
۱. مرور کلی
در بخش اول ، ما با موفقیت فایلهای PDF بینظم و بدون ساختار را با استفاده از Knowledge Catalog و DataScan به جداول تمیز، هوشمند و ساختاریافته در BigQuery تبدیل کردیم. اکنون، ما یک انبار داده قوی داریم. در بخش دوم ، AlloyDB را به عنوان ستون فقرات تراکنشی خود راهاندازی کردیم و جداول BigQuery خود را در آن ادغام کردیم و یک لایه داده یکپارچه بدون کپی کردن حتی یک بایت ایجاد کردیم.
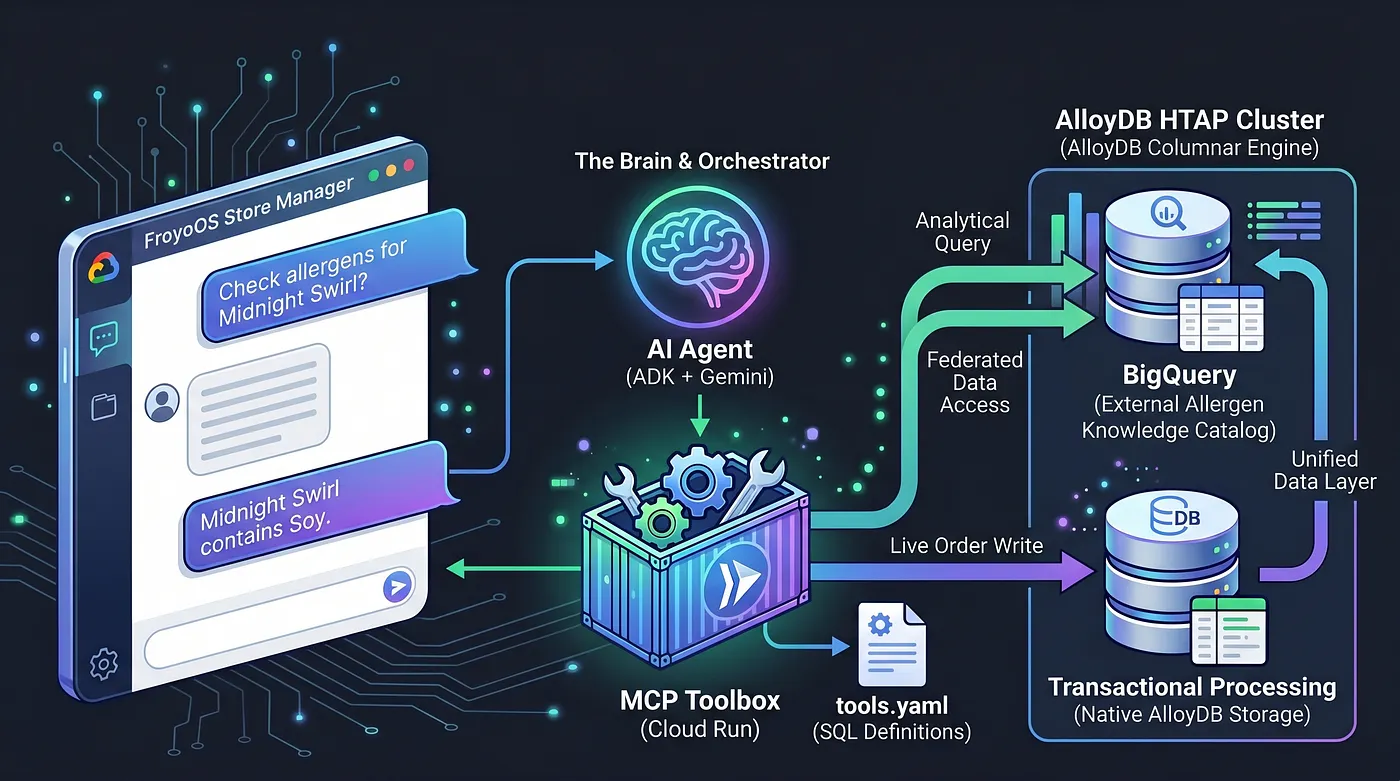
امروز، ما مغز را میسازیم. ما در حال ایجاد یک برنامه چندعاملی - "مدیر فروشگاه FroyoOS" - هستیم که در بالای این لایه داده قرار میگیرد تا به سؤالات پاسخ دهد، مواد حساسیتزا را بررسی کند و سفارشات زنده را پردازش کند.
