
1. Обзор
В первой части мы успешно преобразовали хаотичные, неструктурированные PDF-файлы в чистые, интеллектуальные и структурированные таблицы в BigQuery, используя Knowledge Catalog и DataScan. Теперь у нас есть надежное хранилище данных. Во второй части мы настроили AlloyDB в качестве транзакционной основы и интегрировали в нее наши таблицы BigQuery, создав единый слой данных без дублирования ни одного байта.
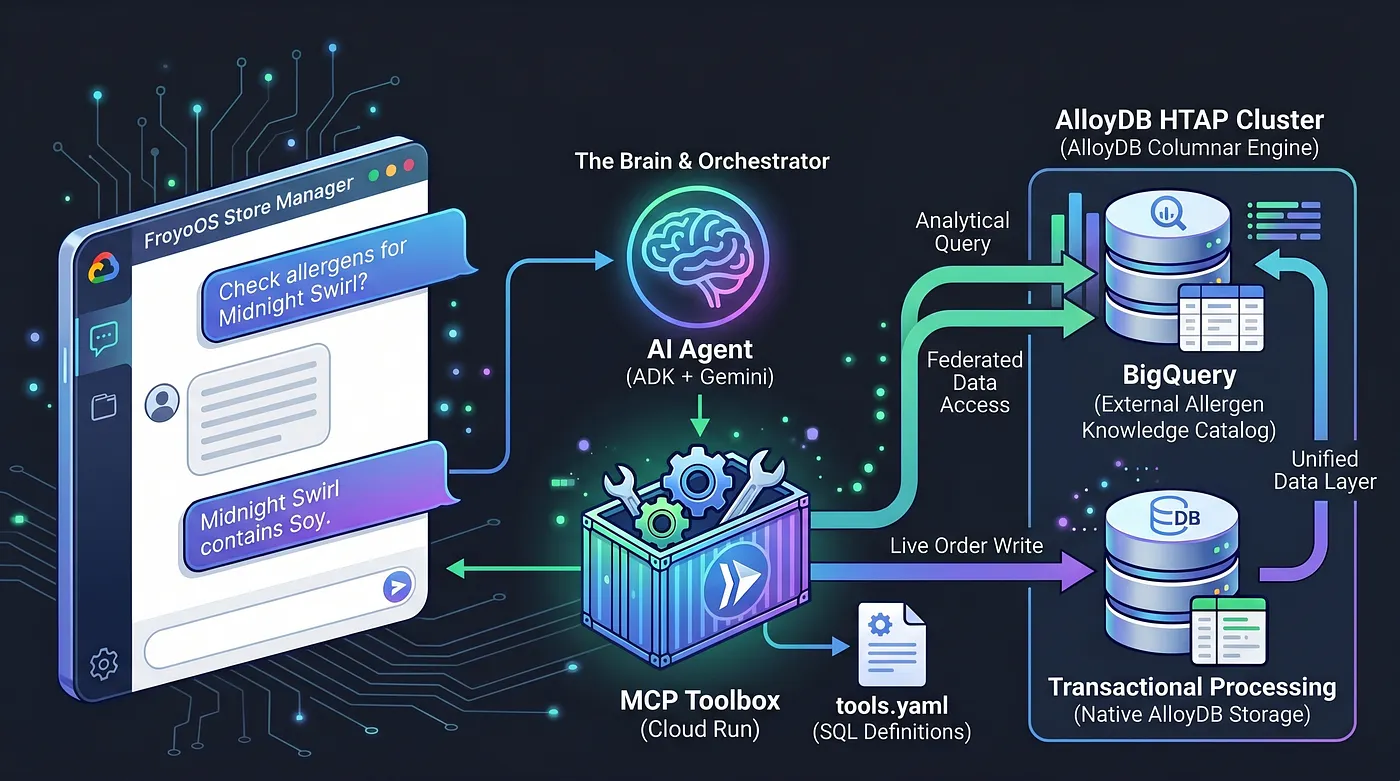
Сегодня мы создаём «мозг» — многоагентное приложение, «Менеджер магазина FroyoOS», которое работает поверх этого слоя данных, отвечает на вопросы, проверяет наличие аллергенов и обрабатывает заказы в режиме реального времени.
