
1. Przegląd
W pierwszym module przechowasz zdjęcia w zasobniku. Spowoduje to wygenerowanie zdarzenia utworzenia pliku, które zostanie obsłużone przez usługę wdrożoną w Cloud Run. Usługa wywoła interfejs Vision API, aby przeprowadzić analizę obrazu i zapisać wyniki w magazynie danych.

Czego się nauczysz
- Cloud Storage
- Cloud Run
- Cloud Vision API
- Cloud Firestore
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail ani Google Workspace, musisz je utworzyć.



- Nazwa projektu to wyświetlana nazwa uczestników tego projektu. Jest to ciąg znaków, który nie jest używany przez interfejsy API Google. Zawsze możesz ją zaktualizować.
- Identyfikator projektu jest unikalny we wszystkich projektach Google Cloud i nie można go zmienić po ustawieniu. Konsola Cloud automatycznie generuje unikalny ciąg znaków. Zwykle nie musisz się tym przejmować. W większości ćwiczeń z programowania musisz odwoływać się do identyfikatora projektu (zwykle oznaczanego jako
PROJECT_ID). Jeśli wygenerowany identyfikator Ci się nie podoba, możesz wygenerować inny losowy identyfikator. Możesz też spróbować własnej nazwy i sprawdzić, czy jest dostępna. Po tym kroku nie można go zmienić i pozostaje on taki przez cały czas trwania projektu. - Warto wiedzieć, że istnieje też trzecia wartość, numer projektu, której używają niektóre interfejsy API. Więcej informacji o tych 3 wartościach znajdziesz w dokumentacji.
- Następnie musisz włączyć płatności w konsoli Cloud, aby korzystać z zasobów i interfejsów API Google Cloud. Wykonanie tego laboratorium nie będzie kosztować dużo, a może nawet nic. Aby wyłączyć zasoby i uniknąć naliczania opłat po zakończeniu tego samouczka, możesz usunąć utworzone zasoby lub projekt. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym module praktycznym będziesz używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:

Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
3. Włącz interfejsy API
W tym module będziesz korzystać z Cloud Functions i interfejsu Vision API, ale najpierw musisz je włączyć w konsoli Google Cloud lub za pomocą gcloud.
Aby włączyć interfejs Vision API w konsoli Cloud, na pasku wyszukiwania wpisz Cloud Vision API:

Wyświetli się strona Cloud Vision API:

Kliknij przycisk ENABLE.
Możesz też włączyć go w Cloud Shell za pomocą narzędzia wiersza poleceń gcloud.
W Cloud Shell uruchom to polecenie:
gcloud services enable vision.googleapis.com
Operacja powinna zakończyć się powodzeniem:
Operation "operations/acf.12dba18b-106f-4fd2-942d-fea80ecc5c1c" finished successfully.
Włącz też Cloud Run i Cloud Build:
gcloud services enable cloudbuild.googleapis.com \ run.googleapis.com
4. Tworzenie zasobnika (konsola)
Utwórz zasobnik na zdjęcia. Możesz to zrobić w konsoli Google Cloud Platform ( console.cloud.google.com) lub za pomocą narzędzia wiersza poleceń gsutil w Cloud Shell lub lokalnym środowisku programistycznym.
Otwórz Miejsce na dane
W menu „hamburger” (☰) otwórz stronę Storage.

Nazwij zasobnik
Kliknij przycisk CREATE BUCKET.

Kliknij CONTINUE.
Wybierz lokalizację
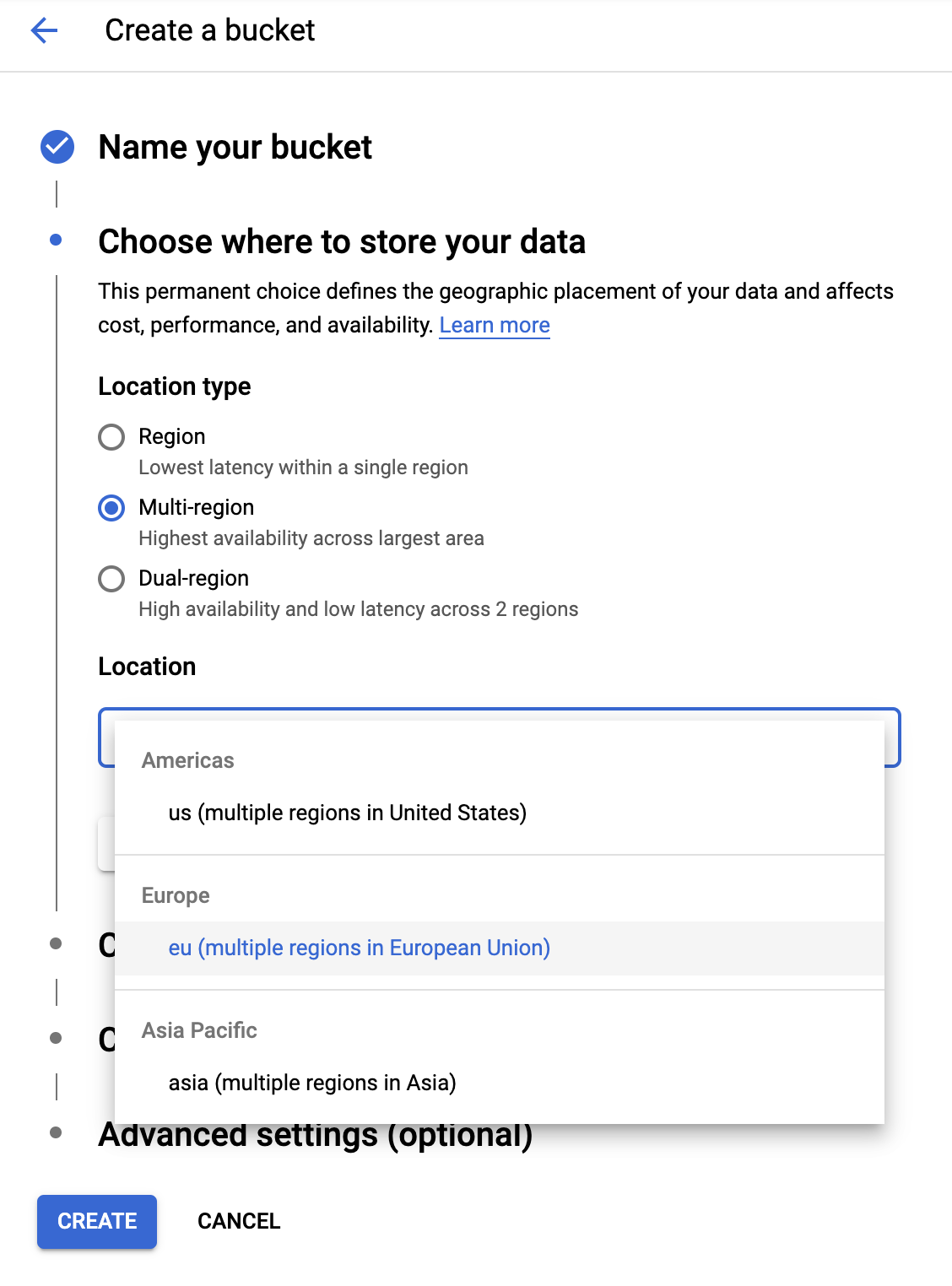
Utwórz zasobnik z wieloma regionami w wybranym regionie (w tym przypadku Europe).
Kliknij CONTINUE.
Wybierz domyślną klasę pamięci masowej
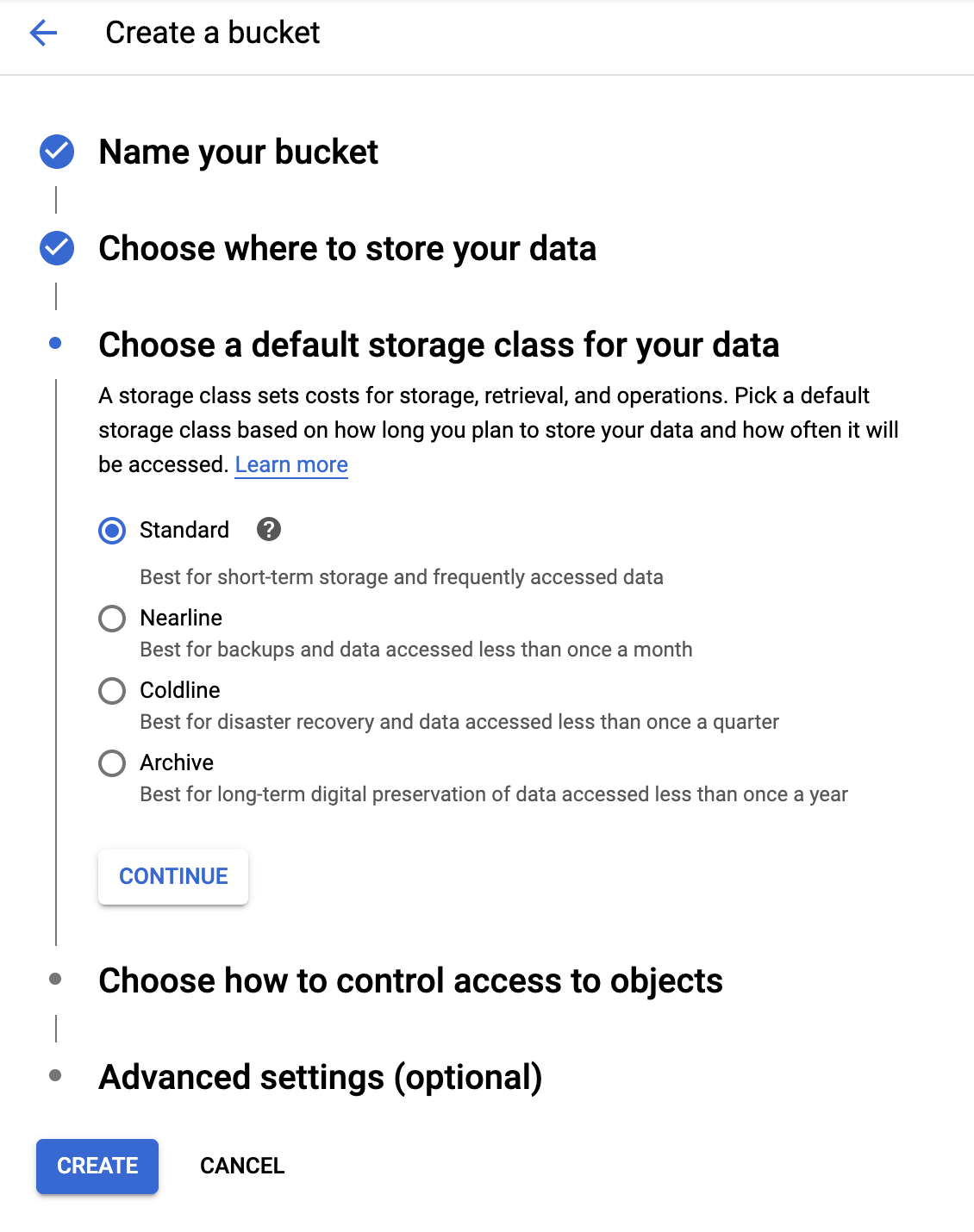
Wybierz klasę pamięci masowej Standard dla swoich danych.
Kliknij CONTINUE.