چالش: جدا کردن هوش مصنوعی از عامل شما
هنگام ساخت یک عامل هوش مصنوعی که نیاز به ارتباط با پایگاههای داده دارد، رایجترین ضدالگو، تحمیل دادهها و منطق هوش مصنوعی به طور مستقیم به برنامه پایتون شماست. این امر باعث میشود برنامه شما با رشد معماری داده شما شکننده، ناامن و نگهداری آن فوقالعاده دشوار شود.
برای حل این مشکل، ما از جعبه ابزار پروتکل زمینه مدل (MCP) استفاده میکنیم. جعبه ابزار MCP به عنوان لایه انتزاع داده یکپارچه ما عمل میکند. ما عملیات پایگاه داده خود را به صورت اعلانی در یک فایل ساده tools.yaml تعریف میکنیم. ما این جعبه ابزار را به عنوان یک نقطه پایانی امن و بدون سرور در Google Cloud Run مستقر میکنیم. عامل هوش مصنوعی ما به سادگی به این نقطه پایانی متصل میشود و میگوید: "ابزار 'place_order' را اجرا کن."
قدرت HTAP
قبل از اینکه شروع به ساخت عامل کنیم، بیایید در مورد اینکه چرا عنوان این پست به طور خاص HTAP (پردازش ترکیبی تراکنشی/تحلیلی) را نام میبرد، صحبت کنیم.
در معماری سنتی، اگر یک عامل هوش مصنوعی نیاز به پردازش سفارش کاربر زنده (یک بار کاری OLTP تراکنشی) و ارجاع متقابل به هزاران نگاشت پیچیده اجزا (یک بار کاری OLAP تحلیلی) داشته باشد، برنامه پایتون شما باید اتصالات به دو پایگاه داده کاملاً متفاوت را مدیریت کند. این امر باعث تأخیر شدید، سربار امنیتی و مدیریت وضعیت شکننده میشود.
ما با ادغام مستقیم انبار داده BigQuery خود در PostgreSQL، AlloyDB را به یک نیروگاه HTAP تبدیل کردیم. به دلیل این معماری HTAP، عامل هوش مصنوعی ما امروزه فقط نیاز دارد با یک نقطه پایانی پایگاه داده ارتباط برقرار کند. این عامل میتواند تراکنشهای زنده را در جدول live_orders وارد کند و اسکنهای تحلیلی سنگین را دقیقاً همزمان روی مجموعه داده froyo_data BigQuery اجرا کند، بدون اینکه حتی یک بایت داده را کپی کند. بیایید ببینیم چگونه این موتور را در اختیار هوش مصنوعی خود قرار میدهیم.
بیایید شروع به ساختن کنیم!
آنچه یاد خواهید گرفت
- نحوه راهاندازی کلاستر، نمونه و شبکهسازی AlloyDB تنها با یک کلیک
- نحوه تنظیم برنامه الحاقی برای آماده شدن برای فدراسیون
- نحوه راه اندازی فدراسیون از BigQuery به AlloyDB
- آن را آزمایش کنید
الزامات
۲. قبل از شروع
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. روی Activate Cloud Shell در بالای کنسول Google Cloud کلیک کنید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر میخواهید احراز هویت کنید
gcloud auth login
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- فعال کردن API های مورد نیاز: برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
اشکالات و عیبیابی
سندرم «پروژه ارواح» | شما |
سنگر بیلینگ | شما پروژه را فعال کردید، اما حساب صورتحساب را فراموش کردید. AlloyDB یک موتور با کارایی بالا است؛ اگر "مخزن بنزین" (صورتحساب) خالی باشد، روشن نمیشود. |
تأخیر انتشار API | شما روی «فعال کردن APIها» کلیک کردهاید، اما خط فرمان هنوز میگوید |
کواگهای سهمیهای | اگر از یک حساب آزمایشی کاملاً جدید استفاده میکنید، ممکن است به سهمیه منطقهای برای نمونههای AlloyDB برسید. اگر |
۳. آمادهسازی دادهها
مطمئن شوید که دادههای ساختاریافتهای که از فایلهای PDF بدون ساختار استخراج کردهایم در BigQuery موجود هستند و فدراسیون دادههای BigQuery در AlloyDB نیز ایجاد و آزمایش شده است. اگر این مراحل را انجام ندادهاید، الان زمان مناسبی است که به ترتیب برای بخشهای ۱ و ۲، مراحل سادهی اینجا و اینجا را اجرا کنید .
