
1. Visão geral
Na Parte 1, transformamos PDFs caóticos e não estruturados em tabelas limpas, inteligentes e estruturadas no BigQuery usando o Knowledge Catalog e o DataScan. Agora temos um data warehouse robusto. Na Parte 2, configuramos o AlloyDB como nossa base transacional e federamos nossas tabelas do BigQuery nele, criando uma camada de dados unificada sem duplicar um único byte.
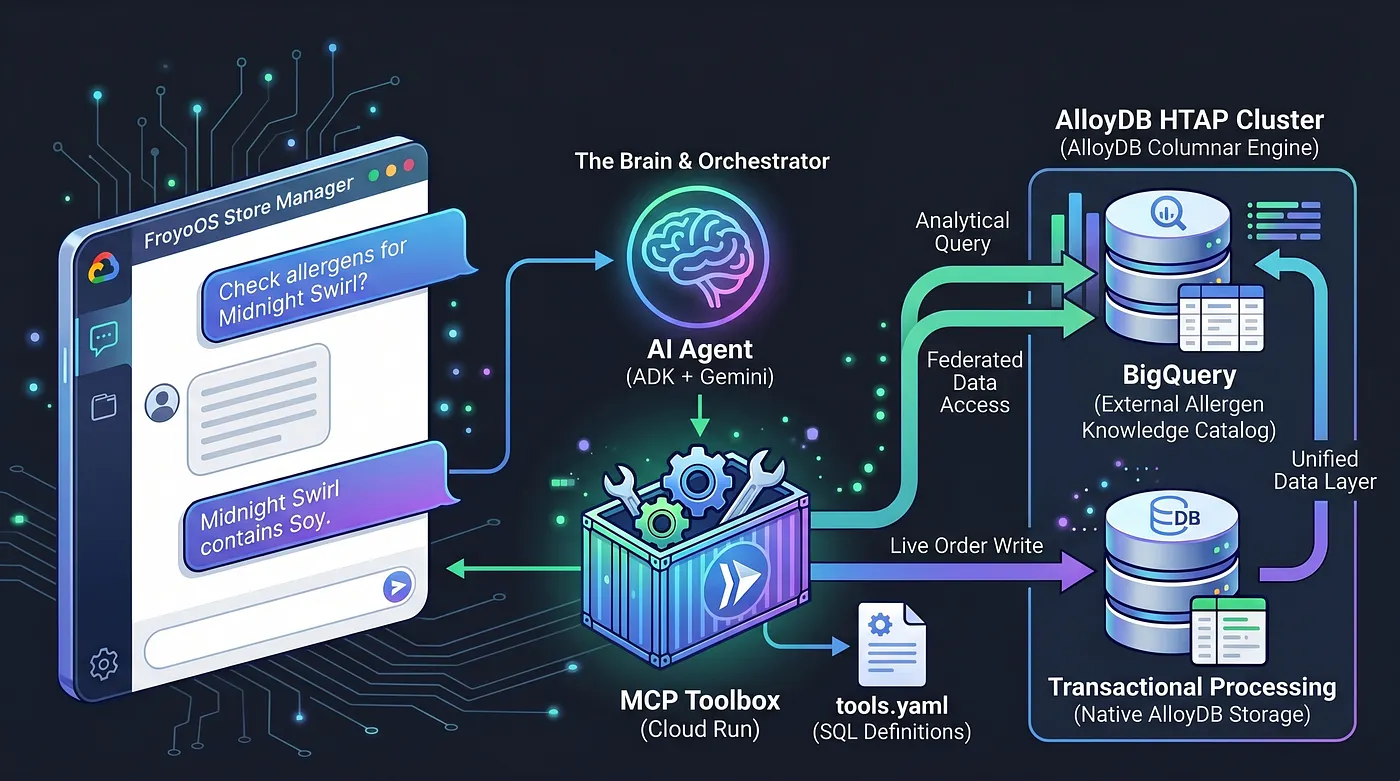
Hoje, vamos criar o cérebro. Estamos criando um aplicativo multiagente, o "FroyoOS Store Manager", que fica acima dessa camada de dados para responder a perguntas, verificar alérgenos e processar pedidos em tempo real.
