
1. Przegląd
W części 1 udało nam się przekształcić chaotyczne, nieuporządkowane pliki PDF w przejrzyste, inteligentne i uporządkowane tabele w BigQuery za pomocą Knowledge Catalog i DataScan. Teraz mamy solidną hurtownię danych. W części 2 skonfigurowaliśmy AlloyDB jako podstawę transakcyjną i sfederowaliśmy z nią tabele BigQuery, tworząc ujednoliconą warstwę danych bez powielania ani jednego bajta.
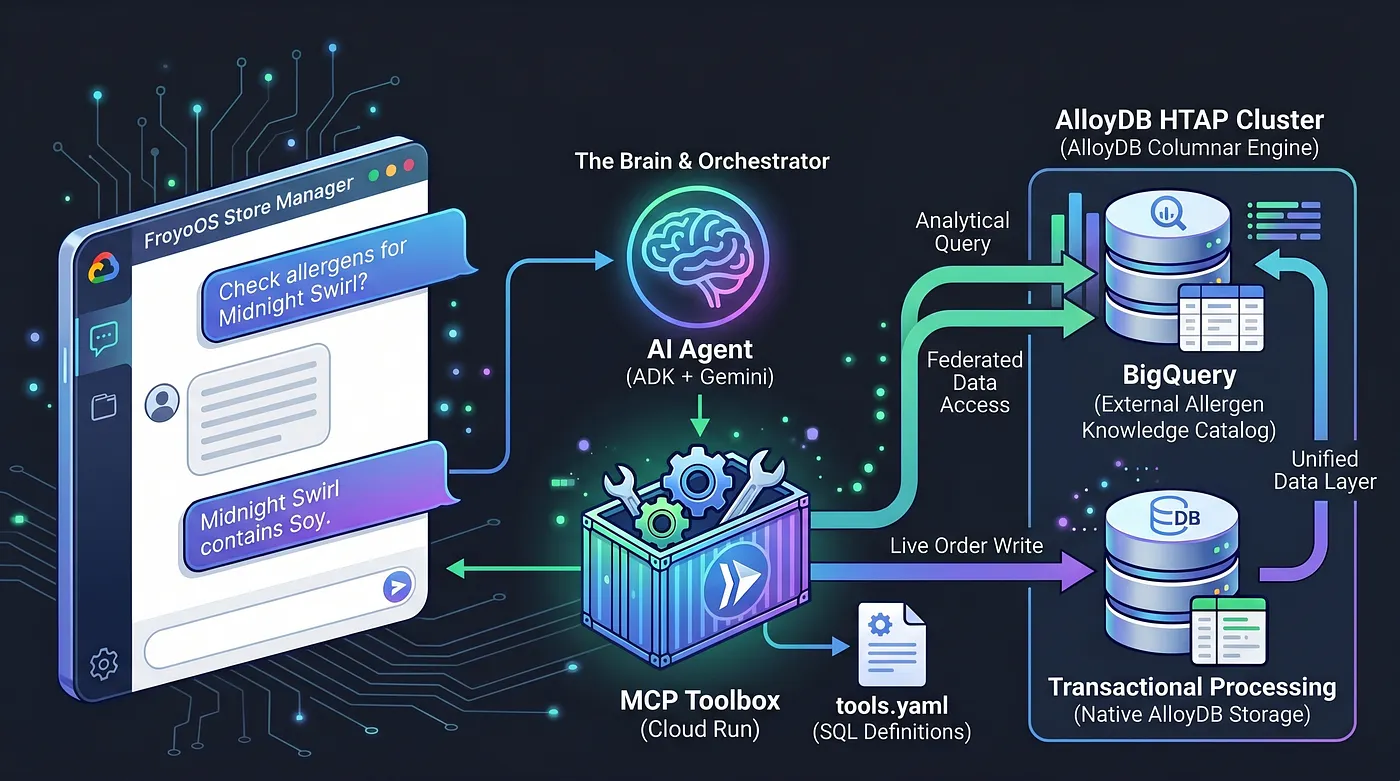
Dziś budujemy mózg. Tworzymy aplikację z wieloma agentami – „FroyoOS Store Manager” – która działa na tej warstwie danych, aby odpowiadać na pytania, sprawdzać alergeny i przetwarzać zamówienia na żywo.
