
1. 概览
在 第 1 部分 中,我们使用 Knowledge Catalog 和 DataScan 成功地将杂乱无章的非结构化 PDF 转换为 BigQuery 中干净、智能且结构化的表格。现在,我们拥有一个强大的数据仓库。在 第 2 部分 中,我们将 AlloyDB 设置为事务型主干,并将 BigQuery 表联合到其中,从而创建一个统一的数据层,而无需复制任何字节。
今天,我们来构建大脑。我们将创建一个多智能体应用“FroyoOS Store Manager”,该应用位于此数据层之上,用于回答问题、检查过敏原和处理实时订单。
挑战:将 AI 与智能体分离
在构建需要与数据库对话的 AI 智能体时,最常见的反模式是将数据和 AI 逻辑直接强制添加到 Python 应用中。随着数据架构的增长,这会使应用变得脆弱、不安全且难以维护。
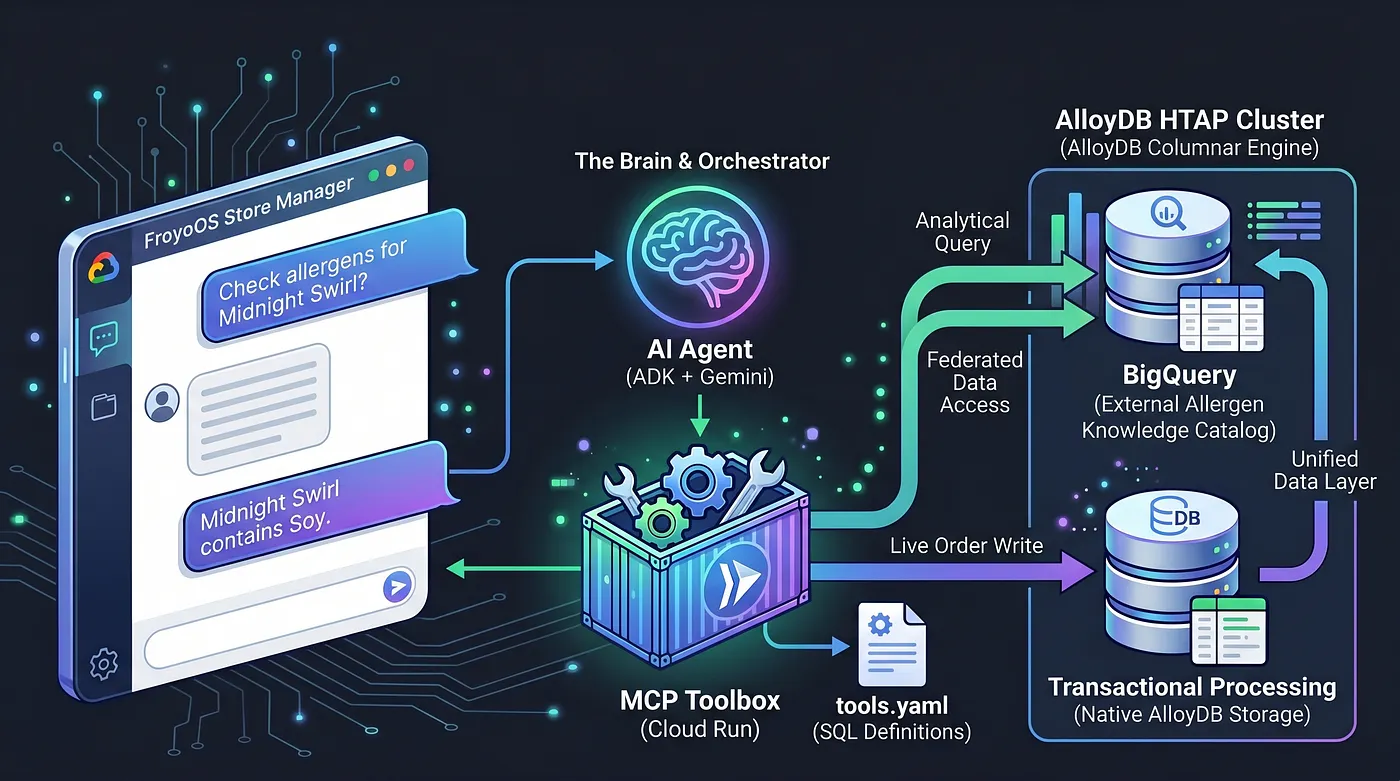
为了解决这个问题,我们使用了 Model Context Protocol (MCP) 工具箱。MCP 工具箱充当我们的统一数据抽象层。我们在一个简单的 tools.yaml 文件中以声明方式定义数据库操作。我们将此工具箱部署为 Google Cloud Run 上的安全无服务器端点。我们的 AI 智能体只需连接到此端点,然后说“执行‘place_order’工具”。
HTAP 的强大功能
在开始构建智能体之前,我们先来讨论一下为什么这篇文章的标题专门提到了 HTAP(混合事务/分析处理)。
在传统架构中,如果 AI 智能体需要处理实时用户订单(事务型 OLTP 工作负载)并交叉对比数千个复杂的配料映射(分析型 OLAP 工作负载),则 Python 应用必须同时处理与两个完全不同的数据库的连接。这会导致严重的延迟、安全开销和脆弱的状态管理。
我们将 BigQuery 数据仓库原生联合到 PostgreSQL 中,从而将 AlloyDB 变成了 HTAP 强力引擎。由于这种 HTAP 架构,我们的 AI 智能体现在只需要与一个数据库端点对话。它可以将实时事务插入到 live_orders 表中,并对联合的 BigQuery froyo_data 数据集运行繁重的分析扫描,而无需复制任何字节的数据。我们来看看如何将此引擎公开给 AI。
我们来开始构建吧!
学习内容
- 如何一键设置 AlloyDB 集群、实例和网络
- 如何设置扩展程序以准备进行联合
- 如何从 BigQuery 设置到 AlloyDB 的联合
- 开始测试
要求
2. 准备工作
创建项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何 检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的激活 Cloud Shell 。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果您想进行身份验证
gcloud auth login
- 如果项目未设置,请使用以下命令进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID>
gcloud config set project <YOUR_PROJECT_ID>
- 启用必需的 API:运行此命令以启用所有必需的 API:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