O desafio: desacoplar a IA do seu agente
Ao criar um agente de IA que precisa se comunicar com bancos de dados, o antipadrão mais comum é forçar os dados e a lógica de IA diretamente no aplicativo Python. Isso torna seu app frágil, inseguro e incrivelmente difícil de manter à medida que sua arquitetura de dados cresce.
Para resolver isso, estamos usando o Toolbox do Protocolo de Contexto de Modelo (MCP). O MCP Toolbox atua como nossa camada de abstração de dados unificada. Definimos nossas operações de banco de dados de forma declarativa em um arquivo tools.yaml simples. Implantamos essa caixa de ferramentas como um endpoint seguro e sem servidor no Google Cloud Run. Nosso agente de IA simplesmente se conecta a esse endpoint e diz: "Execute a ferramenta ‘place_order’".
O poder do HTAP
Antes de começar a criar o agente, vamos falar sobre por que o título deste post chama especificamente o HTAP (processamento transacional/analítico híbrido).
Em uma arquitetura tradicional, se um agente de IA precisasse processar um pedido de usuário em tempo real (uma carga de trabalho transacional OLTP) e comparar milhares de mapeamentos complexos de ingredientes (uma carga de trabalho analítica OLAP), seu aplicativo Python teria que conciliar conexões com dois bancos de dados totalmente diferentes. Isso cria latência grave, sobrecarga de segurança e gerenciamento de estado frágil.
Transformamos o AlloyDB em uma potência HTAP federando nativamente nosso data warehouse do BigQuery diretamente no PostgreSQL. Devido a essa arquitetura HTAP, nosso agente de IA hoje só precisa se comunicar com um endpoint de banco de dados. Ele pode inserir transações em tempo real na tabela live_orders e executar verificações analíticas pesadas no conjunto de dados federado do BigQuery froyo_data no mesmo instante, sem duplicar um único byte de dados. Vamos ver como expomos esse mecanismo à nossa IA.
Vamos começar a criar.
O que você vai aprender
- Como configurar o cluster, a instância e a rede do AlloyDB com um clique de botão
- Como configurar a extensão para se preparar para a federação
- Como configurar a federação do BigQuery para o AlloyDB
- Testar
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Confira se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
- Você vai usar o Cloud Shell, um ambiente de linha de comando em execução no Google Cloud. Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.

- Depois de se conectar ao Cloud Shell, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se você quiser fazer a autenticação
gcloud auth login
- Se o projeto não estiver definido, use este comando:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Ative as APIs necessárias: execute este comando para ativar todas as APIs necessárias:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Armadilhas e solução de problemas
A síndrome do "projeto fantasma" | Você executou |
A barreira de faturamento | Você ativou o projeto, mas esqueceu a conta de faturamento. O AlloyDB é um mecanismo de alto desempenho. Ele não será iniciado se o "tanque de gasolina" (faturamento) estiver vazio. |
Atraso na propagação da API | Você clicou em "Ativar APIs", mas a linha de comando ainda diz |
Quotas | Se você estiver usando uma conta de teste nova, poderá atingir uma quota regional para instâncias do AlloyDB. Se |
3. Como preparar os dados
Verifique se os dados estruturados extraídos de PDFs não estruturados estão disponíveis no BigQuery e se a federação do AlloyDB dos dados do BigQuery também está estabelecida e testada. Se você não concluiu essas etapas, este é um bom momento para executar essas etapas simples aqui e aqui para as partes 1 e 2, respectivamente.
Observação :
Se você estiver testando este codelab, não execute a etapa de limpeza da parte 2 (exclusão do cluster e da instância), porque precisamos da orquestração do AlloyDB para o sistema agêntico demonstrado aqui.
Além desses dados que já criamos na parte 2, precisamos criar mais uma tabela na instância do AlloyDB. Acesse o AlloyDB Studio usando o link:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Mude o nome do cluster no link acima se estiver usando um cluster diferente.
