
1. Descripción general
En la Parte 1, transformamos correctamente los PDFs caóticos y no estructurados en tablas limpias, inteligentes y estructuradas en BigQuery con Knowledge Catalog y DataScan. Ahora tenemos un almacén de datos sólido. En la parte 2, configuramos AlloyDB como nuestra estructura transaccional y federamos nuestras tablas de BigQuery en ella, lo que creó una capa de datos unificada sin duplicar un solo byte.
Hoy, crearemos el cerebro. Estamos creando una aplicación de varios agentes, el "Administrador de FroyoOS Store", que se encuentra sobre esta capa de datos para responder preguntas, verificar alérgenos y procesar pedidos en vivo.
El desafío: Desvincula la IA de tu agente
Cuando se crea un agente de IA que necesita comunicarse con bases de datos, el antipatrón más común es forzar la lógica de datos y de IA directamente en tu aplicación de Python. Esto hace que tu app sea frágil, insegura y muy difícil de mantener a medida que crece tu arquitectura de datos.
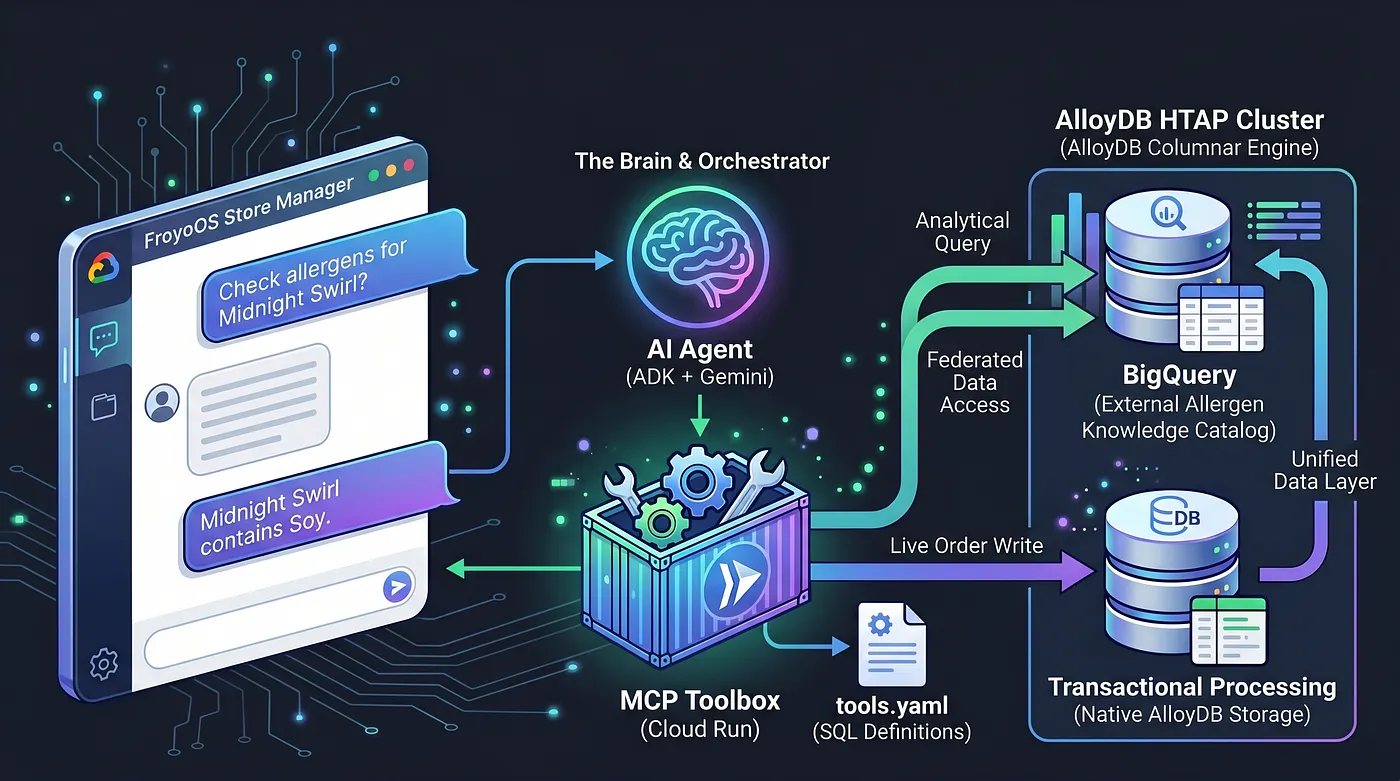
Para resolver este problema, usamos la caja de herramientas del Protocolo de contexto del modelo (MCP). MCP Toolbox actúa como nuestra capa de abstracción de datos unificada. Definimos nuestras operaciones de la base de datos de forma declarativa en un archivo tools.yaml simple. Implementamos esta caja de herramientas como un extremo seguro y sin servidores en Google Cloud Run. Nuestro agente de IA simplemente se conecta a este extremo y dice: "Ejecuta la herramienta 'place_order'".