Wyzwanie: oddzielenie AI od agenta
Podczas tworzenia agenta AI, który musi komunikować się z bazami danych, najczęstszym anty-wzorcem jest wymuszanie bezpośredniego umieszczania danych i logiki AI w aplikacji w Pythonie. Sprawia to, że aplikacja jest podatna na awarie i niebezpieczna, a wraz z rozwojem architektury danych jej utrzymanie staje się niezwykle trudne.
Aby rozwiązać ten problem, używamy zestawu narzędzi Model Context Protocol (MCP). MCP Toolbox działa jako nasza ujednolicona warstwa abstrakcji danych. Operacje na bazie danych definiujemy deklaratywnie w prostym pliku tools.yaml. Wdrażamy ten zestaw narzędzi jako bezpieczny, bezserwerowy punkt końcowy w Google Cloud Run. Nasz agent AI po prostu łączy się z tym punktem końcowym i wydaje polecenie „Uruchom narzędzie place_order”.
Potęga HTAP
Zanim zaczniemy tworzyć agenta, porozmawiajmy o tym, dlaczego w tytule tego posta jest mowa o HTAP (Hybrid Transactional/Analytical Processing).
W tradycyjnej architekturze, jeśli agent AI potrzebowałby przetworzyć zamówienie użytkownika na żywo (transakcyjne obciążenie OLTP) i porównać dane z różnych kanałów z tysiącami złożonych mapowań składników (analityczne obciążenie OLAP), aplikacja w Pythonie musiałaby zarządzać połączeniami z dwiema zupełnie różnymi bazami danych. Powoduje to duże opóźnienia, obciążenie związane z zabezpieczeniami i niestabilne zarządzanie stanem.
Przekształciliśmy AlloyDB w potężną platformę HTAP, natywnie federując naszą hurtownię danych BigQuery bezpośrednio w PostgreSQL. Dzięki tej architekturze HTAP nasz agent AI musi obecnie komunikować się tylko z 1 punktem końcowym bazy danych. Może wstawiać transakcje na żywo do tabeli live_orders i wykonywać intensywne skanowanie analityczne sfederowanego zbioru danych BigQuery froyo_data w tym samym czasie, bez duplikowania ani jednego bajta danych. Zobaczmy, jak udostępniamy ten silnik naszej AI.
Zacznijmy tworzyć.
Czego się nauczysz
- Jak skonfigurować klaster, instancję i sieć AlloyDB jednym kliknięciem
- Konfigurowanie rozszerzenia na potrzeby federacji
- Jak skonfigurować federację z BigQuery do AlloyDB
- Wypróbuj
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli chcesz się uwierzytelnić
gcloud auth login
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API: aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Pułapki i rozwiązywanie problemów
Syndrom „projektu widma” | Uruchomiono polecenie |
Bariera rozliczeniowa | Projekt został włączony, ale zapomniano o koncie rozliczeniowym. AlloyDB to mechanizm o wysokiej wydajności, który nie uruchomi się, jeśli „zbiornik paliwa” (płatności) jest pusty. |
Opóźnienie propagacji interfejsu API | Kliknięto „Włącz interfejsy API”, ale w wierszu poleceń nadal widnieje znak |
Quota Quags | Jeśli korzystasz z nowego konta próbnego, możesz osiągnąć regionalny limit instancji AlloyDB. Jeśli |
3. Przygotowywanie danych
Sprawdź, czy dane strukturalne wyodrębnione z nieustrukturyzowanych plików PDF są dostępne w BigQuery, a federacja danych BigQuery w AlloyDB jest utworzona i przetestowana. Jeśli nie udało Ci się wykonać tych czynności, teraz jest dobry moment, aby wykonać te proste kroki z tego i tego artykułu (część 1 i 2).
Uwaga:
Jeśli korzystasz z tego samouczka, nie wykonuj kroku czyszczenia z części 2 (usuwania klastra i instancji), ponieważ potrzebujemy orkiestracji AlloyDB dla naszego systemu opartego na agentach, który jest tutaj przedstawiony.
Oprócz danych utworzonych w części 2 musimy utworzyć w instancji AlloyDB jeszcze jedną tabelę. Otwórz AlloyDB Studio, klikając ten link:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Jeśli używasz innego klastra, zmień jego nazwę w linku powyżej.
W AlloyDB Studio na nowej karcie Edytora zapytań uruchom to polecenie:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
W bazie danych powinna zostać utworzona tabela live_orders.
