1. ミッション

あなたは未踏のセクターの静寂の中を漂っています。巨大な太陽パルスによって宇宙船が裂け目に引き込まれ、星図に存在しない宇宙のポケットに漂流してしまいました。
数日間の過酷な修理を経て、ついに足元でエンジンのうなりを感じます。ロケットが修理されました。マザーシップへの長距離アップリンクを確保することにも成功しました。出発を許可します。これで帰宅の準備ができました。
ジャンプ ドライブを起動しようとしたとき、静電気の音に混じって遭難信号が聞こえてきました。センサーがヘルプ信号を検出します。5 人の民間人が惑星 X-42 の表面に閉じ込められています。脱出の唯一の望みは、軌道上の母船に遭難信号を送信するために同期する必要がある 15 個の古代のポッドにあります。
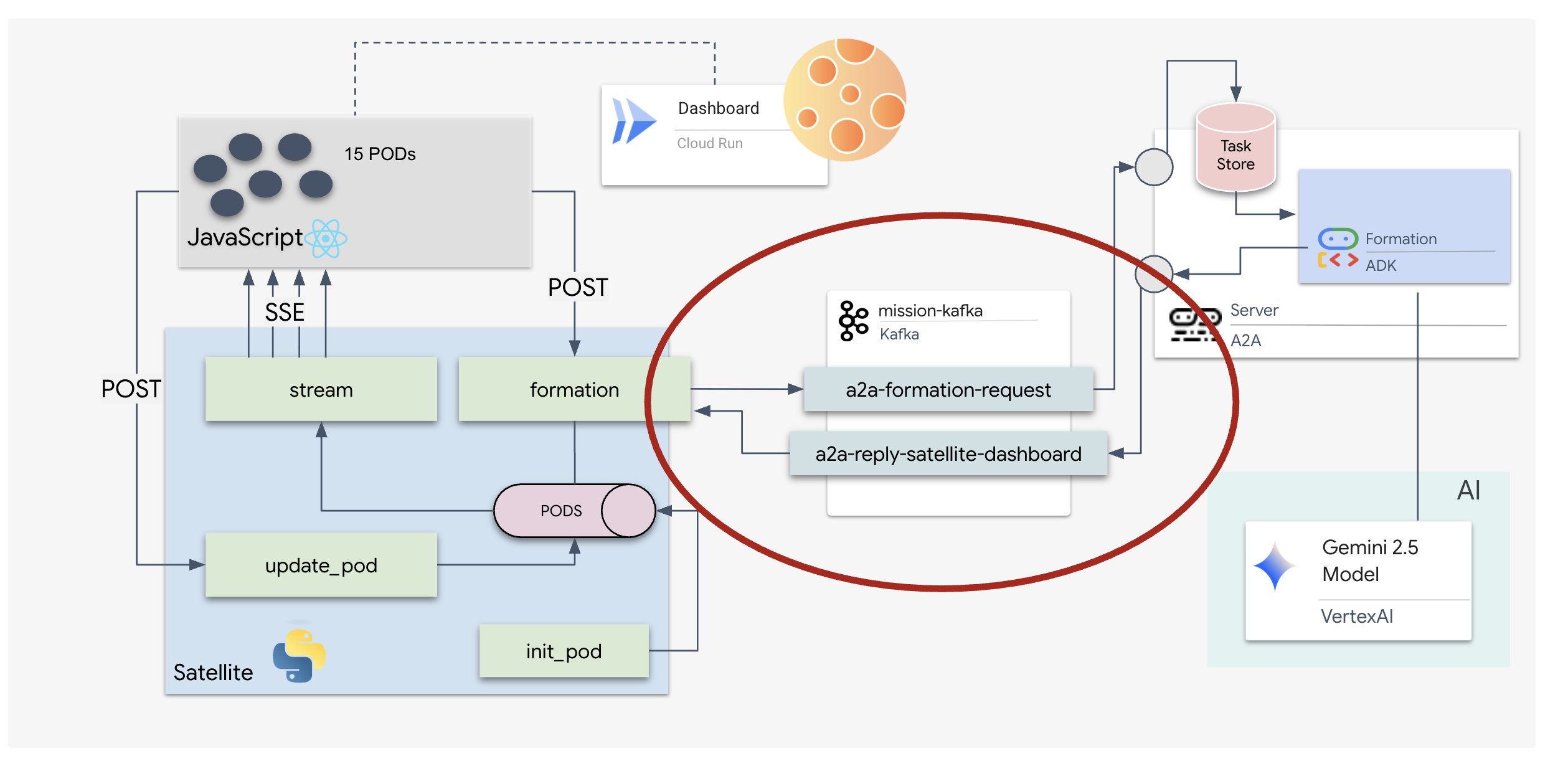
ただし、ポッドはメイン ナビゲーション コンピュータが損傷した衛星ステーションによって制御されています。ポッドはあてもなく漂流しています。衛星へのバックドア接続を確立できましたが、アップリンクは星間干渉が激しく、リクエスト / レスポンス サイクルで大きな遅延が発生しています。
課題
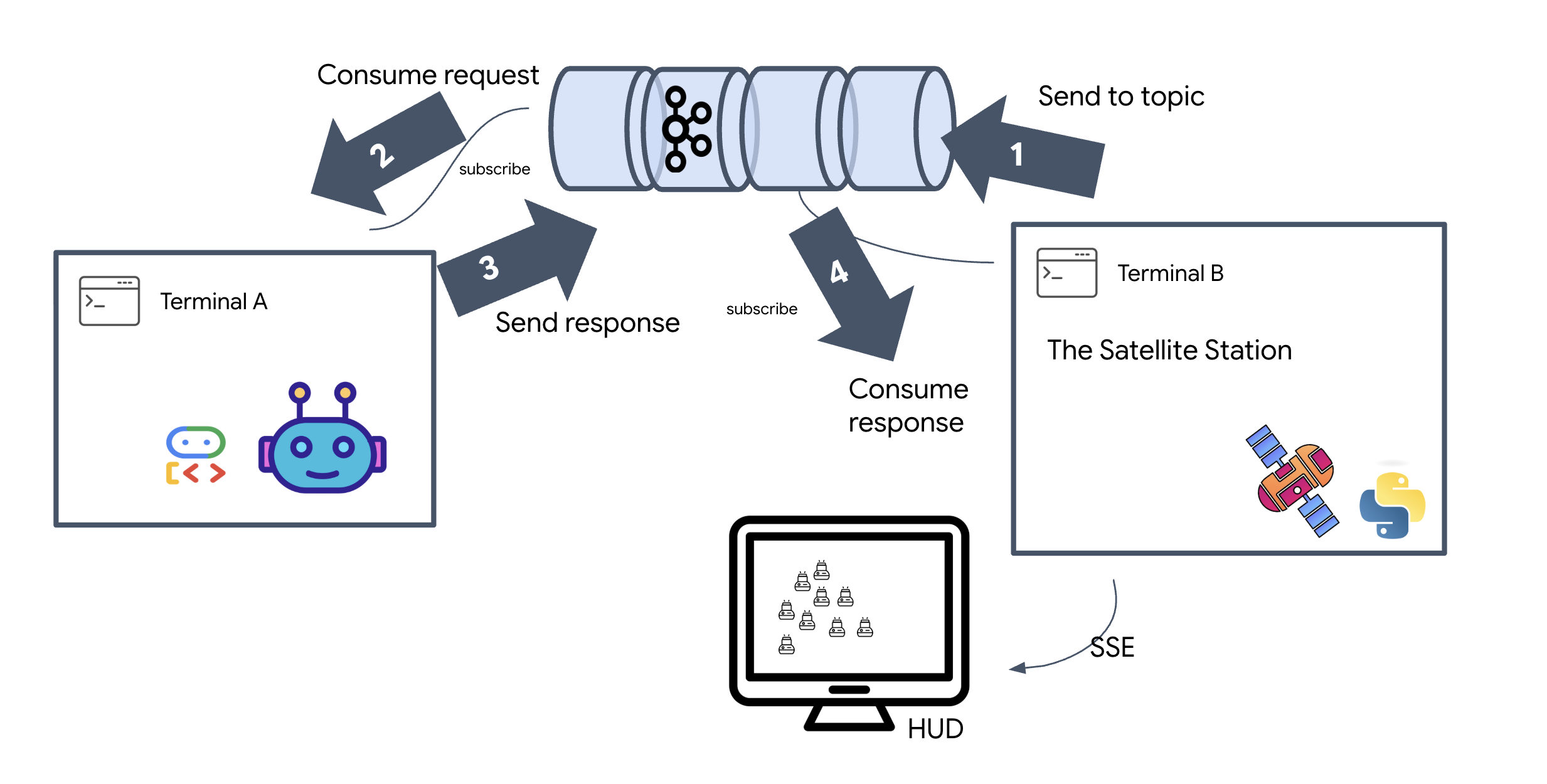
リクエスト/レスポンス モデルは遅すぎるため、イベント ドリブン アーキテクチャ(EDA)とサーバー送信イベント(SSE)をデプロイして、ノイズを介してテレメトリーをストリーミングする必要があります。
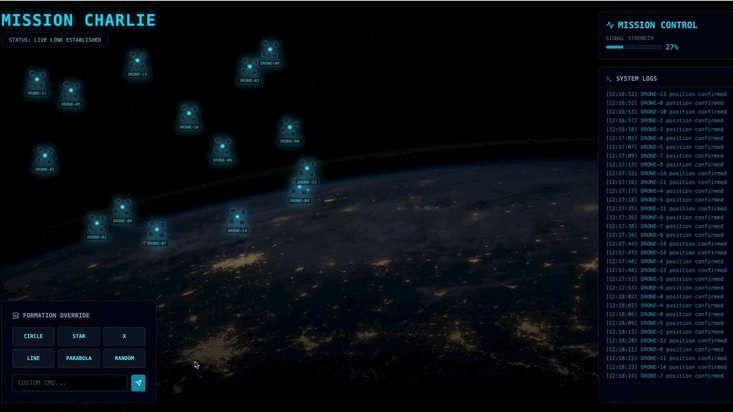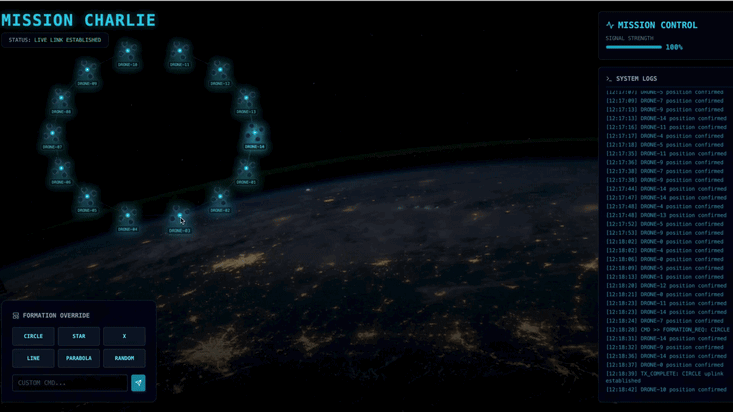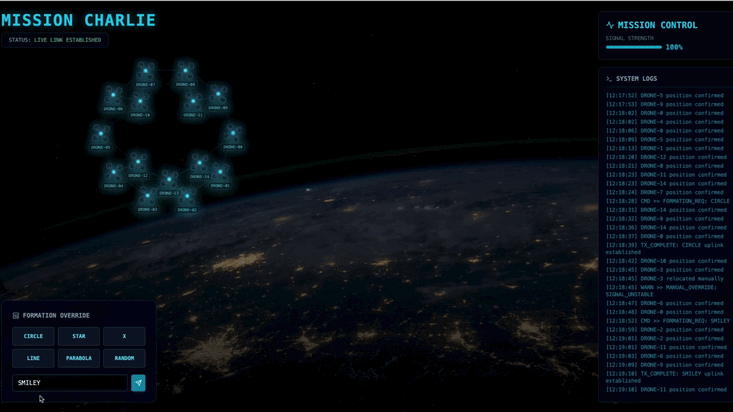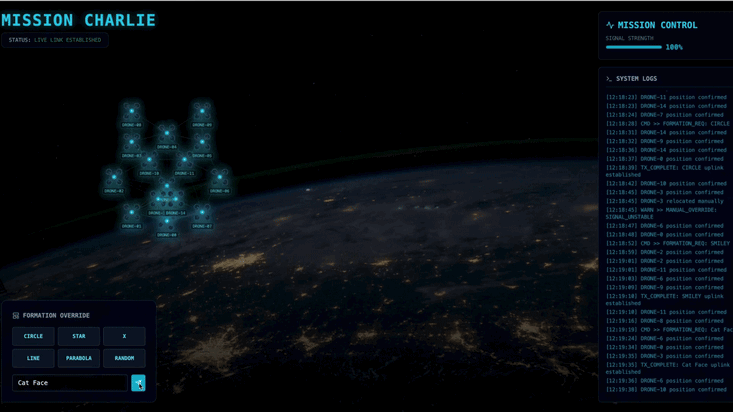
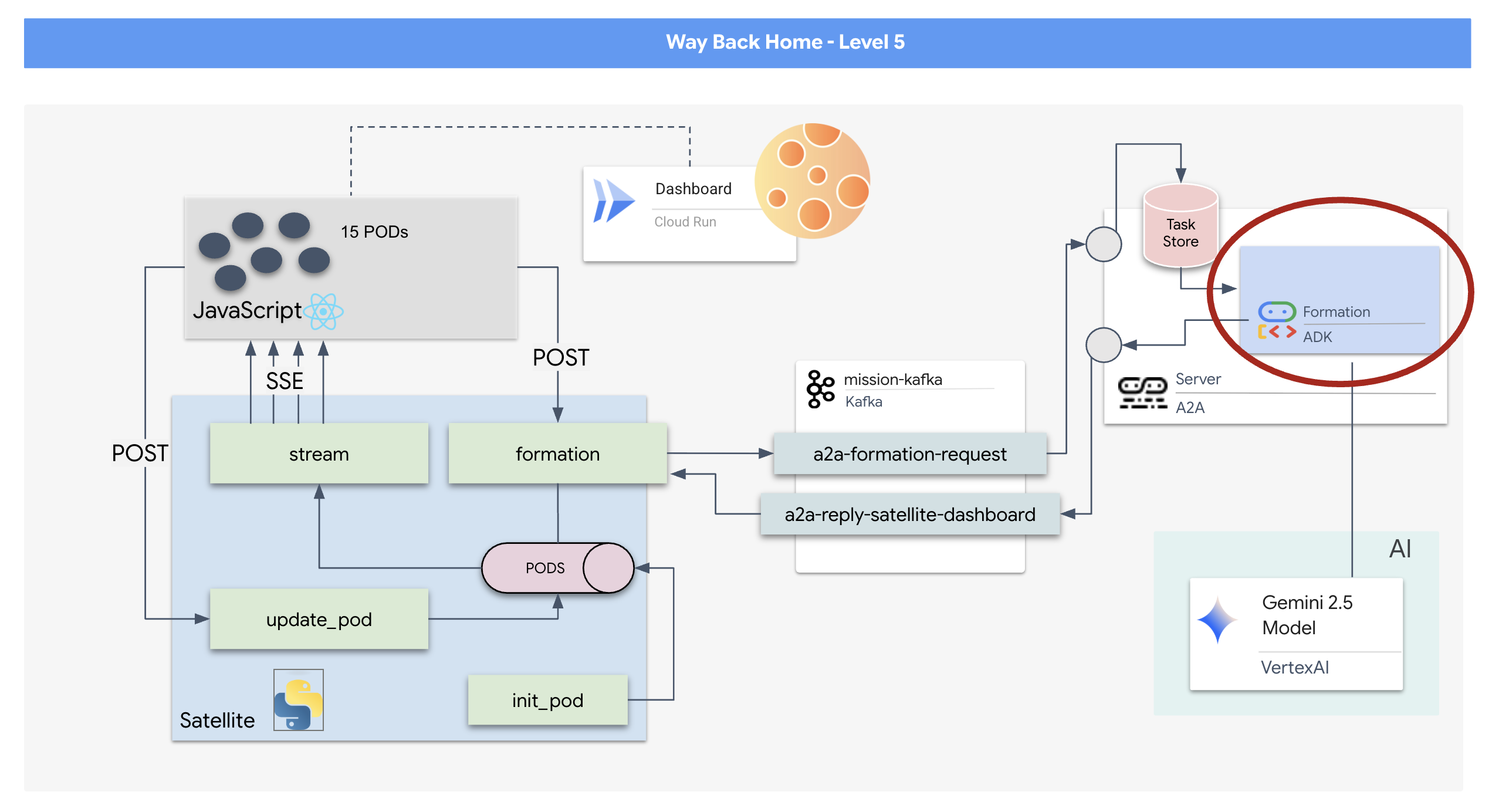
ポッドを特定の信号増幅フォーメーション(円、星、線)に強制的に配置するために必要な複雑なベクトル計算を実行できるカスタム Agent を構築する必要があります。このエージェントをサテライトの新しいアーキテクチャに接続する必要があります。
作業内容
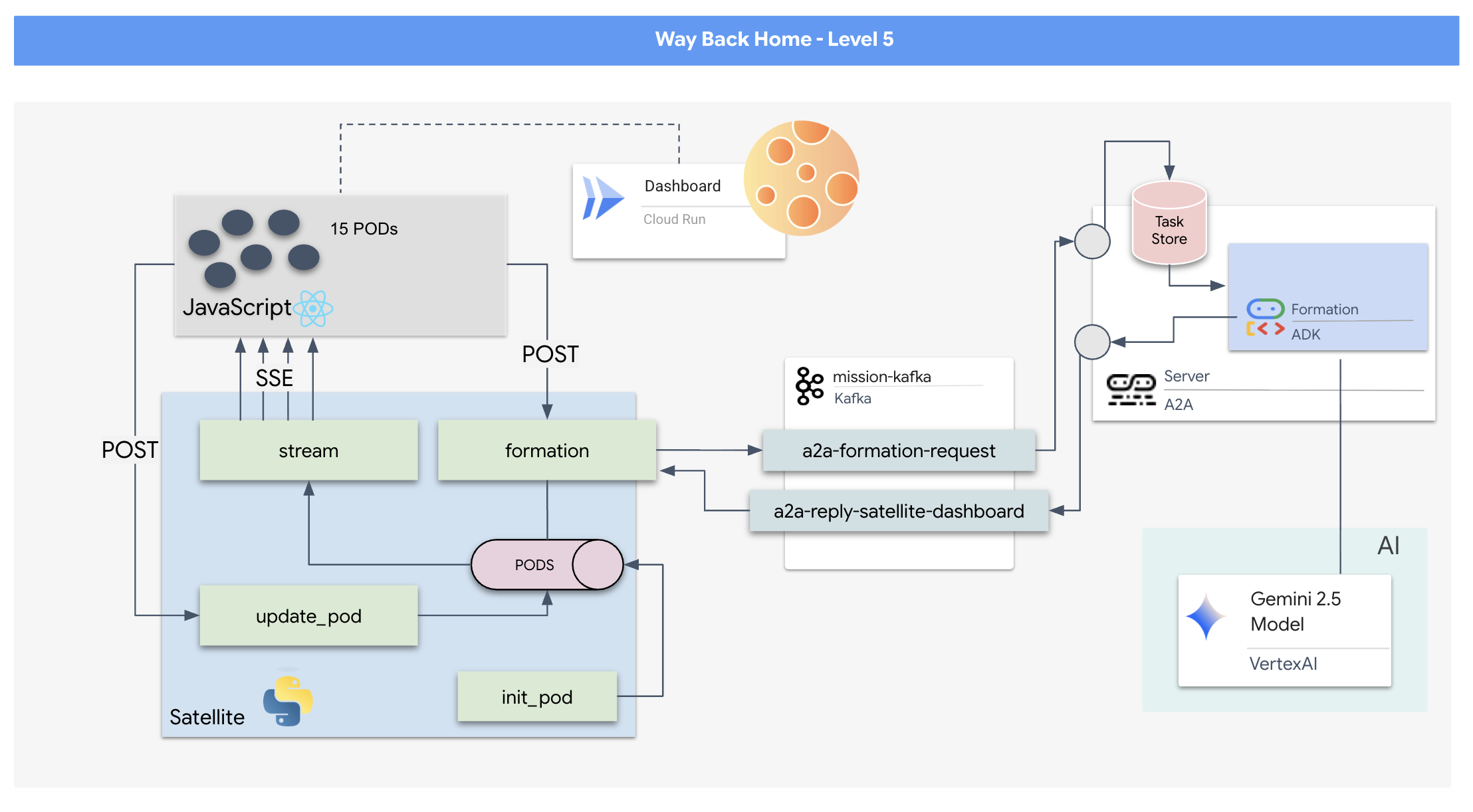
- 15 個の Pod のフリートをリアルタイムで可視化してコマンドする React ベースのヘッドアップ ディスプレイ(HUD)。
- 自然言語コマンドに基づいてポッドの複雑な幾何学的形状を計算する、Google Agent Development Kit(ADK)を使用する 生成 AI エージェント。
- サーバー送信イベント(SSE)を介してフロントエンドと通信する、中央ハブとして機能する Python ベースの Satellite Station バックエンド。
- Apache Kafka を使用して AI エージェントを衛星制御システムから切り離し、復元力のある非同期通信を可能にするイベント ドリブン アーキテクチャ。
学習内容
テクノロジー / コンセプト | 説明 |
Google ADK(Agent Development Kit) | このフレームワークを使用して、Gemini モデルを搭載した特殊な AI エージェントをビルド、テスト、スキャフォールディングします。 |
イベント ドリブン アーキテクチャ(EDA) | コンポーネントがイベントを介して非同期で通信する疎結合システムの構築原則を学び、アプリケーションの復元力とスケーラビリティを高めます。 |
Apache Kafka | Kafka を分散イベント ストリーミング プラットフォームとして設定して使用し、さまざまなマイクロサービス間のコマンドとデータのフローを管理します。 |
サーバー送信イベント(SSE) | FastAPI バックエンドに SSE を実装して、サーバーから React フロントエンドにリアルタイムのテレメトリー データをプッシュし、UI を常に更新します。 |
A2A(Agent-to-Agent)プロトコル | エージェントを A2A サーバーにラップして、より大規模なエージェント エコシステム内で標準化された通信と相互運用性を実現する方法について説明します。 |
FastAPI | この高性能 Python ウェブ フレームワークを使用して、コア バックエンド サービスである Satellite Station を構築します。 |
React | SSE ストリームをサブスクライブする最新のフロントエンド アプリケーションを使用して、動的でインタラクティブなユーザー インターフェースを作成します。 |
システム コントロールの生成 AI | 大規模言語モデル(LLM)をプロンプトして、会話型チャットだけでなく、特定のデータ指向タスク(座標生成など)を実行する方法を学びます。 |
2. 環境をセットアップする
Cloud Shell にアクセスする
👉Google Cloud コンソールの最上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの最上部にあるターミナル型のアイコンです)。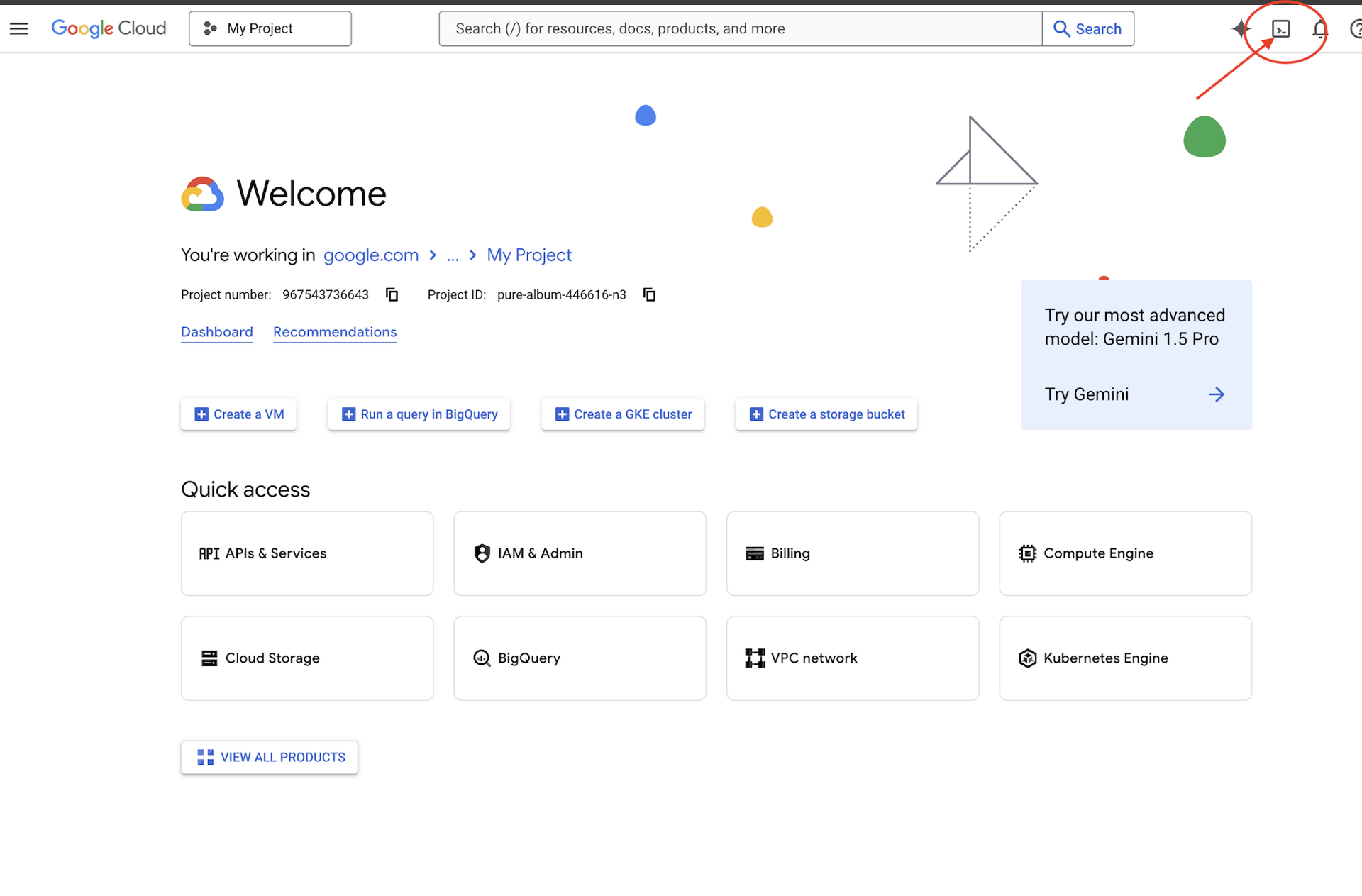
