
১. সংক্ষিপ্ত বিবরণ
প্রথম পর্বে , আমরা নলেজ ক্যাটালগ এবং ডেটাস্ক্যান ব্যবহার করে বিশৃঙ্খল ও অসংগঠিত পিডিএফ ফাইলগুলোকে বিগকোয়েরিতে পরিচ্ছন্ন, ইন্টেলিজেন্ট এবং সুসংগঠিত টেবিলে সফলভাবে রূপান্তর করেছি। এখন আমাদের একটি শক্তিশালী ডেটা ওয়্যারহাউস রয়েছে। দ্বিতীয় পর্বে , আমরা আমাদের ট্রানজ্যাকশনাল ব্যাকবোন হিসেবে অ্যালয়ডিবি স্থাপন করেছি এবং আমাদের বিগকোয়েরি টেবিলগুলোকে এর সাথে ফেডারেট করেছি, যার ফলে একটি বাইটও ডুপ্লিকেট না করে একটি সমন্বিত ডেটা লেয়ার তৈরি হয়েছে।
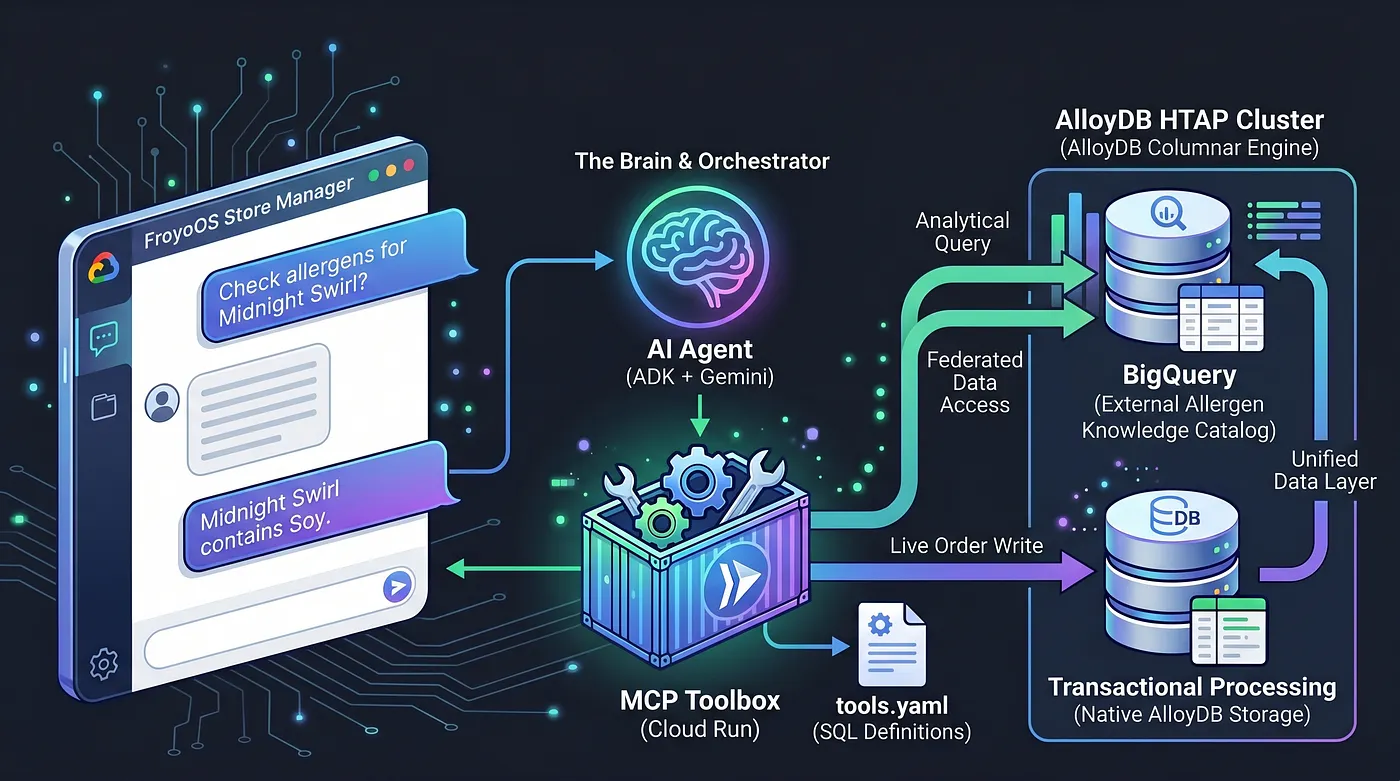
আজ আমরা মূল চালিকাশক্তিটি তৈরি করছি। আমরা একটি মাল্টি-এজেন্ট অ্যাপ্লিকেশন—‘ফ্রয়োওএস স্টোর ম্যানেজার’—তৈরি করছি, যা এই ডেটা লেয়ারের উপরে থেকে প্রশ্নের উত্তর দেবে, অ্যালার্জেন পরীক্ষা করবে এবং চলমান অর্ডারগুলো প্রসেস করবে।
চ্যালেঞ্জ: আপনার এজেন্ট থেকে এআই-কে বিচ্ছিন্ন করা
ডাটাবেসের সাথে যোগাযোগ করতে হয় এমন একটি এআই এজেন্ট তৈরি করার সময়, সবচেয়ে প্রচলিত অ্যান্টি-প্যাটার্ন হলো ডেটা এবং এআই লজিককে সরাসরি আপনার পাইথন অ্যাপ্লিকেশনে অন্তর্ভুক্ত করা। এর ফলে আপনার অ্যাপটি ভঙ্গুর, অসুরক্ষিত হয়ে পড়ে এবং আপনার ডেটা আর্কিটেকচার বড় হওয়ার সাথে সাথে এর রক্ষণাবেক্ষণ করাও অত্যন্ত কঠিন হয়ে যায়।
এর সমাধানে, আমরা মডেল কনটেক্সট প্রোটোকল (MCP) টুলবক্স ব্যবহার করছি। MCP টুলবক্সটি আমাদের সমন্বিত ডেটা অ্যাবস্ট্রাকশন লেয়ার হিসেবে কাজ করে। আমরা একটি সাধারণ tools.yaml ফাইলে আমাদের ডাটাবেস অপারেশনগুলো ডিক্লারেটিভভাবে সংজ্ঞায়িত করি। আমরা এই টুলবক্সটিকে গুগল ক্লাউড রান-এ একটি সুরক্ষিত, সার্ভারবিহীন এন্ডপয়েন্ট হিসেবে ডেপ্লয় করি। আমাদের এআই এজেন্ট কেবল এই এন্ডপয়েন্টের সাথে সংযুক্ত হয়ে বলে, "'place_order' টুলটি এক্সিকিউট করো।"
