
1. ภาพรวม
ใน ส่วนที่ 1 เราได้แปลง PDF ที่ไม่มีโครงสร้างและซับซ้อนให้เป็นตารางที่มีโครงสร้าง ชัดเจน และชาญฉลาดใน BigQuery โดยใช้ Knowledge Catalog และ DataScan ได้สำเร็จ ตอนนี้เรามีคลังข้อมูลที่มีประสิทธิภาพแล้ว ใน ส่วนที่ 2 เราได้ตั้งค่า AlloyDB เป็นแกนหลักในการทำธุรกรรมและรวมตาราง BigQuery เข้ากับ AlloyDB เพื่อสร้างเลเยอร์ข้อมูลแบบรวมโดยไม่ทำซ้ำข้อมูลแม้แต่ไบต์เดียว
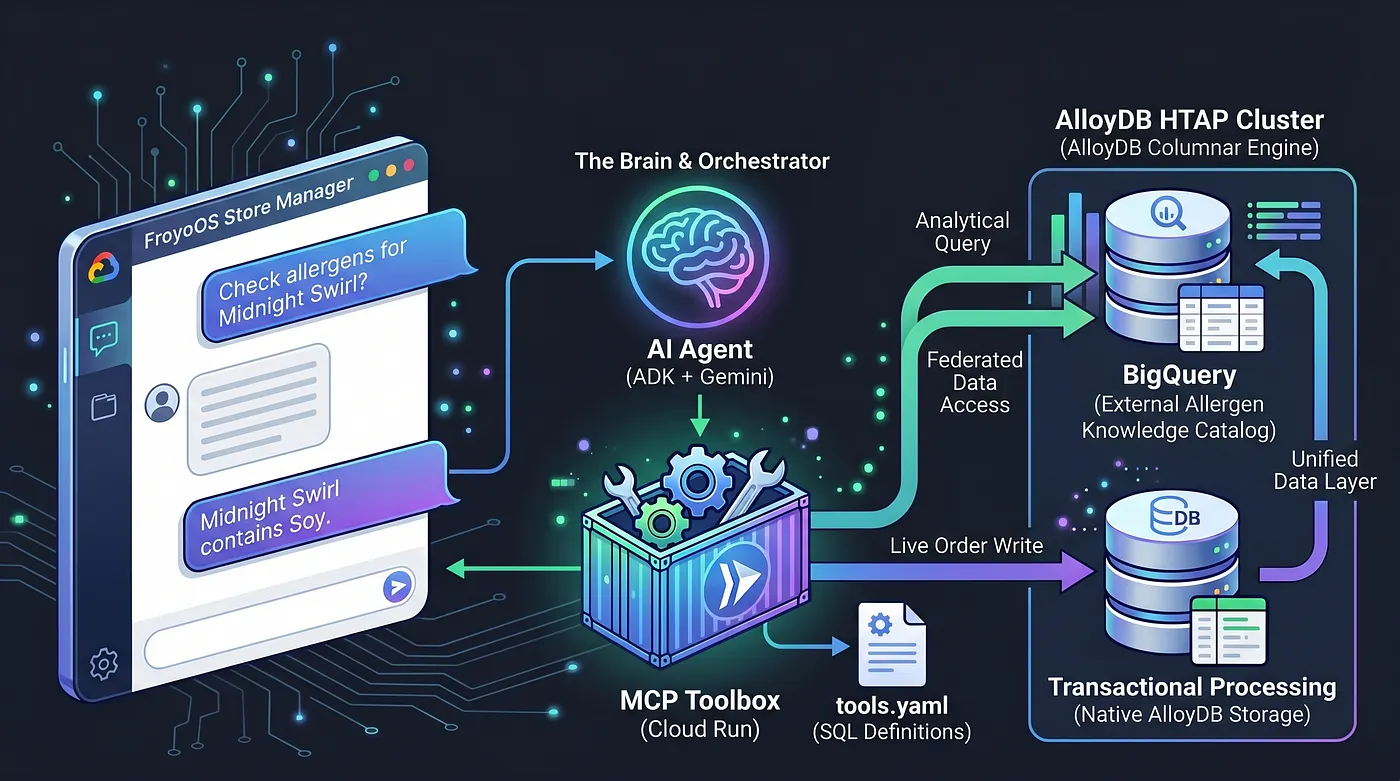
วันนี้เราจะสร้างสมอง เรากำลังสร้างแอปพลิเคชันแบบหลาย Agent หรือ "FroyoOS Store Manager" ซึ่งจะทำงานอยู่เหนือเลเยอร์ข้อมูลนี้เพื่อตอบคำถาม ตรวจสอบสารก่อภูมิแพ้ และประมวลผลคำสั่งซื้อแบบเรียลไทม์
ความท้าทาย: แยก AI ออกจาก Agent
เมื่อสร้าง AI Agent ที่ต้องสื่อสารกับฐานข้อมูล รูปแบบที่ไม่แนะนำที่พบบ่อยที่สุดคือการบังคับให้ข้อมูลและตรรกะ AI เข้าไปอยู่ในแอปพลิเคชัน Python โดยตรง ซึ่งจะทำให้แอปของคุณเปราะบาง ไม่ปลอดภัย และดูแลรักษาได้ยากอย่างยิ่งเมื่อสถาปัตยกรรมข้อมูลเติบโตขึ้น
เราจึงใช้ MCP (Model Context Protocol) Toolbox เพื่อแก้ปัญหานี้ โดย MCP Toolbox จะทำหน้าที่เป็นเลเยอร์การแยกข้อมูลแบบรวม เรากำหนดการดำเนินการฐานข้อมูลอย่างชัดเจนในไฟล์ tools.yaml อย่างง่าย และติดตั้งใช้งาน Toolbox นี้เป็นอุปกรณ์ปลายทางแบบ Serverless ที่ปลอดภัยใน Google Cloud Run AI Agent ของเราเพียงแค่เชื่อมต่อกับอุปกรณ์ปลายทางนี้แล้วพูดว่า "เรียกใช้เครื่องมือ 'place_order'"
ศักยภาพของ HTAP
