
1. 概要
パート 1 では、Knowledge Catalog と DataScan を使用して、混沌とした非構造化 PDF を BigQuery のクリーンでインテリジェントな構造化テーブルに変換しました。現在、堅牢なデータ ウェアハウスが構築されています。パート 2 では、AlloyDB をトランザクション バックボーンとして設定し、BigQuery テーブルを統合して、1 バイトも複製せずに統合データレイヤを作成しました。
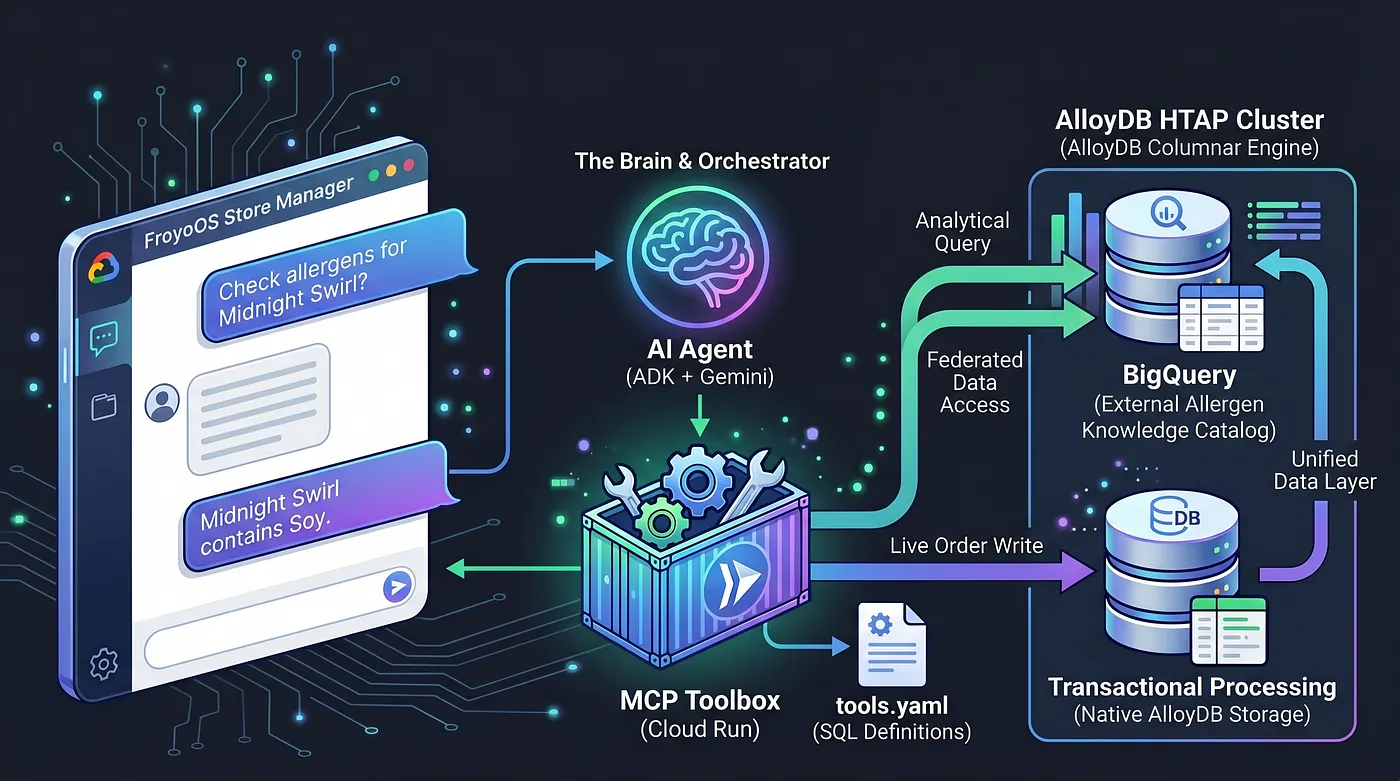
今日は脳を構築します。このデータレイヤの上に、質問への回答、アレルゲンの確認、ライブ注文の処理を行うマルチエージェント アプリケーション「FroyoOS Store Manager」を作成します。
課題: AI をエージェントから切り離す
データベースと通信する必要がある AI エージェントを構築する場合、最も一般的なアンチパターンは、データと AI ロジックを Python アプリケーションに直接強制的に組み込むことです。これにより、アプリが脆弱になり、セキュリティが低下し、データ アーキテクチャの拡大に伴ってメンテナンスが非常に困難になります。
この問題を解決するために、Model Context Protocol(MCP)ツールボックスを使用しています。MCP ツールボックスは、統合データ抽象化レイヤとして機能します。データベース オペレーションは、シンプルな tools.yaml ファイルで宣言的に定義します。このツールボックスは、Google Cloud Run の安全なサーバーレス エンドポイントとしてデプロイされます。AI エージェントは、このエンドポイントに接続して、「place_order ツールを実行して」と指示するだけです。
HTAP のパワー
エージェントの構築を開始する前に、この投稿のタイトルで HTAP(ハイブリッド トランザクション処理/分析処理)を特に取り上げている理由について説明します。
従来のアーキテクチャでは、AI エージェントがユーザーのライブ注文(トランザクション OLTP ワークロード)を処理し、数千もの複雑な成分マッピング(分析 OLAP ワークロード)を相互参照する必要がある場合、Python アプリケーションは 2 つのまったく異なるデータベースへの接続を処理する必要があります。これにより、レイテンシの増加、セキュリティ オーバーヘッドの増加、状態管理の脆弱性が生じます。
BigQuery データ ウェア ハウスを PostgreSQL にネイティブに統合することで、AlloyDB を HTAP の強力なツールにしました。この HTAP アーキテクチャにより、現在の AI エージェントは 1 つのデータベース エンドポイントと通信するだけで済みます。ライブ トランザクションを live_orders テーブルに挿入し、連携された BigQuery froyo_data データセットに対して重い分析スキャンを同時に実行できます。データの 1 バイトも複製することはありません。このエンジンを AI に公開する方法を見てみましょう。
構築を始めましょう。
学習内容
- ボタンをクリックするだけで AlloyDB クラスタ、インスタンス、ネットワーキングを設定する方法
- フェデレーションの準備として拡張機能を設定する方法
- BigQuery から AlloyDB への連携を設定する方法
