
۱. مقدمه
هوش مصنوعی اسناد، یک راهکار درک اسناد است که دادههای بدون ساختار مانند اسناد، ایمیلها و غیره را دریافت کرده و درک، تجزیه و تحلیل و استفاده از دادهها را آسانتر میکند.
با استفاده از آموزش پیشرفته از طریق Document AI Workbench، میتوانید با ارائه مثالهای برچسبگذاری شده اضافی برای انواع اسناد تخصصی و ایجاد یک نسخه مدل جدید، به دقت پردازش اسناد بالاتری دست یابید.
در این آزمایش، شما یک پردازنده تجزیهکننده فاکتور ایجاد خواهید کرد، پردازنده را برای آموزش پیشرفته پیکربندی خواهید کرد، اسناد نمونه را برچسبگذاری خواهید کرد و پردازنده را آموزش پیشرفته خواهید داد.
مجموعه دادههای سند مورد استفاده در این آزمایش شامل فاکتورهای تصادفی تولید شده برای یک شرکت لولهکشی فرضی است.
پیشنیازها
این آزمایشگاه کد بر اساس محتوای ارائه شده در سایر آزمایشگاههای کد هوش مصنوعی اسناد ساخته شده است.
توصیه میشود قبل از ادامه، Codelabs زیر را تکمیل کنید.
- تشخیص نوری کاراکتر (OCR) با هوش مصنوعی اسناد (پایتون)
- تجزیه فرم با هوش مصنوعی اسناد (پایتون)
- پردازندههای تخصصی با هوش مصنوعی اسناد (پایتون)
- مدیریت پردازندههای هوش مصنوعی اسناد با پایتون
- هوش مصنوعی سند: انسان در حلقه
آنچه یاد خواهید گرفت
- پیکربندی آموزش پیشرفته برای پردازنده تجزیهکننده فاکتور.
- دادههای آموزشی هوش مصنوعی سند را با استفاده از ابزار حاشیهنویسی برچسبگذاری کنید.
- یک نسخه مدل جدید را آموزش دهید.
- دقت نسخه جدید مدل را ارزیابی کنید.
آنچه نیاز دارید
۲. راهاندازی
این آزمایشگاه کد فرض میکند که شما مراحل راهاندازی هوش مصنوعی سند که در آزمایشگاه کد مقدماتی ذکر شده است را تکمیل کردهاید.
لطفا قبل از ادامه مراحل زیر را انجام دهید:
۳. یک پردازنده ایجاد کنید
ابتدا باید یک پردازشگر تجزیهکننده فاکتور برای استفاده در این آزمایش ایجاد کنید.
- در کنسول، به صفحه Document AI Overview بروید.

- روی «ایجاد پردازنده» کلیک کنید، به پایین بروید تا به «تخصصی» برسید (یا «تجزیهکننده فاکتور» را در نوار جستجو تایپ کنید) و «تجزیهکننده فاکتور» را انتخاب کنید.

