
1. מבוא

העדכון האחרון: 28 בפברואר 2020
ב-codelab הזה מוצג דפוס של הטמעת נתונים להטמעה של נתונים בתחום הבריאות בפורמט CSV ב-BigQuery בכמות גדולה. בשיעור ה-Lab הזה נשתמש בפייפליין נתונים באצווה של Cloud Data Fusion. נתוני בדיקה ריאליסטיים של שירותי בריאות נוצרו והועמדו לרשותכם בקטגוריה של Cloud Storage (gs://hcls_testing_data_fhir_10_patients/csv/).
בשיעור ה-Lab הזה תלמדו:
- איך להטמיע נתוני CSV (טעינה מתוזמנת באצווה) מ-GCS ל-BigQuery באמצעות Cloud Data Fusion.
- איך ליצור באופן ויזואלי צינור לשילוב נתונים ב-Cloud Data Fusion כדי לטעון, לשנות ולהסתיר נתונים רפואיים בכמות גדולה.
מה צריך כדי להריץ את ה-Codelab הזה?
- צריכה להיות לכם גישה לפרויקט GCP.
- צריכה להיות לכם הרשאת 'בעלים' בפרויקט GCP.
- נתוני בריאות בפורמט CSV, כולל הכותרת.
אם אין לכם פרויקט GCP, אתם יכולים לפעול לפי השלבים האלה כדי ליצור פרויקט GCP חדש.
נתוני בריאות בפורמט CSV נטענו מראש לקטגוריית GCS בכתובת gs://hcls_testing_data_fhir_10_patients/csv/. לכל קובץ CSV של משאב יש מבנה סכמה ייחודי. לדוגמה, ל-Patients.csv יש סכימה שונה מזו של Providers.csv. אפשר למצוא קובצי סכימה שנטענו מראש בכתובת gs://hcls_testing_data_fhir_10_patients/csv_schemas.
אם אתם צריכים מערך נתונים חדש, תמיד תוכלו ליצור אותו באמצעות SyntheaTM. לאחר מכן, מעלים אותו ל-GCS במקום להעתיק אותו מהמאגר בשלב 'העתקת נתוני קלט'.
2. הגדרת פרויקט GCP
מאתחלים משתני מעטפת עבור הסביבה.
כדי למצוא את PROJECT_ID, אפשר לעיין במאמר בנושא זיהוי פרויקטים.
<!-- CODELAB: Initialize shell variables -> <!-- Your current GCP Project ID -> export PROJECT_ID=<PROJECT_ID> <!-- A new GCS Bucket in your current Project - INPUT -> export BUCKET_NAME=<BUCKET_NAME> <!-- A new BQ Dataset ID - OUTPUT -> export DATASET_ID=<DATASET_ID>
יוצרים קטגוריה ב-GCS לאחסון נתוני הקלט ויומני השגיאות באמצעות הכלי gsutil.
gsutil mb -l us gs://$BUCKET_NAME
קבלת גישה למערך הנתונים הסינתטי
- מכתובת האימייל שבה אתם משתמשים כדי להיכנס למסוף Cloud, שולחים אימייל אל hcls-solutions-external+subscribe@google.com ומבקשים להצטרף.
- תקבלו אימייל עם הוראות לאישור הפעולה.

- משתמשים באפשרות להשיב לאימייל כדי להצטרף לקבוצה. אל תלחצו על הלחצן.
- אחרי שתקבלו את אישור ההרשמה באימייל, תוכלו להמשיך לשלב הבא ב-codelab.
העתקת נתוני הקלט.
gsutil -m cp -r gs://hcls_testing_data_fhir_10_patients/csv gs://$BUCKET_NAME
יוצרים מערך נתונים ב-BigQuery.
bq mk --location=us --dataset $PROJECT_ID:$DATASET_ID
3. הגדרת סביבת Cloud Data Fusion
כדי להפעיל את Cloud Data Fusion API ולהעניק את ההרשאות הנדרשות:
מפעילים את ממשקי ה-API.
- עוברים אל GCP Console API Library.
- ברשימת הפרויקטים, בוחרים את הפרויקט הרצוי.
- ב-API Library, בוחרים את ה-API שרוצים להפעיל. אם אתם צריכים עזרה באיתור ה-API, אתם יכולים להשתמש בשדה החיפוש או במסננים.
- בדף ה-API, לוחצים על ENABLE (הפעלה).
יוצרים מכונת Cloud Data Fusion.
- ב-GCP Console, בוחרים את ProjectID.
- בוחרים באפשרות Data Fusion מהתפריט הימני, ואז לוחצים על הלחצן CREATE AN INSTANCE (יצירת מופע) באמצע הדף (יצירה ראשונה), או לוחצים על הלחצן CREATE INSTANCE (יצירת מופע) בתפריט העליון (יצירה נוספת).


