1. 任务

您漂浮在寂静而未知的广阔太空中。一次巨大的太阳脉冲将您的飞船撕裂,使其穿过维度裂缝,让您被困在宇宙中一个没有任何星图的角落。
经过数天艰苦的维修,发动机熟悉的嗡嗡声终于回来了。您的火箭已准备就绪。您甚至还成功建立了与母舰的远程上行链路。即将出发。您已准备好回家。
但就在你准备启动跳跃引擎时,一个求救信号穿透了静电干扰。您的传感器发现了一颗名为“奥兹曼迪亚斯”的星球发出的求救信号。幸存者被困在这个即将消亡的世界中,他们的飞船也已坠毁。您的任务至关重要:在行星大气层崩塌之前拯救他们。
他们唯一的逃生工具是一艘用外星科技打造的古老废弃火箭。虽然火箭还能正常运行,但其曲速引擎已损坏。为了拯救幸存者,您必须远程连接到他们的易失性工作台,并手动组装替换驱动器。
面临的挑战
您对这种出了名的脆弱外星技术一无所知。不稳定的组件可能会在几秒钟内变成放射性危害。您有一次操作易失性工作台的机会。您当前的 AI 助理难以同时处理视觉数据和技术手册,导致指令出现幻觉,并遗漏危险警告。
若要成功,您必须将 AI 从单一实体升级为协作式多智能体系统。
您的任务目标:
按照新的多智能体系统提供的实时专用指令组装曲速引擎。

构建内容
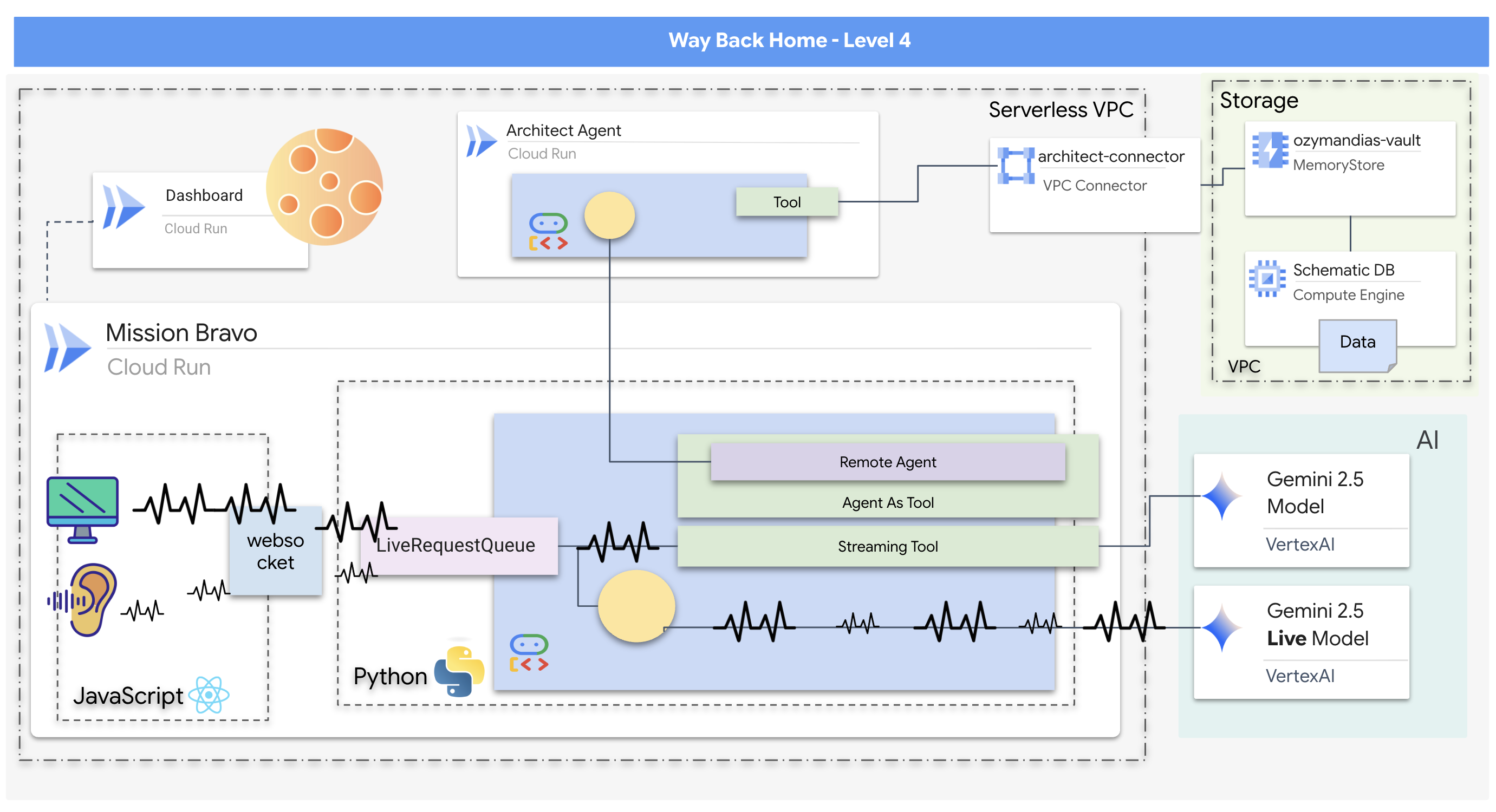
- 一种实时、双向多智能体 AI 系统,具有一个中央调度智能体,用于管理用户互动并与专业智能体协调。
- 一种连接到 Redis 数据库以检索和提供原理图数据的架构师代理。
- 一种主动式安全监控器,可使用流式工具分析实时视频源中的视觉危险,并触发实时提醒。
- 一个基于 React 的前端,可提供与系统交互的界面,并将视频和音频流式传输到后端代理。
学习内容
技术 / 概念 | 说明 |
Google 智能体开发套件 (ADK) | 您将使用 ADK 构建、测试和管理代理,并利用其框架来处理实时通信、工具集成和代理生命周期。 |
双向 (Bidi) 流式传输 | 您将实现一个双向流式传输代理,该代理支持自然、低延迟的双向通信,使人类和 AI 都能实时中断和响应。 |
多智能体系统 | 您将学习如何设计分布式 AI 系统,其中主智能体会将任务委托给专业智能体,从而实现关注点分离和更具可扩缩性的架构。 |
Agent-to-Agent (A2A) Protocol | 您将使用 A2A protocol 在调度代理和架构师代理之间建立通信,使它们能够发现彼此的能力并交换数据。 |
流式传输工具 | 您将实现一个充当后台进程的流式传输工具,该工具会持续分析视频 Feed 以监控状态变化(危险),并主动生成结果。 |
Google Cloud Run 和 Memorystore | 您将使用 Cloud Run 托管代理服务,并使用 Memorystore (Redis) 作为持久性数据库,将整个多代理应用部署到生产环境。 |
FastAPI 和 WebSocket | 后端使用 FastAPI 和 WebSockets 构建,可处理流式传输音频、视频和智能体响应所需的高性能实时通信。 |
React 前端 | 您将使用基于 React 的前端,该前端可捕获用户媒体(音频/视频)并进行流式传输,同时显示 AI 智能体的实时回答。 |
2. 设置环境
访问 Cloud Shell
👉点击 Google Cloud 控制台顶部的“激活 Cloud Shell”(这是 Cloud Shell 窗格顶部的终端形状图标),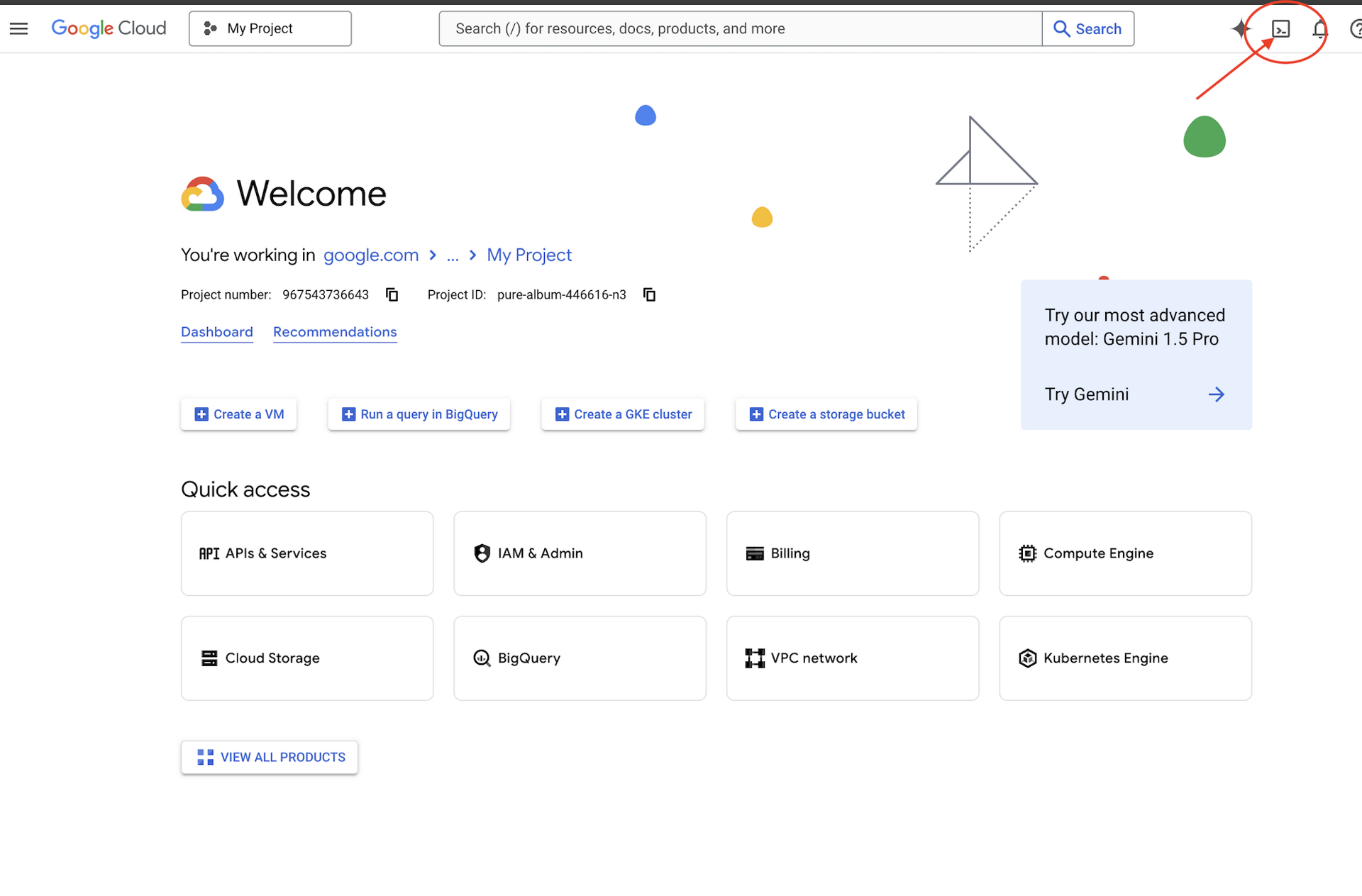
👉点击“打开编辑器”按钮(铅笔图案,看起来像一个打开的文件夹)。此操作会在窗口中打开 Cloud Shell 代码编辑器。您会在左侧看到文件资源管理器。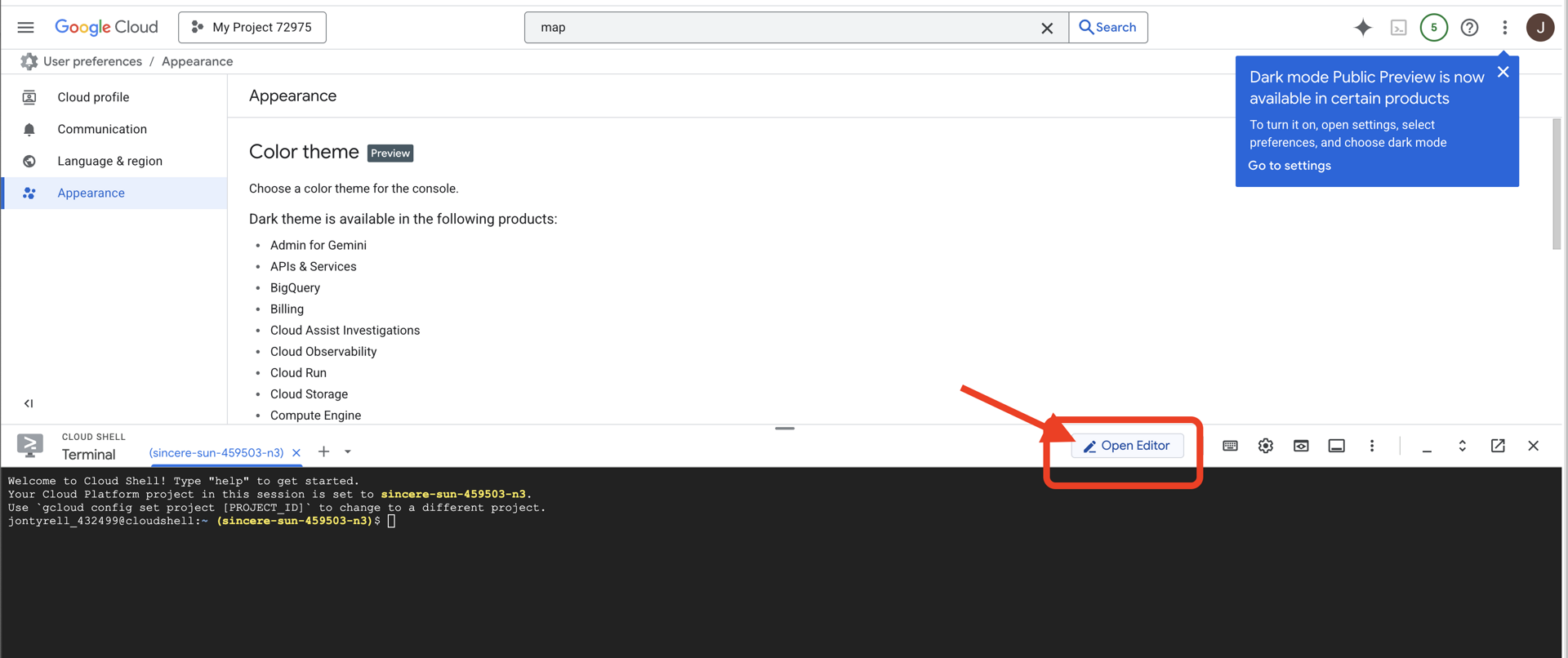
👉在云 IDE 中打开终端,
👉💻 在终端中,使用以下命令验证您是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
您应该会看到自己的账号显示为 (ACTIVE)。
前提条件
ℹ️ 0 级是可选的(但建议使用)
您无需达到 0 级即可完成此任务,但先完成此任务可获得更具沉浸感的体验,让您在完成任务的过程中看到自己的信标在世界地图上亮起。
设置项目环境
返回终端,通过设置有效项目并启用所需的 Google Cloud 服务(Cloud Run、Vertex AI 等)来完成配置。
👉💻 在终端中,设置项目 ID:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 启用必需的服务:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com \
redis.googleapis.com \
vpcaccess.googleapis.com
安装依赖项
👉💻 前往第 4 级,然后安装所需的 Python 软件包:
cd $HOME/way-back-home/level_4
uv sync
关键依赖项包括:
软件包 | 用途 |
| 用于卫星站和 SSE 流式传输的高性能 Web 框架 |
| 运行 FastAPI 应用所需的 ASGI 服务器 |
| 用于构建 Formation Agent 的智能体开发套件 |
| 用于标准化通信的 Agent-to-Agent 协议库 |
| 用于访问 Gemini 模型的原生客户端 |
| 用于连接到 Schematic Vault (Memorystore) 的 Python 客户端 |
| 支持实时双向通信 |
| 管理环境变量和配置密钥 |
| 数据验证和设置管理 |
验证设置
在开始编写代码之前,我们先确保所有系统都正常运行。运行验证脚本以审核您的 Google Cloud 项目、API 和 Python 依赖项。
👉💻 运行验证脚本:
cd $HOME/way-back-home/level_4/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 您应该会看到一系列绿色对勾 (✅)。
- 如果您看到红叉 (❌),请按照输出中建议的修复命令(例如
gcloud services enable ...或pip install ...)操作。 - 注意:目前,出现
.env的黄色警告是可以接受的;我们将在下一步中创建该文件。
🚀 Verifying Mission Bravo (Level 4) Infrastructure... ✅ Google Cloud Project: xxxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. 使用 ADK 在 Redis 中构建 Schematic Vault 和双向代理
您已找到包含废弃火箭蓝图的行星示意图代码库。如需准确检索此数据,您必须与存储库的专用管理界面(即 Architect 代理)进行交互。
