1. La mission

Vous dérivez dans le silence d'un secteur inexploré. Une énorme impulsion solaire a déchiré votre vaisseau à travers une faille, vous laissant bloqué dans une poche de l'univers qui n'existe sur aucune carte stellaire.
Après des jours de réparations épuisantes, vous sentez enfin le ronronnement des moteurs sous vos pieds. Votre fusée est réparée. Vous avez même réussi à établir une liaison montante longue portée avec le vaisseau-mère. Vous êtes autorisé à décoller. Vous êtes prêt à rentrer chez vous.
Mais alors que vous vous préparez à engager le lecteur de saut, un signal de détresse perce la statique. Vos capteurs captent un signal d'aide. Cinq civils sont piégés à la surface de la planète X-42. Leur seul espoir de s'échapper repose sur 15 capsules anciennes qui doivent être synchronisées pour transmettre un signal de détresse à leur vaisseau-mère en orbite.
Cependant, les pods sont contrôlés par une station satellite dont l'ordinateur de navigation principal est endommagé. Les pods dérivent sans but précis. Nous avons réussi à établir une connexion backdoor avec le satellite, mais la liaison montante est fortement perturbée par des interférences interstellaires, ce qui entraîne une latence massive dans les cycles de requête-réponse.
Le défi
Étant donné qu'un modèle de requête/réponse est trop lent, nous devons déployer une architecture basée sur les événements (EDA) avec des événements envoyés par le serveur (SSE) pour diffuser la télémétrie à travers le bruit.
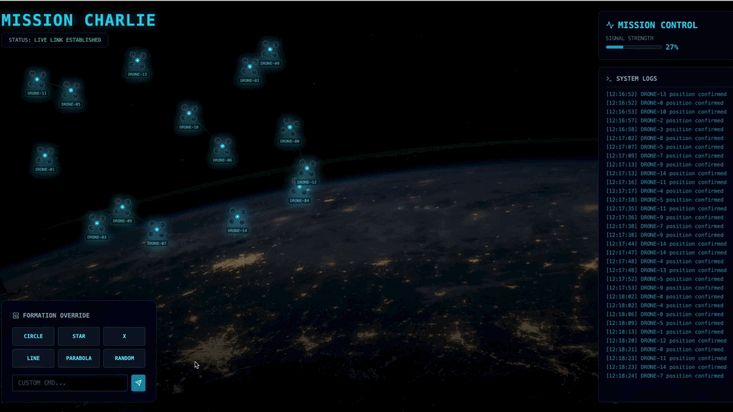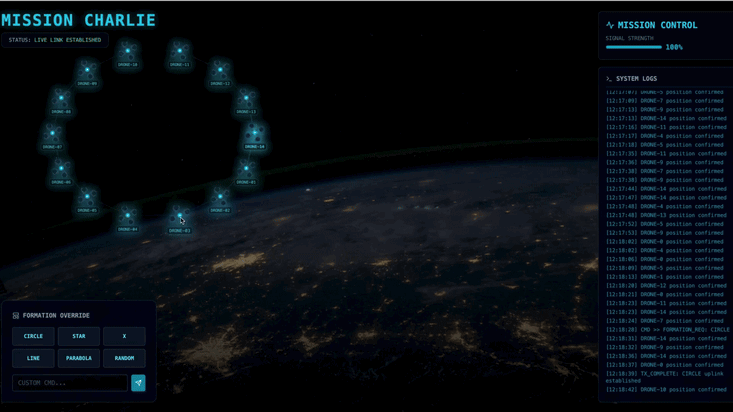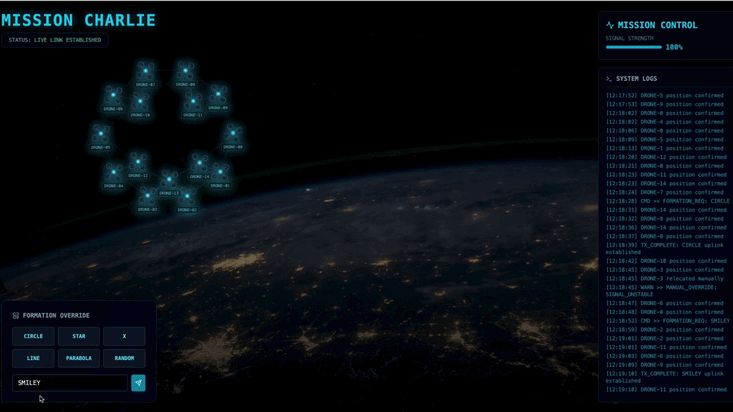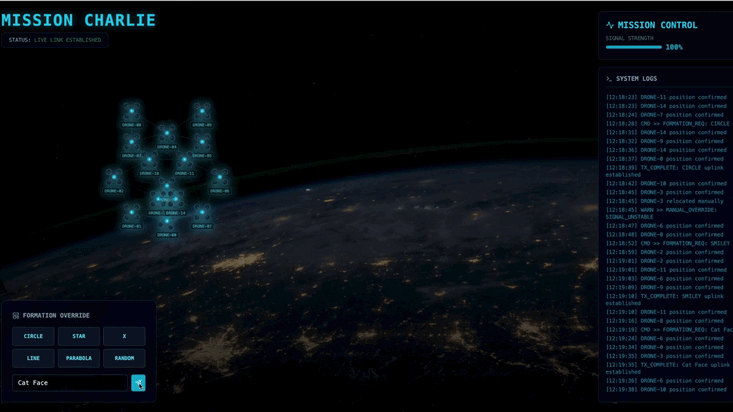
Vous devrez créer un agent personnalisé capable de calculer les opérations mathématiques vectorielles complexes nécessaires pour forcer les pods à adopter des formations spécifiques d'amplification du signal (cercle, étoile, ligne). Vous devez intégrer cet agent à la nouvelle architecture du satellite.
Objectifs de l'atelier
- Un affichage tête haute (HUD) basé sur React pour visualiser et commander une flotte de 15 pods en temps réel.
- Un agent d'IA générative utilisant le Google Agent Development Kit (ADK) qui calcule des formations géométriques complexes pour les pods en fonction de commandes en langage naturel.
- Un backend de station satellite basée sur Python qui sert de hub central et communique avec le frontend via les événements envoyés par le serveur (SSE, Server-Sent Events).
- Une architecture basée sur les événements utilisant Apache Kafka pour dissocier l'agent d'IA du système de contrôle des satellites, ce qui permet une communication résiliente et asynchrone.
Objectifs de l'atelier
Technologie / Concept | Description |
Google ADK (Agent Development Kit) | Vous utiliserez ce framework pour créer, tester et échafauder un agent d'IA spécialisé optimisé par les modèles Gemini. |
Architecture basée sur des événements (EDA) | Vous apprendrez les principes de la création d'un système découplé où les composants communiquent de manière asynchrone par le biais d'événements, ce qui rend l'application plus résiliente et évolutive. |
Apache Kafka | Vous allez configurer et utiliser Kafka comme plate-forme de streaming d'événements distribuée pour gérer le flux de commandes et de données entre différents microservices. |
Événements envoyés par le serveur (SSE) | Vous allez implémenter SSE dans un backend FastAPI pour envoyer des données de télémétrie en temps réel du serveur au frontend React, ce qui permet de maintenir l'interface utilisateur constamment à jour. |
Protocole A2A (Agent-to-Agent) | Vous apprendrez à encapsuler votre agent dans un serveur A2A, ce qui permettra une communication et une interopérabilité standardisées au sein d'un écosystème d'agents plus vaste. |
FastAPI | Vous allez créer le service de backend principal, la station satellite, à l'aide de ce framework Web Python hautes performances. |
React | Vous allez travailler avec une application frontend moderne qui s'abonne à un flux SSE pour créer une interface utilisateur dynamique et interactive. |
IA générative dans le contrôle du système | Vous verrez comment un grand modèle de langage (LLM) peut être invité à effectuer des tâches spécifiques axées sur les données (comme la génération de coordonnées) plutôt que de simplement discuter. |
2. Configurer votre environnement
Accéder à Cloud Shell
👉 Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell), 
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 
👉 Ouvrez le terminal dans l'IDE cloud.
👉💻 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
Votre compte devrait être listé comme (ACTIVE).
Prérequis
ℹ️ Le niveau 0 est facultatif (mais recommandé)
Vous pouvez terminer cette mission sans le niveau 0, mais la terminer en premier vous offre une expérience plus immersive, vous permettant de voir votre balise s'allumer sur la carte du monde à mesure que vous progressez.
Configurer l'environnement du projet
De retour dans votre terminal, finalisez la configuration en définissant le projet actif et en activant les services Google Cloud requis (Cloud Run, Vertex AI, etc.).
👉💻 Dans votre terminal, définissez l'ID du projet :
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Activez les services requis :
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
Installer des dépendances
👉💻 Accédez au niveau 5 et installez les packages Python requis :
cd $HOME/way-back-home/level_5
uv sync
Voici les principales dépendances :
Package | Objectif |
| Framework Web hautes performances pour la station satellite et le streaming SSE |
| Serveur ASGI requis pour exécuter l'application FastAPI |
| Agent Development Kit utilisé pour créer l'agent Formation |
| Bibliothèque de protocole Agent-to-Agent pour une communication standardisée |
| Client Kafka asynchrone pour la boucle d'événements |
| Client natif pour accéder aux modèles Gemini |
| Calculs vectoriels et de coordonnées pour la simulation |
| Prise en charge de la communication bidirectionnelle en temps réel |
| Gère les variables d'environnement et les secrets de configuration |
| Gestion efficace des événements envoyés par le serveur (SSE) |
| Bibliothèque HTTP simple pour les appels d'API externes |
Vérifier la configuration
Avant de nous lancer dans le code, assurons-nous que tous les systèmes sont opérationnels. Exécutez le script de validation pour auditer votre projet Google Cloud, vos API et vos dépendances Python.
👉💻 Exécutez le script de validation :
cd $HOME/way-back-home/level_5/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Une série de coches vertes (✅) devrait s'afficher.
- Si des croix rouges (❌) s'affichent, suivez les commandes de correction suggérées dans le résultat (par exemple,
gcloud services enable ...oupip install ...). - Remarque : Un avertissement jaune pour
.envest acceptable pour le moment. Nous créerons ce fichier à l'étape suivante.
🚀 Verifying Mission Charlie (Level 5) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Mise en forme des positions de pod avec un LLM
Nous devons construire le "cerveau" de notre opération de sauvetage. Il s'agira d'un agent créé à l'aide de Google ADK (Agent Development Kit). Son seul objectif est de servir de navigateur géométrique spécialisé. Alors que les LLM standards aiment discuter, dans l'espace lointain, nous avons besoin de données, pas de dialogue. Nous allons programmer cet agent pour qu'il prenne une commande comme "Star" et renvoie les coordonnées JSON brutes de nos 15 pods.