- מזינים את שם המכונה. בוחרים באפשרות Enterprise.

- לוחצים על הלחצן CREATE (יצירה).
הגדרת הרשאות למופע.
אחרי שיוצרים מופע, מבצעים את השלבים הבאים כדי לתת לחשבון השירות שמשויך למופע הרשאות בפרויקט:
- כדי לעבור לדף הפרטים של המכונה, לוחצים על שם המכונה.

- מעתיקים את חשבון השירות.
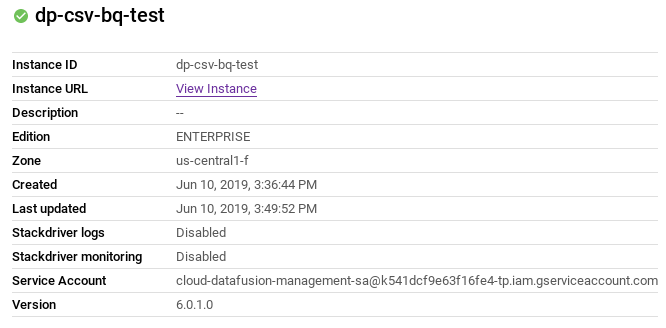
- עוברים לדף IAM של הפרויקט.
- בדף ההרשאות של IAM, מוסיפים את חשבון השירות כחבר חדש ומעניקים לו את התפקיד Cloud Data Fusion API Service Agent. לוחצים על הלחצן Add, מדביקים את 'חשבון השירות' בשדה New members ובוחרים באפשרות Service Management -> Cloud Data Fusion API Server Agent role.

- לוחצים על שמירה.
אחרי שמבצעים את השלבים האלה, אפשר להתחיל להשתמש ב-Cloud Data Fusion. לשם כך, לוחצים על הקישור View Instance (הצגת המכונה) בדף המכונות של Cloud Data Fusion או בדף הפרטים של מכונה.
מגדירים את הכלל בחומת האש.
- עוברים אל מסוף GCP -> VPC Network -> Firewall rules כדי לבדוק אם הכלל default-allow-ssh קיים או לא.

- אם לא, מוסיפים כלל חומת אש שמאפשר את כל תעבורת הנתונים הנכנסת של SSH לרשת שמוגדרת כברירת מחדל.
באמצעות שורת הפקודה:
gcloud beta compute --project={PROJECT_ID} firewall-rules create default-allow-ssh --direction=INGRESS --priority=1000 --network=default --action=ALLOW --rules=tcp:22 --source-ranges=0.0.0.0/0 --enable-logging
באמצעות ממשק המשתמש: לוחצים על Create Firewall Rule (יצירת כלל של חומת אש) וממלאים את הפרטים:


4. יצירת סכימה לטרנספורמציה
עכשיו, אחרי שיש לנו את סביבת Cloud Fusion ב-GCP, נבנה סכימה. אנחנו צריכים את הסכימה הזו כדי לבצע טרנספורמציה של נתוני ה-CSV.
- בחלון Cloud Data Fusion, לוחצים על הקישור 'הצגת המופע' בעמודה 'פעולה'. המערכת תפנה אתכם לדף אחר. לוחצים על כתובת ה-URL שמופיעה כדי לפתוח את המכונה של Cloud Data Fusion. הבחירה שלכם אם ללחוץ על הלחצן 'התחלת סיור' או על הלחצן 'לא, תודה' בחלון הקופץ של הודעת הפתיחה.
- מרחיבים את תפריט ההמבורגר, בוחרים באפשרות Pipeline (צינור) -> Studio (סטודיו).