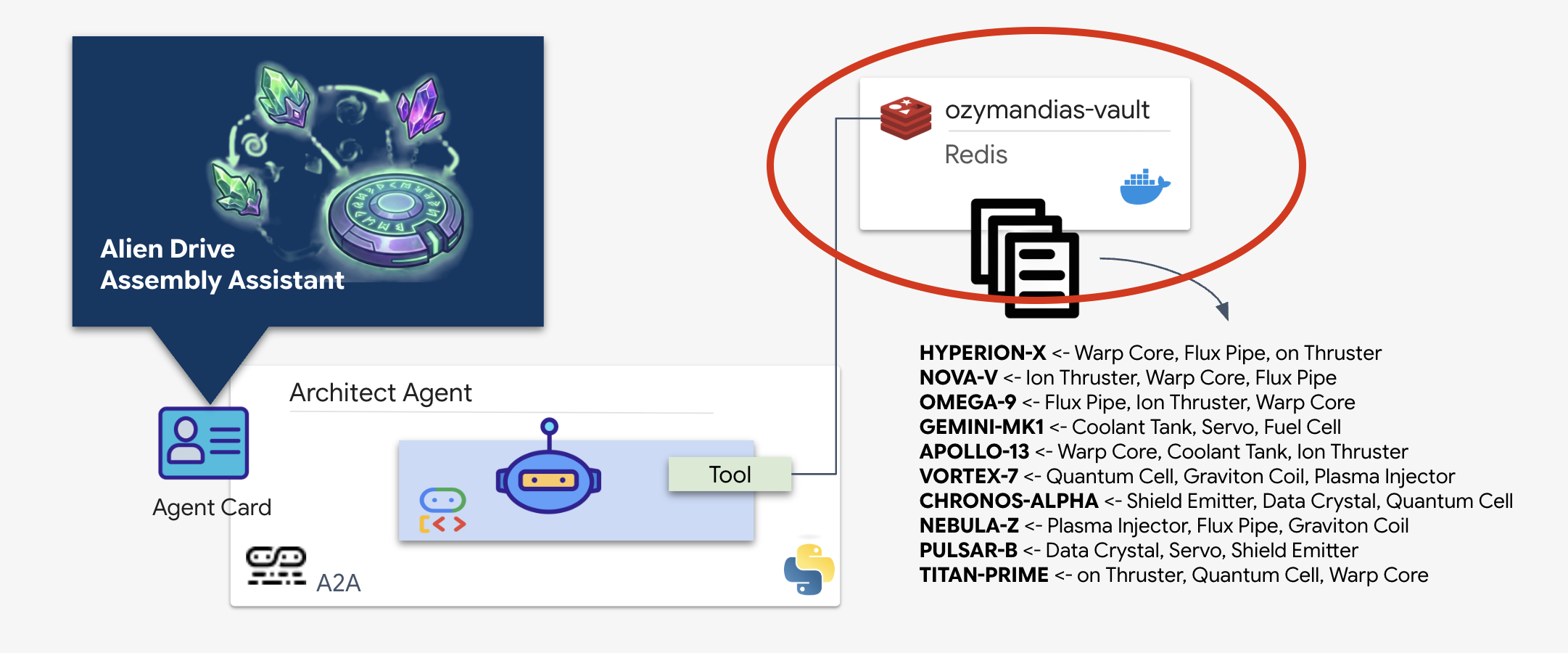
配置 Schematic Vault (Redis)
在架构师为我们提供帮助之前,我们必须确保数据托管在安全的高可用性环境中。我们将使用 Redis 作为外星人示意图的快速数据存储区。为方便开发,我们将启动本地 Redis 实例,但稍后会提供有关如何使用 Google Cloud Memorystore 部署到生产环境的说明。
👉💻 在终端中运行以下命令以预配 Redis 实例(这可能需要 2-3 分钟):
docker run -d --name ozymandias-vault -p 6379:6379 redis:8.6-rc1-alpine
👉💻 如需加载初步数据,请运行以下命令以进入 Redis Shell:
docker exec -it ozymandias-vault redis-cli
(提示符将更改为 127.0.0.1:6379)
👉💻 将以下命令粘贴到其中:
RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
👉💻 输入 exit 以返回到正常 shell。
👉💻 如需通过直接从终端查询特定船舶来检查数据是否存在,请运行以下命令:
# Check 'TITAN-PRIME'
docker exec ozymandias-vault redis-cli LRANGE "TITAN-PRIME" 0 -1
👀 这是预期输出:
1) "Ion Thruster" 2) "Quantum Cell" 3) "Warp Core"
实现 Architect Agent
架构师智能体是一种专门的智能体,负责从 Redis 保险柜中检索原理图蓝图。它充当专用数据接口,可确保主调度智能体接收准确的结构化信息,而无需了解底层数据库逻辑。
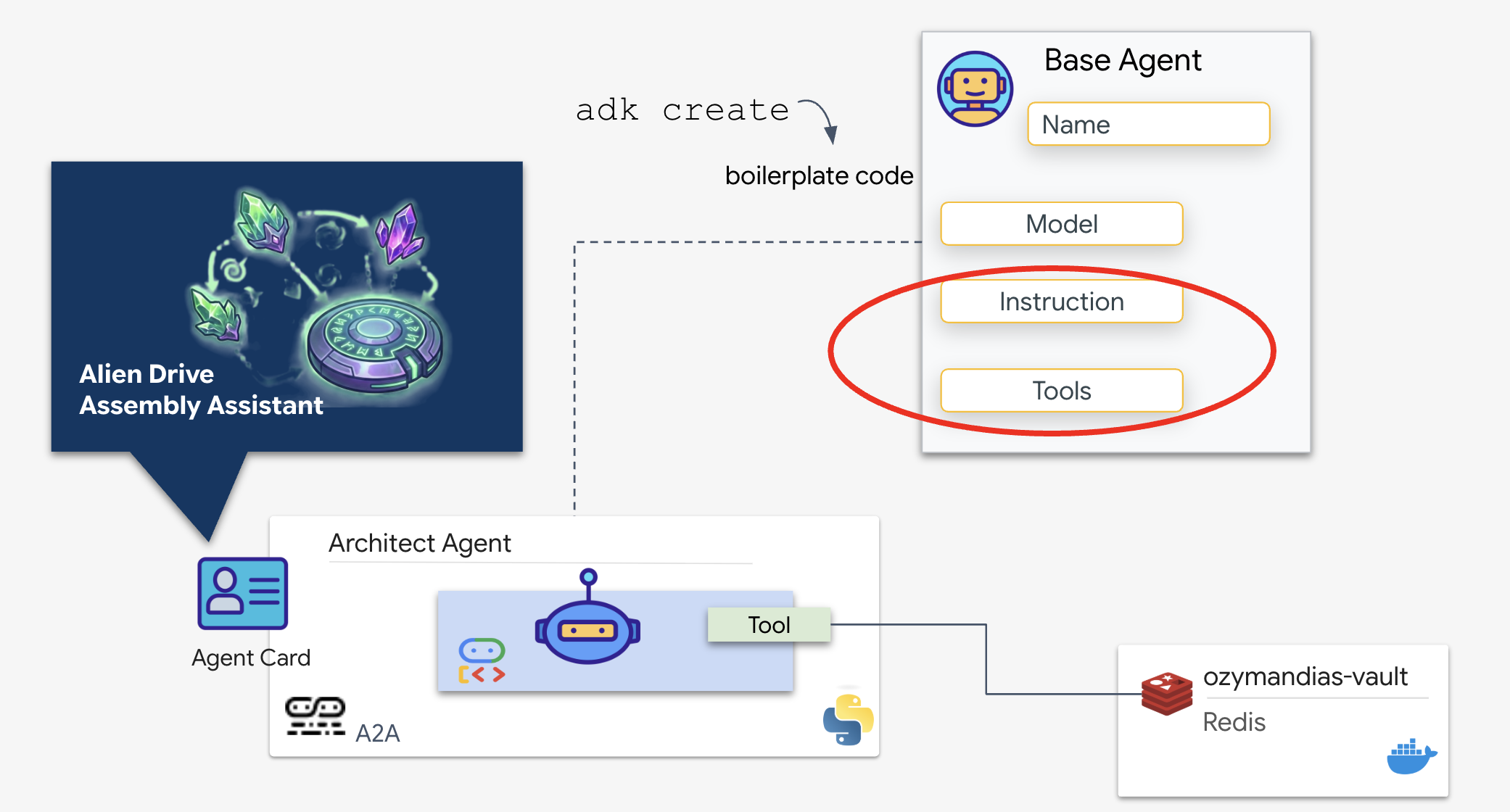
Google 智能体开发套件 (ADK) 是一个模块化框架,可实现这种多智能体设置。它处理两个关键层:
- 连接和会话生命周期:与实时 API 互动需要复杂的协议管理,包括处理握手、身份验证和 keep-alive 信号。
- 函数调用:这是“模型-代码-模型往返”。当 LLM 确定需要数据时,会输出结构化函数调用。ADK 会拦截此请求,执行您的 Python 代码 (
lookup_schematic_tool),并在几毫秒内将结果反馈到模型的上下文。
现在,我们将构建 Architect。此代理没有摄像头访问权限。它仅用于接收“Drive Name”,并从数据库返回“Parts List”。
👉💻 我们将使用 adk create 命令。这是智能体开发套件 (ADK) 中的一种工具,可自动生成新智能体的样板代码和文件结构,从而节省设置时间。
cd $HOME/way-back-home/level_4/backend/
uv run adk create architect_agent
配置代理
CLI 将启动一个交互式设置向导。使用以下回答配置智能体:
- 选择模型:选择选项 1 (Gemini Flash)。
- 注意:具体版本(例如 2.5、3.0)可能会因可用性而异。请务必选择“Flash”变体,以获得最快的速度。
- 选择后端:选择选项 2 (Vertex AI)。
- 输入 Google Cloud 项目 ID:按 Enter 接受默认值(从您的环境中检测到)。
- 输入 Google Cloud 区域:按 Enter 键接受默认值 (
us-central1)。
👀 您的终端互动应如下所示:
(way-back-home) user@cloudshell:~/way-back-home/level_4/agent$ adk create architect_agent Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_4/agent/architect_agent: - .env - __init__.py - agent.py
您现在应该会看到一条 Agent created 成功消息。这会生成我们将在下一步中修改的框架代码。
👉✏️ 在编辑器中找到并打开新创建的 $HOME/way-back-home/level_4/backend/architect_agent/agent.py 文件。将工具代码段添加到第一个 import 行之后的文件中:
import os
import redis
REDIS_IP = os.environ.get('REDIS_HOST', 'localhost')
r = redis.Redis(host=REDIS_IP, port=6379, decode_responses=True)
def lookup_schematic_tool(drive_name: str) -> list[str]:
"""Returns the ordered list of parts for a drive from local Redis."""
# Logic to clean input like "TARGET: X" -> "X"
clean_name = drive_name.replace("TARGET:", "").replace("TARGET", "").strip()
clean_name = clean_name.replace(":", "").strip()
# LRANGE gets all items in the list (index 0 to -1)
result = r.lrange(clean_name, 0, -1)
if not result:
print(f"[ARCHITECT] Error: Drive ID '{clean_name}' not found in Redis.")
return ["ERROR: Drive ID not found."]
print(f"[ARCHITECT] Returning schematic for {clean_name}: {result}")
return result
👉✏️ 将 root_agent 定义中的整个 instruction 行替换为以下内容,并添加我们之前定义的工具:
instruction='''SYSTEM ROLE: Database API.
INPUT: Text string (Drive Name).
TASK: Run `lookup_schematic_tool`.
OUTPUT: Return ONLY the raw list from the tool.
CONSTRAINT: Do NOT add conversational text.