4. Definiowanie abstrakcji (plik tools.yaml)
Najpierw formalnie rejestrujemy nasze operacje na bazie danych. Tworzymy plik tools.yaml, który określa, jak nasz agent wchodzi w interakcję z AlloyDB, która zawiera zarówno dane transakcyjne, jak i analityczne (dane analityczne pochodzą z federacji BigQuery).
- Otwórz terminal Cloud Shell. Przełącz na tryb edytora.
- Utwórz w katalogu głównym nowy folder: „froyo-agent”.
- W folderze utwórz plik tools.yaml i wklej do niego poniższą treść (zastąp wartościami identyfikatora projektu, klastra, instancji i hasła):
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Ograniczyliśmy możliwości agenta do 2 narzędzi: sprawdzania alergenów i składania zamówień.
5. Wdrażanie zestawu narzędzi w Cloud Run
Aby udostępnić ten zestaw narzędzi naszej aplikacji, bezpiecznie wdrażamy go za pomocą interfejsu wiersza poleceń gcloud. W ten sposób utworzymy punkt końcowy warstwy abstrakcji.
- Przejdź do terminala Cloud Shell i otwórz katalog roboczy, uruchamiając to polecenie:
cd froyo-agent
- Zapisz plik tools.yaml w sekrecie o nazwie „tools-froyo”:
gcloud secrets create tools-froyo --data-file=tools.yaml
- Wdrażanie kontenera MCP Toolbox w Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Wartości „network” i „subnet” należy zastąpić, jeśli używasz wartości innych niż te, które zostały skonfigurowane w części 2 ćwiczenia programistycznego.
- Zanotuj wynikowy adres URL Cloud Run (np. https://toolbox-froyo-xxx.run.app).
Użyjemy tego wdrożonego punktu końcowego MCP Toolbox w kroku konfiguracji agenta.
6. Backend agentowy (app.py)
Dzięki temu, że baza danych jest odseparowana, nasz kod w Pythonie może się w całości skupić na orkiestracji i wnioskowaniu.
Używamy pakietu Agent Development Kit (ADK) wraz z Flaskiem. ADK zapewnia pamięć sesji klasy korporacyjnej (InMemorySessionService), co oznacza, że agent zapamiętuje kontekst rozmowy. Jest natywnie zintegrowany z ToolboxSyncClient, co umożliwia płynne pobieranie naszych narzędzi z Cloud Run.
Oto plik app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
Prosta aplikacja Python Flask łączy agenta ADK z narzędziami zdefiniowanymi w naszym Toolboxie, które z kolei wchodzą w interakcję z AlloyDB (a także z federacyjnymi danymi BigQuery) i odpowiadają użytkownikowi.
Aby uzyskać ten projekt w edytorze Cloud Shell, możesz sklonować repozytorium agenta, uruchamiając w terminalu Cloud Shell te polecenia:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
Powinna pojawić się ta struktura projektu:
Aby nadal korzystać z danych bez konta rozliczeniowego:
- W repozytorium udostępniamy te pliki danych:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Pliki te powinny znajdować się w tym samym folderze co app.py.
B. Plik Pythona o nazwie app-nobill.py w tej samej ścieżce
- W folderze głównym projektu znajduje się plik o nazwie app-nobill.py.
- Ten plik ma na celu zapewnienie takiego samego działania aplikacji, ale bez konieczności łączenia się z tymi źródłami danych, ponieważ dane są dostępne w plikach.
- Wszystkie pozostałe pliki wymienione w module powinny być w tej wersji nienaruszone (nie musisz tylko wykonywać pliku app.py).
7. Interfejs i uruchamianie aplikacji
Aby zapewnić menedżerom sklepów odpowiednie wrażenia, stworzyliśmy elegancki interfejs użytkownika w stylu glassmorphism (templates/index.html) z paskiem bocznym z katalogiem produktów na żywo i interaktywnym interfejsem czatu.
Plik index.html znajdziesz w pliku repozytorium:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Przed uruchomieniem aplikacji upewnij się, że w pliku requirements.txt znajdują się zależności o tej treści:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
i wypełnij plik .env:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Jak uzyskać GOOGLE_API_KEY?
Aby skonfigurować klucz interfejsu API Google, postępuj zgodnie z instrukcjami podanymi w tym poście na blogu.
