
1. Panoramica
Nel primo codelab, memorizzerai le immagini in un bucket. Verrà generato un evento di creazione di file che verrà gestito da un servizio di cui è stato eseguito il deployment in Cloud Run. Il servizio effettuerà una chiamata all'API Vision per eseguire l'analisi delle immagini e salvare i risultati in un datastore.

Obiettivi didattici
- Cloud Storage
- Cloud Run
- API Cloud Vision
- Cloud Firestore
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.



- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
3. Abilita API
Per questo lab, utilizzerai Cloud Functions e l'API Vision, ma prima devi abilitarle in Cloud Console o con gcloud.
Per abilitare l'API Vision in Cloud Console, cerca Cloud Vision API nella barra di ricerca:

Verrà visualizzata la pagina dell'API Cloud Vision:

Fai clic sul pulsante ENABLE.
In alternativa, puoi abilitarlo anche in Cloud Shell utilizzando lo strumento a riga di comando gcloud.
In Cloud Shell, esegui questo comando:
gcloud services enable vision.googleapis.com
Dovresti vedere che l'operazione è stata completata correttamente:
Operation "operations/acf.12dba18b-106f-4fd2-942d-fea80ecc5c1c" finished successfully.
Abilita anche Cloud Run e Cloud Build:
gcloud services enable cloudbuild.googleapis.com \ run.googleapis.com
4. Crea il bucket (console)
Crea un bucket di archiviazione per le immagini. Puoi farlo dalla console Google Cloud ( console.cloud.google.com) o con lo strumento a riga di comando gsutil da Cloud Shell o dal tuo ambiente di sviluppo locale.
Vai ad Archiviazione
Dal menu "hamburger" (☰), vai alla pagina Storage.

Assegna un nome al bucket
Fai clic sul pulsante CREATE BUCKET.

Fai clic su CONTINUE.
Scegliere la posizione

Crea un bucket multiregionale nella regione che preferisci (in questo caso Europe).
Fai clic su CONTINUE.
Scegli la classe di archiviazione predefinita

Scegli la classe di archiviazione Standard per i tuoi dati.
Fai clic su CONTINUE.
Impostare il controllo dell'accesso

Poiché lavorerai con immagini accessibili pubblicamente, vuoi che tutte le immagini archiviate in questo bucket abbiano lo stesso controllo dell'accesso uniforme.
Scegli l'opzione di controllo dell'accesso Uniform.
Fai clic su CONTINUE.
Impostare la protezione/crittografia

Mantieni il valore predefinito (Google-managed key)), in quanto non utilizzerai le tue chiavi di crittografia.
Fai clic su CREATE per completare la creazione del bucket.
Aggiungere allUsers come visualizzatore dello spazio di archiviazione
Vai alla scheda Permissions:

Aggiungi un membro allUsers al bucket con il ruolo Storage > Storage Object Viewer nel seguente modo:

Fai clic su SAVE.
5. Crea il bucket (gsutil)
Puoi anche utilizzare lo strumento a riga di comando gsutil in Cloud Shell per creare bucket.
In Cloud Shell, imposta una variabile per il nome univoco del bucket. Cloud Shell ha già impostato GOOGLE_CLOUD_PROJECT sul tuo ID progetto univoco. Puoi aggiungerlo al nome del bucket.
Ad esempio:
export BUCKET_PICTURES=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}
Crea una zona standard multi-regione in Europa:
gsutil mb -l EU gs://${BUCKET_PICTURES}
Assicurati che l'accesso uniforme a livello di bucket sia abilitato:
gsutil uniformbucketlevelaccess set on gs://${BUCKET_PICTURES}
Rendi pubblico il bucket:
gsutil iam ch allUsers:objectViewer gs://${BUCKET_PICTURES}
Se vai alla sezione Cloud Storage della console, dovresti avere un bucket uploaded-pictures pubblico:

Verifica di poter caricare immagini nel bucket e che le immagini caricate siano disponibili pubblicamente, come spiegato nel passaggio precedente.
6. Testa l'accesso pubblico al bucket
Tornando al browser di archiviazione, vedrai il tuo bucket nell'elenco, con accesso "Pubblico" (inclusa un'icona di avviso che ti ricorda che chiunque ha accesso ai contenuti del bucket).