👉[エディタを開く] ボタン(開いたフォルダと鉛筆のアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。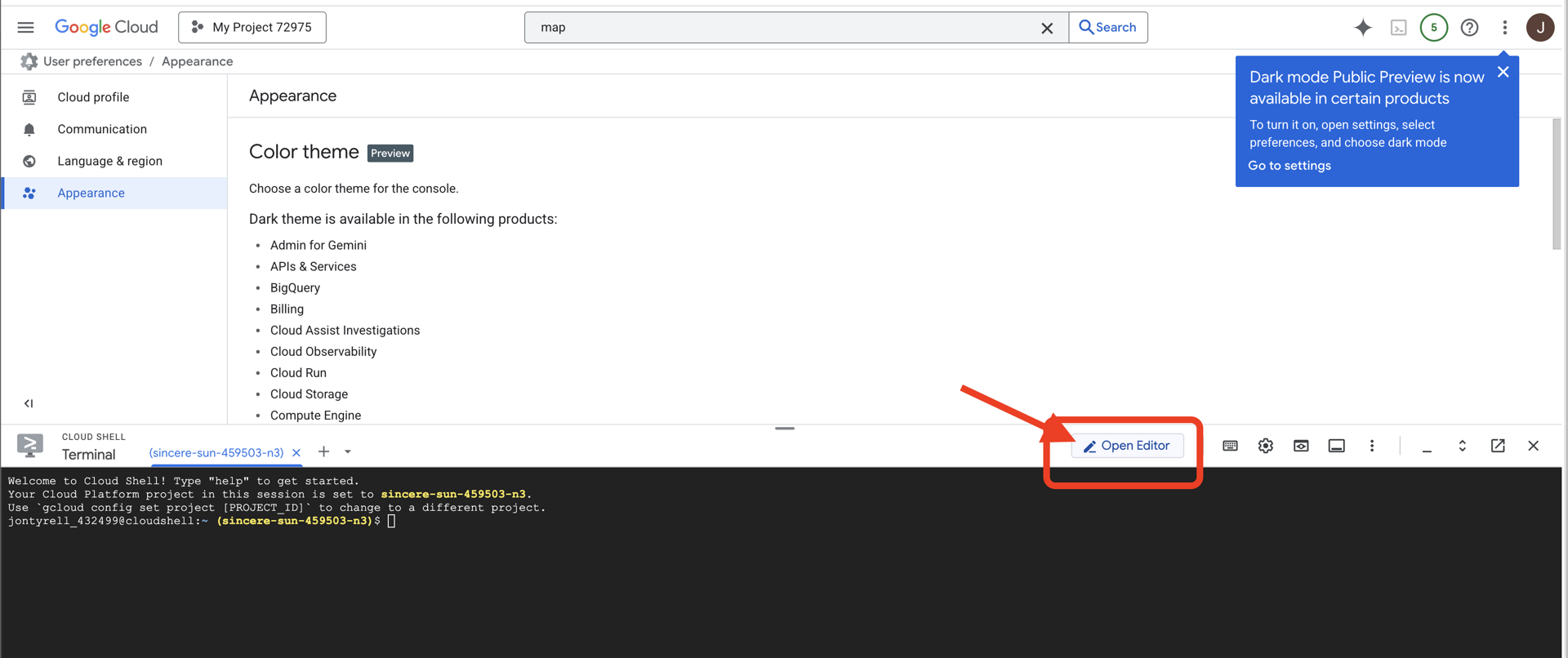
👉クラウド IDE でターミナルを開き、
👉💻 ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
アカウントが (ACTIVE) として表示されます。
前提条件
ℹ️ レベル 0 は省略可能(ただし推奨)
このミッションはレベル 0 なしでも完了できますが、レベル 0 を先に完了すると、進行状況に応じてビーコンがグローバル マップ上で点灯する様子を確認できるため、より没入感のある体験ができます。
プロジェクト環境を設定する
ターミナルに戻り、アクティブなプロジェクトを設定して、必要な Google Cloud サービス(Cloud Run、Vertex AI など)を有効にして、構成を完了します。
👉💻 ターミナルで、プロジェクト ID を設定します。
gcloud config set project $(cat ~/project_id.txt) --quiet
👉💻 必要なサービスを有効にする:
gcloud services enable compute.googleapis.com \
artifactregistry.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
iam.googleapis.com \
aiplatform.googleapis.com \
cloudresourcemanager.googleapis.com
依存関係のインストール
👉💻 レベル 5 に移動し、必要な Python パッケージをインストールします。
cd $HOME/way-back-home/level_5
uv sync
主な依存関係は次のとおりです。
パッケージ | 目的 |
| Satellite Station と SSE ストリーミング用の高性能ウェブ フレームワーク |
| FastAPI アプリケーションの実行に必要な ASGI サーバー |
| Formation Agent の構築に使用される Agent Development Kit |
| 標準化された通信のための Agent-to-Agent プロトコル ライブラリ |
| イベント ループ用の非同期 Kafka クライアント |
| Gemini モデルにアクセスするためのネイティブ クライアント |
| シミュレーションのベクトル数学と座標計算 |
| リアルタイムの双方向通信のサポート |
| 環境変数と構成シークレットを管理します |
| サーバー送信イベント(SSE)の効率的な処理 |
| 外部 API 呼び出し用のシンプルな HTTP ライブラリ |
設定を確認する
コードに入る前に、すべてのシステムが正常であることを確認しましょう。検証スクリプトを実行して、Google Cloud プロジェクト、API、Python の依存関係を監査します。
👉💻 検証スクリプトを実行します。
cd $HOME/way-back-home/level_5/scripts
chmod +x verify_setup.sh
. verify_setup.sh
👀 一連の緑色のチェックマーク(✅)が表示されます。
- 赤い十字(❌)が表示された場合は、出力に表示された修正コマンド(
gcloud services enable ...やpip install ...など)を実行します。 - 注:
.envの黄色い警告は現時点では許容されます。このファイルは次のステップで作成します。
🚀 Verifying Mission Charlie (Level 5) Infrastructure... ✅ Google Cloud Project: xxxxxx ✅ Cloud APIs: Active ✅ Python Environment: Ready 🎉 SYSTEMS ONLINE. READY FOR MISSION.
3. LLM を使用して Pod の位置をフォーマットする
救助作戦の「頭脳」を構築する必要があります。これは、Google ADK(Agent Development Kit)を使用して作成されたエージェントです。その唯一の目的は、特殊な幾何学的ナビゲーターとして機能することです。標準的な LLM はチャットを好みますが、深宇宙では対話ではなくデータが必要です。このエージェントは、「Star」のようなコマンドを受け取り、15 個の Pod の未加工の JSON 座標を返すようにプログラムします。
エージェントをスキャフォールディングする
👉💻 次のコマンドを実行して、エージェント ディレクトリに移動し、ADK 作成ウィザードを起動します。
cd $HOME/way-back-home/level_5/agent
uv run adk create formation
CLI によってインタラクティブな設定ウィザードが起動します。次のレスポンスを使用して、エージェントを構成します。
- モデルを選択: [オプション 1](Gemini Flash)を選択します。
- 注: バージョンは異なる場合があります。速度を重視する場合は、常に「Flash」バリアントを選択します。