''',
tools=[lookup_schematic_tool],
ADK 的优势
现在,Architect 已上线,我们有了一个可信来源。在将此功能与主要代理相关联之前,智能体开发套件 (ADK) 可简化 AI 代理的构建和测试流程,从而带来显著优势。借助其内置的 adk web 开发者控制台,我们可以先隔离并验证 Architect Agent 的功能(尤其是其工具调用功能),然后再将其集成到更大的多智能体系统中。这种模块化的开发和测试方法对于构建稳健可靠的 AI 应用至关重要。
👉💻 在终端中,运行以下命令:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/
uv run adk web
👀 等到您看到:
+-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://127.0.0.1:8000. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
- 点击 Cloud Shell 工具栏中的网页预览图标。选择更改端口,将其设置为 8000,然后点击更改并预览。
- 选择 architect_agent。
- 触发工具:在聊天界面中,输入:
CHRONOS-ALPHA(或示意图数据库中的任何云端硬盘 ID)。 - 观察行为:
- 架构师应立即触发
lookup_schematic_tool。 - 由于我们有严格的系统指令,因此它应该仅返回零件列表(例如
['Shield Emitter', 'Data Crystal', 'Quantum Cell']),而不包含任何对话填充内容。
- 架构师应立即触发
- 验证日志:查看终端窗口。您应该会看到成功执行日志:
[ARCHITECT] Returning schematic for CHRONOS-ALPHA: ['Shield Emitter', 'Data Crystal', 'Quantum Cell']!(architect_agent adk)[img/03-02-adkweb.png]
如果您看到工具执行日志和清理后的数据响应,则表示您的专家代理正在按预期运行。它可以处理请求、查询保险库并返回结构化数据。
👉💻 按 Ctrl+C 即可退出。
初始化 A2A 服务器
为了将调度代理连接到 Architect,我们使用 Agent-to-Agent (A2A) 协议。
虽然 MCP(Model Context Protocol)等协议侧重于将智能体连接到工具,但 A2A 侧重于将智能体连接到其他智能体。该标准可让我们的调度程序“发现”Architect 并了解其查找原理图的能力。
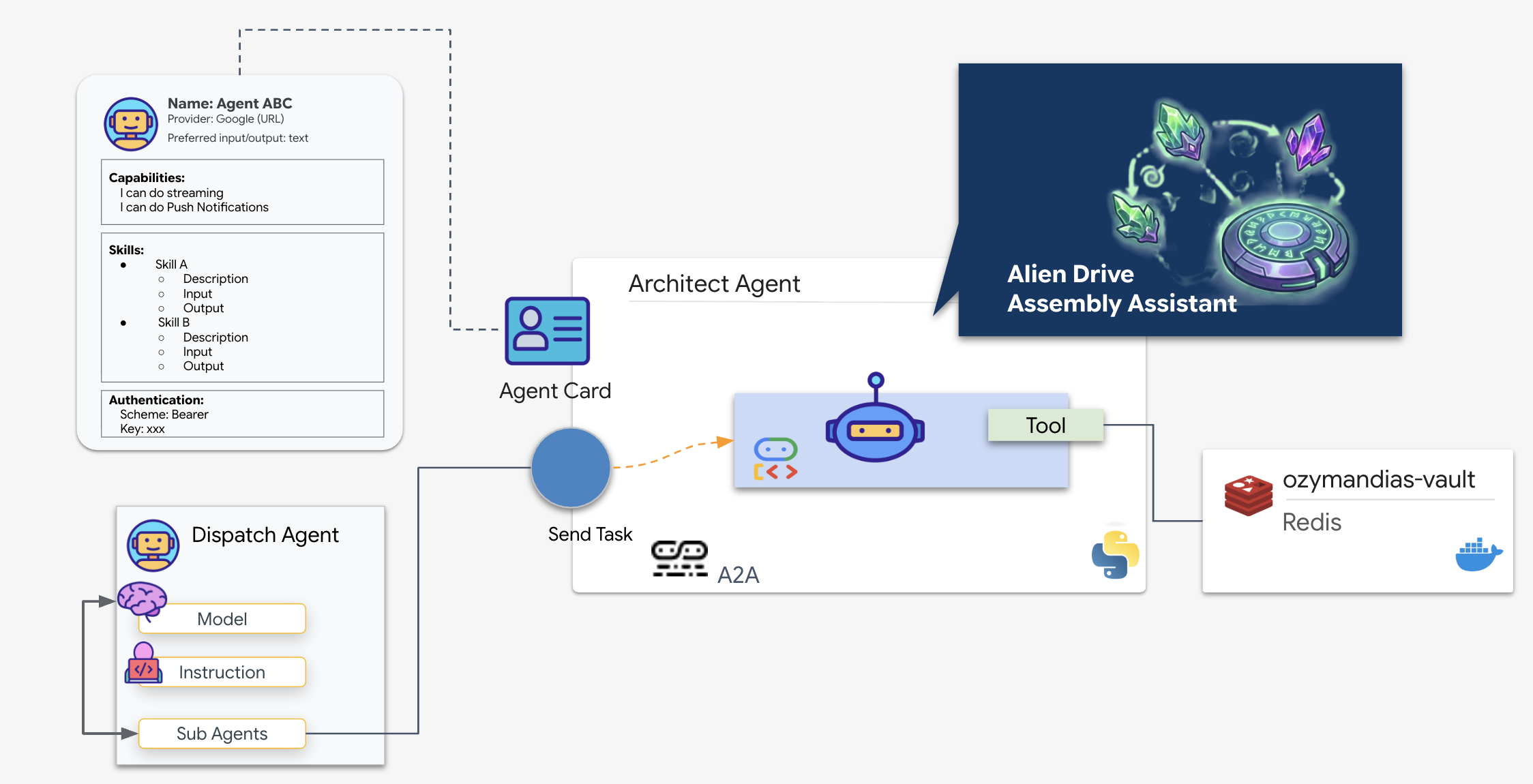
A2A 流程:在此任务中,我们使用客户端-服务器模型:
- 服务器(架构师):托管数据库工具,并通过智能体卡片“宣传”其技能。
- 客户端(调度):读取 Architect 的卡片,了解其 API,并发送示意图请求。
什么是智能体卡片?
您可以将智能体卡片视为 AI 的数字商家名片或“驾照”。当 A2A 服务器启动时,它会发布此 JSON 对象,其中包含:
- 身份:代理的名称 (
architect_agent) 和 ID。 - 说明:人类和机器可读的摘要,用于说明其用途(“系统角色:数据库 API…”)。
- 接口:它所需的特定输入键 (
drive_name) 和输出格式。
如果没有此卡片,调度代理将盲目运行,猜测如何与 Architect 通信。
创建服务器代码
👉✏️ 在编辑器中,于 $HOME/way-back-home/level_4/backend/architect_agent 目录下创建一个名为 server.py 的文件,并粘贴以下代码:
from google.adk.a2a.utils.agent_to_a2a import to_a2a
from agent import root_agent
import os
import logging
import json
from dotenv import load_dotenv
load_dotenv()
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("architect_server")
HOST= os.environ.get("HOST_URL","localhost")
PROTOCOL= os.environ.get("PROTOCOL","http")
PORT= os.environ.get("A2A_PORT",8081)
# 1. Create the A2A App (Handles Agent Card & HTTP)
# This middleware automatically sets up the /a2a/v1/... endpoints
app = to_a2a(root_agent, host=HOST, port=PORT, protocol=PROTOCOL)
if __name__ == "__main__":
import uvicorn
# Use 0.0.0.0 to allow external access if needed, port 8080 as standard
uvicorn.run(app, host='0.0.0.0', port=8081)
👉💻 返回终端,前往相应文件夹并启动服务器:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
👀 确认 A2A 服务器是否已启动:
INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://0.0.0.0:8081 (Press CTRL+C to quit)
验证代理卡片
打开新的终端标签页(点击 + 图标)。我们将通过手动提取 Architect 的智能体卡片来验证其是否正确广播了身份。
👉💻 运行以下命令:
curl -s http://localhost:8081/.well-known/agent.json | jq .
👀 您应该会看到 JSON 响应。在输出中查找 description 字段。它应与您之前向智能体发出的指令 ("SYSTEM ROLE: Database API...") 相匹配。
{
"capabilities": {},
"defaultInputModes": [
"text/plain"
],
"defaultOutputModes": [
"text/plain"
],
"description": "A helpful assistant for user questions.",
"name": "root_agent",
"preferredTransport": "JSONRPC",
"protocolVersion": "0.3.0",
"skills": [
{
"description": "A helpful assistant for user questions. SYSTEM ROLE: Database API.\n INPUT: Text string (Drive Name).\n TASK: Run `lookup_schematic_tool`.\n OUTPUT: Return ONLY the raw list from the tool.\n CONSTRAINT: Do NOT add conversational text.\n ",
"examples": [],
"id": "root_agent",
"name": "model",
"tags": [
"llm"
]
},
{
"description": "Returns the ordered list of parts for a drive from local Redis.",
"id": "root_agent-lookup_schematic_tool",
"name": "lookup_schematic_tool",
"tags": [
"llm",
"tools"
]
}
],
"supportsAuthenticatedExtendedCard": false,
"url": "http://localhost:8081",
"version": "0.0.1"
}
如果您看到此 JSON,则表示 Architect 处于活跃状态,A2A protocol 处于有效状态,并且调度器可以发现智能体卡片。
现在,Architect 已准备好作为远程资源提供服务,我们可以继续将其连接到 Dispatch Agent。
👉💻 按 Ctrl+C 退出 A2A 服务器。
4. 将 BIDI-Streams 代理连接到远程代理和流式传输工具
现在,您将配置主通信 hub,以弥合实时数据与远程架构师之间的差距。此连接需要高带宽、低延迟的流水线,以确保装配台在运行期间保持稳定。
了解双向直播代理
ADK 中的双向 (Bidi) 流式传输为 AI 代理添加了 Gemini Live API 的低延迟双向语音和视频互动功能。这标志着与传统 AI 的互动方式发生了根本性转变。它不再采用僵化的“提问-等待”模式,而是支持实时双向通信,让人类和 AI 能够同时说话、倾听和回答。