- テストする
要件
2. 始める前に
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/agent-app-with-alloydb-htap/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- 認証を行う場合
gcloud auth login
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 必要な API を有効にする: 次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
注意点とトラブルシューティング
「ゴースト プロジェクト」症候群 |
|
請求の バリケード | プロジェクトを有効にしたが、請求先アカウントを忘れた。AlloyDB は高性能エンジンです。ガソリン タンク(課金)が空の場合、起動しません。 |
API 伝播の遅延 | [API を有効にする] をクリックしたのに、コマンドラインに |
割り当て Quags | 新しいトライアル アカウントを使用している場合は、AlloyDB インスタンスのリージョン割り当てに達する可能性があります。 |
3. データの準備
非構造化 PDF から抽出した構造化データが BigQuery で使用可能であり、BigQuery データの AlloyDB 連携も確立され、テストされていることを確認します。まだ完了していない場合は、こちらとこちらの簡単な手順(それぞれパート 1 とパート 2)を今すぐ実行してください。
注:
この Codelab を試す場合は、パート 2 のクリーンアップ手順(クラスタとインスタンスの削除手順)を実行しないでください。ここで説明するエージェント システムには AlloyDB オーケストレーションが必要です。
パート 2 で作成したデータに加えて、AlloyDB インスタンスに追加のテーブルを 1 つ作成する必要があります。次のリンクを使用して AlloyDB Studio に移動します。
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
別のクラスタを使用している場合は、上記のリンクのクラスタ名を変更します。
AlloyDB Studio の新しいクエリエディタ タブで、次のステートメントを実行します。
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
これにより、データベースに live_orders テーブルが作成されます。
4. 抽象化の定義(tools.yaml)
まず、データベース オペレーションを正式に登録します。トランザクション データと分析データ(BigQuery 連携の分析データ)の両方を含む AlloyDB とエージェントがどのようにやり取りするかを定義する tools.yaml ファイルを作成します。
- Cloud Shell ターミナルに移動します。エディタ モードに切り替えます。
- ルート ディレクトリに「froyo-agent」という名前の新しいフォルダを作成します。
- フォルダ内に tools.yaml ファイルを作成し、次の内容を貼り付けます(プロジェクト、クラスタ、インスタンス、パスワードは独自の値に置き換えてください)。