- バックエンドを選択: [オプション 2](Vertex AI)を選択します。
- Google Cloud プロジェクト ID を入力: Enter キーを押して、デフォルト(環境から検出)を受け入れます。
- Google Cloud リージョンを入力: Enter キーを押してデフォルト(
us-central1)を受け入れます。
👀 ターミナルのやり取りは次のようになります。
(way-back-home) user@cloudshell:~/way-back-home/level_5/agent$ adk create formation Choose a model for the root agent: 1. gemini-2.5-flash 2. Other models (fill later) Choose model (1, 2): 1 1. Google AI 2. Vertex AI Choose a backend (1, 2): 2 You need an existing Google Cloud account and project... Enter Google Cloud project ID [your-project-id]: <PRESS ENTER> Enter Google Cloud region [us-central1]: <PRESS ENTER> Agent created in /home/user/way-back-home/level_5/agent/formation: - .env - __init__.py - agent.py
Agent created 成功メッセージが表示されます。これで、これから変更するスケルトン コードが生成されます。
👉✏️ エディタで、新しく作成した $HOME/way-back-home/level_5/agent/formation/agent.py ファイルに移動して開きます。ファイルの内容全体を次のコードに置き換えます。これにより、エージェントの名前が更新され、厳格な運用パラメータが提供されます。
import os
from google.adk.agents import Agent
root_agent = Agent(
name="formation_agent",
model="gemini-2.5-flash",
instruction="""
You are the **Formation Controller AI**.
Your strict objective is to calculate X,Y coordinates for a fleet of **15 Drones** based on a requested geometric shape.
### FIELD SPECIFICATIONS
- **Canvas Size**: 800px (width) x 600px (height).
- **Safe Margin**: Keep pods at least 50px away from edges (x: 50-750, y: 50-550).
- **Center Point**: x=400, y=300 (Use this as the origin for shapes).
- **Top Menu Avoidance**: Do NOT place pods in the top 100px (y < 100) to avoid UI overlap.
### FORMATION RULES
When given a formation name, output coordinates for exactly 15 pods (IDs 0-14).
1. **CIRCLE**: Evenly spaced around a center point (R=200).
2. **STAR**: 5 points or a star-like distribution.
3. **X**: A large X crossing the screen.
4. **LINE**: A horizontal line across the middle.
5. **PARABOLA**: A U-shape opening UPWARDS. Center it at y=400, opening up to y=100. IMPORTANT: Lowest point must be at bottom (high Y value), opening up (low Y value). Screen coordinates have (0,0) at the TOP-LEFT. The vertex should be at the BOTTOM (e.g., y=500), with arms reaching up to y=200.
6. **RANDOM**: Scatter randomly within safe bounds.
7. **CUSTOM**: If the user inputs something else (e.g., "SMILEY", "TRIANGLE"), do your best to approximate it geometrically.
