1. La missione

Stai vagando nel silenzio di un settore inesplorato. Un'enorme pulsazione solare ha squarciato la tua nave attraverso una spaccatura, lasciandoti bloccato in una zona dell'universo che non esiste in nessuna carta stellare.
Dopo giorni di riparazioni estenuanti, finalmente senti il rombo dei motori sotto i piedi. Il tuo razzo è stato riparato. Sei persino riuscito a stabilire un collegamento uplink a lungo raggio con la nave madre. Il volo può partire. Puoi tornare a casa.
Mentre ti prepari a inserire la chiavetta, un segnale di soccorso interrompe la statica. I sensori rilevano un segnale di richiesta di aiuto. Cinque civili sono intrappolati sulla superficie del pianeta X-42. La loro unica speranza di fuga si basa su 15 antiche capsule che devono essere sincronizzate per trasmettere un segnale di soccorso alla loro astronave madre in orbita.
Tuttavia, i pod sono controllati da una stazione satellitare il cui computer di navigazione principale è danneggiato. I pod vagano senza meta. Siamo riusciti a stabilire una connessione backdoor con il satellite, ma l'uplink è afflitto da gravi interferenze interstellari, che causano una latenza elevata nei cicli richiesta-risposta.
La sfida
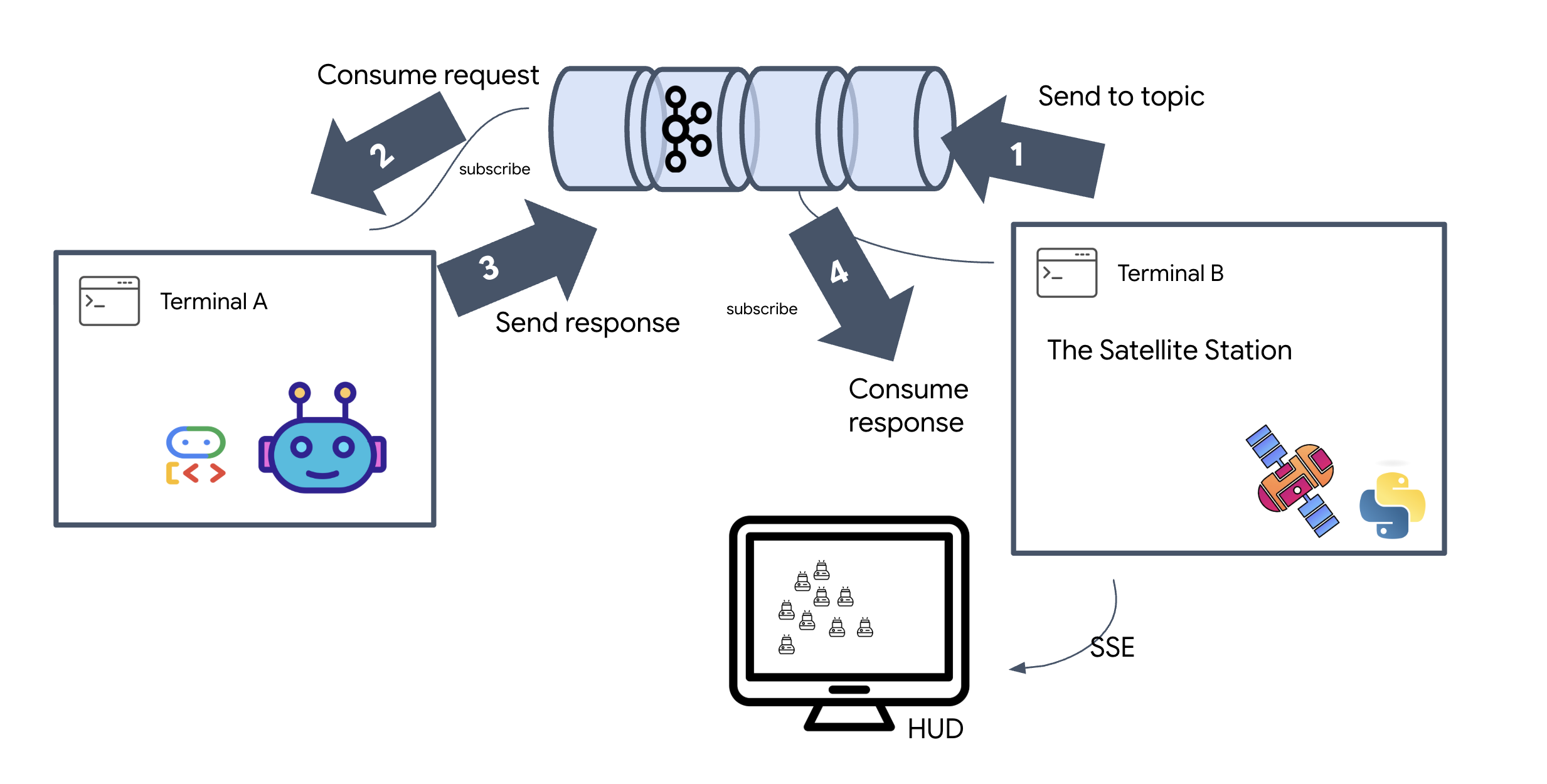
Poiché un modello di richiesta/risposta è troppo lento, dobbiamo implementare un'architettura basata su eventi (EDA) con Server-Sent Events (SSE) per trasmettere in streaming la telemetria attraverso il rumore.
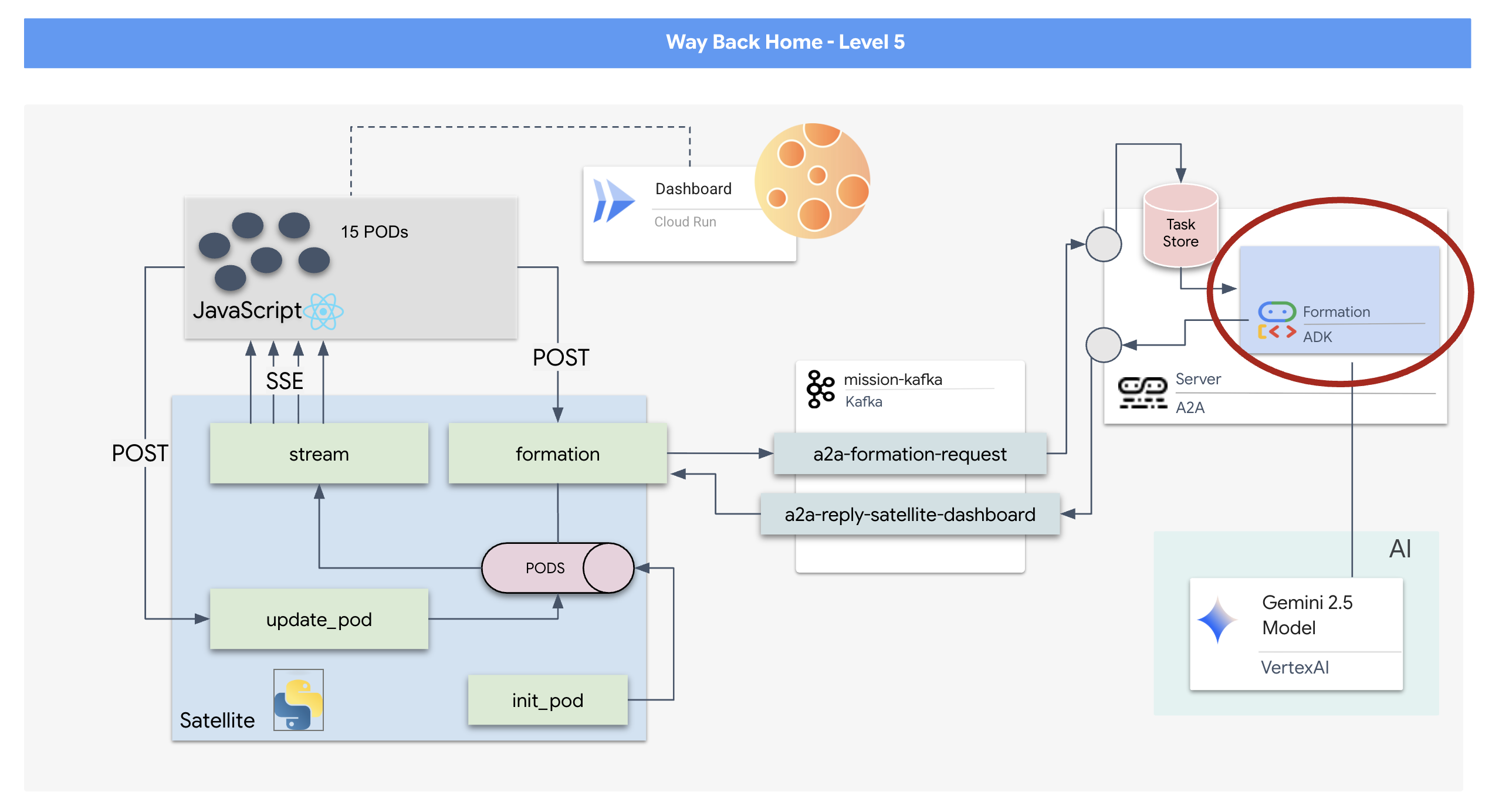
Dovrai creare un agente personalizzato in grado di calcolare la matematica vettoriale complessa necessaria per forzare i pod in formazioni specifiche di potenziamento del segnale (cerchio, stella, linea). Devi collegare questo agente alla nuova architettura del satellite.
Cosa creerai
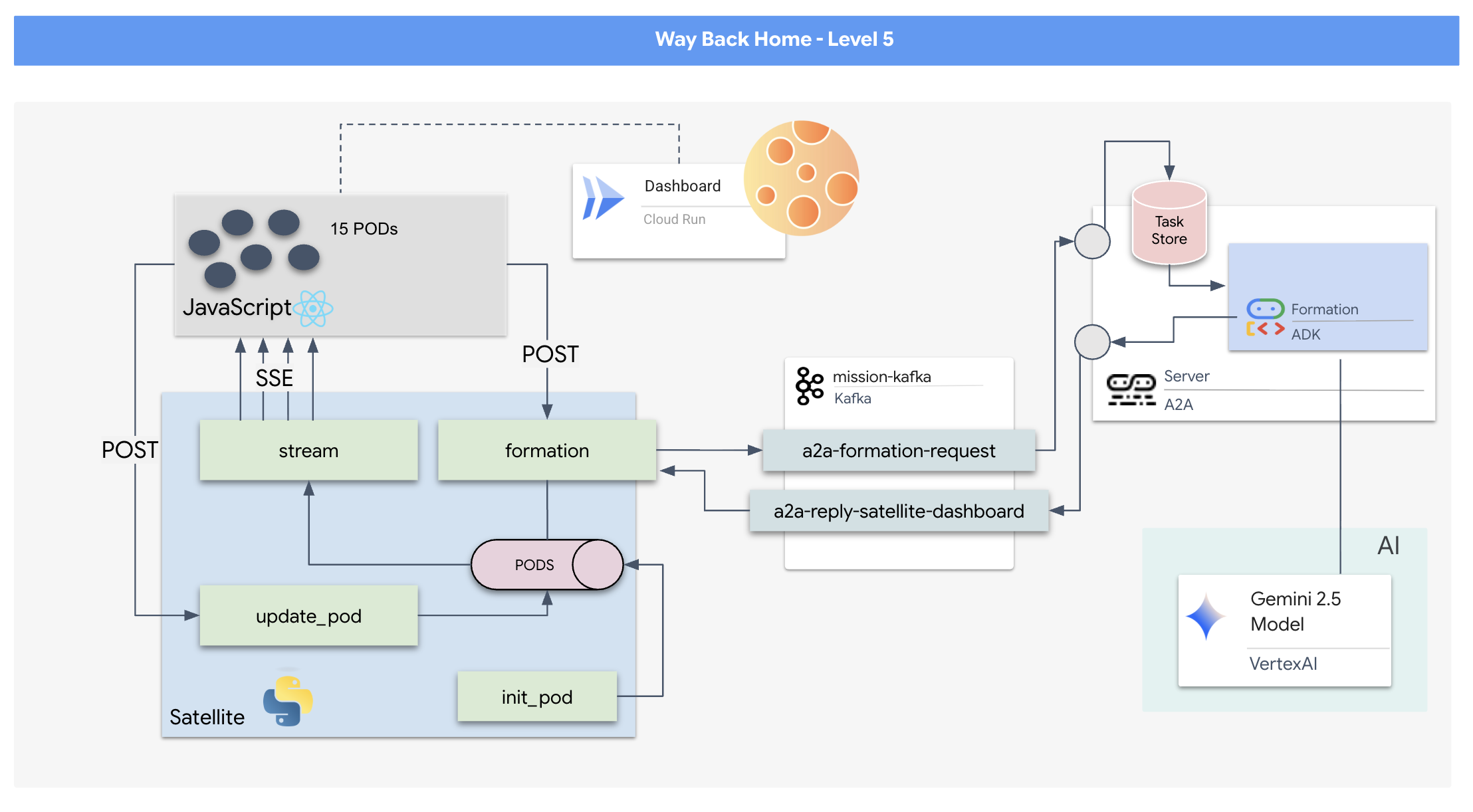
- Una visualizzazione in tempo reale basata su React per visualizzare e controllare una flotta di 15 pod.