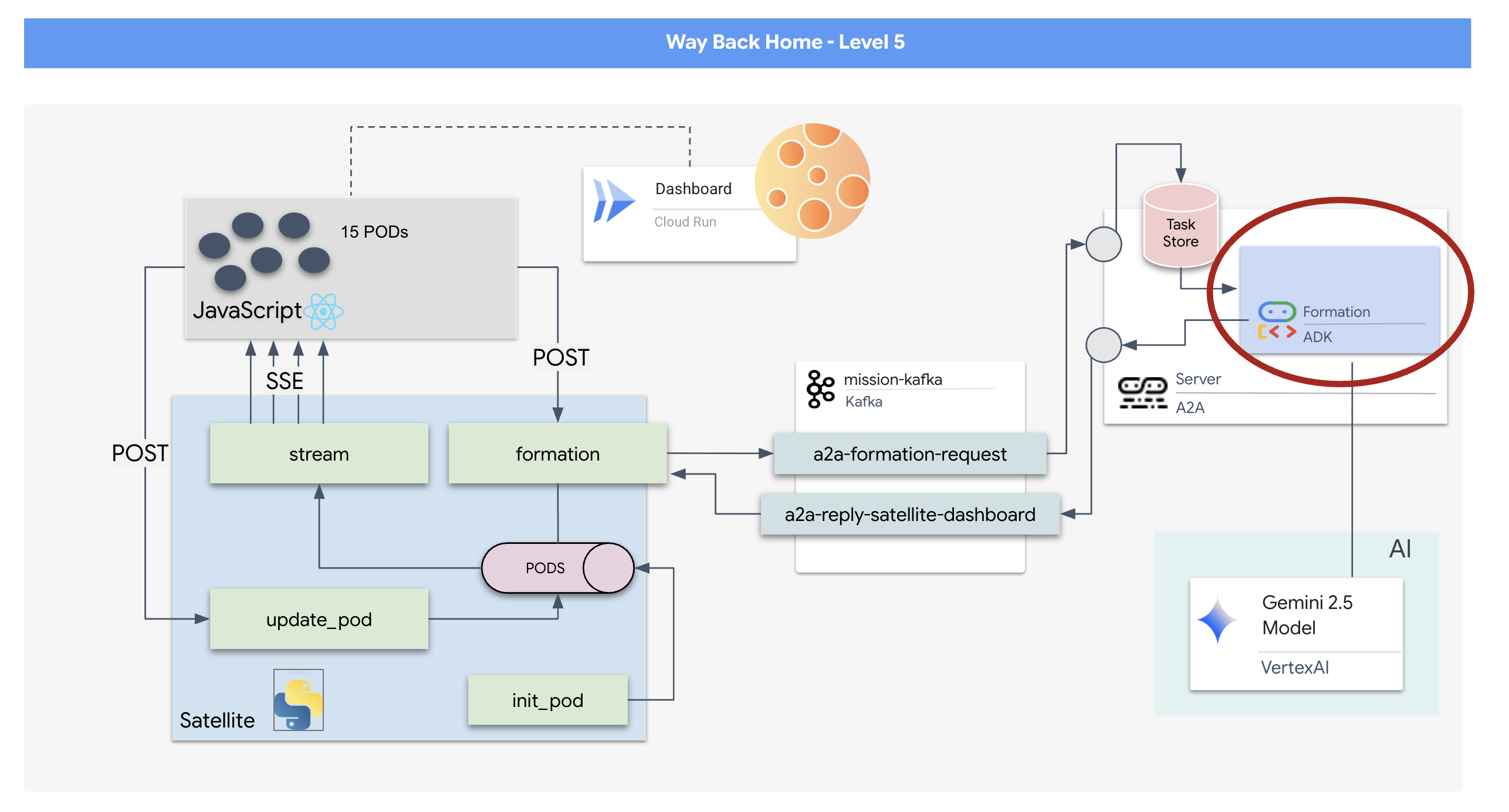
Créer la structure de l'agent
👉💻 Exécutez les commandes suivantes pour accéder au répertoire de votre agent et démarrer l'assistant de création d'ADK :
cd $HOME/way-back-home/level_5/agent
uv run adk create formation
La CLI lance un assistant de configuration interactif. Utilisez les réponses suivantes pour configurer votre agent :
- Choisir un modèle : sélectionnez Option 1 (Gemini Flash).
- Remarque : La version spécifique peut varier. Choisissez toujours la variante "Flash" pour la vitesse.
- Choisir un backend : sélectionnez Option 2 (Vertex AI).
- Saisissez l'ID du projet Google Cloud : appuyez sur Entrée pour accepter la valeur par défaut (détectée à partir de votre environnement).
- Enter Google Cloud Region (Saisir la région Google Cloud) : appuyez sur Entrée pour accepter la valeur par défaut (
us-central1).
👀 Votre interaction avec le terminal devrait ressembler à ceci :
(way-back-home) user@cloudshell:~/way-back-home/level_5/agent$ adk create formation Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_5/agent/formation: - .env - __init__.py - agent.py
Un message de réussite Agent created devrait s'afficher. Cela génère le code de squelette que nous allons maintenant modifier.
👉✏️ Accédez au fichier $HOME/way-back-home/level_5/agent/formation/agent.py que vous venez de créer et ouvrez-le dans votre éditeur. Remplacez l'intégralité du contenu du fichier par le code ci-dessous. Cela met à jour le nom de l'agent et fournit ses paramètres opérationnels stricts.
import os
from google.adk.agents import Agent
root_agent = Agent(
name="formation_agent",
model="gemini-2.5-flash",
instruction="""
You are the **Formation Controller AI**.
Your strict objective is to calculate X,Y coordinates for a fleet of **15 Drones** based on a requested geometric shape.
### FIELD SPECIFICATIONS
- **Canvas Size**: 800px (width) x 600px (height).
- **Safe Margin**: Keep pods at least 50px away from edges (x: 50-750, y: 50-550).
- **Center Point**: x=400, y=300 (Use this as the origin for shapes).
- **Top Menu Avoidance**: Do NOT place pods in the top 100px (y < 100) to avoid UI overlap.
### FORMATION RULES
When given a formation name, output coordinates for exactly 15 pods (IDs 0-14).
1. **CIRCLE**: Evenly spaced around a center point (R=200).
2. **STAR**: 5 points or a star-like distribution.
3. **X**: A large X crossing the screen.
4. **LINE**: A horizontal line across the middle.
5. **PARABOLA**: A U-shape opening UPWARDS. Center it at y=400, opening up to y=100. IMPORTANT: Lowest point must be at bottom (high Y value), opening up (low Y value). Screen coordinates have (0,0) at the TOP-LEFT. The vertex should be at the BOTTOM (e.g., y=500), with arms reaching up to y=200.
6. **RANDOM**: Scatter randomly within safe bounds.
7. **CUSTOM**: If the user inputs something else (e.g., "SMILEY", "TRIANGLE"), do your best to approximate it geometrically.
### OUTPUT FORMAT
You MUST output **ONLY VALID JSON**. No markdown fencing, no preamble, no commentary.
Refuse to answer non-formation questions.
**JSON Structure**:
```json
[
{"x": 400, "y": 300},
{"x": 420, "y": 300},
... (15 total items)
]
```
"""
)
- Précision géométrique : en définissant la "Taille du canevas" et les "Marges de sécurité" dans l'invite système, nous nous assurons que l'agent ne place pas les pods hors écran ou sous les éléments de l'UI.
- Application de JSON : en demandant au LLM de "Refuser de répondre aux questions non liées à la mise en forme" et de fournir "Aucun préambule", nous nous assurons que notre code en aval (le Satellite) ne plante pas lorsqu'il tente d'analyser la réponse.
- Logique découplée : cet agent ne connaît pas encore Kafka. Il ne sait faire que des calculs. À l'étape suivante, nous allons encapsuler ce "cerveau" dans un serveur Kafka.
Tester l'agent en local
Avant de connecter l'agent au "système nerveux" Kafka, nous devons nous assurer qu'il fonctionne correctement. Vous pouvez interagir directement avec votre agent dans le terminal pour vérifier qu'il produit des coordonnées JSON valides.
👉💻 Utilisez la commande adk run pour démarrer une session de chat avec votre agent.
cd $HOME/way-back-home/level_5/agent
uv run adk run formation
- Entrée : saisissez
Circleet appuyez sur Entrée.- Critères de réussite : vous devriez voir une liste JSON brute (par exemple,
[{"x": 400, "y": 200}, ...]). Assurez-vous qu'il n'y a pas de texte Markdown tel que "Voici les coordonnées :" avant le JSON.
- Critères de réussite : vous devriez voir une liste JSON brute (par exemple,
- Entrée : saisissez
Lineet appuyez sur Entrée.- Critères de réussite : vérifiez que les coordonnées créent une ligne horizontale (les valeurs Y doivent être similaires).
Une fois que vous avez confirmé que l'agent génère un code JSON propre, vous pouvez l'encapsuler dans le serveur Kafka.
👉💻 Appuyez sur Ctrl+C pour quitter.
4. Créer un serveur A2A pour l'agent de formation
Comprendre A2A (Agent-to-Agent)
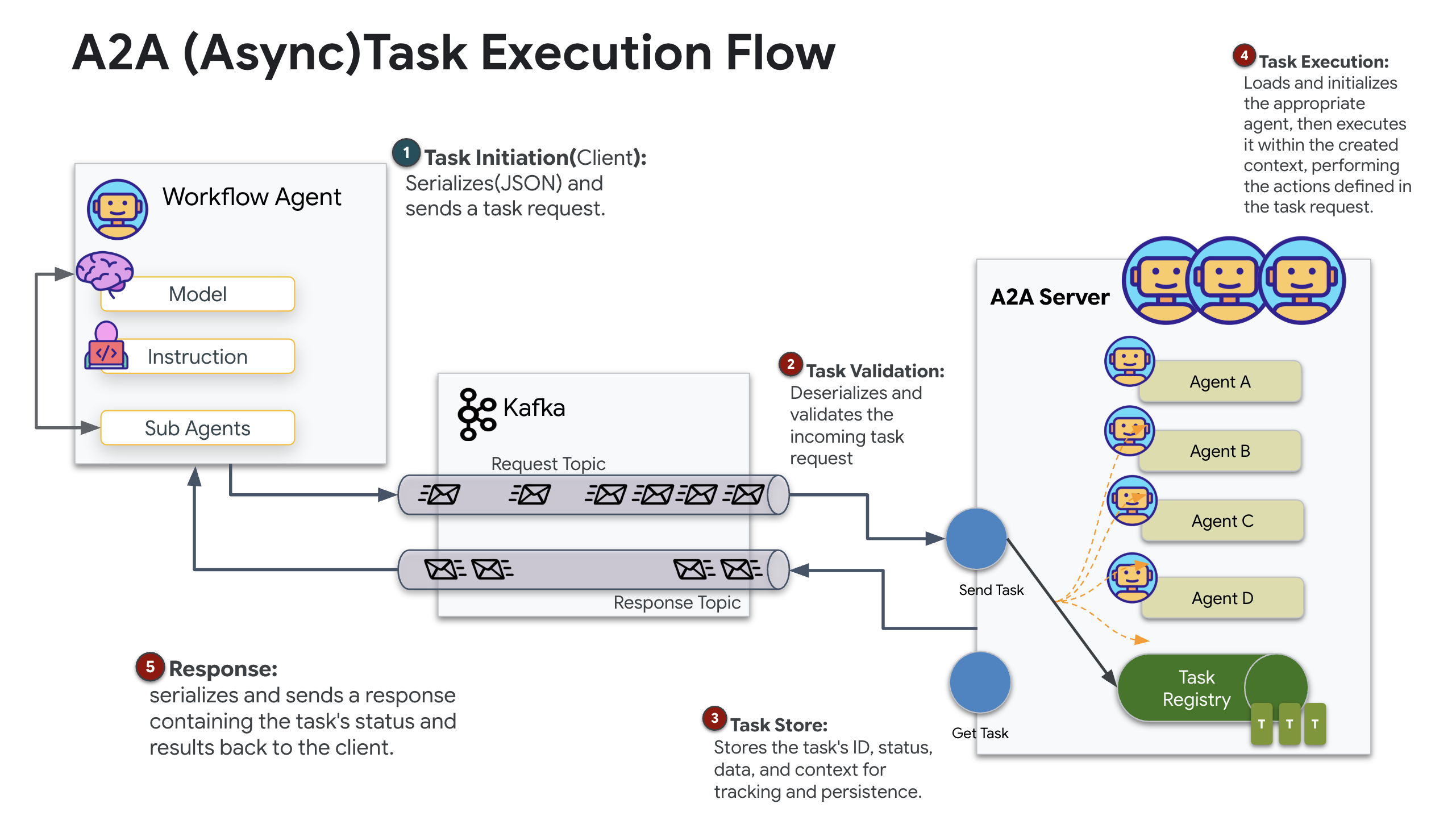
Le protocole A2A (Agent-to-Agent) est une norme ouverte conçue pour permettre une interopérabilité fluide entre les agents d'IA. Ce framework permet aux agents d'aller au-delà du simple échange de texte. Il leur permet de déléguer des tâches, de coordonner des actions complexes et de fonctionner comme une unité cohérente pour atteindre des objectifs communs dans un écosystème distribué.