- نام آن را
codelab-invoice-uptraining(یا هر چیز دیگری که به خاطر دارید) بگذارید و نزدیکترین منطقه را در لیست انتخاب کنید.
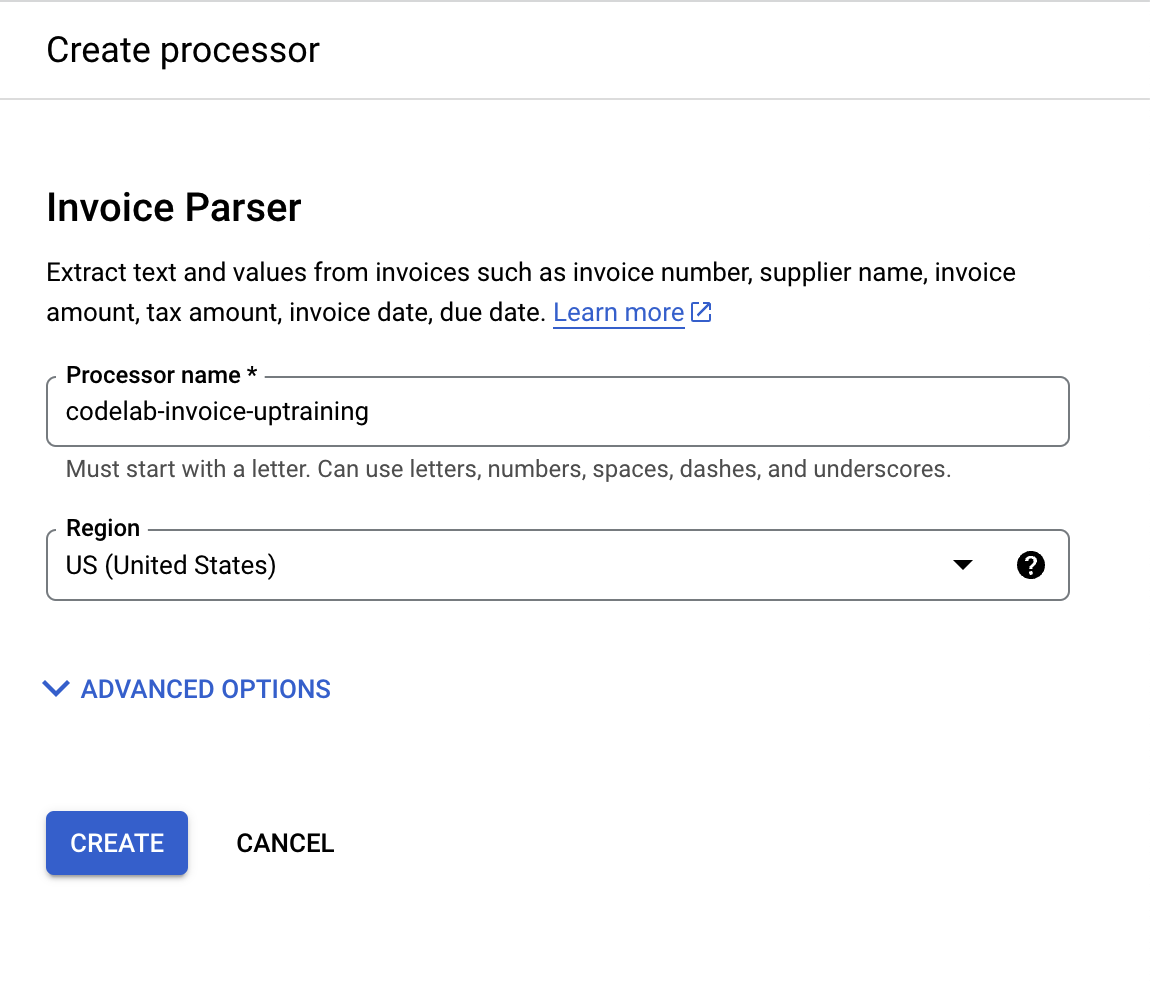
- برای ایجاد پردازنده خود، روی «ایجاد» کلیک کنید. سپس باید صفحه «نمای کلی پردازنده» را مشاهده کنید.
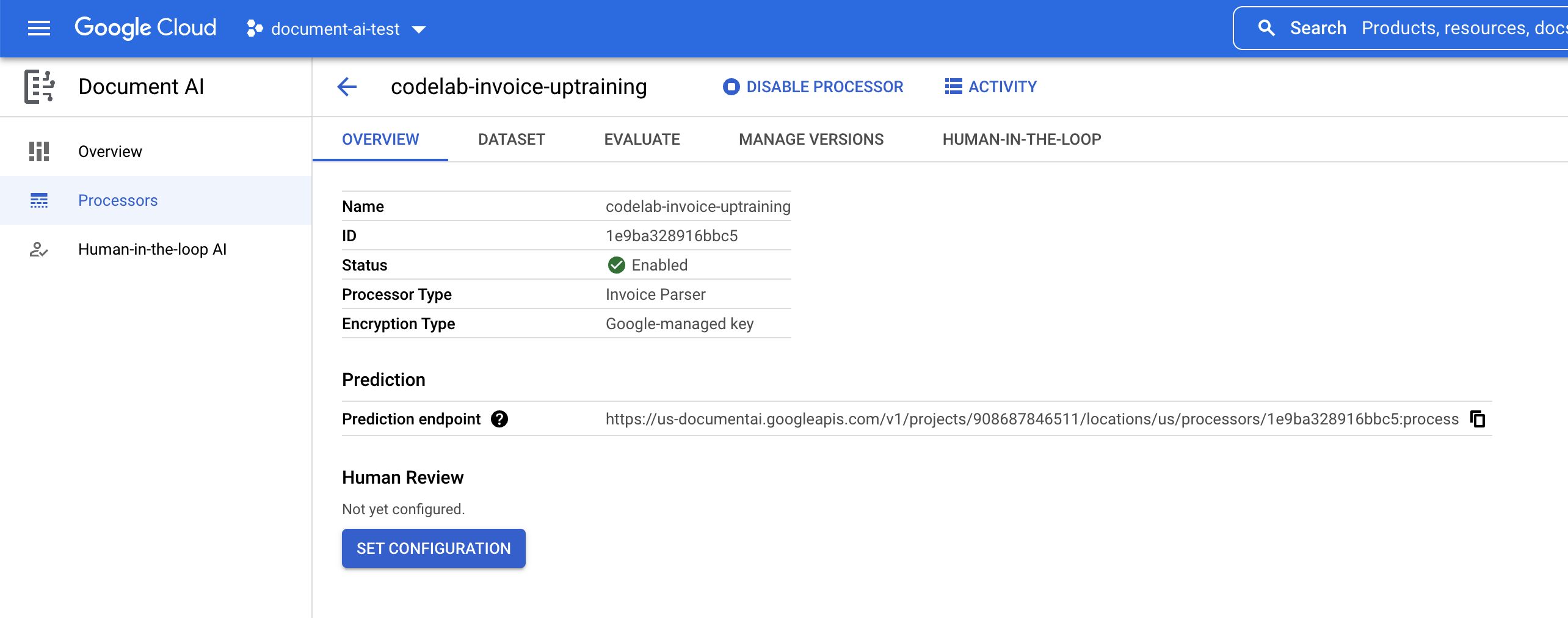
۴. ایجاد یک مجموعه داده
برای آموزش پردازنده، باید یک مجموعه داده شامل دادههای آموزشی و آزمایشی ایجاد کنیم تا به پردازنده در شناسایی موجودیتهایی که میخواهیم استخراج کنیم، کمک کند.
برای ذخیره مجموعه دادهها، باید یک سطل جدید در فضای ذخیرهسازی ابری ایجاد کنید. توجه: این سطل نباید همان سطلی باشد که اسناد شما در حال حاضر در آن ذخیره شدهاند.
- Cloud Shell را باز کنید و دستورات زیر را برای ایجاد یک سطل اجرا کنید. روش دیگر، ایجاد یک سطل جدید در کنسول Cloud است. نام این سطل را ذخیره کنید، بعداً به آن نیاز خواهید داشت.
export PROJECT_ID=$(gcloud config get-value project)
gsutil mb -p $PROJECT_ID "gs://${PROJECT_ID}-uptraining-codelab"
- به برگه Dataset بروید و روی Create Dataset کلیک کنید.

