
1. 簡介
在本程式碼研究室中,您將瞭解如何使用 Document AI 表單剖析器,透過 Python 剖析手寫表單。
我們將以簡單的病患資料登記表為例,但這個程序也適用 DocAI 支援的任何一般表單。
必要條件
本程式碼研究室以其他 Document AI 程式碼研究室的內容為基礎。
建議您先完成下列程式碼研究室,再繼續操作。
課程內容
- 如何使用 Document AI 表單剖析器,剖析及擷取表單掃描檔中的資料。
軟硬體需求
問卷調查
您會如何使用本教學課程?
你對 Python 的使用體驗如何?
您對使用 Google Cloud 服務的體驗滿意嗎?
2. 設定和需求
本程式碼研究室假設您已完成這項程式碼研究室列出的 Document AI 設定步驟。
請先完成下列步驟再繼續:
您也必須安裝 pandas,這是 Python 的開放原始碼資料分析程式庫。
pip3 install --upgrade pandas
3. 建立表單剖析器處理器
在本實驗室,您必須先建立表單剖析器的處理器執行個體,才能用於 Document AI 平台。
- 前往控制台的「Document AI Platform Overview」
- 按一下「建立處理器」,然後選取「表單剖析器」
- 指定處理器名稱,然後從清單中選取區域。
- 點按「建立」即可建立處理器
- 複製處理器 ID。您稍後必須在程式碼中使用此 ID。
在 Cloud 控制台測試處理器
上傳文件即可在控制台測試處理器。按一下「上傳文件」,然後選取要剖析的表單。如果沒有可用的表單,可以下載並使用這份範本。

輸出內容應如下所示: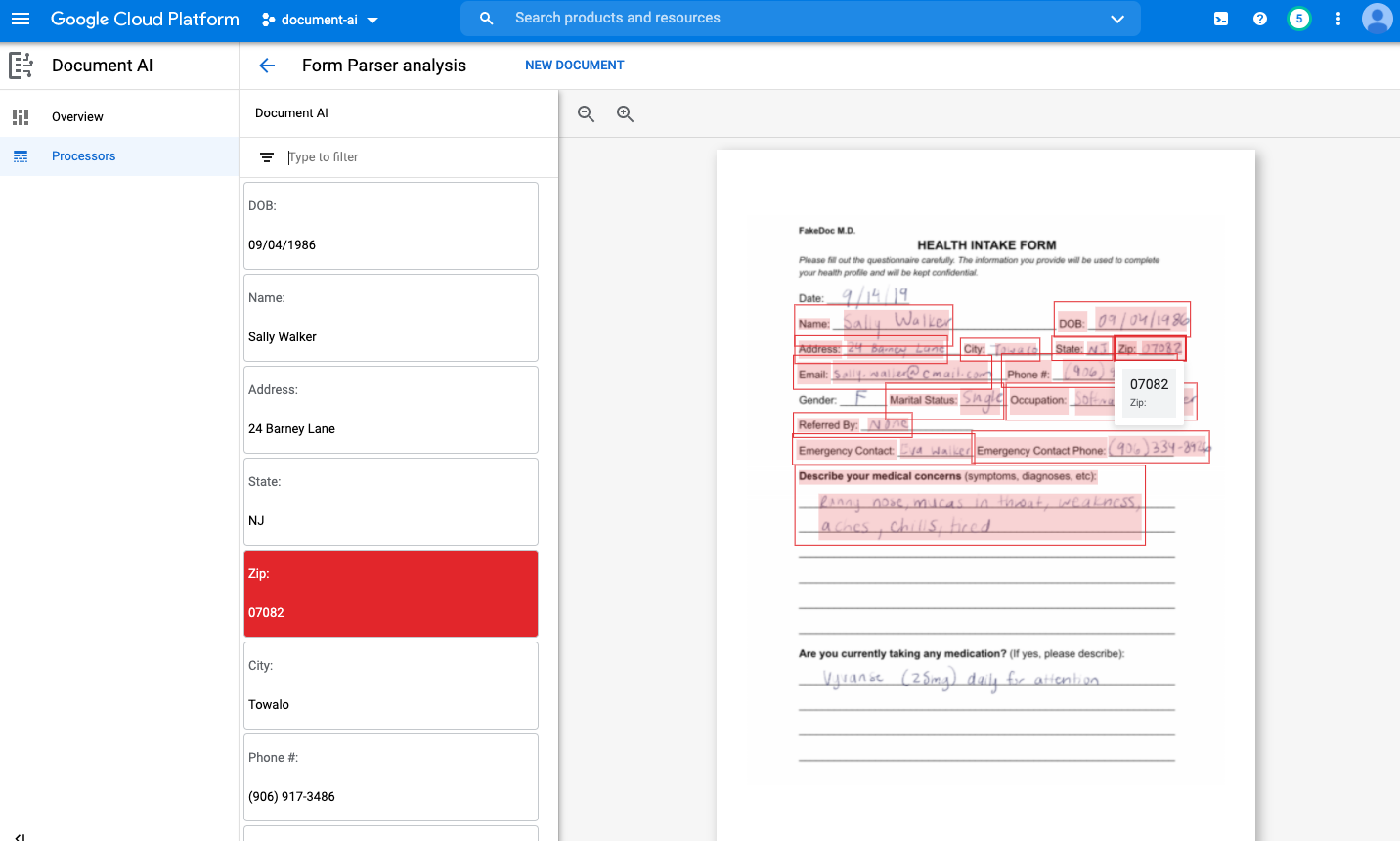
4. 下載範本表單
我們提供一份內含簡易病患資料登記表的範例文件。
你可以透過下列連結下載 PDF。然後上傳至 Cloud Shell 執行個體。
或者,您也可以使用 gsutil 從公開的 Google Cloud Storage Bucket 下載。
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/intake-form.pdf .
