
1. Übersicht
In Teil 1 haben wir mithilfe von Knowledge Catalog und DataScan chaotische, unstrukturierte PDFs in übersichtliche, intelligente und strukturierte Tabellen in BigQuery umgewandelt. Jetzt haben wir ein robustes Data Warehouse. In Teil 2 haben wir AlloyDB als unser transaktionales Rückgrat eingerichtet und unsere BigQuery-Tabellen darin eingebunden. So haben wir eine einheitliche Datenschicht erstellt, ohne ein einziges Byte zu duplizieren.
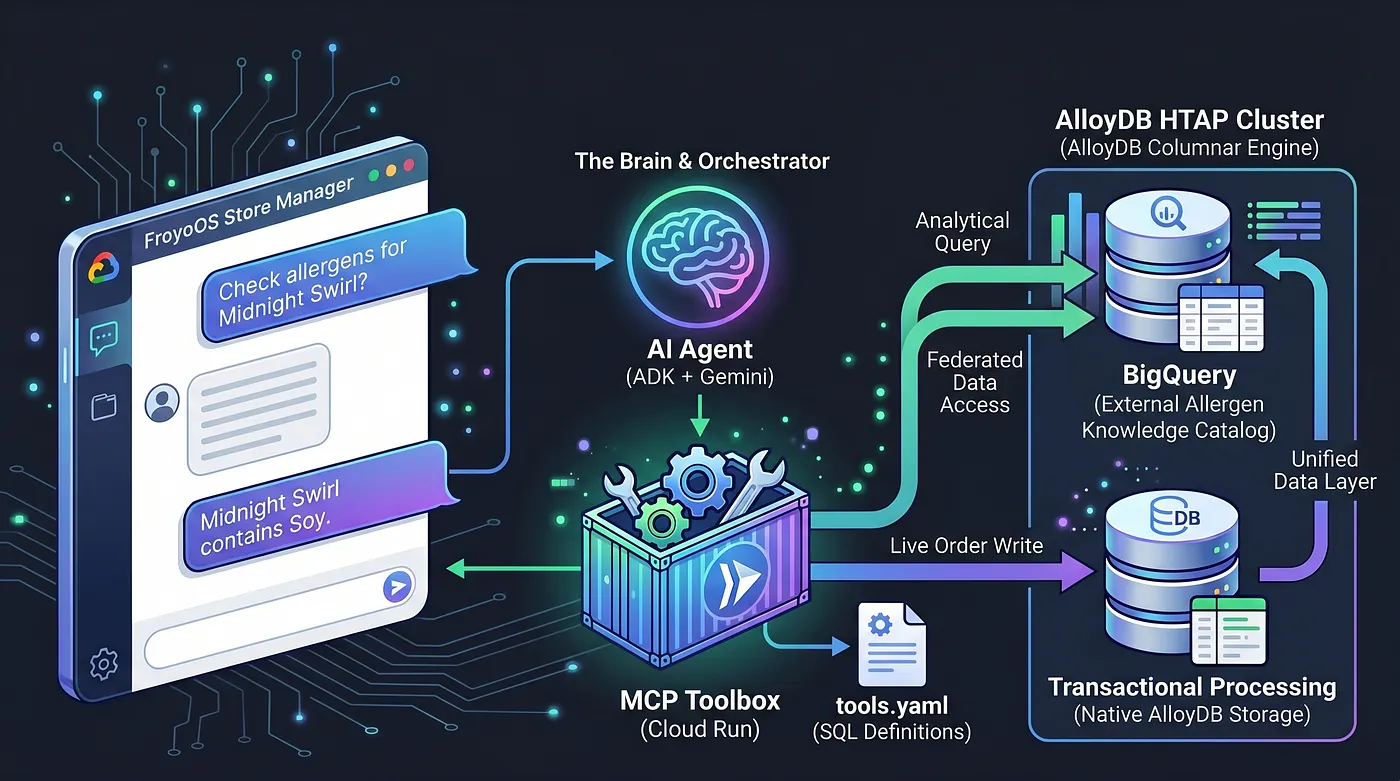
Heute bauen wir das Gehirn. Wir erstellen eine Multi-Agent-Anwendung – den „FroyoOS Store Manager“ –, die auf dieser Datenschicht basiert, um Fragen zu beantworten, Allergene zu prüfen und Live-Bestellungen zu verarbeiten.
