1. Misja

Dryfujesz w cichej, niezbadanej przestrzeni kosmicznej. Potężny impuls słoneczny rozerwał Twój statek w szczelinie wymiarowej, pozostawiając Cię w kieszeni wszechświata, której nie ma na żadnej mapie gwiazd.
Po wielu dniach wyczerpujących napraw wreszcie powraca znajomy szum silników. Twój statek kosmiczny jest sprawny. Udało Ci się nawet nawiązać połączenie z okrętem macierzystym. Odjazd jest bliski. Możesz wrócić do domu.
Gdy przygotowujesz się do włączenia napędu skokowego, przez szum przebija się sygnał alarmowy. Czujniki wykrywają sygnał z prośbą o pomoc z planety o nazwie „Ozymandias”. Ocaleni są uwięzieni na umierającej planecie, a ich statek jest uziemiony. Twoja misja jest kluczowa: musisz uratować ich, zanim atmosfera planety się załamie.
Jedyną szansą na ucieczkę jest starożytna, opuszczona rakieta zbudowana z obcej technologii. Chociaż jest sprawna, jej napęd warp jest zniszczony. Aby uratować ocalałych, musisz zdalnie połączyć się z ich niestabilnym stanowiskiem roboczym i ręcznie złożyć zamienny dysk.
Wyzwanie
Nie masz doświadczenia z tą obcą technologią, która jest znana ze swojej delikatności. Niestabilny komponent może w kilka sekund stać się zagrożeniem radiacyjnym. Masz jedną próbę uruchomienia niestabilnego stanowiska. Twój obecny asystent AI ma problemy z jednoczesnym przetwarzaniem danych wizualnych i instrukcji technicznych, co prowadzi do halucynacji i pomijania ostrzeżeń o zagrożeniach.
Aby odnieść sukces, musisz przekształcić swoją AI z monolitycznego podmiotu w system wieloagentowy oparty na współpracy.
Cele misji:
Złóż napęd Warp Drive, postępując zgodnie ze specjalistycznymi instrukcjami w czasie rzeczywistym z nowego systemu wieloagentowego.

Co utworzysz
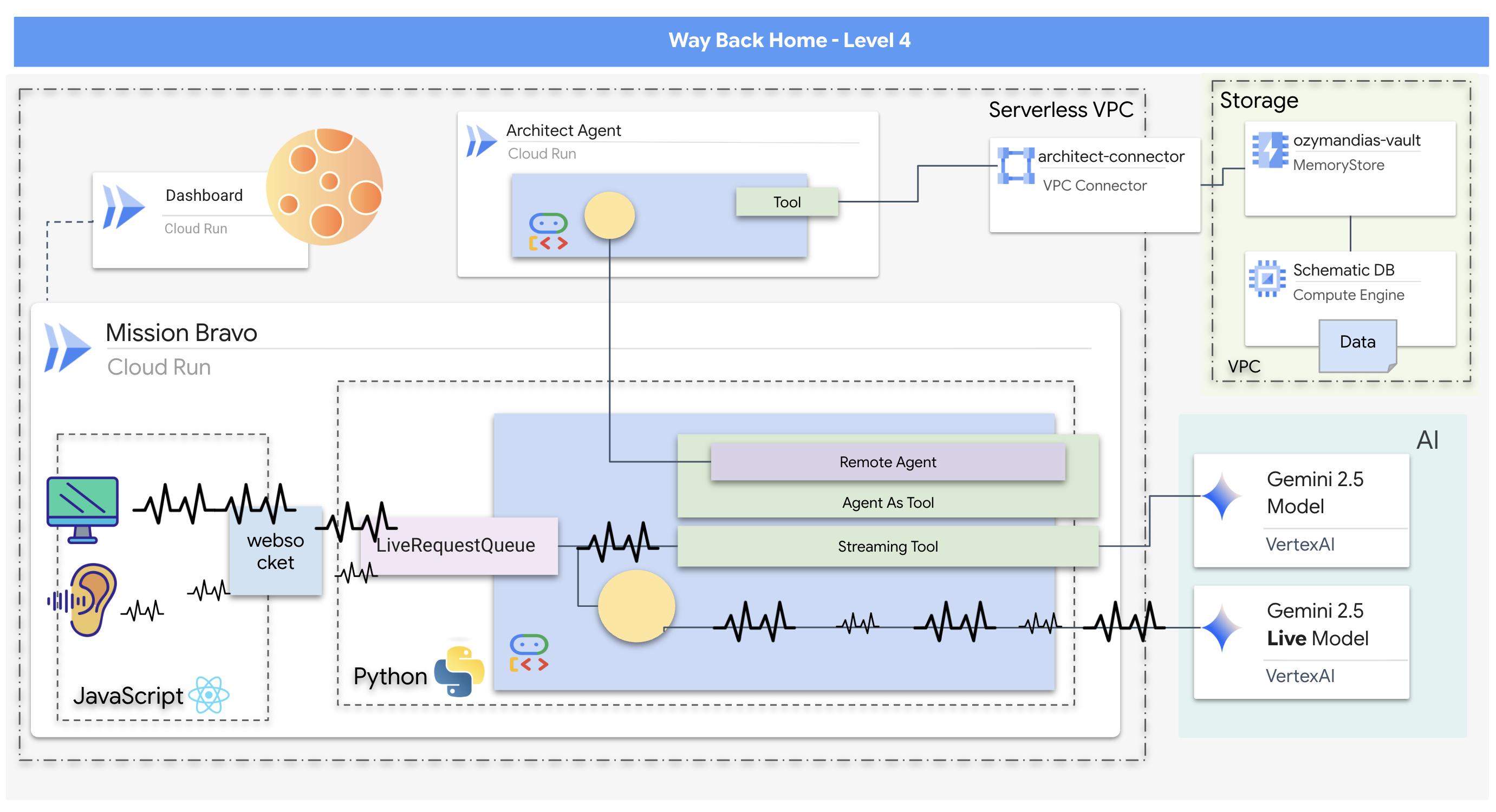
- Dwukierunkowy system AI z wieloma agentami działający w czasie rzeczywistym, w którym centralny agent wysyłający zarządza interakcjami z użytkownikiem i koordynuje działania agentów specjalistycznych.
- Agent architekt, który łączy się z bazą danych Redis, aby pobierać i udostępniać dane schematyczne.
- Proaktywny monitor bezpieczeństwa, który za pomocą narzędzi do przesyłania strumieniowego analizuje obraz na żywo pod kątem zagrożeń wizualnych i wywołuje alerty w czasie rzeczywistym.
- Interfejs oparty na React, który zapewnia interfejs użytkownika do interakcji z systemem, przesyłania strumieniowego wideo i audio do agentów backendu.
Czego się nauczysz
Technologia / Koncepcja | Opis |
Google Agent Development Kit (ADK) | Za pomocą ADK będziesz tworzyć agentów, testować ich i nimi zarządzać, korzystając z jego platformy do obsługi komunikacji w czasie rzeczywistym, integracji narzędzi i cyklu życia agenta. |
Strumieniowanie dwukierunkowe | Wdrożysz agenta dwukierunkowego przesyłania strumieniowego, który umożliwia naturalną, dwukierunkową komunikację z krótkim czasem oczekiwania, dzięki czemu zarówno człowiek, jak i AI mogą przerywać rozmowę i odpowiadać w czasie rzeczywistym. |
Systemy wieloagentowe | Dowiesz się, jak zaprojektować rozproszony system AI, w którym główny agent deleguje zadania do wyspecjalizowanych agentów, co umożliwia rozdzielenie zadań i skalowalną architekturę. |
Protokół Agent-to-Agent (A2A) | Użyjesz protokołu A2A, aby umożliwić komunikację między agentem wysyłającym a agentem architektem, co pozwoli im odkrywać swoje możliwości i wymieniać dane. |
Narzędzia do transmisji strumieniowej | Wdrożysz narzędzie do przesyłania strumieniowego, które będzie działać w tle, stale analizując strumień wideo w celu monitorowania zmian stanu (zagrożeń) i proaktywnego generowania wyników. |
Google Cloud Run i Memorystore | Wdrożysz całą aplikację z wieloma agentami w środowisku produkcyjnym, korzystając z Cloud Run do hostowania usług agentów i Memorystore (Redis) jako trwałej bazy danych. |
FastAPI i WebSockets | Backend jest zbudowany przy użyciu FastAPI i WebSockets, aby obsługiwać wydajną komunikację w czasie rzeczywistym, która jest wymagana do strumieniowania dźwięku, wideo i odpowiedzi agenta. |
Frontend React | Będziesz pracować z interfejsem opartym na React, który rejestruje i przesyła strumieniowo multimedia użytkownika (audio/wideo) oraz wyświetla odpowiedzi w czasie rzeczywistym od agentów AI. |
2. Konfigurowanie środowiska
Dostęp do Cloud Shell
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (ikona terminala u góry panelu Cloud Shell). 
👉 Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików. 
👉Otwórz terminal w chmurowym IDE.
👉💻 W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
Twoje konto powinno być widoczne jako (ACTIVE).
Wymagania wstępne
ℹ️ Poziom 0 jest opcjonalny (ale zalecany)
Możesz ukończyć tę misję bez poziomu 0, ale jej wcześniejsze ukończenie zapewnia lepsze wrażenia, ponieważ w miarę postępów możesz zobaczyć, jak Twój sygnał świetlny zapala się na mapie świata.
Konfigurowanie środowiska projektu
Wróć do terminala i dokończ konfigurację, ustawiając aktywny projekt i włączając wymagane usługi Google Cloud (Cloud Run, Vertex AI itp.).
👉💻 W terminalu ustaw identyfikator projektu:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Włącz wymagane usługi:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
Instalowanie zależności
👉💻 Przejdź do poziomu 4 i zainstaluj wymagane pakiety Pythona:
cd $HOME/way-back-home/level_4
uv sync
Główne zależności:
Pakiet | Cel |
| Wydajny framework internetowy dla stacji satelitarnej i strumieniowania SSE |
| Do uruchomienia aplikacji FastAPI wymagany jest serwer ASGI |
| Pakiet Agent Development Kit użyty do utworzenia agenta Formation Agent |
| Biblioteka protokołów Agent-to-Agent do standardowej komunikacji |
| Natywny klient do uzyskiwania dostępu do modeli Gemini |
| Klient Pythona do łączenia się z Schematic Vault (Memorystore) |
| Obsługa dwukierunkowej komunikacji w czasie rzeczywistym |
| Zarządzanie zmiennymi środowiskowymi i tajnymi danymi konfiguracyjnymi |
| Sprawdzanie poprawności danych i zarządzanie ustawieniami |
Weryfikacja konfiguracji
Zanim przejdziemy do kodu, upewnijmy się, że wszystko działa prawidłowo. Uruchom skrypt weryfikacyjny, aby sprawdzić projekt Google Cloud, interfejsy API i zależności Pythona.
👉💻 Uruchom skrypt weryfikacyjny:
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Powinna się wyświetlić seria zielonych znaczników wyboru (✅).
- Jeśli zobaczysz czerwone krzyżyki (❌), wykonaj sugerowane polecenia naprawy w danych wyjściowych (np.
gcloud services enable ...lubpip install ...). - Uwaga: żółte ostrzeżenie dotyczące
.envjest na razie dopuszczalne. Utworzymy ten plik w następnym kroku.
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Tworzenie magazynu schematów w Redis i dwukierunkowego agenta za pomocą pakietu ADK
Udało Ci się znaleźć repozytorium schematów planetarnych zawierające plany opuszczonej rakiety. Aby dokładnie pobrać te dane, musisz skorzystać z dedykowanego interfejsu zarządzania repozytorium, czyli agenta Architect.
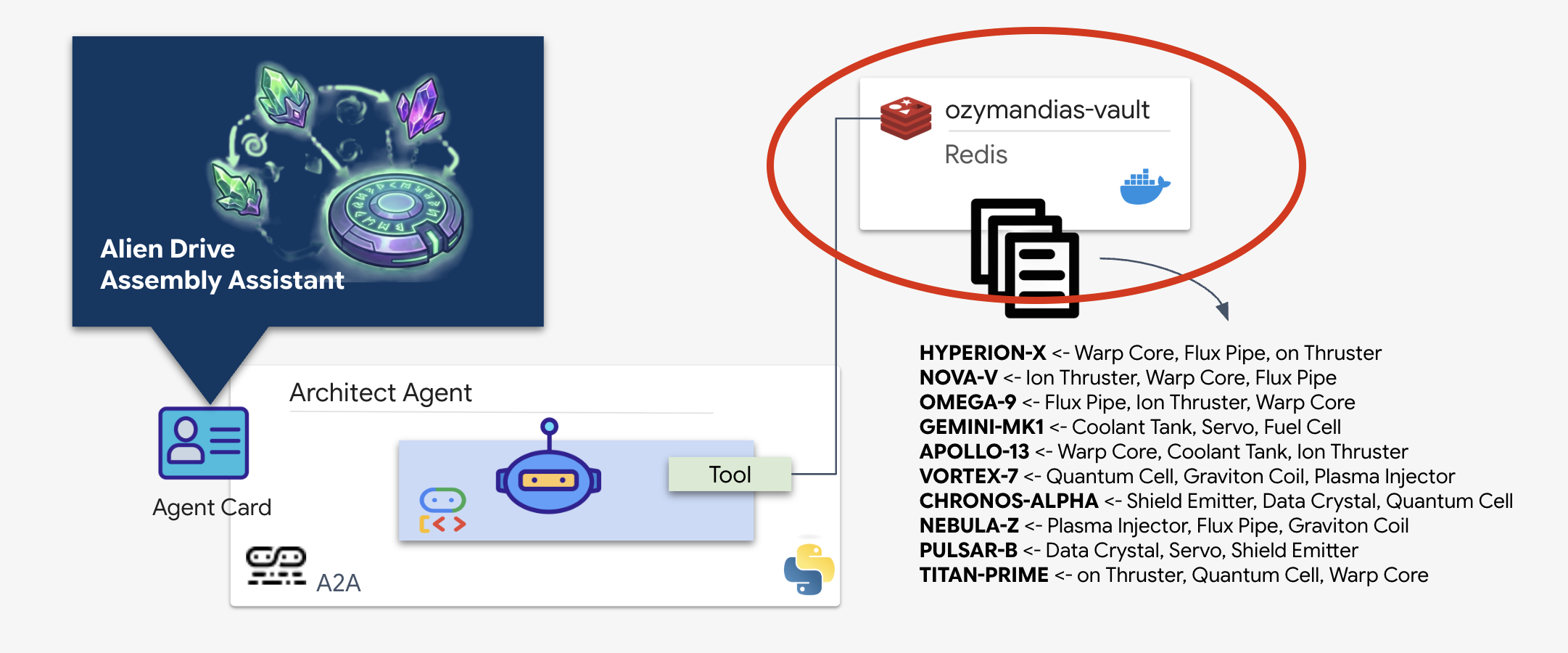
Obsługa administracyjna Vault w Schematic (Redis)
Zanim architekt będzie mógł nam pomóc, musimy mieć pewność, że dane są przechowywane w bezpiecznym środowisku o wysokiej dostępności. Użyjemy Redis jako szybkiego magazynu danych dla naszych schematów obcych. Aby ułatwić sobie programowanie, uruchomimy lokalną instancję Redis, ale instrukcje wdrażania w środowisku produkcyjnym za pomocą Google Cloud Memorystore podamy później.