### OUTPUT FORMAT
You MUST output **ONLY VALID JSON**. No markdown fencing, no preamble, no commentary.
Refuse to answer non-formation questions.
**JSON Structure**:
```json
[
{"x": 400, "y": 300},
{"x": 420, "y": 300},
... (15 total items)
]
```
"""
)
- 幾何学的精度: システム プロンプトで「キャンバス サイズ」と「セーフ マージン」を定義することで、エージェントがポッドを画面外や UI 要素の下に配置しないようにします。
- JSON の強制: LLM に「形式に沿っていない質問には回答しない」と指示し、「前置きなし」で回答するように指示することで、応答の解析を試みたときにダウンストリーム コード(Satellite)がクラッシュしないようにします。
- 分離されたロジック: このエージェントはまだ Kafka を認識していません。数学しかできません。次のステップでは、この「Brain」を Kafka Server でラップします。
エージェントをローカルでテストする
エージェントを Kafka の「神経系」に接続する前に、エージェントが正しく機能していることを確認する必要があります。ターミナルでエージェントを直接操作して、有効な JSON 座標が生成されることを確認できます。
👉💻 adk run コマンドを使用して、エージェントとのチャット セッションを開始します。
cd $HOME/way-back-home/level_5/agent
uv run adk run formation
- 入力: 「
Circle」と入力して Enter キーを押します。- 成功条件: 生の JSON リスト(
[{"x": 400, "y": 200}, ...]など)が表示されるはずです。JSON の前に「座標は次のとおりです」などのマークダウン テキストがないことを確認します。
- 成功条件: 生の JSON リスト(
- 入力: 「
Line」と入力して Enter キーを押します。- 成功条件: 座標が水平線を作成することを確認します(y 値が類似している必要があります)。
エージェントがクリーンな JSON を出力することを確認したら、Kafka サーバーにラップします。
👉💻 終了するには Ctrl+C キーを押します。
4. Formation Agent の A2A サーバーの作成
A2A(Agent-to-Agent)について
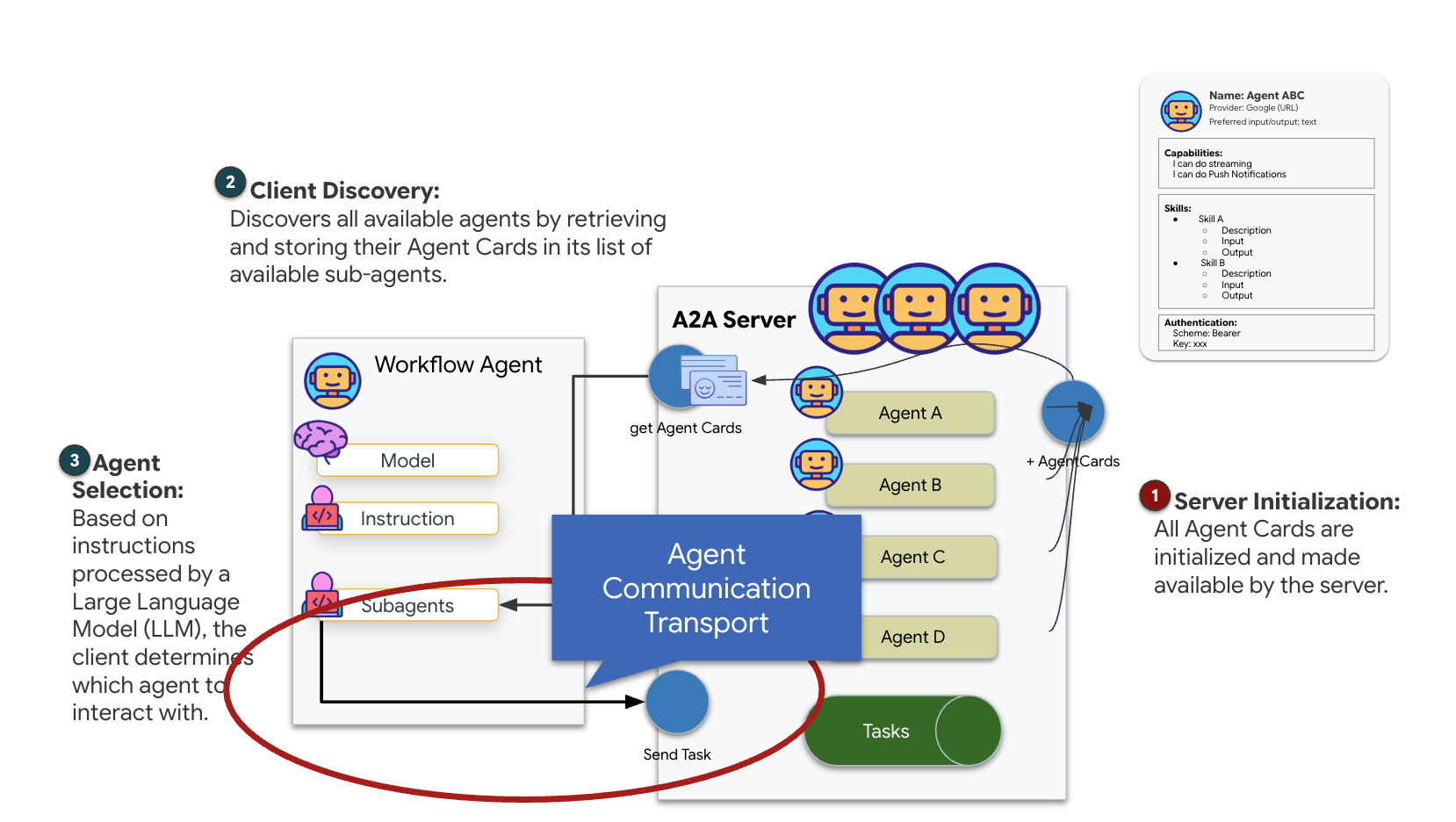
A2A(Agent-to-Agent)プロトコルは、AI エージェント間のシームレスな相互運用性を実現するように設計されたオープン スタンダードです。このフレームワークにより、エージェントは単純なテキスト交換を超えて、タスクの委任、複雑なアクションの調整、分散型エコシステムでの共通の目標達成に向けたまとまりのあるユニットとしての機能が可能になります。
A2A トランスポート(HTTP、gRPC、Kafka)について
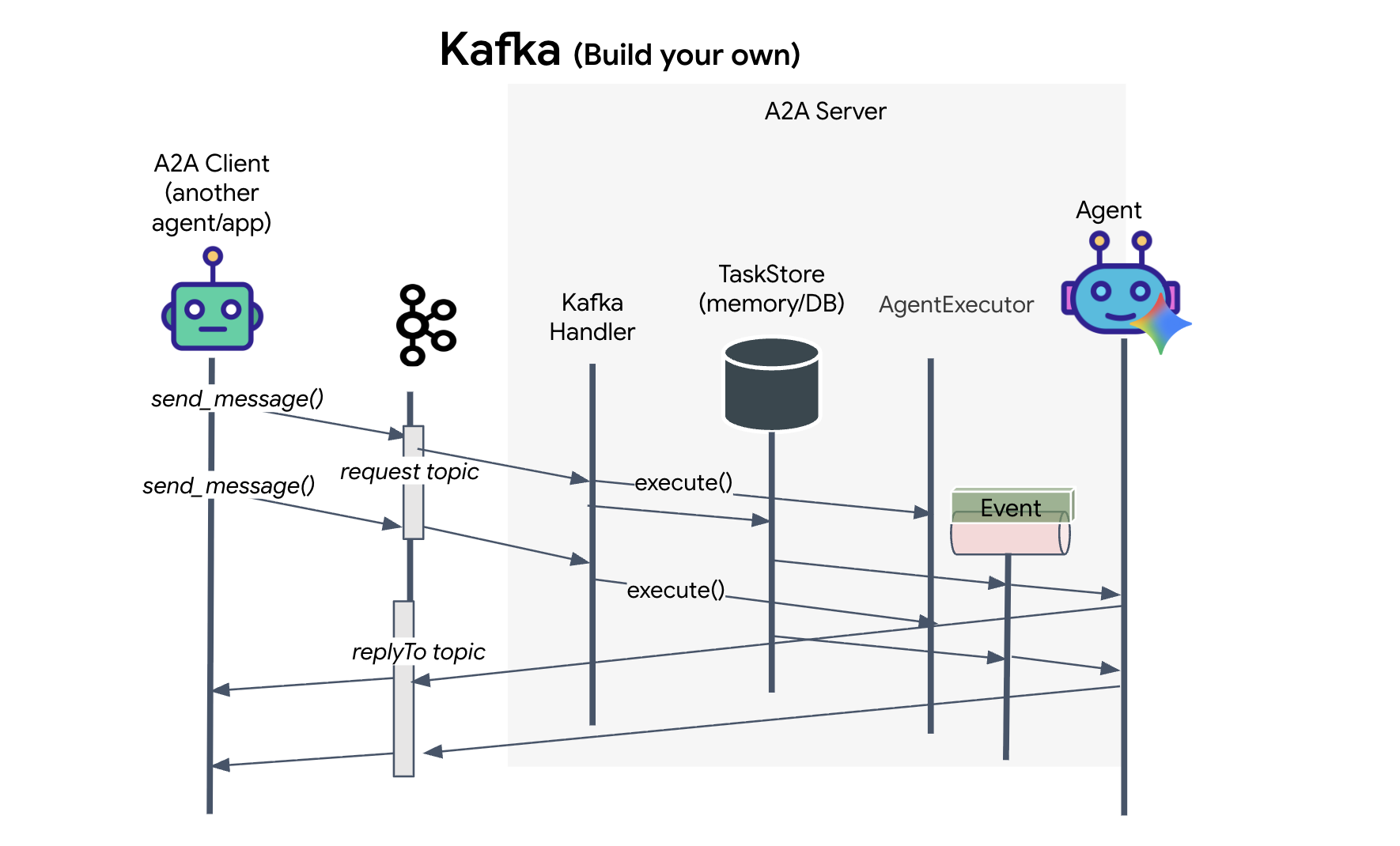
A2A プロトコルは、クライアントとエージェントが通信するための 2 つの異なる方法を提供します。それぞれが異なるアーキテクチャのニーズに対応します。HTTP(JSON-RPC)は、すべてのウェブ環境で普遍的に機能するデフォルトのユビキタス標準です。gRPC は、プロトコル バッファを利用して効率的で厳密な型指定の通信を行う高性能オプションです。ラボでは、Kafka トランスポートも提供しています。これは、システムの分離が優先される堅牢なイベント ドリブン アーキテクチャ向けに設計されたカスタム実装です。
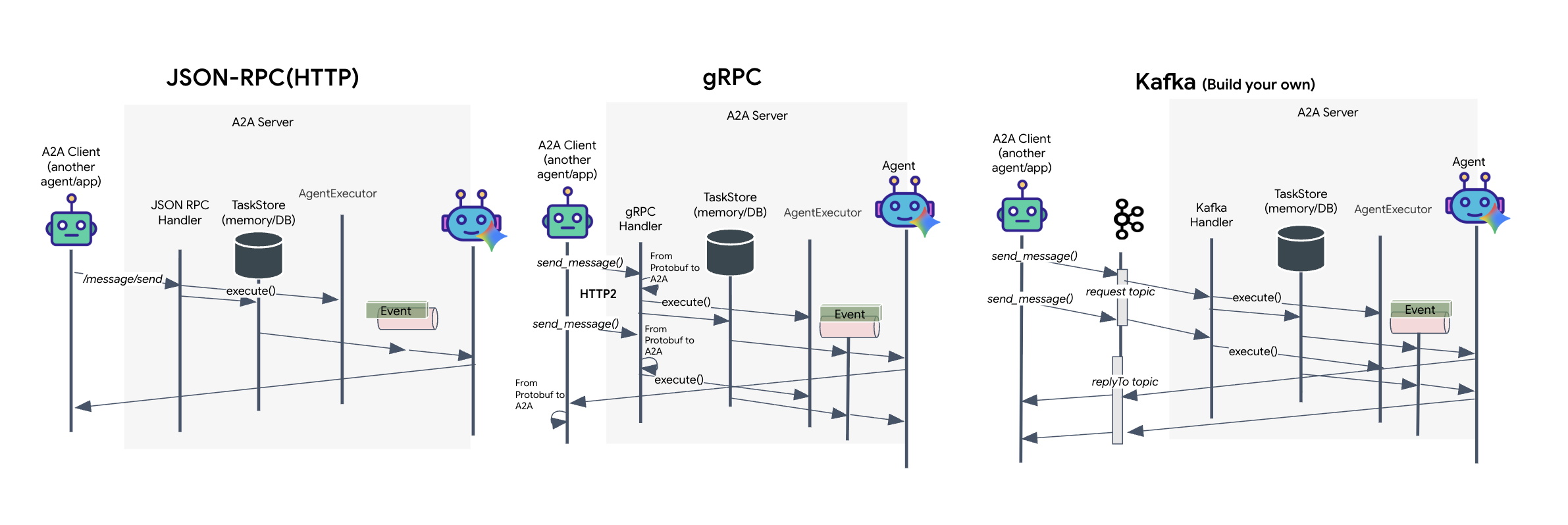
内部的には、これらのトランスポートはデータのフローをまったく異なる方法で処理します。HTTP モデルでは、クライアントが JSON リクエストを送信し、接続を開いたままにして、エージェントがタスクを完了して完全な結果を一度に返すのを待ちます。gRPC は、バイナリデータと HTTP/2 を使用してこれを最適化し、単純なリクエスト / レスポンス サイクルと、エージェントが更新(「思考」や「アーティファクトが作成された」など)をリアルタイムで送信するストリーミングの両方を可能にします。Kafka の実装は非同期で動作します。クライアントは、耐久性の高い「リクエスト トピック」にリクエストをパブリッシュし、別の「返信トピック」をリッスンします。サーバーは、可能なときにメッセージを取得して処理し、結果を返信します。つまり、2 つが直接通信することはありません。
どの方法を選択するかは、速度、複雑さ、永続性に関する具体的な要件によって異なります。HTTP は、簡単に開始してデバッグできるため、シンプルな統合に最適です。gRPC は、低レイテンシとストリーミング タスクの更新が重要な内部サービス間の通信に最適な選択肢です。ただし、Kafka はリクエストをキュー内のディスクに保存するため、エージェント サーバーがクラッシュしたり再起動したりしてもタスクは存続します。HTTP や gRPC では実現できない耐久性と分離を提供するため、復元力のある選択肢として際立っています。
カスタム トランスポート レイヤ: Kafka
Kafka は、オペレーションの頭脳(Formation Agent)を物理的な制御(Satellite Station)から切り離す非同期バックボーンとして機能します。エージェントが複雑なベクトルを計算している間、システムが同期接続で待機することを強制する代わりに、エージェントは結果をイベントとして Kafka トピックにパブリッシュします。これは永続バッファとして機能し、Satellite が独自のペースで指示を消費できるようにします。また、ネットワーク レイテンシが大幅に発生したり、システムが一時的にクラッシュしたりしても、形成データが失われることはありません。
Kafka を使用すると、遅い線形プロセスが、命令とテレメトリーが独立して流れる復元力のあるストリーミング パイプラインに変換され、集中的な AI 処理中もミッションの HUD の応答性が維持されます。
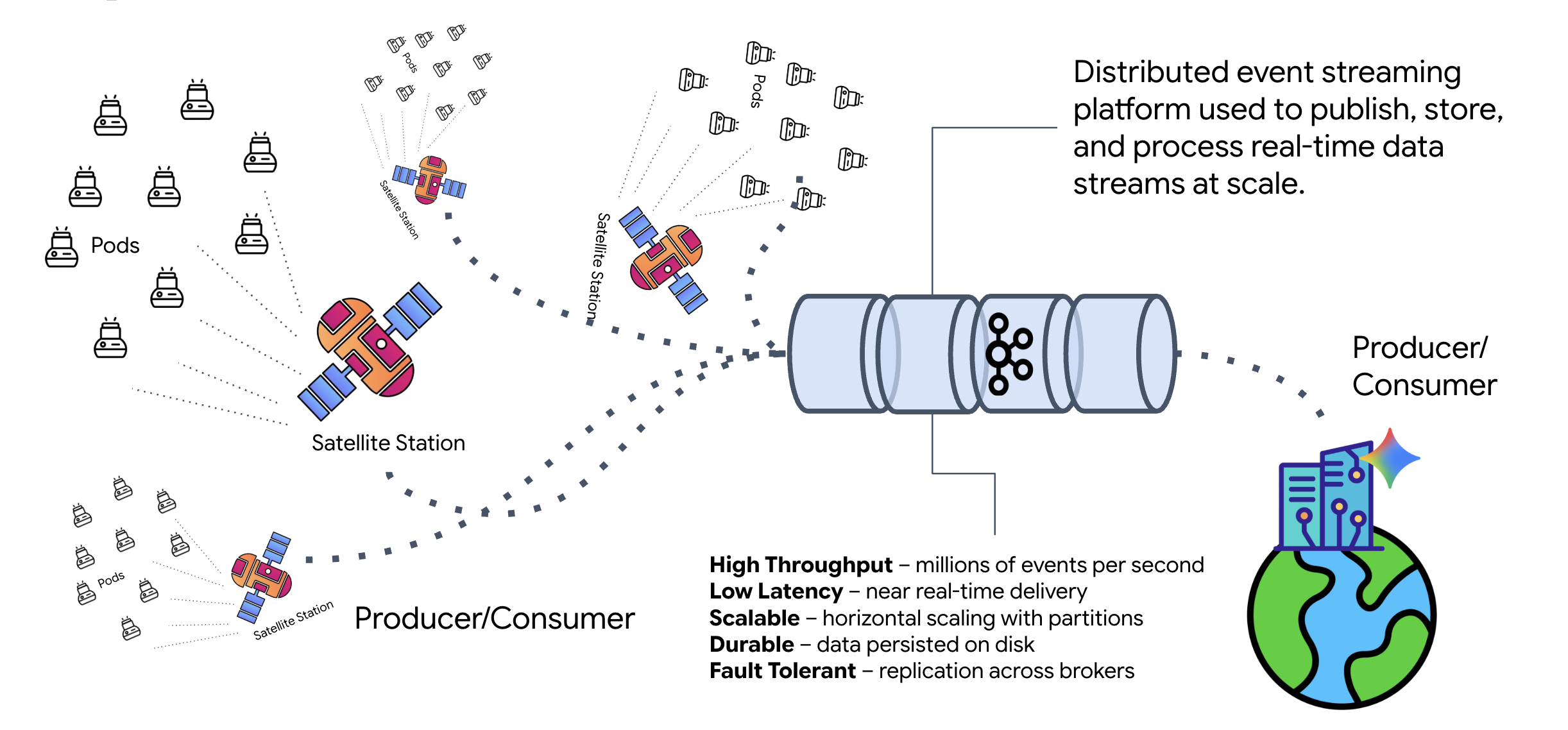
Kafka とは
Kafka は分散型イベント ストリーミング プラットフォームです。イベント ドリブン アーキテクチャ(EDA)では、次のようになります。
- プロデューサーは、「トピック」にメッセージをパブリッシュします。
- コンシューマーはこれらのトピックにサブスクライブし、メッセージが届くと反応します。
Kafka を使用する理由
システムを分離します。Formation エージェントは自律的に動作し、送信者の ID やステータスを知ることなく、受信リクエストを待機します。これにより、責任が分離され、Satellite がオフラインになってもワークフローはそのまま維持されます。Kafka は、Satellite が再接続されるまでメッセージを保存するだけです。