Ustawianie kontroli dostępu
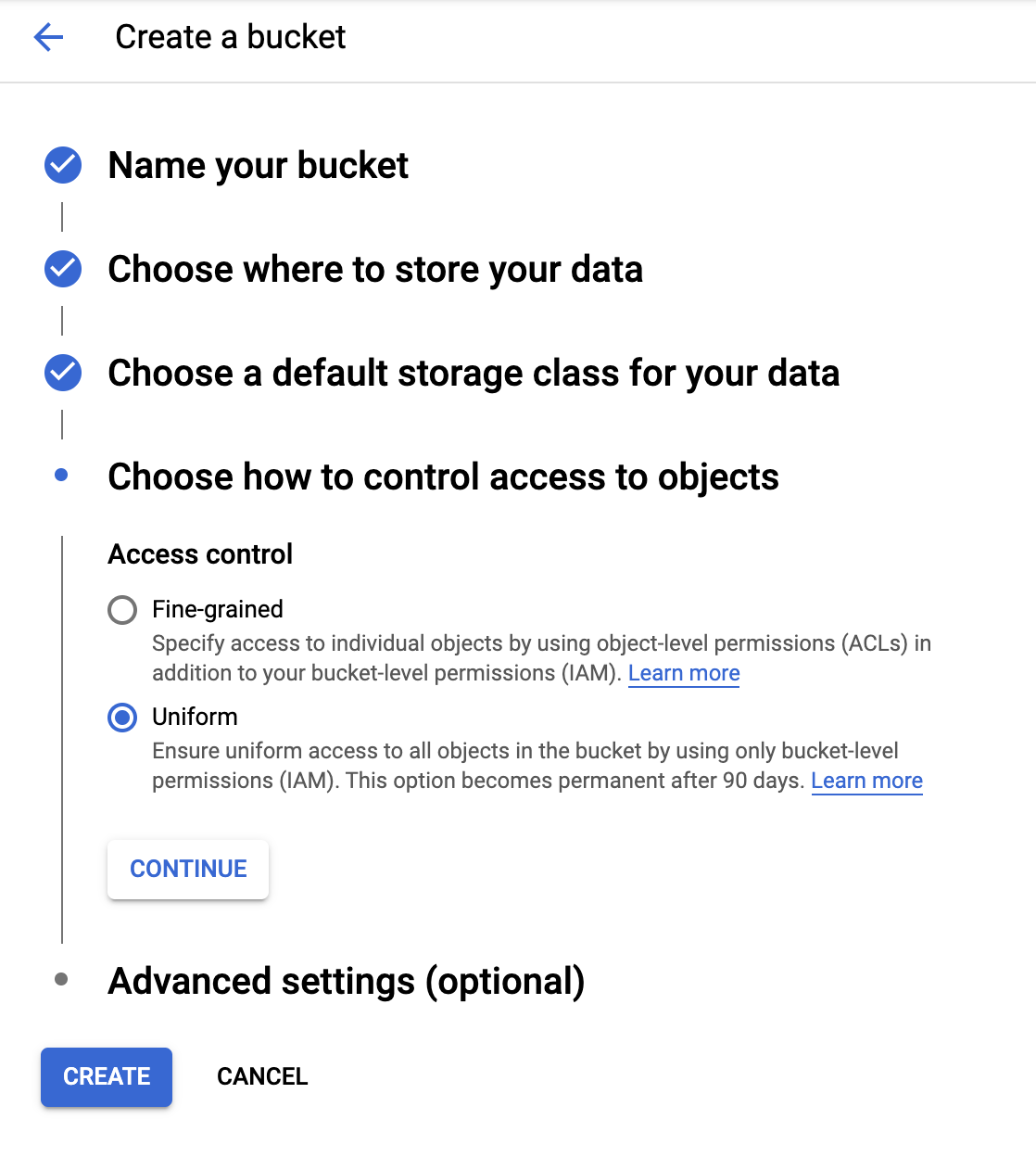
Będziesz pracować z publicznie dostępnymi obrazami, więc chcesz, aby wszystkie zdjęcia przechowywane w tym zasobniku miały takie same, jednolite ustawienia kontroli dostępu.
Wybierz opcję kontroli dostępu Uniform.
Kliknij CONTINUE.
Ustawianie ochrony/szyfrowania
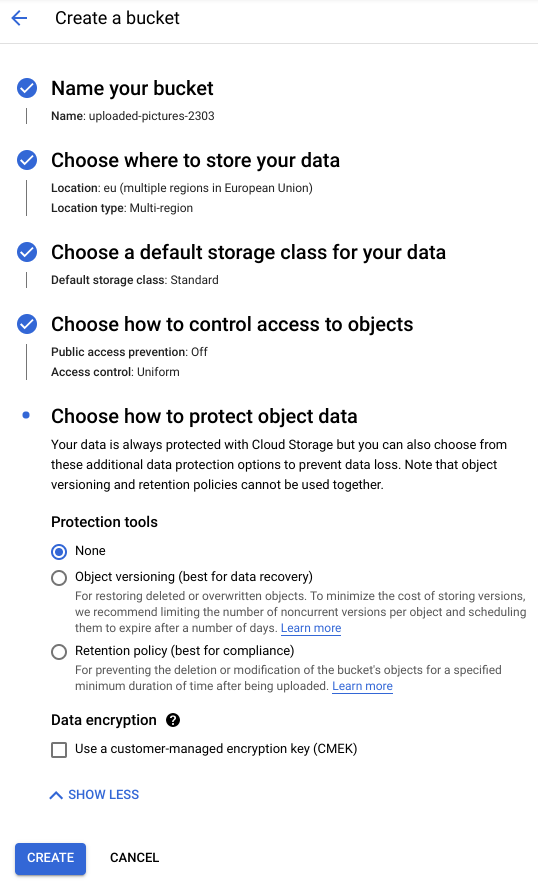
Zachowaj ustawienie domyślne (Google-managed key)), ponieważ nie będziesz używać własnych kluczy szyfrowania.
Kliknij CREATE, aby zakończyć tworzenie zasobnika.
Dodawanie allUsers jako przeglądającego miejsce na dane
Otwórz kartę Permissions:
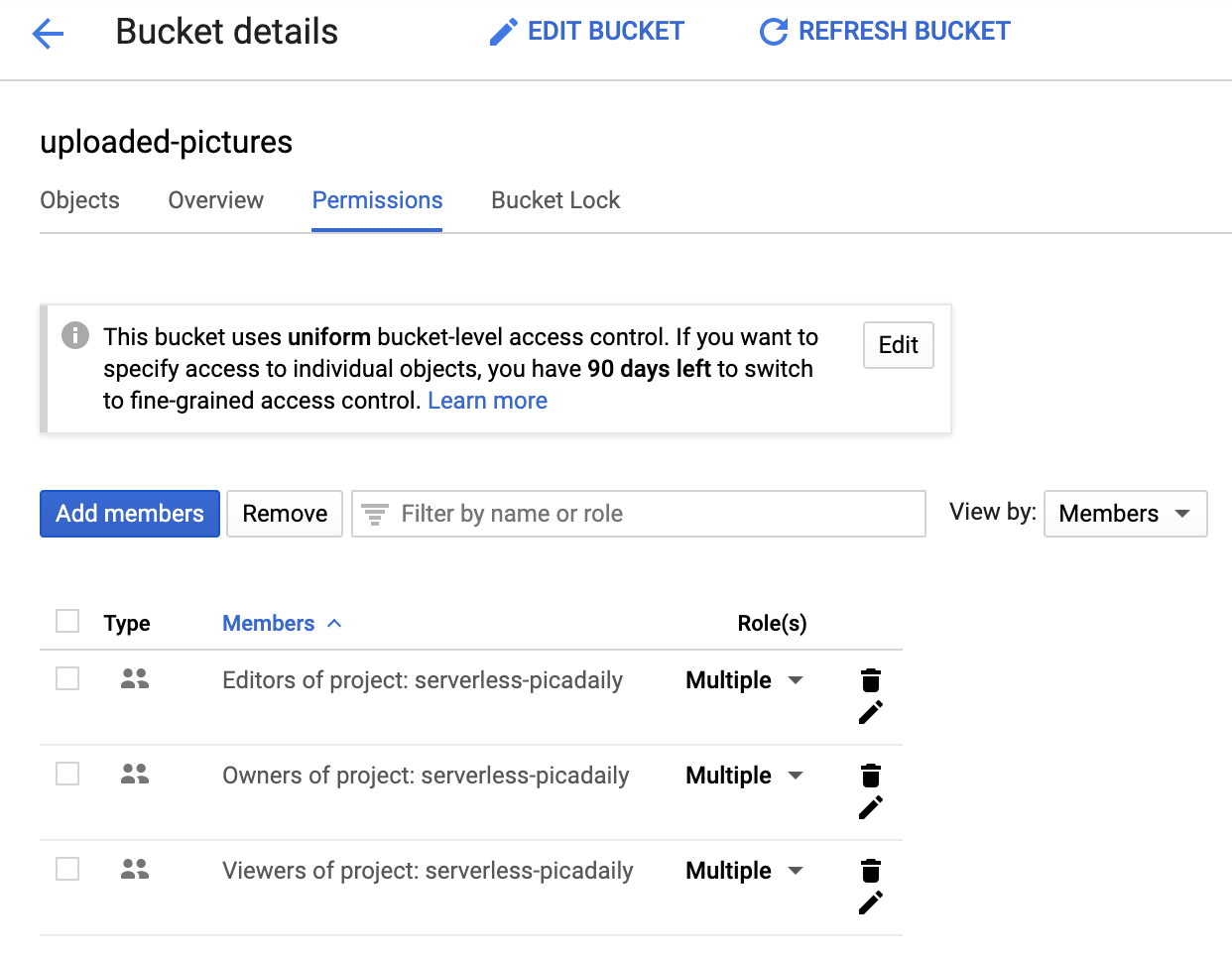
Dodaj do zasobnika użytkownika allUsers z rolą Storage > Storage Object Viewer w ten sposób:
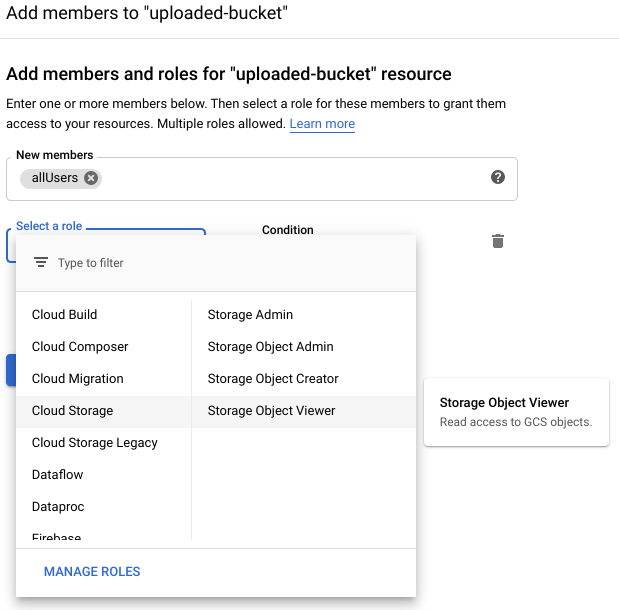
Kliknij SAVE.
5. Tworzenie zasobnika (gsutil)
Do tworzenia zasobników możesz też używać narzędzia wiersza poleceń gsutil w Cloud Shell.
W Cloud Shell ustaw zmienną dla unikalnej nazwy zasobnika. W Cloud Shell zmienna GOOGLE_CLOUD_PROJECT jest już ustawiona na Twój unikalny identyfikator projektu. Możesz dodać go do nazwy zasobnika.