No AlloyDB Studio, em uma nova guia do editor de consultas, execute a seguinte instrução:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Isso vai criar a tabela live_orders no seu banco de dados.
4. Como definir a abstração (o tools.yaml)
Primeiro, registramos formalmente nossas operações de banco de dados. Criamos um arquivo tools.yaml que define como nosso agente interage com o AlloyDB, que tem dados transacionais e analíticos (dados analíticos da federação do BigQuery).
- Acesse o terminal do Cloud Shell. Alterne para o modo de edição.
- Crie uma nova pasta no diretório raiz: "froyo-agent"
- Dentro da pasta, crie um arquivo tools.yaml e cole o seguinte conteúdo: (substitua pelos seus valores de projeto, cluster, instância e senha)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Limitamos os recursos do nosso agente a duas ferramentas: verificar alérgenos e fazer pedidos.
5. Como implantar a caixa de ferramentas no Cloud Run
Para disponibilizar isso ao nosso aplicativo, implantamos a caixa de ferramentas com segurança usando a CLI gcloud. Isso cria nosso endpoint da camada de abstração.
- Alterne para o terminal do Cloud Shell e acesse o diretório de trabalho executando o comando:
cd froyo-agent
- Salve o tools.yaml em um secret chamado "tools-froyo":
gcloud secrets create tools-froyo --data-file=tools.yaml
- Implante o contêiner do MCP Toolbox no Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Os valores de "network" e "subnet" precisam ser substituídos se você usou valores diferentes dos que configuramos no codelab da Parte 2.
- Anote o URL do Cloud Run resultante (por exemplo, https://toolbox-froyo-xxx.run.app).
Vamos usar esse endpoint do MCP Toolbox implantado na etapa de configuração do agente.
6. O back-end agêntico (app.py)
Com nosso banco de dados abstraído, nosso código Python pode se concentrar totalmente na orquestração e no raciocínio.
Estamos usando o Kit de Desenvolvimento de Agente (ADK) com o Flask. O ADK fornece memória de sessão de nível empresarial (InMemorySessionService), o que significa que nosso agente lembra o contexto da conversa. Ele se integra nativamente ao ToolboxSyncClient para extrair nossas ferramentas do Cloud Run.
Confira seu app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
O app Flask Python simples conecta o agente ADK às ferramentas que definimos na nossa caixa de ferramentas, que, por sua vez, interage com o AlloyDB (e os dados federados do BigQuery) e responde ao usuário.
Para receber esse projeto no editor do Cloud Shell, clone o repositório do agente executando os seguintes comandos no terminal do Cloud Shell:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
Você verá a seguinte estrutura de projeto:
Etapas para continuar usando os dados sem a conta de faturamento:
- Os seguintes arquivos de dados estão disponíveis no repositório para sua conveniência:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Esses arquivos precisam estar na mesma pasta que o app.py.
B. O arquivo Python chamado app-nobill.py no mesmo caminho
- Na pasta raiz do projeto, há um arquivo chamado app-nobill.py
- Esse arquivo foi projetado para criar a mesma experiência de app, mas sem a necessidade explícita de se conectar a essas fontes de dados, já que os dados foram disponibilizados em arquivos.
- Todos os outros arquivos mencionados no laboratório também precisam estar intactos para essa versão (basta não executar o arquivo app.py)
7. A interface e a execução do app
Para oferecer uma experiência adequada aos nossos gerentes de loja, criamos uma interface elegante e glassmórfica (templates/index.html) com uma barra lateral de catálogo de produtos em tempo real e uma interface de chat interativa.
Você pode encontrar o index.html no arquivo do repositório aqui:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Antes de executar o aplicativo, verifique se você tem as dependências no arquivo requirements.txt com o seguinte conteúdo:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
e o arquivo .env preenchido:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Como receber sua GOOGLE_API_KEY
Siga as instruções neste blog para configurar sua chave de API do Google.
Como receber seu MCP_TOOLBOX_SERVER_URL
Configuramos isso na etapa anterior deste codelab, e você copiou o endpoint do MCP Toolbox implantado. Use esse link para a variável de ambiente MCP_TOOLBOX_SERVER_URL.
