
1. खास जानकारी
पहले हिस्से में, हमने Knowledge Catalog और DataScan का इस्तेमाल करके, अनस्ट्रक्चर्ड और अव्यवस्थित PDF को BigQuery में साफ़-सुथरी, बेहतर, और स्ट्रक्चर्ड टेबल में बदला. अब हमारे पास एक मज़बूत डेटा वेयरहाउस है. दूसरे हिस्से में, हमने AlloyDB को अपने लेन-देन के लिए बैकबोन के तौर पर सेट अप किया और अपनी BigQuery टेबल को इसमें फ़ेडरेट किया. इससे, हमने एक ही डेटा लेयर बनाई और एक भी बाइट को डुप्लीकेट नहीं किया.
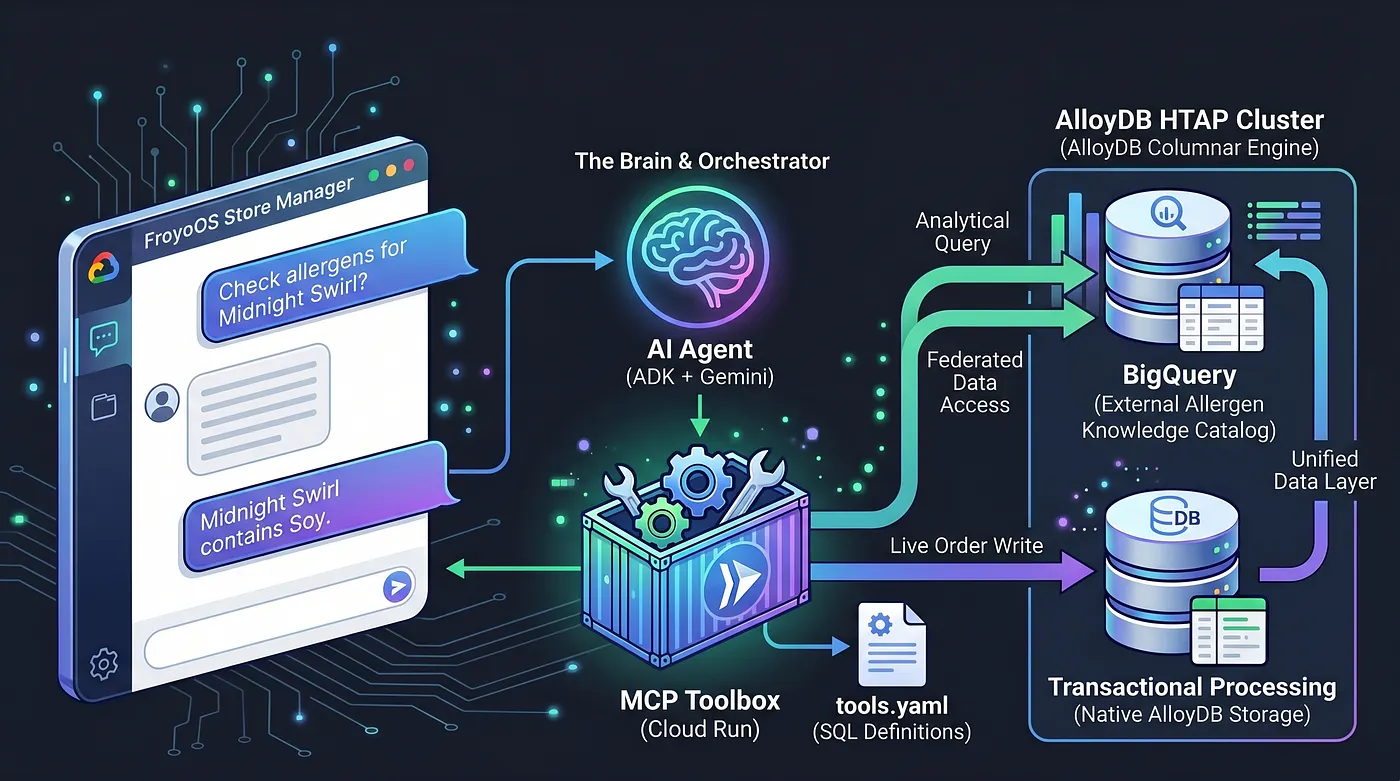
आज हम दिमाग़ बनाएंगे. हम एक मल्टी-एजेंट ऐप्लिकेशन बना रहे हैं. इसका नाम "FroyoOS Store Manager" है. यह ऐप्लिकेशन, इस डेटा लेयर के ऊपर काम करता है. इससे सवालों के जवाब दिए जा सकते हैं, एलर्जी करने वाले कॉम्पोनेंट की जांच की जा सकती है, और लाइव ऑर्डर प्रोसेस किए जा सकते हैं.