Na przykład:
export BUCKET_PICTURES=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}
Utwórz standardową strefę wieloregionową w Europie:
gsutil mb -l EU gs://${BUCKET_PICTURES}
Sprawdź, czy jest włączony jednolity dostęp na poziomie zasobnika:
gsutil uniformbucketlevelaccess set on gs://${BUCKET_PICTURES}
Ustaw zasobnik jako publiczny:
gsutil iam ch allUsers:objectViewer gs://${BUCKET_PICTURES}
Jeśli przejdziesz do sekcji Cloud Storage w konsoli, powinien być tam publiczny uploaded-pictures:
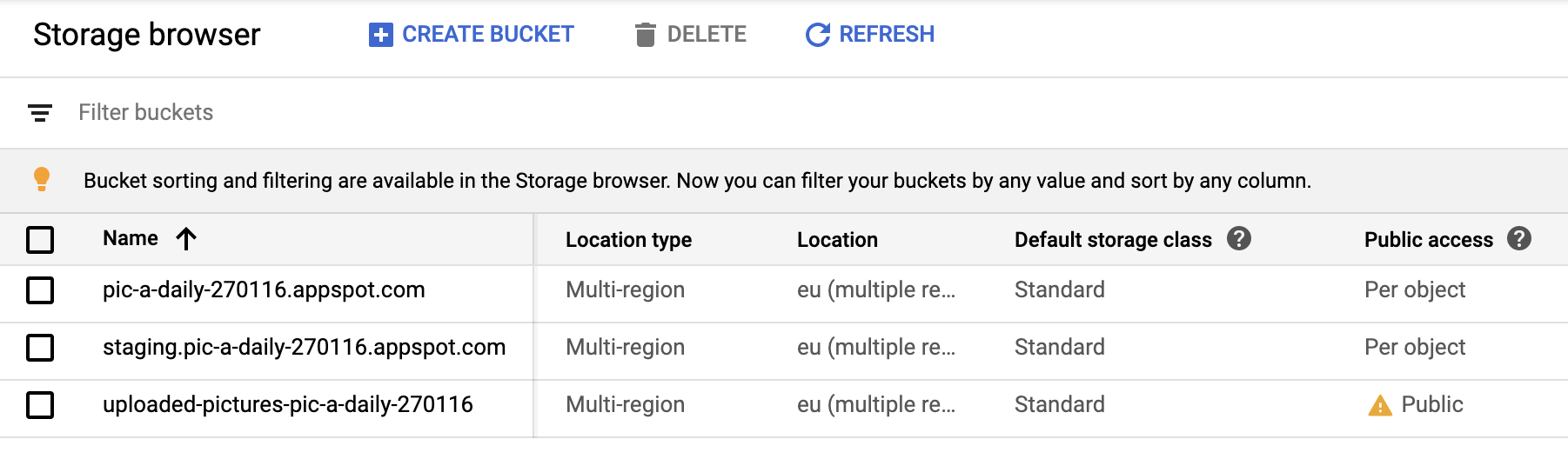
Sprawdź, czy możesz przesyłać zdjęcia do zasobnika i czy przesłane zdjęcia są dostępne publicznie, jak opisano w poprzednim kroku.
6. Testowanie dostępu publicznego do zasobnika
Wracając do przeglądarki pamięci, zobaczysz na liście swój zasobnik z dostępem „Publiczny” (wraz z ostrzeżeniem, że każdy ma dostęp do zawartości tego zasobnika).

Zasobnik jest gotowy do odbierania zdjęć.
Jeśli klikniesz nazwę zasobnika, zobaczysz jego szczegóły.
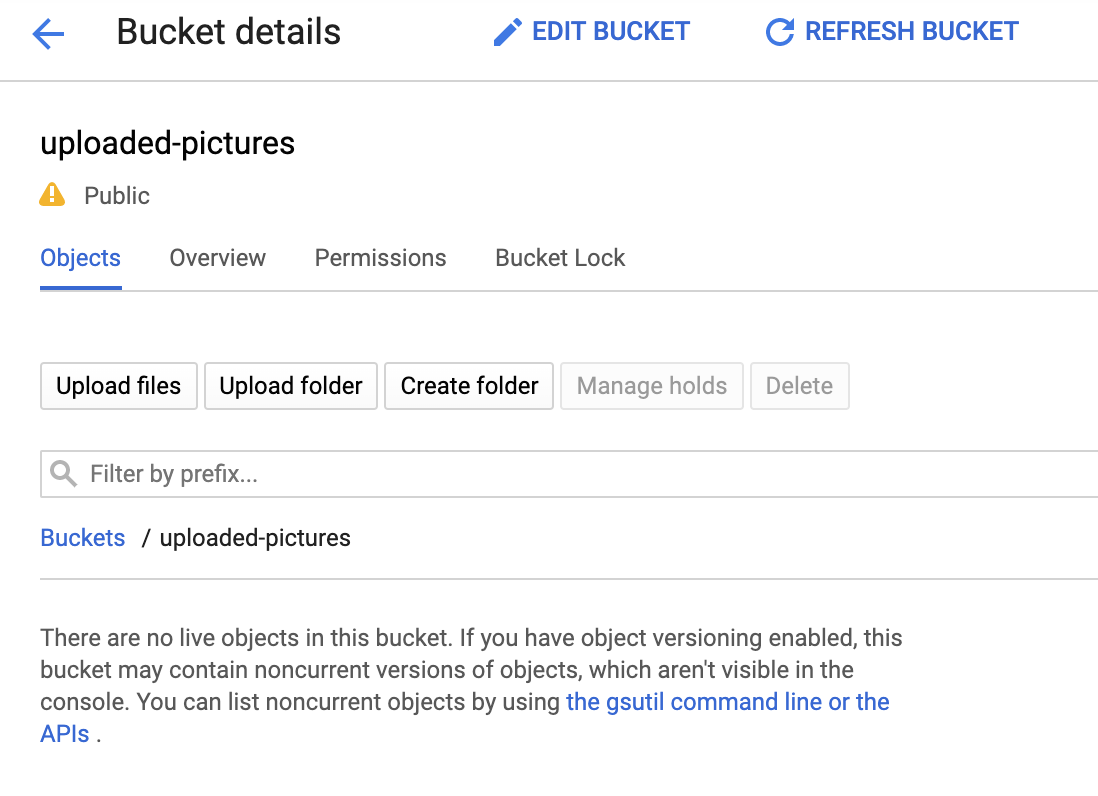
Możesz tam kliknąć przycisk Upload files, aby sprawdzić, czy możesz dodać obraz do zasobnika. Pojawi się wyskakujące okienko z prośbą o wybranie pliku. Po wybraniu plik zostanie przesłany do zasobnika i ponownie zobaczysz public dostęp, który został automatycznie przypisany do tego nowego pliku.
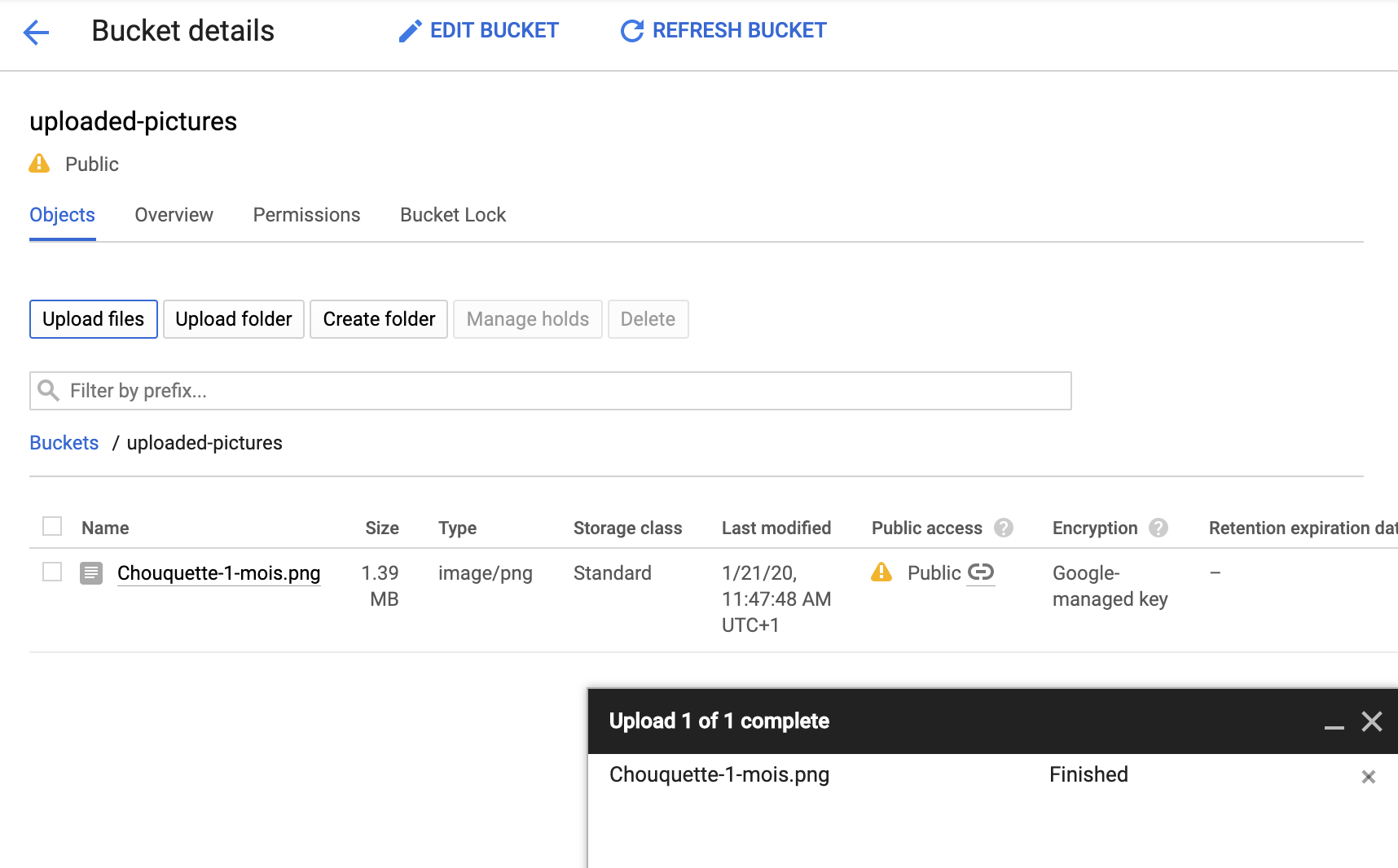
Obok etykiety dostępu Public zobaczysz też małą ikonę linku. Po kliknięciu przeglądarka przejdzie do publicznego adresu URL tego obrazu, który będzie miał postać:
https://storage.googleapis.com/BUCKET_NAME/PICTURE_FILE.png
gdzie BUCKET_NAME to niepowtarzalna globalnie nazwa zasobnika, a następnie nazwa pliku obrazu.
Kliknięcie pola wyboru obok nazwy obrazu spowoduje włączenie przycisku DELETE, dzięki czemu możesz usunąć pierwszy obraz.