👉💻 Aby udostępnić instancję Redis, uruchom w terminalu te polecenia (może to potrwać 2–3 minuty):
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 Aby wczytać dane wstępne, uruchom to polecenie, aby otworzyć powłokę Redis:
docker exec -it ozymandias-vault redis-cli
(Twój prompt zmieni się na 127.0.0.1:6379)
👉💻 Wklej te polecenia:
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 Wpisz exit, aby wrócić do normalnej powłoki.
👉💻 Aby sprawdzić, czy dane istnieją, wysyłając zapytanie do konkretnego statku bezpośrednio z terminala, uruchom:
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 Oto oczekiwane dane wyjściowe:
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
Wdrażanie agenta Architekt
Agent architekt to specjalistyczny agent odpowiedzialny za pobieranie schematycznych planów z naszego magazynu Redis. Działa on jako dedykowany interfejs danych, dzięki czemu główny agent wysyłający otrzymuje dokładne i uporządkowane informacje bez konieczności poznawania logiki bazowej bazy danych.
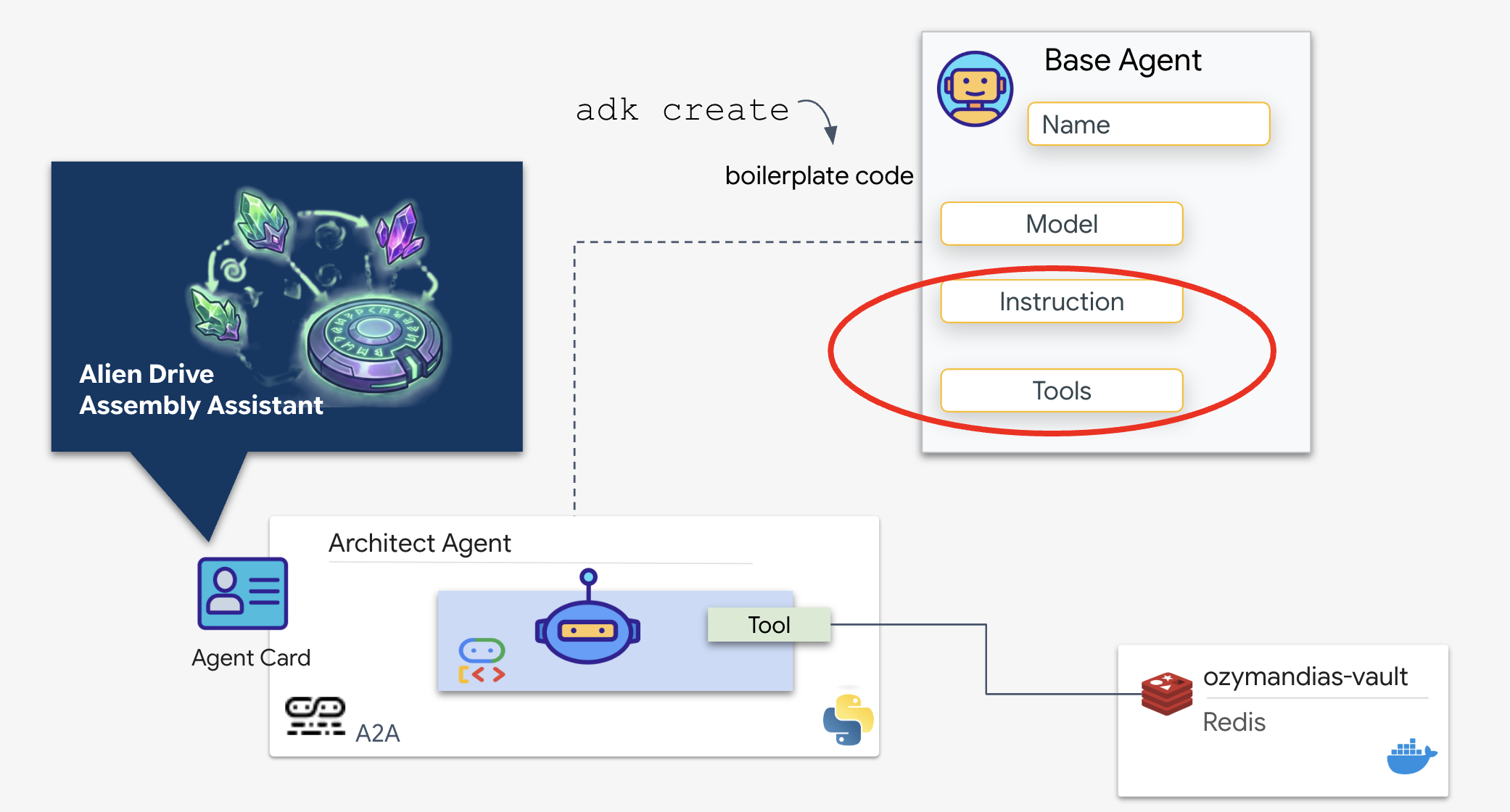
Pakiet Google Agent Development Kit (ADK) to modułowa platforma, która umożliwia konfigurację wielu agentów. Obsługuje 2 kluczowe warstwy:
- Połączenie i cykl życia sesji: interakcja z interfejsami API w czasie rzeczywistym wymaga złożonego zarządzania protokołami, w tym obsługi uzgadniania połączenia, uwierzytelniania i sygnałów utrzymywania aktywności.
- Wywołanie funkcji: to „pełna komunikacja między modelem a kodem”. Gdy LLM uzna, że potrzebuje danych, generuje wywołanie funkcji w formacie strukturalnym. ADK przechwytuje to wywołanie, wykonuje kod Pythona (
lookup_schematic_tool) i w ciągu milisekund przekazuje wynik z powrotem do kontekstu modelu.
Teraz utworzymy architekta. Ten agent nie ma dostępu do kamery. Jego jedynym zadaniem jest otrzymywanie „Nazwy dysku” i zwracanie „Listy części” z bazy danych.
👉💻 Użyjemy polecenia adk create. Jest to narzędzie z pakietu Agent Development Kit (ADK), które automatycznie generuje powtarzalny kod i strukturę plików dla nowego agenta, co pozwala zaoszczędzić czas potrzebny na konfigurację.
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
Konfigurowanie agenta
Interfejs wiersza poleceń uruchomi interaktywnego kreatora konfiguracji. Aby skonfigurować agenta, użyj tych odpowiedzi:
- Wybierz model: kliknij Opcja 1 (Gemini Flash).
- Uwaga: konkretna wersja (np. 2.5, 3.0) może się różnić w zależności od dostępności. Zawsze wybieraj wariant „Flash”, aby uzyskać większą szybkość.
- Wybierz backend: wybierz Opcja 2 (Vertex AI).
- Wpisz identyfikator projektu Google Cloud: naciśnij Enter, aby zaakceptować wartość domyślną (wykrytą w Twoim środowisku).
- Wpisz region Google Cloud: naciśnij Enter, aby zaakceptować wartość domyślną (
us-central1).
👀 Interakcja z terminalem powinna wyglądać podobnie do tej:
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
Powinien wyświetlić się Agent created komunikat o powodzeniu. Spowoduje to wygenerowanie szkieletu kodu, który zmodyfikujemy w następnym kroku.
👉✏️ Otwórz nowo utworzony plik $HOME/way-back-home/level_4/backend/architect_agent/agent.py w edytorze. Dodaj fragment kodu narzędzia do pliku po pierwszym wierszu importu:
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ Zastąp cały wiersz instruction w definicji root_agent tym kodem i dodaj zdefiniowane wcześniej narzędzie:
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
Przewaga ADK
Dzięki Architectowi online mamy teraz jedno źródło wiarygodnych informacji. Zanim połączymy go z głównym agentem, pakiet Agent Development Kit (ADK) zapewni nam znaczną przewagę, upraszczając złożoność tworzenia i testowania agentów AI. Dzięki wbudowanej adk webkonsoli deweloperskiej możemy odizolować i zweryfikować działanie naszego Architect Agent, w szczególności jego możliwości wywoływania narzędzi, zanim zintegrujemy go z większym systemem wieloagentowym. To modułowe podejście do tworzenia i testowania ma kluczowe znaczenie dla budowania solidnych i niezawodnych aplikacji AI.
👉💻 W terminalu uruchom:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 Poczekaj, aż zobaczysz:
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- Na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce. Kliknij Zmień port, ustaw wartość 8000 i kliknij Zmień i wyświetl podgląd.
- Wybierz architect_agent.
- Uruchom narzędzie: w interfejsie czatu wpisz:
CHRONOS-ALPHA(lub dowolny identyfikator Dysku z bazy danych schematów). - Obserwuj zachowanie:
- Architekt powinien natychmiast wywołać
lookup_schematic_tool. - Ze względu na ścisłe instrukcje system powinien zwrócić tylko listę części (np.
['Shield Emitter', 'Data Crystal', 'Quantum Cell']) bez żadnych dodatkowych słów.
- Architekt powinien natychmiast wywołać
- Sprawdź logi: spójrz na okno terminala. Powinien być widoczny dziennik udanego wykonania:
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
Jeśli widzisz dziennik wykonania narzędzia i odpowiedź z przetworzonymi danymi, oznacza to, że specjalista działa zgodnie z oczekiwaniami. Może przetwarzać żądania, wysyłać zapytania do skarbca i zwracać uporządkowane dane.
👉💻 Aby wyjść, naciśnij Ctrl+C.
Inicjowanie serwera A2A
Aby połączyć agenta wysyłającego z agentem Architect, używamy protokołu Agent-to-Agent (A2A).
O ile protokoły takie jak MCP (Model Context Protocol) koncentrują się na łączeniu agentów z narzędziami, o tyle A2A koncentruje się na łączeniu agentów z innymi agentami. Jest to standard, który umożliwia naszemu dyspozytorowi „odkrycie” architekta i zrozumienie jego możliwości wyszukiwania schematów.
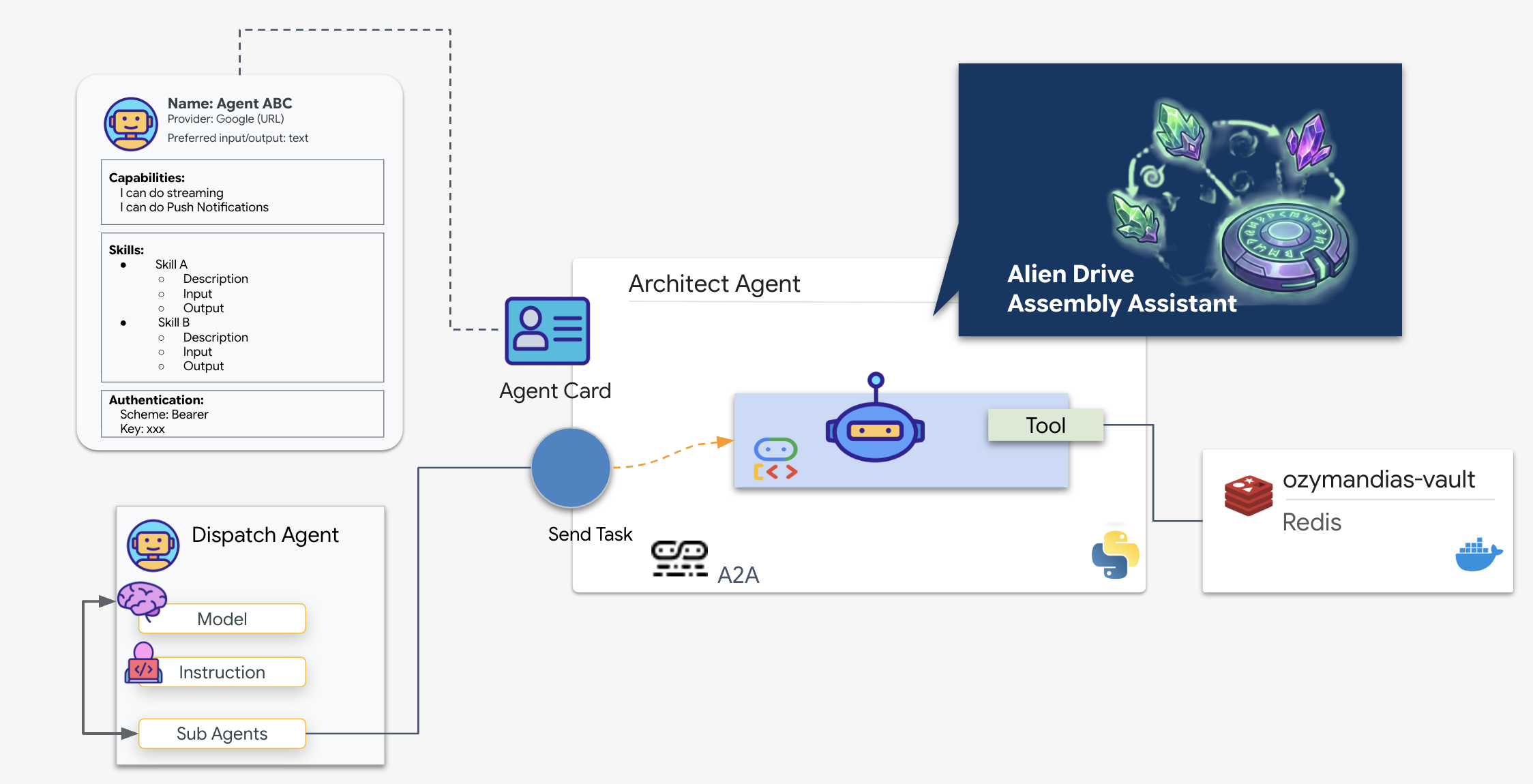
Przepływ A2A: w tej misji używamy modelu klient-serwer:
- Serwer (architekt): hostuje narzędzia do obsługi baz danych i „reklamuje” swoje umiejętności za pomocą karty agenta.
