazard)를 tools 목록에 추가하면 에이전트가 이를 지속적인 백그라운드 프로세스로 취급합니다. 일회성 실행 대신 에이전트가 도구의 출력에 '구독'합니다. 이렇게 하면 Sentinel이 백그라운드에서 위험 알림을 조용히 생성하는 동안 Dispatch가 기본 대화를 계속할 수 있습니다.
👉✏️ $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py의 #REPLACE_AGENT_TOOLS를 다음으로 바꿉니다.
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
인증
👉💻 두 에이전트가 모두 구성되었으므로 실시간 멀티 에이전트 상호작용을 테스트할 수 있습니다.
- 터미널 A에서 Architect Agent를 시작합니다.
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- 새 터미널 (터미널 B)에서 디스패치 에이전트를 실행합니다.
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
adk web 시뮬레이터 내에서 gemini-live와 같은 실시간 멀티모달 모델을 사용하는 멀티 에이전트 시스템을 테스트하려면 특정 워크플로가 필요합니다. 시뮬레이터는 도구 호출을 검사하는 데 유용하지만, 이러한 유형의 모델로 이미지를 처음 처리할 때 호환되지 않는 것으로 알려져 있습니다.
- Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다. 포트 변경을 선택하고 8000으로 설정한 후 변경 및 미리보기를 클릭합니다.
👉dispatch_agent를 선택하고 블루프린트를 업로드하고 예상되는 오류 처리
가장 중요한 단계입니다. 이미지 컨텍스트를 에이전트에게 제공해야 합니다.
- 인터페이스가 로드되면 메시지가 표시될 때 마이크에 액세스하도록 허용합니다.
- 이 청사진 이미지를 컴퓨터에 다운로드합니다.
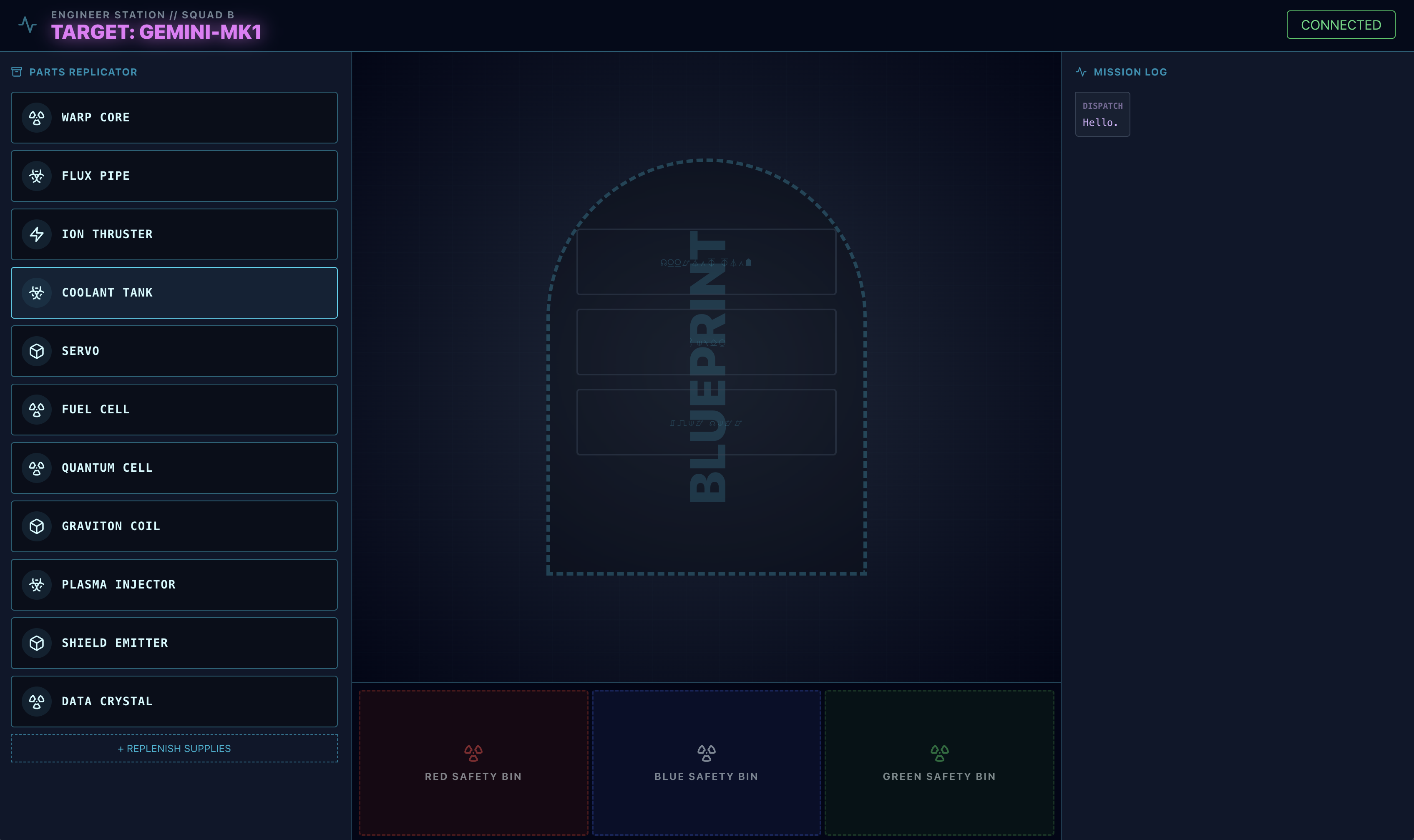
adk web인터페이스에서 클립 아이콘을 클릭하고 방금 다운로드한 청사진 이미지를 업로드합니다.
⚠️⚠️400 INVALID_ARGUMENT 오류가 표시됩니다. 이는 정상적인 동작입니다.⚠️⚠️
이 오류는 adk web 이미지 핸들러가 일회성 업로드를 위한 gemini-live 모델의 API와 완전히 호환되지 않기 때문에 발생합니다. 하지만 이미지가 세션 컨텍스트에 추가되었습니다.
- 👉 오류를 해결하려면 브라우저 페이지를 새로고침하면 됩니다.
어셈블리 프로세스 트리거
👉 다시 로드하면 오류가 사라지고 채팅 기록에 청사진 이미지가 표시됩니다. 이제 에이전트에 필요한 시각적 컨텍스트가 있습니다.
- 마이크 아이콘을 클릭하여 사용 설정합니다. 인터페이스에 '듣는 중...'이 표시됩니다.
- '조립 시작'이라고 음성 명령을 말합니다.
- 상담사가 요청을 처리하고 UI가 '말하는 중...'으로 변경됩니다. 필요한 부품을 나열하는 오디오 전용 응답이 들립니다.