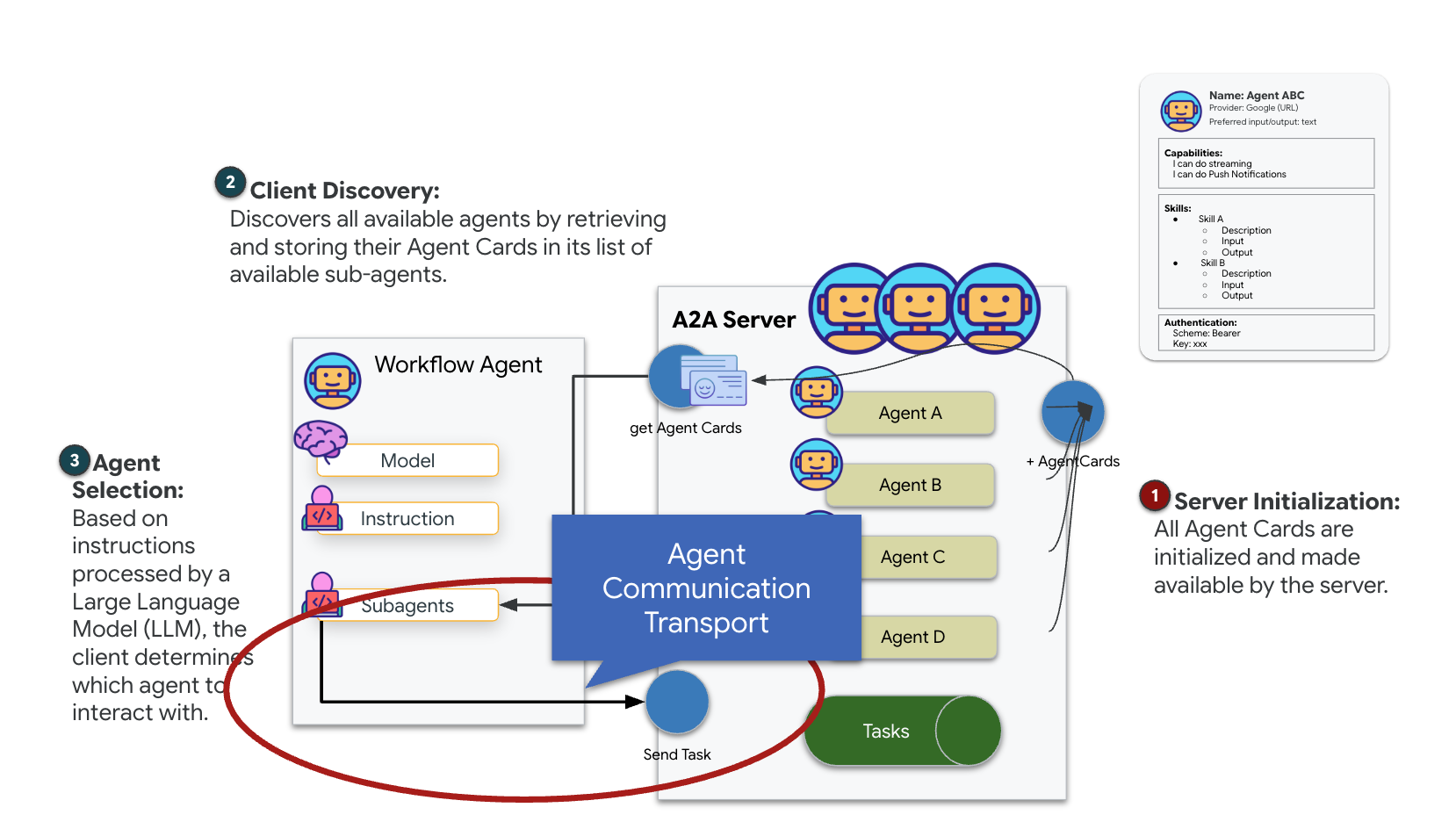
Comprendre les transports A2A : HTTP, gRPC et Kafka
Le protocole A2A offre deux façons distinctes pour les clients et les agents de communiquer, chacune répondant à des besoins architecturaux différents. HTTP (JSON-RPC) est la norme par défaut et omniprésente qui fonctionne universellement dans tous les environnements Web. gRPC est notre option haute performance, qui utilise Protocol Buffers pour une communication efficace et strictement typée. Dans l'atelier, je fournis également un transport Kafka. Il s'agit d'une implémentation personnalisée conçue pour des architectures robustes basées sur des événements, où le découplage des systèmes est une priorité.
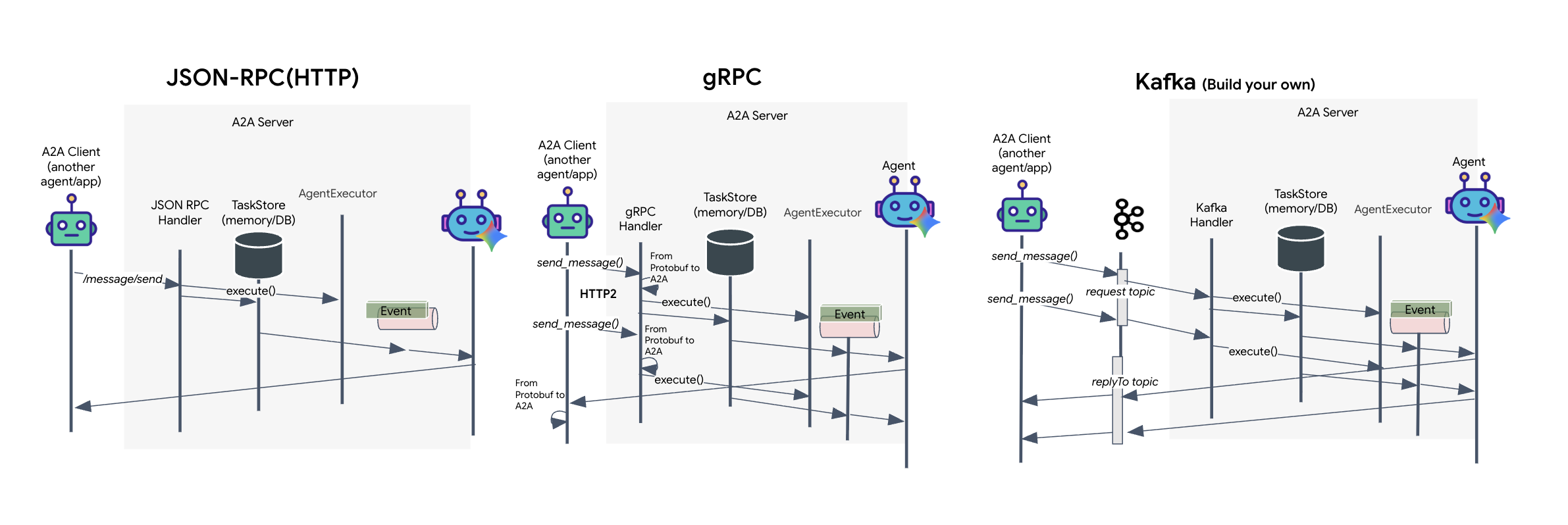
En coulisses, ces transports gèrent le flux de données de manière très différente. Dans le modèle HTTP, le client envoie une requête JSON et maintient la connexion ouverte, en attendant que l'agent termine sa tâche et renvoie le résultat complet en une seule fois. gRPC optimise ce processus en utilisant des données binaires et HTTP/2, ce qui permet à la fois des cycles de requête-réponse simples et le streaming en temps réel, où l'agent envoie des mises à jour (comme "pensée" ou "artefact créé") au fur et à mesure. L'implémentation Kafka fonctionne de manière asynchrone : le client publie une requête dans un "sujet de requête" très durable et écoute sur un "sujet de réponse" distinct. Le serveur récupère le message quand il le peut, le traite et renvoie le résultat. Les deux ne communiquent donc jamais directement entre eux.
Le choix dépend de vos exigences spécifiques en termes de vitesse, de complexité et de persistance. HTTP est le protocole le plus simple pour commencer et déboguer, ce qui le rend idéal pour les intégrations simples. gRPC est le meilleur choix pour la communication interne entre services, où une faible latence et des mises à jour des tâches de streaming sont essentielles. Toutefois, Kafka se distingue comme le choix résilient, car il stocke les requêtes sur le disque dans une file d'attente. Vos tâches survivent même si le serveur de l'agent plante ou redémarre, ce qui offre un niveau de durabilité et de découplage que ni HTTP ni gRPC ne peuvent offrir.