توجه:
اگر این کد را امتحان میکنید، نباید مرحله پاکسازی بخش ۲ (حذف مرحله کلاستر و نمونه) را اجرا کنید، زیرا ما برای سیستم عامل خود که در اینجا نشان داده شده است، به هماهنگی AlloyDB نیاز داریم.
علاوه بر دادههایی که قبلاً در بخش ۲ ایجاد کردیم، باید یک جدول دیگر در نمونه AlloyDB ایجاد کنیم. با استفاده از لینک زیر به AlloyDB Studio بروید:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
اگر از خوشهی دیگری استفاده میکنید، نام خوشه را در لینک بالا تغییر دهید.
در AlloyDB Studio، در یک تب جدید Query Editor، دستور زیر را اجرا کنید:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
این باید جدول live_orders را در پایگاه داده شما ایجاد کند.
۴. تعریف انتزاع (tools.yaml)
ابتدا، ما عملیات پایگاه داده خود را رسماً ثبت میکنیم. ما یک فایل tools.yaml ایجاد میکنیم که نحوه تعامل عامل ما با AlloyDB را تعریف میکند که شامل دادههای تراکنشی و تحلیلی (دادههای تحلیلی از فدراسیون BigQuery) است.
- به ترمینال Cloud Shell خود بروید. به حالت ویرایشگر بروید.
- یک پوشه جدید در دایرکتوری ریشه خود ایجاد کنید: " froyo-agent "
- درون پوشه، یک فایل tools.yaml ایجاد کنید و محتوای زیر را در آن قرار دهید: (با مقادیر دلخواه خود برای پروژه، خوشه، نمونه و رمز عبور جایگزین کنید)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
ما قابلیتهای نمایندگان خود را به دو ابزار محدود کردهایم - بررسی مواد حساسیتزا و ثبت سفارش.
۵. استقرار جعبه ابزار در Cloud Run
برای اینکه این قابلیت در برنامه ما در دسترس قرار گیرد، ما با استفاده از رابط خط فرمان gcloud، جعبه ابزار را به صورت ایمن مستقر میکنیم. این کار نقطه پایانی لایه انتزاعی ما را ایجاد میکند.
- به ترمینال Cloud Shell بروید و با اجرای دستور زیر به دایرکتوری کاری بروید:
cd froyo-agent
- فایل tools.yaml را در یک فایل مخفی با نام "tools-froyo" ذخیره کنید:
gcloud secrets create tools-froyo --data-file=tools.yaml
- کانتینر MCP Toolbox را در Cloud Run مستقر کنید
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
اگر از مقادیری متفاوت از آنچه در بخش ۲ codelab پیکربندی کردهایم استفاده کردهاید، مقادیر «شبکه» و «زیرشبکه» باید جایگزین شوند.
- آدرس اینترنتی Cloud Run حاصل را یادداشت کنید (مثلاً https://toolbox-froyo-xxx.run.app ).
ما از این نقطه پایانی MCP Toolbox مستقر شده در مرحله پیکربندی عامل استفاده خواهیم کرد.
۶. بکاند عامل (app.py)
با حذف پایگاه داده، کد پایتون ما میتواند کاملاً روی هماهنگی و استدلال تمرکز کند.