- בקטע Transform (טרנספורמציה) בפלטת התוספים בצד ימין, לוחצים פעמיים על הצומת Wrangler שיופיע בממשק המשתמש של Data Pipelines.

- מציבים את הסמן מעל צומת ה-Wrangler ולוחצים על Properties (מאפיינים). לוחצים על הלחצן Wrangle ואז בוחרים קובץ מקור מסוג .csv (לדוגמה, patients.csv). בקובץ הזה צריכים להיות כל שדות הנתונים כדי ליצור את הסכימה הרצויה.
- לוחצים על החץ למטה (המרות של עמודות) לצד כל שם עמודה (לדוגמה, body).

- כברירת מחדל, הייבוא הראשוני יניח שיש רק עמודה אחת בקובץ הנתונים. כדי לנתח אותו כקובץ CSV, בוחרים באפשרות ניתוח → CSV, ואז בוחרים את התו להפרדה ומסמנים את התיבה 'הגדרת השורה הראשונה ככותרת' לפי הצורך. לוחצים על הלחצן 'אישור'.
- לוחצים על החץ למטה לצד השדה 'גוף' ובוחרים באפשרות 'מחיקת העמודה' כדי להסיר את השדה 'גוף'. בנוסף, אפשר לנסות טרנספורמציות אחרות, כמו הסרת עמודות, שינוי סוג הנתונים של חלק מהעמודות (ברירת המחדל היא סוג 'מחרוזת'), פיצול עמודות, הגדרת שמות עמודות וכו'.

- בכרטיסיות 'עמודות' ו'שלבי טרנספורמציה' מוצגים סכימת הפלט והמתכון של Wrangler. לוחצים על אישור בפינה השמאלית העליונה. לוחצים על הלחצן 'אימות'. ההודעה הירוקה 'לא נמצאו שגיאות' מציינת שהפעולה הצליחה.

- ב-Wrangler Properties, לוחצים על התפריט הנפתח Actions כדי Export את הסכימה הרצויה לאחסון המקומי לשימוש עתידי בImport אם צריך.
- שומרים את המתכון של Wrangler לשימוש עתידי.
parse-as-csv :body ',' true drop body
- כדי לסגור את החלון Wrangler Properties (מאפייני Wrangler), לוחצים על הלחצן X.
5. פיתוח צמתים לצינור עיבוד הנתונים
בקטע הזה ניצור את רכיבי צינור העיבוד.
- בממשק המשתמש של Data Pipelines, בפינה הימנית העליונה, אמורה להופיע האפשרות Data Pipeline - Batch (צינור נתונים – אצווה) כסוג צינור הנתונים שנבחר.

- בחלונית הימנית יש קטעים שונים כמו Filter (מסנן), Source (מקור), Transform (שינוי), Analytics (ניתוח), Sink (יעד), Conditions and Actions (תנאים ופעולות), Error Handlers (טיפול בשגיאות) ו-Alerts (התראות), שבהם אפשר לבחור צומת או צמתים לצינור.

צומת מקור
- בוחרים את צומת המקור.
- בקטע Source (מקור) בלוח התוספים שמימין, לוחצים לחיצה כפולה על הצומת Google Cloud Storage שמופיע בממשק המשתמש של Data Pipelines.
- מעבירים את העכבר מעל צומת המקור של GCS ולוחצים על מאפיינים.