HTAP-এর শক্তি
এজেন্ট তৈরি শুরু করার আগে, চলুন আলোচনা করা যাক কেন এই পোস্টের শিরোনামে বিশেষভাবে HTAP (হাইব্রিড ট্রানজ্যাকশনাল/অ্যানালিটিক্যাল প্রসেসিং)-এর কথা উল্লেখ করা হয়েছে।
প্রচলিত আর্কিটেকচারে, যদি কোনো এআই এজেন্টের একটি চলমান ব্যবহারকারীর অর্ডার প্রসেস করার (একটি ট্রানজ্যাকশনাল OLTP ওয়ার্কলোড) এবং হাজার হাজার জটিল উপাদানের ম্যাপিং মিলিয়ে দেখার (একটি অ্যানালিটিক্যাল OLAP ওয়ার্কলোড) প্রয়োজন হয়, তাহলে আপনার পাইথন অ্যাপ্লিকেশনটিকে সম্পূর্ণ ভিন্ন দুটি ডেটাবেসের সাথে সংযোগ স্থাপন করতে হবে। এর ফলে মারাত্মক ল্যাটেন্সি, সিকিউরিটি ওভারহেড এবং ভঙ্গুর স্টেট ম্যানেজমেন্ট তৈরি হয়।
আমরা আমাদের BigQuery ডেটা ওয়্যারহাউসকে সরাসরি PostgreSQL-এর সাথে নেটিভভাবে ফেডারেট করার মাধ্যমে AlloyDB-কে একটি শক্তিশালী HTAP সিস্টেমে পরিণত করেছি। এই HTAP আর্কিটেকচারের কারণে, আমাদের AI এজেন্টকে এখন শুধুমাত্র একটি ডাটাবেস এন্ডপয়েন্টের সাথে যোগাযোগ করতে হয়। এটি একই সাথে, এক বাইট ডেটাও ডুপ্লিকেট না করে, live_orders টেবিলে লাইভ ট্রানজ্যাকশন ইনসার্ট করতে পারে এবং ফেডারেটেড BigQuery froyo_data ডেটাসেটের উপর ভারী অ্যানালিটিক্যাল স্ক্যান চালাতে পারে। চলুন দেখি আমরা কীভাবে এই ইঞ্জিনটিকে আমাদের AI-এর কাছে উন্মুক্ত করি।
চলুন নির্মাণ শুরু করা যাক!
