
1. Présentation
Dans la partie 1, nous avons transformé des PDF chaotiques et non structurés en tables propres, intelligentes et structurées dans BigQuery à l'aide de Knowledge Catalog et de DataScan. Nous disposons désormais d'un entrepôt de données robuste. Dans la partie 2, nous avons configuré AlloyDB comme base transactionnelle et y avons fédéré nos tables BigQuery, créant ainsi une couche de données unifiée sans dupliquer un seul octet.
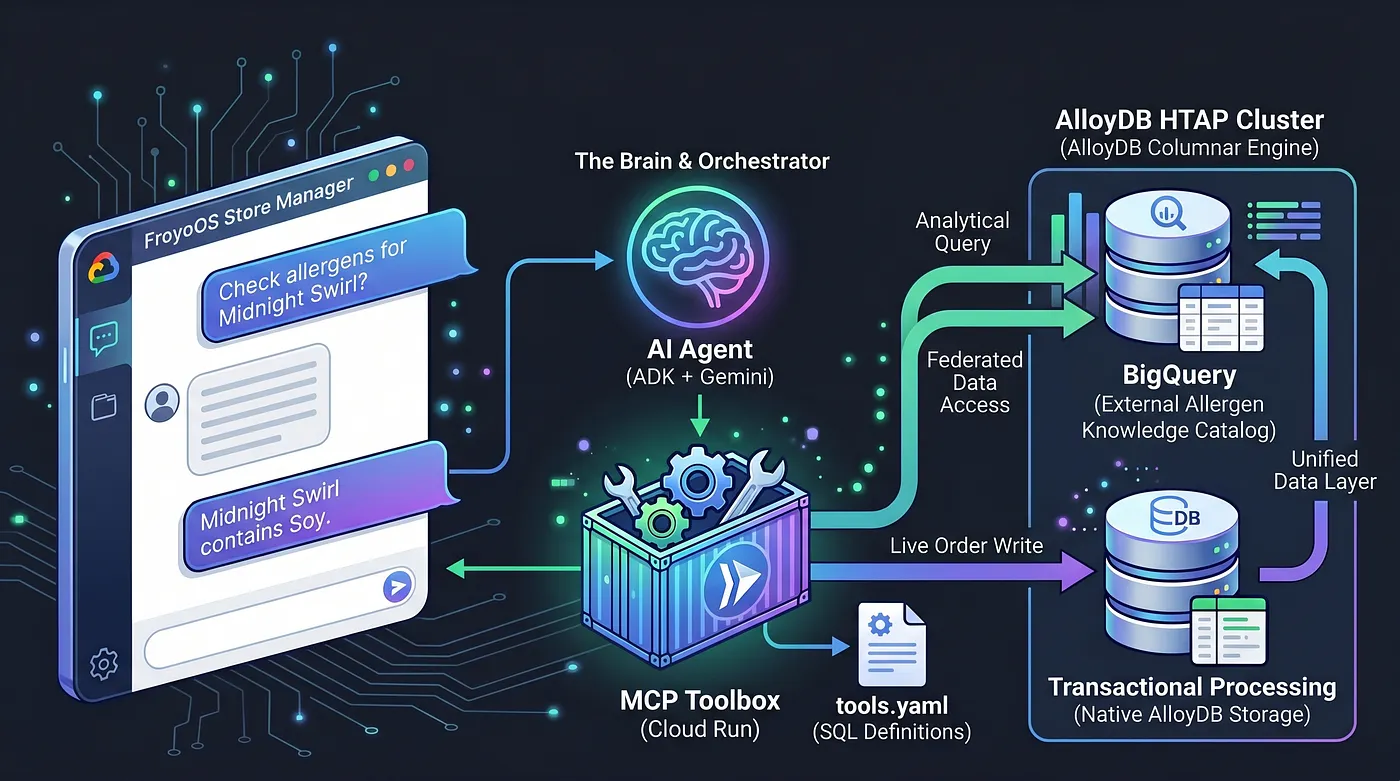
Aujourd'hui, nous allons créer le cerveau. Nous allons créer une application multi-agent, le "FroyoOS Store Manager", qui se trouve au-dessus de cette couche de données pour répondre aux questions, vérifier les allergènes et traiter les commandes en direct.