注意事项和问题排查
“幽灵项目” 综合征 | 您运行了 |
结算 障碍 | 您启用了项目,但忘记了结算账号。AlloyDB 是一种高性能引擎;如果“油箱”(结算)为空,它将无法启动。 |
API 传播 延迟 | 您点击了“启用 API”,但命令行仍然显示 |
配额 陷阱 | 如果您使用的是全新的试用账号,则可能会达到 AlloyDB 实例的区域配额。如果 |
3. 准备数据
确保从非结构化 PDF 中提取的结构化数据在 BigQuery 中可用,并且 BigQuery 数据的 AlloyDB 联合也已建立并经过测试。如果您尚未完成这些步骤,现在可以前往 此处 和 此处 分别完成第 1 部分和第 2 部分中的简单步骤。
注意:
如果您要尝试此 Codelab,则不应执行第 2 部分的清理步骤(删除集群和实例步骤),因为我们需要 AlloyDB 编排来演示此处的智能体系统。
除了我们在第 2 部分中已创建的数据之外,我们还需要在 AlloyDB 实例中创建一个额外的表。使用以下链接前往 AlloyDB Studio:
https://console.cloud.google.com/alloydb/locations/us-central1/clusters/my-alloydb-cluster/studio
如果您使用的是其他集群,请更改上述链接中的集群名称。
在 AlloyDB Studio 的新查询编辑器标签页中,运行以下语句:
CREATE TABLE live_orders (
order_id SERIAL PRIMARY KEY,
customer_name VARCHAR(100),
product_id VARCHAR(100),
quantity INT,
order_status VARCHAR(50) DEFAULT 'Pending',
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
这应该会在您的数据库中创建 live_orders 表。
4. 定义抽象(tools.yaml)
首先,我们正式注册数据库操作。我们创建一个 tools.yaml 文件,用于定义智能体如何与同时包含事务型数据和分析型数据(来自 BigQuery 联合的分析型数据)的 AlloyDB 进行交互。
- 前往 Cloud Shell 终端 。切换到编辑器模式。
- 在根目录中创建一个新文件夹:"froyo-agent"
- 在该文件夹中,创建一个 tools.yaml 文件并粘贴以下内容:(将项目、集群、实例和密码替换为您自己的值)
# tools.yaml
sources:
alloydb-source:
kind: "alloydb-postgres"
project: "*******"
region: "us-central1"
cluster: "my-alloydb-cluster"
instance: "my-primary-inst"
database: "postgres"
user: "postgres"
password: "*******"
ipType: "private"
tools:
check_allergens:
kind: postgres-sql
source: alloydb-source
description: Queries the federated BigQuery tables to find allergens for a product.