ก่อนที่จะเริ่มสร้าง Agent เรามาพูดถึงเหตุผลที่ชื่อของโพสต์นี้ระบุถึง HTAP (Hybrid Transactional/Analytical Processing) โดยเฉพาะ
ในสถาปัตยกรรมแบบดั้งเดิม หาก AI Agent ต้องการประมวลผลคำสั่งซื้อของผู้ใช้แบบเรียลไทม์ (เวิร์กโหลด OLTP เชิงธุรกรรม) และตรวจสอบเพื่อเปรียบเทียบการจับคู่ส่วนผสมที่ซับซ้อนนับพันรายการ (เวิร์กโหลด OLAP เชิงวิเคราะห์) แอปพลิเคชัน Python ของคุณจะต้องจัดการการเชื่อมต่อกับฐานข้อมูล 2 ฐานที่แตกต่างกันโดยสิ้นเชิง ซึ่งจะทำให้เกิดความหน่วงแฝงสูง ค่าใช้จ่ายด้านความปลอดภัย และการจัดการสถานะที่เปราะบาง
เราได้เปลี่ยน AlloyDB ให้เป็นเครื่องมือ HTAP ที่ทรงพลังด้วยการรวมคลังข้อมูล BigQuery เข้ากับ PostgreSQL โดยตรง สถาปัตยกรรม HTAP นี้ทำให้ AI Agent ของเราในปัจจุบันต้องสื่อสารกับอุปกรณ์ปลายทางฐานข้อมูลเพียงอุปกรณ์เดียว โดยสามารถแทรกธุรกรรมแบบเรียลไทม์ลงในตาราง live_orders และเรียกใช้การสแกนเชิงวิเคราะห์ที่ซับซ้อนกับชุดข้อมูล BigQuery froyo_data ที่รวมไว้ได้ในเวลาเดียวกันโดยไม่ทำซ้ำข้อมูลแม้แต่ไบต์เดียว มาดูกันว่าเราจะเปิดเผยเครื่องมือนี้ให้ AI ใช้งานได้อย่างไร
มาเริ่มสร้างกันเลย
สิ่งที่คุณจะได้เรียนรู้
- วิธีตั้งค่าคลัสเตอร์ อินสแตนซ์ และเครือข่าย AlloyDB เพียงคลิกปุ่ม
- วิธีตั้งค่าส่วนขยายเพื่อเตรียมพร้อมสำหรับการรวมศูนย์
- วิธีตั้งค่าการรวมจาก BigQuery ไปยัง AlloyDB
- ลองใช้
ข้อกำหนด
2. ก่อนเริ่มต้น
สร้างโปรเจ็กต์
- ใน คอนโซล Google Cloud ให้เลือกหรือสร้าง โปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธี ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้ว.