चुनौती: एआई को अपने एजेंट से अलग करना
डेटाबेस से बातचीत करने वाले एआई एजेंट को बनाते समय, सबसे आम एंटी-पैटर्न यह होता है कि डेटा और एआई लॉजिक को सीधे तौर पर अपने Python ऐप्लिकेशन में शामिल किया जाए. इससे आपका ऐप्लिकेशन कमज़ोर और असुरक्षित हो जाता है. साथ ही, डेटा आर्किटेक्चर बढ़ने पर, इसे मैनेज करना बहुत मुश्किल हो जाता है.
इस समस्या को हल करने के लिए, हम मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) टूलबॉक्स का इस्तेमाल कर रहे हैं. एमसीपी टूलबॉक्स, डेटा ऐब्स्ट्रैक्शन लेयर के तौर पर काम करता है. हम अपने डेटाबेस ऑपरेशन को, सामान्य tools.yaml फ़ाइल में डिक्लेरेटिव तरीके से तय करते हैं. हम इस टूलबॉक्स को Google Cloud Run पर, सुरक्षित और सर्वरलेस एंडपॉइंट के तौर पर डिप्लॉय करते हैं. हमारा एआई एजेंट, इस एंडपॉइंट से कनेक्ट होता है और कहता है, "‘place_order' टूल को लागू करो."
HTAP की ताकत
एजेंट बनाना शुरू करने से पहले, आइए बात करते हैं कि इस पोस्ट के टाइटल में खास तौर पर एचटीएपी (हाइब्रिड ट्रांज़ैक्शनल/ऐनलिटिकल प्रोसेसिंग) का ज़िक्र क्यों किया गया है.
पारंपरिक आर्किटेक्चर में, अगर किसी एआई एजेंट को उपयोगकर्ता के लाइव ऑर्डर (लेन-देन वाला ओएलटीपी वर्कलोड) को प्रोसेस करना होता है और हज़ारों जटिल सामग्री मैपिंग (विश्लेषणात्मक ओएलएपी वर्कलोड) को क्रॉस-रेफ़रंस करना होता है, तो आपके Python ऐप्लिकेशन को दो अलग-अलग डेटाबेस से कनेक्शन मैनेज करने होते हैं. इससे गंभीर लेटेन्सी, सुरक्षा से जुड़ी समस्याएं, और स्टेट मैनेजमेंट में गड़बड़ियां होती हैं.
हमने AlloyDB को एक एचटीएपी पावरहाउस में बदल दिया है. इसके लिए, हमने अपने BigQuery डेटा वेयरहाउस को सीधे तौर पर PostgreSQL में फ़ेडरेट किया है. इस एचटीएपी आर्किटेक्चर की वजह से, हमारे एआई एजेंट को आज सिर्फ़ एक डेटाबेस एंडपॉइंट से बात करनी होती है. यह live_orders टेबल में लाइव लेन-देन की जानकारी डाल सकता है. साथ ही, फ़ेडरेट किए गए BigQuery froyo_data डेटासेट के ख़िलाफ़, डेटा के विश्लेषण के लिए स्कैन चला सकता है. इसके लिए, डेटा के एक भी बाइट को डुप्लीकेट नहीं किया जाता. आइए, देखते हैं कि हम इस इंजन को अपने एआई के लिए कैसे उपलब्ध कराते हैं.
आइए, बनाना शुरू करें!
आपको क्या सीखने को मिलेगा
- एक बटन पर क्लिक करके, AlloyDB क्लस्टर, इंस्टेंस, और नेटवर्किंग को सेट अप करने का तरीका
- फ़ेडरेशन के लिए तैयारी करने के लिए एक्सटेंशन सेट अप करने का तरीका
- BigQuery से AlloyDB में फ़ेडरेशन सेट अप करने का तरीका
- इसे आज़माएं
ज़रूरी शर्तें
2. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. यह देखने का तरीका जानें कि किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं.
