
1. סקירה כללית
בחלק 1, הצלחנו להפוך קובצי PDF לא מובְנים ומבולגנים לטבלאות נקיות, חכמות ומובְנות ב-BigQuery באמצעות Knowledge Catalog ו-DataScan. עכשיו יש לנו מחסן נתונים חזק. בחלק 2 הגדרנו את AlloyDB כבסיס טרנזקציוני ואיחדנו את הטבלאות ב-BigQuery לתוכו, ויצרנו שכבת נתונים מאוחדת בלי לשכפל אף בייט.
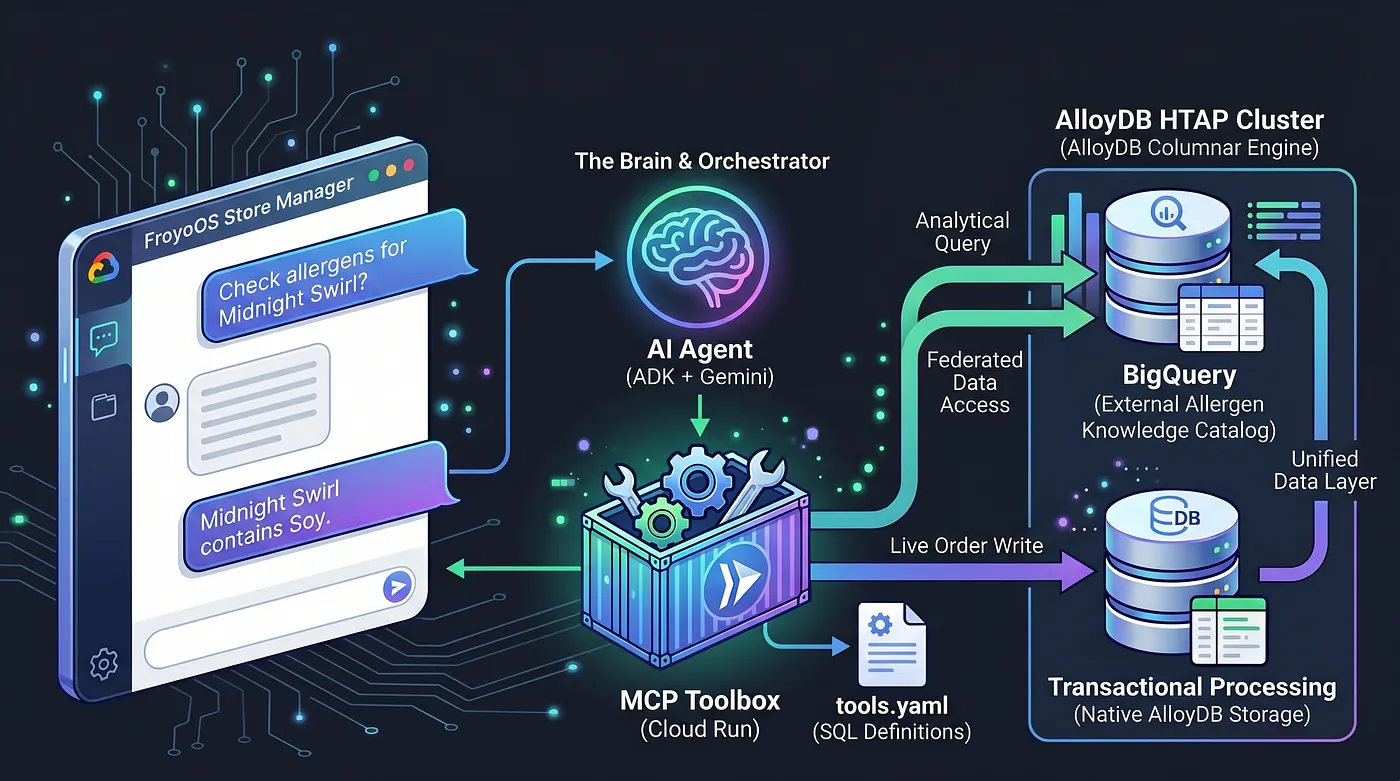
היום אנחנו בונים את המוח. אנחנו יוצרים אפליקציה עם כמה סוכנים – FroyoOS Store Manager – שפועלת מעל שכבת הנתונים הזו כדי לענות על שאלות, לבדוק אלרגנים ולעבד הזמנות בזמן אמת.