- Klient (Dispatch): odczytuje kartę architekta, rozumie jej interfejs API i wysyła żądanie schematu.
Czym jest karta agenta?
Karta agenta to cyfrowa wizytówka lub „prawo jazdy” dla AI. Gdy serwer A2A się uruchamia, publikuje ten obiekt JSON zawierający:
- Tożsamość: nazwa agenta (
architect_agent) i jego identyfikator. - Opis: podsumowanie działania systemu, które jest czytelne dla ludzi i maszyn („Rola systemu: interfejs API bazy danych...”).
- Interfejs: konkretne klawisze wejściowe (
drive_name) i oczekiwane formaty wyjściowe.
Bez tej karty agent wysyłający działałby na ślepo, zgadując, jak komunikować się z architektem.
Tworzenie kodu serwera
👉✏️ W edytorze w katalogu $HOME/way-back-home/level_4/backend/architect_agent utwórz plik o nazwie server.py i wklej do niego ten kod:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 Wróć do terminala, przejdź do folderu i uruchom serwer:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 Sprawdź, czy serwer A2A się uruchamia:
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
Weryfikacja karty agenta
Otwórz nową kartę terminala (kliknij ikonę +). Sprawdzimy, czy architekt prawidłowo transmituje swoją tożsamość, ręcznie pobierając jego kartę agenta.
👉💻 Uruchom to polecenie:
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 Powinna pojawić się odpowiedź JSON. W danych wyjściowych poszukaj pola description. Powinien on być zgodny z instrukcją podaną wcześniej agentowi ("SYSTEM ROLE: Database API...").
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
Jeśli widzisz ten kod JSON, oznacza to, że usługa Architect jest aktywna, protokół A2A jest włączony, a karta agenta jest gotowa do wykrycia przez dyspozytora.
Architekt jest już gotowy do działania jako zasób zdalny, więc możemy go podłączyć do agenta wysyłającego.
👉💻 Naciśnij Ctrl+C, aby zamknąć serwer A2A.
4. Łączenie agenta strumieni dwukierunkowych z agentem zdalnym i narzędziami do przesyłania strumieniowego
Teraz skonfigurujesz główne centrum komunikacji, aby połączyć dane na żywo ze zdalnym architektem. To połączenie wymaga kanału o dużej przepustowości i małych opóźnieniach, aby zapewnić stabilność stanowiska montażowego podczas pracy.
Informacje o agentach dwukierunkowego przesyłania strumieniowego (na żywo)
Strumieniowanie dwukierunkowe w ADK dodaje do agentów AI funkcję dwukierunkowej interakcji głosowej i wideo z niewielkimi opóźnieniami, która jest dostępna w interfejsie Gemini Live API. Jest to fundamentalna zmiana w porównaniu z tradycyjnymi interakcjami z AI. Zamiast sztywnego schematu „zapytaj i poczekaj” umożliwia dwukierunkową komunikację w czasie rzeczywistym, w której zarówno człowiek, jak i AI mogą mówić, słuchać i odpowiadać jednocześnie.
Pomyśl o różnicy między wysyłaniem e-maili a rozmową telefoniczną. Interakcje z tradycyjnym agentem przypominają e-maile: wysyłasz pełną wiadomość, czekasz na pełną odpowiedź, a potem wysyłasz kolejną. Strumieniowanie dwukierunkowe przypomina rozmowę telefoniczną: jest płynne, naturalne i umożliwia przerywanie, wyjaśnianie i odpowiadanie w czasie rzeczywistym.
Najważniejsze cechy:
- Komunikacja dwukierunkowa: ciągła wymiana danych bez czekania na pełne odpowiedzi. AI odpowiada, gdy tylko wykryje, że użytkownik skończył mówić.
- Reagowanie na przerwanie: użytkownicy mogą przerwać agentowi w trakcie odpowiedzi, wprowadzając nowe dane, tak jak w rozmowie z człowiekiem. Jeśli AI wyjaśnia złożony krok, a Ty powiesz „Czekaj, powtórz to”, AI natychmiast się zatrzyma i odpowie na Twoją przerwę.
- Zoptymalizowane pod kątem wielomodalności: dwukierunkowe przesyłanie strumieniowe doskonale sprawdza się w jednoczesnym przetwarzaniu różnych typów danych wejściowych. Możesz rozmawiać z pracownikiem obsługi klienta, pokazując mu części urządzenia za pomocą wideo. Pracownik przetwarza oba strumienie w ramach jednego, ujednoliconego połączenia.
👀 Zanim wdrożymy logikę klienta, przyjrzyjmy się wstępnie wygenerowanemu szkieletowi agenta wysyłkowego. Ten agent będzie komunikować się z użytkownikiem za pomocą głosu i wideo oraz przekazywać zapytania do agenta Architekta.
__init__.py agent.py hazard_db.py
agent.py: to jest „mózg”. Obecnie zawiera podstawową konfigurację strumieniowania dwukierunkowego. Zmodyfikujemy ten plik, aby dodać logikę klienta A2A, dzięki czemu będzie on mógł komunikować się z architektem.hazard_db.py: jest to lokalne narzędzie przeznaczone dla dyspozytora, które zawiera protokoły bezpieczeństwa. Jest ona oddzielona od bazy danych schematów architekta.
Wdrażanie klienta A2A
Aby umożliwić agentowi wysyłkowemu komunikację z naszym zdalnym architektem, musimy zdefiniować zdalnego agenta A2A. Dzięki temu agent Dispatch będzie wiedzieć, gdzie znaleźć architekta i jak wygląda jego „karta agenta”.
👉✏️ Zastąp #REPLACE-REMOTEA2AAGENT w $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py tym tekstem:
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
Jak działają narzędzia do streamowania
W przypadku poprzedniego agenta narzędzia działały zgodnie ze standardowym wzorcem „Żądanie-Odpowiedź”: agent zadawał pytanie, narzędzie udzielało odpowiedzi, a interakcja się kończyła. Na Ozymandiasie jednak zagrożenia nie czekają, aż zapytasz, czy są obecne. W tym celu potrzebujesz narzędzia do strumieniowania.
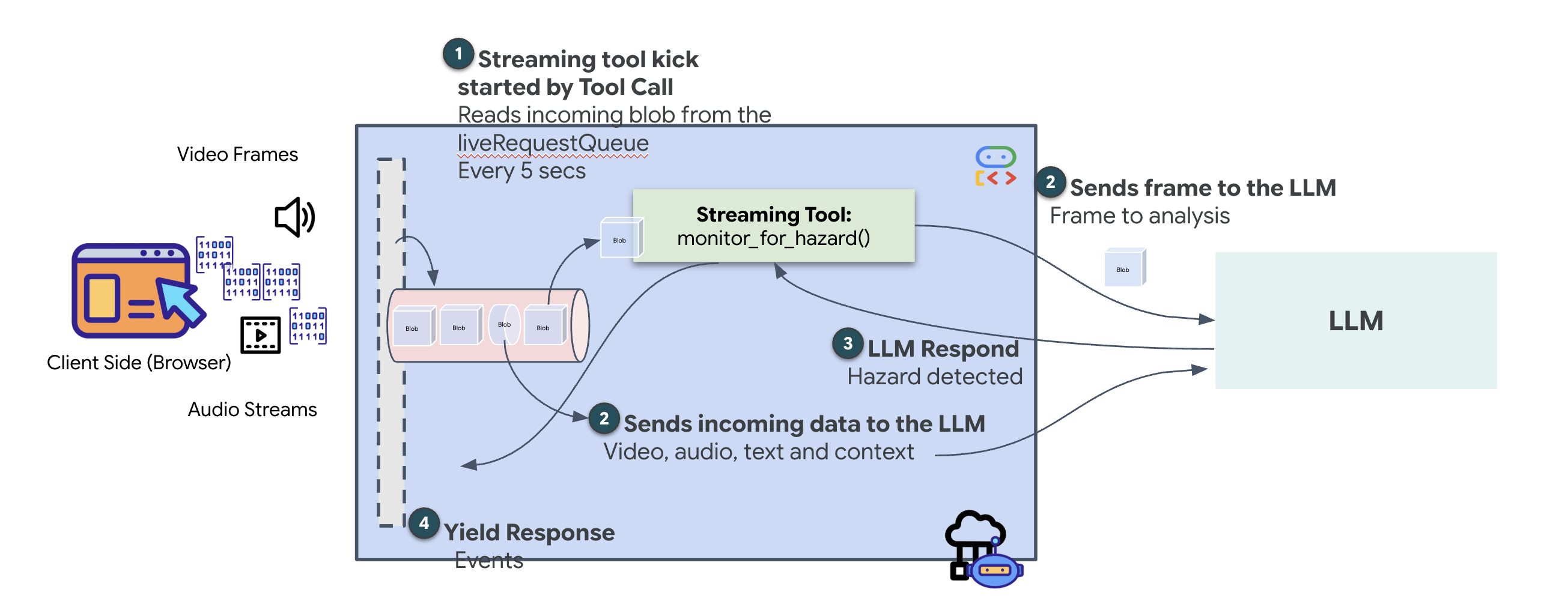
Narzędzia do przesyłania strumieniowego umożliwiają funkcjom przesyłanie wyników pośrednich z powrotem do agenta w czasie rzeczywistym, dzięki czemu agent może reagować na zmiany w miarę ich zachodzenia. Typowe przypadki użycia to monitorowanie zmieniających się cen akcji lub, w naszym przypadku, monitorowanie transmisji na żywo pod kątem zmian stanu.
W przeciwieństwie do standardowych narzędzi narzędzie do przesyłania strumieniowego jest funkcją asynchroniczną, która działa jak AsyncGenerator. Oznacza to, że zamiast return pojedynczej wartości yield wiele aktualizacji w czasie.
Aby zdefiniować narzędzie do streamingu w ADK, musisz spełnić te wymagania techniczne:
- Funkcja asynchroniczna: narzędzie musi być zdefiniowane za pomocą parametru
async def. - Typ zwracany przez AsyncGenerator: funkcja musi mieć typ zwracający
AsyncGenerator. Pierwszy parametr to typ danych, które są zwracane (np.str), a drugi to zwykleNone. - Strumienie wejściowe: korzystamy z narzędzi do przesyłania strumieniowego wideo. W tym trybie rzeczywisty strumień wideo/audio (
LiveRequestQueue) jest przekazywany bezpośrednio do funkcji, co pozwala narzędziu „widzieć” te same klatki, które widzi agent.
Narzędzie do transmisji na żywo to strażnik. Podczas gdy Ty i dyspozytor omawiacie plany, w tle działa strażnik, który cicho przetwarza każdą klatkę filmu, aby zapewnić Ci bezpieczeństwo.
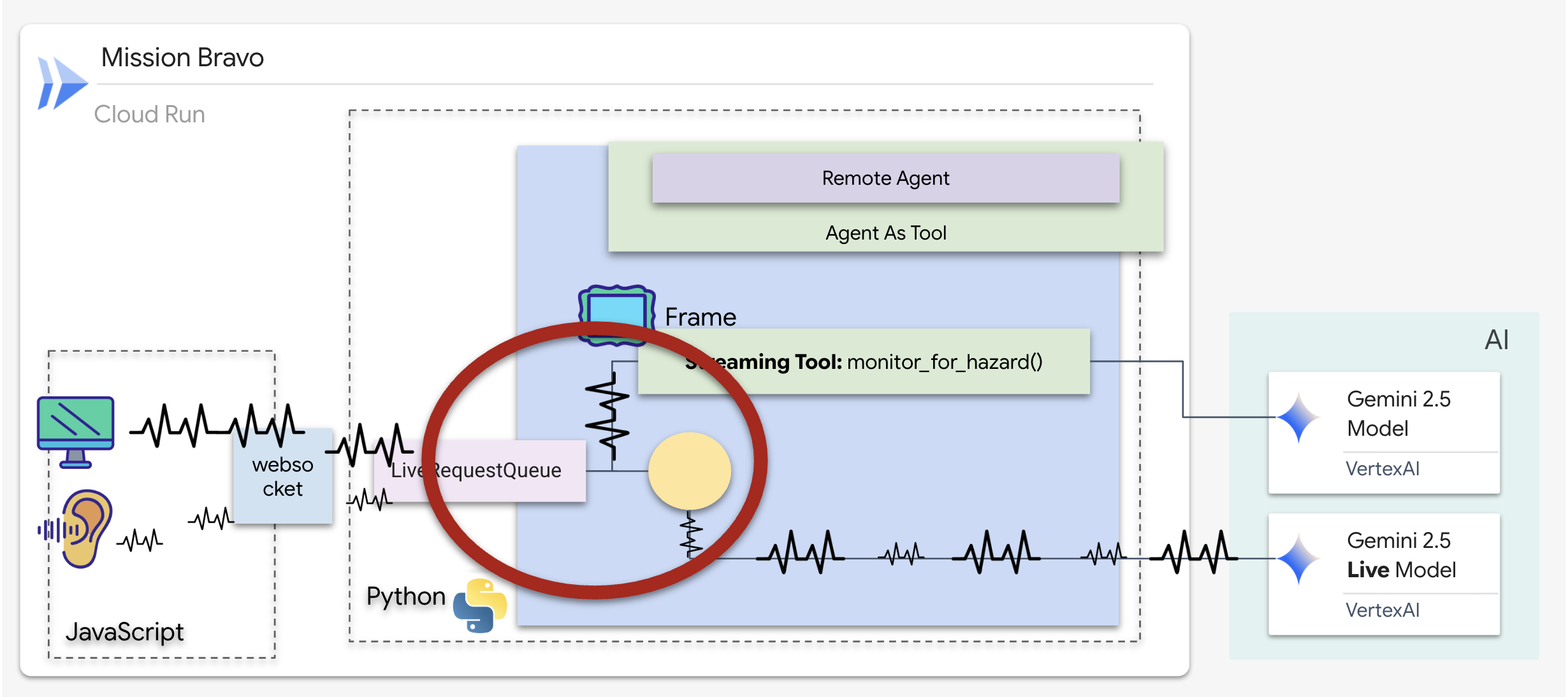
Wdrażanie narzędzia do monitorowania w tle
Teraz wdrożymy narzędzie monitor_for_hazard. Narzędzie będzie pobierać input_stream (klatki filmu), analizować je za pomocą osobnego, prostego wywołania funkcji wizji i yield ostrzegać tylko wtedy, gdy wykryje zagrożenie.