Execute seu app:
No terminal do Cloud Shell, verifique se você está na pasta do projeto e execute os seguintes comandos um por um:
Acesse a pasta raiz do projeto:
cd froyo-data
Instale as dependências:
pip install -r requirements.txt
Execução do arquivo Python:
python app.py
Clique no link que aparece no terminal ou abra http://localhost:8080.
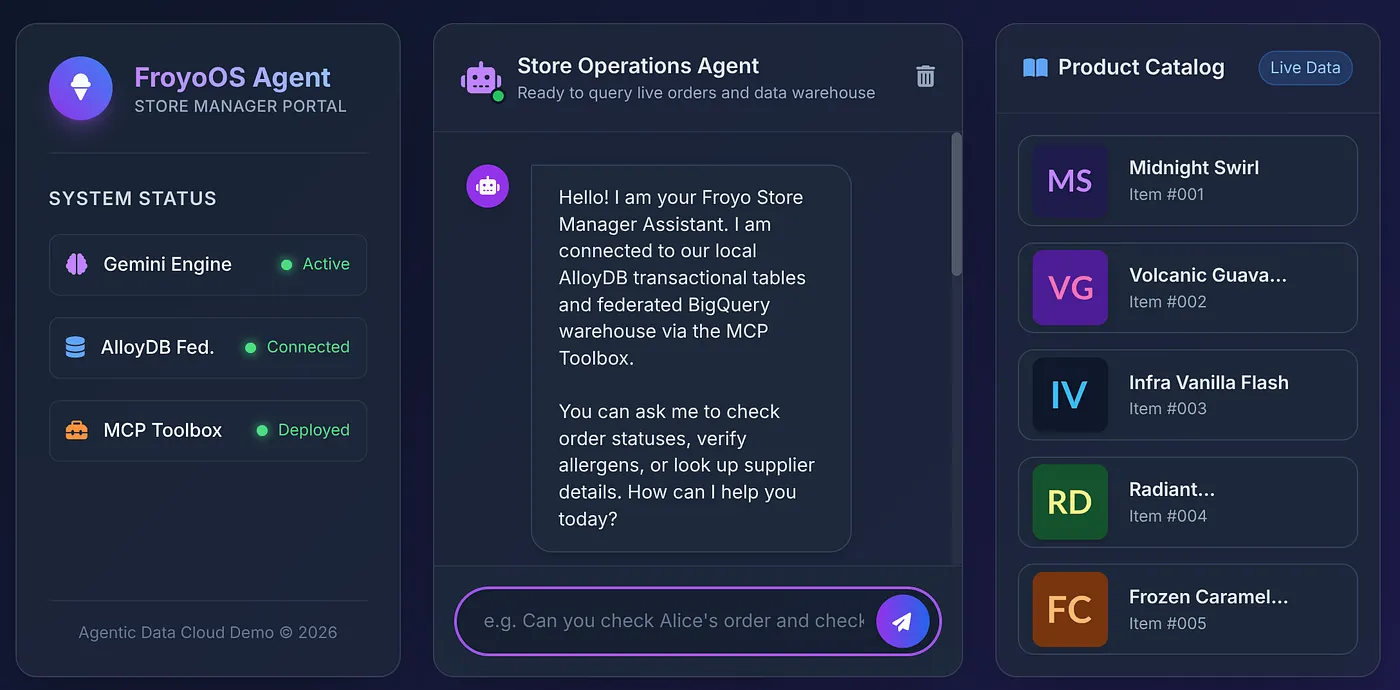
8. O teste final
Vamos clicar em um produto do catálogo para perguntar ao agente:
Does Midnight Swirl have any allergens?