Die Herausforderung: KI von Ihrem Agenten entkoppeln
Beim Erstellen eines KI-Agenten, der mit Datenbanken kommunizieren muss, ist es ein häufiges Anti-Pattern, die Daten- und KI-Logik direkt in Ihre Python-Anwendung zu erzwingen. Dadurch wird Ihre App anfällig, unsicher und unglaublich schwer zu warten, wenn Ihre Datenarchitektur wächst.
Um dieses Problem zu lösen, verwenden wir die MCP-Toolbox (Model Context Protocol). Die MCP Toolbox dient als einheitliche Datenabstraktionsebene. Wir definieren unsere Datenbankvorgänge deklarativ in einer einfachen Datei „tools.yaml“. Wir stellen diese Toolbox als sicheren, serverlosen Endpunkt in Google Cloud Run bereit. Unser KI-Agent stellt einfach eine Verbindung zu diesem Endpunkt her und sagt: „Führe das Tool ‚place_order‘ aus.“
Das Potenzial von HTAP
Bevor wir mit der Entwicklung des Agents beginnen, möchten wir kurz darauf eingehen, warum im Titel dieses Beitrags speziell HTAP (Hybrid Transactional/Analytical Processing) erwähnt wird.
In einer herkömmlichen Architektur müsste Ihre Python-Anwendung Verbindungen zu zwei völlig unterschiedlichen Datenbanken verwalten, wenn ein KI-Agent eine Live-Nutzerbestellung (eine transaktionsorientierte OLTP-Arbeitslast) verarbeiten und Tausende von komplexen Zutatenzuordnungen (eine analytische OLAP-Arbeitslast) abgleichen müsste. Dies führt zu erheblichen Latenzzeiten, Sicherheitsrisiken und einer fragilen Statusverwaltung.
Wir haben AlloyDB zu einem HTAP-Kraftpaket gemacht, indem wir unser BigQuery-Data Warehouse nativ in PostgreSQL eingebunden haben. Aufgrund dieser HTAP-Architektur muss unser KI-Agent heute nur mit einem Datenbankendpunkt kommunizieren. Es kann Live-Transaktionen in die Tabelle live_orders einfügen und gleichzeitig umfangreiche Analysen für das föderierte BigQuery-Dataset froyo_data ausführen, ohne ein einziges Byte an Daten zu duplizieren. Sehen wir uns an, wie wir diese Engine für unsere KI verfügbar machen.
Legen wir los!
Lerninhalte
- AlloyDB-Cluster, ‑Instanz und ‑Netzwerk mit einem Klick einrichten
- Erweiterung einrichten, um sich auf die Föderation vorzubereiten
- Föderation von BigQuery zu AlloyDB einrichten
- Ausprobieren
Voraussetzungen
2. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, können Sie mit dem folgenden Befehl prüfen, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Sie sich authentifizieren möchten,
gcloud auth login
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs: Führen Sie diesen Befehl aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Wichtige Hinweise und Fehlerbehebung
Das „Geisterprojekt“-Syndrom | Sie haben |
Die Abrechnungsbarrikade | Sie haben das Projekt aktiviert, aber das Rechnungskonto vergessen. AlloyDB ist eine leistungsstarke Engine, die nicht startet, wenn der „Benzintank“ (Abrechnung) leer ist. |
Verzögerung bei der API-Weitergabe | Sie haben auf „APIs aktivieren“ geklickt, aber in der Befehlszeile wird weiterhin |
Kontingent -Quags | Wenn Sie ein brandneues Testkonto verwenden, erreichen Sie möglicherweise ein regionales Kontingent für AlloyDB-Instanzen. Wenn |
3. Daten vorbereiten
Prüfen Sie, ob die strukturierten Daten, die wir aus unstrukturierten PDFs extrahiert haben, in BigQuery verfügbar sind und ob die AlloyDB-Föderation von BigQuery-Daten eingerichtet und getestet wurde. Wenn Sie diese Schritte noch nicht ausgeführt haben, ist jetzt ein guter Zeitpunkt, um die einfachen Schritte aus Teil 1 und Teil 2 auszuführen.