Задача: Отделить искусственный интеллект от вашего агента.
При создании ИИ-агента, которому необходимо взаимодействовать с базами данных, наиболее распространенным антипаттерном является внедрение данных и логики ИИ непосредственно в ваше Python-приложение. Это делает ваше приложение хрупким, небезопасным и невероятно сложным в обслуживании по мере роста вашей архитектуры данных.
Для решения этой задачи мы используем Model Context Protocol (MCP) Toolbox. MCP Toolbox выступает в качестве нашего единого уровня абстракции данных. Мы определяем операции с базой данных декларативно в простом файле tools.yaml. Мы развертываем этот инструментарий как защищенную бессерверную конечную точку в Google Cloud Run. Наш ИИ-агент просто подключается к этой конечной точке и говорит: «Выполнить инструмент 'place_order'».
Сила HTAP
Прежде чем приступить к созданию агента, давайте поговорим о том, почему в заголовке этой статьи конкретно упоминается HTAP (гибридная транзакционно-аналитическая обработка).
В традиционной архитектуре, если агенту ИИ необходимо обработать заказ пользователя в режиме реального времени (транзакционная OLTP-нагрузка) и сопоставить тысячи сложных сопоставлений ингредиентов (аналитическая OLAP-нагрузка), вашему приложению на Python пришлось бы одновременно подключаться к двум совершенно разным базам данных. Это создает значительные задержки, дополнительные затраты на безопасность и ненадежное управление состоянием.
Мы превратили AlloyDB в мощную HTAP-платформу, напрямую интегрировав наше хранилище данных BigQuery в PostgreSQL. Благодаря этой HTAP-архитектуре, нашему ИИ-агенту сегодня достаточно взаимодействовать только с одной конечной точкой базы данных. Он может одновременно вставлять транзакции в таблицу live_orders и выполнять сложные аналитические проверки объединенного набора данных BigQuery froyo_data , не дублируя ни одного байта данных. Давайте посмотрим, как мы предоставляем доступ к этому механизму нашему ИИ.
Начнём строительство!
Что вы узнаете
- Как настроить кластер, экземпляр и сеть AlloyDB одним щелчком мыши
- Как настроить расширение для подготовки к созданию федерации
- Как настроить федерацию из BigQuery в AlloyDB
- Проверьте это
Требования
2. Прежде чем начать
Создать проект
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud. Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.

- После подключения к Cloud Shell необходимо проверить, прошли ли вы аутентификацию и установлен ли идентификатор вашего проекта, используя следующую команду:
gcloud auth list
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте.
gcloud config list project
- Если вы хотите пройти аутентификацию
gcloud auth login
- Если ваш проект не задан, используйте следующую команду для его установки:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- Включите необходимые API: Выполните эту команду, чтобы включить все необходимые API:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
Подводные камни и устранение неполадок
Синдром «Проекта-призрака» | Вы выполнили команду |
Баррикада Биллинга | Вы активировали проект, но забыли указать платежный аккаунт. AlloyDB — высокопроизводительный движок; он не запустится, если «топливо» (платежный бак) пуст. |
Задержка распространения API | Вы нажали «Включить API», но в командной строке по-прежнему отображается сообщение |
Квота Квагс | Если вы используете совершенно новую пробную учетную запись, вы можете столкнуться с региональной квотой на экземпляры AlloyDB. Если |
3. Подготовка данных
Убедитесь, что структурированные данные, извлеченные из неструктурированных PDF-файлов, доступны в BigQuery, а также что федерация данных BigQuery в AlloyDB установлена и протестирована. Если вы еще не выполнили эти шаги, сейчас самое время перейти к выполнению простых шагов, описанных здесь и здесь, для частей 1 и 2 соответственно.
Примечание:
Если вы выполняете это практическое задание, вам не следует выполнять этап очистки из части 2 (удаление кластера и экземпляра), поскольку нам необходима оркестрация AlloyDB для нашей агентной системы, продемонстрированной здесь.
В дополнение к данным, которые мы уже создали во второй части, нам необходимо создать еще одну таблицу в экземпляре AlloyDB. Перейдите в AlloyDB Studio по ссылке:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
Измените имя кластера по ссылке выше, если вы используете другой кластер.