Le défi : découpler l'IA de votre agent
Lorsque vous créez un agent IA qui doit communiquer avec des bases de données, l'anti-modèle le plus courant consiste à forcer les données et la logique d'IA directement dans votre application Python. Cela rend votre application fragile, non sécurisée et incroyablement difficile à maintenir à mesure que votre architecture de données se développe.
Pour résoudre ce problème, nous allons utiliser MCP (Model Context Protocol) Toolbox. MCP Toolbox sert de couche d'abstraction de données unifiée. Nous définissons nos opérations de base de données de manière déclarative dans un simple fichier tools.yaml. Nous déployons cette boîte à outils en tant que point de terminaison sans serveur sécurisé sur Google Cloud Run. Notre agent IA se connecte simplement à ce point de terminaison et dit : "Exécute l'outil 'place_order'."
La puissance du traitement HTAP
Avant de commencer à créer l'agent, expliquons pourquoi le titre de cet article mentionne spécifiquement le traitement HTAP (Hybrid Transactional/Analytical Processing).
Dans une architecture traditionnelle, si un agent IA devait traiter une commande utilisateur en direct (une charge de travail transactionnelle OLTP) et croiser des milliers de mappages d'ingrédients complexes (une charge de travail analytique OLAP), votre application Python devrait gérer les connexions à deux bases de données entièrement différentes. Cela crée une latence importante, une surcharge de sécurité et une gestion d'état fragile.
Nous avons transformé AlloyDB en une centrale HTAP en fédérant de manière native notre entrepôt de données BigQuery directement dans PostgreSQL. Grâce à cette architecture HTAP, notre agent IA n'a plus besoin de communiquer qu'avec un seul point de terminaison de base de données. Il peut insérer des transactions en direct dans la table live_orders et exécuter des analyses analytiques lourdes sur l'ensemble de données BigQuery fédéré froyo_data en même temps, sans dupliquer un seul octet de données. Voyons comment nous exposons ce moteur à notre IA.
Au travail !
Points abordés
- Configurer un cluster, une instance et un réseau AlloyDB en un clic
- Configurer une extension pour préparer la fédération
- Configurer la fédération de BigQuery vers AlloyDB
- Effectuer un test
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud reconnaît votre projet.
gcloud config list project
- Si vous souhaitez vous authentifier
gcloud auth login
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Activez les API requises : exécutez cette commande pour activer toutes les API requises :
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Problèmes courants et dépannage
Syndrome du "projet fantôme" | Vous avez exécuté |
Barrière de facturation | Vous avez activé le projet, mais vous avez oublié le compte de facturation. AlloyDB est un moteur hautes performances. Il ne démarre pas si le "réservoir" (facturation) est vide. |
Délai de propagation de l'API | Vous avez cliqué sur "Activer les API", mais la ligne de commande indique toujours |
Quotas | Si vous utilisez un tout nouveau compte d'essai, vous pouvez atteindre un quota régional pour les instances AlloyDB. Si |
3. Préparer les données
Assurez-vous que les données structurées que nous avons extraites des PDF non structurés sont disponibles dans BigQuery, et que la fédération AlloyDB des données BigQuery est également établie et testée. Si vous n'avez pas effectué ces étapes, c'est le bon moment pour les exécuter en suivant les instructions ici et ici pour les parties 1 et 2, respectivement.
Remarque :
Si vous essayez cet atelier de programmation, n'exécutez pas l'étape de nettoyage de la partie 2 (suppression du cluster et de l'instance), car nous avons besoin de l'orchestration AlloyDB pour notre système agentique présenté ici.
En plus des données que nous avons déjà créées dans la partie 2, nous devons créer une table supplémentaire dans l'instance AlloyDB. Accédez à AlloyDB Studio à l'aide du lien suivant :
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Modifiez le nom du cluster dans le lien ci-dessus si vous utilisez un autre cluster.
Dans AlloyDB Studio, dans un nouvel onglet de l'éditeur de requête, exécutez l'instruction suivante :
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Cela devrait créer la table live_orders dans votre base de données.
4. Définir l'abstraction (le fichier tools.yaml)
Tout d'abord, nous enregistrons formellement nos opérations de base de données. Nous créons un fichier tools.yaml qui définit comment notre agent interagit avec AlloyDB, qui contient à la fois les données transactionnelles et analytiques (données analytiques issues de la fédération BigQuery).
- Accédez à votre terminal Cloud Shell. Passez en mode Éditeur.
