
1. Panoramica
In Parte 1, abbiamo trasformato con successo PDF caotici e non strutturati in tabelle pulite, intelligenti e strutturate in BigQuery utilizzando Knowledge Catalog e DataScan. Ora abbiamo un data warehouse robusto. Nella Parte 2, abbiamo configurato AlloyDB come backbone transazionale e abbiamo federato le nostre tabelle BigQuery, creando un livello di dati unificato senza duplicare un singolo byte.
Oggi costruiamo il cervello. Stiamo creando un'applicazione multi-agente, "FroyoOS Store Manager", che si trova sopra questo livello di dati per rispondere alle domande, controllare gli allergeni ed elaborare gli ordini in tempo reale.
La sfida: disaccoppiare l'AI dall'agente
Quando crei un agente AI che deve comunicare con i database, l'anti-pattern più comune è forzare la logica dei dati e dell'AI direttamente nell'applicazione Python. In questo modo, l'app diventa fragile, non sicura e incredibilmente difficile da gestire man mano che l'architettura dei dati cresce.
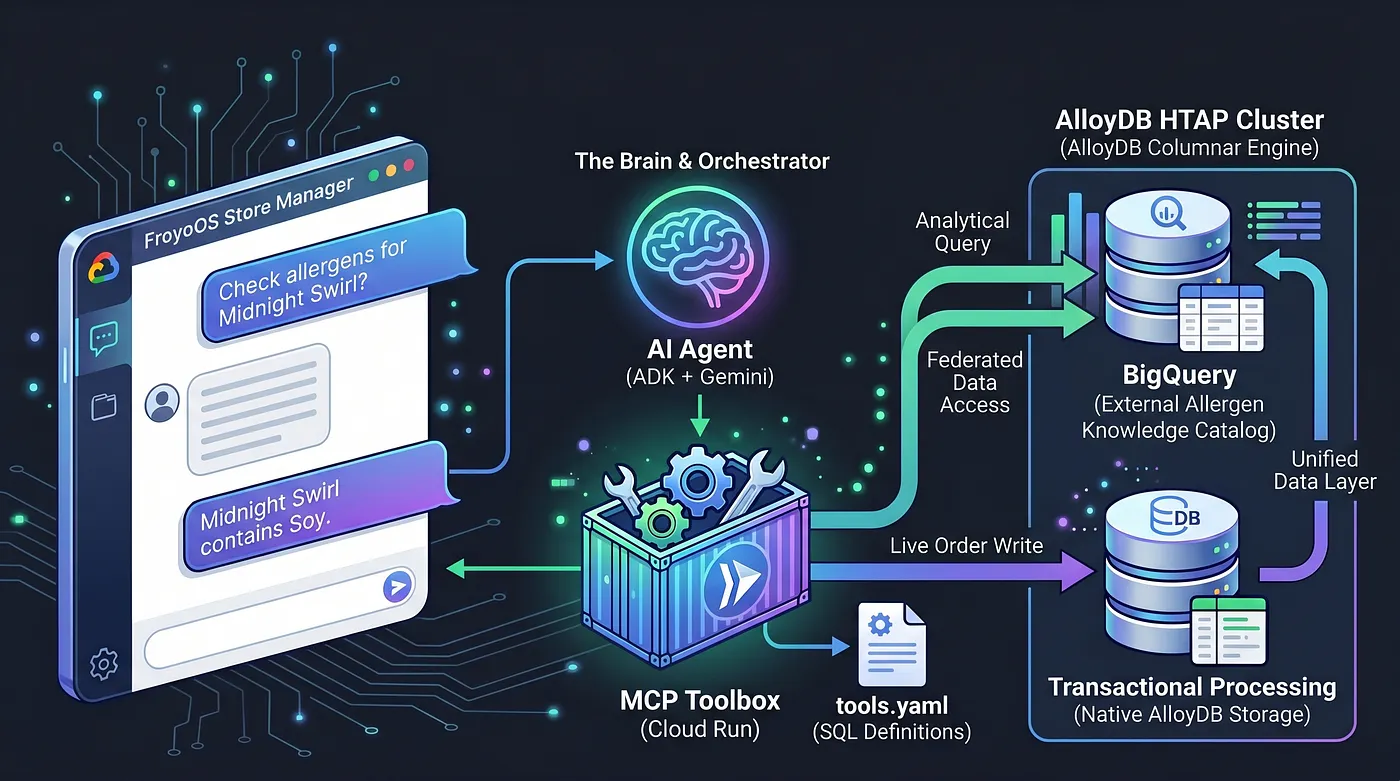
Per risolvere questo problema, utilizziamo MCP (Model Context Protocol) Toolbox. MCP Toolbox funge da livello di astrazione dei dati unificato. Definiamo le operazioni del database in modo dichiarativo in un semplice file tools.yaml. Eseguiamo il deployment di questa toolbox come endpoint serverless sicuro su Google Cloud Run. Il nostro agente AI si connette semplicemente a questo endpoint e dice: "Esegui lo strumento 'place_order'".