האתגר: הפרדת ה-AI מהנציג
כשבונים סוכן AI שצריך לתקשר עם מסדי נתונים, האנטי-תבנית הנפוצה ביותר היא הכנסת הנתונים והלוגיקה של ה-AI ישירות לאפליקציית Python. כך האפליקציה הופכת לפגיעה, לא מאובטחת וקשה מאוד לתחזוקה ככל שארכיטקטורת הנתונים גדלה.
כדי לפתור את הבעיה הזו, אנחנו משתמשים ב-Model Context Protocol (MCP) Toolbox. MCP Toolbox פועל כשכבת הפשטה מאוחדת של הנתונים. אנחנו מגדירים את פעולות מסד הנתונים שלנו באופן הצהרתי בקובץ tools.yaml פשוט. אנחנו פורסים את ערכת הכלים הזו כנקודת קצה מאובטחת בלי שרת ב-Google Cloud Run. סוכן ה-AI שלנו פשוט מתחבר לנקודת הקצה הזו ואומר: 'תפעיל את הכלי place_order'.
הכוח של HTAP
לפני שנתחיל לבנות את הסוכן, נסביר למה בכותרת של הפוסט הזה ציינו במיוחד HTAP (עיבוד היברידי של טרנזקציות וניתוחים).
בארכיטקטורה מסורתית, אם סוכן AI צריך לעבד הזמנה של משתמש בזמן אמת (עומס עבודה של OLTP טרנזקציוני) ולבצע הפניה צולבת לאלפי מיפויי רכיבים מורכבים (עומס עבודה של OLAP אנליטי), אפליקציית Python צריכה לנהל חיבורים לשני מסדי נתונים שונים לחלוטין. התוצאה היא זמן אחזור גבוה, תקורה של אבטחה וניהול מצב לא יציב.
הפכנו את AlloyDB למערכת HTAP עוצמתית על ידי איחוד מקורי של מחסן הנתונים שלנו ב-BigQuery ישירות לתוך PostgreSQL. בגלל ארכיטקטורת ה-HTAP הזו, נציג ה-AI שלנו צריך היום לתקשר רק עם נקודת קצה אחת של מסד נתונים. הוא יכול להוסיף טרנזקציות בזמן אמת לטבלה live_orders ולהריץ סריקות אנליטיות כבדות על מערך הנתונים המאוחד froyo_data ב-BigQuery, בלי לשכפל אף בייט של נתונים. נראה איך אנחנו חושפים את המנוע הזה ל-AI שלנו.
בואו נתחיל לבנות!
מה תלמדו
- איך מגדירים אשכול, מכונה ורשת של AlloyDB בלחיצת כפתור
- איך מגדירים את התוסף כדי להתכונן לאיחוד
- איך מגדירים פדרציה מ-BigQuery ל-AlloyDB
- אני רוצה לנסות
דרישות
2. לפני שמתחילים
יצירת פרויקט
- ב-מסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים או יוצרים פרויקט ב-Google Cloud.
- מוודאים שהחיוב מופעל בפרויקט ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט.
- תשתמשו ב-Cloud Shell, סביבת שורת פקודה שפועלת ב-Google Cloud. לוחצים על 'הפעלת Cloud Shell' בחלק העליון של מסוף Google Cloud.