Couche de transport personnalisée : Kafka
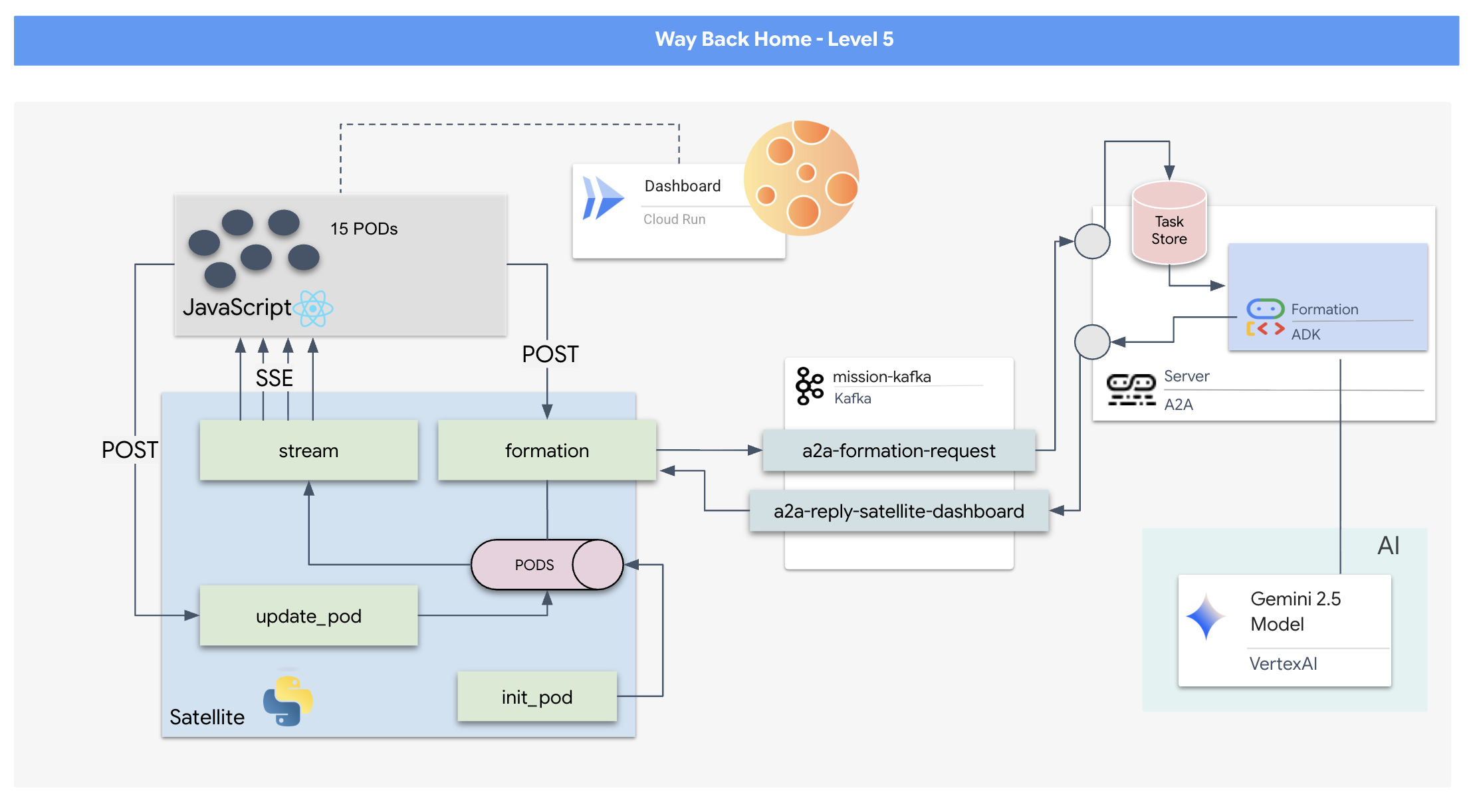
Kafka sert de colonne vertébrale asynchrone qui découple le cerveau de l'opération (agent de formation) des commandes physiques (station satellite). Au lieu de forcer le système à attendre une connexion synchrone pendant que l'agent calcule des vecteurs complexes, l'agent publie ses résultats sous forme d'événements dans un sujet Kafka. Il s'agit d'un tampon persistant qui permet au Satellite de traiter les instructions à son propre rythme et de s'assurer que les données de formation ne sont jamais perdues, même en cas de latence réseau importante ou de plantage temporaire du système.
En utilisant Kafka, vous transformez un processus lent et linéaire en un pipeline de streaming résilient où les instructions et la télémétrie circulent de manière indépendante, ce qui permet de maintenir la réactivité de l'HUD de la mission même lors d'un traitement par IA intense.
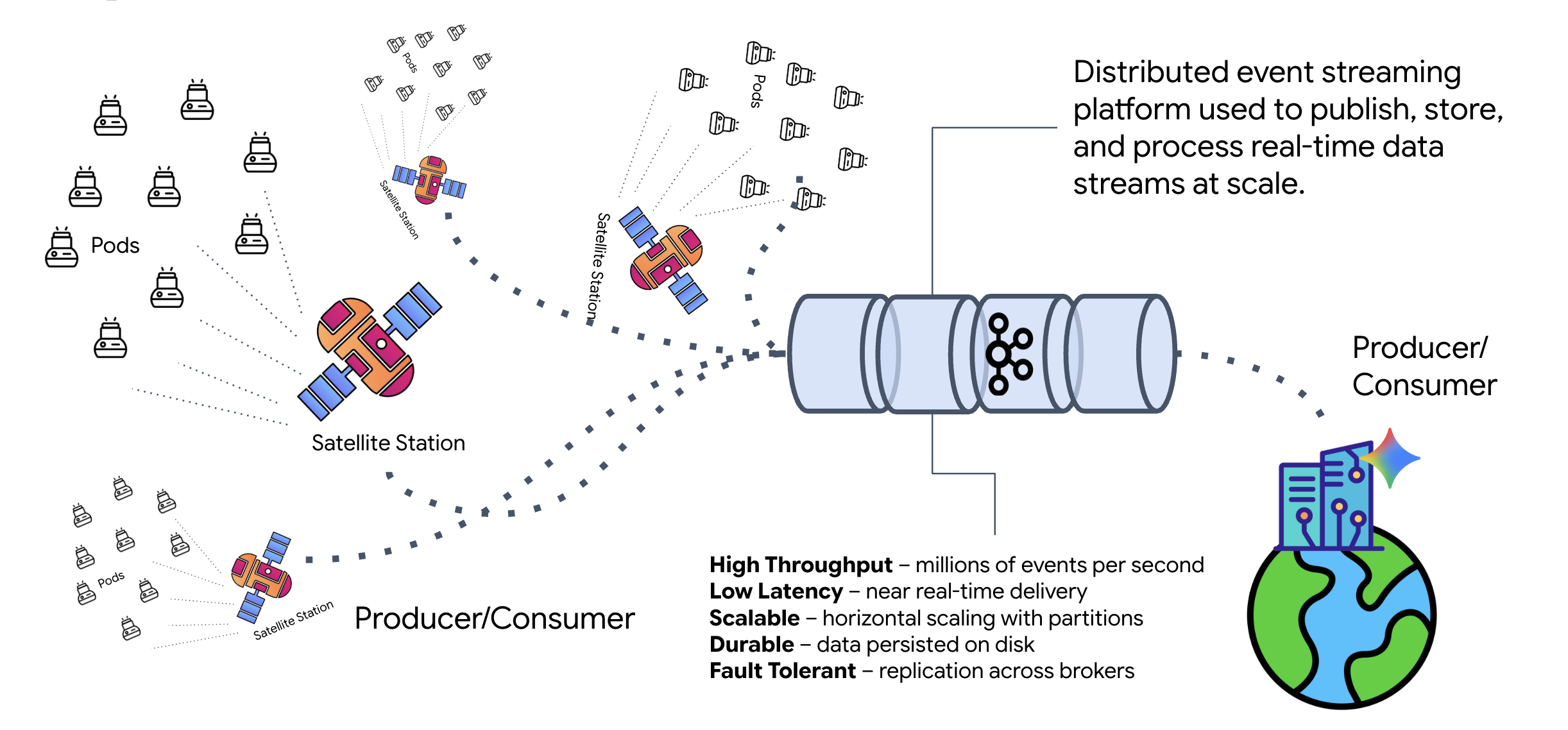
Qu'est-ce que Kafka ?
Kafka est une plate-forme de streaming d'événements distribuée. Dans une architecture basée sur des événements (EDA) :
- Les producteurs publient des messages dans des "sujets".
- Les consommateurs s'abonnent à ces thèmes et réagissent lorsqu'un message arrive.
Pourquoi utiliser Kafka ?
Il découple vos systèmes. L'agent de formation fonctionne de manière autonome. Il attend les requêtes entrantes sans avoir besoin de connaître l'identité ni l'état de l'expéditeur. Cela permet de dissocier les responsabilités, en veillant à ce que le workflow reste intact même si le satellite est hors connexion. Kafka stocke simplement les messages jusqu'à ce que le satellite se reconnecte.
Qu'en est-il de Google Cloud Pub/Sub ?
Vous pouvez tout à fait utiliser Google Cloud Pub/Sub pour cela. Pub/Sub est le service de messagerie sans serveur de Google. Kafka est idéal pour les flux à haut débit et "rejouables", mais Pub/Sub est souvent préféré pour sa facilité d'utilisation. Pour cet atelier, nous utilisons Kafka pour simuler un bus de messages robuste et persistant.
Démarrer le cluster Kafka local
Copiez et collez l'intégralité du bloc de commandes ci-dessous dans votre terminal. Cela téléchargera l'image Kafka officielle et la démarrera en arrière-plan.
👉💻 Exécutez ces commandes dans votre terminal :
# Navigate to the correct mission directory first
cd $HOME/way-back-home/level_5
# Run the Kafka container in detached mode
docker run -d \
--name mission-kafka \
-p 9092:9092 \
-e KAFKA_PROCESS_ROLES='broker,controller' \
-e KAFKA_NODE_ID=1 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
apache/kafka:4.2.0-rc1
👉💻 Vérifiez que le conteneur est en cours d'exécution à l'aide de la commande docker ps.
docker ps
👀 Vous devriez voir un résultat confirmant que le conteneur mission-kafka est en cours d'exécution et que le port 9092 est exposé.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c1a2b3c4d5e6 apache/kafka:4.2.0-rc1 "/opt/kafka/bin/kafka..." 15 seconds ago Up 14 seconds 0.0.0.0:9092->9092/tcp, 9093/tcp mission-kafka
Qu'est-ce qu'un sujet Kafka ?
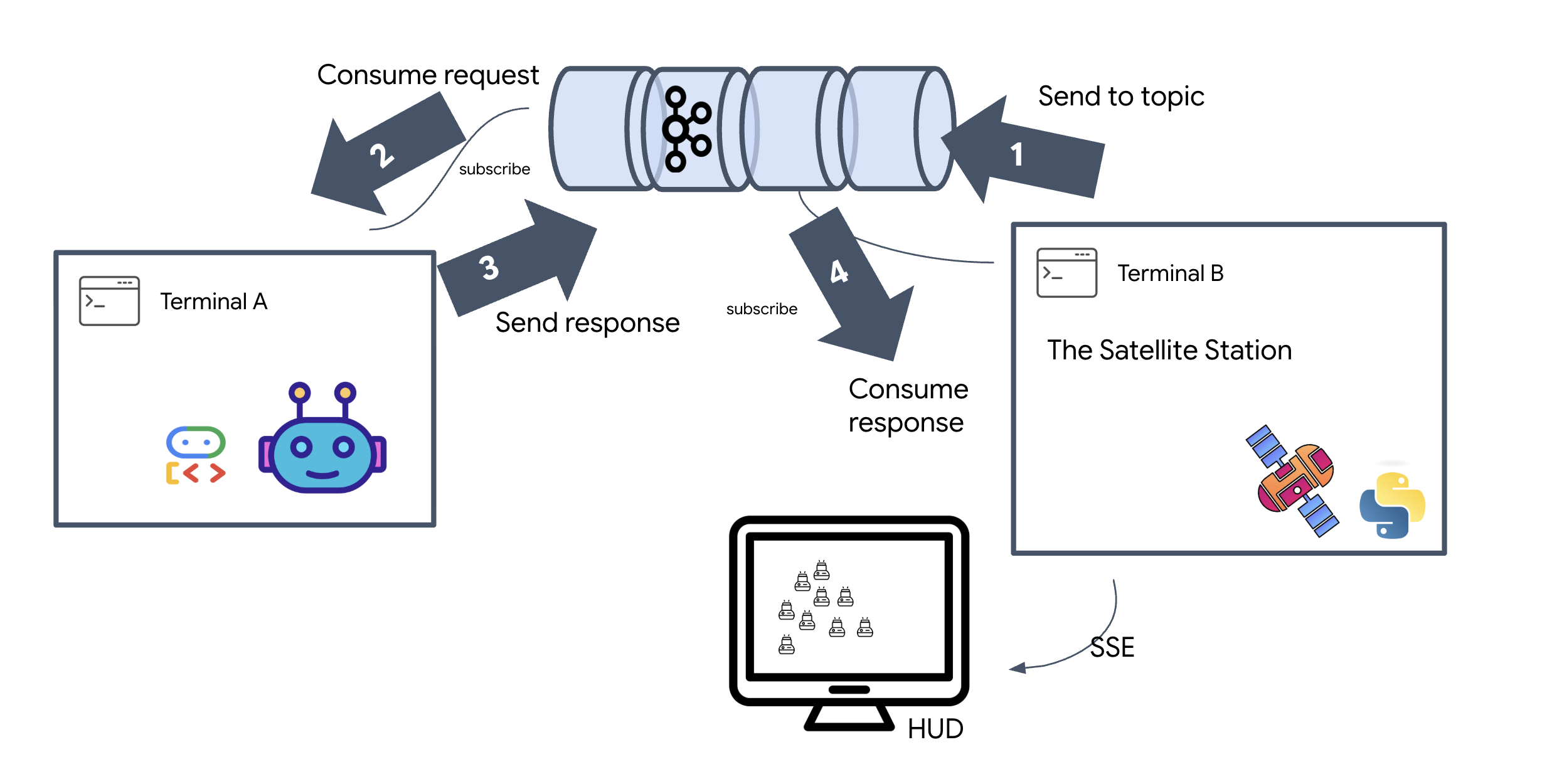
Considérez un sujet Kafka comme un canal ou une catégorie dédiés aux messages. Il s'agit d'un journal dans lequel les enregistrements d'événements sont stockés dans l'ordre dans lequel ils ont été produits. Les producteurs écrivent des messages dans des sujets spécifiques, et les consommateurs les lisent. Cela découple l'expéditeur du destinataire. Le producteur n'a pas besoin de savoir quel consommateur lira les données, il lui suffit de les envoyer au bon "canal". Dans notre mission, nous allons créer deux sujets : un pour envoyer des demandes de formation à l'agent et un autre pour que l'agent publie ses réponses que le satellite pourra lire.