El poder de HTAP
Antes de comenzar a compilar el agente, hablemos sobre por qué el título de esta publicación menciona específicamente el HTAP (procesamiento híbrido transaccional/analítico).
En una arquitectura tradicional, si un agente de IA necesitara procesar un pedido de usuario en vivo (una carga de trabajo transaccional de OLTP) y comparar datos mediante referencia cruzada de miles de asignaciones de ingredientes complejos (una carga de trabajo analítica de OLAP), tu aplicación de Python tendría que hacer malabares con las conexiones a dos bases de datos completamente diferentes. Esto genera una latencia grave, una sobrecarga de seguridad y una administración de estados frágil.
Convertimos AlloyDB en una potencia de HTAP federando de forma nativa nuestro almacén de datos de BigQuery directamente en PostgreSQL. Gracias a esta arquitectura HTAP, nuestro agente de IA solo necesita comunicarse con un extremo de la base de datos. Puede insertar transacciones en vivo en la tabla live_orders y ejecutar análisis analíticos pesados en el conjunto de datos federado froyo_data de BigQuery en el mismo instante, sin duplicar un solo byte de datos. Veamos cómo exponemos este motor a nuestra IA.
¡Comencemos a crear!
Qué aprenderás
- Cómo configurar un clúster, una instancia y una red de AlloyDB con un solo clic
- Cómo configurar la extensión para prepararse para la federación
- Cómo configurar la federación de BigQuery a AlloyDB
- Pruébalo
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
- Usarás Cloud Shell, un entorno de línea de comandos que se ejecuta en Google Cloud. Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.

- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si quieres autenticarte
gcloud auth login
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Habilita las APIs requeridas: Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Problemas potenciales y solución de problemas
El síndrome del "Proyecto fantasma" | Ejecutaste |
La barricada de facturación | Habilitaste el proyecto, pero olvidaste la cuenta de facturación. AlloyDB es un motor de alto rendimiento que no se iniciará si el "tanque de combustible" (facturación) está vacío. |
Retraso en la propagación de la API | Hiciste clic en "Habilitar APIs", pero la línea de comandos aún dice |
Cuota de Quags | Si usas una cuenta de prueba nueva, es posible que alcances una cuota regional para las instancias de AlloyDB. Si falla |
3. Prepara los datos
Asegúrate de que los datos estructurados que extrajimos de los PDFs no estructurados estén disponibles en BigQuery y de que también se haya establecido y probado la federación de datos de BigQuery de AlloyDB. Si no completaste esos pasos, este es un buen momento para hacerlo desde aquí y aquí para las partes 1 y 2, respectivamente.
Nota:
Si estás probando este codelab, no debes ejecutar el paso de limpieza de la parte 2 (el paso para borrar el clúster y la instancia) porque necesitamos la orquestación de AlloyDB para el sistema basado en agentes que se muestra aquí.
Además de los datos que ya creamos en la parte 2, debemos crear una tabla adicional en la instancia de AlloyDB. Ve a AlloyDB Studio con el siguiente vínculo:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Si usas un clúster diferente, cambia el nombre del clúster en el vínculo anterior.
En AlloyDB Studio, en una nueva pestaña del editor de consultas, ejecuta la siguiente instrucción:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Esto debería crear la tabla live_orders en tu base de datos.
4. Cómo definir la abstracción (el archivo tools.yaml)
Primero, registramos formalmente nuestras operaciones de base de datos. Creamos un archivo tools.yaml que define cómo interactúa nuestro agente con AlloyDB, que tiene datos tanto transaccionales como analíticos (datos analíticos de la federación de BigQuery).
- Ve a tu terminal de Cloud Shell. Activa el modo Editor.