- نام سطلی که در مرحله اول ایجاد کردید را در فیلد مسیر مقصد وارد کنید. (
gs://را وارد نکنید)

- صبر کنید تا مجموعه داده ایجاد شود، سپس باید شما را به صفحه مدیریت مجموعه داده هدایت کند.
۵. یک سند آزمایشی را وارد کنید
حالا، بیایید یک نمونه فاکتور pdf را به مجموعه دادههای خود وارد کنیم.
- روی وارد کردن اسناد کلیک کنید

- ما یک نمونه PDF برای استفاده شما در این آزمایش داریم. لینک زیر را کپی کرده و در کادر Source Path قرار دهید. فعلاً گزینه "Data split" را روی "Unassigned" بگذارید. روی Import کلیک کنید.
cloud-samples-data/documentai/codelabs/uptraining/pdfs

- منتظر بمانید تا سند وارد شود. در آزمایشهای من، این کار کمتر از ۱ دقیقه طول کشید.
- وقتی وارد کردن تمام شد، باید سند را در رابط کاربری مدیریت مجموعه دادهها مشاهده کنید. روی آن کلیک کنید تا وارد کنسول برچسبگذاری شوید.

۶. سند آزمایشی را برچسبگذاری کنید
در مرحله بعد، عناصر متنی و برچسبها را برای موجودیتهایی که میخواهیم استخراج کنیم، شناسایی خواهیم کرد. این برچسبها برای آموزش مدل ما جهت تجزیه این ساختار سند خاص و شناسایی انواع صحیح استفاده میشوند.
- اکنون باید در کنسول برچسبگذاری باشید که چیزی شبیه به این خواهد بود.

- روی ابزار «انتخاب متن» کلیک کنید، سپس متن «شرکت بینالمللی لولهکشی مکویلیام پایپینگ» را هایلایت کنید و برچسب
supplier_nameبه آن اختصاص دهید. میتوانید از فیلتر متن برای جستجوی نام برچسبها استفاده کنید.

- متن «14368 Pipeline Ave Chino, CA 91710» را هایلایت کنید و برچسب
supplier_addressبه آن اختصاص دهید.

- متن "10001" را هایلایت کنید و برچسب
invoice_idرا به آن اختصاص دهید.

- متن "2020-01-02" را هایلایت کنید و برچسب
due_dateرا به آن اختصاص دهید.

- به ابزار "Bounding Box" بروید. متن "Knuckle Couplers" را هایلایت کنید و برچسب
line_item/descriptionرا به آن اختصاص دهید.

- متن "9" را هایلایت کنید و برچسب
line_item/quantityرا به آن اختصاص دهید.

- متن "74.43" را هایلایت کنید و برچسب
line_item/unit_priceرا به آن اختصاص دهید.

- متن "669.87" را هایلایت کنید و برچسب
line_item/amountرا به آن اختصاص دهید.

- ۴ مرحلهی قبلی را برای دو آیتم خط بعدی تکرار کنید. پس از تکمیل، باید به این شکل باشد.