7. Przygotowywanie bazy danych
Informacje o zdjęciu podane przez interfejs Vision API zapiszesz w bazie danych Cloud Firestore, czyli szybkiej, w pełni zarządzanej, bezserwerowej, chmurowej bazie danych dokumentów NoSQL. Przygotuj bazę danych, przechodząc do sekcji Firestore w konsoli Cloud:
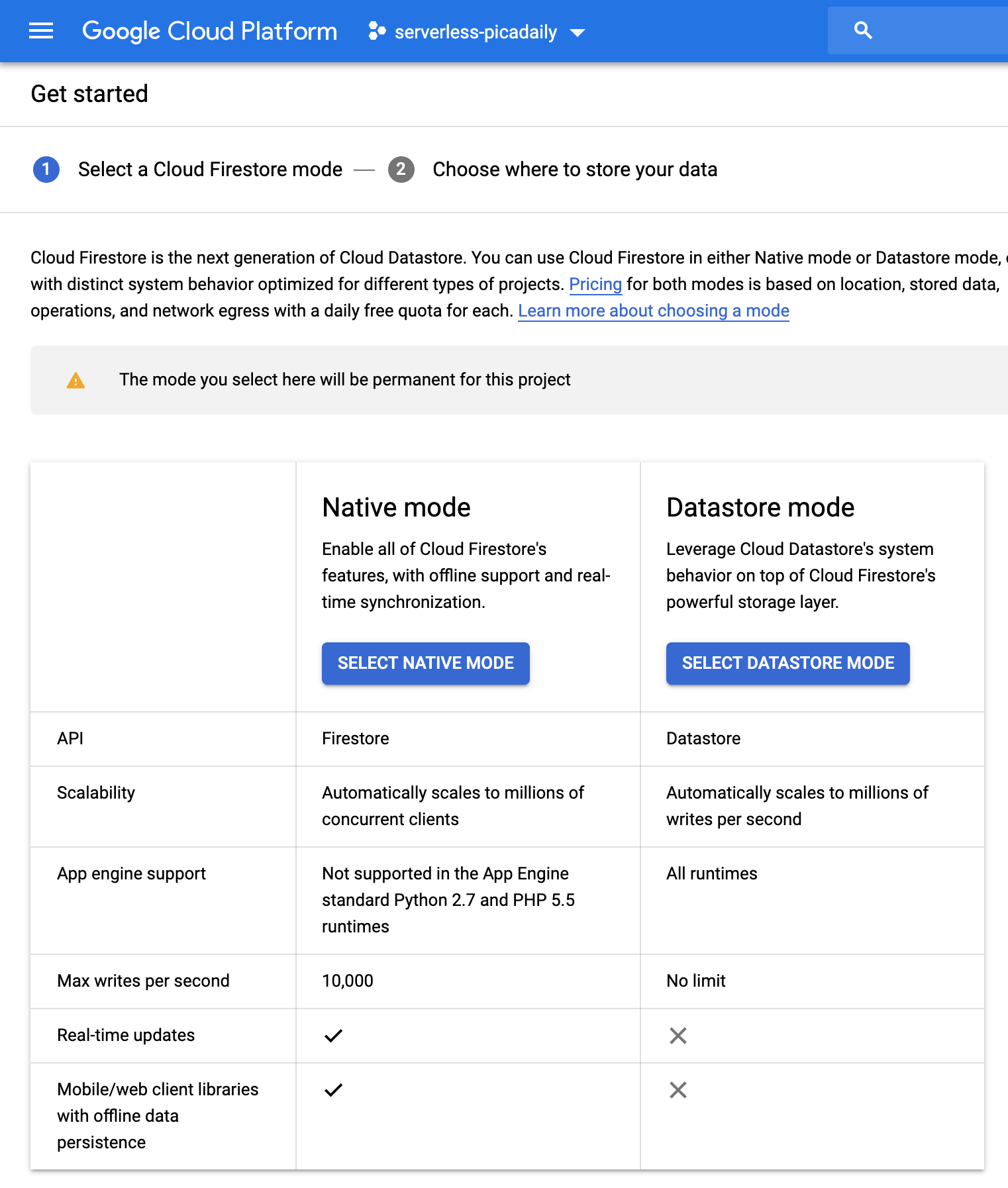
Dostępne są 2 opcje: Native mode lub Datastore mode. Używaj trybu natywnego, który oferuje dodatkowe funkcje, takie jak obsługa offline i synchronizacja w czasie rzeczywistym.
Kliknij SELECT NATIVE MODE.
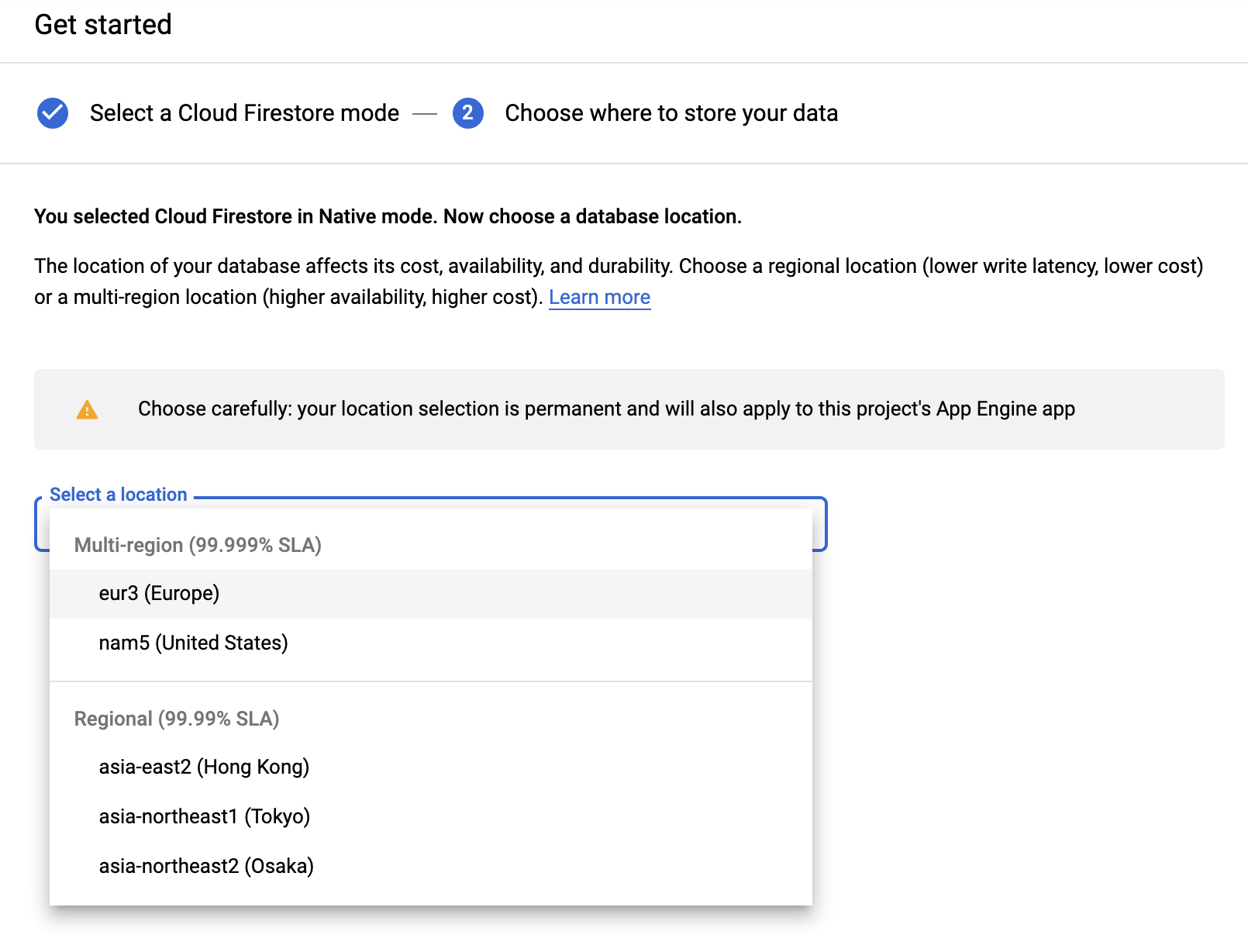
Wybierz region obejmujący wiele lokalizacji (w tym przypadku w Europie, ale najlepiej co najmniej ten sam region, w którym znajdują się Funkcje i zasobnik pamięci).
Kliknij przycisk CREATE DATABASE.
Po utworzeniu bazy danych zobaczysz te informacje:
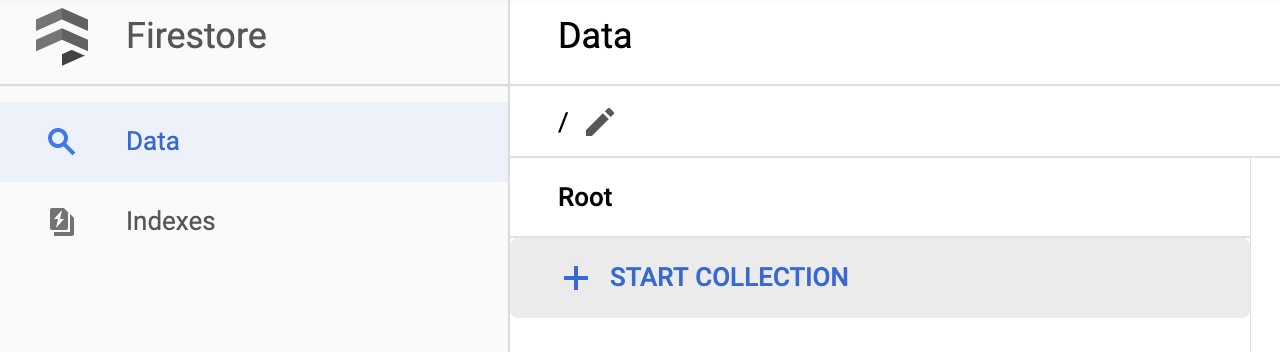
Utwórz nową kolekcję, klikając przycisk + START COLLECTION.
Nazwij kolekcję pictures.
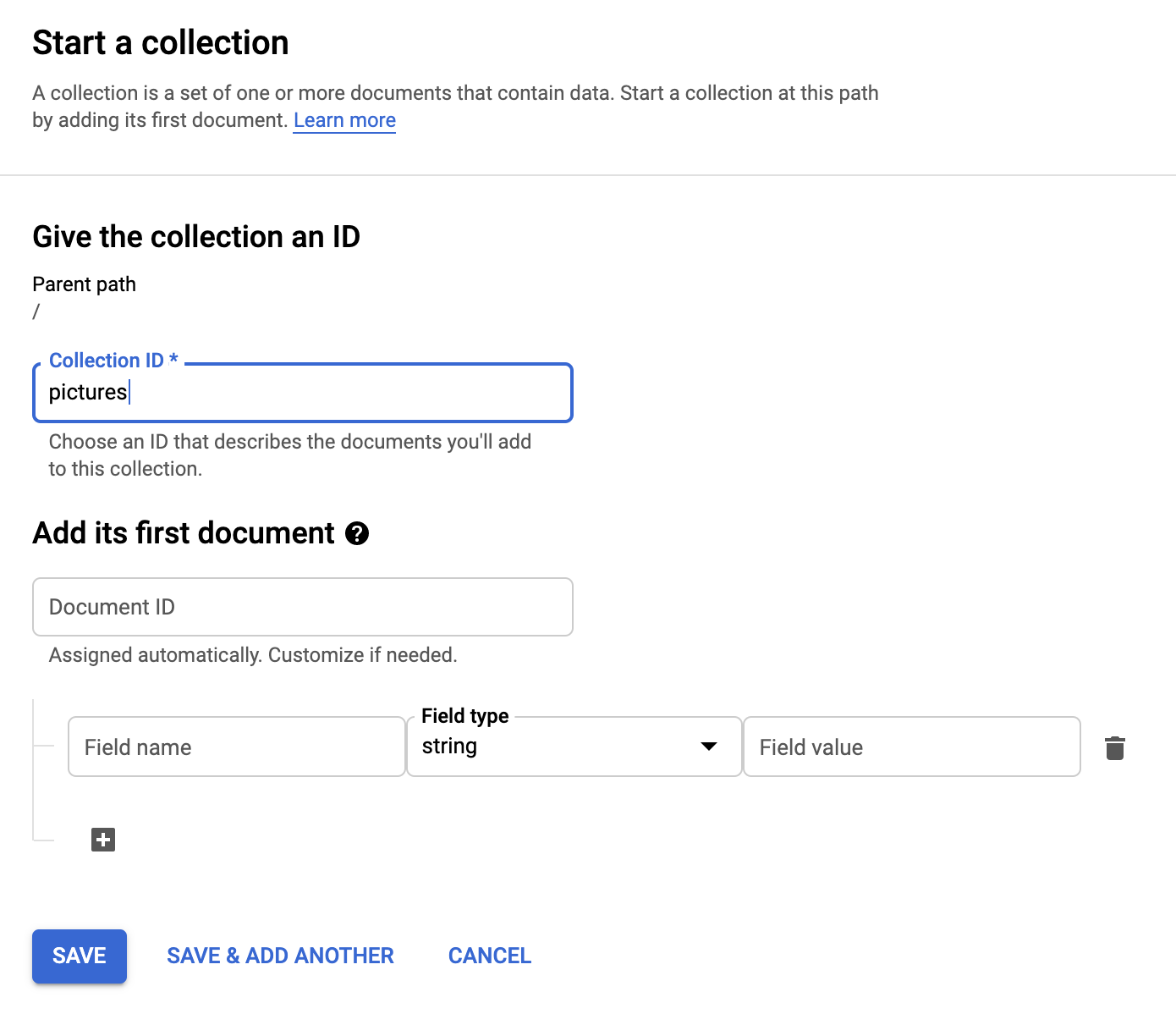
Nie musisz tworzyć dokumentu. Dodasz je programowo, gdy nowe zdjęcia będą przechowywane w Cloud Storage i analizowane przez interfejs Vision API.