В AlloyDB Studio, в новой вкладке «Редактор запросов», выполните следующее выражение:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Это должно создать таблицу live_orders в вашей базе данных.
4. Определение абстракции (файл tools.yaml)
Сначала мы официально регистрируем операции с нашей базой данных. Мы создаём файл tools.yaml, который определяет, как наш агент взаимодействует с AlloyDB, содержащей как транзакционные, так и аналитические данные (аналитические данные из федерации BigQuery).
- Перейдите в терминал Cloud Shell . Переключитесь в режим редактора.
- Создайте новую папку в корневом каталоге: " froyo-agent "
- Внутри папки создайте файл tools.yaml и вставьте в него следующее содержимое: (замените значения project, cluster, instance и password на свои собственные)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
Мы ограничили возможности наших агентов двумя инструментами — проверкой аллергенов и оформлением заказа.
5. Развертывание Toolbox в Cloud Run
Чтобы сделать это доступным для нашего приложения, мы безопасно развертываем набор инструментов с помощью CLI gcloud. Это создает конечную точку нашего уровня абстракции.
- Переключитесь в терминал Cloud Shell и перейдите в рабочий каталог, выполнив команду:
cd froyo-agent
- Сохраните файл tools.yaml в секрете с именем "tools-froyo":
gcloud secrets create tools-froyo --data-file=tools.yaml
- Разверните контейнер MCP Toolbox в Cloud Run.
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
Если вы использовали значения, отличные от тех, которые мы настроили во второй части практического задания, их необходимо заменить.
- Запишите полученный URL-адрес Cloud Run (например, https://toolbox-froyo-xxx.run.app ).
Мы будем использовать эту развернутую конечную точку MCP Toolbox на этапе настройки агента.
6. Агентный бэкэнд (app.py)
Благодаря абстрагированию от базы данных, наш код на Python может полностью сосредоточиться на организации и логическом выводе.
Мы используем Agent Development Kit (ADK) вместе с Flask. ADK предоставляет память сессий корпоративного уровня ( InMemorySessionService ), что означает, что наш агент запоминает контекст разговора. Он нативно интегрируется с ToolboxSyncClient для беспрепятственного получения наших инструментов из Cloud Run .
Вот ваш файл app.py :
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
Простое приложение Python Flask подключает агент ADK к инструментам, определенным в нашем Toolbox, которые, в свою очередь, взаимодействуют с AlloyDB (а также с федеративными данными BigQuery) и отвечают пользователю.
Чтобы добавить этот проект в редактор Cloud Shell, вы можете клонировать репозиторий агента, выполнив следующие команды в терминале Cloud Shell:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
Вы должны увидеть следующую структуру проекта:
Шаги для продолжения использования данных без платёжного аккаунта:
- Для удобства в репозитории доступны следующие файлы данных:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
Эти файлы должны находиться в той же папке, что и файл app.py.
B. Файл Python с именем app-nobill.py находится по тому же пути.
- В корневой папке проекта находится файл с именем app-nobill.py.
- Этот файл предназначен для создания аналогичного пользовательского опыта в приложении, но без явной необходимости подключения к этим источникам данных, поскольку данные уже доступны в файлах.
- Все остальные файлы, упомянутые в лабораторной работе, должны оставаться нетронутыми и в этой версии (просто нет необходимости запускать файл app.py).
7. Пользовательский интерфейс и запуск приложения
Чтобы обеспечить нашим управляющим магазинами максимально комфортный опыт, мы создали элегантный, гибкий пользовательский интерфейс ( templates/index.html ), включающий боковую панель с интерактивным каталогом товаров и интерфейс чата.
Файл index.html можно найти в репозитории по этой ссылке:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
Перед запуском приложения убедитесь, что в файле requirements.txt указаны необходимые зависимости, содержащие следующее содержимое:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
и ваш файл .env заполнен:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
Как получить свой GOOGLE_API_KEY?
Следуйте инструкциям в этом блоге, чтобы настроить свой ключ Google API .
Как получить значение MCP_TOOLBOX_SERVER_URL?