- متن "1,419.57" (کنار Subtotal) را هایلایت کنید و برچسب
net_amountرا به آن اختصاص دهید.
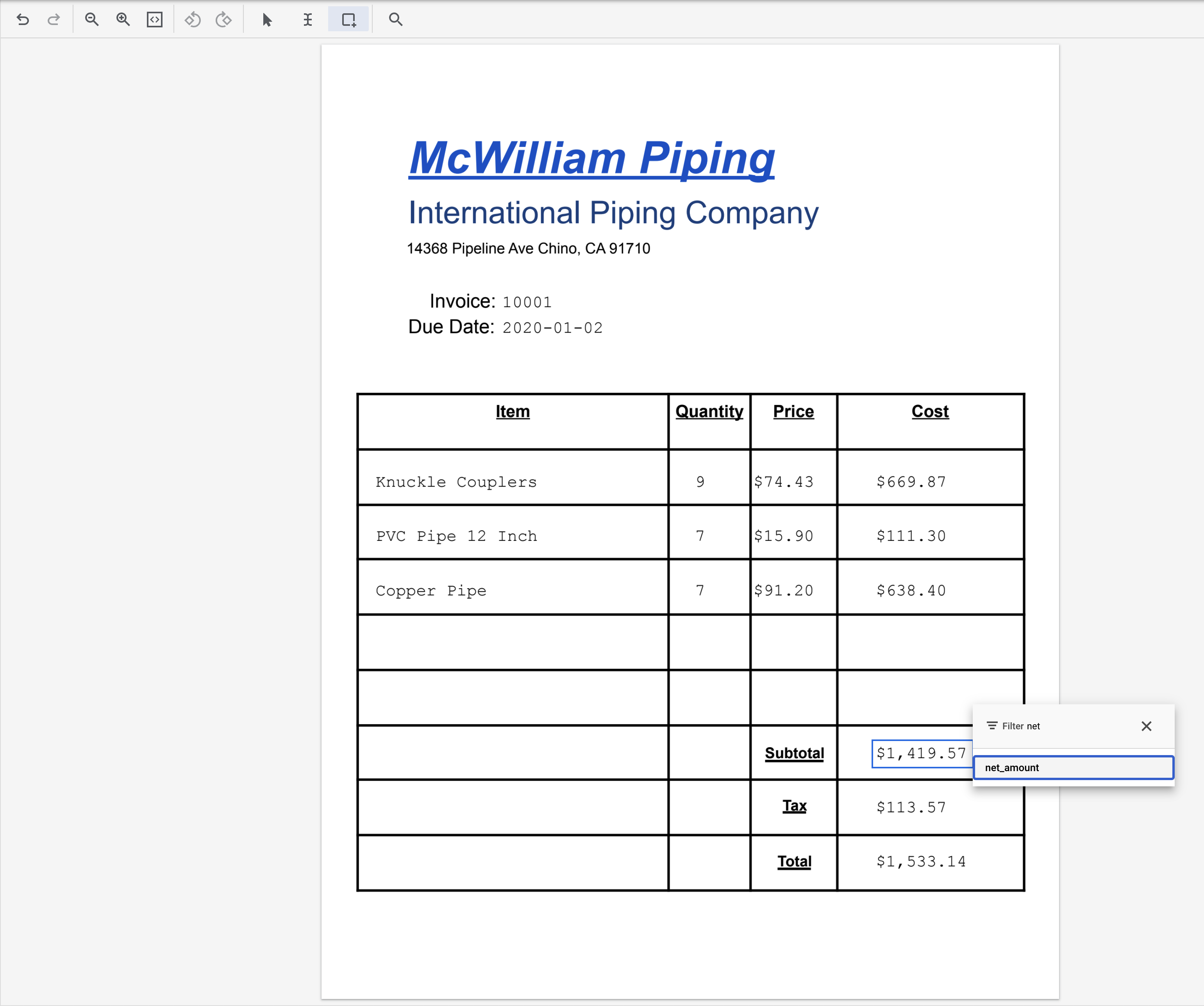
- متن "113.57" (کنار Tax) را هایلایت کنید و برچسب
total_tax_amountرا به آن اختصاص دهید.

- متن "1,533.14" (کنار Total) را هایلایت کنید و برچسب
total_amountرا به آن اختصاص دهید.