👉💻 Exécutez les commandes suivantes pour créer les sujets requis dans le conteneur Docker en cours d'exécution.
# Create the topic for formation requests
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-formation-request \
--bootstrap-server 127.0.0.1:9092
# Create the topic where the satellite dashboard will listen for replies
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-reply-satellite-dashboard \
--bootstrap-server 127.0.0.1:9092
👉💻 Pour vérifier que vos canaux sont ouverts, exécutez la commande list :
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--list \
--bootstrap-server 127.0.0.1:9092
👀 Les noms des sujets que vous venez de créer devraient s'afficher.
a2a-formation-request a2a-reply-satellite-dashboard
Votre instance Kafka est maintenant entièrement configurée et prête à acheminer les données critiques.
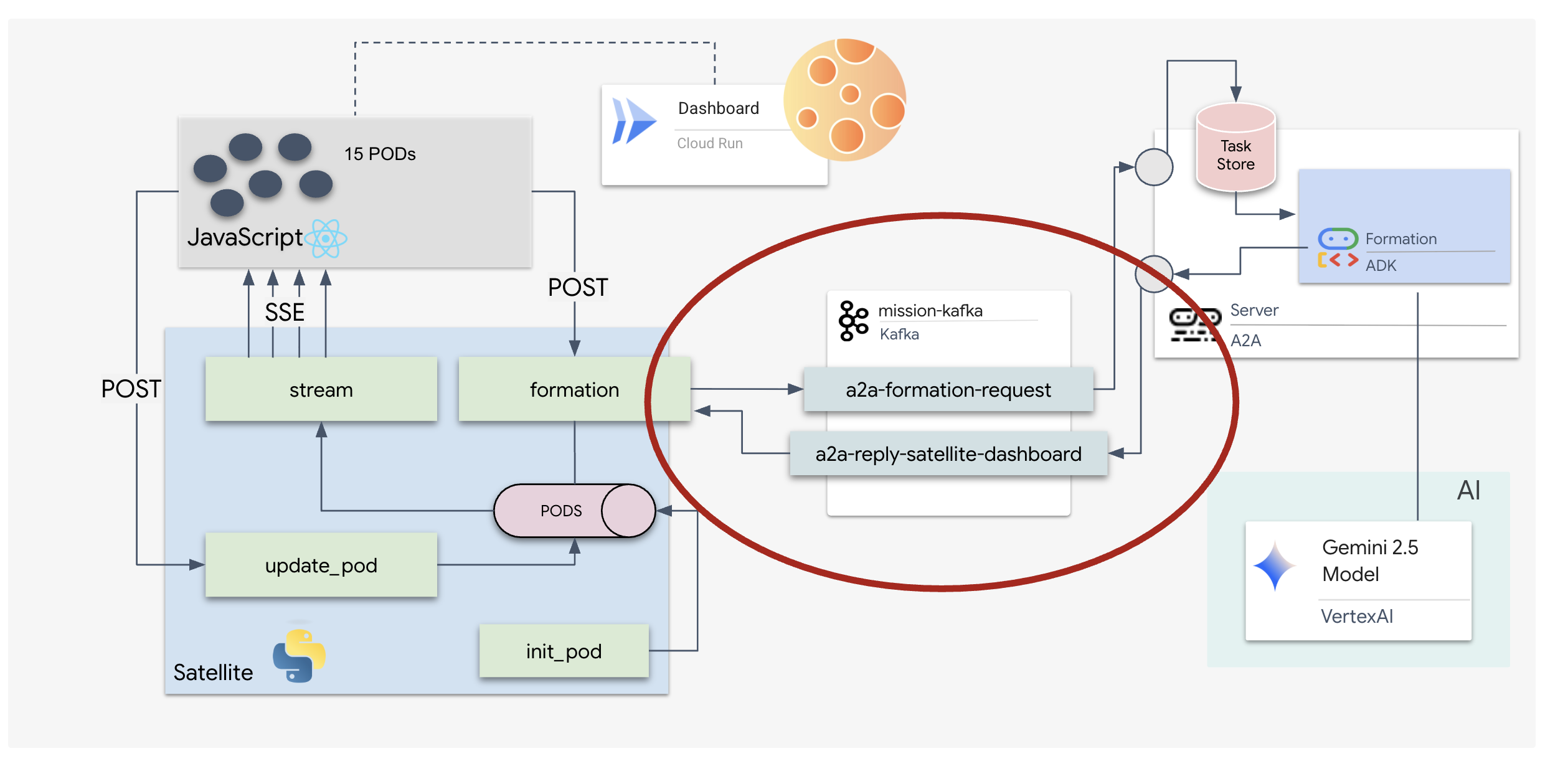
Implémenter le serveur A2A Kafka
Le protocole Agent-to-Agent (A2A) établit un framework standardisé pour l'interopérabilité entre les systèmes agentiques indépendants. Il permet aux agents développés par différentes équipes ou fonctionnant sur différentes infrastructures de se découvrir et de collaborer efficacement sans nécessiter de logique d'intégration personnalisée pour chaque connexion.
L'implémentation de référence, a2a-python, est une bibliothèque de base pour exécuter ces applications agentiques. L'extensibilité est une fonctionnalité essentielle de sa conception. Elle fait abstraction de la couche de communication, ce qui permet aux développeurs de remplacer des protocoles tels que HTTP par d'autres.
Dans ce projet, nous exploitons cette extensibilité à l'aide d'une implémentation Kafka personnalisée : a2a-python-kafka. Nous utiliserons cette implémentation pour montrer comment la norme A2A vous permet d'adapter la communication de l'agent à différents besoins architecturaux. Dans ce cas, nous remplacerons HTTP synchrone par un bus d'événements asynchrone.
Activer A2A pour l'agent Formation
Nous allons maintenant encapsuler notre agent dans un serveur A2A, ce qui le transformera en un service interopérable capable de :
- Écoutez les tâches d'un sujet Kafka.
- Transmettez les tâches reçues à l'agent ADK sous-jacent pour traitement.
- Publiez le résultat dans un sujet de réponse.
👉✏️ Dans $HOME/way-back-home/level_5/agent/agent_to_kafka_a2a.py, remplacez #REPLACE-CREATE-KAFKA-A2A-SERVER par le code suivant :
async def create_kafka_server(
agent: BaseAgent,
*,
bootstrap_servers: str | List[str] = "localhost:9092",
request_topic: str = "a2a-formation-request",
consumer_group_id: str = "a2a-agent-group",
agent_card: Optional[Union[AgentCard, str]] = None,
runner: Optional[Runner] = None,
**kafka_config: Any,
) -> KafkaServerApp:
"""Convert an ADK agent to a A2A Kafka Server application.
Args:
agent: The ADK agent to convert
bootstrap_servers: Kafka bootstrap servers.
request_topic: Topic to consume requests from.
consumer_group_id: Consumer group ID for the server.
agent_card: Optional pre-built AgentCard object or path to agent card
JSON. If not provided, will be built automatically from the
agent.
runner: Optional pre-built Runner object. If not provided, a default
runner will be created using in-memory services.
**kafka_config: Additional Kafka configuration.
Returns:
A KafkaServerApp that can be run with .run() or .start()
"""
# Set up ADK logging
adk_logger = logging.getLogger("google_adk")
adk_logger.setLevel(logging.INFO)
async def create_runner() -> Runner:
"""Create a runner for the agent."""
return Runner(
app_name=agent.name or "adk_agent",
agent=agent,
# Use minimal services - in a real implementation these could be configured
artifact_service=InMemoryArtifactService(),
session_service=InMemorySessionService(),
memory_service=InMemoryMemoryService(),
credential_service=InMemoryCredentialService(),
)
# Create A2A components
task_store = InMemoryTaskStore()
agent_executor = A2aAgentExecutor(
runner=runner or create_runner,
)
# Initialize logic handler
from a2a.server.request_handlers.default_request_handler import DefaultRequestHandler
logic_handler = DefaultRequestHandler(
agent_executor=agent_executor, task_store=task_store
)
# Prepare Agent Card
rpc_url = f"kafka://{bootstrap_servers}/{request_topic}"
# Create Kafka Server App
server_app = KafkaServerApp(
request_handler=logic_handler,
bootstrap_servers=bootstrap_servers,
request_topic=request_topic,
consumer_group_id=consumer_group_id,
**kafka_config
)
return server_app
Ce code configure les composants clés :
- L'exécuteur : fournit l'environnement d'exécution de l'agent (gestion de la mémoire, des identifiants, etc.).
- Task Store : suit l'état des requêtes lorsqu'elles passent de "En attente" à "Terminée".
- Agent Executor : prend une tâche de Kafka et la transmet à l'agent pour calculer les coordonnées.
- KafkaServerApp : gère la connexion physique à l'agent Kafka.
Configurer les variables d'environnement
La configuration ADK a créé un fichier .env contenant vos paramètres Google Vertex AI dans le dossier de l'agent. Nous devons le déplacer à la racine du projet et ajouter les coordonnées de notre cluster Kafka.
Exécutez les commandes suivantes pour copier le fichier et ajouter l'adresse du serveur Kafka :
cd $HOME/way-back-home/level_5
# 1. Copy the API keys from the agent folder to the project root
cp agent/formation/.env .env
# 2. Append the Kafka Bootstrap Server address to the file
echo -e "\nKAFKA_BOOTSTRAP_SERVERS=localhost:9092" >> .env
# 3. Verify the file content
echo "✅ Environment configured. Here are the last few lines:"
tail .env
Vérifier la boucle Interstellar A2A
Nous allons maintenant nous assurer que la boucle d'événements asynchrone fonctionne correctement en effectuant un test réel : nous allons envoyer un signal manuel via le cluster Kafka et observer la réponse de l'agent.