Google Cloud Pub/Sub について
Google Cloud Pub/Sub を使用できます。Pub/Sub は、Google のサーバーレス メッセージング サービスです。Kafka は高スループットで「再生可能」なストリームに適していますが、Pub/Sub は使いやすさからよく使用されます。このラボでは、Kafka を使用して、堅牢で永続的なメッセージ バスをシミュレートします。
ローカル Kafka クラスタを起動する
以下のコマンドブロック全体をコピーしてターミナルに貼り付けます。これにより、公式の Kafka イメージがダウンロードされ、バックグラウンドで起動します。
👉💻 ターミナルで次のコマンドを実行します。
# Navigate to the correct mission directory first
cd $HOME/way-back-home/level_5
# Run the Kafka container in detached mode
docker run -d \
--name mission-kafka \
-p 9092:9092 \
-e KAFKA_PROCESS_ROLES='broker,controller' \
-e KAFKA_NODE_ID=1 \
-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \
-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 \
-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@127.0.0.1:9093 \
-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \
apache/kafka:4.2.0-rc1
👉💻 docker ps コマンドを使用して、コンテナが実行されていることを確認します。
docker ps
👀 mission-kafka コンテナが実行され、ポート 9092 が公開されていることを確認する出力が表示されます。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES c1a2b3c4d5e6 apache/kafka:4.2.0-rc1 "/opt/kafka/bin/kafka..." 15 seconds ago Up 14 seconds 0.0.0.0:9092->9092/tcp, 9093/tcp mission-kafka
Kafka トピックとは
Kafka トピックは、メッセージ専用のチャネルまたはカテゴリと考えることができます。イベント レコードが生成された順序で保存されるログブックのようなものです。プロデューサーは特定のトピックにメッセージを書き込み、コンシューマーはそれらのトピックから読み取ります。これにより、送信側と受信側が切り離されます。プロデューサーは、どのコンシューマーがデータを読み取るかを知る必要はなく、正しい「チャネル」に送信するだけで済みます。このミッションでは、エージェントにフォーメーション リクエストを送信するためのトピックと、エージェントが返信をパブリッシュしてサテライトが読み取れるようにするためのトピックの 2 つを作成します。
👉💻 次のコマンドを実行して、実行中の Docker コンテナ内に必要なトピックを作成します。
# Create the topic for formation requests
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-formation-request \
--bootstrap-server 127.0.0.1:9092
# Create the topic where the satellite dashboard will listen for replies
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--create \
--topic a2a-reply-satellite-dashboard \
--bootstrap-server 127.0.0.1:9092
👉💻 チャンネルが開いていることを確認するには、リスト コマンドを実行します。
docker exec mission-kafka /opt/kafka/bin/kafka-topics.sh \
--list \
--bootstrap-server 127.0.0.1:9092
👀 先ほど作成したトピックの名前が表示されます。
a2a-formation-request a2a-reply-satellite-dashboard
これで、Kafka インスタンスの構成が完了し、ミッション クリティカルなデータをルーティングできるようになりました。
Kafka A2A サーバーの実装
Agent-to-Agent(A2A)プロトコルは、独立したエージェント システム間の相互運用性のための標準化されたフレームワークを確立します。これにより、異なるチームによって開発されたエージェントや、異なるインフラストラクチャで実行されているエージェントが互いを検出し、接続ごとにカスタム統合ロジックを必要とせずに効果的に連携できます。
リファレンス実装 a2a-python は、これらのエージェント アプリケーションを実行するための基盤となるライブラリです。この設計のコア機能は拡張性です。通信レイヤを抽象化することで、デベロッパーは HTTP などのプロトコルを他のプロトコルに置き換えることができます。
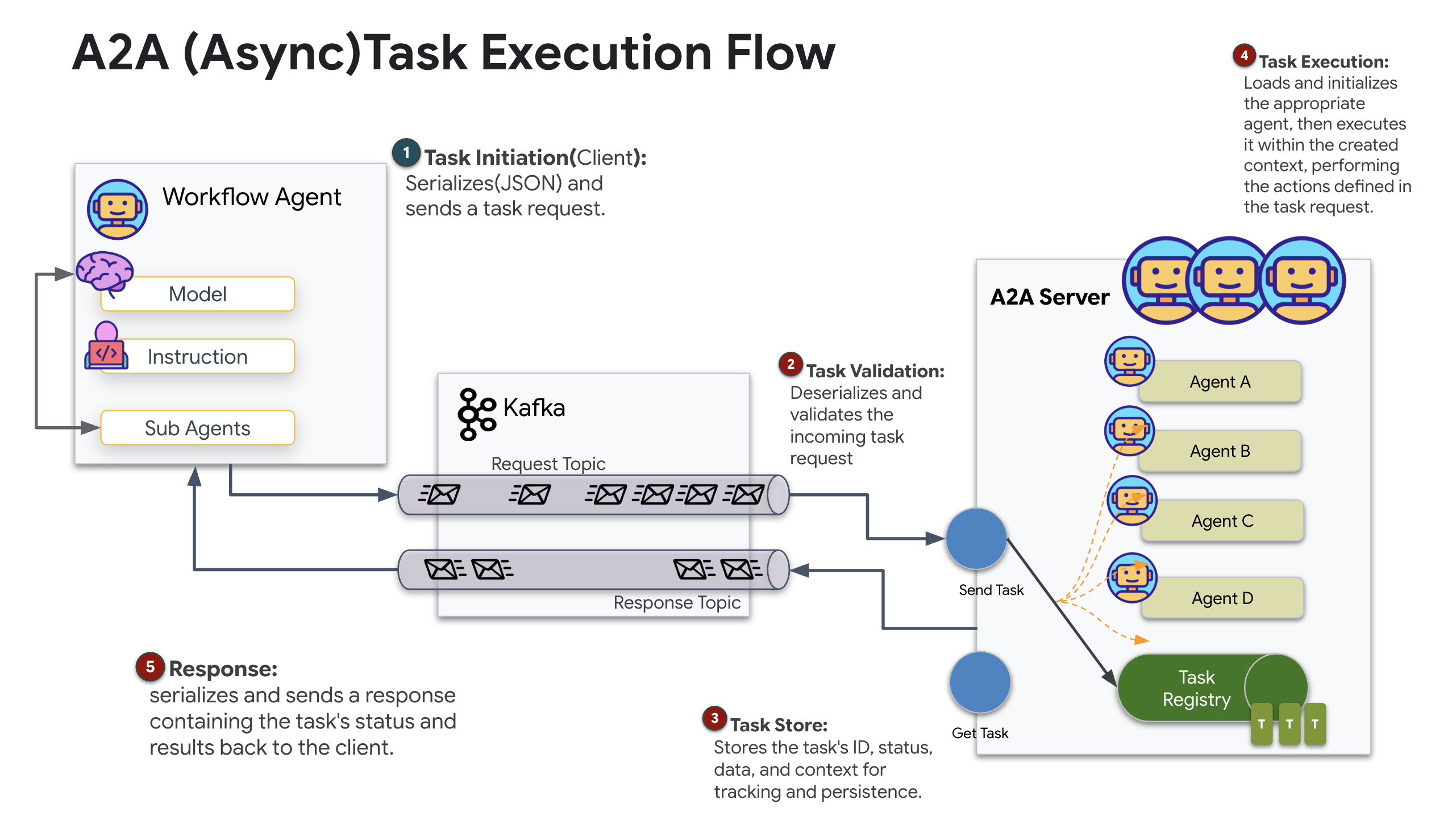
このプロジェクトでは、カスタム Kafka 実装 a2a-python-kafka を使用して、この拡張性を活用しています。この実装を使用して、A2A 標準でエージェント通信をさまざまなアーキテクチャのニーズに合わせて調整する方法を説明します。この例では、同期 HTTP を非同期イベントバスに置き換えます。
Formation エージェントで A2A を有効にする
次に、エージェントを A2A サーバーにラップして、次のことが可能な相互運用可能なサービスにします。
- Kafka トピックからタスクをリッスンします。
- 受信したタスクを基盤となる ADK エージェントに渡して処理します。
- 結果を返信トピックにパブリッシュします。
👉✏️ $HOME/way-back-home/level_5/agent/agent_to_kafka_a2a.py で、#REPLACE-CREATE-KAFKA-A2A-SERVER を次のコードに置き換えます。
async def create_kafka_server(
agent: BaseAgent,
*,
bootstrap_servers: str | List[str] = "localhost:9092",
request_topic: str = "a2a-formation-request",
consumer_group_id: str = "a2a-agent-group",