- یکی از کاراکترهای "$" را هایلایت کنید و برچسب
currencyرا به آن اختصاص دهید.
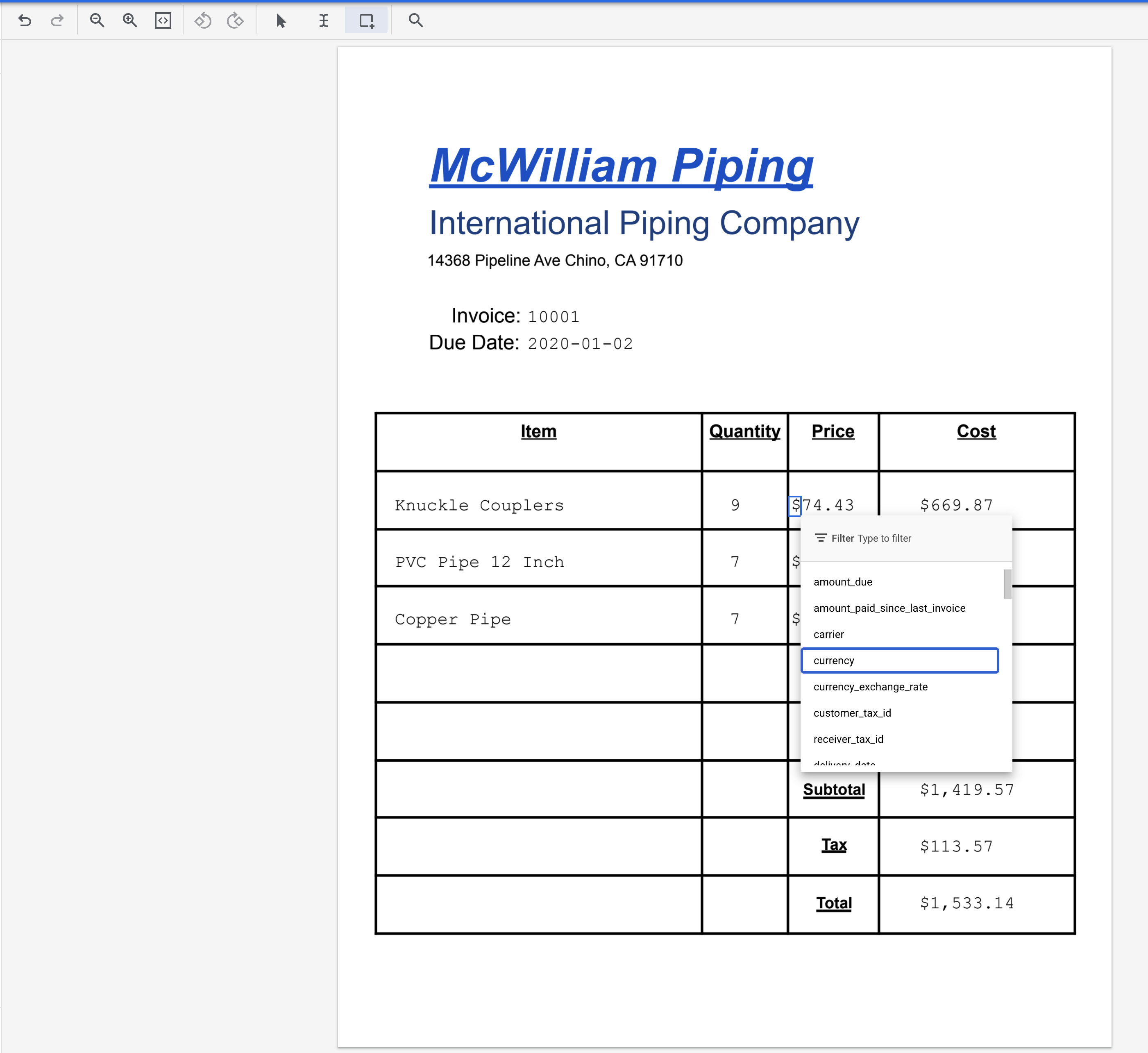
- سند برچسبگذاری شده پس از تکمیل باید به این شکل باشد. توجه داشته باشید که میتوانید با کلیک روی کادر اطراف سند یا نام/مقدار برچسب در منوی سمت چپ، این برچسبها را تنظیم کنید. پس از اتمام برچسبگذاری، روی ذخیره کلیک کنید.

- در اینجا لیست کامل برچسبها و مقادیر آمده است
نام برچسب | متن |
| شرکت لوله کشی بین المللی مک ویلیام پایپینگ |
| ۱۴۳۶۸ خیابان پایپلاین، چینو، کالیفرنیا ۹۱۷۱۰ |
| ۱۰۰۰۱ |
| ۲۰۲۰-۰۱-۰۲ |
| کوپلرهای بند انگشتی |
| ۹ |
| ۷۴.۴۳ |
| ۶۶۹.۸۷ |
| لوله پی وی سی ۱۲ اینچ |
| ۷ |
| ۱۵.۹۰ |
| ۱۱۱.۳۰ |
| لوله مسی |
| ۷ |
| ۹۱.۲۰ |
| ۶۳۸.۴۰ |
| ۱,۴۱۹.۵۷ |
| ۱۱۳.۵۷ |
| ۱,۵۳۳.۱۴ |
| دلار |
۷. اختصاص سند به مجموعه آموزشی
اکنون باید به کنسول مدیریت مجموعه دادهها (Dataset management console) برگشته باشید. توجه داشته باشید که تعداد اسناد دارای برچسب (Labeled documents) و بدون برچسب (Unlabeled documents) و همچنین تعداد برچسبهای فعال تغییر کرده است.