statement: |
SELECT a.allergen_name
FROM consistsof c
INNER JOIN product p ON c.product_id = p.product_id
INNER JOIN ingredient i ON c.ingredient_id = i.ingredient_name
INNER JOIN containsallergen a ON i.ingredient_id = a.ingredient_id
WHERE UPPER(p.product_name) LIKE UPPER($1)
parameters:
- name: product_name
type: string
description: The name of the product to check. (e.g., '%Midnight%')
place_order:
kind: postgres-sql
source: alloydb-source
description: Inserts a new live transaction into the native AlloyDB orders table.
statement: |
INSERT INTO live_orders (customer_name, product_id, quantity)
VALUES ($1, (SELECT product_id FROM product WHERE product_name ILIKE '%' || $2 || '%' LIMIT 1), $3) RETURNING order_id;
parameters:
- name: customer_name
type: string
description: The name of the customer placing the order.
- name: product_name
type: string
description: The name of the product being ordered.
- name: quantity
type: integer
description: The quantity of the product being ordered.
toolsets:
alloydb_tools:
- check_allergens
- place_order
我们将智能体的功能限制为 2 个工具:检查过敏原和下单。
5. 将 Toolbox 部署到 Cloud Run
为了让我们的应用可以使用此工具箱,我们使用 gcloud CLI 安全地部署该工具箱。这将创建我们的抽象层端点。
- 切换到 Cloud Shell 终端,然后运行以下命令进入工作目录:
cd froyo-agent
- 将 tools.yaml 保存到名为“tools-froyo”的 Secret 中:
gcloud secrets create tools-froyo --data-file=tools.yaml
- 将 MCP Toolbox 容器部署到 Cloud Run
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest
gcloud run deploy toolbox-froyo \
--image $IMAGE \
--service-account toolbox-identity \
--region us-central1 \
--set-secrets "/app/tools.yaml=tools-froyo:latest" \
--args="--config=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--network easy-alloydb-vpc \
--subnet easy-alloydb-subnet \
--allow-unauthenticated \
--vpc-egress private-ranges-only
如果您使用的“网络”和“子网”值与我们在第 2 部分 Codelab 中配置的值不同,则需要替换这些值。
- 记下生成的 Cloud Run 网址(例如 https://toolbox-froyo-xxx.run.app)。
我们将在智能体配置步骤中使用此已部署的 MCP Toolbox 端点。
6. 智能体后端 (app.py)
由于数据库已抽象化,我们的 Python 代码可以完全专注于编排和推理。
我们同时使用了 智能体开发套件 (ADK) 和 Flask。ADK 提供企业级会话内存 (InMemorySessionService),这意味着我们的智能体可以记住对话的上下文。它与 ToolboxSyncClient 原生集成,可从 Cloud Run 无缝提取我们的工具。
这是您的 app.py:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/app.py
简单的 Python Flask 应用将 ADK 智能体连接到我们在 Toolbox 中定义的工具,这些工具反过来与 AlloyDB(以及 BigQuery 联合数据)进行交互并响应用户。
如需在 Cloud Shell Editor 中获取此项目,您可以从 Cloud Shell 终端运行以下命令来克隆智能体的代码库:
cd
git clone https://github.com/AbiramiSukumaran/froyo-data
您应该会看到以下项目结构:
在没有结算账号的情况下继续体验数据的步骤:
- 为了方便起见,代码库中提供了以下数据文件:
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.allergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.consistsof.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.containsallergen.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.froyo_data_materialized.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.ingredient.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.product.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.suppliedby.csv
- https://github.com/AbiramiSukumaran/froyo-data/blob/main/froyo_data.supplier.csv
这些文件应与 app.py 位于同一文件夹中。
B. 位于同一路径下的名为 app-nobill.py 的 Python 文件
- 在项目根文件夹中,有一个名为 app-nobill.py 的文件
- 此文件旨在创建相同的应用体验,但无需显式连接到这些数据源,因为数据已在文件中提供。
- 实验中提到的所有其他文件也应在此版本中保持不变(只需无需执行 app.py 文件)
7. 界面和运行应用
为了给我们的 Store Manager 提供适当的体验,我们创建了一个时尚的玻璃拟态界面 (templates/index.html),其中包含实时产品目录边栏和交互式聊天界面。
您可以在此处找到代码库文件中的 index.html:
https://github.com/AbiramiSukumaran/froyo-data/blob/main/templates/index.html
在运行应用之前,请确保 requirements.txt 文件中包含以下内容的依赖项:
Flask>=3.0.0
google-genai>=0.1.0
mcp>=1.0.0
google-adk
toolbox-core
toolbox-langchain
python-dotenv
并填充 .env 文件:
GOOGLE_API_KEY=***
MCP_TOOLBOX_SERVER_URL=***
如何获取 GOOGLE_API_KEY?