- Créez un dossier dans votre répertoire racine : "froyo-agent"
- Dans le dossier, créez un fichier tools.yaml et collez le contenu suivant : (remplacez les valeurs par les vôtres pour le projet, le cluster, l'instance et le mot de passe)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Nous avons limité les capacités de notre agent à deux outils : vérifier les allergènes et passer une commande.
5. Déployer la boîte à outils sur Cloud Run
Pour rendre cette boîte à outils disponible pour notre application, nous la déployons de manière sécurisée à l'aide de gcloud CLI. Cela crée notre point de terminaison de couche d'abstraction.
- Passez au terminal Cloud Shell et accédez au répertoire de travail en exécutant la commande :
cd froyo-agent
- Enregistrez le fichier tools.yaml dans un secret nommé "tools-froyo" :
gcloud secrets create tools-froyo --data-file=tools.yaml
- Déployez le conteneur MCP Toolbox sur Cloud Run.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Les valeurs "network" et "subnet" doivent être remplacées si vous avez utilisé des valeurs différentes de celles que nous avons configurées dans l'atelier de programmation de la partie 2.
- Notez l'URL Cloud Run obtenue (par exemple, https://toolbox-froyo-xxx.run.app).
Nous utiliserons ce point de terminaison MCP Toolbox déployé lors de l'étape de configuration de l'agent.
6. Le backend agentique (app.py)
Notre base de données étant abstraite, notre code Python peut se concentrer entièrement sur l'orchestration et le raisonnement.
Nous utilisons Agent Development Kit (ADK) avec Flask. L'ADK fournit une mémoire de session de niveau entreprise (InMemorySessionService), ce qui signifie que notre agent se souvient du contexte de la conversation. Il s'intègre de manière native à ToolboxSyncClient pour extraire de manière transparente nos outils de Cloud Run.
Voici votre fichier app.py :
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
L'application Python Flask simple connecte l'agent ADK aux outils que nous avons définis dans notre boîte à outils, qui interagit à son tour avec AlloyDB (ainsi qu'avec les données fédérées BigQuery) et répond à l'utilisateur.
Pour obtenir ce projet dans votre éditeur Cloud Shell, vous pouvez cloner le dépôt de l'agent en exécutant les commandes suivantes à partir de votre terminal Cloud Shell :
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
La structure de projet suivante devrait s'afficher :
Étapes à suivre pour continuer à découvrir les données sans compte de facturation :
- Les fichiers de données suivants sont mis à disposition dans le dépôt pour plus de commodité :
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Ces fichiers doivent se trouver dans le même dossier que le fichier app.py.
B. Le fichier Python nommé app-nobill.py dans le même chemin d'accès
- Dans le dossier racine du projet, il existe un fichier nommé app-nobill.py.
- Ce fichier est conçu pour créer la même expérience d'application, mais sans avoir besoin de se connecter explicitement à ces sources de données, car les données ont été mises à disposition dans des fichiers.
- Tous les autres fichiers mentionnés dans l'atelier doivent également être intacts pour cette version (il n'est pas nécessaire d'exécuter le fichier app.py).
7. L'interface utilisateur et l'exécution de l'application
Pour offrir une expérience appropriée à nos responsables de magasin, nous avons créé une interface utilisateur élégante et glassmorphe (templates/index.html) avec une barre latérale de catalogue de produits en direct et une interface de chat interactive.
Vous trouverez le fichier index.html dans le fichier de dépôt ici :
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Avant d'exécuter l'application, assurez-vous que vos dépendances se trouvent dans votre fichier requirements.txt avec le contenu suivant :
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
et que votre fichier .env est rempli :
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Comment obtenir votre GOOGLE_API_KEY ?
Suivez les instructions de cet article de blog pour configurer votre clé API Google.
Comment obtenir votre MCP_TOOLBOX_SERVER_URL ?
Nous avons configuré cette URL à l'étape précédente de cet atelier de programmation et vous avez copié le point de terminaison MCP Toolbox déployé. Utilisez ce lien pour la variable d'environnement MCP_TOOLBOX_SERVER_URL.
Exécutez votre application :
Depuis le terminal Cloud Shell, assurez-vous que vous vous trouvez dans le dossier du projet, puis exécutez les commandes suivantes une par une :
Accédez au dossier racine du projet :
cd froyo-data
Installez les dépendances :
pip install -r requirements.txt
Exécutez le fichier Python :
python app.py
Cliquez sur le lien qui s'affiche dans le terminal ou ouvrez http://localhost:8080.