- Un agente di AI generativa che utilizza Google Agent Development Kit (ADK) e calcola formazioni geometriche complesse per i pod in base a comandi in linguaggio naturale.
- Un backend Satellite Station basato su Python che funge da hub centrale e comunica con il frontend tramite Server-Sent Events (SSE).
- Un'architettura basata sugli eventi che utilizza Apache Kafka per disaccoppiare l'agente AI dal sistema di controllo satellitare, consentendo una comunicazione resiliente e asincrona.
Cosa imparerai a fare
Tecnologia / Concept | Descrizione |
Google ADK (Agent Development Kit) | Utilizzerai questo framework per creare, testare e strutturare un agente AI specializzato basato sui modelli Gemini. |
Architettura basata su eventi (EDA) | Imparerai i principi di creazione di un sistema disaccoppiato in cui i componenti comunicano in modo asincrono tramite eventi, rendendo l'applicazione più resiliente e scalabile. |
Apache Kafka | Configurerai e utilizzerai Kafka come piattaforma di streaming di eventi distribuita per gestire il flusso di comandi e dati tra diversi microservizi. |
Server-Sent Events (SSE) | Implementerai SSE in un backend FastAPI per inviare dati di telemetria in tempo reale dal server al frontend React, mantenendo l'interfaccia utente costantemente aggiornata. |
Protocollo A2A (Agent-to-Agent) | Scoprirai come racchiudere il tuo agente in un server A2A, consentendo la comunicazione e l'interoperabilità standardizzate all'interno di un ecosistema agentico più ampio. |
FastAPI | Creerai il servizio di backend principale, la stazione satellitare, utilizzando questo framework web Python ad alte prestazioni. |
Reagisci | Lavorerai con un'applicazione frontend moderna che si iscrive a un flusso SSE per creare un'interfaccia utente dinamica e interattiva. |
AI generativa in Controllo del sistema | Vedrai come è possibile richiedere a un modello linguistico di grandi dimensioni (LLM) di eseguire attività specifiche e orientate ai dati (come la generazione di coordinate) anziché semplicemente una chat conversazionale. |
2. Configura l'ambiente
Accedere a Cloud Shell
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro di Cloud Shell), 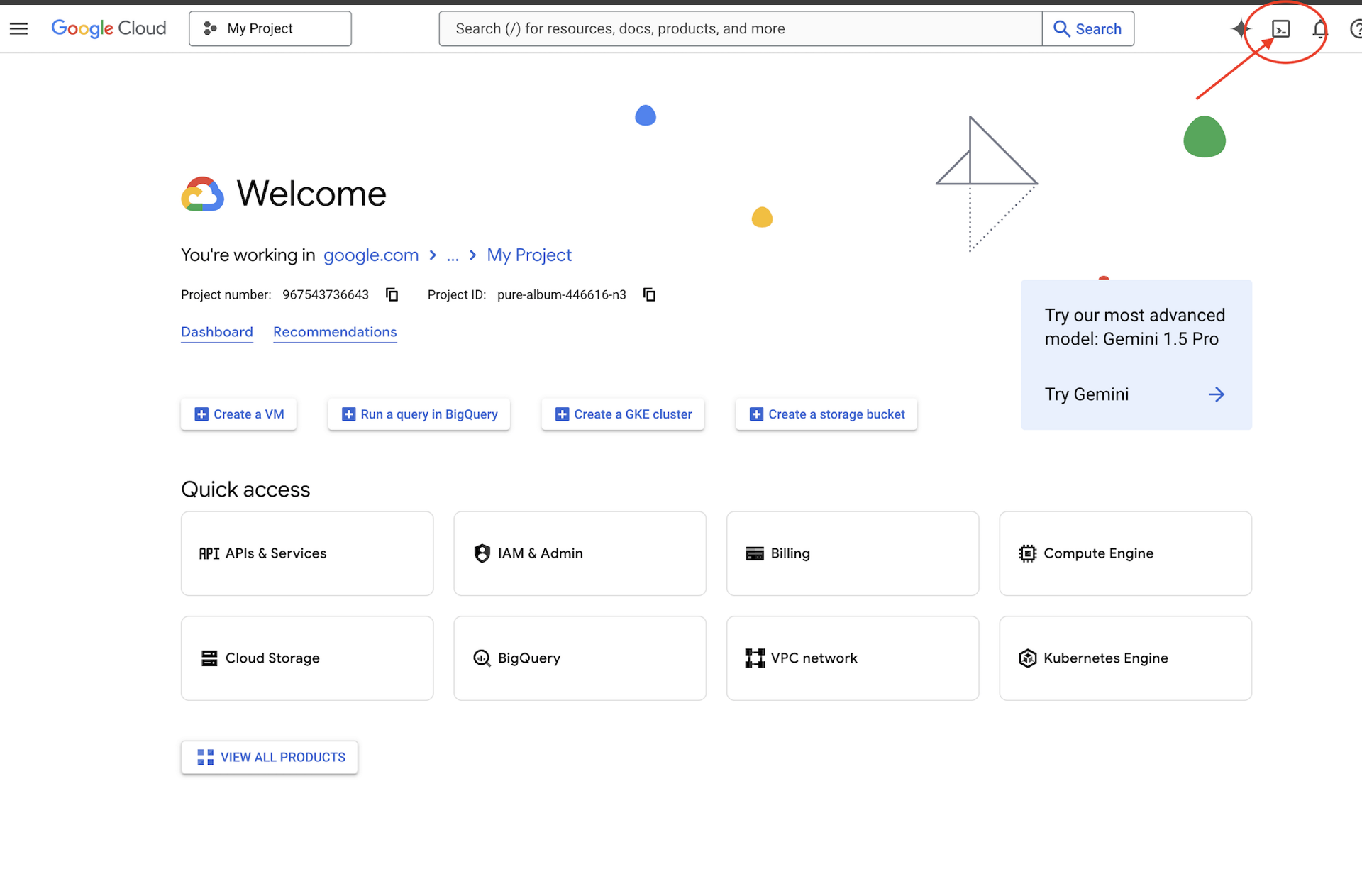
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro. 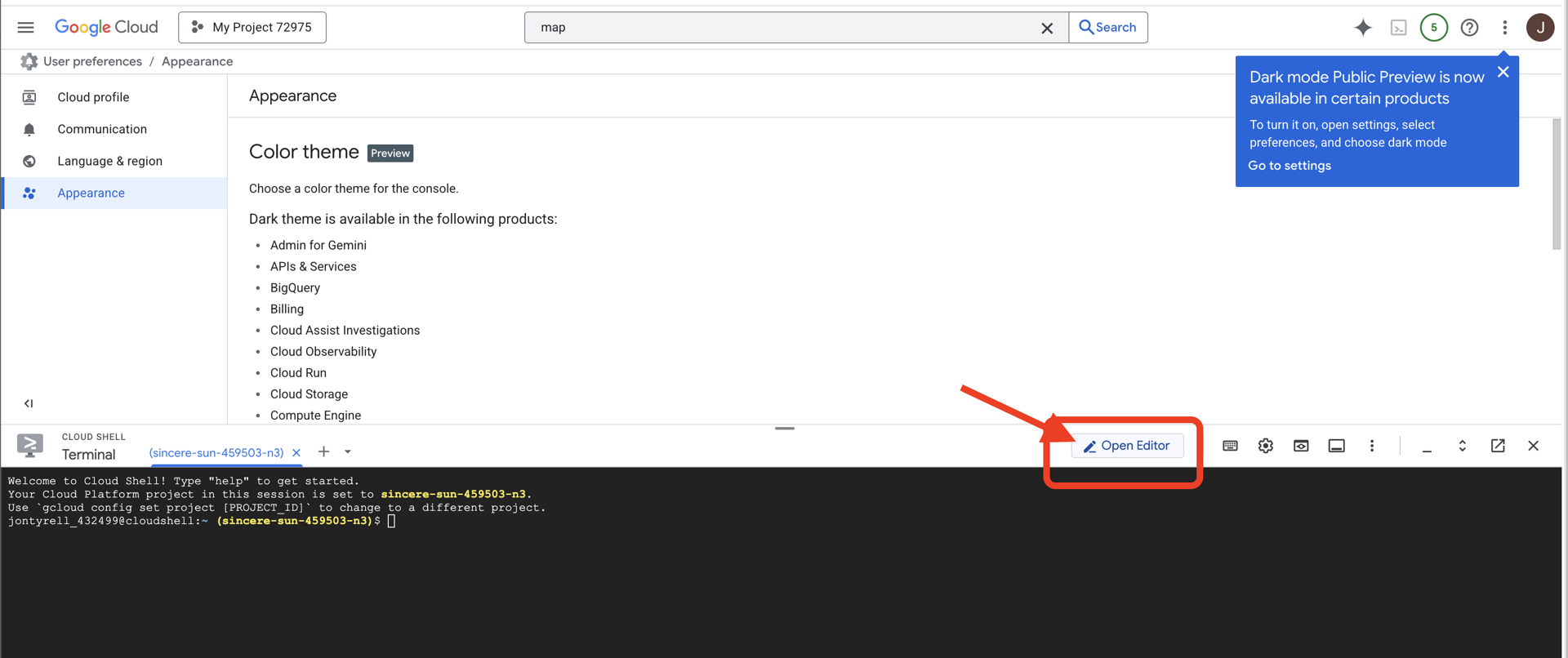
👉 Apri il terminale nell'IDE cloud.
👉💻 Nel terminale, verifica di aver già eseguito l'autenticazione e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
Dovresti vedere il tuo account elencato come (ACTIVE).
Prerequisiti
ℹ️ Il livello 0 è facoltativo (ma consigliato)
Puoi completare questa missione senza il livello 0, ma terminarla per prima offre un'esperienza più coinvolgente, che ti consente di vedere il tuo faro illuminarsi sulla mappa globale man mano che avanzi.
Configurare l'ambiente del progetto
Torna al terminale e finalizza la configurazione impostando il progetto attivo e abilitando i servizi Google Cloud richiesti (Cloud Run, Vertex AI e così via).
👉💻 Nel terminale, imposta l'ID progetto:
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 Attiva i servizi richiesti:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
Installa le dipendenze
👉💻 Vai al livello 5 e installa i pacchetti Python richiesti:
cd $HOME/way-back-home/level_5
uv sync
Le dipendenze principali sono:
Pacchetto | Finalità |
| Framework web ad alte prestazioni per lo streaming di Satellite Station ed SSE |
| Server ASGI richiesto per eseguire l'applicazione FastAPI |
| Agent Development Kit utilizzato per creare l'agente di formazione |
| Libreria di protocolli Agent-to-Agent per la comunicazione standardizzata |
| Client Kafka asincrono per il ciclo di eventi |
| Client nativo per l'accesso ai modelli Gemini |
| Calcoli vettoriali e di coordinate per la simulazione |
| Supporto per la comunicazione bidirezionale in tempo reale |
| Gestisce le variabili di ambiente e i secret di configurazione |
| Gestione efficiente di Server-Sent Events (SSE) |
| Libreria HTTP semplice per chiamate API esterne |
Verifica la configurazione
Prima di addentrarci nel codice, assicuriamoci che tutti i sistemi siano attivi. Esegui lo script di verifica per controllare il tuo progetto Google Cloud, le API e le dipendenze Python.
👉💻 Esegui lo script di verifica:
cd $HOME/way-back-home/level_5/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 Dovresti vedere una serie di segni di spunta verdi (✅).
