
1. Introduction
BigQuery est la base de données d'analyse à faible coût de Google. Elle est entièrement gérée. Avec BigQuery, vous pouvez interroger des téraoctets de données sans avoir besoin d'un administrateur de base de données ni d'infrastructure à gérer. BigQuery utilise le langage SQL que vous connaissez déjà et un modèle de facturation à l'usage. BigQuery vous permet de vous concentrer sur l'analyse des données pour en dégager des informations pertinentes.
Dans cet atelier de programmation, vous allez découvrir comment interroger l'ensemble de données public GitHub, l'un des nombreux ensembles de données publics disponibles dans BigQuery.
Points abordés
- Utiliser BigQuery
- Écrire une requête pour obtenir des insights sur un grand ensemble de données
Prérequis
2. Configuration
Activer BigQuery
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un.
- Connectez-vous à la console Google Cloud Platform ( console.cloud.google.com) et accédez à BigQuery. Vous pouvez également ouvrir l'interface utilisateur Web de BigQuery directement en saisissant l'URL suivante dans votre navigateur.
https://console.cloud.google.com/bigquery
- Acceptez les conditions d'utilisation.
- Avant de pouvoir utiliser BigQuery, vous devez créer un projet. Suivez les instructions pour créer votre projet.
Choisissez un nom de projet et notez son ID.

L'ID du projet est un nom unique parmi tous les projets Google Cloud. Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
Cet atelier de programmation utilise des ressources BigQuery dans les limites du bac à sable BigQuery. Aucun compte de facturation n'est requis. Si vous souhaitez supprimer les limites du bac à sable ultérieurement, vous pouvez ajouter un compte de facturation en vous inscrivant à l'essai sans frais de Google Cloud Platform.
3. Prévisualiser les données GitHub
Ouvrez l'ensemble de données GitHub dans l'interface utilisateur Web de BigQuery.
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
Obtenez un aperçu rapide de l'apparence des données.

4. Interroger les données GitHub
Ouvrez l'éditeur de requête.

Saisissez la requête suivante pour trouver les messages de commit les plus courants dans l'ensemble de données public GitHub :
SELECT subject AS subject,
COUNT(*) AS num_duplicates
FROM `bigquery-public-data.github_repos.sample_commits`
GROUP BY subject
ORDER BY num_duplicates DESC
LIMIT 100
Étant donné que l'ensemble de données GitHub est volumineux, il est utile d'utiliser un ensemble de données échantillon plus petit lors des tests pour réduire les coûts. Utilisez les octets traités sous l'éditeur pour estimer le coût de la requête.
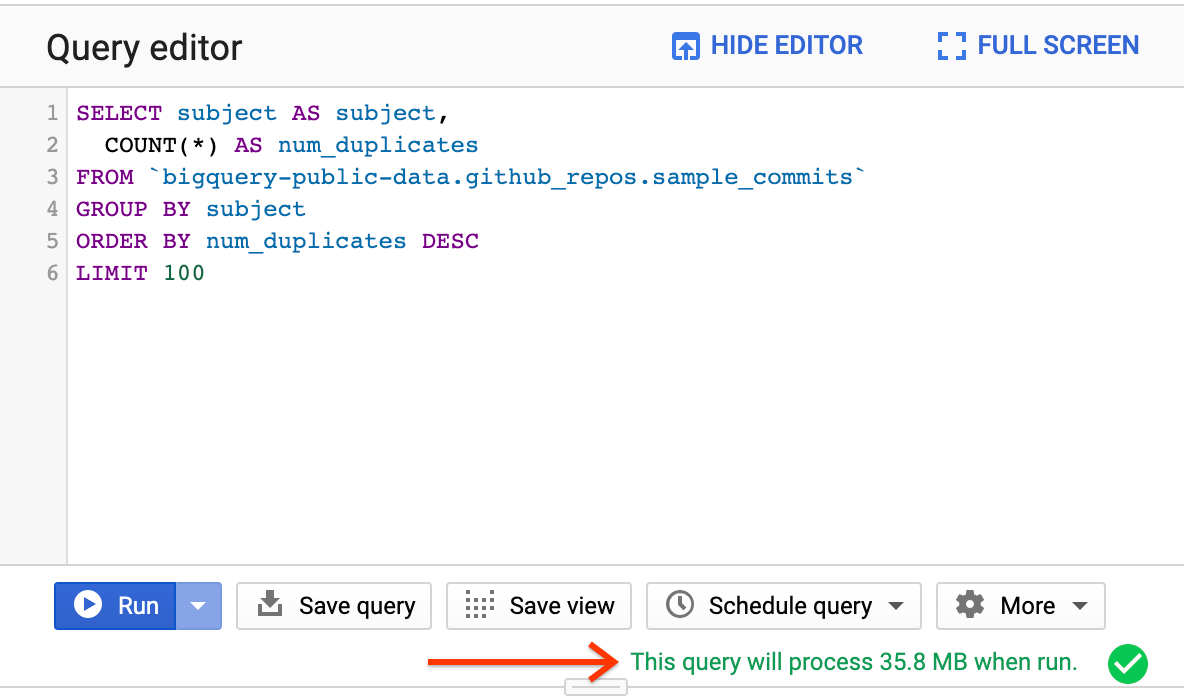
Cliquez sur le bouton Exécuter.
Au bout de quelques secondes, le résultat s'affiche en bas de l'écran. Il indique la quantité de données traitées et la durée de l'opération.