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและโปรเจ็กต์ตั้งค่าเป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากต้องการตรวจสอบสิทธิ์
gcloud auth login
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- เปิดใช้ API ที่จำเป็นโดยเรียกใช้คำสั่งนี้เพื่อเปิดใช้ API ที่จำเป็นทั้งหมด
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
ข้อควรระวังและการแก้ปัญหา
อาการ "โปรเจ็กต์ผี" | คุณเรียกใช้ |
อุปสรรคในการเรียกเก็บเงิน | คุณเปิดใช้โปรเจ็กต์แล้ว แต่ลืมบัญชีสำหรับการเรียกเก็บเงิน AlloyDB เป็นเครื่องมือที่มีประสิทธิภาพสูง ซึ่งจะไม่เริ่มทำงานหาก "ถังน้ำมัน" (การเรียกเก็บเงิน) ว่างเปล่า |
ความล่าช้าในการเผยแพร่ API | คุณคลิก "เปิดใช้ API" แต่บรรทัดคำสั่งยังคงแสดง |
ข้อจำกัดของโควต้า | หากใช้บัญชีทดลองใช้ใหม่ คุณอาจพบโควต้าของภูมิภาคสำหรับอินสแตนซ์ AlloyDB หาก |
3. การเตรียมข้อมูล
ตรวจสอบว่าข้อมูลที่มีโครงสร้างที่เราแยกออกมาจาก PDF ที่ไม่มีโครงสร้างพร้อมใช้งานใน BigQuery และการรวมข้อมูล BigQuery ของ AlloyDB ได้รับการสร้างและทดสอบแล้ว หากยังไม่ได้ทำตามขั้นตอนเหล่านั้น ตอนนี้เป็นเวลาที่เหมาะสมที่จะทำตามขั้นตอนง่ายๆ เหล่านั้นจาก ที่นี่ และ ที่นี่ สำหรับส่วนที่ 1 และ 2 ตามลำดับ
หมายเหตุ
หากคุณกำลังลองใช้ Codelab นี้ คุณไม่ควรเรียกใช้ขั้นตอนการล้างข้อมูลของส่วนที่ 2 (ขั้นตอนการลบคลัสเตอร์และอินสแตนซ์) เนื่องจากเราต้องใช้การจัดระเบียบ AlloyDB สำหรับระบบแบบเป็น Agent ที่แสดงไว้ที่นี่
นอกจากข้อมูลที่เราสร้างไว้แล้วในส่วนที่ 2 เรายังต้องสร้างตารางเพิ่มเติม 1 ตารางในอินสแตนซ์ AlloyDB ไปที่ AlloyDB Studio โดยใช้ลิงก์
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
เปลี่ยนชื่อคลัสเตอร์ในลิงก์ด้านบนหากคุณใช้คลัสเตอร์อื่น