👉✏️ W $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py zastąp #REPLACE_MONITOR_HAZARD tymi regułami:
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
Wdrażanie agenta wysyłającego
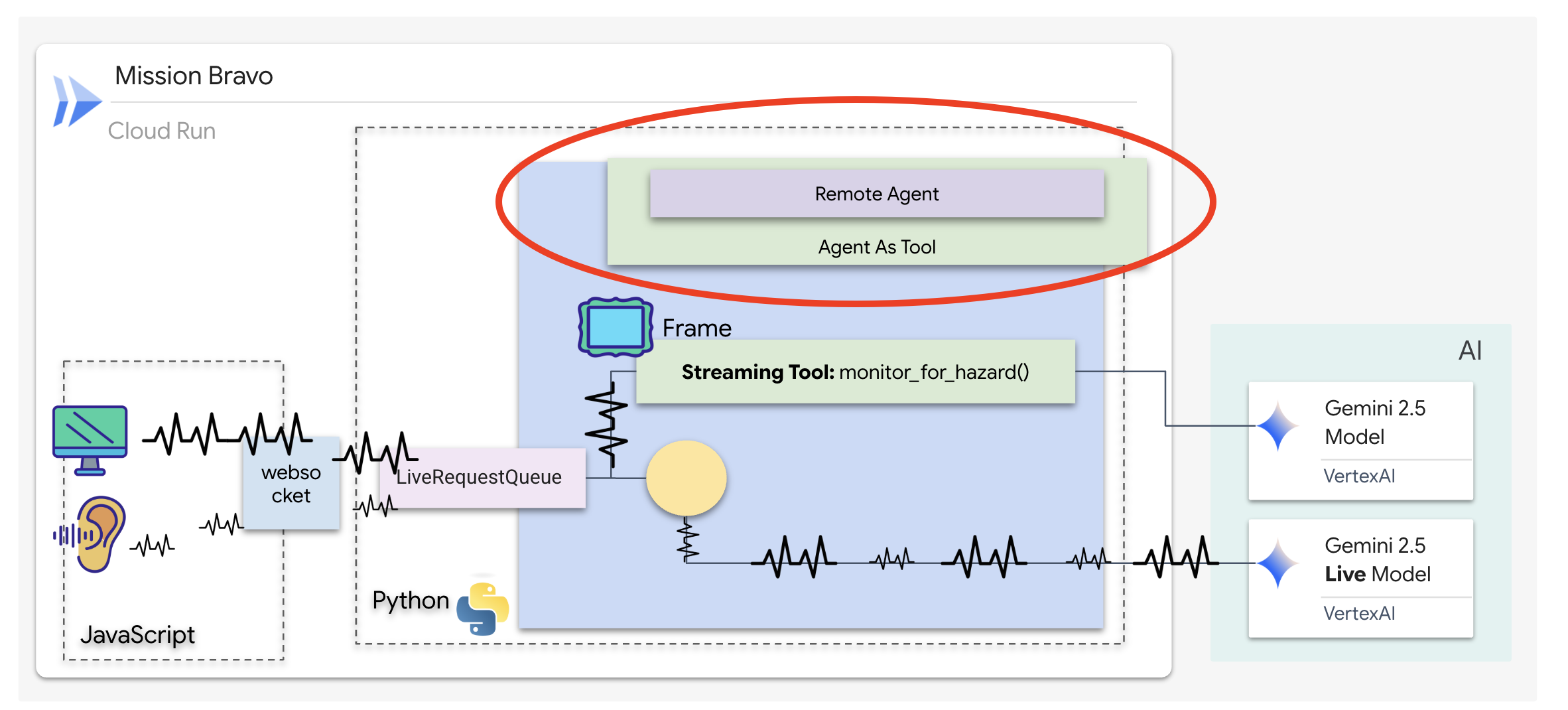
Agent wysyłający to główny interfejs i aranżer. Ponieważ zarządza dwukierunkowym połączeniem strumieniowym (transmisją na żywo głosu i obrazu), musi przez cały czas zachowywać kontrolę nad rozmową. W tym celu użyjemy konkretnej funkcji ADK: Agent-as-a-Tool (Agent jako narzędzie).
Koncepcja: agent jako narzędzie a podagenci
Podczas tworzenia systemów wieloagentowych musisz zdecydować, jak będzie dzielona odpowiedzialność. W naszej misji ratunkowej to rozróżnienie ma kluczowe znaczenie:
- Agent-as-a-Tool: to zalecane podejście w przypadku naszego dwukierunkowego centrum przesyłania strumieniowego. Gdy agent wysyłający (Agent A) wywołuje agenta architekta (Agent B) jako narzędzie, dane architekta są przekazywane z powrotem do agenta wysyłającego. Dispatch interpretuje te dane i generuje odpowiedź. Dispatch zachowuje kontrolę i nadal obsługuje wszystkie kolejne dane wejściowe użytkownika.
- Sub-agent: W przypadku sub-agenta odpowiedzialność jest całkowicie przenoszona. Jeśli Dispatch przekazał Cię do Architekta jako subagenta, rozmawiałbyś bezpośrednio z interfejsem API bazy danych, który nie ma „wizji” ani umiejętności konwersacyjnych. Główny agent (Dispatch) nie będzie miał dostępu do tych informacji.
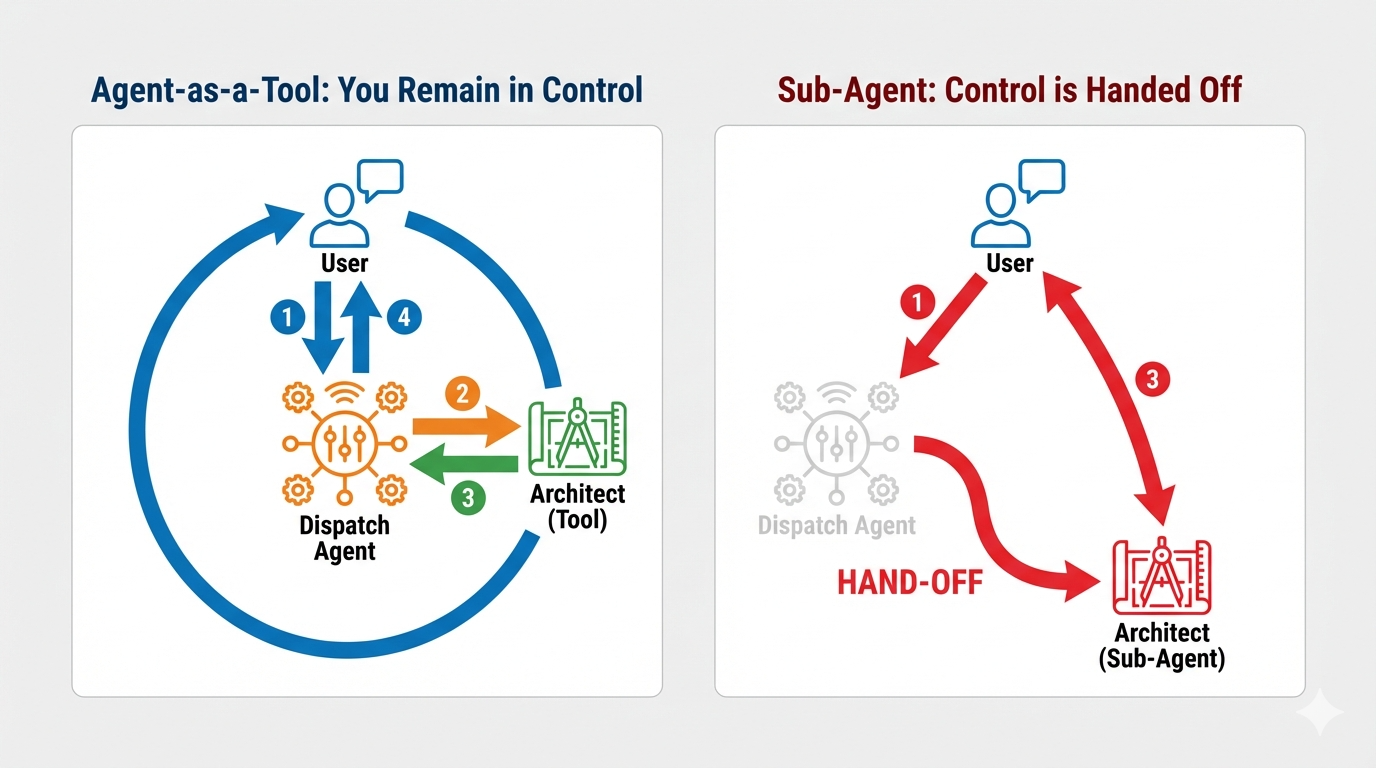
Dzięki wykorzystaniu Agent-as-a-Tool korzystamy ze specjalistycznej wiedzy architekta, zachowując jednocześnie płynną, przypominającą ludzką interakcję dwukierunkowego agenta strumieniowego.
Kodowanie logiki routingu
Teraz umieścimy architect_agent w AgentTool i przekażemy agentowi wysyłki „Mapę logiki”. Ta mapa informuje agenta, kiedy dokładnie ma pobierać dane z magazynu i kiedy ma zgłaszać wyniki działania sentinela w tle.
Aby zapewnić Dispatch „oczy”, które nigdy nie mrugają, musimy przyznać mu dostęp do narzędzia do przesyłania strumieniowego, które utworzyliśmy w poprzednim kroku.
Gdy w ADK dodasz funkcję AsyncGenerator (np. monitor_for_hazard) do listy tools, agent traktuje ją jako trwały proces działający w tle. Zamiast jednorazowego wykonania agent „subskrybuje” dane wyjściowe narzędzia. Dzięki temu Dispatch może kontynuować główną rozmowę, a Sentinel w tle będzie cicho przekazywać alerty o zagrożeniach.
👉✏️ Zastąp #REPLACE_AGENT_TOOLS w $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py tym tekstem:
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
Weryfikacja
👉💻 Po skonfigurowaniu obu agentów możemy przetestować interakcję na żywo z wieloma agentami.
- W terminalu A uruchom agenta architekta:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- W nowym terminalu (terminalu B) uruchom agenta wysyłkowego:
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
Testowanie systemu wieloagentowego, który korzysta z modelu multimodalnego w czasie rzeczywistym, takiego jak gemini-live, w adk web symulatorze wymaga określonego przepływu pracy. Symulator doskonale sprawdza się do sprawdzania wywołań narzędzi, ale ma znaną niezgodność podczas pierwszego przetwarzania obrazów za pomocą tego typu modelu.
- Na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce. Kliknij Zmień port, ustaw go na 8000 i kliknij Zmień i wyświetl podgląd.
👉Wybierz dispatch_agent i prześlij Blueprint oraz obsłuż oczekiwany błąd
To najważniejszy krok. Musimy przekazać agentowi kontekst obrazu.
- Gdy interfejs się wczyta, zezwól na dostęp do mikrofonu, gdy pojawi się prośba.
- Pobierz ten obraz schematu na komputer:
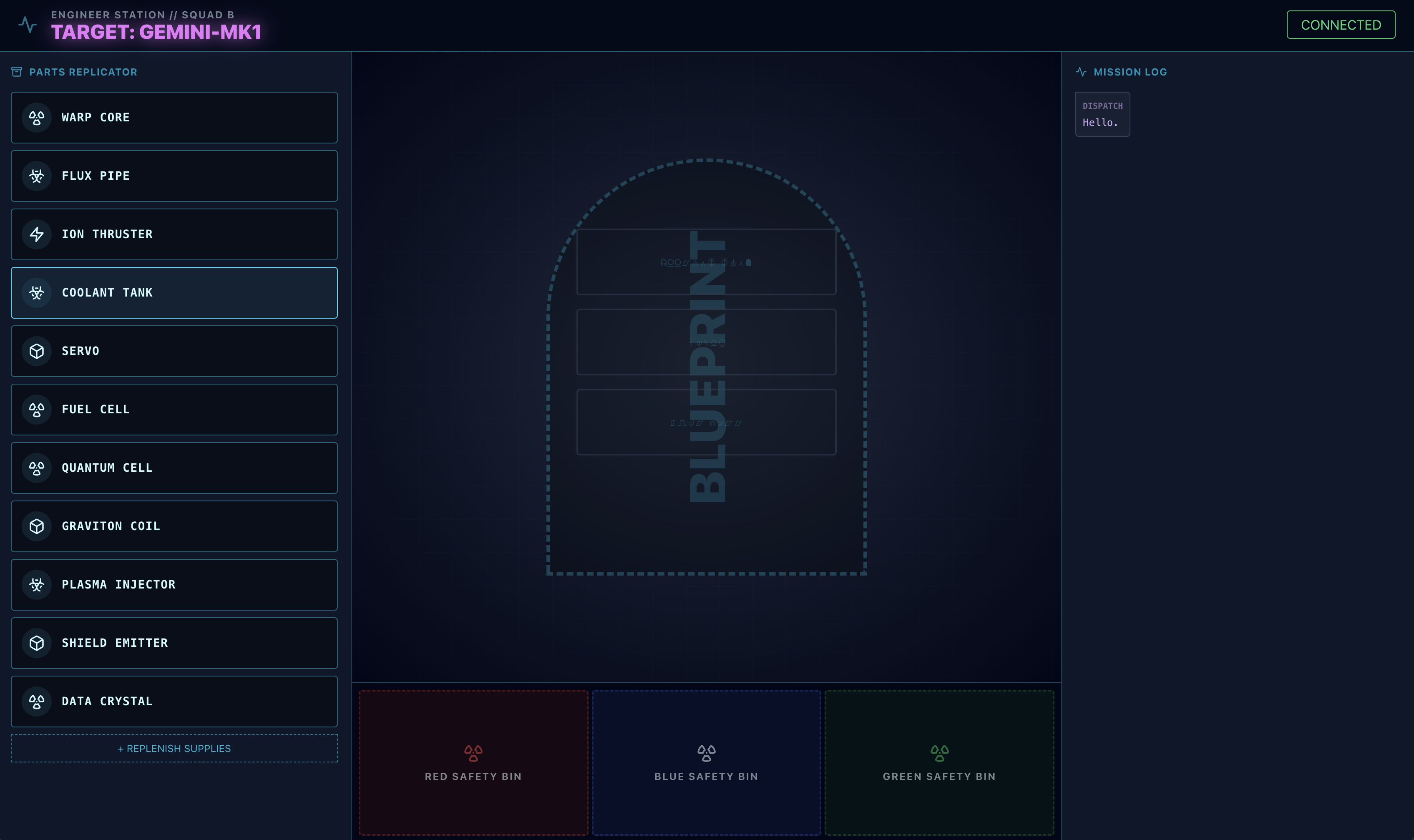
- W interfejsie
adk webkliknij ikonę spinacza i prześlij pobrany przed chwilą obraz projektu.