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपको पुष्टि करनी है
gcloud auth login
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- ज़रूरी एपीआई चालू करें: सभी ज़रूरी एपीआई चालू करने के लिए, यह निर्देश चलाएं:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
समस्याएं और उन्हें हल करने का तरीका
"घोस्ट प्रोजेक्ट" सिंड्रोम | आपने |
बिलिंग बैरिकेड | आपने प्रोजेक्ट चालू कर दिया है, लेकिन बिलिंग खाते की जानकारी नहीं दी है. AlloyDB एक हाई-परफ़ॉर्मेंस इंजन है. अगर "गैस टैंक" (बिलिंग) खाली है, तो यह शुरू नहीं होगा. |
एपीआई के डेटा को अपडेट होने में लगने वाला समय | आपने "एपीआई चालू करें" पर क्लिक किया है, लेकिन कमांड लाइन में अब भी |
कोटा Quags | अगर आपने नया ट्रायल खाता इस्तेमाल करना शुरू किया है, तो हो सकता है कि आप AlloyDB इंस्टेंस के लिए क्षेत्र के हिसाब से तय किए गए कोटे तक पहुंच जाएं. अगर |
3. डेटा तैयार करना
पक्का करें कि अनस्ट्रक्चर्ड PDF से निकाला गया स्ट्रक्चर्ड डेटा, BigQuery में उपलब्ध हो. साथ ही, BigQuery डेटा का AlloyDB फ़ेडरेशन भी सेट अप और टेस्ट किया गया हो. अगर आपने ये चरण पूरे नहीं किए हैं, तो यहां और यहां दिए गए आसान चरणों को अभी पूरा करें. ये चरण, पहले और दूसरे हिस्से के लिए हैं.
ध्यान दें:
अगर आपको यह कोडलैब आज़माना है, तो आपको दूसरे हिस्से में दिए गए क्लीनअप के चरण (क्लस्टर और इंस्टेंस मिटाने का चरण) को पूरा नहीं करना चाहिए. ऐसा इसलिए, क्योंकि हमें यहां दिखाए गए एजेंटिक सिस्टम के लिए, AlloyDB ऑर्केस्ट्रेशन की ज़रूरत है.
हमने दूसरे हिस्से में यह डेटा पहले ही बना लिया है. इसके अलावा, हमें AlloyDB इंस्टेंस में एक और टेबल बनानी होगी. इस लिंक का इस्तेमाल करके, AlloyDB Studio पर जाएं:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
अगर किसी दूसरे क्लस्टर का इस्तेमाल किया जा रहा है, तो ऊपर दिए गए लिंक में क्लस्टर का नाम बदलें.
AlloyDB Studio में, नए क्वेरी एडिटर टैब में जाकर यह स्टेटमेंट चलाएं:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
इससे आपके डेटाबेस में live_orders टेबल बन जाएगी.
4. ऐब्स्ट्रैक्शन तय करना (tools.yaml फ़ाइल)
सबसे पहले, हम अपने डेटाबेस के ऑपरेशन को आधिकारिक तौर पर रजिस्टर करते हैं. हम tools.yaml फ़ाइल बनाते हैं. यह फ़ाइल तय करती है कि हमारा एजेंट, AlloyDB के साथ कैसे इंटरैक्ट करेगा. AlloyDB में लेन-देन और विश्लेषण, दोनों तरह का डेटा होता है. इसमें BigQuery फ़ेडरेशन से मिला विश्लेषण डेटा भी शामिल होता है.
- अपने Cloud Shell टर्मिनल पर जाएं. एडिटर मोड पर टॉगल करें.
- अपनी रूट डायरेक्ट्री में एक नया फ़ोल्डर बनाएं: "froyo-agent"
- फ़ोल्डर में, tools.yaml फ़ाइल बनाएं और इसमें यह कॉन्टेंट चिपकाएं: (प्रोजेक्ट, क्लस्टर, इंस्टेंस, और पासवर्ड के लिए अपनी वैल्यू डालें)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
हमने एजेंट की क्षमताओं को दो टूल तक सीमित कर दिया है — एलर्जी पैदा करने वाले कॉम्पोनेंट की जांच करना और ऑर्डर देना.