- אחרי שמתחברים ל-Cloud Shell, בודקים שכבר בוצע אימות ושהפרויקט מוגדר למזהה הפרויקט באמצעות הפקודה הבאה:
gcloud auth list
- מריצים את הפקודה הבאה ב-Cloud Shell כדי לוודא שפקודת gcloud מכירה את הפרויקט.
gcloud config list project
- אם רוצים לבצע אימות
gcloud auth login
- אם הפרויקט לא מוגדר, משתמשים בפקודה הבאה כדי להגדיר אותו:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- מפעילים את ממשקי ה-API הנדרשים: מריצים את הפקודה הבאה כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
נקודות חשובות ופתרון בעיות
תסמונת 'פרויקט הרפאים' | הפעלת את הפקודה |
מחסום החיוב | הפעלתם את הפרויקט, אבל שכחתם להוסיף חשבון לחיוב. AlloyDB הוא מנוע עם ביצועים גבוהים, והוא לא יופעל אם 'מיכל הדלק' (החיוב) ריק. |
השהיה בהפצת API | לחצתם על 'הפעלת ממשקי API', אבל בשורת הפקודה עדיין מופיעה ההודעה |
מכסות Quags | אם אתם משתמשים בחשבון ניסיון חדש לגמרי, יכול להיות שתגיעו למכסה אזורית של מופעי AlloyDB. אם הפעולה |
3. הכנת הנתונים
מוודאים שהנתונים המובְנים שחולצו מקובצי PDF לא מובְנים זמינים ב-BigQuery, ושהפדרציה של נתוני BigQuery ב-AlloyDB נוצרה ונבדקה. אם לא השלמתם את השלבים האלה, זה הזמן לבצע את השלבים הפשוטים האלה מכאן ומכאן לחלקים 1 ו-2 בהתאמה.
הערה:
אם אתם מנסים את ה-codelab הזה, אל תבצעו את שלב הניקוי של חלק 2 (מחיקת האשכול ושלב המופע) כי אנחנו צריכים את תזמור AlloyDB בשביל המערכת המבוססת-סוכנים שמוצגת כאן.
בנוסף לנתונים האלה שכבר יצרנו בחלק 2, אנחנו צריכים ליצור עוד טבלה אחת במכונת AlloyDB. עוברים אל AlloyDB Studio באמצעות הקישור:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
אם אתם משתמשים באשכול אחר, אתם יכולים לשנות את שם האשכול בקישור שלמעלה.
ב-AlloyDB Studio, בכרטיסייה חדשה של עורך השאילתות, מריצים את ההצהרה הבאה:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
הפעולה הזו אמורה ליצור את הטבלה live_orders במסד הנתונים.
4. הגדרת ההפשטה (הקובץ tools.yaml)
קודם כול, אנחנו רושמים באופן רשמי את פעולות מסד הנתונים שלנו. אנחנו יוצרים קובץ tools.yaml שמגדיר איך הסוכן שלנו מקיים אינטראקציה עם AlloyDB, שכולל גם נתונים טרנזקציוניים וגם נתונים אנליטיים (נתונים אנליטיים מאיחוד BigQuery).
- עוברים אל טרמינל Cloud Shell. עוברים למצב עריכה.
- יוצרים תיקייה חדשה בספריית הבסיס: froyo-agent
- בתוך התיקייה, יוצרים קובץ tools.yaml ומדביקים את התוכן הבא: (צריך להחליף את הערכים של project, cluster, instance ו-password בערכים שלכם)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
הגבלנו את היכולות של הסוכן ל-2 כלים – בדיקת אלרגנים וביצוע הזמנה.
5. פריסת ערכת הכלים ב-Cloud Run
כדי להפוך את ארגז הכלים הזה לזמין לאפליקציה שלנו, אנחנו פורסים אותו בצורה מאובטחת באמצעות ה-CLI של gcloud. הפעולה הזו יוצרת את נקודת הקצה של שכבת ההפשטה.
- עוברים אל Cloud Shell Terminal ונכנסים לספריית העבודה באמצעות הפעלת הפקודה:
cd froyo-agent
- שומרים את הקובץ tools.yaml בסוד בשם tools-froyo:
gcloud secrets create tools-froyo --data-file=tools.yaml
- פריסת קונטיינר MCP Toolbox ל-Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
צריך להחליף את הערכים של network ו-subnet אם השתמשתם בערכים שונים מאלה שהגדרנו ב-codelab בחלק 2.
- רושמים את כתובת ה-URL שמתקבלת ב-Cloud Run (לדוגמה, https://toolbox-froyo-xxx.run.app).