- Crea una carpeta nueva en tu directorio raíz: "froyo-agent".
- Dentro de la carpeta, crea un archivo tools.yaml y pega el siguiente contenido (reemplaza los valores de proyecto, clúster, instancia y contraseña por los tuyos):
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Limitamos las capacidades de nuestro agente a 2 herramientas: verificar alérgenos y hacer el pedido.
5. Implementa Toolbox en Cloud Run
Para que esté disponible en nuestra aplicación, implementamos de forma segura la caja de herramientas con la CLI de gcloud. Esto crea el extremo de nuestra capa de abstracción.
- Activa la terminal de Cloud Shell y navega al directorio de trabajo ejecutando el siguiente comando:
cd froyo-agent
- Guarda el archivo tools.yaml en un secreto llamado "tools-froyo":
gcloud secrets create tools-froyo --data-file=tools.yaml
- Implementa el contenedor de MCP Toolbox en Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Los valores de "network" y "subnet" deben reemplazarse si usaste valores diferentes de los que configuramos en el codelab de la Parte 2.
- Anota la URL de Cloud Run resultante (p.ej., https://toolbox-froyo-xxx.run.app).
Usaremos este extremo de la caja de herramientas de MCP implementado en el paso de configuración del agente.
6. El backend de Agentic (app.py)
Con nuestra base de datos abstraída, nuestro código de Python puede enfocarse por completo en la orquestación y el razonamiento.
Usamos el Kit de desarrollo de agentes (ADK) junto con Flask. El ADK proporciona memoria de sesión de nivel empresarial (InMemorySessionService), lo que significa que nuestro agente recuerda el contexto de la conversación. Se integra de forma nativa con ToolboxSyncClient para extraer nuestras herramientas de Cloud Run sin problemas.
Aquí tienes tu archivo app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
La sencilla app de Flask en Python conecta el agente del ADK a las herramientas que definimos en nuestra caja de herramientas, que a su vez interactúa con AlloyDB (y también con los datos federados de BigQuery) y responde al usuario.
Para obtener este proyecto en el Editor de Cloud Shell, puedes clonar el repositorio del agente ejecutando los siguientes comandos desde la terminal de Cloud Shell:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
Deberías ver la siguiente estructura del proyecto:
Sigue estos pasos para seguir disfrutando de los datos sin la cuenta de facturación:
- Para tu comodidad, los siguientes archivos de datos están disponibles en el repositorio:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Estos archivos deben estar presentes en la misma carpeta que app.py.
B. El archivo de Python llamado app-nobill.py en la misma ruta de acceso
- En la carpeta raíz del proyecto, hay un archivo llamado app-nobill.py.
- Este archivo está diseñado para crear la misma experiencia en la app, pero sin la necesidad explícita de conectarse a estas fuentes de datos, ya que los datos están disponibles en archivos.
- Todos los demás archivos mencionados en el lab también deben estar intactos para esta versión (solo que no es necesario ejecutar el archivo app.py).
7. La IU y la ejecución de la app
Para brindarles a nuestros administradores de la tienda una experiencia adecuada, creamos una IU elegante y glasomórfica (templates/index.html) que incluye una barra lateral del catálogo de productos en vivo y una interfaz de chat interactiva.
Puedes encontrar el archivo index.html en el archivo del repositorio aquí:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Antes de ejecutar la aplicación, asegúrate de tener las dependencias en el archivo requirements.txt con el siguiente contenido:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
y tu archivo .env completado:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
¿Cómo obtener tu GOOGLE_API_KEY?
Sigue las instrucciones de este blog para configurar tu clave de API de Google.
¿Cómo obtener tu MCP_TOOLBOX_SERVER_URL?
Configuramos esto en el paso anterior de este codelab, y copiaste el extremo de MCP Toolbox implementado. Usa ese vínculo para la variable de entorno MCP_TOOLBOX_SERVER_URL.
Ejecuta tu app:
En la terminal de Cloud Shell, asegúrate de estar en la carpeta del proyecto y ejecuta los siguientes comandos uno por uno:
Navega a la carpeta raíz del proyecto:
cd froyo-data
Instala las dependencias:
pip install -r requirements.txt
Ejecuta el archivo de Python:
python app.py
Haz clic en el vínculo que aparece en la terminal o abre http://localhost:8080.