Você verá a resposta:
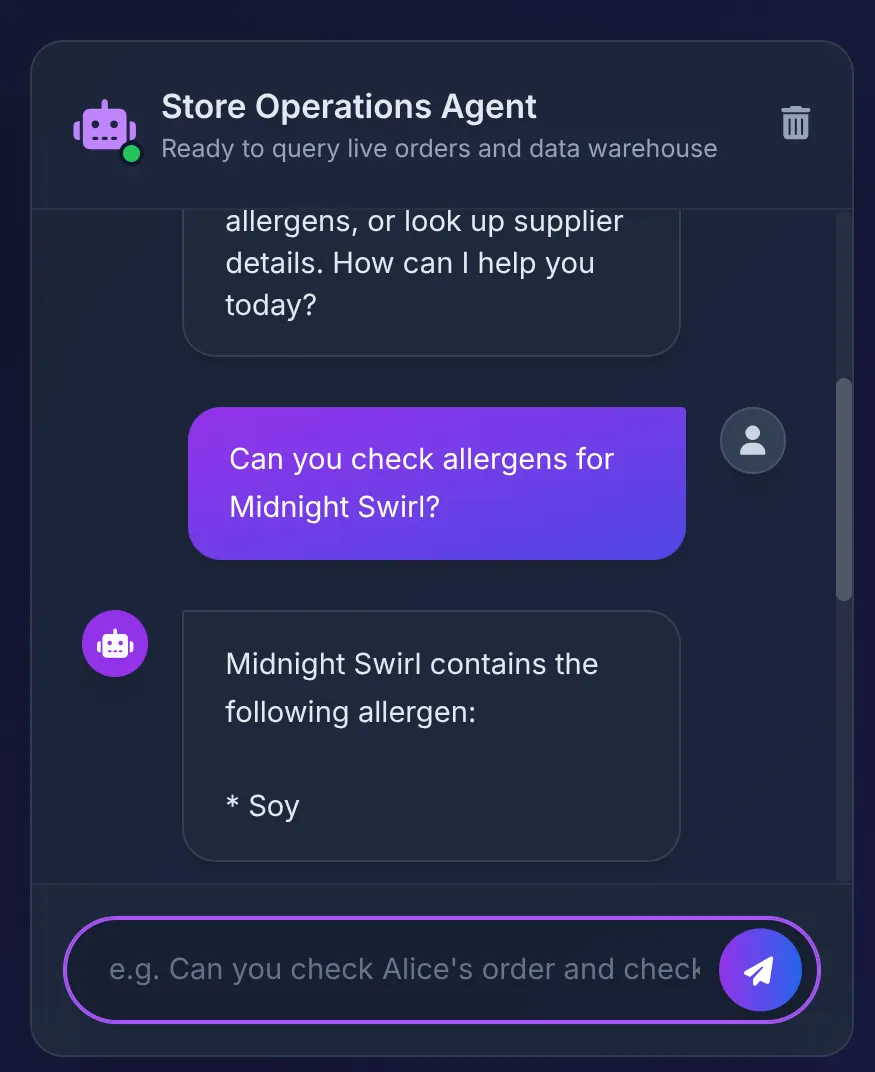
Cenas dos bastidores:
- O agente ADK recebe o comando e decide usar a ferramenta check_allergens.
- Ele chama com segurança o MCP Toolbox no Cloud Run.
- A caixa de ferramentas executa a consulta no AlloyDB, que é federada instantaneamente ao BigQuery para verificar as relações complexas que criamos na Parte 1.
- O banco de dados retorna "Soja", que o agente resume na interface.
Em seguida, dizemos:
Order 2 Midnight Swirl for Alice.