Il tuo bucket è ora pronto a ricevere le immagini.
Se fai clic sul nome del bucket, vengono visualizzati i dettagli.

Lì puoi provare il pulsante Upload files per verificare di poter aggiungere un'immagine al bucket. Verrà visualizzato un popup di selezione dei file che ti chiederà di selezionare un file. Una volta selezionato, verrà caricato nel bucket e vedrai di nuovo l'accesso publicattribuito automaticamente a questo nuovo file.

Accanto all'etichetta di accesso Public, vedrai anche una piccola icona a forma di link. Quando fai clic, il browser si sposta sull'URL pubblico dell'immagine, che avrà il seguente formato:
https://storage.googleapis.com/BUCKET_NAME/PICTURE_FILE.png
dove BUCKET_NAME è il nome univoco globale che hai scelto per il bucket e il nome del file dell'immagine.
Se fai clic sulla casella di controllo accanto al nome dell'immagine, il pulsante DELETE verrà attivato e potrai eliminare la prima immagine.
7. Prepara il database
Memorizzerai le informazioni sull'immagine fornite dall'API Vision nel database Cloud Firestore, un database di documenti NoSQL veloce, serverless, completamente gestito e cloud-native. Prepara il database andando alla sezione Firestore di Cloud Console:

Sono disponibili due opzioni: Native mode o Datastore mode. Utilizza la modalità nativa, che offre funzionalità aggiuntive come il supporto offline e la sincronizzazione in tempo reale.
Fai clic su SELECT NATIVE MODE.

Scegli una regione multipla (in questo caso in Europa, ma idealmente almeno la stessa regione della funzione e del bucket di archiviazione).
Fai clic sul pulsante CREATE DATABASE.
Una volta creato il database, dovresti visualizzare quanto segue:

Crea una nuova raccolta facendo clic sul pulsante + START COLLECTION.
Raccolta di nomi pictures.

Non è necessario creare un documento. Le aggiungerai in modo programmatico man mano che le nuove immagini vengono archiviate in Cloud Storage e analizzate dall'API Vision.
Fai clic su Save.
Firestore crea un primo documento predefinito nella raccolta appena creata. Puoi eliminarlo in sicurezza perché non contiene informazioni utili:

I documenti che verranno creati a livello di programmazione nella nostra raccolta conterranno quattro campi:
- name (stringa): il nome del file dell'immagine caricata, che è anche la chiave del documento
- labels (array di stringhe): le etichette degli elementi riconosciuti dall'API Vision
- color (stringa): il codice colore esadecimale del colore dominante (ad es. #ab12ef)
- created (data): il timestamp di quando sono stati archiviati i metadati di questa immagine
- thumbnail (booleano): un campo facoltativo che sarà presente e sarà true se è stata generata un'immagine miniatura per questa immagine
Poiché eseguiremo la ricerca in Firestore per trovare le immagini per cui sono disponibili miniature e l'ordinamento in base alla data di creazione, dovremo creare un indice di ricerca.
Puoi creare l'indice con il seguente comando in Cloud Shell:
gcloud firestore indexes composite create \
--collection-group=pictures \
--field-config field-path=thumbnail,order=descending \
--field-config field-path=created,order=descending
In alternativa, puoi farlo anche da Cloud Console, facendo clic su Indexes nella colonna di navigazione a sinistra e poi creando un indice composito come mostrato di seguito:
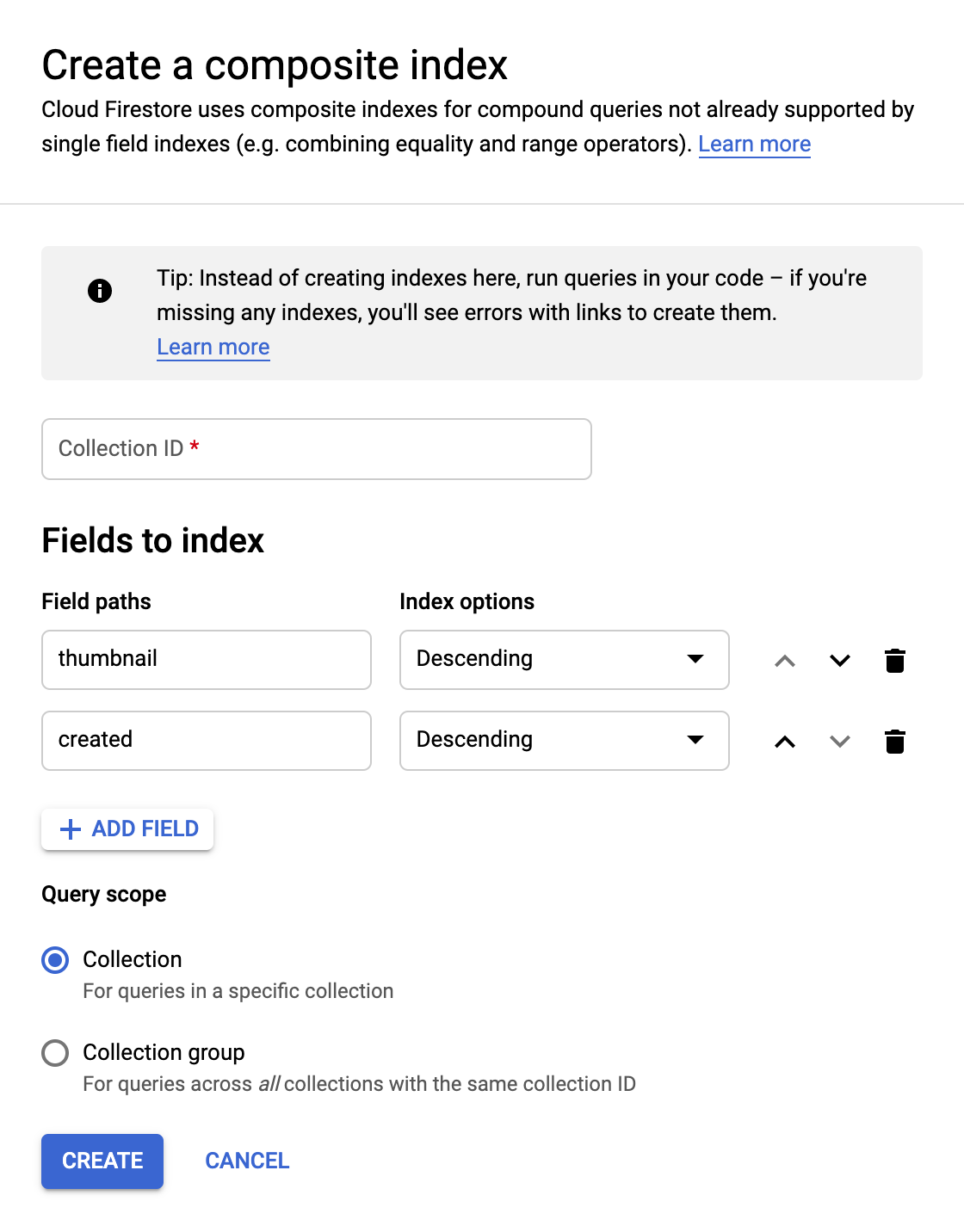
Fai clic su Create. La creazione dell'indice può richiedere alcuni minuti.
8. Clona il codice
Clona il codice, se non l'hai già fatto nel lab precedente:
git clone https://github.com/GoogleCloudPlatform/serverless-photosharing-workshop
A questo punto puoi andare alla directory contenente il servizio per iniziare a creare il lab:
cd serverless-photosharing-workshop/services/image-analysis/java
Per il servizio avrai il seguente layout dei file:

9. Esplora il codice del servizio
Inizia esaminando come vengono abilitate le librerie client Java in pom.xml utilizzando un BOM:
Per prima cosa, apri il file pom.xml che elenca le dipendenze della nostra app Java. L'attenzione è rivolta all'utilizzo delle API Vision, Cloud Storage e Firestore.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0-M3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>services</groupId>
<artifactId>image-analysis</artifactId>
<version>0.0.1</version>
<name>image-analysis</name>
<description>Spring App for Image Analysis</description>
<properties>
<java.version>17</java.version>
<maven.compiler.target>17</maven.compiler.target>
<maven.compiler.source>17</maven.compiler.source>
<spring-cloud.version>2023.0.0-M2</spring-cloud.version>
<testcontainers.version>1.19.1</testcontainers.version>
</properties>
...
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.24.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
—
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-web</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud.functions</groupId>
<artifactId>functions-framework-api</artifactId>
<version>1.1.0</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-firestore</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-storage</artifactId>
</dependency>
La funzionalità è implementata nella classe EventController. Ogni volta che viene caricata una nuova immagine nel bucket, il servizio riceve una notifica per l'elaborazione:
@RestController
public class EventController {
private static final Logger logger = Logger.getLogger(EventController.class.getName());
private static final List<String> requiredFields = Arrays.asList("ce-id", "ce-source", "ce-type", "ce-specversion");
@RequestMapping(value = "/", method = RequestMethod.POST)
public ResponseEntity<String> receiveMessage(
@RequestBody Map<String, Object> body, @RequestHeader Map<String, String> headers) throws IOException, InterruptedException, ExecutionException {
...
}
Il codice procederà alla convalida delle intestazioni Cloud Events:
System.out.println("Header elements");
for (String field : requiredFields) {
if (headers.get(field) == null) {
String msg = String.format("Missing expected header: %s.", field);
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
} else {
System.out.println(field + " : " + headers.get(field));
}
}
System.out.println("Body elements");
for (String bodyField : body.keySet()) {
System.out.println(bodyField + " : " + body.get(bodyField));
}
if (headers.get("ce-subject") == null) {
String msg = "Missing expected header: ce-subject.";
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Ora è possibile creare una richiesta e il codice ne preparerà una da inviare a Vision API:
try (ImageAnnotatorClient vision = ImageAnnotatorClient.create()) {
List<AnnotateImageRequest> requests = new ArrayList<>();
ImageSource imageSource = ImageSource.newBuilder()
.setGcsImageUri("gs://" + bucketName + "/" + fileName)
.build();
Image image = Image.newBuilder()
.setSource(imageSource)
.build();
Feature featureLabel = Feature.newBuilder()
.setType(Type.LABEL_DETECTION)
.build();
Feature featureImageProps = Feature.newBuilder()
.setType(Type.IMAGE_PROPERTIES)
.build();
Feature featureSafeSearch = Feature.newBuilder()
.setType(Type.SAFE_SEARCH_DETECTION)
.build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder()
.addFeatures(featureLabel)
.addFeatures(featureImageProps)
.addFeatures(featureSafeSearch)
.setImage(image)
.build();
requests.add(request);
Ti chiediamo di utilizzare tre funzionalità chiave dell'API Vision:
- Rilevamento delle etichette: per capire cosa c'è nelle foto
- Proprietà dell'immagine: per fornire attributi interessanti dell'immagine (ci interessa il colore dominante dell'immagine)
- SafeSearch: per sapere se l'immagine è sicura da mostrare (non deve contenere contenuti per adulti, medici, osé o violenti)
A questo punto, possiamo effettuare la chiamata all'API Vision:
...
logger.info("Calling the Vision API...");
BatchAnnotateImagesResponse result = vision.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = result.getResponsesList();
...
Per riferimento, ecco come appare la risposta dell'API Vision:
{
"faceAnnotations": [],
"landmarkAnnotations": [],
"logoAnnotations": [],
"labelAnnotations": [
{
"locations": [],
"properties": [],
"mid": "/m/01yrx",
"locale": "",
"description": "Cat",
"score": 0.9959855675697327,
"confidence": 0,
"topicality": 0.9959855675697327,
"boundingPoly": null
},
✄ - - - ✄
],
"textAnnotations": [],
"localizedObjectAnnotations": [],
"safeSearchAnnotation": {
"adult": "VERY_UNLIKELY",
"spoof": "UNLIKELY",
"medical": "VERY_UNLIKELY",
"violence": "VERY_UNLIKELY",
"racy": "VERY_UNLIKELY",
"adultConfidence": 0,
"spoofConfidence": 0,
"medicalConfidence": 0,
"violenceConfidence": 0,
"racyConfidence": 0,
"nsfwConfidence": 0
},
"imagePropertiesAnnotation": {
"dominantColors": {
"colors": [
{
"color": {
"red": 203,
"green": 201,