agent_card: Optional[Union[AgentCard, str]] = None,
runner: Optional[Runner] = None,
**kafka_config: Any,
) -> KafkaServerApp:
"""Convert an ADK agent to a A2A Kafka Server application.
Args:
agent: The ADK agent to convert
bootstrap_servers: Kafka bootstrap servers.
request_topic: Topic to consume requests from.
consumer_group_id: Consumer group ID for the server.
agent_card: Optional pre-built AgentCard object or path to agent card
JSON. If not provided, will be built automatically from the
agent.
runner: Optional pre-built Runner object. If not provided, a default
runner will be created using in-memory services.
**kafka_config: Additional Kafka configuration.
Returns:
A KafkaServerApp that can be run with .run() or .start()
"""
# Set up ADK logging
adk_logger = logging.getLogger("google_adk")
adk_logger.setLevel(logging.INFO)
async def create_runner() -> Runner:
"""Create a runner for the agent."""
return Runner(
app_name=agent.name or "adk_agent",
agent=agent,
# Use minimal services - in a real implementation these could be configured
artifact_service=InMemoryArtifactService(),
session_service=InMemorySessionService(),
memory_service=InMemoryMemoryService(),
credential_service=InMemoryCredentialService(),
)
# Create A2A components
task_store = InMemoryTaskStore()
agent_executor = A2aAgentExecutor(
runner=runner or create_runner,
)
# Initialize logic handler
from a2a.server.request_handlers.default_request_handler import DefaultRequestHandler
logic_handler = DefaultRequestHandler(
agent_executor=agent_executor, task_store=task_store
)
# Prepare Agent Card
rpc_url = f"kafka://{bootstrap_servers}/{request_topic}"
# Create Kafka Server App
server_app = KafkaServerApp(
request_handler=logic_handler,
bootstrap_servers=bootstrap_servers,
request_topic=request_topic,
consumer_group_id=consumer_group_id,
**kafka_config
)
return server_app
このコードは、次の主要コンポーネントを設定します。
- ランナー: エージェントのランタイムを提供します(メモリ、認証情報などを処理します)。
- Task Store: リクエストの状態が「保留中」から「完了」に移行する際に追跡します。
- Agent Executor: Kafka からタスクを取得し、座標を計算するためにエージェントに渡します。
- KafkaServerApp: Kafka ブローカーへの物理接続を管理します。
環境変数を構成する
ADK の設定により、エージェントのフォルダ内に Google Vertex AI の設定を含む .env ファイルが作成されました。これをプロジェクトのルートに移動し、Kafka クラスタの座標を追加する必要があります。
次のコマンドを実行して、ファイルをコピーし、Kafka サーバーのアドレスを追加します。
cd $HOME/way-back-home/level_5
# 1. Copy the API keys from the agent folder to the project root
cp agent/formation/.env .env
# 2. Append the Kafka Bootstrap Server address to the file
echo -e "\nKAFKA_BOOTSTRAP_SERVERS=localhost:9092" >> .env
# 3. Verify the file content
echo "✅ Environment configured. Here are the last few lines:"
tail .env
A2A Interstellar Loop を確認する
次に、実弾射撃テストで非同期イベント ループが正しく機能していることを確認します。Kafka クラスタを介して手動シグナルを送信し、エージェントの応答を監視します。
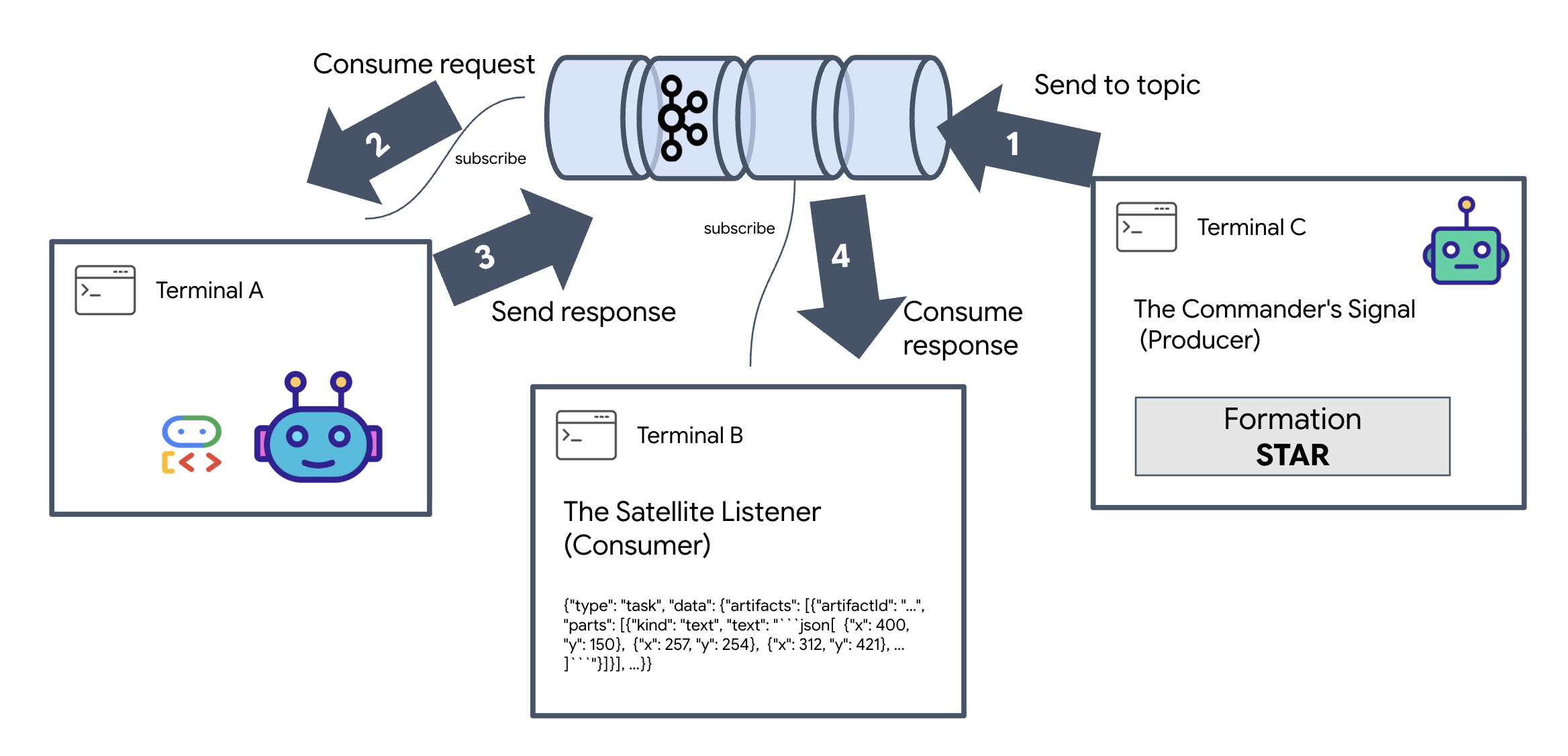
イベントのライフサイクル全体を確認するには、3 つのターミナルを使用します。
ターミナル A: Formation エージェント(A2A Kafka サーバー)
👉💻 このターミナルは、Kafka をリッスンし、Gemini を使用して幾何学的な計算を行う Python プロセスを実行します。
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Install the custom Kafka-enabled A2A library
uv pip install git+https://github.com/weimeilin79/a2a-python-kafka.git
# Start the Agent Server
uv run agent/server.py
次のように表示されるまで待ちます。
[INFO] Kafka Server App Started. Starting to consume requests...