Kliknij Save.
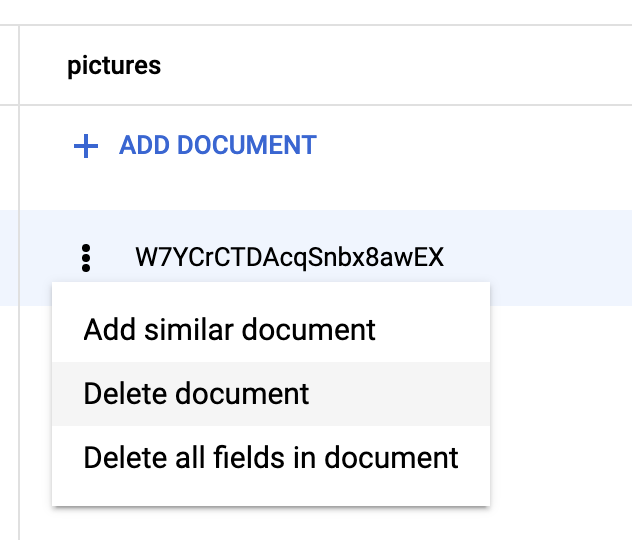
Firestore tworzy pierwszy domyślny dokument w nowo utworzonej kolekcji. Możesz go bezpiecznie usunąć, ponieważ nie zawiera żadnych przydatnych informacji:
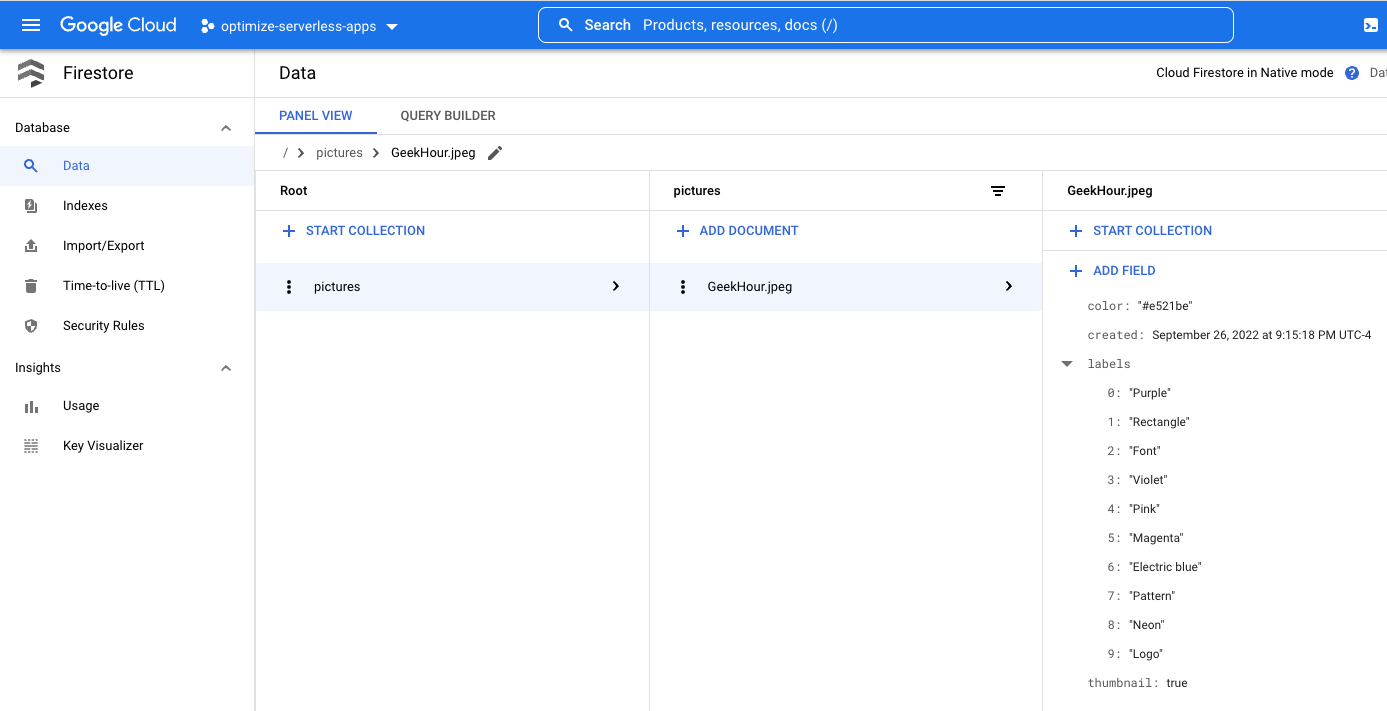
Dokumenty, które zostaną utworzone programowo w naszej kolekcji, będą zawierać 4 pola:
- name (string): nazwa pliku przesłanego zdjęcia, która jest też kluczem dokumentu.
- labels (tablica ciągów znaków): etykiety rozpoznanych elementów przez Vision API.
- color (string): szesnastkowy kod koloru dominującego (np. #ab12ef)
- created (data): sygnatura czasowa wskazująca, kiedy metadane tego obrazu zostały zapisane.
- thumbnail (wartość logiczna): pole opcjonalne, które będzie obecne i będzie miało wartość „true”, jeśli dla tego zdjęcia została wygenerowana miniatura.
Będziemy wyszukiwać w Firestore zdjęcia, dla których dostępne są miniatury, i sortować je według daty utworzenia, więc musimy utworzyć indeks wyszukiwania.
Możesz utworzyć indeks za pomocą tego polecenia w Cloud Shell:
gcloud firestore indexes composite create \
--collection-group=pictures \
--field-config field-path=thumbnail,order=descending \
--field-config field-path=created,order=descending
Możesz też to zrobić w konsoli Google Cloud, klikając Indexes w kolumnie nawigacyjnej po lewej stronie, a następnie tworząc indeks złożony w sposób pokazany poniżej:
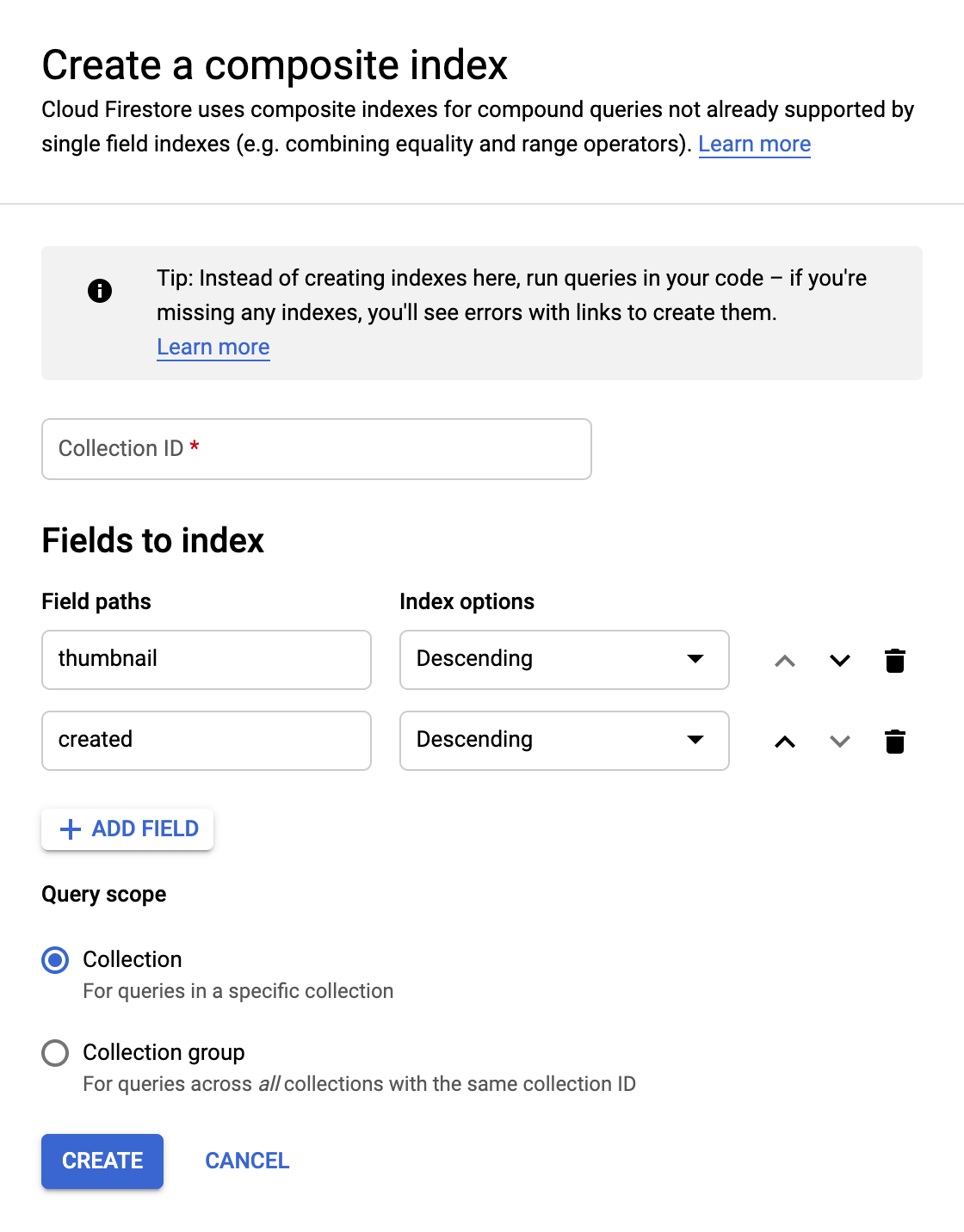
Kliknij Create. Tworzenie indeksu może potrwać kilka minut.
8. Klonowanie kodu
Sklonuj kod, jeśli nie masz go jeszcze z poprzedniego modułu:
git clone https://github.com/GoogleCloudPlatform/serverless-photosharing-workshop
Następnie możesz przejść do katalogu zawierającego usługę, aby rozpocząć tworzenie modułu:
cd serverless-photosharing-workshop/services/image-analysis/java
Usługa będzie miała ten układ pliku:
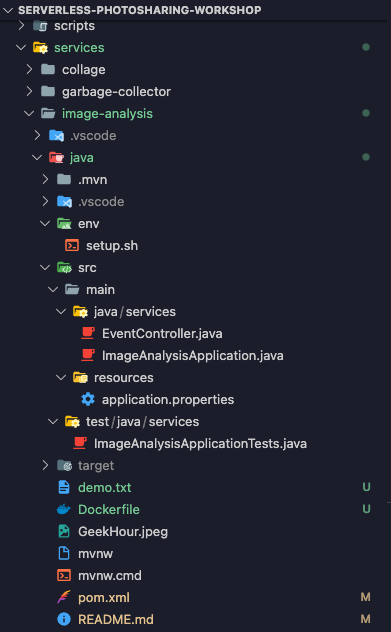
9. Poznaj kod usługi
Zacznij od sprawdzenia, jak włączane są biblioteki klienta Java w pom.xmlza pomocą BOM:
Najpierw otwórz plik pom.xml, który zawiera listę zależności naszej aplikacji w języku Java. Skupimy się na użyciu interfejsów Vision API, Cloud Storage API i Firestore API.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.0-M3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>services</groupId>
<artifactId>image-analysis</artifactId>
<version>0.0.1</version>
<name>image-analysis</name>
<description>Spring App for Image Analysis</description>
<properties>
<java.version>17</java.version>
<maven.compiler.target>17</maven.compiler.target>
<maven.compiler.source>17</maven.compiler.source>
<spring-cloud.version>2023.0.0-M2</spring-cloud.version>
<testcontainers.version>1.19.1</testcontainers.version>
</properties>
...