נשתמש בנקודת הקצה הזו של MCP Toolbox שהופעלה בשלב הגדרת הסוכן.
6. הקצה העורפי של הסוכן (app.py)
המסד הנתונים שלנו מופשט, כך שקוד ה-Python יכול להתמקד לחלוטין בתיאום ובהסקה.
אנחנו משתמשים ב-Agent Development Kit (ADK) לצד Flask. ערכת ה-ADK מספקת זיכרון סשן ברמה ארגונית (InMemorySessionService), כלומר הסוכן זוכר את הקשר השיחה. הוא משתלב באופן טבעי עם ToolboxSyncClient כדי לשלוף את הכלים שלנו מ-Cloud Run בצורה חלקה.
הנה הקובץ app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
אפליקציית Python Flask הפשוטה מחברת את סוכן ה-ADK לכלים שהגדרנו ב-Toolbox, שבתורו מתקשר עם AlloyDB (וגם עם נתונים מאוחדים של BigQuery) ומגיב למשתמש.
כדי להוסיף את הפרויקט הזה ל-Cloud Shell Editor, אפשר לשכפל את המאגר של הסוכן על ידי הפעלת הפקודות הבאות מ-Cloud Shell Terminal:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
אמור להופיע מבנה הפרויקט הבא:
כדי להמשיך ליהנות מהנתונים בלי חשבון לחיוב:
- לנוחותכם, קובצי הנתונים הבאים זמינים במאגר:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
הקבצים האלה צריכים להיות באותה תיקייה שבה נמצא הקובץ app.py.
ב. קובץ Python בשם app-nobill.py באותו נתיב
- בתיקיית השורש של הפרויקט יש קובץ בשם app-nobill.py
- הקובץ הזה נועד ליצור את אותה חוויית שימוש באפליקציה, אבל בלי הצורך המפורש להתחבר למקורות הנתונים האלה, כי הנתונים זמינים בקבצים.
- כל שאר הקבצים שצוינו במעבדה צריכים להיות שלמים גם בגרסה הזו (רק אין צורך להפעיל את הקובץ app.py)
7. ממשק המשתמש והפעלת האפליקציה
כדי לספק חוויה טובה למנהלי החנויות, יצרנו ממשק משתמש אלגנטי עם אפקט זכוכית (templates/index.html) שכולל סרגל צד עם קטלוג מוצרים בזמן אמת וממשק צ'אט אינטראקטיבי.
אפשר למצוא את הקובץ index.html בקובץ המאגר כאן:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
לפני שמריצים את האפליקציה, מוודאים שקובץ התלות requirements.txt מכיל את התוכן הבא:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
וקובץ .env מאוכלס:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
איך מקבלים את מפתח Google API?
כדי להגדיר מפתח Google API, פועלים לפי ההוראות בפוסט הזה בבלוג.
איך מקבלים את כתובת ה-URL של MCP_TOOLBOX_SERVER_URL?
הגדרנו את זה בשלב הקודם ב-Codelab הזה, והעתקתם את נקודת הקצה של MCP Toolbox שנפרסה. משתמשים בקישור הזה בשביל משתנה הסביבה MCP_TOOLBOX_SERVER_URL.
מריצים את האפליקציה:
בטרמינל של Cloud Shell, מוודאים שאתם בתיקיית הפרויקט ומריצים את הפקודות הבאות אחת אחרי השנייה:
עוברים לתיקיית הבסיס של הפרויקט:
cd froyo-data
יחסי תלות של התקנות:
pip install -r requirements.txt
מריצים את קובץ ה-Python:
python app.py
לוחצים על הקישור שמופיע במסוף או פותחים את http://localhost:8080.