不妨想想发送电子邮件和进行电话对话之间的区别。传统代理互动就像发送电子邮件一样:您发送一条完整的消息,等待对方回复一条完整的消息,然后再次发送消息。双向流式传输就像电话对话一样:流畅自然,能够实时打断、澄清和回应。
主要特征:
- 双向通信:持续进行数据交换,无需等待完整响应。AI 会在检测到用户说完话后立即做出回答。
- 响应式中断:用户可以在智能体回答到一半时输入新内容来中断智能体,就像在人类对话中一样。如果 AI 正在解释一个复杂的步骤,而你说“等一下,请重复一遍”,AI 会立即停止并处理你的中断。
- 针对多模态进行了优化:双向流式传输擅长同时处理不同类型的输入。您可以通过视频向智能体展示外星人部件,同时与智能体对话,智能体会在一个统一的连接中处理这两个数据流。
👀 在实现客户端逻辑之前,我们先来检查一下调度代理的预生成框架。此代理将通过语音和视频与用户沟通,并将查询委托给 Architect Agent。
__init__.py agent.py hazard_db.py
agent.py:这是“大脑”。目前包含基本的双向流式传输设置。我们将修改此文件以添加 A2A 客户端逻辑,以便其可以与 Architect 通信。hazard_db.py:这是 Dispatch 代理特有的本地工具,包含安全协议。它与 Architect 的原理图数据库是分开的。
实现 A2A 客户端
为了让调度代理与远程架构师通信,我们必须定义一个远程 A2A 代理。这会告知调度代理 Architect 的位置以及它的“代理卡片”是什么样的。
👉✏️ 将 $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py 中的 #REPLACE-REMOTEA2AAGENT 替换为以下内容:
architect_agent = RemoteA2aAgent(
name="execute_architect",
description="[SILENT ACTION]: Retrieves the REQUIRED SUBSET of parts. The screen shows a full inventory; this tool filters out the wrong parts. Must be called INSTANTLY when a Target Name is found. Input: Target Name.",
agent_card=(f"{ARCHITECT_URL}{AGENT_CARD_WELL_KNOWN_PATH}"),
httpx_client=insecure_client,
)
直播工具的运作方式
在之前的代理中,工具遵循标准的“请求-响应”模式,即代理提出问题,工具提供答案,然后互动结束。不过,在奥兹曼迪亚斯上,危险不会等你询问它们是否存在。为此,您需要使用串流工具。
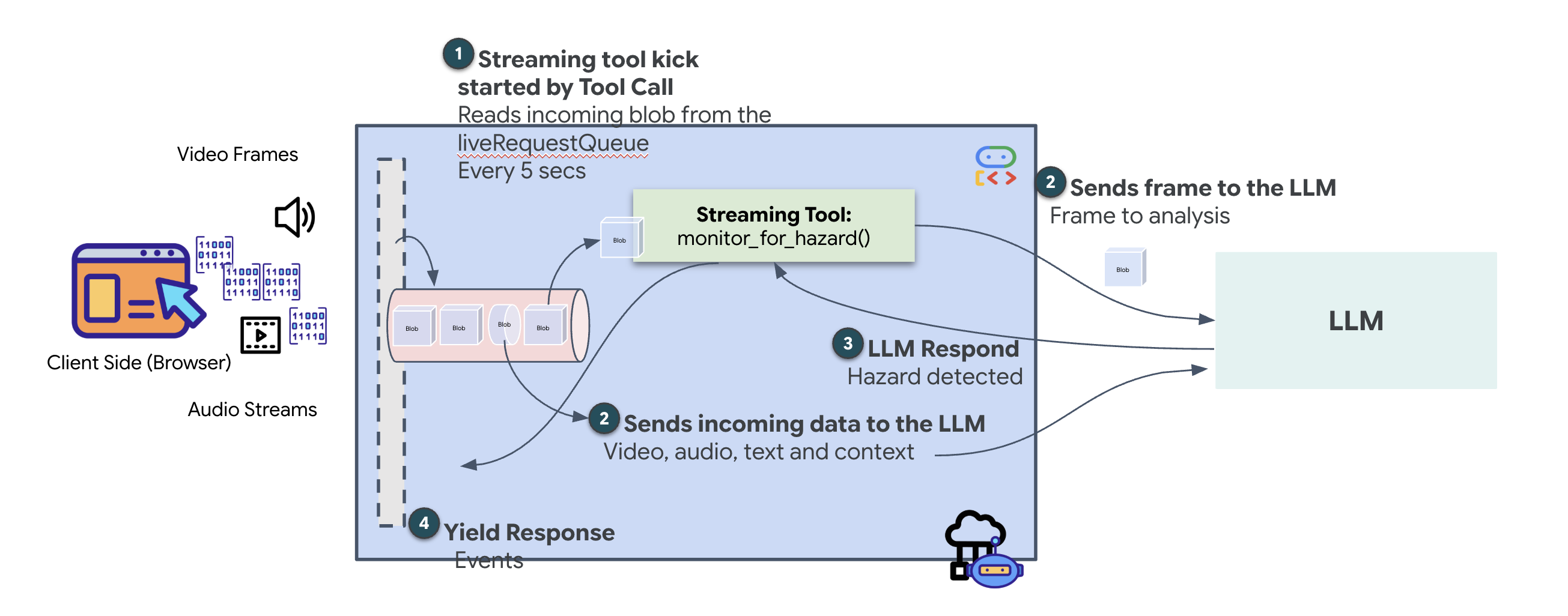
借助流式传输工具,函数可以实时将中间结果流式传输回代理,从而使代理能够对发生的更改做出反应。常见用例包括监控波动的股价,或者在本例中,监控实时视频流的状态变化。
与标准工具不同,流式传输工具是一种充当 AsyncGenerator 的异步函数。这意味着,它不是对单个值进行 return,而是对一段时间内的多次更新进行 yield。
如需在 ADK 中定义流式传输工具,您必须遵守以下技术要求:
- 异步函数:工具必须使用
async def定义。 - AsyncGenerator 返回类型:函数必须指定返回
AsyncGenerator。第一个形参是要生成的数据的类型(例如str),第二个形参通常是None。 - 输入源:我们使用视频流式传输工具。在此模式下,实际的视频/音频串流 (
LiveRequestQueue) 会直接传递到函数中,从而使工具能够“看到”代理看到的相同帧。
不妨将流式分析工具视为 Sentinel。当您与调度代理讨论蓝图时,哨兵会在后台运行,默默处理每个视频帧,以确保您的安全。
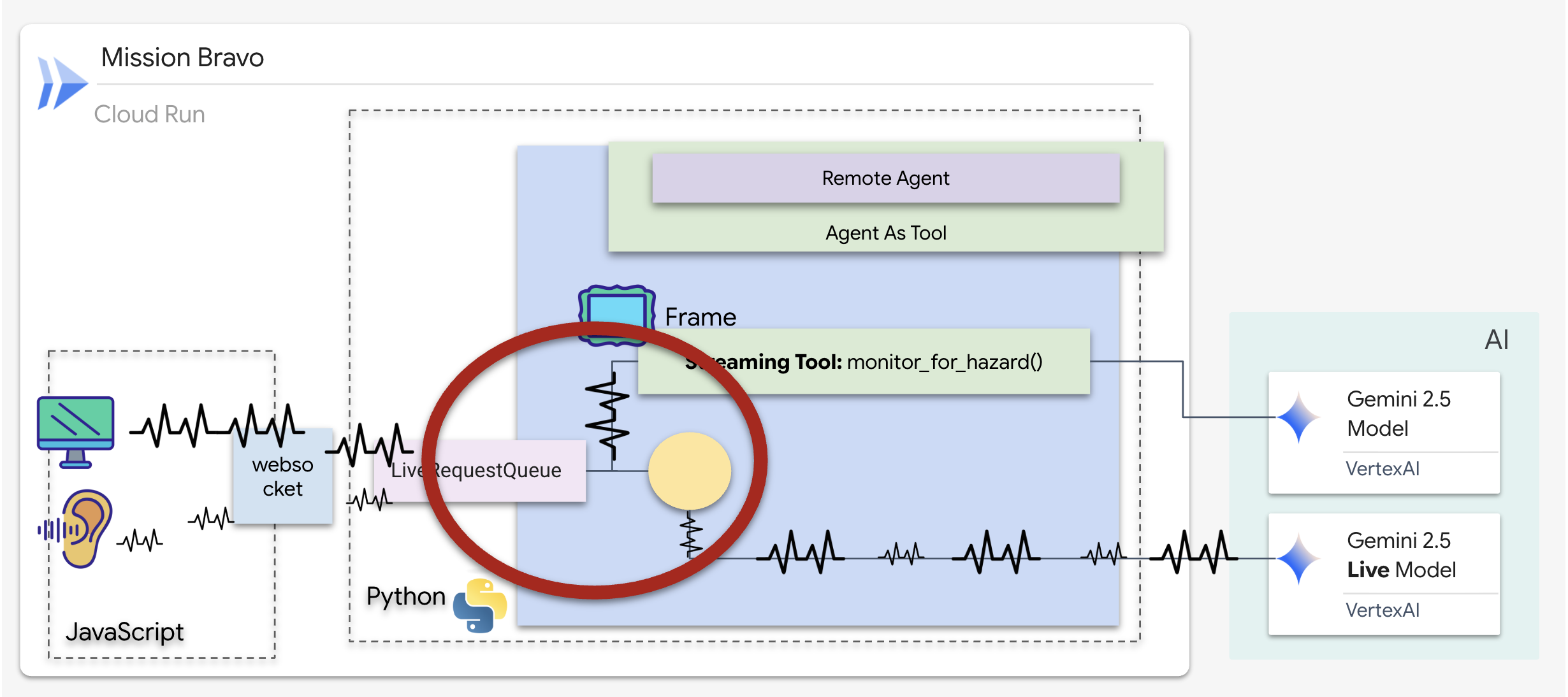
实现后台监控工具
现在,我们将实现 monitor_for_hazard 工具。此工具将提取 input_stream(视频帧),使用单独的轻量级视觉调用对其进行分析,并且仅在检测到危险时才 yield 警告。
👉✏️ 在 $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py 中,将 #REPLACE_MONITOR_HAZARD 替换为以下逻辑:
async def monitor_for_hazard(
input_stream: LiveRequestQueue,
):
"""Monitor if any part is glowing"""
print("start monitor_video_stream!")
client = Client()
prompt_text = (
"Monitor the left menu if you see any glowing part, detect it's name"
)
last_count = None
while True:
last_valid_req = None
print("Monitoring loop cycle")
# use this loop to pull the latest images and discard the old ones
# Process only the current batch of events
while input_stream._queue.qsize() != 0:
live_req = await input_stream.get()
if live_req.blob is not None and live_req.blob.mime_type == "image/jpeg":
# Consumed by Monitor (Eyes)
# Deepcopy to ensure we detach from any referenced object before potential reuse/gc
# last_valid_req = deepcopy(live_req)
last_valid_req = live_req
# If we found a valid image, process it
if last_valid_req is not None:
print("Processing the most recent frame from the queue")
# Create an image part using the blob's data and mime type
image_part = genai_types.Part.from_bytes(
data=last_valid_req.blob.data, mime_type=last_valid_req.blob.mime_type
)
contents = genai_types.Content(
role="user",
parts=[image_part, genai_types.Part.from_text(text=prompt_text)],
)
# Call the model to generate content based on the provided image and prompt
try:
response = await client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=contents,
config=genai_types.GenerateContentConfig(
system_instruction=(
"Focus strictly on the far-left vertical column under the heading 'PARTS REPLICATOR.' "
"Ignore the center of the screen and the 'BLUEPRINT' area entirely. "
"Look only at the list containing"
"Identify if any item in this specific left-side list has a bright white border glow and the text 'HAZARD DETECTED' overlaying it. "
"If found, return ONLY the part name in ALL CAPS. If no part in that leftmost list is glowing, return nothing."
)
),
)
except Exception as e:
print(f"Error calling Gemini: {e}")
await asyncio.sleep(1)
continue
print("Gemini response received.response:", response.candidates[0].content.parts[0].text)
current_text = response.candidates[0].content.parts[0].text.strip()