Hinweis:
Wenn Sie dieses Codelab ausprobieren, sollten Sie den Bereinigungsschritt aus Teil 2 (Löschen des Clusters und der Instanz) nicht ausführen, da wir die AlloyDB-Orchestrierung für das hier gezeigte Agentensystem benötigen.
Zusätzlich zu den Daten, die wir in Teil 2 erstellt haben, müssen wir eine weitere Tabelle in der AlloyDB-Instanz erstellen. Rufen Sie AlloyDB Studio über den folgenden Link auf:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Ändern Sie den Clusternamen im Link oben, wenn Sie einen anderen Cluster verwenden.
Führen Sie in AlloyDB Studio auf einem neuen Tab „Query Editor“ die folgende Anweisung aus:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Dadurch sollte die Tabelle live_orders in Ihrer Datenbank erstellt werden.
4. Abstraktion definieren (tools.yaml)
Zuerst registrieren wir unsere Datenbankvorgänge formal. Wir erstellen eine tools.yaml-Datei, in der definiert wird, wie unser Agent mit AlloyDB interagiert. AlloyDB enthält sowohl die Transaktions- als auch die Analysedaten (Analysedaten aus der BigQuery-Föderation).
- Rufen Sie das Cloud Shell-Terminal auf. Wechseln Sie in den Editormodus.
- Erstellen Sie in Ihrem Stammverzeichnis einen neuen Ordner mit dem Namen froyo-agent.
- Erstellen Sie im Ordner eine Datei namens tools.yaml und fügen Sie den folgenden Inhalt ein. Ersetzen Sie dabei die Platzhalter durch Ihre eigenen Werte für Projekt, Cluster, Instanz und Passwort.
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Wir haben die Funktionen unseres Agenten auf zwei Tools beschränkt: „Allergene prüfen“ und „Bestellung aufgeben“.
5. Toolbox in Cloud Run bereitstellen
Damit die Toolbox für unsere Anwendung verfügbar ist, stellen wir sie sicher über die gcloud CLI bereit. Dadurch wird der Endpunkt für die Abstraktionsebene erstellt.
- Wechseln Sie zum Cloud Shell-Terminal und rufen Sie das Arbeitsverzeichnis mit dem folgenden Befehl auf:
cd froyo-agent
- Speichern Sie die Datei „tools.yaml“ in einem Secret mit dem Namen „tools-froyo“:
gcloud secrets create tools-froyo --data-file=tools.yaml
- MCP Toolbox-Container in Cloud Run bereitstellen
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Die Werte für „network“ und „subnet“ müssen ersetzt werden, wenn Sie andere Werte als die im Codelab in Teil 2 konfigurierten verwendet haben.
- Notieren Sie sich die resultierende Cloud Run-URL (z.B. https://toolbox-froyo-xxx.run.app).
Wir verwenden diesen bereitgestellten MCP Toolbox-Endpunkt im Schritt zur Agent-Konfiguration.
6. Das agentische Backend (app.py)
Da unsere Datenbank abstrahiert ist, kann sich unser Python-Code vollständig auf Orchestrierung und Reasoning konzentrieren.
Wir verwenden das Agent Development Kit (ADK) zusammen mit Flask. Das ADK bietet einen Sitzungsspeicher auf Unternehmensniveau (InMemorySessionService). Das bedeutet, dass sich unser Agent den Kontext der Unterhaltung merkt. Es lässt sich nativ in ToolboxSyncClient einbinden, um unsere Tools nahtlos aus Cloud Run abzurufen.
Hier ist die Datei app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
Die einfache Python Flask-App verbindet den ADK-Agenten mit den Tools, die wir in unserer Toolbox definiert haben. Diese interagieren wiederum mit AlloyDB (und auch mit föderierten BigQuery-Daten) und antworten dem Nutzer.