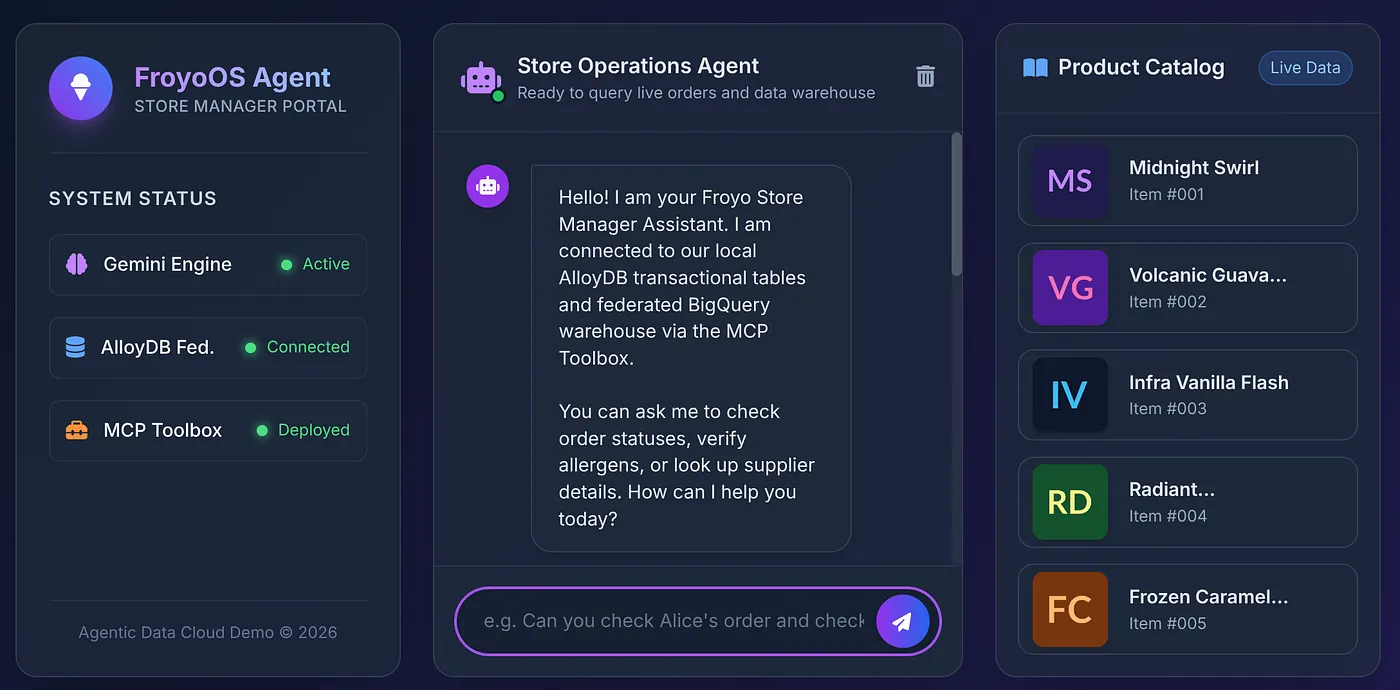
8. המבחן האולטימטיבי
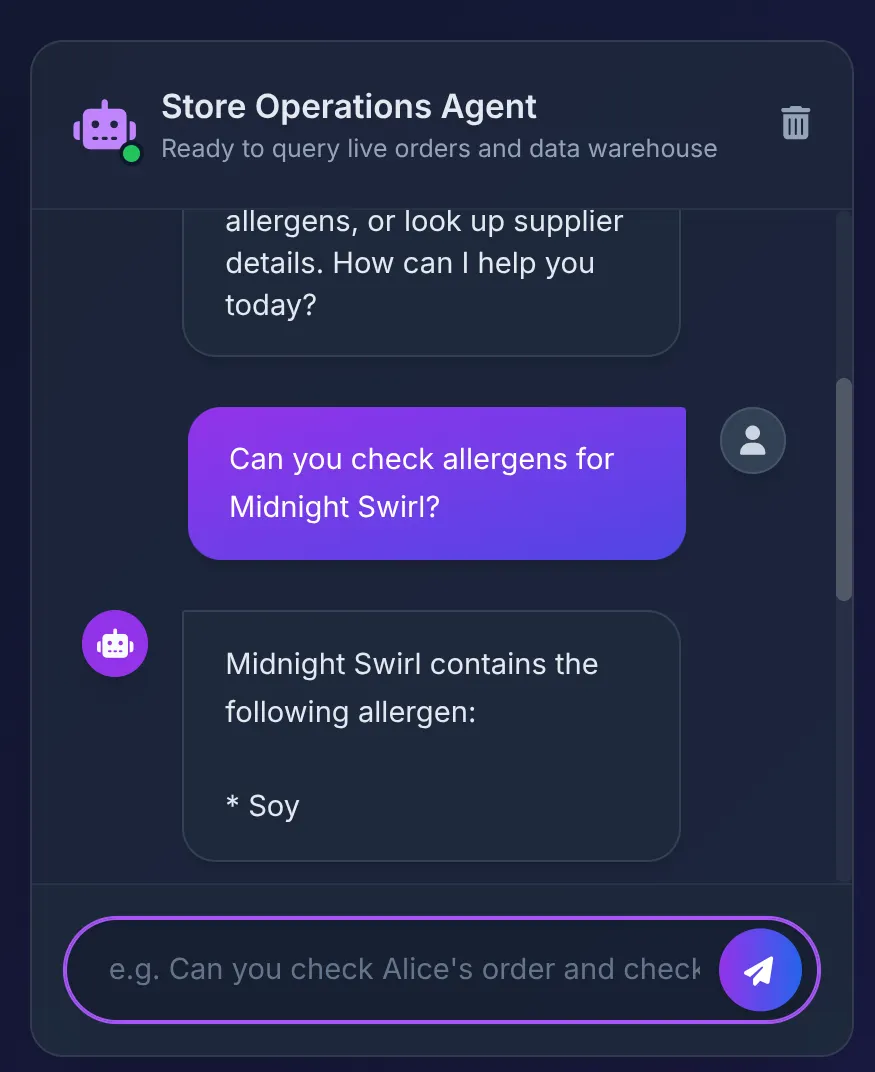
נלחץ על מוצר מהקטלוג כדי לשאול את הנציג:
Does Midnight Swirl have any allergens?
אתם אמורים לראות את התשובה:
מאחורי הקלעים:
- הסוכן ADK מקבל את ההנחיה ומחליט להשתמש בכלי check_allergens.
- הוא קורא באופן מאובטח ל-MCP Toolbox ב-Cloud Run.
- ערכת הכלים מריצה את השאילתה ב-AlloyDB, שמתאחדת באופן מיידי עם BigQuery כדי לסרוק את הקשרים המורכבים שיצרנו בחלק 1.
- מסד הנתונים מחזיר את התוצאה 'סויה', והסוכן מסכם אותה בצורה מסודרת בממשק המשתמש.
בשלב הבא, אנחנו אומרים:
Order 2 Midnight Swirl for Alice.
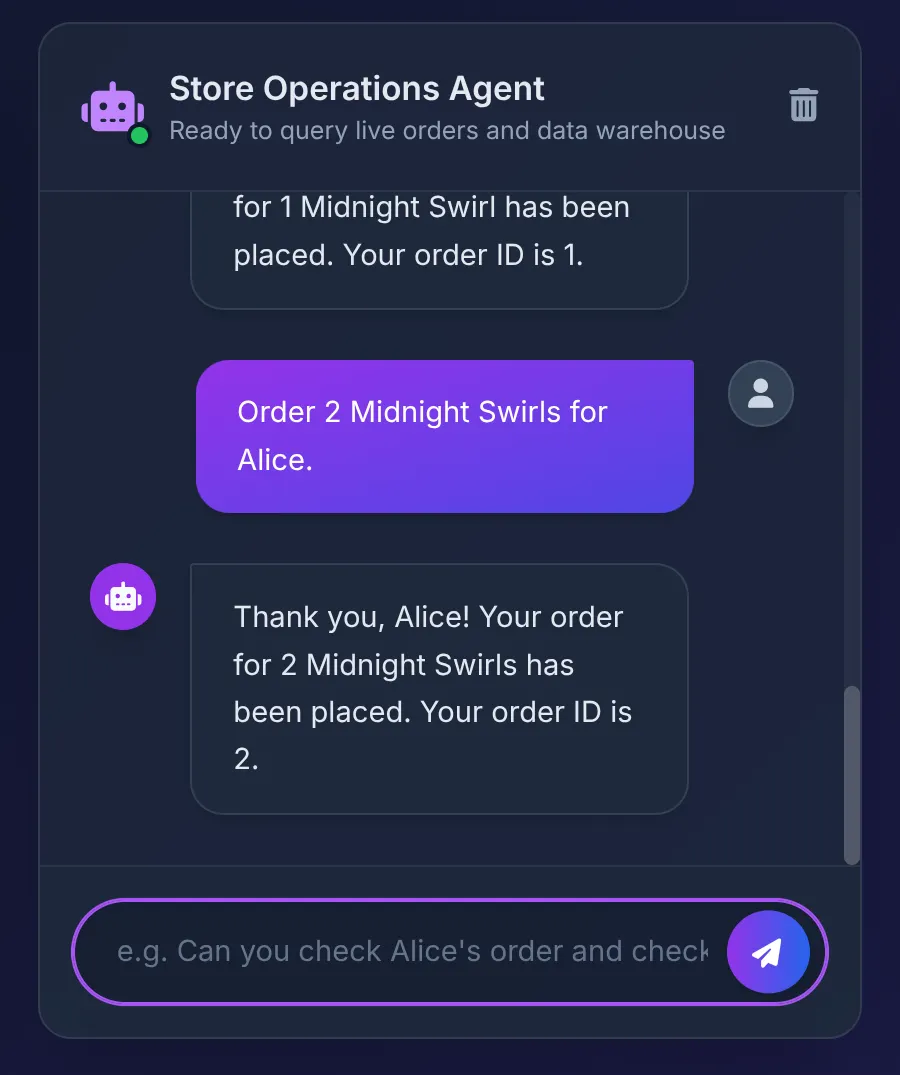