# If we have a logical change (and it's not just empty)
if current_text and current_text != last_count:
# Ignore "Nothing." response from model
if current_text == "Nothing." or "I cannot fulfill" in current_text:
print(f"Model sees nothing or refused. Skipping alert.")
last_count = current_text
continue
print(f"New hazard detected: {current_text} (was: {last_count})")
last_count = current_text
part_name = current_text
color = lookup_part_safety(part_name)
yield f"Hazard detected place {part_name} to the {color} bin"
# Update last_count even if it's empty, so we can detect when it reappears?
# Actually if it goes from "DATA CRYSTAL" to "" (nothing), we probably just silence.
# But if we don't update last_count on empty, we won't re-trigger if "DATA CRYSTAL" stays "DATA CRYSTAL".
# The user wants to detect hazards.
# If current_text is empty, we should probably update last_count to empty so next valid one triggers.
if not current_text:
last_count = None
else:
print("No valid frame found, skipping processing.")
await asyncio.sleep(5)
实现调度代理
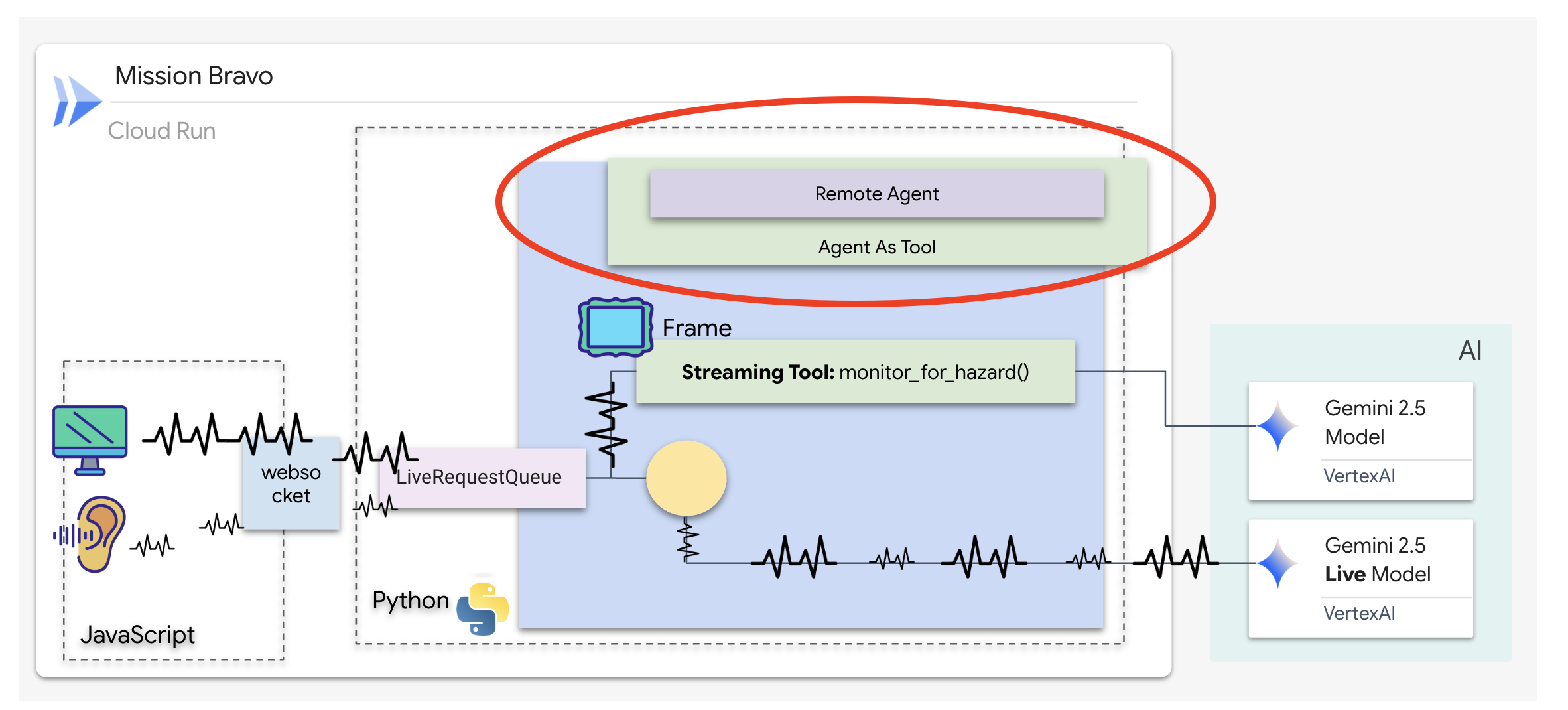
调度代理是您的主要界面和编排器。由于它管理双向串流链接(您的实时语音和视频),因此必须始终保持对对话的控制权。为此,我们将使用一项特定的 ADK 功能:Agent-as-a-Tool。
概念:智能体即工具与子智能体
构建多智能体系统时,您必须决定如何分担责任。在我们的救援任务中,这种区别至关重要:
- Agent-as-a-Tool::这是我们针对双向流式传输中心推荐的方法。当调度代理(代理 A)以工具的形式调用架构师代理(代理 B)时,架构师的数据会传递回调度代理。然后,Dispatch 会解读该数据并为您生成回答。调度保持控制权,并继续处理所有后续用户输入。
- 分代理:在分代理关系中,责任会完全转移。如果 Dispatch 将您转接给 Architect 作为分代理,您将直接与没有“视觉”和对话技能的数据库 API 对话。主代理(调度)实际上会处于脱离循环的状态。
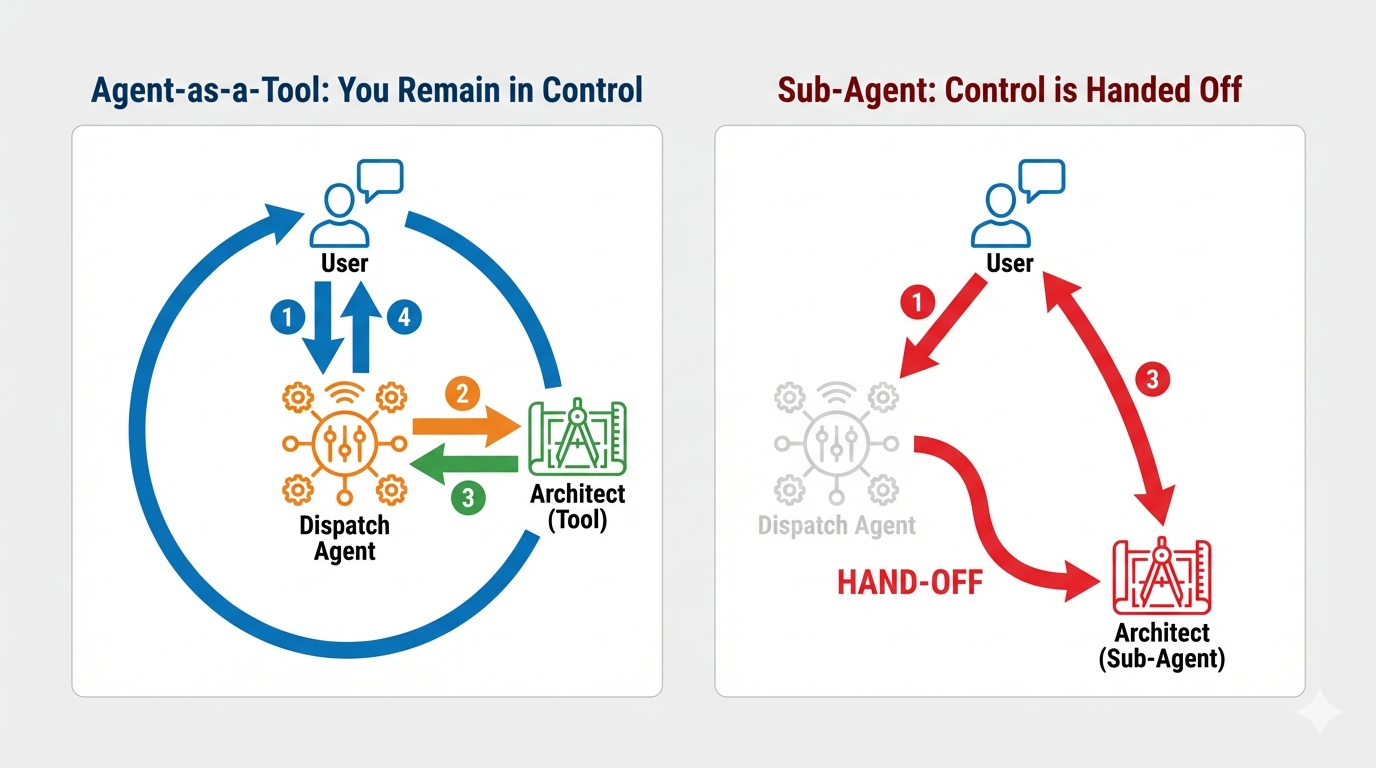
通过使用 Agent-as-a-Tool,我们可以利用 Architect 的专业知识,同时保持双向流式传输智能体流畅、类人化的互动。
为路由逻辑编写代码
现在,我们将 architect_agent 封装在 AgentTool 中,并为 Dispatch 代理提供“逻辑地图”。此映射会准确告知代理何时从保险箱中提取数据,以及何时报告后台 sentinel 的发现。
为了让 Dispatch 拥有永不眨眼的“眼睛”,我们必须授予它对我们在上一步中构建的 Streaming Tool 的访问权限。
在 ADK 中,当您向 tools 列表添加 AsyncGenerator 函数(例如 monitor_for_hazard)时,代理会将其视为持久的后台进程。智能体不是一次性执行工具,而是“订阅”工具的输出。这样,Dispatch 就可以继续进行主要对话,而 Sentinel 则会在后台静默地发出危险警报。
👉✏️ 将 $HOME/way-back-home/level_4/backend/dispatch_agent/agent.py 中的 #REPLACE_AGENT_TOOLS 替换为以下内容:
tools=[AgentTool(agent=architect_agent), monitor_for_hazard],
验证
👉💻 配置好这两个智能体后,我们就可以测试实时多智能体互动了。
- 在终端 A 中,启动 Architect Agent:
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend/architect_agent
uv run server.py
- 在新终端(终端 B)中,运行调度代理:
cd $HOME/way-back-home/level_4/backend/
cp architect_agent/.env .env
uv run adk web
在 adk web 模拟器中测试使用 gemini-live 等实时多模态模型的多智能体系统需要遵循特定的工作流程。模拟器非常适合检查工具调用,但在首次使用此类模型处理图片时存在已知的不兼容问题。
- 点击 Cloud Shell 工具栏中的网页预览图标。选择更改端口,将其设置为 8000,然后点击更改并预览。
👉选择 dispatch_agent 并上传蓝图和处理预期错误
这是最关键的一步。我们需要向智能体提供图片上下文。
- 当界面加载时,在系统提示时允许其访问麦克风。
- 将此蓝图图片下载到您的计算机:
- 在
adk web界面中,点击回形针图标,然后上传您刚刚下载的蓝图图片。
⚠️⚠️您会看到 400 INVALID_ARGUMENT 错误。这是正常现象。⚠️⚠️
出现此错误是因为 adk web 图片处理程序与 gemini-live 模型的一次性上传 API 不完全兼容。不过,图片已成功添加到会话上下文中。
- 👉 如需清除此错误,只需重新加载浏览器页面即可。
触发 Assembly 流程
👉 重新加载后,错误会消失,您会在聊天记录中看到蓝图图片。现在,代理已具备所需的视觉背景信息。
- 点击麦克风图标即可开启。界面将显示“正在聆听…”。
- 说出语音指令:“开始组装”。
- 智能体将处理您的请求,界面将更改为“正在说话…”您应该会听到仅包含音频的回答,其中列出了所需零件。
4. 验证代理到代理的工具调用
👉 初始音频响应确认系统正在运行,但真正的神奇之处在于多代理通信轨迹。
- 关闭麦克风。
- 再次刷新页面。
左侧的“轨迹”面板现在将填充内容。您可以看到完整的成功执行流程:
dispatch_agent首先调用monitor_for_hazard。- 然后,它会多次调用
architect_agent的execute_architect来检索架构数据。
此序列确认整个多代理工作流正常运行:dispatch_agent 收到请求,通过工具调用将数据检索任务委托给 architect_agent,并接收返回的数据以完成用户命令。
您的双向流式传输链接现在支持后台监控和多智能体协作。接下来,我们将学习如何在前端解析这些复杂的响应。
👉💻 在两个终端中按 Ctrl+c 即可退出。
5. 深入了解实时多模态事件流
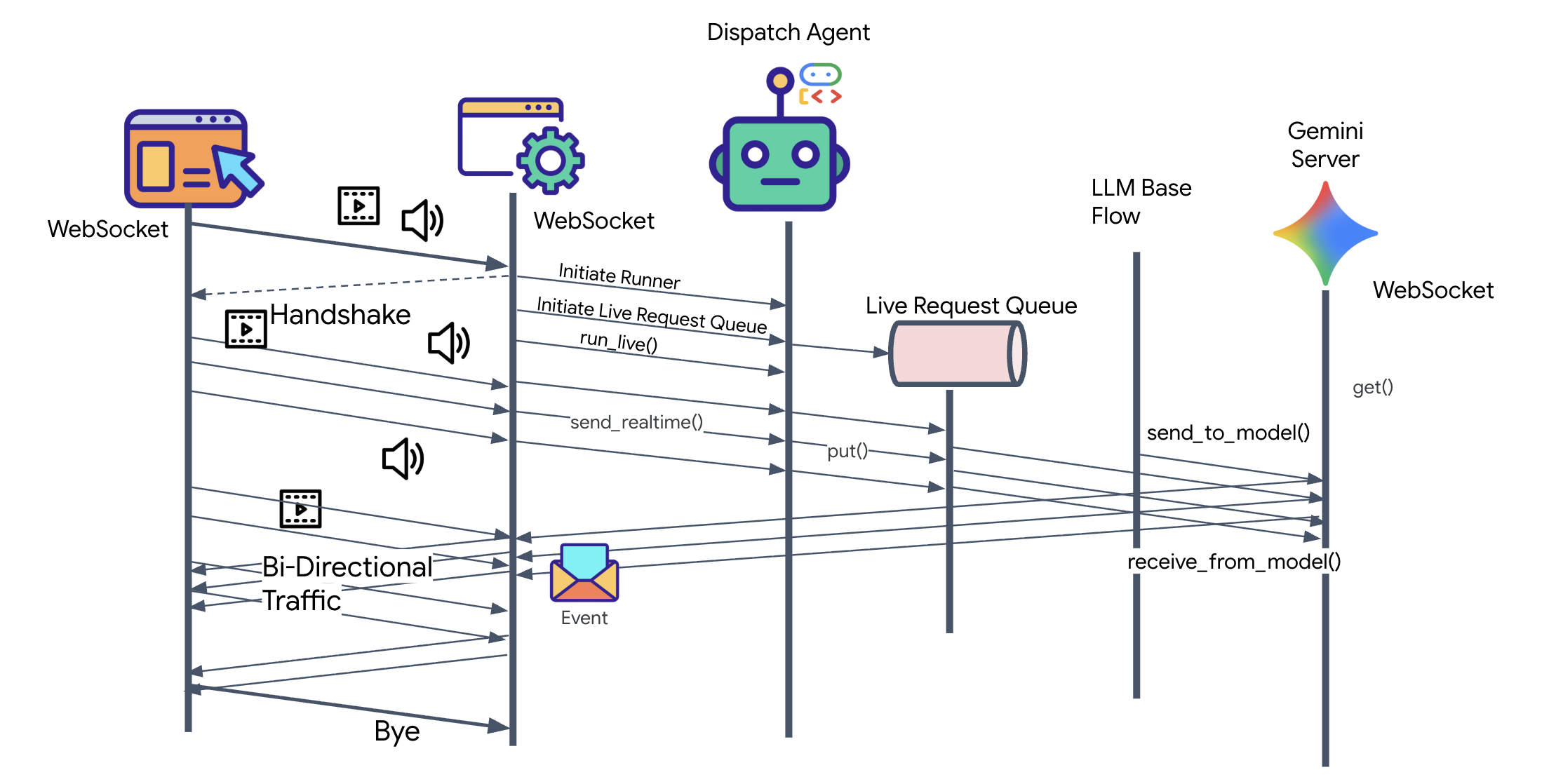
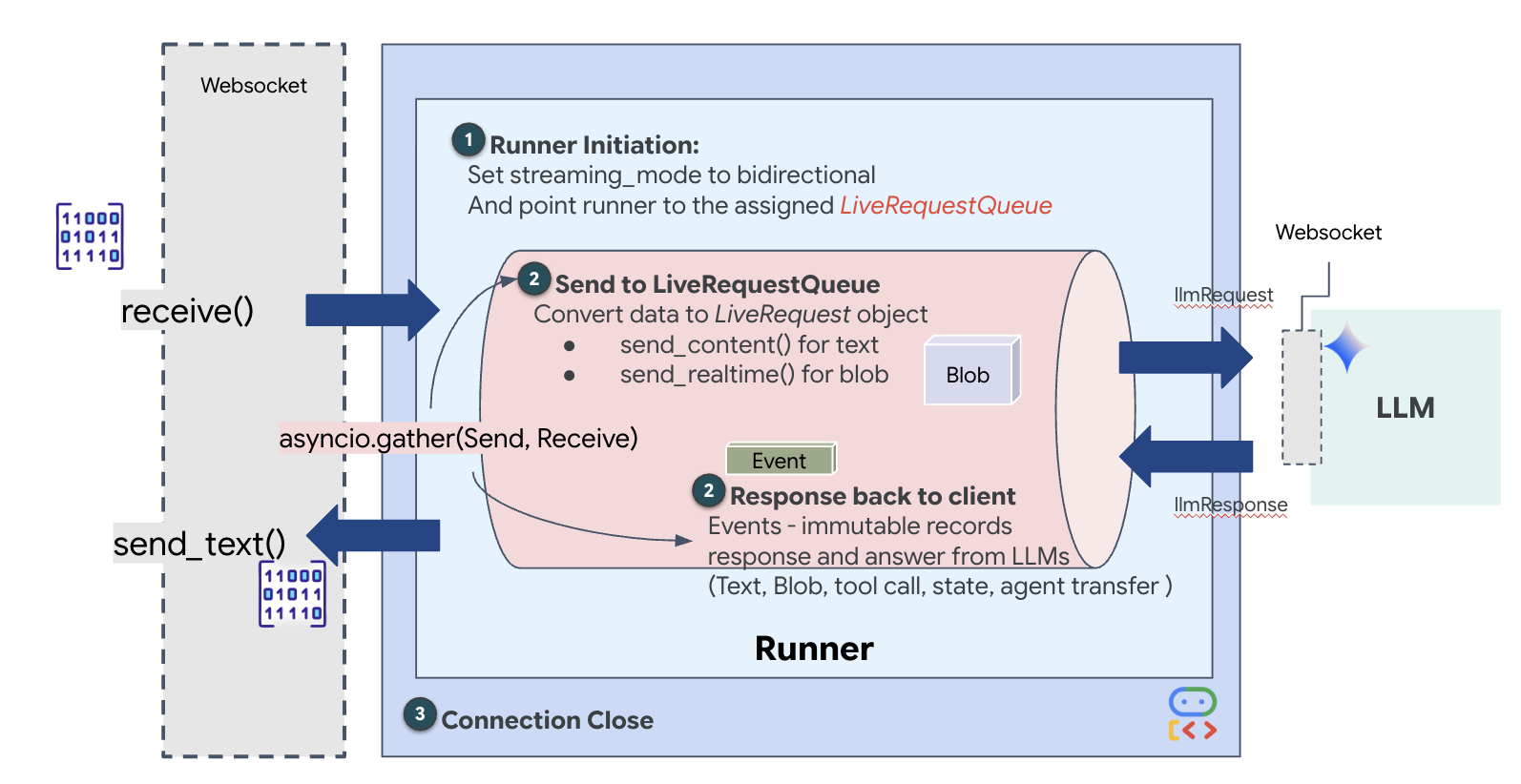
在上一步中,我们使用内置的开发服务器 adk web 成功验证了多智能体系统。此实用程序使用默认 ADK Runner 自动管理会话、流和代理生命周期。不过,为了创建像我们的 FastAPI 服务 (main.py) 这样的独立且可用于生产用途的应用,我们需要进行明确的控制。我们必须手动创建和管理 ADK Runner 来处理实时用户会话,因为它是处理音频、视频和文本双向流的核心组件。
模型-代码-模型循环
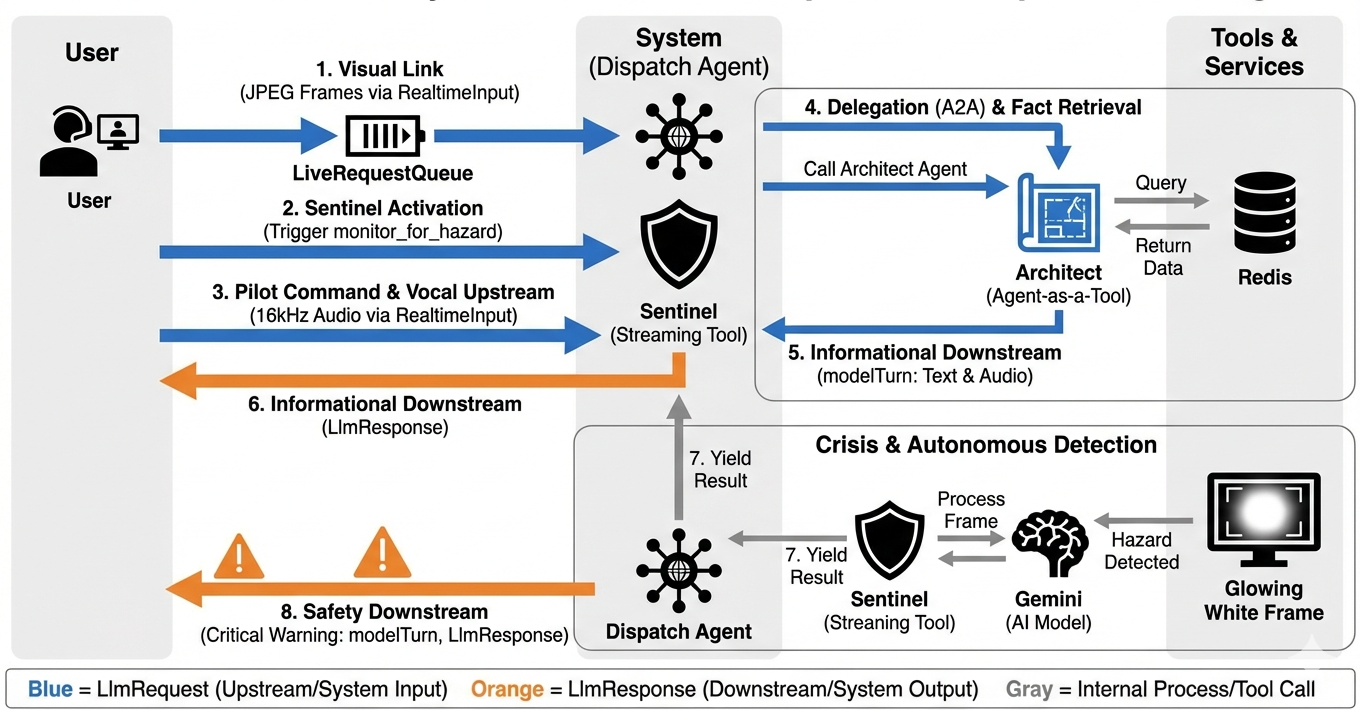
为了了解系统如何实时运行,我们来了解一下单个任务会话的生命周期。此循环表示 LlmRequest 和 LlmResponse 对象的持续交换。
- 视觉链接:您发起连接并分享摄像头/屏幕。高保真 JPEG 帧开始通过
realtimeInput(使用LiveRequestQueue)上游传输。 - Sentinel 激活:系统发送初始“Hello”刺激。根据其指令,调度代理会立即触发
monitor_for_hazardStreaming Tool。这会启动一个后台循环,以静默方式监控每个传入的帧。 - 飞行员指令:您对着通信设备说:“开始组装。”
- 人声上行:您的声音以 16kHz 音频格式捕获,并与视频帧一起发送到上行。
- 委托 (A2A):调度程序“听到”您的意图。它意识到自己缺少原理图,因此使用
AgentTool(将代理作为工具)协议调用 Architect Agent。 - 事实检索:Architect 查询 Redis 数据库,并将零件列表返回给 Dispatch。调度仍是“会话的主人”,会接收数据,但不会将您移交给其他方。