La potenza di HTAP
Prima di iniziare a creare l'agente, parliamo del motivo per cui il titolo di questo post richiama in modo specifico HTAP (Hybrid Transactional/Analytical Processing).
In un'architettura tradizionale, se un agente AI doveva elaborare un ordine utente in tempo reale (un carico di lavoro OLTP transazionale) ed eseguire un controllo incrociato su migliaia di mapping di ingredienti complessi (un carico di lavoro OLAP analitico), l'applicazione Python doveva gestire le connessioni a due database completamente diversi. Ciò comporta una latenza elevata, un overhead di sicurezza e una gestione dello stato fragile.
Abbiamo trasformato AlloyDB in una potenza HTAP federando in modo nativo il nostro data warehouse BigQuery direttamente in PostgreSQL. Grazie a questa architettura HTAP, oggi il nostro agente AI deve comunicare solo con un endpoint di database. Può inserire transazioni in tempo reale nella tabella live_orders ed eseguire scansioni analitiche pesanti sul set di dati BigQuery federato froyo_data nello stesso momento, senza duplicare un singolo byte di dati. Vediamo come esporre questo motore alla nostra AI.
Iniziamo a creare.
Obiettivi didattici
- Come configurare il cluster, l'istanza e la rete AlloyDB con un clic di un pulsante
- Come configurare l'estensione per prepararsi alla federazione
- Come configurare la federazione da BigQuery ad AlloyDB
- Provalo
Requisiti
2. Prima di iniziare
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.

- Una volta eseguita la connessione a Cloud Shell, verifica che il tuo account sia già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui il comando seguente in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se vuoi autenticare
gcloud auth login
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Abilita le API richieste: esegui questo comando per abilitare tutte le API richieste:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Problemi e risoluzione dei problemi
La sindrome del "progetto fantasma" | Hai eseguito |
La barriera di fatturazione | Hai abilitato il progetto, ma hai dimenticato l'account di fatturazione. AlloyDB è un motore ad alte prestazioni; non si avvierà se il "serbatoio" (fatturazione) è vuoto. |
Ritardo di propagazione dell'API | Hai fatto clic su "Abilita API", ma la riga di comando continua a visualizzare |
Quote Quags | Se utilizzi un nuovo account di prova, potresti raggiungere una quota regionale per le istanze AlloyDB. Se |
3. Preparazione dei dati
Assicurati che i dati strutturati che abbiamo estratto dai PDF non strutturati siano disponibili in BigQuery e che la federazione BigQuery dei dati AlloyDB sia stabilita e testata. Se non hai completato questi passaggi, è un buon momento per eseguire quei semplici passaggi da qui e qui per le parti 1 e 2 rispettivamente.
Nota:
Se stai provando questo codelab, non devi eseguire il passaggio di pulizia della parte 2 (eliminazione del cluster e del passaggio dell'istanza) perché abbiamo bisogno dell'orchestrazione AlloyDB per il nostro sistema agentico dimostrato qui.
Oltre a questi dati che abbiamo già creato nella parte 2, dobbiamo creare un'altra tabella nell'istanza AlloyDB. Vai ad AlloyDB Studio utilizzando il link:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Modifica il nome del cluster nel link sopra se utilizzi un cluster diverso.
In AlloyDB Studio, in una nuova scheda Editor di query, esegui la seguente istruzione:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Verrà creata la tabella live_orders nel database.
4. Definizione dell'astrazione (tools.yaml)
Innanzitutto, registriamo formalmente le operazioni del database. Creiamo un file tools.yaml che definisce il modo in cui il nostro agente interagisce con AlloyDB, che contiene sia i dati transazionali sia quelli analitici (dati analitici dalla federazione BigQuery).