Jak uzyskać adres URL serwera MCP_TOOLBOX_SERVER_URL?
Skonfigurowaliśmy to w poprzednim kroku tego modułu, a Ty skopiowałeś(-aś) wdrożony punkt końcowy MCP Toolbox. Użyj tego linku w zmiennej środowiskowej MCP_TOOLBOX_SERVER_URL.
Uruchom aplikację:
W terminalu Cloud Shell, upewniając się, że jesteś w folderze projektu, uruchom kolejno te polecenia:
Przejdź do folderu głównego projektu:
cd froyo-data
Zainstaluj zależności:
pip install -r requirements.txt
Uruchom plik w Pythonie:
python app.py
Kliknij link, który pojawi się w terminalu, lub otwórz adres http://localhost:8080.
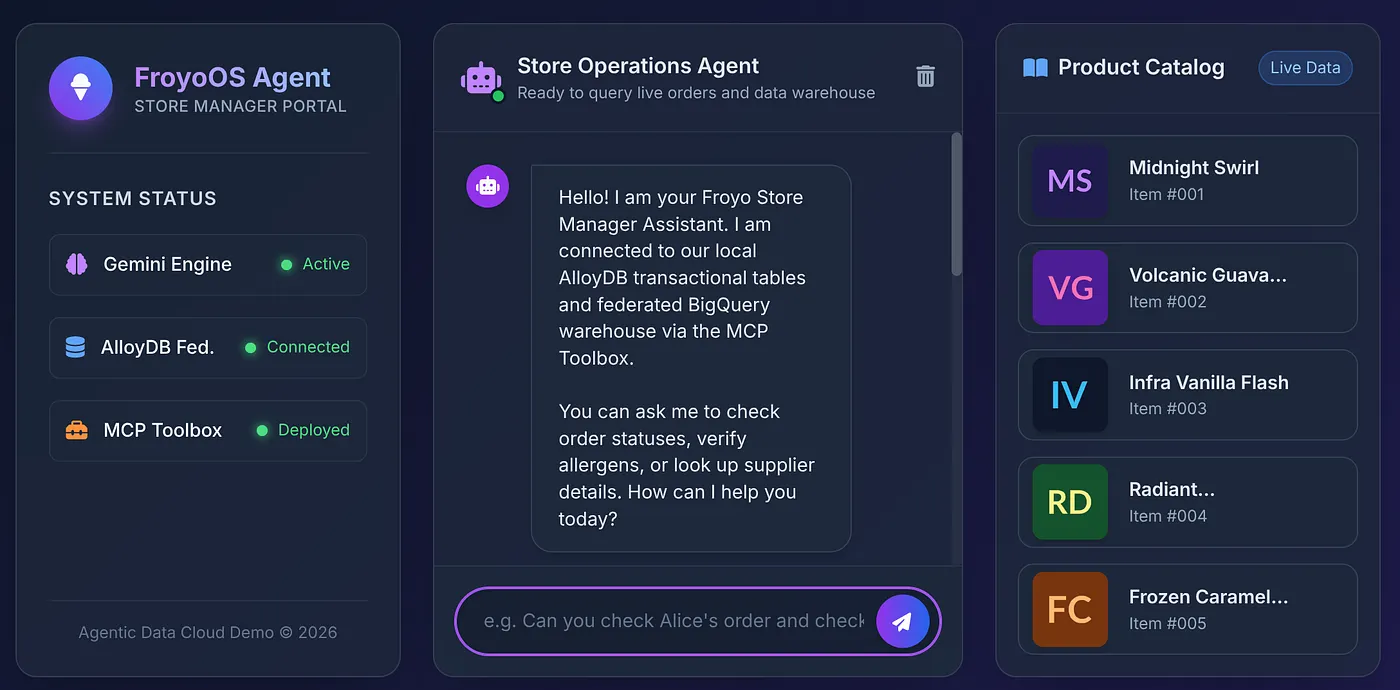