- מזינים את הפרטים בשדות הדרושים. מגדירים את השדות הבאים:
- Label = {any text}
- שם הפניה = {כל טקסט}
- Project ID = זיהוי אוטומטי
- Path = כתובת GCS URL לדלי בפרויקט הנוכחי. לדוגמה, gs://$BUCKET_NAME/csv/
- Format = text
- Path Field = filename
- Path Filename Only = true
- Read Files Recursively = true
- מוסיפים את השדה filename (שם הקובץ) לסכימת הפלט של GCS על ידי לחיצה על הלחצן +.
- לחיצה על Documentation תציג הסבר מפורט. לוחצים על הלחצן 'אימות'. ההודעה הירוקה 'לא נמצאו שגיאות' מציינת שהפעולה הצליחה.
- כדי לסגור את המאפיינים של GCS, לוחצים על הלחצן X.
צומת של טרנספורמציה
- בוחרים את צומת הטרנספורמציה.
- בקטע Transform (טרנספורמציה) בפלטת התוספים בצד ימין, לוחצים פעמיים על הצומת Wrangler שמופיע בממשק המשתמש של Data Pipelines (צינורות נתונים). מחברים את צומת המקור GCS לצומת ההמרה Wrangler.
- מציבים את הסמן מעל צומת ה-Wrangler ולוחצים על Properties (מאפיינים).
- לוחצים על התפריט הנפתח פעולות ובוחרים באפשרות ייבוא כדי לייבא סכימה שמורה (לדוגמה: gs://hcls_testing_data_fhir_10_patients/csv_schemas/ schema (Patients).json), ומדביקים את המתכון השמור מהקטע הקודם.
- אפשר גם להשתמש מחדש בצומת Wrangler מהקטע יצירת סכימה לטרנספורמציה.
- מזינים את הפרטים בשדות הדרושים. מגדירים את השדות הבאים:
- Label = {any text}
- שם השדה להזנת קלט = {*}
- Precondition = {filename != "patients.csv"} כדי להבחין בין כל קובץ קלט (לדוגמה, patients.csv, providers.csv, allergies.csv וכו') לבין צומת המקור.

- מוסיפים צומת JavaScript כדי להריץ את ה-JavaScript שהמשתמש סיפק, שמשנה עוד יותר את הרשומות. ב-codelab הזה, אנחנו משתמשים בצומת JavaScript כדי לקבל חותמת זמן לכל עדכון של רשומה. מחברים את צומת ההמרה של Wrangler לצומת ההמרה של JavaScript. פותחים את Properties (מאפיינים) של JavaScript ומוסיפים את הפונקציה הבאה:

function transform(input, emitter, context) {
input.TIMESTAMP = (new Date()).getTime()*1000;
emitter.emit(input);
}
- לוחצים על הסמל + כדי להוסיף את השדה TIMESTAMP לסכימת הפלט (אם הוא לא קיים). בוחרים את חותמת הזמן כסוג הנתונים.

- לקבלת הסבר מפורט, לוחצים על Documentation (מסמכים). לוחצים על הלחצן 'אימות' כדי לאמת את כל פרטי הקלט. ההודעה הירוקה 'לא נמצאו שגיאות' מציינת שהפעולה הצליחה.
- כדי לסגור את החלון 'מאפייני שינוי הצורה', לוחצים על הלחצן X.
אנונימיזציה והסרת פרטי הזיהוי מהנתונים
- אפשר לבחור עמודות נתונים ספציפיות על ידי לחיצה על החץ למטה בעמודה והחלת כללי מיסוך בהתאם לדרישות (לדוגמה, עמודת מספר הביטוח הלאומי).

- אפשר להוסיף עוד הוראות בחלון Recipe של הצומת Wrangler. לדוגמה, כדי להסיר את הפרטים המזהים, משתמשים בהנחיית הגיבוב עם אלגוריתם הגיבוב לפי התחביר הבא:
hash <column> <algorithm> <encode> <column>: name of the column <algorithm>: Hashing algorithm (i.e. MD5, SHA-1, etc.) <encode>: default is true (hashed digest is encoded as hex with left-padding zeros). To disable hex encoding, set <encode> to false.

צומת יעד
- בוחרים את צומת היעד.
- בקטע Sink בפלטת התוספים בצד ימין, לוחצים פעמיים על הצומת BigQuery שיופיע בממשק המשתמש של Data Pipeline.
- מציבים את הסמן מעל צומת היעד של BigQuery ולוחצים על Properties (מאפיינים).

- ממלאים את שדות החובה. מגדירים את השדות הבאים:
- Label = {any text}
- שם הפניה = {כל טקסט}
- Project ID = זיהוי אוטומטי
- Dataset = מערך נתונים ב-BigQuery שמשמש בפרויקט הנוכחי (כלומר, DATASET_ID)
- Table = {table name}
- לקבלת הסבר מפורט, לוחצים על Documentation (מסמכים). לוחצים על הלחצן 'אימות' כדי לאמת את כל פרטי הקלט. ההודעה הירוקה 'לא נמצאו שגיאות' מציינת שהפעולה הצליחה.