Wenn Sie dieses Projekt im Cloud Shell-Editor aufrufen möchten, können Sie das Repository für den Agenten klonen. Führen Sie dazu die folgenden Befehle im Cloud Shell-Terminal aus:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
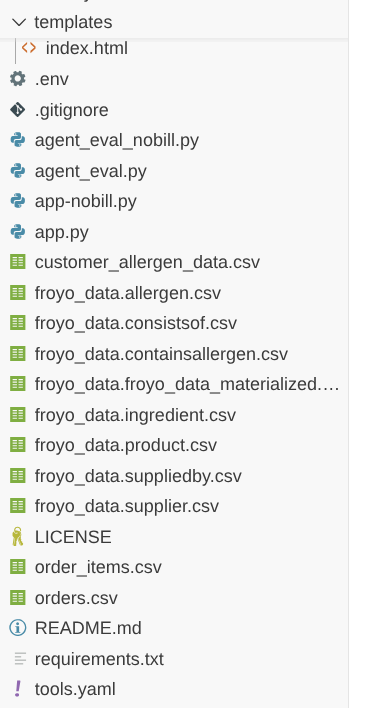
Sie sollten die folgende Projektstruktur sehen:
So können Sie weiterhin auf die Daten zugreifen, ohne ein Abrechnungskonto zu haben:
- Die folgenden Datendateien sind zur besseren Übersicht im Repository verfügbar:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Diese Dateien sollten sich im selben Ordner wie „app.py“ befinden.
B. Die Python-Datei mit dem Namen app-nobill.py im selben Pfad
- Im Stammordner des Projekts befindet sich eine Datei mit dem Namen app-nobill.py.
- Mit dieser Datei soll dieselbe App-Funktionalität erstellt werden, ohne dass eine explizite Verbindung zu diesen Datenquellen erforderlich ist, da die Daten in Dateien verfügbar gemacht wurden.
- Alle anderen im Lab erwähnten Dateien sollten auch für diese Version intakt sein. Die Datei „app.py“ muss nur nicht ausgeführt werden.
7. Benutzeroberfläche und Ausführen der App
Um unseren Store-Managern eine optimale Nutzererfahrung zu bieten, haben wir eine elegante, glasmorphe Benutzeroberfläche (templates/index.html) mit einer Live-Seitenleiste für den Produktkatalog und einer interaktiven Chat-Oberfläche erstellt.
Die Datei „index.html“ finden Sie hier im Repository:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Bevor Sie die Anwendung ausführen, müssen Sie dafür sorgen, dass die Datei requirements.txt die folgenden Abhängigkeiten enthält:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
und Ihre .env-Datei ausgefüllt ist:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Wie erhalte ich meinen GOOGLE_API_KEY?
Folgen Sie der Anleitung in diesem Blog, um Ihren Google API-Schlüssel einzurichten.
MCP_TOOLBOX_SERVER_URL abrufen
Wir haben dies im vorherigen Schritt dieses Codelabs eingerichtet und Sie haben den bereitgestellten MCP Toolbox-Endpunkt kopiert. Verwenden Sie diesen Link für die Umgebungsvariable MCP_TOOLBOX_SERVER_URL.
App ausführen:
Führen Sie im Cloud Shell-Terminal die folgenden Befehle nacheinander aus. Achten Sie darauf, dass Sie sich im Projektordner befinden:
Wechseln Sie zum Stammordner des Projekts:
cd froyo-data
Installieren Sie die Abhängigkeiten:
pip install -r requirements.txt
Python-Datei ausführen:
python app.py
Klicken Sie auf den Link, der im Terminal angezeigt wird, oder öffnen Sie http://localhost:8080.
8. Der ultimative Test
Klicken wir auf ein Produkt im Katalog, um den Agenten zu fragen:
Does Midnight Swirl have any allergens?
