
1. はじめに
BigQuery は、Google が提供する低コストのフルマネージド分析データベースです。BigQuery を使用すると、データベース管理者や管理するインフラストラクチャを必要とせずに、テラバイト単位のデータをクエリできます。BigQuery では、扱いやすい SQL と、使用した分のみを支払う課金モデルが採用されています。このような特徴を活かし、ユーザーは有用な情報を得るためのデータ分析に専念できます。
この Codelab では、GitHub 一般公開データセット(BigQuery で利用可能な一般公開データセットの 1 つ)をクエリする方法について説明します。
学習内容
- BigQuery の使用方法
- 大規模なデータセットから分析情報を得るためのクエリを作成する方法
必要なもの
2. セットアップする
BigQuery を有効にする
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。
- Google Cloud Platform コンソール(console.cloud.google.com)にログインし、BigQuery に移動します。ブラウザに次の URL を入力して、BigQuery ウェブ UI を直接開くこともできます。
https://console.cloud.google.com/bigquery
- 利用規約に同意します。
- BigQuery を使用する前に、プロジェクトを作成する必要があります。プロンプトに従って新しいプロジェクトを作成します。
プロジェクト名を選択し、プロジェクト ID をメモします。

プロジェクト ID は、すべての Google Cloud プロジェクトで一意の名前です。以降、このコードラボでは PROJECT_ID と呼びます。
この Codelab では、BigQuery サンドボックスの上限内の BigQuery リソースを使用します。請求先アカウントは必要ありません。後でサンドボックスの上限を削除する場合は、Google Cloud Platform の無料トライアルに登録して請求先アカウントを追加できます。
3. GitHub データのプレビュー
BigQuery ウェブ UI で GitHub データセットを開きます。
https://console.cloud.google.com/bigquery?p=bigquery-public-data&d=github_repos&t=commits&page=table
データの外観を簡単にプレビューできます。

4. GitHub データをクエリする
クエリエディタを開きます。

次のクエリを入力して、GitHub 一般公開データセットで最も一般的なコミット メッセージを見つけます。
SELECT subject AS subject,
COUNT(*) AS num_duplicates
FROM `bigquery-public-data.github_repos.sample_commits`
GROUP BY subject
ORDER BY num_duplicates DESC
LIMIT 100
GitHub データセットは大きいため、費用を節約するために、テストには小さいサンプル データセットを使用することをおすすめします。エディタの下に表示される処理済みバイト数を使用して、クエリ費用を見積もります。
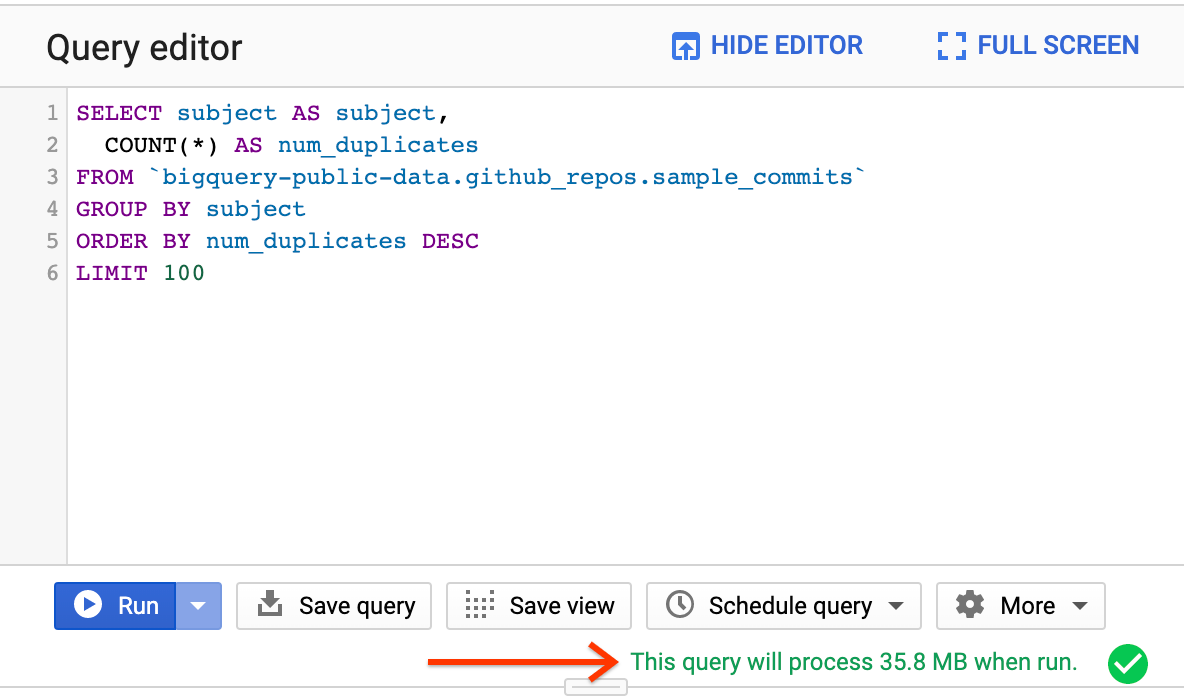
[Run] ボタンをクリックします。
数秒後に、結果が下部に表示され、処理されたデータ量と所要時間が表示されます。

sample_commits テーブルは 2.49 GB ですが、クエリで処理されたのは 35.8 MB のみです。BigQuery はクエリで使用される列のバイトのみを処理するため、処理されるデータの合計量はテーブルサイズよりも大幅に小さくなる可能性があります。クラスタリングとパーティショニングを使用すると、処理されるデータ量をさらに削減できます。
5. 一般公開データの追加
次に、別のデータセット(他の一般公開データセットなど)に対してクエリを実行してみます。
たとえば、次のクエリは、Libraries.io 一般公開データセットで、他のプロジェクトの依存関係としてまだ使用されている、非推奨またはメンテナンスされていない人気のあるプロジェクトを検索します。
SELECT
name,
dependent_projects_count,
language,
status
FROM
`bigquery-public-data.libraries_io.projects_with_repository_fields`
WHERE status IN ('Deprecated', 'Unmaintained')
ORDER BY dependent_projects_count DESC
LIMIT 100
他の組織も、BigQuery でデータを一般公開しています。たとえば、GitHub の GH Archive データセットを使用して、pull リクエスト、リポジトリのスター、オープンされた問題など、GitHub の公開イベントを分析できます。Python Software Foundation の PyPI データセットを使用して、Python パッケージのダウンロード リクエストを分析できます。
6. 完了
BigQuery と SQL を使用して GitHub 一般公開データセットをクエリしました。ペタバイト規模のデータセットをクエリできます。
学習した内容
- SQL 構文を使用して GitHub のコミット レコードをクエリする
- 大規模なデータセットから分析情報を得るためのクエリの作成
詳細
- Kaggle の SQL 入門で SQL を学習します。
- BigQuery ドキュメントをご覧ください。
- GitHub データセットの他のユーザーによる使用方法については、こちらのブログ投稿をご覧ください。
- TIL with BigQuery で、気象データや犯罪データなどを確認する。
- BigQuery コマンドライン ツールを使用してデータを BigQuery に読み込む方法を学習します。
- BigQuery のサブレディットで、他の方が今どのように BigQuery を使用しているかがわかります。