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>libraries-bom</artifactId>
<version>26.24.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
—
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-function-web</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud.functions</groupId>
<artifactId>functions-framework-api</artifactId>
<version>1.1.0</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-firestore</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-vision</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-storage</artifactId>
</dependency>
Funkcja jest zaimplementowana w klasie EventController. Za każdym razem, gdy do zasobnika przesyłany jest nowy obraz, usługa otrzymuje powiadomienie o konieczności przetworzenia:
@RestController
public class EventController {
private static final Logger logger = Logger.getLogger(EventController.class.getName());
private static final List<String> requiredFields = Arrays.asList("ce-id", "ce-source", "ce-type", "ce-specversion");
@RequestMapping(value = "/", method = RequestMethod.POST)
public ResponseEntity<String> receiveMessage(
@RequestBody Map<String, Object> body, @RequestHeader Map<String, String> headers) throws IOException, InterruptedException, ExecutionException {
...
}
Kod przejdzie do weryfikacji nagłówków Cloud Events:
System.out.println("Header elements");
for (String field : requiredFields) {
if (headers.get(field) == null) {
String msg = String.format("Missing expected header: %s.", field);
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
} else {
System.out.println(field + " : " + headers.get(field));
}
}
System.out.println("Body elements");
for (String bodyField : body.keySet()) {
System.out.println(bodyField + " : " + body.get(bodyField));
}
if (headers.get("ce-subject") == null) {
String msg = "Missing expected header: ce-subject.";
System.out.println(msg);
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Możesz teraz utworzyć żądanie, a kod przygotuje je do wysłania do Vision API:
try (ImageAnnotatorClient vision = ImageAnnotatorClient.create()) {
List<AnnotateImageRequest> requests = new ArrayList<>();
ImageSource imageSource = ImageSource.newBuilder()
.setGcsImageUri("gs://" + bucketName + "/" + fileName)
.build();
Image image = Image.newBuilder()
.setSource(imageSource)
.build();
Feature featureLabel = Feature.newBuilder()
.setType(Type.LABEL_DETECTION)
.build();
Feature featureImageProps = Feature.newBuilder()
.setType(Type.IMAGE_PROPERTIES)
.build();
Feature featureSafeSearch = Feature.newBuilder()
.setType(Type.SAFE_SEARCH_DETECTION)
.build();
AnnotateImageRequest request = AnnotateImageRequest.newBuilder()
.addFeatures(featureLabel)
.addFeatures(featureImageProps)
.addFeatures(featureSafeSearch)
.setImage(image)
.build();
requests.add(request);
Prosimy o 3 kluczowe funkcje interfejsu Vision API:
- Wykrywanie etykiet: aby zrozumieć, co znajduje się na zdjęciach.
- Właściwości obrazu: aby podać interesujące atrybuty obrazu (interesuje nas dominujący kolor obrazu).
- Bezpieczne wyszukiwanie: aby sprawdzić, czy obraz jest bezpieczny do wyświetlenia (nie powinien zawierać treści dla dorosłych, medycznych, o charakterze seksualnym ani treści przedstawiających przemoc).
W tym momencie możemy wywołać interfejs Vision API:
...
logger.info("Calling the Vision API...");
BatchAnnotateImagesResponse result = vision.batchAnnotateImages(requests);
List<AnnotateImageResponse> responses = result.getResponsesList();
...
Oto przykład odpowiedzi interfejsu Vision API:
{
"faceAnnotations": [],
"landmarkAnnotations": [],
"logoAnnotations": [],
"labelAnnotations": [
{
"locations": [],
"properties": [],
"mid": "/m/01yrx",
"locale": "",
"description": "Cat",
"score": 0.9959855675697327,
"confidence": 0,
"topicality": 0.9959855675697327,
"boundingPoly": null
},
✄ - - - ✄
],
"textAnnotations": [],
"localizedObjectAnnotations": [],
"safeSearchAnnotation": {
"adult": "VERY_UNLIKELY",
"spoof": "UNLIKELY",
"medical": "VERY_UNLIKELY",
"violence": "VERY_UNLIKELY",
"racy": "VERY_UNLIKELY",
"adultConfidence": 0,
"spoofConfidence": 0,
"medicalConfidence": 0,
"violenceConfidence": 0,
"racyConfidence": 0,
"nsfwConfidence": 0
},
"imagePropertiesAnnotation": {
"dominantColors": {
"colors": [
{
"color": {
"red": 203,
"green": 201,
"blue": 201,
"alpha": null
},
"score": 0.4175916016101837,
"pixelFraction": 0.44456374645233154
},
✄ - - - ✄
]
}
},
"error": null,
"cropHintsAnnotation": {
"cropHints": [
{
"boundingPoly": {
"vertices": [
{ "x": 0, "y": 118 },
{ "x": 1177, "y": 118 },
{ "x": 1177, "y": 783 },
{ "x": 0, "y": 783 }
],
"normalizedVertices": []
},
"confidence": 0.41695669293403625,
"importanceFraction": 1
}
]
},
"fullTextAnnotation": null,
"webDetection": null,
"productSearchResults": null,
"context": null
}
Jeśli nie zostanie zwrócony żaden błąd, możemy przejść dalej. Dlatego mamy ten blok if:
if (responses.size() == 0) {
logger.info("No response received from Vision API.");
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
AnnotateImageResponse response = responses.get(0);
if (response.hasError()) {
logger.info("Error: " + response.getError().getMessage());
return new ResponseEntity<String>(msg, HttpStatus.BAD_REQUEST);
}
Pobierzemy etykiety rzeczy, kategorii lub motywów rozpoznanych na zdjęciu:
List<String> labels = response.getLabelAnnotationsList().stream()
.map(annotation -> annotation.getDescription())
.collect(Collectors.toList());
logger.info("Annotations found:");
for (String label: labels) {
logger.info("- " + label);
}
Chcemy poznać dominujący kolor zdjęcia:
String mainColor = "#FFFFFF";
ImageProperties imgProps = response.getImagePropertiesAnnotation();
if (imgProps.hasDominantColors()) {
DominantColorsAnnotation colorsAnn = imgProps.getDominantColors();
ColorInfo colorInfo = colorsAnn.getColors(0);
mainColor = rgbHex(
colorInfo.getColor().getRed(),
colorInfo.getColor().getGreen(),
colorInfo.getColor().getBlue());
logger.info("Color: " + mainColor);
}
Sprawdźmy, czy zdjęcie jest bezpieczne:
boolean isSafe = false;
if (response.hasSafeSearchAnnotation()) {
SafeSearchAnnotation safeSearch = response.getSafeSearchAnnotation();
isSafe = Stream.of(
safeSearch.getAdult(), safeSearch.getMedical(), safeSearch.getRacy(),
safeSearch.getSpoof(), safeSearch.getViolence())
.allMatch( likelihood ->
likelihood != Likelihood.LIKELY && likelihood != Likelihood.VERY_LIKELY
);
logger.info("Safe? " + isSafe);
}
Sprawdzamy, czy treści nie zawierają prawdopodobnie lub bardzo prawdopodobnie treści dla dorosłych, parodii, treści medycznych, przemocy lub treści o charakterze erotycznym.
Jeśli wynik bezpiecznego wyszukiwania jest prawidłowy, możemy zapisać metadane w Firestore:
// Saving result to Firestore
if (isSafe) {
ApiFuture<WriteResult> writeResult =
eventService.storeImage(fileName, labels,
mainColor);
logger.info("Picture metadata saved in Firestore at " +
writeResult.get().getUpdateTime());
}
...
public ApiFuture<WriteResult> storeImage(String fileName,
List<String> labels,
String mainColor) {
FirestoreOptions firestoreOptions = FirestoreOptions.getDefaultInstance();
Firestore pictureStore = firestoreOptions.getService();
DocumentReference doc = pictureStore.collection("pictures").document(fileName);
Map<String, Object> data = new HashMap<>();
data.put("labels", labels);
data.put("color", mainColor);
data.put("created", new Date());
return doc.set(data, SetOptions.merge());
}
10. Tworzenie obrazów aplikacji za pomocą GraalVM
W tym opcjonalnym kroku utworzysz JIT based app image, a następnie Native Java app image za pomocą GraalVM.
Aby uruchomić kompilację, musisz mieć zainstalowany i skonfigurowany odpowiedni pakiet JDK oraz narzędzie do tworzenia obrazów natywnych. Dostępnych jest kilka opcji.
To start pobierz GraalVM 22.3.x Community Edition i postępuj zgodnie z instrukcjami na stronie instalacji GraalVM.
Ten proces można znacznie uprościć za pomocą narzędzia SDKMAN!
Aby zainstalować odpowiednią dystrybucję JDK za pomocą SDKman, zacznij od użycia polecenia instalacji:
sdk install java 17.0.8-graal
Poinstruuj SDKman, aby używał tej wersji w przypadku kompilacji JIT i AOT:
sdk use java 17.0.8-graal
W Cloudshell możesz zainstalować GraalVM i narzędzie native-image za pomocą tych prostych poleceń:
# download GraalVM wget https://download.oracle.com/graalvm/17/latest/graalvm-jdk-17_linux-x64_bin.tar.gz tar -xzf graalvm-jdk-17_linux-x64_bin.tar.gz ls -lart # configure Java 17 and GraalVM for Java 17 # note the name of the latest GraalVM version, as unpacked by the tar command echo Existing JVM: $JAVA_HOME cd graalvm-jdk-17.0.8+9.1 export JAVA_HOME=$PWD cd bin export PATH=$PWD:$PATH echo JAVA HOME: $JAVA_HOME echo PATH: $PATH cd ../.. # validate the version with java -version # observe Java(TM) SE Runtime Environment Oracle GraalVM 17.0.8+9.1 (build 17.0.8+9-LTS-jvmci-23.0-b14) Java HotSpot(TM) 64-Bit Server VM Oracle GraalVM 17.0.8+9.1 (build 17.0.8+9-LTS-jvmci-23.0-b14, mixed mode, sharing)
Najpierw ustaw zmienne środowiskowe projektu GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
Następnie możesz przejść do katalogu zawierającego usługę, aby rozpocząć tworzenie modułu:
cd serverless-photosharing-workshop/services/image-analysis/java
Utwórz obraz aplikacji JIT:
./mvnw package
Sprawdź log kompilacji w terminalu:
... [INFO] Results: [INFO] [INFO] Tests run: 6, Failures: 0, Errors: 0, Skipped: 0 [INFO] [INFO] [INFO] --- maven-jar-plugin:3.3.0:jar (default-jar) @ image-analysis --- [INFO] Building jar: /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar [INFO] [INFO] --- spring-boot-maven-plugin:3.2.0-M3:repackage (repackage) @ image-analysis --- [INFO] Replacing main artifact /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar with repackaged archive, adding nested dependencies in BOOT-INF/. [INFO] The original artifact has been renamed to /home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis-0.0.1.jar.original [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 15.335 s [INFO] Finished at: 2023-10-10T19:33:25Z [INFO] ------------------------------------------------------------------------
Utwórz obraz natywny(korzystający z kompilacji AOT):
./mvnw native:compile -Pnative
Obserwuj log kompilacji w terminalu, w tym logi kompilacji obrazu natywnego:
Pamiętaj, że kompilacja trwa dość długo, w zależności od urządzenia, na którym testujesz.