ما در کنار Flask از کیت توسعه عامل (ADK) استفاده میکنیم. ADK حافظه جلسه در سطح سازمانی ( InMemorySessionService ) را فراهم میکند، به این معنی که عامل ما زمینه مکالمه را به خاطر میسپارد. این کیت به صورت بومی با ToolboxSyncClient ادغام میشود تا ابزارهای ما را به طور یکپارچه از Cloud Run دریافت کند.
فایل app.py شما به صورت زیر است:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
برنامه ساده پایتون فلاسک، عامل ADK را به ابزارهایی که در جعبه ابزار خود تعریف کردهایم متصل میکند که به نوبه خود با AlloyDB (و همچنین دادههای فدرال BigQuery) تعامل دارد و به کاربر پاسخ میدهد.
برای دریافت این پروژه در ویرایشگر Cloud Shell خود، میتوانید با اجرای دستورات زیر از ترمینال Cloud Shell خود، مخزن مربوط به عامل را کلون کنید:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
شما باید ساختار پروژه زیر را ببینید:
مراحل ادامه استفاده از دادهها بدون نیاز به حساب صورتحساب:
- فایلهای داده زیر برای راحتی در مخزن موجود هستند:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
این فایلها باید در همان پوشهای که فایل app.py قرار دارد، باشند.
ب. فایل پایتون با نام app-nobill.py در همان مسیر
- در پوشه ریشه پروژه، فایلی با نام app-nobill.py وجود دارد.
- این فایل برای ایجاد همان تجربه برنامه طراحی شده است، اما بدون نیاز صریح به اتصال به این منابع داده، زیرا دادهها در فایلها در دسترس قرار گرفتهاند.
- تمام فایلهای دیگر که در تمرین ذکر شدند، باید برای این نسخه نیز دستنخورده باشند (فقط نیازی به اجرای فایل app.py نیست)