ターミナル B: サテライト リスナー(コンシューマー)
👉💻 このターミナルで、返信トピックをリッスンします。これにより、Satellite が指示を待機している状態がシミュレートされます。
# Listen for the AI's response on the satellite channel
docker exec mission-kafka /opt/kafka/bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-reply-satellite-dashboard \
--from-beginning \
--property "print.headers=true"
このターミナルはアイドル状態になります。エージェントがメッセージをパブリッシュするのを待っています。
ターミナル C: 指揮官の信号(プロデューサー)
👉💻 次に、未加工の A2A 形式のリクエストを a2a-formation-request トピックに送信します。エージェントが回答の送信先を認識できるように、特定の Kafka ヘッダーを含める必要があります。
echo 'correlation_id=ping-manual-01,reply_topic=a2a-reply-satellite-dashboard|{"method": "message_send", "params": {"message": {"message_id": "msg-001", "role": "user", "parts": [{"text": "STAR"}]}}, "streaming": false, "agent_card": {"name": "DiagnosticTool", "version": "1.0.0"}}' | \
docker exec -i mission-kafka /opt/kafka/bin/kafka-console-producer.sh \
--bootstrap-server localhost:9092 \
--topic a2a-formation-request \
--property "parse.headers=true" \
--property "headers.key.separator==" \
--property "headers.delimiter=|"
結果の分析
👀 ループが成功したら、ターミナル B に切り替えます。大きな JSON ブロックがすぐに表示されます。送信したヘッダー correlation_id:ping-manual-01 で始まります。その後に task オブジェクトが続きます。この JSON の parts セクションをよく見ると、Gemini が 15 個の Pod に対して計算した未加工の X 座標と Y 座標が表示されます。
{"type": "task", "data": {"artifacts": [{"artifactId": "...", "parts": [{"kind": "text", "text": "```json\n[\n {\"x\": 400, \"y\": 150},\n {\"x\": 257, \"y\": 254},\n {\"x\": 312, \"y\": 421},\n ... \n]\n```"}]}], ...}}
エージェントとレシーバーの分離が完了しました。システムが完全にイベント ドリブンになったため、リクエストとレスポンスのレイテンシの「星間ノイズ」はもはや問題ではありません。
次に進む前に、バックグラウンド プロセスを停止してネットワーク ポートを解放します。
👉💻 各ターミナル(A、B、C)で次の操作を行います。
Ctrl + Cを押して、実行中のプロセスを終了します。
5. 衛星ステーション(A2A Kafka クライアントと SSE)
このステップでは、衛星ステーションを構築します。これは、Kafka クラスタとパイロットのビジュアル表示(React フロントエンド)間のブリッジです。このサーバーは、Kafka クライアント(エージェントと通信するため)と SSE ストリーマー(ブラウザと通信するため)の両方として機能します。
Kafka クライアントとは
Kafka クラスタはラジオ局のようなものです。Kafka クライアントはラジオ受信機です。KafkaClientTransport を使用すると、アプリケーションで次の操作を行えます。
- メッセージを生成する: エージェントに「タスク」(「星の形成」など)を送信します。
- 返信を使用する: 特定の「返信トピック」をリッスンして、エージェントから座標を取得します。
1. 接続の初期化
FastAPI の lifespan イベント ハンドラを使用して、サーバーの起動時に Kafka 接続が開始され、シャットダウン時に正常に閉じられるようにします。
👉✏️ $HOME/way-back-home/level_5/satellite/main.py で、#REPLACE-CONNECT-TO-KAFKA-CLUSTER を次のコードに置き換えます。
@asynccontextmanager
async def lifespan(app: FastAPI):
global kafka_transport
logger.info("Initializing Kafka Client Transport...")
bootstrap_server = os.getenv("KAFKA_BOOTSTRAP_SERVERS")
request_topic = "a2a-formation-request"
reply_topic = "a2a-reply-satellite-dashboard"
# Create AgentCard for the Client
client_card = AgentCard(
name="SatelliteDashboard",
description="Satellite Dashboard Client",
version="1.0.0",
url="https://example.com/satellite-dashboard",
capabilities=AgentCapabilities(),
default_input_modes=["text/plain"],
default_output_modes=["text/plain"],
skills=[]
)
kafka_transport = KafkaClientTransport(
agent_card=client_card,
bootstrap_servers=bootstrap_server,
request_topic=request_topic,
reply_topic=reply_topic,
)
try:
await kafka_transport.start()
logger.info("Kafka Client Transport Started Successfully.")
except Exception as e:
logger.error(f"Failed to start Kafka Client: {e}")
yield
if kafka_transport:
logger.info("Stopping Kafka Client Transport...")
await kafka_transport.stop()
logger.info("Kafka Client Transport Stopped.")
2. コマンドを送信する
ダッシュボードのボタンをクリックすると、/formation エンドポイントがトリガーされます。プロデューサーとして機能し、リクエストを正式な A2A Message にラップしてエージェントに送信します。
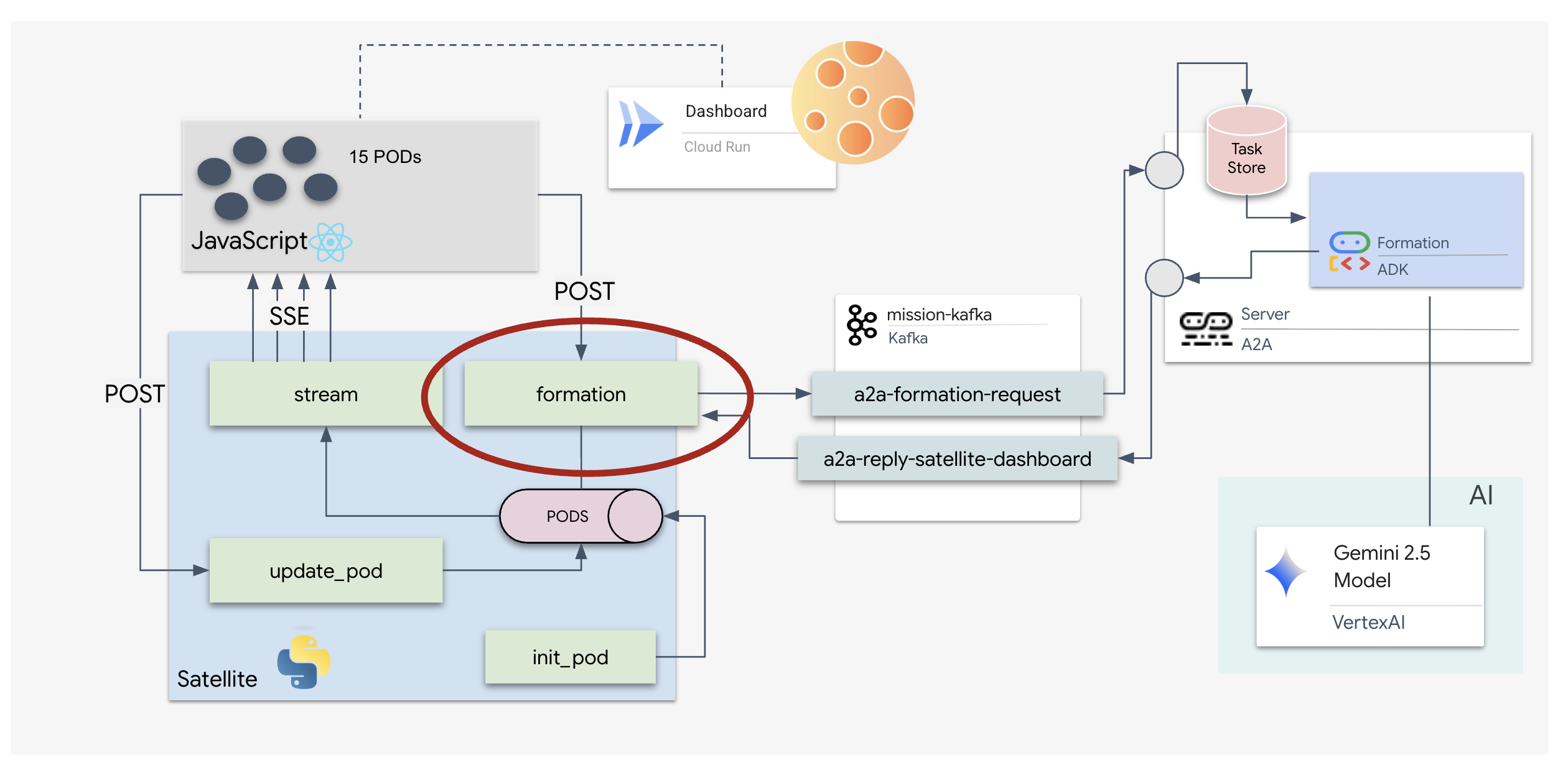
主なロジック:
- 非同期通信:
kafka_transport.send_messageはリクエストを送信し、reply_topicに新しい座標が届くのを待ちます。 - レスポンスの解析: Gemini は、マークダウン ブロック(
json ...など)内の座標を返すことがあります。次のコードは、それらを削除し、文字列をポイントの Python リストに変換します。
👉✏️ $HOME/way-back-home/level_5/satellite/main.py で、#REPLACE-FORMATION-REQUEST を次のコードに置き換えます。
@app.post("/formation")
async def set_formation(req: FormationRequest):
global FORMATION, PODS
FORMATION = req.formation
logger.info(f"Received formation request: {FORMATION}")
if not kafka_transport:
logger.error("Kafka Transport is not initialized!")
return {"status": "error", "message": "Backend Not Connected"}
try:
# Construct A2A Message
prompt = f"Create a {FORMATION} formation"
logger.info(f"Sending A2A Message: '{prompt}'")
from a2a.types import TextPart, Part, Role
import uuid
msg_id = str(uuid.uuid4())
message_parts = [Part(TextPart(text=prompt))]
msg_obj = Message(
message_id=msg_id,
role=Role.user,
parts=message_parts
)
message_params = MessageSendParams(
message=msg_obj
)
# Send and Wait for Response
ctx = ClientCallContext()
ctx.state["kafka_timeout"] = 120.0 # Timeout for GenAI latency
response = await kafka_transport.send_message(message_params, context=ctx)
logger.info("Received A2A Response.")
content = None
if isinstance(response, Message):
content = response.parts[0].root.text if response.parts else None
elif isinstance(response, Task):
if response.artifacts and response.artifacts[0].parts:
content = response.artifacts[0].parts[0].root.text
if content:
logger.info(f"Response Content: {content[:100]}...")
try:
clean_content = content.replace("```json", "").replace("```", "").strip()
coords = json.loads(clean_content)
if isinstance(coords, list):
logger.info(f"Parsed {len(coords)} coordinates.")
for i, pod_target in enumerate(coords):
if i < len(PODS):
PODS[i]["x"] = pod_target["x"]
PODS[i]["y"] = pod_target["y"]
return {"status": "success", "formation": FORMATION}
else:
logger.error("Response JSON is not a list.")