- ما باید این سند را به مجموعه "آموزش" یا "آزمون" اختصاص دهیم. روی سند کلیک کنید.

- روی «اختصاص به مجموعه» کلیک کنید، سپس روی «آموزش» کلیک کنید.
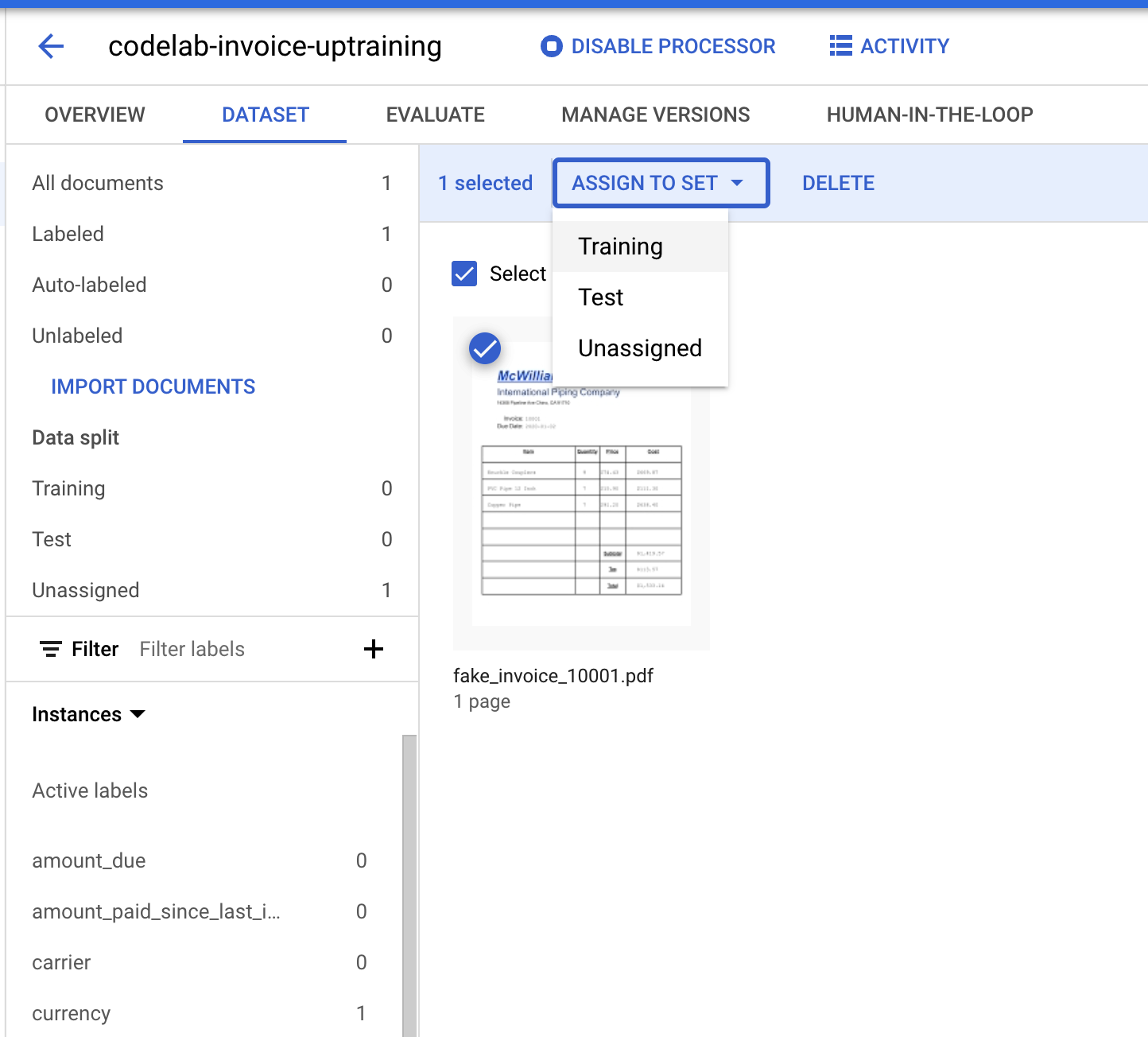
- توجه کنید که اعداد مربوط به تقسیم دادهها تغییر کردهاند.