"blue": 201,
"alpha": null
},
"score": 0.4175916016101837,
"pixelFraction": 0.44456374645233154
},
✄ - - - ✄
]
}
},
"error": null,
"cropHintsAnnotation": {
"cropHints": [
{
"boundingPoly": {
"vertices": [
{ "x": 0, "y": 118 },
{ "x": 1177, "y": 118 },
{ "x": 1177, "y": 783 },
{ "x": 0, "y": 783 }
],
"normalizedVertices": []
},
"confidence": 0.41695669293403625,
"importanceFraction": 1
}
]
},
"fullTextAnnotation": null,
"webDetection": null,
"productSearchResults": null,
"context": null
}
Se non viene restituito alcun errore, possiamo andare avanti, ecco perché abbiamo questo blocco if:
if (responses.size() == 0) {
logger.info("No response received from Vision API.");
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
AnnotateImageResponse response = responses.get(0);
if (response.hasError()) {
logger.info("Error: " + response.getError().getMessage());
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Recupereremo le etichette delle cose, delle categorie o dei temi riconosciuti nell'immagine:
List<String> labels = response.getLabelAnnotationsList().stream()
.map(annotation -> annotation.getDescription())
.collect(Collectors.toList());
logger.info("Annotations found:");
for (String label: labels) {
logger.info("- " + label);
}
Ci interessa conoscere il colore dominante dell'immagine:
String mainColor = "#FFFFFF";
ImageProperties imgProps = response.getImagePropertiesAnnotation();
if (imgProps.hasDominantColors()) {
DominantColorsAnnotation colorsAnn = imgProps.getDominantColors();
ColorInfo colorInfo = colorsAnn.getColors(0);
mainColor = rgbHex(
colorInfo.getColor().getRed(),
colorInfo.getColor().getGreen(),
colorInfo.getColor().getBlue());
logger.info("Color: " + mainColor);
}
Controlliamo se l'immagine è sicura da mostrare:
boolean isSafe = false;
if (response.hasSafeSearchAnnotation()) {
SafeSearchAnnotation safeSearch = response.getSafeSearchAnnotation();
isSafe = Stream.of(
safeSearch.getAdult(), safeSearch.getMedical(), safeSearch.getRacy(),
safeSearch.getSpoof(), safeSearch.getViolence())
.allMatch( likelihood ->
likelihood != Likelihood.LIKELY && likelihood != Likelihood.VERY_LIKELY
);
logger.info("Safe? " + isSafe);
}
Stiamo verificando le caratteristiche relative a contenuti per adulti, parodie, contenuti medici, violenza e contenuti allusivi per capire se non sono probabili o molto probabili.
Se il risultato della ricerca sicura è accettabile, possiamo archiviare i metadati in Firestore:
// Saving result to Firestore
if (isSafe) {
ApiFuture<WriteResult> writeResult =
eventService.storeImage(fileName, labels,
mainColor);
logger.info("Picture metadata saved in Firestore at " +
writeResult.get().getUpdateTime());
}
...
public ApiFuture<WriteResult> storeImage(String fileName,
List<String> labels,
String mainColor) {
FirestoreOptions firestoreOptions = FirestoreOptions.getDefaultInstance();
Firestore pictureStore = firestoreOptions.getService();
DocumentReference doc = pictureStore.collection("pictures").document(fileName);
Map<String, Object> data = new HashMap<>();
data.put("labels", labels);
data.put("color", mainColor);
data.put("created", new Date());
return doc.set(data, SetOptions.merge());
}
10. Creare immagini di app con GraalVM
In questo passaggio facoltativo, creerai un JIT based app image e poi un Native Java app image utilizzando GraalVM.
Per eseguire la build, devi assicurarti di avere una JDK appropriata e che il builder native-image sia installato e configurato. Sono disponibili diverse opzioni.
To start, scarica GraalVM 22.3.x Community Edition e segui le istruzioni riportate nella pagina Installazione di GraalVM.
Questo processo può essere notevolmente semplificato con l'aiuto di SDKMAN!
Per installare la distribuzione JDK appropriata con SDKman, inizia utilizzando il comando di installazione:
sdk install java 17.0.8-graal
Chiedi a SDKman di utilizzare questa versione, sia per le build JIT che AOT:
sdk use java 17.0.8-graal
In Cloudshell, per comodità, puoi installare GraalVM e l'utilità native-image con questi semplici comandi:
# download GraalVM wget https://download.oracle.com/graalvm/17/latest/graalvm-jdk-17_linux-x64_bin.tar.gz tar -xzf graalvm-jdk-17_linux-x64_bin.tar.gz ls -lart # configure Java 17 and GraalVM for Java 17 # note the name of the latest GraalVM version, as unpacked by the tar command echo Existing JVM: $JAVA_HOME cd graalvm-jdk-17.0.8+9.1 export JAVA_HOME=$PWD cd bin export PATH=$PWD:$PATH echo JAVA HOME: $JAVA_HOME echo PATH: $PATH cd ../.. # validate the version with java -version # observe Java(TM) SE Runtime Environment Oracle GraalVM 17.0.8+9.1 (build 17.0.8+9-LTS-jvmci-23.0-b14) Java HotSpot(TM) 64-Bit Server VM Oracle GraalVM 17.0.8+9.1 (build 17.0.8+9-LTS-jvmci-23.0-b14, mixed mode, sharing)
Innanzitutto, imposta le variabili di ambiente del progetto GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
A questo punto puoi andare alla directory contenente il servizio per iniziare a creare il lab:
cd serverless-photosharing-workshop/services/image-analysis/java
Crea l'immagine dell'applicazione JIT:
./mvnw package
Osserva il log di build nel terminale:
... [INFO] Results: [INFO] [INFO] Tests run: 6, Failures: 0, Errors: 0, Skipped: 0 [INFO] [INFO] [INFO] --- maven-jar-plugin:3.3.0:jar (default-jar) @ image-analysis --- [INFO] Building jar: /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar [INFO] [INFO] --- spring-boot-maven-plugin:3.2.0-M3:repackage (repackage) @ image-analysis --- [INFO] Replacing main artifact /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar with repackaged archive, adding nested dependencies in BOOT-INF/. [INFO] The original artifact has been renamed to /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar.original [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 15.335 s [INFO] Finished at: 2023-10-10T19:33:25Z [INFO] ------------------------------------------------------------------------
Crea l'immagine nativa(utilizza AOT):
./mvnw native:compile -Pnative
Osserva il log di build nel terminale, inclusi i log di build delle immagini native:
Tieni presente che la build richiede molto più tempo, a seconda della macchina su cui esegui il test.
...
[2/7] Performing analysis... [*********] (124.5s @ 4.53GB)
29,732 (93.19%) of 31,905 classes reachable
60,161 (70.30%) of 85,577 fields reachable
261,973 (67.29%) of 389,319 methods reachable
2,940 classes, 2,297 fields, and 97,421 methods registered for reflection
81 classes, 90 fields, and 62 methods registered for JNI access
4 native libraries: dl, pthread, rt, z
[3/7] Building universe... (11.7s @ 4.67GB)
[4/7] Parsing methods... [***] (6.1s @ 5.91GB)
[5/7] Inlining methods... [****] (4.5s @ 4.39GB)
[6/7] Compiling methods... [******] (35.3s @ 4.60GB)
[7/7] Creating image... (12.9s @ 4.61GB)
80.08MB (47.43%) for code area: 190,483 compilation units
73.81MB (43.72%) for image heap: 660,125 objects and 189 resources
14.95MB ( 8.86%) for other data
168.84MB in total
------------------------------------------------------------------------------------------------------------------------
Top 10 packages in code area: Top 10 object types in image heap:
2.66MB com.google.cloud.vision.v1p4beta1 18.51MB byte[] for code metadata
2.60MB com.google.cloud.vision.v1 9.27MB java.lang.Class
2.49MB com.google.protobuf 7.34MB byte[] for reflection metadata
2.40MB com.google.cloud.vision.v1p3beta1 6.35MB byte[] for java.lang.String
2.17MB com.google.storage.v2 5.72MB java.lang.String
2.12MB com.google.firestore.v1 4.46MB byte[] for embedded resources
1.64MB sun.security.ssl 4.30MB c.oracle.svm.core.reflect.SubstrateMethodAccessor
1.51MB i.g.xds.shaded.io.envoyproxy.envoy.config.core.v3 4.27MB byte[] for general heap data
1.47MB com.google.cloud.vision.v1p2beta1 2.50MB com.oracle.svm.core.hub.DynamicHubCompanion
1.34MB i.g.x.shaded.io.envoyproxy.envoy.config.route.v3 1.17MB java.lang.Object[]
58.34MB for 977 more packages 9.19MB for 4667 more object types
------------------------------------------------------------------------------------------------------------------------
13.5s (5.7% of total time) in 75 GCs | Peak RSS: 9.44GB | CPU load: 6.13
------------------------------------------------------------------------------------------------------------------------
Produced artifacts:
/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis (executable)
/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis.build_artifacts.txt (txt)
========================================================================================================================
Finished generating '/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis' in 3m 57s.
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:28 min
[INFO] Finished at: 2023-10-10T19:53:30Z
[INFO] ------------------------------------------------------------------------
11. Creare e pubblicare immagini container
Creiamo un'immagine container in due versioni diverse: una come JIT image e l'altra come Native Java image.
Innanzitutto, imposta le variabili di ambiente del progetto GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
Crea l'immagine JIT:
./mvnw spring-boot:build-image -Pji
Osserva il log di build nel terminale:
[INFO] [creator] Timer: Saving docker.io/library/image-analysis-maven-jit:latest... started at 2023-10-10T20:00:31Z [INFO] [creator] *** Images (4c84122a1826): [INFO] [creator] docker.io/library/image-analysis-maven-jit:latest [INFO] [creator] Timer: Saving docker.io/library/image-analysis-maven-jit:latest... ran for 6.975913605s and ended at 2023-10-10T20:00:38Z [INFO] [creator] Timer: Exporter ran for 8.068588001s and ended at 2023-10-10T20:00:38Z [INFO] [creator] Timer: Cache started at 2023-10-10T20:00:38Z [INFO] [creator] Reusing cache layer 'paketo-buildpacks/syft:syft' [INFO] [creator] Adding cache layer 'buildpacksio/lifecycle:cache.sbom' [INFO] [creator] Timer: Cache ran for 200.449002ms and ended at 2023-10-10T20:00:38Z [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-maven-jit:latest' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 43.887 s [INFO] Finished at: 2023-10-10T20:00:39Z [INFO] ------------------------------------------------------------------------