except json.JSONDecodeError as e:
logger.error(f"Failed to parse Agent JSON response: {e}")
else:
logger.error(f"Could not extract content from response type {type(response)}")
except Exception as e:
logger.error(f"Error calling agent via Kafka: {e}")
return {"status": "error", "message": str(e)}
サーバー送信イベント(SSE)
標準 API は「リクエスト-レスポンス」モデルを使用します。HUD には、ポッドの位置の「ライブ ストリーム」が必要です。
SSE の理由: WebSocket(双方向でより複雑)とは異なり、SSE はサーバーからブラウザへのシンプルな一方向のデータ ストリームを提供します。ダッシュボード、株価ティッカー、星間テレメトリーに最適です。
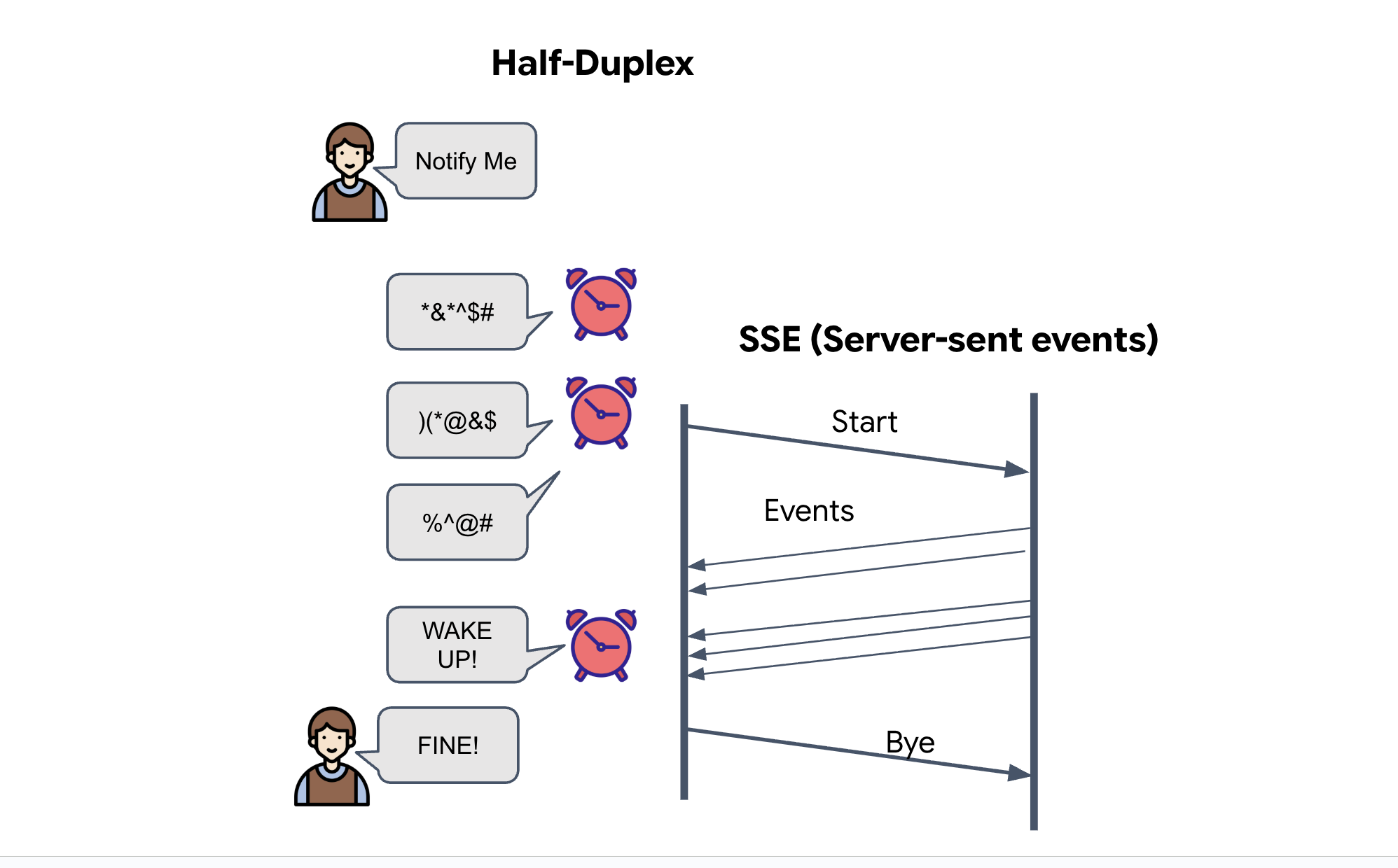
コードでの動作: event_generator を作成します。これは、0.5 秒ごとに 15 個の Pod の現在の位置を取得し、更新としてブラウザに「プッシュ」する無限ループです。
👉✏️ $HOME/way-back-home/level_5/satellite/main.py で、#REPLACE-SSE-STREAM を次のコードに置き換えます。
@app.get("/stream")
async def message_stream(request: Request):
async def event_generator():
logger.info("New SSE stream connected")
try:
while True:
current_pods = list(PODS)
# Send updates one by one to simulate low-bandwidth scanning
for pod in current_pods:
payload = {"pod": pod}
yield {
"event": "pod_update",
"data": json.dumps(payload)
}
await asyncio.sleep(0.02)
# Send formation info occasionally
yield {
"event": "formation_update",
"data": json.dumps({"formation": FORMATION})
}
# Main loop delay
await asyncio.sleep(0.5)
except asyncio.CancelledError:
logger.info("SSE stream disconnected (cancelled)")
except Exception as e:
logger.error(f"SSE stream error: {e}")
return EventSourceResponse(event_generator())
フル ミッション ループを実行する
最終的な UI をリリースする前に、システムがエンドツーエンドで動作することを確認しましょう。エージェントを手動でトリガーし、ワイヤ上の生データ ペイロードを確認します。
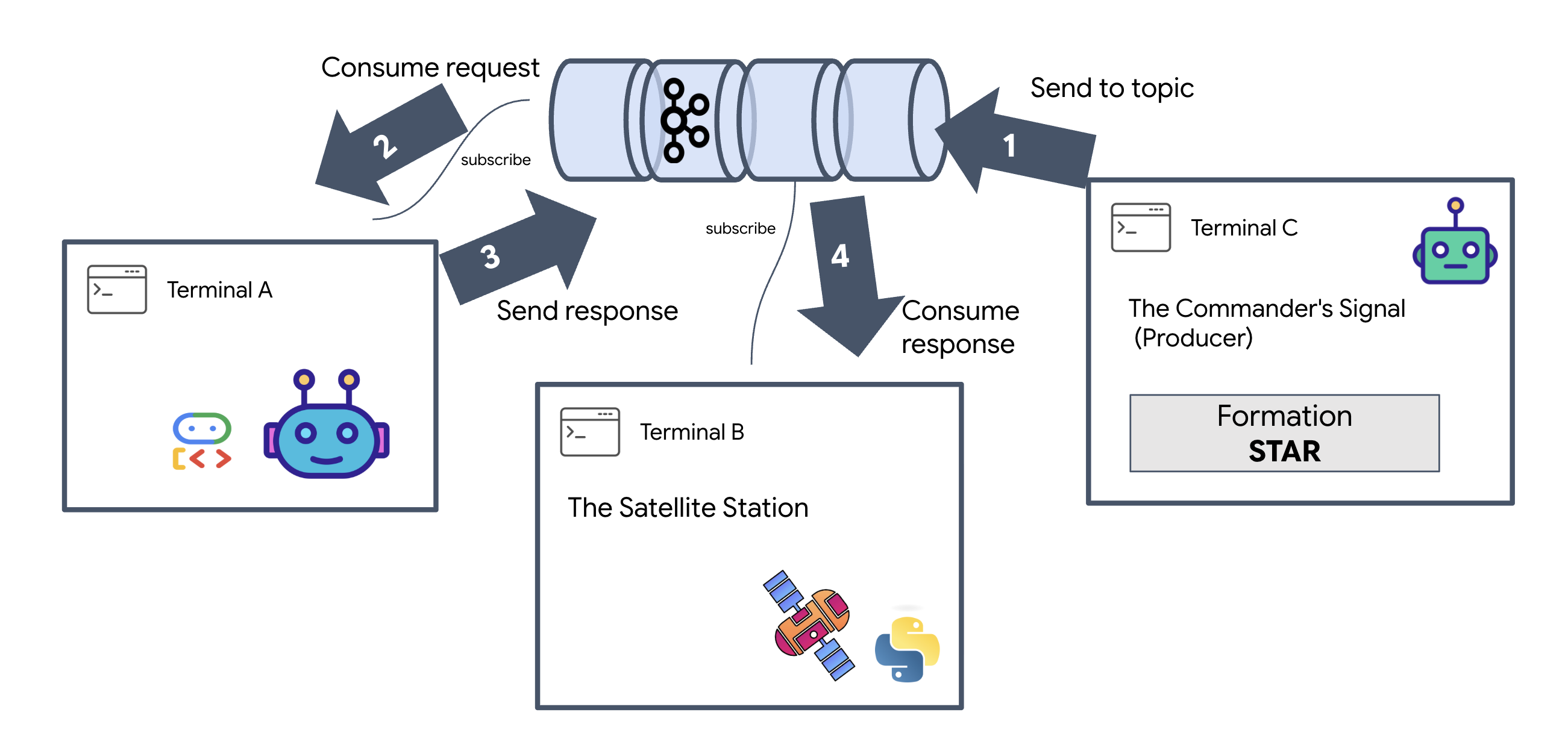
3 つの別々のターミナルタブを開きます。
ターミナル A: Formation Agent(A2A サーバー)
👉💻 これは、タスクをリッスンして幾何学的な計算を行う ADK エージェントです。
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Agent Server
uv run agent/server.py
ターミナル B: 衛星ステーション(Kafka クライアント)
👉💻 この FastAPI サーバーは「受信者」として機能し、Kafka の返信をリッスンして、ライブ SSE ストリームに変換します。
cd $HOME/way-back-home/level_5
# Start the Satellite Station
uv run satellite/main.py
ターミナル C: 手動 HUD
形成コマンドを送信(トリガー): 👉💻 同じターミナル C で、形成プロセスをトリガーします。
# Trigger the STAR formation via the Satellite's API
curl -X POST http://localhost:8000/formation \
-H "Content-Type: application/json" \
-d '{"formation": "STAR"}'
👀 新しい座標が表示されます。
INFO:satellite.main:Received formation request: STAR INFO:satellite.main:Sending A2A Message: 'Create a STAR formation' INFO:satellite.main:Received A2A Response. INFO:satellite.main:Response Content: ```json ... INFO:satellite.main:Parsed 15 coordinates.
これにより、Satellite が内部 Pod の座標を更新したことが確認されます。
👉💻 curl を使用して、まずライブ テレメトリー ストリームをリッスンし、次にフォーメーションの変更をトリガーします。
# Connect to the live telemetry feed.
# You should see 'pod_update' events ticking by.
curl -N http://localhost:8000/stream
👀 curl -N コマンドの出力を確認します。pod_update イベントの x 座標と y 座標は、星の新しい位置を反映するようになります。
続行する前に、実行中のプロセスをすべて停止して、通信ポートを解放します。
各ターミナル(A、B、C、トリガー ターミナル)で: Ctrl + C キーを押します。
6. Go Rescue!
システムが正常に確立されました。さあ、ミッションを実践しましょう。React ベースのヘッドアップ ディスプレイ(HUD)を起動します。このダッシュボードは SSE 経由で Satellite Station に接続され、15 個の Pod をリアルタイムで可視化できます。
コマンドを発行すると、関数を呼び出すだけでなく、Kafka を経由して AI エージェントによって処理され、ライブ テレメトリーとして画面にストリーミングされるイベントがトリガーされます。
2 つの別々のターミナルタブを開きます。
ターミナル A: Formation Agent(A2A サーバー)
👉💻 これは、タスクをリッスンし、Gemini を使用して幾何学的な計算を行う ADK エージェントです。ターミナルで次のコマンドを実行します。
cd $HOME/way-back-home/level_5
# Start the Agent Server
uv run agent/server.py
ターミナル B: 衛星ステーションとビジュアル ダッシュボード
👉💻 まず、フロントエンド アプリケーションをビルドします。
cd $HOME/way-back-home/level_5/frontend/
npm install
npm run build
👉💻 次に、バックエンド ロジックとフロントエンド UI の両方を処理する FastAPI サーバーを起動します。
cd $HOME/way-back-home/level_5
. scripts/check_kafka.sh
# Start the Satellite Station
uv run satellite/main.py
リリースと検証
- 👉 プレビューを開く: Cloud Shell ツールバーで、[ウェブでプレビュー] アイコンをクリックします。[ポートを変更] を選択して「8000」に設定し、[変更してプレビュー] をクリックします。新しいブラウザタブが開き、Starfield の HUD が表示されます。
- 👉 テレメトリー ストリームを確認する:
- UI が読み込まれると、15 個の Pod がランダムに散らばって表示されます。
- ポッドが微妙に脈動している場合や「ジッター」している場合は、SSE ストリームがアクティブであり、Satellite Station が位置情報を正常にブロードキャストしています。

- 👉 Formation を開始する: ダッシュボードの [STAR] ボタンをクリックします。

- 👀 イベントループをトレースする: ターミナルを監視して、アーキテクチャの動作を確認します。
- ターミナル B(衛星ステーション)は
Sending A2A Message: 'Create a STAR formation'をログに記録します。 - ターミナル A(Formation Agent)には、Gemini に問い合わせたときのアクティビティが表示されます。
- ターミナル B(衛星ステーション)は、
Received A2A Responseをログに記録し、座標を解析します。
- ターミナル B(衛星ステーション)は
- 👀 視覚的な確認: ダッシュボード上の 15 個の Pod が、ランダムな位置から 5 つの星の形にスムーズに移動する様子を確認します。
- 👉 テスト:
- 3 つの異なるフォーメーションについては、「X」または「LINE」を試してください。

- カスタム インテント: 手動入力を使用して、「ハート」や「三角形」などの固有のものを入力します。

- 生成 AI を使用しているため、エージェントは説明できる幾何学的形状の計算を試みます。
- 3 つの異なるフォーメーションについては、「X」または「LINE」を試してください。
3 つのパターンを形成したら、接続が正常に再確立されています。
ミッション達成!
データがノイズを中断なく通過すると、ストリームは安定します。あなたの命令で、15 個の古代ポッドが星々を渡りながら同期したダンスを始めます。

3 つの過酷な調整フェーズを経て、テレメトリーがロックされるのを確認しました。調整を繰り返すたびに信号は強くなり、ついに希望の光のように星間干渉を突き破った。
あなたとイベント ドリブン エージェントの優れた実装のおかげで、5 人の生存者は X-42 の表面から空輸され、救助船で安全に保護されました。あなたのおかげで 5 人の命が救われました。
レベル 0 に参加された方は、Way Back Home ミッションの進捗状況を忘れずにご確認ください。星々への旅は続きます。