۸. وارد کردن دادههای از پیش برچسبگذاریشده
آموزش هوش مصنوعی اسناد به حداقل ۱۰ سند در مجموعههای آموزشی و آزمایشی، به همراه ۱۰ نمونه از هر برچسب در هر مجموعه، نیاز دارد.
برای بهترین عملکرد، توصیه میشود حداقل ۵۰ سند در هر مجموعه با ۵۰ نمونه از هر برچسب داشته باشید. دادههای آموزشی بیشتر عموماً برابر با دقت بالاتر است.
برچسبگذاری دستی ۱۰۰ سند زمان زیادی میبرد، بنابراین ما تعدادی سند از پیش برچسبگذاری شده داریم که میتوانید برای این آزمایشگاه وارد کنید.
شما میتوانید فایلهای سند از پیش برچسبگذاری شده را با فرمت Document.json وارد کنید. این فایلها میتوانند نتایج حاصل از فراخوانی یک پردازنده و تأیید صحت با استفاده از Human in the Loop (HITL) باشند.
- روی وارد کردن اسناد کلیک کنید.
- مسیر Cloud Storage زیر را کپی/پیست کنید و آن را به مجموعه آموزش اختصاص دهید.
cloud-samples-data/documentai/codelabs/uptraining/training
- روی «افزودن یک سطل دیگر» کلیک کنید. سپس مسیر ذخیرهسازی ابری زیر را کپی/پیست کنید و آن را به مجموعه آزمایشی اختصاص دهید.
cloud-samples-data/documentai/codelabs/uptraining/test

- روی «وارد کردن» کلیک کنید و منتظر بمانید تا اسناد وارد شوند. این دفعه بیشتر از دفعه قبل طول خواهد کشید زیرا اسناد بیشتری برای پردازش وجود دارد. در آزمایشهای من، این کار حدود ۶ دقیقه طول کشید. میتوانید این صفحه را ترک کنید و بعداً برگردید.

- پس از تکمیل، باید اسناد را در صفحه مدیریت مجموعه دادهها مشاهده کنید.

۹. ویرایش برچسبها
اسناد نمونهای که ما برای این مثال استفاده میکنیم، شامل تمام برچسبهای پشتیبانیشده توسط تجزیهکننده فاکتور نیستند. ما باید برچسبهایی را که استفاده نمیکنیم، قبل از آموزش، غیرفعال علامتگذاری کنیم. همچنین میتوانید مراحل مشابهی را برای اضافه کردن یک برچسب سفارشی قبل از آموزش پیشرفته دنبال کنید.
- روی مدیریت برچسبها (Manage Labels) در گوشه پایین سمت چپ کلیک کنید.
- اکنون باید در کنسول مدیریت برچسب باشید.

- از کادرهای انتخاب و دکمههای غیرفعال کردن / فعال کردن برای علامتگذاری فقط برچسبهای زیر به عنوان فعال استفاده کنید.
-
currency -
due_date -
invoice_id -
line_item/amount -
line_item/description -
line_item/quantity -
line_item/unit_price -
net_amount -
supplier_address -
supplier_name -
total_amount -
total_tax_amount
-
- کنسول پس از تکمیل باید به این شکل باشد. پس از اتمام، روی ذخیره کلیک کنید.

- برای بازگشت به کنسول مدیریت مجموعه دادهها، روی پیکان برگشت کلیک کنید. توجه داشته باشید که برچسبهایی با 0 نمونه به عنوان غیرفعال علامتگذاری شدهاند.

۱۰. اختیاری: برچسبگذاری خودکار اسناد تازه وارد شده
هنگام وارد کردن اسناد بدون برچسب برای پردازندهای با نسخه پردازنده مستقر موجود، میتوانید از برچسبگذاری خودکار برای صرفهجویی در زمان برچسبگذاری استفاده کنید.
- در صفحه قطار ، روی وارد کردن اسناد کلیک کنید.
- مسیر زیر را کپی و جایگذاری کنید. این پوشه شامل ۵ فایل PDF فاکتور بدون برچسب است. از فهرست کشویی تقسیم دادهها ، آموزش را انتخاب کنید.
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled - در بخش برچسبگذاری خودکار ، کادر انتخاب «وارد کردن با برچسبگذاری خودکار» را علامت بزنید.
- یک نسخه پردازنده موجود را برای برچسبگذاری اسناد انتخاب کنید.
- برای مثال:
pretrained-invoice-v1.3-2022-07-15
- روی «وارد کردن» کلیک کنید و منتظر بمانید تا اسناد وارد شوند. میتوانید این صفحه را ترک کنید و بعداً برگردید.
- پس از تکمیل، اسناد در صفحه قطار در بخش برچسبگذاری خودکار ظاهر میشوند.
- شما نمیتوانید از اسناد دارای برچسب خودکار برای آموزش یا آزمایش استفاده کنید، مگر اینکه آنها را به عنوان برچسبگذاری شده علامتگذاری کنید. برای مشاهده اسناد دارای برچسب خودکار، به بخش برچسبگذاری خودکار بروید.
- اولین سند را برای ورود به کنسول برچسبگذاری انتخاب کنید.
- برچسبها، کادرهای محصورکننده و مقادیر را بررسی کنید تا از صحت آنها اطمینان حاصل شود. هر مقداری را که از قلم افتاده است، برچسبگذاری کنید.
- پس از اتمام، علامتگذاری به عنوان برچسبگذاری شده را انتخاب کنید.
- تأیید برچسب را برای هر سند دارای برچسب خودکار تکرار کنید، سپس به صفحه آموزش برگردید تا از دادهها برای آموزش استفاده کنید.
۱۱. مدل را ارتقا دهید
اکنون، ما آمادهایم تا آموزش تجزیهکننده فاکتور خود را آغاز کنیم.
- نسخه جدید آموزش کلیک کنید
- به نسخه خود نامی بدهید که به خاطر بسپارید، مانند
codelab-uptraining-test-1. نسخه پایه، نسخه مدلی است که این نسخه جدید از روی آن ساخته خواهد شد. اگر از پردازنده جدیدی استفاده میکنید، تنها گزینه باید Google Pretrained Next with Uptraining باشد.