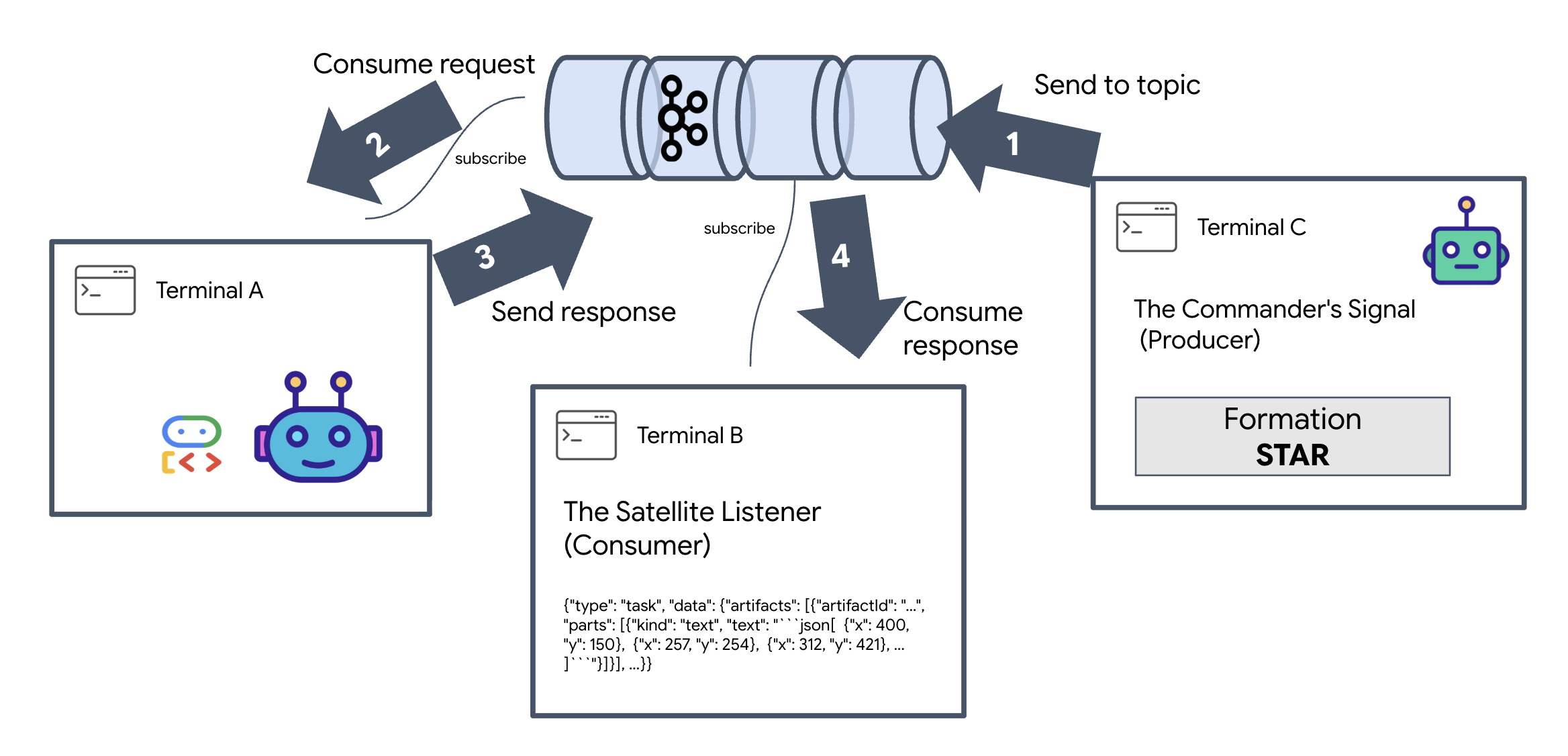
Pour voir le cycle de vie complet d'un événement, nous allons utiliser trois terminaux distincts.
Terminal A : agent de formation (serveur Kafka A2A)
👉💻 Ce terminal exécute le processus Python qui écoute Kafka et utilise Gemini pour effectuer les calculs géométriques.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Install the custom Kafka-enabled A2A library
uv pip install git+https://github.com/weimeilin79/a2a-python-kafka.git
# Start the Agent Server
uv run agent/server.py
Attendez de voir :
[INFO] Kafka Server App Started. Starting to consume requests...
Terminal B : l'écouteur satellite (consommateur)
👉💻 Dans ce terminal, nous allons écouter le sujet de réponse. Cela simule l'attente d'instructions par le satellite.
# Listen for the AI's response on the satellite channel
docker exec mission-kafka /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-reply-satellite-dashboard \
--from-beginning \
--property "print.headers=true"
Ce terminal apparaîtra comme inactif. Il attend que l'agent publie un message.
Terminal C : Le signal du commandant (producteur)
👉💻 Nous allons maintenant envoyer une requête brute au format A2A dans le sujet a2a-formation-request. Nous devons inclure des en-têtes Kafka spécifiques pour que l'agent sache où envoyer la réponse.
echo 'correlation_id=ping-manual-01,reply_topic=a2a-reply-satellite-dashboard|{"method": "message_send", "params": {"message": {"message_id": "msg-001", "role": "user", "parts": [{"text": "STAR"}]}}, "streaming": false, "agent_card": {"name": "DiagnosticTool", "version": "1.0.0"}}' | \
docker exec -i mission-kafka /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-formation-request \
--property "parse.headers=true" \
--property "headers.key.separator==" \
--property "headers.delimiter=|"
Analyser le résultat
👀 Si la boucle réussit, passez au Terminal B. Un grand bloc JSON devrait s'afficher instantanément. Il commencera par l'en-tête que nous avons envoyé, correlation_id:ping-manual-01. suivi d'un objet task. Si vous examinez attentivement la section parts de ce fichier JSON, vous verrez les coordonnées X et Y brutes que Gemini a calculées pour vos 15 pods :
{"type": "task", "data": {"artifacts": [{"artifactId": "...", "parts": [{"kind": "text", "text": "```json\n[\n {\"x\": 400, \"y\": 150},\n {\"x\": 257, \"y\": 254},\n {\"x\": 312, \"y\": 421},\n ... \n]\n```"}]}], ...}}
Vous avez bien dissocié l'agent du récepteur. Le "bruit interstellaire" de la latence des requêtes et des réponses n'a plus d'importance, car notre système est désormais entièrement piloté par les événements.
Avant de continuer, arrêtez les processus en arrière-plan pour libérer les ports réseau.
👉💻 Dans chaque terminal (A, B et C) :
- Appuyez sur
Ctrl + Cpour arrêter le processus en cours d'exécution.
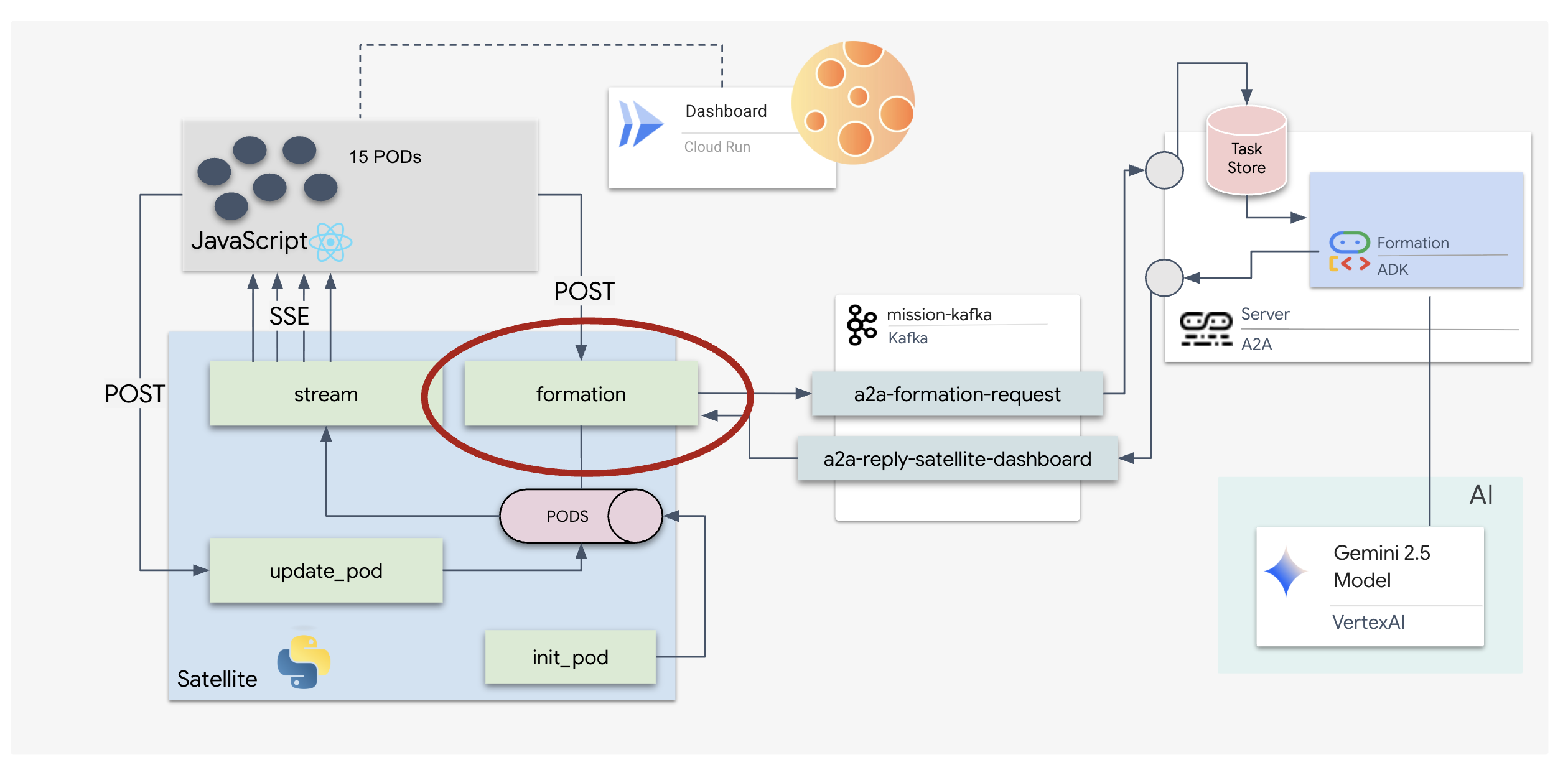
5. Station satellite (client Kafka A2A et SSE)
Au cours de cette étape, nous allons créer la station satellite. Il s'agit du pont entre le cluster Kafka et l'affichage visuel du pilote (le frontend React). Ce serveur agit à la fois en tant que client Kafka (pour communiquer avec l'agent) et en tant que streamer SSE (pour communiquer avec le navigateur).