使用下列指令,確認檔案已下載至 Cloud Shell:
ls -ltr intake-form.pdf
5. 擷取表單鍵/值組合
在這個步驟中,您將使用線上處理 API,呼叫先前建立的表單剖析器處理器。接著,您會擷取文件中找到的鍵/值組合。
線上處理功能適用於傳送單一文件並等待回應。如要傳送多個檔案,或檔案大小超過線上處理功能的頁數上限,也能使用批次處理功能。如需操作說明,請參閱 OCR 程式碼研究室。
對於所有處理器類型,用於發出處理要求的程式碼完全相同,唯一的差異是處理器 ID。
Document 回應物件包含輸入文件的頁面清單。
每個 page 物件都包含表單欄位清單,以及這些欄位在文字中的位置。
下列程式碼會逐一查看每個頁面,並擷取每個鍵、值和可信度分數。這類結構化資料更容易儲存在資料庫中,或用於其他應用程式。
建立名為 form_parser.py 的檔案,並使用下列程式碼。
form_parser.py
import pandas as pd
from google.cloud import documentai_v1 as documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def trim_text(text: str):
"""
Remove extra space characters from text (blank, newline, tab, etc.)
"""
return text.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor in Cloud Console
# The local file in your current working directory
FILE_PATH = "intake-form.pdf"
# Refer to https://cloud.google.com/document-ai/docs/processors-list
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
names = []
name_confidence = []
values = []
value_confidence = []
for page in document.pages:
for field in page.form_fields:
# Get the extracted field names
names.append(trim_text(field.field_name.text_anchor.content))
# Confidence - How "sure" the Model is that the text is correct
name_confidence.append(field.field_name.confidence)
values.append(trim_text(field.field_value.text_anchor.content))
value_confidence.append(field.field_value.confidence)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
{
"Field Name": names,
"Field Name Confidence": name_confidence,
"Field Value": values,
"Field Value Confidence": value_confidence,
}
)
print(df)
現在執行程式碼,您應會看到擷取的文字顯示於控制台。
如果您使用我們的範例文件,應該會看到下列輸出內容:
$ python3 form_parser.py
Field Name Field Name Confidence Field Value Field Value Confidence
0 Phone #: 0.999982 (906) 917-3486 0.999982
1 Emergency Contact: 0.999972 Eva Walker 0.999972
2 Marital Status: 0.999951 Single 0.999951
3 Gender: 0.999933 F 0.999933
4 Occupation: 0.999914 Software Engineer 0.999914
5 Referred By: 0.999862 None 0.999862
6 Date: 0.999858 9/14/19 0.999858
7 DOB: 0.999716 09/04/1986 0.999716
8 Address: 0.999147 24 Barney Lane 0.999147
9 City: 0.997718 Towaco 0.997718
10 Name: 0.997345 Sally Walker 0.997345
11 State: 0.996944 NJ 0.996944
...