ใน AlloyDB Studio ให้เรียกใช้คำสั่งต่อไปนี้ในแท็บ Query Editor ใหม่
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
คำสั่งนี้จะสร้างตาราง live_orders ในฐานข้อมูล
4. การกำหนดการแยกข้อมูล (tools.yaml)
ก่อนอื่น เราจะลงทะเบียนการดำเนินการฐานข้อมูลอย่างเป็นทางการ โดยสร้างไฟล์ tools.yaml ที่กำหนดวิธีที่ Agent โต้ตอบกับ AlloyDB ซึ่งมีทั้งข้อมูลเชิงธุรกรรมและข้อมูลเชิงวิเคราะห์ (ข้อมูลเชิงวิเคราะห์จากการรวม BigQuery)
- ไปที่เทอร์มินัล Cloud Shell เปลี่ยนเป็นโหมด Editor
- สร้างโฟลเดอร์ใหม่ในไดเรกทอรีรากชื่อ "froyo-agent"
- สร้างไฟล์ tools.yaml ภายในโฟลเดอร์ แล้ววางเนื้อหาต่อไปนี้ (แทนที่ด้วยค่าของคุณเองสำหรับโปรเจ็กต์ คลัสเตอร์ อินสแตนซ์ และรหัสผ่าน)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
เราได้จำกัดความสามารถของ Agent ไว้ที่ 2 เครื่องมือ ได้แก่ ตรวจสอบสารก่อภูมิแพ้และสั่งซื้อ
5. การติดตั้งใช้งาน Toolbox ใน Cloud Run
หากต้องการให้แอปพลิเคชันใช้งานได้ เราจะติดตั้งใช้งาน Toolbox อย่างปลอดภัยโดยใช้ gcloud CLI ซึ่งจะสร้างอุปกรณ์ปลายทางเลเยอร์แอบสแตรกชัน
- เปลี่ยนเป็นเทอร์มินัล Cloud Shell แล้วไปที่ไดเรกทอรีการทำงานโดยเรียกใช้คำสั่ง
cd froyo-agent
- บันทึก tools.yaml ในข้อมูลลับชื่อ "tools-froyo"
gcloud secrets create tools-froyo --data-file=tools.yaml
- ติดตั้งใช้งานคอนเทนเนอร์ MCP Toolbox ใน Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
คุณต้องแทนที่ค่า "network" และ "subnet" หากใช้ค่าที่แตกต่างจากที่เรากำหนดค่าไว้ใน Codelab ส่วนที่ 2
- จด URL ของ Cloud Run ที่ได้ (เช่น https://toolbox-froyo-xxx.run.app)
เราจะใช้อุปกรณ์ปลายทาง MCP Toolbox ที่ติดตั้งใช้งานนี้ในขั้นตอนการกำหนดค่า Agent