הנציג מעביר את המחרוזת Midnight Swirl (מערבולת חצות) לארגז הכלים. ה-SQL הבסיסי פותר באופן דינמי את המחרוזת למזהה מספר שלם באמצעות BigQuery, מוסיף את ההזמנה הפעילה ל-AlloyDB ומאשר את העסקה.
Code Repo
9. הסרת המשאבים
לאחר סיום ה-Lab, אל תשכחו למחוק את אשכול AlloyDB ואת המכונה.
הוא אמור לנקות את האשכול יחד עם המופעים שלו.
10. מזל טוב על הנציג!
בואו נחשוב על מה שהשגנו עכשיו:
המערכת שלנו מבוססת-סוכנים ומתקשרת רק עם MCP Toolbox for Databases. הפעולות האלה מתבצעות מאחורי הקלעים: המערכת מטפלת בקריאה לכלי ובנתונים, ומעבירה אותם ללוגיקת ה-AI של האפליקציה. כך התהליך נשאר פשוט:
- האפליקציה העסקית שלנו (שפועלת ב-AlloyDB) יכולה לטפל בסשנים מהירים של משתמשים בו-זמנית.
- כשהוא צריך נתונים אנליטיים מפורטים או הקשר היסטורי (כמו פרטי ספקים או מיפויים מורכבים של רכיבים), הוא שולח שאילתה ל-froyo_dataschema ב-BigQuery.
- Zero ETL. אין פייפליינים שמופעלים. אין מסדי נתונים לא מסונכרנים. אנחנו מאחסנים את הנתונים פעם אחת (ב-BQ) ומבצעים את החישובים במקום שבו אנחנו צריכים אותם.
עכשיו, אחרי שהשלמנו את הבסיס של הסוכן והנתונים – גם הנתונים האנליטיים וגם הנתונים של העסקאות – אפשר לעבור לחלק הבא.
מה השלב הבא?
הסוכן שלנו פועל בצורה מושלמת… בנתיב הרגיל. בחלק 4, נבנה צינור להערכת סוכנים כדי לבדוק באופן קפדני את התוקף, ההצמדה והביצועים של המערכת האג'נטית שלנו. נתראה שם!