4. 에이전트 간 도구 호출 확인
👉 초기 오디오 응답은 시스템이 작동하는지 확인해 주지만, 진정한 마법은 멀티 에이전트 커뮤니케이션 트레이스에 있습니다.
- 마이크를 끕니다.
- 페이지를 한 번 더 새로고침합니다.
이제 왼쪽의 '추적' 패널이 채워집니다. 완전하고 성공적인 실행 흐름을 확인할 수 있습니다.
dispatch_agent는 먼저monitor_for_hazard를 호출합니다.- 그런 다음
architect_agent에 여러execute_architect호출을 실행하여 개략적인 데이터를 가져옵니다.
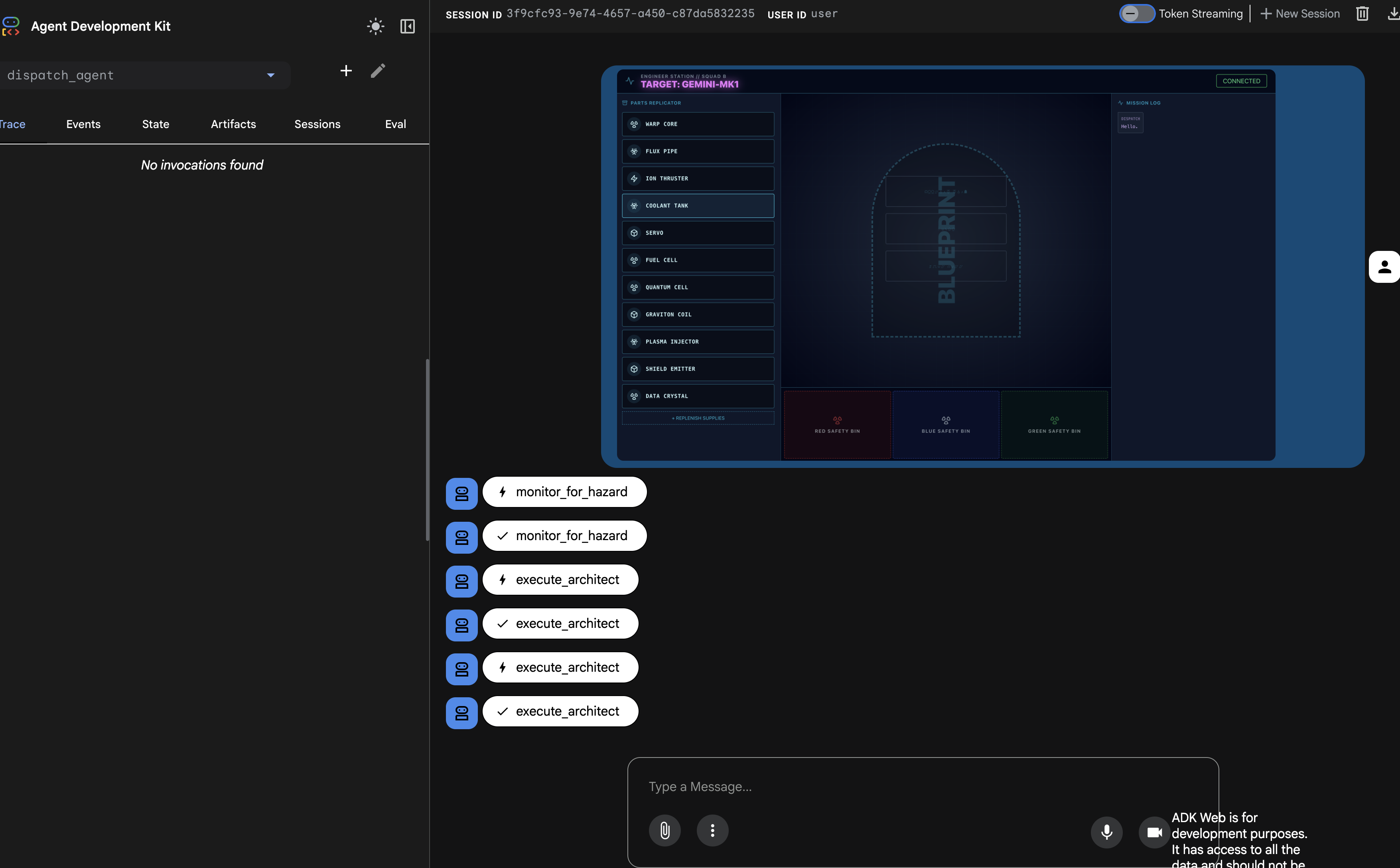
이 시퀀스는 전체 멀티 에이전트 워크플로가 올바르게 작동하는지 확인합니다. dispatch_agent는 요청을 수신하고, 도구 호출을 통해 데이터 검색 작업을 architect_agent에 위임하고, 데이터를 다시 수신하여 사용자의 명령을 실행합니다.
이제 양방향 스트리밍 링크에서 백그라운드 모니터링과 멀티 에이전트 공동작업을 지원합니다. 다음으로 프런트엔드에서 이러한 복잡한 응답을 파싱하는 방법을 알아봅니다.
👉💻 두 터미널에서 Ctrl+c를 눌러 종료합니다.
5. 라이브 멀티모달 이벤트 스트림 심층 분석
이전 단계에서는 내장 개발 서버인 adk web를 사용하여 멀티 에이전트 시스템을 성공적으로 확인했습니다. 이 유틸리티는 기본 ADK 러너를 사용하여 세션, 스트림, 에이전트 수명 주기를 자동으로 관리합니다. 하지만 FastAPI 서비스 (main.py)와 같은 독립형 프로덕션 지원 애플리케이션을 만들려면 명시적 제어가 필요합니다. 라이브 사용자 세션을 처리하려면 ADK 러너를 수동으로 만들고 관리해야 합니다. 오디오, 동영상, 텍스트의 양방향 스트림을 처리하는 핵심 구성요소이기 때문입니다.