...
[2/7] Performing analysis... [*********] (124.5s @ 4.53GB)
29,732 (93.19%) of 31,905 classes reachable
60,161 (70.30%) of 85,577 fields reachable
261,973 (67.29%) of 389,319 methods reachable
2,940 classes, 2,297 fields, and 97,421 methods registered for reflection
81 classes, 90 fields, and 62 methods registered for JNI access
4 native libraries: dl, pthread, rt, z
[3/7] Building universe... (11.7s @ 4.67GB)
[4/7] Parsing methods... [***] (6.1s @ 5.91GB)
[5/7] Inlining methods... [****] (4.5s @ 4.39GB)
[6/7] Compiling methods... [******] (35.3s @ 4.60GB)
[7/7] Creating image... (12.9s @ 4.61GB)
80.08MB (47.43%) for code area: 190,483 compilation units
73.81MB (43.72%) for image heap: 660,125 objects and 189 resources
14.95MB ( 8.86%) for other data
168.84MB in total
------------------------------------------------------------------------------------------------------------------------
Top 10 packages in code area: Top 10 object types in image heap:
2.66MB com.google.cloud.vision.v1p4beta1 18.51MB byte[] for code metadata
2.60MB com.google.cloud.vision.v1 9.27MB java.lang.Class
2.49MB com.google.protobuf 7.34MB byte[] for reflection metadata
2.40MB com.google.cloud.vision.v1p3beta1 6.35MB byte[] for java.lang.String
2.17MB com.google.storage.v2 5.72MB java.lang.String
2.12MB com.google.firestore.v1 4.46MB byte[] for embedded resources
1.64MB sun.security.ssl 4.30MB c.oracle.svm.core.reflect.SubstrateMethodAccessor
1.51MB i.g.xds.shaded.io.envoyproxy.envoy.config.core.v3 4.27MB byte[] for general heap data
1.47MB com.google.cloud.vision.v1p2beta1 2.50MB com.oracle.svm.core.hub.DynamicHubCompanion
1.34MB i.g.x.shaded.io.envoyproxy.envoy.config.route.v3 1.17MB java.lang.Object[]
58.34MB for 977 more packages 9.19MB for 4667 more object types
------------------------------------------------------------------------------------------------------------------------
13.5s (5.7% of total time) in 75 GCs | Peak RSS: 9.44GB | CPU load: 6.13
------------------------------------------------------------------------------------------------------------------------
Produced artifacts:
/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis (executable)
/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis.build_artifacts.txt (txt)
========================================================================================================================
Finished generating '/home/user/serverless-photosharing-workshop/services/image-analysis/java/target/image-analysis' in 3m 57s.
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 04:28 min
[INFO] Finished at: 2023-10-10T19:53:30Z
[INFO] ------------------------------------------------------------------------
11. Tworzenie i publikowanie obrazów kontenerów
Utwórzmy obraz kontenera w 2 wersjach: jednej jako JIT image, a drugiej jako Native Java image.
Najpierw ustaw zmienne środowiskowe projektu GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
Utwórz obraz JIT:
./mvnw spring-boot:build-image -Pji
Sprawdź log kompilacji w terminalu:
[INFO] [creator] Timer: Saving docker.io/library/image-analysis-maven-jit:latest... started at 2023-10-10T20:00:31Z [INFO] [creator] *** Images (4c84122a1826): [INFO] [creator] docker.io/library/image-analysis-maven-jit:latest [INFO] [creator] Timer: Saving docker.io/library/image-analysis-maven-jit:latest... ran for 6.975913605s and ended at 2023-10-10T20:00:38Z [INFO] [creator] Timer: Exporter ran for 8.068588001s and ended at 2023-10-10T20:00:38Z [INFO] [creator] Timer: Cache started at 2023-10-10T20:00:38Z [INFO] [creator] Reusing cache layer 'paketo-buildpacks/syft:syft' [INFO] [creator] Adding cache layer 'buildpacksio/lifecycle:cache.sbom' [INFO] [creator] Timer: Cache ran for 200.449002ms and ended at 2023-10-10T20:00:38Z [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-maven-jit:latest' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 43.887 s [INFO] Finished at: 2023-10-10T20:00:39Z [INFO] ------------------------------------------------------------------------
Utwórz obraz AOT(natywny):
./mvnw spring-boot:build-image -Pnative
Obserwuj dziennik kompilacji w terminalu, w tym dzienniki kompilacji obrazu natywnego.
Uwaga:
- kompilacja trwa znacznie dłużej, w zależności od urządzenia, na którym przeprowadzane są testy;
- Obrazy można dodatkowo skompresować za pomocą UPX, ale ma to niewielki negatywny wpływ na wydajność uruchamiania, dlatego ta kompilacja nie korzysta z UPX – zawsze jest to niewielki kompromis.
... [INFO] [creator] Saving docker.io/library/image-analysis-maven-native:latest... [INFO] [creator] *** Images (13167702674e): [INFO] [creator] docker.io/library/image-analysis-maven-native:latest [INFO] [creator] Adding cache layer 'paketo-buildpacks/bellsoft-liberica:native-image-svm' [INFO] [creator] Adding cache layer 'paketo-buildpacks/syft:syft' [INFO] [creator] Adding cache layer 'paketo-buildpacks/native-image:native-image' [INFO] [creator] Adding cache layer 'buildpacksio/lifecycle:cache.sbom' [INFO] [INFO] Successfully built image 'docker.io/library/image-analysis-maven-native:latest' [INFO] [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 03:37 min [INFO] Finished at: 2023-10-10T20:05:16Z [INFO] ------------------------------------------------------------------------
Sprawdź, czy obrazy zostały utworzone:
docker images | grep image-analysis
Dodaj tagi do 2 obrazów i prześlij je do GCR:
# JIT image
docker tag image-analysis-maven-jit gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit
# Native(AOT) image
docker tag image-analysis-maven-native gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native
docker push gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native
12. Wdrożenie w Cloud Run
Czas wdrożyć usługę.
Usługę wdrożysz 2 razy: raz przy użyciu obrazu JIT, a drugi raz przy użyciu obrazu AOT(natywnego). Oba wdrożenia usługi będą równolegle przetwarzać ten sam obraz z zasobnika na potrzeby porównania.
Najpierw ustaw zmienne środowiskowe projektu GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Wdróż obraz JIT i sprawdź dziennik wdrażania w konsoli:
gcloud run deploy image-analysis-jit \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-jit \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-jit] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-jit] revision [image-analysis-jvm-00009-huc] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-jit-...-ew.a.run.app
Wdróż obraz natywny i sprawdź dziennik wdrażania w konsoli:
gcloud run deploy image-analysis-native \
--image gcr.io/${GOOGLE_CLOUD_PROJECT}/image-analysis-maven-native \
--region europe-west1 \
--memory 2Gi --allow-unauthenticated
...
Deploying container to Cloud Run service [image-analysis-native] in project [...] region [europe-west1]
✓ Deploying... Done.
✓ Creating Revision...
✓ Routing traffic...
✓ Setting IAM Policy...
Done.
Service [image-analysis-native] revision [image-analysis-native-00005-ben] has been deployed and is serving 100 percent of traffic.
Service URL: https://image-analysis-native-...-ew.a.run.app
13. Konfigurowanie aktywatorów Eventarc
Eventarc oferuje standardowe rozwiązanie do zarządzania przepływem zmian stanu (nazywanych zdarzeniami) między odłączonymi mikroserwisami. Po aktywowaniu Eventarc przekierowuje te zdarzenia przez subskrypcje Pub/Sub do różnych miejsc docelowych (w tym dokumencie zobacz Miejsca docelowe zdarzeń), a jednocześnie zarządza przesyłaniem, zabezpieczeniami, autoryzacją, dostrzegalnością i obsługą błędów.
Możesz utworzyć aktywator Eventarc, aby usługa Cloud Run otrzymywała powiadomienia o określonym zdarzeniu lub zbiorze zdarzeń. Określając filtry wyzwalacza, możesz skonfigurować routing zdarzenia, w tym źródło zdarzenia i docelową usługę Cloud Run.
Najpierw ustaw zmienne środowiskowe projektu GCP:
export GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project)
gcloud config set project ${GOOGLE_CLOUD_PROJECT}
gcloud config set run/region
gcloud config set run/platform managed
gcloud config set eventarc/location europe-west1
Przyznaj rolę pubsub.publisher kontu usługi Cloud Storage:
SERVICE_ACCOUNT="$(gsutil kms serviceaccount -p ${GOOGLE_CLOUD_PROJECT})"
gcloud projects add-iam-policy-binding ${GOOGLE_CLOUD_PROJECT} \
--member="serviceAccount:${SERVICE_ACCOUNT}" \
--role='roles/pubsub.publisher'
Skonfiguruj aktywatory Eventarc dla obrazów usług JIT i Native, aby przetwarzać obraz:
gcloud eventarc triggers list --location=eu
gcloud eventarc triggers create image-analysis-jit-trigger \
--destination-run-service=image-analysis-jit \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
gcloud eventarc triggers create image-analysis-native-trigger \
--destination-run-service=image-analysis-native \
--destination-run-region=europe-west1 \
--location=eu \
--event-filters="type=google.cloud.storage.object.v1.finalized" \
--event-filters="bucket=uploaded-pictures-${GOOGLE_CLOUD_PROJECT}" \
--service-account=${PROJECT_NUMBER}-compute@developer.gserviceaccount.com
Zauważ, że utworzone zostały 2 aktywatory:
gcloud eventarc triggers list --location=eu
14. Testowanie wersji usługi
Po pomyślnym wdrożeniu usług opublikujesz obraz w Cloud Storage, sprawdzisz, czy nasze usługi zostały wywołane, co zwraca interfejs Vision API i czy metadane są przechowywane w Firestore.
Wróć do Cloud Storage i kliknij zasobnik utworzony na początku modułu:
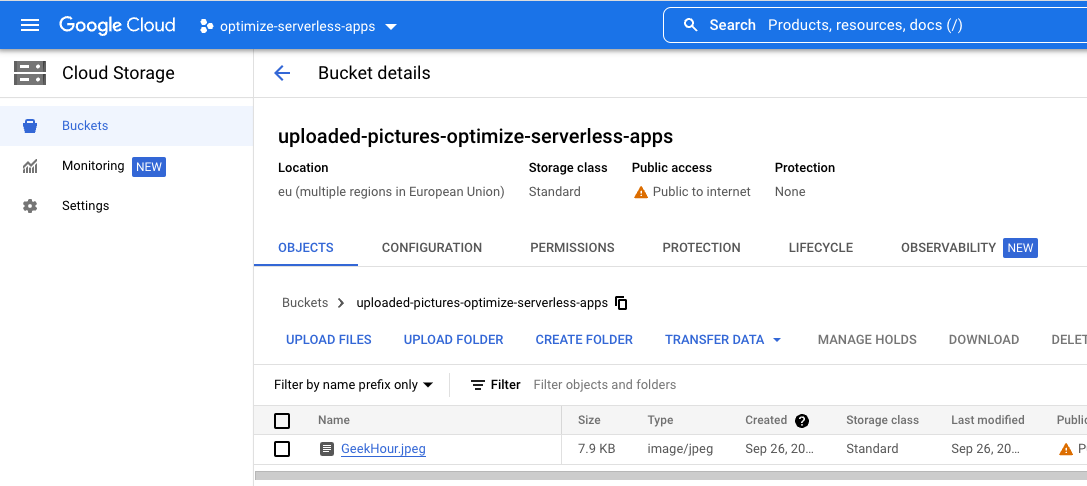
Na stronie z informacjami o zasobniku kliknij przycisk Upload files, aby przesłać zdjęcie.