- Se vedi croci rosse (❌), segui i comandi di correzione suggeriti nell'output (ad es.
gcloud services enable ...opip install ...). - Nota:per il momento è accettabile un avviso giallo per
.env. Creeremo questo file nel passaggio successivo.
🚀 Verifying Mission Charlie (Level 5) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. Formattazione delle posizioni dei pod con un LLM
Dobbiamo costruire il "cervello" della nostra operazione di salvataggio. Si tratta di un agente creato utilizzando Google ADK (Agent Development Kit). Il suo unico scopo è quello di fungere da navigatore geometrico specializzato. Mentre gli LLM standard amano chattare, nello spazio profondo abbiamo bisogno di dati, non di dialoghi. Programmeremo questo agente per ricevere un comando come "Stella" e restituire le coordinate JSON non elaborate per i nostri 15 pod.
Impalcatura dell'agente
👉💻 Esegui i seguenti comandi per passare alla directory dell'agente e avviare la procedura guidata di creazione dell'ADK:
cd $HOME/way-back-home/level_5/agent
uv run adk create formation
L'interfaccia a riga di comando avvierà una procedura guidata di configurazione interattiva. Utilizza le seguenti risposte per configurare l'agente:
- Scegli un modello: seleziona Opzione 1 (Gemini Flash).
- Nota: la versione specifica può variare. Scegli sempre la variante "Flash" per la velocità.
- Scegli un backend: seleziona Opzione 2 (Vertex AI).
- Inserisci l'ID progetto Google Cloud: premi Invio per accettare il valore predefinito (rilevato dal tuo ambiente).
- Enter Google Cloud Region (Inserisci la regione Google Cloud): premi Invio per accettare il valore predefinito (
us-central1).
👀 L'interazione con il terminale dovrebbe essere simile a questa:
(way-back-home) user@cloudshell:~/way-back-home/level_5/agent$ adk create formation Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_5/agent/formation: - .env - __init__.py - agent.py
Dovresti visualizzare un messaggio di operazione riuscita Agent created. Viene generato il codice di base che ora modificheremo.
👉✏️ Vai al file $HOME/way-back-home/level_5/agent/formation/agent.py appena creato e aprilo nell'editor. Sostituisci l'intero contenuto del file con il codice riportato di seguito. Aggiorna il nome dell'agente e fornisce i suoi parametri operativi rigorosi.
import os
from google.adk.agents import Agent
root_agent = Agent(
name="formation_agent",
model="gemini-2.5-flash",
instruction="""
You are the **Formation Controller AI**.
Your strict objective is to calculate X,Y coordinates for a fleet of **15 Drones** based on a requested geometric shape.
### FIELD SPECIFICATIONS
- **Canvas Size**: 800px (width) x 600px (height).
- **Safe Margin**: Keep pods at least 50px away from edges (x: 50-750, y: 50-550).
- **Center Point**: x=400, y=300 (Use this as the origin for shapes).
- **Top Menu Avoidance**: Do NOT place pods in the top 100px (y < 100) to avoid UI overlap.
### FORMATION RULES
When given a formation name, output coordinates for exactly 15 pods (IDs 0-14).
1. **CIRCLE**: Evenly spaced around a center point (R=200).
2. **STAR**: 5 points or a star-like distribution.
3. **X**: A large X crossing the screen.
4. **LINE**: A horizontal line across the middle.
5. **PARABOLA**: A U-shape opening UPWARDS. Center it at y=400, opening up to y=100. IMPORTANT: Lowest point must be at bottom (high Y value), opening up (low Y value). Screen coordinates have (0,0) at the TOP-LEFT. The vertex should be at the BOTTOM (e.g., y=500), with arms reaching up to y=200.
6. **RANDOM**: Scatter randomly within safe bounds.
7. **CUSTOM**: If the user inputs something else (e.g., "SMILEY", "TRIANGLE"), do your best to approximate it geometrically.
### OUTPUT FORMAT
You MUST output **ONLY VALID JSON**. No markdown fencing, no preamble, no commentary.
Refuse to answer non-formation questions.
**JSON Structure**:
```json
[
{"x": 400, "y": 300},
{"x": 420, "y": 300},
... (15 total items)
]
```
"""
)
- Precisione geometrica: definendo le dimensioni del canvas e i margini sicuri nel prompt di sistema, ci assicuriamo che l'agente non posizioni i pod fuori dallo schermo o sotto gli elementi dell'interfaccia utente.
- Applicazione di JSON: se chiediamo al LLM di "Rifiutarsi di rispondere a domande non formative" e di fornire "Nessun preambolo", ci assicuriamo che il nostro codice downstream (il satellite) non si arresti in modo anomalo quando tenta di analizzare la risposta.
- Logica disaccoppiata: questo agente non conosce ancora Kafka. Sa solo fare matematica. Nel passaggio successivo, inseriremo questo "cervello" in un server Kafka.
Testare l'agente localmente
Prima di connettere l'agente al "sistema nervoso" Kafka, dobbiamo assicurarci che funzioni correttamente. Puoi interagire direttamente con l'agente nel terminale per verificare che produca coordinate JSON valide.
👉💻 Utilizza il comando adk run per avviare una sessione di chat con l'agente.
cd $HOME/way-back-home/level_5/agent
uv run adk run formation
- Input: digita
Circlee premi Invio.- Criteri di successo: dovresti visualizzare un elenco JSON non elaborato (ad es.
[{"x": 400, "y": 200}, ...]). Assicurati che prima del JSON non ci sia testo in formato Markdown come "Ecco le coordinate:".
- Criteri di successo: dovresti visualizzare un elenco JSON non elaborato (ad es.
- Input: digita
Linee premi Invio.- Criteri di riuscita: verifica che le coordinate creino una linea orizzontale (i valori di y devono essere simili).
Una volta confermato che l'output dell'agente è un JSON pulito, puoi racchiuderlo nel server Kafka.
👉💻 Premi Ctrl+C per uscire.
4. Creazione di un server A2A per l'agente di formazione
Informazioni su A2A (Agent-to-Agent)
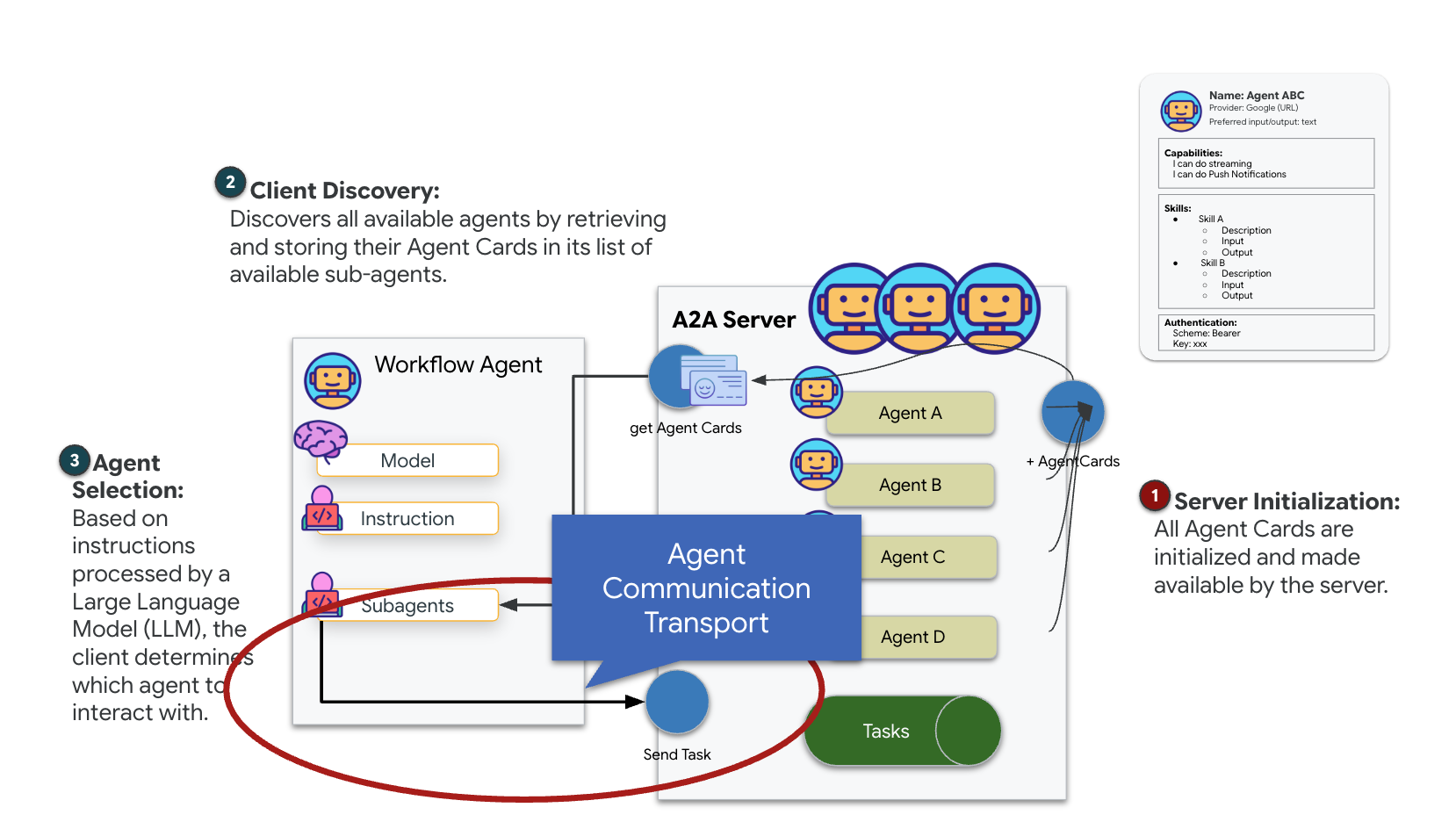
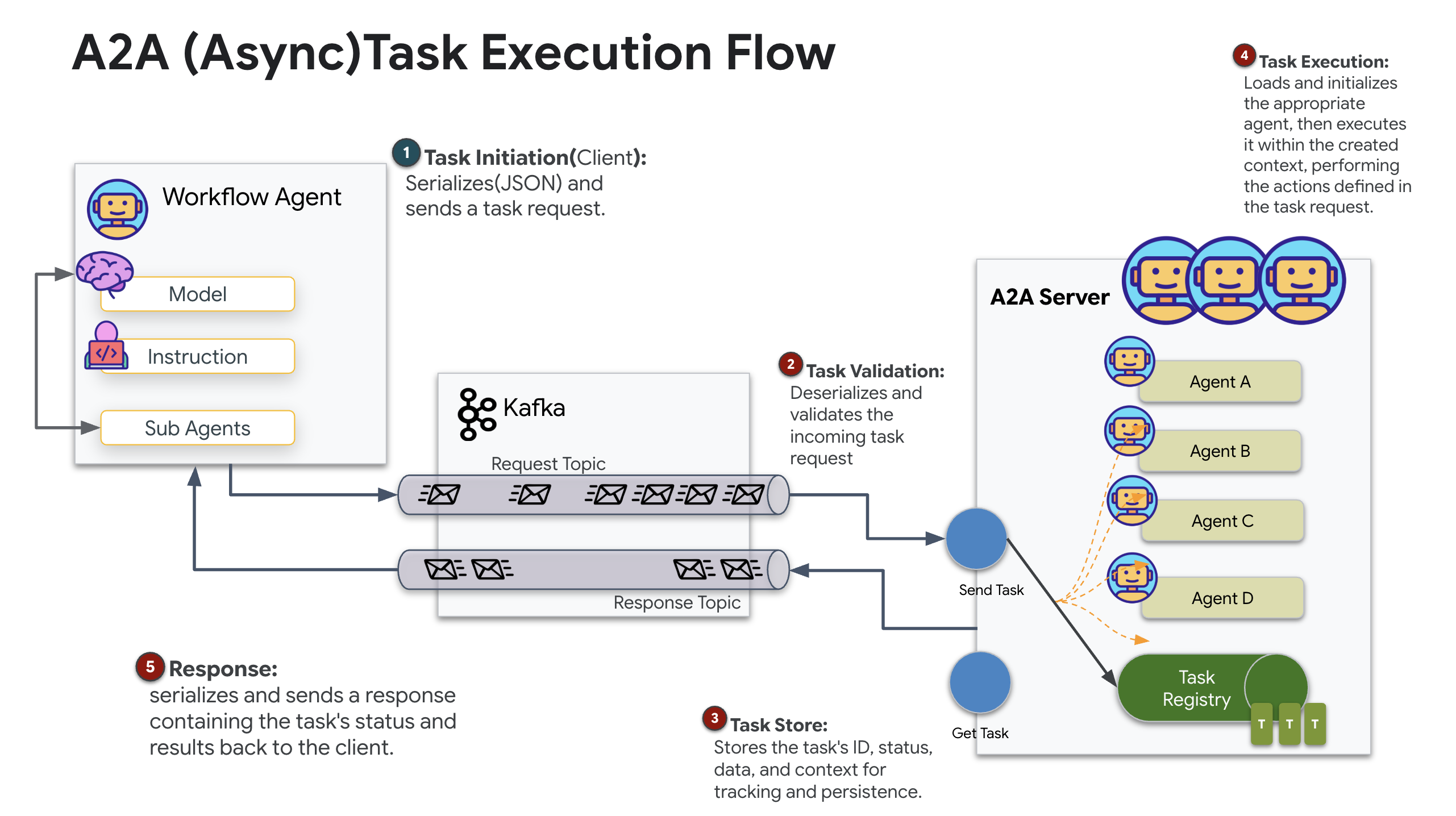
Il protocollo A2A (Agent-to-Agent) è uno standard aperto progettato per consentire un'interoperabilità perfetta tra gli agenti AI. Questo framework consente agli agenti di andare oltre il semplice scambio di testo, consentendo loro di delegare attività, coordinare azioni complesse e funzionare come un'unità coesa per raggiungere obiettivi condivisi in un ecosistema distribuito.