모델-코드-모델 루프
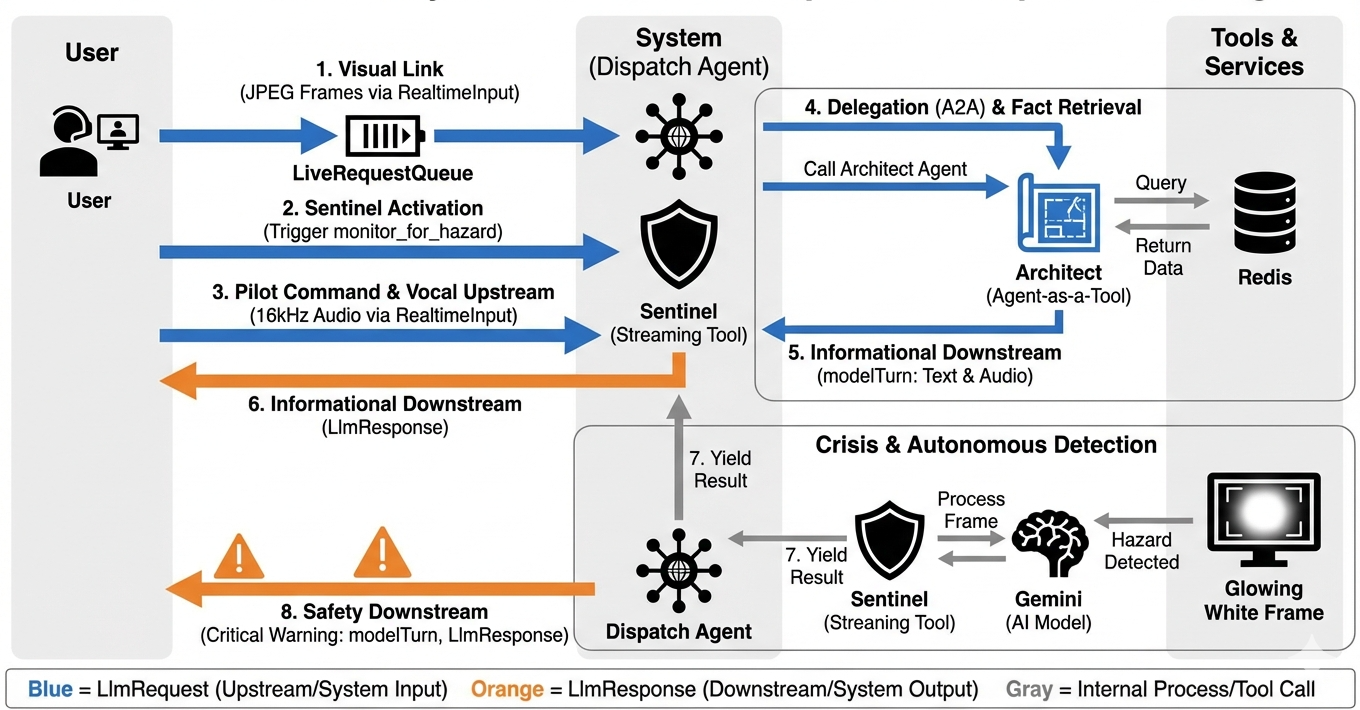
시스템이 실시간으로 작동하는 방식을 이해하려면 단일 미션 세션의 수명 주기를 따라가 보겠습니다. 이 루프는 LlmRequest 객체와 LlmResponse 객체의 지속적인 교환을 나타냅니다.
- 시각적 링크: 연결을 시작하고 웹캠/화면을 공유합니다. 고화질 JPEG 프레임이
realtimeInput를 통해 업스트림으로 흐르기 시작합니다 (LiveRequestQueue사용). - Sentinel 활성화: 시스템에서 초기 'Hello' 자극을 전송합니다. 요청 사항에 따라 디스패치 에이전트는 즉시
monitor_for_hazard스트리밍 도구를 트리거합니다. 이렇게 하면 들어오는 모든 프레임을 자동으로 감시하는 백그라운드 루프가 시작됩니다. - 파일럿 명령: 커뮤니케이션에 '조립을 시작해'라고 말합니다.
- 보컬 업스트림: 내 음성이 16kHz 오디오로 캡처되어 동영상 프레임과 함께 업스트림으로 전송됩니다.
- 위임 (A2A): 디스패치가 사용자의 의도를 '듣습니다'. 회로도가 부족하다는 것을 깨닫고
AgentTool(Agent-as-a-Tool) 프로토콜을 사용하여 Architect Agent를 호출합니다. - 사실 검색: Architect가 Redis 데이터베이스를 쿼리하고 부품 목록을 Dispatch에 반환합니다. 디스패치는 '세션의 마스터'로 유지되어 사용자를 넘겨주지 않고 데이터를 수신합니다.
- 정보 다운스트림: 디스패치는 텍스트와 네이티브 오디오가 모두 포함된
modelTurn(다운스트림)을 전송합니다. '건축가가 확인했습니다. 필수 하위 집합은 워프 코어, 플럭스 파이프, 이온 추진기입니다.' - 위기: 갑자기 작업대의 한 부분이 불안정해지면서 흰색으로 빛나기 시작합니다.
- 자율 감지: 백그라운드
monitor_for_hazard루프 (Sentinel)가 빛을 포함하는 특정 JPEG 프레임을 포착합니다. Gemini를 호출하여 프레임을 처리하고 위험을 식별합니다. - 안전 다운스트림: 스트리밍 도구가 결과를
yields합니다. 이는 양방향 스트리밍 에이전트이므로 디스패치는 현재 상태를 중단하여 즉시 중요한 안전 경고를 다운스트림으로 보낼 수 있습니다. '위험이 감지되었습니다. 데이터 크리스탈을 중화하고 있습니다. 빨간색 쓰레기통으로 옮겨 줘'라고 말합니다.
에이전트의 런타임 구성 설정
ADK의 RunConfig를 사용하면 스트리밍 데이터를 처리하고 다양한 모달리티와 상호작용하는 방식을 비롯하여 에이전트의 동작을 자세히 구성할 수 있습니다.
streaming_mode은(는) 실시간 양방향 통신을 위해 BIDI로 설정되어 사용자와 상담사가 동시에 말하고 들을 수 있습니다. response_modalities 매개변수는 에이전트가 생성할 수 있는 출력 유형(예: 음성 및 텍스트)을 정의합니다. input_audio_transcription는 에이전트가 사용자의 수신 음성을 처리하고 전사하는 방식을 구성합니다. 더 탄력적인 환경을 만들기 위해 session_resumption를 사용하면 연결이 끊긴 경우 상담사가 대화 컨텍스트를 기억하고 다시 시작할 수 있습니다. 마지막으로 proactivity를 사용하면 상담사가 직접적인 사용자 명령 없이도 자발적인 위험 경고를 발령하는 등 행동이나 음성을 시작할 수 있으며, enable_affective_dialog를 사용하면 상담사가 더 자연스럽고 공감적인 대답을 생성할 수 있습니다. ADK의 RunConfig에 대한 자세한 내용은 여기를 참고하세요.
👉✏️ $HOME/way-back-home/level_4/backend/main.py 파일에서 #REPLACE_RUN_CONFIG 자리표시자를 찾아 다음 해부 로직으로 바꿉니다.
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
에이전트 요청 구현
다음으로 WebSocket을 통해 사용자의 휘발성 워크벤치에서 디스패치 에이전트로 실시간 멀티모달 데이터를 스트리밍하는 핵심 통신 업링크를 구현합니다. 상담사가 지속적으로 '보고' (동영상 프레임) '듣게' (음성 명령) 됩니다. 이 로직은 데이터 스트림을 지속적으로 수신하고, 수신되는 바이너리 오디오 청크와 JSON 래핑 텍스트/이미지 패킷을 구분하고, 이를 Blob (멀티미디어용) 또는 Content (텍스트용) 객체로 캡슐화하여 양방향 에이전트 세션을 지원하기 위해 LiveRequestQueue로 전송합니다.