- Vai al terminale Cloud Shell. Passa alla modalità Editor.
- Crea una nuova cartella nella directory principale: "froyo-agent"
- All'interno della cartella, crea un file tools.yaml e incolla i seguenti contenuti: (sostituisci con i tuoi valori per progetto, cluster, istanza e password)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Abbiamo limitato le funzionalità dell'agente a 2 strumenti: controlla gli allergeni ed effettua l'ordine.
5. Deployment della toolbox in Cloud Run
Per renderlo disponibile alla nostra applicazione, eseguiamo il deployment sicuro della toolbox utilizzando gcloud CLI. Viene creato l'endpoint del livello di astrazione.
- Passa al terminale Cloud Shell e vai alla directory di lavoro eseguendo il comando:
cd froyo-agent
- Salva tools.yaml in un secret denominato "tools-froyo":
gcloud secrets create tools-froyo --data-file=tools.yaml
- Esegui il deployment del container MCP Toolbox in Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
I valori "network" e "subnet" devono essere sostituiti se hai utilizzato valori diversi da quelli configurati nel codelab della Parte 2.
- Prendi nota dell'URL di Cloud Run risultante (ad es. https://toolbox-froyo-xxx.run.app).
Utilizzeremo questo endpoint MCP Toolbox di cui è stato eseguito il deployment nel passaggio di configurazione dell'agente.
6. Il backend agentico (app.py)
Con il database astratto, il codice Python può concentrarsi interamente sull'orchestrazione e sul ragionamento.
Utilizziamo Agent Development Kit (ADK) insieme a Flask. L'ADK fornisce una memoria di sessione di livello aziendale (InMemorySessionService), il che significa che il nostro agente ricorda il contesto della conversazione. Si integra in modo nativo con ToolboxSyncClient per estrarre senza problemi i nostri strumenti da Cloud Run.
Ecco il tuo app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
La semplice app Python Flask connette l'agente ADK agli strumenti che abbiamo definito nella nostra toolbox, che a sua volta interagisce con AlloyDB (e anche con i dati federati di BigQuery) e risponde all'utente.
Per inserire questo progetto nell'editor di Cloud Shell, puoi clonare il repository dell'agente eseguendo i seguenti comandi dal terminale Cloud Shell:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
Dovresti visualizzare la seguente struttura del progetto:
Passaggi per continuare a provare i dati senza l'account di fatturazione:
- Per comodità, i seguenti file di dati sono disponibili nel repository:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Questi file devono essere presenti nella stessa cartella di app.py.
B. Il file Python denominato app-nobill.py nello stesso percorso
- Nella cartella principale del progetto è presente un file denominato app-nobill.py
- Questo file è progettato per creare la stessa esperienza dell'app, ma senza la necessità esplicita di connettersi a queste origini dati, poiché i dati sono stati resi disponibili nei file.
- Anche per questa versione tutti gli altri file menzionati nel lab devono essere intatti (non è necessario eseguire il file app.py)
7. L'interfaccia utente e l'esecuzione dell'app
Per offrire ai nostri Store Manager un'esperienza adeguata, abbiamo creato un'interfaccia utente elegante e glassmorfica (templates/index.html) con una barra laterale del catalogo prodotti in tempo reale e un'interfaccia di chat interattiva.
Puoi trovare index.html nel file del repository qui:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Prima di eseguire l'applicazione, assicurati di avere le dipendenze nel file requirements.txt con i seguenti contenuti:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
e il file .env compilato:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Come ottenere la chiave API GOOGLE_API_KEY?
Segui le istruzioni riportate in questo blog per configurare la chiave API Google.
Come ottenere l'URL del server MCP_TOOLBOX_SERVER_URL?
L'abbiamo configurato nel passaggio precedente di questo codelab e hai copiato l'endpoint MCP Toolbox di cui è stato eseguito il deployment. Utilizza questo link per la variabile di ambiente MCP_TOOLBOX_SERVER_URL.
Esegui l'app:
Dal terminale Cloud Shell, assicurandoti di trovarti nella cartella del progetto, esegui i seguenti comandi uno alla volta:
Vai alla cartella principale del progetto:
cd froyo-data
Installa le dipendenze:
pip install -r requirements.txt
Esecuzione del file Python:
python app.py
Fai clic sul link visualizzato nel terminale o apri http://localhost:8080.