6. 剖析資料表
表單剖析器也能從文件中的資料表擷取資料。在本節中,您將下載新的範例文件,並從資料表中擷取資料。由於資料會載入 Pandas,因此只需單一次方法呼叫,就能將資料輸出為 CSV 檔和許多其他格式。
下載含有資料表的範例表單
我們提供一份內含範例表單和資料表的範例文件。
你可以透過下列連結下載 PDF。然後上傳至 Cloud Shell 執行個體。
或者,您也可以使用 gsutil 從公開的 Google Cloud Storage Bucket 下載。
gsutil cp gs://cloud-samples-data/documentai/codelabs/form-parser/form_with_tables.pdf .
使用下列指令,確認檔案已下載至 Cloud Shell:
ls -ltr form_with_tables.pdf
擷取資料表資料
資料表資料的處理要求,與鍵/值組合的擷取要求完全相同,兩者的差異在於我們從回應中擷取資料的欄位。資料表資料會儲存在 pages[].tables[] 欄位。
這個範例會從每個資料表和頁面的資料表標題列和主體列擷取資訊,然後輸出資料表並存為 CSV 檔。
建立名為 table_parsing.py 的檔案,並使用下列程式碼。
table_parsing.py
# type: ignore[1]
"""
Uses Document AI online processing to call a form parser processor
Extracts the tables and data in the document.
"""
from os.path import splitext
from typing import List, Sequence
import pandas as pd
from google.cloud import documentai
def online_process(
project_id: str,
location: str,
processor_id: str,
file_path: str,
mime_type: str,
) -> documentai.Document:
"""
Processes a document using the Document AI Online Processing API.
"""
opts = {"api_endpoint": f"{location}-documentai.googleapis.com"}
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient(client_options=opts)
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type
)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document
)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def get_table_data(
rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> List[List[str]]:
"""
Get Text data from table rows
"""
all_values: List[List[str]] = []
for row in rows:
current_row_values: List[str] = []
for cell in row.cells:
current_row_values.append(
text_anchor_to_text(cell.layout.text_anchor, text)
)
all_values.append(current_row_values)
return all_values
def text_anchor_to_text(text_anchor: documentai.Document.TextAnchor, text: str) -> str:
"""
Document AI identifies table data by their offsets in the entirety of the
document's text. This function converts offsets to a string.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response.strip().replace("\n", " ")
PROJECT_ID = "YOUR_PROJECT_ID"
LOCATION = "YOUR_PROJECT_LOCATION" # Format is 'us' or 'eu'
PROCESSOR_ID = "FORM_PARSER_ID" # Create processor before running sample
# The local file in your current working directory
FILE_PATH = "form_with_tables.pdf"
# Refer to https://cloud.google.com/document-ai/docs/file-types
# for supported file types
MIME_TYPE = "application/pdf"
document = online_process(
project_id=PROJECT_ID,
location=LOCATION,
processor_id=PROCESSOR_ID,
file_path=FILE_PATH,
mime_type=MIME_TYPE,
)
header_row_values: List[List[str]] = []
body_row_values: List[List[str]] = []
# Input Filename without extension
output_file_prefix = splitext(FILE_PATH)[0]
for page in document.pages:
for index, table in enumerate(page.tables):
header_row_values = get_table_data(table.header_rows, document.text)
body_row_values = get_table_data(table.body_rows, document.text)
# Create a Pandas Dataframe to print the values in tabular format.
df = pd.DataFrame(
data=body_row_values,
columns=pd.MultiIndex.from_arrays(header_row_values),
)
print(f"Page {page.page_number} - Table {index}")
print(df)
# Save each table as a CSV file
output_filename = f"{output_file_prefix}_pg{page.page_number}_tb{index}.csv"
df.to_csv(output_filename, index=False)
現在執行程式碼,您應會看到擷取的文字顯示於控制台。
如果您使用我們的範例文件,應該會看到下列輸出內容:
$ python3 table_parsing.py
Page 1 - Table 0
Item Description
0 Item 1 Description 1
1 Item 2 Description 2
2 Item 3 Description 3
Page 1 - Table 1
Form Number: 12345678
0 Form Date: 2020/10/01
1 Name: First Last
2 Address: 123 Fake St
在您執行程式碼的目錄中,也應該會有兩個新的 CSV 檔。
$ ls form_with_tables_pg1_tb0.csv form_with_tables_pg1_tb1.csv table_parsing.py
7. 恭喜
恭喜!您已成功使用 Document AI API 從手寫表單擷取資料。建議您試試其他表單文件。
清除
如要避免系統向您的 Google Cloud 帳戶收取您在本教學課程中所用資源的相關費用:
瞭解詳情
歡迎透過下列後續程式碼研究室,進一步瞭解 Document AI。
資源
授權
這項內容採用的授權為 Creative Commons 姓名標示 2.0 通用授權。