8. Le test ultime
Cliquez sur un produit du catalogue pour poser la question suivante à l'agent :
Does Midnight Swirl have any allergens?
La réponse suivante devrait s'afficher :
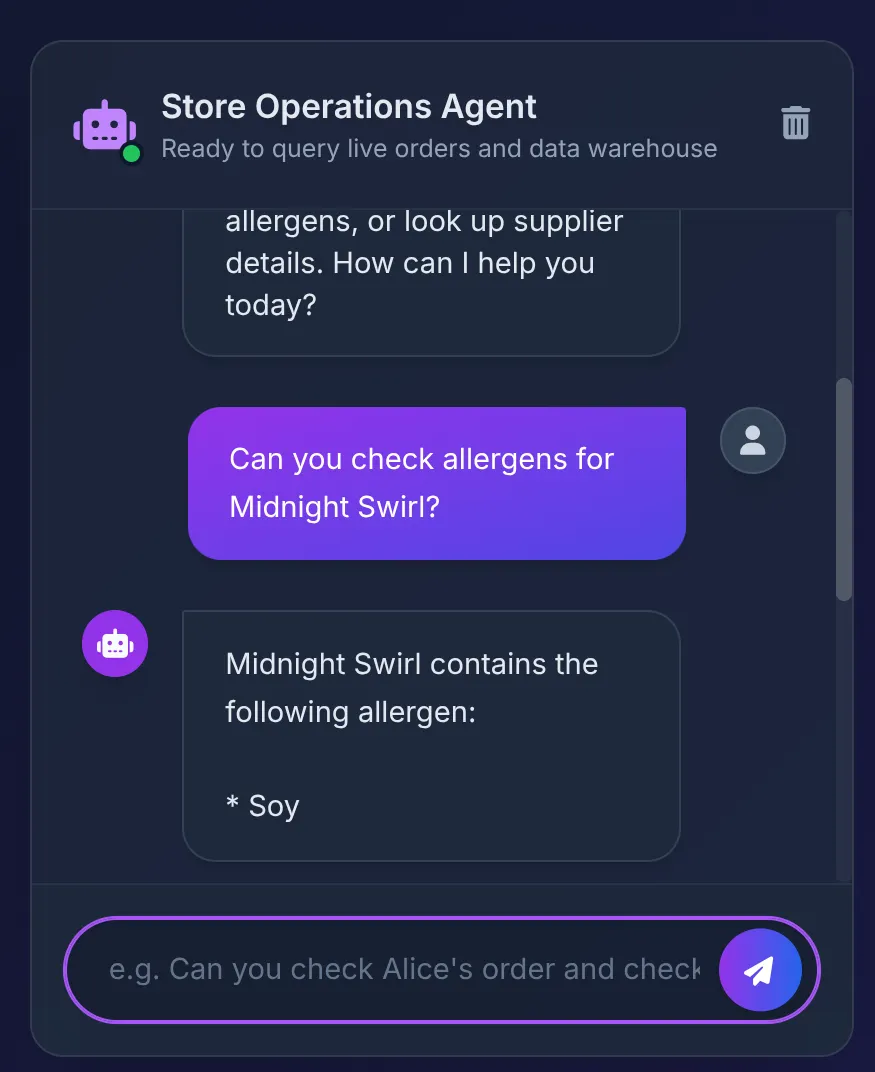
En coulisses :
- L'agent ADK reçoit l'invite et décide d'utiliser l'outil check_allergens.
- Il appelle de manière sécurisée MCP Toolbox sur Cloud Run.
- La boîte à outils exécute la requête dans AlloyDB, qui se fédère instantanément à BigQuery pour analyser les relations complexes que nous avons créées dans la partie 1.
- La base de données renvoie "Soja", que l'agent résume clairement dans l'interface utilisateur.
Ensuite, nous disons :
Order 2 Midnight Swirl for Alice.