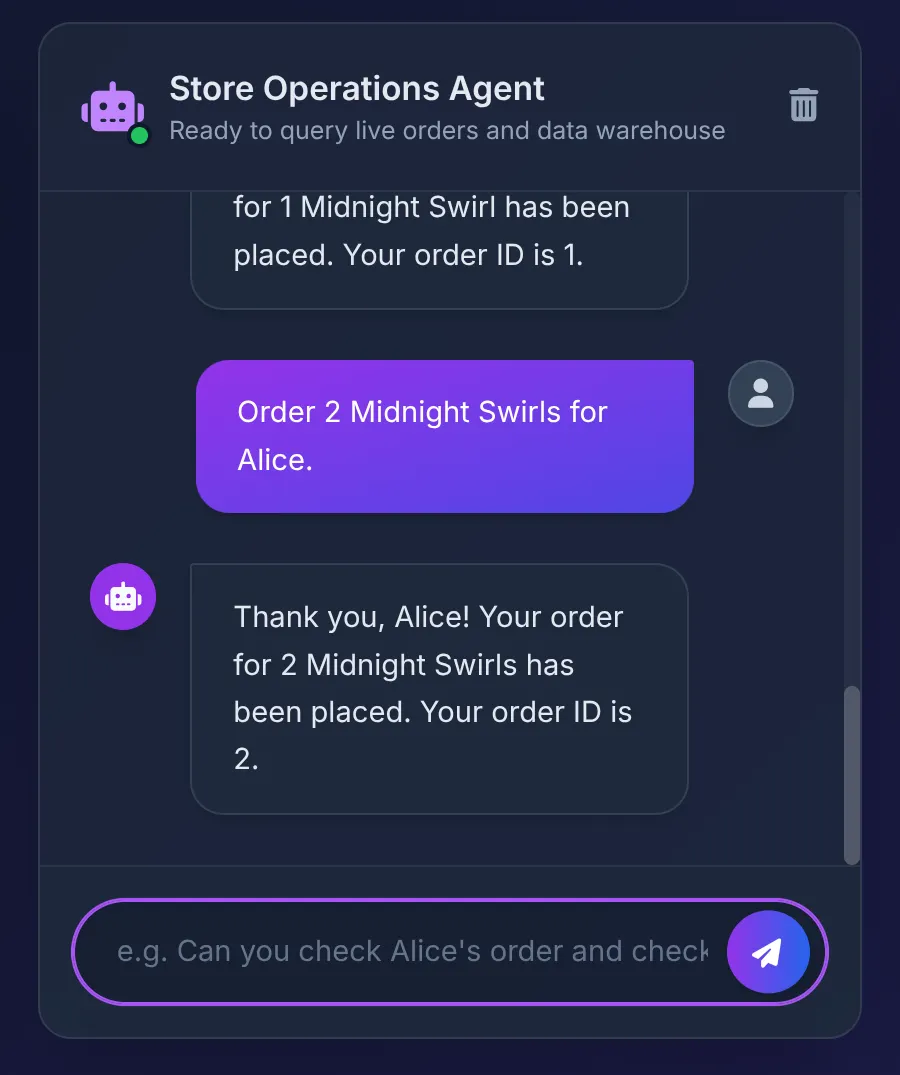
O agente transmite a string "Midnight Swirl" para a caixa de ferramentas. O SQL subjacente resolve dinamicamente a string para um ID inteiro via BigQuery, insere o pedido em tempo real no AlloyDB e confirma a transação.
Repositório de código
9. Limpar
Depois de concluir este laboratório, não se esqueça de excluir o cluster e a instância do AlloyDB.
Ele vai limpar o cluster e as instâncias.
10. Parabéns pelo seu agente!
Pense no que acabamos de realizar:
Nosso sistema agêntico bem orquestrado interage apenas com o MCP Toolbox for Databases. Isso nos bastidores processa a chamada de ferramenta e os dados para a lógica de IA do nosso aplicativo, mantendo o fluxo simples:
- Nosso app transacional (em execução no AlloyDB) pode processar sessões de usuários rápidas e simultâneas.
- Quando ele precisa de dados analíticos pesados ou contexto histórico (como detalhes do fornecedor ou mapeamentos complexos de ingredientes), ele consulta o froyo_dataschema do BigQuery.
- Zero ETL. Nenhum pipeline de dados quebrando. Nenhum banco de dados dessincronizado. Armazenamos uma vez (no BQ) e computamos onde precisamos.
Agora que nosso agente e a base de dados (analítica e transacional) estão completos, vamos passar para a próxima parte.
A seguir
Nosso agente funciona perfeitamente... no caminho feliz. Em Parte 4, vamos criar um pipeline de avaliação de agentes para testar rigorosamente a validade, o fundamento e o desempenho do nosso sistema agêntico. Até lá!