- כדי לסגור את BigQuery Properties, לוחצים על הלחצן X.
6. פיתוח פייפליין נתונים באצווה
חיבור כל הצמתים בצינור
- גוררים חץ של חיבור > מהקצה הימני של צומת המקור ומשחררים אותו בקצה השמאלי של צומת היעד.
- לצינור יכולים להיות כמה ענפים שמקבלים קובצי קלט מאותו צומת מקור GCS.

- נותנים שם לצינור.
זה הכול. יצרתם עכשיו את פייפליין הנתונים הראשון שלכם לעיבוד באצווה, ואתם יכולים לפרוס ולהפעיל אותו.
שליחת התראות על צינורות עיבוד נתונים באימייל (אופציונלי)
כדי להשתמש בתכונה Pipeline Alert SendEmail, צריך להגדיר שרת דואר לשליחת דואר ממופע של מכונה וירטואלית. מידע נוסף זמין בקישור הבא:
שליחת אימייל ממכונה | מאמרי העזרה של Compute Engine
ב-Codelab הזה נגדיר שרת ממסר דואר דרך Mailgun לפי השלבים הבאים:
- כדי להגדיר חשבון ב-Mailgun ולהגדיר את שירות ממסר האימייל, פועלים לפי ההוראות במאמר שליחת אימייל באמצעות Mailgun | חומרי עזר של Compute Engine. בהמשך מפורטים שינויים נוספים.
- מוסיפים את כל כתובות האימייל של הנמענים לרשימת ההרשאות של Mailgun. הרשימה הזו נמצאת באפשרות Mailgun>Sending>Overview בחלונית הימנית.


אחרי שהנמענים ילחצו על 'אני מסכים/ה' באימייל שנשלח מכתובת support@mailgun.net, כתובות האימייל שלהם יישמרו ברשימה המורשית לקבלת התראות על צינורות.

- שלב 3 בקטע 'לפני שמתחילים' – יצירת כלל לחומת האש באופן הבא:

- שלב 3 מתוך 'הגדרת Mailgun כממסר דואר עם Postfix'. בוחרים באפשרות אתר אינטרנט או אינטרנט עם שרת חכם במקום באפשרות רק מקומי, כמו שמופיע בהוראות.

- שלב 4 מתוך 'הגדרת Mailgun כשרת ממסר דואר באמצעות Postfix'. עורכים את vi /etc/postfix/main.cf כדי להוסיף את 10.128.0.0/9 בסוף mynetworks.

- עורכים את vi /etc/postfix/master.cf כדי לשנות את ברירת המחדל של smtp (25) ליציאה 587.

- בפינה השמאלית העליונה של סטודיו Data Fusion, לוחצים על Configure (הגדרה). לוחצים על Pipeline alert (התראה על צינור) ואז על לחצן + כדי לפתוח את החלון Alerts (התראות). בוחרים באפשרות SendEmail.

- ממלאים את טופס ההגדרה של אימייל. בתפריט הנפתח Run Condition בוחרים באפשרות completion, success או failure לכל סוג התראה. אם Include Workflow Token = false, יישלח רק המידע מהשדה Message. אם Include Workflow Token = true, המידע מהשדה Message ופרטים על Workflow Token נשלחים. חובה להשתמש באותיות קטנות בשדה פרוטוקול. אל תשתמשו בכתובת אימייל פיקטיבית בשדה שולח, אלא בכתובת האימייל של החברה שלכם.

7. הגדרה, פריסה, הפעלה או תזמון של צינור עיבוד נתונים

- בפינה השמאלית העליונה של סטודיו Data Fusion, לוחצים על Configure (הגדרה). בוחרים באפשרות Spark for Engine Config (הגדרת מנוע). לוחצים על Save (שמירה) בחלון Configure (הגדרה).

- לוחצים על תצוגה מקדימה כדי לראות תצוגה מקדימה של הנתונים**,** ולוחצים שוב על **תצוגה מקדימה** כדי לחזור לחלון הקודם. אפשר גם **להפעיל** את צינור הנתונים במצב תצוגה מקדימה.

- לוחצים על יומנים כדי לראות את היומנים.
- לוחצים על שמירה כדי לשמור את כל השינויים.
- לוחצים על ייבוא כדי לייבא הגדרת צינור עיבוד נתונים שנשמרה כשיוצרים צינור עיבוד נתונים חדש.
- לוחצים על ייצוא כדי לייצא הגדרה של צינור עיבוד נתונים.
- לוחצים על Deploy (פריסה) כדי לפרוס את צינור עיבוד הנתונים.
- אחרי הפריסה, לוחצים על Run ומחכים עד שהצינור יפעל עד הסוף.