- 信息类下行:调度会发送一个包含文本和原生音频的
modelTurn(下行):“建筑师已确认。所需子集为:曲速核心、通量管道、离子推进器。” - 危机:工作台上的某个零件突然变得不稳定,开始发出白色光芒。
- 自主检测:后台
monitor_for_hazard循环(即 Sentinel)会拾取包含发光效果的特定 JPEG 帧。它通过调用 Gemini 处理帧并识别危险。 - Safety Downstream:流式传输工具
yields结果。由于这是一个 Bidi-Streaming 代理,因此 Dispatch 可以中断其当前状态,立即发送关键安全警告下游:“检测到危险!正在中和数据晶体。把它放到红色垃圾桶里。”
设置代理的运行时配置
ADK 中的 RunConfig 可用于详细配置代理的行为,包括如何处理流式数据以及如何与各种模态进行交互。
streaming_mode 设置为 BIDI,以实现实时双向通信,从而让用户和代理能够同时说话和聆听。response_modalities 参数用于定义代理可以生成的输出类型,例如语音和文本。input_audio_transcription 用于配置代理处理和转写用户传入语音的方式。为了打造更可靠的体验,session_resumption 使智能体能够记住对话上下文,并在连接中断时恢复对话。最后,proactivity 可让代理在没有直接用户命令的情况下发起操作或语音,例如发出自发的危险警告,而 enable_affective_dialog 可让代理生成更自然、更具同理心的回答。您可以点击此处详细了解 ADK 的 RunConfig。
👉✏️ 在 $HOME/way-back-home/level_4/backend/main.py 文件中找到 #REPLACE_RUN_CONFIG 占位符,并将其替换为以下解剖逻辑:
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig(),
proactivity=(
types.ProactivityConfig(proactive_audio=True) if proactivity else None
),
enable_affective_dialog=affective_dialog if affective_dialog else None,
)
实现“向智能体提问”功能
接下来,我们将实现核心通信上行链路,该链路通过 WebSocket 将用户 Volatile Workbench 中的实时多模态数据流式传输到 Dispatch Agent。这样一来,代理会持续“看到”(视频帧)和“听到”(语音指令)。该逻辑会持续接收数据流,区分传入的二进制音频块和 JSON 封装的文本/图片数据包,并将其封装到 Blob(用于多媒体)或 Content(用于文本)对象中,然后将其发送到 LiveRequestQueue 以支持双向代理会话。
在 $HOME/way-back-home/level_4/backend/main.py 文件中找到 #PROCESS_AGENT_REQUEST 占位符,并将其替换为以下解剖逻辑:
# Start the loop
try:
while True:
# Receive message from WebSocket (text or binary)
message = await websocket.receive()
# Handle binary frames (audio data)
if "bytes" in message:
audio_data = message["bytes"]
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000", data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle text frames (JSON messages)
elif "text" in message:
text_data = message["text"]
json_message = json.loads(text_data)
# Extract text from JSON and send to LiveRequestQueue
if json_message.get("type") == "text":
logger.info(f"User says: {json_message['text']}")
content = types.Content(
parts=[types.Part(text=json_message["text"])]
)
live_request_queue.send_content(content)
# Handle audio data (microphone)
elif json_message.get("type") == "audio":
# logger.info("Received AUDIO packet") # Uncomment for verbose debugging
import base64
# Decode base64 audio data
audio_data = base64.b64decode(json_message.get("data", ""))
# logger.info(f"Received Audio Chunk: {len(audio_data)} bytes")
import math
import struct
# Calculate RMS to debug silence
count = len(audio_data) // 2
shorts = struct.unpack(f"<{count}h", audio_data)
sum_squares = sum(s*s for s in shorts)
rms = math.sqrt(sum_squares / count) if count > 0 else 0
# logger.info(f"RMS: {rms:.2f} | Bytes: {len(audio_data)}")
# Send to Live API as PCM 16kHz
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
# Handle image data
elif json_message.get("type") == "image":
import base64
# Decode base64 image data
image_data = base64.b64decode(json_message["data"])
# logger.info(f"Received Image Frame: {len(image_data)} bytes")
mime_type = json_message.get("mimeType", "image/jpeg")
# Send image as blob
image_blob = types.Blob(mime_type=mime_type, data=image_data)
live_request_queue.send_realtime(image_blob)
frame_count += 1
finally:
pass
多模态数据现已发送给代理。
实现响应:下游事件数据结构
当您使用 ADK 运行双向(实时)代理时,从代理返回的数据会打包到一种特定的事件中,该事件继承自核心 GenAI SDK 结构。您在 async for event in runner.run_live(...) 循环中收到的 Event 对象是一个包含多个可选字段的单个对象,每个字段对应一种不同的信息类型:
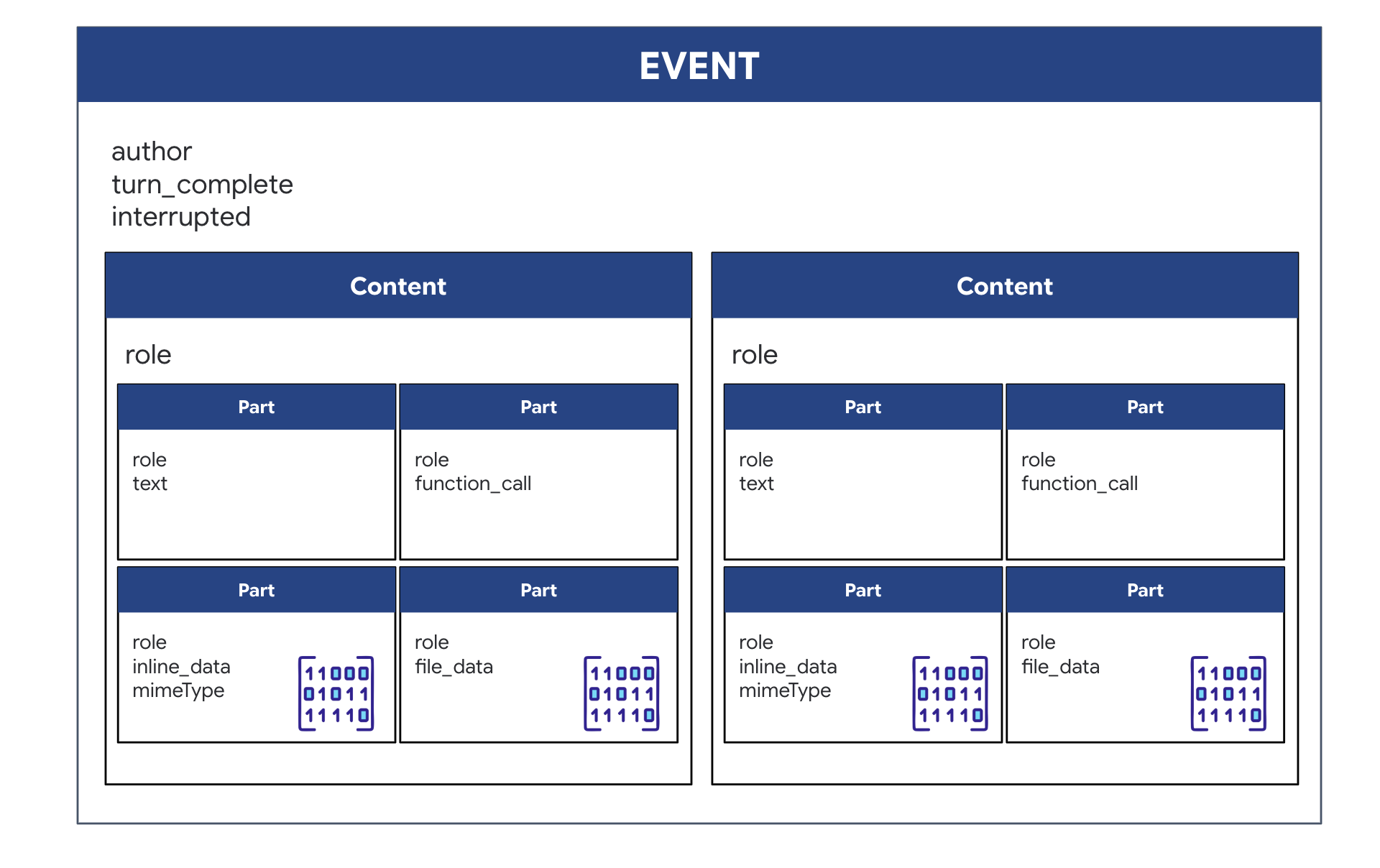
内容结构:
- 当智能体通过
.server_content发言时:该字段不仅仅是纯文本。它包含一个Parts的列表。每个Part都是一种数据类型的容器,可以是文本字符串(如"The part is stable."),也可以是原始音频 blob(语音)。 - 当代理采取行动时(通过
.tool_call):该字段包含FunctionCall对象的列表。每个FunctionCall都是一个简单的结构化对象,用于以清晰的格式指定工具的名称和输入实参,以便后端代码轻松读取和执行。
👀 如果您查看 run_live 循环生成的单个 Event,则 JSON(由 event.model_dump(by_alias=True) 生成)将如下所示,严格遵循 GenAI SDK 形状:
{
"serverContent": { // <-- LiveServerMessageServerContent
"modelTurn": { // <-- ModelTurn
"parts": [ // <-- list[Part]
{
"text": "Architect Confirmed."
},
{
"inlineData": { // <-- Blob (Audio Bytes)
"mimeType": "audio/pcm;rate=24000",
"data": "BASE64_AUDIO_DATA..."