Sie sollten die folgende Antwort sehen:
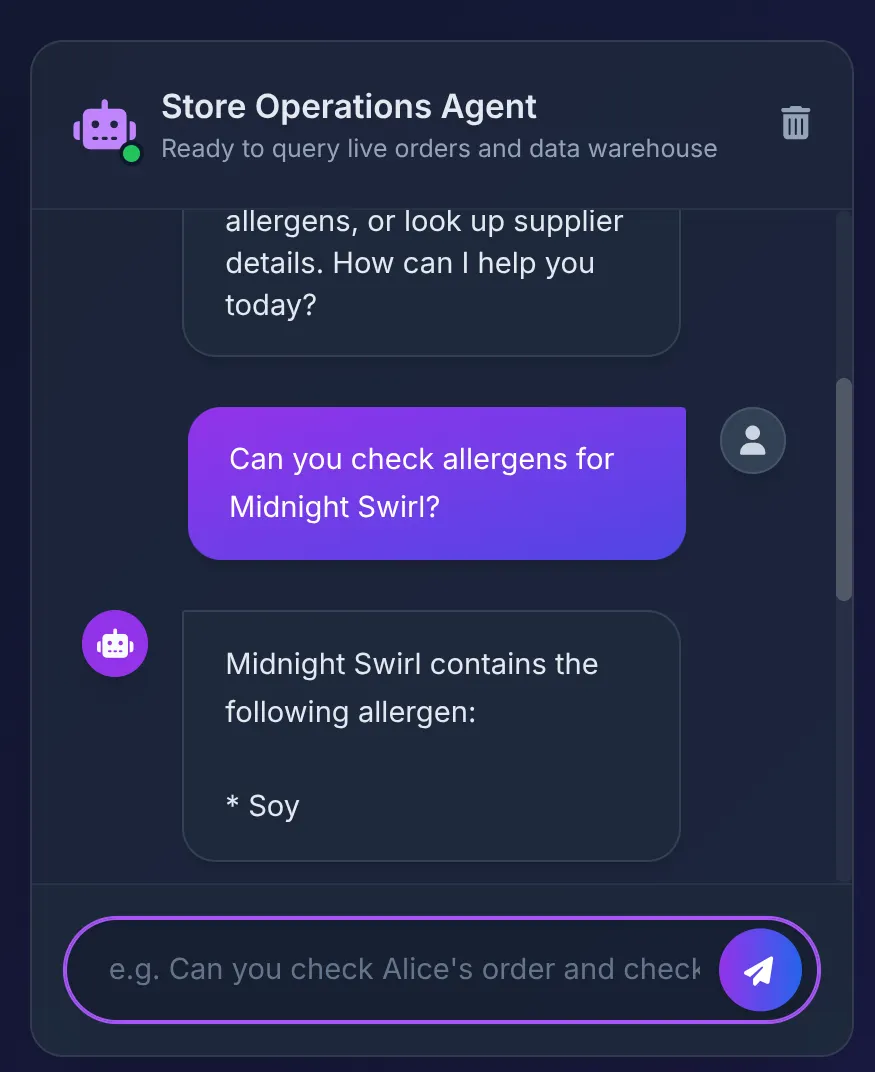
Hinter den Kulissen:
- Der ADK-Agent empfängt den Prompt und entscheidet, das Tool „check_allergens“ zu verwenden.
- Es ruft die MCP Toolbox in Cloud Run sicher auf.
- Die Toolbox führt die Abfrage in AlloyDB aus. Die Daten werden sofort an BigQuery übertragen, um die komplexen Beziehungen zu scannen, die wir in Teil 1 erstellt haben.
- Die Datenbank gibt „Soy“ zurück, was der Agent in der Benutzeroberfläche zusammenfasst.
Als Nächstes sagen wir:
Order 2 Midnight Swirl for Alice.