⚠️⚠️Pojawi się błąd 400 INVALID_ARGUMENT. To normalne.⚠️⚠️
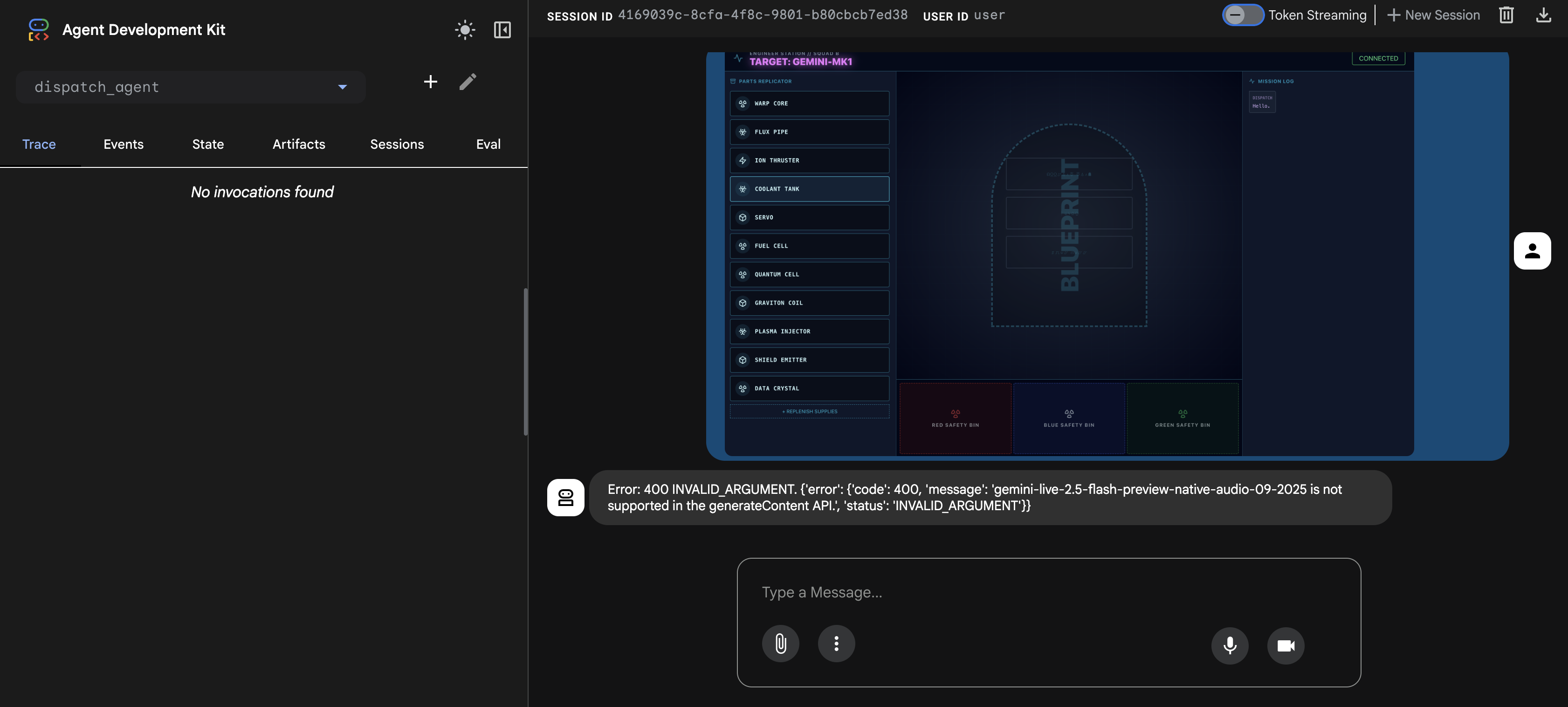
Ten błąd występuje, ponieważ moduł obsługi obrazów adk web nie jest w pełni zgodny z interfejsem API modelu gemini-live w przypadku jednorazowego przesyłania. Obraz został jednak dodany do kontekstu sesji.
- 👉 Aby usunąć błąd, po prostu odśwież stronę przeglądarki.
Uruchamianie procesu montażu
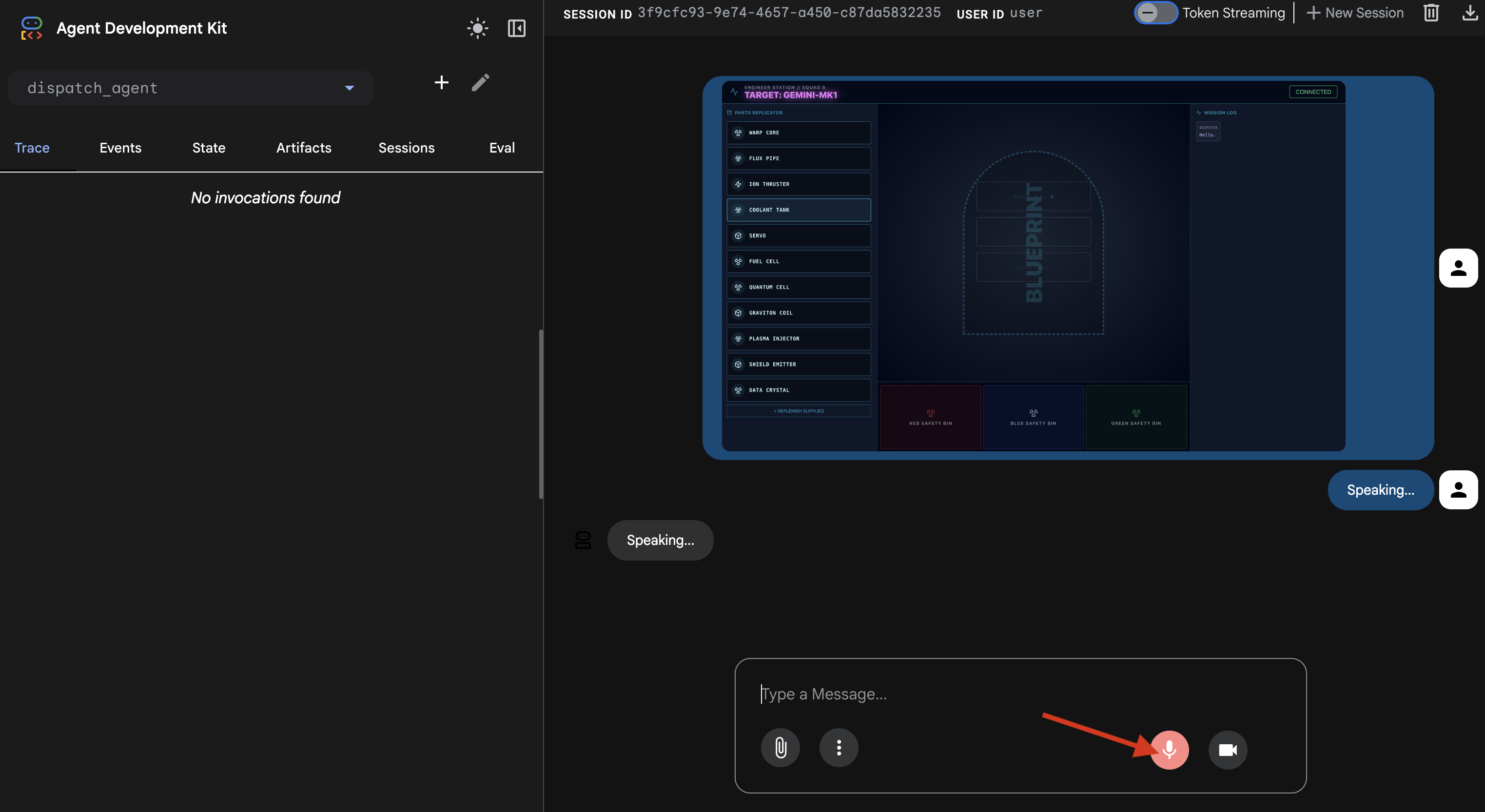
👉 Po ponownym załadowaniu błąd zniknie, a w historii czatu pojawi się obraz schematu. Agent ma teraz potrzebny kontekst wizualny.
- Kliknij ikonę mikrofonu, aby go włączyć. W interfejsie pojawi się komunikat „Słucham…”.
- Wypowiedz polecenie głosowe: „rozpocznij montaż”.
- Agent przetworzy Twoją prośbę, a interfejs zmieni się na „Mówię…”. Powinna pojawić się odpowiedź głosowa z listą wymaganych części.
4. Sprawdzanie wywołań narzędzi przez agenta
👉 Początkowa odpowiedź audio potwierdza, że system działa, ale prawdziwa magia tkwi w śladzie komunikacji między wieloma agentami.
- Wyłącz mikrofon.
- Odśwież stronę jeszcze raz.
Panel „Ślad” po lewej stronie zostanie teraz wypełniony. Możesz zobaczyć pełny, udany przepływ wykonania:
dispatch_agentpierwsze połączeniamonitor_for_hazard,- Następnie wykonuje wiele wywołań
execute_architectdoarchitect_agent, aby pobrać dane schematyczne.
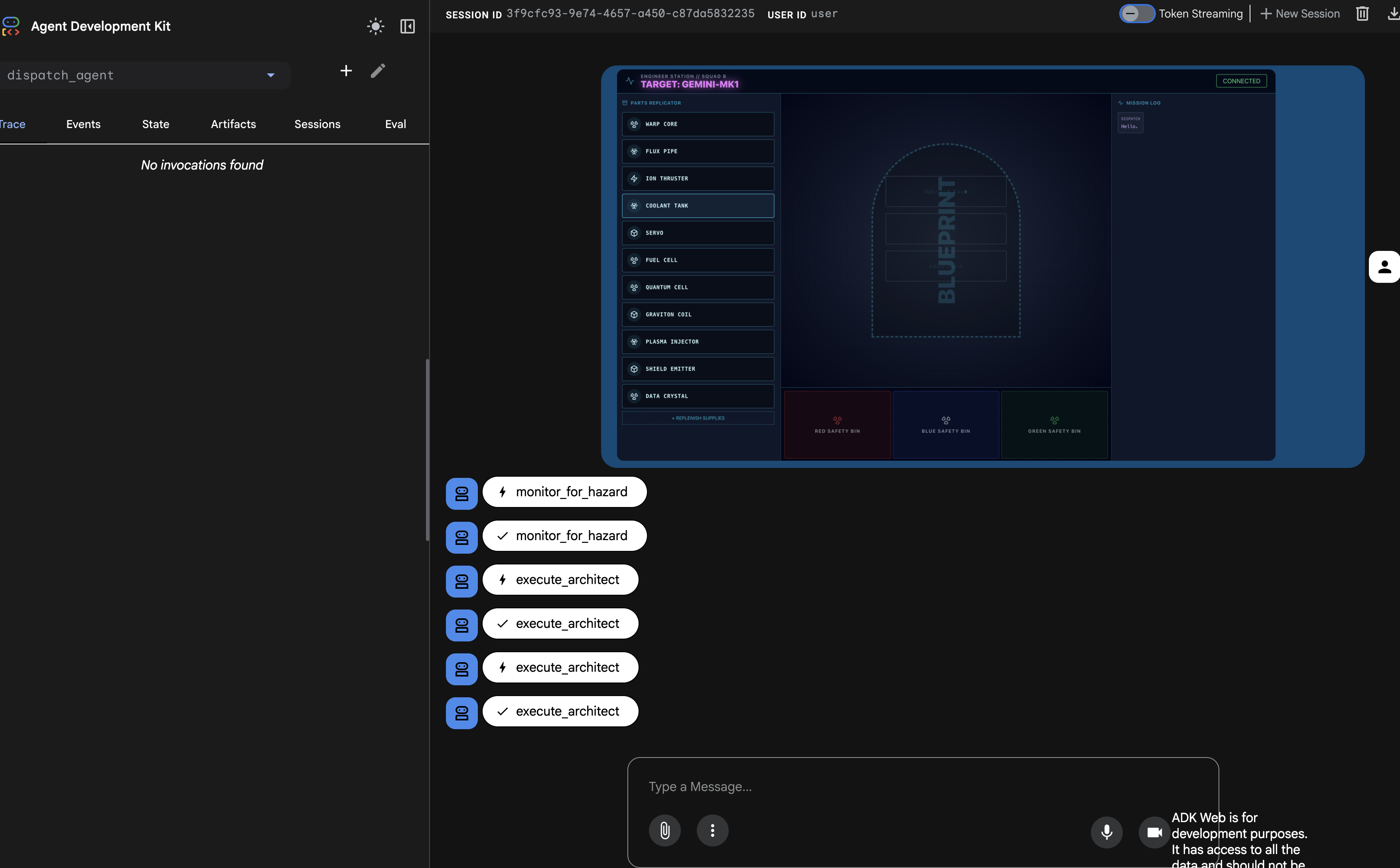
Ta sekwencja potwierdza, że cały przepływ pracy z wieloma agentami działa prawidłowo: dispatch_agent otrzymał prośbę, przekazał zadanie pobierania danych do architect_agent za pomocą wywołania narzędzia i otrzymał dane z powrotem, aby zrealizować polecenie użytkownika.