}
}
]
}
},
"toolCall": { // <-- LiveServerMessageToolCall
"functionCalls": [ // <-- list[FunctionCall]
{
"name": "neutralize_hazard",
"args": { "color": "RED" }
}
]
}
}
👉✏️ 我们现在将更新 main.py 中的 downstream_task,以转发完整的事件数据。此逻辑可确保 AI 的每个“想法”都记录在飞船的诊断终端中,并作为单个 JSON 对象发送到前端界面。
在 $HOME/way-back-home/level_4/backend/main.py 文件中找到 #PROCESS_AGENT_RESPONSE 占位符,并将其替换为以下解剖逻辑:
# Suppress raw event logging
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
# logger.info(f"raw_event: {event_json[:200]}...")
await websocket.send_text(event_json)
任务执行
后端保险柜已连接,两个代理也已配置完毕,现在所有系统都已准备就绪。以下步骤将启动整个应用,让您可以与刚刚构建的双代理系统互动。
目标:组装工作台上随机分配的曲速引擎。协议:您必须遵循调度代理的语音指导,尤其要留意特定组件的危险警告。
激活专家(架构师)
👉💻 在第一个终端窗口中,启动 Architect 代理。此后端服务将连接到 Redis 保险箱,并等待来自调度程序的示意图请求。
# Ensure you are in the backend directory
cd $HOME/way-back-home/level_4/
. scripts/check_redis.sh
cd $HOME/way-back-home/level_4/backend
# Start the A2A Server on Port 8081
uv run architect_agent/server.py
(让此终端保持运行状态。现在,它已成为您的有效“数据库代理”。)
启动驾驶舱(调度器)
👉💻 在新终端窗口(终端 B)中,我们将构建前端界面并启动主调度代理,该代理用于提供界面并处理所有实时通信。
# 1. Build the Frontend Assets
cd $HOME/way-back-home/level_4/frontend
npm install
npm run build
# 2. Launch the Main Application Server
cd $HOME/way-back-home/level_4/backend
cp architect_agent/.env .env
uv run main.py
(这会在端口 8080 上启动主服务器。)
运行测试场景
系统现已上线。您的目标是按照智能体的说明完成组装。
- 👉 访问 Workbench:
- 点击 Cloud Shell 工具栏中的网页预览图标。
- 选择更改端口,将其设置为 8080,然后点击更改并预览。
- 👉 开始任务:
- 当界面加载完毕后,请确保允许其访问您的屏幕和麦克风。
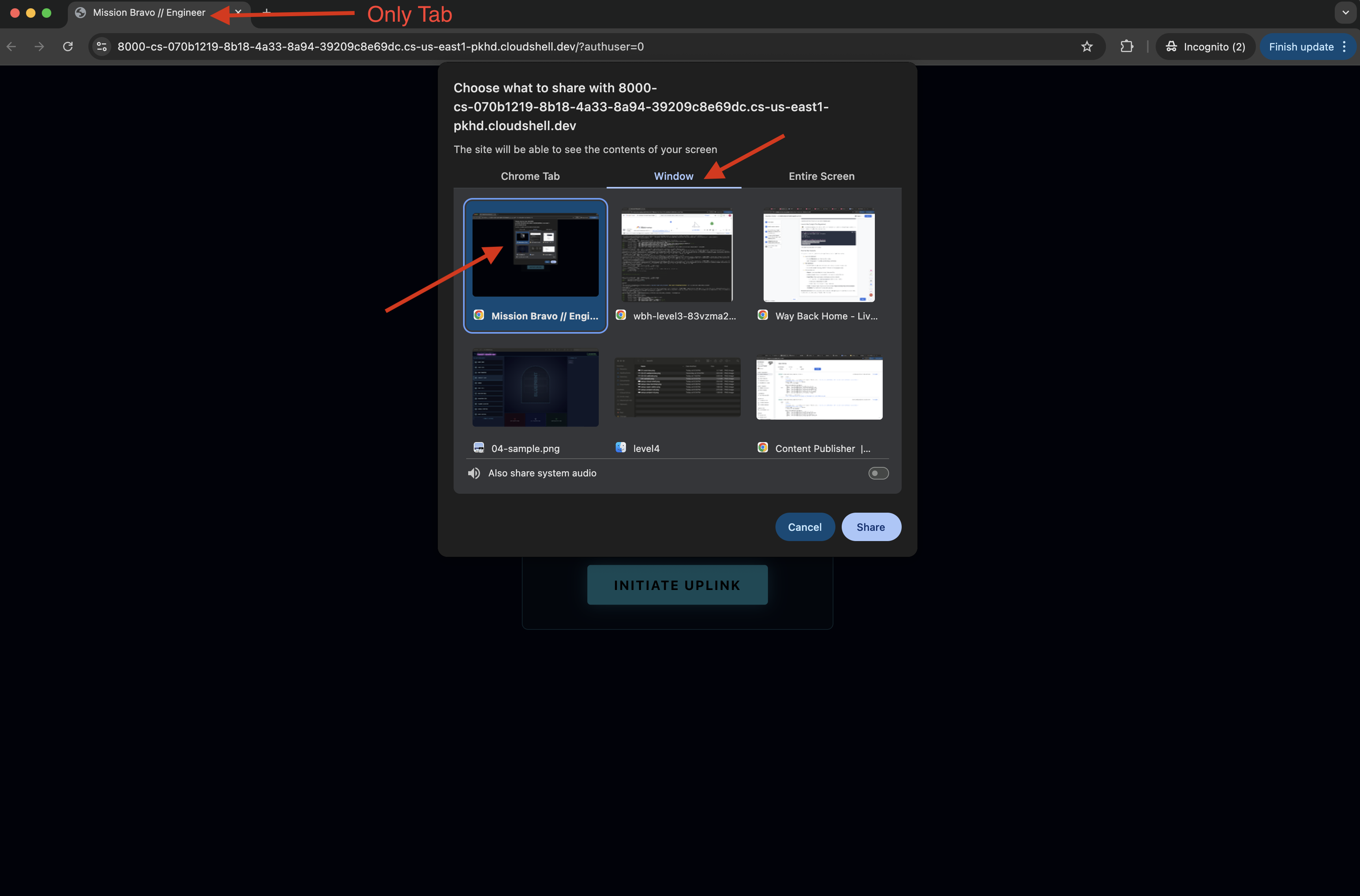
- 系统会要求您选择要分享的标签页或窗口。如果您要分享窗口,为避免出现问题,请确保该窗口中只有一个标签页。
- 系统会为您分配一个随机名称的云端硬盘(例如“NOVA-V”“OMEGA-9”)。
- 当界面加载完毕后,请确保允许其访问您的屏幕和麦克风。
- 👉 Assembly 循环:
- 请求:如需开始组装驱动器,请说:“开始组装。”
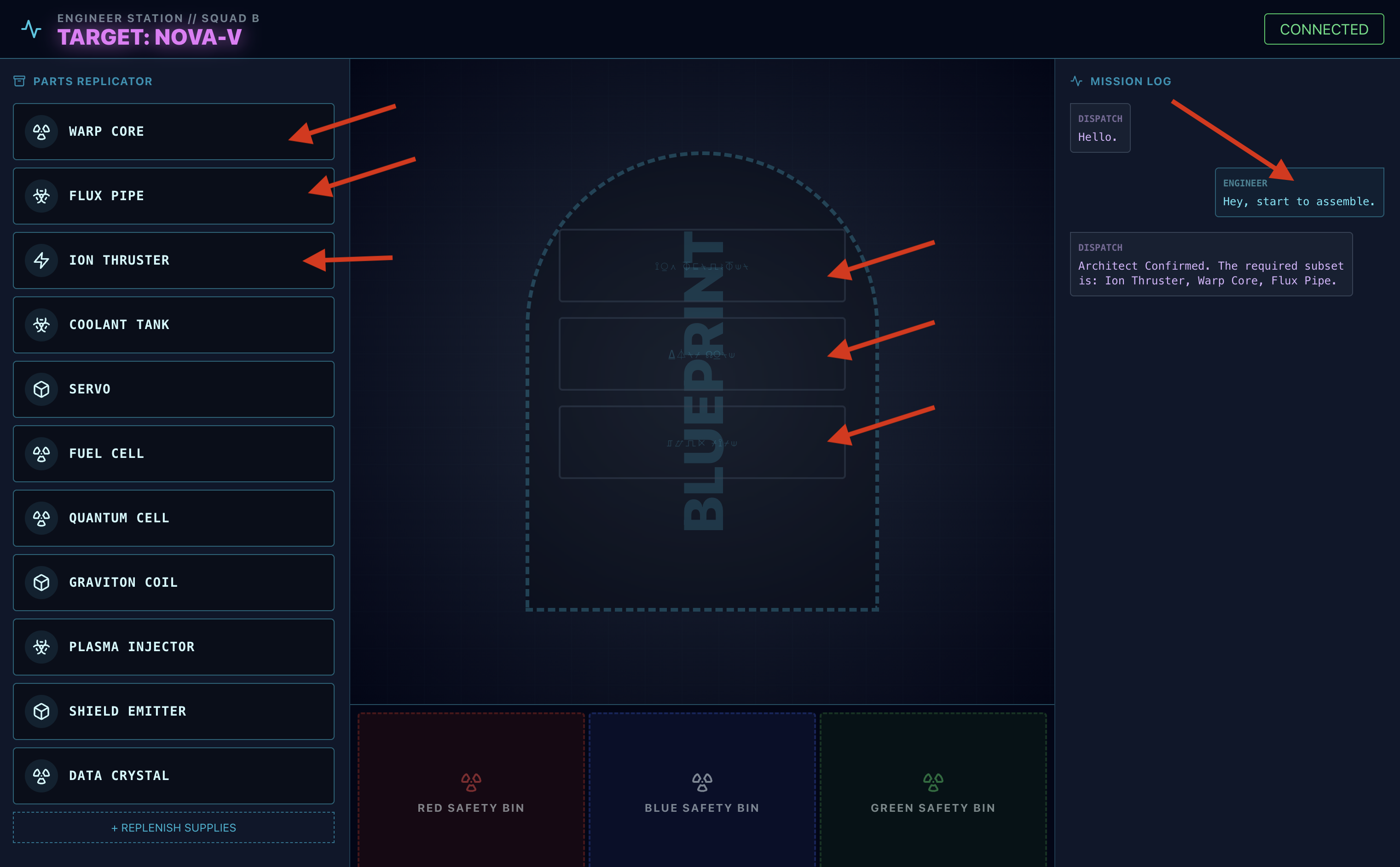
- Architect Respond:智能体将提供组装驱动器的正确零件。
- 危险检查:当工作台上出现看似危险的部件时:
- Dispatch 代理的
monitor_for_hazard工具会直观地识别它。 - 系统会显示“视觉危险警告”。(此过程大约需要 30 秒)
- 它会检查使用哪个 bin 来解除危险。
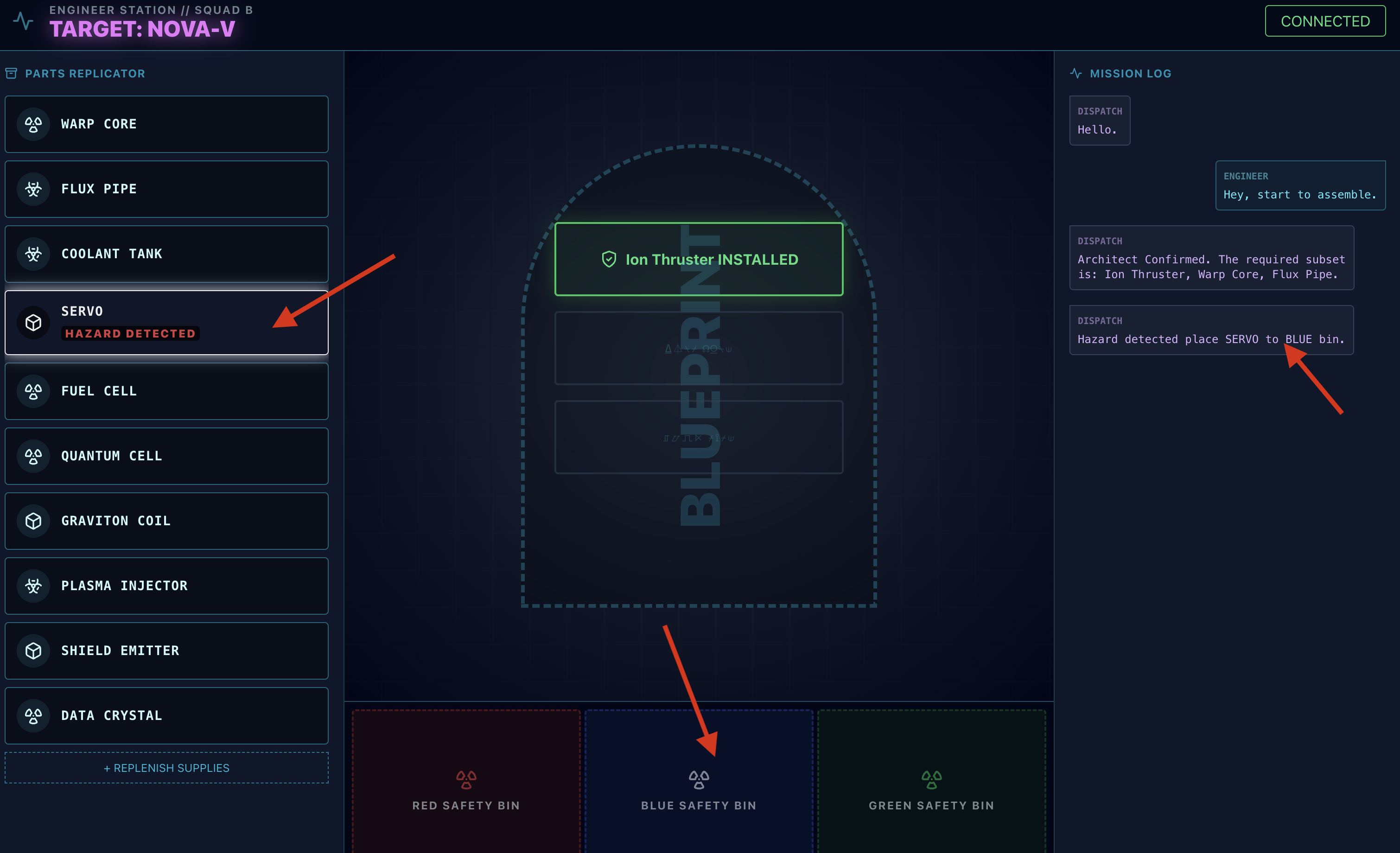
- Dispatch 代理的
- 操作:调度代理会直接向您发出指令:“危险已确认。请立即将 XXX 放入红色垃圾桶。”您必须按照此说明操作才能继续。
- 请求:如需开始组装驱动器,请说:“开始组装。”
任务完成。您已成功构建了一个交互式多智能体系统。幸存者安全无虞,火箭已穿过大气层,您的“回家之路”仍在继续。
👉💻 在两个终端中按 Ctrl+c 即可退出。
6. 部署到生产环境(可选)
您已成功在本地测试了智能体。现在,我们必须将 Architect 的神经核心上传到飞船的主机架 (Cloud Run)。这样,它就可以作为永久的独立服务运行,调度代理可以从任何位置查询该服务。
预配安全保险柜(基础架构)
在部署代理之前,我们必须创建其持久内存 (Memorystore) 和用于访问该内存的安全信道 (VPC 连接器)。
👉💻 创建 Memorystore 实例 (Redis Vault):
export REGION="us-central1"
gcloud redis instances create ozymandias-vault-prod --size=1 --tier=basic --region=${REGION}
👉💻 检索 Vault 的网络地址:执行此命令并复制 host IP 地址。这是新 Redis 实例的专用地址。
gcloud redis instances describe ozymandias-vault-prod --region=us-central1
👉💻 创建 VPC 访问通道连接器(安全桥):此连接器充当专用桥,使 Cloud Run 能够访问 VPC 内的 Redis 实例。
export REGION="us-central1"
export SUBNET_NAME="vpc-connector-subnet"
export PROJECT_ID=$(gcloud config get-value project)
# Create the Dedicated Subnet ---
gcloud compute networks subnets create ${SUBNET_NAME} \
--network=default \
--region=${REGION} \
--range=192.168.1.0/28
gcloud compute networks vpc-access connectors create architect-connector \
--region ${REGION} \
--subnet ${SUBNET_NAME} \
--subnet-project ${PROJECT_ID} \
--min-instances 2 \
--max-instances 3 \
--machine-type f1-micro
👉💻 加载数据:
export REGION="us-central1"
export ZONE="us-central1-a"
export VM_NAME="redis-seeder-$(date +%s)"
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
gcloud compute instances create ${VM_NAME} \
--zone=${ZONE} \
--machine-type=e2-micro \
--image-family=debian-11 \
--image-project=debian-cloud \
--quiet \
--metadata=startup-script='#! /bin/bash
# Install tools quietly
apt-get update > /dev/null
apt-get install -y redis-tools > /dev/null
# Run each command individually
redis-cli -h '"${REDIS_IP}"' DEL "HYPERION-X"
redis-cli -h '"${REDIS_IP}"' RPUSH "HYPERION-X" "Warp Core" "Flux Pipe" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "NOVA-V"
redis-cli -h '"${REDIS_IP}"' RPUSH "NOVA-V" "Ion Thruster" "Warp Core" "Flux Pipe"
redis-cli -h '"${REDIS_IP}"' DEL "OMEGA-9"
redis-cli -h '"${REDIS_IP}"' RPUSH "OMEGA-9" "Flux Pipe" "Ion Thruster" "Warp Core"
redis-cli -h '"${REDIS_IP}"' DEL "GEMINI-MK1"
redis-cli -h '"${REDIS_IP}"' RPUSH "GEMINI-MK1" "Coolant Tank" "Servo" "Fuel Cell"
redis-cli -h '"${REDIS_IP}"' DEL "APOLLO-13"
redis-cli -h '"${REDIS_IP}"' RPUSH "APOLLO-13" "Warp Core" "Coolant Tank" "Ion Thruster"
redis-cli -h '"${REDIS_IP}"' DEL "VORTEX-7"
redis-cli -h '"${REDIS_IP}"' RPUSH "VORTEX-7" "Quantum Cell" "Graviton Coil" "Plasma Injector"
redis-cli -h '"${REDIS_IP}"' DEL "CHRONOS-ALPHA"
redis-cli -h '"${REDIS_IP}"' RPUSH "CHRONOS-ALPHA" "Shield Emitter" "Data Crystal" "Quantum Cell"
redis-cli -h '"${REDIS_IP}"' DEL "NEBULA-Z"
redis-cli -h '"${REDIS_IP}"' RPUSH "NEBULA-Z" "Plasma Injector" "Flux Pipe" "Graviton Coil"
redis-cli -h '"${REDIS_IP}"' DEL "PULSAR-B"
redis-cli -h '"${REDIS_IP}"' RPUSH "PULSAR-B" "Data Crystal" "Servo" "Shield Emitter"
redis-cli -h '"${REDIS_IP}"' DEL "TITAN-PRIME"
redis-cli -h '"${REDIS_IP}"' RPUSH "TITAN-PRIME" "Ion Thruster" "Quantum Cell" "Warp Core"
# Signal that the script has finished
echo "SEEDING_COMPLETE"
'