按照此博客中的说明设置 Google API 密钥。
如何获取 MCP_TOOLBOX_SERVER_网址?
我们在本 Codelab 的上一步中设置了此网址,您复制了已部署的 MCP Toolbox 端点。将该链接用于 MCP_TOOLBOX_SERVER_网址 环境变量。
运行应用:
在 Cloud Shell 终端中,确保您位于项目文件夹中,然后依次运行以下命令:
进入项目根文件夹:
cd froyo-data
安装依赖项:
pip install -r requirements.txt
执行 Python 文件:
python app.py
点击终端中显示的链接,或打开 http://localhost:8080!
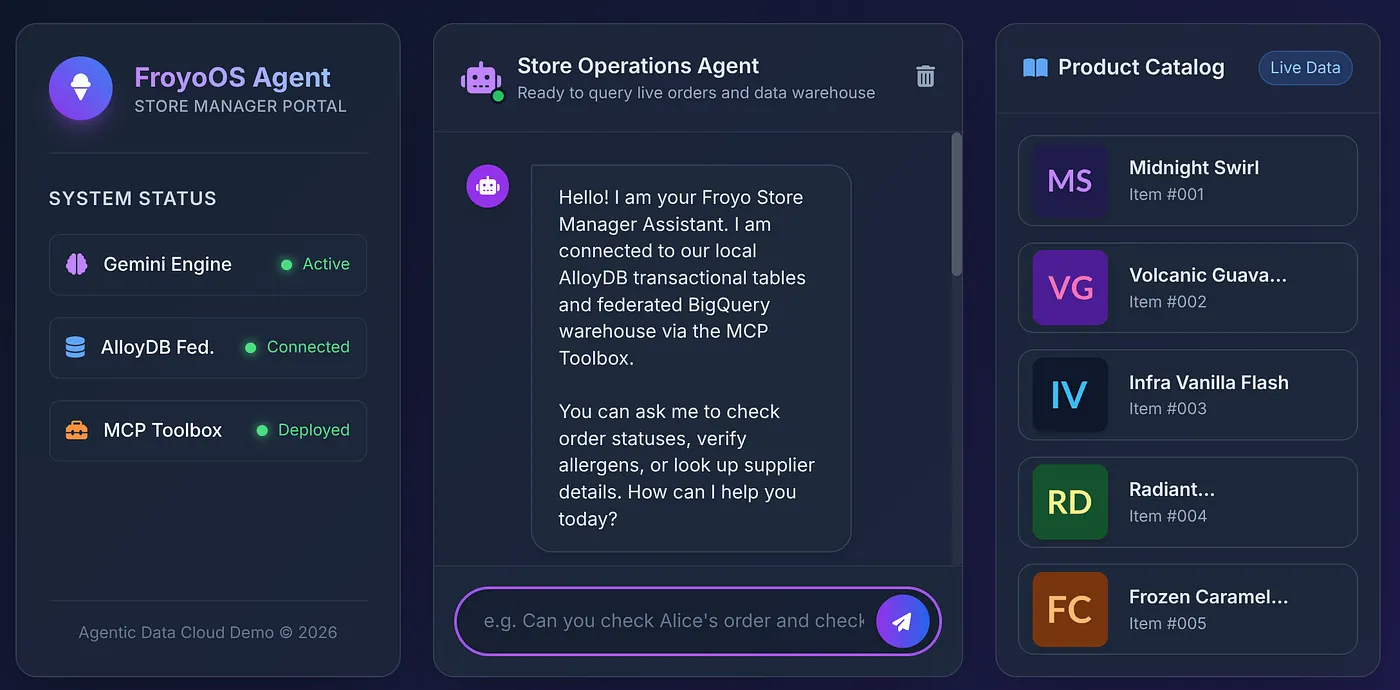
8. 终极测试
我们点击目录中的产品,向智能体提问:
Does Midnight Swirl have any allergens?