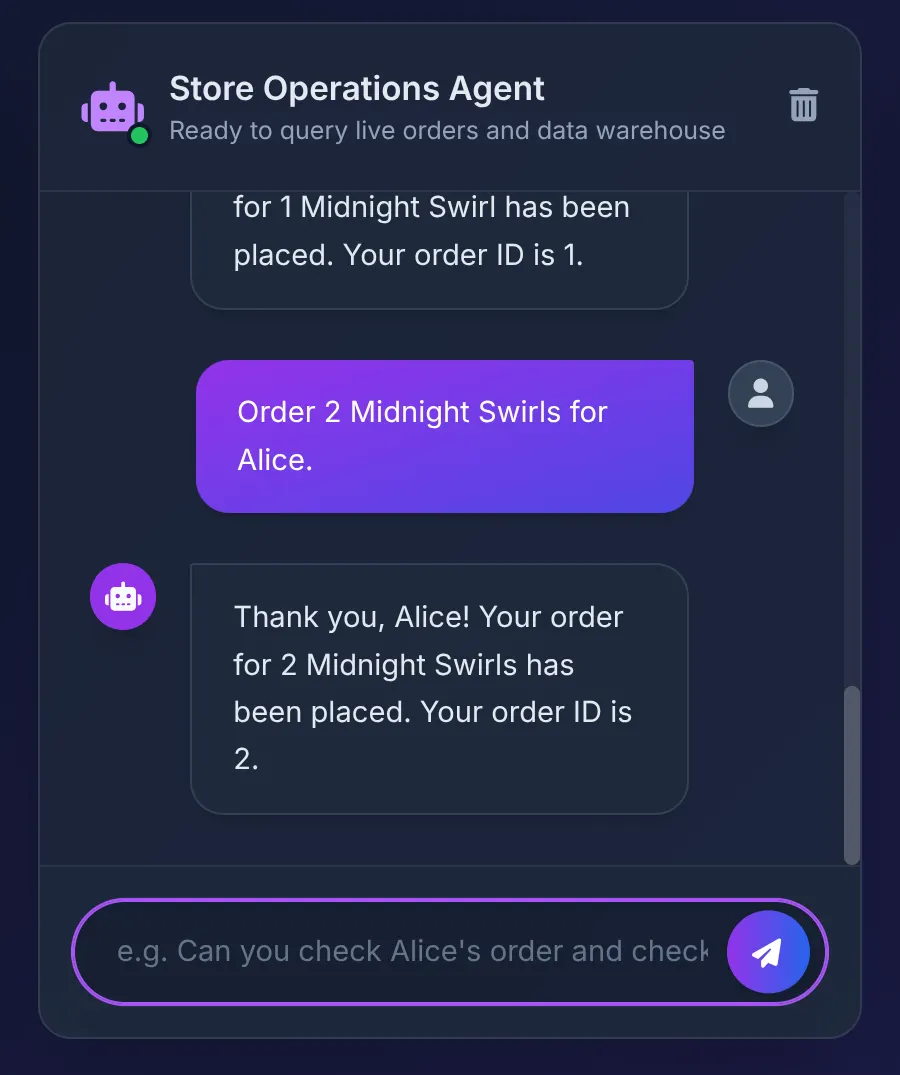
Der Kundenservicemitarbeiter übergibt den String „Midnight Swirl“ an die Toolbox. Das zugrunde liegende SQL löst den String dynamisch über BigQuery in eine Ganzzahl-ID auf, fügt die Live-Bestellung in AlloyDB ein und bestätigt die Transaktion.
Code-Repository
9. Bereinigen
Vergessen Sie nicht, den AlloyDB-Cluster und die AlloyDB-Instanz zu löschen, wenn Sie dieses Lab abgeschlossen haben.
Dadurch sollte der Cluster zusammen mit seinen Instanzen bereinigt werden.
10. Herzlichen Glückwunsch zu Ihrem Agent!
Denken Sie daran, was wir gerade erreicht haben:
Unser gut orchestriertes agentisches System interagiert nur mit der MCP Toolbox for Databases. Im Hintergrund werden der Tool-Aufruf und die Daten-zu-KI-Logik unserer Anwendung verarbeitet, wodurch der Ablauf einfach bleibt:
- Unsere Transaktions-App (die auf AlloyDB ausgeführt wird) kann schnelle, gleichzeitige Nutzersitzungen verarbeiten.
- Wenn umfangreiche Analysedaten oder ein historischer Kontext (z. B. Lieferantendetails oder komplexe Zutatenzuordnungen) erforderlich sind, wird das BigQuery-Schema „froyo_dataschema“ abgefragt.
- Zero ETL Keine Datenpipelines, die unterbrochen werden. Keine nicht synchronisierten Datenbanken. Wir speichern die Daten einmal (in BigQuery) und führen die Berechnungen dann durch, wenn sie benötigt werden.
Nachdem wir nun die Grundlagen für unseren Agenten und unsere Daten – sowohl analytische als auch transaktionale – geschaffen haben, können wir mit dem nächsten Teil fortfahren.
Wie geht es weiter?
Unser KI-Agent funktioniert einwandfrei – zumindest im Idealfall. In Teil 4 erstellen wir eine Pipeline zur Agentenbewertung, um die Gültigkeit, Fundierung und Leistung unseres Agentensystems gründlich zu testen. Bis dann!