5. Cloud Run पर Toolbox को डिप्लॉय करना
इसे हमारे ऐप्लिकेशन के लिए उपलब्ध कराने के लिए, हम gcloud CLI का इस्तेमाल करके टूलबॉक्स को सुरक्षित तरीके से डिप्लॉय करते हैं. इससे हमारा ऐब्स्ट्रैक्शन लेयर एंडपॉइंट बनता है.
- Cloud Shell टर्मिनल पर टॉगल करें और इस कमांड को चलाकर, वर्किंग डायरेक्ट्री में जाएं:
cd froyo-agent
- tools.yaml फ़ाइल को "tools-froyo" नाम के सीक्रेट में सेव करें:
gcloud secrets create tools-froyo --data-file=tools.yaml
- MCP Toolbox कंटेनर को Cloud Run पर डिप्लॉय करना
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
अगर आपने पार्ट 2 के कोडलैब में कॉन्फ़िगर की गई वैल्यू से अलग वैल्यू इस्तेमाल की हैं, तो "नेटवर्क" और "सबनेट" वैल्यू को बदलना होगा.
- Cloud Run का यूआरएल नोट करें. उदाहरण के लिए, https://toolbox-froyo-xxx.run.app.
हम इस डिप्लॉय किए गए एमसीपी टूलबॉक्स एंडपॉइंट का इस्तेमाल, एजेंट कॉन्फ़िगरेशन के चरण में करेंगे.
6. एजेंटिक बैकएंड (app.py)
हमारे डेटाबेस को अलग कर दिया गया है. इसलिए, हमारा Python कोड पूरी तरह से ऑर्केस्ट्रेशन और तर्क पर फ़ोकस कर सकता है.
हम Flask के साथ-साथ Agent Development Kit (ADK) का इस्तेमाल कर रहे हैं. ADK, एंटरप्राइज़-ग्रेड की सेशन मेमोरी (InMemorySessionService) उपलब्ध कराता है. इसका मतलब है कि हमारा एजेंट बातचीत के कॉन्टेक्स्ट को याद रखता है. यह ToolboxSyncClient के साथ नेटिव तौर पर इंटिग्रेट होता है, ताकि हमारे टूल को Cloud Run से आसानी से पुल किया जा सके.
यह रहा आपका app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
Python Flask का सामान्य ऐप्लिकेशन, एडीके एजेंट को हमारे Toolbox में तय किए गए टूल से कनेक्ट करता है. इसके बाद, यह AlloyDB (और BigQuery के फ़ेडरेटेड डेटा से भी) के साथ इंटरैक्ट करता है और उपयोगकर्ता को जवाब देता है.
इस प्रोजेक्ट को Cloud Shell Editor में पाने के लिए, एजेंट की रिपॉज़िटरी को क्लोन किया जा सकता है. इसके लिए, Cloud Shell टर्मिनल में ये कमांड चलाएं:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
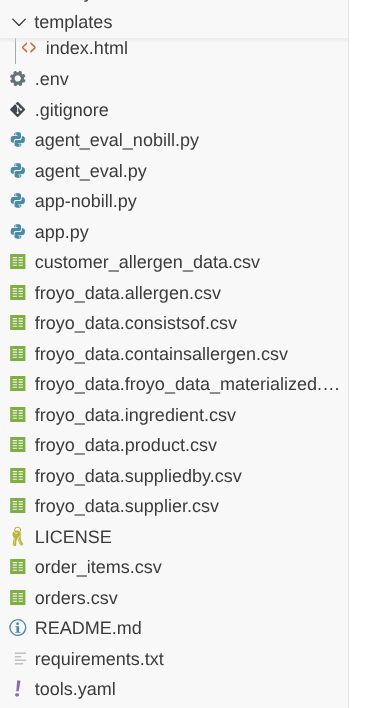
आपको प्रोजेक्ट का यह स्ट्रक्चर दिखेगा:
बिलिंग खाते के बिना डेटा का इस्तेमाल जारी रखने का तरीका:
- ये डेटा फ़ाइलें, इस्तेमाल में आसानी के लिए repo में उपलब्ध कराई गई हैं:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
ये फ़ाइलें, app.py फ़ाइल के साथ एक ही फ़ोल्डर में होनी चाहिए.