8. Najtrudniejszy test
Kliknijmy produkt z katalogu, aby zadać pytanie agentowi:
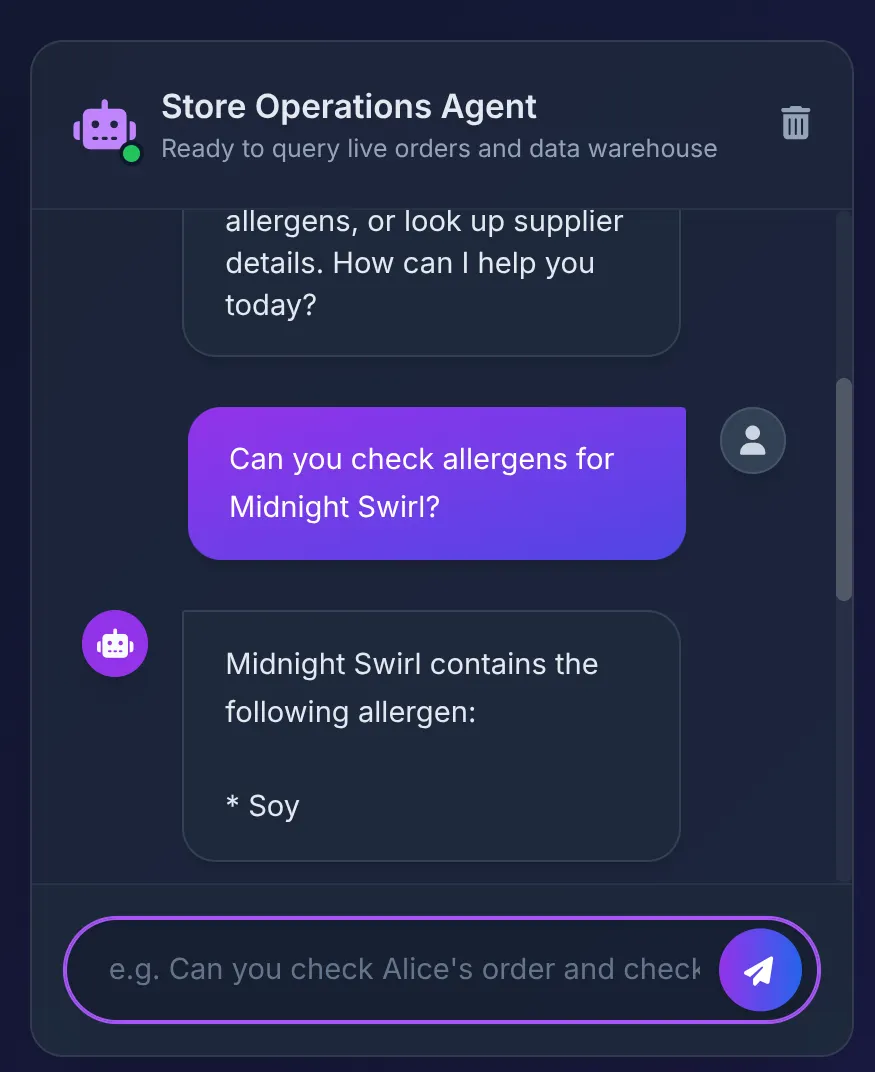
Does Midnight Swirl have any allergens?
Powinna pojawić się odpowiedź:
Sceny zza kulis:
- Agent ADK otrzymuje prompt i decyduje się użyć narzędzia check_allergens.
- Bezpiecznie wywołuje MCP Toolbox w Cloud Run.
- Narzędzie wykonuje zapytanie w AlloyDB, które natychmiast federuje się z BigQuery, aby przeskanować złożone relacje utworzone w części 1.
- Baza danych zwraca „Soy”, a agent zgrabnie podsumowuje te informacje w interfejsie.
Następnie mówimy:
Order 2 Midnight Swirl for Alice.