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
エージェントの機能は、アレルゲンの確認と注文の 2 つのツールに限定されています。
5. ツールボックスを Cloud Run にデプロイする
アプリケーションで使用できるようにするには、gcloud CLI を使用してツールボックスを安全にデプロイします。これにより、抽象化レイヤのエンドポイントが作成されます。
- [Cloud Shell ターミナル] に切り替え、次のコマンドを実行して作業ディレクトリに移動します。
cd froyo-agent
- tools.yaml を「tools-froyo」という名前のシークレットに保存します。
gcloud secrets create tools-froyo --data-file=tools.yaml
- MCP ツールボックス コンテナを Cloud Run にデプロイする
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
パート 2 の Codelab で構成した値と異なる値を使用している場合は、「network」と「subnet」の値を置き換える必要があります。
- 結果の Cloud Run URL(例: https://toolbox-froyo-xxx.run.app)をメモします。
このデプロイされた MCP Toolbox エンドポイントは、エージェント構成の手順で使用します。
6. エージェント型バックエンド(app.py)
データベースが抽象化されているため、Python コードはオーケストレーションと推論に完全に集中できます。
ここでは、Flask とともに Agent Development Kit(ADK)を使用します。ADK はエンタープライズ グレードのセッション メモリ(InMemorySessionService)を提供します。つまり、エージェントは会話のコンテキストを記憶します。ToolboxSyncClient とネイティブに統合されており、Cloud Run からツールをシームレスに取得できます。
app.py は次のとおりです。
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
シンプルな Python Flask アプリは、ADK エージェントをツールボックスで定義したツールに接続します。このツールは AlloyDB(および BigQuery フェデレーション データ)とやり取りし、ユーザーに応答します。
このプロジェクトを Cloud Shell エディタで取得するには、Cloud Shell ターミナルから次のコマンドを実行して、エージェントのリポジトリのクローンを作成します。
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
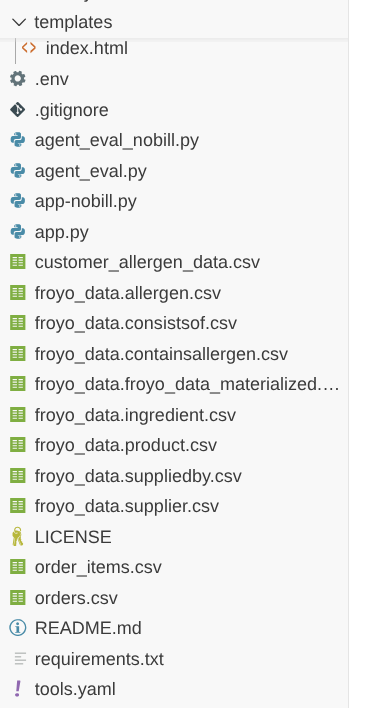
次のようなプロジェクト構造が表示されます。
請求先アカウントなしでデータを引き続き利用する手順:
- 便宜上、次のデータファイルがリポジトリで利用可能になっています。
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
これらのファイルは、app.py と同じフォルダに存在する必要があります。
B. app-nobill.py という名前の Python ファイル(同じパス内)