Połączenie dwukierunkowego strumieniowania może teraz monitorować w tle i umożliwia współpracę wielu agentów. Następnie nauczymy się analizować te złożone odpowiedzi na frontendzie.
👉💻 Aby wyjść, naciśnij Ctrl+c w obu terminalach.
5. Szczegółowe omówienie strumieni wydarzeń multimodalnych na żywo
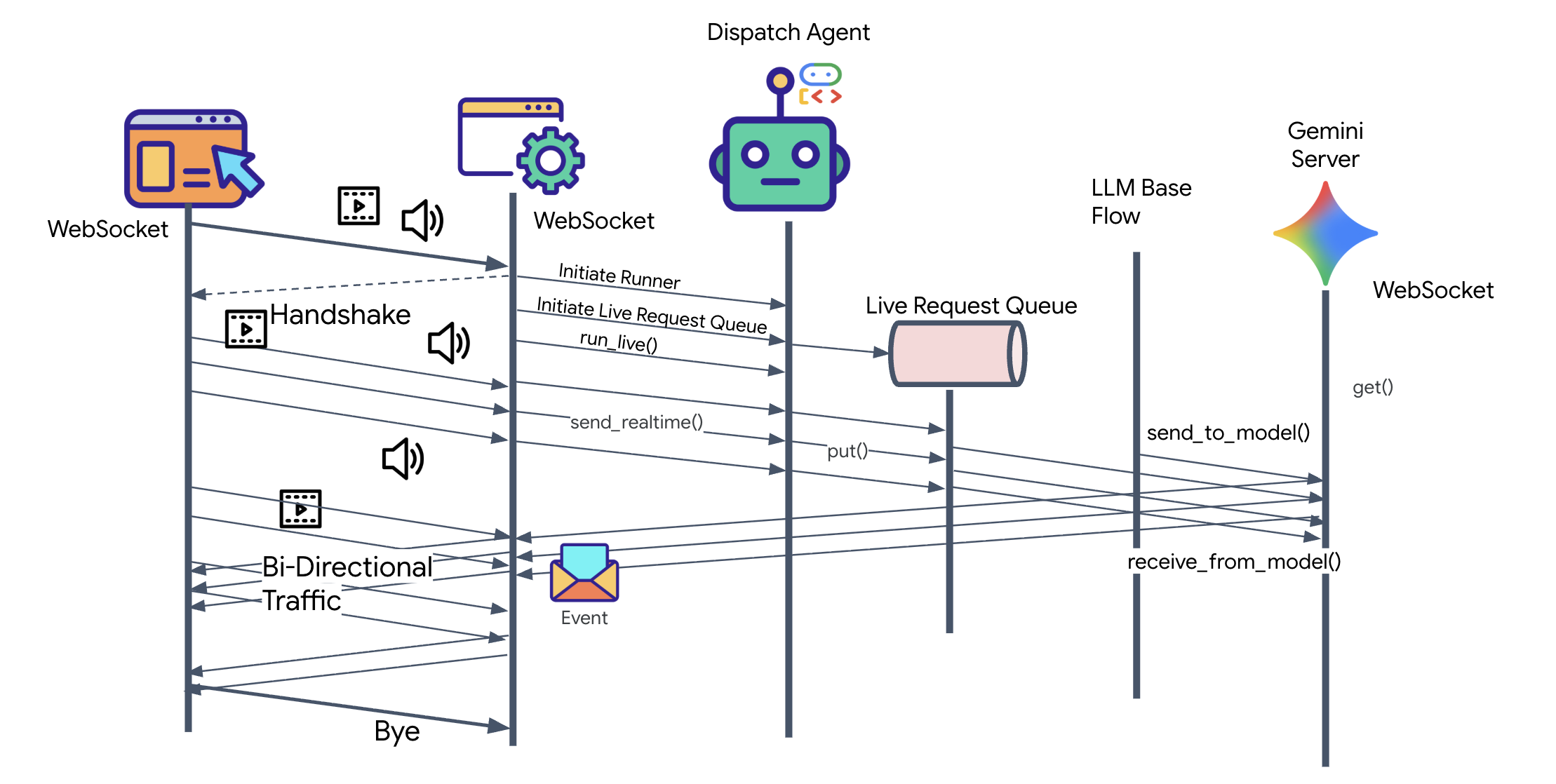
W poprzednim kroku udało nam się zweryfikować system wieloagentowy za pomocą wbudowanego serwera deweloperskiego adk web. To narzędzie korzysta z domyślnego narzędzia ADK do automatycznego zarządzania sesją, strumieniami i cyklem życia agenta. Aby jednak utworzyć samodzielną aplikację gotową do wdrożenia w środowisku produkcyjnym, taką jak nasza usługa FastAPI (main.py), potrzebujemy wyraźnej kontroli. Musimy ręcznie utworzyć i zarządzać ADK Runnerem, aby obsługiwać sesje użytkowników na żywo, ponieważ jest to podstawowy komponent, który przetwarza dwukierunkowe strumienie audio, wideo i tekstowe.
Pętla model–kod–model
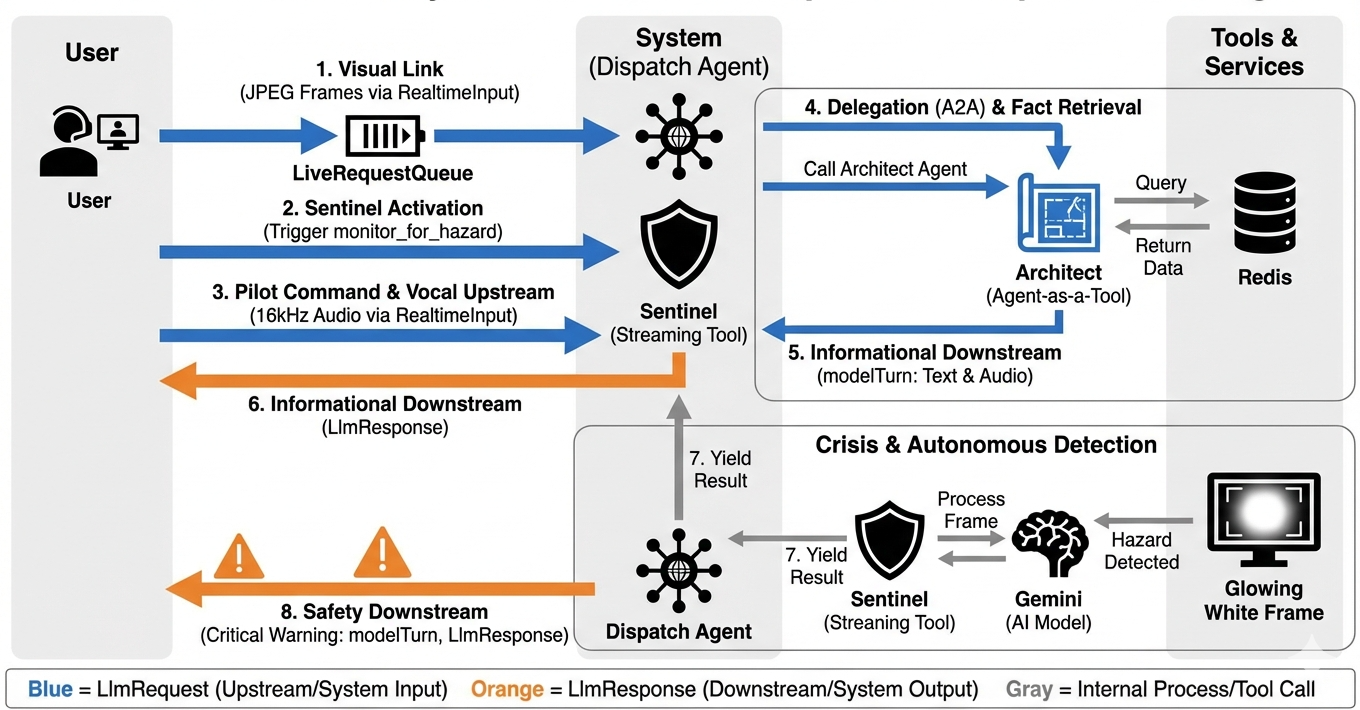
Aby zrozumieć, jak system działa w czasie rzeczywistym, prześledźmy cykl życia pojedynczej sesji misji. Ta pętla reprezentuje ciągłą wymianę obiektów LlmRequest i LlmResponse.
- Połączenie wizualne: inicjujesz połączenie i udostępniasz obraz z kamery internetowej lub ekran. Ramki JPEG o wysokiej jakości zaczynają być przesyłane w górę za pomocą
realtimeInput(przy użyciuLiveRequestQueue). - Aktywacja sygnału: system wysyła początkowy sygnał „Hello”. Zgodnie z instrukcjami agent ds. wysyłki natychmiast uruchamia
monitor_for_hazardnarzędzie do przesyłania strumieniowego. Spowoduje to rozpoczęcie pętli w tle, która będzie cicho obserwować każdą przychodzącą klatkę. - Polecenie pilota: mówisz do komunikatora: „Rozpocznij montaż”.
- Vocal Upstream: Twój głos jest rejestrowany jako dźwięk o częstotliwości 16 kHz i wysyłany w górę wraz z klatkami wideo.
- Delegowanie (A2A): dyspozytor „słyszy” Twoją intencję. Stwierdza, że nie ma schematów, więc wywołuje Architect Agent za pomocą protokołu
AgentTool(Agent-as-a-Tool). - Pobieranie informacji: architekt wysyła zapytanie do bazy danych Redis i zwraca listę części do usługi Dispatch. Usługa Dispatch pozostaje „gospodarzem sesji” i otrzymuje dane bez przekazywania Cię do innej usługi.
- Informational Downstream: wysyła
modelTurn(Downstream) zawierający tekst i oryginalny dźwięk: „Potwierdzenie architekta. Wymagany podzbiór to: Rdzeń warp, Rura strumieniowa, Silnik jonowy”. - Kryzys: nagle część na stole warsztatowym traci stabilność i zaczyna świecić na biało.
- Autonomiczne wykrywanie: pętla
monitor_for_hazardw tle (strażnik) wykrywa konkretną klatkę JPEG zawierającą poświatę. Przetwarza klatkę, wywołując Gemini, i identyfikuje zagrożenie. - Safety Downstream: narzędzie do przesyłania strumieniowego
yieldswynik. Ponieważ jest to agent Bidi-Streaming, Dispatch może przerwać jego bieżący stan, aby natychmiast wysłać krytyczne ostrzeżenie dotyczące bezpieczeństwa Downstream: „Wykryto zagrożenie! Neutralizuję teraz Kryształ Danych. Przenieś go do CZERWONEGO kosza”.
Ustawianie konfiguracji środowiska wykonawczego agenta
Symbol RunConfig w ADK umożliwia szczegółową konfigurację zachowania agenta, w tym sposobu obsługi danych przesyłanych strumieniowo i interakcji z różnymi modalnościami.
W przypadku dwukierunkowej komunikacji w czasie rzeczywistym parametr streaming_mode ma wartość BIDI, co umożliwia użytkownikowi i agentowi jednoczesne mówienie i słuchanie. Parametr response_modalities określa typy danych wyjściowych, które może generować agent, np. głos i tekst. input_audio_transcription określa, jak agent przetwarza i transkrybuje przychodzące wypowiedzi użytkownika. Aby zapewnić większą stabilność, session_resumptionumożliwia agentowi zapamiętanie kontekstu rozmowy i wznowienie jej w przypadku utraty połączenia. proactivity umożliwia agentowi inicjowanie działań lub mowy bez bezpośredniego polecenia użytkownika, np. wydawanie spontanicznych ostrzeżeń o zagrożeniach, a enable_affective_dialog pozwala agentowi generować bardziej naturalne i empatyczne odpowiedzi. Więcej informacji o konfiguracji RunConfig pakietu ADK znajdziesz tutaj.
👉✏️ Znajdź w pliku $HOME/way-back-home/level_4/backend/main.py obiekt zastępczy #REPLACE_RUN_CONFIG i zastąp go poniższą logiką podziału:
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
Wdrażanie żądania w przypadku agenta
Następnie wdrożymy podstawowe łącze komunikacyjne, które przesyła strumieniowo w czasie rzeczywistym dane multimodalne z niestabilnego środowiska roboczego użytkownika do agenta wysyłającego za pomocą protokołu WebSocket. Dzięki temu agent będzie stale „widzieć” (klatki wideo) i „słyszeć” (polecenia głosowe). Logika stale odbiera strumień danych, rozróżnia przychodzące binarne fragmenty audio i pakiety tekstu/obrazu w formacie JSON oraz umieszcza je w obiektach Blob (w przypadku multimediów) lub Content (w przypadku tekstu), a następnie wysyła do kolejki LiveRequestQueue, aby obsługiwać dwukierunkową sesję agenta.