B. app-nobill.py नाम की Python फ़ाइल उसी पाथ में मौजूद है
- प्रोजेक्ट के रूट फ़ोल्डर में, app-nobill.py नाम की फ़ाइल मौजूद है
- इस फ़ाइल को एक जैसा ऐप्लिकेशन अनुभव देने के लिए डिज़ाइन किया गया है. हालांकि, इसमें इन डेटा सोर्स से कनेक्ट करने की ज़रूरत नहीं होती, क्योंकि डेटा को फ़ाइलों में उपलब्ध कराया गया है.
- लैब में बताई गई अन्य सभी फ़ाइलें, इस वर्शन के लिए भी मौजूद होनी चाहिए. हालांकि, app.py फ़ाइल को चलाने की ज़रूरत नहीं है
7. यूज़र इंटरफ़ेस (यूआई) और ऐप्लिकेशन चलाना
हमने स्टोर मैनेजर को बेहतर अनुभव देने के लिए, एक स्लीक, ग्लासमॉर्फ़िक यूज़र इंटरफ़ेस (templates/index.html) बनाया है. इसमें लाइव प्रॉडक्ट कैटलॉग साइडबार और इंटरैक्टिव चैट इंटरफ़ेस शामिल है.
आपको repo फ़ाइल में index.html यहां मिल सकता है:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
ऐप्लिकेशन चलाने से पहले, पक्का करें कि आपकी requirements.txt फ़ाइल में ये डिपेंडेंसी मौजूद हों:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
और आपकी .env फ़ाइल में जानकारी भरी गई हो:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
GOOGLE_API_KEY कैसे पाएं?
Google API पासकोड सेट अप करने के लिए, इस ब्लॉग में दिए गए निर्देशों का पालन करें.
MCP_TOOLBOX_SERVER_URL कैसे पाएं?
हमने इस कोडलैब के पिछले चरण में इसे सेट अप किया था. साथ ही, आपने डिप्लॉय किए गए MCP टूलबॉक्स एंडपॉइंट को कॉपी किया था. उस लिंक का इस्तेमाल MCP_TOOLBOX_SERVER_URL एनवायरमेंट वैरिएबल के लिए करें.