8. Il test definitivo
Facciamo clic su un prodotto del catalogo per chiedere all'agente:
Does Midnight Swirl have any allergens?
Dovresti vedere la risposta:
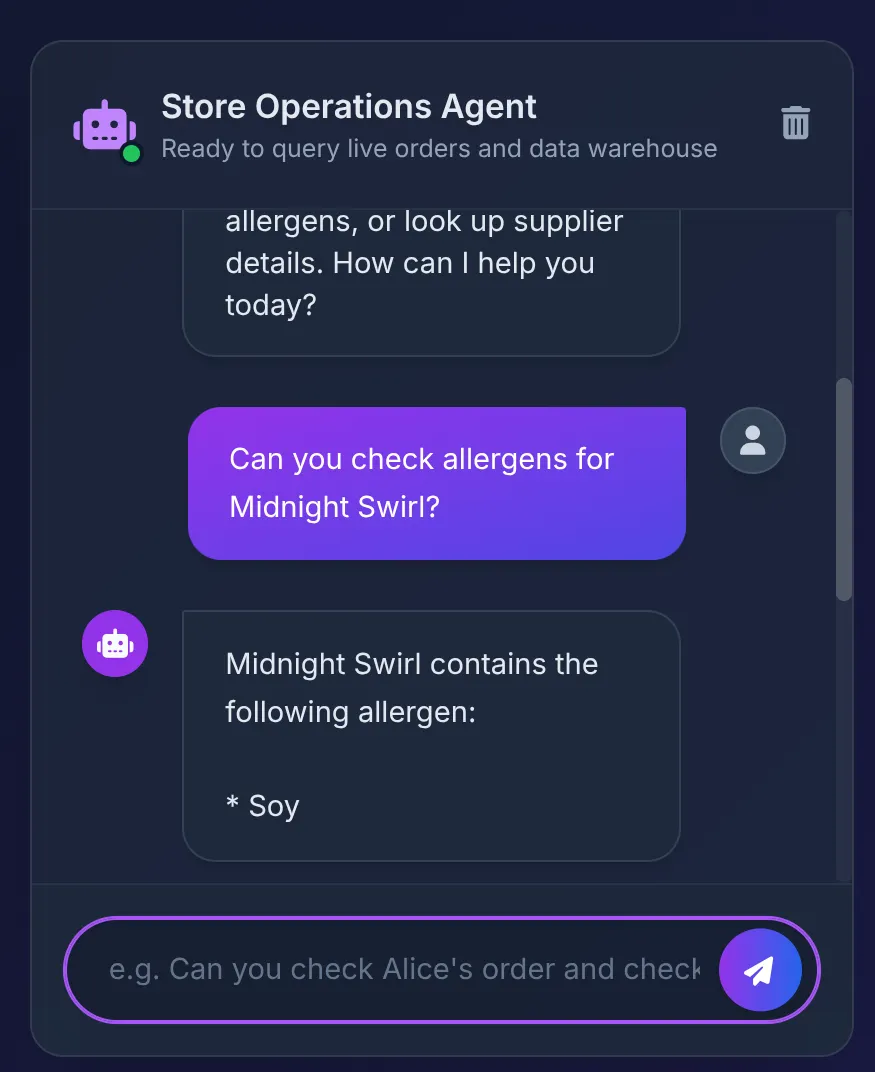
Dietro le quinte:
- L'agente ADK riceve il prompt e decide di utilizzare lo strumento check_allergens.
- Chiama in modo sicuro MCP Toolbox su Cloud Run.
- La toolbox esegue la query in AlloyDB, che si federa immediatamente a BigQuery per scansionare le relazioni complesse che abbiamo creato nella Parte 1.
- Il database restituisce "Soy", che l'agente riassume in modo ordinato nell'interfaccia utente.
Poi diciamo:
Order 2 Midnight Swirl for Alice.