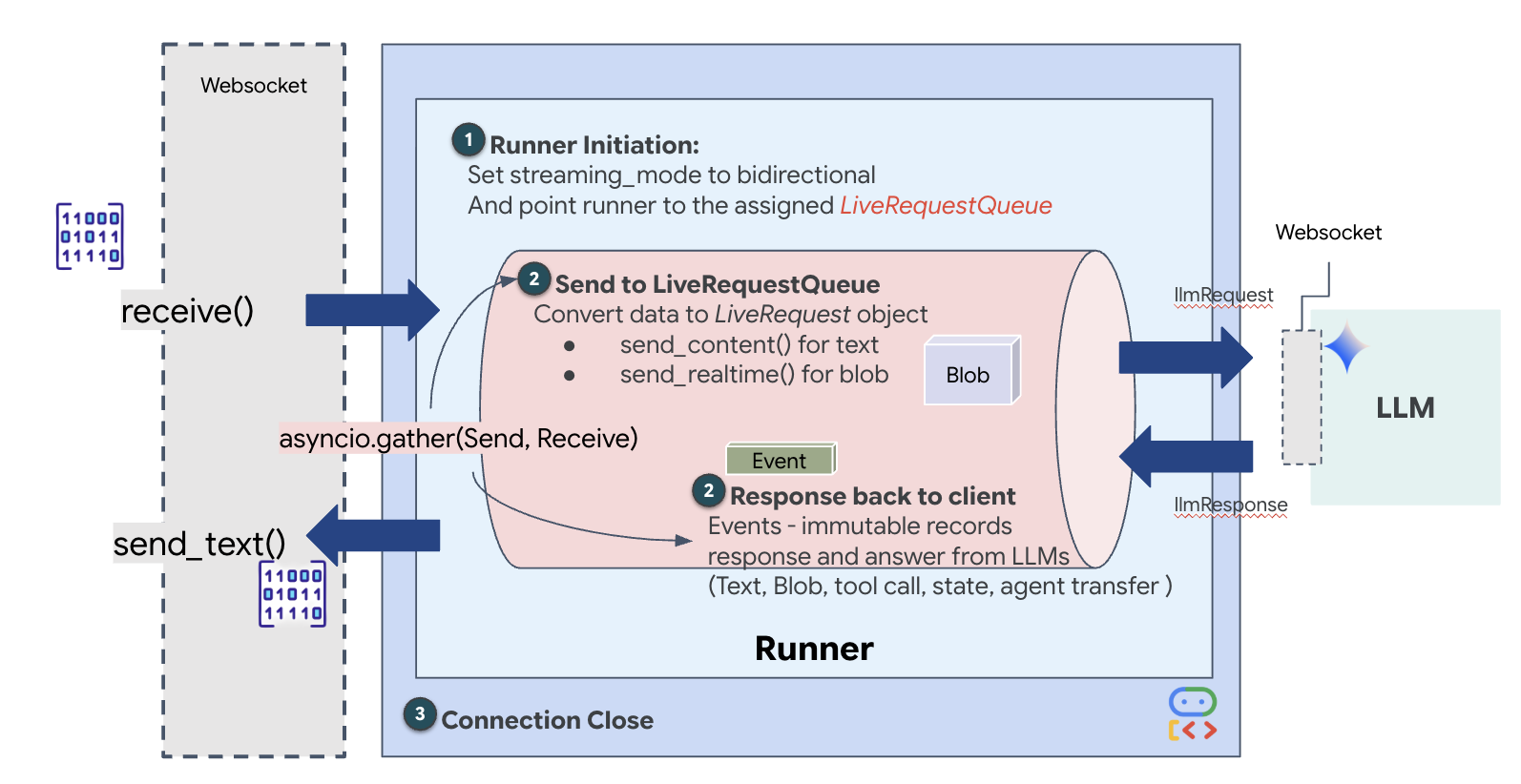
Znajdź w pliku $HOME/way-back-home/level_4/backend/main.py obiekt zastępczy #PROCESS_AGENT_REQUEST i zastąp go tą logiką podziału:
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
Dane multimodalne są teraz wysyłane do agenta.
Implementowanie odpowiedzi: struktura danych zdarzenia podrzędnego
Gdy używasz dwukierunkowego (aktywnego) agenta z ADK, dane zwracane przez agenta są pakowane w określony typ zdarzenia, który dziedziczy z podstawowych struktur pakietu SDK GenAI. Event obiekt otrzymywany w pętli async for event in runner.run_live(...) to pojedynczy obiekt zawierający kilka pól opcjonalnych, z których każde służy do przechowywania innego typu informacji:
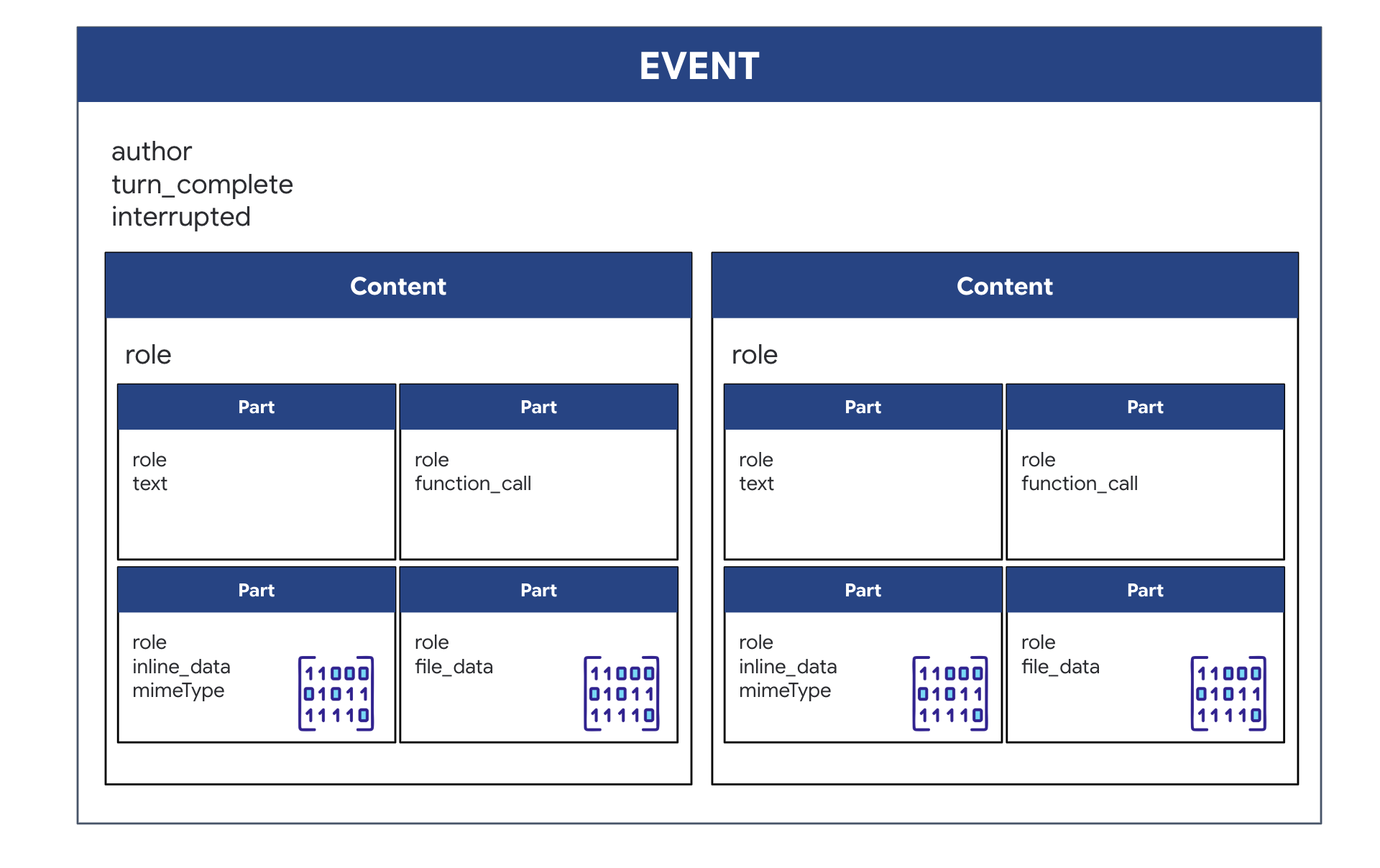
Struktura treści:
- Gdy pracownik obsługi klienta mówi (za pomocą
.server_content): to pole nie zawiera tylko zwykłego tekstu. Zawiera listęParts. Każdy elementPartjest kontenerem na jeden typ danych – ciąg tekstowy (np."The part is stable.") lub surowy plik audio (głos). - Gdy agent podejmuje działania (za pomocą
.tool_call): pole zawiera listę obiektówFunctionCall. KażdyFunctionCallto prosty, strukturalny obiekt, który określa nazwę narzędzia i argumenty wejściowe w przejrzystym formacie, który kod backendu może łatwo odczytać i wykonać.
👀 Jeśli przyjrzysz się pojedynczemu Event wygenerowanemu przez pętlę run_live, kod JSON (wygenerowany przez event.model_dump(by_alias=True)) będzie wyglądać tak, ściśle według kształtów GenAI SDK:
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ Zaktualizujemy teraz downstream_task w main.py, aby przekazywać pełne dane zdarzenia. Ta logika zapewnia, że każda „myśl” AI jest rejestrowana w terminalu diagnostycznym statku i wysyłana jako pojedynczy obiekt JSON do interfejsu użytkownika.
Znajdź w pliku $HOME/way-back-home/level_4/backend/main.py obiekt zastępczy #PROCESS_AGENT_RESPONSE i zastąp go tą logiką podziału:
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
Realizacja misji
Po połączeniu skarbca backendu i skonfigurowaniu obu agentów wszystkie systemy są gotowe do działania. Wykonanie tych czynności spowoduje uruchomienie pełnej aplikacji, co umożliwi Ci interakcję z utworzonym właśnie systemem 2 agentów.
Cel: zmontuj losowo przypisany napęd warp, który pojawi się na Twoim stole warsztatowym. Protokół: musisz postępować zgodnie z instrukcjami głosowymi agenta, zwłaszcza z ostrzeżeniami o zagrożeniach dotyczących poszczególnych komponentów.
Aktywowanie specjalisty (architekta)
👉💻 W pierwszym oknie terminala uruchom agenta Architect. Ta usługa backendu połączy się z magazynem Redis i będzie czekać na żądania schematów od dyspozytora.
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
(Nie zamykaj tego terminala. Jest to teraz Twój aktywny „agent bazy danych”).
Uruchamianie kokpitu (dyspozytora)
👉💻 W nowym oknie terminala (Terminal B) utworzymy interfejs użytkownika i uruchomimy głównego agenta Dispatch, który obsługuje interfejs użytkownika i całą komunikację na żywo.
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(Uruchomi to serwer główny na porcie 8080).
Uruchomienie scenariusza testowego
System jest już aktywny. Twoim celem jest postępowanie zgodnie z instrukcjami agenta, aby dokończyć montaż.
- 👉 Otwórz stronę Workbench:
- Na pasku narzędzi Cloud Shell kliknij ikonę Podgląd w przeglądarce.
- Kliknij Zmień port, ustaw go na 8080 i kliknij Zmień i wyświetl podgląd.
- 👉 Rozpocznij misję:
- Gdy interfejs się wczyta, zezwól mu na dostęp do ekranu i mikrofonu.
- Jeśli udostępniasz okno, aby uniknąć problemów, upewnij się, że jest to JEDYNA karta w oknie.
- Zostanie Ci przypisany dysk o losowej nazwie (np. „NOVA-V”, „OMEGA-9”).
- Gdy interfejs się wczyta, zezwól mu na dostęp do ekranu i mikrofonu.
- 👉 Pętla Assembly:
- Prośba: aby rozpocząć montaż napędu, powiedz: „Rozpocznij montaż”.
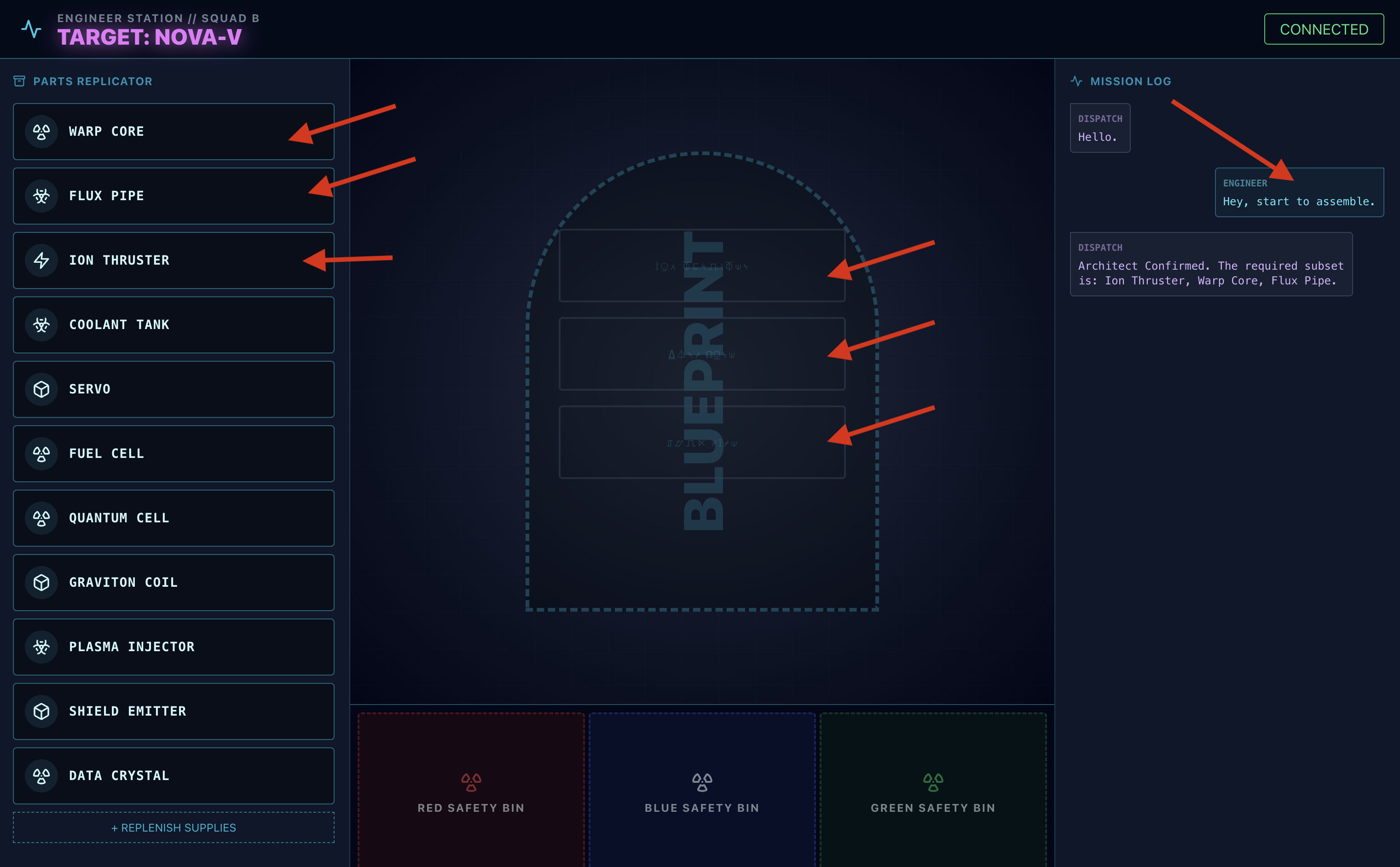
- Odpowiedź architekta: agent poda prawidłowe części do złożenia napędu.