6. แบ็กเอนด์แบบเป็น Agent (app.py)
เมื่อแยกฐานข้อมูลออกไปแล้ว โค้ด Python ของเราจึงมุ่งเน้นไปที่การจัดระเบียบและการให้เหตุผลได้อย่างเต็มที่
เราใช้ Agent Development Kit (ADK) ร่วมกับ Flask ADK มีหน่วยความจำเซสชันระดับองค์กร (InMemorySessionService) ซึ่งหมายความว่า Agent ของเราจะจดจำบริบทของการสนทนาได้ และผสานรวมกับ ToolboxSyncClient ได้อย่างราบรื่นเพื่อดึงเครื่องมือของเราจาก Cloud Run ได้อย่างง่ายดาย
นี่คือ app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
แอป Python Flask อย่างง่ายจะเชื่อมต่อ Agent ADK กับเครื่องมือที่เรากำหนดไว้ใน Toolbox ซึ่งจะโต้ตอบกับ AlloyDB (และข้อมูลที่รวมจาก BigQuery ด้วย) และตอบกลับผู้ใช้
หากต้องการรับโปรเจ็กต์นี้ใน Cloud Shell Editor คุณสามารถโคลนที่เก็บสำหรับ Agent ได้โดยเรียกใช้คำสั่งต่อไปนี้จากเทอร์มินัล Cloud Shell
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
คุณควรเห็นโครงสร้างโปรเจ็กต์ต่อไปนี้
ขั้นตอนในการสัมผัสกับข้อมูลต่อไปโดยไม่มีบัญชีสำหรับการเรียกเก็บเงิน
- เราได้จัดเตรียมไฟล์ข้อมูลต่อไปนี้ไว้ในที่เก็บเพื่อความสะดวก
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
ไฟล์เหล่านี้ควรอยู่ในโฟลเดอร์เดียวกับ app.py
ข. ไฟล์ Python ชื่อ app-nobill.py ในเส้นทางเดียวกัน
- ในโฟลเดอร์รากของโปรเจ็กต์จะมีไฟล์ชื่อ app-nobill.py
- ไฟล์นี้ออกแบบมาเพื่อสร้างประสบการณ์การใช้งานแอปแบบเดียวกัน แต่ไม่จำเป็นต้องเชื่อมต่อกับแหล่งข้อมูลเหล่านี้อย่างชัดเจน เนื่องจากเราได้จัดเตรียมข้อมูลไว้ในไฟล์แล้ว
- ไฟล์อื่นๆ ทั้งหมดตามที่ระบุไว้ใน Lab ควรยังคงอยู่ครบถ้วนในเวอร์ชันนี้ด้วย (เพียงแค่ไม่ต้องเรียกใช้ไฟล์ app.py)
7. UI และการเรียกใช้แอป