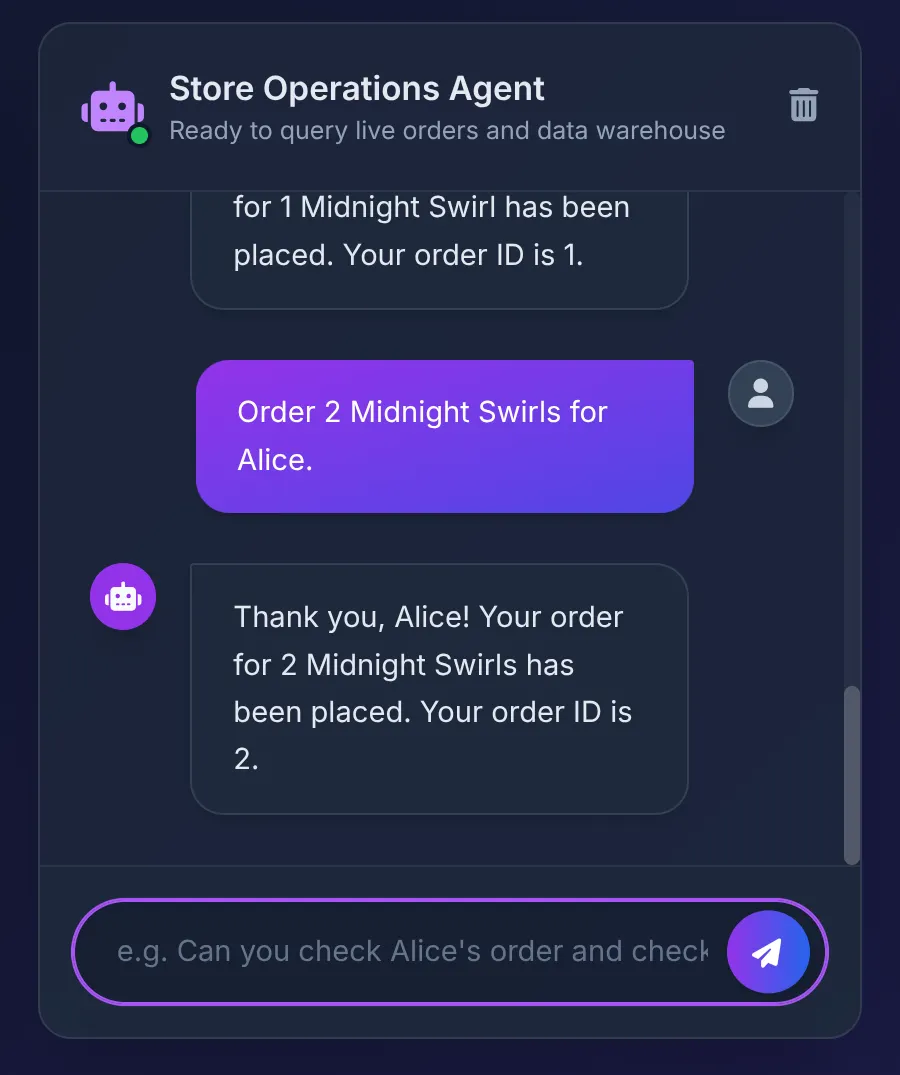
L'agente passa la stringa "Midnight Swirl" alla toolbox. L'SQL sottostante risolve dinamicamente la stringa in un ID intero tramite BigQuery, inserisce l'ordine in tempo reale in AlloyDB e conferma la transazione.
Repository di codice
9. Libera spazio
Al termine di questo lab, non dimenticare di eliminare il cluster e l'istanza AlloyDB.
Dovrebbe liberare spazio nel cluster e nelle relative istanze.
10. Congratulazioni per il tuo agente.
Pensa a cosa abbiamo appena realizzato:
Il nostro sistema agentico ben orchestrato interagisce solo con MCP Toolbox for Databases. Questo gestisce dietro le quinte la chiamata dello strumento e la logica dei dati all'AI della nostra applicazione, mantenendo il flusso semplice:
- La nostra app transazionale (in esecuzione su AlloyDB) può gestire sessioni utente rapide e simultanee.
- Quando ha bisogno di dati analitici pesanti o di un contesto storico (come i dettagli del fornitore o i mapping di ingredienti complessi), esegue query sullo schema froyo_data di BigQuery.
- Nessun ETL. Nessuna pipeline di dati interrotta. Nessun database non sincronizzato. Archiviamo una volta (in BQ) ed eseguiamo il calcolo dove ci serve.
Ora che la base dell'agente e dei dati, sia analitici che transazionali, è completa, passiamo alla parte successiva.
Prossime novità
Il nostro agente funziona perfettamente... nel percorso felice. In Parte 4, creeremo una pipeline di valutazione dell'agente per testare rigorosamente la validità, la base e le prestazioni del nostro sistema agentico. A presto.