- Sprawdzanie zagrożeń: gdy na stole warsztatowym pojawi się część, która wydaje się niebezpieczna:
- Narzędzie
monitor_for_hazardagenta wysyłającego wizualnie zidentyfikuje ten problem. - Wygeneruje to „ALARM WIZUALNY”. (Zajmie to około 30 sekund)
- Sprawdzi, którego kosza użyć, aby wyłączyć zagrożenie.
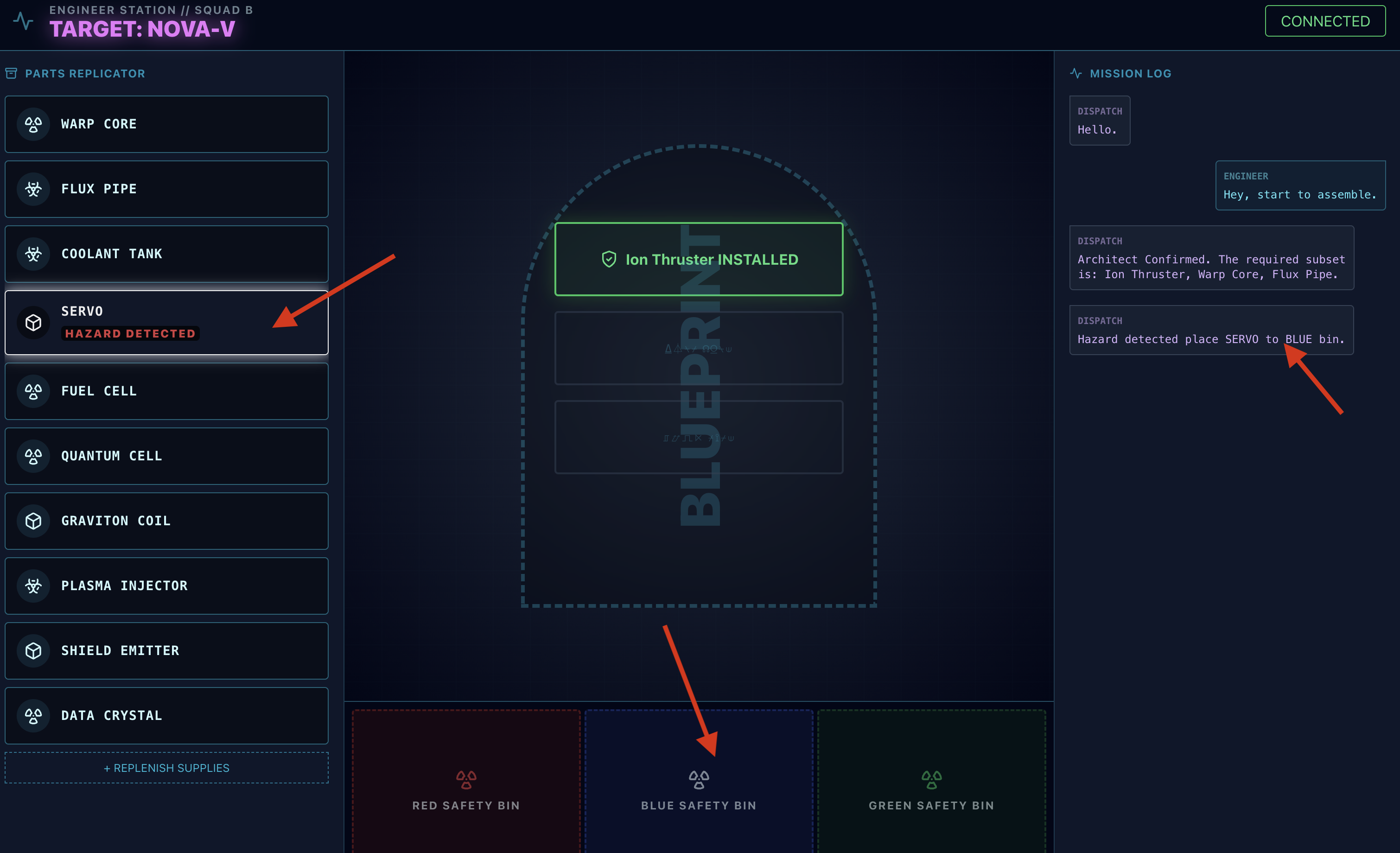
- Narzędzie
- Działanie: dyspozytor wyda Ci bezpośrednie polecenie: „Potwierdzono zagrożenie. Umieść XXX w czerwonym pojemniku." Aby przejść dalej, musisz wykonać tę instrukcję.
- Prośba: aby rozpocząć montaż napędu, powiedz: „Rozpocznij montaż”.
Misja zakończona. Udało Ci się utworzyć interaktywny system wieloagentowy. Ocaleni są bezpieczni, rakieta opuściła atmosferę, a Twoja „Droga do domu” trwa dalej.
👉💻 Aby wyjść, naciśnij Ctrl+c w obu terminalach.
6. Wdróż w gałęzi produkcyjnej (opcjonalnie)
Udało Ci się przetestować agenta lokalnie. Teraz musimy przesłać rdzeń neuronowy Architekta do komputerów głównych statku (Cloud Run). Dzięki temu będzie działać jako stała, niezależna usługa, do której agent Dispatch może wysyłać zapytania z dowolnego miejsca.
Udostępnianie bezpiecznego magazynu (infrastruktury)
Zanim wdrożymy agenta, musimy utworzyć jego pamięć trwałą (Memorystore) i bezpieczny kanał dostępu do niej (VPC Connector).
👉💻 Utwórz instancję Memorystore (Redis Vault):
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 Pobierz adres sieciowy Vault: wykonaj to polecenie i skopiuj host adres IP. Jest to adres prywatny nowej instancji Redis.
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 Utwórz oprogramowanie sprzęgające dostęp do VPC (bezpieczny most): to oprogramowanie sprzęgające działa jak prywatny most, który umożliwia Cloud Run dostęp do instancji Redis w sieci VPC.
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 Wczytaj dane:
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
Wdrażanie aplikacji agenta
Kompilowanie i tworzenie obrazu agenta
👉💻 Przejdź do katalogu backendu i utwórz plik Dockerfile.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 Spakuj aplikację do obrazu kontenera.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
Wdrożenie w Cloud Run
👉💻 Wdróż agenta w Cloud Run. Wstrzykniemy adres IP Redis i połączymy oprogramowanie sprzęgające VPC bezpośrednio z poleceniem uruchamiania. Dzięki temu agent rozpoczyna pracę z bezpiecznym, prywatnym połączeniem z bazą danych.
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 Sprawdź, czy serwer A2A jest uruchomiony.
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
Po zakończeniu polecenia zobaczysz URL usługi. Agent Architect jest teraz dostępny w chmurze, na stałe połączony ze swoim magazynem i gotowy do udostępniania danych schematycznych innym agentom.
Wdrażanie Dispatch Hub na komputerze centralnym w środowisku produkcyjnym
Po uruchomieniu agenta Architekta w chmurze musimy wdrożyć centrum dystrybucji. Ten agent będzie głównym interfejsem użytkownika, który będzie obsługiwać strumienie głosowe i wideo na żywo oraz przekazywać zapytania do bazy danych do bezpiecznego punktu końcowego Architekta.
👉💻 Uruchom w terminalu Cloud Shell to polecenie. W katalogu backendu zostanie utworzony kompletny, wieloetapowy plik Dockerfile.
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
Kompilowanie i tworzenie obrazu agenta lub frontendu
👉💻 Przejdź do katalogu backendu zawierającego kod agenta Dispatch (main.py) i zapakuj go w obraz kontenera.
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
Wdrożenie w Cloud Run
👉💻 Wdróż centrum dystrybucji w Cloud Run. Wstrzykniemy adres URL Architecta jako zmienną środowiskową, tworząc kluczowe połączenie między naszymi 2 agentami natywnymi dla chmury.
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
Po zakończeniu działania polecenia zobaczysz adres URL usługi (np. https://mission-bravo-...run.app). Aplikacja jest już aktywna w chmurze.
👉 Otwórz stronę Google Cloud Run i wybierz z listy usługę biometric-scout. 
👉 Znajdź publiczny adres URL wyświetlany u góry strony Szczegóły usługi. 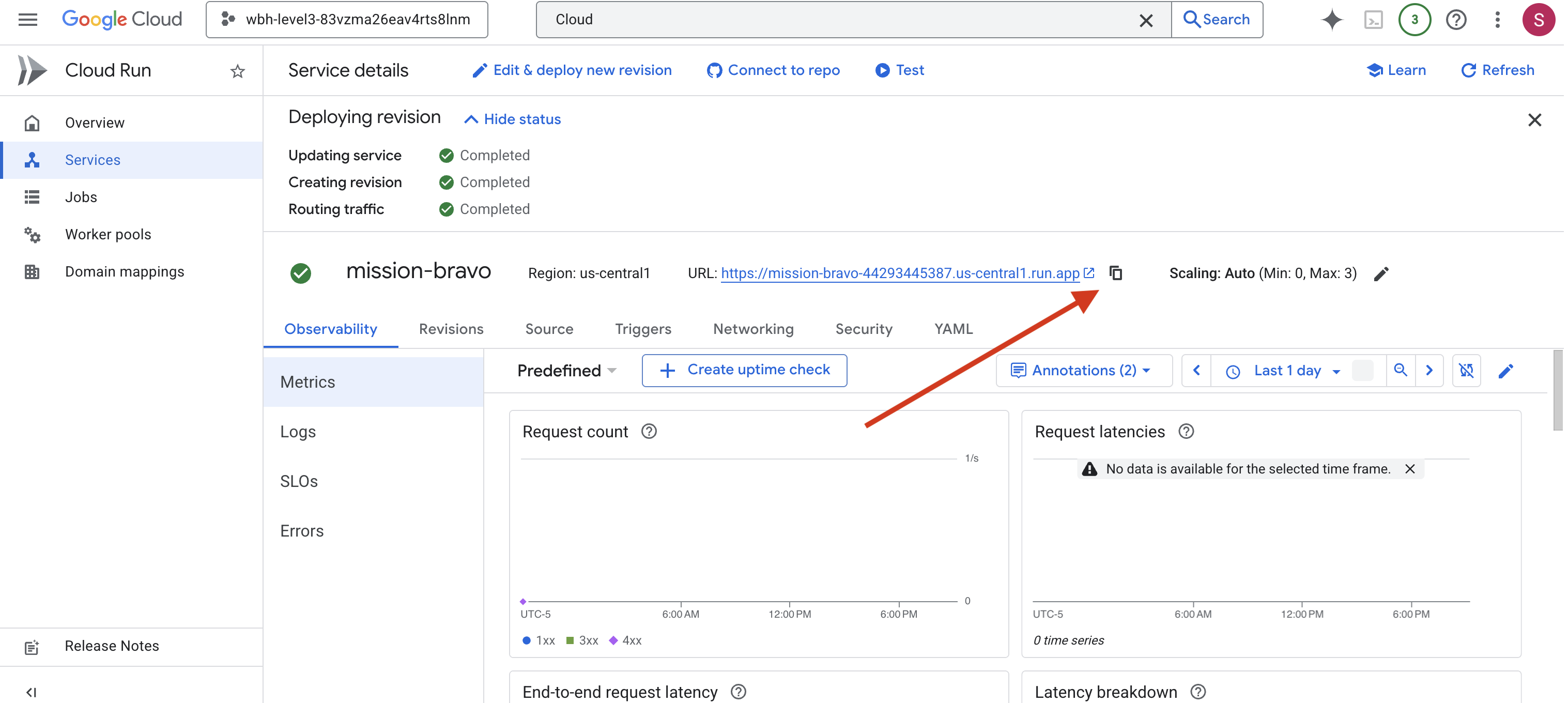
Ostateczne sprawdzenie systemów (test kompleksowy)
👉 Teraz możesz korzystać z systemu na żywo.
- Pobierz adres URL: skopiuj URL usługi z wyniku ostatniego polecenia wdrażania (powinien kończyć się znakiem
run.app). - Otwórz Cockpit: wklej adres URL w przeglądarce.
- Nawiązywanie kontaktu: po wczytaniu interfejsu zezwól mu na dostęp do ekranu i mikrofonu.
- Prośba o dane: gdy dysk zostanie przypisany, poproś o rozpoczęcie montażu. Przykład: „Zacznij montaż”

Teraz korzystasz z w pełni wdrożonego systemu wieloagentowego działającego w całości w Google Cloud.
System wieloagentowy blokuje ostatni pierścień zabezpieczający, a niestabilne promieniowanie stabilizuje się.
„Napęd Warp: STABILIZOWANY. Rescue Craft: ENGINES IGNITED."

Na monitorze statek obcych wznosi się w górę, ledwo unikając rozpadającej się powierzchni Ozymandiasa, gdy atmosfera się załamuje. Wprowadza statek na bezpieczną orbitę, a w komunikatorze rozlegają się głosy ocalałych – wstrząśniętych, ale żywych. Po zakończeniu akcji ratunkowej i odblokowaniu drogi do domu połączenie zdalne zostaje przerwane.
Dzięki Tobie ocaleni zostali uratowani.
Jeśli udało Ci się ukończyć poziom 0, nie zapomnij sprawdzić, na jakim etapie jest Twoja misja powrotu do domu.