8. La prueba definitiva
Hagamos clic en un producto del catálogo para preguntarle al agente:
Does Midnight Swirl have any allergens?
Deberías ver la siguiente respuesta:
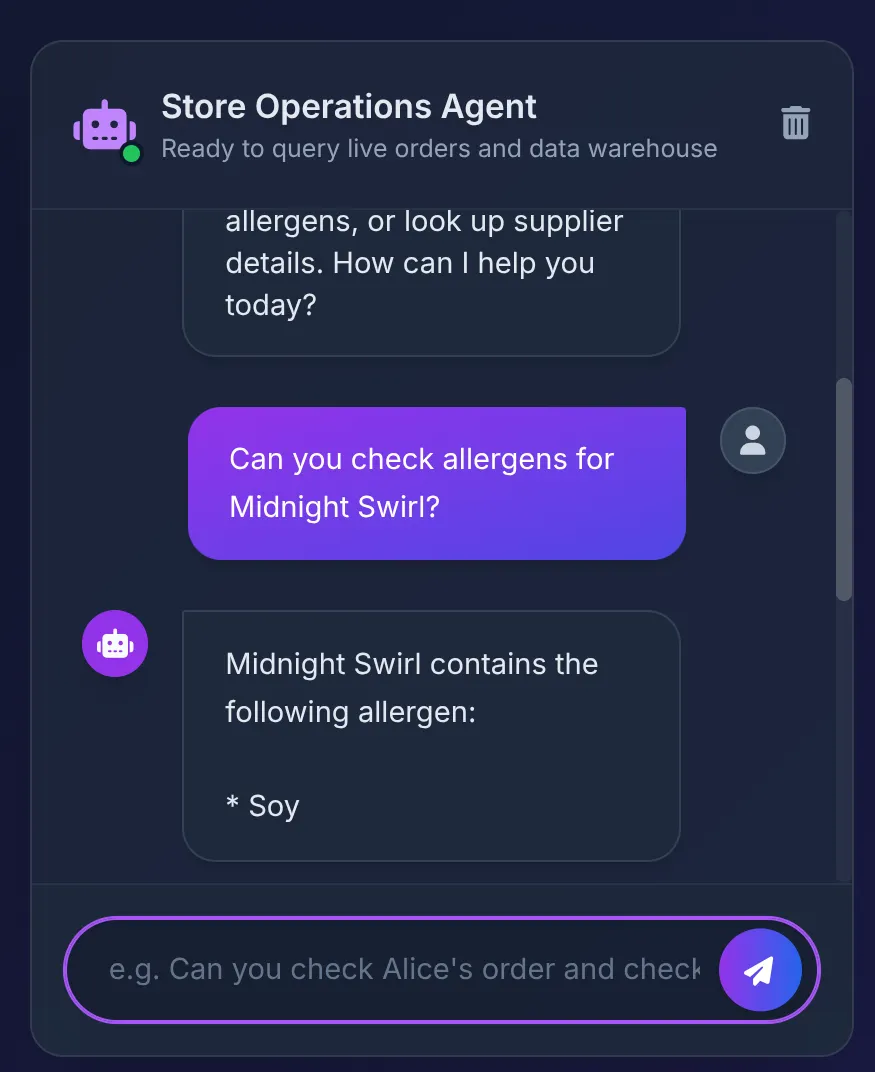
Tras bambalinas:
- El agente de ADK recibe la instrucción y decide usar la herramienta check_allergens.
- Llama de forma segura a MCP Toolbox en Cloud Run.
- La caja de herramientas ejecuta la consulta en AlloyDB, que se federa de inmediato a BigQuery para analizar las relaciones complejas que creamos en la Parte 1.
- La base de datos devuelve "Soy", que el agente resume de forma clara en la IU.
A continuación, decimos lo siguiente:
Order 2 Midnight Swirl for Alice.