আপনি যা শিখবেন
- এক ক্লিকেই কীভাবে AlloyDB ক্লাস্টার, ইনস্ট্যান্স এবং নেটওয়ার্কিং সেট আপ করবেন
- ফেডারেশনের জন্য প্রস্তুতি নিতে কীভাবে এক্সটেনশন সেট আপ করবেন
- BigQuery থেকে AlloyDB-তে ফেডারেশন কীভাবে সেট আপ করবেন
- পরীক্ষা করে দেখুন
প্রয়োজনীয়তা
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
- SQL সম্পর্কে প্রাথমিক ধারণা।
২. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন ।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনি যদি প্রমাণীকরণ করতে চান
gcloud auth login
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- প্রয়োজনীয় API-গুলো সক্রিয় করুন: সমস্ত প্রয়োজনীয় API সক্রিয় করতে এই কমান্ডটি চালান:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
অপ্রত্যাশিত সমস্যা ও সমাধান
"ঘোস্ট প্রজেক্ট" সিন্ড্রোম | আপনি |
বিলিং ব্যারিকেড | আপনি প্রজেক্টটি চালু করেছেন, কিন্তু বিলিং অ্যাকাউন্টটি দিতে ভুলে গেছেন। AlloyDB একটি উচ্চ-ক্ষমতাসম্পন্ন ইঞ্জিন; এর 'গ্যাস ট্যাঙ্ক' (বিলিং) খালি থাকলে এটি চালু হবে না। |
এপিআই প্রচার বিলম্ব | আপনি "এপিআই সক্ষম করুন" এ ক্লিক করেছেন, কিন্তু কমান্ড লাইনে এখনও |
কোটা কোয়াগস | আপনি যদি একটি একেবারে নতুন ট্রায়াল অ্যাকাউন্ট ব্যবহার করেন, তাহলে AlloyDB ইনস্ট্যান্সের জন্য আপনার আঞ্চলিক কোটা শেষ হয়ে যেতে পারে। যদি |
৩. ডেটা প্রস্তুত করা
নিশ্চিত করুন যে, আমরা অসংগঠিত পিডিএফ থেকে যে সংগঠিত ডেটা বের করেছি তা BigQuery-তে আছে এবং BigQuery ডেটার AlloyDB ফেডারেশনও প্রতিষ্ঠিত ও পরীক্ষিত হয়েছে। যদি আপনি সেই ধাপগুলো সম্পন্ন না করে থাকেন, তবে যথাক্রমে পার্ট ১ এবং পার্ট ২-এর জন্য এখান থেকে এবং এখান থেকে সেই সহজ ধাপগুলো সম্পন্ন করার এটাই উপযুক্ত সময়।
দ্রষ্টব্য:
আপনি যদি এই কোডল্যাবটি চেষ্টা করে থাকেন, তবে আপনার পার্ট ২-এর ক্লিনআপ ধাপটি (ক্লাস্টার এবং ইনস্ট্যান্স মুছে ফেলার ধাপ) চালানো উচিত নয়, কারণ এখানে প্রদর্শিত আমাদের এজেন্টিক সিস্টেমের জন্য AlloyDB অর্কেস্ট্রেশন প্রয়োজন।
পার্ট ২-এ আমরা ইতিমধ্যে যে ডেটা তৈরি করেছি, তার পাশাপাশি AlloyDB ইনস্ট্যান্সে আমাদের আরও একটি টেবিল তৈরি করতে হবে। এই লিঙ্কটি ব্যবহার করে AlloyDB Studio-তে যান:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
আপনি যদি ভিন্ন ক্লাস্টার ব্যবহার করেন, তাহলে উপরের লিঙ্কে ক্লাস্টারের নামটি পরিবর্তন করুন।