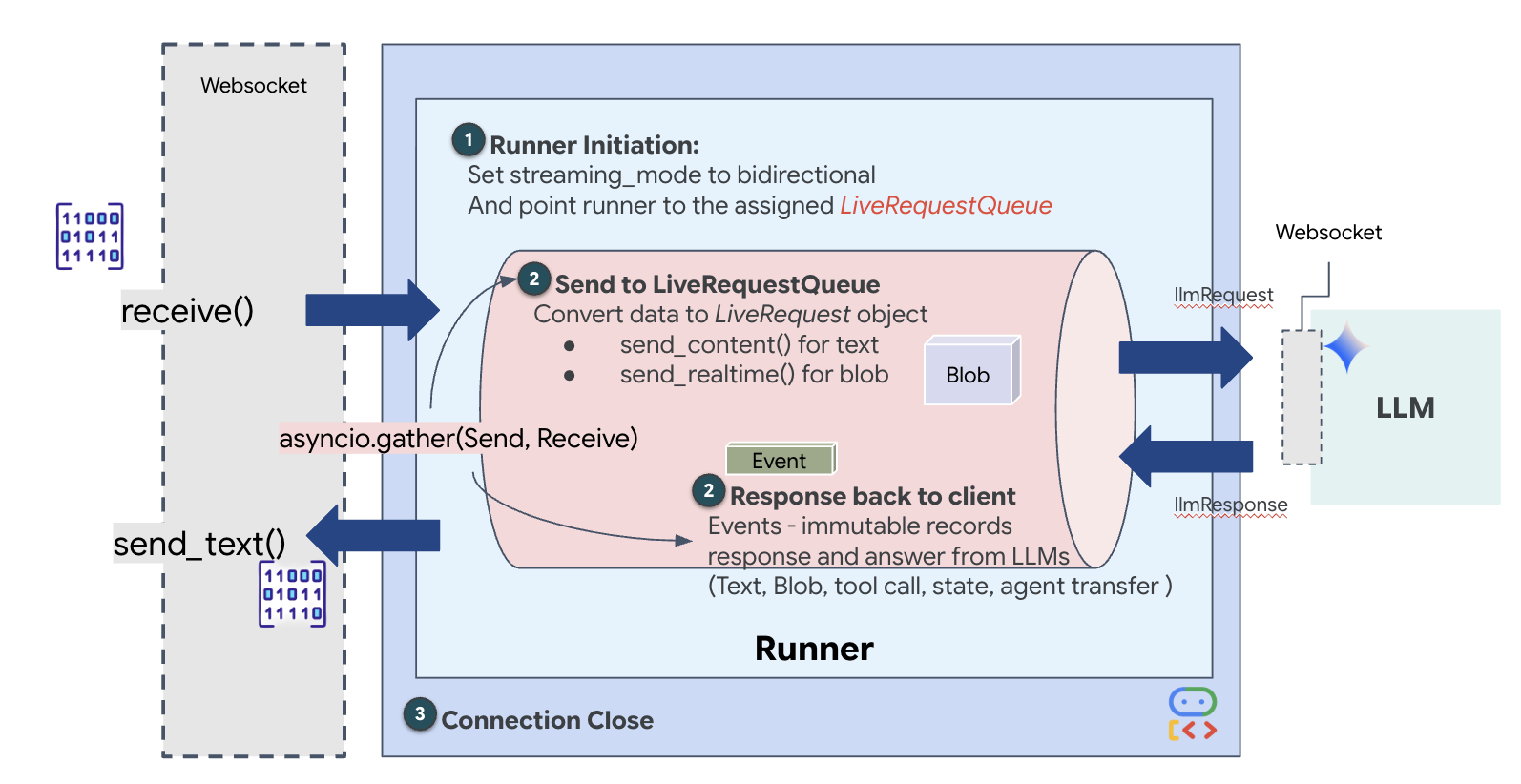
$HOME/way-back-home/level_4/backend/main.py 파일에서 #PROCESS_AGENT_REQUEST 자리표시자를 찾아 다음 분석 로직으로 바꿉니다.
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
이제 멀티모달 데이터가 에이전트에게 전송됩니다.
응답 구현: 다운스트림 이벤트 데이터 구조
ADK로 양방향 (실시간) 에이전트를 실행하면 에이전트에서 다시 전송되는 데이터가 핵심 GenAI SDK 구조에서 상속되는 특정 유형의 이벤트로 패키징됩니다. async for event in runner.run_live(...) 루프에서 수신하는 Event 객체는 여러 선택적 필드가 포함된 단일 객체이며, 각 필드는 서로 다른 유형의 정보를 나타냅니다.