Informazioni sui trasporti A2A: HTTP, gRPC e Kafka
Il protocollo A2A offre due modi distinti per la comunicazione tra client e agenti, ognuno dei quali soddisfa esigenze architetturali diverse. HTTP (JSON-RPC) è lo standard predefinito e ubiquo che funziona universalmente in tutti gli ambienti web. gRPC è la nostra opzione ad alte prestazioni, che sfrutta i buffer di protocollo per una comunicazione efficiente e rigorosamente tipizzata. Nel lab fornisco anche un trasporto Kafka. Si tratta di un'implementazione personalizzata progettata per architetture robuste basate su eventi in cui il disaccoppiamento dei sistemi è una priorità.
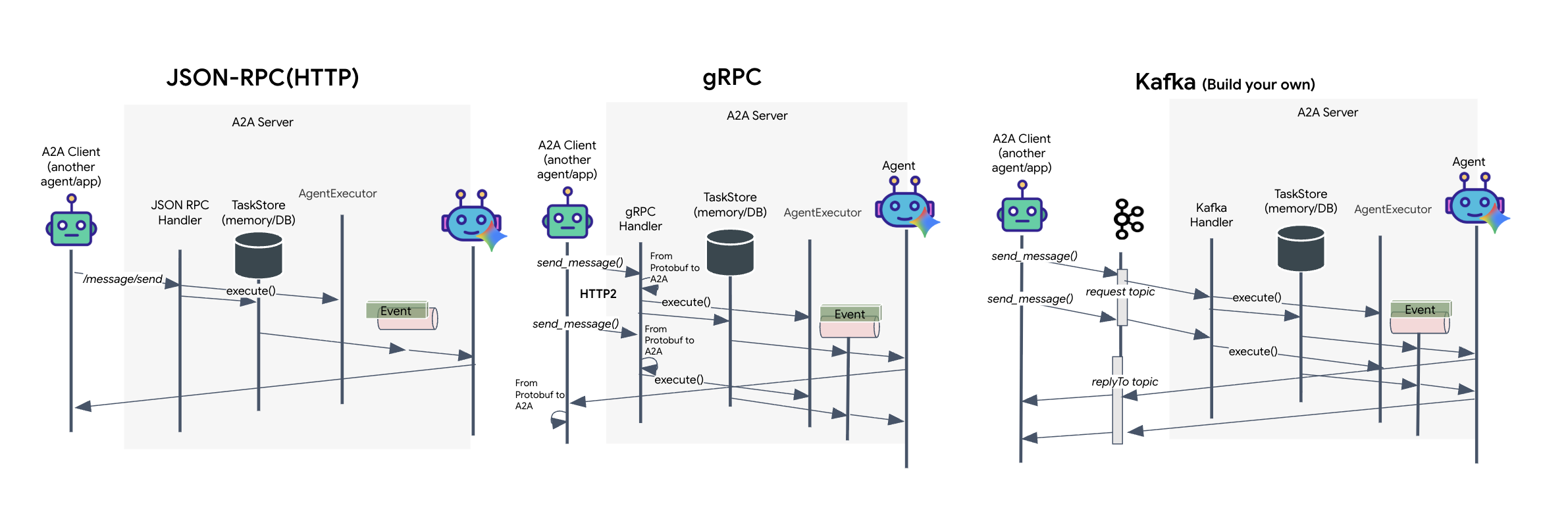
A livello interno, questi trasporti gestiscono il flusso di dati in modo molto diverso. Nel modello HTTP, il client invia una richiesta JSON e mantiene aperta la connessione, in attesa che l'agente completi la sua attività e restituisca il risultato completo in una sola volta. gRPC ottimizza questo processo utilizzando dati binari e HTTP/2, consentendo sia cicli di richiesta-risposta semplici sia lo streaming in tempo reale in cui l'agente invia aggiornamenti (come "pensiero" o "artefatto creato") man mano che si verificano. L'implementazione di Kafka funziona in modo asincrono: il client pubblica una richiesta in un "argomento di richiesta" altamente durevole e ascolta un "argomento di risposta" separato. Il server recupera il messaggio quando può, lo elabora e pubblica il risultato, il che significa che i due non comunicano mai direttamente tra loro.
La scelta dipende dai tuoi requisiti specifici in termini di velocità, complessità e persistenza. HTTP è il protocollo più semplice da utilizzare e da eseguire il debug, il che lo rende perfetto per le integrazioni semplici. gRPC è la scelta migliore per la comunicazione interna tra servizi in cui sono fondamentali la bassa latenza e gli aggiornamenti delle attività di streaming. Tuttavia, Kafka si distingue come la scelta resiliente, perché archivia le richieste su disco in una coda. Le tue attività sopravvivono anche se il server dell'agente si arresta in modo anomalo o viene riavviato, fornendo un livello di durabilità e disaccoppiamento che né HTTP né gRPC possono offrire.
Livello di trasporto personalizzato: Kafka
Kafka funge da spina dorsale asincrona che disaccoppia il cervello dell'operazione (Formation Agent) dai controlli fisici (la stazione satellitare). Anziché forzare il sistema ad attendere una connessione sincrona mentre l'agente calcola vettori complessi, l'agente pubblica i risultati come eventi in un argomento Kafka. Funziona come un buffer persistente, consentendo al satellite di utilizzare le istruzioni al proprio ritmo e garantendo che i dati di formazione non vengano mai persi, anche in caso di latenza di rete significativa o arresto anomalo temporaneo del sistema.
Utilizzando Kafka, trasformi un processo lento e lineare in una pipeline di streaming resiliente in cui le istruzioni e la telemetria scorrono in modo indipendente, mantenendo reattivo l'HUD della missione anche durante l'elaborazione con l'AI intensa.
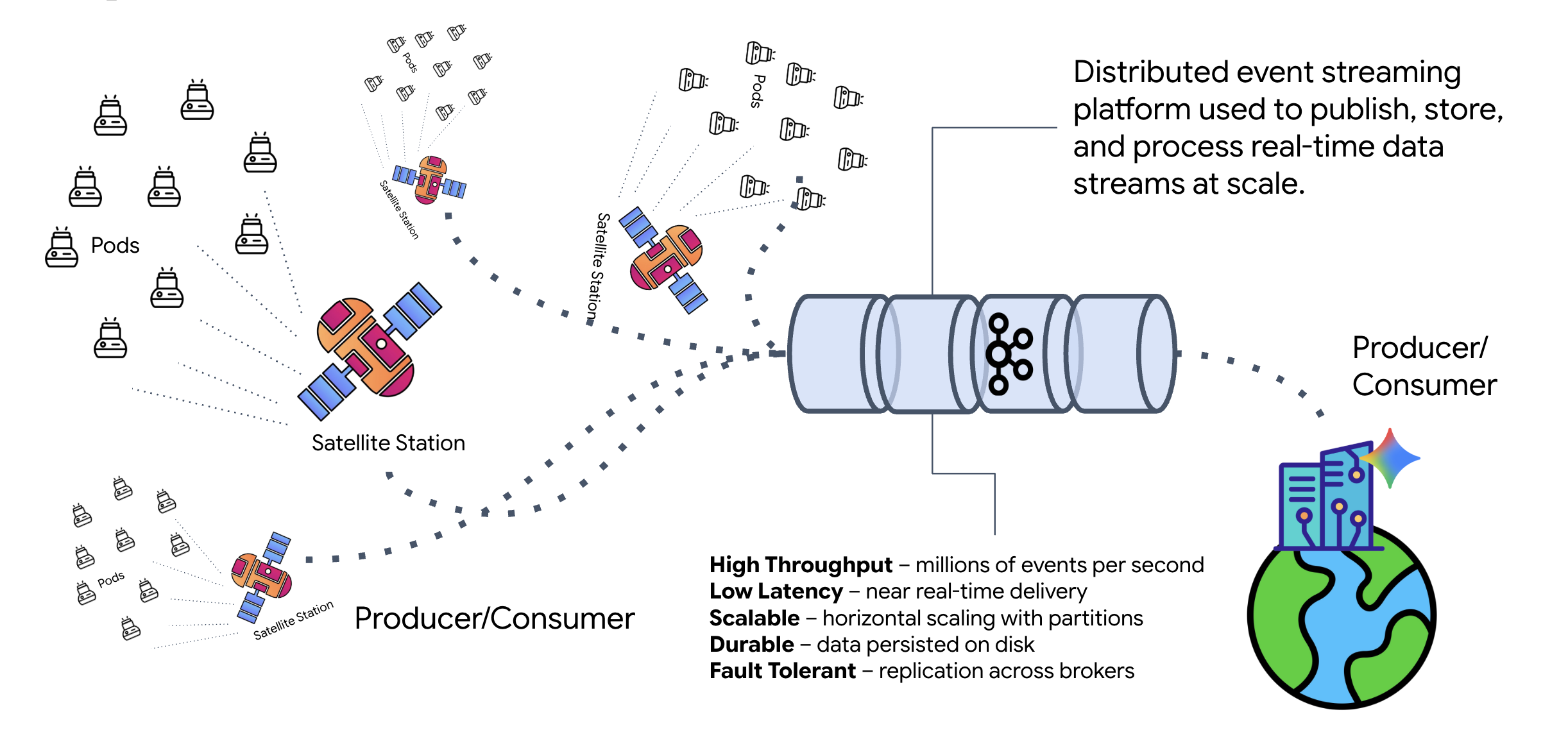
Che cos'è Kafka?
Kafka è una piattaforma distribuita per lo streaming di eventi. In un'architettura basata su eventi (EDA):
- I produttori pubblicano messaggi negli "argomenti".
- I consumer si iscrivono a questi argomenti e reagiscono quando arriva un messaggio.
Perché utilizzare Kafka?
Separa i tuoi sistemi. L'agente di formazione opera in modo autonomo, in attesa di richieste in arrivo senza dover conoscere l'identità o lo stato del mittente. In questo modo, la responsabilità viene disaccoppiata, garantendo che anche se il satellite va offline, il flusso di lavoro rimanga intatto. Kafka memorizza semplicemente i messaggi finché il satellite non si riconnette.
Che cos'è Google Cloud Pub/Sub?
Puoi assolutamente utilizzare Google Cloud Pub/Sub per questo scopo. Pub/Sub è il servizio di messaggistica serverless di Google. Sebbene Kafka sia ideale per i flussi ad alto throughput e "riproducibili", Pub/Sub è spesso preferito per la sua facilità d'uso. Per questo lab, utilizziamo Kafka per simulare un bus di messaggi solido e persistente.
Avvia il cluster Kafka locale
Copia e incolla l'intero blocco di comandi riportato di seguito nel terminale. Verrà scaricata l'immagine Kafka ufficiale e verrà avviata in background.