AlloyDB Studio-তে, একটি নতুন Query Editor ট্যাবে, নিম্নলিখিত স্টেটমেন্টটি চালান:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
এটি আপনার ডাটাবেসে live_orders টেবিলটি তৈরি করবে।
৪. অ্যাবস্ট্রাকশনের সংজ্ঞা নির্ধারণ (tools.yaml)
প্রথমে, আমরা আমাদের ডাটাবেস অপারেশনগুলো আনুষ্ঠানিকভাবে নিবন্ধন করি। আমরা একটি tools.yaml ফাইল তৈরি করি যা নির্ধারণ করে যে আমাদের এজেন্ট কীভাবে AlloyDB-এর সাথে যোগাযোগ করবে, যেখানে লেনদেনমূলক এবং বিশ্লেষণমূলক উভয় ডেটাই রয়েছে (বিশ্লেষণমূলক ডেটা BigQuery ফেডারেশন থেকে প্রাপ্ত)।
- আপনার ক্লাউড শেল টার্মিনালে যান। এডিটর মোডে টগল করুন।
- আপনার রুট ডিরেক্টরিতে " froyo-agent " নামে একটি নতুন ফোল্ডার তৈরি করুন।
- ফোল্ডারটির ভিতরে একটি tools.yaml ফাইল তৈরি করুন এবং নিম্নলিখিত বিষয়বস্তু পেস্ট করুন: (project, cluster, instance, এবং password-এর জন্য আপনার নিজের মান দিয়ে প্রতিস্থাপন করুন)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
আমরা আমাদের এজেন্টের সক্ষমতা দুটি টুলে সীমাবদ্ধ করেছি — অ্যালার্জেন পরীক্ষা করা এবং অর্ডার দেওয়া।
৫. ক্লাউড রানে টুলবক্স স্থাপন করা
আমাদের অ্যাপ্লিকেশনে এটি উপলব্ধ করার জন্য, আমরা gcloud CLI ব্যবহার করে টুলবক্সটি নিরাপদে ডেপ্লয় করি। এর মাধ্যমে আমাদের অ্যাবস্ট্রাকশন লেয়ার এন্ডপয়েন্ট তৈরি হয়।
- ক্লাউড শেল টার্মিনালে যান এবং নিম্নলিখিত কমান্ডটি চালিয়ে ওয়ার্কিং ডিরেক্টরিতে প্রবেশ করুন:
cd froyo-agent
- tools.yaml ফাইলটি 'tools-froyo' নামের একটি সিক্রেটে সেভ করুন:
gcloud secrets create tools-froyo --data-file=tools.yaml
- ক্লাউড রানে এমসিপি টুলবক্স কন্টেইনারটি স্থাপন করুন
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
পার্ট ২ কোডল্যাবে আমরা যে মানগুলো কনফিগার করেছিলাম, তার থেকে ভিন্ন মান ব্যবহার করে থাকলে 'network' এবং 'subnet' মানগুলো প্রতিস্থাপন করতে হবে।
- প্রাপ্ত ক্লাউড রান ইউআরএলটি লিখে রাখুন (যেমন, https://toolbox-froyo-xxx.run.app )।
আমরা এজেন্ট কনফিগারেশন ধাপে এই ডেপ্লয় করা এমসিপি টুলবক্স এন্ডপয়েন্টটি ব্যবহার করব।
৬. এজেন্টিক ব্যাকএন্ড (app.py)
আমাদের ডাটাবেসকে আড়াল করে রাখায়, আমাদের পাইথন কোড সম্পূর্ণরূপে সমন্বয় ও যুক্তির ওপর মনোযোগ দিতে পারে।