您应该会看到以下响应:
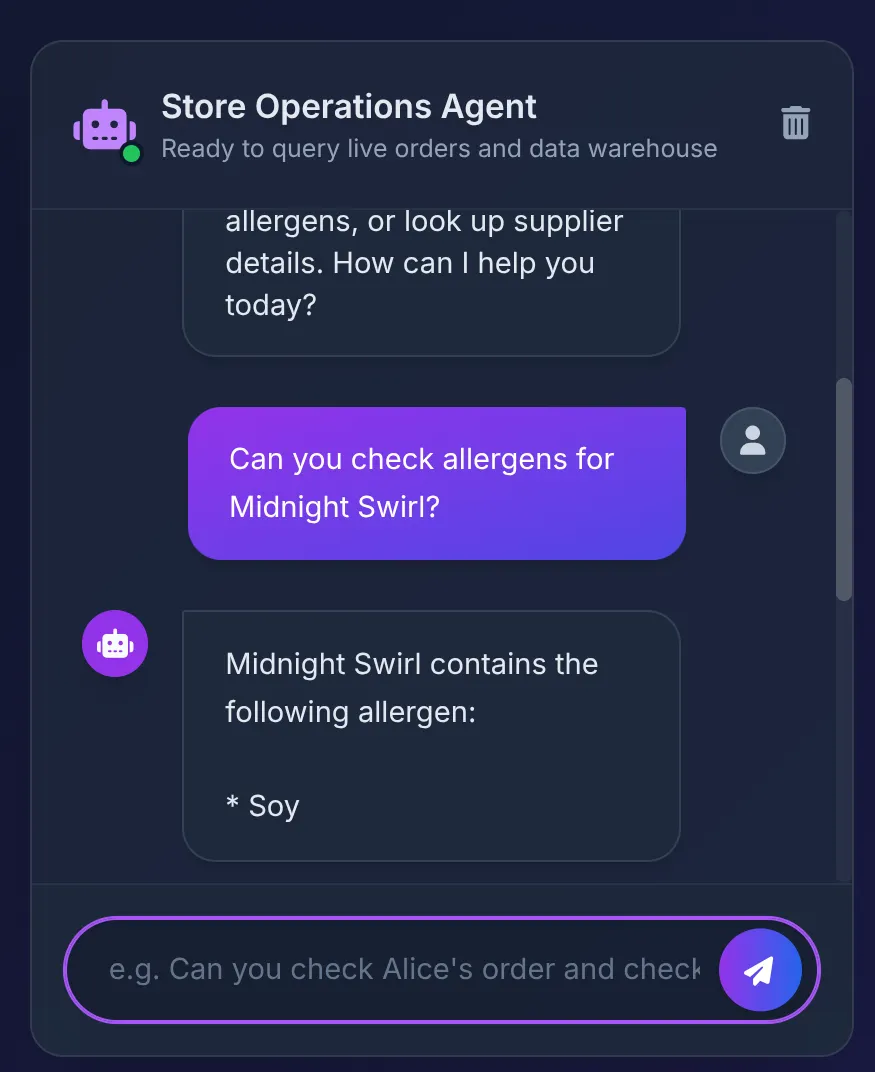
幕后故事:
- ADK 智能体收到提示,并决定使用 check_allergens 工具。
- 它安全地调用 Cloud Run 上的 MCP Toolbox。
- Toolbox 在 AlloyDB 中执行查询,AlloyDB 会立即联合到 BigQuery,以扫描我们在第 1 部分中构建的复杂关系。
- 数据库返回“Soy”,智能体会在界面中简洁地汇总该信息。
接下来,我们说:
Order 2 Midnight Swirl for Alice.