เราได้สร้าง UI ที่สวยงามแบบ Glassmorphism (templates/index.html) พร้อมแถบด้านข้างแคตตาล็อกผลิตภัณฑ์แบบเรียลไทม์และอินเทอร์เฟซการแชทแบบโต้ตอบเพื่อให้ผู้จัดการร้านได้รับประสบการณ์การใช้งานที่เหมาะสม
คุณสามารถดูไฟล์ index.html ในไฟล์ที่เก็บได้ที่นี่
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
ก่อนเรียกใช้แอปพลิเคชัน โปรดตรวจสอบว่าคุณมีข้อมูลอ้างอิงในไฟล์ requirements.txt ที่มีเนื้อหาต่อไปนี้
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
และไฟล์ .env ที่มีข้อมูลต่อไปนี้
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
วิธีรับ GOOGLE_API_KEY
ทำตามวิธีการในบล็อกนี้เพื่อตั้งค่า Google API Key
วิธีรับ MCP_TOOLBOX_SERVER_URL
เราได้ตั้งค่านี้ไว้ในขั้นตอนก่อนหน้าใน Codelab นี้ และคุณได้คัดลอกอุปกรณ์ปลายทาง MCP Toolbox ที่ติดตั้งใช้งานแล้ว ใช้ลิงก์นั้นสำหรับตัวแปรสภาพแวดล้อม MCP_TOOLBOX_SERVER_URL
เรียกใช้แอปโดยทำดังนี้
จากเทอร์มินัล Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้ทีละรายการ โดยตรวจสอบว่าคุณอยู่ในโฟลเดอร์โปรเจ็กต์
ไปที่โฟลเดอร์รากของโปรเจ็กต์
cd froyo-data
ติดตั้งข้อมูลอ้างอิง
pip install -r requirements.txt
เรียกใช้ไฟล์ Python
python app.py
คลิกลิงก์ที่ปรากฏในเทอร์มินัลหรือเปิด http://localhost:8080!
8. การทดสอบขั้นสุดท้าย
มาคลิกผลิตภัณฑ์จากแคตตาล็อกเพื่อถาม Agent กัน
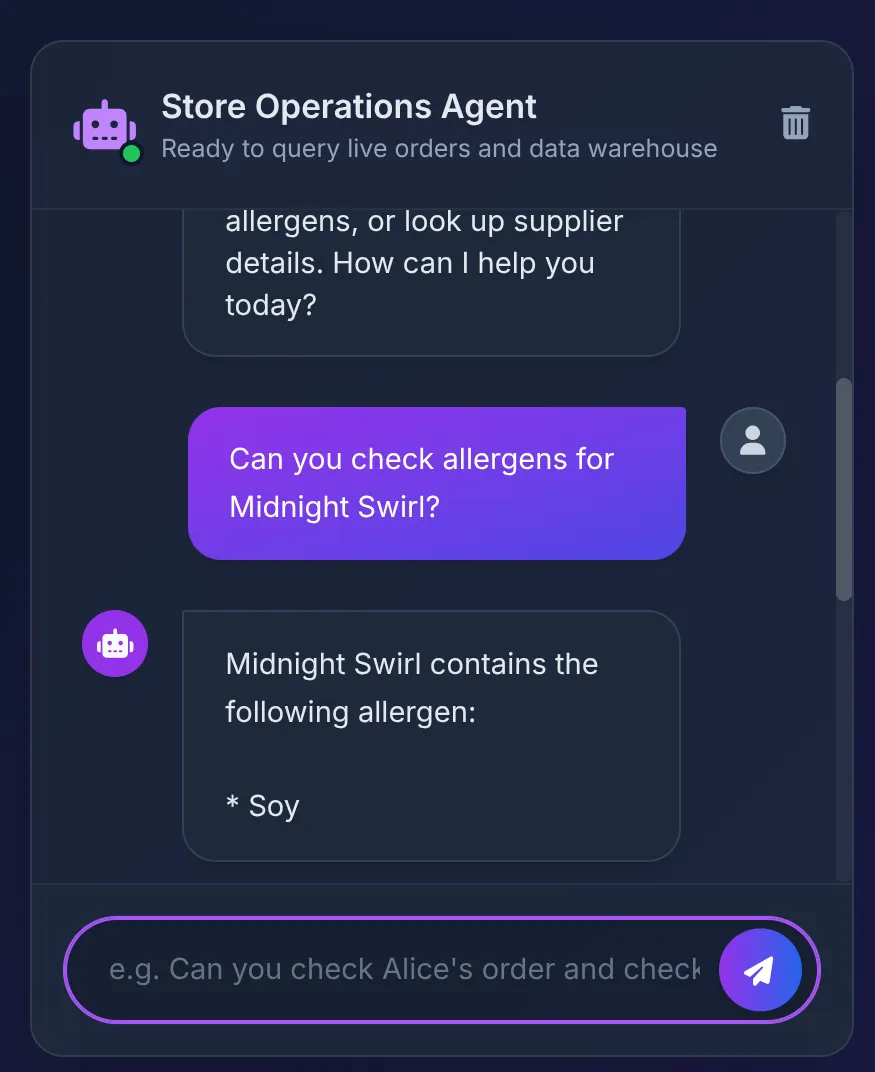
Does Midnight Swirl have any allergens?
คุณควรเห็นการตอบกลับต่อไปนี้
เบื้องหลัง:
- Agent ADK ได้รับข้อความแจ้งและตัดสินใจใช้เครื่องมือ check_allergens
- โดยจะเรียกใช้ MCP Toolbox ใน Cloud Run อย่างปลอดภัย
- Toolbox จะเรียกใช้การค้นหาใน AlloyDB ซึ่งจะรวมเข้ากับ BigQuery ทันทีเพื่อสแกนความสัมพันธ์ที่ซับซ้อนที่เราสร้างไว้ในส่วนที่ 1