আমরা ফ্লাস্কের পাশাপাশি এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করছি। ADK এন্টারপ্রাইজ-গ্রেড সেশন মেমরি ( InMemorySessionService ) প্রদান করে, যার মানে আমাদের এজেন্ট কথোপকথনের প্রেক্ষাপট মনে রাখে। এটি ক্লাউড রান থেকে আমাদের টুলগুলো নির্বিঘ্নে পুল করার জন্য টুলবক্সসিঙ্কক্লায়েন্টের সাথে নেটিভভাবে ইন্টিগ্রেট করে।
এই নিন আপনার app.py :
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
এই সাধারণ পাইথন ফ্লাস্ক অ্যাপটি ADK এজেন্টকে আমাদের টুলবক্সে সংজ্ঞায়িত টুলগুলোর সাথে সংযুক্ত করে, যা ফলস্বরূপ AlloyDB (এবং BigQuery ফেডারেটেড ডেটাও)-এর সাথে ইন্টারঅ্যাক্ট করে এবং ব্যবহারকারীকে প্রতিক্রিয়া জানায়।
আপনার ক্লাউড শেল এডিটরে এই প্রজেক্টটি পেতে, আপনি আপনার ক্লাউড শেল টার্মিনাল থেকে নিম্নলিখিত কমান্ডগুলি চালিয়ে এজেন্টের জন্য রিপোজিটরিটি ক্লোন করতে পারেন:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
আপনাকে নিম্নলিখিত প্রকল্প কাঠামোটি দেখতে হবে:
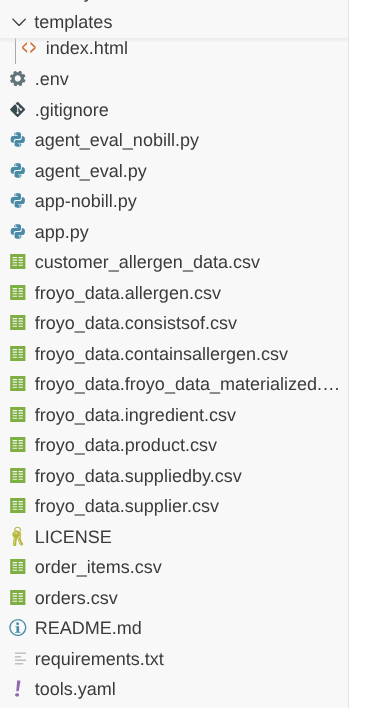
বিলিং অ্যাকাউন্ট ছাড়াই ডেটা উপভোগ করা চালিয়ে যাওয়ার পদক্ষেপ:
- সুবিধার্থে রিপোটিতে নিম্নলিখিত ডেটা ফাইলগুলি উপলব্ধ করা হয়েছে:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
এই ফাইলগুলো app.py ফাইলের সাথে একই ফোল্ডারে থাকতে হবে।
B. একই পাথে থাকা app-nobill.py নামের পাইথন ফাইলটি।
- প্রজেক্টের রুট ফোল্ডারে app-nobill.py নামের একটি ফাইল আছে।
- এই ফাইলটি একই অ্যাপ অভিজ্ঞতা তৈরি করার জন্য ডিজাইন করা হয়েছে, কিন্তু এর জন্য এই ডেটা উৎসগুলির সাথে সরাসরি সংযোগ করার প্রয়োজন নেই, কারণ ডেটা ফাইল আকারে উপলব্ধ করা হয়েছে।
- ল্যাবে উল্লিখিত অন্য সব ফাইল এই সংস্করণের জন্যও অক্ষত থাকা উচিত (শুধু app.py ফাইলটি চালানোর প্রয়োজন নেই)।
৭. ইউআই এবং অ্যাপটি চালানো
আমাদের স্টোর ম্যানেজারদের একটি উপযুক্ত অভিজ্ঞতা দেওয়ার জন্য, আমরা একটি লাইভ প্রোডাক্ট ক্যাটালগ সাইডবার এবং একটি ইন্টারেক্টিভ চ্যাট ইন্টারফেস সম্বলিত একটি মসৃণ, গ্লাসমর্ফিক UI ( templates/index.html ) তৈরি করেছি।
আপনি রিপো ফাইলে index.html ফাইলটি এখানে খুঁজে পাবেন:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
অ্যাপ্লিকেশনটি চালানোর আগে, নিশ্চিত করুন যে আপনার requirements.txt ফাইলে নিম্নলিখিত বিষয়বস্তু সহ আপনার ডিপেন্ডেন্সিগুলো রয়েছে:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
এবং আপনার .env ফাইলটি পূরণ করা হয়েছে:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
আপনার GOOGLE_API_KEY কীভাবে পাবেন?