Мы настроили это на предыдущем шаге этого практического занятия, и вы скопировали развернутую конечную точку MCP Toolbox. Используйте эту ссылку для переменной среды MCP_TOOLBOX_SERVER_URL.
Запустите приложение:
В терминале Cloud Shell, убедившись, что вы находитесь в папке проекта, выполните следующие команды по очереди:
Перейдите в корневую папку проекта:
cd froyo-data
Установите зависимости:
pip install -r requirements.txt
Выполнение файла Python:
python app.py
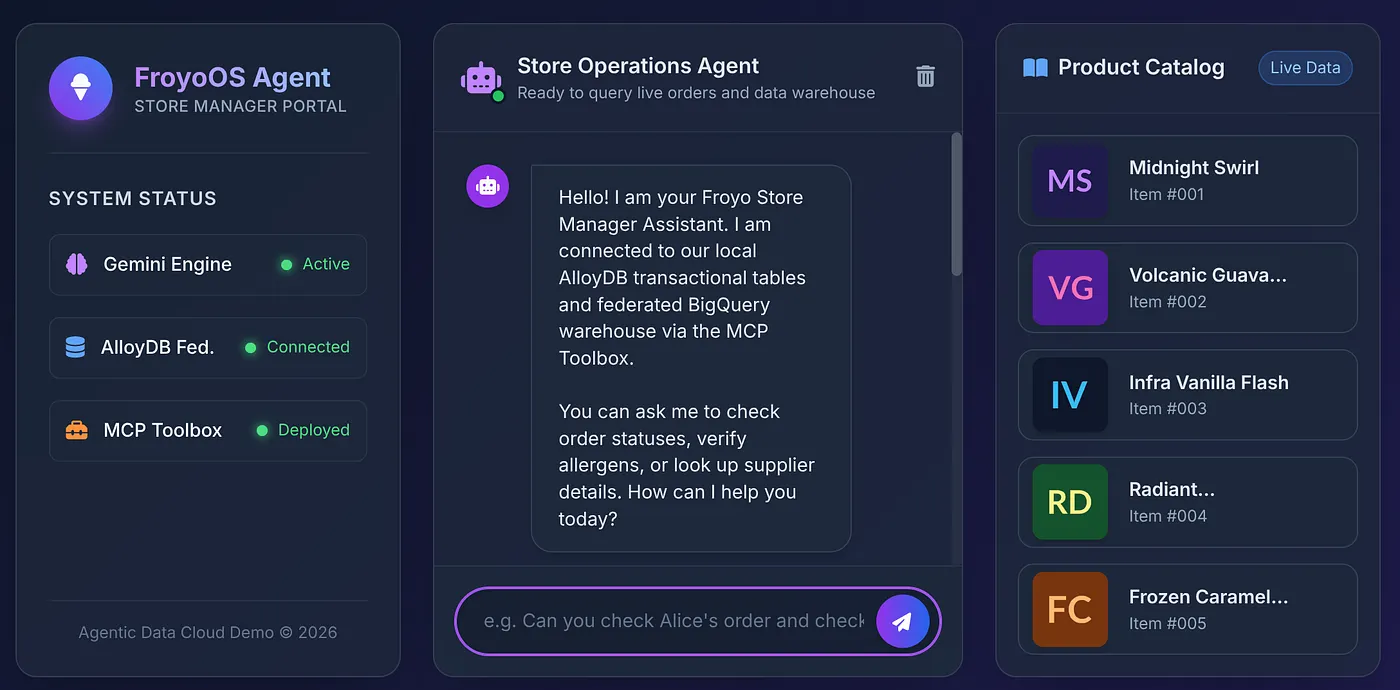
Нажмите на ссылку, которая появится в терминале, или откройте http://localhost:8080 !