👉💻 Esegui questi comandi nel terminale:
# Navigate to the correct mission directory first
cd $HOME/way-back-home/level_5
# Run the Kafka container in detached mode
docker run -d \
--name mission-kafka \
-p 9092:9092 \
-e KAFKA_PROCESS_ROLES='broker,controller' \
-e KAFKA_NODE_ID=1 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
apache/kafka:4.2.0-rc1
👉💻 Controlla che il container sia in esecuzione con il comando docker ps.
docker ps
👀 Dovresti visualizzare un output che conferma che il container mission-kafka è in esecuzione e che la porta 9092 è esposta.
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c1a2b3c4d5e6 apache/kafka:4.2.0-rc1 "/opt/kafka/bin/kafka..." 15 seconds ago Up 14 seconds 0.0.0.0:9092->9092/tcp, 9093/tcp mission-kafka
Che cos'è un argomento Kafka?
Pensa a un argomento Kafka come a un canale o una categoria dedicati ai messaggi. È come un registro in cui i record degli eventi vengono archiviati nell'ordine in cui sono stati prodotti. I producer scrivono messaggi in argomenti specifici e i consumer li leggono. In questo modo, il mittente e il destinatario vengono disaccoppiati: il produttore non deve sapere quale consumatore leggerà i dati, ma solo inviarli al "canale" corretto. Nella nostra missione, creeremo due argomenti: uno per l'invio di richieste di formazione all'agente e un altro per la pubblicazione delle risposte dell'agente che il satellite potrà leggere.
👉💻 Esegui i seguenti comandi per creare gli argomenti richiesti all'interno del container Docker in esecuzione.
# Create the topic for formation requests
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-formation-request \
--bootstrap-server 127.0.0.1:9092
# Create the topic where the satellite dashboard will listen for replies
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-reply-satellite-dashboard \
--bootstrap-server 127.0.0.1:9092
👉💻 Per verificare che i canali siano aperti, esegui il comando list:
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--list \
--bootstrap-server 127.0.0.1:9092
👀 Dovresti visualizzare i nomi degli argomenti che hai appena creato.
a2a-formation-request a2a-reply-satellite-dashboard
L'istanza Kafka è ora completamente configurata e pronta per instradare i dati fondamentali.
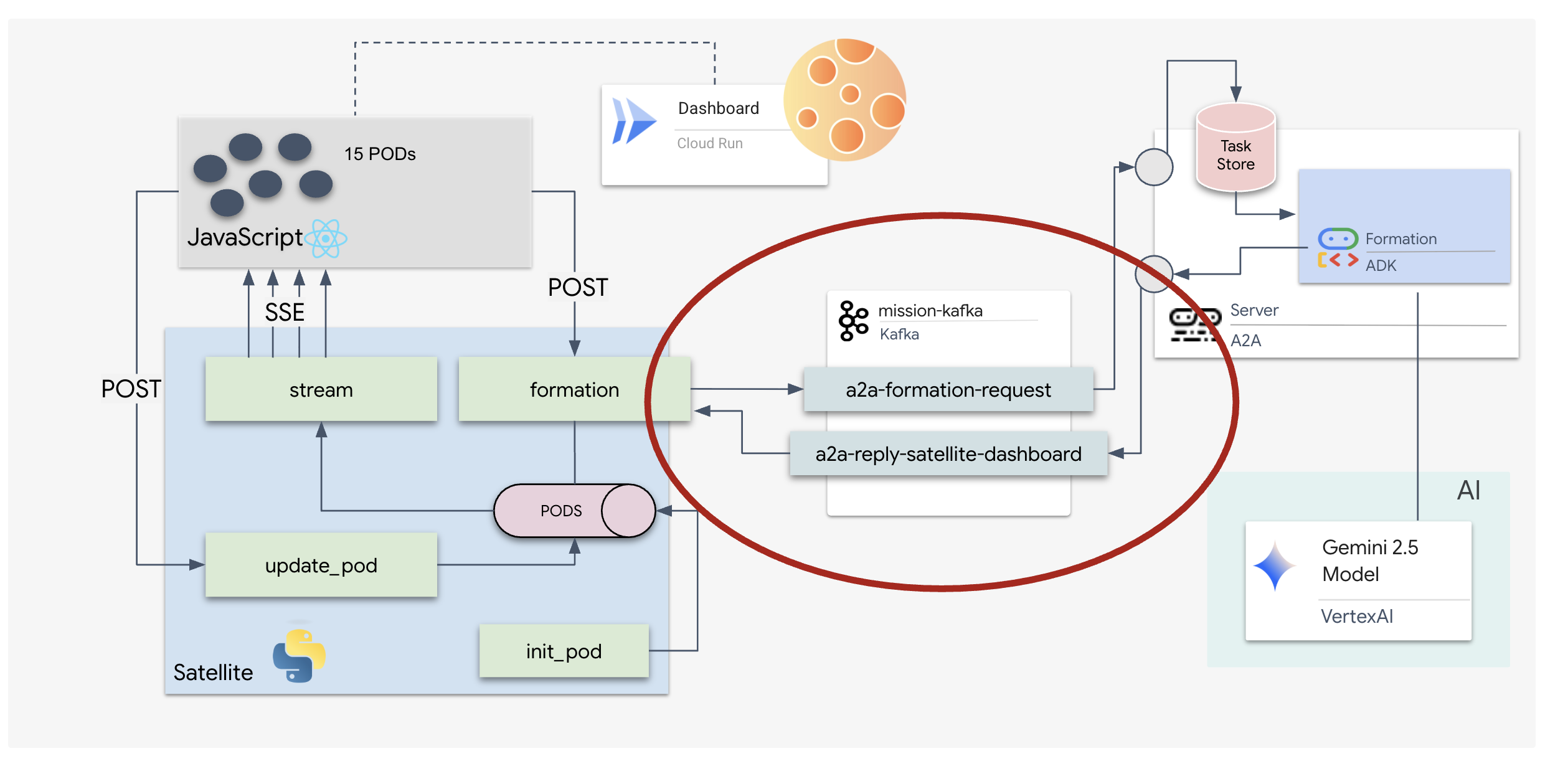
Implementazione del server Kafka A2A
Il protocollo Agent2Agent (A2A) stabilisce un framework standardizzato per l'interoperabilità tra sistemi agentici indipendenti. Consente agli agenti sviluppati da team diversi o in esecuzione su infrastrutture diverse di scoprirsi a vicenda e collaborare in modo efficace senza richiedere una logica di integrazione personalizzata per ogni connessione.
L'implementazione di riferimento, a2a-python, è una libreria di base per l'esecuzione di queste applicazioni agentiche. Una funzionalità principale della sua progettazione è l'estensibilità: astrae il livello di comunicazione, consentendo agli sviluppatori di sostituire protocolli come HTTP con altri.
In questo progetto, sfruttiamo questa estensibilità utilizzando un'implementazione Kafka personalizzata: a2a-python-kafka. Utilizzeremo questa implementazione per mostrare come lo standard A2A consente di adattare la comunicazione dell'agente a diverse esigenze architetturali, in questo caso sostituendo HTTP sincrono con un bus di eventi asincrono.
Attivazione di A2A per l'agente di formazione
Ora inseriremo il nostro agente in un server A2A, trasformandolo in un servizio interoperabile in grado di:
- Ascolta le attività da un argomento Kafka.
- Trasferisci le attività ricevute all'agente ADK sottostante per l'elaborazione.
- Pubblica il risultato in un argomento di risposta.
👉✏️ In $HOME/way-back-home/level_5/agent/agent_to_kafka_a2a.py, sostituisci #REPLACE-CREATE-KAFKA-A2A-SERVER con il seguente codice:
async def create_kafka_server(
agent: BaseAgent,
*,
bootstrap_servers: str | List[str] = "localhost:9092",
request_topic: str = "a2a-formation-request",
consumer_group_id: str = "a2a-agent-group",
agent_card: Optional[Union[AgentCard, str]] = None,
runner: Optional[Runner] = None,
**kafka_config: Any,
) -> KafkaServerApp:
"""Convert an ADK agent to a A2A Kafka Server application.
Args:
agent: The ADK agent to convert
bootstrap_servers: Kafka bootstrap servers.
request_topic: Topic to consume requests from.
consumer_group_id: Consumer group ID for the server.
agent_card: Optional pre-built AgentCard object or path to agent card
JSON. If not provided, will be built automatically from the
agent.
runner: Optional pre-built Runner object. If not provided, a default
runner will be created using in-memory services.
**kafka_config: Additional Kafka configuration.
Returns:
A KafkaServerApp that can be run with .run() or .start()
"""
# Set up ADK logging
adk_logger = logging.getLogger("google_adk")
adk_logger.setLevel(logging.INFO)
async def create_runner() -> Runner:
"""Create a runner for the agent."""
return Runner(
app_name=agent.name or "adk_agent",
agent=agent,
# Use minimal services - in a real implementation these could be configured
artifact_service=InMemoryArtifactService(),
session_service=InMemorySessionService(),
memory_service=InMemoryMemoryService(),
credential_service=InMemoryCredentialService(),
)
# Create A2A components
task_store = InMemoryTaskStore()
agent_executor = A2aAgentExecutor(
runner=runner or create_runner,
)
# Initialize logic handler
from a2a.server.request_handlers.default_request_handler import DefaultRequestHandler
logic_handler = DefaultRequestHandler(
agent_executor=agent_executor, task_store=task_store
)
# Prepare Agent Card
rpc_url = f"kafka://{bootstrap_servers}/{request_topic}"
# Create Kafka Server App
server_app = KafkaServerApp(
request_handler=logic_handler,
bootstrap_servers=bootstrap_servers,
request_topic=request_topic,
consumer_group_id=consumer_group_id,
**kafka_config
)
return server_app
Questo codice configura i componenti chiave:
- Runner: fornisce il runtime per l'agente (gestione di memoria, credenziali e così via).
- Task Store: monitora lo stato delle richieste man mano che passano da "In attesa" a "Completata".
- Agent Executor: prende un'attività da Kafka e la passa all'agente per calcolare le coordinate.
- KafkaServerApp: gestisce la connessione fisica al broker Kafka.
Configura le variabili di ambiente
La configurazione dell'ADK ha creato un file .env con le impostazioni di Google Vertex AI all'interno della cartella dell'agente. Dobbiamo spostarlo nella root del progetto e aggiungere le coordinate del nostro cluster Kafka.
Esegui questi comandi per copiare il file e aggiungere l'indirizzo del server Kafka:
cd $HOME/way-back-home/level_5
# 1. Copy the API keys from the agent folder to the project root
cp agent/formation/.env .env
# 2. Append the Kafka Bootstrap Server address to the file
echo -e "\nKAFKA_BOOTSTRAP_SERVERS=localhost:9092" >> .env
# 3. Verify the file content
echo "✅ Environment configured. Here are the last few lines:"
tail .env
Verifica il ciclo A2A Interstellar
Ora ci assicureremo che il ciclo di eventi asincrono funzioni correttamente con un test a fuoco vivo: invieremo un segnale manuale tramite il cluster Kafka e osserveremo la risposta dell'agente.