Crea l'immagine AOT(Native):
./mvnw spring-boot:build-image -Pnative
Osserva il log di build nel terminale, inclusi i log di build delle immagini native.
Nota:
- che la build richiede un po' più tempo, a seconda del computer su cui esegui il test
- le immagini possono essere ulteriormente compresse con UPX, ma hanno un piccolo impatto negativo sulle prestazioni di avvio, pertanto questa build non utilizza UPX, si tratta sempre di un leggero compromesso
... [INFO] [creator] Saving docker.io/library/image-analysis-maven-native:latest... [INFO] [creator] *** Images (13167702674e): [INFO] [creator] docker.io/library/image-analysis-maven-native:latest [INFO] [creator] Adding cache layer 'paketo-buildpacks/bellsoft-liberica:native-image-svm' [INFO] [creator] Adding cache layer 'paketo-buildpacks/syft:syft' [INFO] [creator] Adding cache layer 'paketo-buildpacks/native-image:native-image' [INFO] [creator] Adding cache layer 'buildpacksio/lifecycle:cache.sbom' [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-maven-native:latest' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 03:37 min [INFO] Finished at: 2023-10-10T20:05:16Z [INFO] ------------------------------------------------------------------------
Verifica che le immagini siano state create:
docker images | grep image-analysis
Tagga ed esegui il push delle due immagini su GCR:
# JIT image
docker tag image-analysis-maven-jit gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit
# Native(AOT) image
docker tag image-analysis-maven-native gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native
12. Esegui il deployment in Cloud Run
È ora di eseguire il deployment del servizio.
Esegui il deployment del servizio due volte: una volta utilizzando l'immagine JIT e la seconda volta utilizzando l'immagine AOT(nativa). Entrambi i deployment del servizio elaboreranno la stessa immagine dal bucket in parallelo, a scopo di confronto.
Innanzitutto, imposta le variabili di ambiente del progetto GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Esegui il deployment dell'immagine JIT e osserva il log di deployment nella console:
gcloud run deploy image-analysis-jit \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-jit] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-jit] revision [image-analysis-jvm-00009-huc] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-jit-...-ew.a.run.app
Esegui il deployment dell'immagine nativa e osserva il log di deployment nella console:
gcloud run deploy image-analysis-native \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-native] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-native] revision [image-analysis-native-00005-ben] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-native-...-ew.a.run.app
13. Configura i trigger Eventarc
Eventarc offre una soluzione standardizzata per gestire il flusso delle modifiche dello stato, chiamate eventi, tra microservizi disaccoppiati. Quando viene attivato, Eventarc indirizza questi eventi tramite le sottoscrizioni Pub/Sub a varie destinazioni (in questo documento, vedi Destinazioni degli eventi) e gestisce per te la distribuzione, la sicurezza, l'autorizzazione, l'osservabilità e la gestione degli errori.
Puoi creare un trigger Eventarc in modo che il tuo servizio Cloud Run riceva notifiche di un evento o di un insieme di eventi specifici. Specificando i filtri per il trigger, puoi configurare il routing dell'evento, inclusi l'origine evento e il servizio Cloud Run di destinazione.
Innanzitutto, imposta le variabili di ambiente del progetto GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Concedi pubsub.publisher al service account Cloud Storage:
SERVICE_ACCOUNT="$(gsutil kms serviceaccount -p ${GOOGLE_CLOUD_PROJECT})"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role='roles/pubsub.publisher'
Configura i trigger Eventarc per le immagini dei servizi JIT e nativi per elaborare l'immagine:
gcloud eventarc triggers list --location=eu
gcloud eventarc triggers create image-analysis-jit-trigger \
--destination-run-service=image-analysis-jit \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
gcloud eventarc triggers create image-analysis-native-trigger \
--destination-run-service=image-analysis-native \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
Nota che sono stati creati due trigger:
gcloud eventarc triggers list --location=eu
14. Versioni del servizio di test
Una volta completati i deployment dei servizi, pubblica un'immagine in Cloud Storage, verifica se i nostri servizi sono stati richiamati, cosa restituisce l'API Vision e se i metadati sono archiviati in Firestore.
Torna a Cloud Storage e fai clic sul bucket che abbiamo creato all'inizio del lab:

Una volta nella pagina dei dettagli del bucket, fai clic sul pulsante Upload files per caricare un'immagine.
Ad esempio, un'immagine GeekHour.jpeg viene fornita con il codebase in /services/image-analysis/java. Seleziona un'immagine e premi Open button:

Ora puoi controllare l'esecuzione del servizio, a partire da image-analysis-jit, seguito da image-analysis-native.
Dal menu "hamburger" (☰), vai al servizio Cloud Run > image-analysis-jit.
Fai clic su Log e osserva l'output:

Infatti, nell'elenco dei log, posso vedere che è stato richiamato il servizio JIT image-analysis-jit.
I log indicano l'inizio e la fine dell'esecuzione del servizio. Nel mezzo, possiamo vedere i log inseriti nella funzione con le istruzioni di log a livello INFO. Vediamo:
- I dettagli dell'evento che attiva la nostra funzione.
- I risultati non elaborati della chiamata API Vision,
- Le etichette trovate nell'immagine che abbiamo caricato,
- Le informazioni sui colori dominanti,
- Se l'immagine è sicura da mostrare.
- e alla fine i metadati dell'immagine sono stati archiviati in Firestore.
Ripeti la procedura per il servizio image-analysis-native.
Dal menu "hamburger" (☰), vai al servizio Cloud Run > image-analysis-native.
Fai clic su Log e osserva l'output:

Ora devi verificare se i metadati dell'immagine sono stati archiviati in Fiorestore.
Sempre dal menu "hamburger" (☰), vai alla sezione Firestore. Nella sottosezione Data (visualizzata per impostazione predefinita), dovresti vedere la raccolta pictures con un nuovo documento aggiunto, corrispondente all'immagine che hai appena caricato:

15. Pulizia (facoltativo)
Se non intendi continuare con gli altri lab della serie, puoi eseguire la pulizia delle risorse per risparmiare sui costi e per essere un buon cittadino del cloud. Puoi ripulire le risorse singolarmente nel seguente modo.
Elimina il bucket:
gsutil rb gs://${BUCKET_PICTURES}
Elimina la funzione:
gcloud functions delete picture-uploaded --region europe-west1 -q
Elimina la raccolta Firestore selezionando Elimina raccolta dalla raccolta:

In alternativa, puoi eliminare l'intero progetto:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
16. Complimenti!
Complimenti! Hai implementato correttamente il primo servizio chiave del progetto.
Argomenti trattati
- Cloud Storage
- Cloud Run
- API Cloud Vision
- Cloud Firestore
- Immagini Java native