ऐप्लिकेशन चलाएं:
Cloud Shell टर्मिनल में, पक्का करें कि आप प्रोजेक्ट फ़ोल्डर में हों. इसके बाद, एक-एक करके ये कमांड चलाएं:
प्रोजेक्ट के रूट फ़ोल्डर में जाएं:
cd froyo-data
डिपेंडेंसी इंस्टॉल करें:
pip install -r requirements.txt
Python फ़ाइल को एक्ज़ीक्यूट किया जा रहा है:
python app.py
टर्मिनल में दिखने वाले लिंक पर क्लिक करें या http://localhost:8080 खोलें!
8. द अल्टिमेट टेस्ट
आइए, एजेंट से सवाल पूछने के लिए कैटलॉग में मौजूद किसी प्रॉडक्ट पर क्लिक करें:
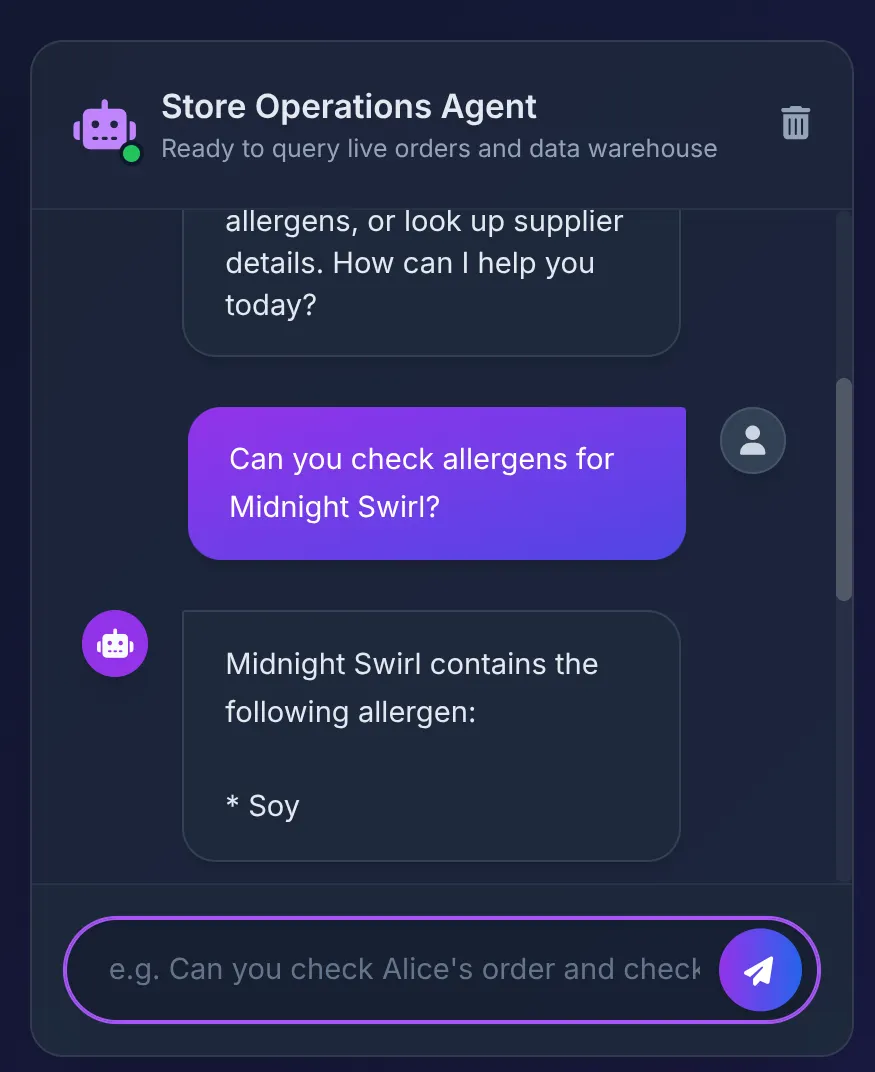
Does Midnight Swirl have any allergens?
आपको यह जवाब दिखेगा:
पर्दे के पीछे की गतिविधियां:
- ADK एजेंट को प्रॉम्प्ट मिलता है और वह check_allergens टूल का इस्तेमाल करने का फ़ैसला करता है.
- यह Cloud Run पर मौजूद MCP Toolbox को सुरक्षित तरीके से कॉल करता है.
- टूलबॉक्स, AlloyDB में क्वेरी को एक्ज़ीक्यूट करता है. यह तुरंत BigQuery से फ़ेडरेट हो जाता है, ताकि पहले हिस्से में बनाए गए जटिल संबंधों को स्कैन किया जा सके.
- डेटाबेस "Soy" दिखाता है. एजेंट, इसे यूज़र इंटरफ़ेस (यूआई) में साफ़ तौर पर दिखाता है.
इसके बाद, हम कहते हैं:
Order 2 Midnight Swirl for Alice.
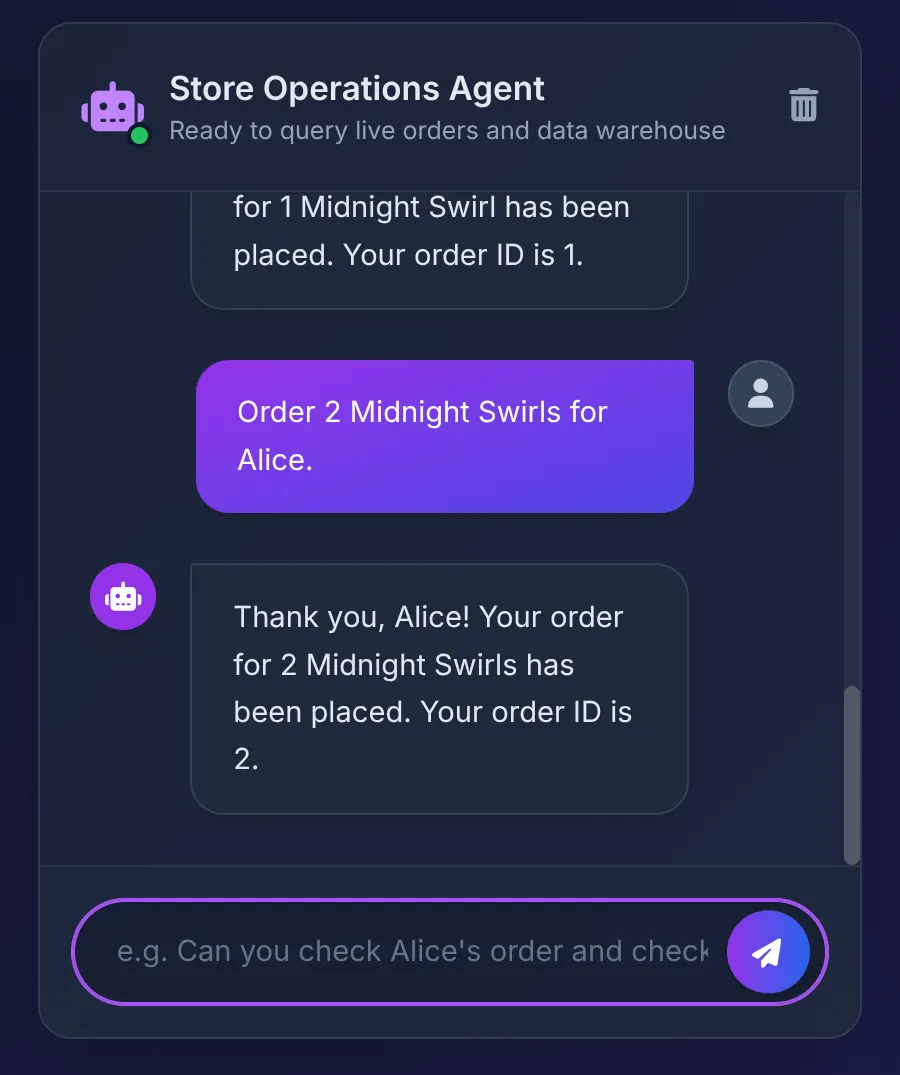
एजेंट, टूलबॉक्स को "Midnight Swirl" स्ट्रिंग भेजता है. मौजूदा एसक्यूएल, BigQuery के ज़रिए स्ट्रिंग को डाइनैमिक तरीके से पूर्णांक आईडी में बदलता है. इसके बाद, लाइव ऑर्डर को AlloyDB में डालता है और लेन-देन की पुष्टि करता है.