- プロジェクトのルートフォルダに、app-nobill.py という名前のファイルがあります。
- このファイルは、同じアプリ エクスペリエンスを作成するように設計されていますが、データがファイルで利用可能になっているため、これらのデータソースに明示的に接続する必要はありません。
- ラボで説明した他のすべてのファイルは、このバージョンでもそのまま残しておく必要があります(app.py ファイルを実行する必要はありません)。
7. UI とアプリの実行
ストア マネージャーに適切なエクスペリエンスを提供するため、ライブの商品カタログ サイドバーとインタラクティブなチャット インターフェースを備えた、洗練されたグラスモーフィック UI(templates/index.html)を作成しました。
index.html は、リポジトリ ファイルの次の場所にあります。
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
アプリケーションを実行する前に、requirements.txt ファイルに次の内容の依存関係があることを確認してください。
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
.env ファイルに値が設定されます。
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
GOOGLE_API_KEY を取得する方法
このブログの手順に沿って、Google API キーを設定します。
MCP_TOOLBOX_SERVER_URL を取得する方法
この Codelab の前のステップで設定し、デプロイされた MCP ツールボックス エンドポイントをコピーしました。このリンクを MCP_TOOLBOX_SERVER_URL 環境変数で使用します。
アプリを実行します。
Cloud Shell ターミナルから、プロジェクト フォルダにいることを確認して、次のコマンドを 1 つずつ実行します。
プロジェクトのルートフォルダに移動します。
cd froyo-data
依存関係をインストールします。
pip install -r requirements.txt
Python ファイルを実行します。
python app.py
ターミナルに表示されたリンクをクリックするか、http://localhost:8080 を開きます。
8. 究極のテスト
カタログから商品をクリックして、エージェントに質問してみましょう。
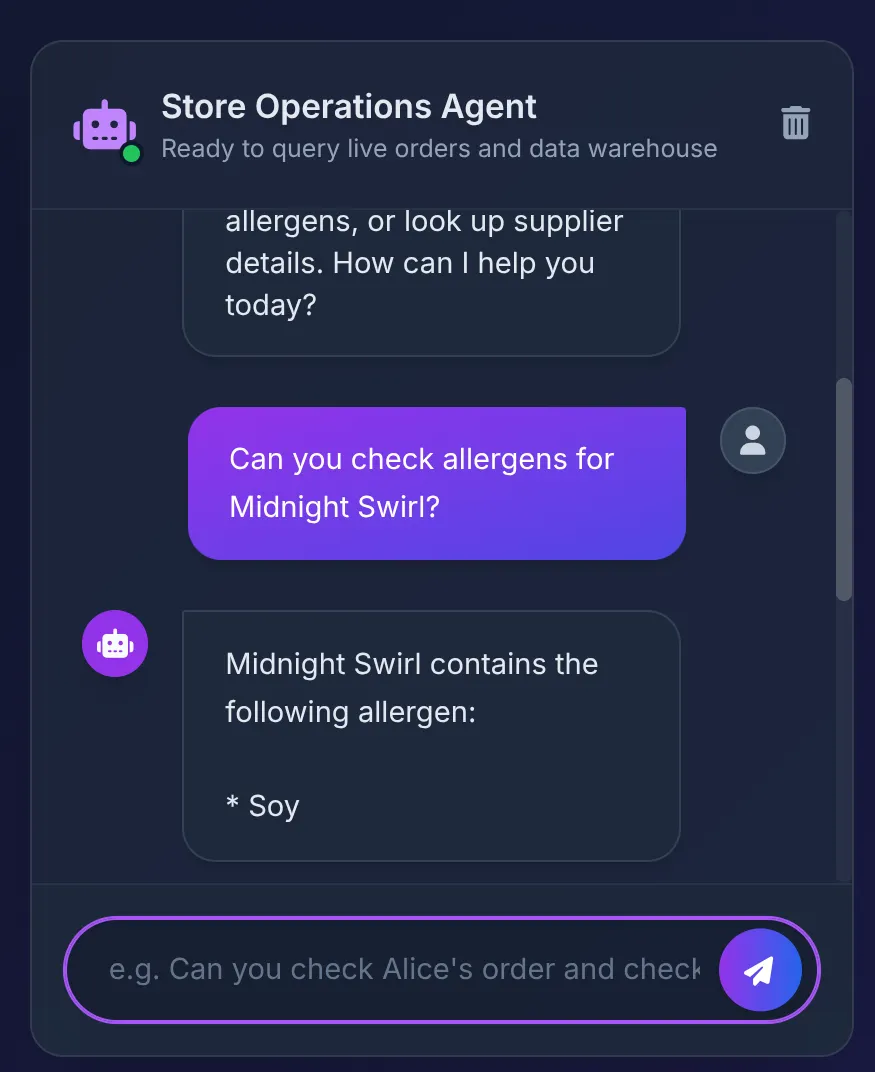
Does Midnight Swirl have any allergens?
次のようなレスポンスが表示されます。
舞台裏:
- ADK エージェントはプロンプトを受け取り、check_allergens ツールを使用することを決定します。
- Cloud Run の MCP ツールボックスを安全に呼び出します。
- ツールボックスは AlloyDB でクエリを実行し、すぐに BigQuery に連携して、パート 1 で構築した複雑な関係をスキャンします。
- データベースから「Soy」が返され、エージェントが UI でそれを適切に要約します。
次に、次のように言います。
Order 2 Midnight Swirl for Alice.