- ฐานข้อมูลจะแสดงผล "ถั่วเหลือง" ซึ่ง Agent จะสรุปอย่างเรียบร้อยใน UI
จากนั้นเราจะพูดว่า
Order 2 Midnight Swirl for Alice.
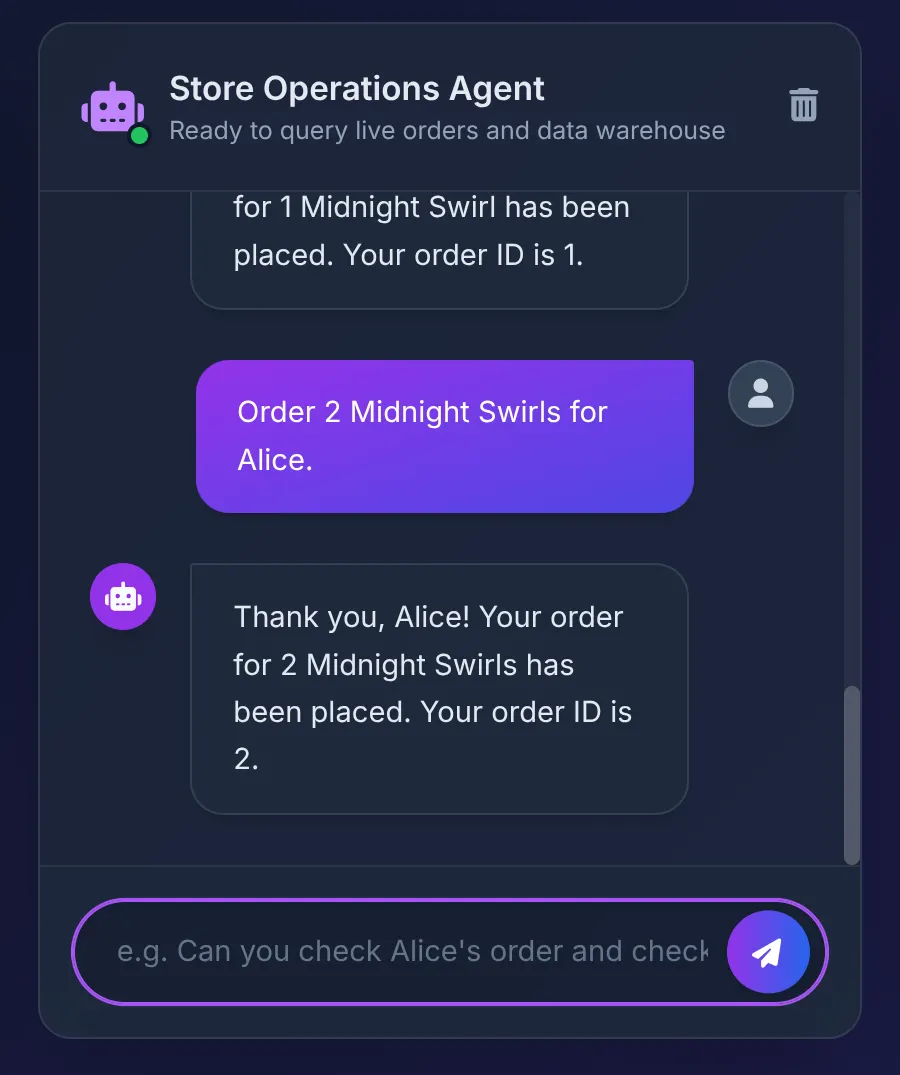
Agent จะส่งสตริง "Midnight Swirl" ไปยัง Toolbox SQL ที่อยู่เบื้องหลังจะแปลงสตริงเป็นรหัสจำนวนเต็มแบบไดนามิกผ่าน BigQuery แทรกคำสั่งซื้อแบบเรียลไทม์ลงใน AlloyDB และยืนยันธุรกรรม
ที่เก็บโค้ด
9. ล้างข้อมูล
เมื่อทำ Lab นี้เสร็จแล้ว อย่าลืมลบคลัสเตอร์และอินสแตนซ์ AlloyDB
ระบบควรล้างข้อมูลคลัสเตอร์พร้อมกับอินสแตนซ์
10. ขอแสดงความยินดีกับ Agent ของคุณ
ลองพิจารณาสิ่งที่เราเพิ่งทำสำเร็จ
ระบบแบบเป็น Agent ที่มีการจัดระเบียบอย่างดีของเราจะโต้ตอบกับ MCP Toolbox สำหรับฐานข้อมูลเท่านั้น ซึ่งจะจัดการการเรียกใช้เครื่องมือและตรรกะข้อมูลไปยัง AI ของแอปพลิเคชันของเราในเบื้องหลัง ทำให้ขั้นตอนการทำงานง่ายขึ้น ดังนี้
- แอปเชิงธุรกรรมของเรา (ที่ทำงานใน AlloyDB) สามารถจัดการเซสชันของผู้ใช้พร้อมกันจำนวนมากได้อย่างรวดเร็ว
- เมื่อต้องการข้อมูลเชิงวิเคราะห์จำนวนมากหรือบริบทในอดีต (เช่น รายละเอียดซัพพลายเออร์หรือการจับคู่ส่วนผสมที่ซับซ้อน) แอปจะค้นหา froyo_dataschema ของ BigQuery
- ไม่มี ETL ไม่มีไปป์ไลน์ข้อมูลหยุดทำงาน ไม่มีฐานข้อมูลที่ไม่ซิงค์ เราจัดเก็บข้อมูลเพียงครั้งเดียว (ใน BQ) และประมวลผลเมื่อต้องการ
เมื่อ Agent และรากฐานข้อมูลของเราทั้งเชิงวิเคราะห์และเชิงธุรกรรมเสร็จสมบูรณ์แล้ว เราจะไปยังส่วนถัดไป
ขั้นตอนถัดไป
Agent ของเราทำงานได้อย่างสมบูรณ์แบบ... ในกรณีที่ไม่มีปัญหา ในส่วนที่ 4 เราจะสร้างไปป์ไลน์การประเมิน Agent เพื่อทดสอบความถูกต้อง ความน่าเชื่อถือ และประสิทธิภาพของระบบแบบเป็น Agent อย่างเข้มงวด แล้วเจอกัน