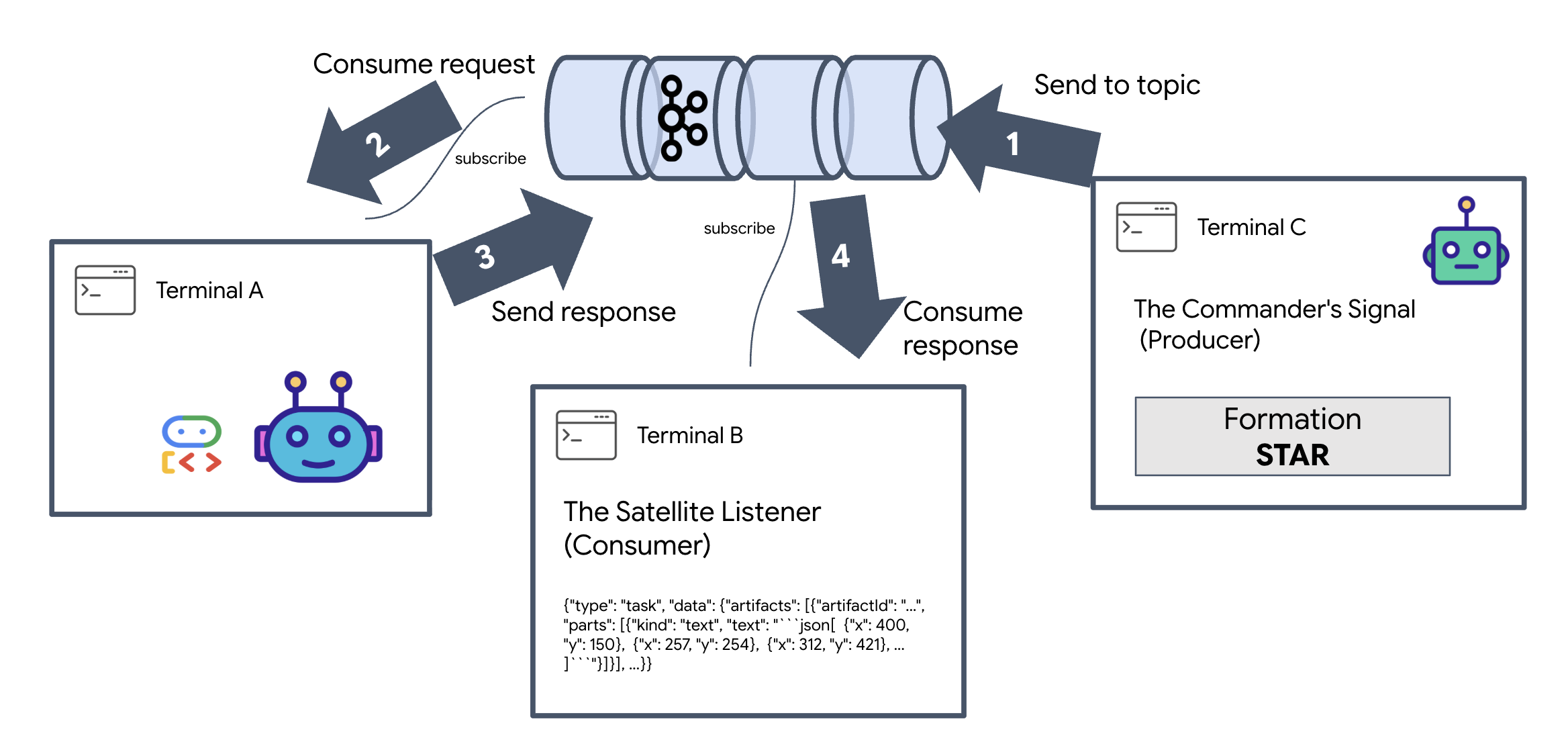
Per visualizzare l'intero ciclo di vita di un evento, utilizzeremo tre terminali separati.
Terminal A: l'agente di formazione (server Kafka A2A)
👉💻 Questo terminale esegue il processo Python che ascolta Kafka e utilizza Gemini per eseguire i calcoli geometrici.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Install the custom Kafka-enabled A2A library
uv pip install git+https://github.com/weimeilin79/a2a-python-kafka.git
# Start the Agent Server
uv run agent/server.py
Attendi finché non vedi:
[INFO] Kafka Server App Started. Starting to consume requests...
Terminal B: The Satellite Listener (Consumer)
👉💻 In questo terminale, ascolteremo l'argomento di risposta. In questo modo viene simulata l'attesa di istruzioni da parte del satellite.
# Listen for the AI's response on the satellite channel
docker exec mission-kafka /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-reply-satellite-dashboard \
--from-beginning \
--property "print.headers=true"
Questo terminale apparirà inattivo. È in attesa che l'agente pubblichi un messaggio.
Terminal C: The Commander's Signal (Producer)
👉💻 Ora invieremo una richiesta non elaborata in formato A2A all'argomento a2a-formation-request. Dobbiamo includere intestazioni Kafka specifiche, in modo che l'agente sappia dove inviare la risposta.
echo 'correlation_id=ping-manual-01,reply_topic=a2a-reply-satellite-dashboard|{"method": "message_send", "params": {"message": {"message_id": "msg-001", "role": "user", "parts": [{"text": "STAR"}]}}, "streaming": false, "agent_card": {"name": "DiagnosticTool", "version": "1.0.0"}}' | \
docker exec -i mission-kafka /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-formation-request \
--property "parse.headers=true" \
--property "headers.key.separator==" \
--property "headers.delimiter=|"
Analisi del risultato
👀 Se il loop ha esito positivo, passa al terminale B. Un grande blocco JSON dovrebbe apparire immediatamente. Inizierà con l'intestazione che abbiamo inviato correlation_id:ping-manual-01. Seguito da un oggetto task. Se esamini attentamente la sezione parts all'interno del JSON, vedrai le coordinate X e Y non elaborate che Gemini ha calcolato per i tuoi 15 pod:
{"type": "task", "data": {"artifacts": [{"artifactId": "...", "parts": [{"kind": "text", "text": "```json\n[\n {\"x\": 400, \"y\": 150},\n {\"x\": 257, \"y\": 254},\n {\"x\": 312, \"y\": 421},\n ... \n]\n```"}]}], ...}}
Hai disaccoppiato l'agente dal ricevitore. Il "rumore interstellare" della latenza richiesta-risposta non ha più importanza perché il nostro sistema è ora interamente basato sugli eventi.
Prima di procedere, interrompi i processi in background per liberare le porte di rete.
👉💻 In ogni terminale (A, B e C):
- Premi
Ctrl + Cper terminare il processo in esecuzione.
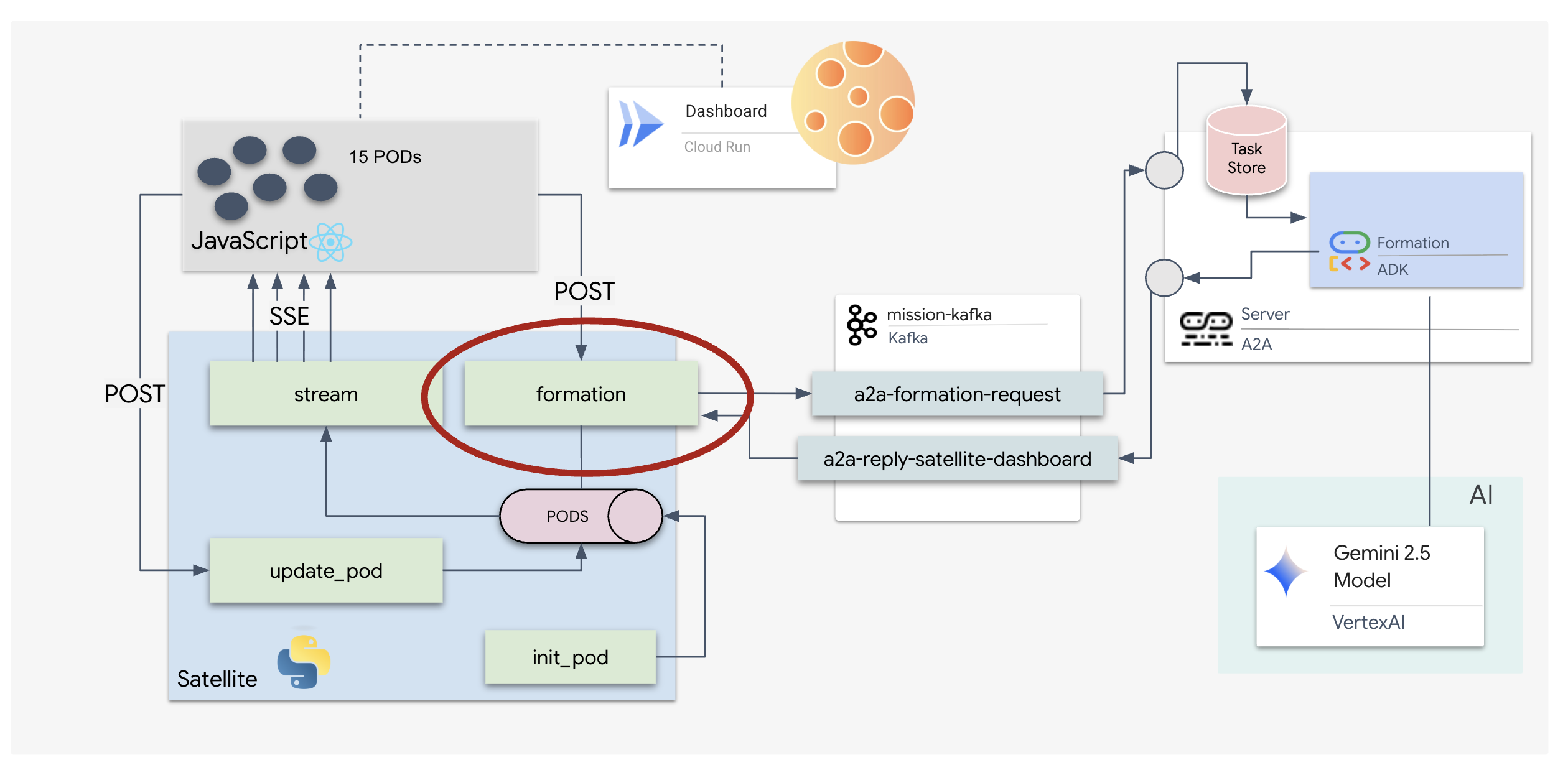
5. The Satellite Station (A2A Kafka Client and SSE)
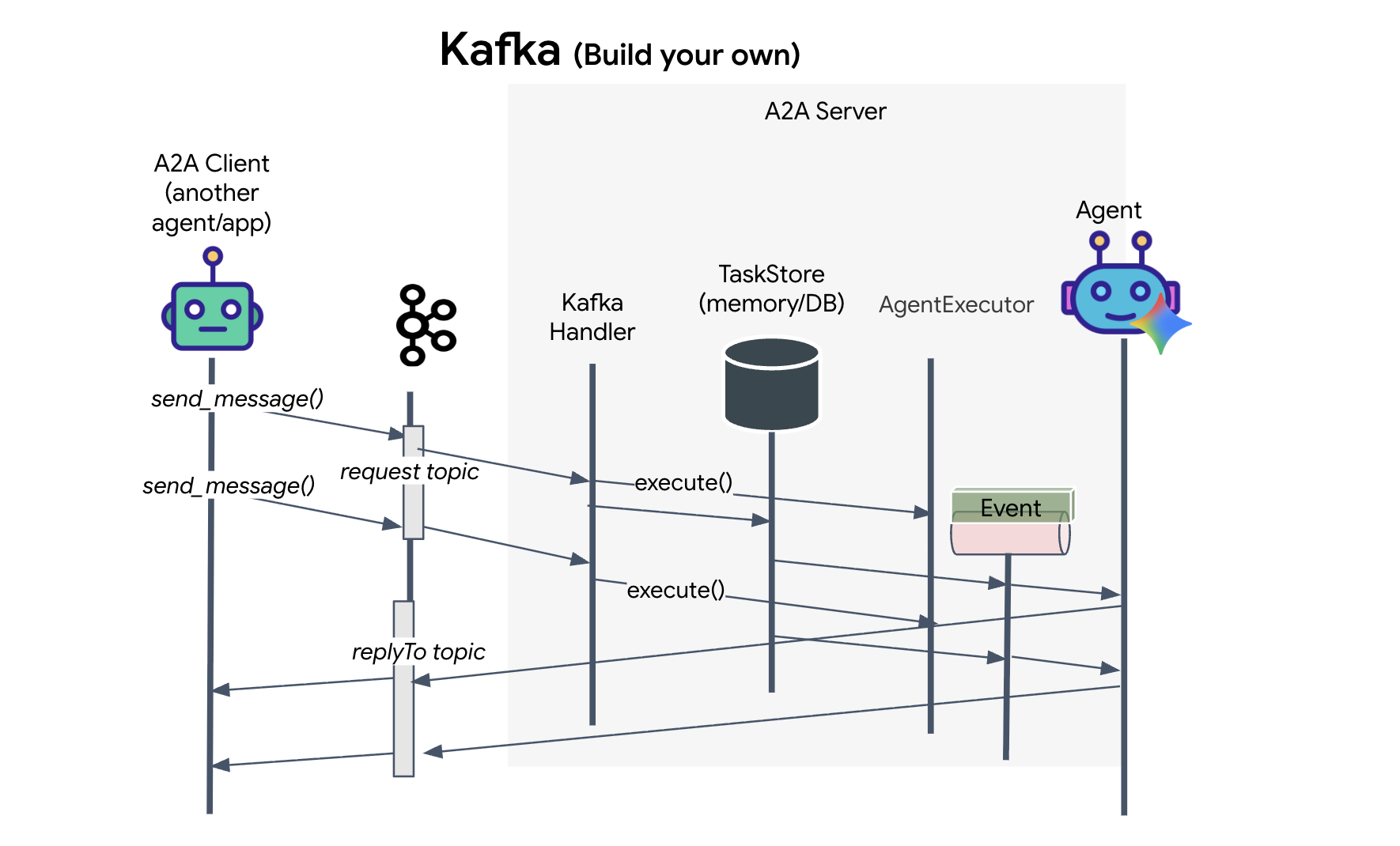
In questo passaggio, creiamo la stazione satellitare. Questo è il ponte tra il cluster Kafka e la visualizzazione del pilota (il frontend React). Questo server funge sia da client Kafka (per comunicare con l'agente) sia da streamer SSE (per comunicare con il browser).