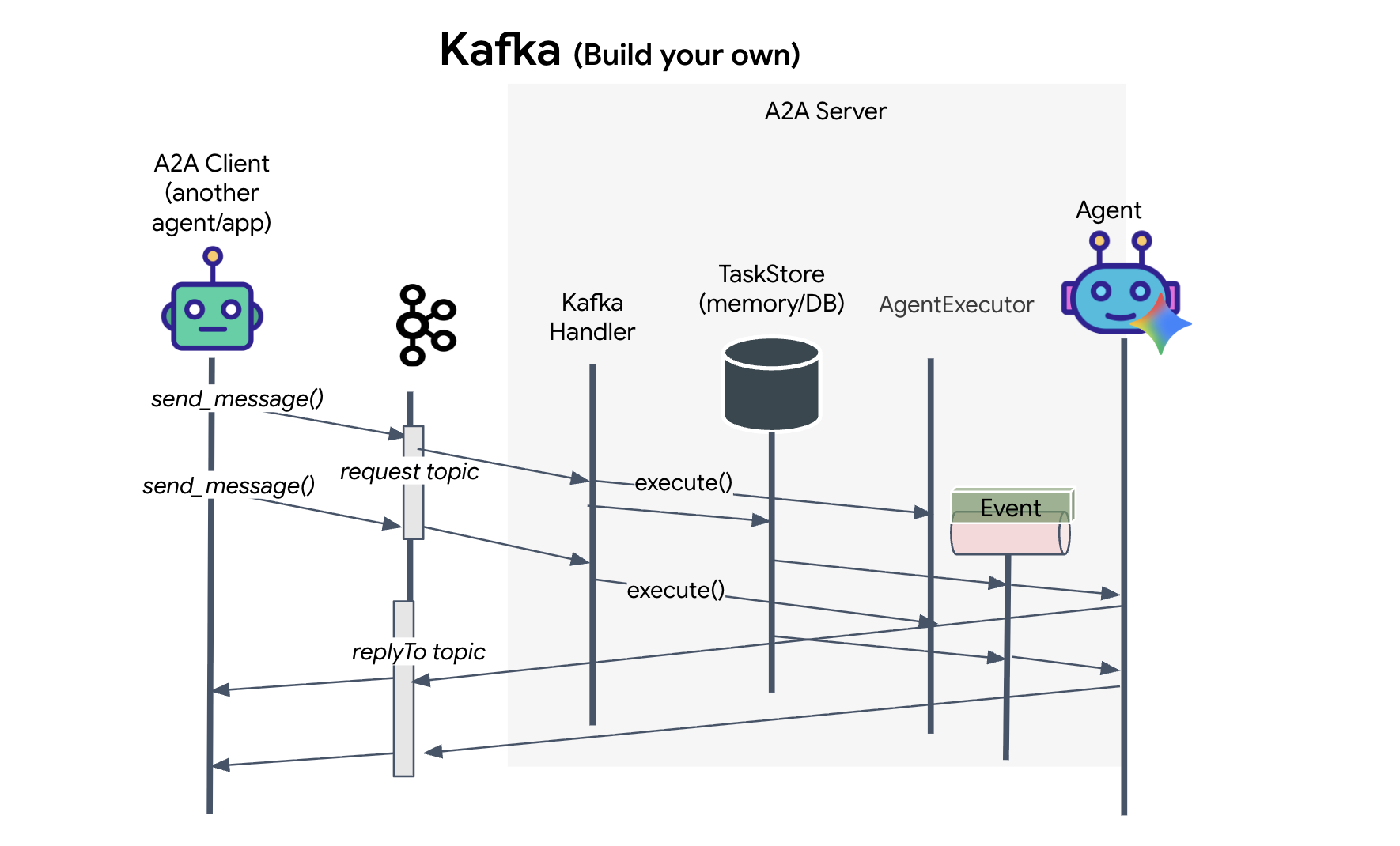
Qu'est-ce qu'un client Kafka ?
Considérez le cluster Kafka comme une station de radio. Un client Kafka est le récepteur radio. KafkaClientTransport permet à notre application de :
- Produire un message : envoyez une "tâche" (par exemple, "Formation d'étoiles") à l'agent.
- Consommer une réponse : écoutez un "sujet de réponse" spécifique pour récupérer les coordonnées de l'agent.
1. Initialiser la connexion
Nous utilisons le gestionnaire d'événements lifespan de FastAPI pour nous assurer que la connexion Kafka démarre au démarrage du serveur et se ferme correctement à son arrêt.
👉✏️ Dans $HOME/way-back-home/level_5/satellite/main.py, remplacez #REPLACE-CONNECT-TO-KAFKA-CLUSTER par le code suivant :
@asynccontextmanager
async def lifespan(app: FastAPI):
global kafka_transport
logger.info("Initializing Kafka Client Transport...")
bootstrap_server = os.getenv("KAFKA_BOOTSTRAP_SERVERS")
request_topic = "a2a-formation-request"
reply_topic = "a2a-reply-satellite-dashboard"
# Create AgentCard for the Client
client_card = AgentCard(
name="SatelliteDashboard",
description="Satellite Dashboard Client",
version="1.0.0",
url="https://example.com/satellite-dashboard",
capabilities=AgentCapabilities(),
default_input_modes=["text/plain"],
default_output_modes=["text/plain"],
skills=[]
)
kafka_transport = KafkaClientTransport(
agent_card=client_card,
bootstrap_servers=bootstrap_server,
request_topic=request_topic,
reply_topic=reply_topic,
)
try:
await kafka_transport.start()
logger.info("Kafka Client Transport Started Successfully.")
except Exception as e:
logger.error(f"Failed to start Kafka Client: {e}")
yield
if kafka_transport:
logger.info("Stopping Kafka Client Transport...")
await kafka_transport.stop()
logger.info("Kafka Client Transport Stopped.")
2. Envoyer une commande
Lorsque vous cliquez sur un bouton du tableau de bord, le point de terminaison /formation est déclenché. Il agit en tant que producteur, en encapsulant votre requête dans un Message A2A formel et en l'envoyant à l'agent.
Logique clé :
- Communication asynchrone :
kafka_transport.send_messageenvoie la requête et attend que les nouvelles coordonnées arrivent surreply_topic. - Analyse des réponses : Gemini peut renvoyer des coordonnées dans des blocs Markdown (par exemple,
json ...). Le code ci-dessous les supprime et convertit la chaîne en liste Python de points.
👉✏️ Dans $HOME/way-back-home/level_5/satellite/main.py, remplacez #REPLACE-FORMATION-REQUEST par le code suivant :
@app.post("/formation")
async def set_formation(req: FormationRequest):
global FORMATION, PODS
FORMATION = req.formation
logger.info(f"Received formation request: {FORMATION}")
if not kafka_transport:
logger.error("Kafka Transport is not initialized!")
return {"status": "error", "message": "Backend Not Connected"}
try:
# Construct A2A Message
prompt = f"Create a {FORMATION} formation"
logger.info(f"Sending A2A Message: '{prompt}'")
from a2a.types import TextPart, Part, Role
import uuid
msg_id = str(uuid.uuid4())
message_parts = [Part(TextPart(text=prompt))]
msg_obj = Message(
message_id=msg_id,
role=Role.user,
parts=message_parts
)
message_params = MessageSendParams(
message=msg_obj
)
# Send and Wait for Response
ctx = ClientCallContext()
ctx.state["kafka_timeout"] = 120.0 # Timeout for GenAI latency
response = await kafka_transport.send_message(message_params, context=ctx)
logger.info("Received A2A Response.")
content = None
if isinstance(response, Message):
content = response.parts[0].root.text if response.parts else None
elif isinstance(response, Task):
if response.artifacts and response.artifacts[0].parts:
content = response.artifacts[0].parts[0].root.text
if content:
logger.info(f"Response Content: {content[:100]}...")
try:
clean_content = content.replace("```json", "").replace("```", "").strip()
coords = json.loads(clean_content)
if isinstance(coords, list):
logger.info(f"Parsed {len(coords)} coordinates.")
for i, pod_target in enumerate(coords):
if i < len(PODS):
PODS[i]["x"] = pod_target["x"]
PODS[i]["y"] = pod_target["y"]
return {"status": "success", "formation": FORMATION}
else:
logger.error("Response JSON is not a list.")
except json.JSONDecodeError as e:
logger.error(f"Failed to parse Agent JSON response: {e}")
else:
logger.error(f"Could not extract content from response type {type(response)}")
except Exception as e:
logger.error(f"Error calling agent via Kafka: {e}")
return {"status": "error", "message": str(e)}
Événements envoyés par le serveur (SSE)
Les API standards utilisent un modèle "demande-réponse". Pour notre HUD, nous avons besoin d'un flux en direct des positions des pods.
Pourquoi utiliser SSE ? Contrairement aux WebSockets (qui sont bidirectionnels et plus complexes), SSE fournit un flux de données unidirectionnel simple du serveur au navigateur. Il est idéal pour les tableaux de bord, les tickers boursiers ou la télémétrie interstellaire.
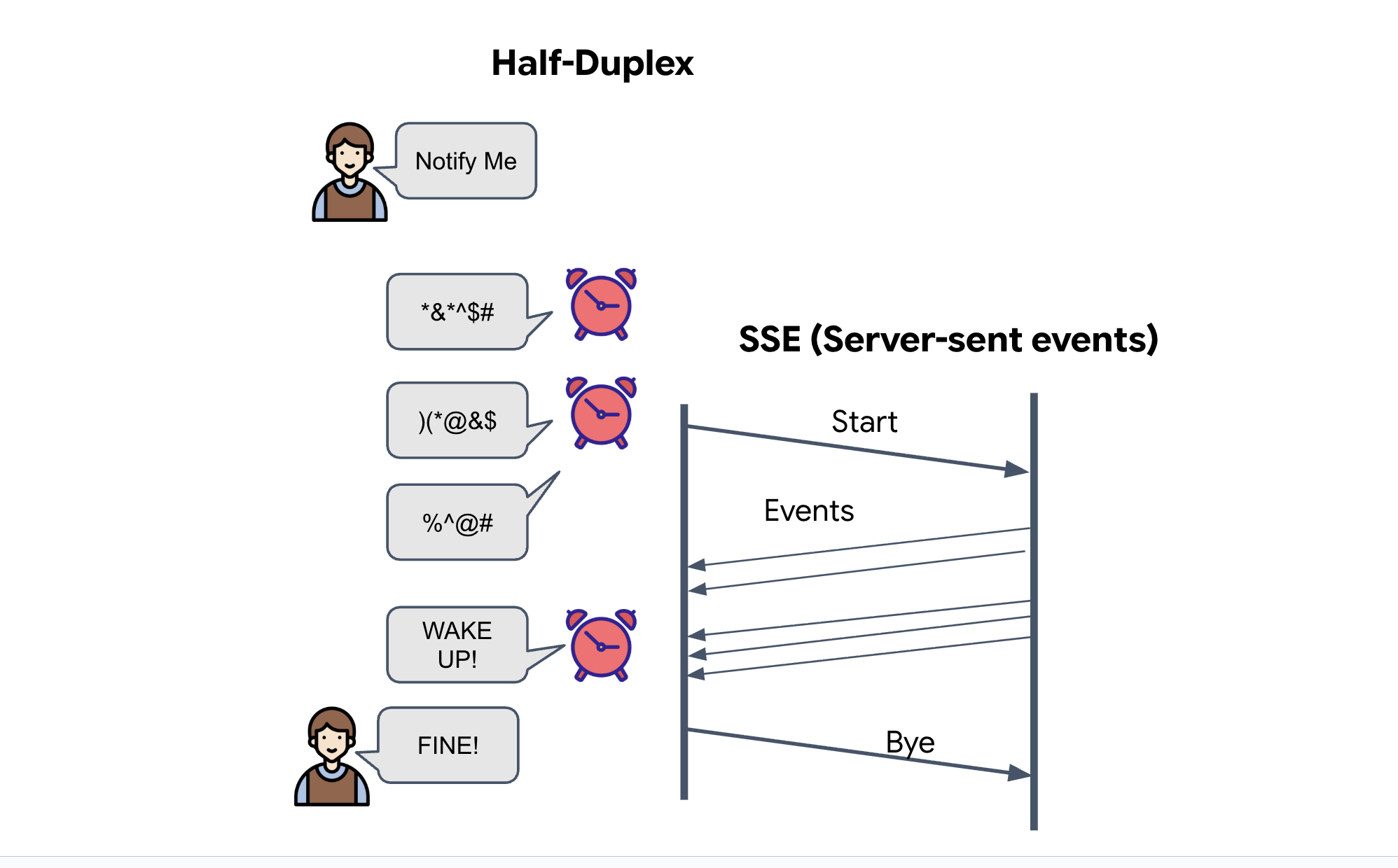
Fonctionnement dans notre code : nous créons un event_generator, une boucle sans fin qui prend la position actuelle des 15 pods toutes les demi-secondes et les "pousse" vers le navigateur en tant que mise à jour.