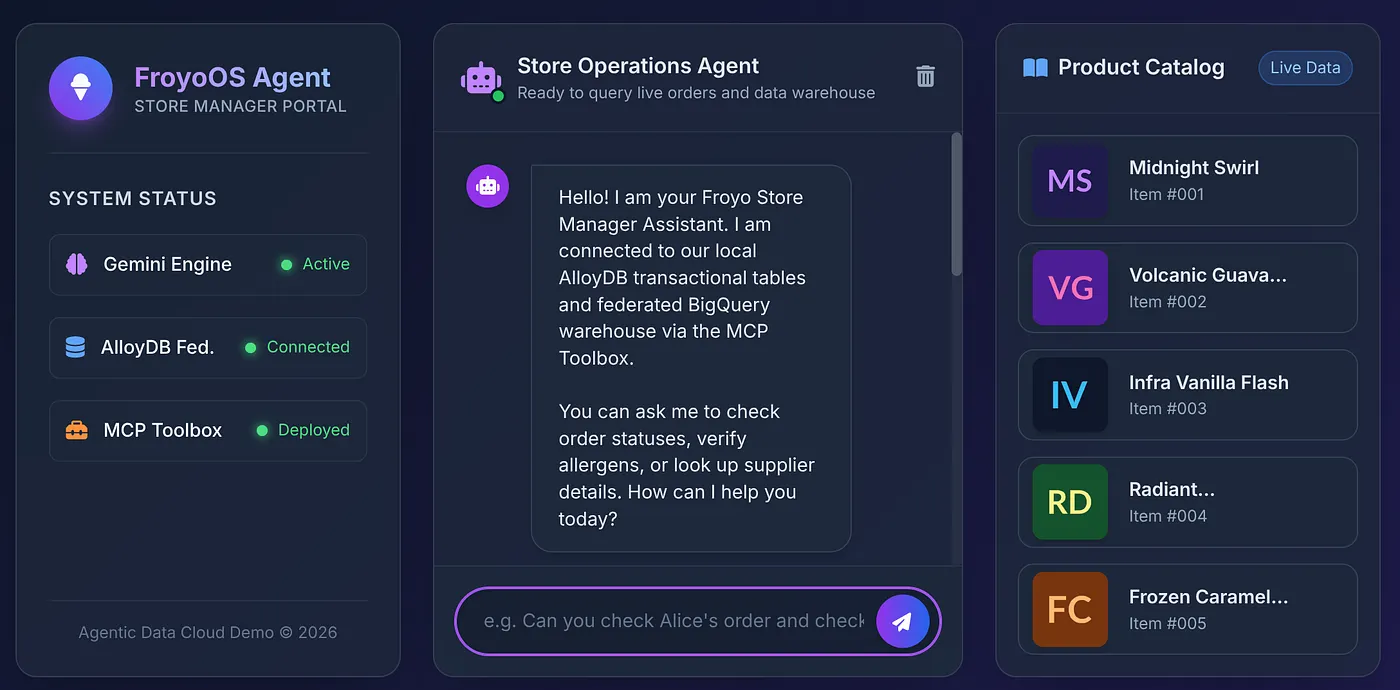
۷. رابط کاربری و اجرای برنامه
برای اینکه به مدیران فروشگاه خود تجربهای مناسب ارائه دهیم، یک رابط کاربری شیک و شیشهای ( templates/index.html ) ایجاد کردیم که شامل یک نوار کناری کاتالوگ محصولات زنده و یک رابط چت تعاملی است.
میتوانید فایل index.html را در فایل repo اینجا پیدا کنید:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
قبل از اجرای برنامه، مطمئن شوید که وابستگیهای خود را در فایل requirements.txt با محتوای زیر دارید:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
و فایل .env شما پر شد:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
چگونه GOOGLE_API_KEY خود را دریافت کنیم؟
برای تنظیم کلید API گوگل خود، دستورالعملهای این وبلاگ را دنبال کنید.
چگونه MCP_TOOLBOX_SERVER_URL خود را دریافت کنیم؟
ما این را در مرحله قبل در این آزمایشگاه کد تنظیم کردیم و شما نقطه پایانی MCP Toolbox مستقر شده را کپی کردید. از آن لینک برای متغیر محیطی MCP_TOOLBOX_SERVER_URL استفاده کنید.
برنامه خود را اجرا کنید:
از ترمینال Cloud Shell، مطمئن شوید که در پوشه پروژه هستید، دستورات زیر را یکی یکی اجرا کنید:
به پوشه ریشه پروژه بروید:
cd froyo-data
نصب وابستگیها:
pip install -r requirements.txt
اجرای فایل پایتون:
python app.py
روی لینکی که در ترمینال نمایش داده میشود کلیک کنید یا http://localhost:8080 را باز کنید!
۸. آزمون نهایی
بیایید روی یک محصول از کاتالوگ کلیک کنیم تا از نماینده بپرسیم:
Does Midnight Swirl have any allergens?