- (اختیاری) همچنین میتوانید برای مشاهده معیارهای مربوط به برچسبها در مجموعه دادههای خود، گزینه «مشاهده آمار برچسبها» را انتخاب کنید.

- برای شروع فرآیند آموزش پیشرفته، روی شروع آموزش کلیک کنید. شما باید به صفحه مدیریت مجموعه دادهها هدایت شوید. میتوانید وضعیت آموزش را در سمت راست مشاهده کنید. تکمیل آموزش چند ساعت طول میکشد. میتوانید این صفحه را ترک کرده و بعداً برگردید.

- اگر روی نام نسخه کلیک کنید، به صفحه مدیریت نسخهها هدایت میشوید که شناسه نسخه و وضعیت فعلی کار آموزشی را نشان میدهد.

۱۲. نسخه جدید مدل را آزمایش کنید
پس از اتمام کار آموزشی (در آزمایشهای من حدود ۱ ساعت طول کشید)، اکنون میتوانید نسخه جدید مدل را آزمایش کرده و از آن برای پیشبینیها استفاده کنید.
- به صفحه مدیریت نسخهها بروید. در اینجا میتوانید وضعیت فعلی و امتیاز F1 را مشاهده کنید.

- قبل از استفاده از این نسخه مدل، باید آن را مستقر کنیم. روی نقطههای عمودی در سمت راست کلیک کنید و گزینه Deploy Version را انتخاب کنید.

- هنگام انتظار برای استقرار نسخه، از پنجره بازشو، گزینه Deploy را انتخاب کنید. این کار چند دقیقه طول میکشد. پس از استقرار، میتوانید این نسخه را به عنوان نسخه پیشفرض نیز تنظیم کنید.

- پس از اتمام استقرار، به برگه ارزیابی (Evaluate Tab) بروید. سپس روی منوی کشویی نسخه (Version) کلیک کنید و نسخه تازه ایجاد شده خود را انتخاب کنید.

- در این صفحه، میتوانید معیارهای ارزیابی شامل امتیاز F1، دقت و فراخوانی را برای کل سند و همچنین برچسبهای جداگانه مشاهده کنید. میتوانید اطلاعات بیشتر در مورد این معیارها را در مستندات AutoML بخوانید.
- فایل PDF لینکشده در زیر را دانلود کنید. این یک سند نمونه است که در مجموعه آموزش یا آزمون گنجانده نشده است.
- روی «بارگذاری سند آزمون» کلیک کنید و فایل PDF را انتخاب کنید.

- موجودیتهای استخراجشده باید چیزی شبیه به این باشند.

۱۳. نتیجهگیری
تبریک میگوییم، شما با موفقیت از هوش مصنوعی اسناد برای آموزش پیشرفته تجزیهگر فاکتور استفاده کردید. اکنون میتوانید از این پردازنده برای تجزیه فاکتورها، درست مانند هر پردازنده تخصصی دیگری، استفاده کنید.
برای بررسی نحوه مدیریت پاسخ پردازش، میتوانید به آزمایشگاه کد پردازندههای تخصصی مراجعه کنید.
پاکسازی
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این آموزش:
- در کنسول ابری، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژه خود را انتخاب کنید و سپس روی حذف کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن (Shut down) کلیک کنید.
منابع
- مستندات میز کار هوش مصنوعی
- آینده اسناد - لیست پخش یوتیوب
- مستندسازی هوش مصنوعی
- کتابخانه کلاینت پایتون برای مستندسازی هوش مصنوعی
- نمونههای هوش مصنوعی اسناد
مجوز
این اثر تحت مجوز عمومی Creative Commons Attribution 2.0 منتشر شده است.