8. Главное испытание
Давайте выберем товар из каталога и зададим вопрос агенту:
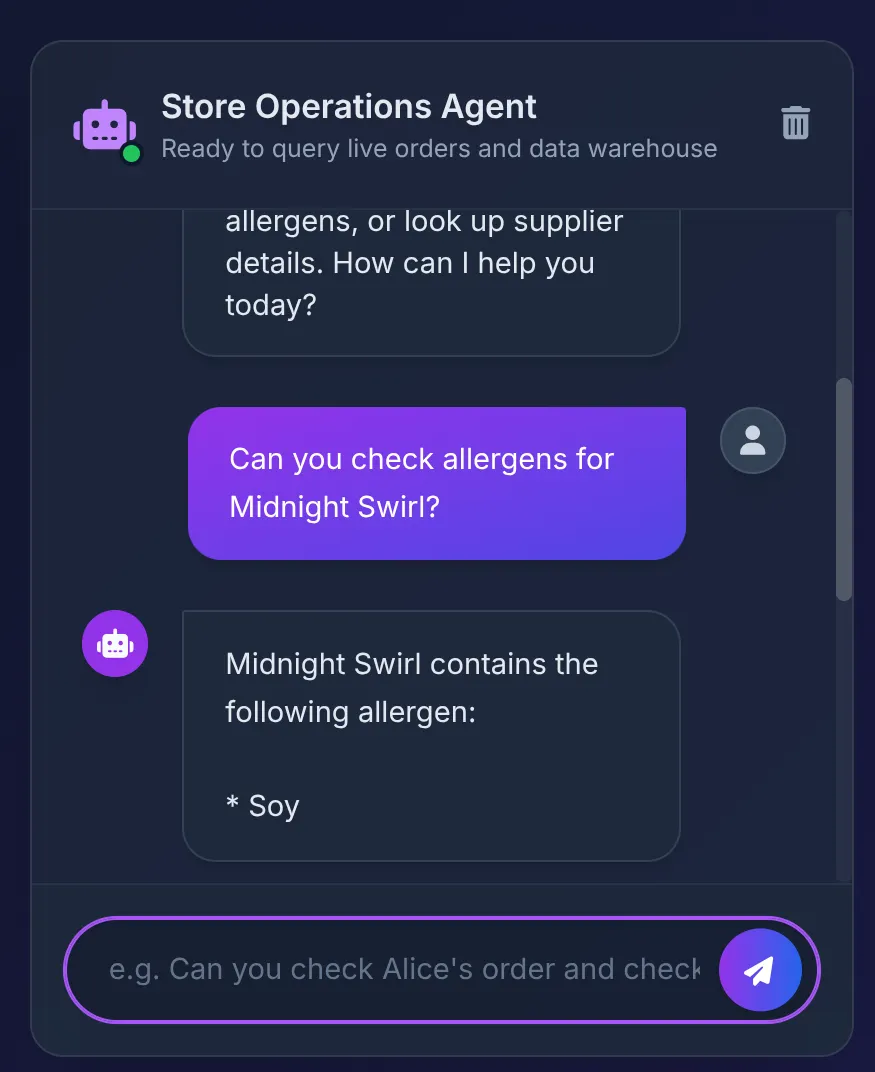
Does Midnight Swirl have any allergens?
Вы должны увидеть ответ:
За кулисами:
- Агент ADK получает запрос и принимает решение использовать инструмент check_allergens.
- Он обеспечивает безопасный вызов MCP Toolbox в Cloud Run.
- Панель инструментов выполняет запрос в AlloyDB, которая мгновенно передает его в BigQuery для сканирования сложных связей, которые мы построили в Части 1.
- База данных возвращает "Сою", которую агент лаконично отображает в пользовательском интерфейсе.
Далее мы говорим:
Order 2 Midnight Swirl for Alice.