कोड रिपॉज़िटरी
9. व्यवस्थित करें
इस लैब को पूरा करने के बाद, AlloyDB क्लस्टर और इंस्टेंस को मिटाना न भूलें.
इससे क्लस्टर और उसके इंस्टेंस मिट जाएंगे.
10. एजेंट की सुविधा पाने के लिए आपको बधाई!
सोचें कि हमने अभी क्या-क्या किया:
हमारा एजेंटिक सिस्टम, डेटाबेस के लिए MCP Toolbox के साथ इंटरैक्ट करता है. यह पर्दे के पीछे, टूल कॉल और डेटा को हमारे ऐप्लिकेशन के एआई लॉजिक के हिसाब से मैनेज करता है. इससे फ़्लो आसान बना रहता है:
- हमारा लेन-देन वाला ऐप्लिकेशन (AlloyDB पर चल रहा है), एक साथ कई उपयोगकर्ता सेशन को तेज़ी से हैंडल कर सकता है.
- जब इसे विश्लेषण के लिए ज़्यादा डेटा या पुराने कॉन्टेक्स्ट की ज़रूरत होती है, तब यह BigQuery froyo_dataschema से क्वेरी करता है. जैसे, सप्लायर की जानकारी या जटिल सामग्री की मैपिंग.
- ज़ीरो ईटीएल. डेटा पाइपलाइन में कोई रुकावट नहीं आती. कोई भी डेटाबेस सिंक नहीं किया गया है. हम डेटा को एक बार (BQ में) सेव करते हैं और जहां ज़रूरत होती है वहां इसका इस्तेमाल करते हैं.
अब हमारा एजेंट और डेटा फ़ाउंडेशन, दोनों तैयार हैं. इनमें ऐनलिटिकल और ट्रांज़ैक्शनल डेटा शामिल है. अब हम अगले हिस्से पर चलते हैं.
आगे क्या करना है?
हमारा एजेंट, सामान्य तौर पर ठीक से काम करता है. चौथे हिस्से में, हम एजेंट के आकलन की पाइपलाइन बनाएंगे. इससे हम अपने एजेंटिक सिस्टम की परफ़ॉर्मेंस, भरोसेमंद स्रोतों से जानकारी लेने की क्षमता, और जवाबों के सही होने की पुष्टि कर पाएंगे. चलिए, इवेंट में मिलते हैं!