আপনার গুগল এপিআই কী (Google API Key) সেট আপ করতে এই ব্লগের নির্দেশাবলী অনুসরণ করুন।
আপনার MCP_TOOLBOX_SERVER_URL কীভাবে পাবেন?
আমরা এই কোডল্যাবের আগের ধাপে এটি সেট আপ করেছি এবং আপনি ডেপ্লয় করা MCP টুলবক্স এন্ডপয়েন্টটি কপি করেছেন। MCP_TOOLBOX_SERVER_URL এনভায়রনমেন্ট ভেরিয়েবলের জন্য সেই লিঙ্কটি ব্যবহার করুন।
আপনার অ্যাপটি চালান:
ক্লাউড শেল টার্মিনাল থেকে, প্রজেক্ট ফোল্ডারে আছেন তা নিশ্চিত করে, নিচের কমান্ডগুলো এক এক করে চালান:
প্রজেক্টের রুট ফোল্ডারে প্রবেশ করুন:
cd froyo-data
নির্ভরতা ইনস্টল করুন:
pip install -r requirements.txt
পাইথন ফাইলটি চালানো হচ্ছে:
python app.py
টার্মিনালে প্রদর্শিত লিঙ্কে ক্লিক করুন অথবা http://localhost:8080 খুলুন!
৮. চূড়ান্ত পরীক্ষা
এজেন্টকে জিজ্ঞাসা করার জন্য চলুন ক্যাটালগ থেকে একটি পণ্য ক্লিক করি:
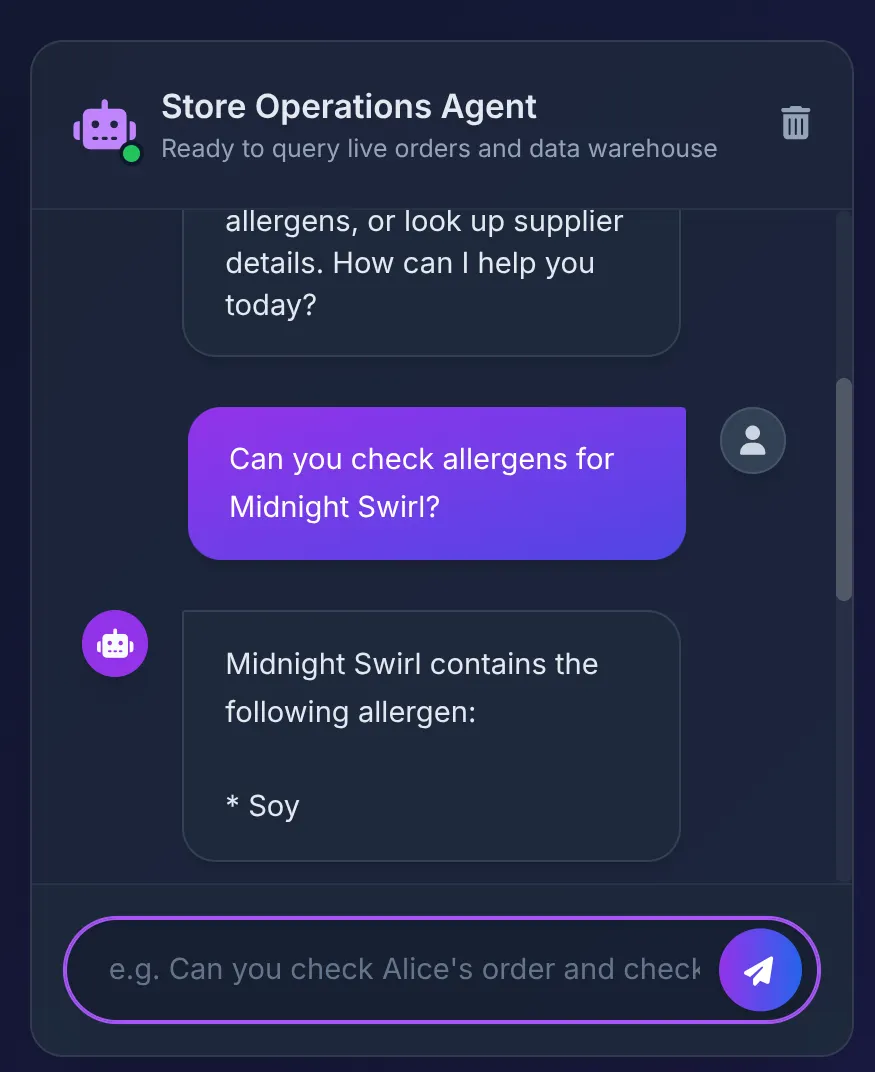
Does Midnight Swirl have any allergens?