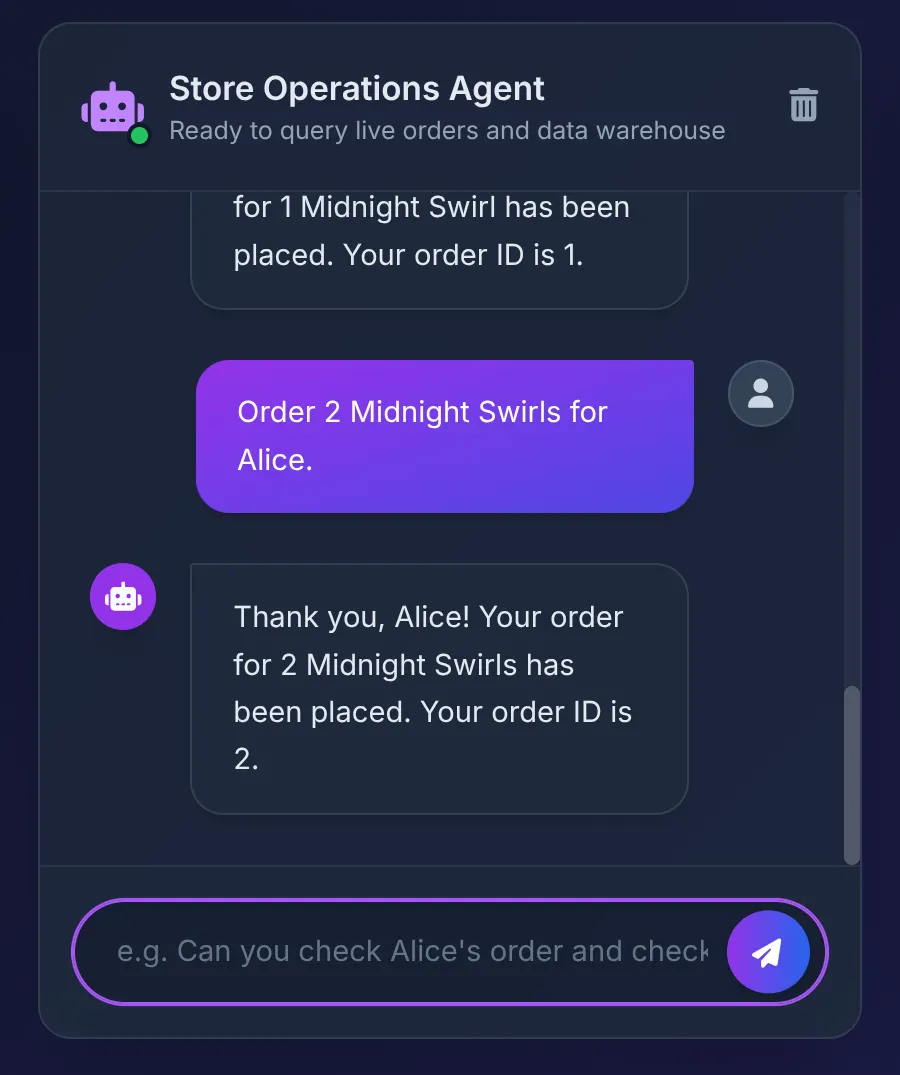
Агент передает строку "Midnight Swirl" в Toolbox. Базовый SQL-запрос динамически преобразует строку в целочисленный идентификатор с помощью BigQuery, вставляет ордер в AlloyDB и подтверждает транзакцию.
Репозиторий кода
9. Уборка
После завершения этой лабораторной работы не забудьте удалить кластер и экземпляр AlloyDB.
Это должно привести к очистке кластера вместе с его экземплярами.
10. Поздравляем с назначением агента!
Подумайте о том, чего мы только что добились:
Наша хорошо организованная агентная система взаимодействует только с MCP Toolbox для работы с базами данных. В фоновом режиме она обрабатывает вызовы инструментов и логику передачи данных в ИИ нашего приложения, обеспечивая простоту рабочего процесса:
- Наше транзакционное приложение (работающее на AlloyDB) способно обрабатывать быстрые одновременные пользовательские сессии.
- Когда требуются обширные аналитические данные или исторический контекст (например, информация о поставщиках или сложные сопоставления ингредиентов), система обращается к схеме данных froyo_dataschema в BigQuery.
- Никаких ETL-процессов. Никаких сбоев в конвейерах обработки данных. Никаких рассинхронизированных баз данных. Мы храним данные один раз (в BQ) и вычисляем их там, где это необходимо.
Теперь, когда наша база данных и агентов — как аналитическая, так и транзакционная — завершена, перейдем к следующей части.
Что дальше?
Наш агент работает безупречно... на оптимальном пути. В части 4 мы создадим конвейер оценки агента, чтобы тщательно проверить достоверность, обоснованность и производительность нашей агентной системы. До встречи!