Na przykład GeekHour.jpeg jest dostarczany z bazą kodu w folderze /services/image-analysis/java. Wybierz obraz i naciśnij Open button:
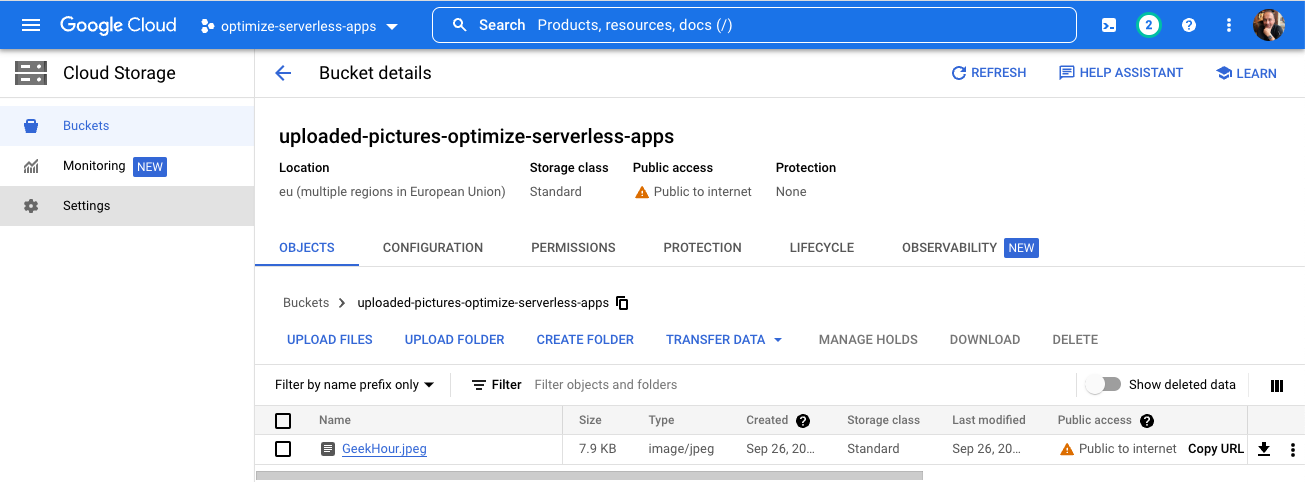
Możesz teraz sprawdzić wykonanie usługi, zaczynając od image-analysis-jit, a następnie image-analysis-native.
W menu (☰) przejdź do usługi Cloud Run > image-analysis-jit.
Kliknij Logi i przyjrzyj się wynikom:
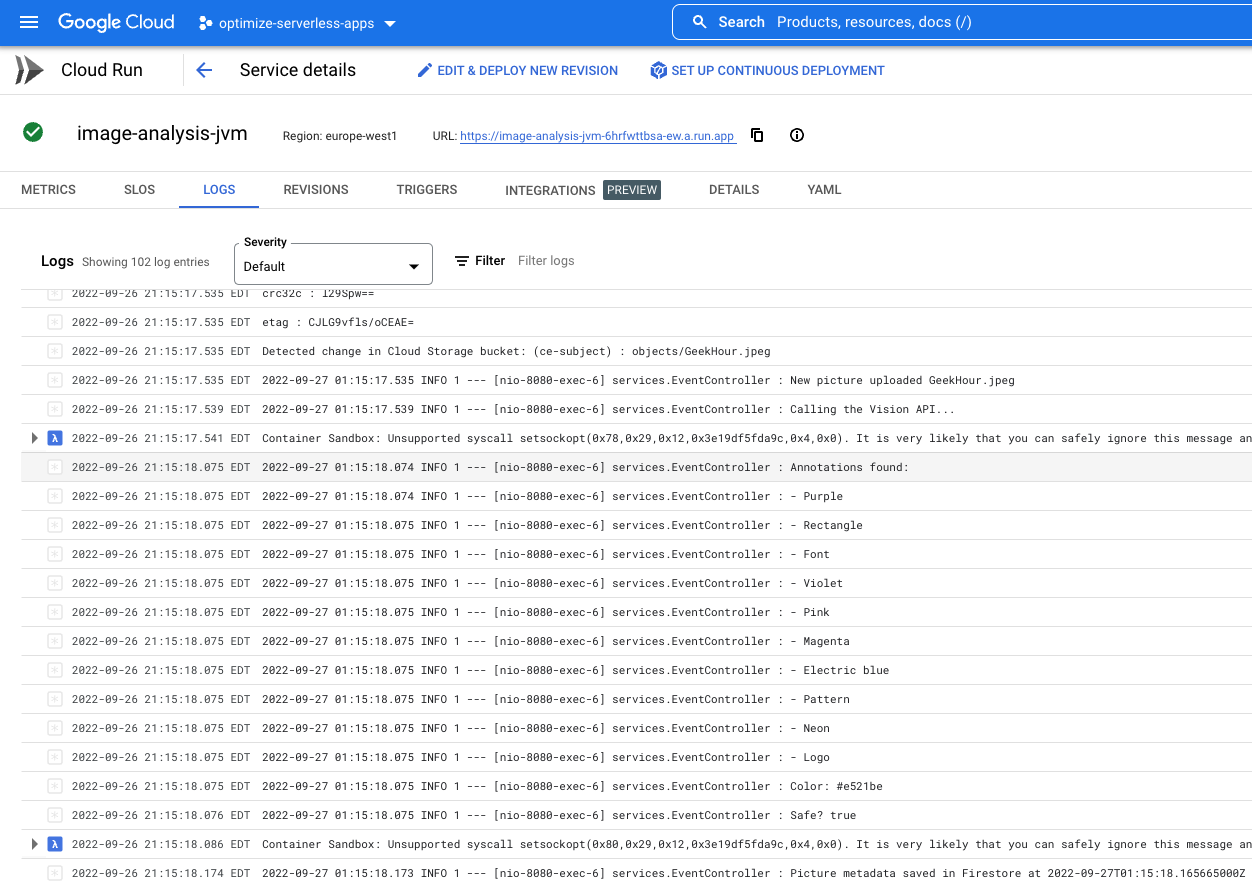
Na liście logów widać, że usługa JIT image-analysis-jit została wywołana.
Logi wskazują początek i koniec wykonania usługi. Pomiędzy nimi widzimy logi umieszczone w funkcji za pomocą instrukcji logowania na poziomie INFO. Widzimy:
- szczegóły zdarzenia, które wywołało naszą funkcję,
- Nieprzetworzone wyniki wywołania interfejsu Vision API.
- etykiety znalezione na przesłanym przez nas zdjęciu;
- informacje o kolorach dominujących,
- czy obraz jest bezpieczny do wyświetlenia,
- Metadane obrazu zostały ostatecznie zapisane w Firestore.
Powtórz ten proces w przypadku usługi image-analysis-native.
W menu (☰) przejdź do usługi Cloud Run > image-analysis-native.
Kliknij Logi i przyjrzyj się wynikom:
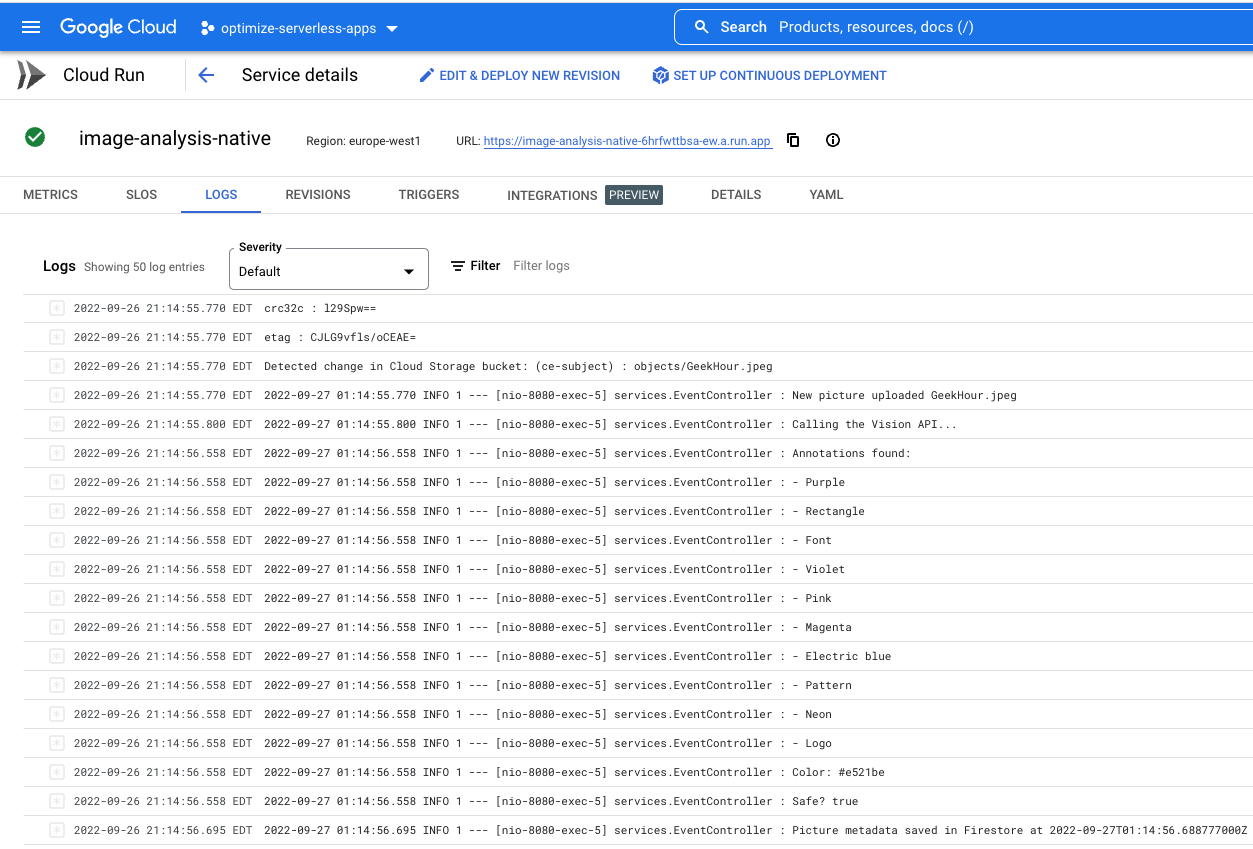
Sprawdź teraz, czy metadane obrazu zostały zapisane w Fiorestore.
Ponownie w menu „hamburger” (☰) otwórz sekcję Firestore. W podsekcji Data (wyświetlanej domyślnie) powinna pojawić się kolekcja pictures z dodanym nowym dokumentem odpowiadającym właśnie przesłanemu zdjęciu:
15. Zwalnianie miejsca (opcjonalnie)
Jeśli nie zamierzasz kontynuować pracy z innymi ćwiczeniami z tej serii, możesz usunąć zasoby, aby zaoszczędzić pieniądze i być dobrym użytkownikiem chmury. Możesz zwolnić miejsce, czyszcząc poszczególne zasoby w ten sposób:
Usuń zasobnik:
gsutil rb gs://${BUCKET_PICTURES}
Usuń funkcję:
gcloud functions delete picture-uploaded --region europe-west1 -q
Usuń kolekcję Firestore, wybierając opcję Usuń kolekcję:
Możesz też usunąć cały projekt:
gcloud projects delete ${GOOGLE_CLOUD_PROJECT}
16. Gratulacje!
Gratulacje! Udało Ci się wdrożyć pierwszą kluczową usługę projektu.
Omówione zagadnienia
- Cloud Storage
- Cloud Run
- Cloud Vision API
- Cloud Firestore
- Obrazy natywne Javy