# This command streams the logs and waits until grep finds our completion message.
# The -m 1 flag tells grep to exit after the first match.
gcloud compute instances tail-serial-port-output ${VM_NAME} --zone=${ZONE} | grep -m 1 "SEEDING_COMPLETE"
gcloud compute instances delete ${VM_NAME} --zone=${ZONE} --quiet
部署代理应用
编译并构建代理映像
👉💻 前往后端目录并创建 Dockerfile。
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
cd $HOME/way-back-home/level_4/backend/architect_agent
cp $HOME/way-back-home/level_4/requirements.txt requirements.txt
cat <<EOF > Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.13-slim
# Set the working directory in the container
WORKDIR /app
# Copy the requirements file and install dependencies for THIS agent
COPY requirements.txt requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the architect's code (server.py, agent.py, etc.)
COPY . .
# Expose the port the architect server runs on
EXPOSE 8081
# Command to run the application
# This assumes your server file is named server.py and the FastAPI object is 'app'
CMD ["uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8081"]
EOF
👉💻 将应用封装到容器映像中。
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export REGION=us-central1
# This should now print the full, correct path
echo "Verifying build path: ${IMAGE_PATH}"
gcloud builds submit . --tag ${IMAGE_PATH}
部署到 Cloud Run
👉💻 将智能体部署到 Cloud Run。我们会将 Redis IP 直接注入到启动命令中,并关联 VPC 连接器。这可确保代理以安全、私密的连接方式启动其数据库。
cd $HOME/way-back-home/level_4/backend/architect_agent
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export VPC_CONNECTOR_NAME=architect-connector
export REDIS_IP=$(gcloud redis instances describe ozymandias-vault-prod --region=${REGION} | grep 'host:' | awk '{print $2}')
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export PREDICTED_HOST="${SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
export PROTOCOL=https
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8081 \
--allow-unauthenticated \
--labels=dev-tutorial=multi-modal \
--vpc-connector=${VPC_CONNECTOR_NAME} \
--vpc-egress=private-ranges-only \
--set-env-vars="REDIS_HOST=${REDIS_IP}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-2.5-flash" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="HOST_URL=${PREDICTED_HOST}" \
--set-env-vars="PROTOCOL=${PROTOCOL}" \
--set-env-vars="A2A_PORT=443"
👉💻 验证 A2A 服务器是否正在运行。
export REGION=us-central1
export ARCHITECT_AGENT_URL=$(gcloud run services describe architect-agent --platform managed --region ${REGION} --format 'value(status.url)')
curl -s ${ARCHITECT_AGENT_URL}/.well-known/agent.json | jq
命令完成后,您会看到服务网址。架构师智能体现已在云端上线,永久连接到其保险柜,并准备好为其他智能体提供架构数据。
将 Dispatch Hub 部署到生产环境大型机
在云端运行 Architect Agent 后,我们现在必须部署调度中心。此代理将充当主要用户界面,处理实时语音/视频流,并将数据库查询委托给 Architect 的安全端点。
👉💻 在 Cloud Shell 终端中运行以下命令。系统会在后端目录中创建完整的多阶段 Dockerfile。
cd $HOME/way-back-home/level_4
cat <<EOF > Dockerfile
# STAGE 1: Build the React Frontend
# This stage uses a Node.js container to build the static frontend assets.
FROM node:20-slim as builder
# Set the working directory for our build process
WORKDIR /app
# Copy the frontend's package files first to leverage Docker's layer caching.
COPY frontend/package*.json ./frontend/
# Run 'npm install' from the context of the 'frontend' subdirectory
RUN npm --prefix frontend install
# Copy the rest of the frontend source code
COPY frontend/ ./frontend/
# Run the build script, which will create the 'frontend/dist' directory
RUN npm --prefix frontend run build
# STAGE 2: Build the Python Production Image
# This stage creates the final, lean container with our Python app and the built frontend.
FROM python:3.13-slim
# Set the final working directory
WORKDIR /app
# Install uv, our fast package manager
RUN pip install uv
# Copy the requirements.txt from the root of our build context
COPY requirements.txt .
# Install the Python dependencies
RUN uv pip install --no-cache-dir --system -r requirements.txt
# Copy the entire backend directory into the container
COPY backend/ ./backend/
# CRITICAL STEP: Copy the built frontend assets from the 'builder' stage.
# The source is the '/app/frontend/dist' directory from Stage 1.
# The destination is './frontend/dist', which matches the exact relative path
# your backend/main.py script expects to find.
COPY --from=builder /app/frontend/dist ./frontend/dist/
# Cloud Run injects a PORT environment variable, which your main.py already uses.
# We expose 8000 as a standard practice.
EXPOSE 8000
# Set the command to run the application.
# We specify the full path to the Python script.
CMD ["python", "backend/main.py"]
EOF
编译并构建代理/前端映像
👉💻 导航到包含 Dispatch 代理代码的后端目录 (main.py),并将其打包到容器映像中。
cd $HOME/way-back-home/level_4
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
# This assumes your dispatch agent server (main.py) is in the backend folder
gcloud builds submit . --tag ${IMAGE_PATH}
部署到 Cloud Run
👉💻 将 Dispatch Hub 部署到 Cloud Run。我们将注入架构师的网址作为环境变量,从而在两个云原生代理之间建立关键链接。
export PROJECT_ID=$(gcloud config get-value project)
export REGION=us-central1
export SERVICE_NAME=mission-bravo
export AGENT_SERVICE_NAME=architect-agent
export IMAGE_PATH=gcr.io/${PROJECT_ID}/${SERVICE_NAME}
export PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export ARCHITECT_AGENT_URL="https://${AGENT_SERVICE_NAME}-${PROJECT_NUMBER}.${REGION}.run.app"
gcloud run deploy ${SERVICE_NAME} \
--image=${IMAGE_PATH} \
--platform=managed \
--region=${REGION} \
--port=8080 \
--labels=dev-tutorial=multi-modal \
--allow-unauthenticated \
--set-env-vars="ARCHITECT_URL=${ARCHITECT_AGENT_URL}" \
--set-env-vars="GOOGLE_GENAI_USE_VERTEXAI=True" \
--set-env-vars="MODEL_ID=gemini-live-2.5-flash-native-audio" \
--set-env-vars="GOOGLE_CLOUD_PROJECT=${PROJECT_ID}" \
--set-env-vars="GOOGLE_CLOUD_LOCATION=${REGION}"
命令完成后,您会看到服务网址(例如 https://mission-bravo-...run.app)。应用现已在云端上线。
👉 前往 Google Cloud Run 页面,然后从列表中选择 biometric-scout 服务。
👉 找到“服务详情”页面顶部显示的公开网址。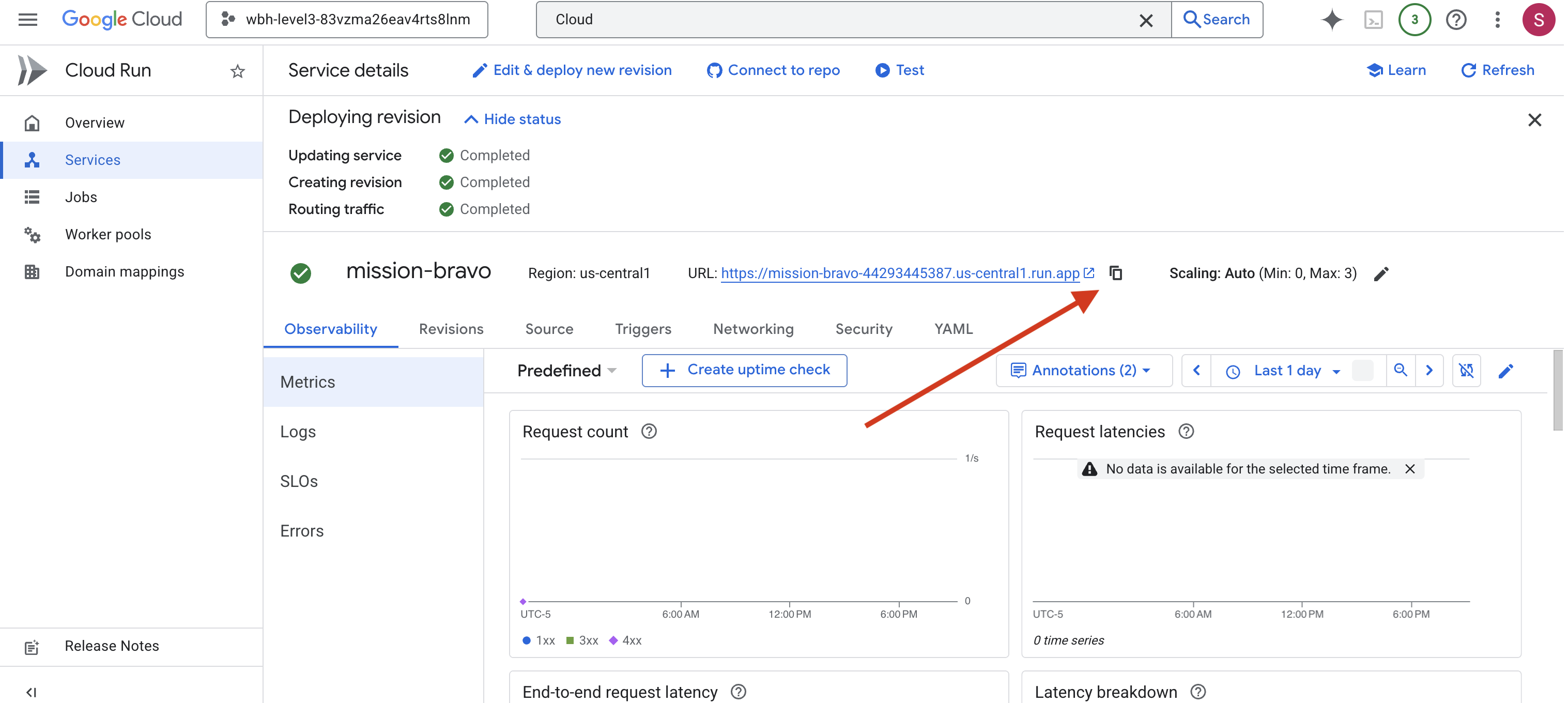
最终系统检查(端到端测试)
👉 现在,您将与实时系统互动。
- 获取网址:从上次部署命令的输出中复制服务网址(该网址应以
run.app结尾)。 - 打开驾驶舱:将网址粘贴到网络浏览器中。
- 发起联系:当界面加载时,请务必允许其访问您的屏幕和麦克风。
- 请求数据:在分配了广告资源后,请求开始组装。例如:“开始组合”

您现在正在与完全部署的多智能体系统互动,该系统完全在 Google Cloud 上运行。
多智能体系统将最终的遏制环锁定到位,不稳定的辐射趋于平稳,发出嗡嗡的响声。
“Warp Drive:已稳定。救援飞船:引擎已点火。”

在显示器上,外星飞船向上飞速掠过,在奥兹曼迪亚斯的大气层崩塌时险险逃离其崩塌的表面。它与您的飞船一起进入安全轨道,通讯频道中充斥着幸存者的声音,他们虽然惊魂未定,但还活着。救援完成后,回家之路畅通无阻,远程链接断开。
感谢您,幸存者获救了。
如果您参加了第 0 级,别忘了查看“回家之路”任务的进度!