شما باید پاسخ را ببینید:
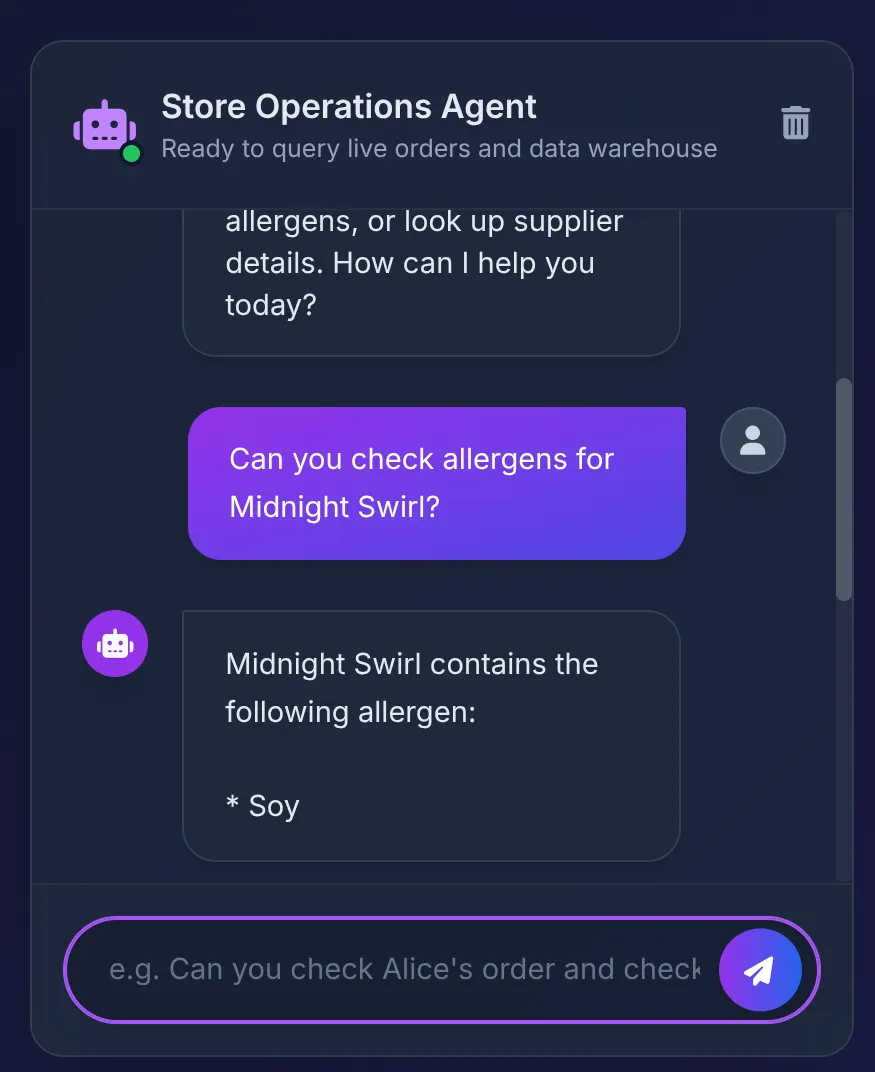
پشت صحنه:
- عامل ADK اعلان را دریافت میکند و تصمیم میگیرد از ابزار check_allergens استفاده کند.
- این ابزار به طور ایمن MCP Toolbox را در Cloud Run فراخوانی میکند.
- جعبه ابزار، کوئری را در AlloyDB اجرا میکند که فوراً با BigQuery ادغام میشود تا روابط پیچیدهای را که در بخش اول ایجاد کردیم، اسکن کند.
- پایگاه داده "Soy" را برمیگرداند، که عامل به طور خلاصه در رابط کاربری نمایش میدهد.
در ادامه، میگوییم:
Order 2 Midnight Swirl for Alice.
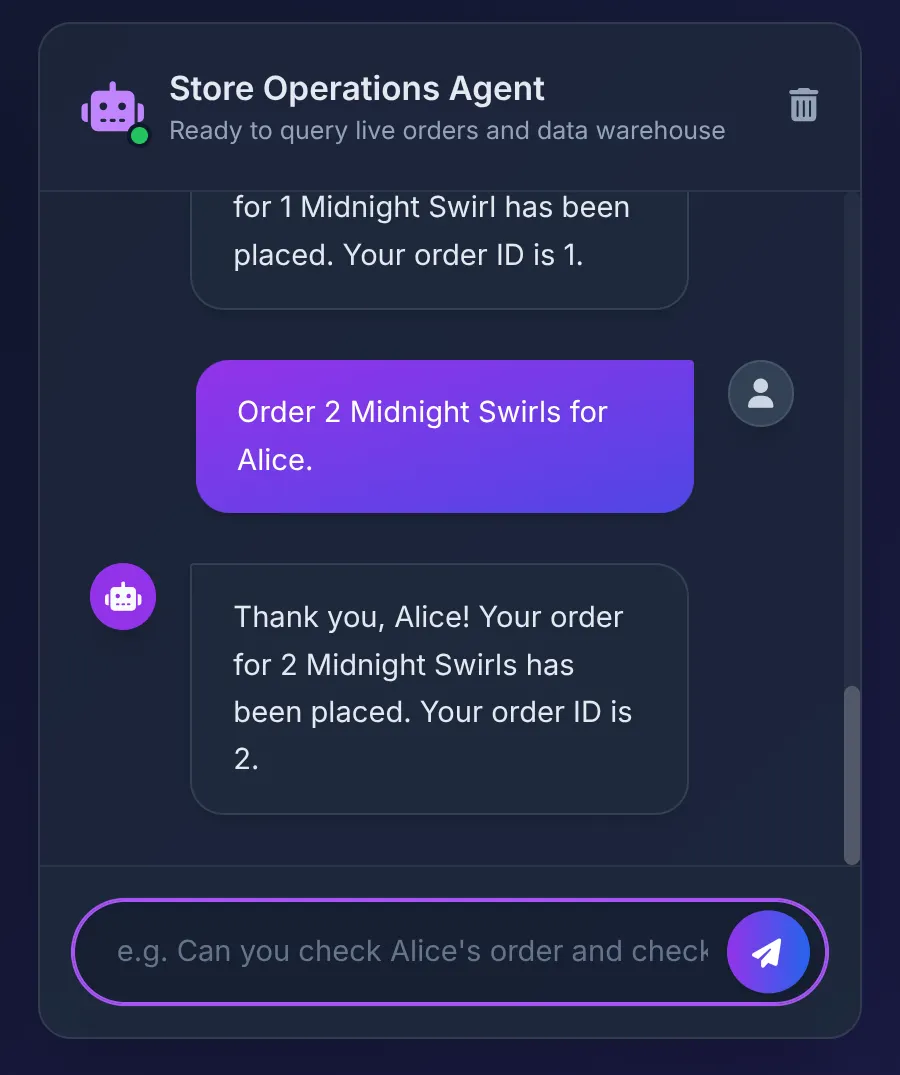
عامل رشته "Midnight Swirl" را به جعبه ابزار (Toolbox) ارسال میکند. SQL مربوطه به صورت پویا رشته را از طریق BigQuery به یک شناسه عدد صحیح تبدیل میکند، سفارش زنده را در AlloyDB وارد میکند و تراکنش را تأیید میکند.
مخزن کد
۹. تمیز کردن
پس از انجام این آزمایش، فراموش نکنید که کلاستر و نمونه AlloyDB را حذف کنید.
باید کلاستر را به همراه نمونه(های) آن پاکسازی کند.
۱۰. به خاطر نمایندهات به تو تبریک میگویم!