👉✏️ Dans $HOME/way-back-home/level_5/satellite/main.py, remplacez #REPLACE-SSE-STREAM par le code suivant :
@app.get("/stream")
async def message_stream(request: Request):
async def event_generator():
logger.info("New SSE stream connected")
try:
while True:
current_pods = list(PODS)
# Send updates one by one to simulate low-bandwidth scanning
for pod in current_pods:
payload = {"pod": pod}
yield {
"event": "pod_update",
"data": json.dumps(payload)
}
await asyncio.sleep(0.02)
# Send formation info occasionally
yield {
"event": "formation_update",
"data": json.dumps({"formation": FORMATION})
}
# Main loop delay
await asyncio.sleep(0.5)
except asyncio.CancelledError:
logger.info("SSE stream disconnected (cancelled)")
except Exception as e:
logger.error(f"SSE stream error: {e}")
return EventSourceResponse(event_generator())
Exécuter la boucle de mission complète
Vérifions que le système fonctionne de bout en bout avant de lancer l'UI finale. Nous allons déclencher manuellement l'agent et voir la charge utile des données brutes sur le réseau.
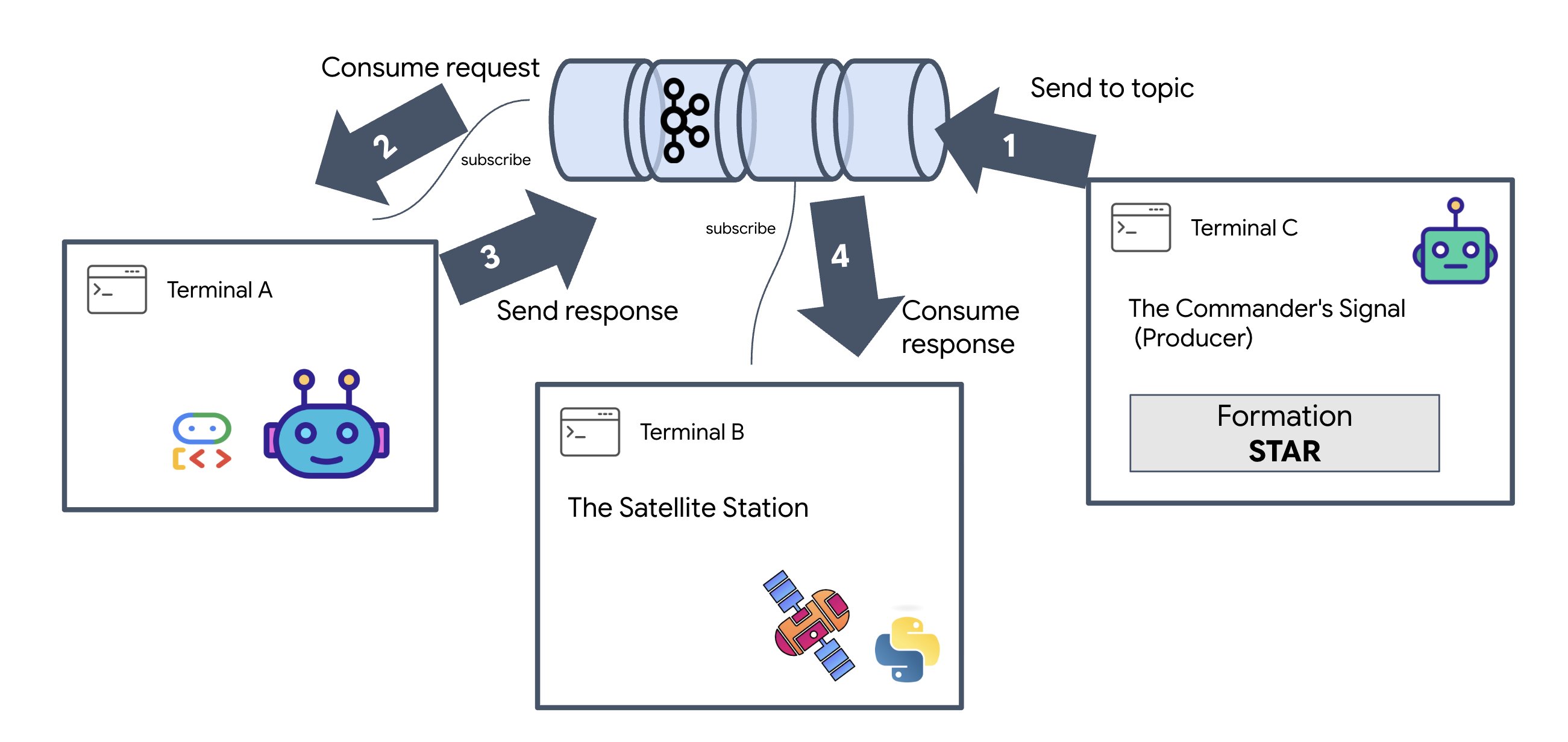
Ouvrez trois onglets de terminal distincts.
Terminal A : l'agent de formation (serveur A2A)
👉💻 Il s'agit de l'agent ADK qui écoute les tâches et effectue les calculs géométriques.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Agent Server
uv run agent/server.py
Terminal B : la station satellite (client Kafka)
👉💻 Ce serveur FastAPI agit en tant que "récepteur", en écoutant les réponses Kafka et en les transformant en flux SSE en direct.
cd $HOME/way-back-home/level_5
# Start the Satellite Station
uv run satellite/main.py
Terminal C : HUD manuel
Envoyer la commande de formation (déclencheur) : 👉💻 Dans le même terminal C, déclenchez le processus de formation :
# Trigger the STAR formation via the Satellite's API
curl -X POST http://localhost:8000/formation \
-H "Content-Type: application/json" \
-d '{"formation": "STAR"}'
👀 Les nouvelles coordonnées devraient s'afficher.
INFO:satellite.main:Received formation request: STAR INFO:satellite.main:Sending A2A Message: 'Create a STAR formation' INFO:satellite.main:Received A2A Response. INFO:satellite.main:Response Content: ```json ... INFO:satellite.main:Parsed 15 coordinates.
Cela confirme que le satellite a mis à jour les coordonnées de son pod interne.
👉💻 Nous allons utiliser curl pour écouter le flux de télémétrie en direct, puis déclencher un changement de formation.
# Connect to the live telemetry feed.
# You should see 'pod_update' events ticking by.
curl -N http://localhost:8000/stream
👀 Examinez le résultat de votre commande curl -N. Les coordonnées x et y dans les événements pod_update commenceront à refléter les nouvelles positions de la formation Star.
Avant de continuer, arrêtez tous les processus en cours d'exécution pour libérer les ports de communication.
Dans chaque terminal (A, B, C et le terminal de déclenchement), appuyez sur Ctrl + C.
6. Go Rescue !
Vous avez correctement configuré le système. Il est maintenant temps de donner vie à la mission. Nous allons maintenant lancer l'affichage tête haute (HUD) basé sur React. Ce tableau de bord se connecte à la station satellite via SSE, ce qui vous permet de visualiser les 15 pods en temps réel.
Lorsque vous émettez une commande, vous n'appelez pas seulement une fonction. Vous déclenchez un événement qui transite par Kafka, est traité par un agent d'IA et est renvoyé sur votre écran sous forme de télémétrie en direct.
Ouvrez deux onglets de terminal distincts.
Terminal A : l'agent de formation (serveur A2A)
👉💻 Il s'agit de l'agent ADK qui écoute les tâches et effectue des calculs géométriques à l'aide de Gemini. Dans le terminal, exécutez la commande suivante :
cd $HOME/way-back-home/level_5
# Start the Agent Server
uv run agent/server.py
Terminal B : la station satellite et le tableau de bord visuel
👉💻 Commencez par créer l'application d'interface.
cd $HOME/way-back-home/level_5/frontend/
npm install
npm run build
👉💻 Démarrez maintenant le serveur FastAPI, qui servira à la fois la logique de backend et l'UI de frontend.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Satellite Station
uv run satellite/main.py
Lancer et valider
- 👉 Ouvrez l'aperçu : dans la barre d'outils Cloud Shell, cliquez sur l'icône Aperçu sur le Web. Sélectionnez Modifier le port, définissez-le sur 8000, puis cliquez sur Modifier et prévisualiser. Un nouvel onglet de navigateur s'ouvre et affiche votre HUD Starfield.
- 👉 Vérifier le flux de télémétrie :
- Une fois l'UI chargée, vous devriez voir 15 pods dispersés de manière aléatoire.
- Si les pods pulsent légèrement ou "tremblent", votre flux SSE est actif et la station satellite diffuse correctement ses positions.

- 👉 Lancer une formation : cliquez sur le bouton STAR du tableau de bord.

- 👀 Suivez la boucle d'événements : regardez vos terminaux pour voir l'architecture en action :
- Terminal B (gare satellite) enregistrera :
Sending A2A Message: 'Create a STAR formation'. - L'agent de formation du terminal A affichera l'activité lorsqu'il consultera Gemini.
- Le terminal B (station satellite) enregistre
Received A2A Responseet analyse les coordonnées.
- Terminal B (gare satellite) enregistrera :
- 👀 Confirmation visuelle : regardez les 15 pods de votre tableau de bord passer en douceur de leur position aléatoire à une formation en étoile à cinq branches.
- 👉 Expérience :
- Pour trois formations différentes, essayez X ou LINE.

- Intention personnalisée : saisissez manuellement un élément unique, comme Cœur ou Triangle.

- Comme vous utilisez l'IA générative, l'agent tentera de calculer les valeurs mathématiques de n'importe quelle forme géométrique que vous pourrez décrire.
- Pour trois formations différentes, essayez X ou LINE.
Une fois que vous avez formé trois motifs, la connexion est rétablie. 
MISSION ACCOMPLIE !
Le flux se stabilise à mesure que les données traversent le bruit sans interruption. Sous vos ordres, les 15 capsules antiques commencent leur danse synchronisée à travers les étoiles.

Au cours de trois phases de calibration exténuantes, vous avez vu la télémétrie se verrouiller. À chaque alignement, le signal devenait plus fort, finissant par percer les interférences interstellaires comme un phare d'espoir.
Grâce à vous et à votre implémentation magistrale de l'agent événementiel, les cinq survivants ont été héliportés depuis la surface de X-42 et sont désormais en sécurité à bord du navire de sauvetage. Grâce à vous, cinq vies ont été sauvées.
Si vous avez participé au niveau 0, n'oubliez pas de vérifier votre progression dans la mission "Retour à la maison" ! Votre voyage de retour vers les étoiles continue.