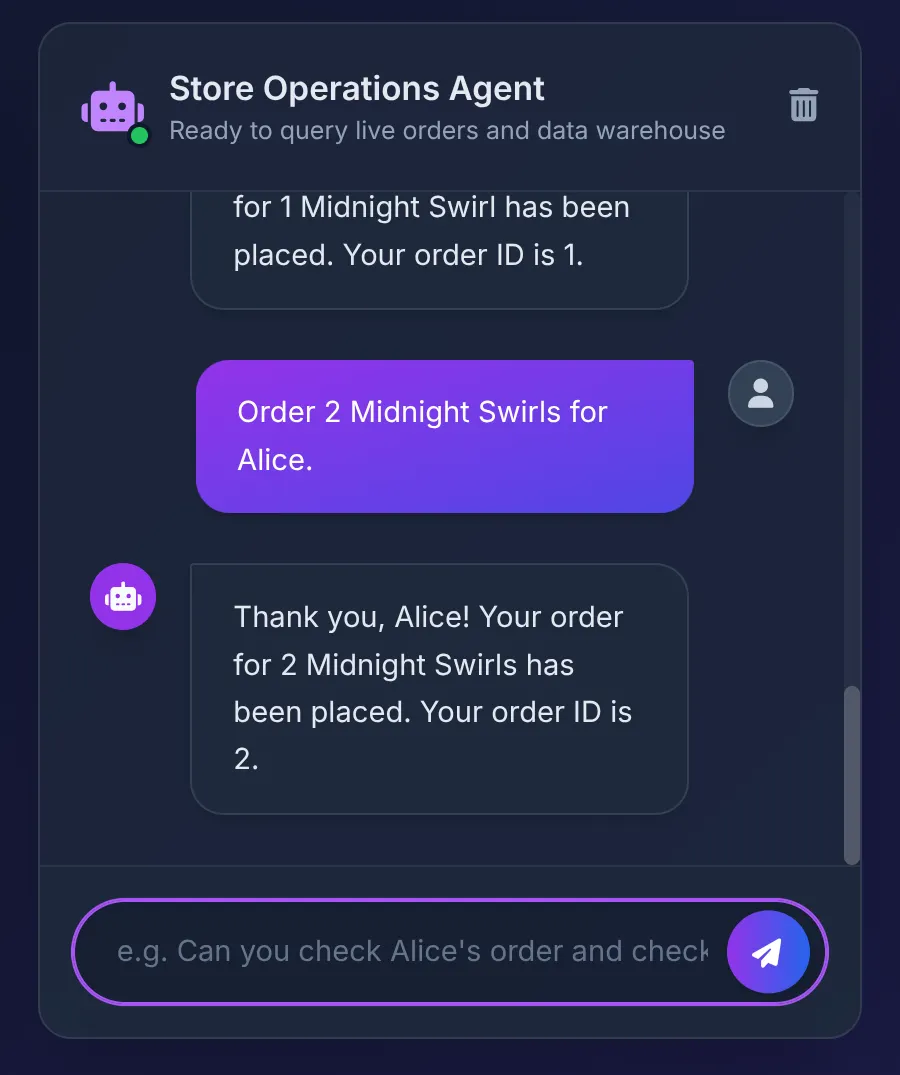
El agente pasa la cadena "Midnight Swirl" a la caja de herramientas. El SQL subyacente resuelve de forma dinámica la cadena en un ID de número entero a través de BigQuery, inserta el pedido activo en AlloyDB y confirma la transacción.
Repositorio de código
9. Limpia
Cuando termines este lab, no olvides borrar el clúster y la instancia de AlloyDB.
Debería limpiar el clúster junto con sus instancias.
10. ¡Felicitaciones por tu agente!
Piensa en lo que acabamos de lograr:
Nuestro sistema de agentes bien orquestado interactúa solo con MCP Toolbox para bases de datos. Tras bambalinas, esto controla la llamada a la herramienta y la lógica de datos a IA de nuestra aplicación, lo que mantiene el flujo simple:
- Nuestra app transaccional (que se ejecuta en AlloyDB) puede controlar sesiones de usuarios rápidas y simultáneas.
- Cuando necesita datos analíticos detallados o contexto histórico (como detalles del proveedor o asignaciones complejas de ingredientes), consulta froyo_dataschema de BigQuery.
- Zero ETL No se interrumpen las canalizaciones de datos. No hay bases de datos desincronizadas. Almacenamos los datos una vez (en BQ) y los calculamos donde los necesitamos.
Ahora que completamos la base de datos y el agente, tanto analíticos como transaccionales, pasemos a la siguiente parte.
Próximos pasos
Nuestro agente funciona perfectamente… en la ruta feliz. En la parte 4, crearemos una canalización de evaluación de agentes para probar de forma rigurosa la validez, la fundamentación y el rendimiento de nuestro sistema basado en agentes. ¡Nos vemos!