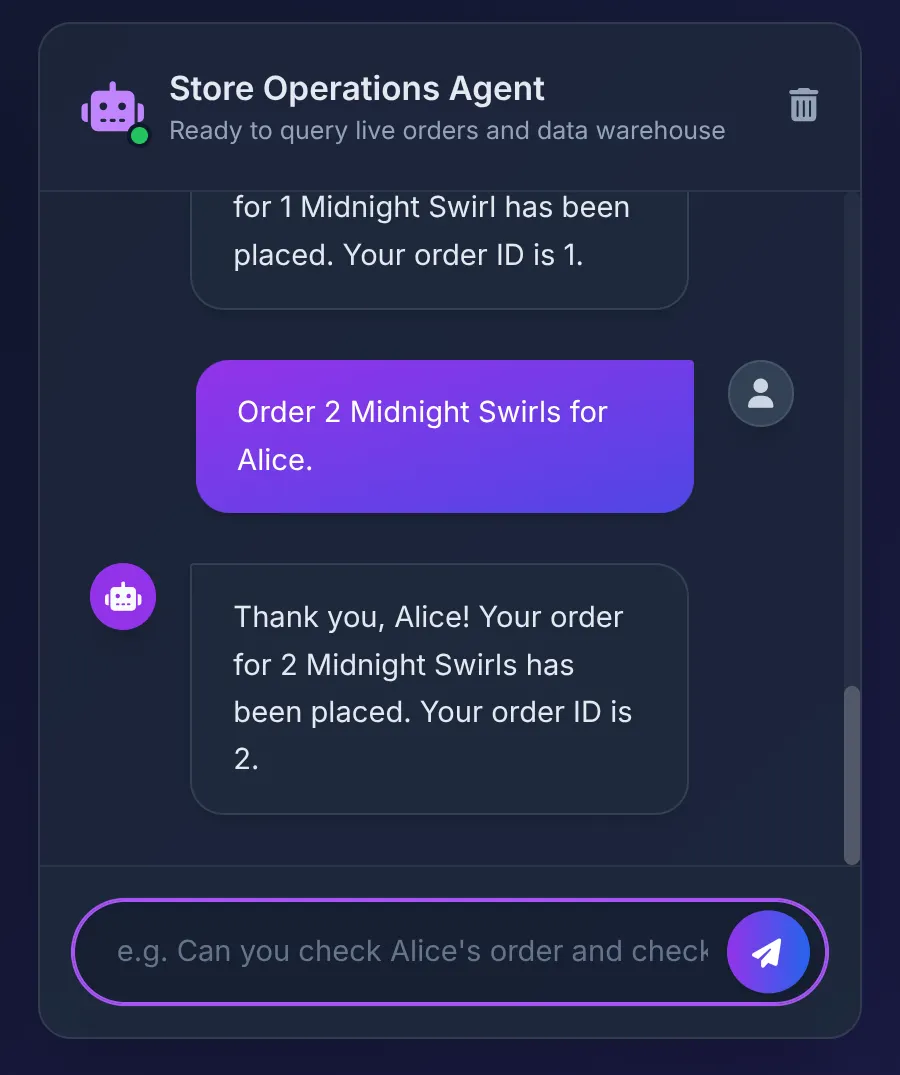
エージェントが文字列「Midnight Swirl」を Toolbox に渡します。基盤となる SQL は、BigQuery を介して文字列を整数 ID に動的に解決し、ライブ注文を AlloyDB に挿入して、トランザクションを確認します。
コード リポジトリ
9. クリーンアップ
このラボが完了したら、AlloyDB クラスタとインスタンスを削除することを忘れないでください。
クラスタとそのインスタンスをクリーンアップする必要があります。
10. エージェントの認定おめでとうございます。
ここで、達成したことを振り返ってみましょう。
適切にオーケストレートされたエージェント システムは、データベース向け MCP ツールボックスとのみ連携します。これにより、ツール呼び出しとアプリケーションの AI ロジックへのデータの処理がバックグラウンドで行われ、フローが簡素化されます。
- Google のトランザクション アプリ(AlloyDB で実行)は、高速で同時ユーザー セッションを処理できます。
- 分析データや履歴コンテキスト(サプライヤーの詳細や複雑な成分マッピングなど)が必要な場合は、BigQuery froyo_dataschema をクエリします。
- ゼロ ETL。データ パイプラインが中断されない。同期されていないデータベースはありません。1 回保存(BQ 内)し、必要な場所で計算します。
エージェントとデータ基盤(分析用とトランザクション用の両方)が完成したので、次の部分に進みましょう。
次のステップ
エージェントはハッピーパスで完璧に動作します。パート 4 では、エージェント システムの有効性、グラウンディング、パフォーマンスを厳密にテストするためのエージェント評価パイプラインを構築します。ご参加をお待ちしております。