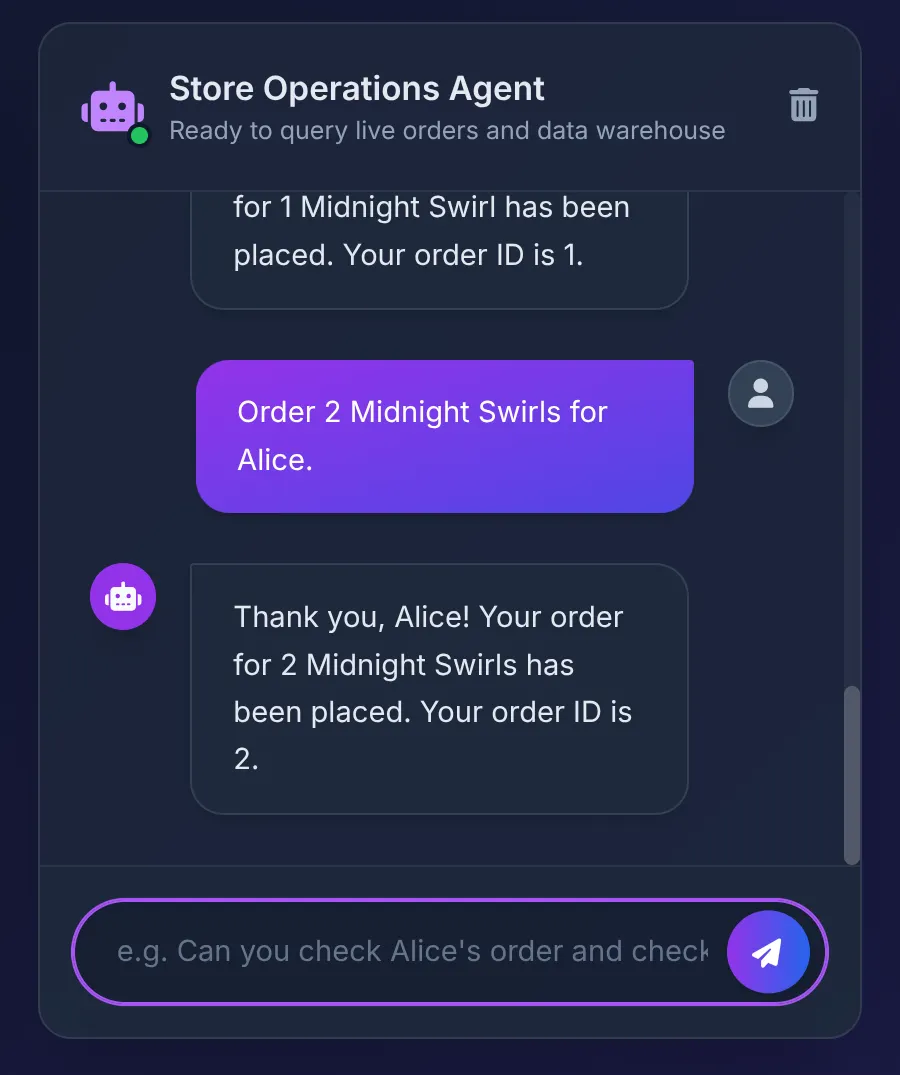
智能体将字符串“Midnight Swirl”传递给 Toolbox。底层 SQL 通过 BigQuery 将字符串动态解析为整数 ID,将实时订单插入到 AlloyDB 中,并确认事务。
代码库
9. 清理
完成此实验后,请不要忘记删除 AlloyDB 集群和实例。
它应该会清理集群及其实例。
10. 恭喜您拥有了自己的智能体!
想想我们刚刚完成了什么:
我们精心编排的智能体系统仅与 MCP Toolbox for Databases 进行交互。幕后处理工具调用和应用的数据到 AI 逻辑,保持流程简单:
- 我们的事务型应用(在 AlloyDB 上运行)可以处理快速、并发的用户会话。
- 当它需要繁重的分析数据或历史上下文(例如供应商详细信息或复杂的配料映射)时,它会查询 BigQuery froyo_dataschema。
- 零 ETL。没有数据流水线中断。没有不同步的数据库。我们存储一次(在 BQ 中),并在需要时进行计算。
现在,我们的智能体和数据基础(包括分析型和事务型)都已完成,接下来我们进入下一部分。
后续还有哪些变化?
我们的智能体在正常路径上运行良好。在 第 4 部分 中,我们将构建一个智能体评估流水线,以严格测试智能体系统的有效性、基础性和性能。期待您的到来!