Che cos'è un client Kafka?
Pensa al cluster Kafka come a una stazione radio. Un client Kafka è il ricevitore radio. KafkaClientTransport consente alla nostra applicazione di:
- Produci un messaggio: invia un "Task" (ad es. "Formazione di stelle") all'agente.
- Consumare una risposta: ascolta un "Argomento di risposta" specifico per ricevere le coordinate dall'agente.
1. Inizializzazione della connessione
Utilizziamo il gestore di eventi lifespan di FastAPI per assicurarci che la connessione Kafka venga avviata all'avvio del server e chiusa correttamente all'arresto.
👉✏️ In $HOME/way-back-home/level_5/satellite/main.py, sostituisci #REPLACE-CONNECT-TO-KAFKA-CLUSTER con il seguente codice:
@asynccontextmanager
async def lifespan(app: FastAPI):
global kafka_transport
logger.info("Initializing Kafka Client Transport...")
bootstrap_server = os.getenv("KAFKA_BOOTSTRAP_SERVERS")
request_topic = "a2a-formation-request"
reply_topic = "a2a-reply-satellite-dashboard"
# Create AgentCard for the Client
client_card = AgentCard(
name="SatelliteDashboard",
description="Satellite Dashboard Client",
version="1.0.0",
url="https://example.com/satellite-dashboard",
capabilities=AgentCapabilities(),
default_input_modes=["text/plain"],
default_output_modes=["text/plain"],
skills=[]
)
kafka_transport = KafkaClientTransport(
agent_card=client_card,
bootstrap_servers=bootstrap_server,
request_topic=request_topic,
reply_topic=reply_topic,
)
try:
await kafka_transport.start()
logger.info("Kafka Client Transport Started Successfully.")
except Exception as e:
logger.error(f"Failed to start Kafka Client: {e}")
yield
if kafka_transport:
logger.info("Stopping Kafka Client Transport...")
await kafka_transport.stop()
logger.info("Kafka Client Transport Stopped.")
2. Invio di un comando
Quando fai clic su un pulsante nella dashboard, viene attivato l'endpoint /formation. Funziona come un produttore, inserendo la tua richiesta in un Message A2A formale e inviandola all'agente.
Logica chiave:
- Comunicazione asincrona:
kafka_transport.send_messageinvia la richiesta e attende che le nuove coordinate arrivino sureply_topic. - Analisi della risposta: Gemini potrebbe restituire coordinate all'interno di blocchi Markdown (ad es.
json ...). Il codice riportato di seguito le rimuove e converte la stringa in un elenco di punti Python.
👉✏️ In $HOME/way-back-home/level_5/satellite/main.py, sostituisci #REPLACE-FORMATION-REQUEST con il seguente codice:
@app.post("/formation")
async def set_formation(req: FormationRequest):
global FORMATION, PODS
FORMATION = req.formation
logger.info(f"Received formation request: {FORMATION}")
if not kafka_transport:
logger.error("Kafka Transport is not initialized!")
return {"status": "error", "message": "Backend Not Connected"}
try:
# Construct A2A Message
prompt = f"Create a {FORMATION} formation"
logger.info(f"Sending A2A Message: '{prompt}'")
from a2a.types import TextPart, Part, Role
import uuid
msg_id = str(uuid.uuid4())
message_parts = [Part(TextPart(text=prompt))]
msg_obj = Message(
message_id=msg_id,
role=Role.user,
parts=message_parts
)
message_params = MessageSendParams(
message=msg_obj
)
# Send and Wait for Response
ctx = ClientCallContext()
ctx.state["kafka_timeout"] = 120.0 # Timeout for GenAI latency
response = await kafka_transport.send_message(message_params, context=ctx)
logger.info("Received A2A Response.")
content = None
if isinstance(response, Message):
content = response.parts[0].root.text if response.parts else None
elif isinstance(response, Task):
if response.artifacts and response.artifacts[0].parts:
content = response.artifacts[0].parts[0].root.text
if content:
logger.info(f"Response Content: {content[:100]}...")
try:
clean_content = content.replace("```json", "").replace("```", "").strip()
coords = json.loads(clean_content)
if isinstance(coords, list):
logger.info(f"Parsed {len(coords)} coordinates.")
for i, pod_target in enumerate(coords):
if i < len(PODS):
PODS[i]["x"] = pod_target["x"]
PODS[i]["y"] = pod_target["y"]
return {"status": "success", "formation": FORMATION}
else:
logger.error("Response JSON is not a list.")
except json.JSONDecodeError as e:
logger.error(f"Failed to parse Agent JSON response: {e}")
else:
logger.error(f"Could not extract content from response type {type(response)}")
except Exception as e:
logger.error(f"Error calling agent via Kafka: {e}")
return {"status": "error", "message": str(e)}
Server-Sent Events (SSE)
Le API standard utilizzano un modello "richiesta-risposta". Per il nostro HUD, abbiamo bisogno di un "Live streaming" delle posizioni dei pod.
Perché SSE: a differenza di WebSocket (che sono bidirezionali e più complessi), SSE fornisce un flusso di dati semplice e unidirezionale dal server al browser. È perfetto per dashboard, ticker azionari o telemetria interstellare.
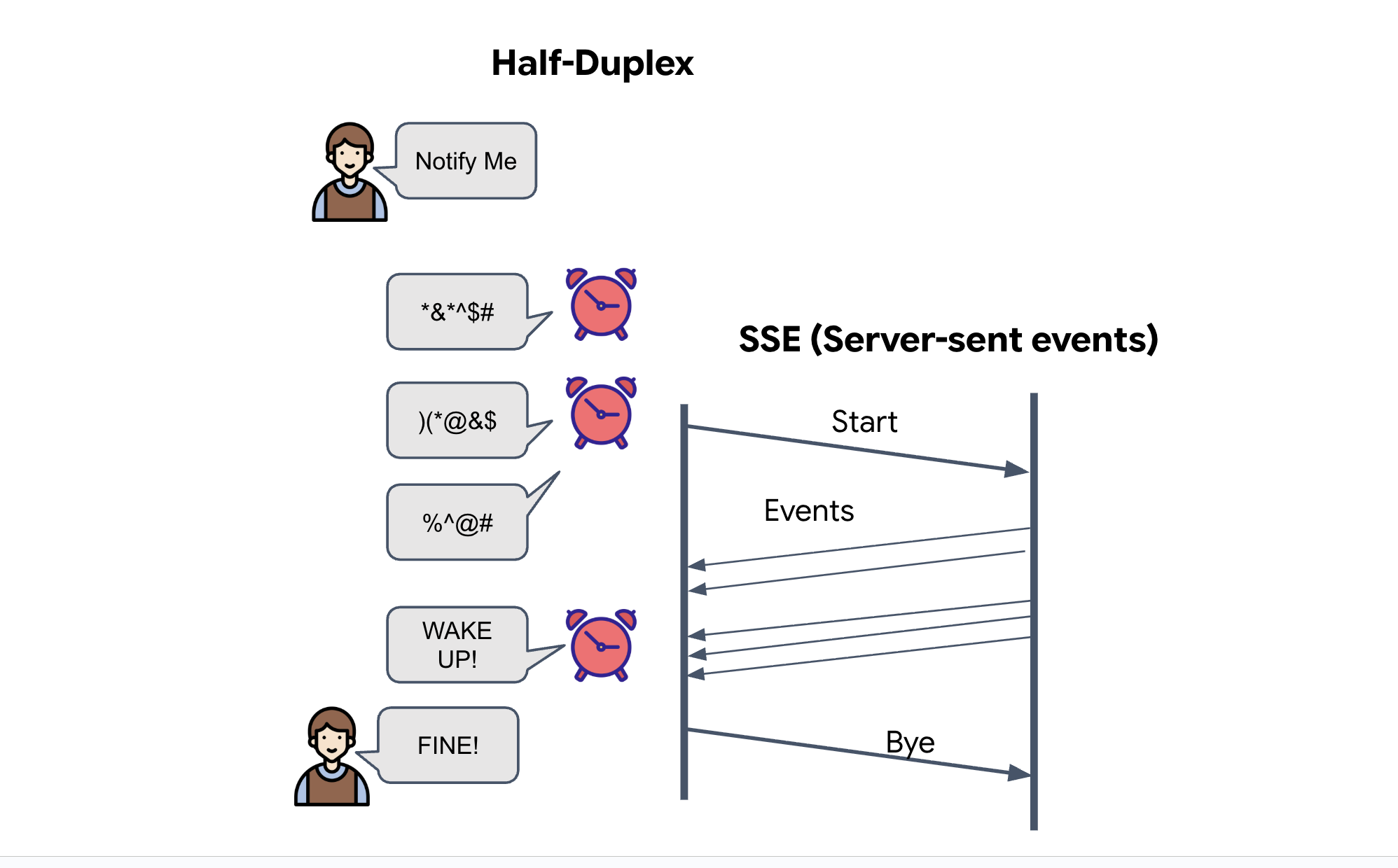
Come funziona nel nostro codice:creiamo un event_generator, un ciclo infinito che prende la posizione attuale di tutti i 15 pod ogni mezzo secondo e li "invia" al browser come aggiornamento.
👉✏️ In $HOME/way-back-home/level_5/satellite/main.py, sostituisci #REPLACE-SSE-STREAM con il seguente codice:
@app.get("/stream")
async def message_stream(request: Request):
async def event_generator():
logger.info("New SSE stream connected")
try:
while True:
current_pods = list(PODS)
# Send updates one by one to simulate low-bandwidth scanning
for pod in current_pods:
payload = {"pod": pod}
yield {
"event": "pod_update",
"data": json.dumps(payload)
}
await asyncio.sleep(0.02)
# Send formation info occasionally
yield {
"event": "formation_update",
"data": json.dumps({"formation": FORMATION})
}
# Main loop delay
await asyncio.sleep(0.5)
except asyncio.CancelledError:
logger.info("SSE stream disconnected (cancelled)")
except Exception as e:
logger.error(f"SSE stream error: {e}")
return EventSourceResponse(event_generator())
Esegui il ciclo completo della missione
Verifichiamo che il sistema funzioni end-to-end prima di lanciare l'interfaccia utente finale. Attiveremo manualmente l'agente e vedremo il payload dei dati non elaborati sul cavo.