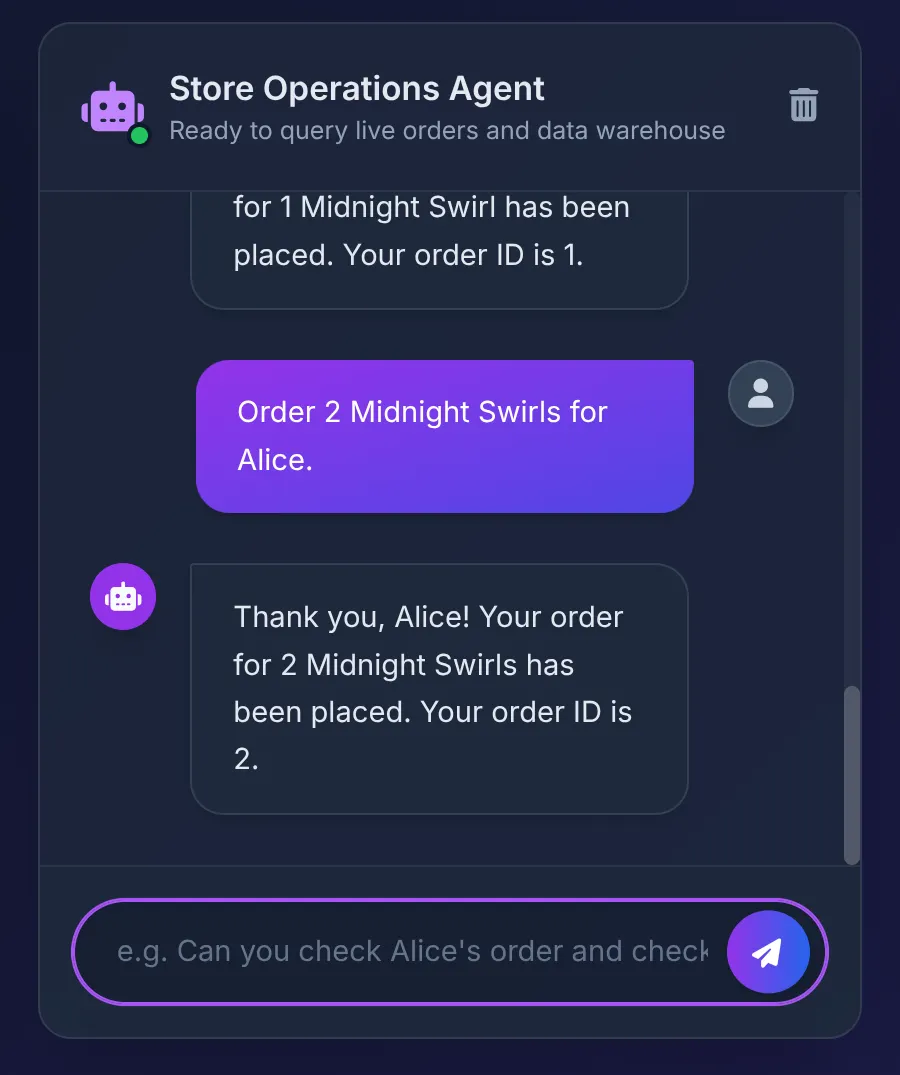
Agent przekazuje ciąg znaków „Midnight Swirl” do Przybornika. Podstawowy kod SQL dynamicznie przekształca ciąg znaków w identyfikator liczbowy za pomocą BigQuery, wstawia zamówienie na żywo do AlloyDB i potwierdza transakcję.
Repozytorium kodu
9. Czyszczenie danych
Po ukończeniu tego laboratorium nie zapomnij usunąć klastra i instancji AlloyDB.
Powinien on zwalniać miejsce w klastrze wraz z jego instancjami.
10. Gratulujemy uzyskania statusu agenta!
Zastanów się, co właśnie osiągnęliśmy:
Nasz dobrze zorganizowany system agentów wchodzi w interakcje tylko z zestawem narzędzi MCP dla baz danych. Za kulisami obsługuje wywołanie narzędzia i logikę przekazywania danych do AI w naszej aplikacji, co upraszcza proces:
- Nasza aplikacja transakcyjna (działająca na AlloyDB) może obsługiwać szybkie, równoczesne sesje użytkowników.
- Gdy potrzebuje obszernych danych analitycznych lub kontekstu historycznego (np. szczegółów dostawcy lub złożonych map składników), wysyła zapytanie do schematu danych froyo_dataschema w BigQuery.
- Zero ETL. Żadne potoki danych nie są uszkodzone. Brak niesynchronizowanych baz danych. Przechowujemy dane tylko raz (w BQ) i przetwarzamy je tam, gdzie są potrzebne.
Skoro mamy już gotowe podstawy agenta i danych – zarówno analitycznych, jak i transakcyjnych – możemy przejść do następnej części.
Co dalej?
Nasz agent działa doskonale… w przypadku pozytywnego scenariusza. W części 4 utworzymy potok oceny agenta, aby rygorystycznie przetestować ważność, podstawy i wydajność naszego systemu opartego na agentach. Do zobaczenia!