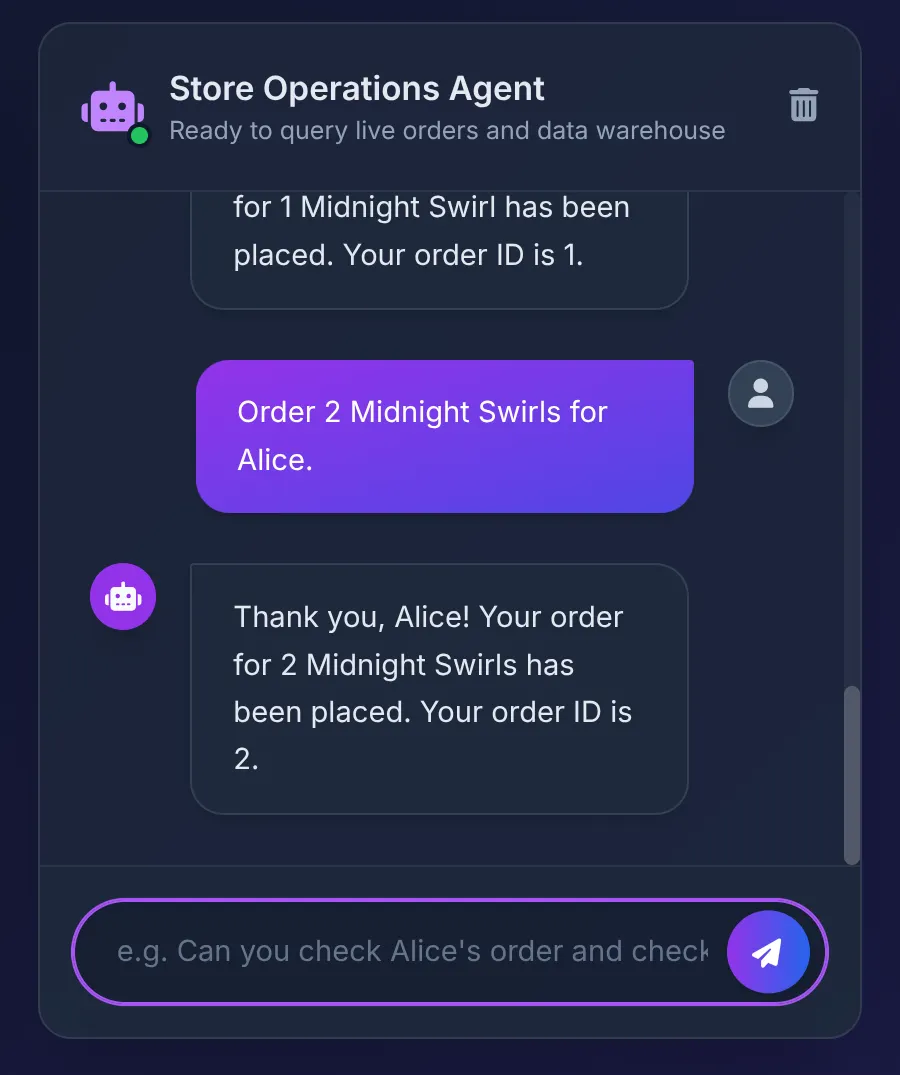
L'agent transmet la chaîne "Midnight Swirl" à la boîte à outils. Le code SQL sous-jacent résout dynamiquement la chaîne en un ID entier via BigQuery, insère la commande en direct dans AlloyDB et confirme la transaction.
Dépôt de code
9. Libérer de l'espace
Une fois cet atelier terminé, n'oubliez pas de supprimer le cluster et l'instance AlloyDB.
Le cluster et ses instances devraient être nettoyés.
10. Félicitations pour votre agent !
Réfléchissez à ce que nous venons d'accomplir :
Notre système agentique bien orchestré interagit uniquement avec MCP Toolbox for Databases. En coulisses, il gère l'appel d'outil et les données de la logique d'IA de notre application, ce qui simplifie le flux :
- Notre application transactionnelle (exécutée sur AlloyDB) peut gérer des sessions utilisateur rapides et simultanées.
- Lorsqu'elle a besoin de données analytiques volumineuses ou d'un contexte historique (comme les informations sur les fournisseurs ou les mappages d'ingrédients complexes), elle interroge le schéma froyo_data de BigQuery.
- Aucun ETL. Aucun pipeline de données ne s'interrompt. Aucune base de données désynchronisée. Nous stockons une seule fois (dans BQ) et calculons où nous en avons besoin.
Maintenant que notre agent et notre base de données (analytiques et transactionnelles) sont complets, passons à la partie suivante.
Et ensuite ?
Notre agent fonctionne parfaitement... sur le chemin idéal. Dans la partie 4, nous allons créer un pipeline d'évaluation d'agent pour tester rigoureusement la validité, la mise à la terre et les performances de notre système agentique. J'espère vous y retrouver !