- כדי לשכפל את צינור המכירות, לוחצים על הכפתור פעולות ובוחרים באפשרות 'שכפול'.
- כדי לייצא את הגדרות צינור עיבוד הנתונים, לוחצים על פעולות ואז על ייצוא.
- אם רוצים להגדיר טריגרים של צינורות, לוחצים על Inbound triggers (טריגרים נכנסים) או על Outbound triggers (טריגרים יוצאים) בקצה השמאלי או הימני של חלון Studio.
- לוחצים על תזמון כדי לתזמן את הפעלת צינור הנתונים וטעינת הנתונים באופן תקופתי.

- בכרטיסייה סיכום מוצגים תרשימים של היסטוריית ההרצה, רשומות, יומני שגיאות ואזהרות.
8. אימות
- הצינור Validate הופעל בהצלחה.

- מוודאים שלמערך הנתונים ב-BigQuery יש את כל הטבלאות.
bq ls $PROJECT_ID:$DATASET_ID
tableId Type Labels Time Partitioning
----------------- ------- -------- -------------------
Allergies TABLE
Careplans TABLE
Conditions TABLE
Encounters TABLE
Imaging_Studies TABLE
Immunizations TABLE
Medications TABLE
Observations TABLE
Organizations TABLE
Patients TABLE
Procedures TABLE
Providers TABLE
- קבלת התראות באימייל (אם הוגדרו).
איך רואים את התוצאות
כדי לראות את התוצאות אחרי הפעלת הצינור:
- מריצים שאילתה על הטבלה בממשק המשתמש של BigQuery. מעבר לממשק המשתמש של BigQuery
- מעדכנים את השאילתה שלמטה לשם הפרויקט, מערך הנתונים והטבלה שלכם.

9. סידור וארגון
כדי להימנע מחיובים בחשבון Google Cloud Platform בגלל השימוש במשאבים שנעשה במסגרת המדריך הזה:
בסיום המדריך, חשוב למחוק את המשאבים שיצרתם ב-GCP כדי שלא יתפסו חלק מהמכסה שלכם ולא תחויבו עליהם בעתיד. בסעיפים הבאים מוסבר איך למחוק או להשבית את המשאבים האלו.
מחיקת מערך הנתונים ב-BigQuery
כדי למחוק את מערך הנתונים ב-BigQuery שיצרתם במסגרת המדריך הזה, פועלים לפי ההוראות האלה.
מחיקת קטגוריית GCS
כדי למחוק את קטגוריית ה-GCS שיצרתם כחלק מההדרכה הזו, פועלים לפי ההוראות הבאות.
מחיקת מכונת Cloud Data Fusion
פועלים לפי ההוראות כדי למחוק את מופע Cloud Data Fusion.
מחיקת הפרויקט
הדרך הקלה ביותר לבטל את החיוב היא למחוק את הפרויקט שיצרתם בשביל המדריך.
כדי למחוק את הפרויקט:
- במסוף GCP, נכנסים לדף Projects. כניסה לדף Projects
- ברשימת הפרויקטים, בוחרים את הפרויקט שרוצים למחוק ולוחצים על מחיקה.
- כדי למחוק את הפרויקט, כותבים את מזהה הפרויקט בתיבת הדו-שיח ולוחצים על Shut down.
10. מזל טוב
סיימתם בהצלחה את סדנת הקוד להטמעת נתונים בתחום הבריאות ב-BigQuery באמצעות Cloud Data Fusion.
ייבאתם נתוני CSV מ-Google Cloud Storage ל-BigQuery.
יצרתם באופן ויזואלי את צינור עיבוד הנתונים לשילוב נתונים כדי לטעון, לשנות ולהסתיר נתונים של שירותי בריאות בכמות גדולה.
עכשיו אתם יודעים מהם השלבים העיקריים שצריך לבצע כדי להתחיל את התהליך של ניתוח נתונים בתחום הבריאות באמצעות BigQuery ב-Google Cloud Platform.