Même si la table sample_commits fait 2,49 Go, la requête n'a traité que 35,8 Mo. BigQuery ne traite que les octets des colonnes utilisées dans la requête. La quantité totale de données traitées peut donc être nettement inférieure à la taille de la table. Le clustering et le partitionnement permettent de réduire encore davantage la quantité de données traitées.
5. Plus de données publiques
Essayez maintenant d'interroger un autre ensemble de données, par exemple l'un des autres ensembles de données publics.
Par exemple, la requête suivante recherche les projets populaires obsolètes ou non gérés dans l'ensemble de données public Libraries.io qui sont toujours utilisés comme dépendance dans d'autres projets :
SELECT
name,
dependent_projects_count,
language,
status
FROM
`bigquery-public-data.libraries_io.projects_with_repository_fields`
WHERE status IN ('Deprecated', 'Unmaintained')
ORDER BY dependent_projects_count DESC
LIMIT 100
D'autres organisations ont également rendu leurs données publiques dans BigQuery. Par exemple, l'ensemble de données GH Archive de GitHub peut être utilisé pour analyser les événements publics sur GitHub, tels que les demandes d'extraction, les étoiles de dépôt et les problèmes ouverts. L'ensemble de données PyPI de la Python Software Foundation peut être utilisé pour analyser les demandes de téléchargement de packages Python.
6. Félicitations !
Vous avez utilisé BigQuery et SQL pour interroger l'ensemble de données public GitHub. Vous pouvez interroger des ensembles de données à l'échelle du pétaoctet.
Sujets abordés
- Utiliser la syntaxe SQL pour interroger les enregistrements des commits GitHub
- Écrire une requête pour obtenir des insights sur un grand ensemble de données
En savoir plus
- Apprenez le langage SQL avec le cours Introduction to SQL de Kaggle.
- Consultez la documentation BigQuery.
- Découvrez comment d'autres utilisateurs utilisent l'ensemble de données GitHub dans cet article de blog.
- Explorez les données météorologiques, les données sur la criminalité et plus encore dans Aujourd'hui, j'ai appris avec BigQuery.
- Découvrez comment charger des données dans BigQuery à l'aide de l'outil de ligne de commande BigQuery.
- Consultez le subreddit BigQuery pour découvrir d'autres utilisations actuelles de BigQuery.