আপনার প্রতিক্রিয়াটি দেখা উচিত:
নেপথ্যে:
- ADK এজেন্ট প্রম্পটটি গ্রহণ করে check_allergens টুলটি ব্যবহার করার সিদ্ধান্ত নেয়।
- এটি ক্লাউড রান-এ থাকা এমসিপি টুলবক্সকে নিরাপদে কল করে।
- টুলবক্সটি AlloyDB-তে কোয়েরিটি এক্সিকিউট করে, যা সাথে সাথেই BigQuery-তে ফেডারেট করে পার্ট ১-এ আমাদের তৈরি করা জটিল সম্পর্কগুলো স্ক্যান করে।
- ডাটাবেস থেকে "Soy" পাওয়া যায়, যা এজেন্ট UI-তে সুন্দরভাবে সংক্ষিপ্ত করে দেখায়।
এরপর, আমরা বলি:
Order 2 Midnight Swirl for Alice.
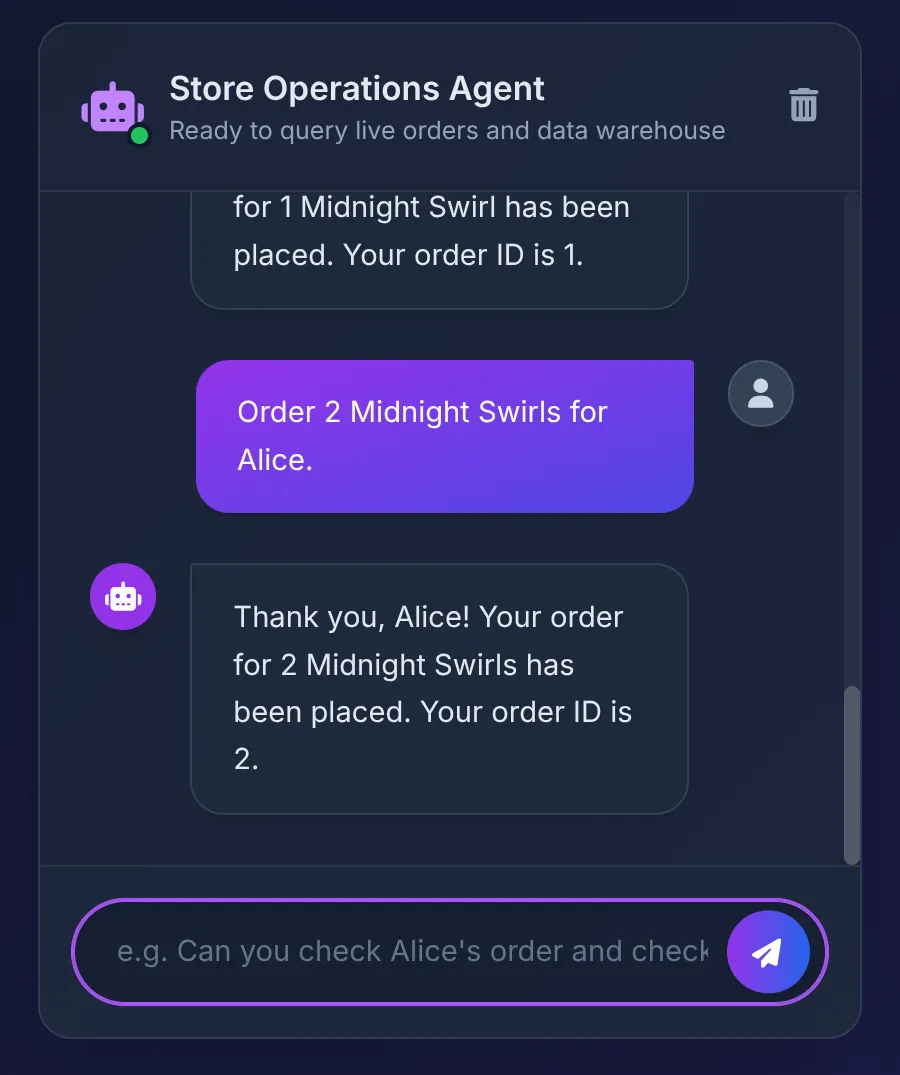
এজেন্ট "Midnight Swirl" স্ট্রিংটি টুলবক্সে পাঠায়। অন্তর্নিহিত SQL, BigQuery-এর মাধ্যমে ডায়নামিকভাবে স্ট্রিংটিকে একটি ইন্টিজার আইডিতে রূপান্তর করে, লাইভ অর্ডারটি AlloyDB-তে প্রবেশ করায় এবং লেনদেনটি নিশ্চিত করে।
কোড রিপো
৯. পরিষ্কার করুন
এই ল্যাবটি সম্পন্ন হয়ে গেলে, AlloyDB ক্লাস্টার এবং ইনস্ট্যান্সটি মুছে ফেলতে ভুলবেন না।
এটি ক্লাস্টারটিকে তার ইনস্ট্যান্স(গুলি) সহ পরিষ্কার করে দেবে।
১০. আপনার এজেন্টের জন্য অভিনন্দন!
আমরা এইমাত্র যা অর্জন করেছি তা নিয়ে ভাবুন:
আমাদের সুসংগঠিত এজেন্টিক সিস্টেমটি ডাটাবেসের জন্য শুধুমাত্র এমসিপি টুলবক্সের সাথে যোগাযোগ করে। এটি নেপথ্যে থেকে আমাদের অ্যাপ্লিকেশনের টুল কল এবং ডেটা থেকে এআই-তে ডেটা পাঠানোর লজিক পরিচালনা করে, যার ফলে কার্যপ্রবাহটি সরল থাকে।
- আমাদের ট্রানজ্যাকশনাল অ্যাপটি (AlloyDB-তে চালিত) দ্রুত গতিতে একই সাথে একাধিক ব্যবহারকারীর সেশন পরিচালনা করতে পারে।
- যখন ব্যাপক বিশ্লেষণমূলক ডেটা বা ঐতিহাসিক প্রেক্ষাপটের (যেমন সরবরাহকারীর বিবরণ বা জটিল উপাদানের ম্যাপিং) প্রয়োজন হয়, তখন এটি BigQuery froyo_dataschema-কে কোয়েরি করে।
- কোনো ETL নেই। ডেটা পাইপলাইন বিকল হওয়ার কোনো সম্ভাবনা নেই। ডেটাবেসগুলোর মধ্যে অসামঞ্জস্যতা নেই। আমরা ডেটা একবারই (BQ-তে) সংরক্ষণ করি এবং প্রয়োজন অনুযায়ী গণনা করি।
এখন যেহেতু আমাদের এজেন্ট এবং ডেটার ভিত্তি — বিশ্লেষণাত্মক ও লেনদেনমূলক উভয়ই — সম্পূর্ণ হয়েছে, চলুন পরবর্তী অংশে যাওয়া যাক।
এরপর কী?
আমাদের এজেন্ট নিখুঁতভাবে কাজ করছে... একদম সঠিক পথে। চতুর্থ পর্বে , আমরা আমাদের এজেন্টিক সিস্টেমের বৈধতা, ভিত্তি এবং কর্মক্ষমতা পুঙ্খানুপুঙ্খভাবে পরীক্ষা করার জন্য একটি এজেন্ট মূল্যায়ন পাইপলাইন তৈরি করব। সেখানেই দেখা হবে!