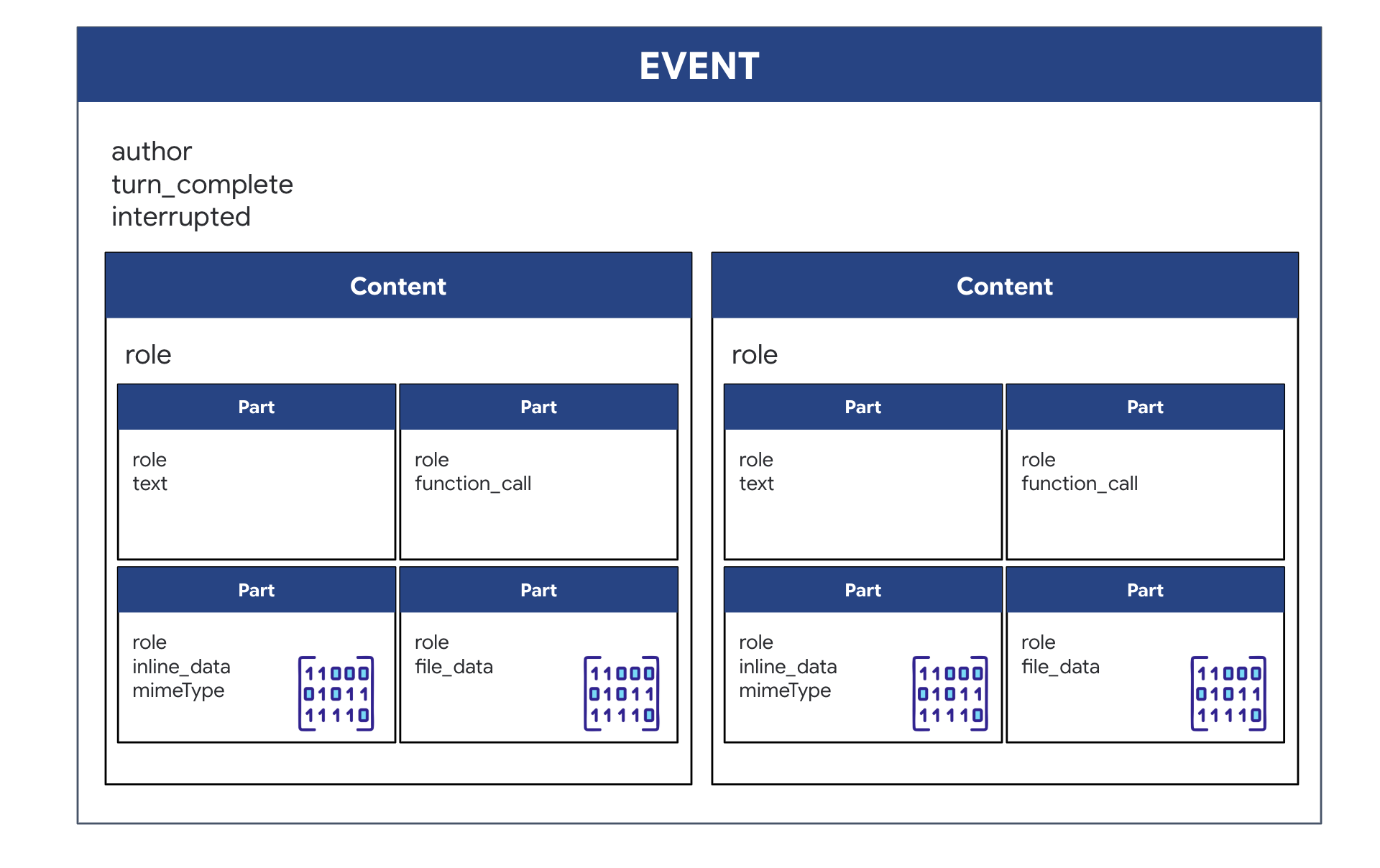
콘텐츠 구조:
- 상담사가 말하는 경우 (
.server_content를 통해): 필드는 일반 텍스트가 아닙니다. 여기에는Parts목록이 포함됩니다. 각Part는 텍스트 문자열 (예:"The part is stable.") 또는 원시 오디오 blob (음성)과 같은 한 가지 유형의 데이터를 위한 컨테이너입니다. - 에이전트가 행동하는 경우 (
.tool_call를 통해): 필드에FunctionCall객체 목록이 포함됩니다. 각FunctionCall는 백엔드 코드에서 쉽게 읽고 실행할 수 있는 깔끔한 형식으로 도구의 이름과 입력 인수를 지정하는 간단한 구조화된 객체입니다.
👀 run_live 루프에서 생성된 단일 Event를 살펴보면 GenAI SDK 모양을 엄격하게 따르는 JSON (event.model_dump(by_alias=True)에 의해 생성됨)은 다음과 같습니다.
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ 이제 main.py의 downstream_task을 업데이트하여 전체 이벤트 데이터를 전달합니다. 이 로직은 AI의 모든 '생각'이 우주선의 진단 터미널에 기록되고 프런트엔드 UI로 단일 JSON 객체로 전송되도록 합니다.
$HOME/way-back-home/level_4/backend/main.py 파일에서 #PROCESS_AGENT_RESPONSE 자리표시자를 찾아 다음 분석 로직으로 바꿉니다.
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
미션 실행
백엔드 볼트가 연결되고 두 에이전트가 모두 구성되면 모든 시스템이 이제 미션 준비 상태가 됩니다. 다음 단계를 따르면 전체 애플리케이션이 실행되어 방금 빌드한 2개 에이전트 시스템과 상호작용할 수 있습니다.
목표: 작업대에 표시되는 무작위로 할당된 워프 드라이브를 조립합니다. 프로토콜: 특히 특정 구성요소에 대한 위험 경고 등 디스패치 상담사의 음성 안내를 따라야 합니다.
전문가 (건축가) 활성화
👉💻 첫 번째 터미널 창에서 Architect 에이전트를 실행합니다. 이 백엔드 서비스는 Redis 저장소에 연결되고 디스패처의 개략적인 요청을 기다립니다.
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
이 터미널을 실행된 상태로 둡니다. 이제 활성 '데이터베이스 에이전트'가 됩니다.)
Cockpit (디스패처) 실행
👉💻 새 터미널 창 (터미널 B)에서 프런트엔드 UI를 빌드하고 사용자 인터페이스를 제공하고 모든 실시간 커뮤니케이션을 처리하는 기본 디스패치 에이전트를 시작합니다.
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(이렇게 하면 포트 8080에서 기본 서버가 시작됩니다.)
테스트 시나리오 실행
이제 시스템이 작동합니다. 목표는 에이전트의 안내에 따라 조립을 완료하는 것입니다.
- 👉 Workbench 액세스:
- Cloud Shell 툴바에서 웹 미리보기 아이콘을 클릭합니다.
- 포트 변경을 선택하고 8080으로 설정한 다음 변경 및 미리보기를 클릭합니다.
- 👉 미션 시작:
- 인터페이스가 로드되면 화면과 마이크에 액세스하도록 허용해야 합니다.