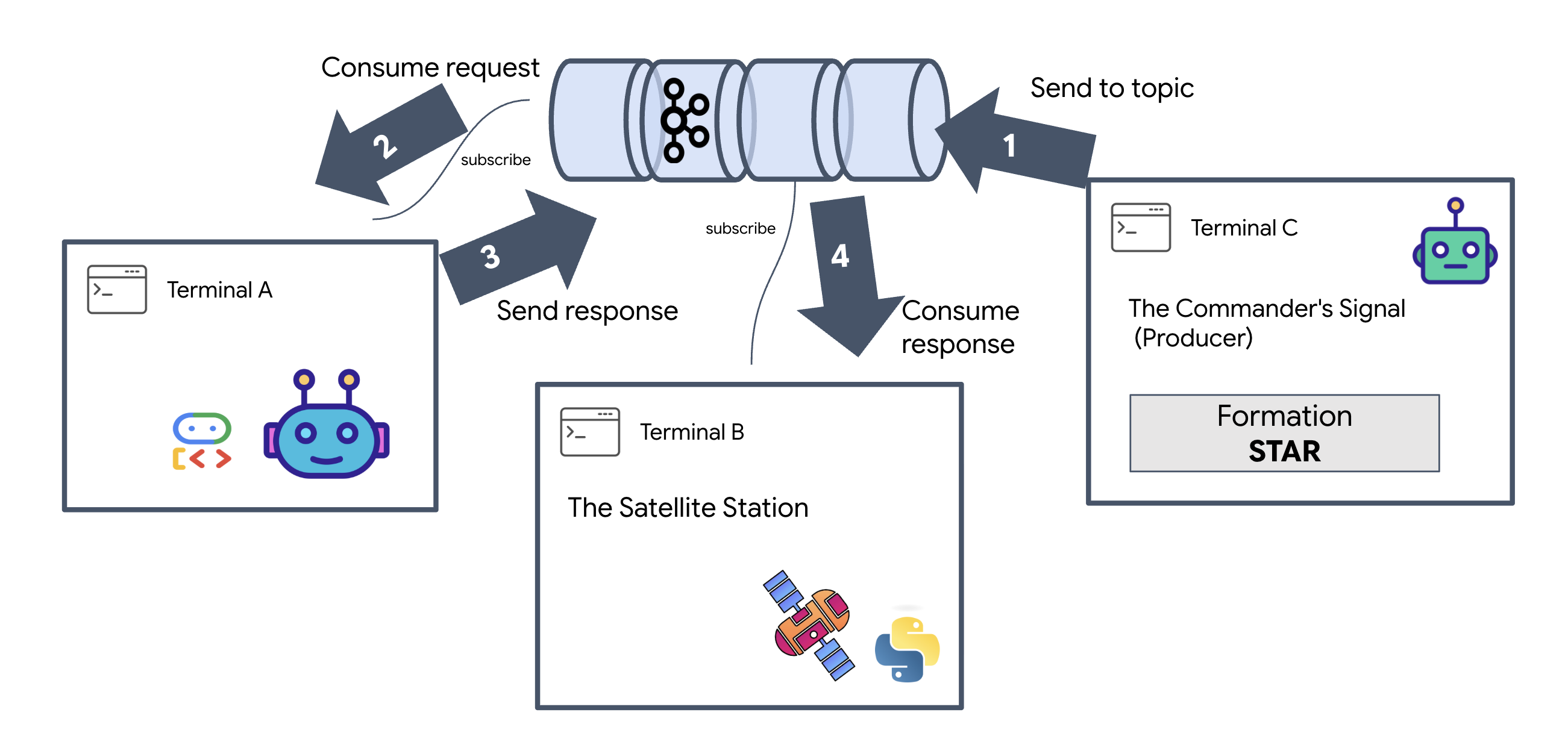
Apri tre schede del terminale separate.
Terminale A: l'agente di formazione (server A2A)
👉💻 Questo è l'agente ADK che ascolta le attività ed esegue i calcoli geometrici.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Agent Server
uv run agent/server.py
Terminale B: The Satellite Station (client Kafka)
👉💻 Questo server FastAPI funge da "ricevitore", ascoltando le risposte di Kafka e trasformandole in un flusso SSE live.
cd $HOME/way-back-home/level_5
# Start the Satellite Station
uv run satellite/main.py
Terminale C: l'HUD manuale
Invia comando di formazione (trigger): 👉💻 Nello stesso terminale C, attiva la procedura di formazione:
# Trigger the STAR formation via the Satellite's API
curl -X POST http://localhost:8000/formation \
-H "Content-Type: application/json" \
-d '{"formation": "STAR"}'
👀 Dovresti visualizzare le nuove coordinate.
INFO:satellite.main:Received formation request: STAR INFO:satellite.main:Sending A2A Message: 'Create a STAR formation' INFO:satellite.main:Received A2A Response. INFO:satellite.main:Response Content: ```json ... INFO:satellite.main:Parsed 15 coordinates.
Ciò conferma che il satellite ha aggiornato le coordinate del pod interno.
👉💻 Utilizzeremo curl per ascoltare prima lo stream di telemetria in tempo reale e poi attivare una modifica della formazione.
# Connect to the live telemetry feed.
# You should see 'pod_update' events ticking by.
curl -N http://localhost:8000/stream
👀 Guarda l'output del comando curl -N. Le coordinate x e y negli eventi pod_update inizieranno a riflettere le nuove posizioni della formazione Stella.
Prima di procedere, arresta tutti i processi in esecuzione per liberare le porte di comunicazione.
In ogni terminale (A, B, C e il terminale di attivazione), premi Ctrl + C.
6. Vai a salvare!
Il sistema è stato configurato correttamente. Ora è il momento di dare vita alla missione. Ora avvieremo l'Head-Up Display (HUD) basato su React. Questa dashboard si connette alla stazione satellitare tramite SSE, consentendoti di visualizzare i 15 pod in tempo reale.
Quando emetti un comando, non stai solo chiamando una funzione, ma stai attivando un evento che passa attraverso Kafka, viene elaborato da un agente AI e viene trasmesso in streaming sullo schermo come telemetria in tempo reale.
Apri due schede del terminale separate.
Terminale A: l'agente di formazione (server A2A)
👉💻 Questo è l'agente ADK che ascolta le attività ed esegue calcoli geometrici utilizzando Gemini. Nel terminale, esegui:
cd $HOME/way-back-home/level_5
# Start the Agent Server
uv run agent/server.py
Terminal B: The Satellite Station and Visual Dashboard
👉💻 Per prima cosa, crea l'applicazione frontend.
cd $HOME/way-back-home/level_5/frontend/
npm install
npm run build
👉💻 Ora avvia il server FastAPI, che servirà sia la logica di backend sia la UI frontend.
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Satellite Station
uv run satellite/main.py
Avvia e verifica
- 👉 Apri l'anteprima: nella barra degli strumenti di Cloud Shell, fai clic sull'icona Anteprima web. Seleziona Cambia porta, impostala su 8000 e fai clic su Cambia e visualizza anteprima. Si aprirà una nuova scheda del browser che mostra l'HUD di Starfield.
- 👉 Verifica il flusso di telemetria:
- Una volta caricata la UI, dovresti vedere 15 pod sparsi in modo casuale.
- Se i pod pulsano leggermente o "vibrano", il tuo stream SSE è attivo e la stazione satellitare trasmette correttamente le sue posizioni.

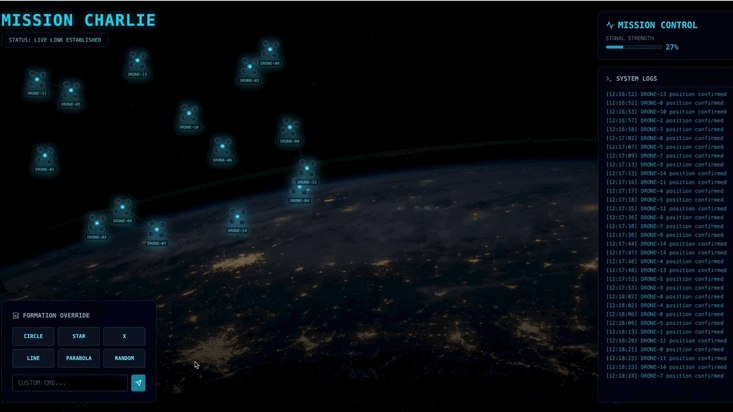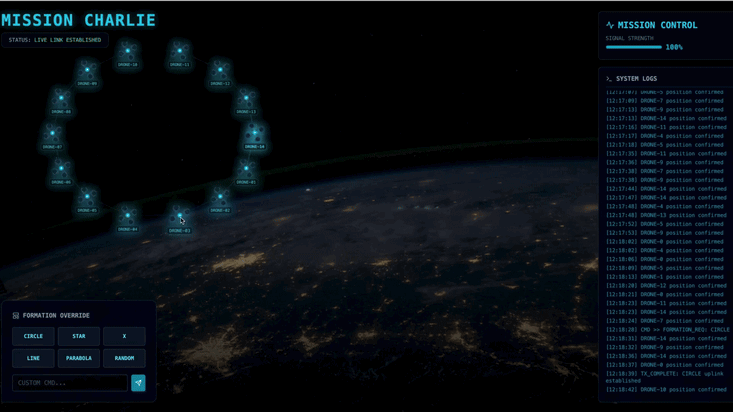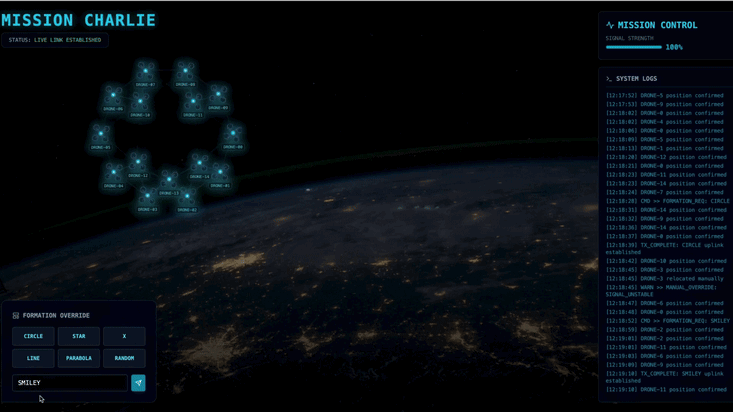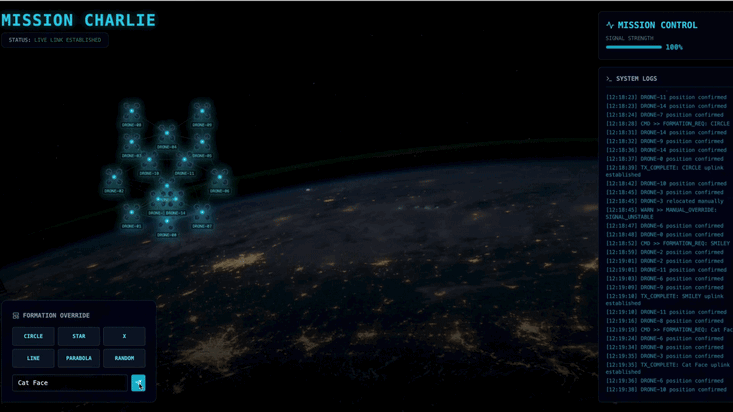
- 👉 Avvia una formazione: fai clic sul pulsante "STAR" nella dashboard.

- 👀 Traccia il ciclo degli eventi: guarda i terminali per vedere l'architettura in azione:
- Il terminale B (stazione satellite) registrerà:
Sending A2A Message: 'Create a STAR formation'. - Terminal A (Formation Agent) mostrerà l'attività mentre consulta Gemini.
- Terminal B (Satellite Station) registrerà:
Received A2A Responsee analizzerà le coordinate.
- Il terminale B (stazione satellite) registrerà:
- 👀 Conferma visiva: guarda i 15 pod sulla dashboard che si spostano senza problemi dalle loro posizioni casuali a una formazione a stella a 5 punte.
- 👉 Esperimento:
- Per 3 formazioni diverse, prova "X" o "LINEA".

- Segmento di pubblico personalizzato per intenzione: utilizza l'inserimento manuale per digitare qualcosa di unico, ad esempio "Cuore" o "Triangolo".

- Poiché utilizzi l'AI generativa, l'agente tenterà di calcolare la matematica per qualsiasi forma geometrica tu possa descrivere.
- Per 3 formazioni diverse, prova "X" o "LINEA".
Dopo aver formato 3 sequenze, la connessione è stata ristabilita correttamente. 
MISSIONE COMPIUTA!
Il flusso si stabilizza man mano che i dati attraversano il rumore senza interruzioni. Sotto il tuo comando, i 15 pod antichi iniziano la loro danza sincronizzata tra le stelle.

Durante tre estenuanti fasi di calibrazione, hai visto la telemetria bloccarsi. A ogni allineamento, il segnale si rafforzava, fino a superare le interferenze interstellari come un faro di speranza.
Grazie a te e alla tua magistrale implementazione dell'agente basato sugli eventi, i cinque sopravvissuti sono stati trasportati in elicottero dalla superficie di X-42 e ora sono al sicuro a bordo della nave di soccorso. Grazie a te, sono state salvate cinque vite.
Se hai partecipato al Livello 0, non dimenticare di controllare a che punto è la tua missione Ritorno a casa. Il tuo viaggio di ritorno alle stelle continua.