به کاری که تازه انجام دادیم فکر کنید:
سیستم عامل هماهنگ ما فقط با MCP Toolbox برای پایگاههای داده تعامل دارد. این سیستم در پشت صحنه، فراخوانی ابزار و منطق هوش مصنوعی برنامه ما را مدیریت میکند و جریان کار را ساده نگه میدارد:
- برنامه تراکنشی ما (که روی AlloyDB اجرا میشود) میتواند جلسات کاربری سریع و همزمان را مدیریت کند.
- وقتی به دادههای تحلیلی سنگین یا پیشینهی تاریخی (مانند جزئیات تأمینکنندگان یا نگاشتهای پیچیدهی مواد تشکیلدهنده) نیاز دارد، از BigQuery froyo_dataschema پرسوجو میکند.
- بدون ETL. بدون خرابی خطوط لوله داده. بدون پایگاههای داده ناهمگام. ما یک بار (در BQ) ذخیره میکنیم و هر جا که نیاز داشته باشیم، محاسبه میکنیم.
حالا که پایه و اساس عامل و داده ما - چه تحلیلی و چه تراکنشی - کامل شده است، بیایید به بخش بعدی برویم.
قدم بعدی چیست؟
عامل ما کاملاً درست کار میکند... در مسیر درست. در بخش ۴ ، ما قصد داریم یک خط لوله ارزیابی عامل بسازیم تا اعتبار، پایه و عملکرد سیستم عامل خود را به طور دقیق آزمایش کنیم. آنجا میبینمت!