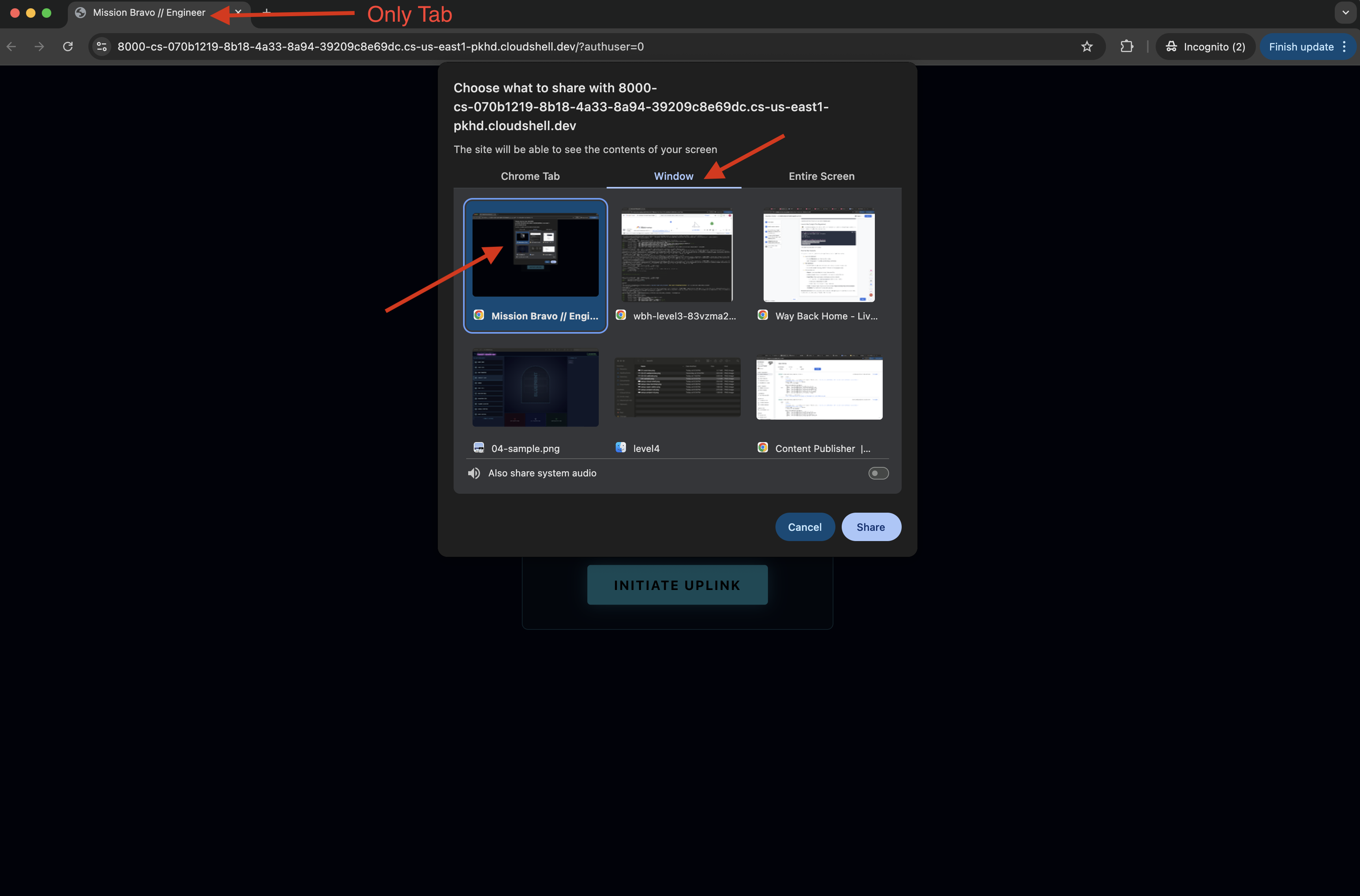
- 창을 공유하는 경우 문제를 방지하기 위해 창에 탭이 하나만 있는지 확인하세요. 탭 또는 창을 선택하여 공유하라는 메시지가 표시됩니다.
- 임의의 이름 (예: 'NOVA-V', 'OMEGA-9')이 지정된 드라이브가 할당됩니다.
- 인터페이스가 로드되면 화면과 마이크에 액세스하도록 허용해야 합니다.
- 👉 어셈블리 루프:
- 요청: 드라이브 조립을 시작하려면 '조립 시작'이라고 말합니다.
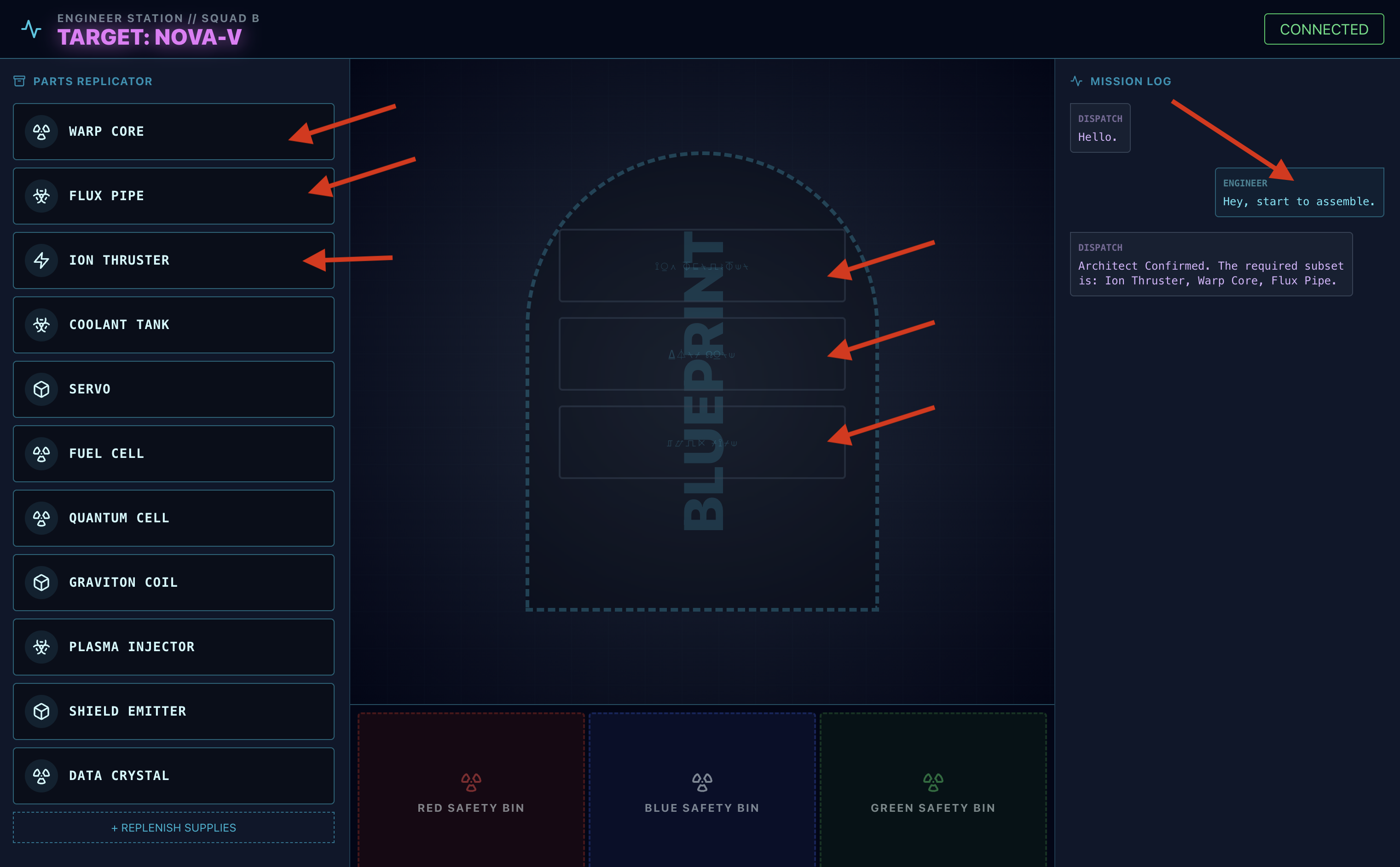
- Architect Respond: 상담사가 드라이브를 조립하는 데 필요한 올바른 부품을 제공합니다.
- 위험 확인: 워크벤치에서 부품이 위험한 것으로 보이는 경우:
- 디스패치 에이전트의
monitor_for_hazard도구는 이를 시각적으로 식별합니다. - '시각적 위험 알림'이 표시됩니다. (30초 정도 걸립니다.)
- 위험을 해제하는 데 사용할 빈을 확인합니다.
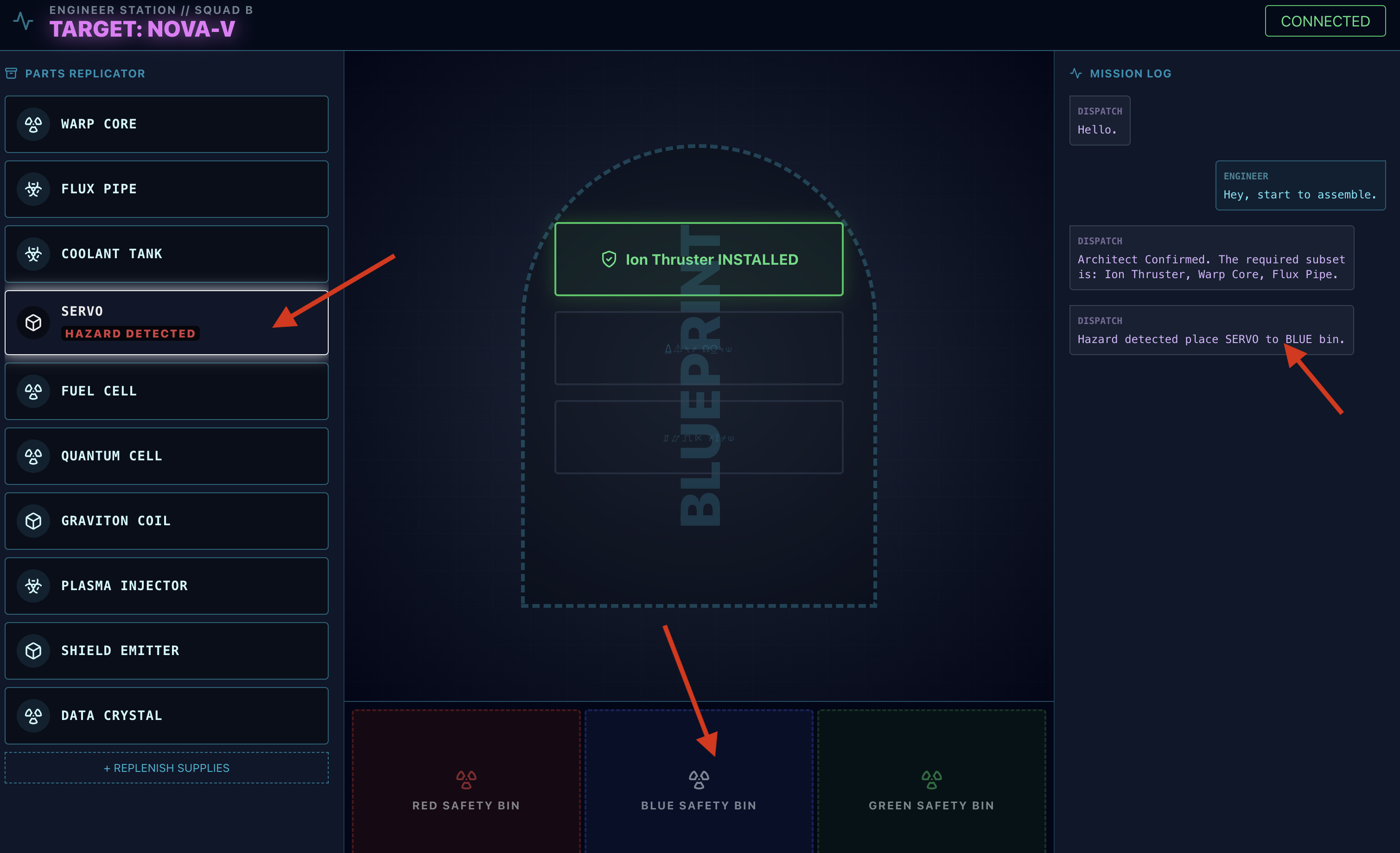
- 디스패치 에이전트의
- 조치: 디스패치 상담사가 '위험이 확인되었습니다. XXX를 즉시 빨간색 쓰레기통에 넣으세요'라고 말해 줘. 계속하려면 이 안내를 따라야 합니다.
- 요청: 드라이브 조립을 시작하려면 '조립 시작'이라고 말합니다.
미션 완료 대화형 멀티 에이전트 시스템을 성공적으로 빌드했습니다. 생존자는 안전하고 로켓은 대기를 벗어났으며 '집으로 가는 길'은 계속됩니다.
👉💻 두 터미널에서 Ctrl+c를 눌러 종료합니다.
6. 프로덕션에 배포 (선택사항)
로컬에서 에이전트를 성공적으로 테스트했습니다. 이제 Architect의 신경망 코어를 함선의 메인프레임 (Cloud Run)에 업로드해야 합니다. 이렇게 하면 디스패치 에이전트가 어디서나 쿼리할 수 있는 영구적인 독립 서비스로 작동할 수 있습니다.
Secure Vault (인프라) 프로비저닝
에이전트를 배포하기 전에 에이전트의 영구 메모리 (Memorystore)와 영구 메모리에 액세스하는 보안 채널 (VPC 커넥터)을 만들어야 합니다.
👉💻 Memorystore 인스턴스 (Redis Vault)를 만듭니다.
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Vault의 네트워크 주소 가져오기: 이 명령어를 실행하고 host IP 주소를 복사합니다. 새 Redis 인스턴스의 비공개 주소입니다.
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 VPC 액세스 커넥터 (보안 브리지) 만들기: 이 커넥터는 비공개 브리지 역할을 하여 Cloud Run이 VPC 내의 Redis 인스턴스에 액세스할 수 있도록 합니다.
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 데이터 로드:
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
에이전트 애플리케이션 배포
에이전트 이미지 컴파일 및 빌드
👉💻 백엔드 디렉터리로 이동하여 Dockerfile을 만듭니다.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 애플리케이션을 컨테이너 이미지로 패키징합니다.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
Cloud Run에 배포
👉💻 Cloud Run에 에이전트를 배포합니다. Redis IP를 삽입하고 VPC 커넥터를 실행 명령에 직접 연결합니다. 이렇게 하면 에이전트가 데이터베이스에 안전한 비공개 연결로 시작됩니다.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 A2A 서버가 실행 중인지 확인합니다.
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
명령어가 완료되면 서비스 URL이 표시됩니다. 이제 아키텍트 에이전트가 클라우드에서 실행되며, 보관소에 영구적으로 연결되어 다른 에이전트에게 개략적인 데이터를 제공할 준비가 되었습니다.
프로덕션 메인프레임에 디스패치 허브 배포
이제 클라우드에서 Architect Agent가 작동하므로 Dispatch Hub를 배포해야 합니다. 이 에이전트는 기본 사용자 인터페이스 역할을 하며, 실시간 음성/동영상 스트림을 처리하고 데이터베이스 쿼리를 아키텍트의 보안 엔드포인트에 위임합니다.
👉💻 Cloud Shell 터미널에서 다음 명령어를 실행합니다. 백엔드 디렉터리에 완전한 다단계 Dockerfile이 생성됩니다.
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
에이전트/프런트엔드 이미지 컴파일 및 빌드
👉💻 디스패치 에이전트의 코드가 포함된 백엔드 디렉터리 (main.py)로 이동하여 컨테이너 이미지로 패키징합니다.
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
Cloud Run에 배포
👉💻 디스패치 허브를 Cloud Run에 배포합니다. Architect URL을 환경 변수로 삽입하여 두 클라우드 네이티브 에이전트 간의 중요한 연결을 만듭니다.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
명령어가 완료되면 서비스 URL (예: https://mission-bravo-...run.app)이 표시됩니다. 이제 애플리케이션이 클라우드에서 라이브로 제공됩니다.
👉 Google Cloud Run 페이지로 이동하여 목록에서 biometric-scout 서비스를 선택합니다. 
👉 서비스 세부정보 페이지 상단에 표시된 공개 URL을 찾습니다. 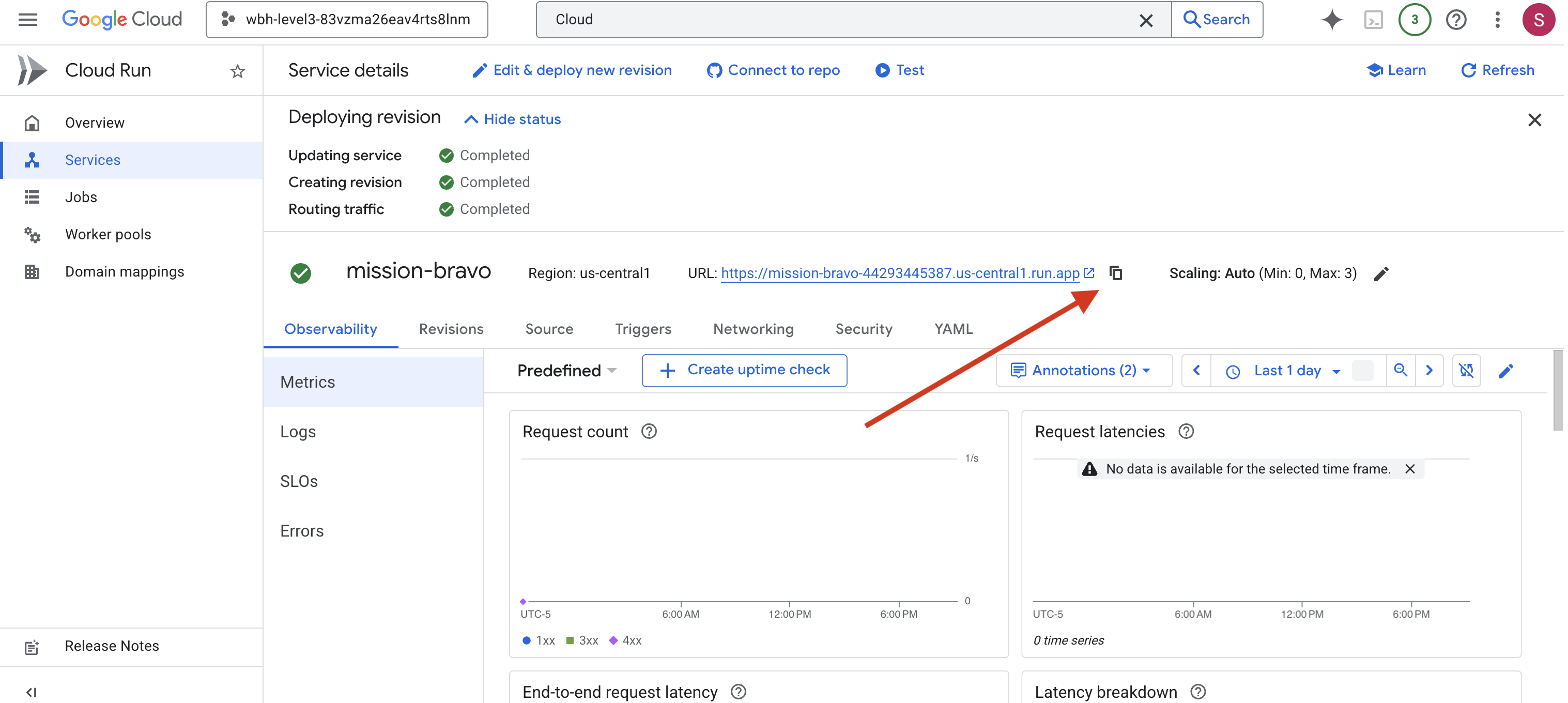
최종 시스템 확인 (엔드 투 엔드 테스트)
👉 이제 실제 시스템과 상호작용합니다.
- URL 가져오기: 마지막 배포 명령어의 출력에서 서비스 URL을 복사합니다 (
run.app로 끝나야 함). - Cockpit 열기: URL을 웹브라우저에 붙여넣습니다.
- 연락처 시작: 인터페이스가 로드되면 화면과 마이크에 액세스하도록 허용해야 합니다.
- 데이터 요청: 드라이브가 할당되면 조립을 시작하라고 요청합니다. 예: '조립 시작'

이제 Google Cloud에서 완전히 실행되는 완전히 배포된 멀티 에이전트 시스템과 상호작용하고 있습니다.
멀티 에이전트 시스템이 최종 격리 링을 제자리에 고정하고 불규칙한 방사선이 일정한 소리로 평탄해집니다.
'워프 드라이브: 안정화됨. Rescue Craft: 엔진이 점화되었습니다.'

모니터에서 외계인 우주선이 위로 솟아오르며 대기가 붕괴되는 오지맨디아스의 무너지는 표면을 간신히 벗어납니다. 안전한 궤도로 진입한 우주선 옆에 착륙하고, 통신에는 생존자들의 목소리가 가득합니다. 모두 충격에 휩싸였지만 살아 있습니다. 구조가 완료되고 집으로 가는 길이 명확해지면 원격 링크가 끊어집니다.
덕분에 생존자를 구조할 수 있었습니다.
레벨 0에 참여한 경우 집으로 돌아가는 미션에서 진행 상황을 확인하세요.